
Audio Classification Algorithm for Hearing Aids Based on Robust Band Entropy Information

Abstract
:1. Introduction
- To achieve effective performance, we first present a novel supervised method, SEM-RF. A novel-feature SEM based on the similarity and stability of band signals is introduced to improve the classification accuracy of each audio environment. An RF model was applied to perform high-speed classification.
- For the problem of the decreasing classification accuracy of the SEM-RF algorithm in speech mixed environments, ImSEM-RF is proposed. The SEM features and corresponding phase features are fused on multiple time resolutions to form a multi-MP feature, which improves the stability of the feature with which the speech signal interferes.
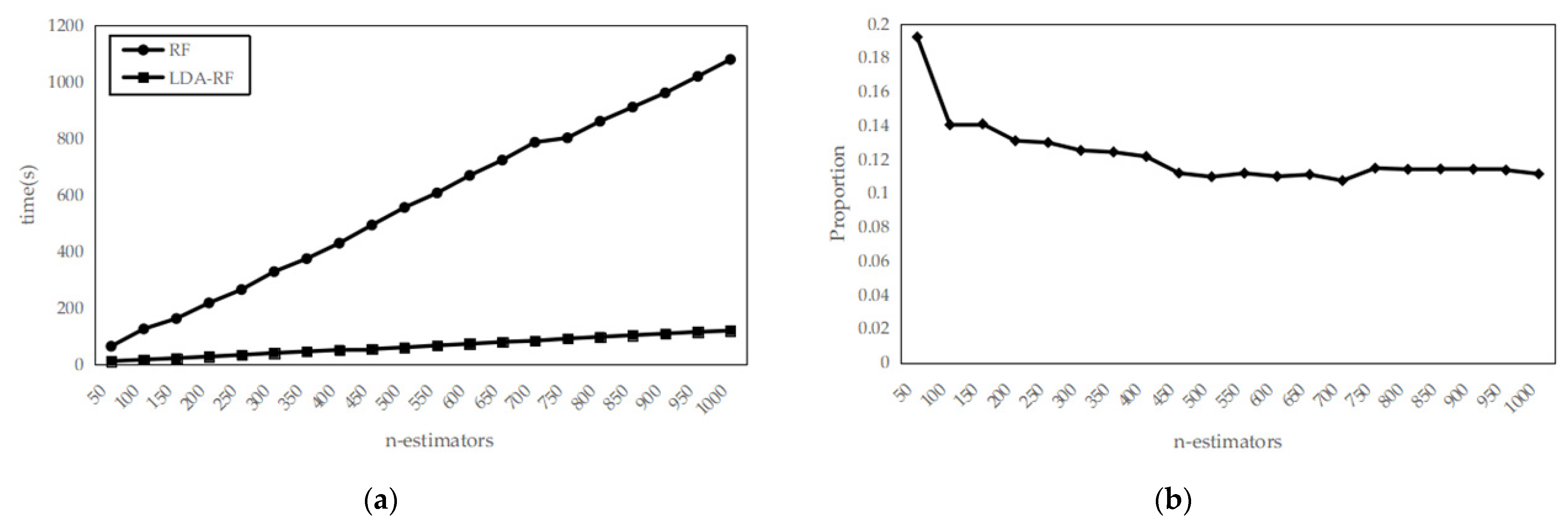
- An improved ensemble learning method based on linear discriminant analysis and random forest, LDA-RF, is proposed. High-dimensional features are converted into low-dimensional features to reduce redundant information and time complexity. The calculation speed is accelerated during model training and prediction.
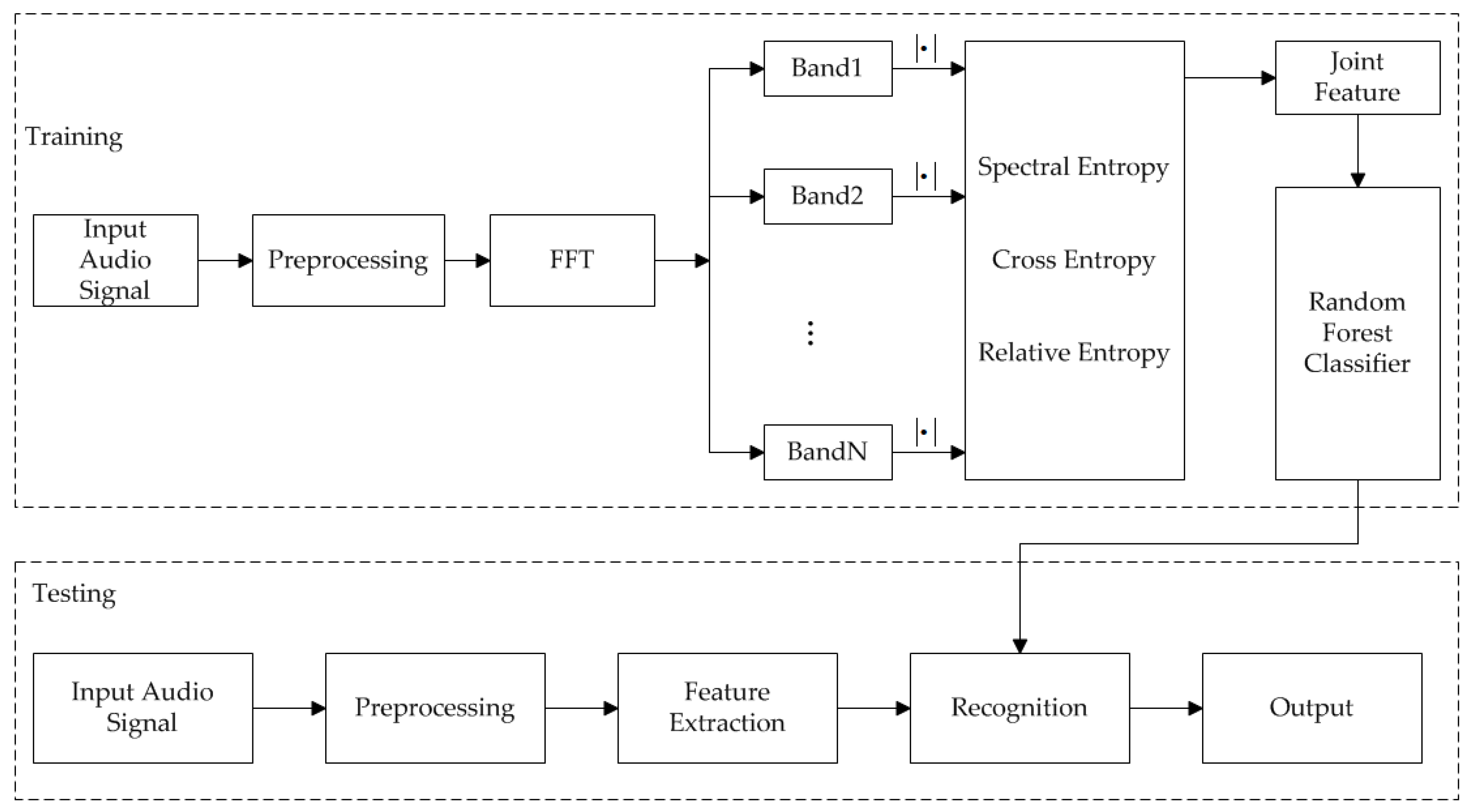
2. SEM-RF Method
2.1. Band Spectral Feature
2.1.1. Band Spectral Entropy
2.1.2. Band Cross Entropy
2.1.3. Band Relative Entropy
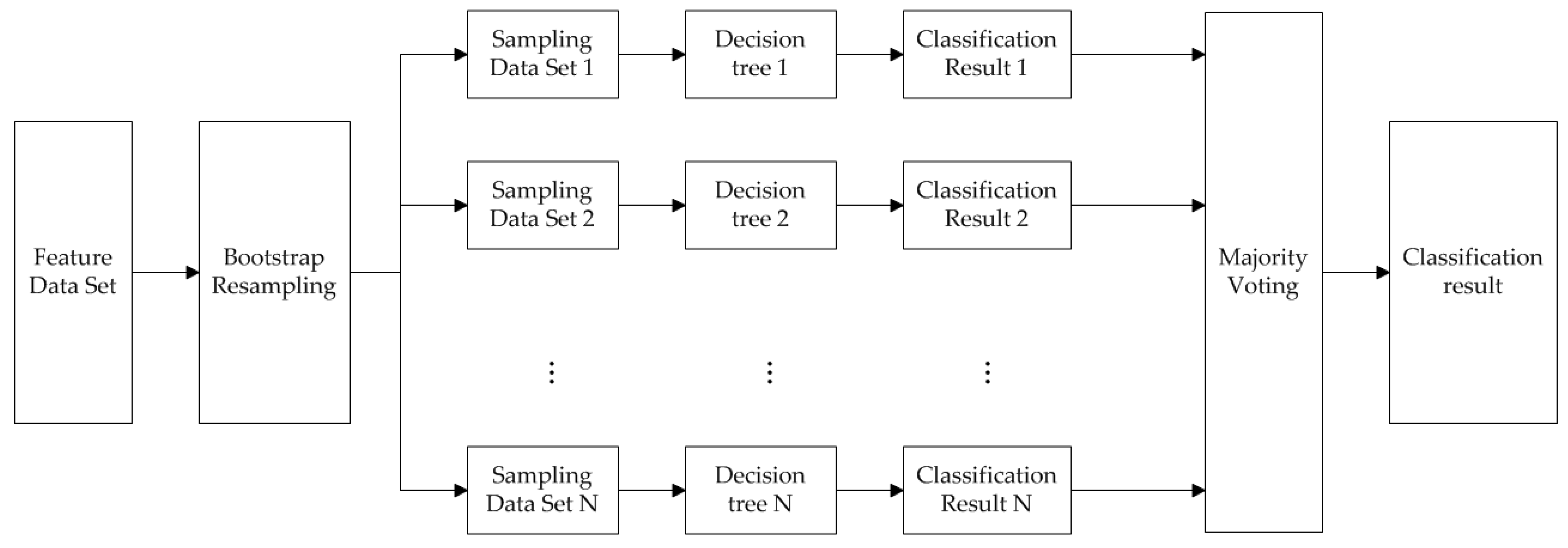
2.2. RF Model
2.3. SEM-RF Algorithm
3. Robust Multi-MP Feature
3.1. Magnitude Phase Features
3.2. Multi-Time Resolution Fusion Feature
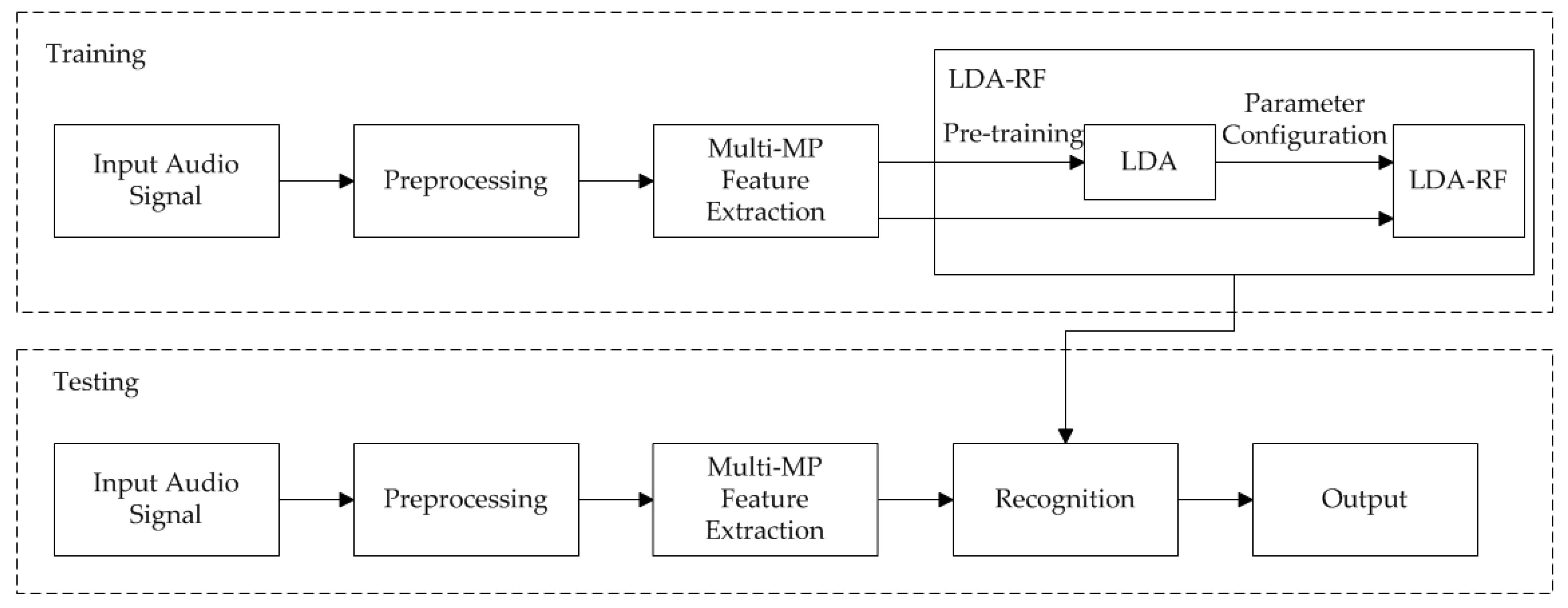
4. ImSEM-RF
4.1. LDA
4.2. ImSEM-RF Algorithm
5. Experimental Results
5.1. Data Set
5.2. Experimental Setup
5.3. Experimental Results
5.3.1. SEM-RF Classification Results
5.3.2. ImSEM-RF Classification Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gerlach, L.; Payá-Vayá, G.; Blume, H. A Survey on Application Specific Processor Architectures for Digital Hearing Aids. J. Signal Process. Syst. 2021, 1–16. [Google Scholar] [CrossRef]
- Kates, J.M. Digital Hearing Aids; Plural Publishing: San Diego, CA, USA, 2008. [Google Scholar]
- Pandey, A.; Mathews, V.J. Low-Delay Signal Processing for Digital Hearing Aids. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 699–710. [Google Scholar] [CrossRef]
- Alexandre, E.; Cuadra, L.; Gil-Pita, R. Sound Classification in Hearing Aids by the Harmony Search Algorithm; Springer: Berlin/Heidelberg, Germany, 2009; Volume 191, pp. 173–188. [Google Scholar] [CrossRef]
- Alexandre, E.; Cuadra, L.; Alvarez, L.; Rosa-Zurera, M. NN-based automatic sound classifier for digital hearing aids. In Proceedings of the 2007 IEEE International Symposium on Intelligent Signal Processing, Xiamen, China, 28 November–1 December 2007; pp. 1–6. [Google Scholar] [CrossRef]
- Tanweer, S.; Mobin, A.; Alam, A. Environmental Noise Classification using LDA, QDA and ANN Methods. Indian J. Sci. Technol. 2016, 9, 1–8. [Google Scholar] [CrossRef]
- Liu, T.; Yan, D.; Wang, R.; Yan, N.; Chen, G. Identification of Fake Stereo Audio Using SVM and CNN. Information 2021, 12, 263. [Google Scholar] [CrossRef]
- Barkana, B.D.; Saricicek, I. Environmental Noise Source Classification Using Neural Networks. In Proceedings of the 2010 Seventh International Conference on Information Technology: New Generations, Washington, DC, USA, 12–14 April 2010; pp. 259–263. [Google Scholar] [CrossRef]
- Nordqvist, P.; Leijon, A. An efficient robust sound classification algorithm for hearing aids. J. Acoust. Soc. Am. 2004, 115, 3033–3041. [Google Scholar] [CrossRef] [PubMed]
- Büchler, M.; Allegro, S.; Launer, S.; Dillier, N. Sound Classification in Hearing Aids Inspired by Auditory Scene Analysis. EURASIP J. Adv. Signal Process. 2005, 2005, 387845. [Google Scholar] [CrossRef] [Green Version]
- Lamarche, L.; Giguère, C.; Gueaieb, W.; Aboulnasr, T.; Othman, H. Adaptive environment classification system for hearing aids. J. Acoust. Soc. Am. 2010, 127, 3124–3135. [Google Scholar] [CrossRef] [PubMed]
- Saki, F.; Kehtarnavaz, N. Background noise classification using random forest tree classifier for cochlear implant applications. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3591–3595. [Google Scholar] [CrossRef]
- Saki, F.; Sehgal, A.; Panahi, I.; Kehtarnavaz, N. Smartphone-based real-time classification of noise signals using subband features and random forest classifier. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2204–2208. [Google Scholar] [CrossRef]
- Alavi, Z.; Azimi, B. Application of Environment Noise Classification towards Sound Recognition for Cochlear Implant Users. In Proceedings of the 2019 6th International Conference on Electrical and Electronics Engineering (ICEEE), Istanbul, Turkey, 16–17 April 2019; pp. 144–148. [Google Scholar] [CrossRef]
- Saki, F.; Kehtarnavaz, N. Automatic switching between noise classification and speech enhancement for hearing aid devices. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 736–739. [Google Scholar] [CrossRef]
- Alamdari, N.; Kehtarnavaz, N. A Real-Time Smartphone App for Unsupervised Noise Classification in Realistic Audio Environments. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Hüwel, A.; Adiloğlu, K.; Bach, J.-H. Hearing aid Research Data Set for Acoustic Environment Recognition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 706–710. [Google Scholar] [CrossRef]
- Yuxin, Z.; Yan, D. A voice activity detection algorithm based on spectral entropy analysis of sub-frequency band. BioTechnol. Indian J. 2014, 10, 12342–12348. [Google Scholar]
- Powell, G.E.; Percival, I.C. A spectral entropy method for distinguishing regular and irregular motion of Hamiltonian systems. J. Phys. A Math. Gen. 1979, 12, 2053–2071. [Google Scholar] [CrossRef]
- Chen, X.; Kar, S.; Ralescu, D.A. Cross-entropy measure of uncertain variables. Inf. Sci. 2012, 201, 53–60. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1, pp. 71–73. [Google Scholar]
- Polykovskiy, D.; Novikov, A. Bayesian Methods for Machine Learning. Coursera and National Research University Higher School of Economics. 2018. Available online: https://www.hse.ru/en/edu/courses/220780748 (accessed on 10 October 2021).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random forests. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar] [CrossRef]
- Biau, G. Analysis of a random forests model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar]
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar] [CrossRef]
- Wang, D.; Lim, J. The unimportance of phase in speech enhancement. IEEE Trans. Acoust. Speech Signal Process. 1982, 30, 679–681. [Google Scholar] [CrossRef]
- Paraskevas, I.; Chilton, E. Combination of magnitude and phase statistical features for audio classification. Acoust. Res. Lett. Online 2004, 5, 111–117. [Google Scholar] [CrossRef]
- Owens, F.J. Signal Processing of Speech; Macmillan International Higher Education: London, UK, 1993. [Google Scholar]
- Orfanidis, S.J. Introduction to Signal Processing; Pearson Education, Inc.: Boston, MA, USA, 2016. [Google Scholar]
- Balakrishnama, S.; Ganapathiraju, A. Linear discriminant analysis-a brief tutorial. Inst. Signal Inf. Processing 1998, 18, 1–8. [Google Scholar]
- Xanthopoulos, P.; Pardalos, P.M.; Trafalis, T.B. Linear discriminant analysis. In Robust Data Mining; Springer: New York, NY, USA, 2013; pp. 27–33. [Google Scholar] [CrossRef]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear discriminant analysis: A detailed tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef] [Green Version]
- Mirzahasanloo, T.; Kehtarnavaz, N. Real-time dual-microphone noise classification for environment-adaptive pipelines of cochlear implants. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 5287–5290. [Google Scholar] [CrossRef]
- Mancini, R.; Carter, B. Op Amps for Everyone; Texas Instruments: Dallas, TX, USA, 2009; pp. 10–11. [Google Scholar]
- Szendro, P.; Vincze, G.; Szasz, A. Pink-noise behaviour of biosystems. Eur. Biophys. J. 2001, 30, 227–231. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| In Traffic | In Vehicle | Music | Quiet Indoors | Rever- Berant | Wind | Cocktail Party | Test Set | |
|---|---|---|---|---|---|---|---|---|
| P&E RF | 89.22% | 96.15% | 97.60% | 91.09% | 52.86% | 89.86% | 92.37% | 90.99% |
| SEM-RF | 100.00% | 99.17% | 99.69% | 95.96% | 79.59% | 97.94% | 96.80% | 97.58% |
| In Traffic | In Vehicle | Music | Quiet Indoors | Rever- Berant | Wind | Test Set | |
|---|---|---|---|---|---|---|---|
| SEM feature | 89.65% | 91.11% | 97.13% | 95.42% | 82.81% | 88.50% | 91.83% |
| MP joint feature | 90.51% | 91.30% | 98.22% | 96.41% | 82.62% | 89.53% | 92.55% |
| Multi-MP feature | 91.80% | 94.24% | 99.02% | 97.25% | 85.52% | 93.23% | 94.42% |
| In Traffic | In Vehicle | Music | Quiet Indoors | Rever- Berant | Wind | Test Set | |
|---|---|---|---|---|---|---|---|
| Multi-MP-RF | 91.80% | 94.24% | 99.02% | 97.25% | 85.52% | 93.23% | 94.42% |
| ImSEM-RF | 88.43% | 94.05% | 98.07% | 94.05% | 88.96% | 93.28% | 93.92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, W.; Fan, X. Audio Classification Algorithm for Hearing Aids Based on Robust Band Entropy Information. Information 2022, 13, 79. https://doi.org/10.3390/info13020079
Jin W, Fan X. Audio Classification Algorithm for Hearing Aids Based on Robust Band Entropy Information. Information. 2022; 13(2):79. https://doi.org/10.3390/info13020079
Chicago/Turabian StyleJin, Weiyun, and Xiaohua Fan. 2022. "Audio Classification Algorithm for Hearing Aids Based on Robust Band Entropy Information" Information 13, no. 2: 79. https://doi.org/10.3390/info13020079
APA StyleJin, W., & Fan, X. (2022). Audio Classification Algorithm for Hearing Aids Based on Robust Band Entropy Information. Information, 13(2), 79. https://doi.org/10.3390/info13020079