
Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review


Abstract
1. Introduction
2. Research Methodology
2.1. Research Objectives
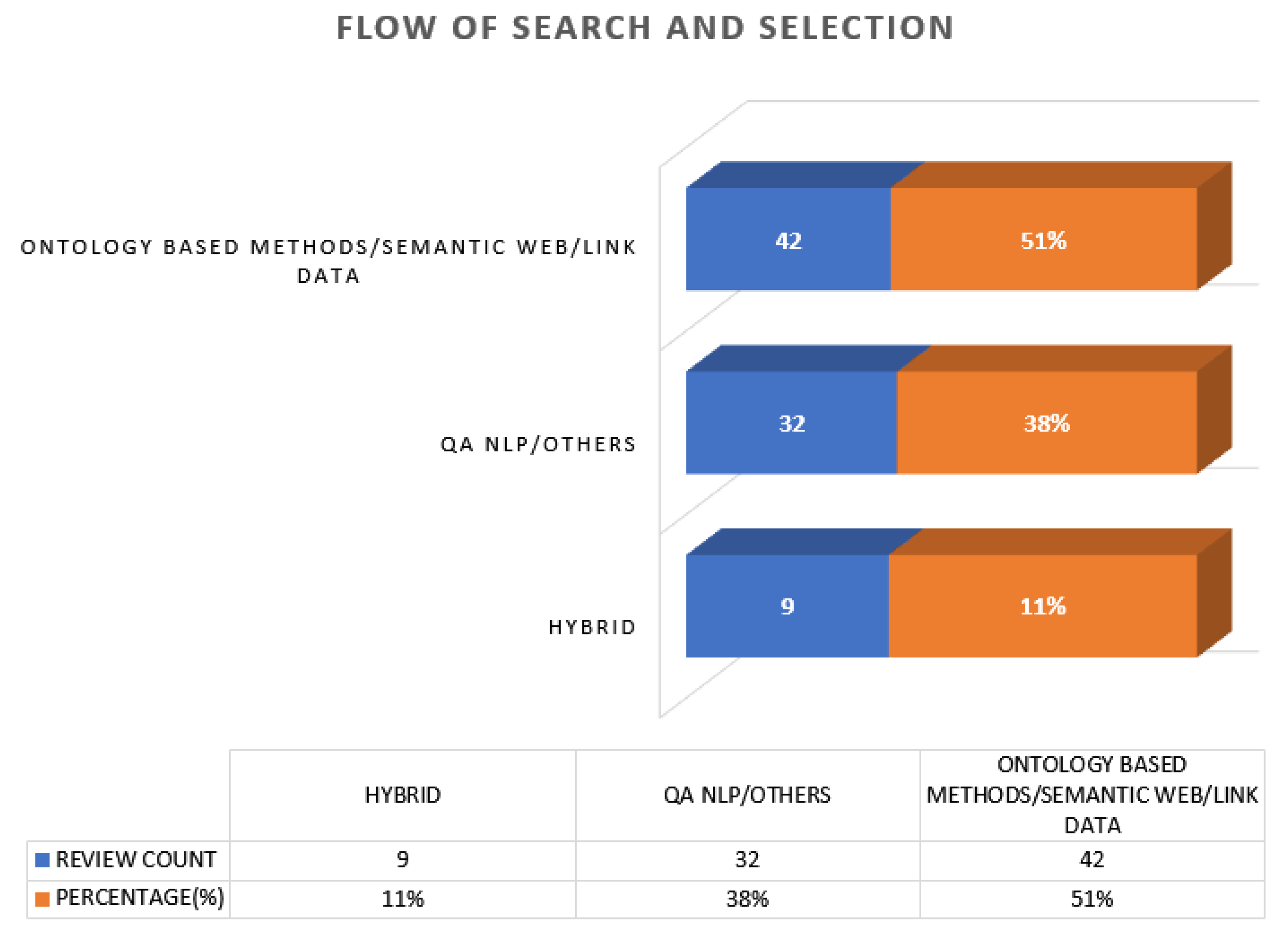
2.2. Research Questions
2.3. Criteria for Inclusion and Exclusion Study
3. Related Works
3.1. Knowledge-Based QA Systems
3.2. Representation of Knowledge
3.3. Ontology
3.4. Review of the Most Existing Methodologies
3.5. Current Mobile QA Systems for Pilgrimage Domain
4. The Challenges of the QA System
5. QA System Evaluation
6. Discussion

{kind=link}
{kind=link}
| Methods | Techniques | Technique for Evaluation | Ref. |
|---|---|---|---|
| Querying Agent | RDF, OWL, Spatiotemporal Information representations | Two evaluation stages: a. Air Quality Index calculation. b. Manual verification by health experts | [27,47] |
| Single, Multiple, Hybrid Ontology | Semantic information description. Design, Development, Integration, Validation, Ontology Iteration | No evaluation available | [55] |
| Semantic Search System | KB preparation, Query processing, Entity mapping, Formal query and Answer generation | Disambiguation evaluation: System achieved 103 correct answers out of 133 questions. 64% recall, 76% precision | [58] |
| Ontology. Decision Support system | Knowledge querying, Reasoning based on ontology model | Five sets of rollover stability data under different conditions used for evaluation: accuracy, effectiveness | [52] |
| RDF, SPARQL | NLP. Ontology entity mapping, Retrieve and Manipulate data in RDF | Quranic ontology, Arabic Mooney Geography dataset for evaluation. System achieved 64% recall, 76% precision | [52,58] |
| Semantic QA | Ontology reasoning, custom rules, Semantic QA system | Custom rules and query set for system evaluation. Result: Backward chaining ontology outperforms the in-memory reasoning system | [16] |
| IR | Quran’s concept hierarchy, vocabulary search system, Quranic WordNet, Knowledge repository, IR tools | Performance metrics evaluation: precision, recall, F-measure. Comparisons with similar frameworks | [56,59] |
| FrameSTEP | Raw trajectories, Annotation, Semantic graphs, Ontology | Segmentation Granularity Extent Context Type and availability | [27,47] |
| Ontology, Semantic Knowledge, Word2vec | OWL, Word embedding, fuzzy ontology | Bi-LSTM improved features extraction and text classification. Evaluation based on machine learning: SVM, CNN, RNN, LSTM. Metrics: Precision, Recall, Accuracy | [48] |
| Intelligent Mobile Agent | Ontology, DBPedia, WordNet. | IMAT was validated by Mobile Client Application implementation it helps testing of important IMAT features | [52,53,58,59] |
| IR | Math-aware QA system, Ask Platypus. A single mathematical formula is returned to NLQ in English or Hindi | Metrics: Precision, Recall, Accuracy, Function Measures | [56,59] |
| Linked Open data Framework | Concepts and Relation extraction, NLP, KB | Evaluation shows improved result in most tasks of ontology generation compared to those obtained in existing frameworks | [46] |
| IR | RDF, OWL, SPARQL | No evaluation available | [49,56,59] |
| Classification and Mining | NLP, Linguistic features, | Neural Networks capable of handling complexity, classified Hadith 94% accuracy. Mining method: Vector space model, Cosine similarity, Enriched queries—Obtained 88.9% accuracy | [64] |
| Semantic Search | IR, Quran-based QA system, Neural Networks classification | Evaluation of classification shows approximately 90% accuracy | [87] |
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khan, J.R.; Siddiqui, F.A.; Siddiqui, A.A.; Saeed, M.; Touheed, N. Enhanced ontological model for the Islamic Jurisprudence system. In Proceedings of the 2017 International Conference on Information and Communication Technologies (ICICT), Karachi, Pakistan, 30–31 December 2017; pp. 180–184. [Google Scholar]
- Siciliani, L. Question Answering over Knowledge Bases. In European Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2018; pp. 283–293. [Google Scholar]
- Hu, H. A Study on Question Answering System Using Integrated Retrieval Method. Ph.D. Thesis, The University of Tokushima, Tokushima, Japan, February 2006. Available online: http://citeseerx.ist.psu.edu/viewdoc/download (accessed on 20 April 2021).
- Abdi, A.; Idris, N.; Ahmad, Z. QAPD: An ontology-based question answering system in the physics domain. Soft Comput. 2018, 22, 213–230. [Google Scholar] [CrossRef]
- Buranarach, M.; Supnithi, T.; Thein, Y.M.; Ruangrajitpakorn, T.; Rattanasawad, T.; Wongpatikaseree, K.; Lim, A.O.; Tan, Y.; Assawamakin, A. OAM: An ontology application management framework for simplifying ontology-based semantic web application development. Int. J. Softw. Eng. Knowl. Eng. 2016, 26, 115–145. [Google Scholar] [CrossRef]
- Vandenbussche, P.Y.; Atemezing, G.A.; Poveda-Villalón, M.; Vatant, B. Linked Open Vocabularies (LOV): A gateway to reusable semantic vocabularies on the Web. Semant. Web 2017, 8, 437–452. [Google Scholar] [CrossRef]
- Hastings, J.; Chepelev, L.; Willighagen, E.; Adams, N.; Steinbeck, C.; Dumontier, M. The chemical information ontology: Provenance and disambiguation for chemical data on the biological semantic web. PLoS ONE 2011, 6, e25513. [Google Scholar] [CrossRef]
- Jiang, S.; Wu, W.; Tomita, N.; Ganoe, C.; Hassanpour, S. Multi-Ontology Refined Embeddings (MORE): A Hybrid Multi-Ontology and Corpus-based Semantic Representation for Biomedical Concepts. arXiv 2020, arXiv:2004.06555. [Google Scholar] [CrossRef]
- Raganato, A.; Camacho-Collados, J.; Navigli, R. Word sense disambiguation: A unified evaluation framework and empirical comparison. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 99–110. [Google Scholar]
- Chaplot, D.S.; Salakhutdinov, R. Knowledge-based word sense disambiguation using topic models. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Raganato, A.; Bovi, C.D.; Navigli, R. Neural sequence learning models for word sense disambiguation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1156–1167. [Google Scholar]
- Wang, Y.; Wang, M.; Fujita, H. Word sense disambiguation: A comprehensive knowledge exploitation framework. Knowl. Based Syst. 2020, 190, 105030. [Google Scholar] [CrossRef]
- Soares, M.A.C.; Parreiras, F.S. A literature review on question answering techniques, paradigms and systems. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 635–646. [Google Scholar]
- Yao, X. Feature-Driven Question Answering with Natural Language Alignment. Ph.D. Thesis, Johns Hopkins University, Baltimore, MD, USA, July 2014. [Google Scholar]
- Mohasseb, A.; Bader-El-Den, M.; Cocea, M. Question categorization and classification using grammar based approach. Inf. Process. Manag. 2018, 54, 1228–1243. [Google Scholar] [CrossRef]
- Shi, H.; Chong, D.; Yan, G. Evaluating an optimized backward chaining ontology reasoning system with innovative custom rules. Inf. Discov. Deliv. 2018, 46, 45–56. [Google Scholar] [CrossRef]
- Green, B.F., Jr.; Wolf, A.K.; Chomsky, C.; Laughery, K. Baseball: An automatic question-answerer. In Western Joint IRE-AIEE-ACM Computer Conference; Association for Computing Machinery: New York, NY, USA, 1961; pp. 219–224. [Google Scholar]
- Woods, W.A. Progress in natural language understanding: An application to lunar geology. In Proceedings of the June 4–8, 1973, National Computer Conference and Exposition; Association for Computing Machinery: New York, NY, USA, 1973; pp. 441–450. [Google Scholar]
- Katz, B. From sentence processing to information access on the world wide web. In AAAI Spring Symposium on Natural Language Processing for the World Wide Web; Stanford University: Stanford, CA, USA, 1997; Volume 1, p. 997. [Google Scholar]
- Kwok, C.C.; Etzioni, O.; Weld, D.S. Scaling question answering to the web. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 150–161. [Google Scholar]
- Zheng, Z. AnswerBus question answering system. In Proceedings of the Human Language Technology Conference (HLT 2002), San Diego, CA, USA, 7 February 2002; Volume 27. [Google Scholar]
- Parikh, J.; Murty, M.N. Adapting question answering techniques to the web. In Proceedings of the Language Engineering Conference, Hyderabad, India, 13–15 December 2002; pp. 163–171. [Google Scholar]
- Bhatia, P.; Madaan, R.; Sharma, A.; Dixit, A. A comparison study of question answering systems. J. Netw. Commun. Emerg. Technol. 2015, 5, 192–198. [Google Scholar]
- Chung, H.; Song, Y.I.; Han, K.S.; Yoon, D.S.; Lee, J.Y.; Rim, H.C.; Kim, S.H. A practical QA system in restricted domains. In Proceedings of the Conference on Question Answering in Restricted Domains, Barcelona, Spain, 25 July 2004; pp. 39–45. [Google Scholar]
- Mishra, A.; Mishra, N.; Agrawal, A. Context-aware restricted geographical domain question answering system. In Proceedings of the 2010 International Conference on Computational Intelligence and Communication Networks, Bhopal, India, 26–28 November 2010; pp. 548–553. [Google Scholar]
- Clark, P.; Thompson, J.; Porter, B. A knowledge-based approach to question-answering. Proc. AAAI 1999, 99, 43–51. [Google Scholar]
- Meng, X.; Wang, F.; Xie, Y.; Song, G.; Ma, S.; Hu, S.; Bai, J.; Yang, Y. An Ontology-Driven Approach for Integrating Intelligence to Manage Human and Ecological Health Risks in the Geospatial Sensor Web. Sensors 2018, 18, 3619. [Google Scholar] [CrossRef]
- Yang, M.C.; Lee, D.G.; Park, S.Y.; Rim, H.C. Knowledge-based question answering using the semantic embedding space. Expert Syst. Appl. 2015, 42, 9086–9104. [Google Scholar] [CrossRef]
- Firebaugh, M.W. Artificial Intelligence: A Knowledge Based Approach; PWS-Kent Publishing Co.: Boston, MA, USA, 1989. [Google Scholar]
- Ziaee, A.A. A philosophical Approach to Artificial Intelligence and Islamic Values. IIUM Eng. J. 2011, 12, 73–78. [Google Scholar] [CrossRef]
- Allen, J. Natural Language Understanding; Benjamin/Cummings Publishing Company: San Francisco, CA, USA, 1995. [Google Scholar]
- Dubien, S. Question Answering Using Document Tagging and Question Classification. Ph.D. Thesis, University of Lethbridge, Lethbridge, Alberta, 2005. [Google Scholar]
- Guo, Q.; Zhang, M. Question answering based on pervasive agent ontology and Semantic Web. Knowl. Based Syst. 2009, 22, 443–448. [Google Scholar] [CrossRef]
- Cui, W.; Xiao, Y.; Wang, H.; Song, Y.; Hwang, S.W.; Wang, W. KBQA: Learning question answering over QA corpora and knowledge bases. arXiv 2019, arXiv:1903.02419. [Google Scholar] [CrossRef]
- Dong, J.; Wang, Y.; Yu, R. Application of the Semantic Network Method to Sightline Compensation Analysis of the Humble Administrator’s Garden. Nexus Netw. J. 2021, 23, 187–203. [Google Scholar] [CrossRef]
- Shortliffe, E. Computer-Based Medical Consultations: MYCIN; Elsevier: Amsterdam, The Netherlands, 2012; Volume 2. [Google Scholar]
- Stokman, F.N.; de Vries, P.H. Structuring knowledge in a graph. In Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 1988; pp. 186–206. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Lin, Y.; Han, X.; Xie, R.; Liu, Z.; Sun, M. Knowledge representation learning: A quantitative review. arXiv 2018, arXiv:1812.10901. [Google Scholar]
- Dai, Z.; Li, L.; Xu, W. Cfo: Conditional focused neural question answering with large-scale knowledge bases. arXiv 2016, arXiv:1606.01994. [Google Scholar]
- Chen, Y.; Wu, L.; Zaki, M.J. Bidirectional attentive memory networks for question answering over knowledge bases. arXiv 2019, arXiv:1903.02188. [Google Scholar]
- Mohammed, S.; Shi, P.; Lin, J. Strong baselines for simple question answering over knowledge graphs with and without neural networks. arXiv 2017, arXiv:1712.01969. [Google Scholar]
- Zhang, Z.; Liu, G. Study of ontology-based intelligent question answering model for online learning. In Proceedings of the 2009 First International Conference on Information Science and Engineering, Nanjing, China, 26–28 December 2009; pp. 3443–3446. [Google Scholar]
- Shadbolt, N.; Berners-Lee, T.; Hall, W. The semantic web revisited. IEEE Intell. Syst. 2006, 21, 96–101. [Google Scholar] [CrossRef]
- Besbes, G.; Baazaoui-Zghal, H.; Moreno, A. Ontology-based question analysis method. In International Conference on Flexible Query Answering Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 100–111. [Google Scholar]
- Alobaidi, M.; Malik, K.M.; Sabra, S. Linked open data-based framework for automatic biomedical ontology generation. BMC Bioinform. 2018, 19, 319. [Google Scholar] [CrossRef] [PubMed]
- Nogueira, T.P.; Braga, R.B.; de Oliveira, C.T.; Martin, H. FrameSTEP: A framework for annotating semantic trajectories based on episodes. Expert Syst. Appl. 2018, 92, 533–545. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Kwak, D. Fuzzy Ontology and LSTM-Based Text Mining: A Transportation Network Monitoring System for Assisting Travel. Sensors 2019, 19, 234. [Google Scholar] [CrossRef]
- Wimmer, H.; Chen, L.; Narock, T. Ontologies and the Semantic Web for Digital Investigation Tool Selection. J. Digit. For. Secur. Law 2018, 13, 6. [Google Scholar] [CrossRef]
- Singh, J.; Sharan, D.A. A comparative study between keyword and semantic based search engines. In Proceedings of the International Conference on Cloud, Big Data and Trust, Madhya Pradesh, India, 13–15 November 2013; pp. 13–15. [Google Scholar]
- Alobaidi, M.; Malik, K.M.; Hussain, M. Automated ontology generation framework powered by linked biomedical ontologies for disease-drug domain. Comput. Methods Programs Biomed. 2018, 165, 117–128. [Google Scholar] [CrossRef]
- Xu, F.; Liu, X.; Zhou, C. Developing an ontology-based rollover monitoring and decision support system for engineering vehicles. Information 2018, 9, 112. [Google Scholar] [CrossRef]
- Dhayne, H.; Chamoun, R.K.; Sabha, R.A. IMAT: Intelligent Mobile Agent. In Proceedings of the 2018 IEEE International Multidisciplinary Conference on Engineering Technology (IMCET), Beirut, Lebanon, 14–16 November 2018; pp. 1–8. [Google Scholar]
- Nanda, J.; Simpson, T.W.; Kumara, S.R.; Shooter, S.B. A Methodology for Product Family Ontology Development Using Formal Concept Analysis and Web Ontology Language. J. Comput. Inf. Sci. Eng. 2006, 6, 103–113. [Google Scholar] [CrossRef]
- Subhashini, R.; Akilandeswari, J. A survey on ontology construction methodologies. Int. J. Enterp. Comput. Bus. Syst. 2011, 1, 60–72. [Google Scholar]
- Schubotz, M.; Scharpf, P.; Dudhat, K.; Nagar, Y.; Hamborg, F.; Gipp, B. Introducing MathQA: A Math-Aware question answering system. Inf. Discov. Deliv. 2018, 46, 214–224. [Google Scholar] [CrossRef]
- AlAgha, I.M.; Abu-Taha, A. AR2SPARQL: An arabic natural language interface for the semantic web. Int. J. Comput. Appl. 2015, 125, 19–27. [Google Scholar] [CrossRef]
- Hakkoum, A.; Kharrazi, H.; Raghay, S. A Portable Natural Language Interface to Arabic Ontologies. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 69–76. [Google Scholar] [CrossRef]
- Afzal, H.; Mukhtar, T. Semantically enhanced concept search of the Holy Quran: Qur’anic English WordNet. Arab. J. Sci. Eng. 2019, 44, 3953–3966. [Google Scholar] [CrossRef]
- Ullah, M.A.; Hossain, S.A. Ontology-Based Information Retrieval System for University: Methods and Reasoning. In Emerging Technologies in Data Mining and Information Security; Springer: Berlin/Heidelberg, Germany, 2019; pp. 119–128. [Google Scholar]
- Syarief, M.; Agustiono, W.; Muntasa, A.; Yusuf, M. A Conceptual Model of Indonesian Question Answering System based on Semantic Web. J. Phys. Conf. Ser. 2020, 1569, 022089. [Google Scholar]
- Jabalameli, M.; Nematbakhsh, M.; Zaeri, A. Ontology-lexicon–based question answering over linked data. ETRI J. 2020, 42, 239–246. [Google Scholar] [CrossRef]
- Diefenbach, D.; Both, A.; Singh, K.; Maret, P. Towards a question answering system over the semantic web. Semant. Web 2020, 11, 421–439. [Google Scholar] [CrossRef]
- Saloot, M.A.; Idris, N.; Mahmud, R.; Ja’afar, S.; Thorleuchter, D.; Gani, A. Hadith data mining and classification: A comparative analysis. Artif. Intell. Rev. 2016, 46, 113–128. [Google Scholar] [CrossRef]
- White, R.W.; Richardson, M.; Yih, W. Questions vs. queries in informational search tasks. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 135–136. [Google Scholar]
- del Carmen Rodrıguez-Hernández, M.; Ilarri, S.; Trillo-Lado, R.; Guerra, F. Towards keyword-based pull recommendation systems. ICEIS 2016 2016, 1, 207–214. [Google Scholar]
- Rahman, M.M.; Yeasmin, S.; Roy, C.K. Towards a context-aware IDE-based meta search engine for recommendation about programming errors and exceptions. In Proceedings of the 2014 Software Evolution Week-IEEE Conference on Software Maintenance, Reengineering, and Reverse Engineering (CSMR-WCRE), Antwerp, Belgium, 3–6 February 2014; pp. 194–203. [Google Scholar]
- Giri, K. Role of ontology in semantic web. Desidoc J. Libr. Inf. Technol. 2011, 31, 116–120. [Google Scholar] [CrossRef]
- Maglaveras, N.; Koutkias, V.; Chouvarda, I.; Goulis, D.; Avramides, A.; Adamidis, D.; Louridas, G.; Balas, E. Home care delivery through the mobile telecommunications platform: The Citizen Health System (CHS) perspective. Int. J. Med. Inform. 2002, 68, 99–111. [Google Scholar] [CrossRef]
- Sherif, M.; Ngonga Ngomo, A.C. Semantic Quran: A multilingual resource for natural-language processing. Semant. Web 2015, 6, 339–345. [Google Scholar] [CrossRef]
- Al-Feel, H. The roadmap for the Arabic chapter of DBpedia. In Proceedings of the 14th International Conference on Telecom. and Informatics (TELE-INFO’15), Sliema, Malta, 17–19 August 2015; pp. 115–125. [Google Scholar]
- Hakkoum, A.; Raghay, S. Semantic Q&A System on the Qur’an. Arab. J. Sci. Eng. 2016, 41, 5205–5214. [Google Scholar]
- Sulaiman, S.; Mohamed, H.; Arshad, M.R.M.; Yusof, U.K. Hajj-QAES: A knowledge-based expert system to support hajj pilgrims in decision making. In Proceedings of the 2009 International Conference on Computer Technology and Development, Kota Kinabalu, Malaysia, 13–15 November 2009; Volume 1, pp. 442–446. [Google Scholar]
- Sharef, N.M.; Murad, M.A.; Mustapha, A.; Shishechi, S. Semantic question answering of umrah pilgrims to enable self-guided education. In Proceedings of the 2013 13th International Conference on Intellient Systems Design and Applications, Salangor, Malaysia, 8–10 December 2013; pp. 141–146. [Google Scholar]
- Mohamed, H.H.; Arshad, M.R.H.M.; Azmi, M.D. M-HAJJ DSS: A mobile decision support system for Hajj pilgrims. In Proceedings of the 2016 3rd International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 15–17 August 2016; pp. 132–136. [Google Scholar]
- Abdelazeez, M.A.; Shaout, A. Pilgrim Communication Using Mobile Phones. J. Image Graph. 2016, 4, 59–62. [Google Scholar] [CrossRef]
- Khan, E.A.; Shambour, M.K.Y. An analytical study of mobile applications for Hajj and Umrah services. Appl. Comput. Inform. 2018, 14, 37–47. [Google Scholar] [CrossRef]
- Rodrigo, A.; Penas, A. A study about the future evaluation of Question-Answering systems. Knowl. Based Syst. 2017, 137, 83–93. [Google Scholar] [CrossRef]
- Al-Harbi, O.; Jusoh, S.; Norwawi, N.M. Lexical disambiguation in natural language questions (NLQs). arXiv 2017, arXiv:1709.09250. [Google Scholar]
- Navigli, R. Natural Language Understanding: Instructions for (Present and Future) Use. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; Volume 18, pp. 5697–5702. [Google Scholar]
- Pillai, L.R.; Veena, G.; Gupta, D. A combined approach using semantic role labelling and word sense disambiguation for question generation and answer extraction. In Proceedings of the 2018 Second International Conference on Advances in Electronics, Computers and Communications (ICAECC), Bangalore, India, 9–10 February 2018; pp. 1–6. [Google Scholar]
- Dreisbach, C.; Koleck, T.A.; Bourne, P.E.; Bakken, S. A systematic review of natural language processing and text mining of symptoms from electronic patient-authored text data. Int. J. Med Inform. 2019, 125, 37–46. [Google Scholar] [CrossRef]
- Zheng, W.; Cheng, H.; Yu, J.X.; Zou, L.; Zhao, K. Interactive natural language question answering over knowledge graphs. Inf. Sci. 2019, 481, 141–159. [Google Scholar] [CrossRef]
- Dimitrakis, E.; Sgontzos, K.; Tzitzikas, Y. A survey on question answering systems over linked data and documents. J. Intell. Inf. Syst. 2020, 55, 233–259. [Google Scholar] [CrossRef]
- Li, X.; Hu, D.; Li, H.; Hao, T.; Chen, E.; Liu, W. Automatic question answering from Web documents. Wuhan Univ. J. Nat. Sci. 2007, 12, 875–880. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A survey on knowledge graphs: Representation, acquisition and applications. arXiv 2020, arXiv:2002.00388. [Google Scholar]
- Hamed, S.K.; Ab Aziz, M.J. A Question Answering System on Holy Quran Translation Based on Question Expansion Technique and Neural Network Classification. J. Comput. Sci. 2016, 12, 169–177. [Google Scholar] [CrossRef]
- Fernández, M.; Cantador, I.; López, V.; Vallet, D.; Castells, P.; Motta, E. Semantically enhanced information retrieval: An ontology-based approach. J. Web Semant. 2011, 9, 434–452. [Google Scholar] [CrossRef]
Short Biography of Authors
 | Ammar F. Arbaaeen received the B.Sc. (Hons) degree in Mobile andWireless Computing from The University ofWestminster, UK, in 2011 and the M.Sc. degree in Advanced Computer Science from The University of Manchester, Manchester, UK, in 2012. He is currently pursuing the Ph.D. degree in Computer Science at IIUM University, Malaysia. From 2013 to 2014, he was a Research Assistant with the Transportation and Crowd Management Centre of Research Excellence. In 2014, he joined Umm Al-Qura University as a lecturer and member of the Information and Scientific Services Department with The Institute of Hajj and Umrah Research, KSA. His research interests are to investigate how to semantically enhance question answering technology in order to understand and support human precisely includes NLP, semantics, and knowledge graph technology. |
 | Asadullah Shah started his career as a Computer Technology lecturer in 1986. Before joining IIUM in January 2011, he worked in Pakistan as a full professor (2001-2010) at Isra, IOBM and SIBA. He earned his Ph.D. in Multimedia Communication from the University of Surrey UK in 1998. He has published 180 articles in ISI and Scopus indexed publications. In addition to that, he has published 12 books. Since 2012, he has been working as a resource person and delivering workshops on proposal writing, research methodologies and literature review at Student Learning Unit (SLeU), KICT, International Islamic University Malaysia and consultancies to other organizations. Professor Shah is a winner of many gold, silver and bronze medals in his career and reviewer for many ISI, and Scopus indexed journals, and other journals of high repute. Currently, he is supervising many Ph.D. projects in KICT in the field of IT and CS. |


| Category | Description |
|---|---|
| 1 | Metadata of the paper, comprising the title of the paper, author, date, problems identified, methods used, findings and future studies [13] |
| 2 | Defined which main techniques were selected for the paper e.g., Ontology based, Natural Language Processing, Semantic Web Links Data/ Knowledge based, hybrid based, etc. [14] |
| 3 | Was based on ontology-based techniques used for the approach [13] |
| 4 | Deals with the metrics used to evaluate the precision and recall for the paper reviewed on question answering (QA) [13] |
| 5 | Detailed classifications such as method and findings used [13] |
| Category | Ontology-Based/Semantic Web/Link Data | QA NLP/ Others | Total Relevant |
|---|---|---|---|
| Total Number of Review Papers | 37 | 46 | 83 |
| Review papers Ontology QA | 52 | 18 | 70 |
| Review papers with Correct Ontology QA | 23 | 17 | 40 |
| Precision | 41.2 % | 93.6% | 53.5% |
| Recall | 59.1 % | 32.9% | 44.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arbaaeen, A.; Shah, A. Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review. Information 2021, 12, 200. https://doi.org/10.3390/info12050200
Arbaaeen A, Shah A. Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review. Information. 2021; 12(5):200. https://doi.org/10.3390/info12050200
Chicago/Turabian StyleArbaaeen, Ammar, and Asadullah Shah. 2021. "Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review" Information 12, no. 5: 200. https://doi.org/10.3390/info12050200
APA StyleArbaaeen, A., & Shah, A. (2021). Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review. Information, 12(5), 200. https://doi.org/10.3390/info12050200