Corpus-Based Paraphrase Detection Experiments and Review



Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. From Semantic Similarity to Paraphrase Detection
3.2. Methodology
3.3. Evaluation Framework
3.4. Experiment Setup
3.4.1. Environment
3.4.2. Corpora
Clough and Stevenson Corpus of Plagiarized Short Answers
Microsoft Paraphrase Corpus (MSRP)
Webis Crowd Paraphrase Corpus 2011 (Webis-CPC-11)
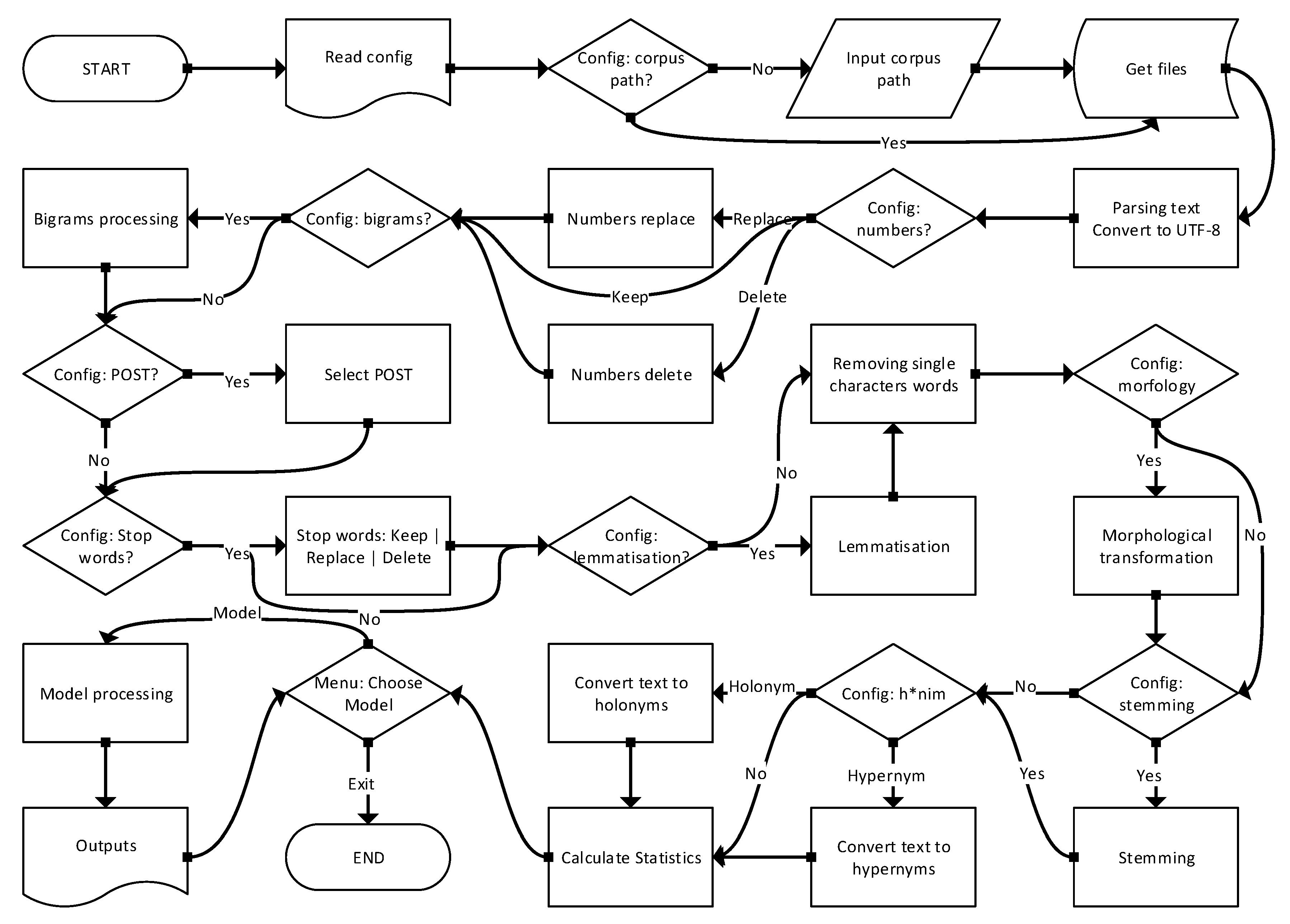
3.4.3. Text Pre-Processing
- Determination of empty files and their registration. Empty files are the reason for the differences in the number of documents before and after text pre-processing.
- Extraction of plain text from documents (parsing). Some files contained problematic text encoding, especially in the Webis corpus. Every symbol out of utf-8 was transcoded into it or deleted.
- Three variants of number manipulation were tested: deleting them, replacing them with the <NUM> token, and leaving them in the text. Experiments have shown that the best results are achieved by leaving them.
- Bigrams can affect model results. For bigram formation we used Phrases from genism model’s module. Experiments have shown that the results are better without the use of bigrams, so there was no need to implement n-grams.
- Filtering text with specific part of speech tags (POST) did not produce better results in several POST combinations. For POS filtering, we used the tagger from the nltk package.
- Stop word processing went in three directions. We tried to (1) delete them, (2) replace them with the token <STOPWORD>, and (3) keep them all. Stop words were left in documents because leaving them gave us better results. This is in contrast to the common and logical practice of text pre-processing, which produces worse results, we suppose because the context of the word is thus preserved. Numbers were left in the text for the same reason.
- Word lemmatization using WordNet Lemmatizer. Lemmatization is the process of converting a word to its base form—grouping together words with similar meanings but in different inflected forms. While stemming just removes the last few characters, often leading to incorrect meanings and spelling errors, lemmatization correctly identifies the base forms of words. With the lemmatization, we obtained slightly better results than without it.
- Removing single character words because using them does not improve results, but increases the complexity of models and calculations.
- Morphing words using Morphy from WordNet. Morphology in WordNet uses two types of processes to try to convert the string passed into one that can be found in the WordNet database. That slightly improved our results.
- Stemming with three different stemmers (Snowball, Porter, and Porter2), but the stemmers did not contribute to the results, on the contrary.
- Usage of hypernyms and holonyms from WordNet did not improve results.
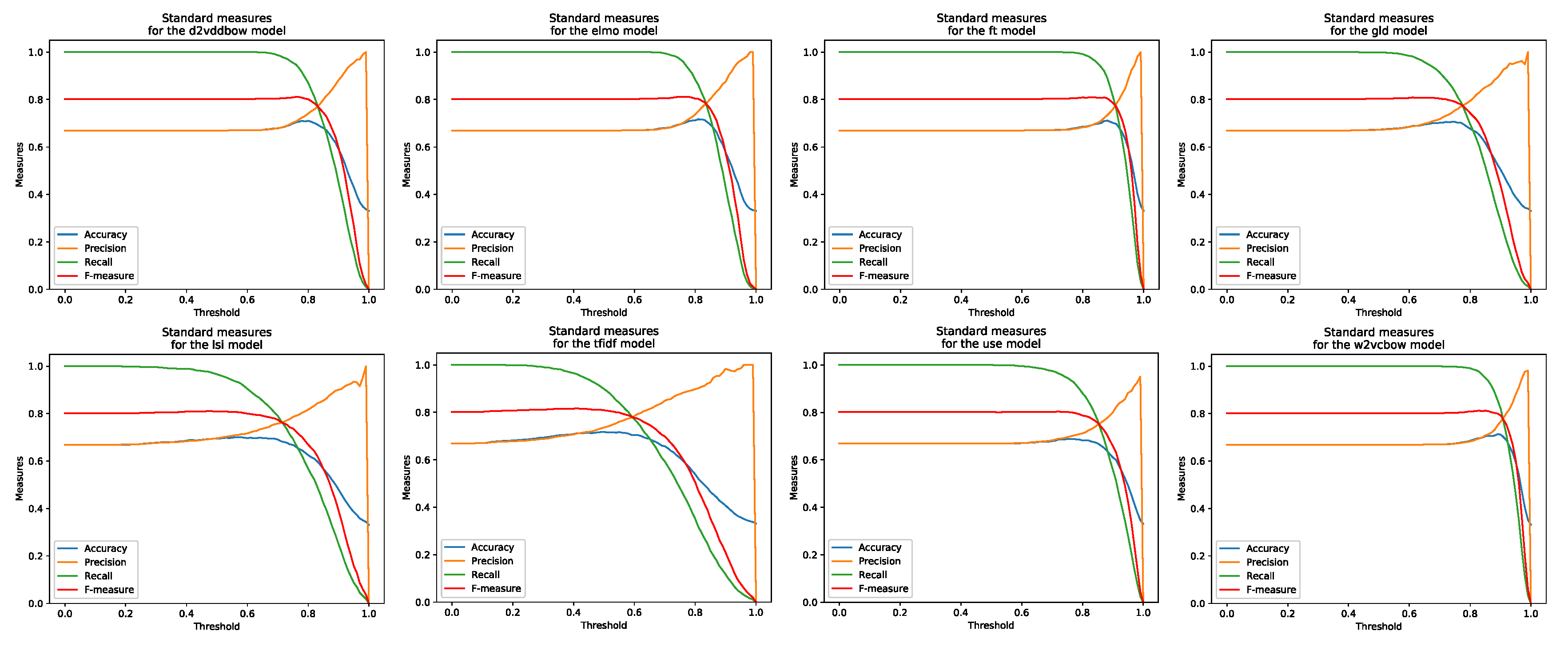
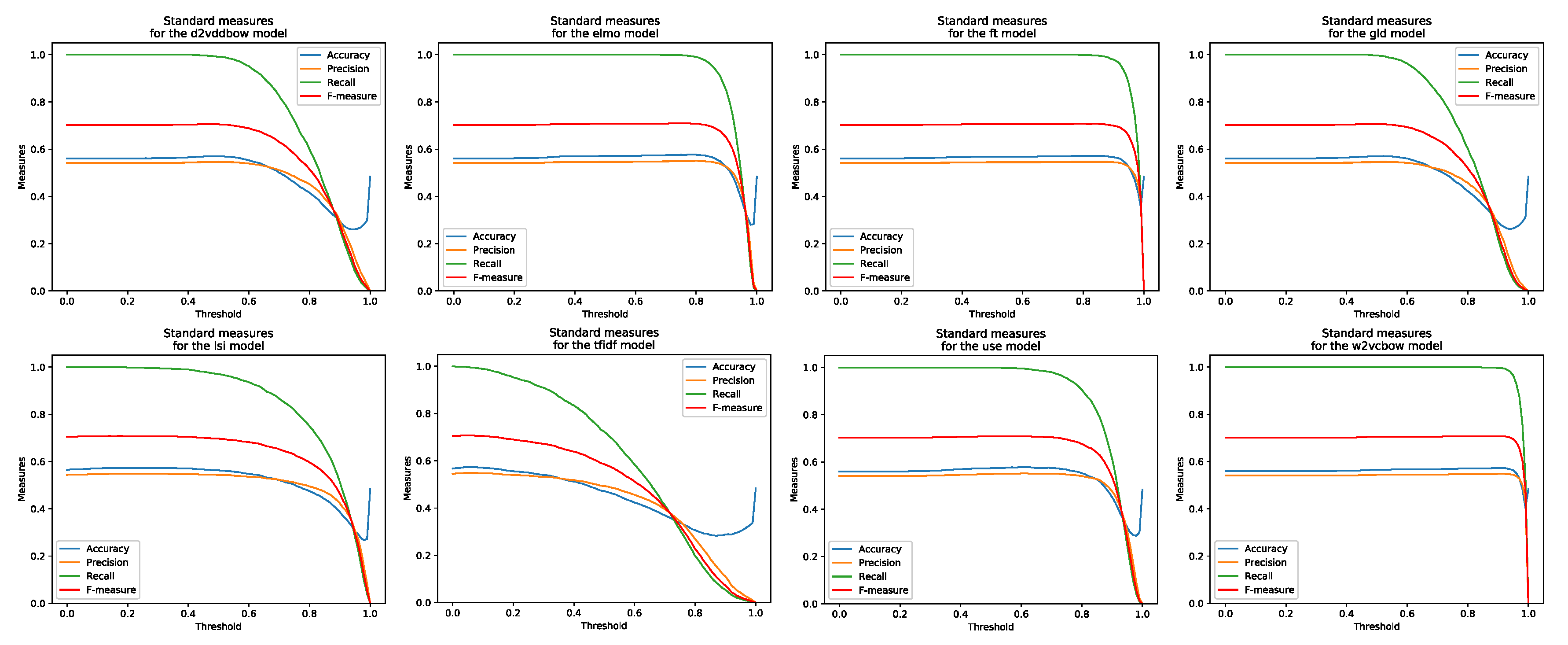
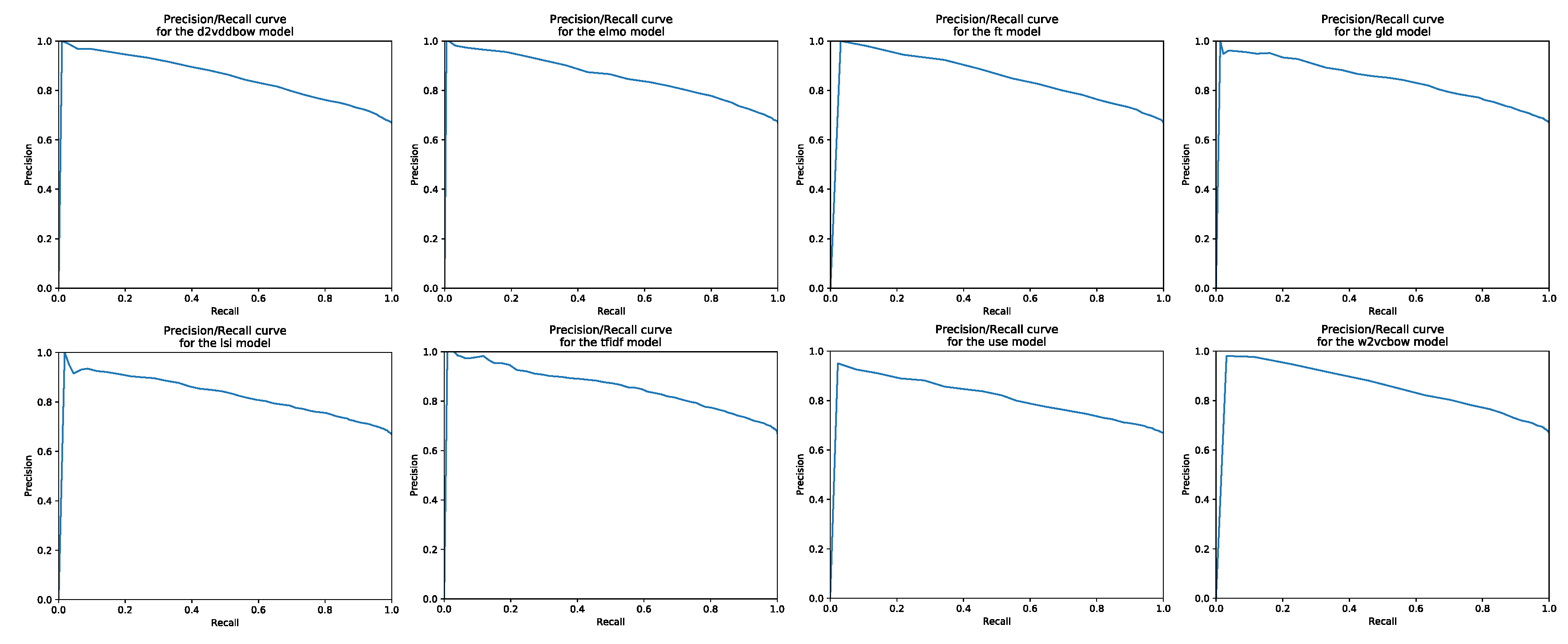
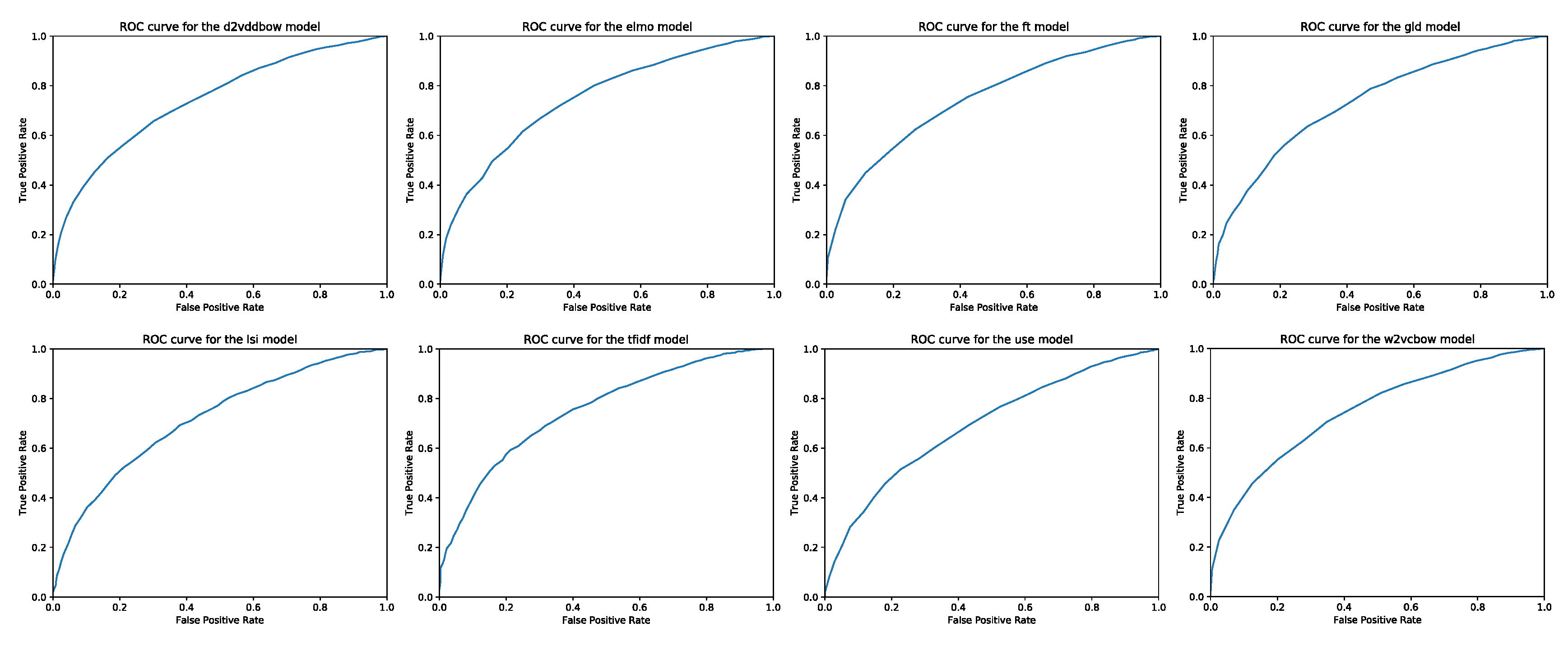
4. Results and Discussion
- Line diagram—comparative representation of standard measures.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
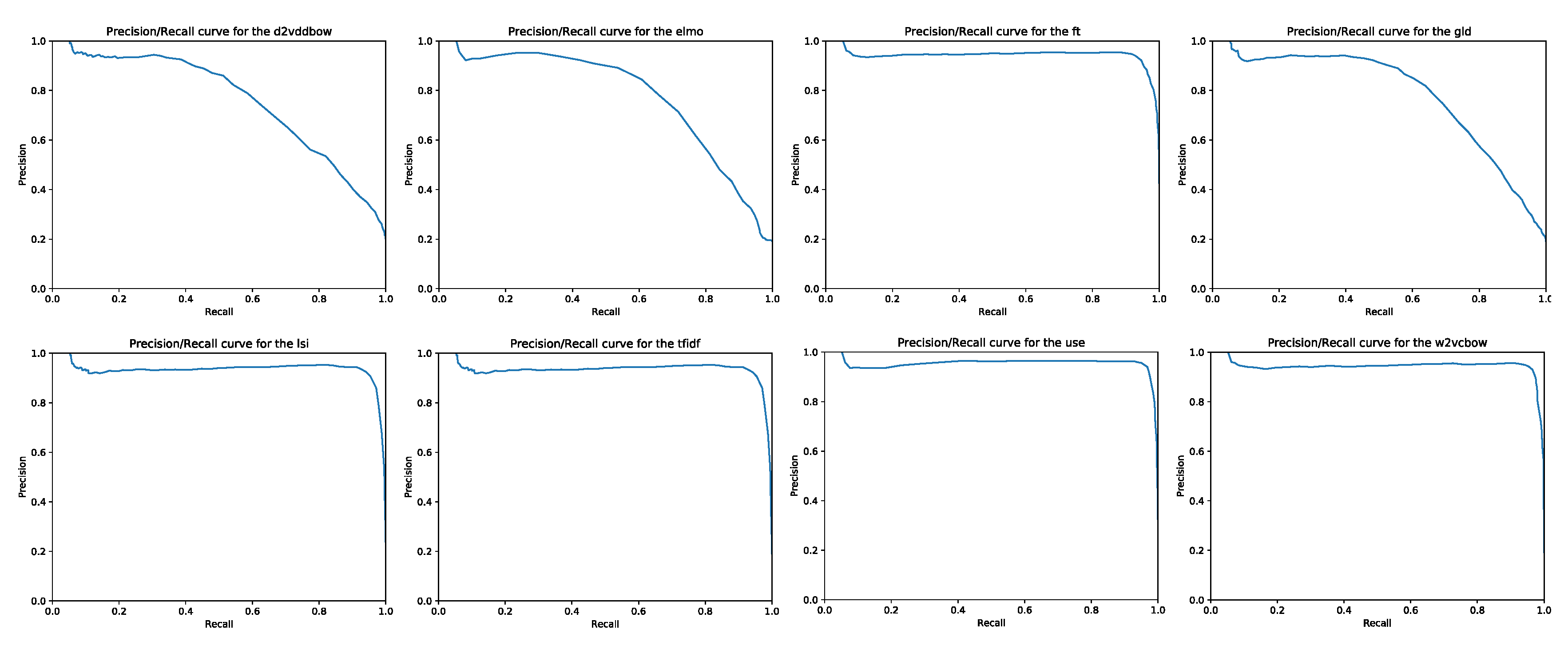
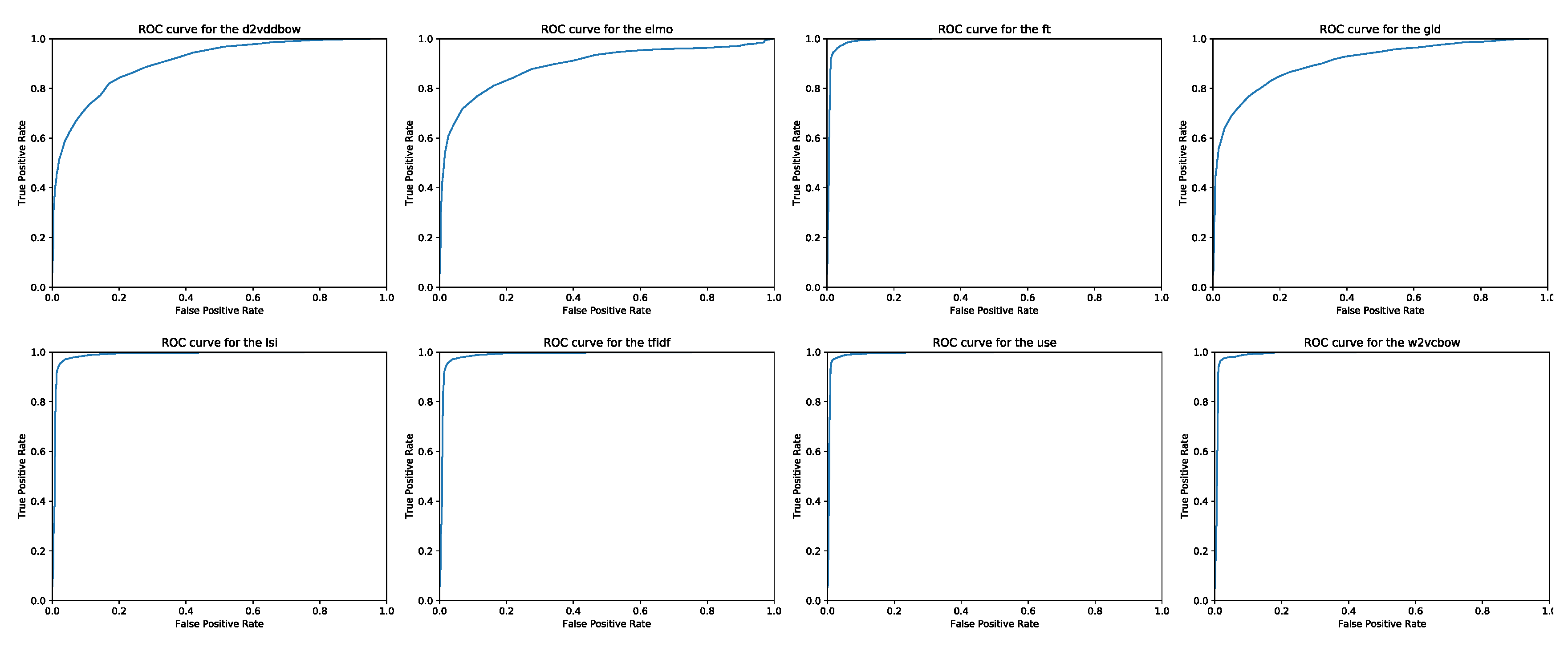
Appendix A. P/R Diagrams and ROC Curves






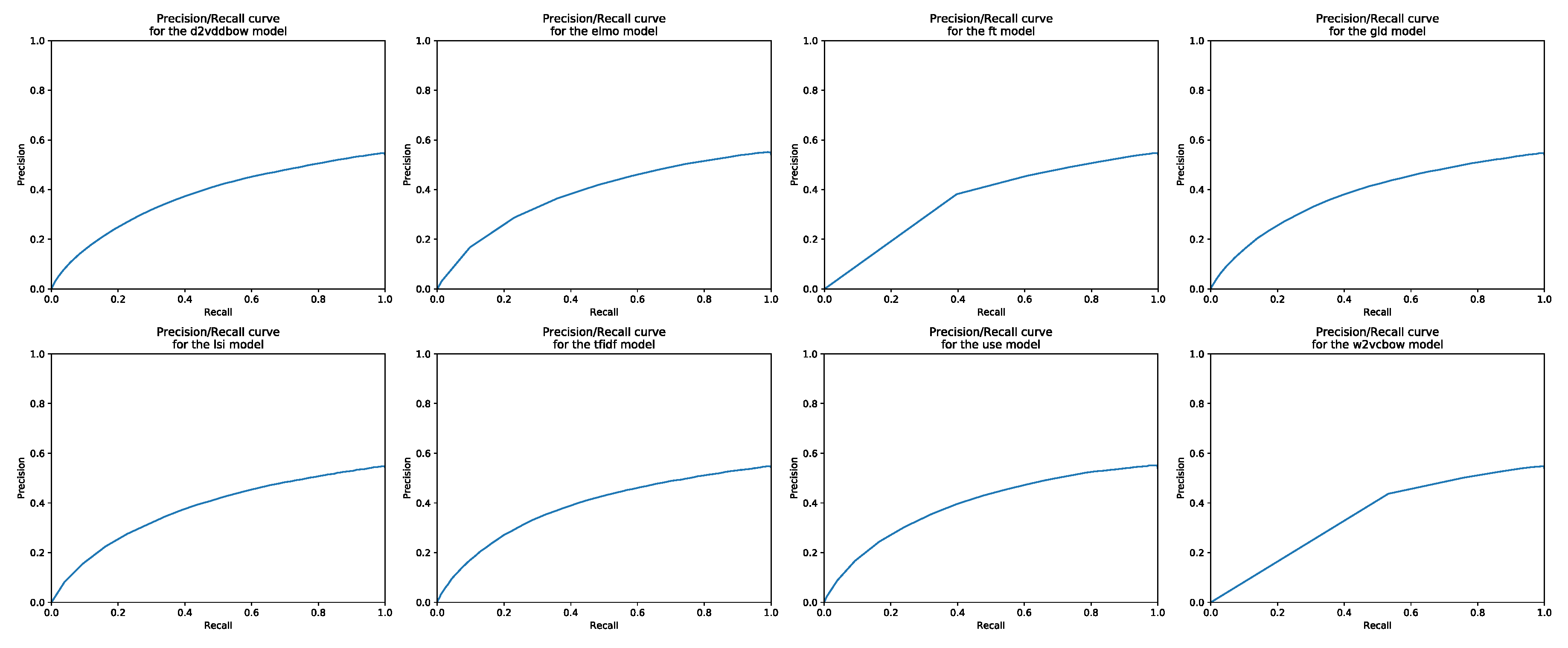
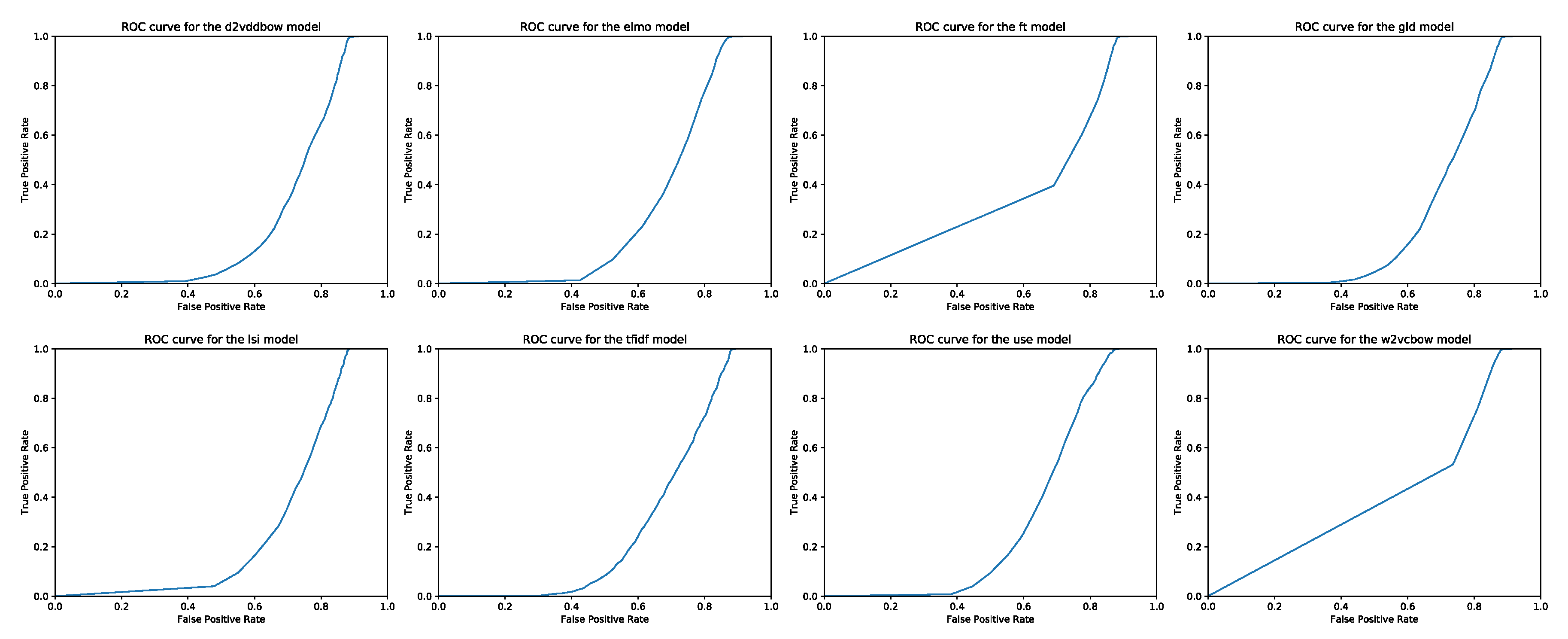
Appendix B. Some Official Annotations for the Initial 25 Pairs of Webis Corpus

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Original | Paraphrased | O.R. |
| 5 | “I have heard many accounts of him,” said Emily, “all differing from each other: I think, however, that the generality of people rather incline to Mrs. Dalton’s opinion than to yours, Lady Margaret.” I can easily believe it. | “I have heard many accounts of him,” said Emily, “all different from each other: I think, however, that the generality of the people rather inclined to the view of Ms Dalton to yours, Lady Margaret”. That I can not believe. | 0 |
| 9 | “Gentle swain, under the king of outlaws,” said he, “the unfortunate Gerismond, who having lost his kingdom, crowneth his thoughts with content, accounting it better to govern among poor men in peace, than great men in danger”. | “gentle swain, under the king of outlaws,” said he, “the fortunate gerismond, who having lost his Kingdom, crowneth his thoughts with the content, accounting it better to govern among poor men in peace, the great men in danger”. | 0 |
| 12 | [Greek: DEMOSTHENOUS O PERI TÊS PARAPRESBEIAS LOGOS.] DEMOSTHENES DE FALSA LEGATIONE. By RICHARD SHILLETO, M.A., Trinity College, Cambridge. Second Edition, carefully revised. Cambridge: JOHN DEIGHTON. London: GEORGE BELL. | [Hellene: DEMOSTHENOUS O PERI TÊS PARAPRESBEIAS LOGOS.] Speechmaker DE FALSA LEGATIONE. By RICHARD SHILLETO, M.A., Divine College, Metropolis. Indorse Edition, carefully revised. Metropolis: Evangel DEIGHTON. Author: Martyr Push. | 0 |
| 13 | [Greek: DEMOSTHENOUS O PERI TÊS PARAPRESBEIAS LOGOS.] DEMOSTHENES DE FALSA LEGATIONE. By RICHARD SHILLETO, M.A., Trinity College, Cambridge. Second Edition, carefully revised. Cambridge: JOHN DEIGHTON. London: GEORGE BELL. | [Greek: DEMOSTHENOUS O PERI TES PARAPRESBEIAS LOGOS.] DEMOSTHENES DE FALSA LEGATIONE. By RICHARD SHILLETO, M.A., Trinity College, Cambridge. Second Edition, carefully revised. Cambridge: JOHN DEIGHTON. London: GEORGE BELL. | 0 |
| 21 | “Thus you’ve heard about the new silk?” said Mrs. Lawton. “To be sure I have,” rejoined Sukey. “Everybody’s talking about it. Do show it to me, Catharine; that’s a dear.” The dress was brought forth from its envelope of white linen. | When Sukey saw the unique white dress, she claimed to have no idea what it was made of “But I told you about the new silk yesterday.” “You really didn’t. I haven’t heard a word about it.” | 1 |
| 25 | I forgot to mention she added a very minute piece of mace, not enough to make its flavour distinguishable; and that the coffee-pot must be of tin, and uncovered, or it cannot form a thick cream on the surface, which it ought to do. | I forgot to name she supplemental a rattling microscopic fix of official, not sufficiency to modify its sort different; and that the coffee-pot moldiness be of tin, and denuded, or it cannot taxon a jellylike elite on the cover, which it ought to do. | 0 |
Appendix C. Some Official Annotations for the Initial 25 Pairs of MSRP Corpus
| # | ID1 | Sentence1 | ID2 | Sentence2 | O.R. |
| 11 | 222621 | Shares of Genentech, a much larger company with several products on the market, rose more than 2 percent. | 222514 | Shares of Xoma fell 16 percent in early trade, while shares of Genentech, a much larger company with several products on the market, were up 2 percent. | 0 |
| 12 | 3131772 | Legislation making it harder for consumers to erase their debts in bankruptcy court won overwhelming House approval in March. | 3131625 | Legislation making it harder for consumers to erase their debts in bankruptcy court won speedy, House approval in March and was endorsed by the White House. | 0 |
| 13 | 58747 | The Nasdaq composite index increased 10.73, or 0.7 percent, to 1,514.77. | 58516 | The Nasdaq Composite index, full of technology stocks, was lately up around 18 points. | 0 |
| 16 | 142746 | Gyorgy Heizler, head of the local disaster unit, said the coach was carrying 38 passengers. | 142671 | The head of the local disaster unit, Gyorgy Heizler, said the coach driver had failed to heed red stop lights. | 0 |
| 17 | 1286053 | Rudder was most recently senior vice president for the Developer and Platform Evangelism Business. | 1286069 | Senior Vice President Eric Rudder, formerly head of the Developer and Platform Evangelism unit, will lead the new entity. | 0 |
| 18 | 1563874 | As well as the dolphin scheme, the chaos has allowed foreign companies to engage in damaging logging and fishing operations without proper monitoring or export controls. | 1563853 | Internal chaos has allowed foreign companies to set up damaging commercial logging and fishing operations without proper monitoring or export controls. | 0 |
| 19 | 2029631 | Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war. | 2029565 | His wife said he was “100 percent behind George Bush” and looked forward to using his years of training in the war. | 0 |
| 21 | 2044342 | “I think you’ll see a lot of job growth in the next two years,” he said, adding the growth could replace jobs lost. | 2044457 | “I think you’ll see a lot of job growth in the next two years,” said Mankiw. | 0 |
| 25 | 1713015 | A BMI of 25 or above is considered overweight; 30 or above is considered obese. | 1712982 | A BMI between 18.5 and 24.9 is considered normal, over 25 is considered overweight and 30 or greater is defined as obese. | 0 |
References
- Agarwal, B.; Ramampiaro, H.; Langseth, H.; Ruocco, M. A Deep Network Model for Paraphrase Detection in Short Text Messages. Inf. Process. Manag. 2017, 54, 922–937. [Google Scholar] [CrossRef]
- Foltýnek, T.; Dlabolová, D.; Anohina-Naumeca, A.; Razı, S.; Kravjar, J.; Kamzola, L.; Guerrero-Dib, J.; Çelik, Ö.; Weber-Wulff, D. Testing of Support Tools for Plagiarism Detection. arXiv 2020, arXiv:2002.04279. [Google Scholar]
- El Mostafa, H.; Benabbou, F. A deep learning based technique for plagiarism detection: A comparative study. IAES Int. J. Artif. Intell. IJ-AI 2020, 9, 81–90. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31th International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. Available online: http://www.jmlr.org/proceedings/papers/v32/le14.pdf (accessed on 22 February 2017).
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Stroudsburg, PA, USA, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 427–431. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers); Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 2227–2237. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-C´espedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Clough, P.; Stevenson, M. Developing a corpus of plagiarised short answers. Lang. Resour. Eval. 2011, 45, 5–24. [Google Scholar] [CrossRef]
- Corley, C.; Csomai, A.; Mihalcea, R. A Knowledge-based Approach to Text-to-Text Similarity. In Recent Advances in Natural Language Processing IV: Selected Papers from RANLP 2005; John Benjamins Publishing: Amsterdam, The Netherlands, 2007; Volume 292, pp. 210–219. [Google Scholar]
- Corley, C.; Mihalcea, R. Measuring the semantic similarity of texts. In Proceedings of the ACL Workshop on Empirical Modeling of Semantic Equivalence and Entailment, Ann Arbor, MI, USA, 30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 13–18. Available online: http://dl.acm.org/citation.cfm?id=1631865 (accessed on 18 December 2016).
- Mihalcea, R.; Corley, C.; Strapparava, C. Corpus-based and knowledge-based measures of text semantic similarity. In Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; pp. 775–780. [Google Scholar]
- Fernando, S.; Stevenson, M. A semantic similarity approach to paraphrase detection. In Proceedings of the 11th Annual Research Colloquium of the UK Special Interest Group for Computational Linguistics; UK Special Interest Group for Computational Linguistics: Hailsham, UK, 2008; pp. 45–52. [Google Scholar]
- Callison-Burch, C. Syntactic Constraints on Paraphrases Extracted from Parallel Corpora. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; Association for Computational Linguistics: Stroudsburg, PA, USA, 2008; pp. 196–205. Available online: https://pdfs.semanticscholar.org/e43b/feb05481d307ec4de5e9a94c9040d940d11b.pdf (accessed on 25 December 2019).
- Chong, M.; Specia, L.; Mitkov, R. Using natural language processing for automatic detection of plagiarism. In Proceedings of the 4th International Plagiarism Conference (IPC 2010), Newcastle, UK, 21–23 June 2010; Citeseer: State College, PA, USA, 2010. Available online: https://pdfs.semanticscholar.org/636d/4c0b0fe6919abe6eb546907d28ed39bf56e6.pdf (accessed on 24 October 2015).
- Socher, R.; Huang, E.H.; Pennington, J.; Ng, A.Y.; Manning, C.D. Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2011; pp. 801–809. Available online: http://papers.nips.cc/paper/4204-dynamic-pooling-and-unfolding-recursive-autoencoders-for-paraphrase-detection.pdf (accessed on 26 December 2019).
- Šarić, F.; Glavaš, G.; Karan, M.; Šnajder, J.; Bašić, B.D. Takelab: Systems for Measuring Semantic Text Similarity. In Proceedings of the First Joint Conference on Lexical and Computational Semantics (*SEM), Montréal, QC, Canada, 7–8 June 2012; pp. 441–448. Available online: http://dl.acm.org/citation.cfm?id=2387708 (accessed on 1 November 2015).
- Chong, M.Y.M. A Study on Plagiarism Detection and Plagiarism Direction Identification Using Natural Language Processing Techniques; University of Wolverhampton: Wolverhampton, UK, 2013; Available online: http://wlv.openrepository.com/wlv/handle/2436/298219 (accessed on 27 April 2016).
- Mikolov, T.; Kombrink, S.; Deoras, A.; Burget, L.; Černocký, J. RNNLM—Recurrent Neural Network Language Modeling Toolkit. In Proceedings of the ASRU 2011, Waikoloa, HI, USA, 11–15 December 2011; pp. 1–4. [Google Scholar]
- Banea, C.; Chen, D.; Mihalcea, R.; Cardie, C.; Wiebe, J. Simcompass: Using deep learning word embeddings to assess cross-level similarity. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin, Ireland, 23–24 August 2014; pp. 560–565. Available online: http://www.aclweb.org/old_anthology/S/S14/S14-2.pdf#page=580 (accessed on 23 February 2017).
- Socher, R. Recursive Deep Learning for Natural Language Processing and Computer Vision; Stanford University: Stanford, CA, USA, 2014; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.646.5649&rep=rep1&type=pdf (accessed on 23 February 2017).
- Kong, L.; Lu, Z.; Qi, H.; Han, Z. Detecting High Obfuscation Plagiarism: Exploring Multi-Features Fusion via Machine Learning. Int. J. e-Serv. Sci. Technol. 2014, 7, 385–396. Available online: https://pdfs.semanticscholar.org/54ee/30ba7a1c86d66d0670c8be8cf16cce562850.pdf (accessed on 28 February 2017). [CrossRef][Green Version]
- Gipp, B. Citation-based Plagiarism Detection—Detecting Disguised and Cross-language Plagiarism using Citation Pattern Analysis; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2014; pp. 1–350. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882v2. [Google Scholar]
- Yin, W.; Schütze, H. Convolutional neural network for paraphrase identification. In Proceedings of the NAACL HLT 2015—2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 901–911. [Google Scholar] [CrossRef]
- Gharavi, E.; Bijari, K.; Zahirnia, K.; Veisi, H. A Deep Learning Approach to Persian Plagiarism Detection. In Proceedings of the FIRE 2016—Forum for Information Retrieval Evaluation, Kolkata, India, 7–10 December 2016; Available online: https://pdfs.semanticscholar.org/b0a8/7335289264368a7ee804acc7715fc4799310.pdf (accessed on 19 February 2017).
- Thompson, V.; Bowerman, C. Methods for Detecting Paraphrase Plagiarism. arXiv 2017, arXiv:1712.10309. [Google Scholar]
- Zhou, J.; Liu, G.; Sun, H. Paraphrase Identification Based on Weighted URAE, Unit Similarity and Context Correlation Feature. In Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2018; pp. 41–53. [Google Scholar] [CrossRef]
- Li, Z.; Jiang, X.; Shang, L.; Li, H. Paraphrase Generation with Deep Reinforcement Learning; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2018; pp. 3865–3878. [Google Scholar] [CrossRef]
- Wu, W.; Wang, H.; Liu, T.; Ma, S.; Key, M. Phrase-level Self-Attention Networks for Universal Sentence Encoding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3729–3738. Available online: https://www.aclweb.org/anthology/D18-1408.pdf (accessed on 8 March 2020).
- Zablocki, E.; Piwowarski, B.; Soulier, L.; Gallinari, P. Learning multi-modal word representation grounded in visual context. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning, New Orleans, LA, USA, 2–7 February 2018; Available online: https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/viewPaper/16113 (accessed on 8 March 2020).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. Advances in neural information processing systems. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- El Desouki, M.I.; Gomaa, W.H.; Abdalhakim, H. A Hybrid Model for Paraphrase Detection Combines pros of Text Similarity with Deep Learning. Int. J. Comput. Appl. 2019, 178, 18–23. [Google Scholar] [CrossRef]
- Gomaa, W.H.; Fahmy, A.A. SimAll: A flexible tool for text similarity. In Proceedings of the Seventeenth Conference On Language Engineering ESOLEC, Cairo, Egypt, 6–7 December 2017; pp. 122–127. [Google Scholar]
- Ahmed, M.; Samee, M.R.; Mercer, R.E. Improving Tree-LSTM with Tree Attention. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; Available online: https://ieeexplore.ieee.org/abstract/document/8665673/ (accessed on 8 March 2020).
- Tenney, I.; Xia, P.; Chen, B.; Wang, A.; Poliak, A.; Thomas McCoy, R.; Kim, N.; Van Durme, B.; Bowman, S.R.; Das, D.; et al. What do you learn from context? Probing for sentence structure in contextualized word representations. arXiv 2019, arXiv:1905.06316. [Google Scholar]
- Shuang, K.; Zhang, Z.; Loo, J.; Su, S. Convolution–deconvolution word embedding: An end-to-end multi-prototype fusion embedding method for natural language processing. In Information Fusion; Elsevier, B.V.: Amsterdam, The Netherlands, 2020; Volume 53, pp. 112–122. [Google Scholar] [CrossRef]
- Harispe, S.; Sánchez, D.; Ranwez, S.; Janaqi, S.; Montmain, J. A framework for unifying ontology-based semantic similarity measures: A study in the biomedical domain. J. Biomed. Inform. 2014, 48, 38–53. [Google Scholar] [CrossRef] [PubMed]
- Magnolini, S. A Survey on Paraphrase Recognition; DWAI@AI*IA: Pisa, Italy, 2014. [Google Scholar]
- El Desouki, M.I.; Gomaa, W.H. Exploring the Recent Trends of Paraphrase Detection. Int. J. Comput. Appl. Found. Comput. Sci. 2019, 182, 1–5. [Google Scholar] [CrossRef]
- Croft, W.B.; Metzler, D.; Strohmann, T. Search Engines: Information Retrieval in Practice; Pearson Education: London, UK, 2010; 518p, Available online: http://ciir.cs.umass.edu/downloads/SEIRiP.pdf (accessed on 3 July 2015).
- Sahami, M.; Heilman, T.D. A Web-based Kernel Function for Measuring the Similarity of Short Text Snippets. In Proceedings of the 15th International Conference on World Wide Web, Edinburgh, UK, 23–26 May 2006; Available online: http://www.google.com/apis (accessed on 12 January 2020).
- Nawab, R.M.A.; Stevenson, M.; Clough, P. Retrieving Candidate Plagiarised Documents Using Query Expansion. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Heidelberg, Germany, 2012; pp. 207–218. [Google Scholar] [CrossRef]
- Ruder, S.; Vulić, I.; Søgaard, A. A Survey of Cross-lingual Word Embedding Models. J. Artif. Intell. Res. 2017, 65, 569–631. [Google Scholar] [CrossRef]
- Lin, C.; On, F.O. Orange: A method for evaluating automatic evaluation metrics for machine translation. In Proceedings of the 20th International Conference on Computational Linguistics, La Rochelle, France, 7–13 April 2019; Available online: https://dl.acm.org/citation.cfm?id=1220427 (accessed on 12 January 2020).
- Landauer, T.K.; Laham, D.; Derr, M. From paragraph to graph: Latent semantic analysis for information visualization. Proc. Natl. Acad. Sci. USA 2004, 101, 5214–5219. [Google Scholar] [CrossRef]
- Neverova, N.; Wolf, C.; Taylor, G.W.; Nebout, F. Multi-scale deep learning for gesture detection and localization. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2015; pp. 474–490. [Google Scholar] [CrossRef]
- Deng, L.; Hinton, G.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8599–8603. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. Available online: http://wordnet.princeton.edu (accessed on 4 November 2019).
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.-S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. Available online: http://dl.acm.org/citation.cfm?id=361220 (accessed on 9 June 2016). [CrossRef]
- Turney, P.D.; Pantel, P. From Frequency to Meaning: Vector Space Models of Semantics. J. Artif. Intell. Res. 2010, 37, 141–188. [Google Scholar] [CrossRef]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Comput. Res. Repos. 2016. [Google Scholar] [CrossRef]
- Clough, P.; Stevenson, M. Creating a Corpus of Plagiarised Academic Texts. In Proceedings of the Corpus Linguistics Conference, Liverpool, UK, 20–23 July 2009. [Google Scholar]
- Dolan, B.; Quirk, C.; Brockett, C. Unsupervised construction of large paraphrase corpora. In Proceedings of the 20th International Conference on Computational Linguistics—COLING ’04, Geneva, Switzerland, 23−27 August 2004; Association for Computational Linguistics: Stroudsburg, PA, USA, 2004; p. 350-es. [Google Scholar] [CrossRef]
- Burrows, S.; Potthast, M.; Stein, B. Paraphrase acquisition via crowdsourcing and machine learning. ACM Trans. Intell. Syst. Technol. 2013, 4, 1. [Google Scholar] [CrossRef]
- Burrows, S.; Potthast, M.; Stein, B.; Eiselt, A. Webis Crowd Paraphrase Corpus 2011 (Webis-CPC-11). Zenodo 2013. [Google Scholar] [CrossRef]
- Islam, A.; Inkpen, D. Semantic similarity of short texts. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP, Borovets, Bulgaria, 27–29 September 2007; pp. 291–297. [Google Scholar] [CrossRef]
- Rus, V.; Mccarthy, P.M.; Lintean, M.C.; Mcnamara, D.S.; Graesser, A.C. Paraphrase Identification with Lexico-Syntactic Graph Subsumption. FLAIRS Conference; Association for the Advancement of Artificial Intelligence: Menlo Park, CA, USA, 2008; pp. 201–206. Available online: www.aaai.org (accessed on 24 January 2020).
- Hassan, S. Measuring Semantic Relatedness Using Salient Encyclopedic Concepts; University of North Texas: Denton, TX, USA, 2011; Available online: http://search.proquest.com/pqdtglobal/docview/1011651248/abstract/B23136BDFD3F4ADAPQ/7 (accessed on 3 July 2016).
- Milajevs, D.; Kartsaklis, D.; Sadrzadeh, M.; Purver, M. Evaluating Neural Word Representations in Tensor-Based Compositional Settings. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 708–719. [Google Scholar] [CrossRef]
- Cheng, J.; Kartsaklis, D. Syntax-aware multi-sense word embeddings for deep compositional models of meaning. In Conference Proceedings—EMNLP 2015: Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics (ACL): Lisbon, Portugal, 2015; pp. 1531–1542. [Google Scholar] [CrossRef]
- He, H.; Gimpel, K.; Lin, J. Multi-perspective sentence similarity modeling with convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015), Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 1576–1586. [Google Scholar] [CrossRef]
- Madnani, N.; Tetreault, J.; Chodorow, M. Re-examining machine translation metrics for paraphrase identification. In Proceedings of the NAACL HLT 2012—2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Montreal, QC, Canada, 8 June 2012; pp. 182–190. [Google Scholar]







| Property | C&S | MSRP | Webis-CPC-11 |
|---|---|---|---|
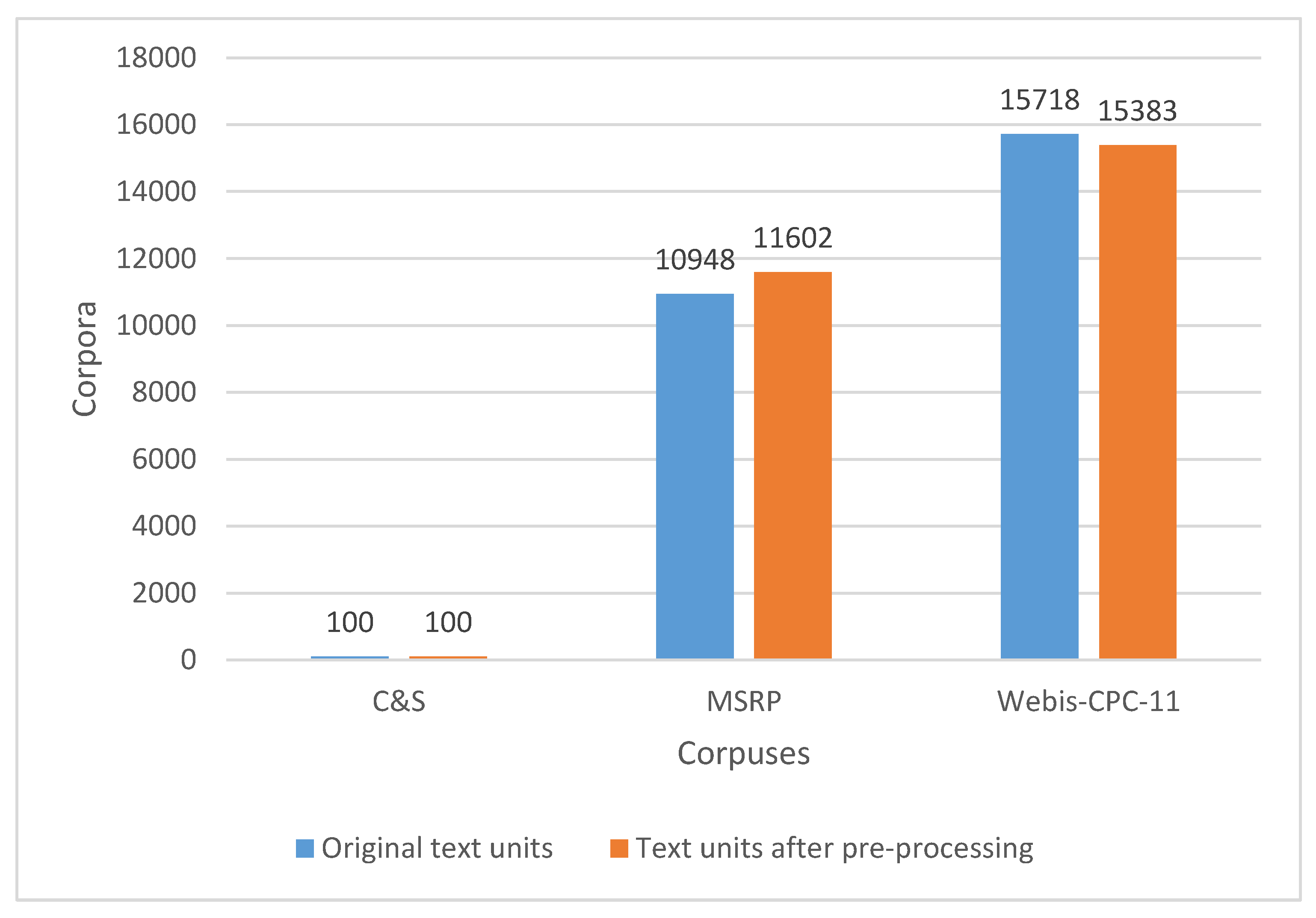
| Original text units | 100 | 10,948 | 15,718 |
| Text units after preprocessing | 100 | 11,602 | 15,383 (not empty) |
| Type of text units | Small text | Pairs of small texts | Pairs of small texts |
| Similarity marks | 4 levels | 0/1 | 0/1 |
| Source of judgement | Predefined | Three judges | Crowdsourcing |
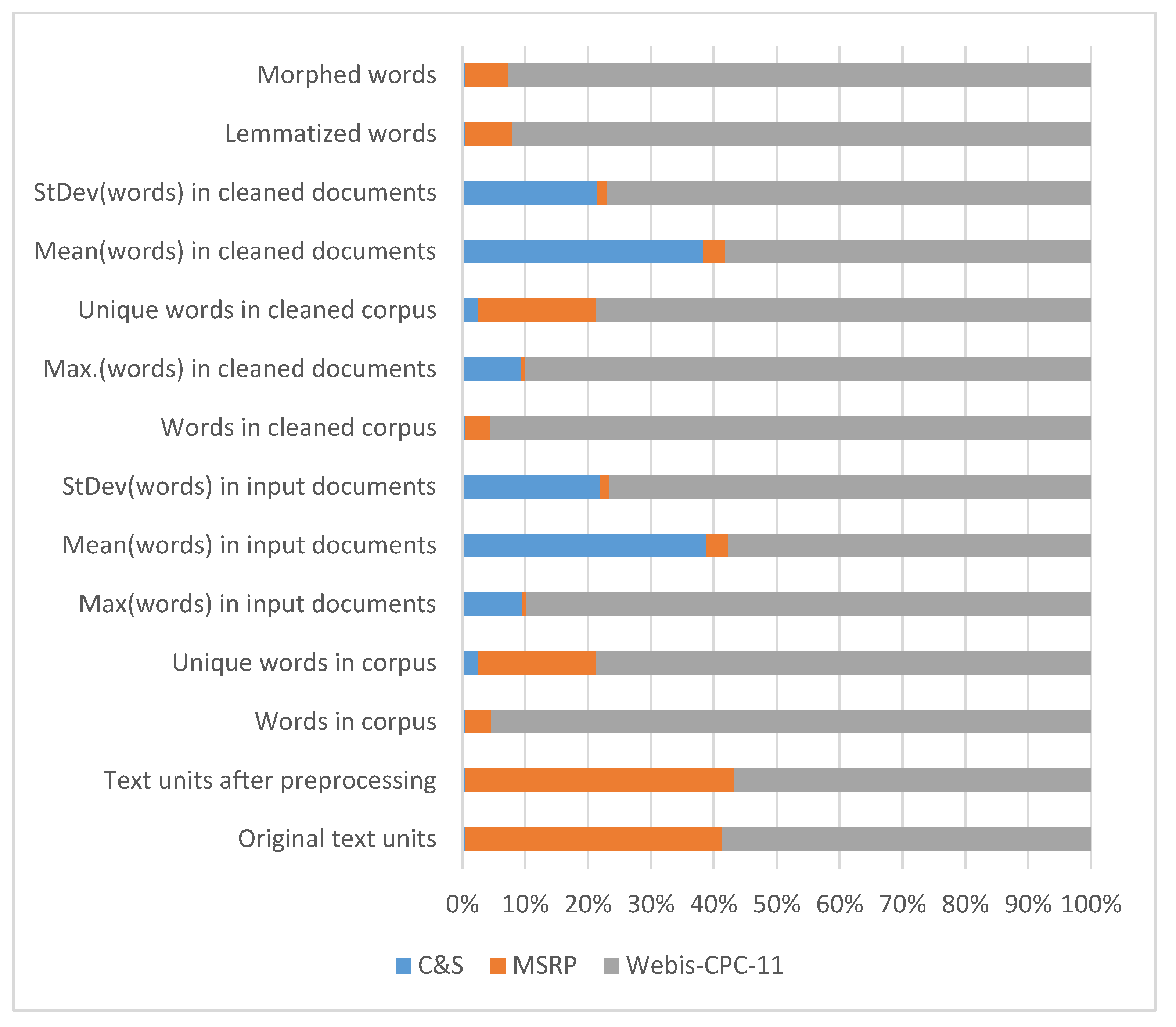
| Words in corpus | 21,555 | 212,690 | 4,930,050 |
| Unique words in corpus | 2119 | 15,851 | 66,412 |
| Max(words) in input documents | 532 | 34 | 4993 |
| Mean(words) in input documents | 215.55 | 19.43 | 320.49 |
| StDev(words) in input documents | 77.82 | 5.26 | 272.76 |
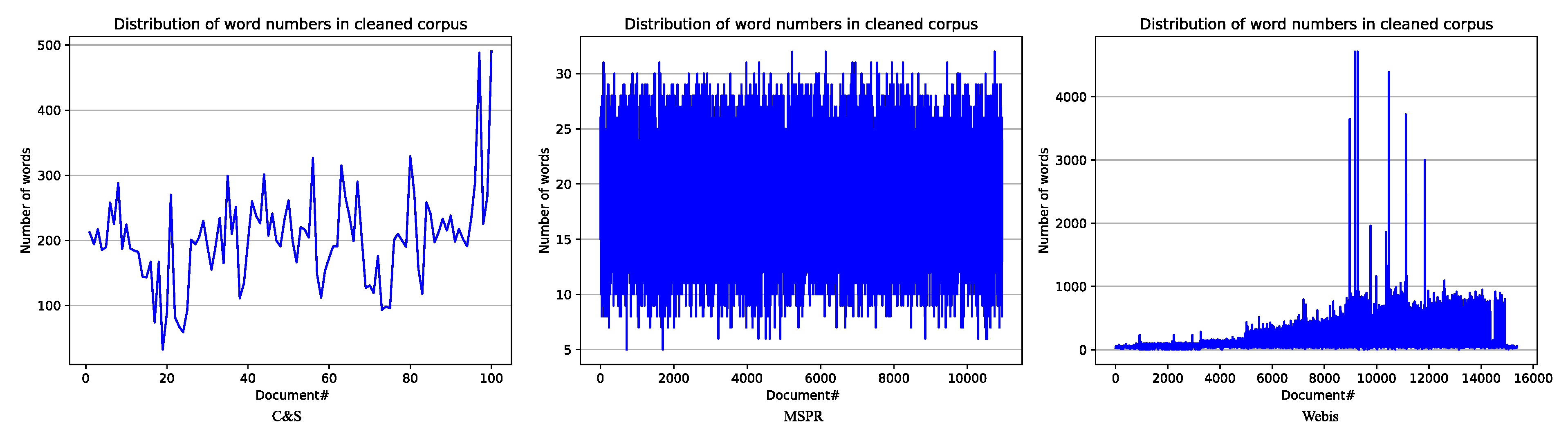
| Words in cleaned corpus | 20,167 | 202,063 | 4,711,213 |
| Max.(words) in cleaned documents | 490 | 32 | 4715 |
| Unique words in cleaned corpus | 1669 | 12,808 | 53,325 |
| Mean(words) in cleaned documents | 201.67 | 18.46 | 306.26 |
| StDev(words) in cleaned documents | 72.67 | 5.02 | 260.51 |
| Lemmatized words | 2404 | 37,491 | 465,592 |
| Morphed words | 2140 | 39,409 | 528,692 |
| Technique | Variants|Comments |
|---|---|
| Parsing | Necessary |
| Transcoding | UTF-8 |
| Tokenization | Numbers and stop words replaced with token |
| Phrasing (bigrams) | Yes/No |
| Part-of-speech tagging | ‘NN’, ‘NNS’, ‘NNP’, ‘NNPS’, ‘VB’, ‘VBD’, ‘VBG’, ‘VBN’, ‘VBP’, ‘VBZ’, ‘JJ’, ‘JJR’, ‘JJS’, ‘RB’, ‘RBR’, ‘RBS’/Not used |
| Conversion | Delete/replace/keep |
| WordNet Lemmatization | Yes/No |
| WordNet Morphing | Yes/No |
| Stemming | Snowball/Porter/Porter2/None |
| WordNet Hyper/Holonym | Hypernym/Holonym/None |
| Model | Threshold | Accuracy | Precision | Recall | F1 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CS | MS | W | CS | MS | W | CS | MS | W | CS | MS | W | CS | MS | W | |
| USE | 0.73 | 0.72 | 0.61 | 0.988 | 0.673 | 0.577 | 0.965 | 0.675 | 0.551 | 0.974 | 0.965 | 0.995 | 0.968 | 0.794 | 0.709 |
| TF-IDF | 0.1 | 0.37 | 0.07 | 0.981 | 0.706 | 0.573 | 0.941 | 0.697 | 0.548 | 0.965 | 0.976 | 0.994 | 0.951 | 0.813 | 0.707 |
| Doc2Vec2 | 0.7 | 0.39 | 0.48 | 0.908 | 0.655 | 0.569 | 0.862 | 0.655 | 0.546 | 0.634 | 1.0 | 0.994 | 0.726 | 0.792 | 0.705 |
| Glove-D | 0.74 | 0.42 | 0.47 | 0.856 | 0.657 | 0.569 | 0.619 | 0.657 | 0.545 | 0.722 | 0.998 | 0.999 | 0.662 | 0.792 | 0.706 |
| LSI-LSA | 0.42 | 0.54 | 0.29 | 0.899 | 0.679 | 0.572 | 0.973 | 0.673 | 0.548 | 0.497 | 0.99 | 0.995 | 0.654 | 0.802 | 0.707 |
| Word2Vec1 | 0.63 | 0.83 | 0.9 | 0.721 | 0.69 | 0.572 | 0.412 | 0.687 | 0.548 | 1.0 | 0.966 | 0.996 | 0.582 | 0.803 | 0.707 |
| ELMO | 0.77 | 0.48 | 0.77 | 0.561 | 0.655 | 0.577 | 0.317 | 0.655 | 0.55 | 0.965 | 1.0 | 0.996 | 0.472 | 0.792 | 0.709 |
| FastText | 0.33 | 0.79 | 0.86 | 0.194 | 0.676 | 0.572 | 0.194 | 0.671 | 0.547 | 1.0 | 0.991 | 0.994 | 0.325 | 0.800 | 0.706 |
| ID | Corpus | Base | Approach | Thr | F (%) | |
|---|---|---|---|---|---|---|
| [12] (2005) | MSRP | Words | 6K | 0.5 | 81.2 | |
| [13] (2006) | MSRP | Words | 2C, 6K | 0.5 | 81.3 | |
| [62] (2007) | MSRP | Sentence, Paragraph | 1C | 1K | 0.6 | 81.3 |
| [14] (2008) | MSRP | Words | 6K | 0.8 | 82.4 | |
| [63] (2008) | MSRP (balanced) | Words, Phrase, Text | lexicon-syntactic | NS | 68 | |
| [17] (2011) | Gigaword (t), MSRP (e) | Words, Phrases | 1C | 0.5 | 83.6 | |
| [64] (2011) | Wikipedia (t) | Text, Concepts | 1C, 1K | 0.65-0.95 | 81.4 | |
| [19] (2013) | PAN-PC-10 | 5-g Words | 4C, 1K | 0.03 | 68.74 | |
| [19] (2013) | PAN-PC-10 | 5-g Words | 6C | NSF | 81.1 | |
| [19] (2013) | PAN-PC-10 | Paragraph | 6C | NSF | 99.2 (c), 92.6 (p) | |
| [19] (2013) | C&S | 3-g Words | 7C | NSF | 96.2 (c), 97.3 (p) | |
| [65] (2014) | MSRP | Sentence | 4C | 1K | NSF | 82 |
| [66] (2015) | MSRP, BNC | Words, Sentences | 2C, 1K | NSF | 85.3 | |
| [67] (2015) | MSRP | n-gram Words | 1C, 2K | NSF | 84.73 | |
| [1] (2017) | MSRP | Words, Sentences | 4C, 3K | NSF | 84.5 | |
| [28] (2017) | Webis | Paragraph | 3C | NSF | 86.5 | |
| [28] (2017) | C&S | Paragraph | 3C | NSF | 89.7 | |
| [1] (2017) | SemEval 2015 Twitter | Words, Sentences | 4C, 3K | NSF | 75.1 | |
| [31] (2018) | MSRP | Phrases | 5C | SNLI | 82.3 | |
| [35] (2019) | MSRP, BookCorpus | Sentences | 20C | NSF | 83.5 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vrbanec, T.; Meštrović, A. Corpus-Based Paraphrase Detection Experiments and Review. Information 2020, 11, 241. https://doi.org/10.3390/info11050241
Vrbanec T, Meštrović A. Corpus-Based Paraphrase Detection Experiments and Review. Information. 2020; 11(5):241. https://doi.org/10.3390/info11050241
Chicago/Turabian StyleVrbanec, Tedo, and Ana Meštrović. 2020. "Corpus-Based Paraphrase Detection Experiments and Review" Information 11, no. 5: 241. https://doi.org/10.3390/info11050241
APA StyleVrbanec, T., & Meštrović, A. (2020). Corpus-Based Paraphrase Detection Experiments and Review. Information, 11(5), 241. https://doi.org/10.3390/info11050241