1. Introduction
The usage of Artificial intelligence (AI) technologies is widespread in virtually every sector of human activity. Public administration institutions and governments seek to take advantage of AI to deal with specific needs and opportunities related to their access to substantial amounts of both structured and unstructured information. Natural language processing (NLP) techniques are being used to handle both web-originated text (such as in social networks or newswire) and, most importantly, written information produced in the process of an ever more direct interaction between citizens and governmental institutions [
1].
By providing public services through virtual counters, governmental institutions are often required to respond to large numbers of citizen contacts (such as requests or complaints), a process that may quickly become intractable, depending on the size of the country or administrative region covered by the institution. Furthermore, without properly designed contact forms, the quality of the information received inevitably becomes an issue. NLP techniques can help address this information overload and improve public services [
2] by automating the processing of textual data.
The Portuguese Economic and Food Safety Authority (ASAE) (
http://www.asae.gov.pt/welcome-to-website-asae.aspx, accessed on 13 December 2021) is focused on food safety and economic surveillance, being responsible for the inspection of economic operators, in order to assess risks in the economic and food chains and enforce regulatory legislation. ASAE is a country-wide organization that needs to manage a large quantity of diversified information. One of its main inputs comprises complaints submitted by citizens or institutions concerning the activity of economic operators. Such complaints may arrive in multiple ways, including e-mail and contact forms.
It is ASAE’s responsibility to handle incoming complaints. When doing so, ASAE officers need to extract the targeted economic operator, determine the economic activity with which the complaint is related, identify any infractions implied by the complaint’s content, and decide upon ASAE’s competence to further act on the complaint (e.g., by carrying out an inspection procedure), since in many cases the complaint needs to be forwarded to another competent entity. Given the high number of yearly complaints (tens of thousands, a number that can only increase given the recent release of an electronic complaints book mobile app, which streamlines the process of posting complaints), the use of human labor to analyze and properly handle them is a bottleneck, bringing the need to automate part of the process. However, one must bear in mind that complaints can be seen as user-generated content [
3] provided in free-form text fields, bringing high variability to the quality of the content written by citizens. Effectively automating complaint handling is thus a challenging task.
This paper addresses this real-world problem, considering complaint handling in three separate classification tasks that are related to the internal processing of complaints within ASAE. Building on previous insights [
4,
5], we explore text representation alternatives, including recent trends in language modeling, with the aim of improving classification results. Being aware that Portuguese is a lower-resourced language for NLP, we also explore different preprocessing pipelines, and focus on assessing results both in terms of quantitative metrics (e.g., accuracy, macro-F1) and, most importantly, feature analysis.
While this work is based on a real-world challenging dataset, the insights we get from addressing it can be useful for researchers dealing with similarly modeled classification tasks. These include extremely imbalanced hierarchical multi-class tasks and sparse multi-label tasks, that we have modeled in a number of ways—sticking with a specific hierarchical level or relaxing the problem to a single-label classification task. To deal with the inherent fuzziness of the thus obtained classes, we explore ranking approaches, among other techniques. These are also sensible for the sake of developing models that encompass the needs of a concrete application, where the human must be included in the loop—as such, more than providing black-box machine learning models with adequate levels of performance, we put an emphasis on developing solutions that allow for some kind of explainability on the suggested predictions. For that, we analyze the qualitative impact of different preprocessing and feature extraction techniques, by closely inspecting the most salient features in each class.
Moreover, we expect that the conclusions drawn from our study are equally important to those addressing data with similar characteristics, namely by comprising non-curated textual content expressed in a less-resourced language (Portuguese in our case). ASAE complaints comprise multiple-domain user-generated content, resulting in high variability in terms of language and style. This demands robust preprocessing pipelines, for which we have explored different approaches.
The main contributions of the paper can be summarized as follows:
We develop a comprehensive study of different NLP techniques employed to process user-generated text with high variability of content and style, constrained by the limited performance of available tools for a less-resourced language.
We analyze the impact of the decisions made in the NLP pipeline on the traceability of the predictions made by the system without comprising performance, which can be useful in human-in-the-loop scenarios.
We provide insights on how to deal with challenging machine learning tasks derived from a real-world problem, combining unbalanced datasets, multi-label settings, the fuzziness of the label boundaries, and the peculiarities of user-generated text.
We carry out an empirical analysis of different text representation approaches, either relying on extensive feature engineering or off-the-shelf neural language models, concluding that conventional techniques remain competitive in these challenging setups.
The rest of the paper is structured as follows.
Section 2, looks into related works in analyzing user-generated content and, more specifically, complaint-related data. In
Section 3, we characterize the complaint data focused in this work, the complaint processing tasks we address, and how we have chosen to address them. Given the wide range of approaches we have followed to address these tasks, for easier reading we provide, in
Section 4, a glimpse of the alternatives explored. Then, in
Section 5, we provide some competitive baselines for each of the addressed tasks, following a conservative preprocessing pipeline, by adopting a simple representation strategy, and by using a set of classifiers found to be promising in previous work [
4,
5]. We compare the classifiers in terms of performance metrics and focus on the most promising model by carrying out an error analysis and a qualitative inspection of the features employed. In
Section 6 we explore feature engineering alternatives, with the aim of improving results both in quantitative and qualitative terms. While doing so, we uncover the limitations of certain NLP tools when handling Portuguese. In
Section 7 we consider the case of taking advantage of subword information. In
Section 8 we follow alternative representations based on word embeddings and language models.
Section 9 wraps up the main findings of this journey, and includes the take-home messages of this work. Finally,
Section 10 concludes.
2. Related Work
There are several works on the analysis of user-generated content, but they mostly study social media data [
6], with a focus on tasks such as sentiment analysis and opinion mining [
7] or address predicting the usefulness of product reviews [
8]. Forte and Brazdil [
9] focus on sentiment polarity of Portuguese comments, and use a lexicon-based approach enriched with domain-specific terms, formulating specific rules for negation and amplifiers.
Given its importance in the industry, customer feedback analysis has received significant attention from the NLP community. A 2017 task on the matter [
10] addressed four languages (English, French, Spanish, and Japanese) and concentrated on a single goal: to distinguish, from Microsoft Office customer feedback, between comment, request, bug, complaint, and meaningless. This classification system has been proposed by Liu et al. [
11] to provide meaning across languages. In the provided multi-lingual corpus, each example comprises a single sentence. The annotated part of the corpus has a total of 11,122 sentences, divided among train, development, and test sets, and is imbalanced both in terms of language (where English is more prevalent) and classes (with most examples consisting of comments and complaints). An additional set of 28,838 unannotated sentences was included in the corpus, with the aim of enabling the usage of semi-supervised approaches. The best overall performing model, by Plank [
12], is based on a Support Vector Machine classifier exploiting both multilingual word embeddings and character n-grams. For the English language, however, Wang et al. [
13] score best by using a deep learning approach based on a bidirectional GRU model with attention mechanisms.
Ordenes et al. [
14] propose a framework for analyzing customer experience feedback, using a linguistics-based model. This approach explores the identification of activities, resources, and context, so as to automatically distinguish compliments from complaints, regarding different aspects of customer feedback. The work focuses on a single activity domain and, in the end, aims at obtaining a refined sentiment analysis model.
Traditional approaches to text categorization employ feature-based sparse models, using bag-of-words and Term Frequency-Inverse Document Frequency (TF-IDF) encoding. In such settings, common in the preprocessing stage is the use of near-synonym dictionaries to substitute words with similar senses. For instance, in the context of insurance complaint handling, Dong and Wang [
15] make use of synonyms and Chi-square statistics to reduce the dimensionality of the feature space. In general, filtering out words that do not meet specified thresholds is a means to obtain a denser matrix of features. More recent techniques, such as word embeddings [
16] and recurrent neural networks (RNNs) [
17], have also been used in complaint classification. Assawinjaipetch et al. [
18] employ these methods to classify complaints of a single company into one of nine classes, related to the specific aspect that is being criticized.
Given the noisy nature of user-generated content, dealing with complaints as a multi-label classification problem can be effective, even when the original problem is single-labeled. Ranking algorithms [
3,
19] are a promising approach in this regard, providing a set of predictions sorted by confidence. These techniques have been applied in complaint analysis by Fauzan and Khodra [
20], although with modest results.
Kalyoncu et al. [
21] approach customer complaint analysis from a topic modeling perspective, using techniques such as Latent Dirichlet Allocation (LDA) [
22]. This work is not so much focused on automatically processing complaints, but instead on providing a visualization tool for mobile network operators.
The tasks we address in this paper contain some distinguishing properties, as follows. Complaint data is not focused on a single domain. In fact, as we will show in
Section 3, economic activity classification at ASAE makes use of a hierarchical taxonomic structure, covering a wide range of domains of activity. Furthermore, infraction prediction is a multi-label problem, given that for any complaint there may be more than one implied infraction, with different severity degrees. Properly addressing this problem is crucial to help ASAE in prioritizing complaint handling. Finally, determining institutional competence is a fuzzy problem, as in many cases more than one competent authority is needed to properly handle a complaint.
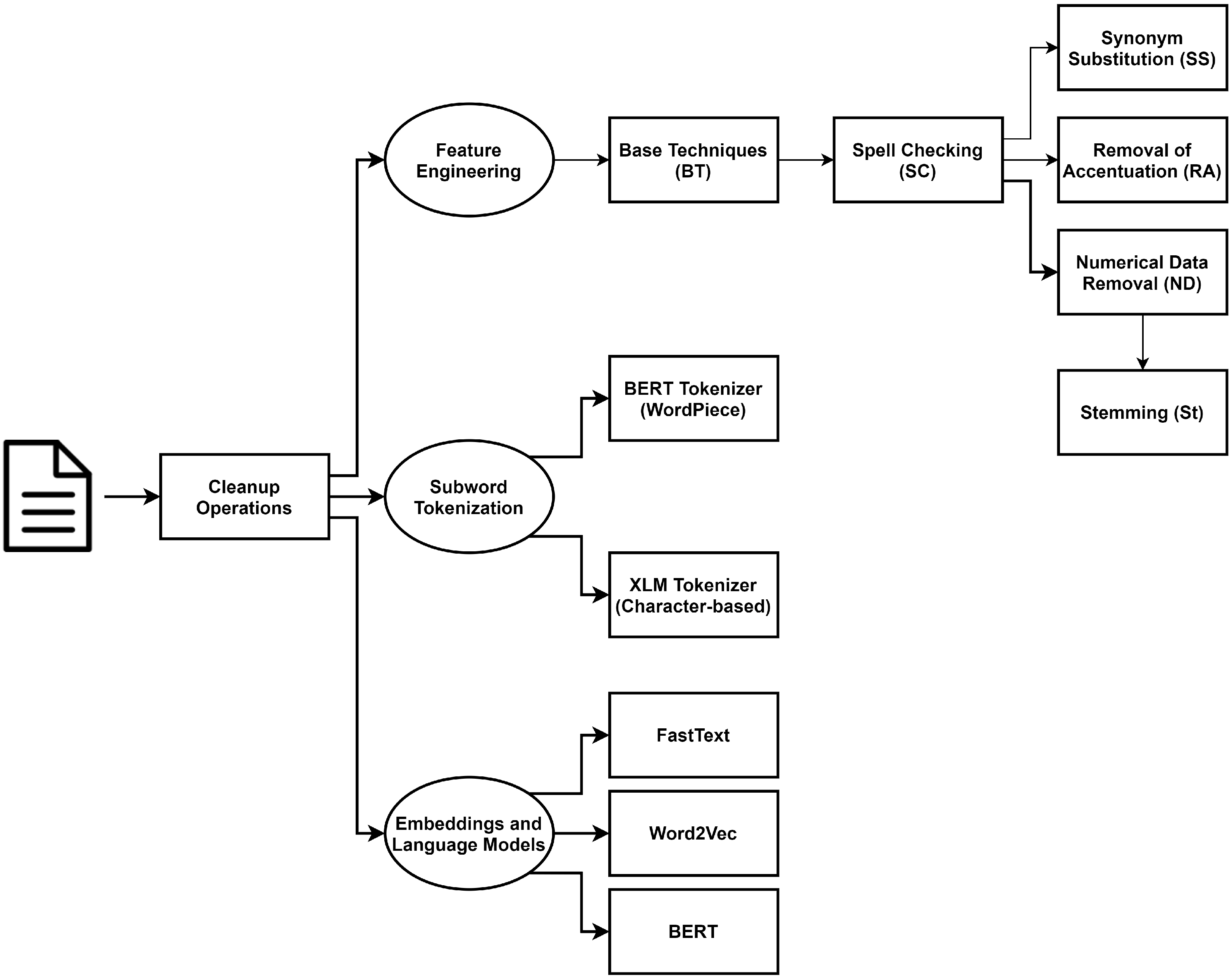
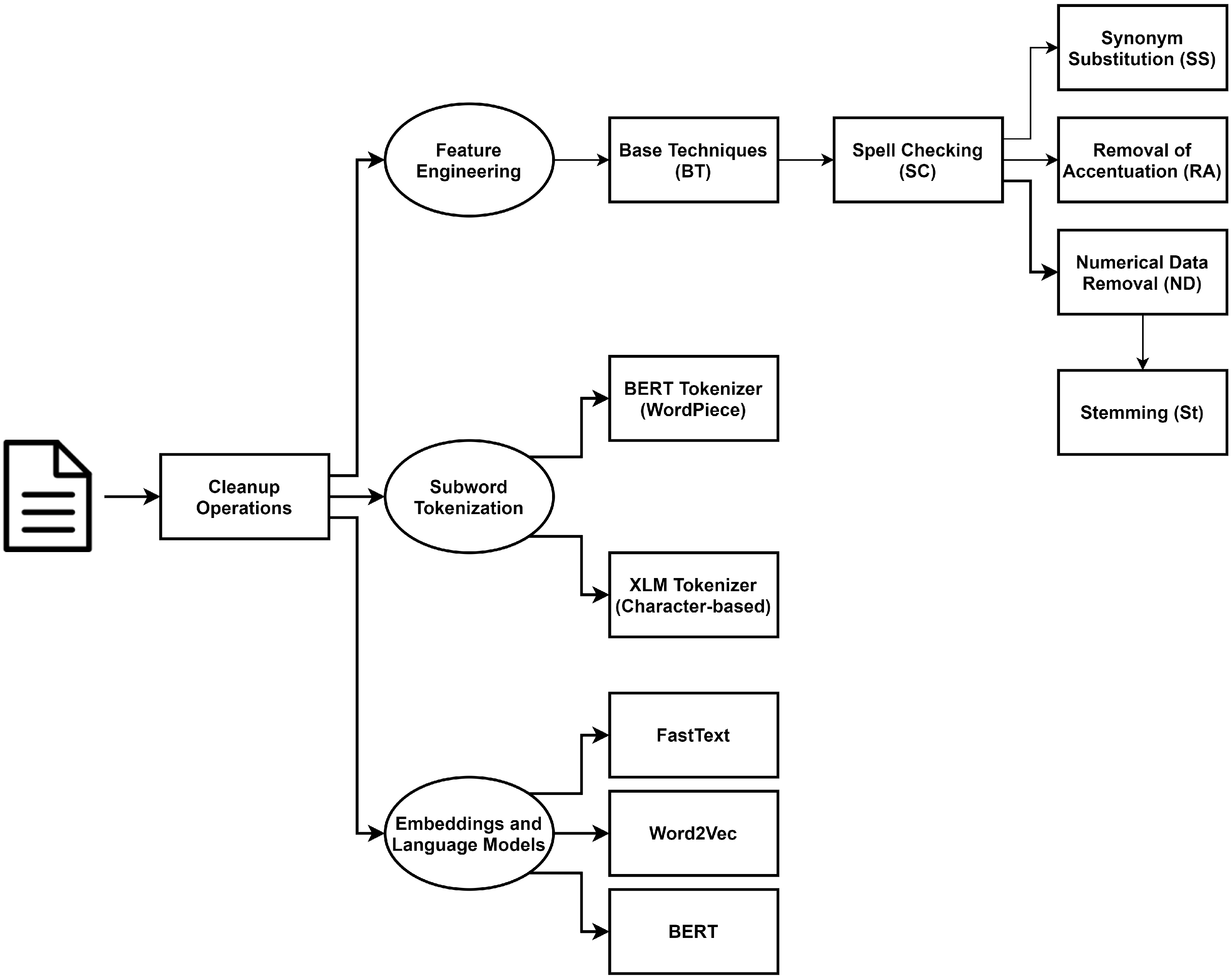
8. Embeddings and Language Models
Taking into account recent advances in the NLP community, we employ word embeddings and language models as encoding techniques. For that, we make use of the dataset after applying the cleanup operations mentioned in
Section 5.
For word embeddings, we report experiments with pre-trained Word2Vec embeddings [
31] using Convolutional Neural Networks (CNN) [
32] to encode the input sequence. We also report results using the FastText model [
33].
The CNN approach uses Word2Vec [
31] embeddings pre-trained with continuous bag-of-words with 300 dimensions for Portuguese, which were obtained from Hartmann et al. [
34]. The CNN architecture consists of four layers. An embedding layer is followed by
n parallel convolution layers with 100 output channels and a 1D max-pooling layer with a kernel size equal to the length of each layer. The outputs of the pooling layer are concatenated and passed to a fully-connected layer. The convolution layer has a kernel of
i by embedding dimension, where
n is equal to the number of different
i applied. Instead of explicitly using n-grams as in FastText, this leverages the convolution layer kernels to mimic this operation. In this experiment, we used 3 parallel convolutional layers with kernel sizes that go from 3 to 5.
FastText embeddings were trained from scratch. The FastText model consists of three layers: an 100 dimension embedding layer, an average pooling layer that normalizes the input length, and a fully connected layer.
For language models, we employ BERT [
35], which has been widely acknowledged to perform well in several downstream tasks. We make use of the pre-trained model “bert-base-multilingual-cased” provided by HuggingFace [
29], which includes Portuguese as one of the languages on which the language model has been trained. Each complaint is tokenized using WordPiece tokenization. The maximum sequence length that the BERT model can process is 512 tokens. Consequently, we truncate the tokenized input sequence to 510 tokens, and add the special delimiter [CLS] (the initial token) and [SEP] (the end of sequence token), as expected for the BERT model. The resulting input sequence is fed to the BERT model, and the corresponding [CLS] token hidden representation is used as the semantic-level representation, as suggested by Devlin et al. [
35]. On top of the BERT model, we add one fully-connected hidden layer with 768 neurons (as suggested by Sun et al. [
36]), and a final softmax layer with 11 neurons (the number of classes). All layers (those in the BERT model and the fully connected layer) are fine-tuned for the task at hand. The model was trained on a single GPU GeForce RTX 2080 TI, for 10 epochs, with a batch size of 8. To avoid catastrophic forgetting, we apply a 1-cycle policy annealing (OCPA) [
37] to the learning rate, similar to Sun et al. [
36], with an initial learning rate of
that was increased during the first epoch, reaching
, and then reduced for 9 epochs.
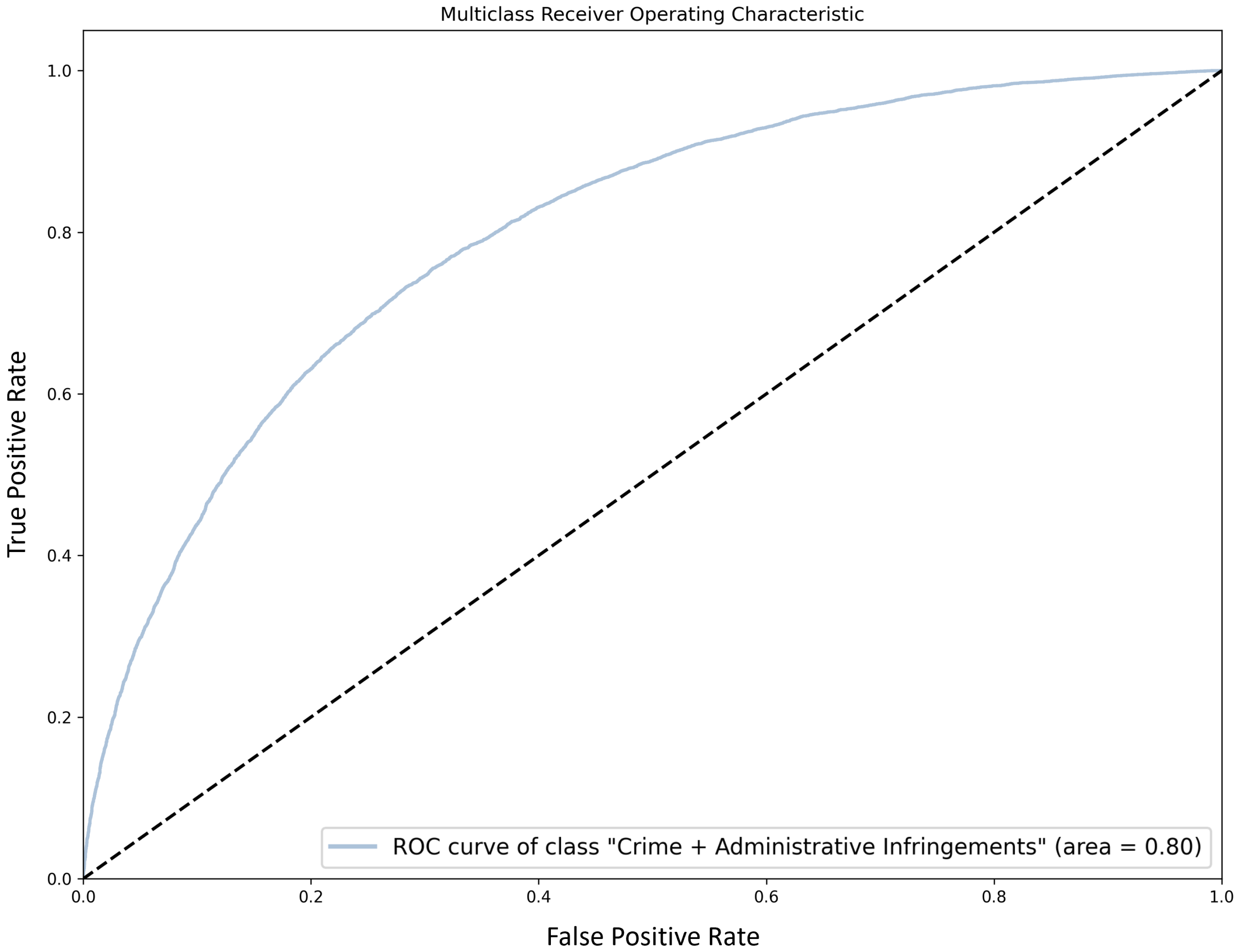
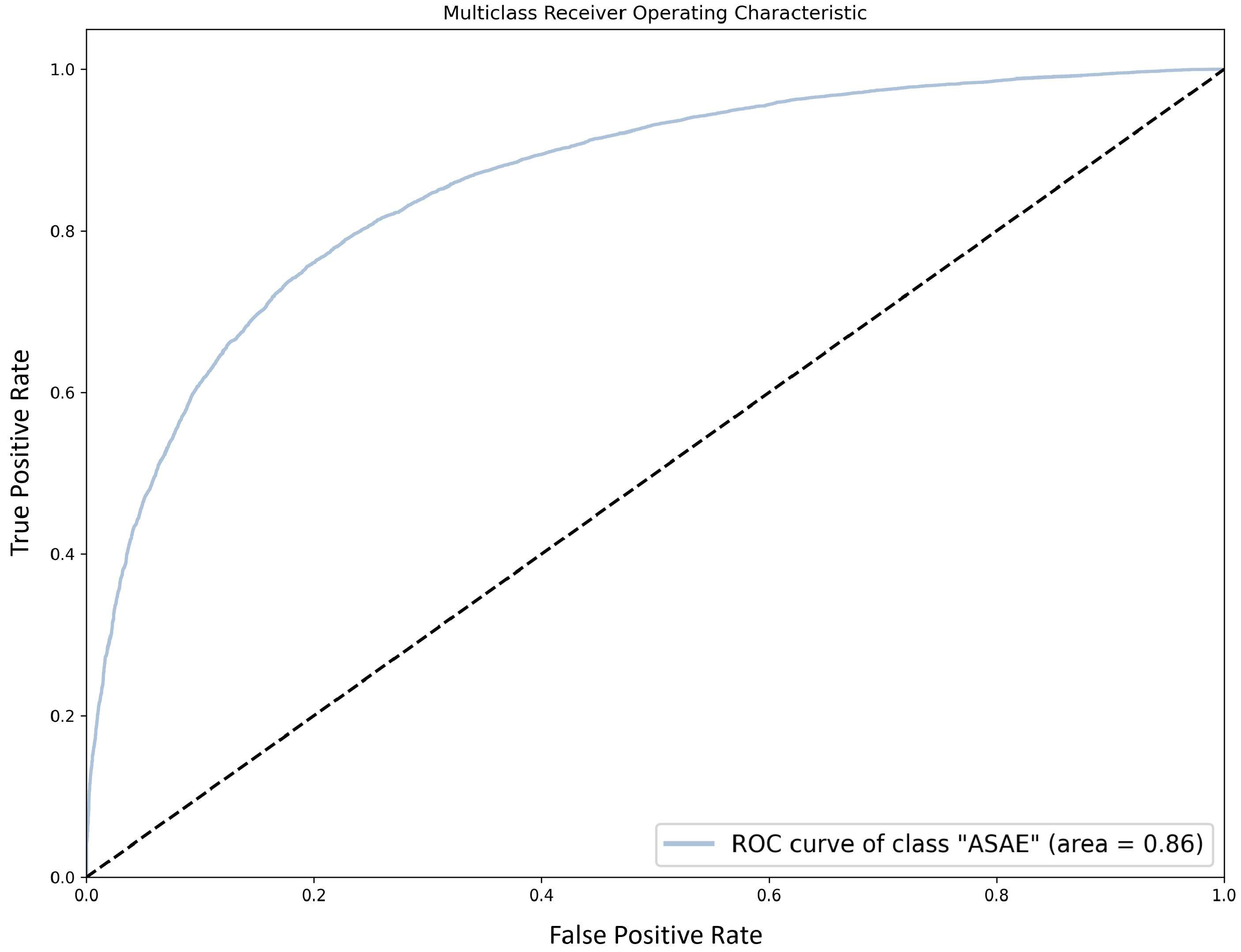
Table 22 presents the results obtained for the different experiments described above. Compared to the results reported in
Section 5.1.1, we observe that the models that are based on word embeddings perform worse. On the other hand, the BERT-based model is able to obtain a slight improvement in both accuracy and macro-F1, lower than
.
9. Discussion
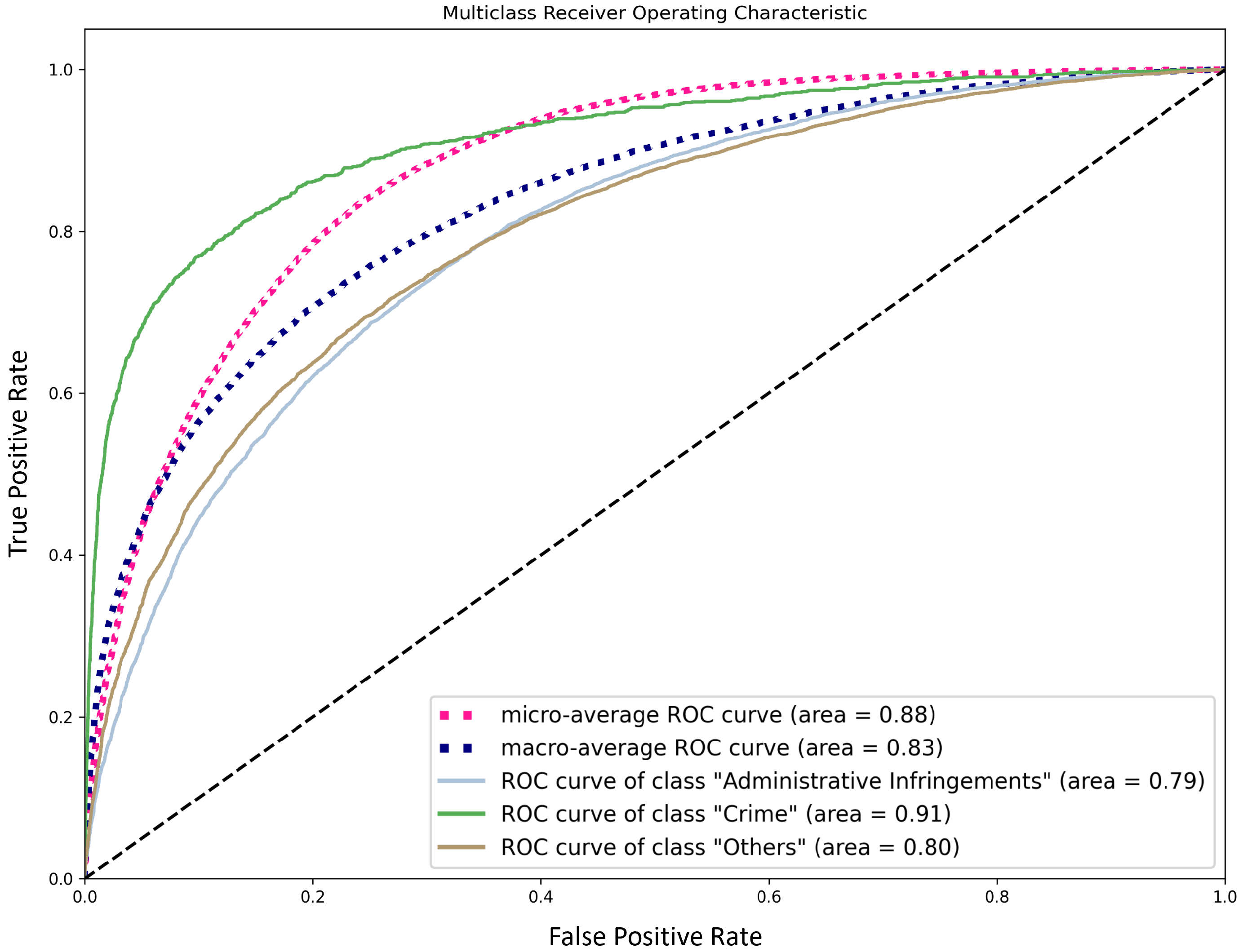
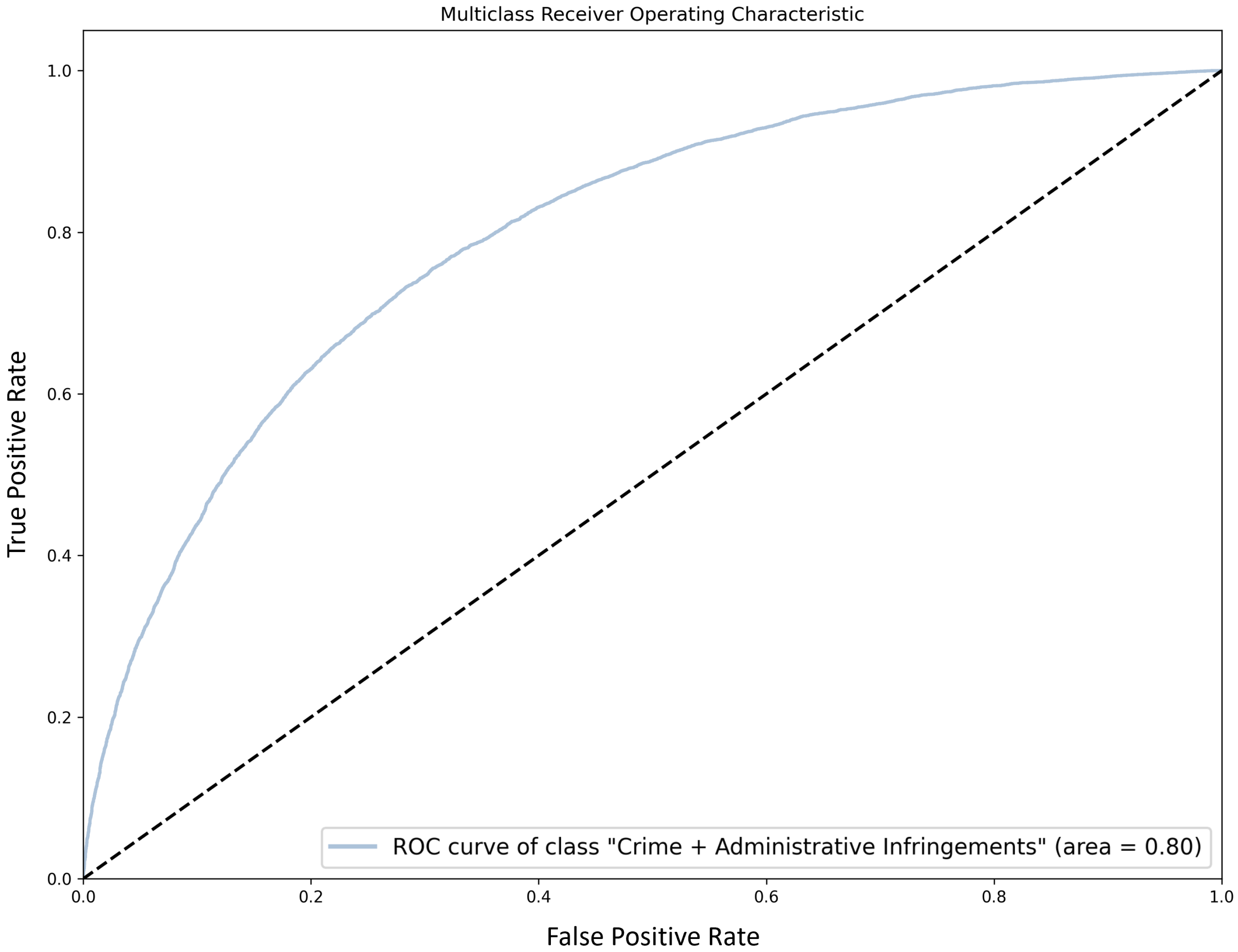
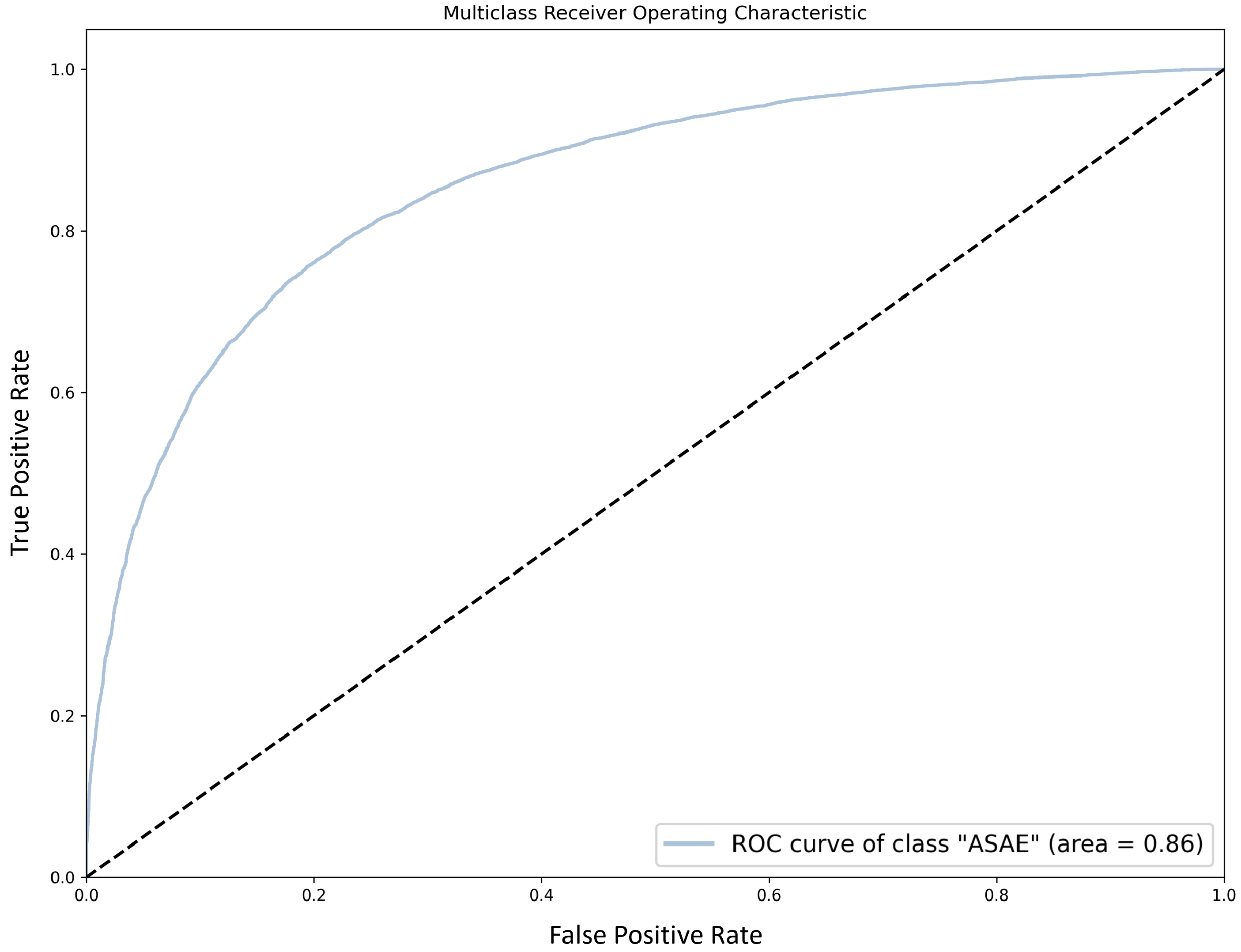
This paper reports on the use of different NLP techniques to address a real-world complex problem, related to the automatic processing and classification of complaints written in Portuguese. We have discussed, evaluated, and analyzed different preprocessing, representation, and classification models, as per
Figure 1.
Some of the main findings relate to the limitations of NLP tools for lesser-resourced languages. As noticed in the feature analysis carried out in this research, both lemmatizers and stemmers alike leave room for improvement, and hamper the performance of classification algorithms (namely SVM) when using word-level features. As performant they may be on benchmark datasets [
23], NLP tools are always dependent on the data on which they have been trained, in particular for neural-based approaches such as Stanza.
One thing to do is to train such models on domain data, assuming we have enough of it. The FastText approach reported in
Section 8 goes in that direction, although the obtained results have fallen back. Using embeddings trained for the same language is also a sensible approach. However, our attempt to exploit Portuguese Word2Vec embeddings did not succeed, perhaps due to genre shift (although the embeddings used have been trained with more than 1 billion tokens, complaint-like data does not seem to be included).
Not surprisingly, fine-tuning BERT to our task makes a quick jump to scores in line with the best ones obtained with feature-based techniques. Nevertheless, the amount of data available does not bring significant improvements, beating the best SVM model by a small margin. Still, this is accomplished without the need for any preprocessing, which is in line with the findings of Maslej-Krešňáková et al. [
38]. Despite the fact that there exist BERT models for (Brazilian) Portuguese [
39], we leave for future work evaluating if using such models brings significant improvements over the multilingual variant we have used. Training a BERT model from scratch is computationally expensive, and it is not likely that enough complaint-related data is available to include this particular genre in the training set. Our main concern in using neural models is the lack of explainability that one can extract, which is still an open debate [
40,
41,
42]. Since feature-based explanations are more consolidated and well-established, we leave for future work exploring recent advances towards the explainability of Transformer-based models.
Given the broad set of topics covered in our dataset, we cannot employ domain-oriented feature engineering approaches, as is sometimes used in sentiment analysis in closed domains [
43]. We did try out several ways to clean and reduce the vocabulary, including spell checking, synonym substitution, accentuation, and numerical data removal, and stemming. Our findings are non-conclusive as to the best approach both in terms of performance and feature analysis. However, a combination of spell checking and numerical data removal seems to be the most sensible approach to produce a model that can be used in the real world. Based on this observation, we can further fine-tune the model to our needs.
Looking deeper into the classification problems addressed, we note that many of the most salient features identified for economic activity prediction are entities, in some of the classes (class V in particular). These entities concern, in most cases, economic operators that can be easily associated with a specific economy sector. As such, and despite the fact that even in such cases the complaints that address these entities may concern different activities, a wise approach to tackle economic activity prediction may go through named entity recognition. Recognized entities can then be cross-referenced with ASAE’s database in order to try to unmistakably identify the targeted economic operator, and through that obtain its economic activity.
Addressing a multi-label classification problem as if it were single-label, for data scarceness reasons, has its perils. Our experience in approaching implied infraction detection as infraction severity prediction, although promising, brought additional challenges related to the fact that classes are less distinguishable. While infraction labels are groupable in different severity levels, being able to distinguish among those levels is hard. The workaround that we suggest is to tune classification thresholds to the needs of the target application in terms of precision/recall desired for each of the classes.
Techniques to deal with imbalanced datasets (including over/under-sampling, cost-sensitive learning, or data augmentation) are ways to improve the performance of classifiers. While we did not progress much in these lines, preliminary experiments did not succeed when using over/under sampling [
4].
Finally, a note on the feasibility of automated complaint classification when handling real-world data. Besides being imbalanced regarding all addressed classification tasks, ASAE’s complaint data is also significantly noisy. More than including misclassified examples (which is a general problem in many datasets), noise is mainly originated from certain complaints not including in themselves the information used by the human operator to classify them: in some cases, they simply refer back to a previous complaint, which is not traceable by automated means; in other cases, it is clear that the human has made use of additional knowledge to decide on the obtained label. These problems make automatic complaint processing even more challenging.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}