3. The Real Data Description and Analysis
Both to determine the model parameters and to verify the model, the real data collected at the weather stations located in the southern part of West Siberia (Russia) from 1988 to 2017 were used [
34,
35]. I studied the properties of the average daily WCI and constructed the proper stochastic models for the two areas. The first area (Area 1) is located between
and
north latitude,
and
east longitude. The size of the area is approximately 260 km
240 km. There are 7 weather stations in this area: Bakchar (the weather station with the World Meteorological Organization index 29328), Pervomajskoe (29348), Tomsk (29430), Bolotnoe (29539), Tajga (29541), Ogurcovo (29638), and Kemerovo (29645). The second area (Area 2) is larger: It is situated between
and
north latitude,
and
east longitude (the size of the area is approximately 790 km
330 km). Weather stations Severnoe (29418), Bolotnoe (29539), Tajga (29541), Tisul’ (29557), Tatarsk (29605), Barabinsk (29612), Ogurcovo (29638), Kemerovo (29645), Kamen’-na-Obi (29822), Barnaul (29838), and Kuzedeevo (29849) are located in the Area 2. The station Ogurcovo is situated in the city of Novosibirsk.
Figure 1 shows the positions of the weather stations in the areas in question.
It should be noted that the WCI is not measured at a weather station, but it could be easily calculated with the above-given definition, Equations (1) and (2), using the values of the air temperature and the wind obtained at the station. At all the weather stations considered, the air temperature and the wind speed data were collected eight times per day at the synoptic hours (00:00, 03:00, 06:00, 09:00, 12:00, 15:00, 18:00, and 21:00 UTC). So, for each day, when the observations were made, eight values of the WCI could be calculated. These eight values of the WCI were used to determine the real average daily WCI. Hereinafter, the random field of the WCI (both real and simulated) will be considered, where is the number of stations in the area in question, is the average daily WCI at the station number in the given day.
In order to construct a proper stochastic model, one should pay attention to the fact that the real fields
of the WCI are heterogeneous.
Figure 2 shows examples of the sample mean of the average daily WCI at the weather stations in the Area 1. One can easily see that the sample mean varies from one station to another. The properties of the spatial field of the average daily WCI are time-dependent also. This should be taken into account when one constructs a model of a spatio-temporal field. Since in this paper only spatial fields were studied, this time dependence is out of range of my interests.
The spatial fields of the average daily WCI were strongly correlated.
Figure 3 shows the correlation coefficients
of the field
as a function of the distance between the stations
and
One can see that the correlation coefficients even between remote stations were significant. As a comparison,
Figure 4 shows the correlations coefficients
and
of the random fields of the average daily temperature and the average daily wind speed, respectively. The correlation function of the wind speed field decreased faster than the correlation of the WCI field, and the decrease rates of the correlation functions of the temperature and WCI fields were similar. To reduce the statistical error of the estimation of all the characteristics considered over a small sample of the real data, the sample size was increased artificially. To do it, the moving averaging procedure with a symmetric two-side smoothing window with a width of
days was applied. To estimate the characteristic for the given day, data collected in that day, data collected during
days before the given day, and
days after the day in question were used. In this paper,
.
4. Stochastic Model
The method of the inverse distribution function (MIDF) is used for the simulation of the random field of the average daily WCI [
18,
26,
36]. This method allows one to simulate a non-Gaussian process with the given one-dimensional distributions and the given correlation structure. It is shown in [
16] that the mixtures
of the two Gaussian distributions will sufficiently approximate the sample histograms of the real average daily WCI. The correlation structure of the field
is defined by the
correlation matrix
that is estimated on the real data. Let us recall the idea of the MIDF. In the framework of the MIDF, simulating of the field
with the given densities
and the given correlation matrix
comes to an algorithm (let us call it the Algorithm 1) with the three steps [
11,
16]:
| Algorithm 1. |
Step 1. At this step, a correlation matrix of an auxiliary standard Gaussian process is calculated. The entry of the matrix is the solution of the equation
where the function is the distribution density of a bivariate Gaussian vector with zero mean, variance equal to , the correlation coefficient , is a cumulative distribution function (CDF) of a standard normal distribution, and and are the CDFs corresponding to the densities and , respectively.
|
Step 2. After calculating the matrix , a trajectory of the auxiliary standard Gaussian field with the correlation matrix is simulated. This could be done using the Cholesky method or the spectral decomposition of the matrix (see [ 18]).
|
Step 3. Finally, the trajectory of the Gaussian vector is transformed to the trajectory of the non-Gaussian vector :
|
One should note that there is no analytical solution of the Equation (3). This is why one have to solve this equation numerically. Since the integral in the right part of Equation (3) is a continuous monotonically increasing function on [−1;1] (see, for example, [
18]), the simplest method for solving the Equation (3) is the numerical inversion of the integral as a function of the correlation coefficient using its tabulated values. In this paper, the bisection method was used. If the matrix
, obtained at the first step using the Equation (3), is not positive definite, it must be regularized. In this paper, a method of regularization based on the substitution of negative eigenvalues of the matrix
with small positive numbers was used [
18]. After the regularization, the matrix
required normalization. Steps 2 and 3 were repeated as many times as trajectories were required. For the transformation Equation (4) the tabulated values of
were used.
Let me list the main advantages of the model proposed.
Many of the dynamic models that are used to simulate the fields of the air temperature and other meteorological parameters (using these models one may calculate the WCI) require as the input information some data related to the geographical properties of the area (whether the area is mountainous or plain, are there any huge water bodies or not, the elevation of the weather stations above the sea level, etc.). The stochastic approach does not require this additional information.
The most time-consuming step of the above-described algorithm is Step 1. Step 2 and Step 3 do not require a lot of time to be conducted. Once the matrix is calculated, one may repeat Steps 2 and 3 as many times as needed to obtain the required accuracy of the estimations, and the increase in accuracy insignificantly influences the total computational time.
The model proposed could be easily transformed to a model of a conditional random field of the average daily WCI. For the time-series of the WCI, such transformation is presented in [
17]. The conditional model allows one to forecast the bioclimatic index in question.
If one simulates the field of the average daily WCI only at the weather stations, the above-described approach could be used (let us call it the Model 1). In the next section, the results of the verification of the Model 1 are given. However, if it is necessary to simulate the field not only at the weather stations but also in the nodes of some regular or irregular grid, one must determine the distribution density of the WCI in each node and determine the
correlation matrix of the field, where
is a number of nodes in the grid. There are a lot of methods (both deterministic and stochastic) for determining the distribution parameters in a node of the grid. For example, one may calculate the parameters using the interpolation from the nearest neighbor, triangulation, different types of kriging, conditional interpolation technique, etc. (see, for example, [
37,
38]). The most common approach to determining the
correlation matrix of the field is approximating the sample correlation coefficients (that form the matrix
) with an analytical function of the continuous argument and calculating the correlation coefficients between each pair of nodes as a value of this function in the corresponding points [
39,
40]. For approximating of the correlation coefficients of the meteorological time series and fields functions
are often used. Here
is a distance between two points with the coordinates
and
. The correlation functions defined by Equations (5)–(8) depend only on the distance between points and do not depend on the exact position of the points
and
in the considered area or on the direction of the vector
. The function Equation (9) depends both on distance and on direction and does not depend on the parallel shift of the vector
. The numerical experiments show that the sample correlation coefficients of the field of the average daily WCI were approximated sufficiently well with the function Equation (5) when
and with the function Equation (9). To choose the parameters of the approximating functions, the functional
was minimized on the condition that the function
was positive definite.
Before one starts to simulate the field of the WCI on a grid with the correlation functions Equations (5) or (9), it is necessary to study how such an approximation influences the quality of the simulation of the field at the weather stations. Let the Model 2 and Model 3 be the models of the field of the WCI based on the MIDF, in which the matrix was substituted with the matrices calculated with the Equations (5) and (9) with the parameters that minimize the functional Equation (10). In the next section, the results of the verification of the Model 2 and the Model 3 are given.
5. Verification of the Model
To verify a model, it was necessary to compare estimations of various characteristics that were based on the simulated and real data. Only such characteristics must be considered that, on the one hand, were reliably estimated by means of real data and, on the other hand, were not input parameters of the model. In this section, several examples of such characteristics used for verification of the Models 1–3 are given.
It should be noted that it is possible to simulate as many trajectories as needed to provide a required accuracy of the estimation when the simulated data are used. In this paper, for all estimations based on the simulated data, I attained the accuracy above . Thus, in all the tables presented, the estimations based on the simulated trajectories are given with significant digits only.
From now on, is a standard deviation of the characteristic under consideration when estimating with the real data. Since for the Models 1–3 only one-dimensional distributions of the field and its correlation structure were defined, it was not possible to write down theoretical formulas for the variance (and, therefore, for ) of the characteristics of the field related to its multi-dimensional distributions. This is why the values , presented in tables below, were numerically estimated.
The first characteristic considered was the average number
of stations in the area where the average daily WCI was above the given level
. The estimations of the
on the real and simulated data are presented in the
Table 1 and
Table 2. The number
did not depend on the correlation structure of the field, this is why the estimations of this characteristic on the trajectories obtained with the Models 1–3 were the same. The values of
was defined by the one-dimensional distributions in each point of the field. For both Area 1 and Area 2 and for all the considered days, the estimations of the
based on the simulated data belonged to the confidence intervals
corresponding to the real data. This fact confirmed that the mixtures of the two Gaussian distributions, used for approximation of the sample histograms, described sufficiently well the one-dimensional distributions of the real field.
The next characteristic used for the verification of the models was the probability
. This characteristic was closely related to the
dimensional distribution of the average daily WCI.
Table 3 and
Table 4 show the examples of the corresponding estimations, obtained with the real and simulated data. When I considered the relatively high levels
, where the estimating of
was reliable (lines 1–5 in
Table 3 and
Table 4), in approximately 95% of numerical experiments performed the absolute difference of
assessed with real data and data simulated with the Model 1 and Model 3 was less than
, and this difference never exceeded
The deviations of the simulated with the Model 2 data estimations of
from the corresponding estimations based on the real data did not exceed
and
in 86% and 94% of the experiments conducted, respectively. This means that all three models reproduced well the characteristic in question. In the last four lines (lines 6–9) in the
Table 3 and
Table 4 the estimations of
for the extremely low values of
are given. The estimations with the real data were statistically unreliable and, even more, if we consider the real data, the event “
when
” never happened. One could see that the Models 1–3 gave realistic results. This results were close to each other because the only difference between these models was the type of the correlation function (that characterizes the two-dimensional distributions of the field), and
was related to the
dimensional distribution of the WCI field.
Another characteristic used for the comparison of the real and the simulated fields of the average daily WCI was the probability
that at least at
stations the average daily WCI did not exceed the level
.
Figure 5 shows the estimations of
for several values of
and
. One can clearly see that the simulation data based on estimations of
rapidly decreased both as functions of
and as functions of
. Nonmonotonicity of the real data based on estimations is explained with the statistical error of the estimation. For both areas in question, for all the considered days, values of
, and levels
, the estimations of the
based on the data simulated with the Models 1–3 belonged to the confidence intervals
, corresponding to the real data.
Let us consider one more characteristic used for verification of the stochastic models. Let
be a probability of the event “the average daily WCI at the
and
differs by more than
”, i.e.,
Table 5 and
Table 6 show the examples of the corresponding estimations obtained with the real and simulated data. The results in these tables are given for the pairs of stations Bolotnoe and Ogurcovo and Bolotnoe and Kemerovo when the simulation was conducted for the Area 1. The numerical experiments showed that all of the three models in question more or less precisely reproduced this characteristic of the real field. The estimations of the probability Equation (11), calculated with the trajectories obtained with the Model 3, approximately 1.2–1.3 times more often belonged to the confidence interval
than the estimations based on the Model 2. The possible explanation is that the characteristic in question was closely related to the correlation structure of the field, and the correlation function Equation (9) used in the Model 3 was closer (in the sense of the functional Equation (10)) to the sample correlation coefficients of the real field of the average daily WCI.
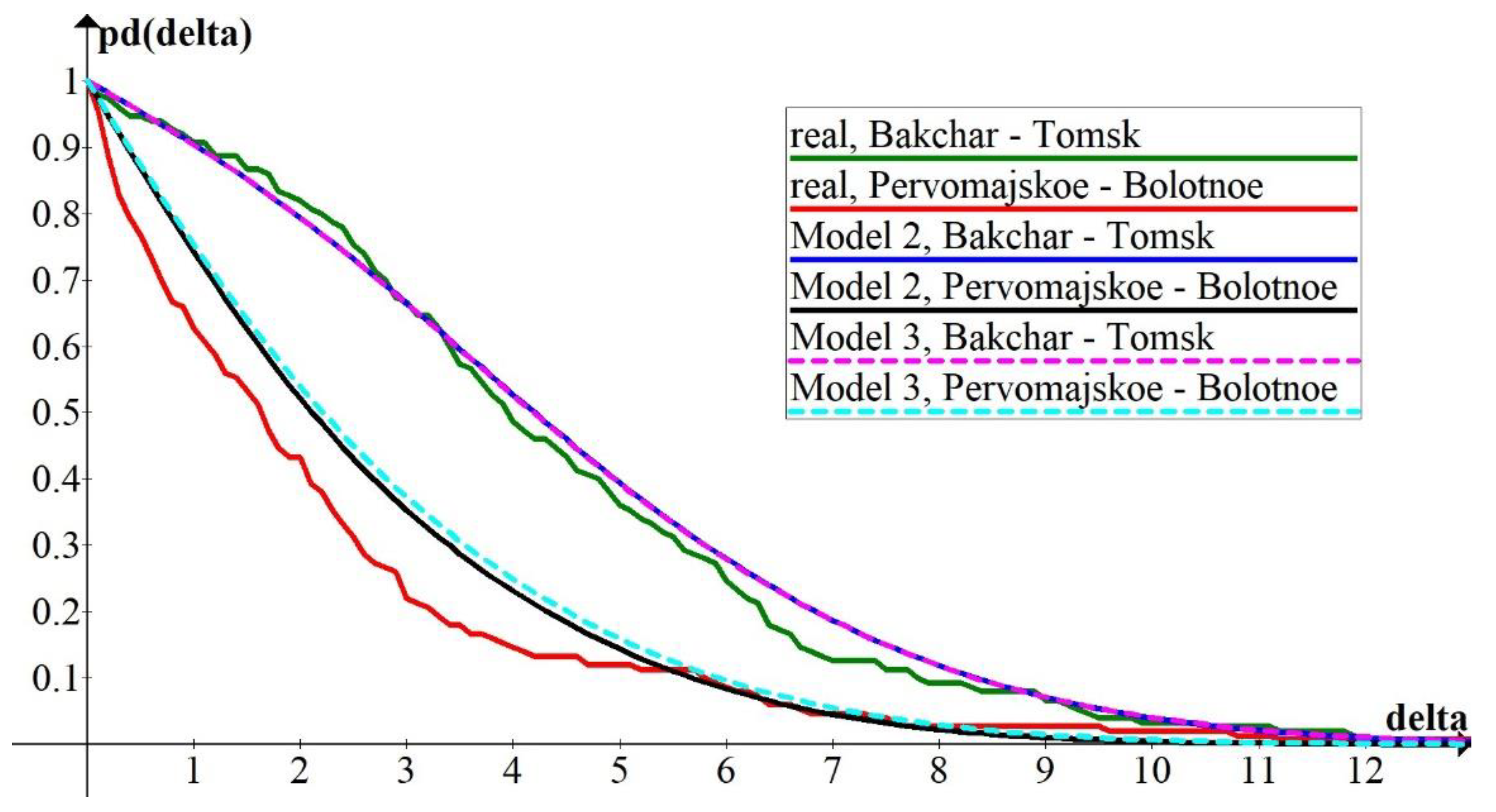
Figure 6 presents the estimations of
for the pairs of stations Bakchar and Tomsk and Pervomajskoe and Bolotnoe. One can see that, despite the fact that all four stations are situated in the same climatic zone and the distance between Bakchar and Tomsk is almost equal to the distance between Pervomajskoe and Bolotnoe, there is a significant distinction between the decreased rates of
as a function of
. The most probable explanation of this fact is that the correlation coefficient between the average daily WCI at the weather stations Pervomajskoe and Bolotnoe was higher than the correlation between the average daily WCI in Bakchar and Tomsk, and, therefore, the probability of the sufficient difference in values of the WCI at the first pair of stations was less than the corresponding probability at the second pair of stations.
In this section, four characteristics used for the verification of the models were presented. For each of the characteristics only several values of the arguments were considered. For instance, the probability was presented only for four pairs of stations (Bolotnoe-Ogurcovo, Bolotnoe-Kemerovo, Bakchar-Tomsk, and Pervomajskoe-Bolotnoe), though for each of the areas there were pairs of stations. In fact, for both Area 1 and Area 2 I considered 15 different characteristics. For each of the characteristic in question, I compared the simulated and the real data based on estimations for all possible values of the arguments (if the number of possible values was finite) or, if an argument was continuous (like in ), a fine grid with a small step in this argument was used for the verification. The results of this detailed numerical analysis showed that the trajectories obtained with the models proposed were close in their statistical properties to the real fields of the average daily wind chill index. Therefore, these models could be used for studying of those properties of the field that are unreliably estimated by means of real data. Since the Model 3 reproduced the characteristics of the real field a little more accurately than the Model 2, the Model 3 will be used for simulating of the spatial and spatio-temporal fields of the average daily wind chill index on a regular grid.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}