Prevention of Unintended Appearance in Photos Based on Human Behavior Analysis


Abstract
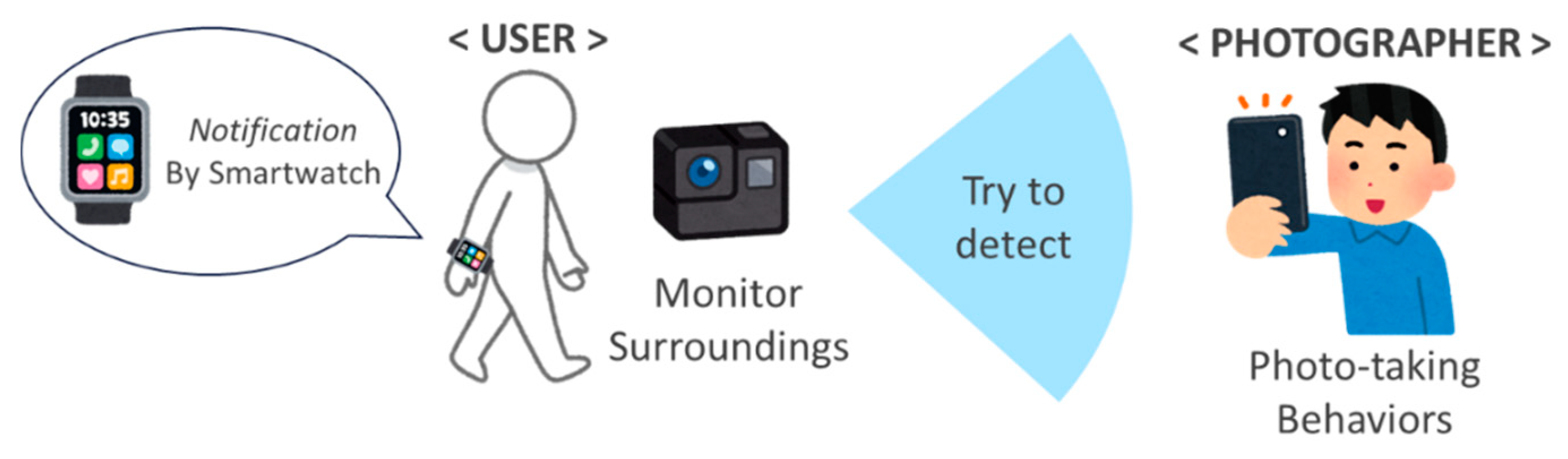
1. Introduction
2. Related Works
2.1. Photographer-Site Methods
2.2. Photographed Person-Site Methods
3. Proposed Approach
3.1. Photo-Taking Recognition Algorithm
| Algorithm 1: Proposed Algorithm | |
| Input: Monitored Video, DP Threshold | |
| Output: 0: Photo-Taking Behavior, 1: Net-Surfing Behavior | |
| 1: | Initiate OpenPose |
| 2: | Analyze the monitored video |
| 3: | return arm parts’ skeleton information |
| 4: | Calculate the arm’s length and angle of bending arm |
| 5: | (I) length of upper arm, (II) length of lower arm, (III) angle of bending arm |
| 6: | return (I)~(III) value |
| 7: | Calculate DP scores |
| 8: | DP matching (reference data: photo-taking behavior) |
| 9: | returnDP score |
| 10: | If DP score ≤ threshold Then |
| 11: | Judged as photo-taking behavior |
| 12: | return0: photo-taking behavior |
| 13: | Else |
| 14: | Judged as net-surfing behavior |
| 15: | return 1: net-surfing behavior |
| 16: | End if |
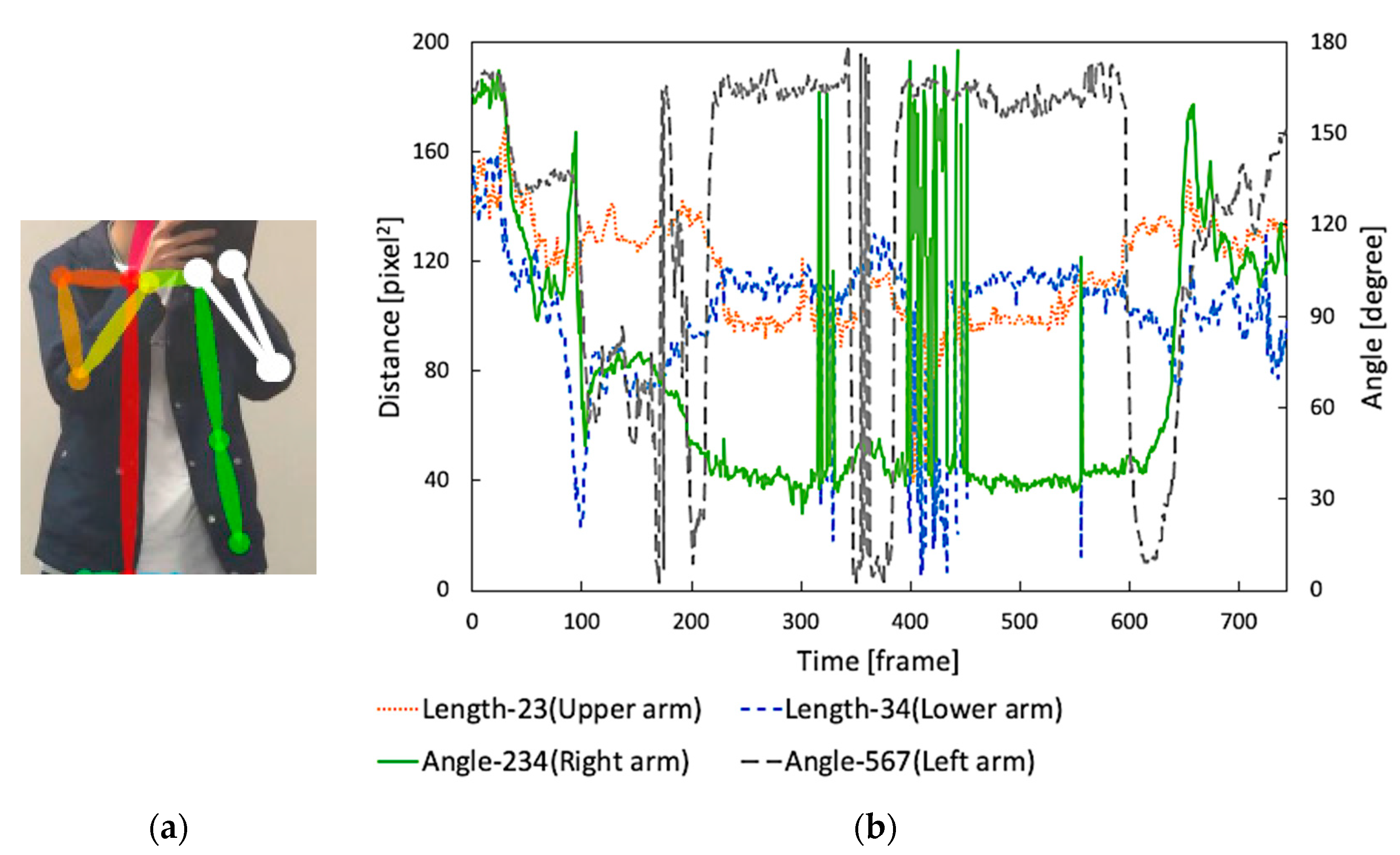
3.2. How Does the Proposed Approach Work in Reality?
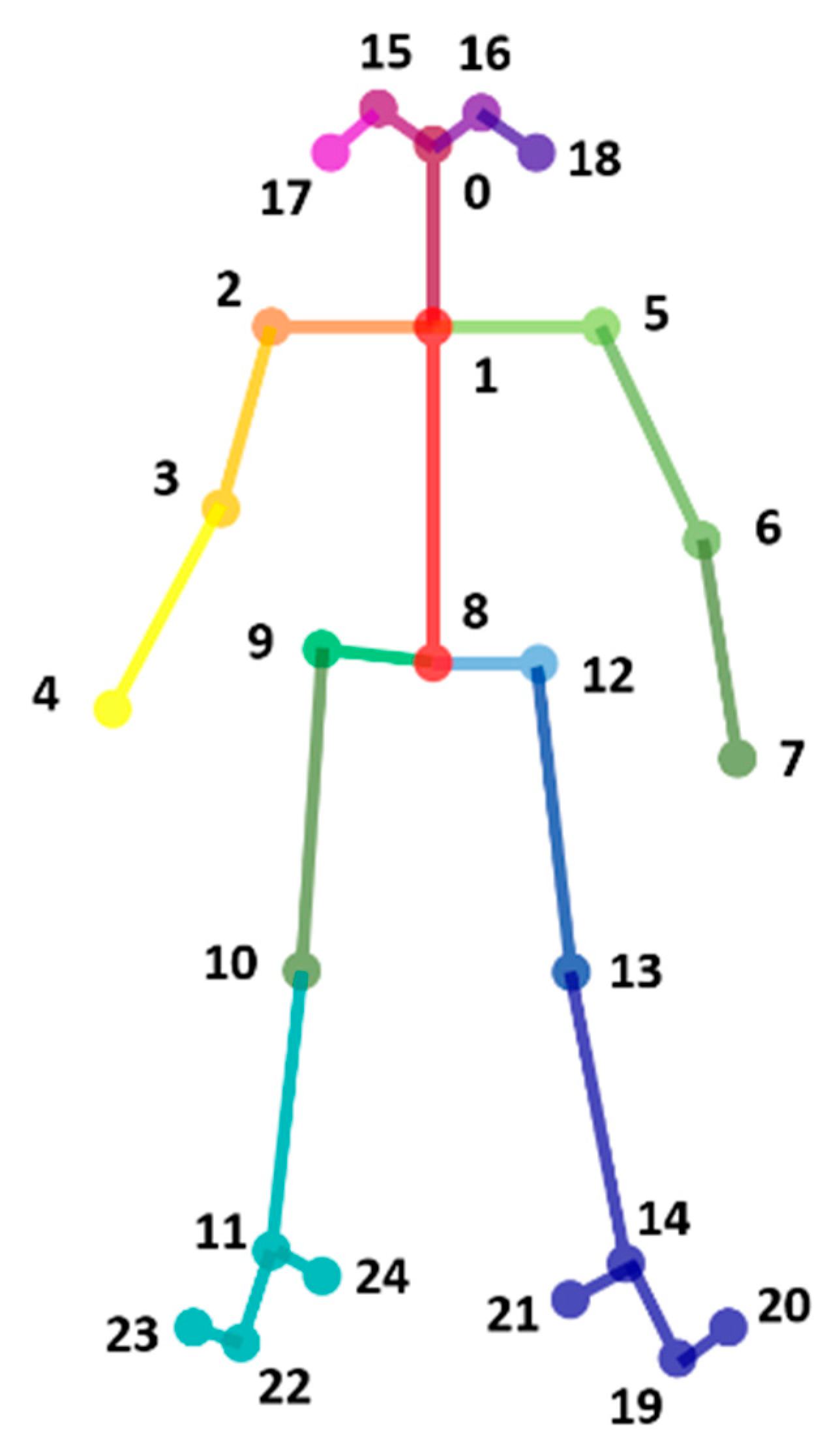
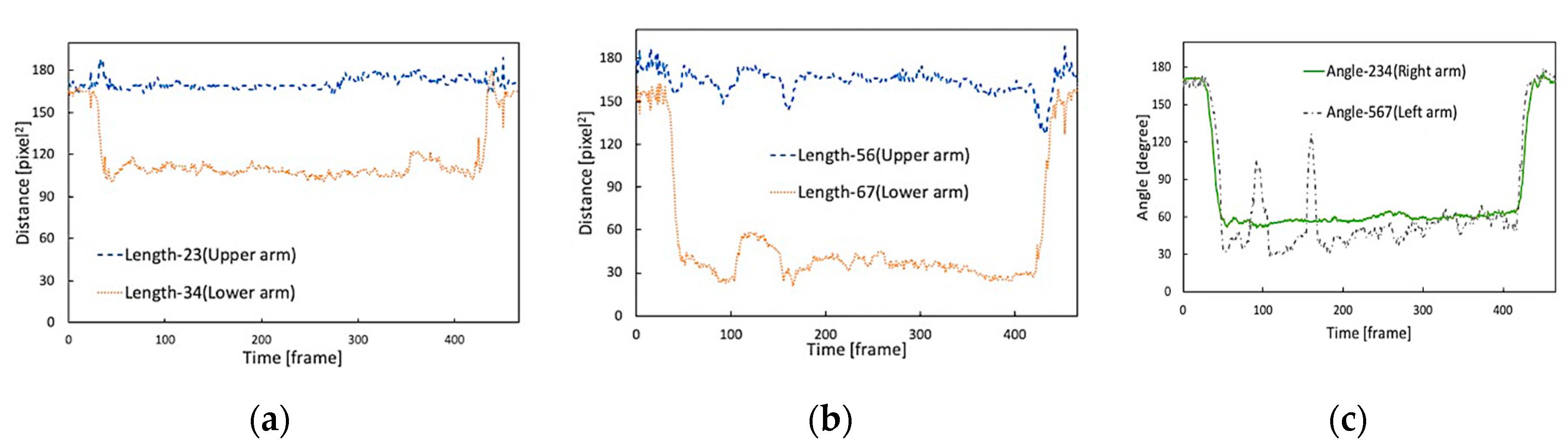
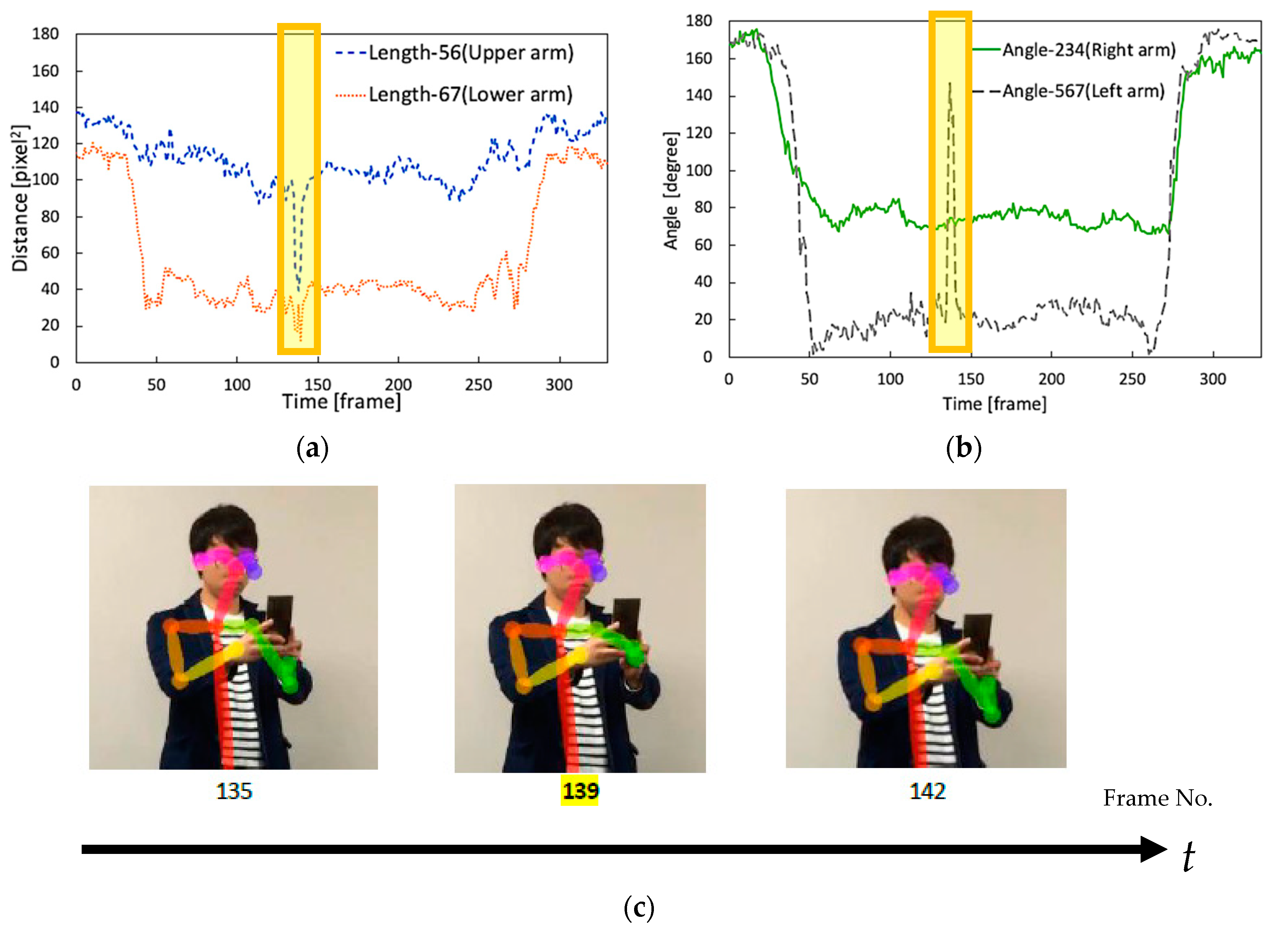
3.3. Extract Human Skeleton Information
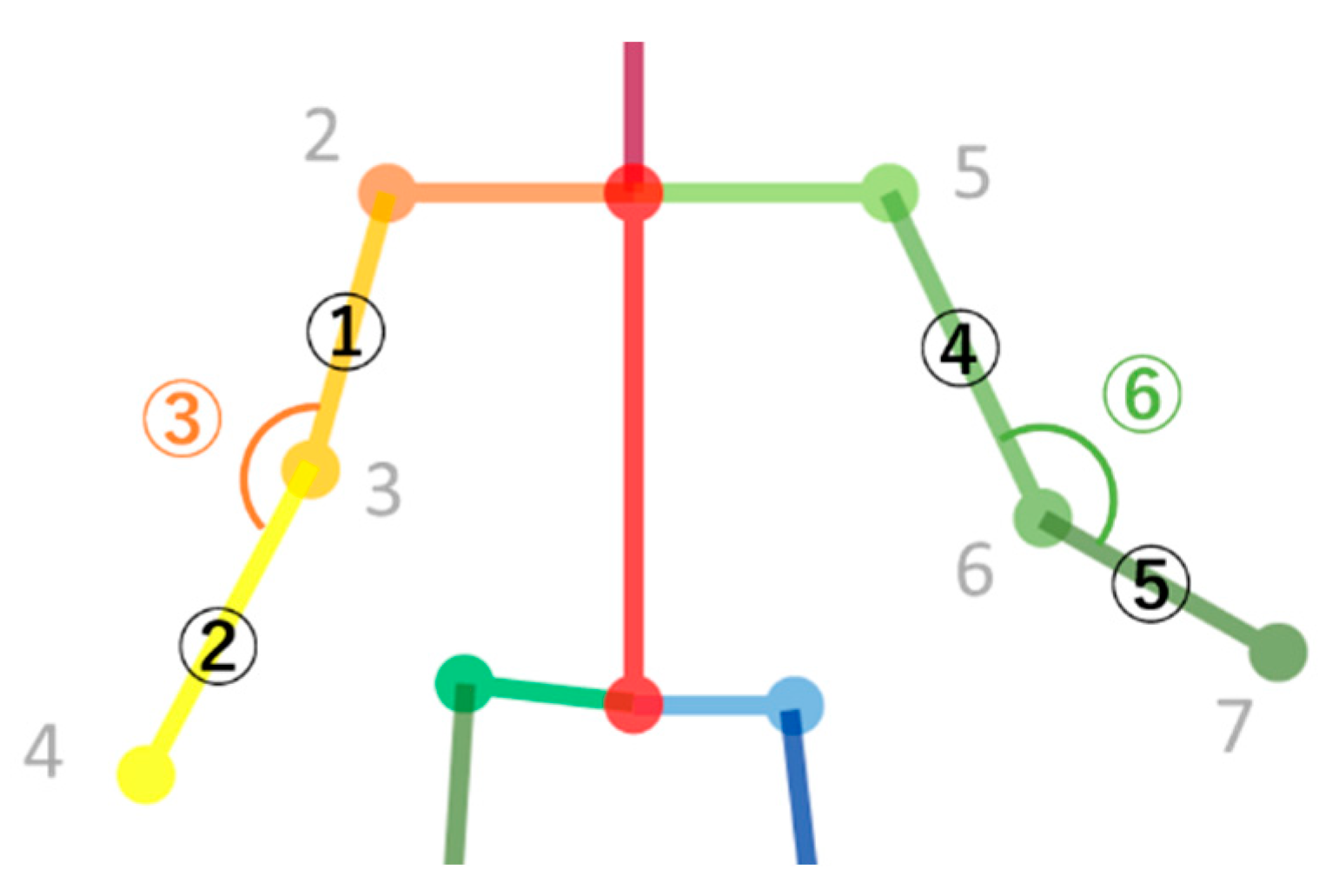
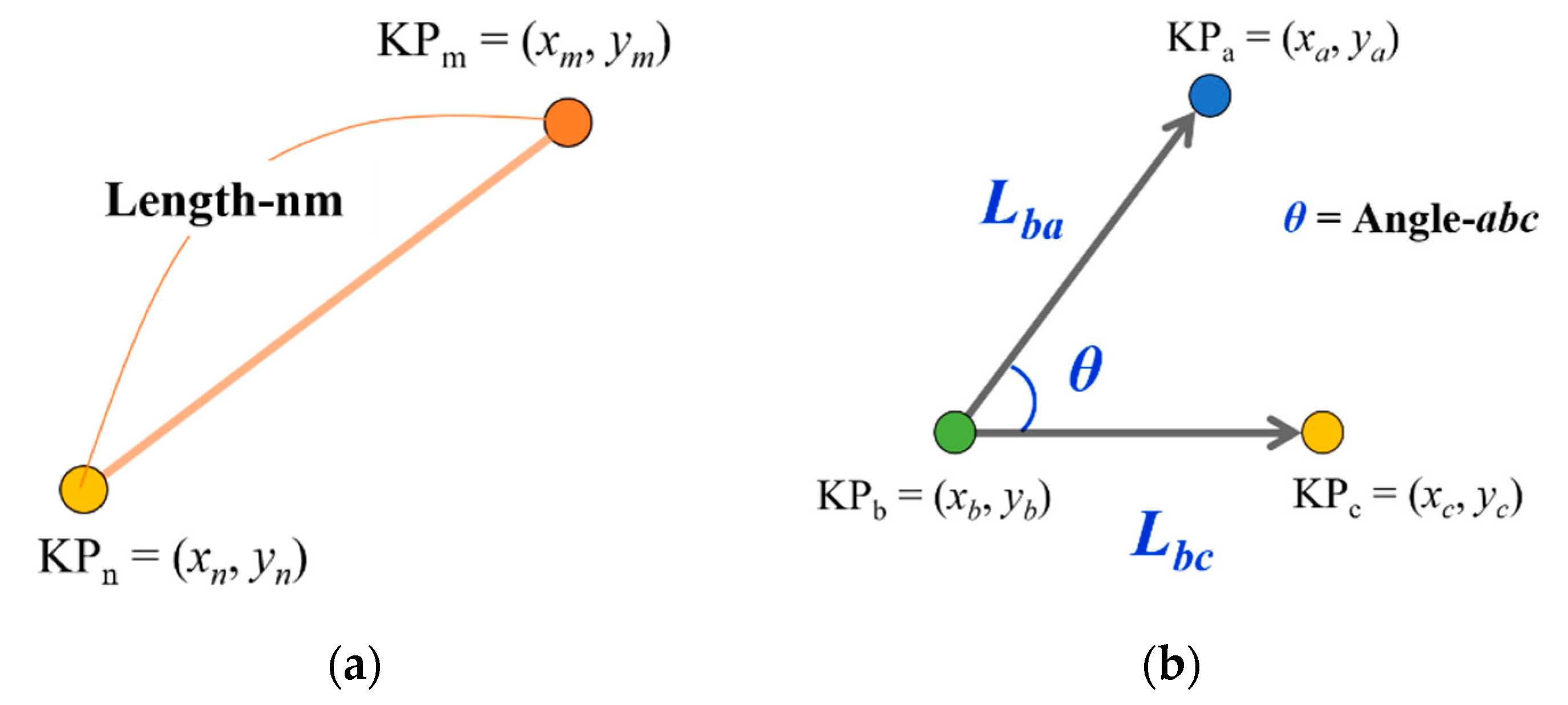
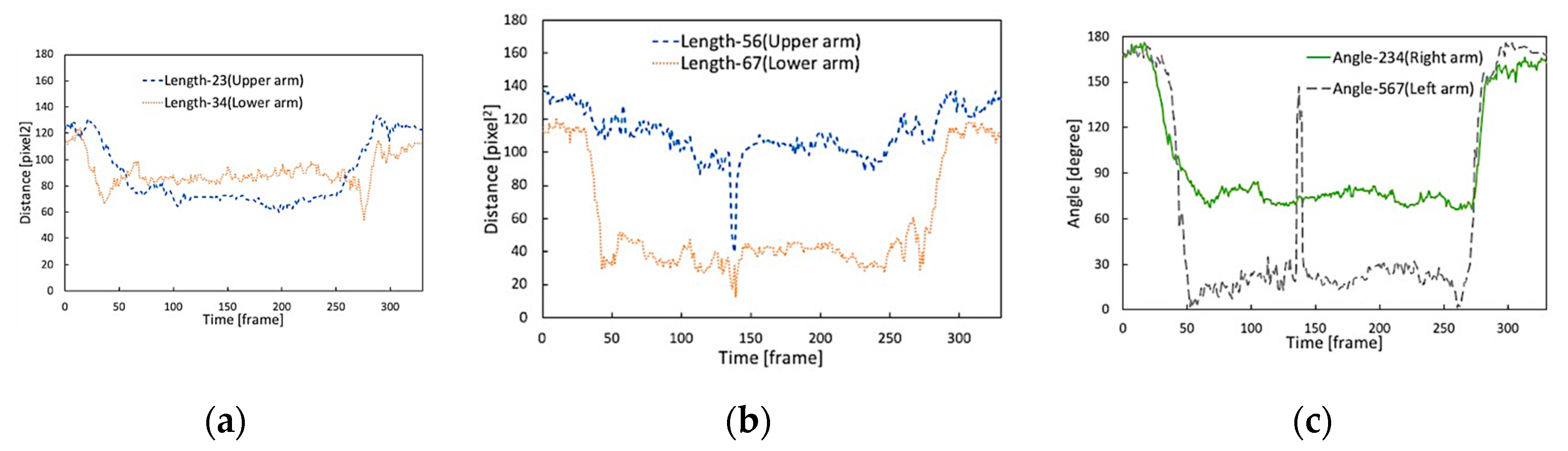
- Calculation of the arm’s length (I) and (II)
- Calculation of the angle of bending arm (III)
3.4. Threshold for Recognizing Photo-Taking Behavior
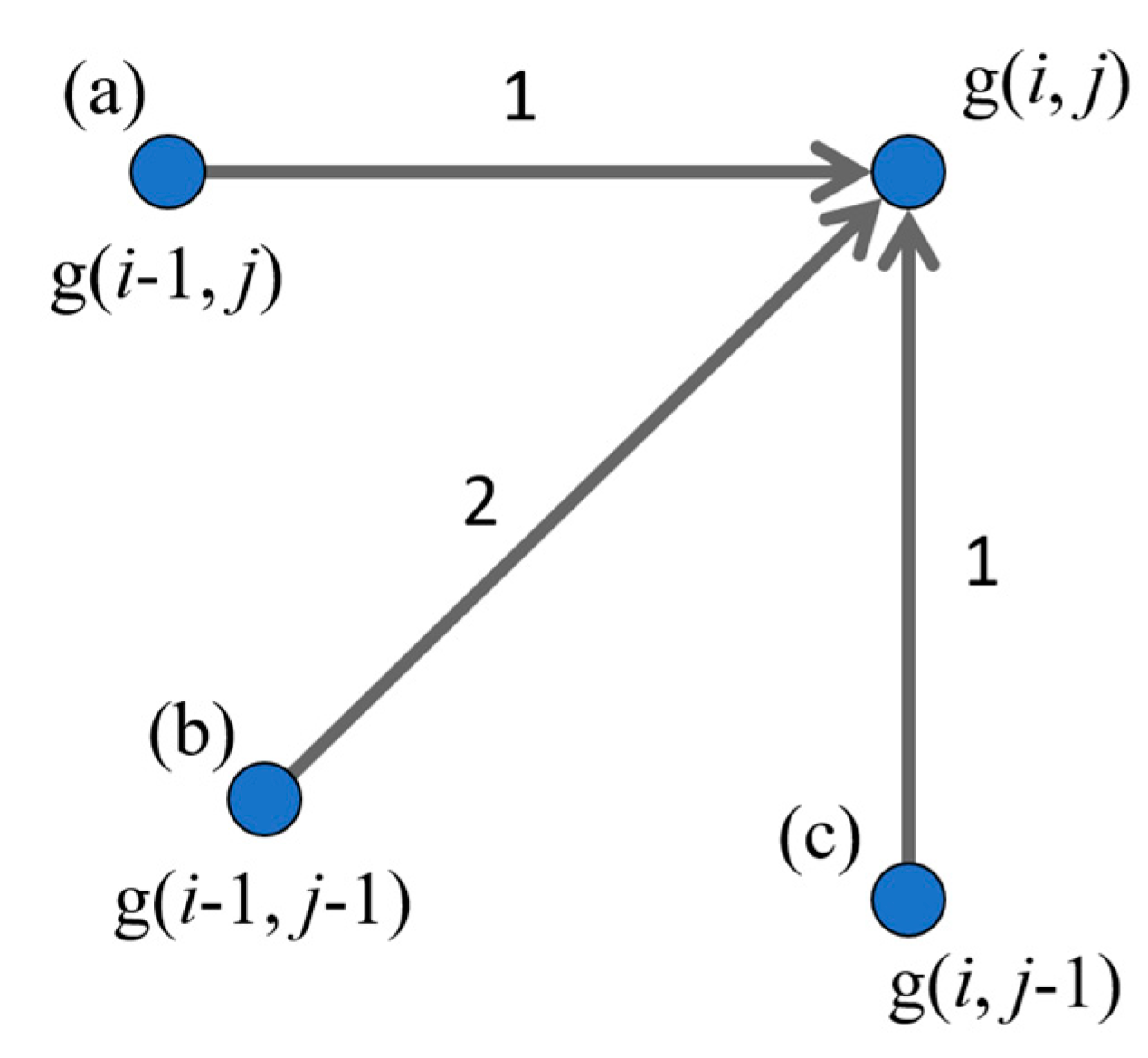
3.4.1. DP Matching
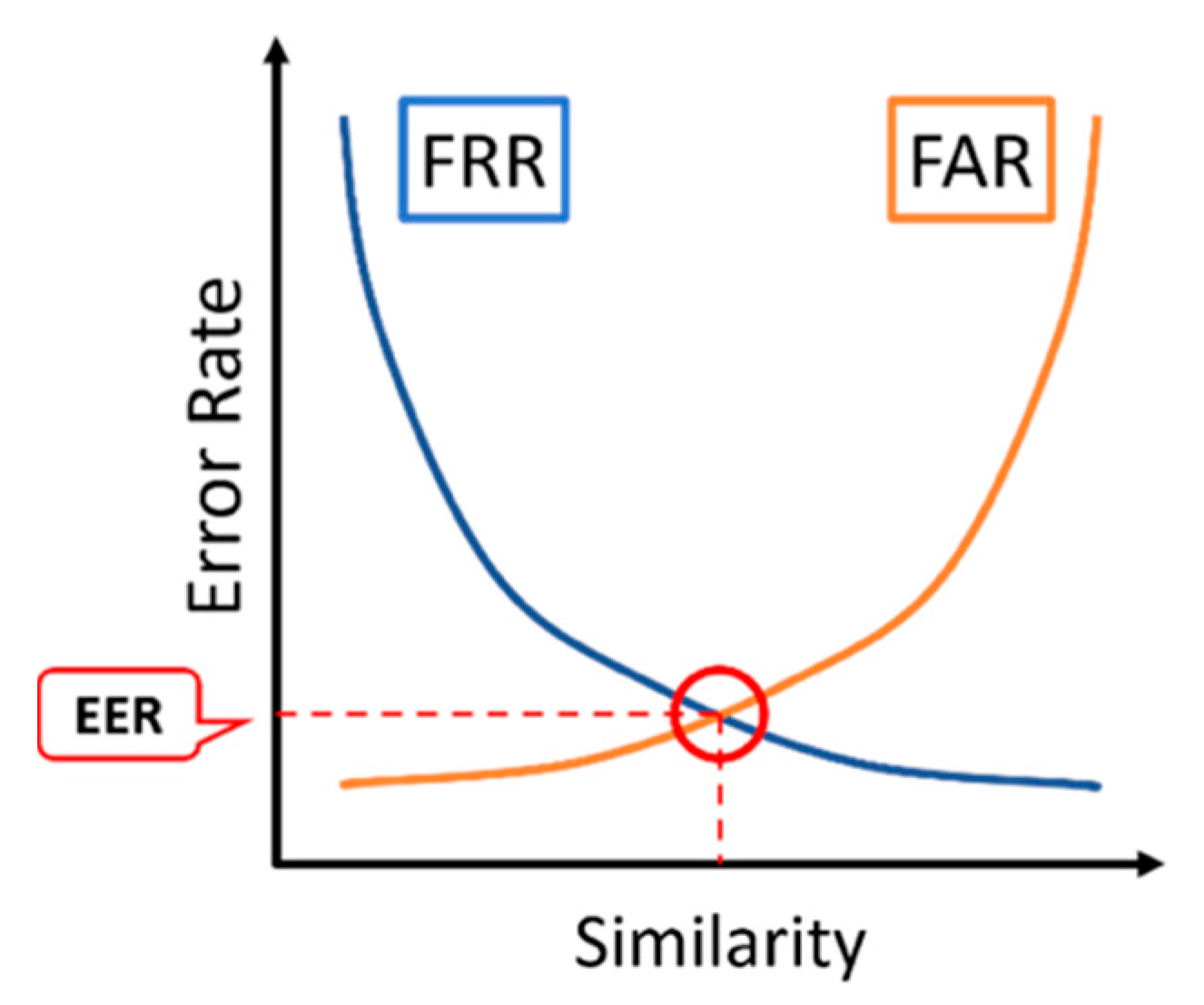
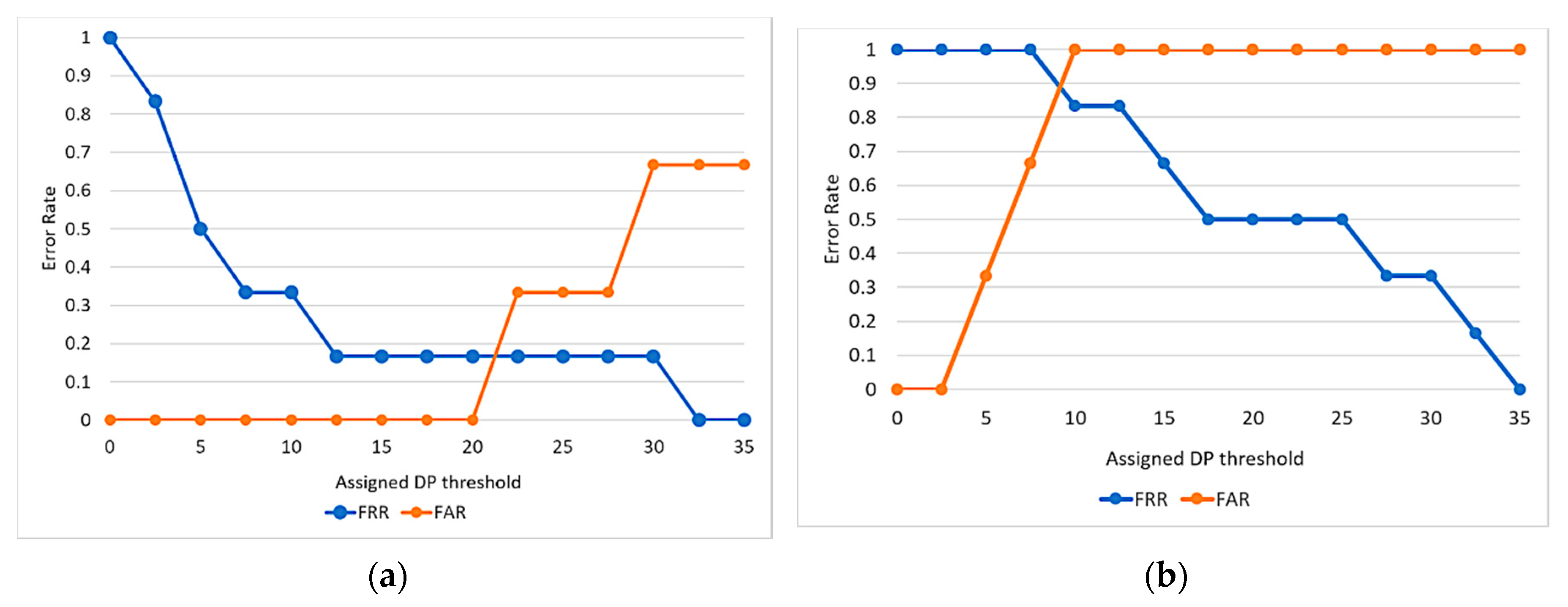
3.4.2. FAR and FRR and DP Threshold Determination
4. Evaluations
4.1. Dataset Collection
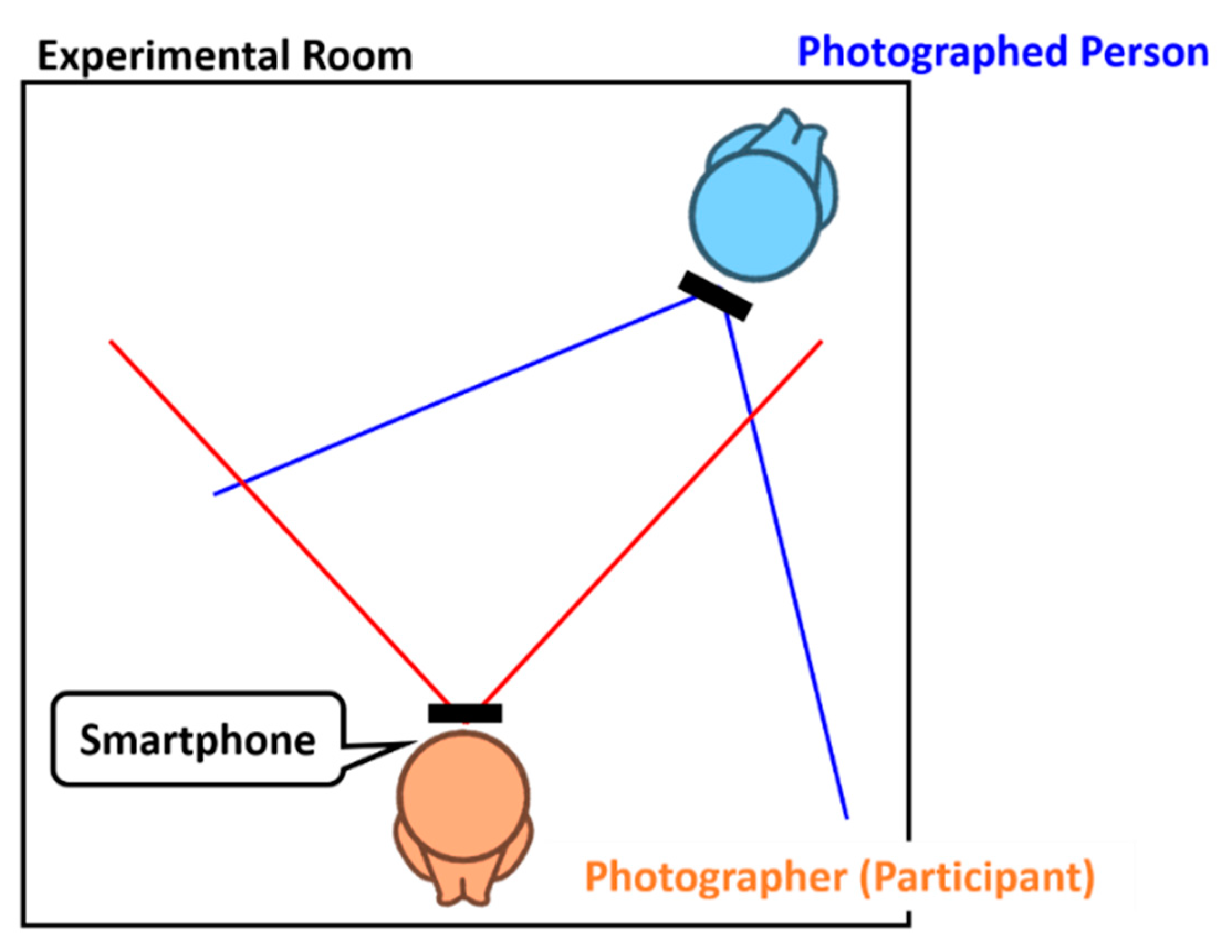
4.1.1. Experimental Setup and Data Acquisition
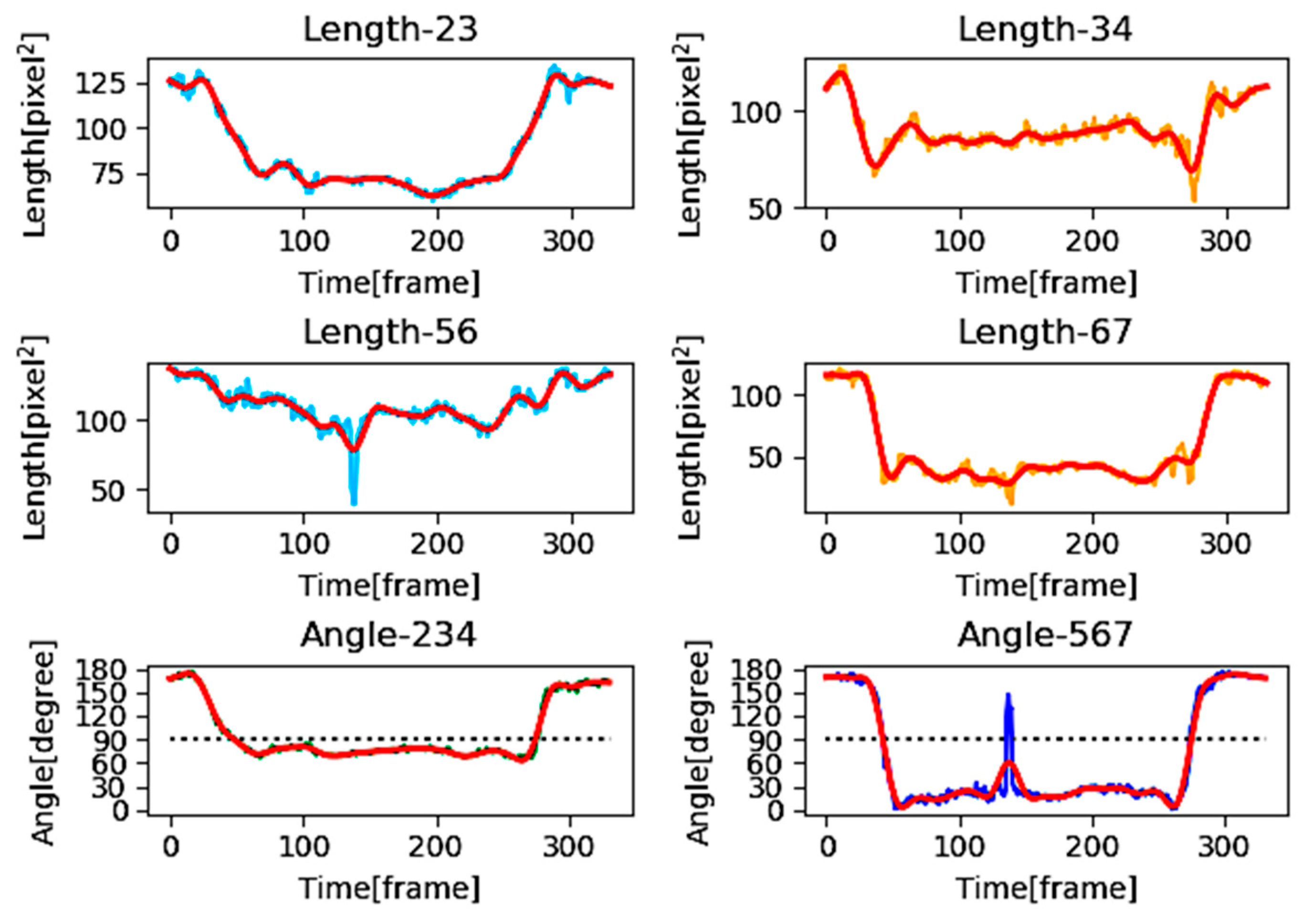
4.1.2. Data Pre-Processing
4.2. Determination of DP Threshold
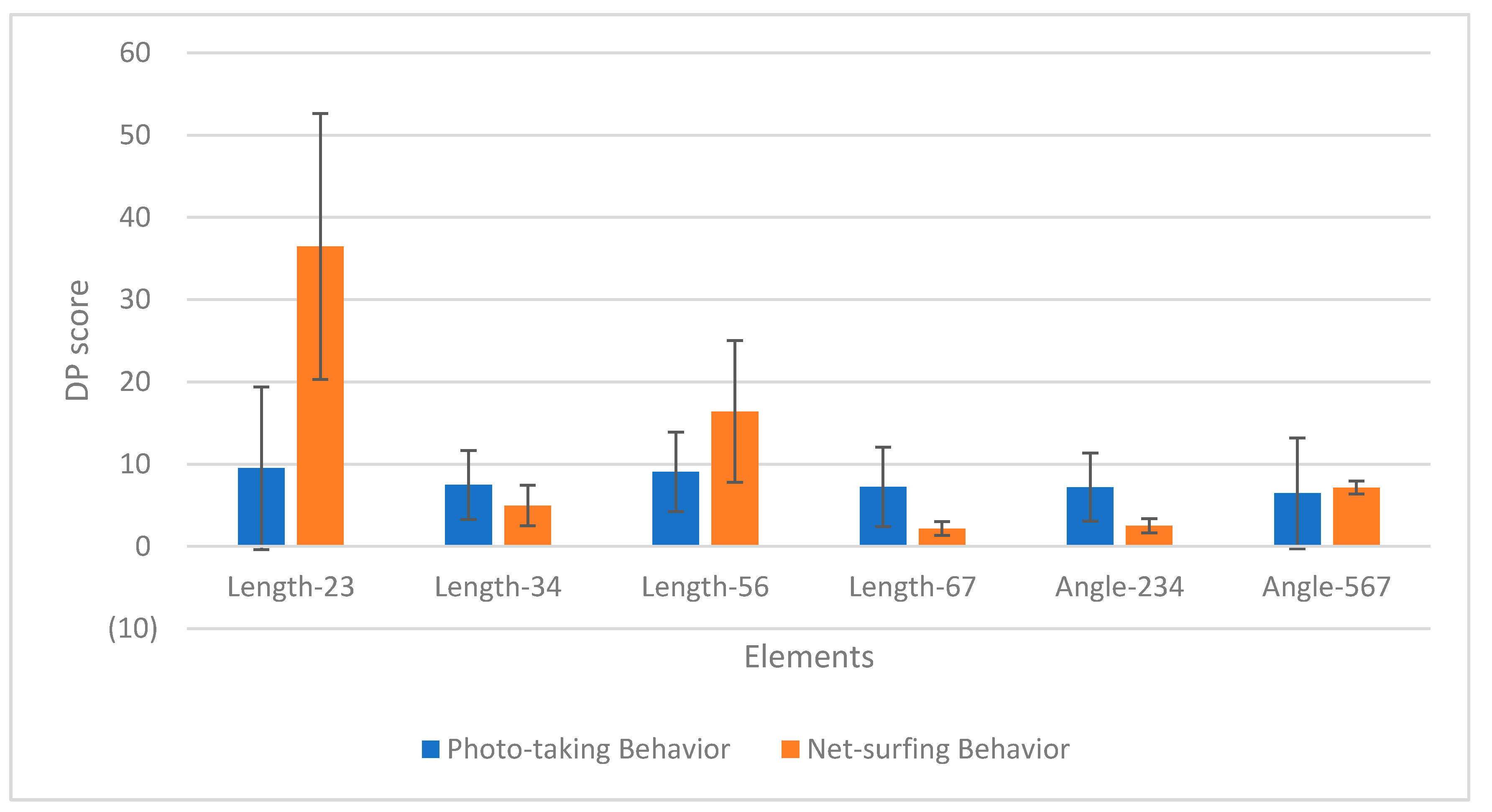
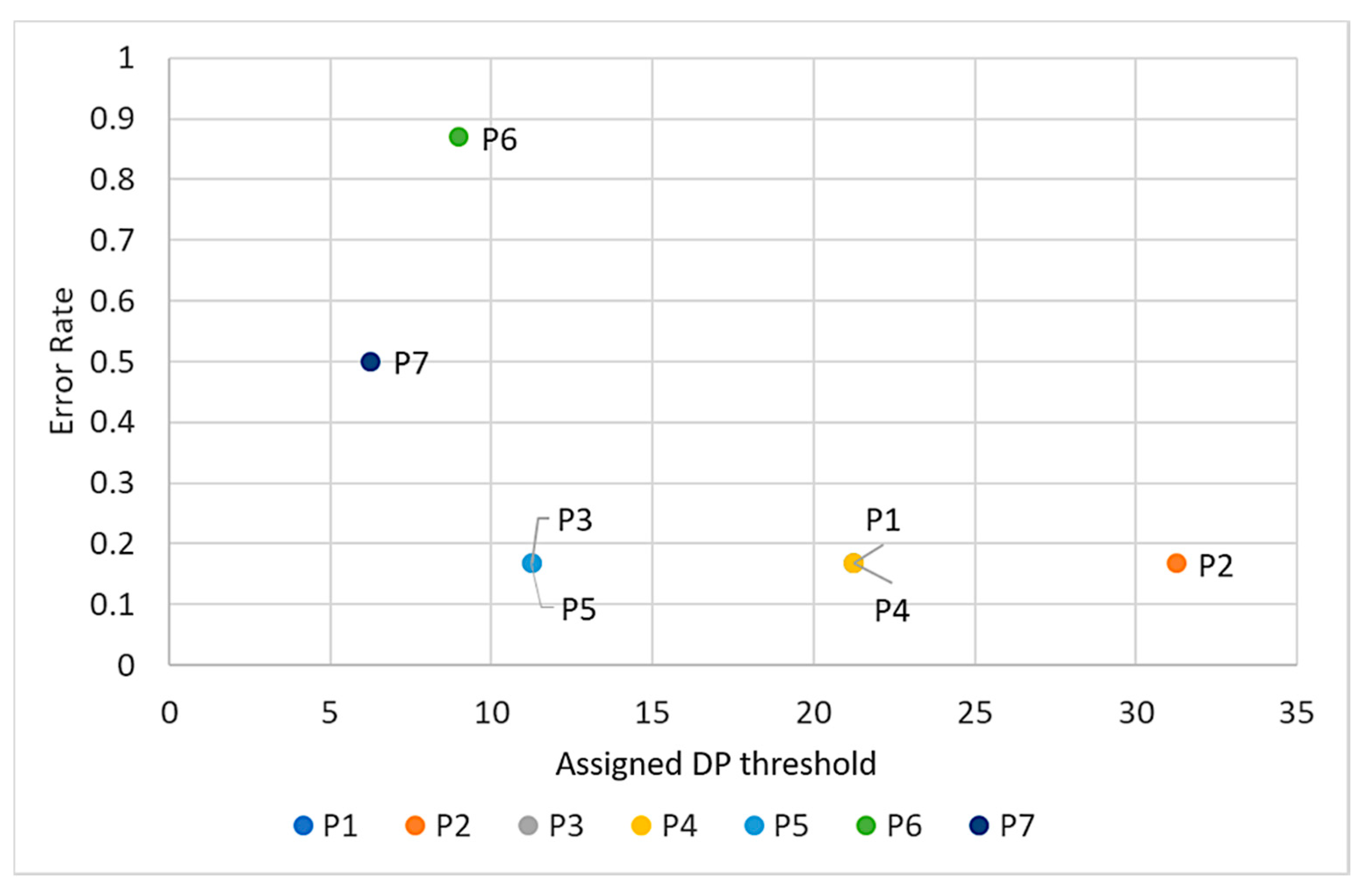
4.3. Performance Evaluation of the Proposed Approach
4.4. Overal Discussion and Future Works
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- We Are Social, Digital in 2019. Available online: https://wearesocial.com/global-digital-report-2019 (accessed on 31 January 2020).
- Ministry of Internal Affairs and Communications, White Paper Information and Communications in Japan,” Part2, Figure 5-2-1-1, Transitions in Household Ownership Rates for ICT Devices. p. 65. Available online: https://www.soumu.go.jp/main_sosiki/joho_tsusin/eng/whitepaper/2018/index.html (accessed on 2 October 2020).
- Ministry of Internal Affairs and Communications, White Paper Information and Communications in Japan, Part1, Figure 4-2-1-2, Terminals Connected to the Internet. p. 42. Available online: https://www.soumu.go.jp/main_sosiki/joho_tsusin/eng/whitepaper/2018/index.html (accessed on 2 October 2020).
- McCarthy, B.C.; Feis, A. Rogue NYPD Cops Are Using Facial Recognition App Clearview. Available online: https://nypost.com/2020/01/23/rogue-nypd-cops-are-using-sketchy-facial-recognition-app-clearview/ (accessed on 15 July 2020).
- Frome, A.; Cheung, G.; Abdulkader, A.; Zennaro, M.; Wu, B.; Bissacco, A.; Adam, H.; Neven, H.; Vincent, L. Large-scale privacy protection in Google Street View. In Proceedings of the IEEE Computer Vision (ICCV2009), Kyoto, Japan, 29 September–2 October 2009; pp. 2373–2380. [Google Scholar]
- Google Street View, Google-Contributed Street View Imaginary Policy. Available online: https://www.google.com/streetview/policy/#blurring-policy (accessed on 17 July 2020).
- Koyama, T.; Nakashima, Y.; Babaguchi, N. Real-time privacy protection system for social videos using intentionally-captured persons detection. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; Volume 6, pp. 1–6. [Google Scholar]
- Guardian Project, ObscuraCam: Secure Smart Camera. Available online: https://guardianproject.info/apps/obscuracam/ (accessed on 17 July 2020).
- Hasan, R.; Crandall, D.; Fritz, M.; Kapadia, A. Automatically Detecting Bystanders in Photos to Reduce Privacy Risks. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–20 May 2020; pp. 318–335. [Google Scholar] [CrossRef]
- Bo, C.; Guobin, S.; Jie, L.; Xiang-Yang, L.; YongGuang, Z.; Feng, Z. Privacy. tag: Privacy concern expressed and respected. In Proceedings of the 12th ACM Conference on Embedded Network Sensor Systems, Memphis, TN, USA, 23–26 November 2014; pp. 163–176. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2584–2593. [Google Scholar]
- Pallas, F.; Ulbricht, M.-R.; Jaume-Palasí, L.; Höppner, U. Offlinetags: A novel privacy approach to online photo sharing. In Proceedings of the Extended Abstracts of the 32nd Annual ACM Conference on Human Factors in Computing Systems—CHI EA ’14. Association for Computing Machinery, New York, NY, USA, 26 April–1 May 2014; pp. 2179–2184. [Google Scholar] [CrossRef]
- Shu, J.; Rui, Z.; Pan, H. Cardea: Context-aware visual privacy protection for photo taking and sharing. In Proceedings of the 9th ACM Multimedia Systems, Amsterdam, The Netherlands, 12–15 June 2018; pp. 304–315. [Google Scholar]
- Li, A.; Li, Q.; Gao, W. PrivacyCamera: Cooperative Privacy-Aware Photographing with Mobile Phones. In Proceedings of the 2016 13th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), London, UK, 27–30 June 2016; pp. 1–9. [Google Scholar]
- Aditya, P.; Sen, R.; Druschel, P.; Oh, S.J.; Benenson, R.; Fritz, M.; Schiele, B.; Bhattacharjee, B.; Wu, T.T. Epub I-Pic: A platform for privacy-compliant image capture. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services-MobiSys ’16, Singapore, 26–30 June 2016; pp. 235–248. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, K.; Li, X.-Y.; Liu, C.; Ding, X.; Liu, Y. Privacy-friendly photo capturing and sharing system. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 524–534. [Google Scholar] [CrossRef]
- Cao, Z.; Šimon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Ribaric, S.; Ariyaeeinia, A.; Pavešić, N. De-identification for privacy protection in multimedia content: A survey. Signal Process. Image Commun. 2016, 47, 131–151. [Google Scholar] [CrossRef]
- Kitahara, I.; Kogure, K.; Hagita, N. Stealth vision for protecting privacy. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 26 August 2004; Volume 4, pp. 404–407. [Google Scholar]
- Wu, Y.; Yang, F.; Ling, H. Privacy-Protective-GAN for Face De-identification. arXiv 2018, arXiv:1806.08906. [Google Scholar]
- Dimiccoli, M.; Marín, J.; Thomaz, E. Mitigating Bystander Privacy Concerns in Egocentric Activity Recognition with Deep Learning and Intentional Image Degradation. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 1, 1–18. [Google Scholar] [CrossRef]
- Yamada, T.; Gohshi, S.; Echizen, I.; Yamada, T. Privacy Visor: Method Based on Light Absorbing and Reflecting Properties for Preventing Face Image Detection. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Washington, DC, USA, 13–16 October 2013; pp. 1572–1577. [Google Scholar]
- Perez, A.; Zeadally, S.; Matos Garcia, L.J.; Mouloud, J.A.; Griffith, S. FacePET: Enhancing Bystanders Facial Privacy with Smart Wear- ables/Internet of Things. Electronics 2018, 7, 379. [Google Scholar] [CrossRef]
- Kaihoko, Y. Identification of Photo-taking behaviors using Optical Flow Vector. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 306–312. [Google Scholar] [CrossRef]
- ZDNet, Americans Spend Far More Time on Their Smartphones than They Think. Available online: https://www.zdnet.com/article/americans-spend-far-more-time-on-their-smartphones-than-they-think/ (accessed on 28 August 2020).
- Bhowmik, M.K.; Saha, K.; Majumder, S.; Majumder, G.; Saha, A.; Sarma, A.N.; Nasipuri, M. Thermal Infrared Face Recognition—A Biometric Identification Technique for Robust Security system. Rev. Refinements New Ideas Face Recognit. 2011. [Google Scholar] [CrossRef]
- False Acceptance Rate (FAR) and False Recognition Rate (FRR) in Biometrics. Available online: https://www.bayometric.com/false-acceptance-rate-far-false-recognition-rate-frr/ (accessed on 15 July 2020).
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index Factors | Joint Position (Keypoint) | Arm Parts | Index Number in Figure 3 | Expression in This Paper | |
|---|---|---|---|---|---|
| Right | I | 2–3 | Right Upper arm | ① | Length-23 |
| II | 3–4 | Right Lower arm | ② | Length-34 | |
| III | 2–3–4 | Angle of the bending right arm | ③ | Angle-234 | |
| Left | I | 5–6 | Left Upper arm | ④ | Length-56 |
| II | 6–7 | Left Lower arm | ⑤ | Length-67 | |
| III | 5–6–7 | Angle of the bending left arm | ⑥ | Angle-567 |
| Photo-Taking Behavior | Net-Surfing Behavior | |
|---|---|---|
| Dataset1 | ||
| Dataset2 |
| Length-23 | Length-34 | Length-56 | Length-67 | Angle-234 | Angle-567 | ||
|---|---|---|---|---|---|---|---|
| Photo-taking behavior | P2 | 1.69 | 2.41 | 5.84 | 6.23 | 9.11 | 4.33 |
| P3 | 6.54 | 14.57 | 3.41 | 4.62 | 8.98 | 2.73 | |
| P4 | 3.39 | 3.36 | 4.76 | 4.38 | 2.28 | 1.65 | |
| P5 | 3.92 | 6.40 | 10.28 | 17.9 | 14.53 | 21.34 | |
| P6 | 30.64 | 10.93 | 16.87 | 5.9 | 4.44 | 3.91 | |
| P7 | 10.89 | 7.21 | 13.2 | 4.4 | 3.91 | 4.80 | |
| Average | 9.51 | 7.48 | 9.06 | 7.24 | 7.21 | 6.46 | |
| S.T. | 9.89 | 4.20 | 4.84 | 4.82 | 4.15 | 6.74 | |
| Net-surfing behavior | N1 | 58.88 | 8.50 | 28.6 | 2.04 | 3.48 | 6.31 |
| N2 | 21.48 | 3.18 | 11.17 | 3.26 | 2.73 | 8.20 | |
| N3 | 29.05 | 3.27 | 9.5 | 1.25 | 1.39 | 6.94 | |
| Average | 36.47 | 4.98 | 16.42 | 2.18 | 2.54 | 7.15 | |
| S.T. | 16.15 | 2.49 | 8.64 | 0.83 | 0.86 | 0.78 |
| Reference Data: Photo-Taking Behavior (Dataset1) | |||||||
|---|---|---|---|---|---|---|---|
| length-23(Right Upper arm) | |||||||
| P1 | P2 | P3 | P4 | P5 | |||
| Input Data (Dataset2) | Photo-taking behavior | P8 | 8.10 | 7.89 | 5.69 | 8.27 | 3.40 |
| P9 | 4.60 | 6.68 | 3.84 | 4.04 | 5.91 | ||
| P10 | 0.93 | 2.84 | 5.17 | 2.96 | 3.28 | ||
| P11 | 8.44 | 9.49 | 2.07 | 3.33 | 3.22 | ||
| P12 | 1.14 | 2.30 | 5.74 | 2.81 | 2.91 | ||
| P13 | 5.61 | 6.00 | 1.42 | 1.93 | 3.65 | ||
| P14 | 21.10 | 28.43 | 7.01 | 17.08 | 10.18 | ||
| P15 | 13.59 | 13.74 | 10.18 | 13.51 | 3.14 | ||
| Net-surfing behavior | N4 | 35.44 | 43.55 | 15.57 | 32.08 | 22.06 | |
| N5 | 24.26 | 33.34 | 10.02 | 22.68 | 12.71 | ||
| N6 | 14.62 | 19.47 | 11.26 | 17.28 | 6.67 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaihoko, Y.; Tan, P.X.; Kamioka, E. Prevention of Unintended Appearance in Photos Based on Human Behavior Analysis. Information 2020, 11, 468. https://doi.org/10.3390/info11100468
Kaihoko Y, Tan PX, Kamioka E. Prevention of Unintended Appearance in Photos Based on Human Behavior Analysis. Information. 2020; 11(10):468. https://doi.org/10.3390/info11100468
Chicago/Turabian StyleKaihoko, Yuhi, Phan Xuan Tan, and Eiji Kamioka. 2020. "Prevention of Unintended Appearance in Photos Based on Human Behavior Analysis" Information 11, no. 10: 468. https://doi.org/10.3390/info11100468
APA StyleKaihoko, Y., Tan, P. X., & Kamioka, E. (2020). Prevention of Unintended Appearance in Photos Based on Human Behavior Analysis. Information, 11(10), 468. https://doi.org/10.3390/info11100468