
New Approach of Measuring Human Personality Traits Using Ontology-Based Model from Social Media Data



Abstract
:1. Introduction
2. Theoretical Background
2.1. Personality Measurement
2.2. Social Media and Big Five Personality
- Using social media services: An extroverts character tends to find social media easy to use and valuable.
- Selecting social contacts: Users tend to choose contacts with similar Agreeableness, Extraversion, and Openness. However, generally they prefer to stay in touch with people of high Agreeableness.
- Keeping many contacts: As one expects, the personality trait that keeps the most with social connections is Extraversion.
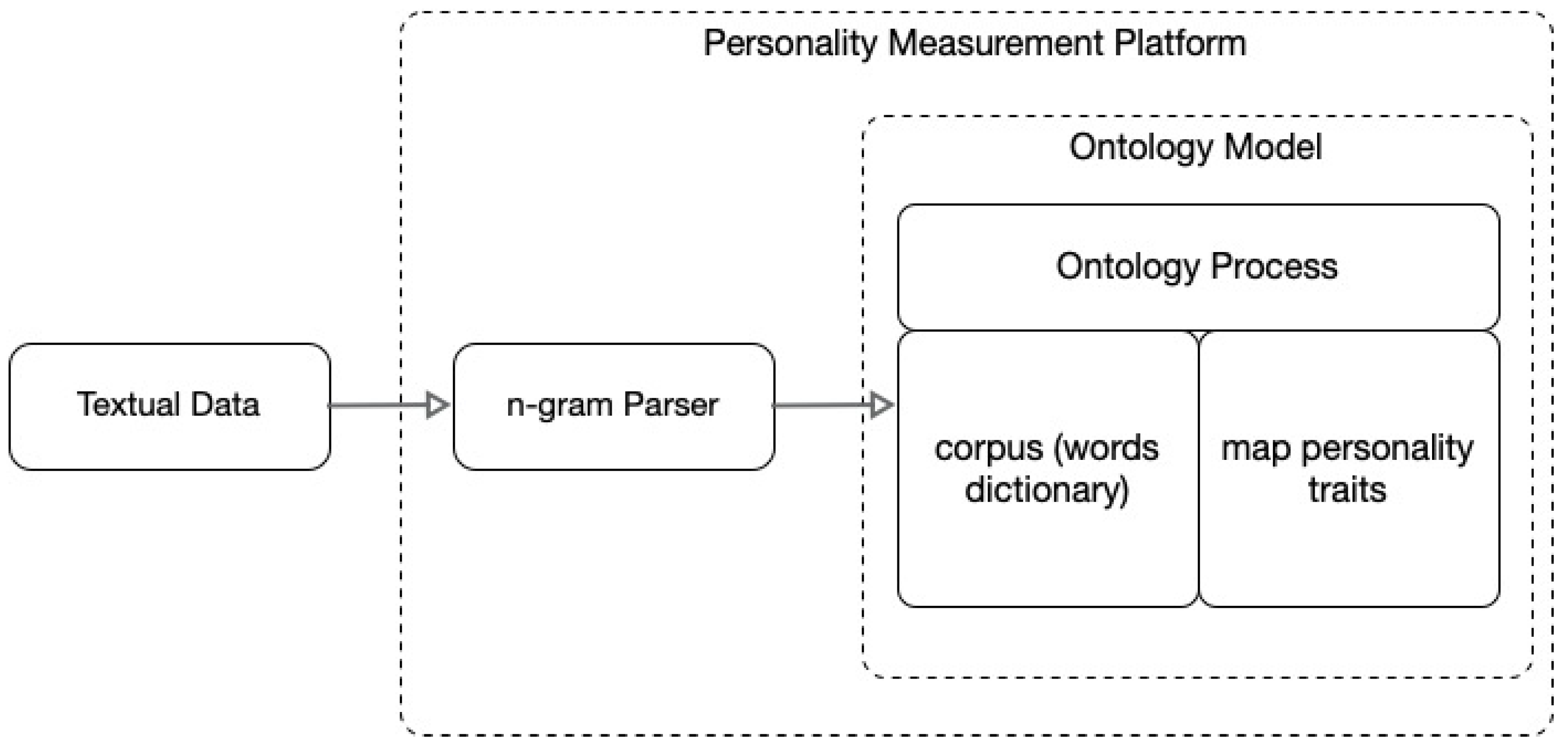
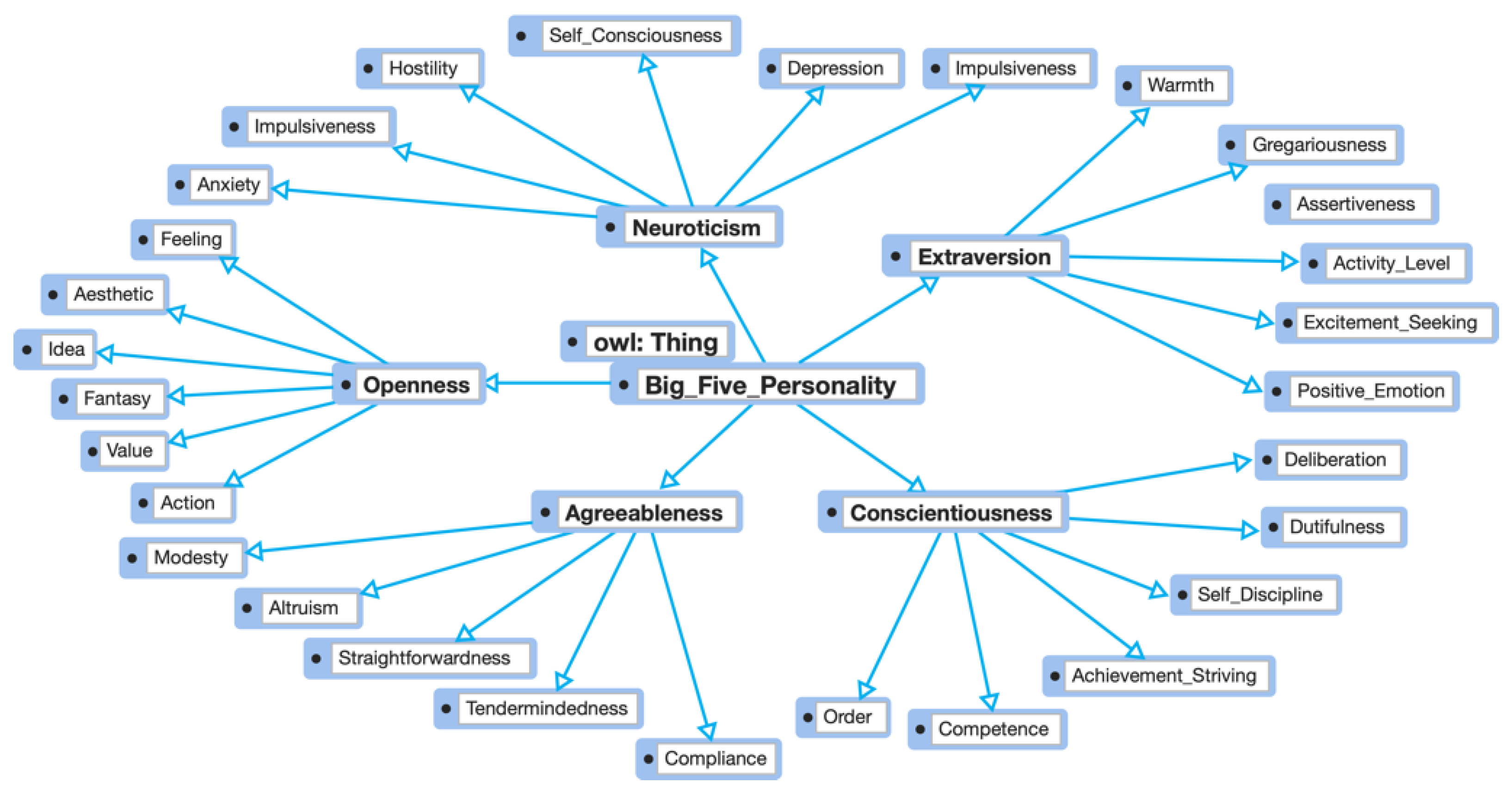
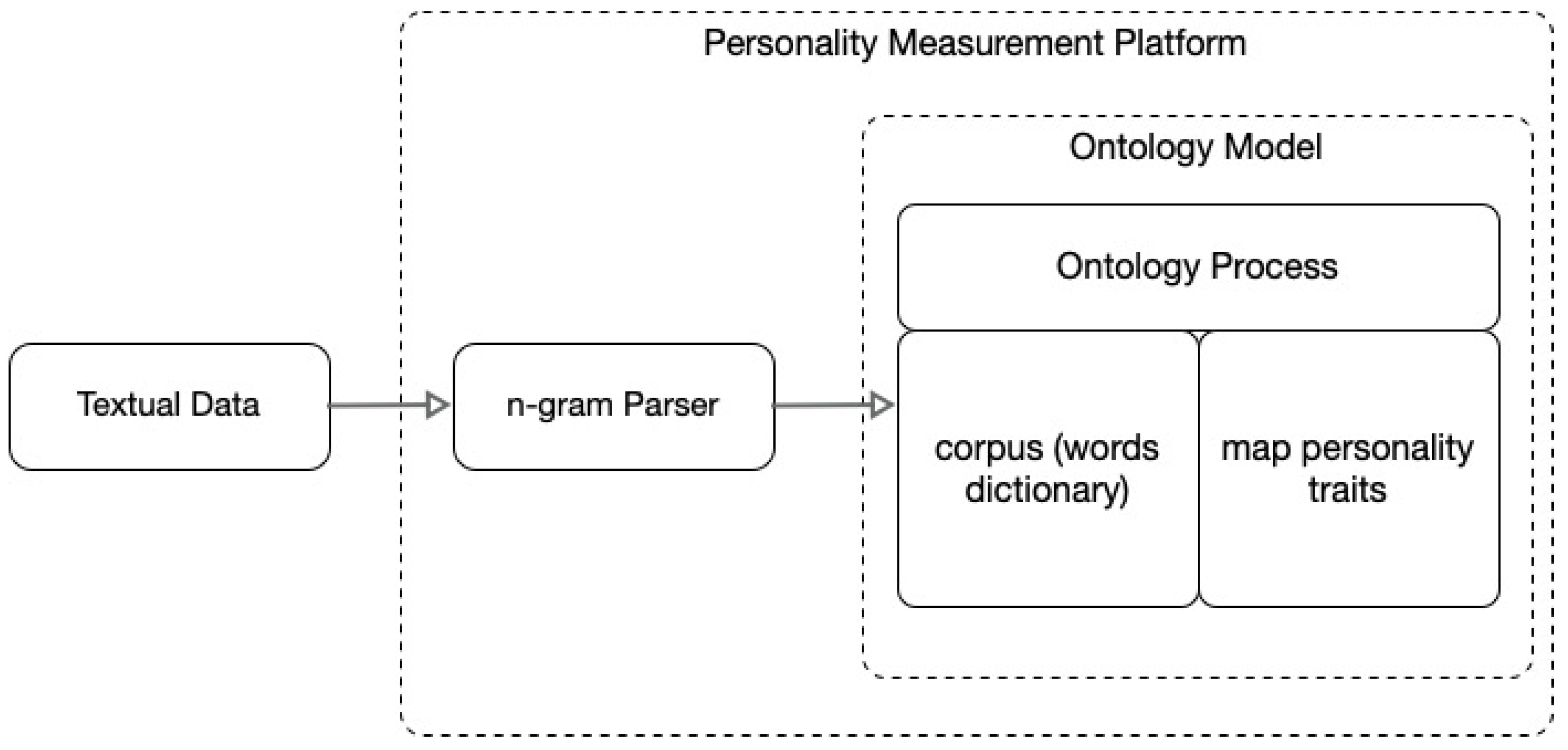
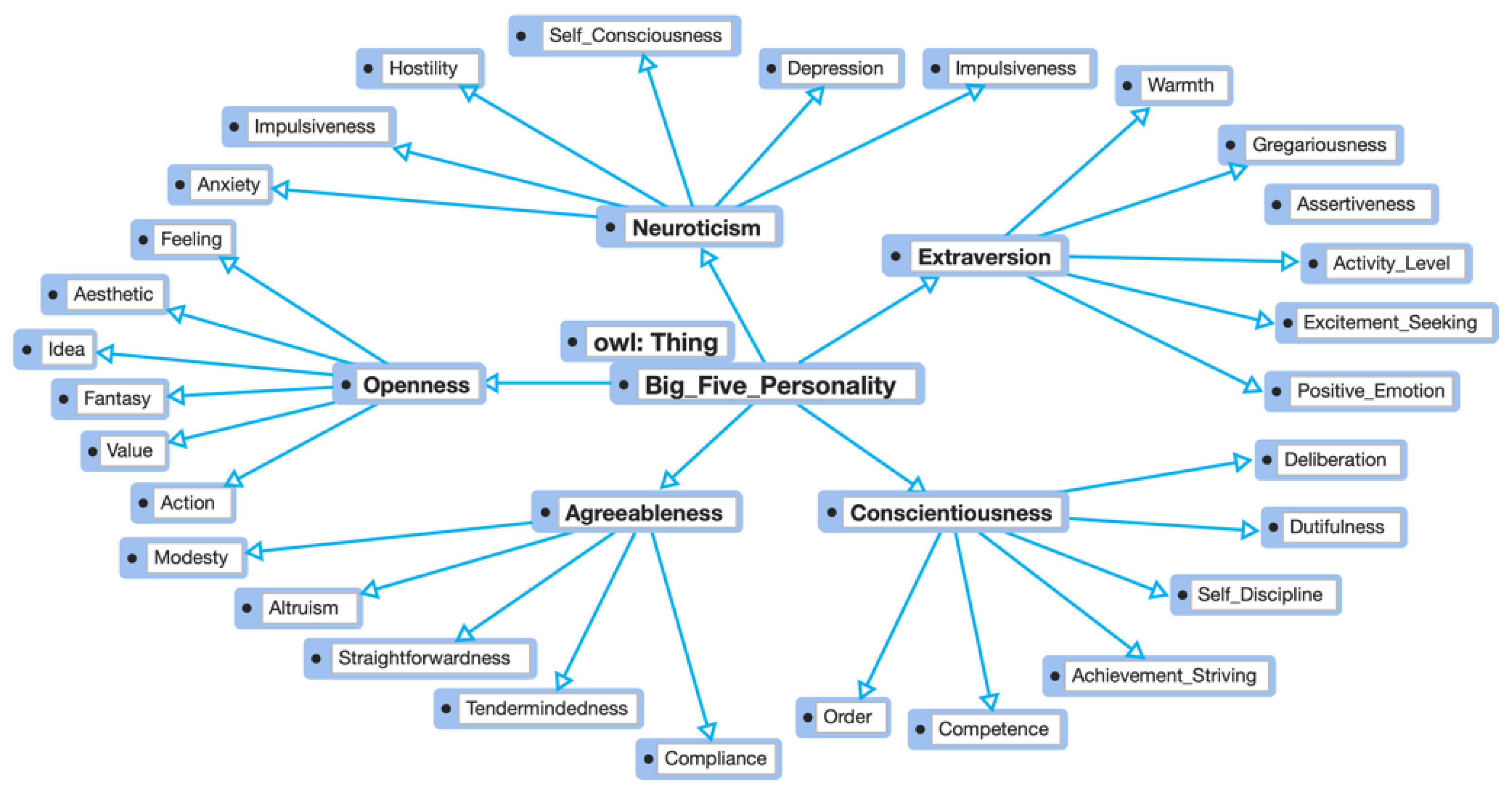
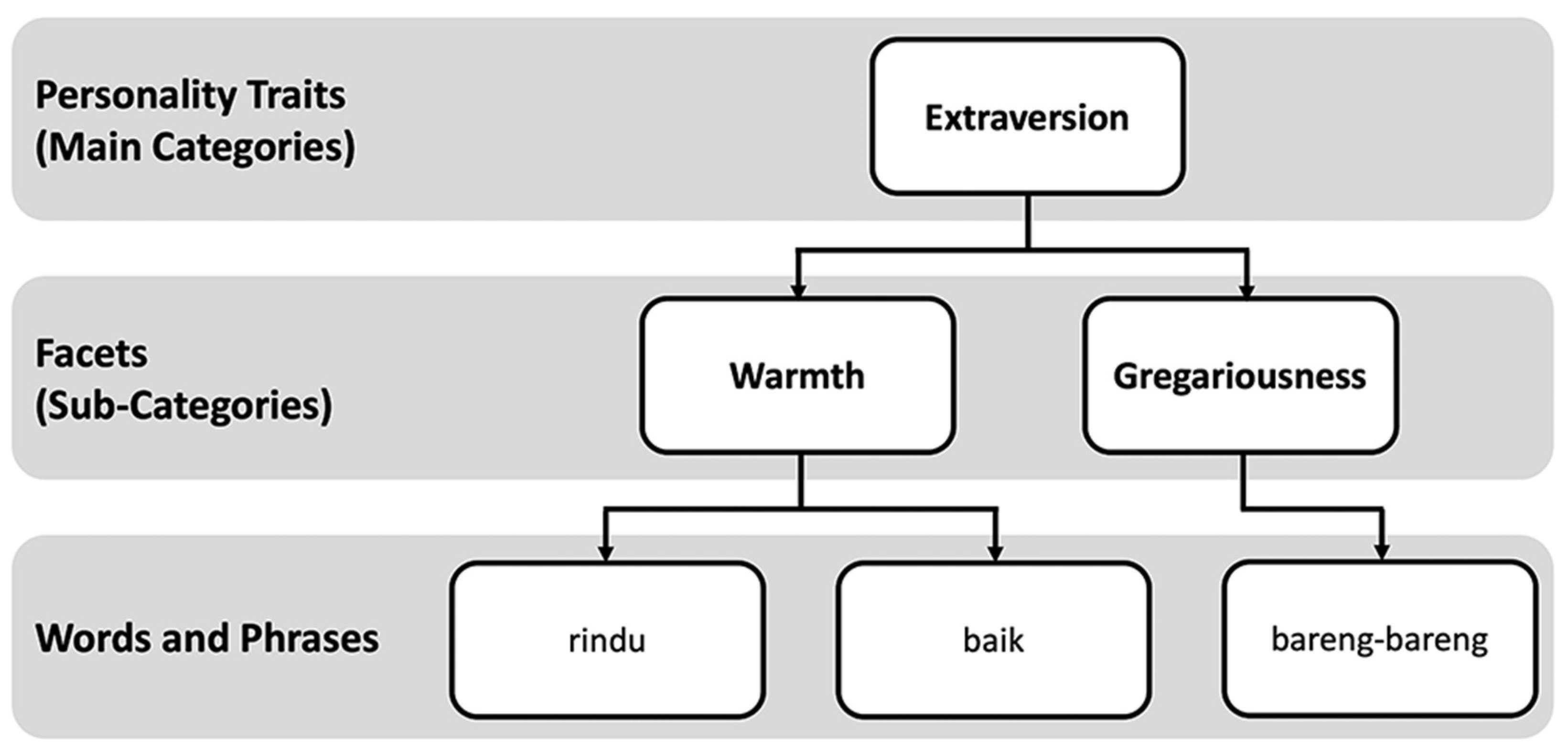
2.3. Ontology Model
3. Methodology
3.1. Participants
3.2. Procedure
3.3. Datasets
- Public figure’s account.
- Actively interacting with other users.
- Giving opinions.
- Share a lot of daily activities.
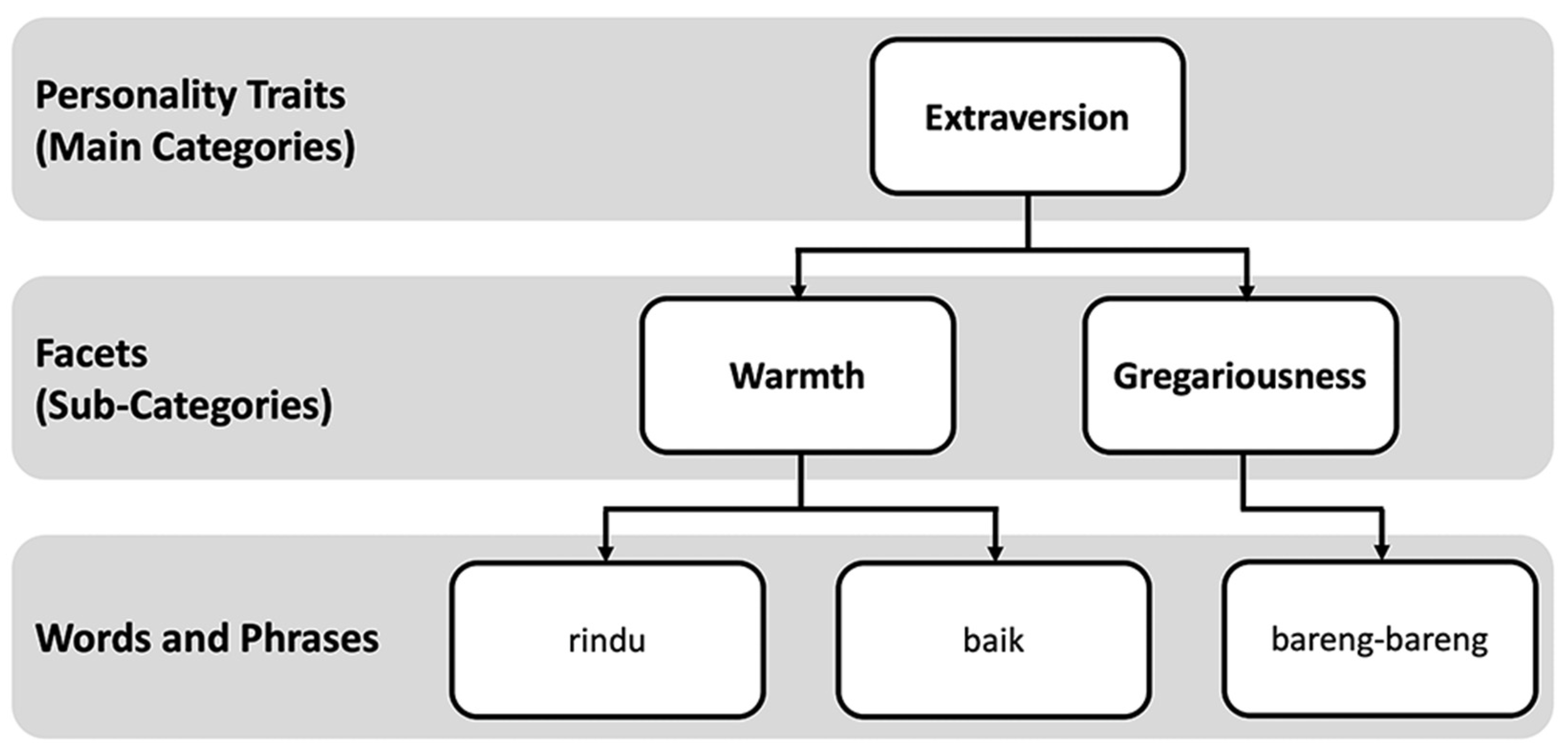
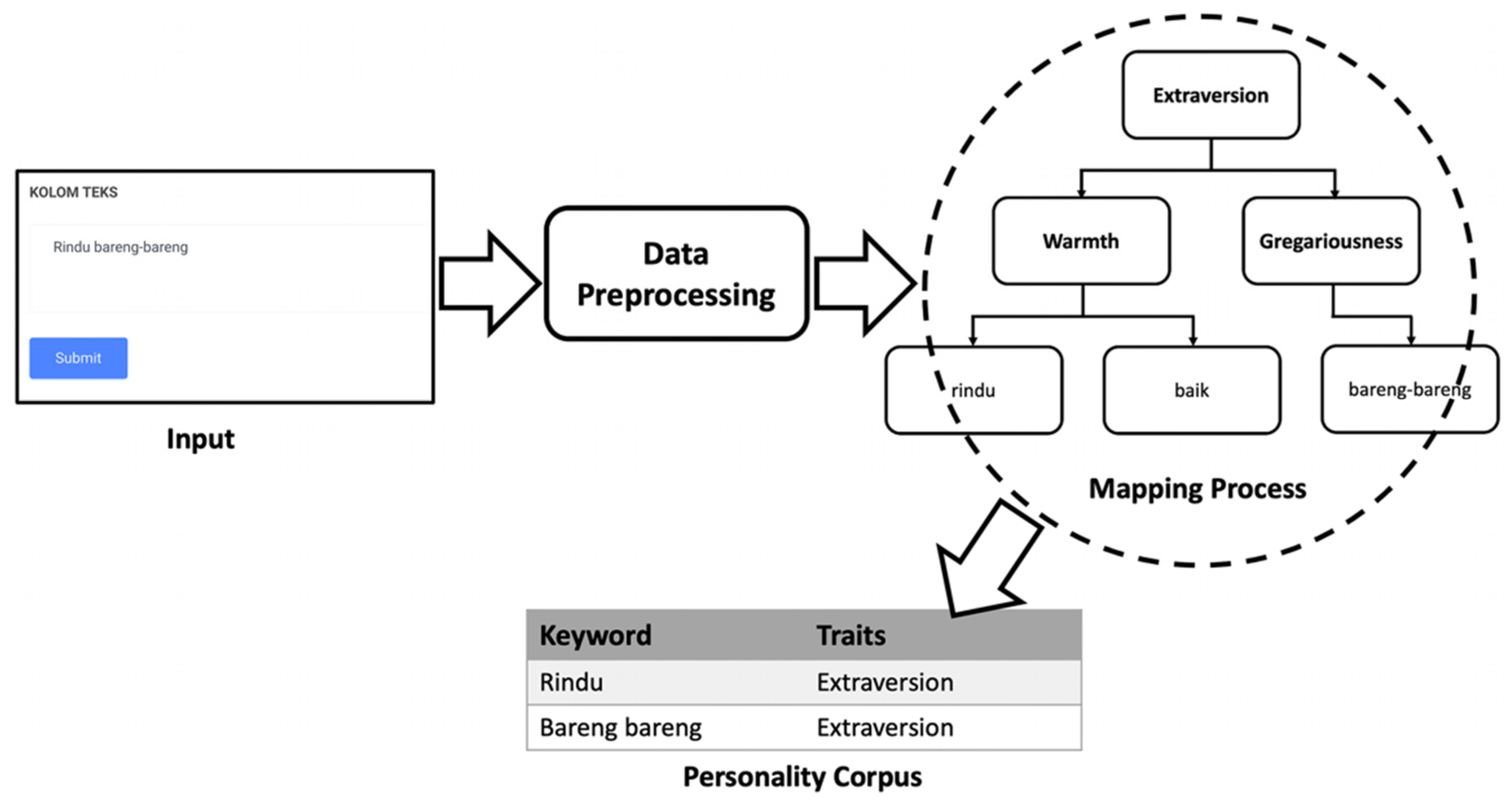
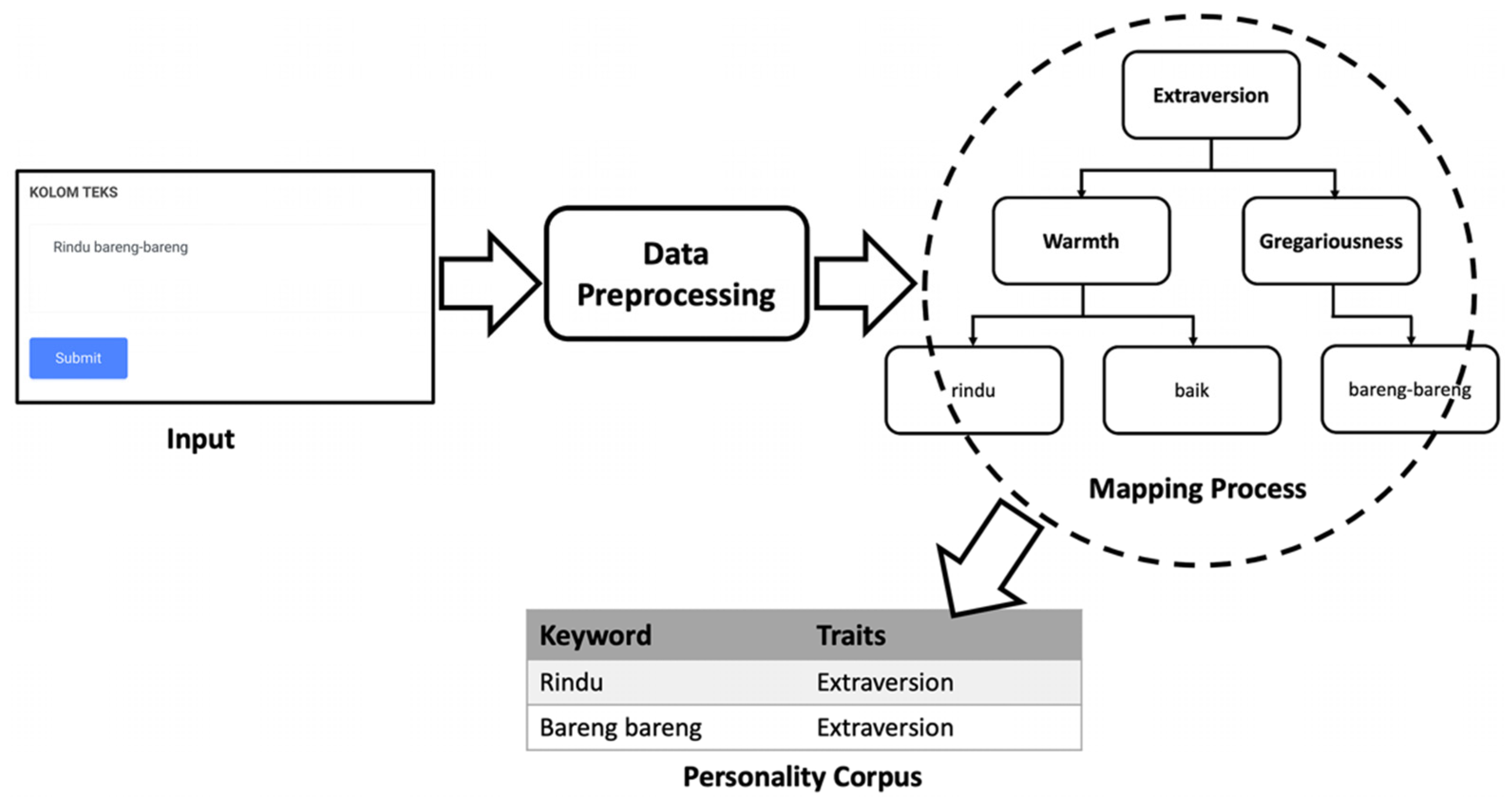
3.4. Ontology Model Development
- To ensure the correctness of the mapping.
- To measure model performance or the accuracy of the personality class decision. The model is validated by two domain experts in the psychology discipline. The validation process requires the experts to validate every single keyword in the ontology model that corresponded to the available traits in the Big Five Personality model.
- Protégé OWL provides multiuser support for synchronous knowledge entry.
- Protégé OWL can be extended with back-ends for alternative file formats. Currents formats include Clips, XML, RDF, and OWL.
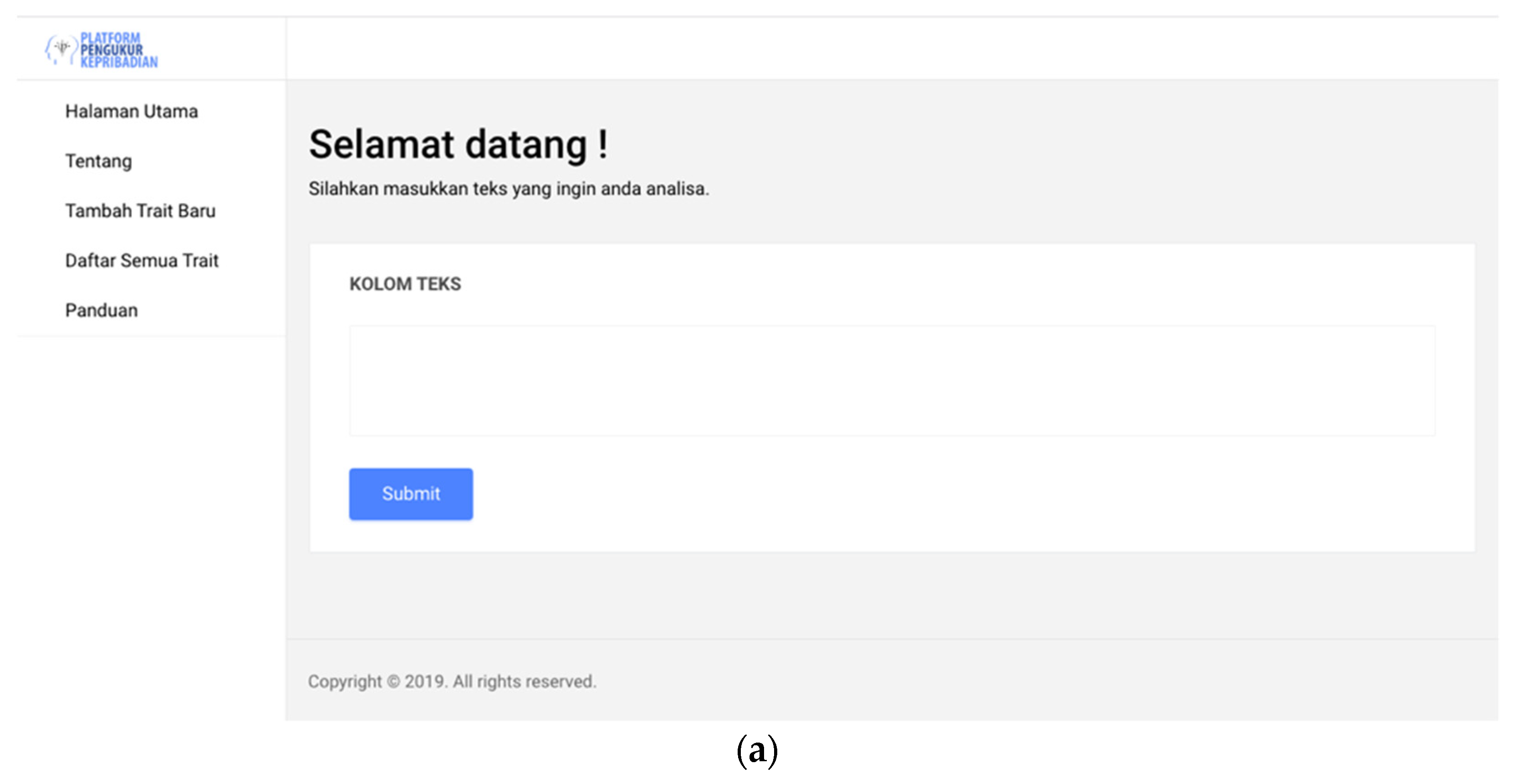
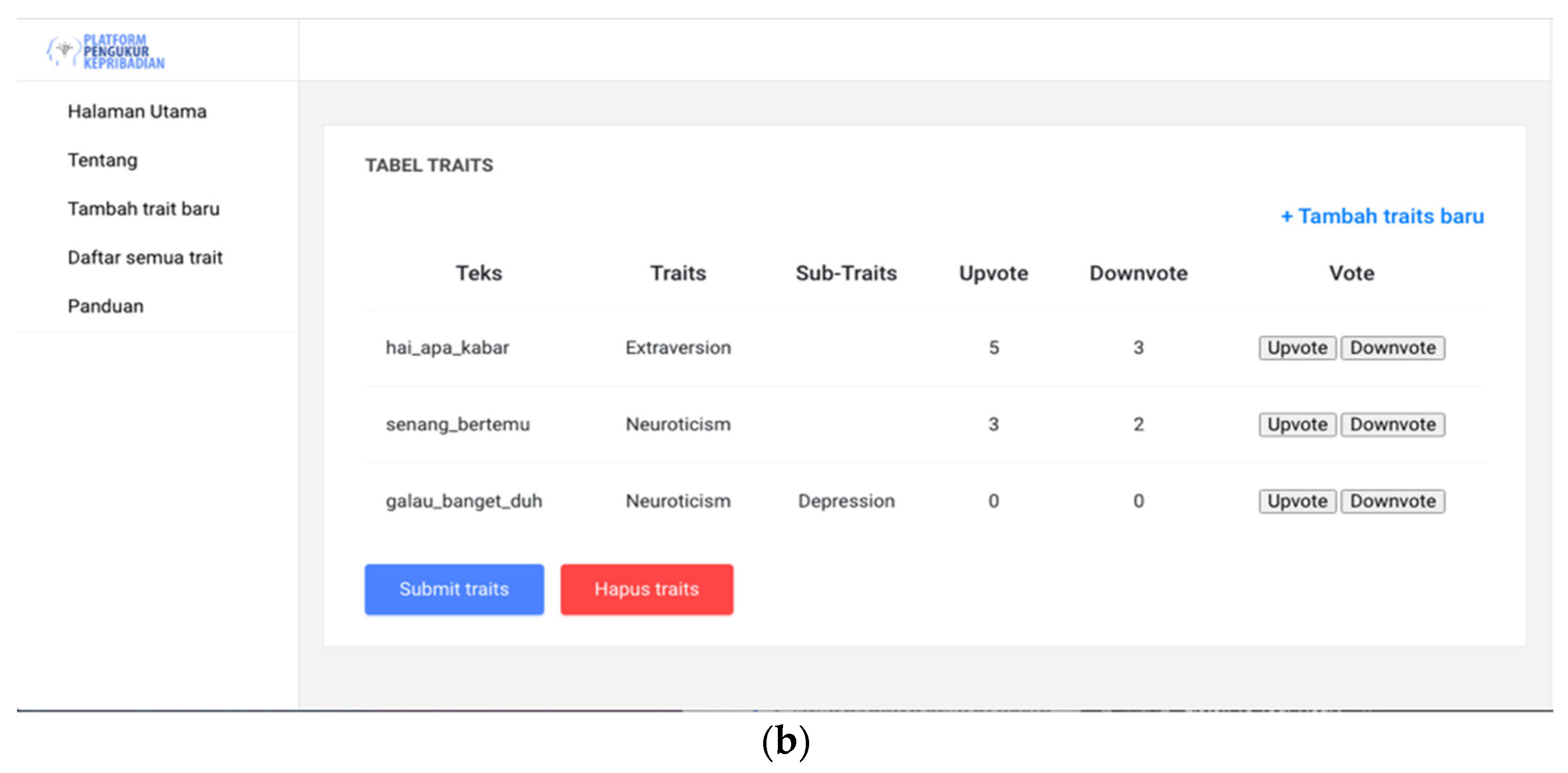
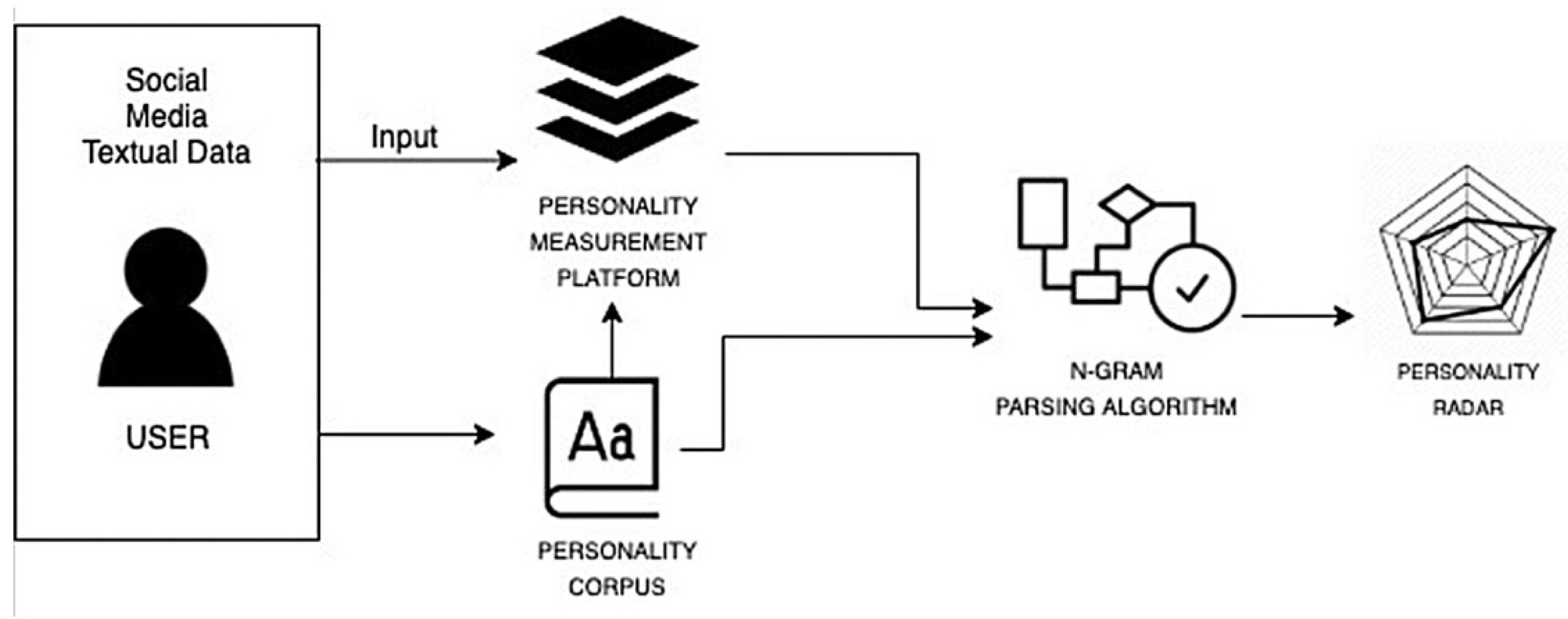
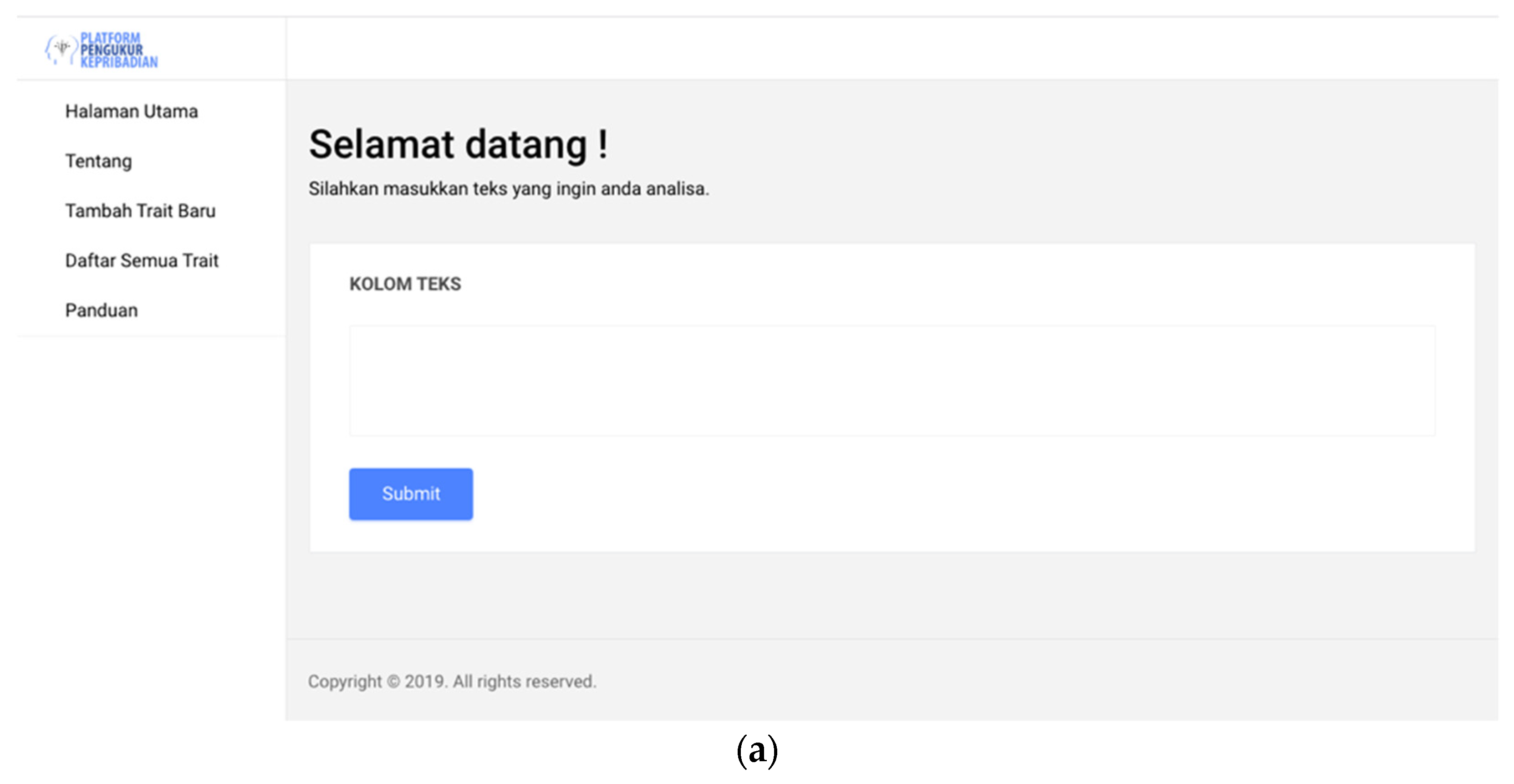
3.5. Proposed Platform
3.6. Personality Measurement
4. Analysis and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- John, O.P.; Donahue, E.M.; Kentle, R.L. Big Five Inventory (BFI); American Psychological Association: Washington, DC, USA, 1991. [Google Scholar]
- Goldberg, L.R. The development of markers for the Big Five factor structure. Psychol. Assess. 1992, 4, 26–42. [Google Scholar] [CrossRef]
- Costa, P.T.; McCrae, R.R. Normal personality assessment in clinical practice: The NEO Personality Inventory. Psychol. Assess. 1992, 4, 5–13. [Google Scholar] [CrossRef]
- Robins, R.W.; Hendin, H.M.; Trzesniewski, K.H. Measuring global self-esteem: Construct validation of a single-item measure and the Rosenberg self-esteem scale. Personal. Soc. Psychol. Bull. 2001, 27, 151–161. [Google Scholar] [CrossRef]
- Rammstedt, B.; Rammsayer, T. Gender differences in self-estimated intelligence and their relation to gender-role orientation. Eur. J. Personal. 2002, 16, 369–382. [Google Scholar] [CrossRef]
- Gosling, S.D.; Rentfrow, P.J.; Swann, W.B., Jr. A very brief measure of the Big-Five personality domains. J. Res. Personal. 2003, 37, 504–528. [Google Scholar] [CrossRef]
- Rammstedt, B.; John, O.P. Measuring personality in one minute or less: A 10-item short version of the Big Five Inventory in English and German. J. Res. Personal. 2007, 41, 203–212. [Google Scholar] [CrossRef]
- Burisch, M. Test length and validity revisited. Eur. J. Personal. 1997, 11, 303–315. [Google Scholar] [CrossRef]
- Farr, J.L.; Tippins, N.T. (Eds.) Handbook of Employee Selection; Taylor & Francis Group: New York, NY, USA, 2017. [Google Scholar]
- Hilgert, L.; Kroh, M.; Richter, D. The effect of face-to-face interviewing on personality measurement. J. Res. Personal. 2016, 63, 133–136. [Google Scholar] [CrossRef] [Green Version]
- Hunt, C.; Andrews, G. Measuring personality disorder: The use of self-report questionnaires. J. Personal. Disord. 1992, 6, 125–133. [Google Scholar] [CrossRef]
- Dwivedula, R.; Bredillet, C.N.; Müller, R. Personality and work motivation as determinants of project success: The mediating role of organizational and professional commitment. Int. J. Manag. Dev. 2016, 1, 229–245. [Google Scholar] [CrossRef]
- Golbeck, J.; Robles, C.; Edmondson, M.; Turner, K. Predicting Personality from Twitter. In Proceedings of the IEEE 3rd International Conference on Privacy, Security, Risk, and Trust and the 3rd International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011. [Google Scholar]
- Setyawan, M.A. Ontological Search Engine on Twitter to Collect Data for Bandung Happiness Index Measurement. In Proceedings of the Indonesia Symposium on Computing (IndoSC), Bandung, Indonesia, 24–25 September 2016. [Google Scholar]
- Pratama, B.Y.; Sarno, R. Personality classification based on Twitter text using Naive Bayes, KNN, and SVM. In Proceedings of the IEEE International Conference on Data and Software Engineering (ICoDSE), Yogyakarta, Indonesia, 25–26 November 2015; pp. 170–174. [Google Scholar]
- Stachl, C.; Au, Q.; Schoedel, R.; Gosling, S.D.; Harari, G.M.; Buschek, D.; Volkel, S.T.; Schuwerk, T.; Oldemeier, M.; Ullman, T.; et al. Predicting personality from patterns of behavior collected with smartphones. Proc. Natl. Acad. Sci. USA 2020, 117, 17680–17687. [Google Scholar] [CrossRef] [PubMed]
- Farnadi, G.; Sitaraman, G.; Sushmita, S.; Celli, F.; Kosinski, M.; Stillwell, D.; De Cock, M. Computational personality recognition in social media. User Modeling User-Adapt. Interact. 2016, 26, 109–142. [Google Scholar] [CrossRef] [Green Version]
- Bleidorn, W.; Hopwood, C.J.; Wright, A.G. Using big data to advance personality theory. Curr. Opin. Behav. Sci. 2017, 18, 79–82. [Google Scholar] [CrossRef]
- Alamsyah, A.; Widiyanesti, S.; Putra, M.R.D.; Sari, P.K. Personality Measurement Design for Ontology-Based Platform using Social Media Text. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 100–107. [Google Scholar] [CrossRef]
- Hathaway, S.R.; McKinley, J.C. The Minnesota Multiphasic Personality Inventory; American Psychological Association: Washington, DC, USA, 2016. [Google Scholar]
- Hogan, R.; Hogan, J. Personality, and status. In Personality, Social Skills, and Psychopathology: An Individual Differences Approach; Gilbert, D.G., Connolly, J.J., Eds.; Plenum Press: New York, NY, USA, 1991; pp. 137–154. [Google Scholar] [CrossRef]
- Gough, H.G. Cross-Cultural Validation a Measure of Asocial Behavior. Psychol. Rep. 1965, 7, 379–387. [Google Scholar] [CrossRef]
- Conway, M.; O’Connor, D. Social media, big data, and mental health: Current advances and ethical implications. Curr. Opin. Psychol. 2016, 9, 77–82. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldberg, L.R.; Johnson, J.A.; Eber, H.W.; Hogan, R.; Ashton, M.C.; Cloninger, C.R.; Gough, H.G. The international personality item pool and the future of public-domain personality measures. J. Res. Personal. 2006, 40, 84–96. [Google Scholar] [CrossRef]
- Costa, P.T.; McCrae, R.R. The five-factor model of personality and its relevance to personality disorders. J. Personal. Disord. 1992, 6, 343–359. [Google Scholar] [CrossRef]
- Cieciuch, J.; Łaguna, M. The Big Five and beyond: Personality traits and their measurement. Rocz. Psychol. 2014, 17, 249–257. [Google Scholar]
- Quercia, D.; Kosinski, M.; Stillwell, D.; Crowcroft, J. Our Twitter Profiles, Our Selves: Predicting Personality with Twitter. In Proceedings of the 2011 IEEE 3rd International Conference on Privacy, Security, Risk and Trust and 2011 IEEE 3rd International Conference on Social Computing, Security, Boston, MA, USA, 9–11 October 2011; pp. 180–185. [Google Scholar] [CrossRef]
- Zhao, D.; Rosson, M.B. How and why people Twitter: The role that micro-blogging plays in informal communication at work. In Proceedings of the ACM 2009 International Conference on Supporting Group Work (GROUP ‘09), Sanibel, FL, USA, 10–13 May 2009; pp. 243–252. [Google Scholar] [CrossRef]
- Pak, A.; Paroubek, P. Twitter-based system: Using Twitter for disambiguating sentiment ambiguous adjectives. In Proceedings of the ACL 2010 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July2010; pp. 436–439. [Google Scholar]
- Zhao, W.X.; Jiang, J.; He, J.; Song, Y.; Achananuparp, P.; Lim, E.P.; Li, X. Topical keyphrase extraction from Twitter. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 379–388. [Google Scholar]
- Finin, T.; Murnane, W.; Karandikar, A.; Keller, N.; Martineau, J.; Dredze, M. Annotating named entities in Twitter data with crowdsourcing. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, Los Angeles, CA, USA, 6 June 2010; pp. 80–88. [Google Scholar]
- Barbier, G.; Liu, H. Data mining in social media. In Social Network Data Analytics; Springer: Boston, MA, USA, 2011; pp. 327–352. [Google Scholar]
- Farnadi, G.; Zoghbi, S.; Moens, M.F.; De Cock, M. Recognizing personality traits using Facebook status updates. In Proceedings of the 7th International AAAI conference on weblogs and social (WCPR13), Bostan, MA, USA, 11 July 2013. [Google Scholar]
- Lambiotte, R.; Kosinski, M. Tracking the digital footprints of personality. Proc. IEEE 2014, 102, 1934–1939. [Google Scholar] [CrossRef]
- Wu, W.; Li, H.; Wang, H.; Zhu, K.Q. Probase: A probabilistic taxonomy for text understanding. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AR, USA, 20–24 May 2012; pp. 481–492. [Google Scholar]
- Aaberge, T.; Akerkar, R. Ontology and Ontology Construction: Background and Practices. Int. J. Comput. Sci. Appl. 2012, 9, 32–41. [Google Scholar]
- Sewwandi, D.; Perera, K.; Sandaruwan, S.; Lakchani, O.; Nugaliyadde, A.; Thelijjagoda, S. Linguistic features-based personality recognition using social media data. In Proceedings of the 6th National Conference on Technology and Management (NCTM), Malabe, Sri Lanka, 27 January 2017; pp. 63–68. [Google Scholar]
- Egloff, M.; Lieto, A.; Picca, D. An Ontological Model for Inferring Psychological Profiles and Narratives Roles of Character. In Proceedings of the Digital Humanities Conference, Mexico City, Mexico, 26–29 June 2018. [Google Scholar]
- McCrae, J.; Spohr, D.; Cimiano, P. Linking Lexical Resources and Ontologies on Semantic Web with Lemon. In Proceedings of the 8th Extended Semantic Web Conference (ESWC), Heraklion, Greece, 29 May–2 June 2011; pp. 245–259. [Google Scholar]
- Alamsyah, A.; Putra, M.R.D.; Fadhilah, D.D.; Nurwianti, F.; Ningsih, E. Ontology Modelling Approach for Personality Measurement Based on Social Media Activity. In Proceedings of the 6th International Conference on Information and Communication Technology (ICoICT), Bandung, Indonesia, 3–5 May 2018; pp. 507–513. [Google Scholar] [CrossRef]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford Knowledge Systems Laboratory Technical Report KSL-01-05 and Stanford Medical Informatics Technical Report SMI-2001-0880; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Azucar, D.; Marengo, D.; Settanni, M. Predicting the Big 5 personality traits from digital footprints on social media: A meta-analysis. Personal. Individ. Differ. 2018, 124, 150–159. [Google Scholar] [CrossRef]
- Kuss, D.J.; Griffiths, M.D. Online social networking and addiction—A review of the psychological literature. Int. J. Environ. Res. Public Health 2011, 8, 3528–3552. [Google Scholar] [CrossRef] [Green Version]
- Seidman, G. Self-presentation and belonging on Facebook: How personality influences social media use and motivations. Personal. Individ. Differ. 2013, 54, 402–407. [Google Scholar] [CrossRef]
- Arusada, M.D.N.; Putri, N.A.S.; Alamsyah, A. Training Data Optimization Strategy for Multiclass Text Classification. In Proceedings of the 5th International Conference on Information and Communication Technology (ICOICT), Melaka, Malaysia, 17–19 May 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Zheng, H.; Wu, C. Predicting Personality Using Facebook Status Based on Semi-supervised Learning. In Proceedings of the 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; pp. 59–64. [Google Scholar]
- Morin, P. Data Structures for Strings. Available online: https://cglab.ca/~morin/teaching/5408/notes/strings.pdf (accessed on 15 April 2012).
- Cavnar, W.B.; Trenkle, J.M. N-gram-based text categorization. In Proceedings of the SDAIR-94, 3rd Anual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 11 April 1994. [Google Scholar]
- Pauls, A.; Klein, D. Faster and smaller n-gram language models. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 258–267. [Google Scholar]
- Konstabel, K.; Lönnqvist, J.E.; Walkowitz, G.; Konstabel, K.; Verkasalo, M. The ‘Short Five’(S5): Measuring personality traits using comprehensive single items. Eur. J. Personal. 2012, 26, 13–29. [Google Scholar] [CrossRef]
- Vazire, S. Informant reports A cheap, fast, and easy method for personality assessment. J. Res. Personal. 2006, 40, 472–481. [Google Scholar] [CrossRef]
- Park, G.; Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Kosinski, M.; Stillwell, D.J.; Seligman, M.E. Automatic personality assessment through social media language. J. Personal. Soc. Psychol. 2015, 108, 934. [Google Scholar] [CrossRef] [Green Version]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Qiu, L.; Lin, H.; Ramsay, J.; Yang, F. You are what you tweet: Personality expression and perception on Twitter. J. Res. Personal. 2012, 46, 710–718. [Google Scholar] [CrossRef]
- Gao, R.; Hao, B.; Bai, S.; Li, L.; Li, A.; Zhu, T. Improving user profile with personality traits predicted from social media content. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 355–358. [Google Scholar]
- Li, L.; Li, A.; Hao, B.; Guan, Z.; Zhu, T. Predicting active users’ personalities based on micro-blogging behaviors. PLoS ONE 2014, 9, e84997. [Google Scholar] [CrossRef]
- Wei, H.; Zhang, F.; Yuan, N.J.; Cao, C.; Fu, H.; Xie, X.; Ma, W.Y. Beyond the words: Predicting user personality from heterogeneous information. In Proceedings of the of 10th ACM international conference on web search and data mining, Cambridge, UK, 6–10 February 2017; pp. 305–314. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
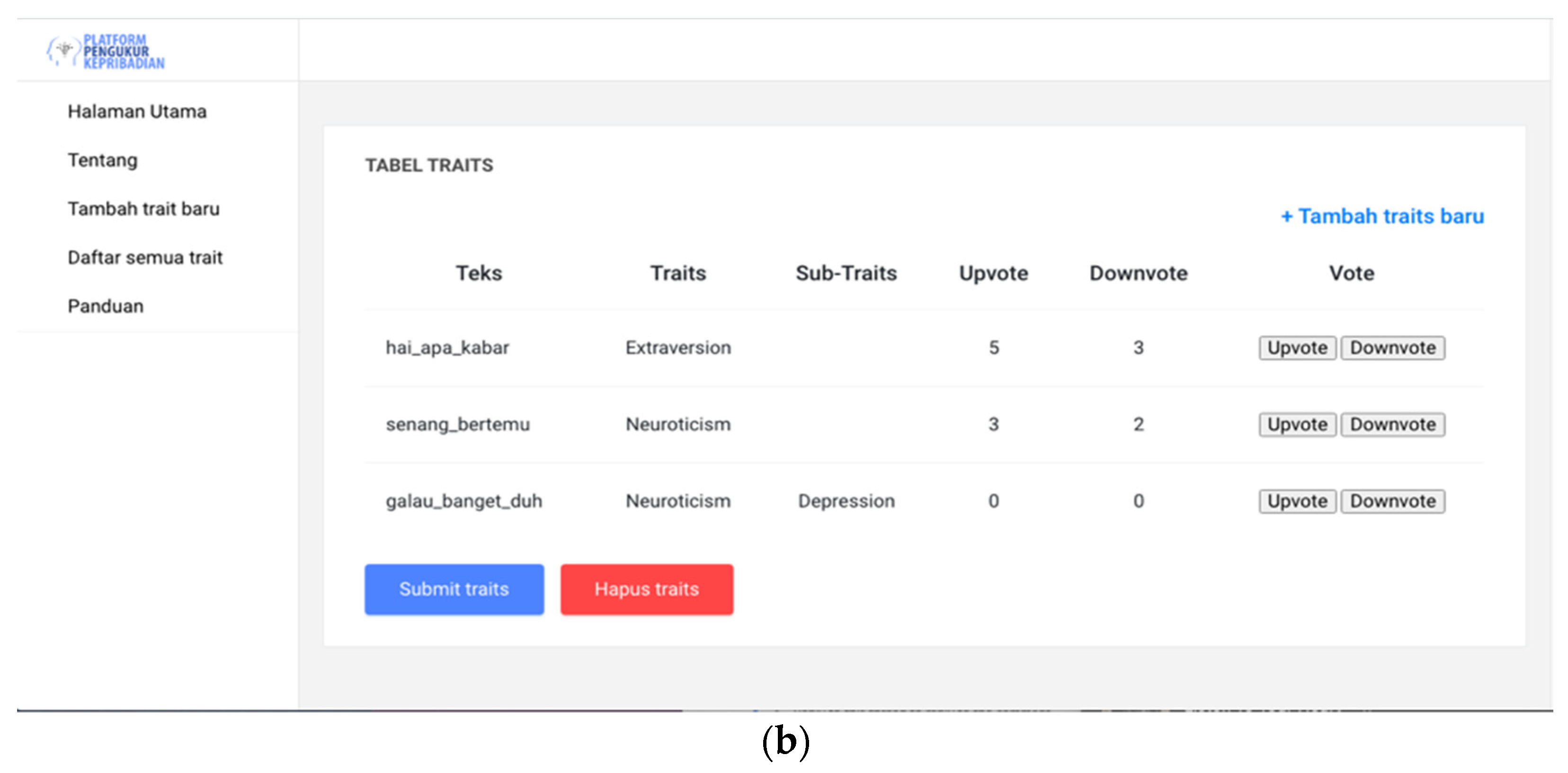{kind=link}
| Personality Traits | Definition | Sub-Trait/Facet |
|---|---|---|
| Openness | The openness to experience: the degree to which an individual exhibits intellectual curiosity, self-awareness, and nonconformance. | Aesthetic, Fantasy, Action, Idea, Feeling, Value. |
| Conscientiousness | The degree to which individuals value planning, acquire the tenacity quality, and achievement oriented. | Competence, Order, Dutifulness, Achievement-Striving, Self-Discipline, Deliberation. |
| Extraversion | The degree to which individuals involved with the external world, encounter enthusiasm and other positive emotions. | Warmth, Gregariousness, Assertiveness, Activity-Level, Excitement-Seeking, Positive Emotion. |
| Agreeableness | The degree to which individuals value mutual effort and social harmony, modesty, dignity, and trustworthiness. | Trust, Compliance, Altruism, Straightforwardness, Modesty, Tendermindedness. |
| Neuroticism | The degree to which individuals deal with negative feelings and their propensity to overreact emotionally. | Anxiety, Depression, Hostility, Self-Consciousness, Impulsiveness, Vulnerability. |
| Tweets | Keyword | Traits |
|---|---|---|
| Jelek banget | Jelek | Neuroticism |
| Banget | Agreeableness | |
| Jelek banget | Jelek_banget | Neuroticism |
| Radix Tree | n-Gram |
|---|---|
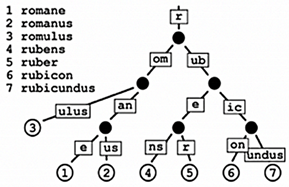 | 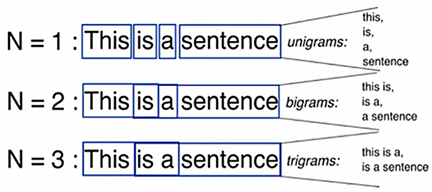 |
| Function | Algorithm |
|---|---|
| The looping for j function | while i < len(token): tmp = [] tmp_trait = [] for j in range(len(phrase)): if token[i] in phrase[j]: tmp.append(phrase[j]) tmp_trait.append(traits[j]) max = 0 trait = ‘ ’ |
| The looping for k function | for k in range(len(tmp)): if re.sub(‘_’, ‘ ’, tmp[k].lower()) in sent: if len(tmp[k].split(‘_’)) > max: trait = tmp_trait[k] max = len(tmp[k].split(‘_’)) |
| The if function | if max > 0: list_freq[list_trait.index(trait)] += 1 i += max else: i += 1 |
| Account | Result |
|---|---|
| @faldomaldini | 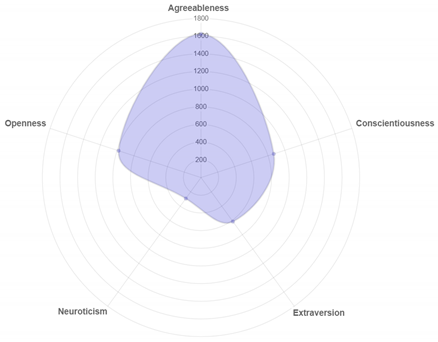 |
| @benakribo | 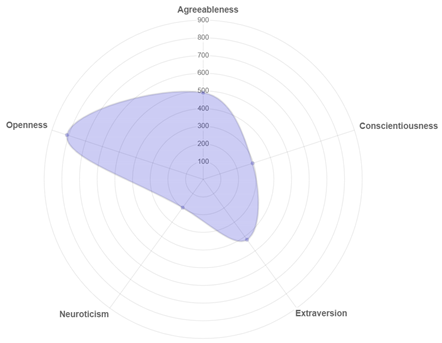 |
| @shitlicious | 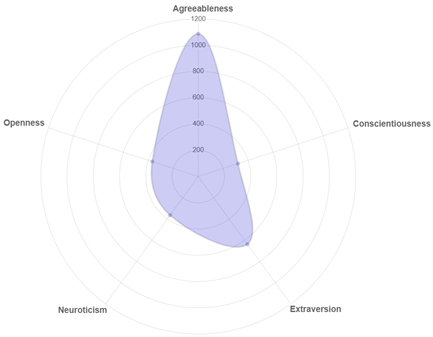 |
| @fajarnugros | 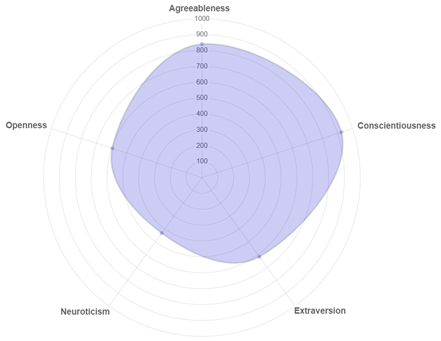 |
| Twitter Account | First 10 Tweets | First 20 Tweets | First 30 Tweets |
|---|---|---|---|
| @faldomaldini | Agreeableness | Agreeableness | Agreeableness |
| @benakribo | Openness | Openness | Openness |
| @fajarnugros | Openness | Agreeableness | Agreeableness |
| @shitlicious | Agreeableness | Agreeableness | Openness |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alamsyah, A.; Dudija, N.; Widiyanesti, S. New Approach of Measuring Human Personality Traits Using Ontology-Based Model from Social Media Data. Information 2021, 12, 413. https://doi.org/10.3390/info12100413
Alamsyah A, Dudija N, Widiyanesti S. New Approach of Measuring Human Personality Traits Using Ontology-Based Model from Social Media Data. Information. 2021; 12(10):413. https://doi.org/10.3390/info12100413
Chicago/Turabian StyleAlamsyah, Andry, Nidya Dudija, and Sri Widiyanesti. 2021. "New Approach of Measuring Human Personality Traits Using Ontology-Based Model from Social Media Data" Information 12, no. 10: 413. https://doi.org/10.3390/info12100413
APA StyleAlamsyah, A., Dudija, N., & Widiyanesti, S. (2021). New Approach of Measuring Human Personality Traits Using Ontology-Based Model from Social Media Data. Information, 12(10), 413. https://doi.org/10.3390/info12100413