
Automatic Curation of Court Documents: Anonymizing Personal Data


Abstract
:1. Introduction
“That none of the officials of the agency, including the Commissioner in charge, verified or observed any kind of misplaced conduct of Mr. ****. That the complaint was made by Ms. ****, who was the head of the Prison and ordered the others (...) That the only thing Mr. **** admits is that he bought a [mobile] chip from Ms. ****, but not for that reason he can accuse you of abuse, much less rape.”
2. Related Work
3. De-Identification of Legal Texts
Que ninguno de los funcionarios de la dependencia, incluso el Comisario a cargo constataron u observaron algún tipo de conducta fuera de lugar del Sr.Juan Pérez.Que la denuncia fue realizada por la Sra.María Rodríguezque es quien lideraba la Cárcel y ordenaba a las demás (…) Que lo único admitido por el Sr.Pérezes que compró un chip a la Sra.Juana Fernández, pero no por eso se lo puede acusar de abuso y mucho menos de violación.
That none of the officials of the dependency, including the Commissioner in charge, stated or observed any type of misplaced conduct by Mr.Juan Pérez. That the complaint was made by Mrs.María Rodríguezwho led the jail and ordered the others (…) that the only thing admitted by Mr.Pérezis that he bought a chip from Mrs.Juana Fernández, but that does not mean he can be accused of abuse and much less of rape.
- Rodríguez Martínez, Juan Líber c/ Pérez Rodríguez, Pedro y otros.Rodríguez Martínez, Juan Líber against Pérez Rodríguez, Pedro and others.
- (…) Sres. Pedro y Juan Pérez, deduce recursos de apelación.(…) Misters Pedro y Juan Pérez, deduct appeals.
- No puede considerarse que Pedro Pérez ha omitido contestar la demanda (…)It can not be considered that Pedro Pérez has omitted to answer the demand (…)
- Se intimó la aceptación de Pedro a fs. 32 vta. y a Juan a fs. 36/37 (…)It was asked the acceptance of Pedro in p. 32 and Juan in pp. 36/37 (…).
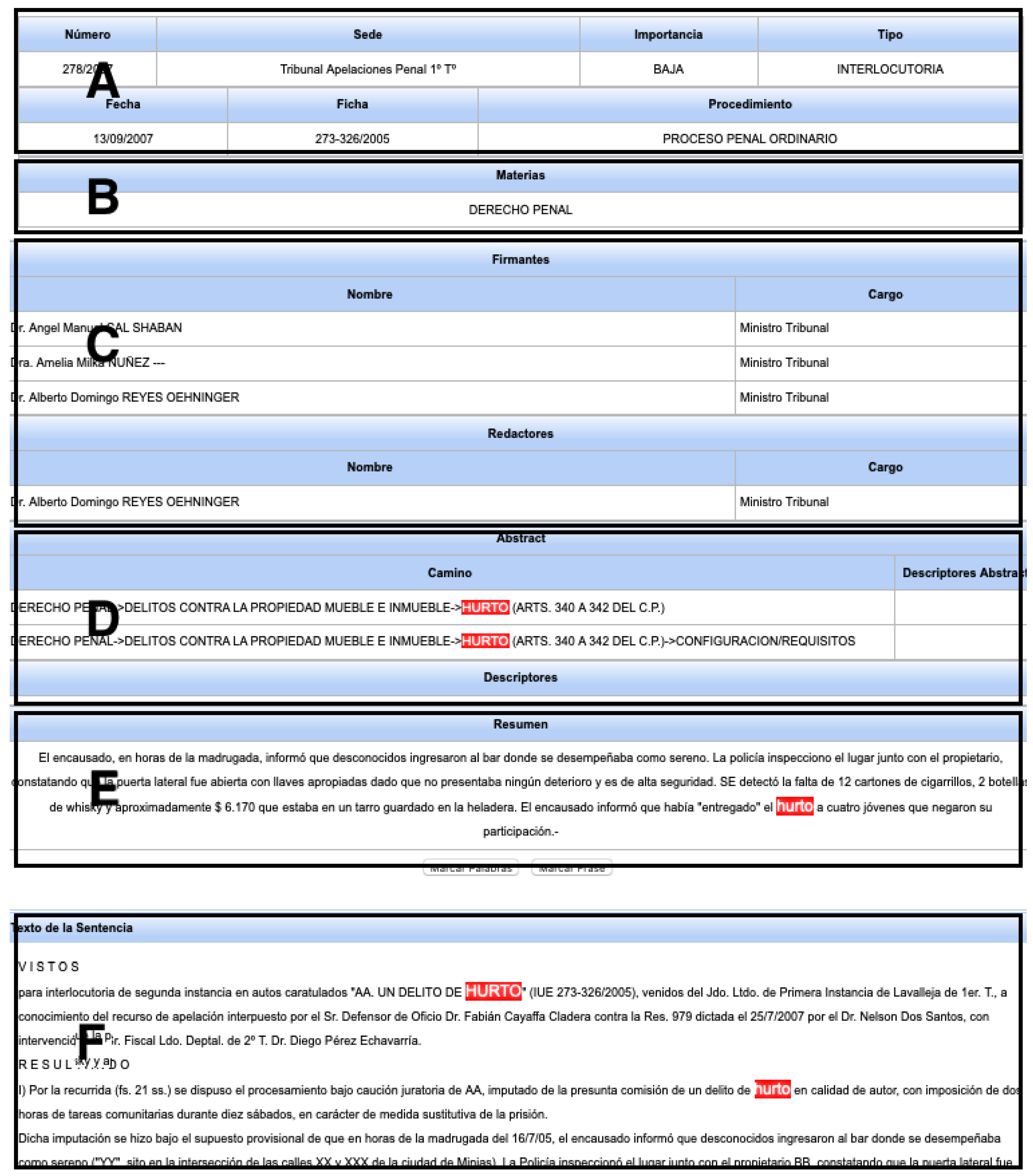
4. Corpus
5. NER Training
6. Co-Reference Resolution
7. Conclusions and Further Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- República Oriental del Uruguay. Protección de Datos Personales y Acción de “Habeas Data”; Ley 18331; Registro Nacional de Leyes y Decretos (Tomo 1, Semestre 2): Montevideo, Uruguay, 2008; p. 378. [Google Scholar]
- Sweeney, L. Replacing personally-identifying information in medical records, the Scrub system. AMIA Annu. Symp. Proc. 1996, 1996, 333–337. [Google Scholar]
- Durrett, G.; Klein, D. A Joint Model for Entity Analysis: Coreference, Typing, and Linking. Trans. Assoc. Comput. Linguist. 2014, 2, 477–490. [Google Scholar] [CrossRef]
- Balog, K. Entity Linking. In Entity-Oriented Search; Springer International Publishing: Cham, Switzerland, 2018; pp. 147–188. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Padró, L.; Stanilovsky, E. FreeLing 3.0: Towards Wider Multilinguality. In Proceedings of the Language Resources and Evaluation Conference (LREC 2012), Istanbul, Turkey, 23–25 May 2012. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics (ACL) System Demonstrations; Association for Computational Linguistics: Stroudsburg, PA, USA, 2014; pp. 55–60. [Google Scholar]
- Honnibal, M.; Montani, I. spaCy 2: Natural Language Understanding with Bloom Embeddings. Convolutional Neural Netw. Increm. Parsing 2017, 7, 411–420. [Google Scholar]
- Cardie, C.; Wagstaff, K. Noun Phrase Coreference as Clustering. In Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999. [Google Scholar]
- Soon, W.M.; Ng, H.T.; Lim, D.C.Y. A Machine Learning Approach to Coreference Resolution of Noun Phrases. Comput. Linguist. 2001, 27, 521–544. [Google Scholar] [CrossRef]
- Mitra, R.; Jeuniaux, P.; Angheluta, R.; Moens, M.F. Progressive Fuzzy Clustering for Noun Phrase Coreference Resolution; DIR 2003: Fourth Dutch-Belgian Information Retrieval Workshop, University of Amsterdam: Amsterdam, NL, USA, 2003; pp. 10–15. [Google Scholar]
- Zheng, J.; Chapman, W.W.; Crowley, R.S.; Savova, G.K. Coreference resolution: A review of general methodologies and applications in the clinical domain. J. Biomed. Informatics 2011, 44, 1113–1122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Y.; Jiang, J.; Zhao, W.X.; Li, S.; Wang, H. Joint Learning for Coreference Resolution with Markov Logic. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 1245–1254. [Google Scholar]
- Ma, X.; Liu, Z.; Hovy, E. Unsupervised Ranking Model for Entity Coreference Resolution. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1012–1018. [Google Scholar] [CrossRef]
- Centers for Medicare & Medicaid Services, United States of America. The Health Insurance Portability and Accountability Act (HIPAA); U.S. Dept. of Labor, Employee Benefits Security Administration: Washington, DC, USA, 1996.
- European Parliament and Council of the European Union. Regulation (UE) 2016/679; Official Journal of the European Union, L119: Luxembourg, 2016. [Google Scholar]
- Dernoncourt, F.; Lee, J.Y.; Uzuner, Ö.; Szolovits, P. De-identification of Patient Notes with Recurrent Neural Networks. arXiv 2016, arXiv:1606.03475. [Google Scholar] [CrossRef] [PubMed]
- Gupta, D.; Saul, M.; Gilbertson, J. Evaluation of a Deidentification (De-Id) Software Engine to Share Pathology Reports and Clinical Documents for Research. Am. J. Clin. Pathol. 2004, 121, 176–186. [Google Scholar] [CrossRef] [PubMed]
- Aramaki, E.; Imai, T.; Miyo, K.; Ohe, K. Automatic deidentification by using sentence features and label consistency. In i2b2 Workshop on Challenges in Natural Language Processing for Clinical Data; i2b2: Washington, DC, USA, 2006; pp. 10–11. [Google Scholar]
- Krishnan, V.; Manning, C.D. An Effective Two-stage Model for Exploiting Non-local Dependencies in Named Entity Recognition. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 17–21 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 1121–1128. [Google Scholar] [CrossRef] [Green Version]
- Gardner, J.; Xiong, L.; Science, C. HIDE: An Integrated System for Health Information DE-identi cation. In Proceedings of the 2008 21st IEEE International Symposium on Computer-Based Medical Systems; IEEE: New York, NY, USA, 2008; pp. 254–259. [Google Scholar] [CrossRef] [Green Version]
- Uzuner, O.; Sibanda, T.C.; Luo, Y.; Szolovits, P. A de-identifier for medical discharge summaries. Artif. Intell. Med. 2008, 42, 13–35. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 260–270. [Google Scholar] [CrossRef]
- Chalapathy, R.; Zare Borzeshi, E.; Piccardi, M. Bidirectional LSTM-CRF for Clinical Concept Extraction. In Proceedings of the Clinical Natural Language Processing Workshop (ClinicalNLP), Osaka, Japan, 11 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 7–12. [Google Scholar]
- Lee, J.Y.; Dernoncourt, F.; Uzuner, O.; Szolovits, P. Feature-Augmented Neural Networks for Patient Note De-identification. In Proceedings of the Clinical Natural Language Processing Workshop (ClinicalNLP), Osaka, Japan, 11 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 17–22. [Google Scholar]
- Li, J.; Chen, X.; Hovy, E.; Jurafsky, D. Visualizing and Understanding Neural Models in NLP. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 681–691. [Google Scholar]
- Liu, Z.; Tang, B.; Wang, X.; Chen, Q. De-identification of clinical notes via recurrent neural network and conditional random field. J. Biomed. Inform. 2017, 75, S34–S42. [Google Scholar] [CrossRef] [PubMed]
- Jia, C.; Liang, X.; Zhang, Y. Cross-Domain NER using Cross-Domain Language Modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2464–2474. [Google Scholar] [CrossRef]
- Sharma, S.; Gamoura, S.; Prasad, D.; Aneja, A. Emerging Legal Informatics towards Legal Innovation: Current status and future challenges and opportunities. Leg. Inf. Manag. J. 2021, 1, 27. [Google Scholar]
- Bayardo, R.J.; Agrawal, R. Data privacy through optimal k-anonymization. In Proceedings of the International Conference on Data Engineering, Tokyo, Japan, 5–8 April 2005; pp. 217–228. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J.; Sánchez, D.; Rufian-Torrell, G. Anonymization of nominal data based on semantic marginality. Inf. Sci. 2013, 242, 35–48. [Google Scholar] [CrossRef]
- Newhauser, W.; Jones, T.; Swerdloff, S.; Newhauser, W.; Cilia, M.; Carver, R.; Halloran, A.; Zhang, R. Anonymization of DICOM electronic medical records for radiation therapy. Comput. Biol. Med. 2014, 53, 134–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Yang, L.T.; Liu, C.; Chen, J. A scalable two-phase top-down specialization approach for data anonymization using mapreduce on cloud. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 363–373. [Google Scholar] [CrossRef]
- Heatherly, R.; Rasmussen, L.V.; Peissig, P.L.; Pacheco, J.A.; Harris, P.; Denny, J.C.; Malin, B.A. A multi-institution evaluation of clinical profile anonymization. J. Am. Med. Inform. Assoc. 2016, 23, e131–e137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karle, T.; Vora, D. PRIVACY preservation in big data using anonymization techniques. In Proceedings of the 2017 International Conference on Data Management, Analytics and Innovation (ICDMAI), Pune, India, 24–26 February 2017. [Google Scholar] [CrossRef]
- Patil, D.; Mohapatra, R.K.; Babu, K.S. Evaluation of generalization based K-anonymization algorithms. In Proceedings of the 2017 Third International Conference on Sensing, Signal Processing and Security (ICSSS), Chennai, India, 4–5 May 2017; pp. 171–175. [Google Scholar] [CrossRef]
- Li, Y.; Baldwin, T.; Cohn, T. Towards Robust and Privacy-preserving Text Representations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 25–30. [Google Scholar] [CrossRef] [Green Version]
- Friedrich, M.; Köhn, A.; Wiedemann, G.; Biemann, C. Adversarial Learning of Privacy-Preserving Text Representations for De-Identification of Medical Records. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5829–5839. [Google Scholar] [CrossRef]
- Mamede, N.; Baptista, J.; Dias, F. Automated anonymization of text documents. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation, Vancouver, BC, Canada, 24–29 July 2016; pp. 1287–1294. [Google Scholar] [CrossRef]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 2145–2158. [Google Scholar]
- Baevski, A.; Edunov, S.; Liu, Y.; Zettlemoyer, L.; Auli, M. Cloze-driven Pretraining of Self-attention Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 5360–5369. [Google Scholar] [CrossRef] [Green Version]
- Glaser, I.; Schamberger, T.; Matthes, F. Anonymization of german legal court rulings. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law, São Paulo, Brazil, 21–25 June 2021; pp. 205–209. [Google Scholar]
- Csányi, G.M.; Nagy, D.; Vági, R.; Vadász, J.P.; Orosz, T. Challenges and Open Problems of Legal Document Anonymization. Symmetry 2021, 13, 1490. [Google Scholar] [CrossRef]
- Tamper, M.; Oksanen, A.; Tuominen, J.; Hyvönen, E.; Hietanen, A. Anonymization Service for Finnish Case Law: Opening Data without Sacrificing Data Protection and Privacy of Citizens. In Proceedings of the Law via the Internet: Knowledge of the Law in the Big Data Age, Florence, Italy, 11–12 October 2018. [Google Scholar]
- Stenetorp, P.; Pyysalo, S.; Topić, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. BRAT: A Web-based Tool for NLP-Assisted Text Annotation. In Proceedings of the Demonstrations Session at EACL 2012, Avignon, France, 23–27 April 2012. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bagga, A.; Baldwin, B. Algorithms for Scoring Coreference Chains. In Proceedings of the The First International Conference on Language Resources and Evaluation Workshop on Linguistics Coreference, Granada, Spain, 28–30 May 1998; pp. 563–566. [Google Scholar]
- Vilain, M.; Burger, J.; Aberdeen, J.; Connolly, D.; Hirschman, L. A Model-theoretic Coreference Scoring Scheme. In Proceedings of the 6th Conference on Message Understanding, Columbia, MD, USA, 6–8 November 1995; Association for Computational Linguistics: Stroudsburg, PA, USA, 1995; pp. 45–52. [Google Scholar] [CrossRef] [Green Version]
- Luo, X. On Coreference Resolution Performance Metrics. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 25–32. [Google Scholar] [CrossRef]
- Màrquez, L.; Recasens, M.; Sapena, E. Coreference Resolution: An Empirical Study Based on SemEval-2010 Shared Task 1. Lang. Resour. Eval. 2013, 47, 661–694. [Google Scholar] [CrossRef] [Green Version]
- Moosavi, N.S.; Strube, M. Which Coreference Evaluation Metric Do You Trust? A Proposal for a Link-based Entity Aware Metric. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 632–642. [Google Scholar] [CrossRef]
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 410–420. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Drop-out | 0.10, 0.20, 0.30, 0.35, 0.40, 0.50, 0.60 |
| Stop criteria | 20 rounds without performance improvement or 500 |
| NER reset | True/False |
| PER tag | Retrain PER or a new PER-X tag |
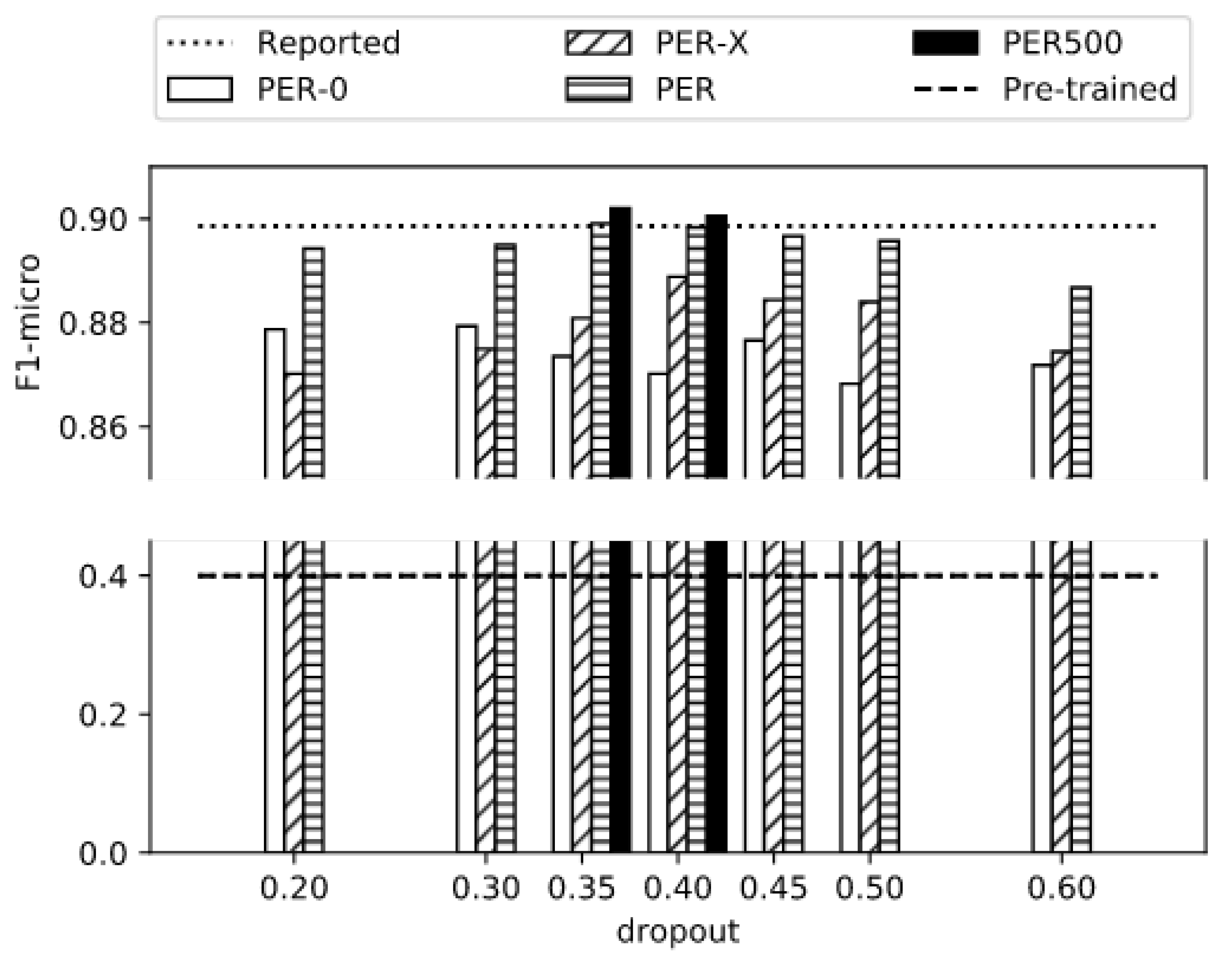
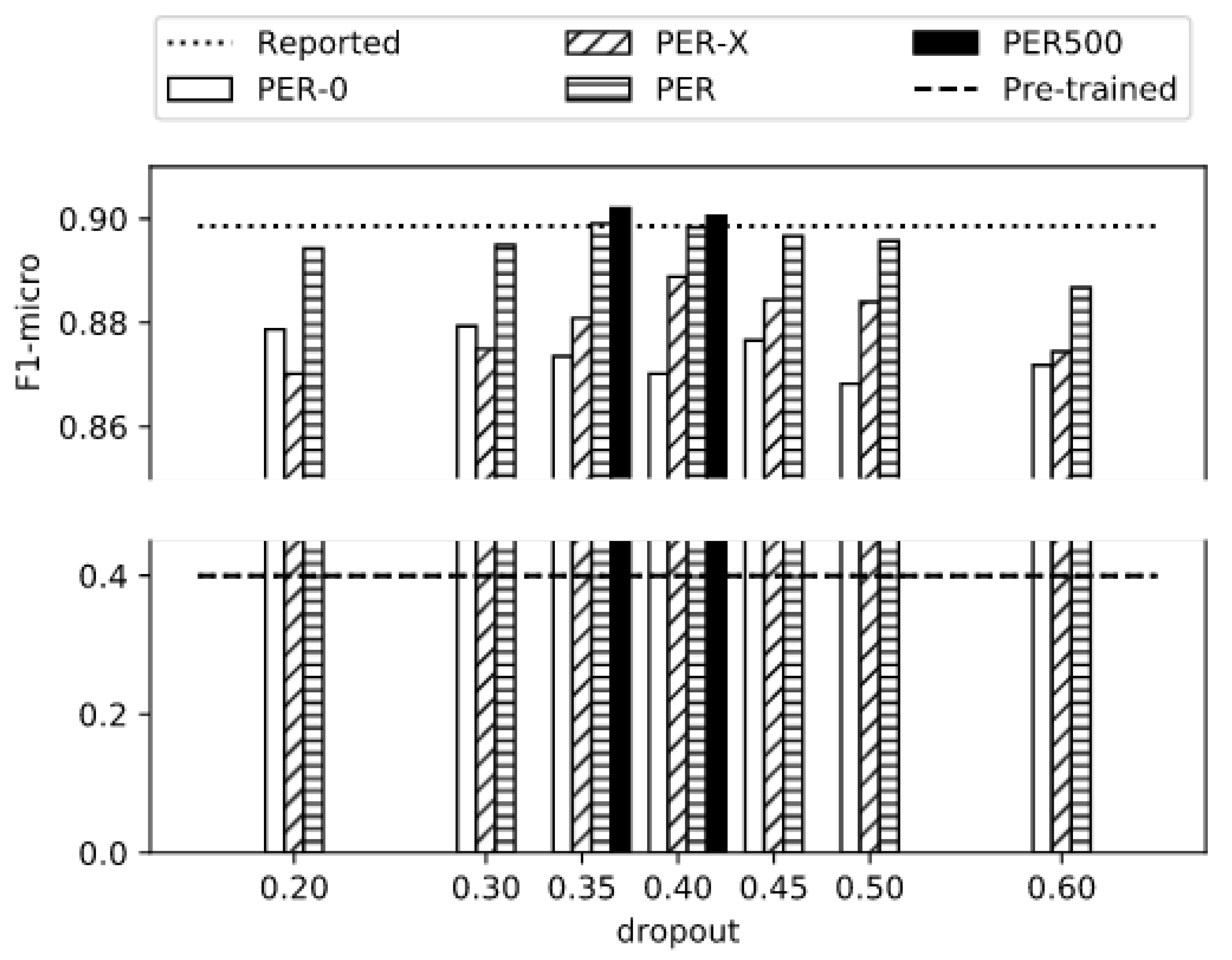
| Experiment | Dropout | Iteration | F1-micro | P-micro | R-micro | Doc.Acc. |
|---|---|---|---|---|---|---|
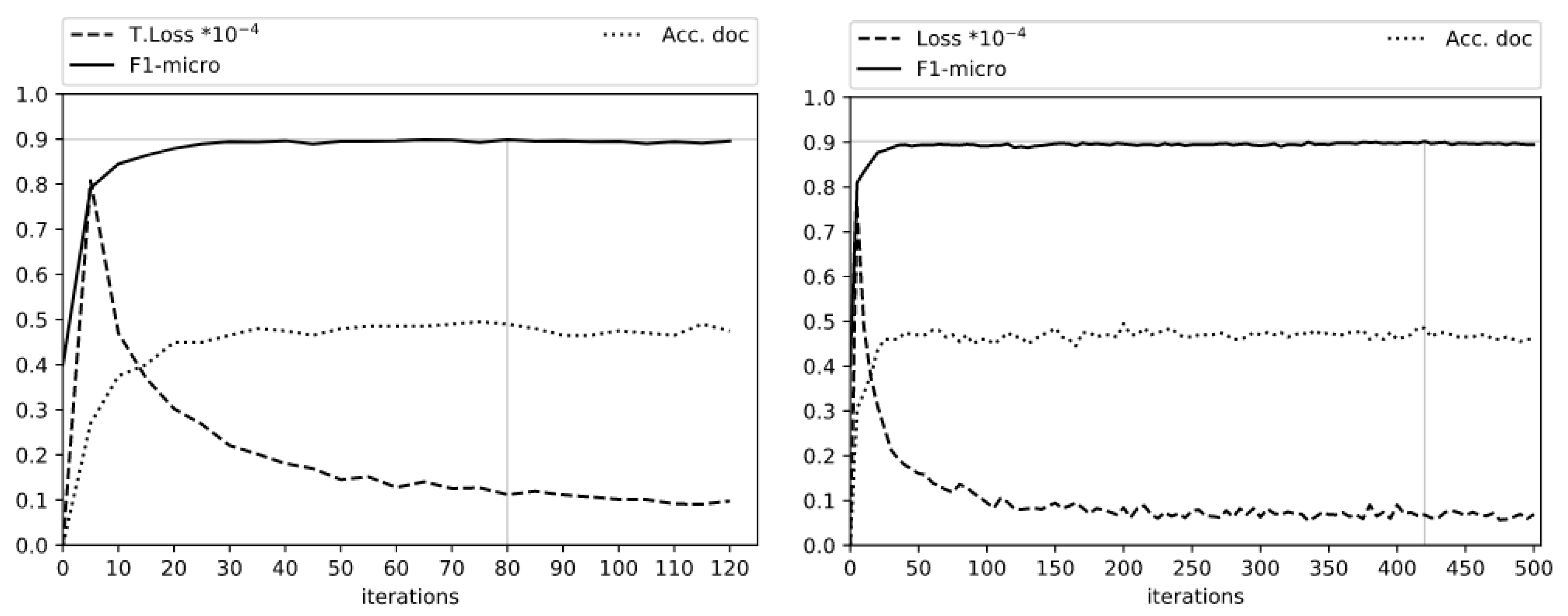
| PER500 | 0.35 | 420 | 0.9021 | 0.8992 | 0.9050 | 0.4850 |
| PER | 0.35 | 80 | 0.8991 | 0.8792 | 0.9198 | 0.4900 |
| Reported | – | – | 0.8971 | 0.8986 | 0.8957 | – |
| PER-X | 0.40 | 205 | 0.8888 | 0.8853 | 0.8923 | 0.4500 |
| PER-0 | 0.30 | 60 | 0.8793 | 0.8515 | 0.9090 | 0.3900 |
| Pre-Trained | – | – | 0.3999 | 0.3002 | 0.5986 | 0.0000 |
| Parameter | Values |
|---|---|
| Distance | Overlap, Jaccard, Sorensen, Tversky, Bag, LCSSTR, Hamming, Goto-H, Bag, Entropy-NCD, Strcmp95, Jaro-Winkler, Smith-Waterman, LCSSEQ, Postfix, Needleman-Wunsch, Ratcliff-Obershelp, Levenshtein, Damerau-Levenshtein |
| Threshold | From 0.05 to 0.95 step 0.05 |
| Linkage | Average (other options were discarded in preliminary tests) |
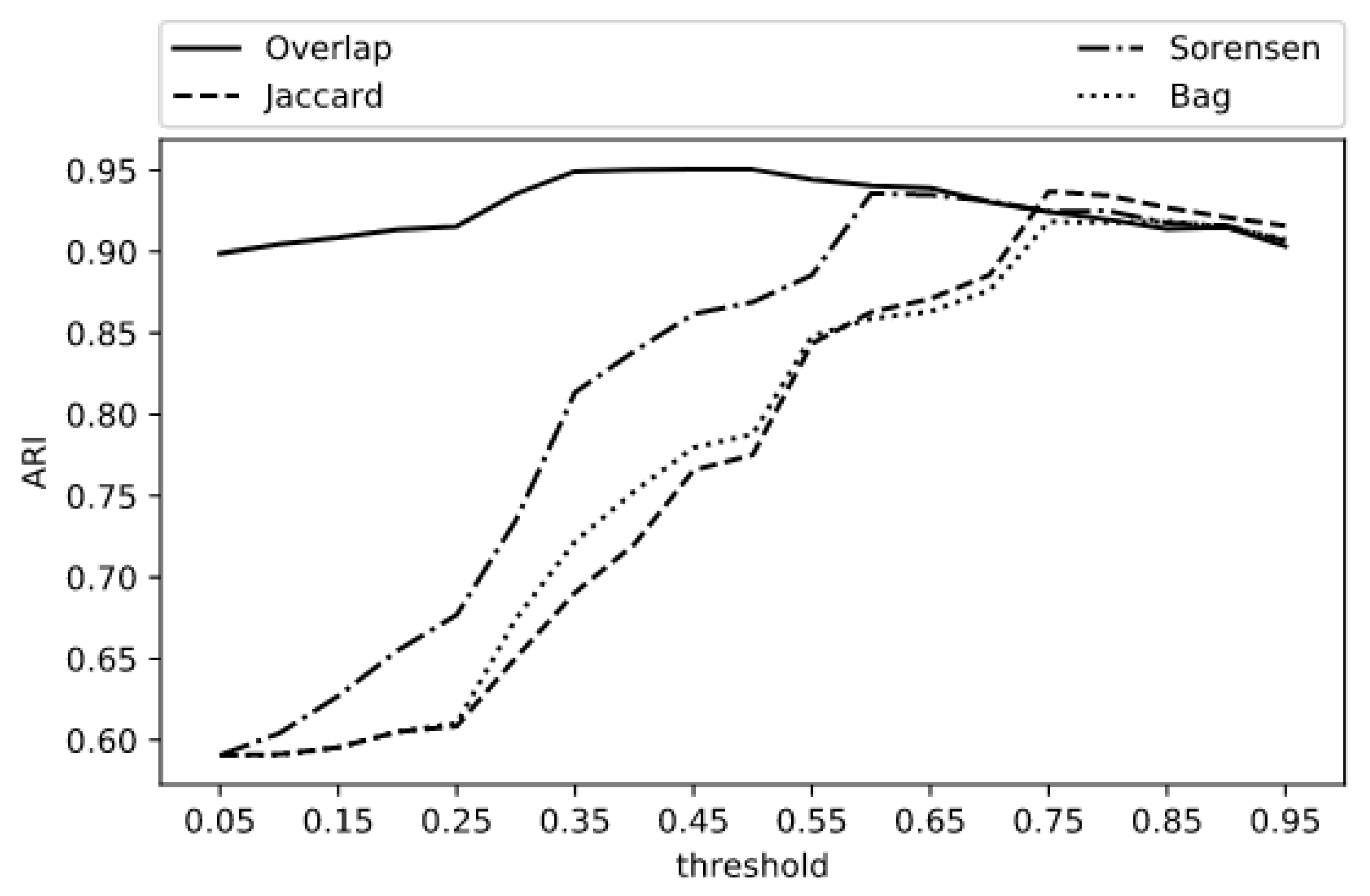
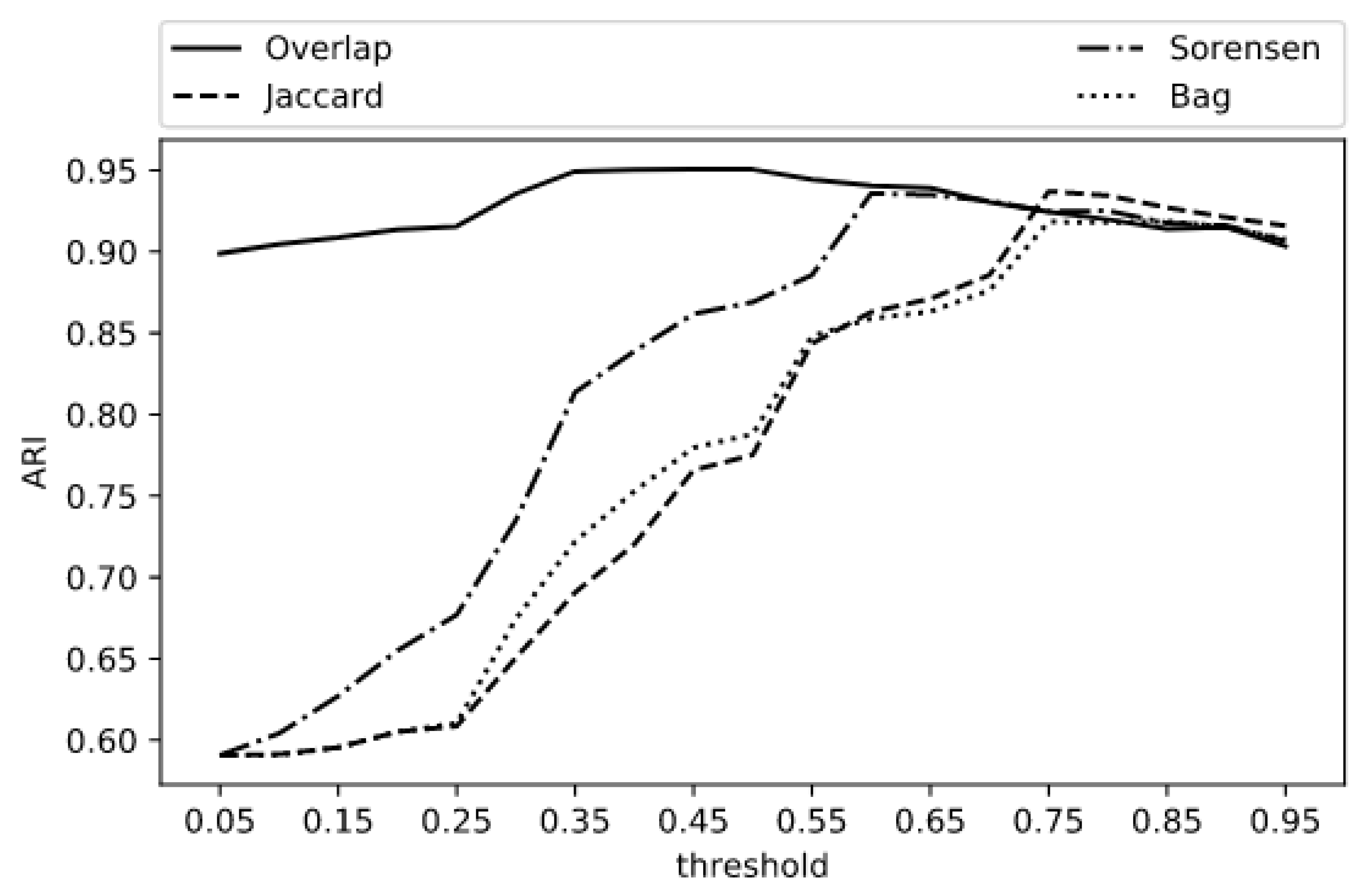
| Experiment | Comp | Homo | V-Measure | ARI | Doc.Acc. |
|---|---|---|---|---|---|
| Overlap 0.45 | 0.9666 | 0.9860 | 0.9695 | 0.9506 | 0.8095 |
| Jaccard 0.75 | 0.9644 | 0.9777 | 0.9609 | 0.9370 | 0.7902 |
| Sorensen 0.60 | 0.9633 | 0.9778 | 0.9603 | 0.9357 | 0.7864 |
| Bag 0.85 | 0.9718 | 0.9528 | 0.9491 | 0.9187 | 0.7580 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garat, D.; Wonsever, D. Automatic Curation of Court Documents: Anonymizing Personal Data. Information 2022, 13, 27. https://doi.org/10.3390/info13010027
Garat D, Wonsever D. Automatic Curation of Court Documents: Anonymizing Personal Data. Information. 2022; 13(1):27. https://doi.org/10.3390/info13010027
Chicago/Turabian StyleGarat, Diego, and Dina Wonsever. 2022. "Automatic Curation of Court Documents: Anonymizing Personal Data" Information 13, no. 1: 27. https://doi.org/10.3390/info13010027
APA StyleGarat, D., & Wonsever, D. (2022). Automatic Curation of Court Documents: Anonymizing Personal Data. Information, 13(1), 27. https://doi.org/10.3390/info13010027