Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence


Abstract
1. Introduction
1.1. Scientific Computing and Machine Learning in Python
1.2. Optimizing Python’s Performance for Numerical Computing and Data Processing
2. Classical Machine Learning
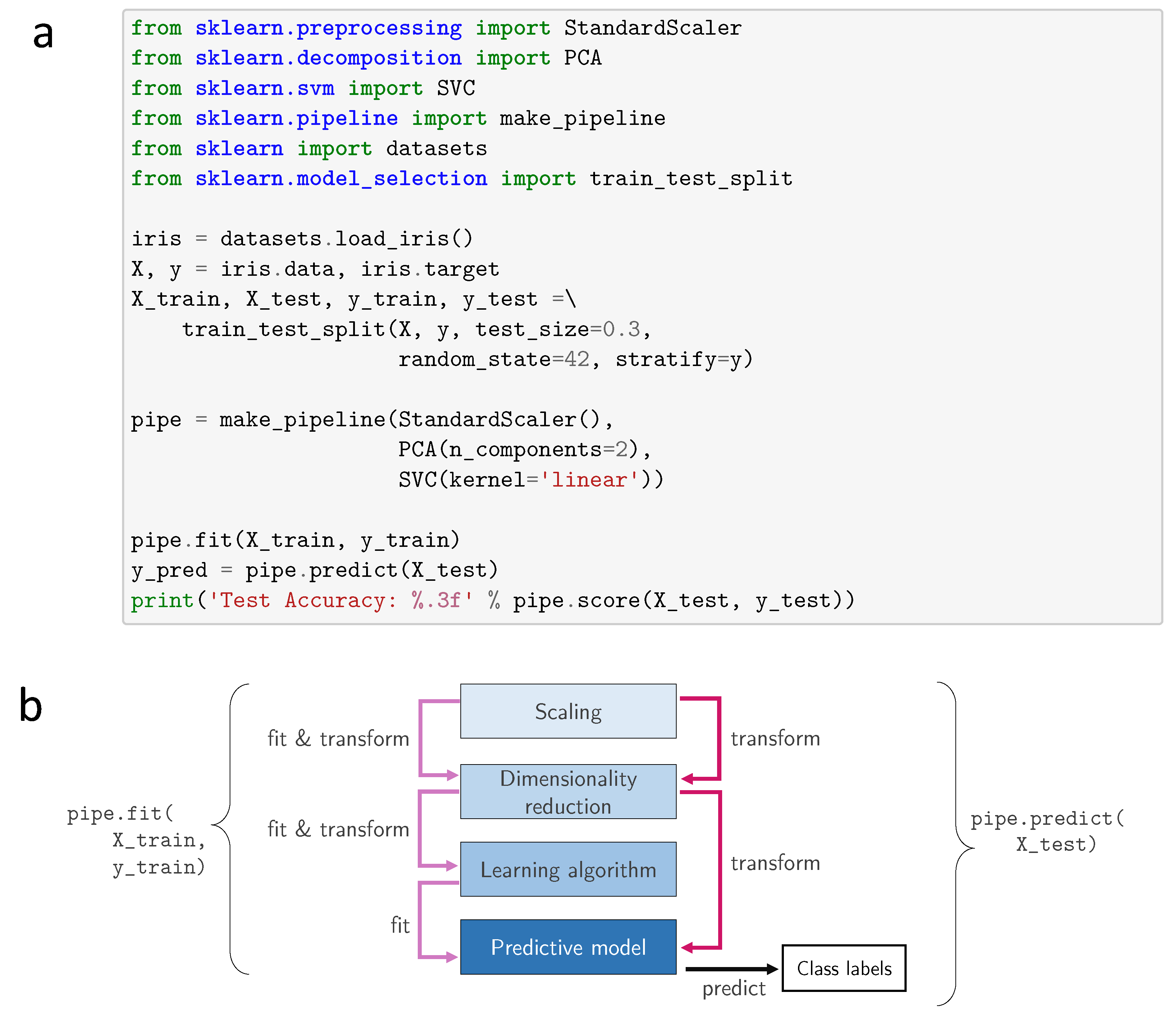
2.1. Scikit-learn, the Industry Standard for Classical Machine Learning
2.2. Addressing Class Imbalance
2.3. Ensemble Learning: Gradient Boosting Machines and Model Combination
2.4. Scalable Distributed Machine Learning
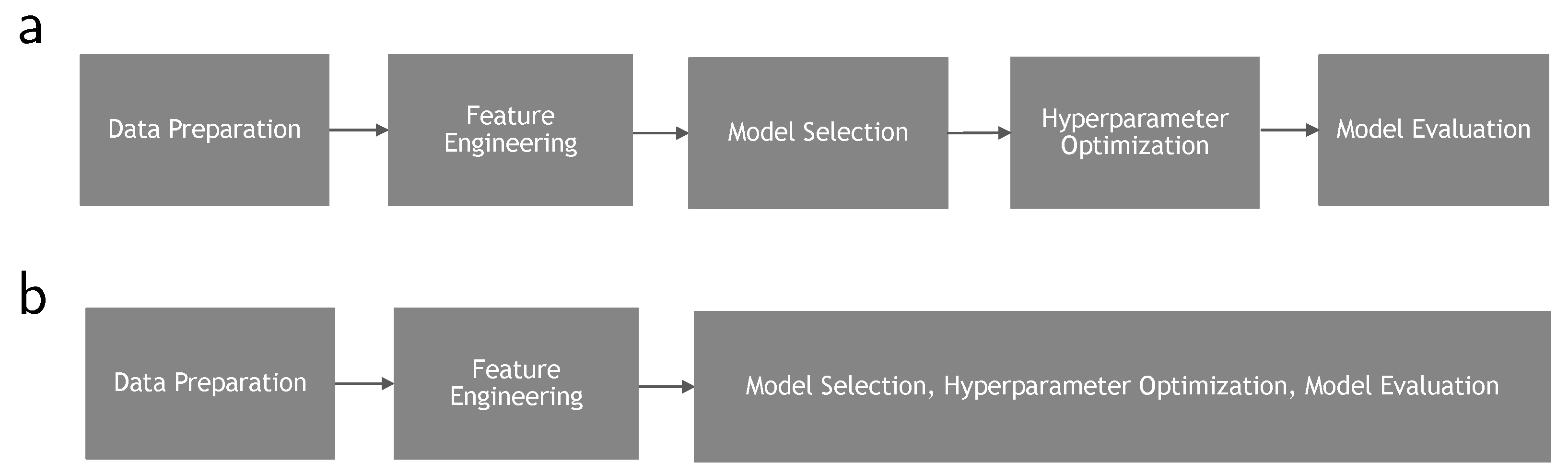
3. Automatic Machine Learning (AutoML)
3.1. Data Preparation and Feature Engineering
3.2. Hyperparameter Optimization and Model Evaluation
3.3. Neural Architecture Search
- Entire structure: Generates the entire network from the ground-up by choosing and chaining together a set of primitives, such as convolutions, concatenations, or pooling. This is known as macro search.
- Cell-based: Searches for combinations of a fixed number of hand-crafted building blocks, called cells. This is known as micro search.
- Hierarchical: Extends the cell-based approach by introducing multiple levels and chaining together a fixed number of cells, iteratively using the primitives defined in lower layers to construct the higher layers. This combines macro and micro search.
- Morphism-based structure: Transfers knowledge from an existing well-performing network to a new architecture.
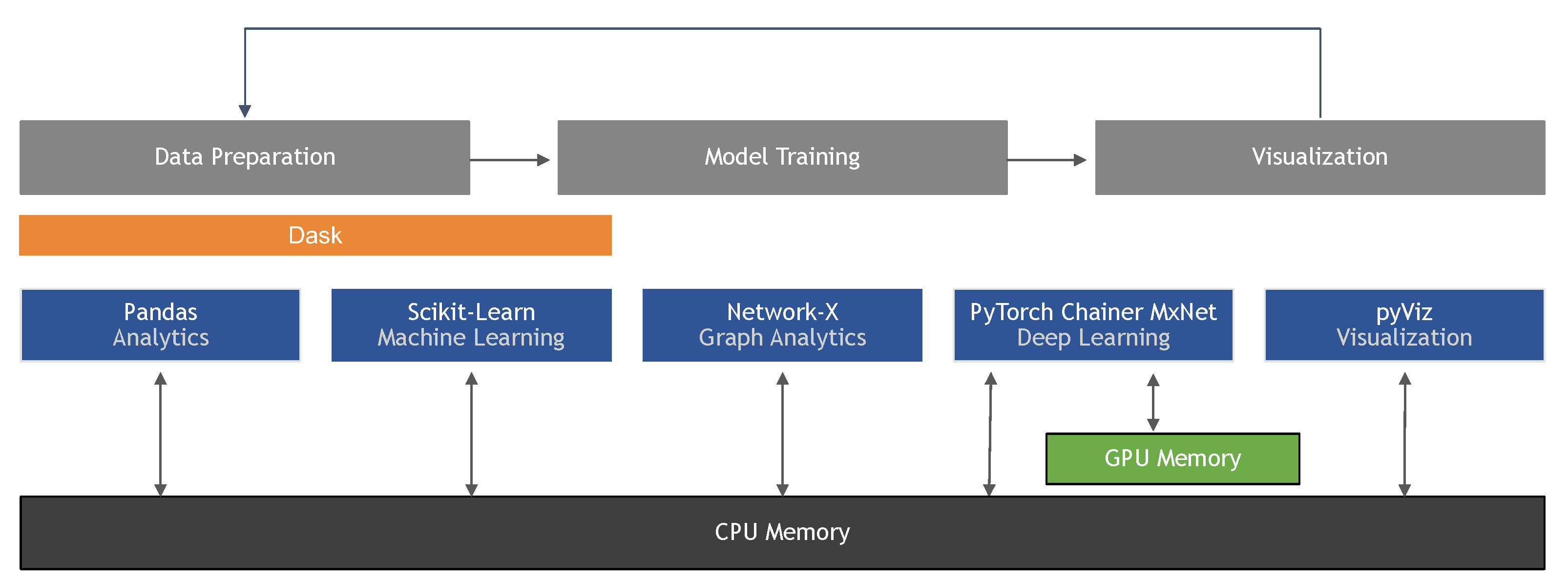
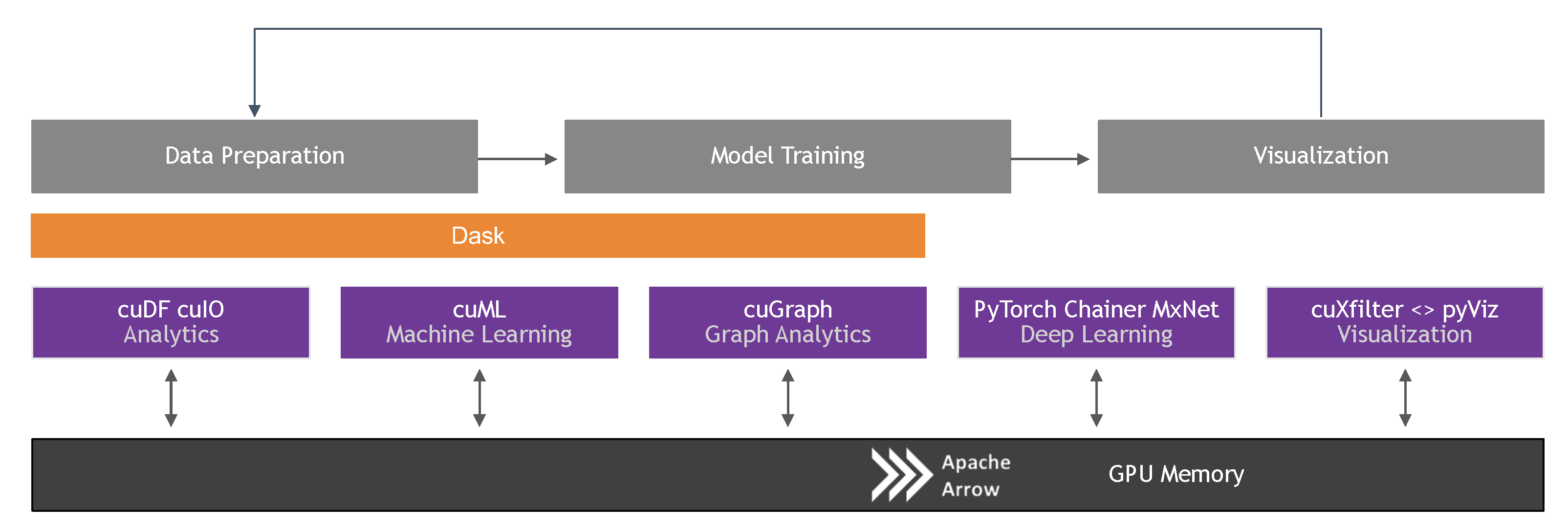
4. GPU-Accelerated Data Science and Machine Learning
4.1. General Purpose GPU Computing for Machine Learning
4.2. End-to-End Data Science: RAPIDS
4.3. NDArray and Vectorized Operations
4.4. Interoperability
4.5. Classical Machine Learning on GPUs
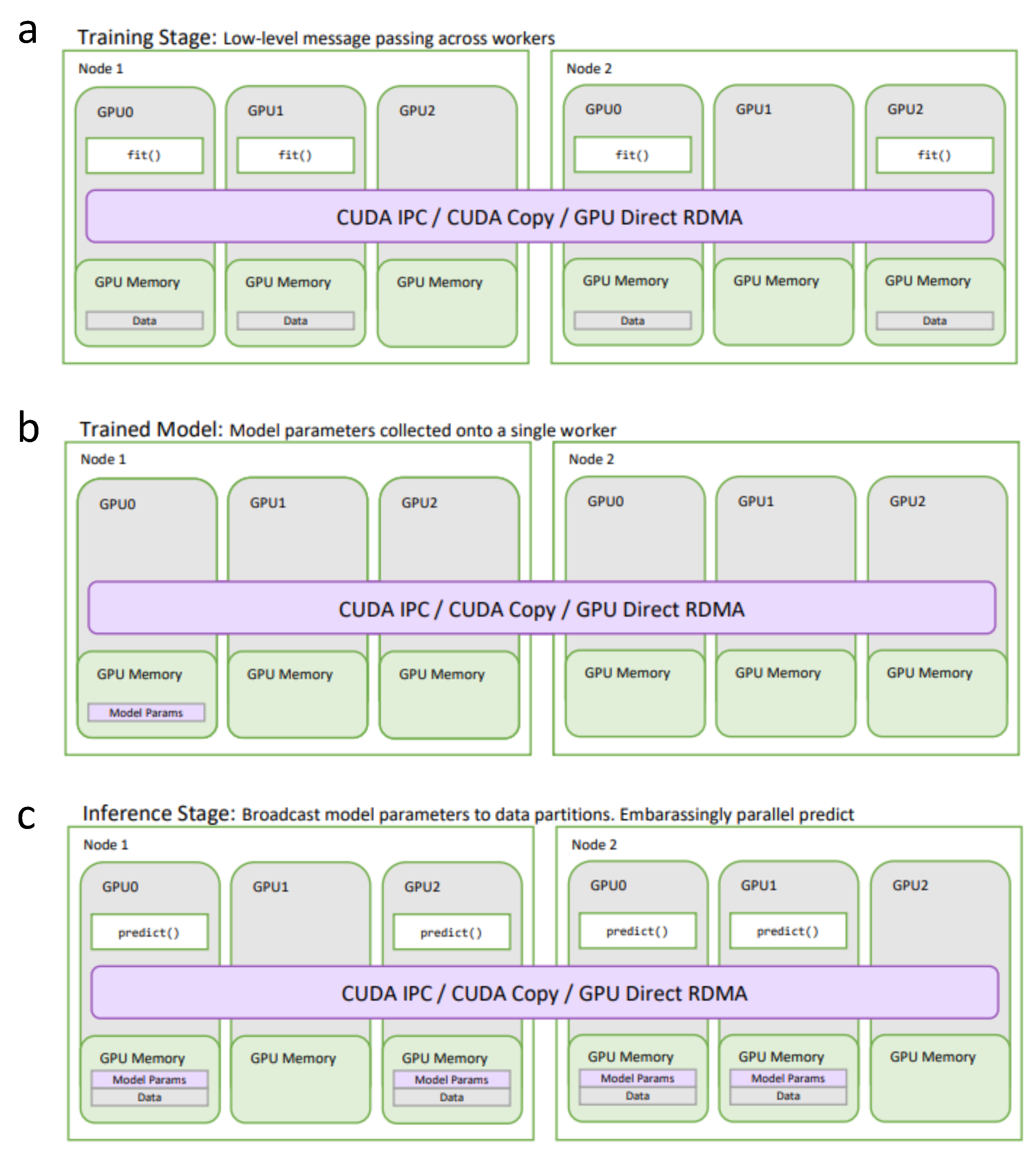
4.6. Distributed Data Science and Machine Learning on GPUs
5. Deep Learning
5.1. Static Data Flow Graphs
5.2. Dynamic Graph Libraries with Eager Execution
5.3. JIT and Computational Efficiency
5.4. Deep Learning APIs
5.5. New Algorithms for Accelerating Large-Scale Deep Learning
6. Explainability, Interpretability, and Fairness of Machine Learning Models
6.1. Feature Importance
6.2. Constraining Nonlinear Models
6.3. Logic and Reasoning
6.4. Explaining with Interactive Visualizations
6.5. Privacy
6.6. Fairness
7. Adversarial Learning
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| API | Application programming interface |
| Autodifff | Automatic differentiation |
| AutoML | Automatic machine learning |
| BERT | Bidirectional Encoder Representations from Transformers model |
| BO | Bayesian optimization |
| CDEP | Contextual Decomposition Explanation Penalization |
| Classical ML | Classical machine learning |
| CNN | Convolutional neural network |
| CPU | Central processing unit |
| DAG | Directed acyclic graph |
| DL | Deep learning |
| DNN | Deep neural network |
| ETL | Extract translate load |
| GAN | Generative adversarial networks |
| GBM | Gradient boosting machines |
| GPU | Graphics processing unit |
| HPO | Hyperparameter optimization |
| IPC | Inter-process communication |
| JIT | Just-in-time |
| LSTM | long-short term memory |
| MPI | Message-passing interface |
| NAS | Neural architecture search |
| NCCL | NVIDIA Collective Communications Library |
| OPG | One-process-per-GPU |
| PNAS | Progressive neural architecture search |
| RL | Reinforcement learning |
| RNN | Recurrent neural network |
| SIMT | Single instruction multiple thread |
| SIMD | Single instruction multiple data |
| SGD | Stochastic gradient descent |
References
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Piatetsky, G. Python Leads the 11 Top Data Science, Machine Learning Platforms: Trends and Analysis. 2019. Available online: https://www.kdnuggets.com/2019/05/poll-top-data-science-machine-learning-platforms.html (accessed on 1 February 2020).
- Biham, E.; Seberry, J. PyPy: Another version of Py. eSTREAM, ECRYPT Stream Cipher Proj. Rep. 2006, 38, 2006. [Google Scholar]
- Developers, P. How fast is PyPy? 2020. Available online: https://speed.pypy.org (accessed on 1 February 2020).
- Team, G. The State of the Octoverse 2020. Available online: https://octoverse.github.com (accessed on 25 March 2020).
- Oliphant, T.E. Python for scientific computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Mckinney, W. pandas: A Foundational Python Library for Data Analysis and Statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Preston-Werner, T. Semantic Versioning 2.0.0. 2013. Semantic Versioning. Available online: https://semver.org/ (accessed on 26 January 2020).
- Authors, N. NumPy Receives First Ever Funding, Thanks to Moore Foundation. 2017. Available online: https://numfocus.org/blog/numpy-receives-first-ever-funding-thanks-to-moore-foundation (accessed on 1 February 2020).
- Fedotov, A.; Litvinov, V.; Melik-Adamyan, A. Speeding up Numerical Calculations in Python. 2016. Available online: http://russianscdays.org/files/pdf16/26.pdf (accessed on 1 February 2020).
- Blackford, L.S.; Petitet, A.; Pozo, R.; Remington, K.; Whaley, R.C.; Demmel, J.; Dongarra, J.; Duff, I.; Hammarling, S.; Henry, G.; et al. An updated set of basic linear algebra subprograms (BLAS). ACM Trans. Math. Softw. 2002, 28, 135–151. [Google Scholar]
- Angerson, E.; Bai, Z.; Dongarra, J.; Greenbaum, A.; McKenney, A.; Du Croz, J.; Hammarling, S.; Demmel, J.; Bischof, C.; Sorensen, D. LAPACK: A portable linear algebra library for high-performance computers. In Proceedings of the 1990 ACM/IEEE Conference on Supercomputing, New York, NY, USA, 12–16 November 1990; pp. 2–11. [Google Scholar]
- Team, O. OpenBLAS: An Optimized BLAS Library. 2020. Available online: https://www.openblas.net (accessed on 1 February 2020).
- Team, I. Python Accelerated (Using Intel® MKL). 2020. Available online: https://software.intel.com/en-us/blogs/python-optimized (accessed on 1 February 2020).
- Diefendorff, K.; Dubey, P.K.; Hochsprung, R.; Scale, H. Altivec extension to PowerPC accelerates media processing. IEEE Micro 2000, 20, 85–95. [Google Scholar] [CrossRef]
- Pedregosa, F.; Michel, V.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; Cournapeau, D.; Pedregosa, F.; Varoquaux, G.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the Scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Team, I. Using Intel® Distribution for Python. 2020. Available online: https://software.intel.com/en-us/distribution-for-python (accessed on 1 February 2020).
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012; p. 2. [Google Scholar]
- Rocklin, M. Dask: Parallel computation with blocked algorithms and task scheduling. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 130–136. [Google Scholar]
- Team, A.A. Apache Arrow—A Cross-Language Development Platform for In-memory Data. 2020. Available online: https://arrow.apache.org/ (accessed on 1 February 2020).
- Team, A.P. Apache Parquet Documentation. 2020. Available online: https://parquet.apache.org (accessed on 1 February 2020).
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache Spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Developers, R. Fast and Simple Distributed Computing. 2020. Available online: https://ray.io (accessed on 1 February 2020).
- Developers, M. Faster Pandas, Even on Your Laptop. 2020. Available online: https://modin.readthedocs.io/en/latest/#faster-pandas-even-on-your-laptop (accessed on 1 February 2020).
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Raschka, S. Model evaluation, model selection, and algorithm selection in machine learning. arXiv 2018, arXiv:1811.12808. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of online learning and an application to boosting. In Proceedings of the European Conference on Computational Learning Theory, Barcelona, Spain, 13–15 March 1995; pp. 23–37. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, X.; Cheng, C.; Ding, X. Combining machine learning models using Combo library. arXiv 2019, arXiv:1910.07988. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3147–3155. [Google Scholar]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python, Scikit-learn, and TensorFlow 2; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Sill, J.; Takács, G.; Mackey, L.; Lin, D. Feature-weighted linear stacking. arXiv 2009, arXiv:0911.0460. [Google Scholar]
- Lorbieski, R.; Nassar, S.M. Impact of an extra layer on the stacking algorithm for classification problems. JCS 2018, 14, 613–622. [Google Scholar] [CrossRef]
- Raschka, S. MLxtend: Providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J. Open Source Softw. 2018, 3, 638. [Google Scholar] [CrossRef]
- Cruz, R.M.; Sabourin, R.; Cavalcanti, G.D. Dynamic classifier selection: Recent advances and perspectives. Inf. Fusion 2018, 41, 195–216. [Google Scholar] [CrossRef]
- Deshai, N.; Sekhar, B.V.; Venkataramana, S. MLlib: Machine learning in Apache Spark. Int. J. Recent Technol. Eng. 2019, 8, 45–49. [Google Scholar]
- Barker, B. Message passing interface (MPI). In Proceedings of the Workshop: High Performance Computing on Stampede, Austin, TX, USA, 15–20 November 2015; Volume 262. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 847–855. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Auto-sklearn: Efficient and robust automated machine learning. In Automated Machine Learning; Springer: Switzerland, Cham, 2019; pp. 113–134. [Google Scholar]
- Olson, R.S.; Moore, J.H. TPOT: A tree-based pipeline optimization tool for automating machine learning. In Automated Machine Learning; Springer: Switzerland, Cham, 2019; pp. 151–160. [Google Scholar]
- Team, H. H2O AutoML. 2020. Available online: http://docs.h2o.ai/h2o/latest-stable/h2o-docs/automl.html (accessed on 1 February 2020).
- Jin, H.; Song, Q.; Hu, X. Auto-Keras: An efficient neural architecture search system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Dalian, China, 21–23 November 2019; pp. 1946–1956. [Google Scholar]
- Gijsbers, P.; LeDell, E.; Thomas, J.; Poirier, S.; Bischl, B.; Vanschoren, J. An open source AutoML benchmark. arXiv 2019, arXiv:1907.00909. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.T.; Blum, M.; Hutter, F. Efficient and robust automated machine learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2962–2970. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. arXiv 2019, arXiv:1908.00709. [Google Scholar]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Sievert, S.; Augspurger, T.; Rocklin, M. Better and faster hyperparameter optimization with Dask. In Proceedings of the 18th Python in Science Conference, Austin, TX, USA, 8–14 July 2019; pp. 118–125. [Google Scholar]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A novel bandit-based approach to hyperparameter optimization. J. Mach. Learn. Res. 2018, 18, 6765–6816. [Google Scholar]
- Snoek, J.; Rippel, O.; Swersky, K.; Kiros, R.; Satish, N.; Sundaram, N.; Patwary, M.; Prabhat, M.; Adams, R. Scalable Bayesian optimization using deep neural networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2171–2180. [Google Scholar]
- Bergstra, J.S.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems 24; Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Granada, Spain, 2011; pp. 2546–2554. [Google Scholar]
- Falkner, S.; Klein, A.; Hutter, F. BOHB: Robust and efficient hyperparameter optimization at scale. arXiv 2018, arXiv:1807.01774. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Negrinho, R.; Gormley, M.; Gordon, G.J.; Patil, D.; Le, N.; Ferreira, D. Towards modular and programmable architecture search. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13715–13725. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Goldberg, D.E.; Deb, K. A comparative analysis of selection schemes used in genetic algorithms. In Foundations of Genetic Algorithms; Elsevier: Amsterdam, The Netherlands, 1991; Volume 1, pp. 69–93. [Google Scholar]
- Liu, H.; Simonyan, K.; Vinyals, O.; Fernando, C.; Kavukcuoglu, K. Hierarchical representations for efficient architecture search. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient neural architecture search via parameter sharing. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Vienna, Austria, 25–31 July 2018; Volume 9, pp. 6522–6531. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Switzerland, Cham, 2018; Volume 11205, pp. 19–35. [Google Scholar]
- Kandasamy, K.; Neiswanger, W.; Schneider, J.; Póczos, B.; Xing, E.P. Neural architecture search with Bayesian optimisation and optimal transport. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 2016–2025. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Xie, S.; Zheng, H.; Liu, C.; Lin, L. SNAS: Stochastic neural architecture search. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google file system. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, Bolton Landing, NY, USA, 19–22 Octeber 2003; pp. 29–43. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data Processing on Large Clusters. In Proceedings of the OSDI’04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, USA, 6–8 December 2004; pp. 137–150. [Google Scholar]
- Steinkraus, D.; Buck, I.; Simard, P. Using GPUs for machine learning algorithms. In Proceedings of the Eighth International Conference on Document Analysis and Recognition (ICDAR’05), Seoul, Korea, 29 August–1 September 2005; pp. 1115–1120. [Google Scholar]
- Cirecsan, D.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Deep big simple neural nets excel on hand-written digit recognition. arXiv 2010, arXiv:1003.0358 v1. [Google Scholar]
- Klöckner, A. PyCuda: Even simpler GPU programming with Python. In Proceedings of the GPU Technology Conference, Berkeley, CA, USA, 20–23 September 2010. [Google Scholar]
- Brereton, R.G.; Lloyd, G.R. Support vector machines for classification and regression. Analyst 2010, 135, 230–267. [Google Scholar] [CrossRef]
- Ocsa, A. SQL for GPU Data Frames in RAPIDS Accelerating end-to-end data science workflows using GPUs. In Proceedings of the LatinX in AI Research at ICML 2019, Long Beach, CA, USA, 10 June 2019. [Google Scholar]
- Lam, S.K.; Pitrou, A.; Seibert, S. Numba: A LLVM-based Python JIT compiler. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, Austin, TX, USA, 15 November 2015. [Google Scholar]
- Nishino, R.; Loomis, S.H.C. CuPy: A NumPy-compatible library for NVIDIA GPU calculations. In Proceedings of the Workshop on Machine Learning Systems (LearningSys) in the Thirty-first Annual Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Tokui, S.; Oono, K.; Hido, S.; Clayton, J. Chainer: A next-generation open source framework for deep learning. In Proceedings of the Workshop on Machine Learning Systems (LearningSys) in the Twenty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), Tbilisi, Georgia, 16–19 October 2015; Volume 5. [Google Scholar]
- Developers, G. XLA—TensorFlow, Compiled. 2017. Available online: https://developers.googleblog.com/2017/03/xla-tensorflow-compiled.html (accessed on 1 February 2020).
- Frostig, R.; Johnson, M.J.; Leary, C. Compiling machine learning programs via high-level tracing. In Proceedings of the Systems for Machine Learning, Montreal, QC, Canada, 4 December 2018. [Google Scholar]
- Zhang, H.; Si, S.; Hsieh, C.J. GPU-acceleration for large-scale tree boosting. arXiv 2017, arXiv:1706.08359. [Google Scholar]
- Dünner, C.; Parnell, T.; Sarigiannis, D.; Ioannou, N.; Anghel, A.; Ravi, G.; Kandasamy, M.; Pozidis, H. Snap ML: A hierarchical framework for machine learning. In Proceedings of the Thirty-Second Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 15 November 2018. [Google Scholar]
- Johnson, J.; Douze, M.; Jegou, H. Billion-scale similarity search with GPUs. In IEEE Transactions on Big Data; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; p. 1. [Google Scholar]
- Maaten, L.V.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Chan, D.M.; Rao, R.; Huang, F.; Canny, J.F. t-SNE-CUDA: GPU-accelerated t-SNE and its applications to modern data. In Proceedings of the 2018 30th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Lyon, France, 24–27 September 2018; pp. 330–338. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with Python. In Proceedings of the 9th Python in Science Conference. Scipy, Austin, TX, USA, 28 June–3 July 2010; Volume 57, p. 61. [Google Scholar]
- Shainer, G.; Ayoub, A.; Lui, P.; Liu, T.; Kagan, M.; Trott, C.R.; Scantlen, G.; Crozier, P.S. The development of Mellanox/NVIDIA GPUDirect over InfiniBand—A new model for GPU to GPU communications. Comput. Sci. Res. Dev. 2011, 26, 267–273. [Google Scholar] [CrossRef]
- Potluri, S.; Hamidouche, K.; Venkatesh, A.; Bureddy, D.; Panda, D.K. Efficient inter-node MPI communication using GPUDirect RDMA for InfiniBand clusters with NVIDIA GPUs. In Proceedings of the 2013 42nd International Conference on Parallel Processing, Lyon, France, 1–4 October 2013; pp. 80–89. [Google Scholar]
- Anderson, D.P.; Cobb, J.; Korpela, E.; Lebofsky, M.; Werthimer, D. SETI@ home: An experiment in public-resource computing. Commun. ACM 2002, 45, 56–61. [Google Scholar] [CrossRef]
- Smith, V.; Forte, S.; Ma, C.; Takáč, M.; Jordan, M.I.; Jaggi, M. CoCoA: A general framework for communication-efficient distributed optimization. J. Mach. Learn. Res. 2017, 18, 8590–8638. [Google Scholar]
- Shamis, P.; Venkata, M.G.; Lopez, M.G.; Baker, M.B.; Hernandez, O.; Itigin, Y.; Dubman, M.; Shainer, G.; Graham, R.L.; Liss, L.; et al. UCX: An open source framework for HPC network APIs and beyond. In Proceedings of the 2015 IEEE 23rd Annual Symposium on High-Performance Interconnects, Washington, DC, USA, 26–28 August 2015; pp. 40–43. [Google Scholar]
- Rajendran, K. NVIDIA GPUs and Apache Spark, One Step Closer 2019. Available online: https://medium.com/rapids-ai/nvidia-gpus-and-apache-spark-one-step-closer-2d99e37ac8fd (accessed on 25 March 2020).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Raschka, S. Naive Bayes and text classification I–introduction and theory. arXiv 2014, arXiv:1410.5329. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, New York, NY, USA, 3 March 2014; pp. 675–678. [Google Scholar]
- Team, T.T.D.; Al-Rfou, R.; Alain, G.; Almahairi, A.; Angermueller, C.; Bahdanau, D.; Ballas, N.; Bastien, F.; Bayer, J.; Belikov, A.; et al. Theano: A Python framework for fast computation of mathematical expressions. arXiv 2016, arXiv:1605.02688. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation OSDI 16), San Diego, CA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Seide, F.; Agarwal, A. CNTK: Microsoft’s open-source deep-learning toolkit. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13 August 2016; p. 2135. [Google Scholar]
- Markham, A.; Jia, Y. Caffe2: Portable High-Performance Deep Learning Framework from Facebook; NVIDIA Corporation: Santa Clara, CA, USA, 2017. [Google Scholar]
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An open-source deep learning platform from industrial practice. Front. Data Domputing 2019, 1, 105–115. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. MXNet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Collobert, R.; Kavukcuoglu, K.; Farabet, C. Torch7: A matlab-like environment for machine learning. In Proceedings of the BigLearn, NeurIPS Workshop, Sierra Nevada, Spain, 16–17 December 2011. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Neubig, G.; Dyer, C.; Goldberg, Y.; Matthews, A.; Ammar, W.; Anastasopoulos, A.; Ballesteros, M.; Chiang, D.; Clothiaux, D.; Cohn, T.; et al. DyNet: The dynamic neural network toolkit. arXiv 2017, arXiv:1701.03980. [Google Scholar]
- He, H. The State of Machine Learning Frameworks in 2019. 2019. Available online: https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/ (accessed on 1 February 2020).
- Coleman, C.; Narayanan, D.; Kang, D.; Zhao, T.; Zhang, J.; Nardi, L.; Bailis, P.; Olukotun, K.; Ré, C.; Zaharia, M. DAWNBench: An end-to-end deep learning benchmark and competition. Training 2017, 100, 102. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Team, T. TensorFlow 2.0 is Now Available! 2019. Available online: https://blog.tensorflow.org/2019/09/tensorflow-20-is-now-available.html (accessed on 1 February 2020).
- Harris, E.; Painter, M.; Hare, J. Torchbearer: A model fitting library for PyTorch. arXiv 2018, arXiv:1809.03363. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. 2019. Available online: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf (accessed on 1 February 2020).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18-22 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, Y. Introducing GPipe, An Open Source Library for Efficiently Training Large-scale Neural Network Models. 2019. Available online: https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html (accessed on 1 February 2020).
- Hegde, V.; Usmani, S. Parallel and distributed deep learning. In Technical Report; Stanford University: Stanford, CA, USA, 2016. [Google Scholar]
- Ben-Nun, T.; Hoefler, T. Demystifying parallel and distributed deep learning: An in-depth concurrency analysis. ACM Comput. Surv. 2019, 52, 1–43. [Google Scholar] [CrossRef]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, D.; Chen, M.; Lee, H.; Ngiam, J.; Le, Q.V.; Wu, Y.; et al. GPipe: Efficient training of giant neural networks using pipeline parallelism. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 103–112. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009; pp. 248–255. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Gupta, S. EfficientNet-EdgeTPU: Creating Accelerator-Optimized Neural Networks with AutoML. 2020. Available online: https://ai.googleblog.com/2019/08/efficientnet-edgetpu-creating.html (accessed on 1 February 2020).
- Choi, J.; Wang, Z.; Venkataramani, S.; Chuang, P.I.J.; Srinivasan, V.; Gopalakrishnan, K. PACT: Parameterized clipping activation for quantized neural networks. arXiv 2018, arXiv:1805.06085. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2704–2713. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet classification using binary convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 525–542. [Google Scholar]
- Zhang, D.; Yang, J.; Ye, D.; Hua, G. LQ-Nets: Learned quantization for highly accurate and compact deep neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 365–382. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental network quantization: Towards lossless CNNs with low-precision weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. DoReFa-Net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Bernstein, J.; Zhao, J.; Azizzadenesheli, K.; Anandkumar, A. signSGD with majority vote is communication efficient and fault tolerant. In Proceedings of the International Conference on Learning Representations (ICLR) 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Nguyen, A.P.; Martínez, M.R. MonoNet: Towards Interpretable Models by Learning Monotonic Features. arXiv 2019, arXiv:1909.13611. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. ‘Why should i Trust You?’ Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2017; pp. 4765–4774. [Google Scholar]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. arXiv 2017, arXiv:1704.02685. [Google Scholar]
- Rafique, H.; Wang, T.; Lin, Q. Model-agnostic linear competitors–when interpretable models compete and collaborate with black-box models. arXiv 2019, arXiv:1909.10467. [Google Scholar]
- Rieger, L.; Singh, C.; Murdoch, W.J.; Yu, B. Interpretations are useful: Penalizing explanations to align neural networks with prior knowledge. arXiv 2019, arXiv:1909.13584. [Google Scholar]
- Murdoch, W.J.; Liu, P.J.; Yu, B. Beyond word importance: Contextual decomposition to extract interactions from LSTMs. arXiv 2018, arXiv:1801.05453. [Google Scholar]
- Zhuang, J.; Dvornek, N.C.; Li, X.; Yang, J.; Duncan, J.S. Decision explanation and feature importance for invertible networks. arXiv 2019, arXiv:1910.00406. [Google Scholar]
- Bride, H.; Hou, Z.; Dong, J.; Dong, J.S.; Mirjalili, A. Silas: High performance, explainable and verifiable machine learning. arXiv 2019, arXiv:1910.01382. [Google Scholar]
- Bride, H.; Dong, J.; Dong, J.S.; Hóu, Z. Towards dependable and explainable machine learning using automated reasoning. In Proceedings of the International Conference on Formal Engineering Methods, Gold Coast, QLD, Australia, 12–16 November 2018; pp. 412–416. [Google Scholar]
- Dietterich, T.G. Learning at the knowledge level. Mach. Learn. 1986, 1, 287–315. [Google Scholar]
- Rabold, J.; Siebers, M.; Schmid, U. Explaining black-box classifiers with ILP–empowering LIME with Aleph to approximate nonlinear decisions with relational rules. In Proceedings of the International Conference on Inductive Logic Programming, Ferrara, Italy, 12 April 2018; pp. 105–117. [Google Scholar]
- Rabold, J.; Deininger, H.; Siebers, M.; Schmid, U. Enriching visual with verbal explanations for relational concepts–combining LIME with Aleph. arXiv 2019, arXiv:1910.01837. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- VanderPlas, J.; Granger, B.; Heer, J.; Moritz, D.; Wongsuphasawat, K.; Satyanarayan, A.; Lees, E.; Timofeev, I.; Welsh, B.; Sievert, S. Altair: Interactive statistical visualizations for Python. J. Open Source Softw. 2018, 1, 1–2. [Google Scholar]
- Hohman, F.; Park, H.; Robinson, C.; Chau, D.H.P. Summit: Scaling deep learning interpretability by visualizing activation and attribution summarizations. IEEE Trans. Vis. Comput. Graph. 2019, 26, 1096–1106. [Google Scholar] [CrossRef]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. 2017. Available online: https://distill.pub/2017/feature-visualization/ (accessed on 1 February 2020).
- Carter, S. Exploring Neural Networks with Activation Atlases. 2019. Available online: https://ai.googleblog.com/2019/03/exploring-neural-networks.html (accessed on 1 February 2020).
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Hoover, B.; Strobelt, H.; Gehrmann, S. exBERT: A visual analysis tool to explore learned representations in transformers models. arXiv 2019, arXiv:1910.05276. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar]
- Adiwardana, D.; Luong, M.T.; Thus, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a human-like open-domain chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Joo, H.; Simon, T.; Sheikh, Y. Total capture: A 3D deformation model for tracking faces, hands, and bodies. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8320–8329. [Google Scholar]
- Huang, D.A.; Nair, S.; Xu, D.; Zhu, Y.; Garg, A.; Fei-Fei, L.; Savarese, S.; Niebles, J.C. Neural task graphs: Generalizing to unseen tasks from a single video demonstration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8565–8574. [Google Scholar]
- McMahan, H.B.; Andrew, G.; Erlingsson, U.; Chien, S.; Mironov, I.; Papernot, N.; Kairouz, P. A general approach to adding differential privacy to iterative training procedures. arXiv 2018, arXiv:1812.06210. [Google Scholar]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Xu, C.; Doshi, T. Fairness Indicators: Scalable Infrastructure for Fair ML Systems. 2019. Available online: https://ai.googleblog.com/2019/12/fairness-indicators-scalable.html (accessed on 1 February 2020).
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1625–1634. [Google Scholar]
- Papernot, N.; Carlini, N.; Goodfellow, I.; Feinman, R.; Faghri, F.; Matyasko, A.; Hambardzumyan, K.; Juang, Y.L.; Kurakin, A.; Sheatsley, R.; et al. Cleverhans v2.0.0: An adversarial machine learning library. arXiv 2016, arXiv:1610.00768. [Google Scholar]
- Rauber, J.; Brendel, W.; Bethge, M. Foolbox: A Python toolbox to benchmark the robustness of machine learning models. arXiv 2017, arXiv:1707.04131. [Google Scholar]
- Nicolae, M.I.; Sinn, M.; Tran, M.N.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; Molloy, I.M.; et al. Adversarial robustness toolbox v0.4.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Ling, X.; Ji, S.; Zou, J.; Wang, J.; Wu, C.; Li, B.; Wang, T. Deepsec: A uniform platform for security analysis of deep learning model. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–19 May 2019; pp. 673–690. [Google Scholar]
- Goodman, D.; Xin, H.; Yang, W.; Yuesheng, W.; Junfeng, X.; Huan, Z. Advbox: A toolbox to generate adversarial examples that fool neural networks. arXiv 2020, arXiv:2001.05574. [Google Scholar]
- Sabour, S.; Cao, Y.; Faghri, F.; Fleet, D.J. Adversarial manipulation of deep representations. arXiv 2015, arXiv:1511.05122. [Google Scholar]
- Chen, P.Y.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C.J. ZOO: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Miyato, T.; Maeda, S.i.; Koyama, M.; Nakae, K.; Ishii, S. Distributional smoothing with virtual adversarial training. arXiv 2015, arXiv:1507.00677. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. In Proceedings of the NeurIPS Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Engstrom, L.; Tran, B.; Tsipras, D.; Schmidt, L.; Madry, A. Exploring the landscape of spatial robustness. arXiv 2017, arXiv:1712.02779. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Jang, U.; Wu, X.; Jha, S. Objective metrics and gradient descent algorithms for adversarial examples in machine learning. In Proceedings of the 33rd Annual Computer Security Applications Conference, Orlando, FL, USA, 4–8 December 2017; pp. 262–277. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European symposium on security and privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (sp), San Jose, CA, USA, 25 May 2017; pp. 39–57. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- He, W.; Li, B.; Song, D. Decision boundary analysis of adversarial examples. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, P.Y.; Sharma, Y.; Zhang, H.; Yi, J.; Hsieh, C.J. EAD: Elastic-net attacks to deep neural networks via adversarial examples. In Proceedings of the Thirty-second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. arXiv 2017, arXiv:1712.04248. [Google Scholar]
- Chen, J.; Jordan, M.I.; Wainwright, M.J. HopSkipJumpAttack: A query-efficient decision-based attack. arXiv 2019, arXiv:1904.021443. [Google Scholar]
- Goodfellow, I.; Qin, Y.; Berthelot, D. Evaluation methodology for attacks against confidence thresholding models. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Hosseini, H.; Xiao, B.; Jaiswal, M.; Poovendran, R. On the limitation of convolutional neural networks in recognizing negative images. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 352–358. [Google Scholar]
- Tramèr, F.; Boneh, D. Adversarial training and robustness for multiple perturbations. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5858–5868. [Google Scholar]
- Uesato, J.; O’Donoghue, B.; Oord, A.V.D.; Kohli, P. Adversarial risk and the dangers of evaluating against weak attacks. arXiv 2018, arXiv:1802.05666. [Google Scholar]
- Grosse, K.; Pfaff, D.; Smith, M.T.; Backes, M. The limitations of model uncertainty in adversarial settings. arXiv 2018, arXiv:1812.02606. [Google Scholar]
- Alaifari, R.; Alberti, G.S.; Gauksson, T. ADef: An iterative algorithm to construct adversarial deformations. arXiv 2018, arXiv:1804.07729. [Google Scholar]
- Rony, J.; Hafemann, L.G.; Oliveira, L.S.; Ayed, I.B.; Sabourin, R.; Granger, E. Decoupling direction and norm for efficient gradient-based L2 adversarial attacks and defenses. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4322–4330. [Google Scholar]
- Narodytska, N.; Kasiviswanathan, S.P. Simple black-box adversarial perturbations for deep networks. arXiv 2016, arXiv:1612.06299. [Google Scholar]
- Schott, L.; Rauber, J.; Bethge, M.; Brendel, W. Towards the first adversarially robust neural network model on MNIST. arXiv 2018, arXiv:1805.09190. [Google Scholar]
- Alzantot, M.; Sharma, Y.; Chakraborty, S.; Zhang, H.; Hsieh, C.J.; Srivastava, M.B. GenAttack: Practical black-box attacks with gradient-free optimization. In Proceedings of the Genetic and Evolutionary Computation Conference, Prague, Prague, Czech Republic, 13–17 July 2019; pp. 1111–1119. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Zantedeschi, V.; Nicolae, M.I.; Rawat, A. Efficient defenses against adversarial attacks. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 39–49. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer encoding: One hot way to resist adversarial examples. In Proceedings of the International Conference of Machine Learning Research, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Ross, A.S.; Doshi-Velez, F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Proceedings of the Thirty-second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; Van Der Maaten, L. Countering adversarial images using input transformations. arXiv 2017, arXiv:1711.00117. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A. Mitigating adversarial effects through randomization. arXiv 2017, arXiv:1711.01991. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging generative models to understand and defend against adversarial examples. arXiv 2017, arXiv:1710.10766. [Google Scholar]
- Cao, X.; Gong, N.Z. Mitigating evasion attacks to deep neural networks via region-based classification. In Proceedings of the 33rd Annual Computer Security Applications Conference, Orlando, FL, USA, 4–8 December 2017; pp. 278–287. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Hohman, F.; Chen, L.; Kounavis, M.E.; Chau, D.H. Keeping the bad guys out: Protecting and vaccinating deep learning with JPEG compression. arXiv 2017, arXiv:1705.02900. [Google Scholar]
- Raschka, S.; Kaufman, B. Machine learning and AI-based approaches for bioactive ligand discovery and GPCR-ligand recognition. arXiv 2020, arXiv:2001.06545. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R.; et al. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast graph representation learning with PyTorch Geometric. arXiv 2019, arXiv:1903.02428. [Google Scholar]
- Law, S. STUMPY: A powerful and scalable Python library for time series data mining. J. Open Source Softw. 2019, 4, 1504. [Google Scholar] [CrossRef]
- Carpenter, B.; Gelman, A.; Hoffman, M.; Lee, D.; Goodrich, B.; Betancourt, M.; Brubaker, M.A.; Li, P.; Riddell, A. Stan: A probabilistic programming language. J. Stat. Softw. 2016. [Google Scholar] [CrossRef]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2016, 2016. [Google Scholar] [CrossRef]
- Tran, D.; Kucukelbir, A.; Dieng, A.B.; Rudolph, M.; Liang, D.; Blei, D.M. Edward: A library for probabilistic modeling, inference, and criticism. arXiv 2016, arXiv:1610.09787. [Google Scholar]
- Schreiber, J. Pomegranate: Fast and flexible probabilistic modeling in python. J. Mach. Learn. Res. 2017, 18, 5992–5997. [Google Scholar]
- Bingham, E.; Chen, J.P.; Jankowiak, M.; Obermeyer, F.; Pradhan, N.; Karaletsos, T.; Singh, R.; Szerlip, P.; Horsfall, P.; Goodman, N.D. Pyro: Deep universal probabilistic programming. J. Mach. Learn. Res. 2019, 20, 973–978. [Google Scholar]
- Phan, D.; Pradhan, N.; Jankowiak, M. Composable effects for flexible and accelerated probabilistic programming in NumPyro. arXiv 2019, arXiv:1912.11554. [Google Scholar]
- Broughton, M.; Verdon, G.; McCourt, T.; Martinez, A.J.; Yoo, J.H.; Isakov, S.V.; Massey, P.; Niu, M.Y.; Halavati, R.; Peters, E.; et al. TensorFlow Quantum: A Software Framework for Quantum Machine Learning. arXiv 2020, arXiv:2003.02989. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and Shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef]
- Quach, K. DeepMind Quits Playing Games with AI, Ups the Protein Stakes with Machine-Learning Code. 2018. Available online: https://www.theregister.co.uk/2018/12/06/deepmind_alphafold_games/ (accessed on 1 February 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cleverhans v3.0.1 | FoolBox v2.3.0 | ART v1.1.0 | DEEPSEC (2019) | AdvBox v0.4.1 | |
|---|---|---|---|---|---|
| Supported frameworks | |||||
| TensorFlow | yes | yes | yes | no | yes |
| MXNet | yes | yes | yes | no | yes |
| PyTorch | no | yes | yes | yes | yes |
| PaddlePaddle | no | no | no | no | yes |
| (Evasion) attack mechanisms | |||||
| Box-constrained L-BFGS [173] | yes | no | no | yes | no |
| Adv. manipulation of deep repr. [180] | yes | no | no | no | no |
| ZOO [181] | no | no | yes | no | no |
| Virtual adversarial method [182] | yes | yes | yes | no | no |
| Adversarial patch [183] | no | no | yes | no | no |
| Spatial transformation attack [184] | no | yes | yes | no | no |
| Decision tree attack [185] | no | no | yes | no | no |
| FGSM [186] | yes | yes | yes | yes | yes |
| R+FGSM [187] | no | no | no | yes | no |
| R+LLC [187] | no | no | no | yes | no |
| U-MI-FGSM [188] | yes | yes | no | yes | no |
| T-MI-FGSM [188] | yes | yes | no | yes | no |
| Basic iterative method [189] | no | yes | yes | yes | yes |
| LLC/ILLC [189] | no | yes | no | yes | no |
| Universal adversarial perturbation [190] | no | no | yes | yes | no |
| DeepFool [191] | yes | yes | yes | yes | yes |
| NewtonFool [192] | no | yes | yes | no | no |
| Jacobian saliency map [193] | yes | yes | yes | yes | yes |
| CW/CW2 [194] | yes | yes | yes | yes | yes |
| Projected gradient descent [195] | yes | no | yes | yes | yes |
| OptMargin [196] | no | no | no | yes | no |
| Elastic net attack [197] | yes | yes | yes | yes | no |
| Boundary attack [198] | no | yes | yes | no | no |
| HopSkipJumpAttack [199] | yes | yes | yes | no | no |
| MaxConf [200] | yes | no | no | no | no |
| Inversion attack [201] | yes | yes | no | no | no |
| SparseL1 [202] | yes | yes | no | no | no |
| SPSA [203] | yes | no | no | no | no |
| HCLU [204] | no | no | yes | no | no |
| ADef [205] | no | yes | no | no | no |
| DDNL2 [206] | no | yes | no | no | no |
| Local search [207] | no | yes | no | no | no |
| Pointwise attack [208] | no | yes | no | no | no |
| GenAttack [209] | no | yes | no | no | no |
| Defense mechanisms | |||||
| Feature squeezing [210] | no | no | yes | no | yes |
| Spatial smoothing [210] | no | no | yes | no | yes |
| Label smoothing [210] | no | no | yes | no | yes |
| Gaussian augmentation [211] | no | no | yes | no | yes |
| Adversarial training [195] | no | no | yes | yes | yes |
| Thermometer encoding [212] | no | no | yes | yes | yes |
| NAT [213] | no | no | no | yes | no |
| Ensemble adversarial training [187] | no | no | no | yes | no |
| Distillation as a defense [214] | no | no | no | yes | no |
| Input gradient regularization [215] | no | no | no | yes | no |
| Image transformations [216] | no | no | yes | yes | no |
| Randomization [217] | no | no | no | yes | no |
| PixelDefend [218] | no | no | yes | yes | no |
| Regr.-based classfication [219] | no | no | no | yes | no |
| JPEG compression [220] | no | no | yes | no | no |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raschka, S.; Patterson, J.; Nolet, C. Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence. Information 2020, 11, 193. https://doi.org/10.3390/info11040193
Raschka S, Patterson J, Nolet C. Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence. Information. 2020; 11(4):193. https://doi.org/10.3390/info11040193
Chicago/Turabian StyleRaschka, Sebastian, Joshua Patterson, and Corey Nolet. 2020. "Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence" Information 11, no. 4: 193. https://doi.org/10.3390/info11040193
APA StyleRaschka, S., Patterson, J., & Nolet, C. (2020). Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence. Information, 11(4), 193. https://doi.org/10.3390/info11040193