Research on Knowledge Gap Identification Method in Innovative Organizations under the “Internet+” Environment


Abstract
1. Introduction
2. Literature Review
2.1. The Definition and Identification of Knowledge Gaps
2.2. The Application of Knowledge Gap Identification
3. The Identification Method of Knowledge Gap under “Internet+” Environment
3.1. The Construction of the Network of Complete Knowledge Topics under the “Internet+” Environment
3.2. The Construction of Reserved Knowledge Topic Network
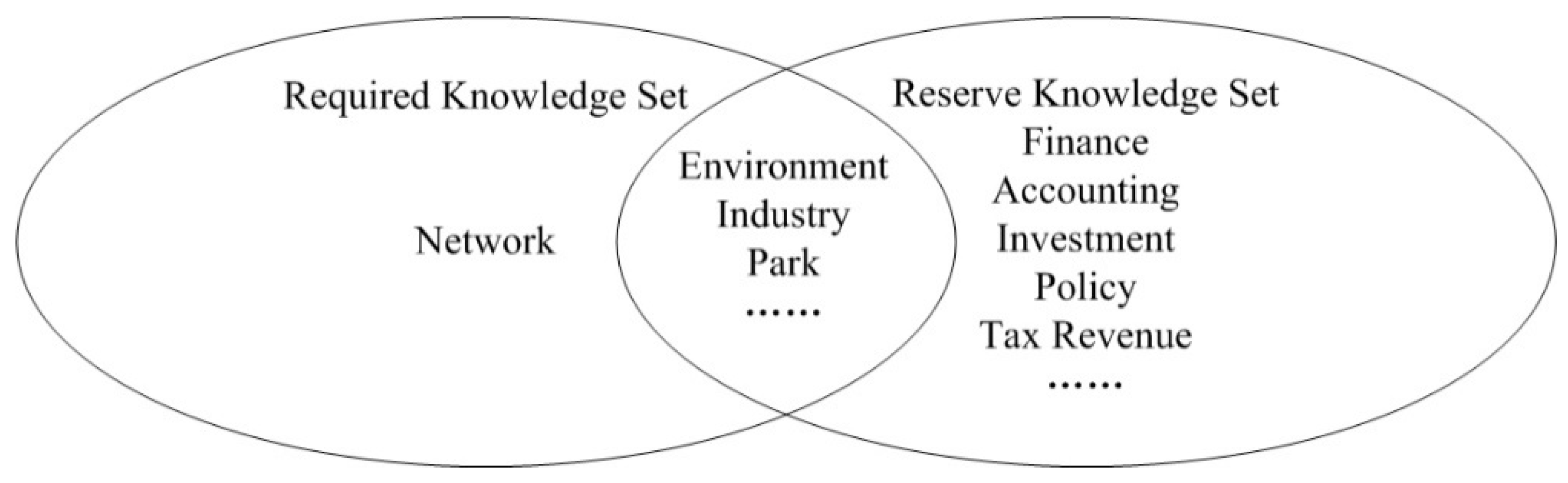
3.3. The Required Knowledge Topic Identification
3.4. Knowledge Gap Identification and Filling
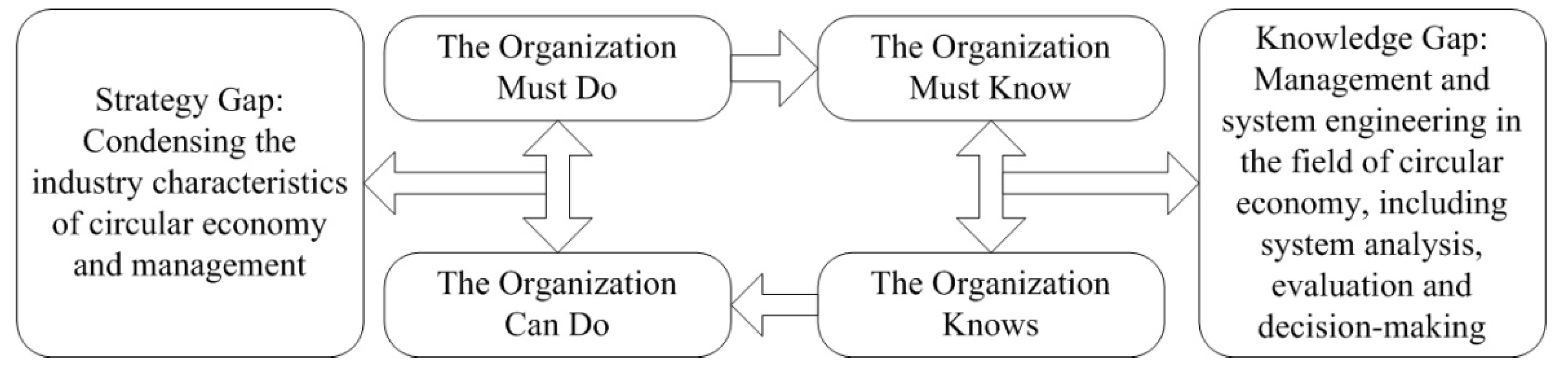
4. Case Study
5. Results and Discussion
6. Conclusions and Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, P.; Guo, Y.H.; Li, Y. The Impact of Internet Development on the Transformation and Upgrading of Regional Industrial Struct—Research Based on Mediating Effect. J. Ind. Technol. Econ. 2020, 39, 135–144. [Google Scholar]
- Zhang, Y.S.; Wang, D.M. Research on the Random Supervision of the Risk of Internet Financial Enterprises Excessive Innovation. Econ. Rev. 2017, 7, 100–105. [Google Scholar]
- Dang, X.H.; Gong, Z.G. Impact of multidimensional proximities on cross region technology innovation cooperation: Experical analysis based on Chinese coinvent patent data. Stud. Sci. Sci. 2013, 31, 1590–1600. [Google Scholar]
- Glisson, C. The role of organizational culture and climate in innovation and effectiveness. Hum. Serv. Organi. Manag. Leadersh. Gov. 2015, 39, 245–250. [Google Scholar] [CrossRef]
- Grillitsch, M.; Asheim, B. Place-based innovation policy for industrial diversification in regions. Eur. Plan. Stud. 2018, 26, 1638–1662. [Google Scholar] [CrossRef]
- Han, Y.; Gao, C.Y. Compensation of knowledge gaps among high-tech enterprises. Stud. Sci. Sci. 2009, 27, 1370–1375. [Google Scholar]
- Mohd, S.S.A.; Prakoonwit, S.; Sahandi, R.; Khan, W.; Ramachandran, M. Big data analytics—A review of data-mining models for small and medium enterprises in the transportation sector. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1238. [Google Scholar] [CrossRef]
- Zack, M.H. Developing a Knowledge Strategy. Calif. Manag. Rev. 1999, 41, 125–145. [Google Scholar] [CrossRef]
- Qiu, J.N.; Wu, M.J.; Nian, C.L. Research on identifying organizational knowledge gap. Sci. Res. Manag. 2013, 34, 85–93. [Google Scholar]
- Chen, J.H.; Sun, Q.X.; Zhu, Y.L. Study on the identification method and filling strategies of knowledge gap. Stud. Sci. Sci. 2007, 25, 750–755. [Google Scholar]
- Liu, X.; Jia, W.; Wang, Y.; Guo, H.; Ren, Y.; Li, Z. Knowledge discovery and semantic learning in the framework of axiomatic fuzzy set theory. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1268. [Google Scholar] [CrossRef]
- Rashid, J.; Shah, S.M.A.; Irtaza, A. Fuzzy topic modeling approach for text mining over short text. Inf. Process. Manag. 2019, 56, 102060. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, J.; Li, D.; Yu, H.; Liu, G. Hot topic detection based on a refined TF-IDF algorithm. IEEE Access 2019, 7, 26996–27007. [Google Scholar] [CrossRef]
- Tang, M.; Xia, Y.; Tang, B.; Zhou, Y.; Cao, B.; Hu, R. Mining Collaboration Patterns between APIs for Mashup Creation in Web of Things. IEEE Access 2019, 7, 14206–14215. [Google Scholar] [CrossRef]
- Haider, S. Organizational knowledge gaps: Concept and implications. In Proceedings of the Druid Summer Conference, Copenhagen, Denmark, 12–14 June 2003. [Google Scholar]
- Vos, J.P.; Keizer, J.A.; Halman, J.I.M. Diagnosing Constraints in Knowledge of SMEs. Technol. Forecast. Soc. Chang. 1998, 58, 227–239. [Google Scholar] [CrossRef]
- Dang, X.H.; Ren, B.Q. Research on Knowledge Gaps and Compensation Strategies in Enterprises’ Technological Innovation under Network Environment. Sci. Res. Manag. 2005, 3, 12–16. [Google Scholar]
- Lafuente-Ruiz-de-Sabando, A.; Zorrilla, P.; Forcada, J. A review of higher education image and reputation literature: Knowledge gaps and a research agenda. Eur. Res. Manag. Bus. Econ. 2018, 24, 8–16. [Google Scholar] [CrossRef]
- Li, G.H.; Chen, C.; Luo, J.Q. The Study on the Implements of Knowledge Gaps in Servitization of Manufacturing Based on Evolutionary Game Theory. Ind. Eng. Manag. 2014, 19, 40–46. [Google Scholar]
- Malhotra, A.; Majchrzak, A.; Niemiec, R.M. Using Public Crowds for Open Strategy Formulation: Mitigating the Risks of Knowledge Gaps. Long Rang Plan. 2017, 50, 397–410. [Google Scholar] [CrossRef]
- Qiu, J.N.; Nian, C.L. A construction method of organizational knowledge structure and its applications in the patent documents. Sci. Res. Manag. 2012, 33, 48–56. [Google Scholar]
- Li, G.; Liu, X.H. Research on the selection of research team members based on knowledge gap. Sci. Technol. Prog. Policy 2015, 32, 139–143. [Google Scholar]
- Zhang, L.Y.; Li, Y.N.; Gu, L.Z. Knowledge Risk Identification of Construction Projects from the Perspective of Knowledge Gap. J. Engin. Manag. 2015, 29, 89–94. [Google Scholar]
- Li, C.; Yang, H.T. Research on the Underlying Mechanism of Different Knowledge Gap Affecting Organization Innovation and Countermeasures. Sci. Technol. Prog. Policy 2012, 29, 115–118. [Google Scholar]
- Nalchigar, S.; Yu, E. Business-driven data analytics: A conceptual modeling framework. Data Knowl. Eng. 2018, 117, 359–372. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Leydesdorff, L. On the normalization and visualization of author co-citation data: Salton’s Cosine versus the Jaccard index. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 77–85. [Google Scholar] [CrossRef]
- Leung, X.Y.; Sun, J.; Bai, B. Bibliometrics of social media research: A co-citation and co-word analysis. Int. J. Hosp. Manag. 2017, 66, 35–45. [Google Scholar] [CrossRef]
- Ba, Z.H. Research on the Domain Theme Evolution Analysis Based on Keywords Semantic Network. Inf. Stud. Theory Appl. 2016, 3, 14. [Google Scholar]
- Zhang, J. A method of intelligence key words extraction based on improved TF-IDF. J. Intell. 2014, 33, 153–155. [Google Scholar]
- Wang, J.Z.; Qiu, T.X. Focused topic Web crawler based on improved TF-IDF alogorithm. J. Comp. Appl. 2015, 35, 2901–2904. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| No | Theme | Fuzzy Membership | |||||
|---|---|---|---|---|---|---|---|
| 1 | Park | 0.48 | 0.14 | 0.04 | 1.00 | 0.00 | 0.00 |
| 2 | Trend | 0.33 | 0.09 | 0.30 | 0.00 | 1.00 | 0.00 |
| 3 | Recourse | 0.30 | 0.09 | 0.29 | 0.00 | 1.00 | 0.00 |
| 4 | Circulation pattern | 0.23 | 0.07 | - | 1.00 | 0.00 | 0.00 |
| 5 | Network | 0.22 | 0.06 | 0.09 | 1.00 | 0.00 | 0.00 |
| 6 | Network structure | 0.22 | 0.06 | 0.05 | 1.00 | 0.00 | 0.00 |
| 7 | Environment | 0.20 | 0.06 | 0.28 | 0.00 | 1.00 | 0.00 |
| 8 | Eigenvector | 0.19 | 0.06 | - | 1.00 | 0.00 | 0.00 |
| 9 | Dynamics | 0.19 | 0.05 | 0.16 | 0.40 | 0.60 | 0.00 |
| 10 | System | 0.17 | 0.05 | 0.51 | 0.00 | 0.00 | 1.00 |
| 11 | Economics | 0.15 | 0.04 | 0.55 | 0.00 | 0.00 | 1.00 |
| 12 | Complexity | 0.15 | 0.04 | - | 1.00 | 0.00 | 0.00 |
| 13 | Network topology | 0.11 | 0.03 | - | 1.00 | 0.00 | 0.00 |
| 14 | Measurement | 0.11 | 0.03 | 0.13 | 0.70 | 0.30 | 0.00 |
| 15 | Modeling | 0.11 | 0.03 | 0.46 | 0.00 | 0.00 | 1.00 |
| 16 | Index | 0.10 | 0.03 | 0.54 | 0.00 | 0.00 | 1.00 |
| 17 | Substance | 0.10 | 0.03 | 0.22 | 0.00 | 1.00 | 0.00 |
| 18 | Information | 0.10 | 0.03 | 0.28 | 0.00 | 1.00 | 0.00 |
| Methods | SWOT [8] | Venn Diagram [10] | Method in This Research |
|---|---|---|---|
| Set up the knowledge requirements set | Organization members adopt brainstorming and other methods to discuss and clarify the strategic intention of the organization and determine the knowledge needed to carry out its expected strategy. | Set up a knowledge demand set and draw a knowledge structure chart by means of brainstorming, interview, and investigation. | TF-IDF algorithm is used to extract the subject words in the text of the required knowledge carrier and construct the requirement knowledge network. |
| Create a knowledge store set | Perform a knowledge-based SWOT analysis to create a map of existing knowledge resources. | Establish a knowledge storage set, describe organizational status, and draw a knowledge distribution map. | Semantic vectorization is carried out based on the Word2Vec model, and the knowledge co-occurrence relationship and semantic association are considered to establish the subject network of reserve knowledge. |
| Identification of knowledge gaps | Identify knowledge gaps by matching organizational knowledge resources and capabilities to strategic opportunities and threats. | Manually compare knowledge structure diagrams and knowledge distribution diagrams to identify the knowledge gap. | Feature vector centrality is used to describe the importance of the required knowledge topic in the reserve knowledge topic network and identify organizational knowledge gaps. |
| Knowledge gap compensation method | Transform an organization’s knowledge strategy into an organizational and technical architecture to support knowledge creation, management, and utilization processes to bridge these gaps | Proposed three kinds of knowledge gaps, knowledge gaps with knowledge accumulation, and knowledge gaps without knowledge accumulation. | Establish a fuzzy evaluation set to evaluate organizational knowledge satisfaction ability. If the ability evaluation is better, the knowledge required by the organization can be fully satisfied within the organization. Instead, seek support outside the organization or gradually meet the requirements of knowledge topics through special training and other means. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, L.; An, X.; Zhang, S.; Wang, X. Research on Knowledge Gap Identification Method in Innovative Organizations under the “Internet+” Environment. Information 2020, 11, 572. https://doi.org/10.3390/info11120572
Qi L, An X, Zhang S, Wang X. Research on Knowledge Gap Identification Method in Innovative Organizations under the “Internet+” Environment. Information. 2020; 11(12):572. https://doi.org/10.3390/info11120572
Chicago/Turabian StyleQi, Lin, Xuejiao An, Shuo Zhang, and Xiang Wang. 2020. "Research on Knowledge Gap Identification Method in Innovative Organizations under the “Internet+” Environment" Information 11, no. 12: 572. https://doi.org/10.3390/info11120572
APA StyleQi, L., An, X., Zhang, S., & Wang, X. (2020). Research on Knowledge Gap Identification Method in Innovative Organizations under the “Internet+” Environment. Information, 11(12), 572. https://doi.org/10.3390/info11120572