
Simple but Effective Knowledge-Based Query Reformulations for Precision Medicine Retrieval



Abstract
1. Introduction
2. Resources
2.1. Test Collections
2.1.1. Scientific Literature
- abstracts from MEDLINE (https://www.nlm.nih.gov/bsd/pmresources.html, accessed on 23 September 2021);
- abstracts from the American Society of Clinical Oncology (ASCO) (https://www.asco.org/, accessed on 23 September 2021),
- abstracts from proceedings of the American Association for Cancer Research (AACR) (https://www.aacr.org/, accessed on 23 September 2021).
2.1.2. Clinical Trials
2.1.3. Topics
2.2. Knowledge Resources
2.2.1. Systematized Nomenclature of Medicine—Clinical Terms
2.2.2. Medical Subject Headings
2.2.3. National Cancer Institute Thesaurus
2.2.4. Unified Medical Language Systems Metathesaurus
2.2.5. Cancer Biomarkers Database
3. Methodology
3.1. Indexing
3.2. Pre-Retrieval Query Reformulation
3.2.1. Query Expansion
3.2.2. Query Reduction
3.3. Retrieval
3.4. Post-Retrieval Query Reformulation
3.5. Filtering
- minimum age represents the minimum age required for a patient to be considered eligible for the trial. In case of absence of the attribute, we avoided setting a lower threshold on patient’s age.
- maximum age represents the maximum age required for a patient to be considered eligible for the trial. In case of absence of the attribute, we avoided setting an upper threshold on patient’s age.
- gender represents the gender required for a patient to be considered eligible for the trial. In case of absence of the attribute, we kept the trial regardless of patient’s gender.
3.6. Rank Fusion
4. Preliminary Study: TREC Precision Medicine 2018
4.1. Experimental Setup
4.1.1. Test Collection and Knowledge Resource
4.1.2. Evaluation Measures
4.1.3. Experimental Procedure
- Use MetaMap to select the UMLS concepts belonging to neop and gngm semantic types in the clinical trials and create a new field <concepts>.
- Index the fields <docid>, <text>, <max_age>, <min_age>, <gender>, and <concepts>.
- Use MetaMap to select the UMLS concepts belonging to neop for <disease> and gngm, comd for <gene>.
- Get name variants of selected concepts from all the knowledge sources contained within UMLS and expand the original query with them.
- Weight expansion terms with a value .
- Perform retrieval with the pre-retrieval reformulated query using BM25.
- Take the top k clinical trials retrieved by BM25 using the pre-retrieval reformulated query.
- Select document concepts that match the concepts associated to query terms.
- Select neighbor concepts—restricted to neop, gngm, and aapp semantic types—that present a hierarchical or associative relation within UMLS with matched concepts.
- Obtain from neighbor concepts all the name variants belonging to the knowledge sources contained within UMLS.
- Expand the pre-retrieval reformulated query with the name variants of neighbor concepts.
- Weight expansion terms with a value .
- Perform retrieval with the post-retrieval reformulated query using BM25.
- Filter out candidate clinical trials for which the patient is not eligible.
4.1.4. Parameters
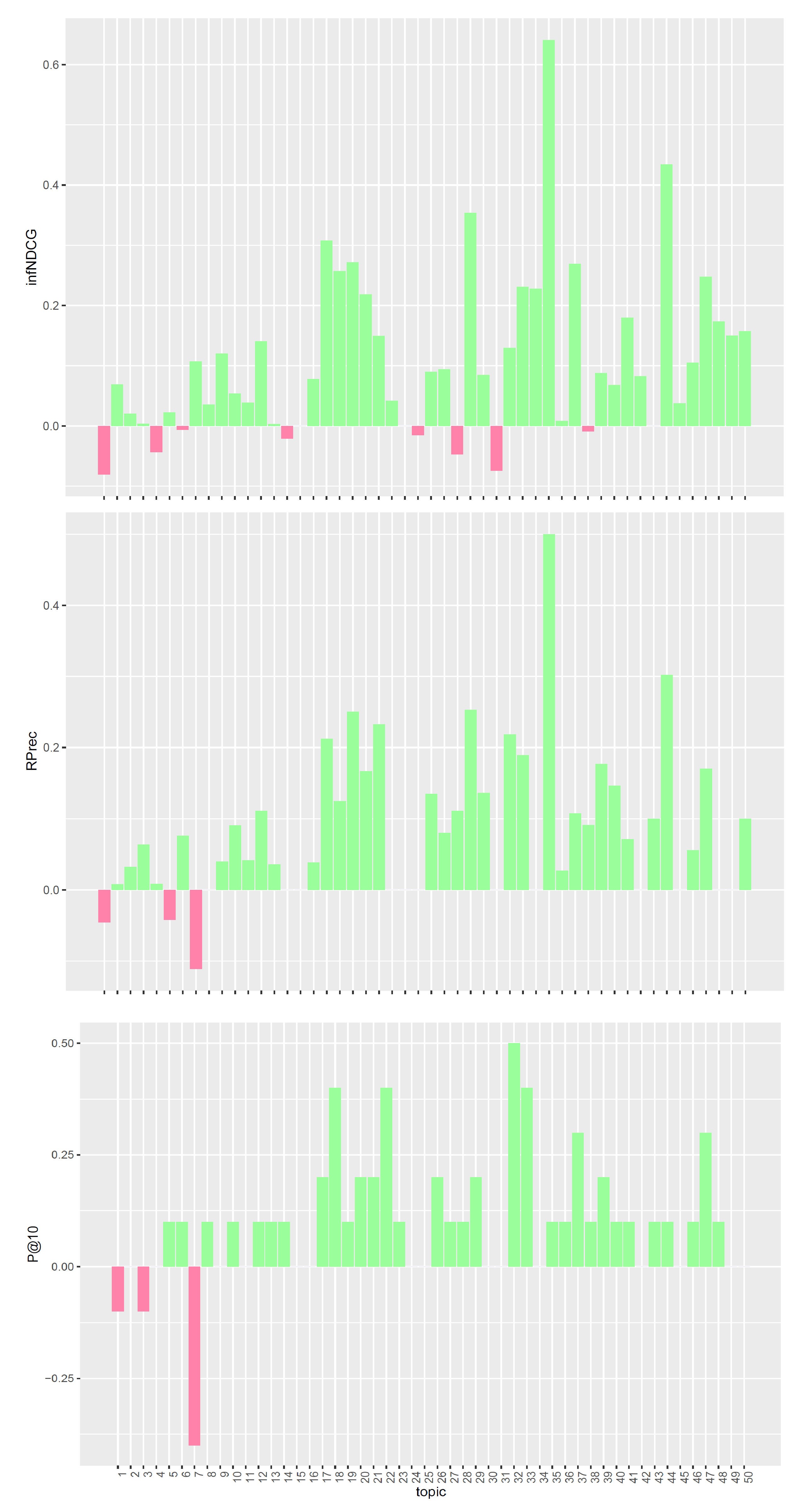
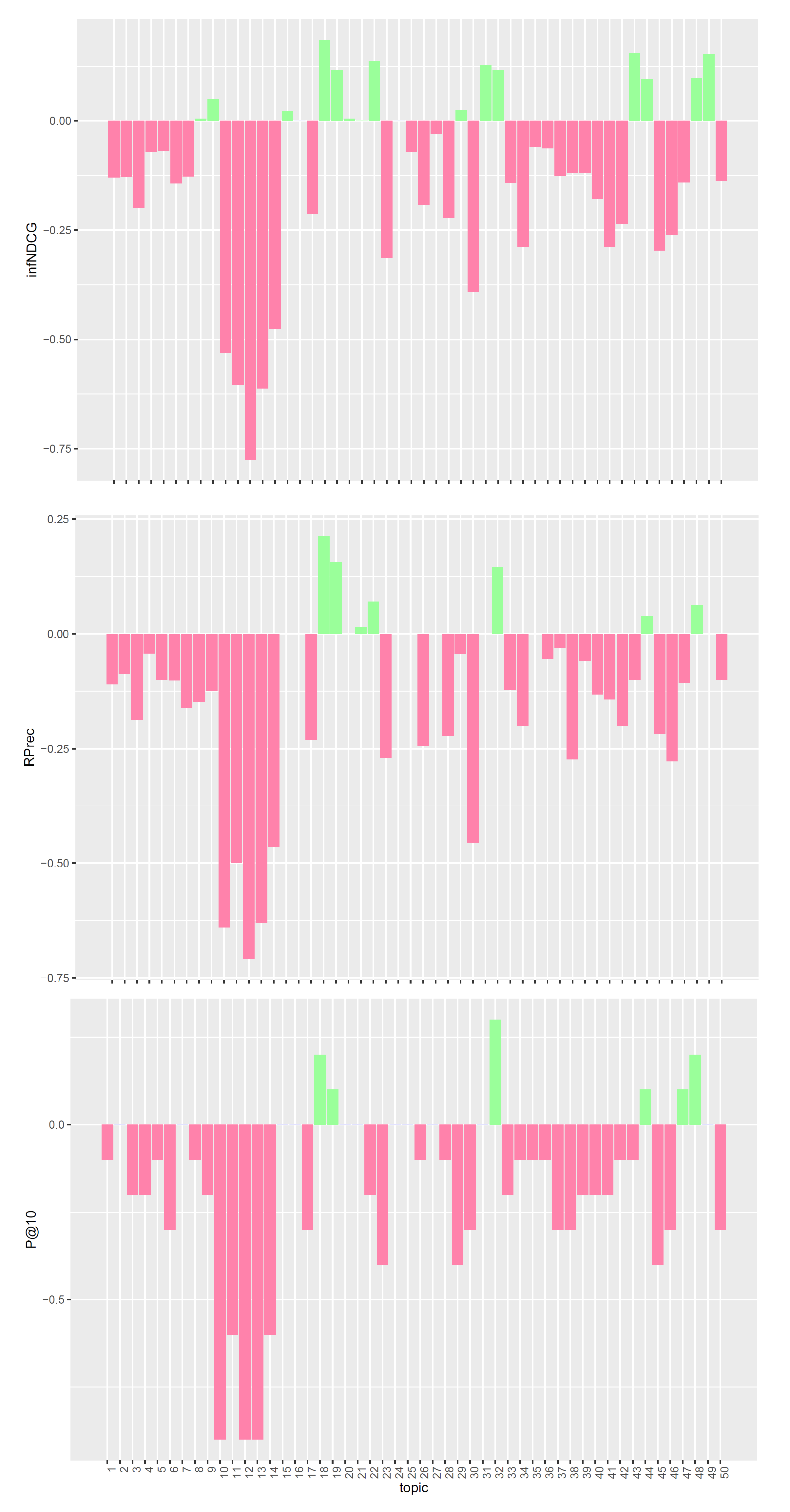
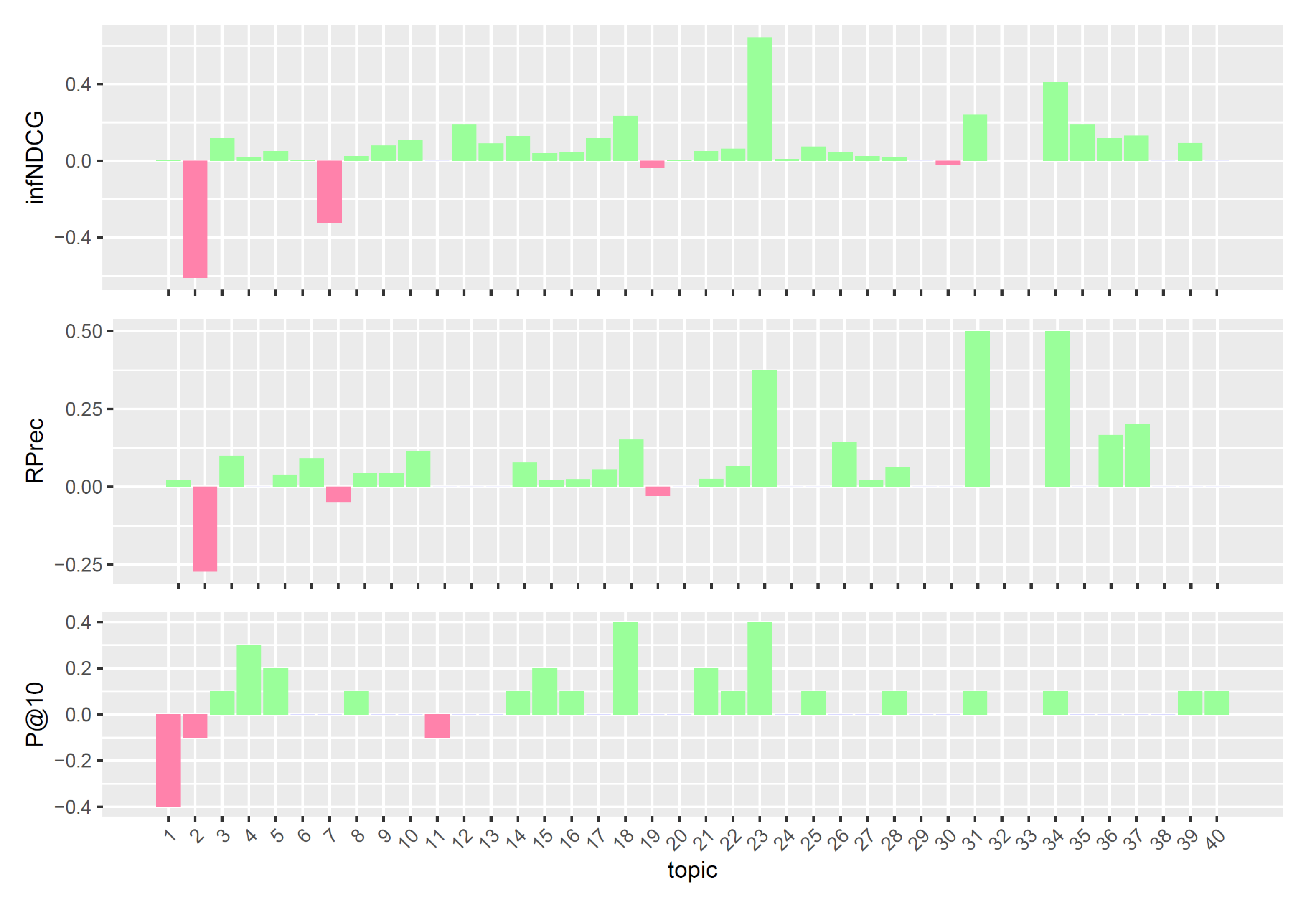
4.2. Experimental Results
Comparison with TREC PM 2018 Top Systems
5. In-Depth Analysis of Query Reformulations
5.1. Experimental Setup
5.1.1. Test Collections and Knowledge Resources
5.1.2. Evaluation Measures
5.1.3. Experimental Procedure
- Index clinical trials with the following fields: <docid>, <text>, <max_age>, <min_age>, and <gender>.
- Index scientific literature with the following fields: <docid> and <text>.
- Extract from queries the UMLS concepts belonging to neop for <disease>, gngm/comd for <gene>, and all for <other> using MetaMap.
- Get the name variants of extracted concepts from NCI, MeSH, SNOMED CT, and UMLS metathesaurus knowledge resources.
- Expand topics not mentioning blood-related cancers with the term “solid”.
- Reduce topics by removing, whenever present, gene mutations from the <gene> field.
- Remove the <other> query field whenever present.
- Adopt any combination of the previous reformulation strategies.
- Weight expansion terms with a value .
- Perform a search using reformulated queries with BM25.
- Filter out candidate clinical trials for which the patient is not eligible.
5.1.4. Parameters
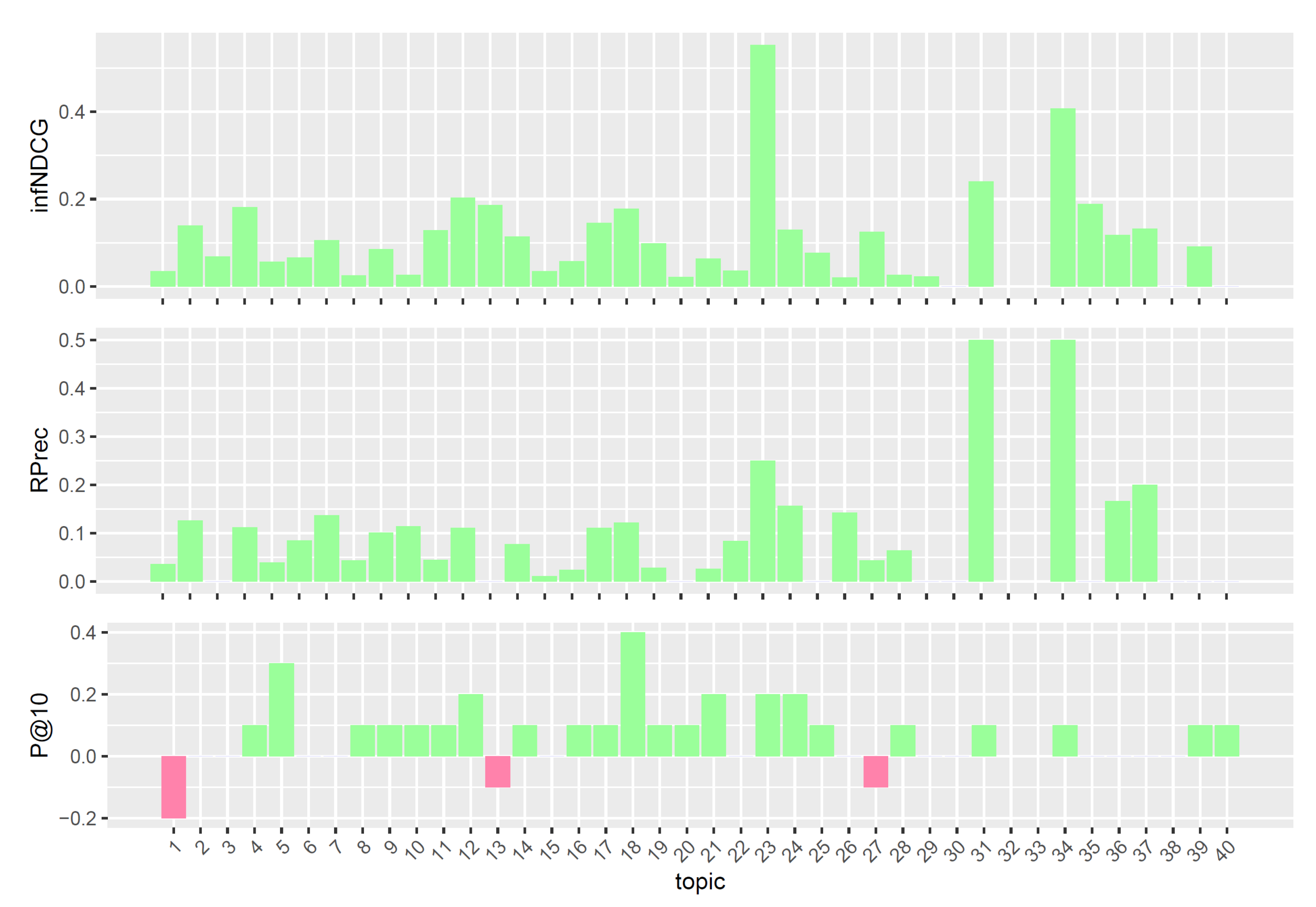
5.2. Experimental Results
5.2.1. Analysis of Query Reformulations
5.2.2. Comparison with TREC PM Systems
6. Validation Study: TREC Precision Medicine 2019
6.1. Experimental Setup
6.1.1. Test Collection and Knowledge Resources
6.1.2. Evaluation Measures
6.1.3. Experimental Procedure
- Perform rank fusion using CombSUM and min-max normalization over the three most effective query reformulations for Clinical Trials.
- Perform rank fusion using CombSUM and min-max normalization over the three most effective query reformulations for Scientific Literature.
- base: refers to the baseline model, that is BM25 plus filtering.
- neop/reduced: refers to neop expansion over reduced queries.
- solid/original: refers to “solid” expansion over original queries.
- solid/reduced: refers to “solid” expansion over reduced queries.
- qrefs/combined: refers to the combination of the above query reformulations using CombSUM.
- base: refers to the baseline model, that is BM25.
- neop/original: refers to neop expansion over original queries.
- neop+comd/original: refers to neop and comd expansions over original queries.
- neop+gngm/original: refers to the neop and gngm expansions over original queries.
- qrefs/combined: refers to the combination of the above query reformulations using CombSUM.
6.1.4. Parameters
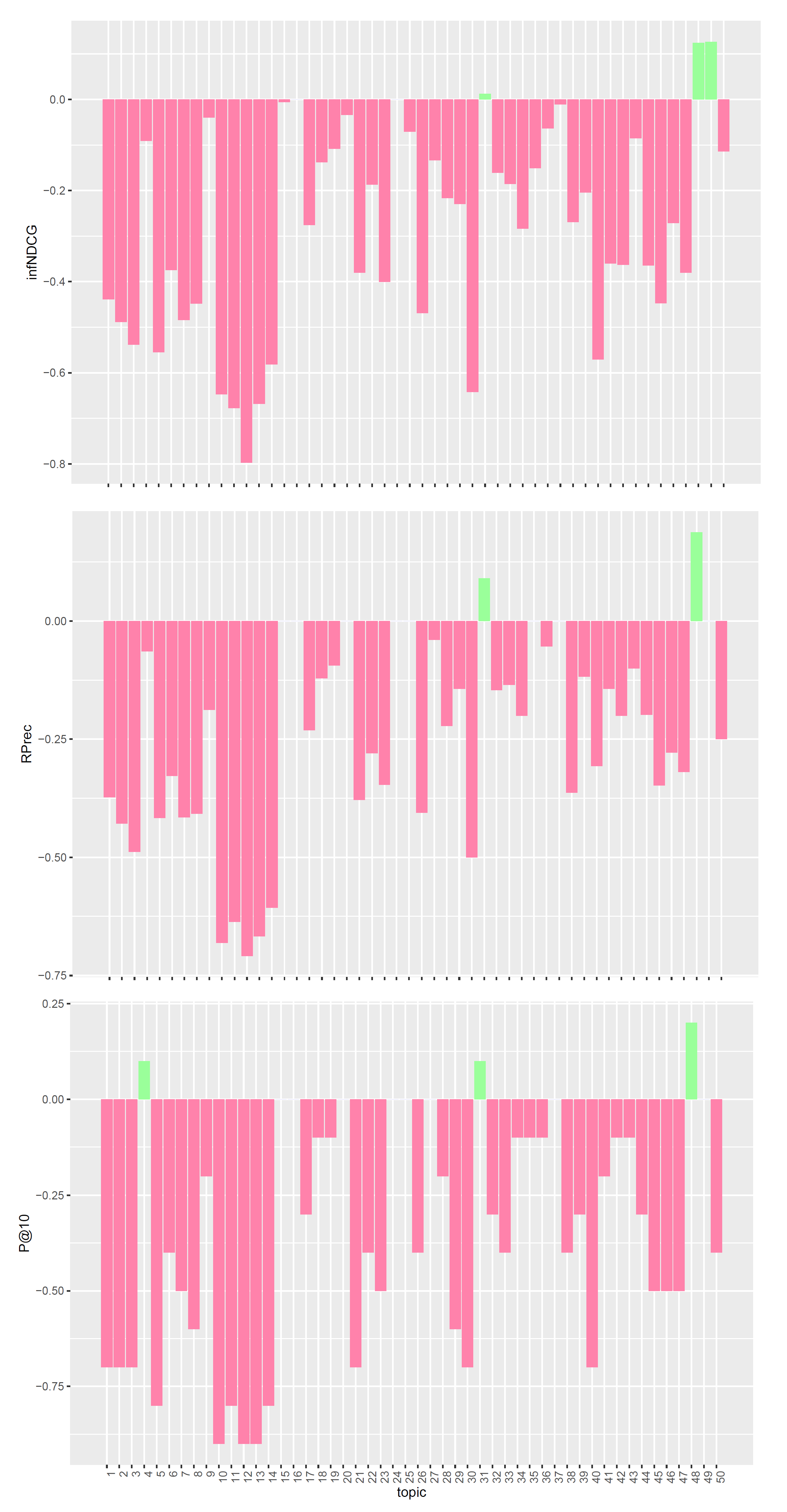
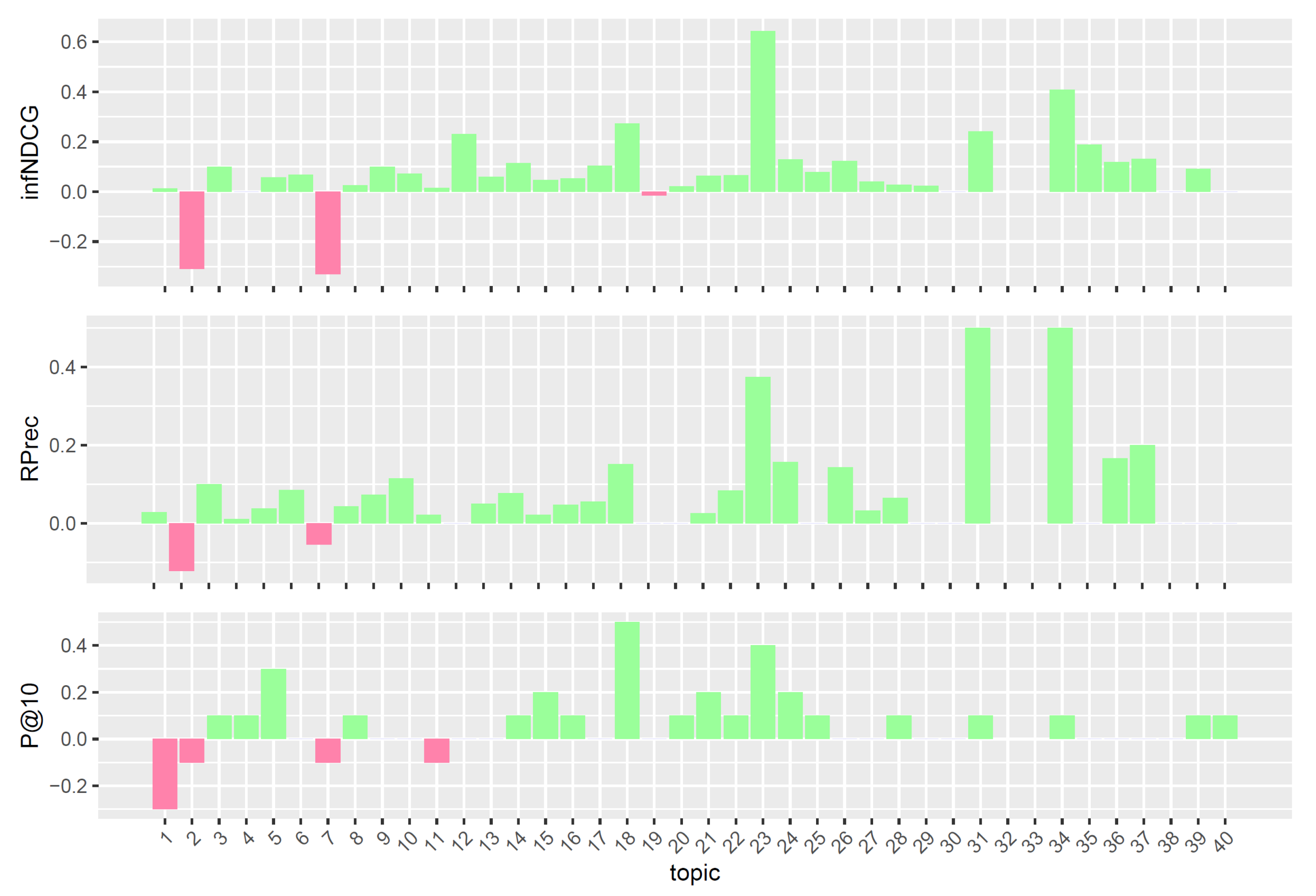
6.2. Experimental Results
Comparison with TREC PM 2019 Top Systems
7. A Posteriori Analysis of Query Reformulations
7.1. Experimental Setup
7.1.1. Test Collections and Knowledge Resources
7.1.2. Evaluation Measures
7.1.3. Experimental Procedure
7.1.4. Parameters
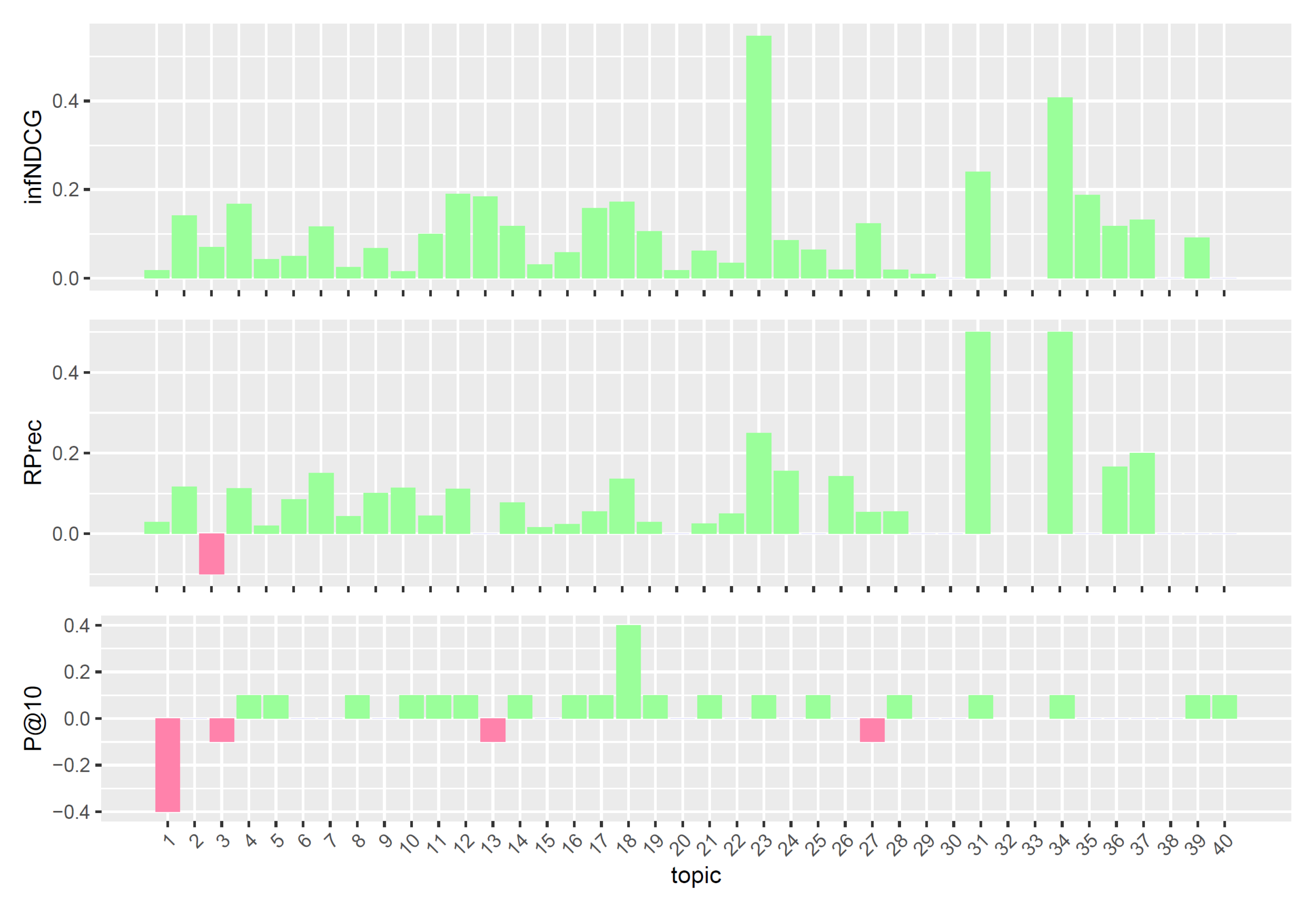
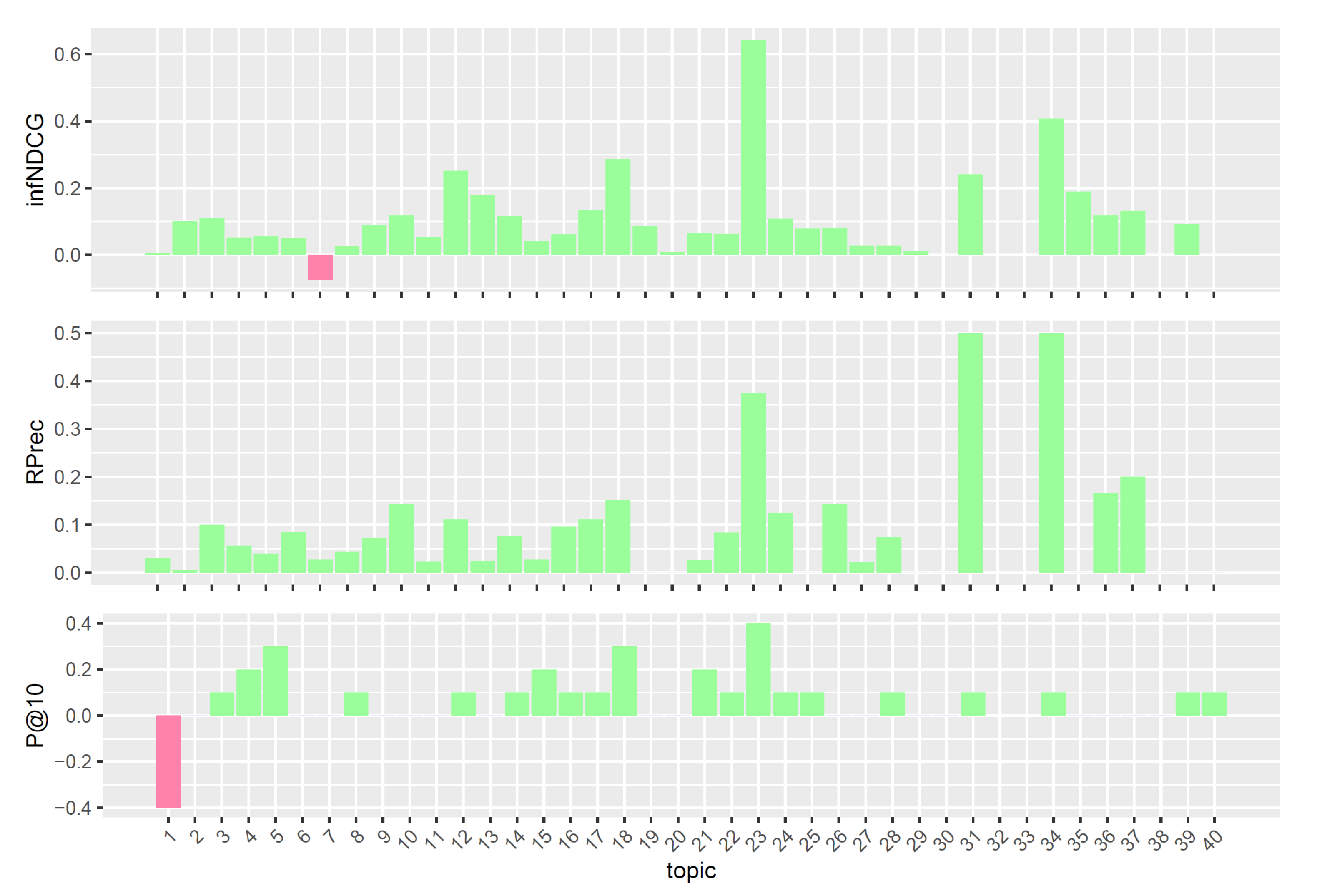
7.2. Experimental Results
7.2.1. Analysis of Query Reformulations
7.2.2. Comparison with TREC PM Systems
8. Conclusions and Future Work
- Preliminary study: The study, conducted on the TREC PM 2018 Clinical Trials task, showed that the proposed query expansion approach introduces noise and significantly decreases retrieval performances. In particular, we found that the detrimental effect of the query expansions depends on the lack of an appropriate weighting scheme on query terms and the uncontrolled use of all the knowledge resources contained within UMLS. Thus, the study highlighted what features are required to build effective query expansions, and what instead should be avoided.
- In-depth analysis: The analysis, performed to investigate approaches that can be effective in both scientific literature and clinical trials retrieval, showed that no strong trend emerges for either task. However, we found query reformulations that perform well in both tasks and achieve top results in several evaluation measures both in TREC PM 2017 and in 2018.
- Validation study: The study, carried out to investigate whether the proposed query reformulations also hold in TREC PM 2019, confirmed the effectiveness of the query reformulations in the Clinical Trials task—with promising performances in precision-oriented measures.
- A posteriori analysis: The analysis, based on the results achieved over the three years of the Clinical Trials task, helped to identify a robust subset of query reformulations for clinical trials retrieval. The selected query reformulations can be used at the early stages of the IR pipeline to retrieve relevant clinical trials in top positions of the ranking list.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Goeuriot, L.; Jones, G.J.F.; Kelly, L.; Müller, H.; Zobel, J. Medical Information Retrieval: Introduction to the Special Issue. Inf. Retr. J. 2016, 19, 1–5. [Google Scholar] [CrossRef]
- Hersh, W.R. Information Retrieval: A Health and Biomedical Perspective; Health and Informatics Series; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Edinger, T.; Cohen, A.M.; Bedrick, S.; Ambert, K.H.; Hersh, W.R. Barriers to Retrieving Patient Information from Electronic Health Record Data: Failure Analysis from the TREC Medical Records Track. In Proceedings of the AMIA 2012, American Medical Informatics Association Annual Symposium, Chicago, IL, USA, 3–7 November 2012; AMIA: Bethesda, MD, USA, 2012. [Google Scholar]
- Koopman, B.; Zuccon, G. Why Assessing Relevance in Medical IR is Demanding. In Proceedings of the Medical Information Retrieval Workshop at SIGIR co-located with the 37th annual international ACM SIGIR conference (ACM SIGIR 2014), Gold Coast, Australia, 11 July 2014; Volume 1276, pp. 16–19. [Google Scholar]
- Koopman, B.; Zuccon, G.; Bruza, P.; Sitbon, L.; Lawley, M. Information retrieval as semantic inference: A Graph Inference model applied to medical search. Inf. Retr. J. 2016, 19, 6–37. [Google Scholar] [CrossRef]
- Furnas, G.W.; Landauer, T.K.; Gomez, L.M.; Dumais, S.T. The Vocabulary Problem in Human-System Communication. Commun. ACM 1987, 30, 964–971. [Google Scholar] [CrossRef]
- Crestani, F. Exploiting the Similarity of Non-Matching Terms at Retrieval Time. Inf. Retr. 2000, 2, 23–43. [Google Scholar] [CrossRef]
- Srinivasan, P. Retrieval Feedback in MEDLINE. J. Am. Med. Inform. Assoc. 1996, 3, 157–167. [Google Scholar] [CrossRef][Green Version]
- Srinivasan, P. Query Expansion and MEDLINE. Inf. Process. Manag. 1996, 32, 431–443. [Google Scholar] [CrossRef]
- Aronson, A.R.; Rindflesch, T.C. Query expansion using the UMLS Metathesaurus. In Proceedings of the American Medical Informatics Association Annual Symposium, AMIA 1997, Nashville, TN, USA, 25–29 October 1997; AMIA: Bethesda, MD, USA, 1997. [Google Scholar]
- Hersh, W.R.; Price, S.; Donohoe, L. Assessing Thesaurus-based Query Expansion Using the UMLS Metathesaurus. In Proceedings of the American Medical Informatics Association Annual Symposium, AMIA 2000, Los Angeles, CA, USA, 4–8 November 2000; AMIA: Bethesda, MD, USA, 2000. [Google Scholar]
- Hersh, W.R.; Bhupatiraju, R.T. TREC GENOMICS Track Overview. In Proceedings of the Twelfth Text REtrieval Conference, TREC 2003, Gaithersburg, MD, USA, 18–21 November 2003; pp. 14–23. [Google Scholar]
- Hersh, W.R.; Bhupatiraju, R.T.; Ross, L.; Cohen, A.M.; Kraemer, D.; Johnson, P. TREC 2004 Genomics Track Overview. In Proceedings of the Thirteenth Text REtrieval Conference, TREC 2004, Gaithersburg, MD, USA, 16–19 November 2004; NIST: Gaithersburg, MD, USA, 2004; Volume 500–261. [Google Scholar]
- Hersh, W.R.; Cohen, A.M.; Yang, J.; Bhupatiraju, R.T.; Roberts, P.M.; Hearst, M.A. TREC 2005 Genomics Track Overview. In Proceedings of the Fourteenth Text REtrieval Conference, TREC 2005, Gaithersburg, MD, USA, 15–18 November 2005; NIST: Gaithersburg, MD, USA, 2005; Volume 500–266. [Google Scholar]
- Hersh, W.R.; Cohen, A.M.; Roberts, P.M.; Rekapalli, H.K. TREC 2006 Genomics Track Overview. In Proceedings of the Fifteenth Text REtrieval Conference, TREC 2006, Gaithersburg, MD, USA, 14–17 November 2006; NIST: Gaithersburg, MD, USA, 2006; Volume 500–272. [Google Scholar]
- Hersh, W.R.; Cohen, A.M.; Ruslen, L.; Roberts, P.M. TREC 2007 Genomics Track Overview. In Proceedings of the Sixteenth Text REtrieval Conference, TREC 2007, Gaithersburg, MD, USA, 5–9 November 2007. [Google Scholar]
- Roberts, K.; Simpson, M.; Demner-Fushman, D.; Voorhees, E.; Hersh, W. State-of-the-art in biomedical literature retrieval for clinical cases: A survey of the TREC 2014 CDS track. Inf. Retr. J. 2016, 19, 113–148. [Google Scholar] [CrossRef]
- Roberts, K.; Simpson, M.S.; Voorhees, E.M.; Hersh, W.R. Overview of the TREC 2015 Clinical Decision Support Track. In Proceedings of the Twenty-Fourth Text REtrieval Conference, TREC 2015, Gaithersburg, MD, USA, 17–20 November 2015; NIST: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Roberts, K.; Demner-Fushman, D.; Voorhees, E.M.; Hersh, W.R. Overview of the TREC 2016 Clinical Decision Support Track. In Proceedings of the Twenty-Fifth Text REtrieval Conference, TREC 2016, Gaithersburg, MD, USA, 15–18 November 2016; NIST: Gaithersburg, MD, USA, 2016. [Google Scholar]
- Roberts, K.; Demner-Fushman, D.; Voorhees, E.M.; Hersh, W.R.; Bedrick, S.; Lazar, A.J.; Pant, S. Overview of the TREC 2017 Precision Medicine Track. In Proceedings of the Twenty-Sixth Text REtrieval Conference, TREC 2017, Gaithersburg, MD, USA, 15–17 November 2017; NIST: Gaithersburg, MD, USA, 2017; Volume 26. [Google Scholar]
- Roberts, K.; Demner-Fushman, D.; Voorhees, E.M.; Hersh, W.R.; Bedrick, S.; Lazar, A.J. Overview of the TREC 2018 Precision Medicine Track. In Proceedings of the Twenty-Seventh Text REtrieval Conference, TREC 2018, Gaithersburg, MD, USA, 14–16 November 2018; NIST: Gaithersburg, MD, USA, 2018; Volume 500–331. [Google Scholar]
- Roberts, K.; Demner-Fushman, D.; Voorhees, E.M.; Hersh, W.R.; Bedrick, S.; Lazar, A.J.; Pant, S.; Meric-Bernstam, F. Overview of the TREC 2019 Precision Medicine Track. In Proceedings of the Twenty-Eighth Text REtrieval Conference, TREC 2019, Gaithersburg, MD, USA, 13–15 November 2019; NIST: Gaithersburg, MD, USA, 2019; Volume 1250. [Google Scholar]
- López-García, P.; Oleynik, M.; Kasác, Z.; Schulz, S. TREC 2017 Precision Medicine - Medical University of Graz. In Proceedings of the Twenty-Sixth Text REtrieval Conference, TREC 2017, Gaithersburg, MD, USA, 15–17 November 2017; NIST: Gaithersburg, MD, USA, 2017; Volume 500–324. [Google Scholar]
- Oleynik, M.; Faessler, E.; Sasso, A.M.; Kappattanavar, A.; Bergner, B.; Cruz, H.F.D.; Sachs, J.P.; Datta, S.; Böttinger, E.P. HPI-DHC at TREC 2018 Precision Medicine Track. In Proceedings of the Twenty-Seventh Text REtrieval Conference, TREC 2018, Gaithersburg, MD, USA, 14–16 November 2018; NIST: Gaithersburg, MD, USA, 2018; Volume 500–331. [Google Scholar]
- Sondhi, P.; Sun, J.; Zhai, C.; Sorrentino, R.; Kohn, M.S. Leveraging Medical Thesauri and Physician Feedback for Improving Medical Literature Retrieval for Case Queries. J. Am. Med. Inform. Assoc. 2012, 19, 851–858. [Google Scholar] [CrossRef] [PubMed]
- Zhu, D.; Wu, S.T.; Carterette, B.; Liu, H. Using Large Clinical Corpora for Query Expansion in Text-Based Cohort Identification. J. Biomed. Inform. 2014, 49, 275–281. [Google Scholar] [CrossRef] [PubMed]
- Diao, L.; Yan, H.; Li, F.; Song, S.; Lei, G.; Wang, F. The Research of Query Expansion Based on Medical Terms Reweighting in Medical Information Retrieval. EURASIP J. Wirel. Comm. Netw. 2018, 2018, 105. [Google Scholar] [CrossRef]
- Agosti, M.; Di Nunzio, G.M.; Marchesin, S. The University of Padua IMS Research Group at TREC 2018 Precision Medicine Track. In Proceedings of the Twenty-Seventh Text REtrieval Conference, TREC 2018, Gaithersburg, MD, USA, 14–16 November 2018; NIST: Gaithersburg, MD, USA, 2018; Volume 500–331. [Google Scholar]
- Agosti, M.; Di Nunzio, G.M.; Marchesin, S. An Analysis of Query Reformulation Techniques for Precision Medicine. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2019, Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019; pp. 973–976. [Google Scholar]
- Di Nunzio, G.M.; Marchesin, S.; Agosti, M. Exploring how to Combine Query Reformulations for Precision Medicine. In Proceedings of the Twenty-Eighth Text REtrieval Conference, TREC 2019, Gaithersburg, MD, USA, 13–15 November 2019; NIST: Gaithersburg, MD, USA, 2019; Volume 1250. [Google Scholar]
- Agosti, M.; Di Nunzio, G.M.; Marchesin, S. A Post-Analysis of Query Reformulation Methods for Clinical Trials Retrieval. In Proceedings of the 28th Italian Symposium on Advanced Database Systems, Villasimius, Sud Sardegna, Italy (Virtual Due to Covid-19 Pandemic), 21–24 June 2020; Volume 2646, pp. 152–159. [Google Scholar]
- Marchesin, S. Developing Unsupervised Knowledge-Enhanced Models to Reduce the Semantic Gap in Information Retrieval. Ph.D. Thesis, Doctoral School in Information Engineering, Department of Information Engineering, University of Padova, Padova, Italy, 2021. [Google Scholar]
- Donnelly, K. SNOMED-CT: The advanced terminology and coding system for eHealth. Stud. Health Technol. Inform. 2006, 121, 279. [Google Scholar] [PubMed]
- Lipscomb, C.E. Medical Subject Headings (MeSH). Bull. Med. Libr. Assoc. 2000, 88, 265. [Google Scholar] [PubMed]
- Sioutos, N.; de Coronado, S.; Haber, M.W.; Hartel, F.W.; Shaiu, W.L.; Wright, L.W. NCI Thesaurus: A semantic model integrating cancer-related clinical and molecular information. J. Biomed. Inform. 2007, 40, 30–43. [Google Scholar] [CrossRef] [PubMed]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef] [PubMed]
- Tamborero, D.; Rubio-Perez, C.; Deu-Pons, J.; Schroeder, M.P.; Vivancos, A.; Rovira, A.; Tusquets, I.; Albanell, J.; Rodon, J.; Tabernero, J. Cancer Genome Interpreter Annotates the Biological and Clinical Relevance of Tumor Alterations. Genome Med. 2018, 10, 25. [Google Scholar] [CrossRef] [PubMed]
- Dienstmann, R.; Jang, I.S.; Bot, B.; Friend, S.; Guinney, J. Database of Genomic Biomarkers for Cancer Drugs and Clinical Targetability in Solid Tumors. Cancer Discov. 2015, 5, 118–123. [Google Scholar] [CrossRef] [PubMed]
- Aronson, A.R. Effective mapping of biomedical text to the UMLS Metathesaurus: The MetaMap program. In Proceedings of the AMIA Symposium, Whasington, DC, USA, 3–7 November 2001; American Medical Informatics Association: Bethesda, MD, USA, 2001; p. 17. [Google Scholar]
- Goodwin, T.R.; Skinner, M.A.; Harabagiu, S.M. UTD HLTRI at TREC 2017: Precision Medicine Track. In Proceedings of the Twenty-Sixth Text REtrieval Conference, TREC 2017, Gaithersburg, MD, USA, 15–17 November 2017; NIST: Gaithersburg, MD, USA, 2017; Volume 500–324. [Google Scholar]
- Robertson, S.E.; Zaragoza, H. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Gurulingappa, H.; Toldo, L.; Schepers, C.; Bauer, A.; Megaro, G. Semi-Supervised Information Retrieval System for Clinical Decision Support. In Proceedings of the Twenty-Fifth Text REtrieval Conference, TREC 2016, Gaithersburg, MD, USA, 15–18 November 2016; NIST: Gaithersburg, MD, USA, 2016; Volume 500–321. [Google Scholar]
- Shaw, J.A.; Fox, E.A. Combination of Multiple Searches. In Proceedings of the Third Text REtrieval Conference, TREC 1994, Gaithersburg, MD, USA, 2–4 November 1994; NIST: Gaithersburg, MD, USA, 1994; Volume 500–225, pp. 105–108. [Google Scholar]
- Lipani, A.; Lupu, M.; Hanbury, A.; Aizawa, A. Verboseness Fission for BM25 Document Length Normalization. In Proceedings of the 2015 International Conference on The Theory of Information Retrieval, Northampton, Massachusetts, USA, 27–30 September 2015; ACM: New York, NY, USA, 2015. ICTIR ’15. pp. 385–388. [Google Scholar]
- Vechtomova, O. The Role of Multi-word Units in Interactive Information Retrieval. In Proceedings of the 27th European Conference on IR Research, ECIR 2005, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3408, pp. 403–420. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P@10 | infNDCG | Rprec | |
|---|---|---|---|
| base | 0.5680 | 0.5421 | 0.4142 |
| QE | 0.2920 | 0.3003 | 0.1908 |
| QE/PRF | 0.1180 | 0.1468 | 0.0865 |
| median | 0.4680 | 0.4297 | 0.3268 |
| Semantic Type | Field Other | sl | ct | sl | ct | sl | ct | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Line | Year | Neop | Comd | Gngm | oth | oth_exp | Orig | Solid | P_10 | P_10 | infNDCG | infNDCG | Rprec | Rprec |
| 1 | 2018 | y | y | n | n | n | y | n | 0.5660 | 0.5540 | 0.4912 | 0.5266 | 0.3288 | 0.4098 |
| 2 | 2018 | y | n | n | n | n | y | n | 0.5640 | 0.5600 | 0.4961 | 0.5264 | 0.3288 | 0.4138 |
| 3 | 2018 | y | n | y | n | n | y | n | 0.5480 | 0.5660 | 0.4941 | 0.5292 | 0.3266 | 0.4116 |
| 4 | 2018 | n | n | n | n | n | y | n | 0.5460 | 0.5680 | 0.4876 | 0.5411 | 0.3240 | 0.4197 |
| 5 | 2018 | n | n | n | n | n | y | 0.1 | 0.5440 | 0.5740 | 0.4877 | 0.5403 | 0.3247 | 0.4179 |
| 6 | 2018 | n | y | n | n | n | y | n | 0.5440 | 0.5540 | 0.4853 | 0.5403 | 0.3236 | 0.4130 |
| 7 | 2018 | y | n | n | n | n | n | n | 0.5420 | 0.5700 | 0.4636 | 0.5345 | 0.3180 | 0.4134 |
| 8 | 2018 | n | n | y | n | n | y | n | 0.5340 | 0.5640 | 0.4877 | 0.5337 | 0.3229 | 0.4106 |
| 9 | 2018 | n | n | n | n | n | n | 0.1 | 0.5300 | 0.5820 | 0.4635 | 0.5446 | 0.3148 | 0.4205 |
| 10 | 2018 | y | n | y | n | n | n | n | 0.5140 | 0.5680 | 0.4572 | 0.5393 | 0.3144 | 0.4122 |
| 11 | 2017 | y | n | y | n | n | n | 0.1 | 0.5033 | 0.3759 | 0.3984 | − | 0.2697 | 0.3206 |
| 12 | 2017 | n | n | y | n | n | n | 0.1 | 0.4900 | 0.3931 | 0.3881 | − | 0.2677 | 0.3263 |
| 13 | 2017 | n | n | n | n | n | n | 0.1 | 0.4800 | 0.4034 | 0.3931 | − | 0.2728 | 0.3361 |
| 14 | 2017 | y | n | n | n | n | n | 0.1 | 0.4767 | 0.3862 | 0.3974 | − | 0.2714 | 0.3202 |
| 15 | 2017 | n | n | n | n | n | n | n | 0.4733 | 0.3931 | 0.3943 | − | 0.2732 | 0.3241 |
| 16 | 2017 | y | n | y | n | n | y | 0.1 | 0.4733 | 0.3828 | 0.3567 | − | 0.2329 | 0.3253 |
| 17 | 2017 | n | n | y | n | n | y | n | 0.4633 | 0.3862 | 0.3442 | − | 0.2254 | 0.3243 |
| TREC PM Participant Identifier | ||||||||||||||
| 18 | 2018 | UTDHLTRI | 0.6160 | 0.5380 | 0.4797 | 0.4794 | < | 0.3920 | ||||||
| 19 | 2018 | UCAS | 0.5980 | 0.5460 | 0.5580 | 0.5347 | 0.3654 | 0.4005 | ||||||
| 20 | 2018 | udel_fang | 0.5800 | 0.5240 | 0.5081 | 0.5057 | 0.3289 | 0.3967 | ||||||
| 21 | 2018 | NOVASearch | < | 0.5520 | < | 0.4992 | < | 0.3931 | ||||||
| 22 | 2018 | Poznan | < | 0.5580 | < | 0.4894 | < | 0.4101 | ||||||
| 2018 | Top 10 threshold | 0.5800 | 0.5240 | 0.4710 | 0.4736 | 0.2992 | 0.3658 | |||||||
| 2018 | Best combination of our approach | (1) 0.5660 | (9 ‡) 0.5820 | (2) 0.4961 | (9 ‡) 0.5446 | (1) 0.3288 | (9 ‡) 0.4205 | |||||||
| 23 | 2017 | UTDHLTRI | 0.6300 | 0.4172 | 0.4647 | − | 0.2993 | − | ||||||
| 24 | 2017 | udel_fang | 0.5067 | < | 0.3897 | − | 0.2503 | − | ||||||
| 25 | 2017 | NOVASearch | < | 0.3966 | < | − | < | − | ||||||
| 26 | 2017 | Poznan | < | 0.3690 | < | - | < | − | ||||||
| 27 | 2017 | UCAS | < | 0.3724 | < | − | 0.2282 | − | ||||||
| 2017 | Top 10 threshold | 0.4667 | 0.3586 | 0.3555 | − | 0.2282 | − | |||||||
| 2017 | Best combination of our approach | (11) 0.5033 | (13 ‡) 0.4034 | (11) 0.3984 | − | (15) 0.2732 | (13 ‡) 0.3361 | |||||||
| (a) TREC PM 2019 Clinical Trials task | |||
| P@10 | infNDCG | Rprec | |
| base | 0.5053 | 0.6186 | 0.4337 |
| neop/reduced | 0.5237 | 0.5755 | 0.4135 |
| solid/original | 0.5368 | 0.6239 | 0.4386 |
| solid/reduced | 0.5316 | 0.5940 | 0.4264 |
| qrefs/combined | 0.5342 | 0.5706 | 0.4381 |
| median | 0.4658 | 0.5137 | 0.3477 |
| (b) TREC PM 2019 Scientific Literature task | |||
| P@10 | infNDCG | Rprec | |
| base | 0.5125 | 0.4747 | 0.2977 |
| neop/original | 0.5150 | 0.4645 | 0.2982 |
| neop+comd/original | 0.5125 | 0.4636 | 0.2964 |
| neop+gngm/original | 0.5050 | 0.4740 | 0.2999 |
| qrefs/combined | 0.5075 | 0.4665 | 0.2986 |
| median | 0.5450 | 0.4559 | 0.2806 |
| A: | Analysis of Query Reformulations | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Line | Year | Neop | Comd | Gngm | oth | oth_exp | Orig | Solid | P@10 | infNDCG | Rprec |
| 1 | 2017 | n | n | y | n | n | n | 0.1 | 0.3931 | − | 0.3263 |
| 2 | 2017 | n | n | n | n | n | n | 0.1 | 0.4034 | − | 0.3361 |
| 3 | 2017 | y | n | n | n | n | n | 0.1 | 0.3862 | − | 0.3202 |
| 4 | 2017 | n | n | n | n | n | n | n | 0.3931 | − | 0.3241 |
| 5 | 2017 | n | n | y | n | n | y | n | 0.3862 | − | 0.3243 |
| 6 | 2018 | n | n | n | · | · | y | n | 0.5680 | 0.5411 | 0.4197 |
| 7 | 2018 | n | n | n | · | · | y | 0.1 | 0.5740 | 0.5403 | 0.4179 |
| 8 | 2018 | y | n | n | · | · | n | n | 0.5700 | 0.5345 | 0.4134 |
| 9 | 2018 | n | n | n | · | · | n | 0.1 | 0.5820 | 0.5446 | 0.4205 |
| 10 | 2018 | y | n | y | · | · | n | n | 0.5680 | 0.5393 | 0.4122 |
| 11 | 2019 | n | n | n | · | · | y | 0.1 | 0.5368 | 0.6239 | 0.4386 |
| 12 | 2019 | y | n | n | · | · | n | n | 0.5237 | 0.5755 | 0.4135 |
| 13 | 2019 | n | n | n | · | · | n | 0.1 | 0.5316 | 0.5940 | 0.4264 |
| 14 | 2019 | n | n | y | · | · | n | 0.1 | 0.5263 | 0.6070 | 0.4302 |
| 15 | 2019 | n | n | n | · | · | n | n | 0.5105 | 0.5853 | 0.4239 |
| B: | Comparison with TREC PM other Participants | ||||||||||
| Line | Year | TREC PM Participant Identifier | P@10 | infNDCG | Rprec | ||||||
| 1 | 2017 | BiTeM | 0.3586 | − | − | ||||||
| 2 | 2017 | cbnu | < | − | − | ||||||
| 3 | 2017 | CSIROmed | < | − | − | ||||||
| 4 | 2017 | ECNUica | < | − | − | ||||||
| 5 | 2017 | Poznan | 0.3690 | − | − | ||||||
| 2017 | Top 10 threshold | 0.3586 | − | − | |||||||
| 2017 | Best combination of our approach | (A.2 ) 0.4034 | − | 0.3361 | |||||||
| 6 | 2018 | BiTeM | < | < | < | ||||||
| 7 | 2018 | cbnu | < | < | < | ||||||
| 8 | 2018 | CSIROmed | < | < | < | ||||||
| 9 | 2018 | ECNUica | < | < | < | ||||||
| 10 | 2018 | Poznan | 0.5580 | 0.4894 | 0.4101 | ||||||
| 2018 | Top 10 threshold | 0.5240 | 0.4736 | 0.3658 | |||||||
| 2018 | Best combination of our approach | (A.9 ) 0.5820 | 0.5446 | 0.4205 | |||||||
| 11 | 2019 | BiTeM | 0.4711 | 0.4963 | 0.3698 | ||||||
| 12 | 2019 | cbnu | 0.4921 | 0.5568 | 0.4121 | ||||||
| 13 | 2019 | CSIROmed | 0.4921 | 0.4930 | 0.3586 | ||||||
| 14 | 2019 | ECNUica | 0.5053 | 0.5355 | 0.4001 | ||||||
| 15 | 2019 | Poznan | 0.4421 | 0.4810 | 0.3503 | ||||||
| 2019 | Top 10 threshold | 0.3658 | 0.4320 | 0.3230 | |||||||
| 2019 | Best combination of our approach | (A.11) 0.5368 | 0.6239 | 0.4386 | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marchesin, S.; Di Nunzio, G.M.; Agosti, M. Simple but Effective Knowledge-Based Query Reformulations for Precision Medicine Retrieval. Information 2021, 12, 402. https://doi.org/10.3390/info12100402
Marchesin S, Di Nunzio GM, Agosti M. Simple but Effective Knowledge-Based Query Reformulations for Precision Medicine Retrieval. Information. 2021; 12(10):402. https://doi.org/10.3390/info12100402
Chicago/Turabian StyleMarchesin, Stefano, Giorgio Maria Di Nunzio, and Maristella Agosti. 2021. "Simple but Effective Knowledge-Based Query Reformulations for Precision Medicine Retrieval" Information 12, no. 10: 402. https://doi.org/10.3390/info12100402
APA StyleMarchesin, S., Di Nunzio, G. M., & Agosti, M. (2021). Simple but Effective Knowledge-Based Query Reformulations for Precision Medicine Retrieval. Information, 12(10), 402. https://doi.org/10.3390/info12100402