AndroDFA: Android Malware Classification Based on Resource Consumption †

 , ,
, ,
Abstract
1. Introduction
- It is easier to reproduce.AndroDFA only employs publicly available tools and does not require any modification to the execution environment, either emulated or real. Conversely, DroidScribe relies on CopperDroid, an emulator for Android apps, which is not publicly available and can be only accessed through an online service. Furthermore, it is not suitable for batch experiments, since it can take as input just one sample at a time, and the submission procedure cannot be automated because it requires an anti-bot challenge-response test. Finally, at the time of writing, the service has not analyzed enqueued apps since July 2015.
- It relies only on monitoring data that can be also gathered on physical devices.DroidScribe cannot be executed on physical devices because it requires an emulator, namely CopperDroid. AndroDFA can instead run by design on both emulated and real smartphones because it only relies on the proc file system. This is a key factor as modern mobile malware can detect the emulated environment and hide its malicious behavior.
2. Background
2.1. Detrended Fluctuation Analysis
2.2. Pearson’s Correlation Coefficient
2.3. Mutual Information
2.4. Principal Component Analysis
2.5. Support Vector Machines
3. Related Work
4. Family Classification Methodology
4.1. Fingerprint Generation
4.2. Classification and Training
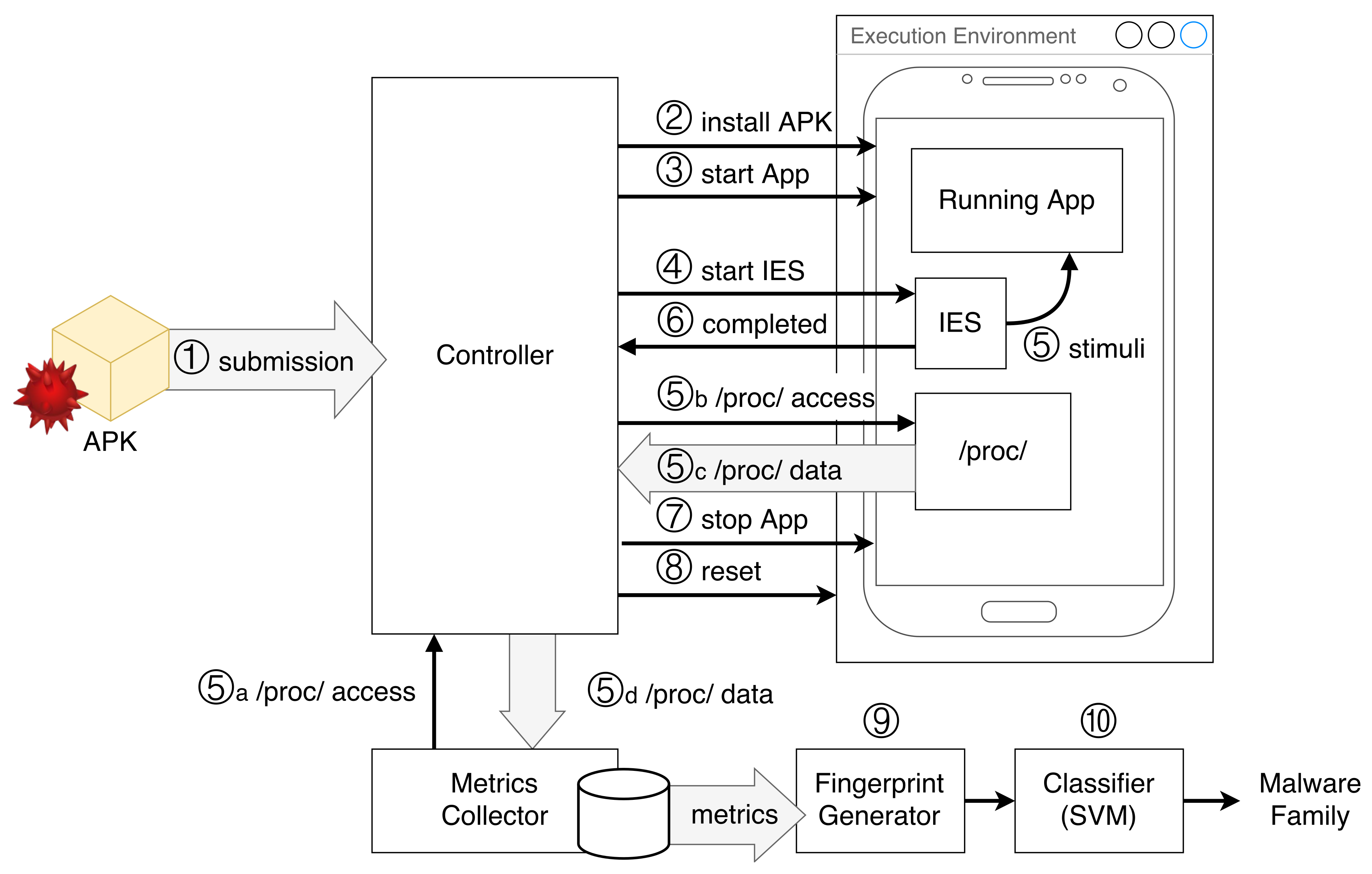
5. Architecture and Prototype Implementation
5.1. Architecture
5.2. Prototype Implementation
- VirtualBox (https://www.virtualbox.org/) is an open-source hypervisor. It allows virtualizing a guest operating system on a physical machine potentially running a different OS.
- Genymotion (https://www.genymotion.com/) is an Android emulator based on VirtualBox for virtual environment creation. Genymotion provides all the features of a real mobile device, which can be controlled and monitored using VirtualBox’s command-line interface.
- Android Emulator (https://developer.android.com/studio/run/emulator): This is the standard Android Emulator provided with the Android SDK. We built our prototype integrating both Genymotion and Android Emulator to detect if the results depended on the particular emulation environment used.
- Android Debug Bridge (https://developer.android.com/studio/command-line/adb.html) (ADB) is a command-line tool that enables the OS to interact with an Android device and have access to all its resources. ADB also handles installation, as well as the launch and termination of applications.
- UI/Application Exerciser Monkey (https://developer.android.com/studio/test/monkey.html) is a program running on Android devices that can be invoked by the command-line through ADB. It generates stimuli for Android apps by simulating a wide variety of inputs including touches, movements, clicks, system events, and activity launches.
- NOnLinear measures for Dynamical Systems (https://github.com/CSchoel/nolds) (NOLDS) is a Python package that includes different algorithms for one-dimensional time series analysis, including DFA, sample entropy, and the Hurst exponent.
- NumPy (http://www.numpy.org/) is a Python package for scientific computing. We employed it to compute the correlation matrix.
- Scikit-learn [32] is a Python package with several machine learning algorithms for supervised and unsupervised learning, including SVMs.
Tools’ Integration
5.3. Performing Analysis on Real Devices
6. Experimental Evaluation
6.1. Datasets
- Drebin dataset [30]: This is a public collection of malware samples collected between 2010 and 2012, which can be used for research purposes. It contains 5560 malicious applications from 179 different families. The Drebin dataset has been widely employed in the related literature [14,18,27,33,34]. Since we compared our solution to DroidScribe, in our experiments, we selected the same families used to evaluate DroidScribe.
- AMD dataset [35]: This is a recent dataset of Android malware labeled by family. It contains 24,553 samples belonging to 71 different families collected until 2017. We selected a subset of this dataset, which includes 13 different families (detailed below), each with more than 20 samples.
6.2. Experiments on the Drebin Dataset
6.2.1. Experimental Setup
6.2.2. Time Requirements
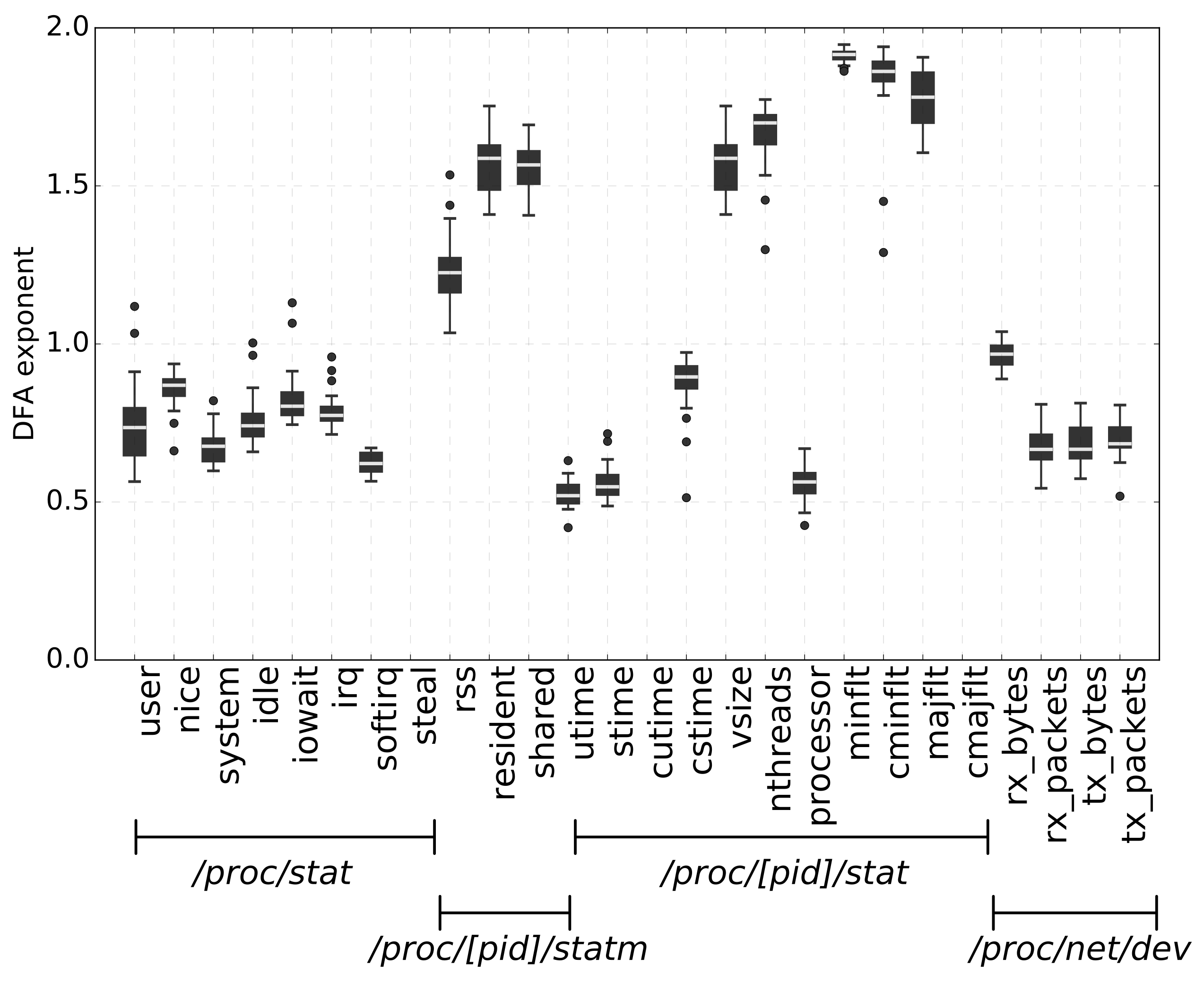
6.2.3. Stability of the DFA exponent
6.2.4. SVM Training and Test
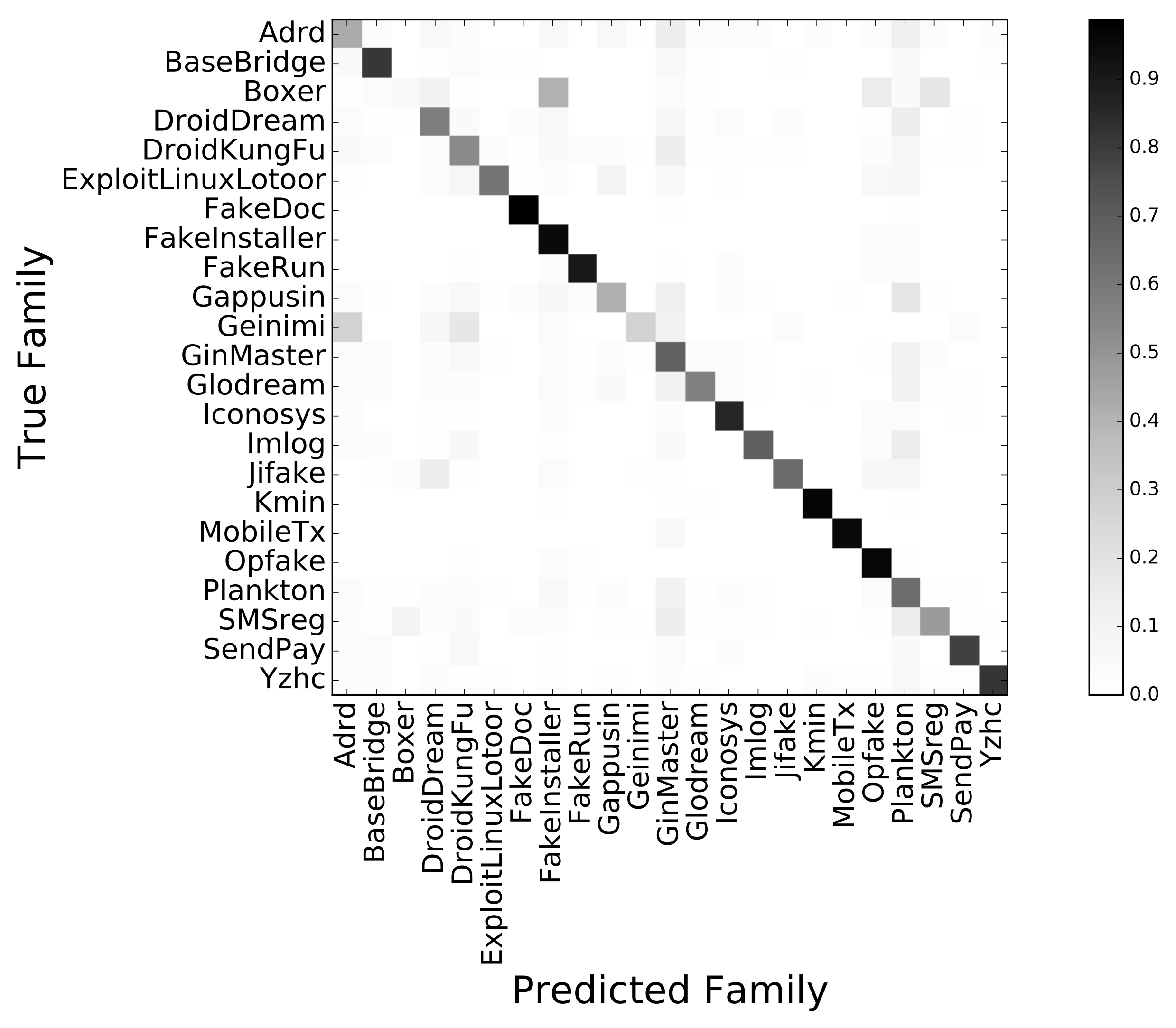
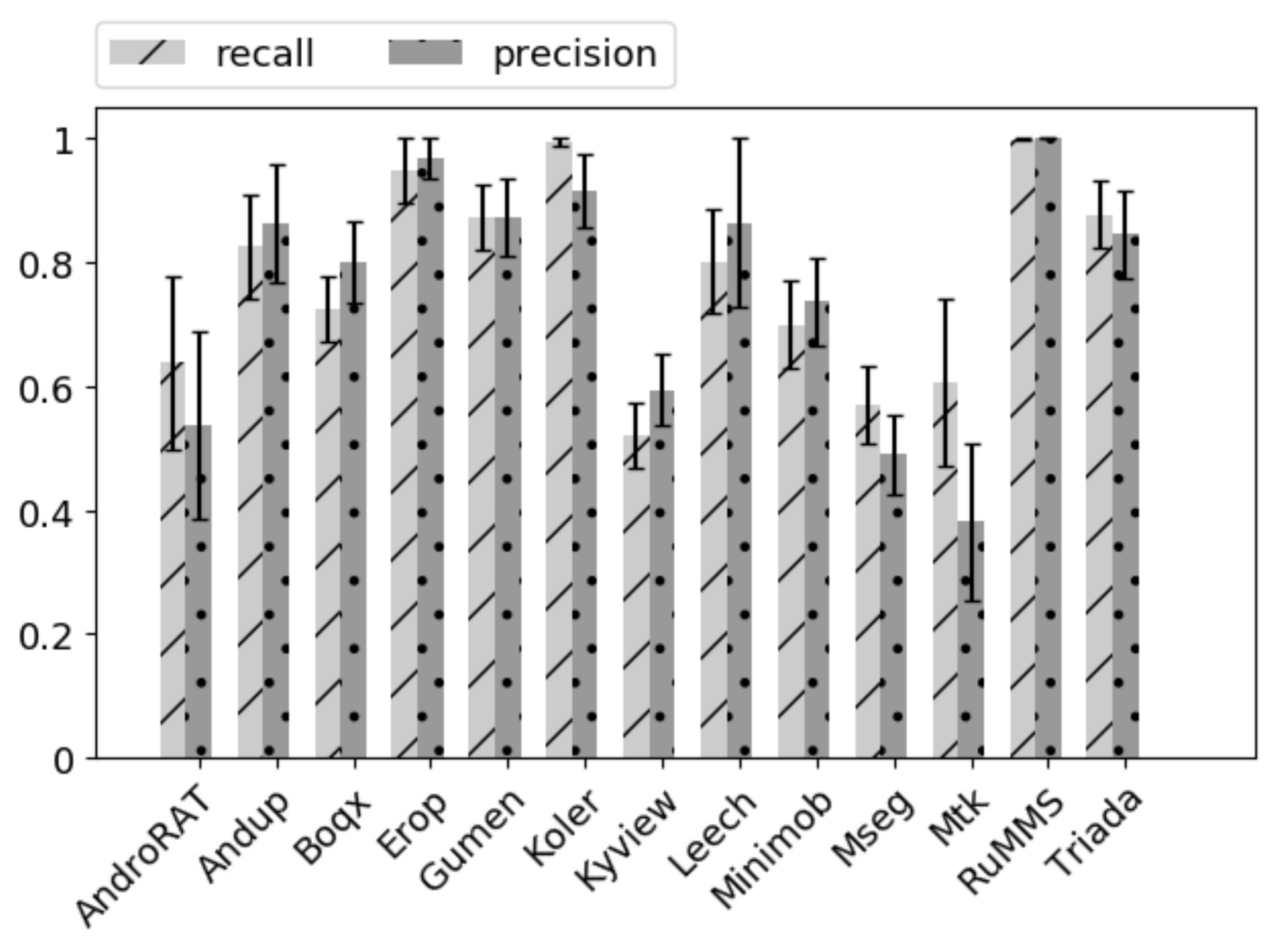
6.2.5. Results
6.2.6. Comparison with DroidScribe
6.3. Experiment on the AMD Dataset
6.3.1. Experimental Setup
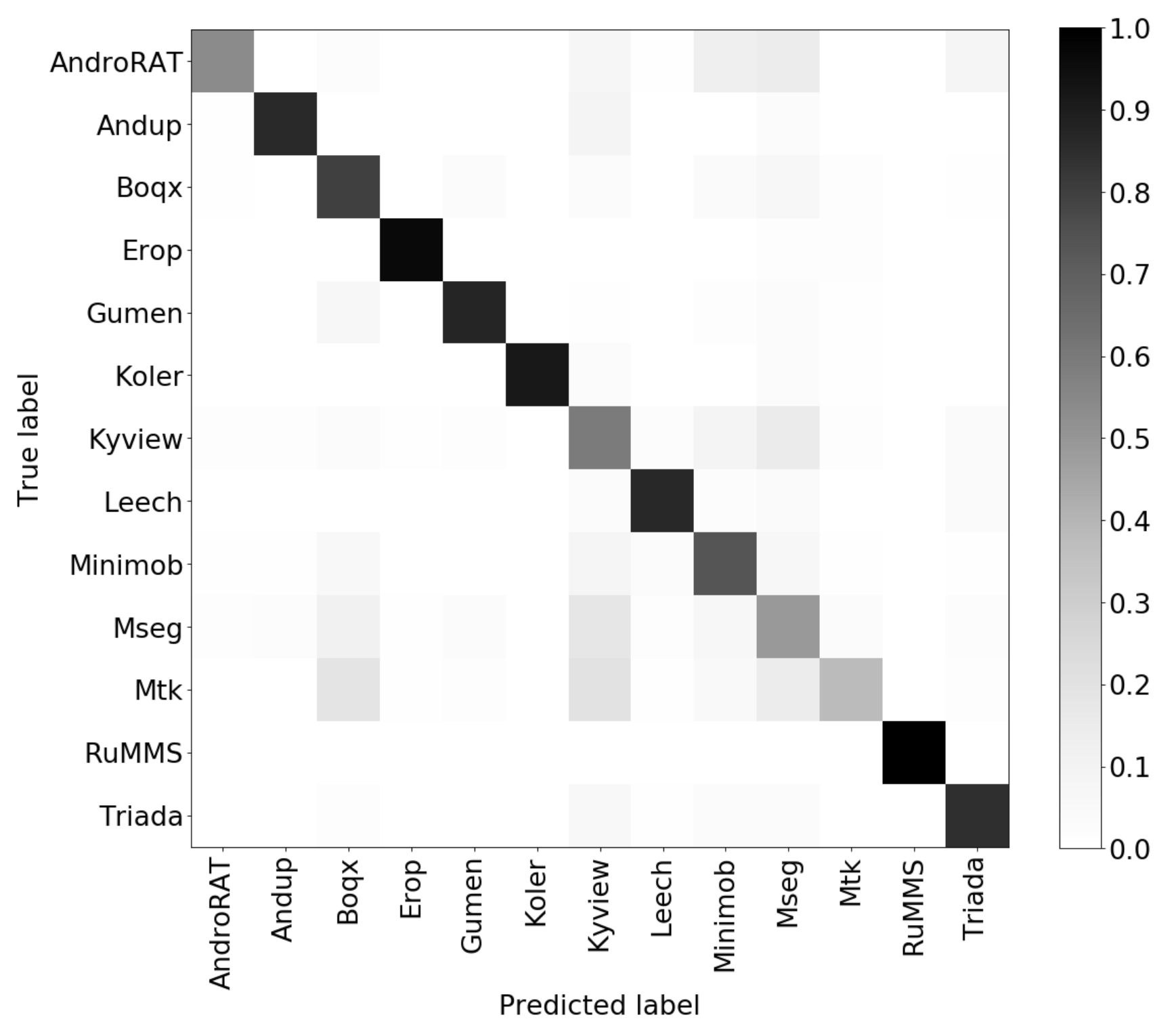
6.3.2. Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gartner. Market Share: Final PCs, Ultramobiles and Mobile Phones, All Countries, 4Q16. 2017. Available online: http://www.gartner.com/newsroom/id/3609817 (accessed on 15 June 2020).
- Tam, K.; Feizollah, A.; Anuar, N.B.; Salleh, R.; Cavallaro, L. The evolution of android malware and android analysis techniques. ACM Comput. Surveys (CSUR) 2017, 49, 76. [Google Scholar] [CrossRef]
- Nokia. Nokia Threat Intelligence Report? 2019. 2018. Available online: https://pages.nokia.com/T003B6-Threat-Intelligence-Report-2019.html (accessed on 15 June 2020).
- Symantec. Internet Security Threat Report. 2016. Available online: https://www.symantec.com/content/dam/symantec/docs/reports/istr-21-2016-en.pdf (accessed on 15 June 2020).
- You, I.; Yim, K. Malware obfuscation techniques: A brief survey. In Proceedings of the 5th International Conference on Broadband, Wireless Computing, Communication and Applications, (BWCCA), Fukuoka, Japan, 4–6 November 2010; pp. 297–300. [Google Scholar]
- Pomilia, M. A Study on Obfuscation Techniques for Android Malware. 2016. Available online: https://midlab.diag.uniroma1.it/articoli/matteo_pomilia_master_thesis.pdf (accessed on 15 June 2020).
- Laurenza, G.; Ucci, D.; Aniello, L.; Baldoni, R. An Architecture for Semi-Automatic Collaborative Malware Analysis for CIs. In Proceedings of the 3rd International Workshop on Reliability and Security Aspects for Critical Infrastructure, Toulouse, France, 28 June–1 July 2016. [Google Scholar]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Symantec. Internet Security Threat Report; Symantec: Tempe, AZ, USA, 2018. [Google Scholar]
- Peng, C.K.; Buldyrev, S.V.; Havlin, S.; Simons, M.; Stanley, H.E.; Goldberger, A.L. Mosaic Organization of DNA Nucleotides. Phys. Rev. E 1994, 49, 1685–1689. [Google Scholar] [CrossRef] [PubMed]
- Pearson, K. Note on Regression and Inheritance in the Case of Two Parents. Proc. R. Soc. Lond. 1895, 58, 240–242. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 1991; Volume 4, p. 10. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Wiley Online Library: Hoboken, NJ, USA, 2002. [Google Scholar]
- Dash, S.K.; Suarez-Tangil, G.; Khan, S.; Tam, K.; Ahmadi, M.; Kinder, J.; Cavallaro, L. Droidscribe: Classifying Android Malware Based on Runtime Behavior. In Proceedings of the 37th Symposium on Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 252–261. [Google Scholar]
- Hardstone, R.; Poil, S.S.; Schiavone, G.; Jansen, R.; Nikulin, V.V.; Mansvelder, H.D.; Linkenkaer-Hansen, K. Detrended fluctuation analysis: A scale-free view on neuronal oscillations. Front. Physiol. 2012, 75, 450. [Google Scholar] [CrossRef] [PubMed]
- Ross, B.C. Mutual information between discrete and continuous data sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef] [PubMed]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Karbab, E.B.; Debbabi, M.; Alrabaee, S.; Mouheb, D. DySign: Dynamic Fingerprinting for the Automatic Detection of Android Malware. In Proceedings of the 11th International Conference on Malicious and Unwanted Software, (MALWARE), Fajardo, PR, USA, 18–22 October 2016; pp. 1–8. [Google Scholar]
- Reina, A.; Fattori, A.; Cavallaro, L. A System Call-centric Analysis and Stimulation Technique to Automatically Reconstruct Android Malware Behaviors. In Proceedings of the 6th European Workshop on Systems Security (EuroSec), Prague, Czech Republic, 14 April 2013. [Google Scholar]
- Shehu, Z.; Ciccotelli, C.; Ucci, D.; Aniello, L.; Baldoni, R. Towards the Usage of Invariant-Based App Behavioral Fingerprinting for the Detection of Obfuscated Versions of Known Malware. In Proceedings of the 10th International Conference on Next Generation Mobile Applications, Security and Technologies (NGMAST), Cardiff, UK, 24–26 August 2016; pp. 121–126. [Google Scholar]
- Bickford, J.; Lagar-Cavilla, H.A.; Varshavsky, A.; Ganapathy, V.; Iftode, L. Security versus energy tradeoffs in host-based mobile malware detection. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011; pp. 225–238. [Google Scholar]
- Merlo, A.; Migliardi, M.; Fontanelli, P. On energy-based profiling of malware in android. In Proceedings of the 2014 International Conference on High Performance Computing & Simulation (HPCS), Bologna, Italy, 21–25 July 2014; pp. 535–542. [Google Scholar]
- Caviglione, L.; Gaggero, M.; Lalande, J.F.; Mazurczyk, W.; Urbański, M. Seeing the unseen: Revealing mobile malware hidden communications via energy consumption and artificial intelligence. IEEE Trans. Inf. Forensics Secur. 2015, 11, 799–810. [Google Scholar] [CrossRef]
- Liu, L.; Yan, G.; Zhang, X.; Chen, S. VirusMeter: Preventing Your Cellphone from Spies. In Proceedings of the 12th International Symposium Research in Attacks, Intrusions, and Defenses, (RAID), Saint-Malo, France, 23–25 September 2009; Volume 5758, pp. 244–264. [Google Scholar]
- Kim, H.; Smith, J.; Shin, K.G. Detecting Energy-greedy Anomalies and Mobile Malware Variants. In Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services, (MOBYSYS), Breckenridge, CO, USA, 17–20 June 2008; pp. 239–252. [Google Scholar]
- Amos, B.; Turner, H.; White, J. Applying Machine Learning Classifiers to Dynamic Android Malware Detection at Scale. In Proceedings of the 9th International Wireless Communications and Mobile Computing Conference (IWCMC), Sardinia, Italy, 1–5 July 2013; pp. 1666–1671. [Google Scholar]
- Canfora, G.; Medvet, E.; Mercaldo, F.; Visaggio, C.A. Acquiring and Analyzing App Metrics for Effective Mobile Malware Detection. In Proceedings of the 2016 International Workshop on Security and Privacy Analytics, New Orleans, LA, USA, 11 March 2016; pp. 50–57. [Google Scholar]
- Mutti, S.; Fratantonio, Y.; Bianchi, A.; Invernizzi, L.; Corbetta, J.; Kirat, D.; Kruegel, C.; Vigna, G. BareDroid: Large-scale Analysis of Android Apps on Real Devices. In Proceedings of the 31st Computer Security Applications Conference, (ACSAC), Los Angeles, CA, USA, 7–11 December 2015; pp. 71–80. [Google Scholar]
- Massarelli, L.; Aniello, L.; Ciccotelli, C.; Querzoni, L.; Ucci, D.; Baldoni, R. Android malware family classification based on resource consumption over time. In Proceedings of the 2017 12th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, Puerto Rico, 11–14 October 2017; pp. 31–38. [Google Scholar]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and Explainable Detection of Android Malware in Your Pocket. In Proceedings of the 21st Network and Distributed System Security Symposium, (NDSS), San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Gonzalez, H.; Stakhanova, N.; Ghorbani, A.A. DroidKin: Lightweight Detection of Android Apps Similarity. In Proceedings of the 10th International Conference on Security and Privacy in Communication Networks (SECURECOMM), Beijing, China, 24–26 September 2014; pp. 436–453. [Google Scholar]
- Suarez-Tangil, G.; Dash, S.K.; Ahmadi, M.; Kinder, J.; Giacinto, G.; Cavallaro, L. DroidSieve: Fast and Accurate Classification of Obfuscated Android Malware. In Proceedings of the 7th Conference on Data and Application Security and Privacy (CODASPY), Scottsdale, AZ, USA, 22–24 March 2017; pp. 309–320. [Google Scholar]
- Wei, F.; Li, Y.; Roy, S.; Ou, X.; Zhou, W. Deep ground truth analysis of current android malware. In Proceedings of the 14th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, (DIMVA), Bonn, Germany, 6–7 July 2017; pp. 252–276. [Google Scholar]
- Gianazza, A.; Maggi, F.; Fattori, A.; Cavallaro, L.; Zanero, S. Puppetdroid: A user-centric ui exerciser for automatic dynamic analysis of similar android applications. arXiv 2014, arXiv:1402.4826. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File (/proc/) | Metric | Description |
|---|---|---|
| [pid]/statm | vss | Total program size |
| rss | Resident set size | |
| shared | Shared pages | |
| rmsize | Size of resident file mappings | |
| net/dev | Rx_packets | Packets received over WiFi |
| Rx_bytes | Bytes received over WiFi | |
| Tx_packets | Packets sent over WiFi | |
| Tx_bytes | Bytes sent over WiFi | |
| stat | u_cpu | CPU time in user mode |
| s_cpu | CPU time in kernel mode | |
| i_cpu | CPU idle time | |
| io_cpu | CPU time in I/O wait | |
| irq_cpu | CPU time servicing interrupt | |
| sirq_cpu | CPU time servicing softirq | |
| st_cpu | CPU time spent in other operating systems | |
| [pid]/stat | utime | Time spent by the process in user mode |
| stime | Time spent by the process in kernel mode | |
| cutime | Time spent by the process waiting for children scheduled in user mode | |
| cstime | Time spent by the process waiting for children scheduled in kernel mode | |
| num_threads | Number of threads | |
| processor | CPU number last executed on | |
| min | Number of minor faults the process made that do not require loading a memory page from disk | |
| cmin | Number of minor faults that the process’s waited-for children made | |
| maj | Number of major faults the process made that required loading a memory page from disk | |
| cmaj | Number of major faults that the process’s waited-for children made |
| Family | No. of Packages |
|---|---|
| Mseg | 195 |
| Minimob | 153 |
| Andup | 40 |
| Leech | 55 |
| Erop | 40 |
| Kyview | 155 |
| Mtk | 59 |
| Koler | 62 |
| AndroRAT | 31 |
| RuMMS | 366 |
| Boqx | 191 |
| Triada | 152 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Massarelli, L.; Aniello, L.; Ciccotelli, C.; Querzoni, L.; Ucci, D.; Baldoni, R. AndroDFA: Android Malware Classification Based on Resource Consumption. Information 2020, 11, 326. https://doi.org/10.3390/info11060326
Massarelli L, Aniello L, Ciccotelli C, Querzoni L, Ucci D, Baldoni R. AndroDFA: Android Malware Classification Based on Resource Consumption. Information. 2020; 11(6):326. https://doi.org/10.3390/info11060326
Chicago/Turabian StyleMassarelli, Luca, Leonardo Aniello, Claudio Ciccotelli, Leonardo Querzoni, Daniele Ucci, and Roberto Baldoni. 2020. "AndroDFA: Android Malware Classification Based on Resource Consumption" Information 11, no. 6: 326. https://doi.org/10.3390/info11060326
APA StyleMassarelli, L., Aniello, L., Ciccotelli, C., Querzoni, L., Ucci, D., & Baldoni, R. (2020). AndroDFA: Android Malware Classification Based on Resource Consumption. Information, 11(6), 326. https://doi.org/10.3390/info11060326