Effectiveness of the Execution and Prevention of Metric-Based Adversarial Attacks on Social Network Data † †

 , ,
, ,
Abstract
1. Introduction
- Experimentation on synthetic networks with 200 nodes (synthetic-large network).
- Experimentation on empirical networks with less than 1000 nodes (empirical-small network).
- Experimentation on empirical network with more than 1000 nodes (empirical-large network).
- Comparison of change in centrality measures across network topologies and sizes.
- Correlation between changes in centrality measures and node centrality ranks across attacks to explore an attack mitigation strategy.
2. Related Work
2.1. Adversarial Attacks
2.2. Adversarial Attacks on Social Networks
2.3. Network Robustness
3. Methods
3.1. Experimental Design
3.1.1. Target Node Sampling
3.1.2. Adversarial Moves
3.1.3. Execution Time Limit
3.1.4. Evaluation of Perturbed Networks
3.2. Data Sets
3.2.1. Synthetic Networks
- Small-World Networks: A small-world network is parameterized via k and p. The parameter k defines the number of neighbors that a new node can be further connected to during graph generation. The parameter p defines the probability of rewiring an edge. We used and for generating small-world networks [24,25].
- Scale-Free Networks: Scale-free networks are parameterized via m, where m represents the number of edges that are preferentially attached to existing nodes based on their degree. We used for generating scale-free networks [26].
- Random Networks: A random network is parametrized via p. Here, p is the probability of creating a new edge when generating the network. We used for generating random networks [27].
- Cellular Networks: We generate cellular networks by generating five random networks (with as discussed previously) with 20 nodes each (total of 100 nodes) for small networks, and 40 nodes each (total 200 nodes) for large networks. Each pair of networks is then connected by an edge between a randomly selected pair of nodes in those networks.
3.2.2. Empirical Networks
3.3. Experimental Setup
3.3.1. Centrality Measurement
- Degree centrality: counts the number of neighbors per node;
- Closeness centrality: measures how close a node is to other nodes in the network;
- Betweenness centrality: measures the number of times a node is located on the shortest path between a pair of nodes;
- Eigenvector centrality: is recursively defined as a node being connected to other influential nodes with respect to node degree.
3.3.2. Sampling Tier
3.3.3. Reach Type
- Local moves: performing an adversarial attack on the adversary’s ego network.
- Global level moves: performing an adversarial attack anywhere in the network, including within the target node’s ego-network.
4. Experimentation Tool for Testing and Mitigating Adversarial Attacks on Networks
- (1)
- Generate synthetic networks: The tool can import predefined network data (in edge list format) through the configuration file. Alternatively, the user can generate synthetic graphs with a script. The script allows the user to tweak the parameters for generating graphs, including the type and number of graphs. This script uses NetworkX Graph Generators, which provides documentation for how these generators work. In this version, we support the construction of four network types: scale-free, small-world, random, and cellular, as defined in Section 3.2.1.
- (2)
- Generate experiment configuration: Once an edge list is created, we can generate a configuration file for our experiment network tool. We prepared a script that creates bulk/batch configuration files to run experiments. The configuration files follow a specific data model that is saved as a JSON structure (more details in the repository). This script generates many configuration files and folders in the output-experiments target folder. One configuration file represents one experiment.
- (3)
- Adversarial attack framework runtime: The runtime script is the main implementation of the experimental framework we proposed in Section 3.1. This script executes an experiment based on the configuration file provided. Depending on what moves and goals were specified in the configuration file, the tool will find all possible adversarial moves given the adversarial budget, available moves, and respective cost, within the time limit period. All experiment configurations will be executed in parallel. After moves have been executed and evaluation metrics have been calculated, the tool chooses the optimal move based on the largest change in the evaluation metric for the target node. The runtime will save the optimal move, the network data, and centrality measures before and after adversarial attack execution as the result of each experiment.
- (4)
- Result analysis and visualization: Besides the experimental framework, we also provide a Jupyter Notebook script that helps to visualize the results of these experiments. The notebook will aggregate all experimental results from the runtime, and plot the set of optimal moves for each network type and change in centrality measure. The analysis also includes the move and cross-measures comparison and correlation between centrality measures and ranks for the purpose of attack mitigation.
5. Results and Discussion
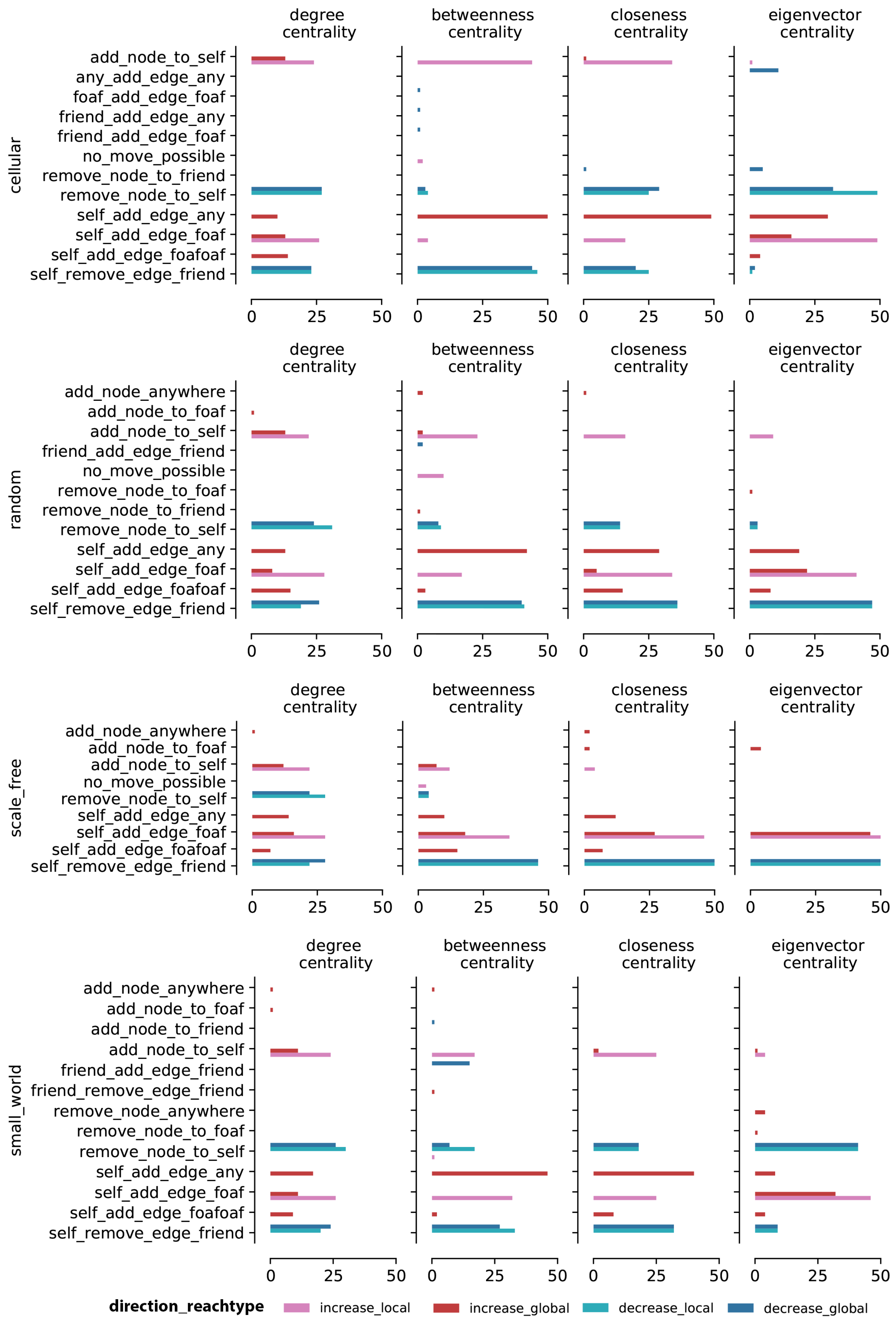
5.1. Optimal Moves across Configurations
5.1.1. Optimal Moves for Synthetic Networks
5.1.2. Optimal Moves Comparison between Small and Large Synthetic Networks
5.1.3. Optimal Moves for Empirical Networks
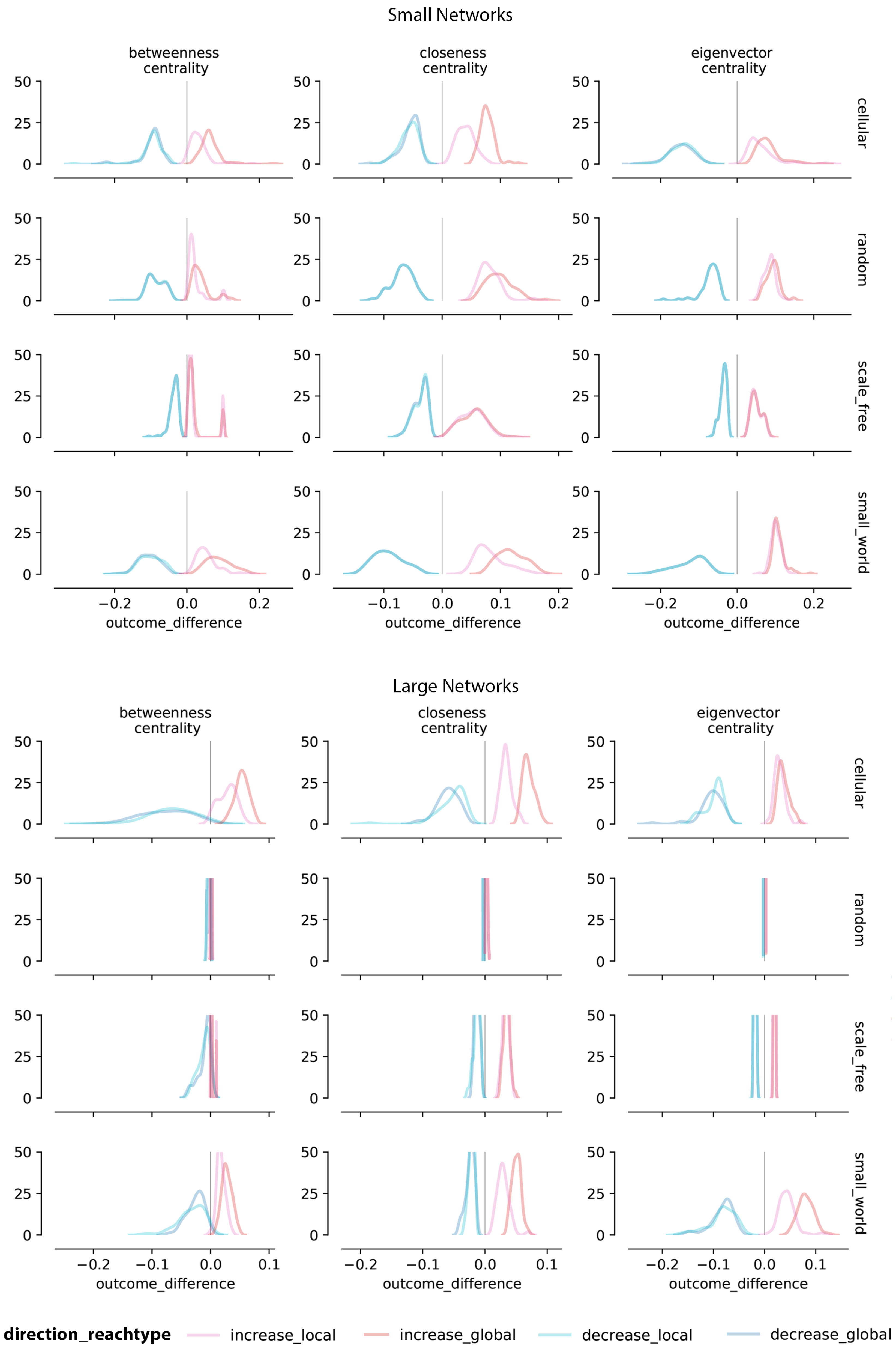
5.2. Change in Centrality Measures after Adversarial Moves
5.2.1. Change in Centrality Measures for Synthetic Networks
5.2.2. Change in Centrality Measures for Empirical Networks
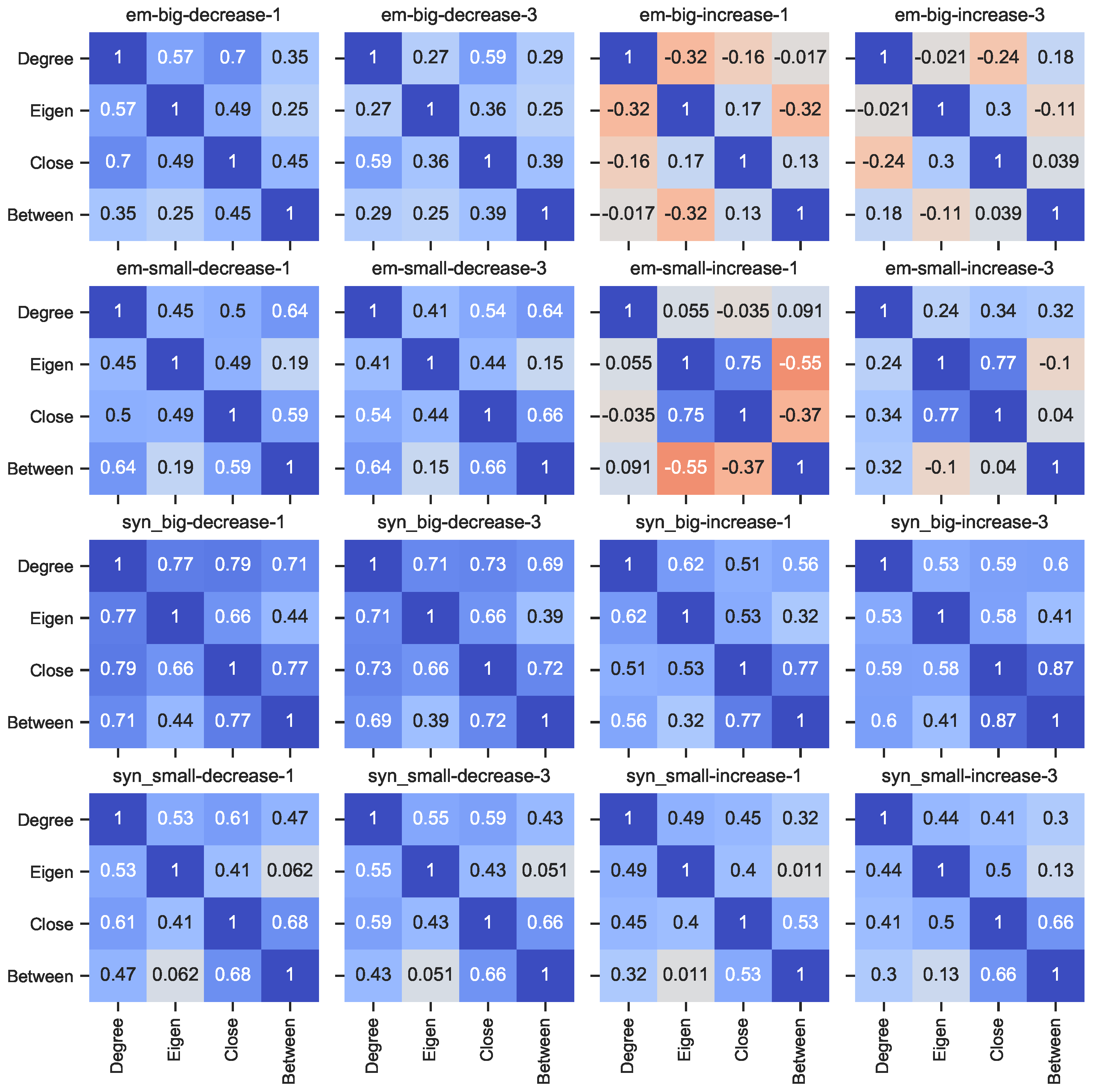
5.3. Centrality Measures Correlation Analysis as a Strategy for Mitigation of Attacks
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SNA | Social Network Analysis |
| GAN | Generative Adversarial Network |
| ROAM | Remove One, Add Many |
| GraphGAN | Graph Generative Adversarial Network |
| CS | Computer Science |
| PhD | Doctor of Philosophy |
| U.S. | United States |
| HIV | Human Immunodeficiency Virus |
| JSON | Java Script Object Notation |
References
- Borgatti, S.P.; Carley, K.M.; Krackhardt, D. On the robustness of centrality measures under conditions of imperfect data. Soc. Netw. 2006, 28, 124–136. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Carlini, N.; Wagner, D. Audio adversarial examples: Targeted attacks on speech-to-text. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Ebrahimi, J.; Rao, A.; Lowd, D.; Dou, D. HotFlip: White-Box Adversarial Examples for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 31–36. [Google Scholar] [CrossRef]
- Chen, J.; Wu, Y.; Xu, X.; Chen, Y.; Zheng, H.; Xuan, Q. Fast gradient attack on network embedding. arXiv 2018, arXiv:1809.02797. [Google Scholar]
- Waniek, M.; Michalak, T.P.; Wooldridge, M.J.; Rahwan, T. Hiding individuals and communities in a social network. Nat. Hum. Behav. 2018, 2, 139–147. [Google Scholar] [CrossRef]
- Avram, M.V.; Mishra, S.; Parulian, N.N.; Diesner, J. Adversarial perturbations to manipulate the perception of power and influence in networks. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 986–994. [Google Scholar]
- Avram, M.V.; Mishra, S.; Parulian, N.N.; Chin, C.L.; Diesner, J. Social Network Adversarial Perturbations. 2019. Available online: https://github.com/uiuc-ischool-scanr/social-network-adversarial-perturbations (accessed on 1 June 2020).
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yu, S.; Vorobeychik, Y.; Alfeld, S. Adversarial Classification on Social Networks. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’18, Stockholm, Sweden, 10–15 July 2018; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2018; pp. 211–219. [Google Scholar]
- Zhang, H.; Goel, A.; Govindan, R.; Mason, K.; Roy, B.V. Making Eigenvector-Based Reputation Systems Robust to Collusion. In Algorithms and Models for the Web-Graph Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 92–104. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.; Wang, J.; Zhao, M.; Zhang, W.; Zhang, F.; Xie, X.; Guo, M. GraphGAN: Graph Representation Learning With Generative Adversarial Nets. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Entezari, N.; Al-Sayouri, S.A.; Darvishzadeh, A.; Papalexakis, E.E. All You Need Is Low (Rank) Defending Against Adversarial Attacks on Graphs. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 169–177. [Google Scholar]
- Tang, J.; Sun, J.; Wang, C.; Yang, Z. Social influence analysis in large-scale networks. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June –1 July 2009; ACM: New York, NY, USA, 2009; pp. 807–816. [Google Scholar]
- Valente, T.W.; Coronges, K.; Lakon, C.; Costenbader, E. How Correlated Are Network Centrality Measures? Connect (Tor) 2008, 28, 16–26. [Google Scholar] [PubMed]
- Schoch, D.; Valente, T.W.; Brandes, U. Correlations among centrality indices and a class of uniquely ranked graphs. Soc. Netw. 2017, 50, 46–54. [Google Scholar] [CrossRef]
- Meo, P.D.; Musial-Gabrys, K.; Rosaci, D.; Sarnè, G.M.; Aroyo, L. Using centrality measures to predict helpfulness-based reputation in trust networks. ACM Trans. Internet Technol. (TOIT) 2017, 17, 1–20. [Google Scholar] [CrossRef]
- Karrer, B.; Levina, E.; Newman, M.E.J. Robustness of community structure in networks. Phys. Rev. E 2008, 77. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Diesner, J. Distortive effects of initial-based name disambiguation on measurements of large-scale coauthorship networks. J. Assoc. Inf. Sci. Technol. 2015, 67, 1446–1461. [Google Scholar] [CrossRef]
- Kim, J.; Diesner, J. The effect of data pre-processing on understanding the evolution of collaboration networks. J. Inf. 2015, 9, 226–236. [Google Scholar] [CrossRef]
- Diesner, J.; Evans, C.; Kim, J. Impact of Entity Disambiguation Errors on Social Network Properties. In Proceedings of the International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Mishra, S.; Fegley, B.D.; Diesner, J.; Torvik, V.I. Self-citation is the hallmark of productive authors, of any gender. PLoS ONE 2018, 13, e0195773. [Google Scholar] [CrossRef] [PubMed]
- Barrat, A.; Weigt, M. On the properties of small-world network models. Eur. Phys. J. B-Condens. Matter Complex Syst. 2000, 13, 547–560. [Google Scholar] [CrossRef]
- Humphries, M.D.; Gurney, K. Network ‘small-world-ness’: A quantitative method for determining canonical network equivalence. PLoS ONE 2008, 3, e0002051. [Google Scholar] [CrossRef] [PubMed]
- Magner, A.; Janson, S.; Kollias, G.; Szpankowski, W. On symmetry of uniform and preferential attachment graphs. Electron. J. Comb. 2014, 21, 3–32. [Google Scholar] [CrossRef]
- Yates, P.D.; Mukhopadhyay, N.D. An inferential framework for biological network hypothesis tests. BMC Bioinform. 2013, 14, 94. [Google Scholar] [CrossRef] [PubMed]
- Weeks, M.R.; Clair, S.; Borgatti, S.P.; Radda, K.; Schensul, J.J. Social networks of drug users in high-risk sites: Finding the connections. AIDS Behav. 2002, 6, 193–206. [Google Scholar] [CrossRef]
- Grund, T.U.; Densley, J.A. Ethnic homophily and triad closure: Mapping internal gang structure using exponential random graph models. J. Contemp. Crim. Justice 2015, 31, 354–370. [Google Scholar] [CrossRef]
- Freeman, L.C. Finding Social Groups: A Meta-Analysis of the Southern Women Data; The National Academies Press: Washington, DC, USA, 2003. [Google Scholar]
- Knuth, D.E. The Stanford GraphBase: A Platform for Combinatorial Computing; AcM Press: New York, NY, USA, 1993. [Google Scholar]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Johnson, D.S. The genealogy of theoretical computer science: A preliminary report. ACM SIGACT News 1984, 16, 36–49. [Google Scholar] [CrossRef]
- Opsahl, T.; Agneessens, F.; Skvoretz, J. Node centrality in weighted networks: Generalizing degree and shortest paths. Soc. Netw. 2010, 32, 245–251. [Google Scholar] [CrossRef]
- Morris, M.; Rothenberg, R. HIV Transmission Network Metastudy Project: An Archive of Data From Eight Network Studies, 1988–2001; Inter-university Consortium for Political and Social Research: Ann Arbor, MI, USA, 2011. [Google Scholar]
- Guimera, R.; Danon, L.; Diaz-Guilera, A.; Giralt, F.; Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 2003, 68, 065103. [Google Scholar]
- Leskovec, J.; Mcauley, J.J. Learning to discover social circles in ego networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 539–547. [Google Scholar]
- Avram, M.V.; Mishra, S.; Parulian, N.N.; Diesner, J. Simulation Data for Adversarial Perturbations to Manipulate the Perception of Power and Influence in Networks; University of Illinois at Urbana-Champaign: Champaign, IL, USA, 2019. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.; S Chult, D. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2008. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Case | Possible Attack | Goal |
|---|---|---|---|
| Image | Image generation | Generative Adversarial Networks [2] | Improve image generation |
| Text | Sentence labeling | Change text elements (characters or words) [5] | Change target label |
| Audio | Speech recognition | Add noise to audio signal [4] | Change target words or phrases |
| Networks | Recommender system; Information diffusion; Social influence; Network security | GraphGAN [13]; Add/remove nodes and edges [7] | Improve link prediction; Change relevance of nodes and edges |
| Waniek et al. [7] | Ours | |
|---|---|---|
| Goal | Node hiding | Node hiding or node prominence |
| Allowed changes | Local edge changes | Local and global edge changes, addition of nodes (e.g., introducing fake identities), removal of nodes (e.g., deleting accounts) |
| Attack success criteria | Decrease in ranking | Demoting from top x (=10th) percentile by decreasing centrality measure and promoting from bottom y (=10th) percentile by increasing centrality measure |
| Ranking criteria | Centrality measures and models of influence | Centrality measures |
| Experimental costs of adversarial move | 3 | 1 (stricter) |
| Experiments | Apply ROAM in multiple rounds | Exhaustive search over possible moves in synthetic small-scale networks |
| Network Name | #Nodes | #Edges (density) | Avg Degree | Avg Clust. Coeff. | Triangles | Node Representation | Edge Representation |
|---|---|---|---|---|---|---|---|
| Empirical-small networks | |||||||
| Drug net [28] | 115 | 195 (0.0297) | 3.39 | 0.258 | 35 | Drug users | Acquaintanceship between drug users |
| London gang [29] | 35 | 315 (0.529) | 11.7 | 0.633 | 860 | Gang members | Gang members hanging out together, co-offending |
| Southern women [30] | 18 | 139 (0.908) | 15.5 | 0.937 | 631 | Women | Women attending events together |
| Les Miserables co-occurence [31] | 77 | 254 (0.0868) | 6.60 | 0.573 | 467 | Characters in Les Miserables & Characters appearing together in the same chapter | |
| Zachary karate club [32] | 34 | 78 (0.139) | 4.59 | 0.570 | 45 | Members of a karate club | Interaction/communication between members |
| Twitter retweet [33] | 96 | 117 (0.0257) | 2.44 | 0.0600 | 12 | Twitter user | Twitter retweets |
| Empirical-large networks | |||||||
| CS PhD network [34] | 1022 | 1045 (0.00200) | 2.05 | 0.0110 | 4 | Advisors or PhD students | Advising of PhD Students by professors |
| U.S. flights [35] | 1574 | 17,215 (0.0139) | 21.9 | 0.637 | 245,172 | Airports & Flights between airports | |
| HIV [36] | 2161 | 1844 (0.000790) | 1.71 | 0.000 | 0 | HIV-infected persons and their close partners | Drug, needle, or sexual exchange |
| Email [37] | 1133 | 5452 (0.00850) | 9.62 | 0.220 | 5343 | Members of university | Email exchanges |
| Facebook [38] | 4039 | 88,234 (0.0108) | 43.7 | 0.606 | 1,612,010 | Facebook users | Friendship between users |
| Graph Type | Reach Type | Betweenness Centrality | Closeness Centrality | Eigenvector Centrality | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Increase | Decrease | Increase | Decrease | Increase | Decrease | ||||||||
| Synthetic-small networks | |||||||||||||
| Small-world | Local | 0.046 | 0.398 | −0.100 | −0.467 | 0.082 | 0.472 | −0.091 | −0.480 | 0.010 | 0.485 | −0.124 | −0.512 |
| Global | 0.088 | 0.675 | −0.106 | −0.464 | 0.118 | 0.691 | −0.091 | −0.480 | 0.109 | 0.560 | −0.124 | −0.512 | |
| Cellular | Local | 0.031 | 0.475 | −0.095 | −0.314 | 0.039 | 0.399 | −0.054 | −0.455 | 0.065 | 0.441 | −0.140 | −0.645 |
| Global | 0.066 | 0.722 | −0.092 | −0.304 | 0.077 | 0.811 | −0.054 | −0.401 | 0.079 | 0.581 | −0.147 | −0.594 | |
| Random | Local | 0.021 | 0.178 | −0.087 | −0.253 | 0.082 | 0.242 | −0.068 | −0.209 | 0.085 | 0.263 | −0.071 | −0.181 |
| Global | 0.039 | 0.355 | −0.088 | −0.255 | 0.097 | 0.311 | −0.068 | −0.209 | 0.095 | 0.280 | −0.071 | −0.180 | |
| Scale-free | Local | 0.017 | 0.255 | −0.037 | −0.076 | 0.049 | 0.213 | −0.037 | −0.051 | 0.049 | 0.243 | −0.036 | −0.061 |
| Global | 0.018 | 0.311 | −0.037 | −0.076 | 0.054 | 0.223 | −0.037 | −0.051 | 0.050 | 0.235 | −0.036 | −0.061 | |
| Synthetic-large networks | |||||||||||||
| Small-world | Local | 0.018 | 0.589 | −0.032 | −0.266 | 0.029 | 0.414 | −0.022 | −0.269 | 0.044 | 0.565 | −0.083 | −0.529 |
| Global | 0.028 | 0.616 | −0.026 | −0.249 | 0.050 | 0.800 | −0.024 | −0.322 | 0.081 | 0.828 | −0.083 | −0.497 | |
| Cellular | Local | 0.029 | 0.723 | −0.067 | −0.366 | 0.034 | 0.498 | −0.054 | −0.429 | 0.029 | 0.373 | −0.098 | −0.773 |
| Global | 0.054 | 0.783 | −0.077 | −0.437 | 0.699 | 0.886 | −0.060 | −0.498 | 0.576 | 0.371 | −0.105 | −0.782 | |
| Random | Local | 0.001 | 0.021 | −0.002 | −0.013 | 0.002 | 0.028 | −0.002 | −0.023 | 0.002 | 0.033 | −0.002 | −0.032 |
| Global | 0.001 | 0.032 | −0.002 | −0.019 | 0.002 | 0.021 | −0.002 | −0.021 | 0.002 | 0.035 | −0.002 | −0.028 | |
| Scale-free | Local | 0.001 | 0.163 | −0.012 | −0.005 | 0.033 | 0.368 | −0.013 | −0.009 | 0.019 | 0.365 | −0.019 | −0.021 |
| Global | 0.002 | 0.375 | −0.010 | −0.004 | 0.035 | 0.388 | −0.013 | −0.008 | 0.020 | 0.371 | −0.019 | −0.021 | |
| Directionality | Reach Type | Betweenness Centrality | Closeness Centrality | Eigenvector Centrality | |||
|---|---|---|---|---|---|---|---|
| Empirical-small networks | |||||||
| Increase | Local | 0.016 | 0.531 | 0.057 | 0.294 | 0.018 | 0.174 |
| Global | 0.088 | 0.736 | 0.107 | 0.605 | 0.060 | 0.451 | |
| Decrease | Local | −0.051 | −0.134 | −0.064 | −0.102 | −0.068 | −0.120 |
| Global | −0.091 | −0.210 | −0.067 | −0.108 | −0.082 | −0.161 | |
| Empirical-large networks | |||||||
| Increase | Local | 0.014 | 0.539 | 0.048 | 0.330 | 0.009 | 0.223 |
| Global | 0.041 | 0.789 | 0.076 | 0.767 | 0.051 | 0.616 | |
| Decrease | Local | −0.049 | −0.086 | −0.025 | −0.286 | −0.025 | −0.242 |
| Global | −0.037 | −0.044 | −0.027 | −0.266 | −0.007 | −0.146 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parulian, N.N.; Lu, T.; Mishra, S.; Avram, M.; Diesner, J. Effectiveness of the Execution and Prevention of Metric-Based Adversarial Attacks on Social Network Data †. Information 2020, 11, 306. https://doi.org/10.3390/info11060306
Parulian NN, Lu T, Mishra S, Avram M, Diesner J. Effectiveness of the Execution and Prevention of Metric-Based Adversarial Attacks on Social Network Data †. Information. 2020; 11(6):306. https://doi.org/10.3390/info11060306
Chicago/Turabian StyleParulian, Nikolaus Nova, Tiffany Lu, Shubhanshu Mishra, Mihai Avram, and Jana Diesner. 2020. "Effectiveness of the Execution and Prevention of Metric-Based Adversarial Attacks on Social Network Data †" Information 11, no. 6: 306. https://doi.org/10.3390/info11060306
APA StyleParulian, N. N., Lu, T., Mishra, S., Avram, M., & Diesner, J. (2020). Effectiveness of the Execution and Prevention of Metric-Based Adversarial Attacks on Social Network Data †. Information, 11(6), 306. https://doi.org/10.3390/info11060306