1. Introduction
The development of the web has led to more widespread and visible content. However, the rapid growth in the amount of data available resulted in the need to include more semantics in websites, leading to the creation of the semantic web. In order to enable the implementation of the semantic web, new technologies have been developed (e.g., linked data) and existing technologies were incorporated (e.g., thesauri, ontologies, semantic bases). The addition of semantics and the incorporation of technologies allowed the evolution of search and research mechanisms on the web, which innovates the way data are discovered, accessed, integrated, and used [
1].
The semantic web aims to provide a space of shared semantic information, qualitatively changing experiences on the web [
2]. With the help of such technologies, user participation on the Internet has become more active and enabled content creation besides the adaptation and development of applications for varied fields. One of the fields that benefit from greater user participation on the internet is geographic information.
Citizens (users) are using mobile devices to collect geographic information using web-based mapping interfaces to tag and annotate geographic characteristics such as adding geotags to photographs. These actions originated the term Volunteered Geographic Information (VGI) [
3]. However, discovering and properly using VGI data still face several challenges, such as ambiguity in terms employed by the user and precision of geographic coordinates. One of the ways to mitigate these issues is by adding semantics to VGI using linked data.
The linked data concept arose to aid in the discovery, access, and use of online data. Linked data are semi-structured data that allow specifying semantic relationships among themselves. Using such concept, data on the internet become semi-structured nodes of a semantic network [
1]. The semantic relationships expressed by linked data facilitate their discovery across different data repositories, besides allowing semantic searches to the performed [
4].
Given the use of semantic relationships to relate data and, therefore, improve sharing, the linked data concept has been suggested as an approach in semantic enrichment of VGI [
5,
6]. Nonetheless, manually adding semantics to VGI is a costly, tedious, error-prone task [
7]. Requiring users to describe the semantics and semantic relationships of previously produced volunteered geographic data is impractical either due to the lack of user knowledge on how to properly specify data semantics or due to the burden of this task, which would prevent users from producing new geographic data. Therefore, an automated process is required to semantically enrich large amounts of VGI in an attempt to meet the needs of a specific application domain and provide a more thorough description of user-generated data. However, existing works focus on the textual data of the VGI contributions to semantically enrich them [
8] or proposes a semi-automatic to tackle this task [
9].
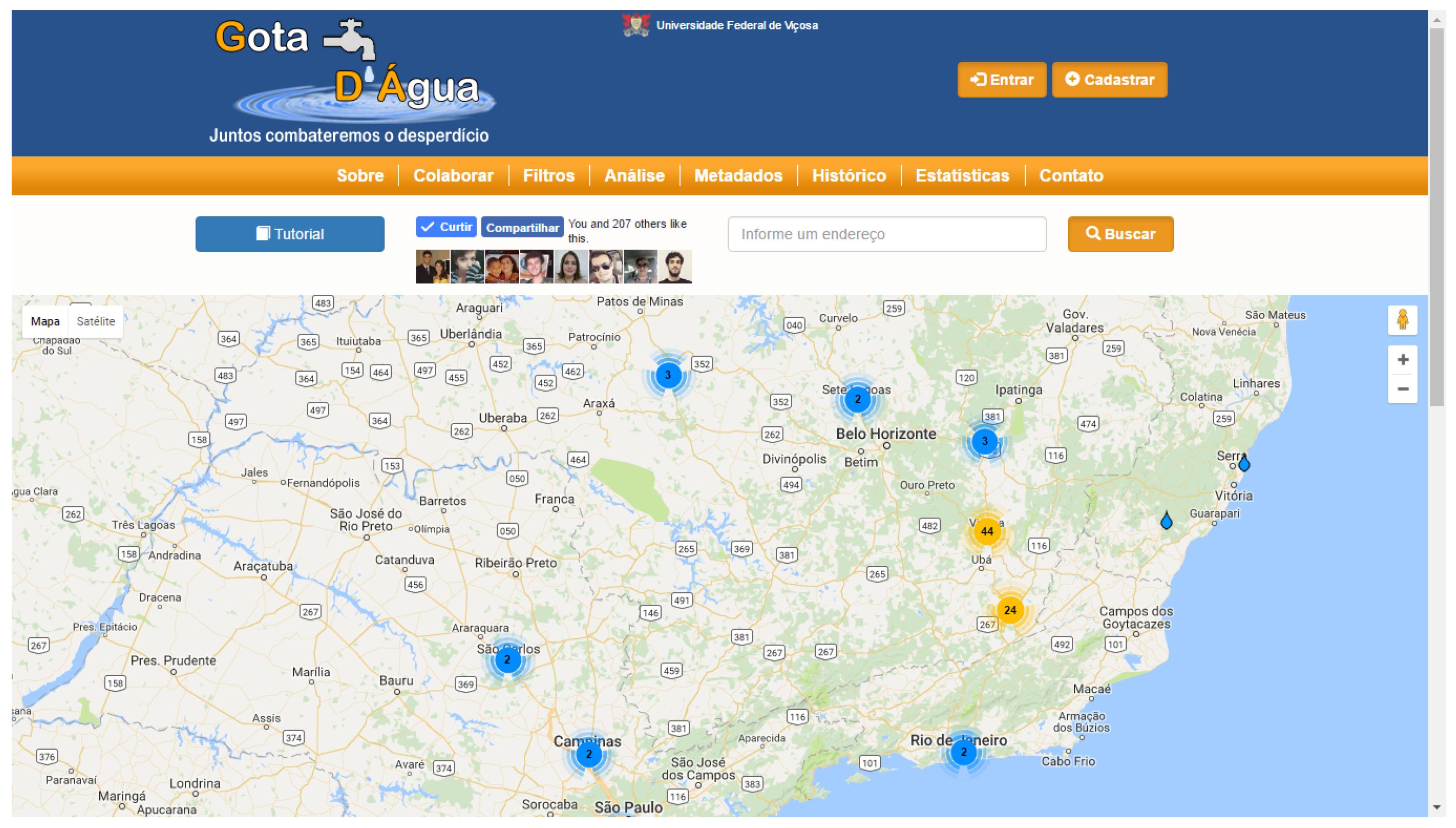
This paper proposes a method to semantically enrich VGI that present little textual data and it is based on spatial relations of proximity. The VGI semantically enriched by the proposed approach can be used to build a thesaurus, which further contributes to add semantics to the data. From this, semantic analyses can be performed on such data and, consequently, improve their discovery and use in the semantic web. Moreover, adding semantics to VGI allows finding or solving inconsistencies and ambiguities, thus improving the quality of user-generated data. In our case, a VGI system with contributions related to water waste called Gota D’Água (water drop, in free translation) was used as study case to demonstrate analyses with the contributions that are only possible after the semantic enrichment process.
The remainder of the paper is structured as follows.
Section 2 makes a review of the main concepts involved in the study.
Section 3 presents some related works.
Section 4 presents the method proposed.
Section 5 describes the study case.
Section 6 discusses the results obtained and, finally,
Section 7 makes some final considerations.
4. A Method for VGI Enrichment with Linked Data and Thesaurus Creation
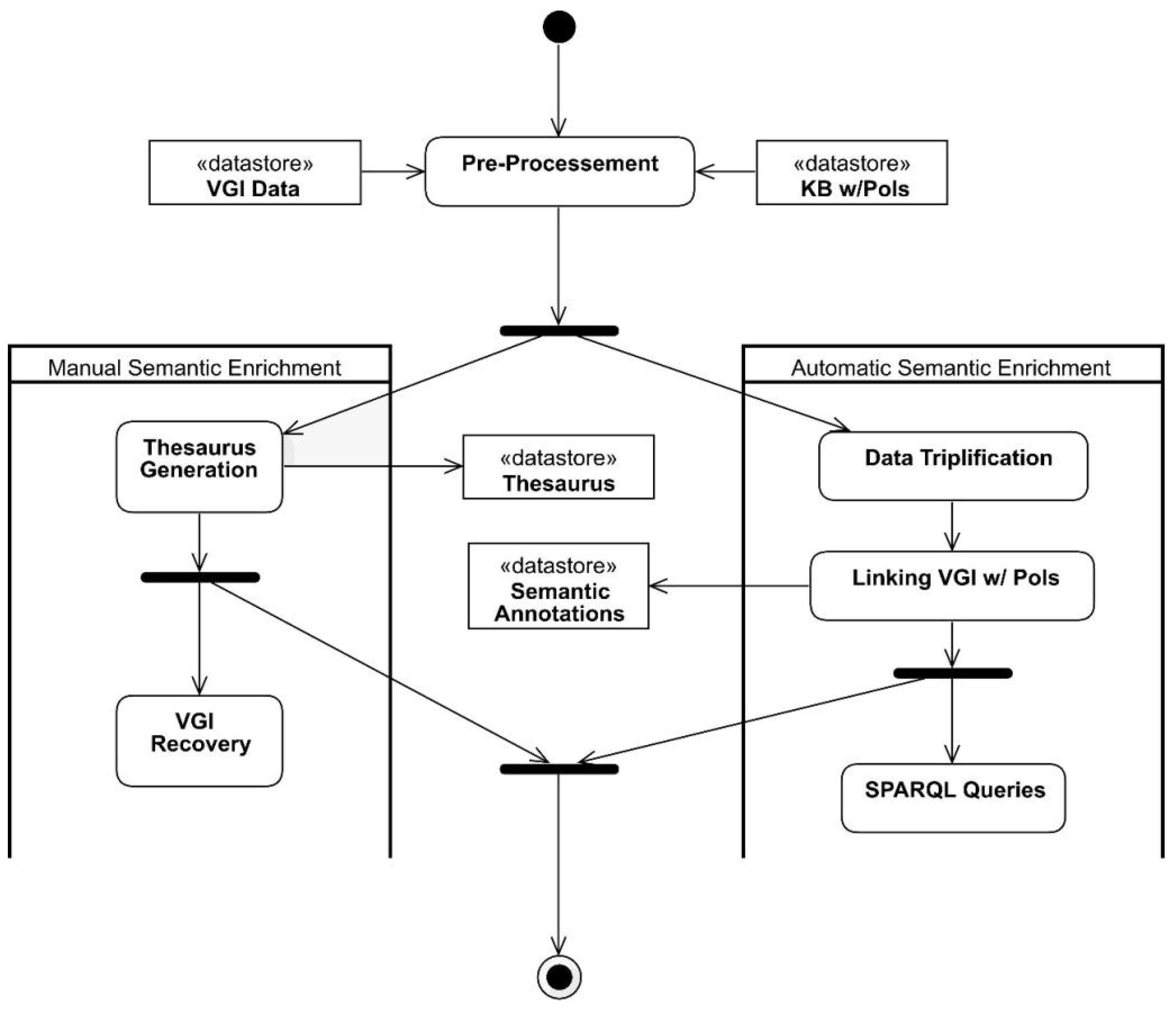
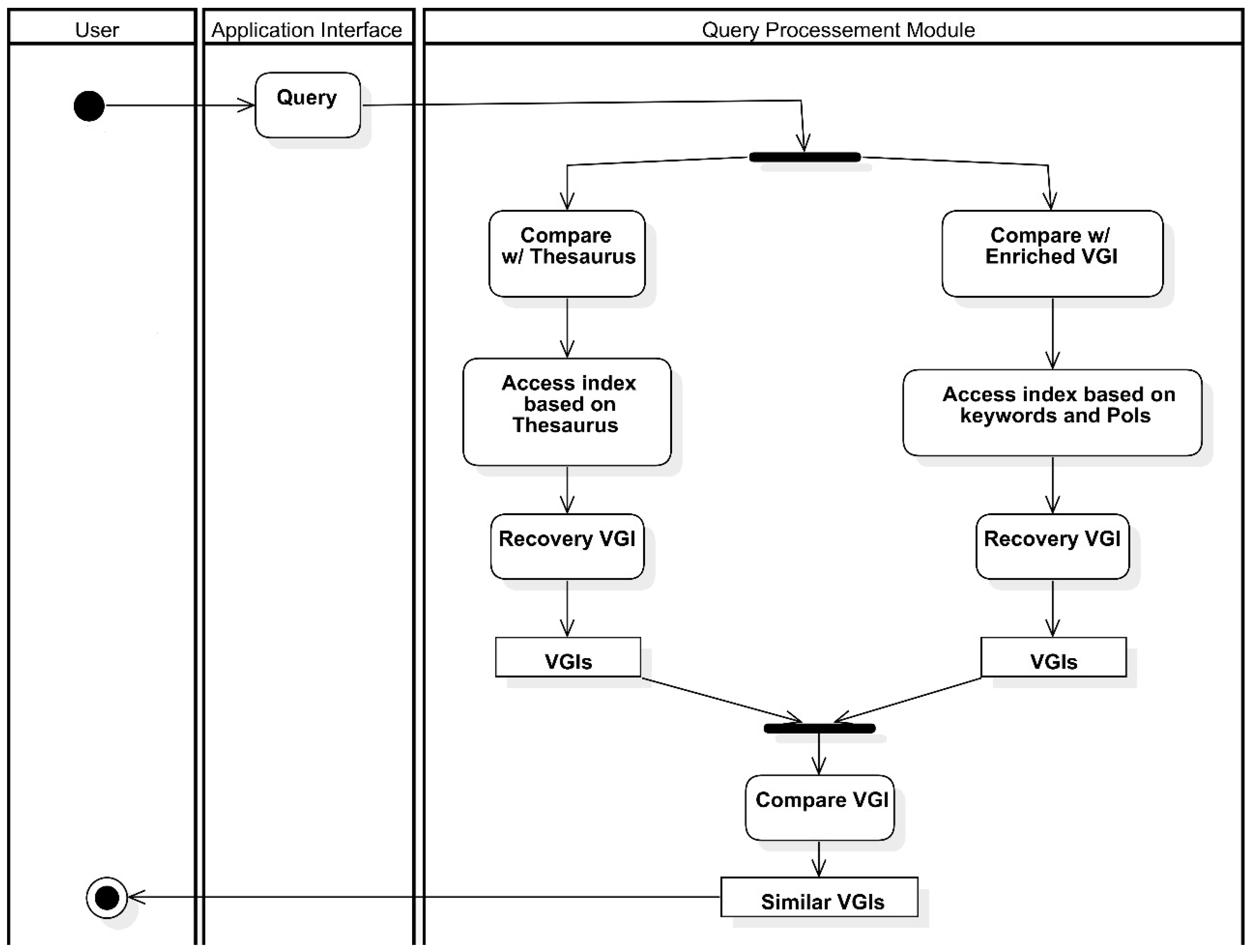
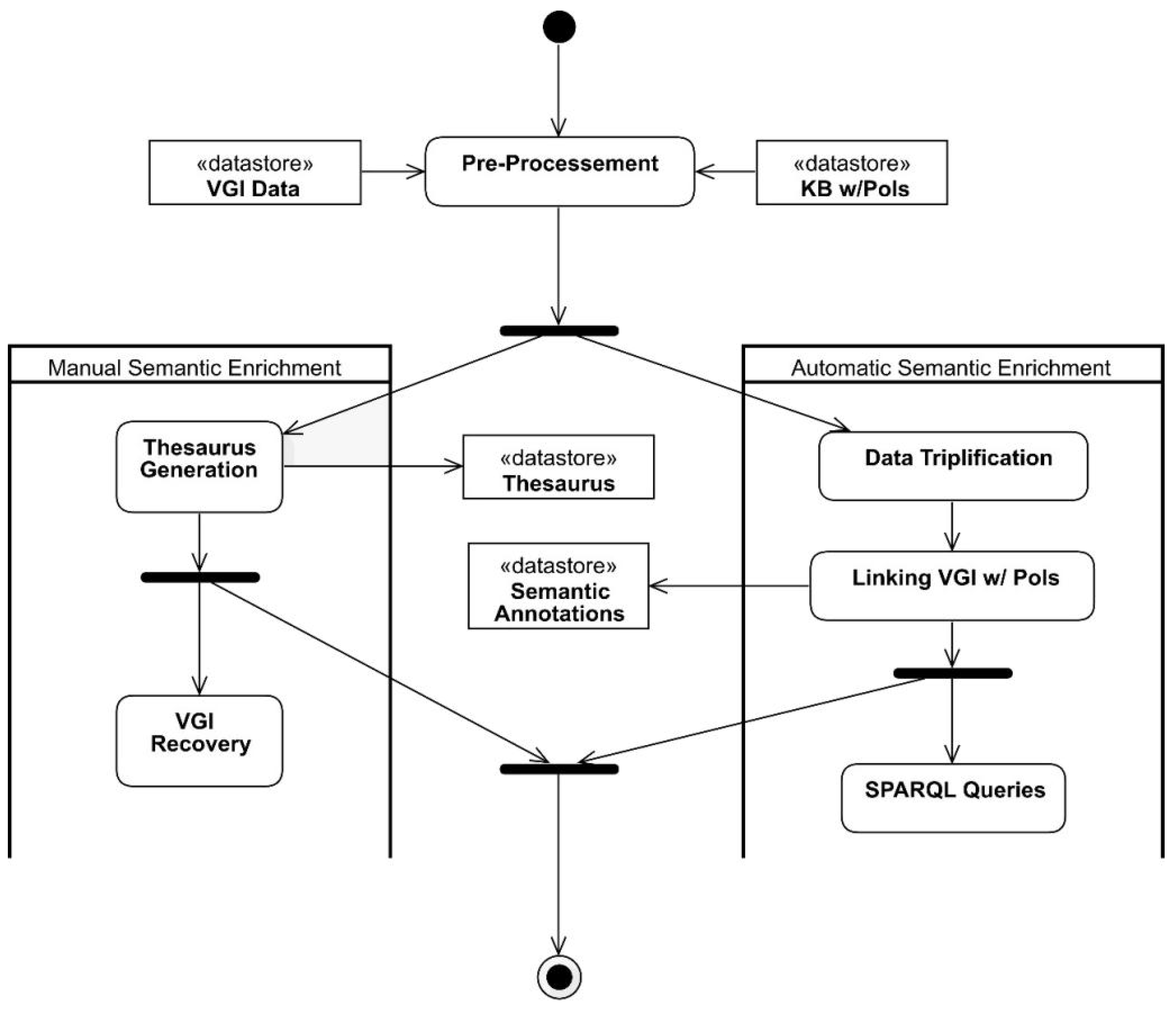
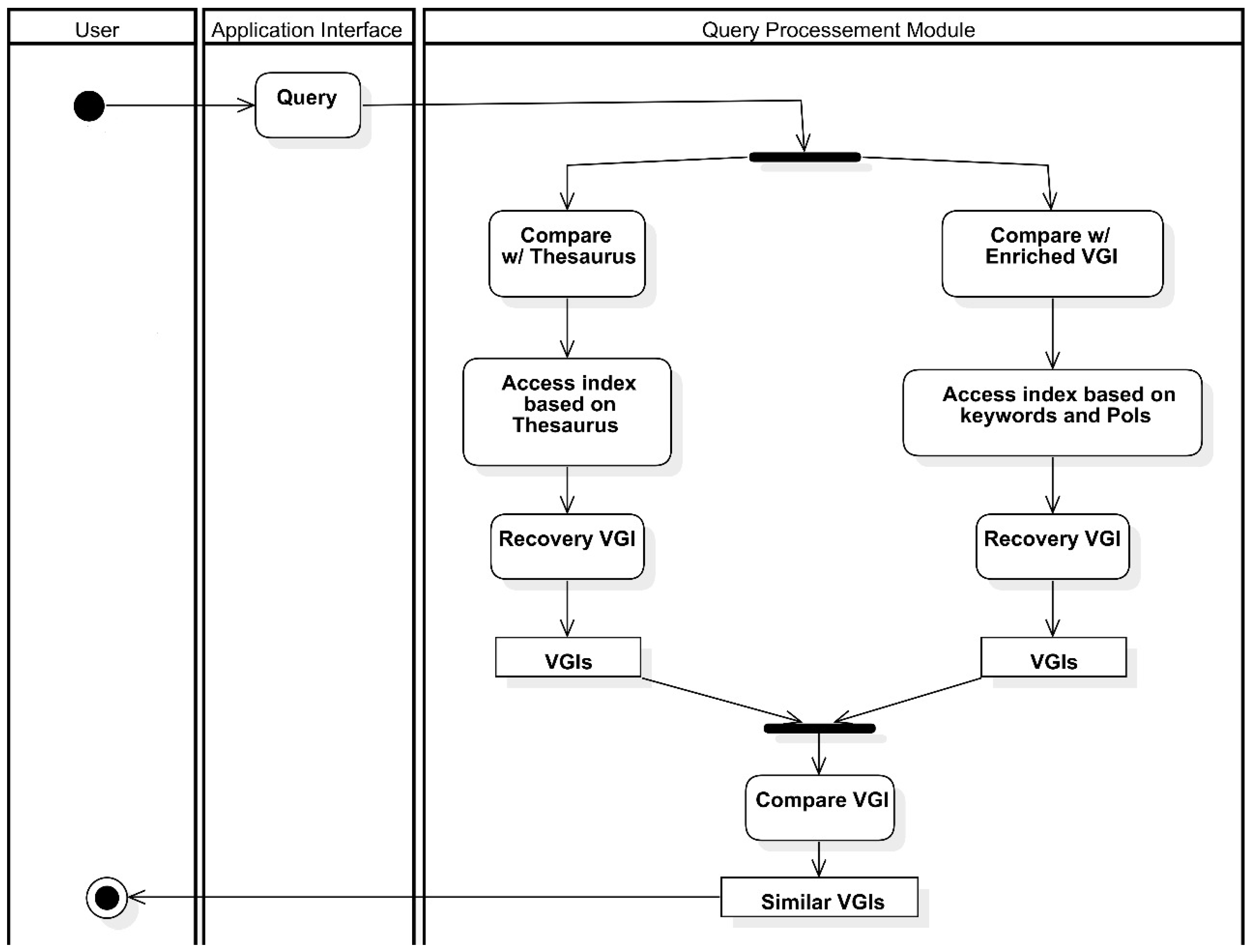
This section presents the process proposed for semantic enrichment of VGI with linked data. The process aims to semantically enrich VGI contributions based on (i) their geographic coordinates while annotating the contributions with possible places of interest (PoI) for the user in the context in which the contribution is found and (ii) the texts of the contributions, attempting to find relevant words and to attribute appropriate meaning to generate a thesaurus.
Figure 1 presents a flowchart of the process proposed. The process inputs are the VGI contributions to be semantically enriched and a database (e.g., knowledge base, LOD repository) containing the PoIs of the region to which the geographic coordinates of the contributions point. Both the VGI contributions and the database containing the PoIs undergo a pre-processing step, where noise (e.g., grammar mistakes, time and space inconsistencies), duplicates, and other issues in the data are corrected.
After pre-processing, the VGI contributions are semantically enriched by two distinct tasks that may occur simultaneously, namely automated semantic enrichment and manual semantic enrichment. Manual semantic enrichment, in the scope of this research, consists of generating a thesaurus from the textual elements present in the VGI contributions. A process similar to that used in [
28] was adopted to generate the thesaurus.
Thesaurus generation may be semi-automated with tools for disambiguation of relevant words (word sense disambiguation—WSD) and tools that identify mentions to real-world entities and link such mentions to semantically well-described resources that properly describe them in the context in which they are found (entity linking—EL tools) [
29]. However, these tools still lack satisfactory results when the text to be annotated has little context, such as social media posts and VGI contributions. Thus, the use of such tools was not considered in the process during thesaurus generation.
Automated semantic enrichment consists in annotating VGI contributions with the PoIs of the user for the contribution context. In order to extract all the potential of semantic enrichment, i.e., facilitate its discovery and use by applications, VGI contributions were triplified using the RDF standard. An algorithm was developed to perform the triplification. Although there are tools for data triplification, such as Triplify (
http://aksw.org/Projects/Triplify.html), a simple algorithm was sufficient to perform the task given the simplified structure of the data used in the study case (
Section 5). Moreover, due to its simplicity and as it is not the target of this study, the triplification algorithm is not presented.
After triplification of the VGI contributions, the next step of the process is the automatic semantic enrichment of the contributions, more specifically, the connection of the contributions with PoIs.
Algorithm for Automatic VGI Semantic Enrichment
Algorithm 1 consists in the algorithm proposed for linking VGI contributions of the users with PoIs. The algorithm uses geospatial operations to find the possible places of interest for the user. Therefore, the algorithm works with any library or database management system (DBMS) with support for geospatial operations among different geometries.
| Algorithm 1 Algorithm for automated volunteered geographic information (VGI) enrichment with places of interest. |
Require: // VGI set // Knowledge base that contains places of interest // Threshold in meters for spatial distance Output: // Initially empty set of semantic annotations
- 1:
- 2:
for each do - 3:
for each do - 4:
- 5:
end for - 6:
- 7:
end for - 8:
return SA
|
The algorithm inputs consists of a set of VGI contributions V, a knowledge base P containing the PoIs to be used to enrich the VGI set V, and a value in meters for the buffer size to be used in the geospatial operations. The output of the algorithm is a set of semantic annotations as RDF files and is initially an empty set. For each contribution , a circular buffer with radius is generated around geographic position v. It can be noted that, although it is not present in the algorithm to approximate what was implemented, the buffer to be generated may assume several other geometries (e.g., rectangular, complex geometries) so as to better adapt to the needs of several applications. After the creation of the buffer, it is verified which places are geographically within the buffer. For each of those places, a semantic annotation is created, whose subject will be the URI for VGI v and whose object is the URI of PoI p. The predicate value will change depending on the type of issue described in v. For example, if the type of issue of a contribution v is “leak,” the predicate value is “influence,” whereas if the type of issue is “waste,” the predicate value is “notify.” After all PoIs p are annotated to v, annotations contained in R are added to the set. Finally, set is returned.
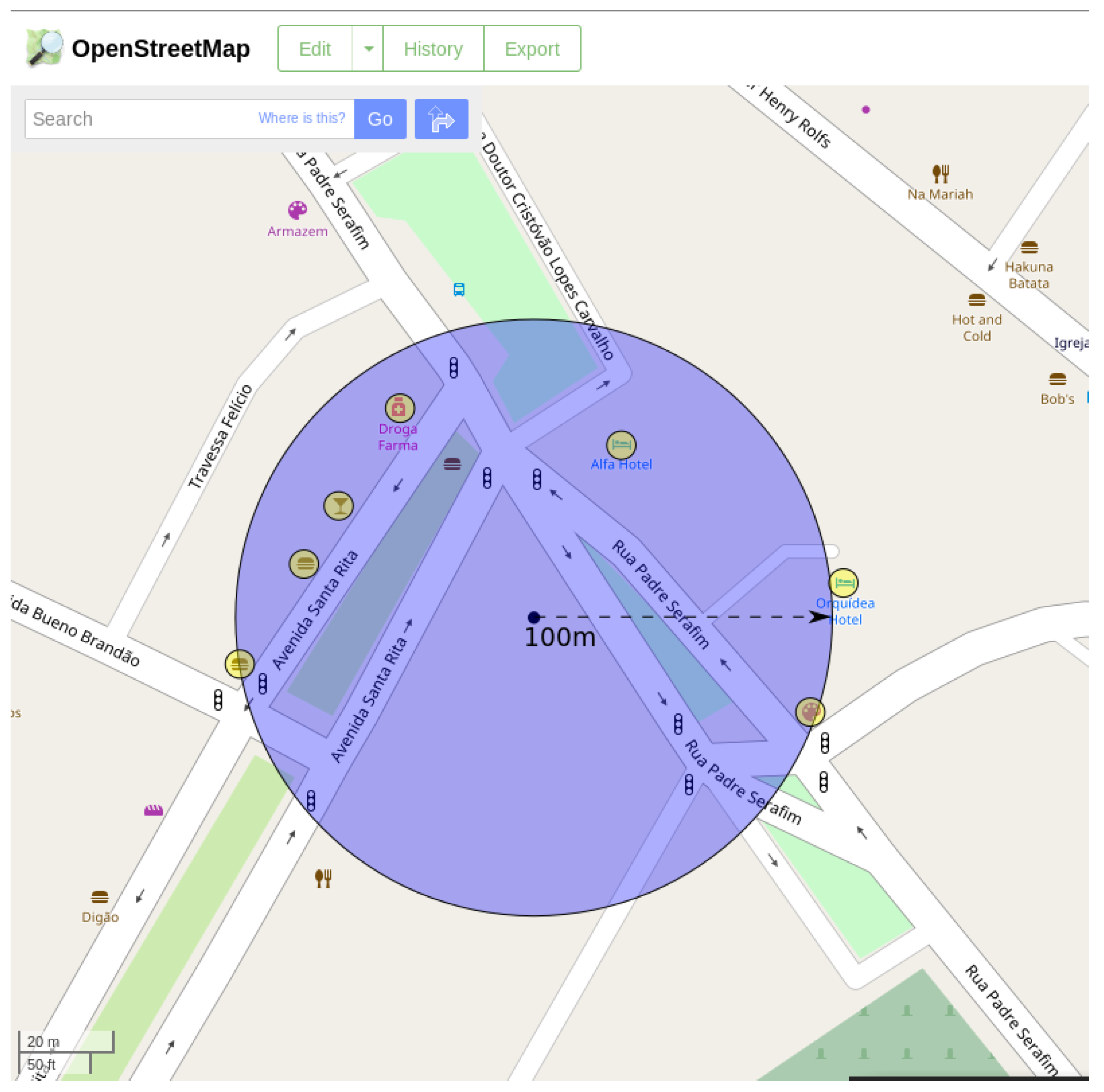
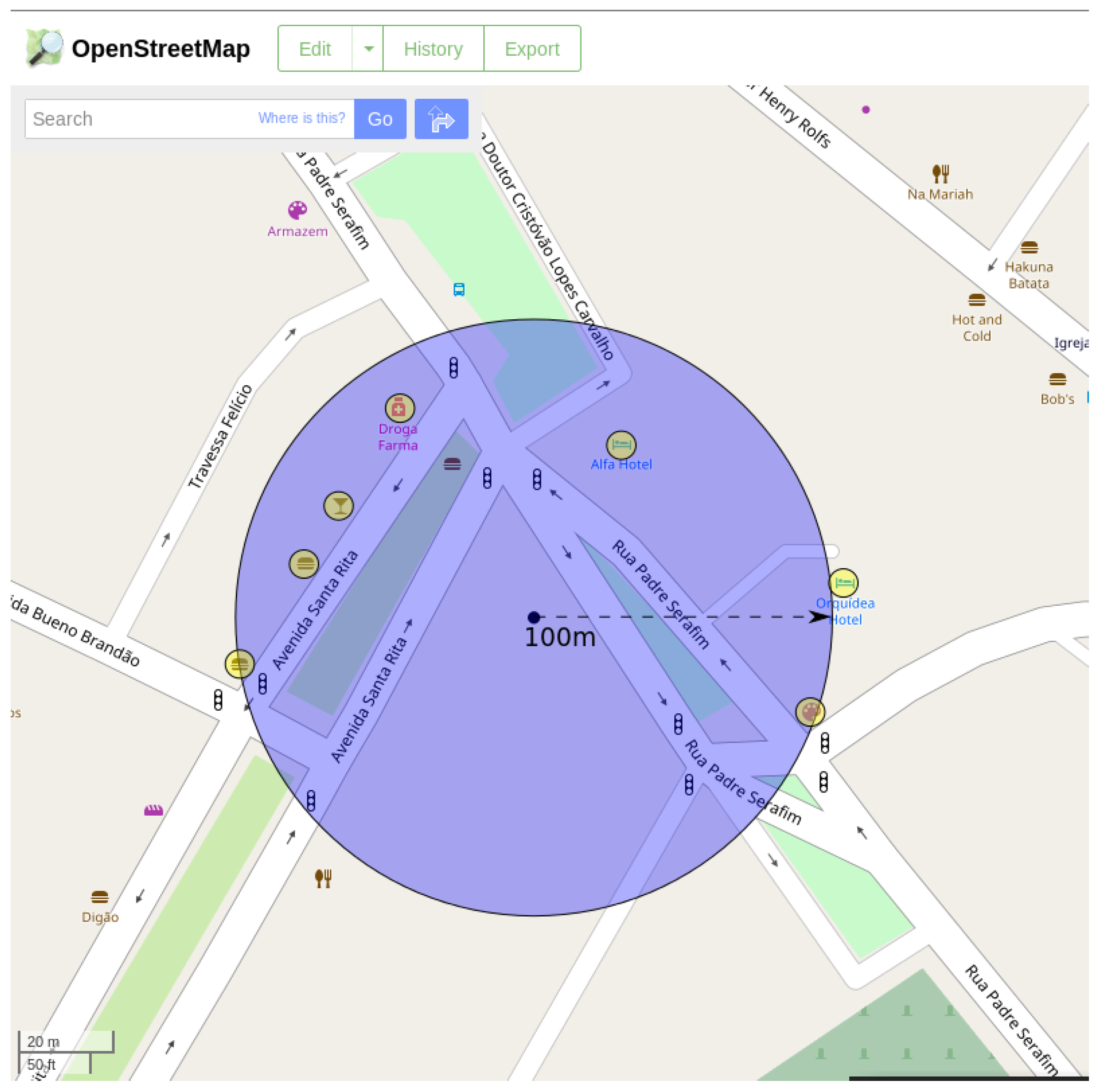
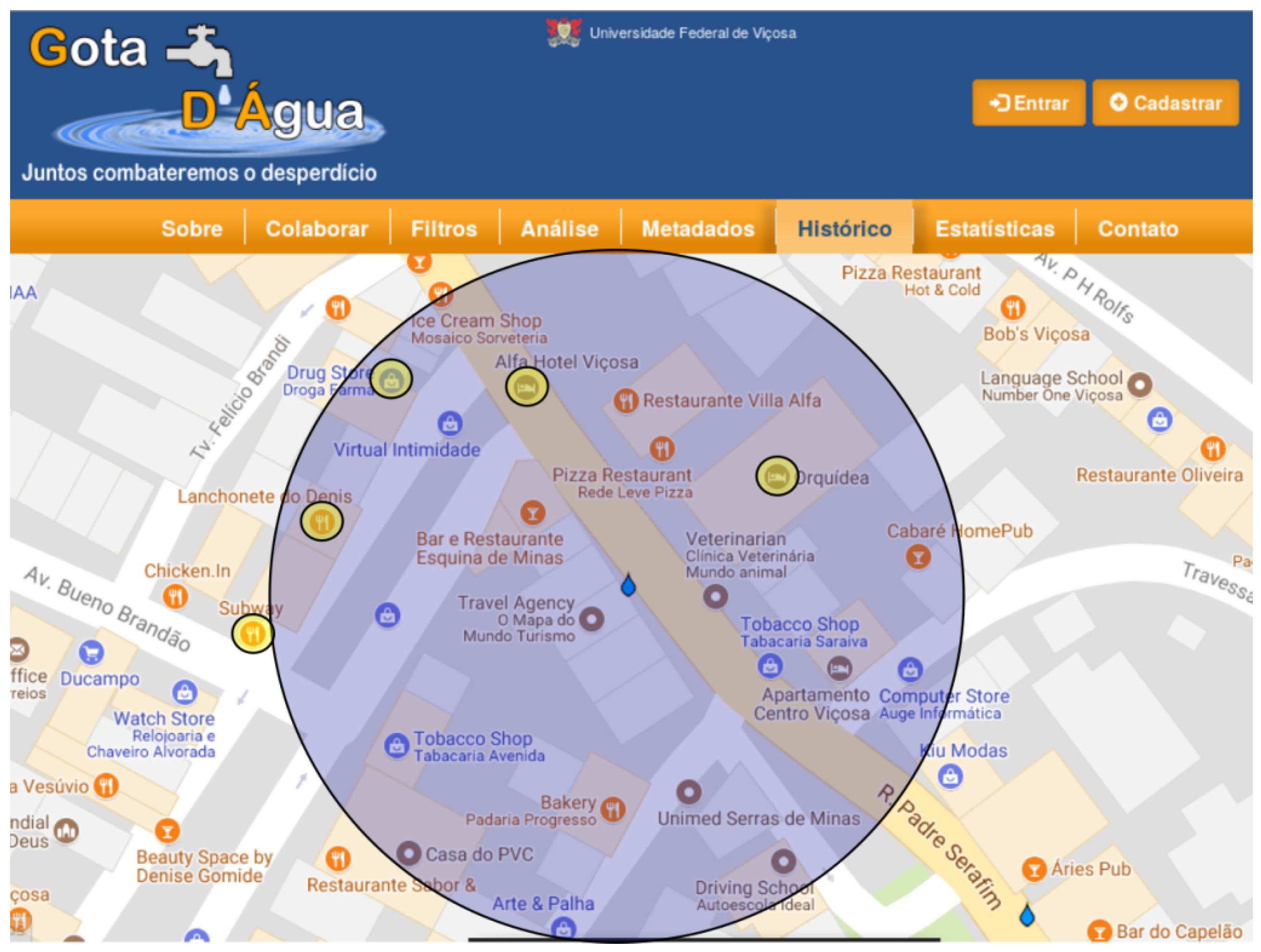
To exemplify how the algorithm works, a VGI contribution was randomly selected from the database of the Gota D’Água system (used as study case and described in
Section 5). When the algorithm is applied, a buffer with 100 m radius is created around the geographic coordinate of the contribution while verifying which of the PoIs in OSM are contained in this buffer.
Table 1 shows which places (represented by yellow circles) are contained in the buffer region (represented by a blue circle) in
Figure 2 around the place of the contribution.
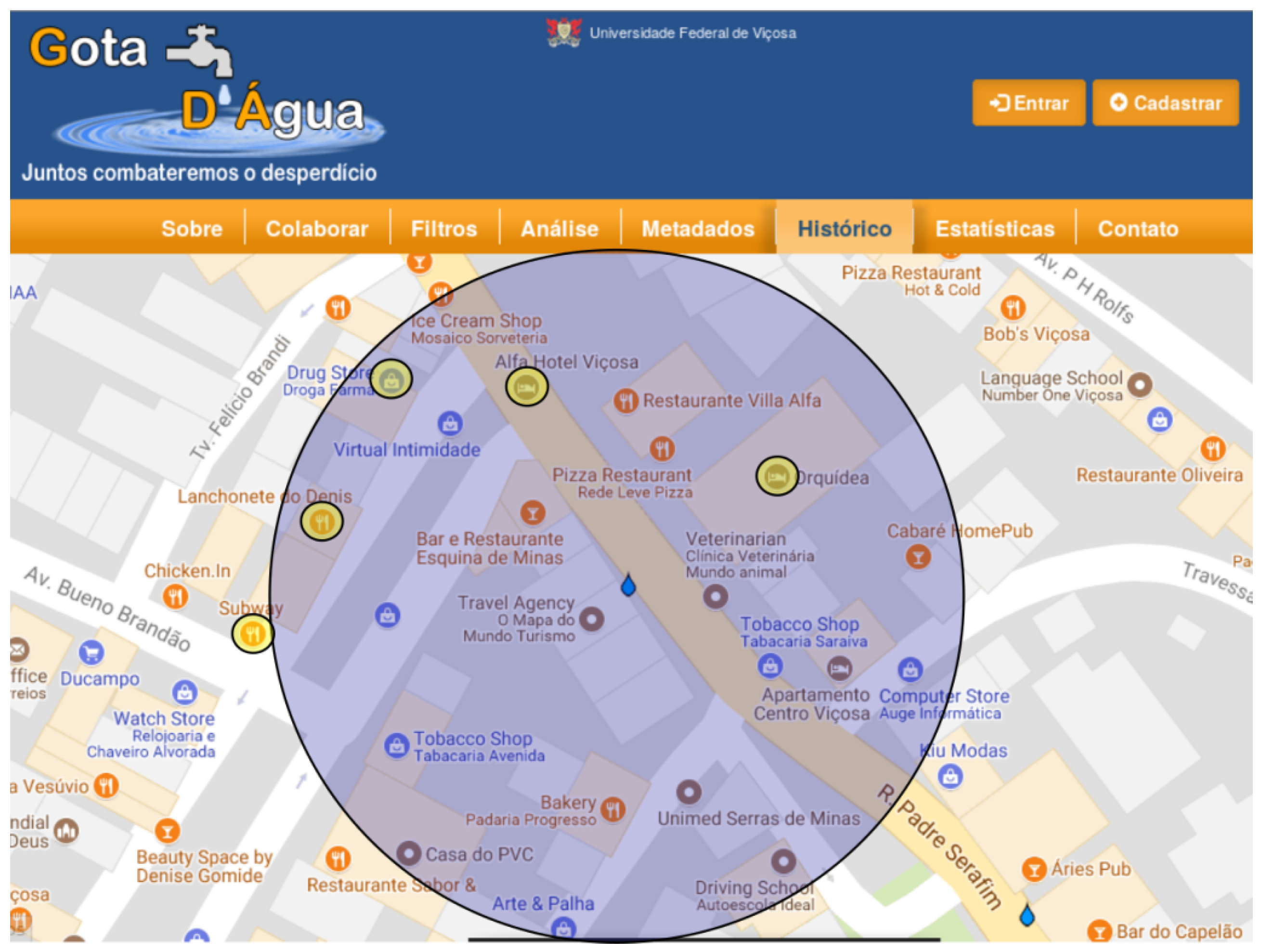
Figure 2 and
Figure 3 show the buffer enveloping the businesses near the contribution in different representations. While
Figure 2 is represented in OSM,
Figure 3 is represented in Google Maps. Note that the choice of knowledge base containing the PoIs impacts the number of semantic annotations generated. As shown in
Figure 2 and
Figure 3, due to the difference in the number of registered PoIs between OSM and Google Maps, the result returned by the algorithm significantly varies according to the PoI base.
6. Discussion
The Gota D’Água VGI system, used in this paper as study case, allows users from different parts of Brazil to contribute information on different types of issues related to water shortage and/or waste. VGI normally has little context attached to it since users choose to write short messages for several reasons, such as lack of time, convenience, difficulty in using the system, etc.
According to [
33], when working with semantic enrichment with little text or multimedia content such as social media posts, the results have little precision due to the lack of context. It is believed that the same also occurs with VGI, which usually has succinct contributions. Since the descriptions of user contributions in the Gota D’Água system are little detailed, the objective of this research is not to be more precise than existing approaches in the literature, but rather to show the viability and applicability of automated semantic enrichment of VGI.
With the generation of semantic annotations in VGI adopting the RDF standard, queries can be made to be answered by the system using the SPARQL language, which makes the system create logical inferences. The SPARQL language allows a query to be used to formulate questions ranging from a simple graphical standard of correspondence to more complex queries involving several RDF repositories around the web [
34]. Although the SPARQL language is equivalent to SQL, i.e., any SPARQL expression can be translated into an SQL expression with no loss of semantics [
35,
36], expressing a semantic query in SPARQL is friendlier than in SQL. In addition, DBMSs that have SPARQL support have specific query optimization modules for semantic queries.
The simplicity of the method proposed in this study to semantically enrich VGI contributions allows it to be implemented in a variety of applications of several domains and may be adapted according to the needs of each domain. Moreover, the method proposed aims to use geospatial operations that already exist in a database since these databases implement optimized geospatial operations for large datasets, which adds to the efficiency of the method.
In order to assess the method described in
Section 4, the following steps must be executed: Formulating questions related to the water distribution subject, whose answers are obtained via SPARQL queries. The SPARQL queries are made based on the triplified data of the Gota D’Água system and on the semantic annotations in RDF generated by the semantic enrichment. A small number of contributions is manually examined and annotated. The method proposed generates similar annotations and a certain level of imprecision is already expected. After validation of the semantic enrichment method, the queries are executed so as to attempt to answer the previously proposed questions. The data obtained are transcribed in the research results in
Section 5.2.
The greatest difficulty of the research is dealing with the fact that VGI contributions are succinct. For example, many contributions in the Gota D’Água system have no type of comment attached to them and feature only the type, the geographic location, and timestamp of the contribution. Such lack of details prevents the use of tools such as EL, WSD and other semantic enrichment methods that may generate new semantic annotations and, consequently, contribute to the results of queries to be executed. Furthermore, given the limited number of contributions, messages with little context and small number of attributes per contribution, the possible queries to demonstrate the applicability of semantic enrichment have limited scope. However, the queries presented in this study show the usefulness of semantic enrichment and enable answering useful questions to the organs responsible for water supply.
Author Contributions
Conceptualization, L.S.d.C., I.L.O. and J.L.-F.; Methodology, L.S.d.C., I.L.O. and A.M.; Software, L.S.d.C. and I.L.O.; Validation, L.S.d.C.; Analysis, L.S.d.C. and I.L.O.; Resources, L.S.d.C. and J.L.-F.; Data Curation, L.S.d.C.; Writing-Original Draft Preparation, L.S.d.C., I.L.O., J.L.-F. and A.M.; Writing-Review and Editing, L.S.d.C., I.L.O. and J.L.-F.; Supervision, J.L.-F.; Project Administration, J.L.-F.; Funding Acquisition, J.L.-F.
Funding
This research was funded by Fundação de Amparo à Pesquisa do Estado de Minas Gerais—FAPEMIG grant number APQ 03763-12.
Acknowledgments
The authors would like to thank Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—CAPES for the scholarship.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2011; pp. 205–227. [Google Scholar]
- Goodchild, M.F. Citizens as voluntary sensors: Spatial data infrastructure in the world of Web 2.0. Int. J. Spat. Data Infrastruct. Res. 2012, 2, 4–32. [Google Scholar]
- Elwood, S.; Goodchild, M.F.; Sui, D.Z. Researching volunteered geographic information: Spatial data, geographic research, and new social practice. Ann. Assoc. Am. Geogr. 2012, 102, 571–590. [Google Scholar] [CrossRef]
- Clarke, C. A resource list management tool for undergraduate students based on linked open data principles. In Proceedings of the European Semantic Web Conference, Crete, Greece, 31 May–4 June 2009; pp. 697–707. [Google Scholar]
- Schade, S.; Granell, C.; Diaz, L. Augmenting SDI with linked data. In Proceedings of the Workshop on Linked Spatiotemporal Data, in conjunction with the 6th International Conference on Geographic Information Science (GIScience 2010), Zurich, Switzerland, 14 September 2010. [Google Scholar]
- Stadler, C.; Lehmann, J.; Höffner, K.; Auer, S. Linkedgeodata: A core for a web of spatial open data. Semant. Web 2012, 3, 333–354. [Google Scholar]
- Bontcheva, K.; Rout, D.P. Making sense of social media streams through semantics: A survey. Semant. Web 2014, 5, 373–403. [Google Scholar]
- Ronzhin, S. Semantic Enrichment of Volunteered Geographic Information Using Linked Data: A Use Case Scenario for Disaster Management. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2015. [Google Scholar]
- Sorrentino, S.; Bergamaschi, S.; Fusari, E.; Beneventano, D. Semantic annotation and publication of linked open data. In Proceedings of the International Conference on Computational Science and Its Applications, Ho Chi Minh City, Vietnam, 24–27 June 2013; pp. 462–474. [Google Scholar]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Haklay, M.; Weber, P. Openstreetmap: User-generated street maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Zielstra, D.; Zipf, A. A comparative study of proprietary geodata and volunteered geographic information for Germany. In Proceedings of the 13th AGILE International Conference on Geographic Information Science, Guimarães, Portugal, 11–14 May 2010. [Google Scholar]
- Neis, P.; Zielstra, D. Recent developments and future trends in volunteered geographic information research: The case of OpenStreetMap. Future Internet 2014, 6, 76–106. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the quality of volunteered geographic information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Foody, G.M.; See, L.; Fritz, S.; Van der Velde, M.; Perger, C.; Schill, C.; Boyd, D.S. Assessing the accuracy of volunteered geographic information arising from multiple contributors to an internet based collaborative project. Trans. GIS 2013, 17, 847–860. [Google Scholar] [CrossRef]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef]
- Fan, H.; Yang, B.; Zipf, A.; Rousell, A. A polygon-based approach for matching OpenStreetMap road networks with regional transit authority data. Int. J. Geogr. Inf. Sci. 2016, 30, 748–764. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Minghini, M.; Molinari, M.; Mooney, P. Towards an automated comparison of OpenStreetMap with authoritative road datasets. Trans. GIS 2017, 21, 191–206. [Google Scholar] [CrossRef]
- Azevedo, P.C.N. Uma Proposta Para Visualização de Linked Data Sobre Enchentes na Bacia do Rio Doce. Ph.D. Thesis, Universidade FUMEC, Belo Horizonte, MG, Brazil, 2014. [Google Scholar]
- Beneventano, D.; Bergamaschi, S.; Sorrentino, S.; Vincini, M.; Benedetti, F. Semantic annotation of the CEREALAB database by the AGROVOC linked dataset. Ecol. Inf. 2015, 26, 119–126. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Chen, Y.; Chilton, L.; Connolly, D.; Dhanaraj, R.; Hollenbach, J.; Lerer, A.; Sheets, D. Tabulator: Exploring and analyzing linked data on the semantic web. In Proceedings of the 3rd International Semantic Web User Interaction Workshop, Athens, GA, USA, 5–9 November 2006; p. 159. [Google Scholar]
- Lehmann, J.; Bizer, C.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia—A Crystallization Point for the Web of Data. J. Web Semant. 2009, 7, 154–165. [Google Scholar]
- Moreira, J.D.C.; Neto, F.M.M.; da Costa, A.A.L.; Sombra, E.L.; de Aliança Neto, A.S.; de Medeiros Valentim, R.A. Um sistema de enriquecimento semântico de perfil de usuário baseado em traços digitais para apoio à aprendizagem informal no contexto da saúde. RENOTE 2014, 12. [Google Scholar] [CrossRef]
- Clarke, M.; Harley, P. How smart is your content? Using semantic enrichment to improve your user experience and your bottom line. Science 2014, 37, 41. [Google Scholar]
- Moro, A.; Raganato, A.; Navigli, R. Entity linking meets word sense disambiguation: a unified approach. Trans. Assoc. Comput. Linguist. 2014, 2, 231–244. [Google Scholar] [CrossRef]
- de Moura, T.H.V.; Davis, C.A., Jr. Linked Geospatial Data: desafios e oportunidades de pesquisa. In Proceedings of the XIV GEOINFO, Campos do Jordão, Brazil, 24–27 November 2013; p. 13. [Google Scholar]
- CEPIS—Centro Pan-Americano da Engenharia Sanitária e Ciencias do Ambiente. Tesauro de Engenharia Sanitária e Ambiental. 2005. Available online: http://www.bvsde.paho.org/bvsair/e/manuales/tesa/tespo.pdf (accessed on 26 June 2019).
- Gao, H.; Barbier, G.; Goolsby, R. Harnessing the crowdsourcing power of social media for disaster relief. IEEE Intell. Syst. 2011, 26, 10–14. [Google Scholar] [CrossRef]
- Moreira, M.P.; Moura, M.A. Construindo Tesauros a Partir de Tesauros Existentes: A Experiência do TCI-Tesauro em Ciência da Informação. 2006. Available online: http://www.brapci.inf.br/_repositorio/2010/01/pdf_6c43aff315_0007598.pdf (accessed on 26 June 2019).
- Moreira, A.; Alvarenga, L.; Oliveira, A.P. Thesaurus and Ontology: A Study of the Definitions Found in the Computer and Information Science Literature, by Means of an Analytical Synthetic Method. Knowl. Organ. 2004, 31, 231–244. [Google Scholar]
- Rosati, I.; Bergami, C.; Stanca, E.; Roselli, L.; Tagliolato, P.; Oggioni, A.; Fiore, N.; Pugnetti, A.; Zingone, A.; Boggero, A.; et al. A thesaurus for phytoplankton trait-based approaches: Development and applicability. Ecol. Inf. 2017, 42, 129–138. [Google Scholar] [CrossRef]
- Guo, W.; Li, H.; Ji, H.; Diab, M. Linking tweets to news: A framework to enrich short text data in social media. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 239–249. [Google Scholar]
- World Wide Web Consortium. SPARQL 1.1 Overview. W3C Recommendation. 2013. Available online: http://travesia.mcu.es/portalnb/jspui/handle/10421/7464 (accessed on 26 June 2019).
- Chebotko, A.; Lu, S.; Fotouhi, F. Semantics preserving SPARQL-to-SQL translation. Data Knowl. Eng. 2009, 68, 973–1000. [Google Scholar] [CrossRef]
- Elliott, B.; Cheng, E.; Thomas-Ogbuji, C.; Ozsoyoglu, Z.M. A complete translation from SPARQL into efficient SQL. In Proceedings of the 2009 International Database Engineering & Applications Symposium, Calabria, Italy, 16–18 September 2009; pp. 31–42. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}