
Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes

 ,
,  ,
,  and
and
Abstract
1. Introduction
- It automatically labels the polarity of both English and Filipino language tweets.
- It reports the sentiments of Filipinos towards COVID-19 vaccines.
- The government can use this study as a tool to make wise decisions regarding the vaccination program.
- The proposed model can continuously analyze incoming tweets to monitor any updates or changes in the attitudes of Filipinos towards COVID-19 vaccines.
2. Related Literature
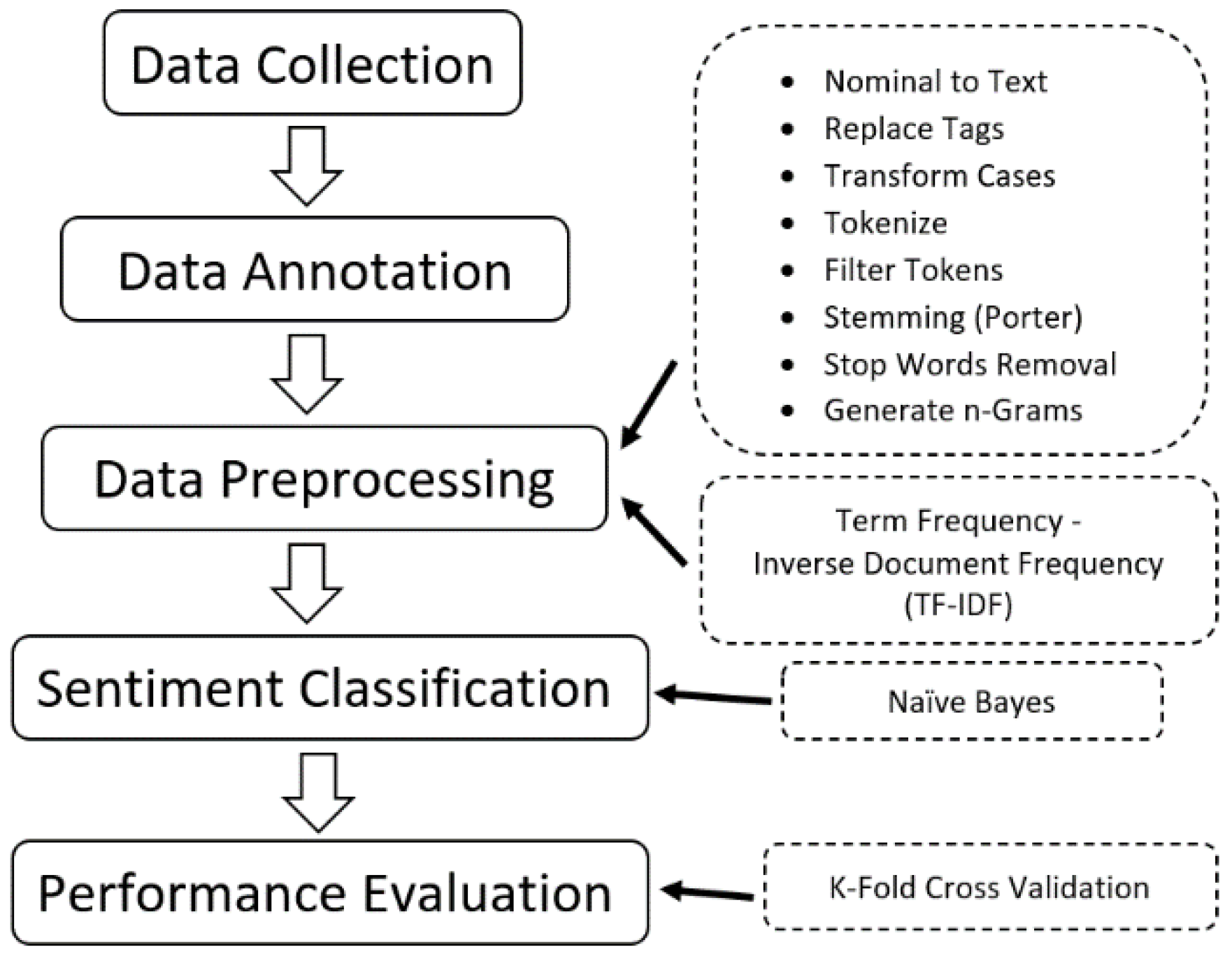
3. Materials and Methods
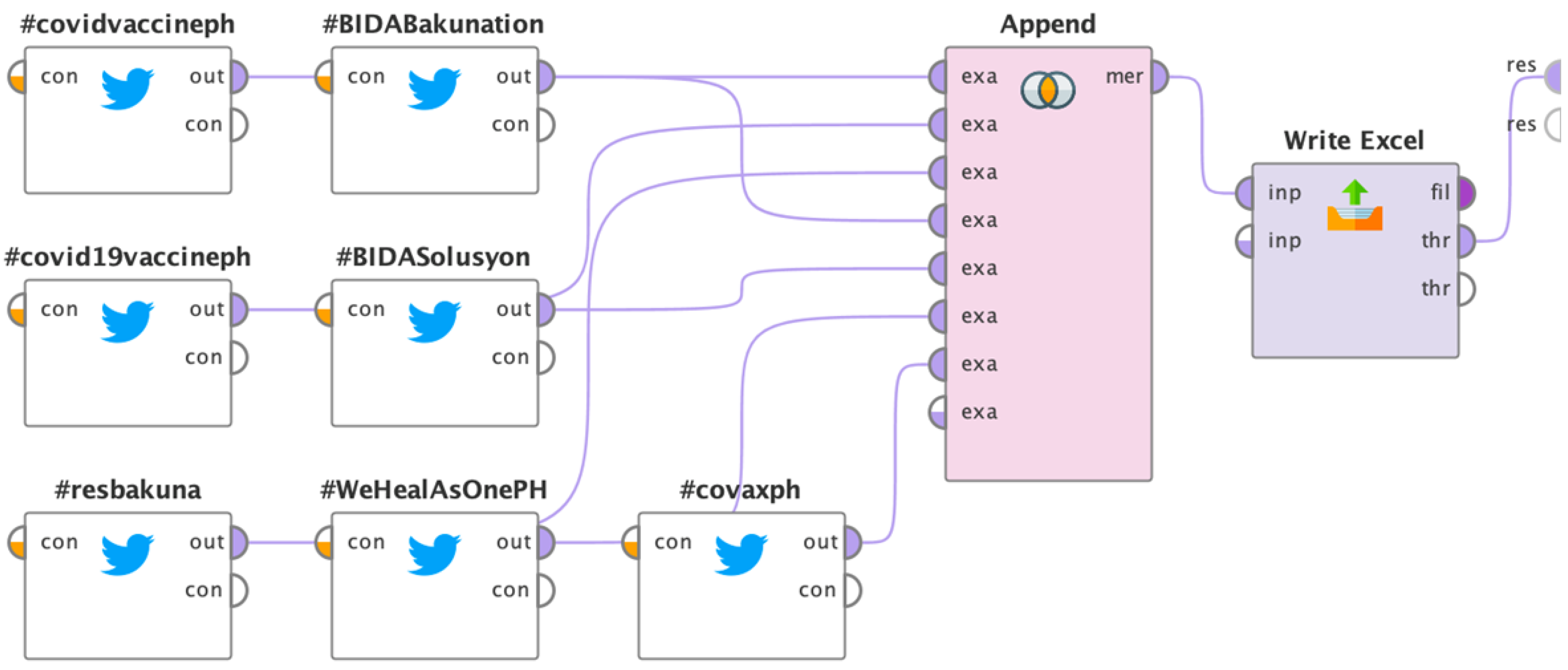
3.1. Data Collection
3.2. Data Annotation
3.3. Data Preparation and Preprocessing
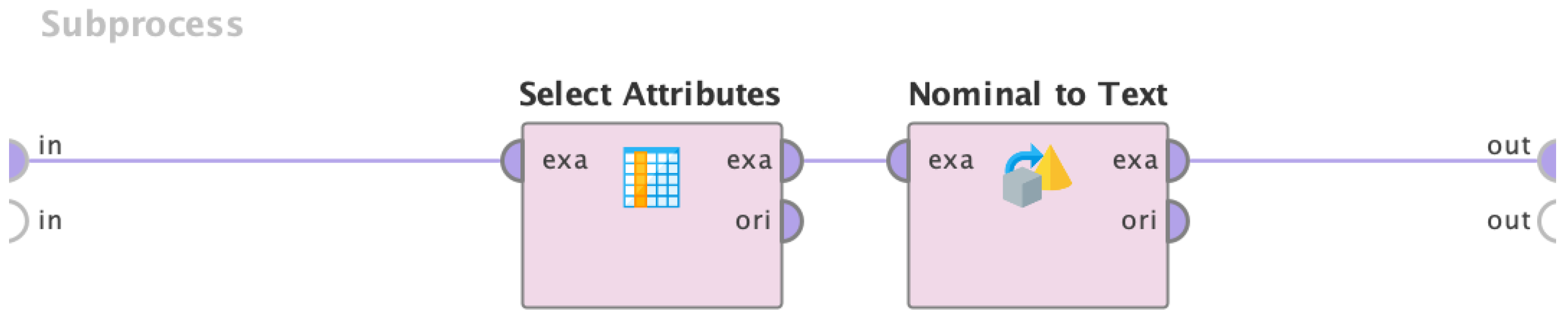
3.3.1. Conversion of Nominal Values to Text
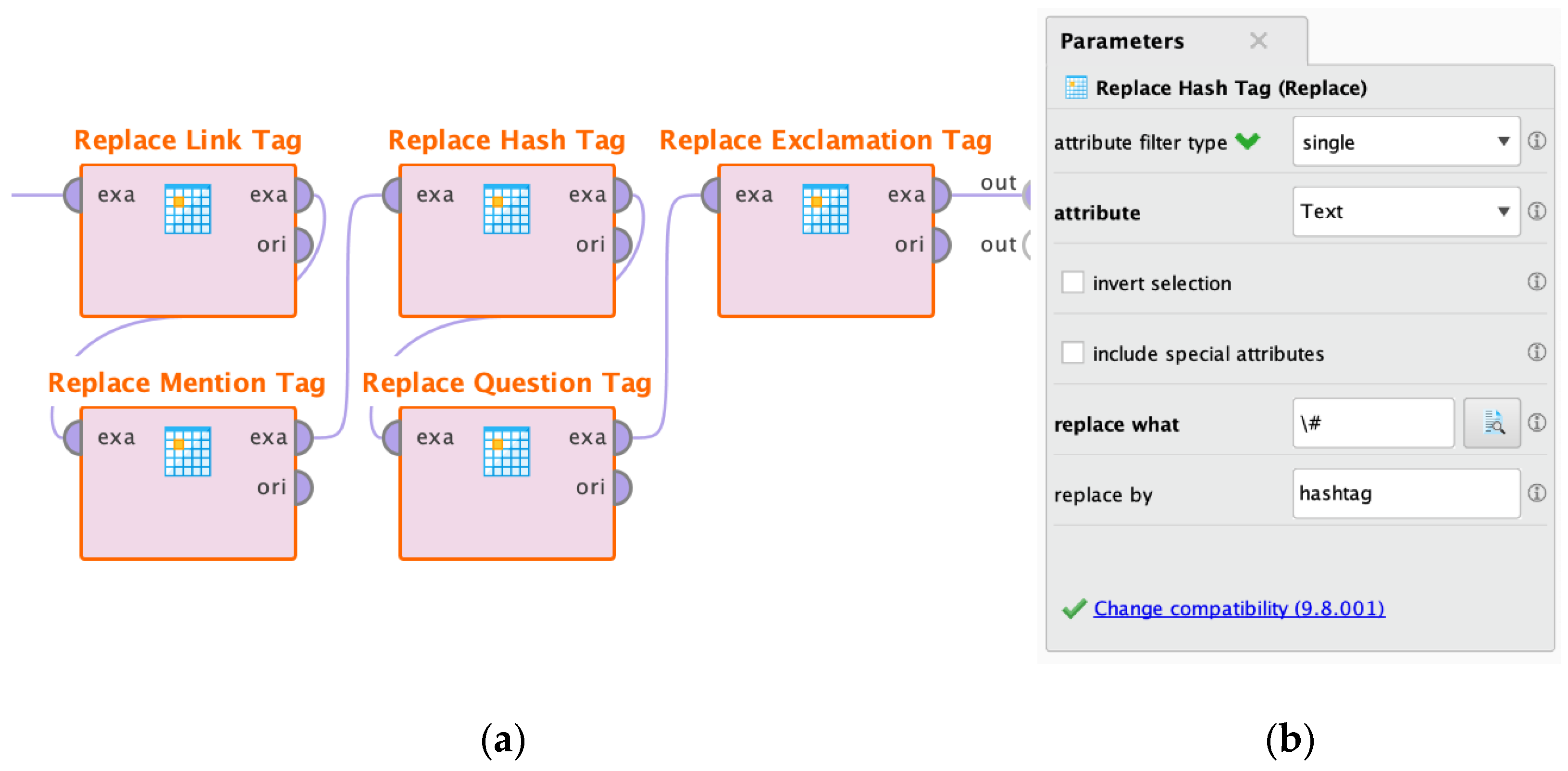
3.3.2. Replacing Tags
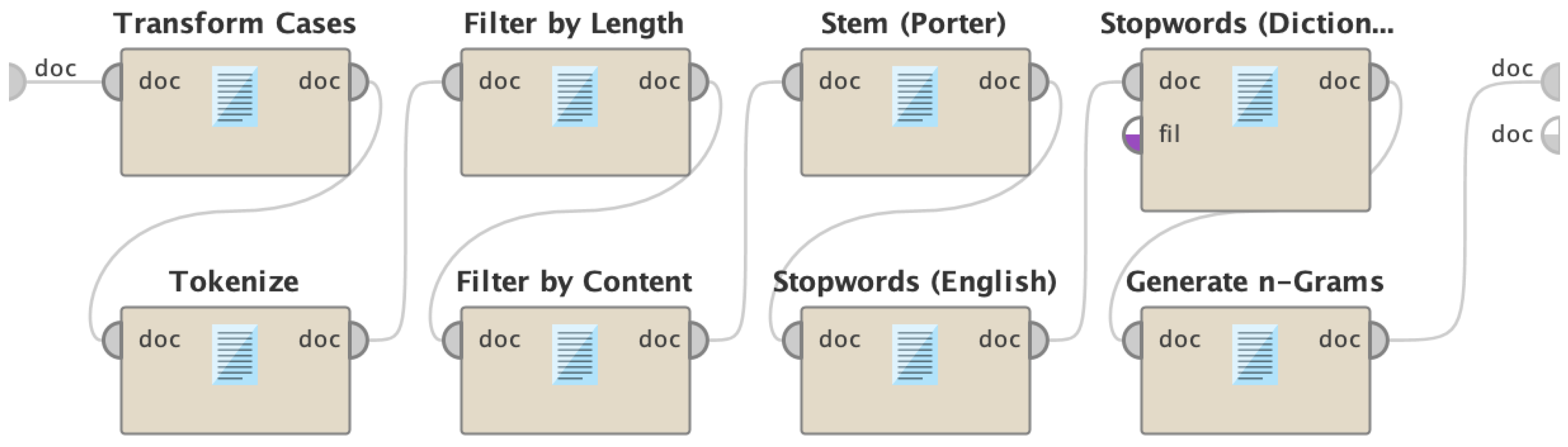
3.3.3. Process Documents from Data
- Transform cases: This process transforms all the uppercase letters into lowercase and vice versa. The researchers chose to transform to lowercase in the parameter section.
- Filter tokens by length: This process traverses throughout the tokenized terms and filters words shorter or longer than a specified number of characters. The researchers used a minimum of 4 and a maximum of 25 characters per word.
- Stop words removal: In this process, stop words were removed. The Filter Stop Words English operator was used to process the English tweets. Words such as the, a, an, with, of, etc. were removed. Tagalog stop words, such as ang, at, kay, na, o, din, ba, etc., were also removed using a text file containing Tagalog stop words as an input to the Filter Stop Words Dictionary operator. These two filter operators were used to cater for both English and Tagalog tweets present in the dataset.
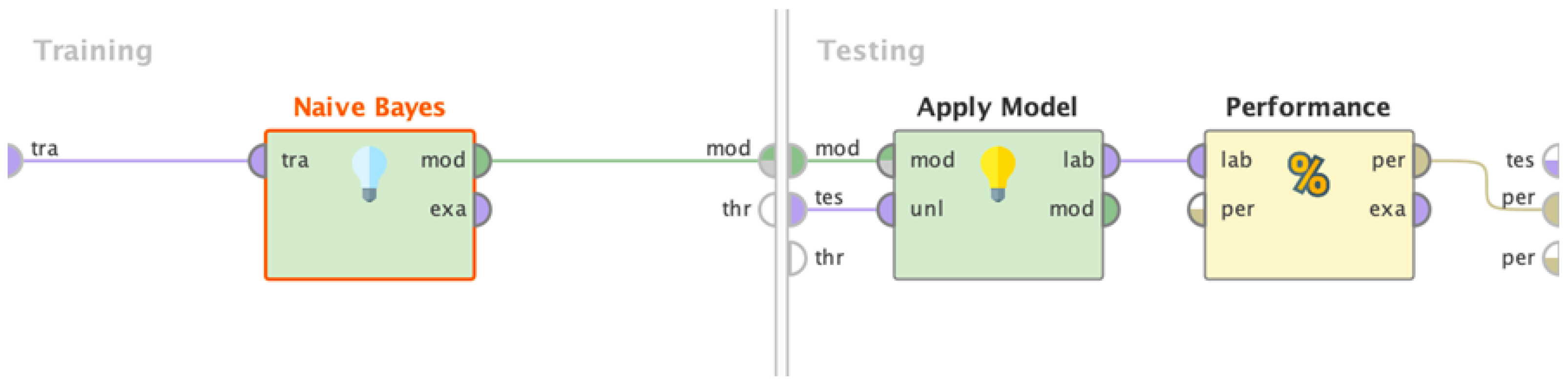
3.4. Sentiment Classification
3.5. Performance Evaluation
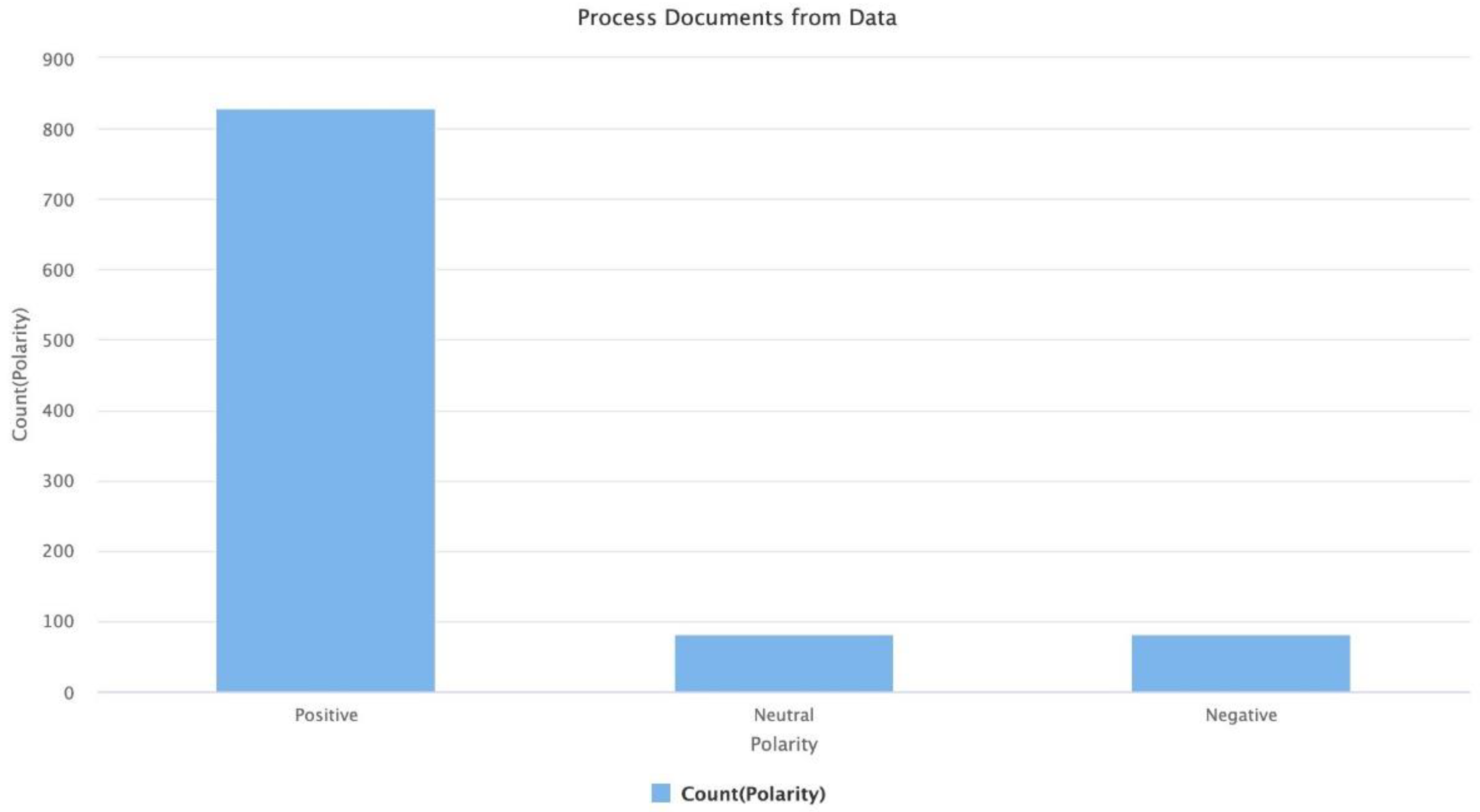
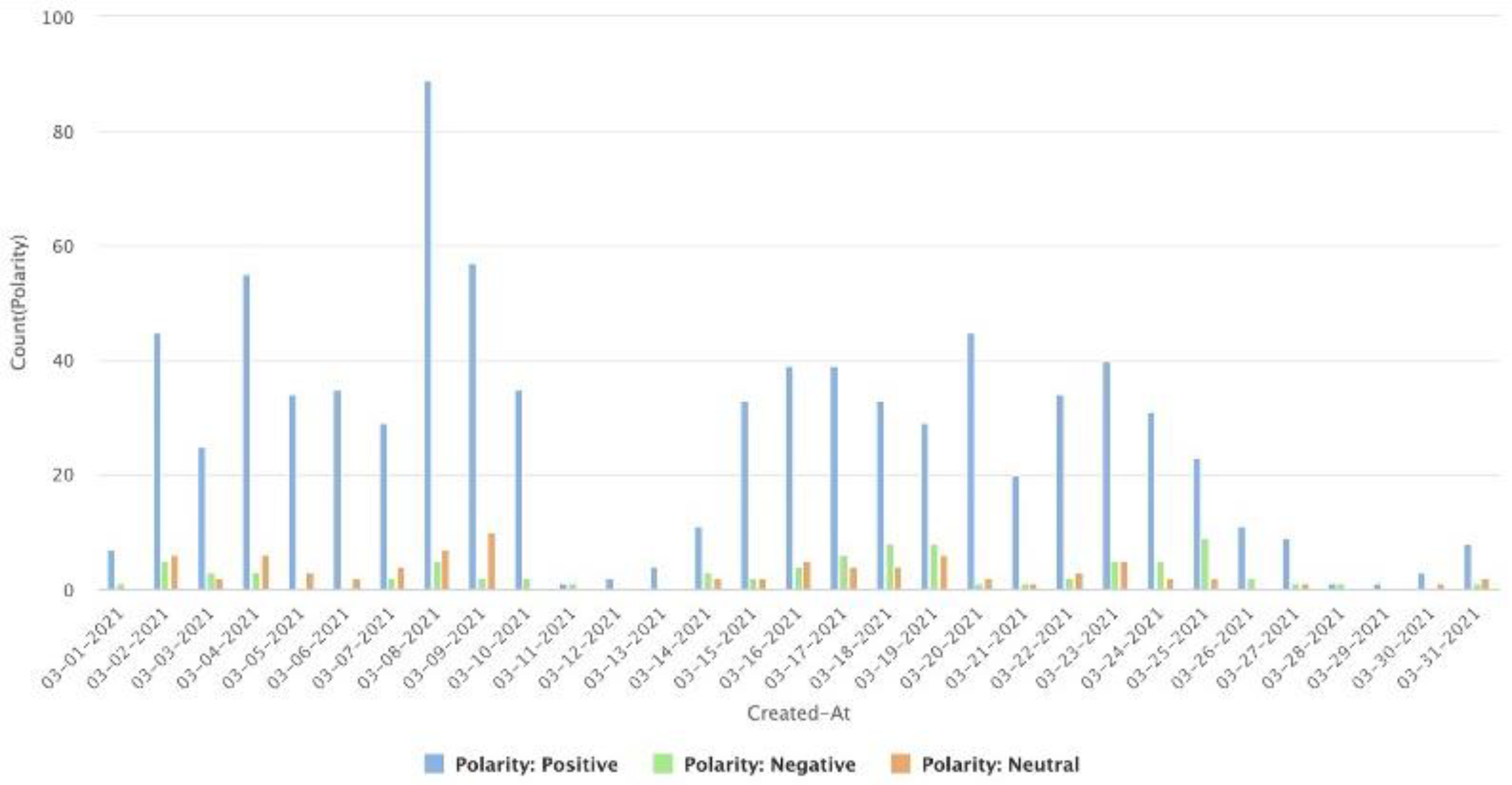
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Jan, A.; Mata, M.N.; Albinsson, P.A.; Martins, J.M.; Hassan, R.B.; Mata, P.N. Alignment of Islamic Banking Sustainability Indicators with Sustainable Development Goals: Policy Recommendations for Addresing the COVID-19 Pandemic. Sustainability 2021, 13, 2607. [Google Scholar] [CrossRef]
- Galea, S.; Merchant, R.M.; Lurie, N. The Mental Health Consequences of COVID-19 and Physical Distancing the Need for Prevention and Early Intervention. JAMA Intern. Med. 2020, 180, 817–818. [Google Scholar] [CrossRef] [PubMed]
- Tirachini, A.; Cats, O. COVID-19 and Public Transportation: Current Assessment, Prospects, and Research Needs. J. Public Transp. 2020, 22. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, M.; Singh, G. A chaotic and stressed environment for 2019-nCoV suspected, infected and other people in India: Fear of mass destruction and causality. Asian J. Psychiatry 2020, 51, 102049. [Google Scholar] [CrossRef] [PubMed]
- Madarang, C.R.S. COVID-19 Vaccines Reach All Southeast Asian Nations except Philippines. Interaksyon, 26 February 2021. Available online: https://interaksyon.philstar.com/politics-issues/2021/02/26/186349/covid-19-vaccines-reach-all-southeast-asian-nations-except-philippines/ (accessed on 7 April 2021).
- Tomacruz, S. Philippines Receives First COVID-19 Vaccine Delivery from Sinovac. Rappler, 28 February 2021. Available online: https://www.rappler.com/nation/philippines-receives-first-delivery-covid-19-vaccine-sinovac-february-28-2021 (accessed on 8 April 2021).
- Reuters. Philippines to Continue AstraZeneca Vaccinations Amid Suspensions in Europe. Reuters, 12 March 2021. Available online: https://www.reuters.com/article/us-health-coronavirus-philippines-vaccin-idUSKBN2B403X (accessed on 8 April 2021).
- De Leon, D. Philippines Receives 400,000 More Sinovac Doses from China. Rappler, 24 March 2021. Available online: https://www.rappler.com/nation/philippines-receives-more-china-sinovac-vaccines-march-24-2021 (accessed on 8 April 2021).
- Venzon, C. Philippines Starts COVID Vaccinations, Courtesy of China. Nikkei Asia, 1 March 2021. Available online: https://asia.nikkei.com/Spotlight/Coronavirus/COVID-vaccines/Philippines-starts-COVID-vaccinations-courtesy-of-China (accessed on 8 April 2021).
- Department of Health (Philippines). The Philippine National Deployment and Vaccination Plan for COVID-19 Vaccines. January 2021. Available online: https://doh.gov.ph/sites/default/files/basic-page/The%20Philippine%20National%20COVID-19%20Vaccination%20Deployment%20Plan.pdf (accessed on 8 April 2021).
- Sharma, S. GitHub. 8 May 2018. Available online: https://github.com/stuti-sharma/Sentiment-Analysis-Twitter-RapidMiner (accessed on 5 April 2021).
- Ndasauka, Y.; Hou, J.; Wang, Y.; Yang, L.; Yang, Z.; Ye, Z.; Hao, Y.; Fallgatter, A.J.; Kong, Y.; Zhang, X. Excessive use of Twitter among college students in the UK: Validation of the Microblog Excessive Use Scale and relationship to social interaction and loneliness. Comput. Hum. Behav. 2016, 55, 963–971. [Google Scholar] [CrossRef]
- Cureg, M.Q.; De La Cruz, J.A.D.; Solomon, J.C.A.; Saharkhiz, A.T.; Balan, A.K.D.; Samonte, M.J.C. Sentiment Analysis on Tweets with Punctuations, Emoticons, and Negations. In Proceedings of the 2019 2nd International Conference on Information Science and Systems, Tokyo, Japan, 16–19 March 2019. [Google Scholar]
- Guo, X.; Li, J. A Novel Twitter Sentiment Analysis Model with Baseline Correlation for Financial Market Prediction with Improved Efficiency. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019. [Google Scholar]
- Samonte, M.J.C.; Garcia, J.M.R.; Lucero, V.J.L.; Santos, S.C.B. Sentiment and opinion analysis on Twitter about local airlines. In Proceedings of the 3rd International Conference on Communication and Information Processing, Tokyo, Japan, 24–26 November 2017. [Google Scholar]
- Liu, B. Sentiment Analysis and Subjectivity. In Handbook of Natural Language Processing; 2010; Available online: https://www.cs.uic.edu/~liub/FBS/NLP-handbook-Liub-final.pdf (accessed on 9 May 2021).
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharrya, U.R. ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Wei, L.; Wei, S.; Ji, S.; Cambria, E. BiERU: Bidirectional Emotional Recurrent Unit for Conversational Sentiment Analysis. arXiv 2020, arXiv:2006.00492. [Google Scholar]
- Ali, F.; Ali, A.; Imran, M.; Naqvi, R.A.; Siddiqi, M.H.; Kwak, K.-S. Traffic accident detection and condition analysis based on social networking data. Accid. Anal. Prev. 2021, 151, 105973. [Google Scholar] [CrossRef] [PubMed]
- Ali, F.; Sappagh, S.; Islam, S.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K.-S. An Intelligent Healthcare Monitoring Framework using Wearable Sensors and Social Neworking Data. Future Gener. Comput. Syst. 2020, 114, 23–43. [Google Scholar] [CrossRef]
- Rapid Miner Documentation. Rapid Miner. 2021. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/bayesian/naive_bayes.html (accessed on 5 April 2021).
- Delizo, J.P.D.; Abisado, M.B.; De Los Trinos, M.I.P. Philippine Twitter Sentiments during Covid-19 Pandemic using Multinomial Naïve-Bayes. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 408–412. [Google Scholar]
- Khurana, S. Naive Bayes Classifiers Geeks for Geeks. 15 May 2020. Available online: https://www.geeksforgeeks.org/naive-bayes-classifiers/ (accessed on 3 May 2021).
- Navlani, A. Naive Bayes Classification using Scikit-learn. 5 September 2020. Available online: https://avinashnavlani.medium.com/naive-bayes-classification-using-scikit-learn-60bc5176f868 (accessed on 4 May 2021).
- Form Plus Blog. 10 December 2020. Available online: https://www.formpl.us/blog/nominal-ordinal-interval-ratio-variable-example#:~:text=A%20nominal%20variable%20is%20a,intrinsic%20ordering%20of%20these%20categories.&text=Some%20examples%20of%20nominal%20variables,%2C%20Name%2C%20phone%2C%20etc (accessed on 27 April 2021).
- Hamdaoui, Y. TF(Term Frequency)-IDF(Inverse Document Frequency) from Scratch in Python. 10 December 2019. Available online: https://towardsdatascience.com/tf-term-frequency-idf-inverse-document-frequency-from-scratch-in-python-6c2b61b78558 (accessed on 5 May 2021).
- Pros and Cons of Rapid Miner Studio 2021. 2021. Available online: https://www.trustradius.com/products/rapidminer-studio/reviews?qs=pros-and-cons (accessed on 6 May 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Priority | Population Group |
|---|---|
| Priority Group A | 1. Frontline workers in health facilities. |
| 2. Senior citizens aged 60 years and above. | |
| 3. Persons with comorbidities. | |
| 4. Frontline personnel in essential sectors. | |
| Priority Group B | 1. Teachers and social workers. |
| 2. Other government workers. | |
| 3. Other essential workers. | |
| 4. Sociodemographic groups at significantly higher risk. | |
| 5. Overseas Filipino workers. | |
| 6. Other remaining workforce. | |
| Priority Group C | Rest of the Filipino population not otherwise included in Priority Groups A and B. |
| Authors | Classifier | Results | Reference |
|---|---|---|---|
| Samonte et al. | Naïve Bayes | 66.67% accuracy | [15] |
| Abisado et al. | Multinomial Naïve Bayes | 72.17% accuracy | [22] |
| Proposed method | Naïve Bayes | 81.77% accuracy |
| Date of Creation | Polarity | Text |
|---|---|---|
| 8 March 2021 | Positive | Have confidence! The doctor is (vacc)in(ated). UPLB alumna Dr. Sharon Madriñan-Garcia receives a first dose of Sinovac vaccine at the Ospital ng Palawan. #Bakunado #Resbakuna #KasanggaNgBida #ScienceWorks #VaccinesWork #VaccinationSavesLives |
| 8 March 2021 | Positive | 1st dose done! I was expecting it to be painful & be getting that swell-feels after but there wasn’t. Glad to be vaccinated after 1 year of covid19 exposure. I hope & pray this all ends so we can watch @BTS_twt again #RESBAKUNA #vaccinated #GetVaccinated #HealthIsWealth |
| 8 March 2021 | Positive | H O P E Got my first dose today. #RESBAKUNA #BIDABakunation #BIDASolusyon+ #VaccinesWork |
| 8 March 2021 | Positive | Got my first dose of Sinovac vaccine. #VaccineWorks #Resbakuna |
| 8 March 2021 | Positive | Get vaccinated! I got my Covid19 vaccine #Resbakuna #Sinovac #1stdose @ Jose B. Lingad Memorial General Hospital |
| 8 March 2021 | Positive | #ResBAKUNA with SinoVac done. |
| 8 March 2021 | Positive | SINOVAC Vaccination todayyy #RESBAKUNA #SINOVAC |
| 8 March 2021 | Positive | 1st dose done #RESBAKUNA #vaccinated |
| 8 March 2021 | Positive | Got my 1st shot today. #RESBAKUNA |
| 8 March 2021 | Neutral | today pala is the 1st day of vaccination sa bpmc #resbakuna |
| 8 March 2021 | Positive | * gets the @UniofOxford @AstraZeneca vaccine * Side effects include a temporary British accent lasting for a few hours. Me: Bloody hell that was painful! But cheers for the vaccine, mate! #VaccinesWork #RESBAKUNA |
| Polarity | Tweet |
|---|---|
| Positive | I find it very comforting to see that we are not just counting COVID-19 cases but also the number of people getting vaccinated. Bright days are coming. #RESBAKUNA |
| Felt an overwhelming sense of hope today. Vaccine saves lives. Praying for a brighter tomorrow. #ResBakuna #COVID-19Vaccine | |
| Anyone can be a HERO but getting vaccinated can make you SUPER! Finally received my first dose of the vaccine, today! | |
| Neutral | I RESPECT the Philippine FDA recommendation that Sinovac is NOT for healthworkers. I also RESPECT the healthworkers who did NOT RESPECT the FDA recommendation by getting vaccinated with Sinovac #DuktorDapatAngHUWARAN #RESBAKUNA |
| This right is never different from what the feminists are trying to advocate: Our body, our choice. #MyBodyMyChoice | |
| Hello guys sino na sa inyo ang nakapagpa bakuna? #RESBAKUNA | |
| Negative | 2nd day. Sama pakiramdam ko pra akong ttrangkasuhin, feeling sleepy and uhaw na uhaw #astrazenecavaccine #firstdose #RESBAKUNA |
| Feverish. Headache. Hungry. It was so weird that this vaccine made me feel so hungry. Imagine feeling sick, but hungry. #resbakuna | |
| Karamihan sa frontline healthcare workers sa Palawan ang tumangging magpaturok sa COVID-19 vaccine na gawa ng Sinovac at piniling hintayin ang bakuna ng AstraZeneca. |
| Label. | Predicted Positive | Predicted Neutral | Predicted Negative | Class Precision |
|---|---|---|---|---|
| True Positive | 745 | 57 | 26 | 89.98% |
| True Neutral | 47 | 29 | 6 | 35.37% |
| True Negative | 38 | 7 | 38 | 45.78% |
| Class Recall | 89.76% | 31.18% | 54.29% |
| Positive | Neutral | Negative | |||
|---|---|---|---|---|---|
| Word | Count | Word | Count | Word | Count |
| resbakuna | 655 | resbakuna | 58 | vaccine | 74 |
| vaccine | 645 | vaccine | 56 | covid | 62 |
| covid | 424 | covid | 41 | resbakuna | 34 |
| bidabakunation | 223 | sinovac | 14 | astrazeneca | 13 |
| bidasolusyon | 217 | bidabakunation | 13 | bakuna | 12 |
| explain | 162 | bidasolusyon | 13 | hindi | 11 |
| dose | 145 | explain | 11 | vaccinated | 11 |
| astrazeneca | 124 | health | 9 | covidvaccineph | 10 |
| sinovac | 99 | astrazeneca | 7 | sinovac | 10 |
| bakuna | 96 | bakuna | 7 | health | 9 |
| shot | 51 | city | 6 | kaya | 9 |
| magpabakuna | 50 | respect | 6 | explain | 8 |
| health | 49 | dose | 5 | workers | 8 |
| medical | 48 | getting | 4 | bidasolusyon | 7 |
| thank | 46 | healthworkers | 4 | people | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villavicencio, C.; Macrohon, J.J.; Inbaraj, X.A.; Jeng, J.-H.; Hsieh, J.-G. Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes. Information 2021, 12, 204. https://doi.org/10.3390/info12050204
Villavicencio C, Macrohon JJ, Inbaraj XA, Jeng J-H, Hsieh J-G. Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes. Information. 2021; 12(5):204. https://doi.org/10.3390/info12050204
Chicago/Turabian StyleVillavicencio, Charlyn, Julio Jerison Macrohon, X. Alphonse Inbaraj, Jyh-Horng Jeng, and Jer-Guang Hsieh. 2021. "Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes" Information 12, no. 5: 204. https://doi.org/10.3390/info12050204
APA StyleVillavicencio, C., Macrohon, J. J., Inbaraj, X. A., Jeng, J.-H., & Hsieh, J.-G. (2021). Twitter Sentiment Analysis towards COVID-19 Vaccines in the Philippines Using Naïve Bayes. Information, 12(5), 204. https://doi.org/10.3390/info12050204