Image Aesthetic Assessment Based on Latent Semantic Features


Abstract
1. Introduction
- (1)
- The superpixel block algorithm that is based on the weighted density of POI is designed to extract local handcraft features of the image. The spatial information loss and the feature dimension are both dramatically reduced, due to introducing spatial attributes. Additionally, the density of POI measures the complexity of local areas. It increases the relationship between image features and aesthetic complexity attributes.
- (2)
- The aesthetic features are coded by visual word and then mapped into multiple semantic documents. Additionally, the indescribable aesthetic information is mined through the feature documents. The combination of invisible latent semantic features and visible semantic features greatly improves the classification effect of image aesthetics.
2. Related Work
2.1. Feature-Based Approach
2.2. Methods Based on Color Distribution
3. Method Formulation
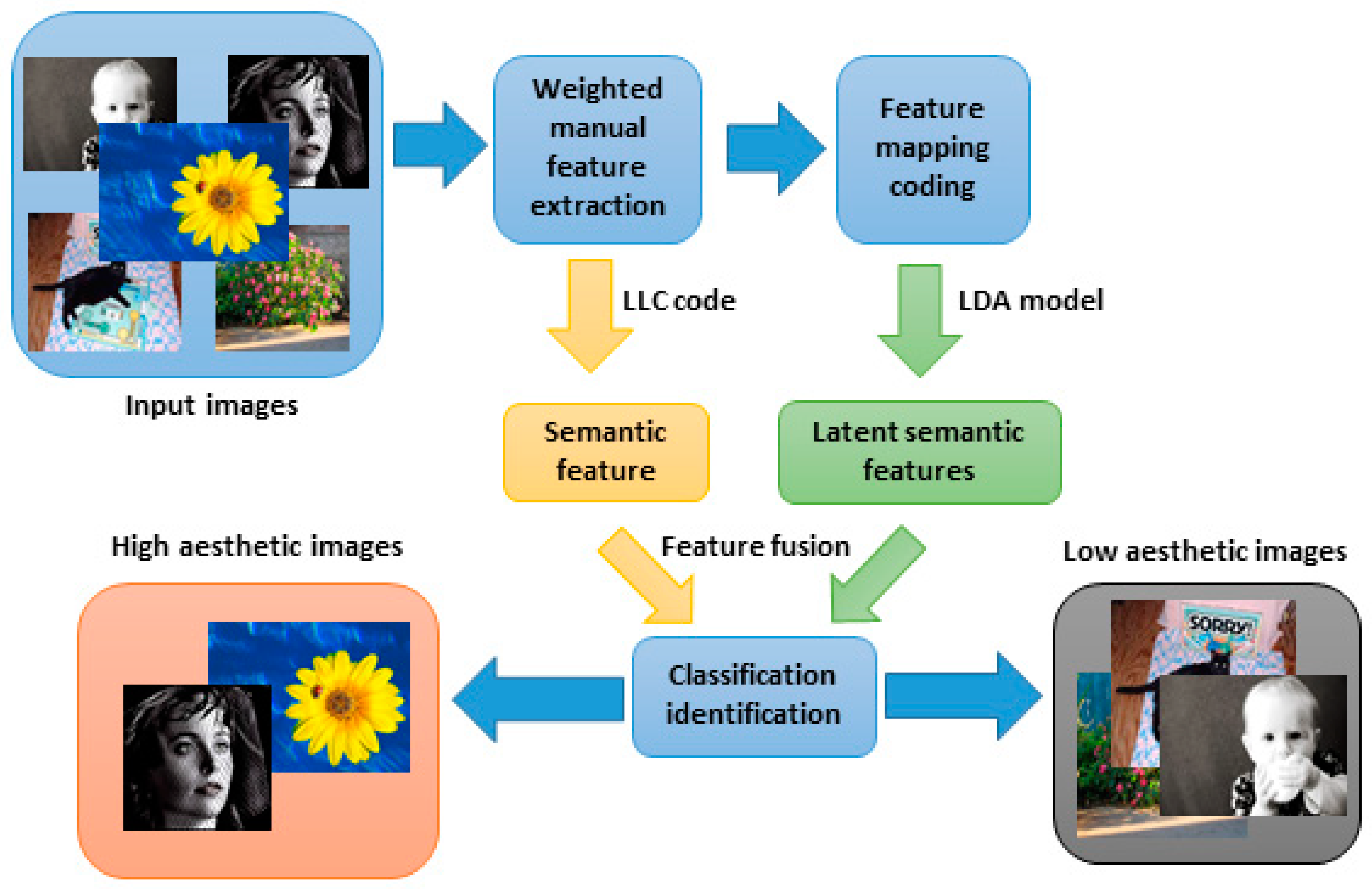
3.1. Image Aesthetic Assessment Framework Based on Latent Semantic Features
3.2. Feature Extraction
3.2.1. Superpixel Segmentation Based on Density Weighted POI
3.2.2. Superpixel Block Centroid Feature Descriptor
3.2.3. The Color Texture Feature Descriptor
3.3. Feature Mapping Coding
3.3.1. Semantic Features
3.3.2. Feature Mapping Coding
3.3.3. Latent Semantic Features
3.3.4. Assessment Model
4. Experiment Database Settings
4.1. Feature Extraction
4.2. Experimental Steps
4.3. Parameter Analysis
4.4. System Analysis and Comparison
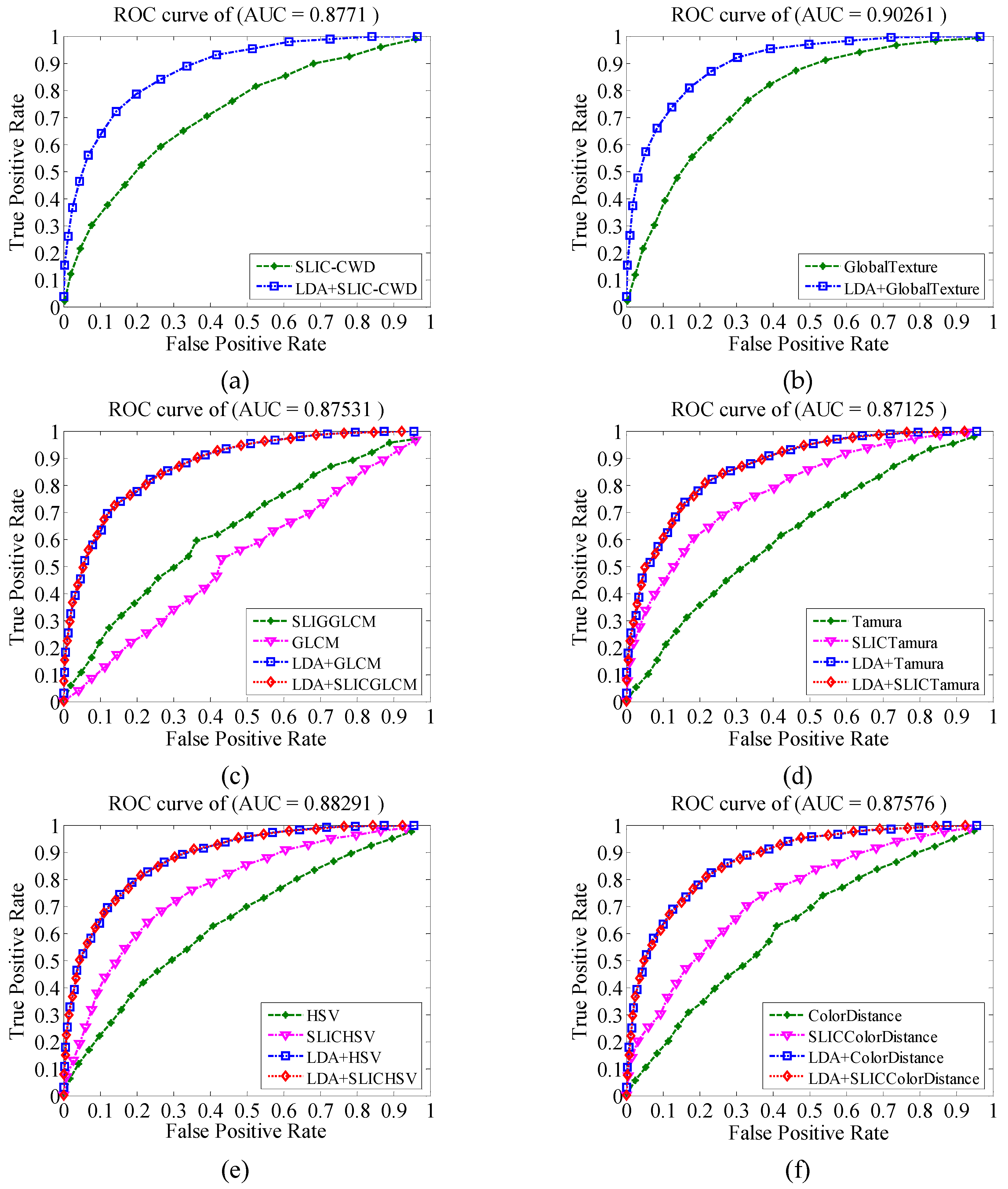
4.4.1. System Output Analysis
4.4.2. Compared with Other Aesthetic Classification Models
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zha, Z.; Yang, L.; Mei, T. Visual query suggestion: Towards capturing user intent in internet image search. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2010, 6, 1–19. [Google Scholar] [CrossRef]
- Obrador, P.; Oliveira, R.; Oliver, N. Supporting personal photo storytelling for social albums. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 561–570. [Google Scholar]
- Wang, W.; Cai, D.; Wang, L. Synthesized computational aesthetic evaluation of photos. Neurocomputing 2016, 172, 244–252. [Google Scholar] [CrossRef]
- Lu, P.; Peng, X.; Zhu, X. An EL-LDA based general color harmony model for photo aesthetics assessment. Signal Process. 2016, 120, 731–745. [Google Scholar] [CrossRef]
- Guo, L.; Xiong, Y.; Huang, Q. Image esthetic assessment using both hand-crafting and semantic features. Neurocomputing 2014, 143, 14–26. [Google Scholar] [CrossRef]
- Dong, Z.; Tian, X. Multi-level photo quality assessment with multi-view features. Neurocomputing 2015, 168, 308–319. [Google Scholar] [CrossRef]
- Zhang, L.; Gao, Y.; Zimmermann, R. Fusion of multichannel local and global structural cues for photo aesthetics evaluation. IEEE Trans. Image Process. 2014, 23, 1419–1429. [Google Scholar] [CrossRef]
- Aydın, T.O.; Smolic, A.; Gross, M. Automated aesthetic analysis of photographic images. IEEE Trans. Vis. Comput. Graph. 2015, 21, 31–42. [Google Scholar] [CrossRef]
- Liu, C.; Chen, L.C.; Schroff, F. Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation. arXiv 2019, arXiv:1901.02985. [Google Scholar]
- Kim, C.; Shin, D.; Yang, C.N. Self-embedding fragile watermarking scheme to restoration of a tampered image using AMBTC. Pers. Ubiquitous Comput. 2018, 22, 11–22. [Google Scholar] [CrossRef]
- Kligvasser, I.; Rott Shaham, T.; Michaeli, T. xUnit: Learning a spatial activation function for efficient image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 2433–2442. [Google Scholar]
- More, V.; Agrawal, P. Study on Aesthetic Analysis of Photographic Images Techniques to Produce High Dynamic Range Images. Int. J. Comput. Appl. 2017, 159, 34–38. [Google Scholar] [CrossRef]
- Setchi, R.; Asikhia, O.K. Exploring User Experience with Image Schemas, Sentiments, and Semantics. IEEE Trans Affect. Comput. 2019, 10, 182–195. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Murray, N.; Marchesotti, L.; Perronnin, F. AVA: A large-scale database for aesthetic visual analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2408–2415. [Google Scholar]
- Luo, W.; Wang, X.; Tang, X. Content-based photo quality assessment. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2206–2213. [Google Scholar]
- Dhar, S.; Ordonez, V.; Berg, T.L. High level describable attributes for predicting aesthetics and interestingness. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Colorado Springs, CO, USA, 21–23 June 2011; pp. 1657–1664. [Google Scholar]
- Moon, P.; Spencer, D.E. Geometric formulation of classical color harmony. JOSA 1944, 34, 46–59. [Google Scholar] [CrossRef]
- Zhang, T.; Yu, M.; Guo, Y. Content-Aware Retargeted Image Quality Assessment. Information 2019, 10, 111. [Google Scholar] [CrossRef]
- Datta, R.; Joshi, D.; Li, J. Studying aesthetics in photographic images using a computational approach. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 288–301. [Google Scholar]
- Obrador, P.; Schmidt-Hackenberg, L.; Oliver, N. The role of image composition in image aesthetics. In Proceedings of the IEEE International Conference on Image Processing(ICIP), Hong Kong, China, 12–15 September 2010; pp. 3185–3188. [Google Scholar]
- Liu, Z.; Wang, Z.; Yao, Y. Deep active learning with contaminated tags for image aesthetics assessment. IEEE Trans. Image Process. 2018, 1. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, X.; Lu, W. A Gated Peripheral-Foveal Convolutional Neural Network for Unified Image Aesthetic Prediction. IEEE Trans. Multimed. 2019, 21, 2815–2826. [Google Scholar] [CrossRef]
- Nishiyama, M.; Okabe, T.; Sato, I. Aesthetic quality classification of photographs based on color harmony. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Colorado Springs, CO, USA, 21–23 June 2011; pp. 33–40. [Google Scholar]
- Marchesotti, L.; Perronnin, F.; Larlus, D. Assessing the aesthetic quality of photographs using generic image descriptors. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1784–1791. [Google Scholar]
- Vedaldi, A.; Fulkerson, B. VLFeat: An open and portable library of computer vision algorithms. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1469–1472. [Google Scholar]
- Wang, J.; Yang, J.; Yu, K. Locality-constrained linear coding for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Gandhi, A.; Alahari, K.; Jawahar, C.V. Decomposing bag of words histograms. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Sydney, Australia, 3–6 December 2013; pp. 305–312. [Google Scholar]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. Turbopixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 31, 2290–2297. [Google Scholar] [CrossRef]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef]
- Gaetano, R.; Masi, G.; Poggi, G.; Verdoliva, L.; Scarpa, G. Marker-controlled watershed-based segmentation of multiresolution remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2014, 53, 2987–3004. [Google Scholar] [CrossRef]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed cuts: Thinnings, shortest path forests, and topological watersheds. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 925–939. [Google Scholar] [CrossRef]
- Ciecholewski, M.; Spodnik, J.H. Semi–automatic corpus callosum segmentation and 3d visualization using active contour methods. Symmetry 2018, 10, 589. [Google Scholar] [CrossRef]
- Zhang, X.; Xiong, B.; Dong, G.; Kuang, G. Ship segmentation in SAR images by improved nonlocal active contour model. Sensors 2018, 18, 4220. [Google Scholar] [CrossRef] [PubMed]
- Achanta, R.; Shaji, A.; Smith, K. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Nazir, A.; Ashraf, R.; Hamdani, T. Content based image retrieval system by using HSV color histogram, discrete wavelet transform and edge histogram descriptor. In Proceedings of the IEEE International Conference on Computing, Mathematics and Engineering Technologies, Sukkur, Pakistan, 3–4 March 2018; pp. 1–6. [Google Scholar]
- Deselaers, T.; Keysers, D.; Ney, H. Features for image retrieval: An experimental comparison. Inf. Retr. 2008, 11, 77–107. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Mentzer, F.; Agustsson, E.; Tschannen, M. Conditional probability models for deep image compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 19–21 June 2018; pp. 4394–4402. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Feature Space (GMM) | Feature Space (SVM) | ||||
|---|---|---|---|---|---|---|
| LDA | LLC (Descriptors) | SLIC (Local) | LDA | LLC (Descriptors) | SLIC (Local) | |
| SLIC-count | 300 | 300 | 300 | 300 | 300 | 300 |
| Codebook-K | 1024 | 1024 | 1024 | 1024 | 1024 | 1024 |
| Topic-K | 256 | N/A | N/A | 256 | N/A | N/A |
| Topic size | 64 | N/A | N/A | 64 | N/A | N/A |
| Kernel-N | 8 | 8 | 8 | N/A | N/A | N/A |
| Kernel Number | LDA Feature Space (GMM) | ||||
|---|---|---|---|---|---|
| 128-64 | 256-64 | 256-128 | 512-64 | 512-128 | |
| 4 | 0.6522 | 0.5074 | 0.5688 | 0.5323 | 0.6454 |
| 8 | 0.6807 | 0.6907 | 0.6338 | 0.5969 | 0.6805 |
| 16 | 0.6366 | 0.6009 | 0.5864 | 0.5227 | 0.6402 |
| 32 | 0.6221 | 0.6374 | 0.6783 | 0.5351 | 0.5949 |
| 64 | 0.6322 | 0.5022 | 0.6506 | 0.5748 | 0.5608 |
| SLIC-Count | SLIC Feature Space (SVM-RBF) | |||||
|---|---|---|---|---|---|---|
| ColorDistance | HSV | LBP | Gabor | Tamura | SLIC-CWD | |
| 100 | 0.6338 | 0.6919 | 0.7525 | 0.7284 | 0.6450 | 0.6346 |
| 200 | 0.6478 | 0.7012 | 0.7834 | 0.7521 | 0.6623 | 0.6739 |
| 300 | 0.6590 | 0.6992 | 0.7838 | 0.7525 | 0.6839 | 0.6671 |
| 400 | 0.6450 | 0.7024 | 0.7942 | 0.7529 | 0.6903 | 0.6651 |
| Codebook-K | Feature Space ( SVM-RBF ) | ||||||
|---|---|---|---|---|---|---|---|
| Dense | SIFT | WSIFT | SURF | WSURF | ORB | WORB | |
| 256 | 0.7545 | 0.6963 | 0.7076 | 0.6767 | 0.7084 | 0.5812 | 0.6502 |
| 512 | 0.7722 | 0.6959 | 0.7072 | 0.6747 | 0.7188 | 0.5913 | 0.6639 |
| 1024 | 0.7846 | 0.7208 | 0.7236 | 0.6927 | 0.7304 | 0.6053 | 0.6683 |
| 1536 | 0.7938 | 0.7196 | 0.7172 | 0.7092 | 0.7329 | 0.5820 | 0.6635 |
| 2048 | 0.7890 | 0.7202 | 0.7200 | 0.7020 | 0.7272 | 0.5880 | 0.6602 |
| Topic-K | Topic Size 64 | Topic Size 128 | ||
|---|---|---|---|---|
| GMM | SVM (Line) | GMM | SVM (Line) | |
| 128 | 0.6807 | 0.6193 | N/A | N/A |
| 256 | 0.6907 | 0.6740 | 0.6783 | 0.6782 |
| 512 | 0.5969 | 0.6414 | 0.6805 | 0.6455 |
| Feature | Ave | ||
|---|---|---|---|
| Ave | High | Low | |
| Dense-SIFT | 0.7938 | 0.8033 | 0.7838 |
| SIFT | 0.7252 | 0.7411 | 0.7084 |
| SURF | 0.7333 | 0.7659 | 0.6984 |
| SLIC-CWD | 0.6558 | 0.6851 | 0.6247 |
| HSV | 0.6073 | 0.6159 | 0.5982 |
| SLIC-HSV | 0.7084 | 0.7053 | 0.7117 |
| Color Distance | 0.5945 | 0.6330 | 0.5534 |
| SLIC-Color Distance | 0.6843 | 0.6944 | 0.6736 |
| Global Texture | 0.7060 | 0.7084 | 0.7034 |
| Tamura | 0.5913 | 0.6244 | 0.5559 |
| SLIC-Tamura | 0.7100 | 0.7084 | 0.7117 |
| LBP | 0.6871 | 0.7356 | 0.6355 |
| SLIC-LBP | 0.7874 | 0.7939 | 0.7804 |
| Gabor | 0.6835 | 0.7084 | 0.6570 |
| SLIC-Gabor | 0.7898 | 0.8017 | 0.7771 |
| GLCM | 0.6033 | 0.6011 | 0.6056 |
| SLIC-GLCM | 0.5263 | 0.5583 | 0.4921 |
| LDA | 0.7930 | 0.7986 | 0.7871 |
| All features | 0.8428 | 0.8507 | 0.8343 |
| Feature | Dimension | Ave |
|---|---|---|
| SIFT | 256 + 1024 | 0.8151 |
| SURF | 256 + 1024 | 0.8103 |
| ORB | 256 + 512 | 0.7926 |
| SLIC-CWD | 256 + 512 | 0.7882 |
| HSV | 256 + 64 | 0.8043 |
| SLIC-HSV | 256 + 512 | 0.8151 |
| Color Distance | 256 + 64 | 0.7906 |
| SLIC-Color Distance | 256 + 512 | 0.7942 |
| Global Texture | 256 + 64 | 0.8171 |
| Tamura | 256 + 64 | 0.7926 |
| SLIC-Tamura | 256 + 512 | 0.8010 |
| LBP | 256 + 64 | 0.8151 |
| SLIC-LBP | 256 + 512 | 0.8351 |
| Gabor | 256 + 64 | 0.8067 |
| SLIC-Gabor | 256 + 512 | 0.8379 |
| GLCM | 256 + 64 | 0.7874 |
| SLIC-GLCM | 256 + 512 | 0.7830 |
| Acc | High | Low |
|---|---|---|
| High | 0.8515 | 0.1485 |
| Low | 0.1765 | 0.8235 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, G.; Bi, R.; Guo, Y.; Peng, W. Image Aesthetic Assessment Based on Latent Semantic Features. Information 2020, 11, 223. https://doi.org/10.3390/info11040223
Yan G, Bi R, Guo Y, Peng W. Image Aesthetic Assessment Based on Latent Semantic Features. Information. 2020; 11(4):223. https://doi.org/10.3390/info11040223
Chicago/Turabian StyleYan, Gang, Rongjia Bi, Yingchun Guo, and Weifeng Peng. 2020. "Image Aesthetic Assessment Based on Latent Semantic Features" Information 11, no. 4: 223. https://doi.org/10.3390/info11040223
APA StyleYan, G., Bi, R., Guo, Y., & Peng, W. (2020). Image Aesthetic Assessment Based on Latent Semantic Features. Information, 11(4), 223. https://doi.org/10.3390/info11040223