Learning Improved Semantic Representations with Tree-Structured LSTM for Hashtag Recommendation: An Experimental Study

Abstract
:1. Introduction
- We take the initiative to study how the syntactic structure can be utilized for hashtag recommendation, and our experimental results have indicated that the syntactic structure is indeed useful in the recommendation task. To the best of our knowledge, few studies address this task in a systematic and comprehensive way.
- We propose and compare various approaches to represent the text for hashtag recommendation, and extensive experiments demonstrate the powerful predictive ability of our deep neural network models on two real-world datasets.
2. Methodology for Hashtag Recommendation
2.1. Traditional Approach with Shallow Textual Features
2.1.1. Naive Bayes (NB)
2.1.2. Latent Dirichlet Allocation (LDA)
2.1.3. Term Frequency-Inverse Document Frequency (TF-IDF)
2.2. Neural Network Approach with Deep Textual Features
2.2.1. FastText
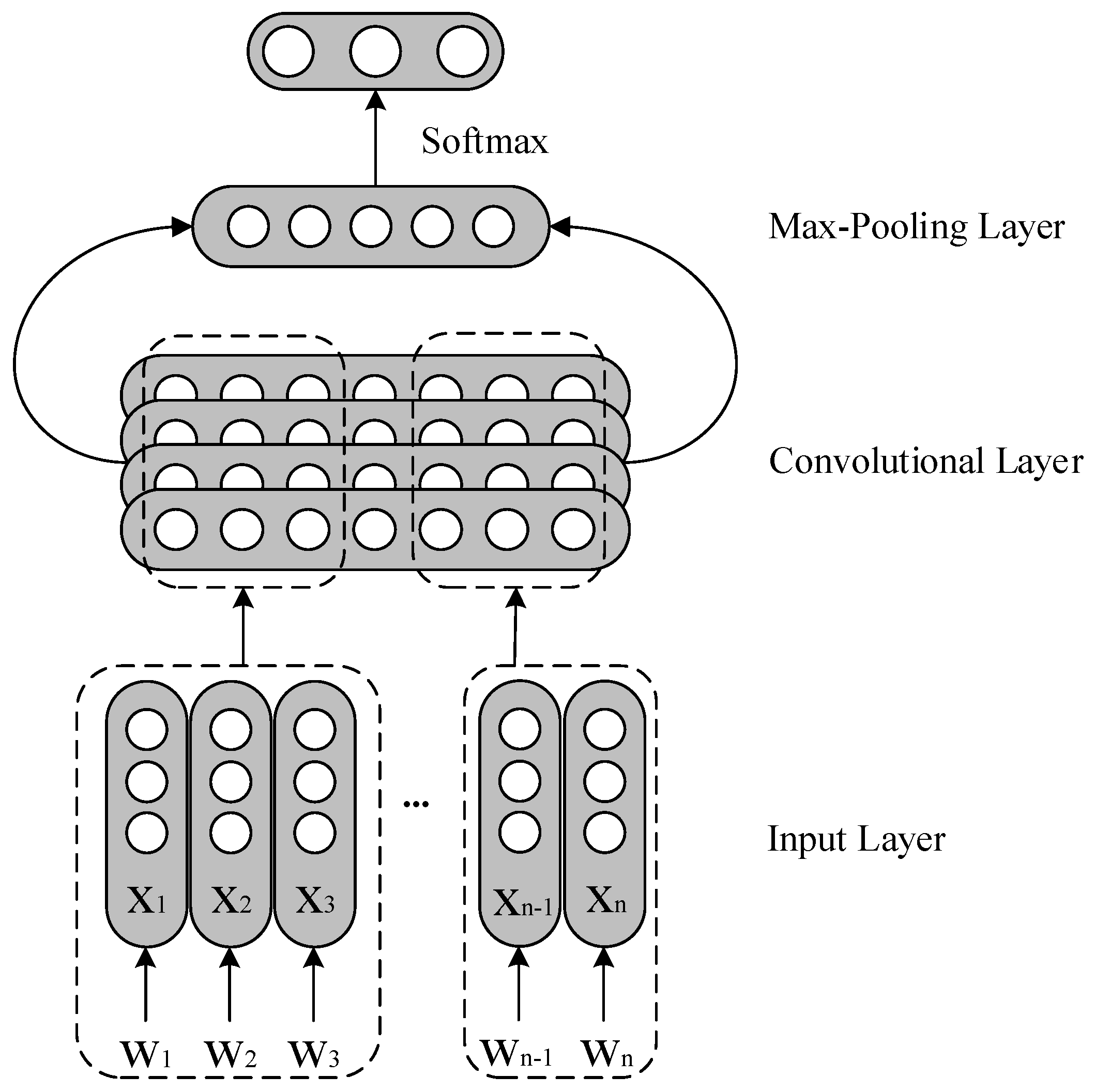
2.2.2. Convolutional Neural Network (CNN)
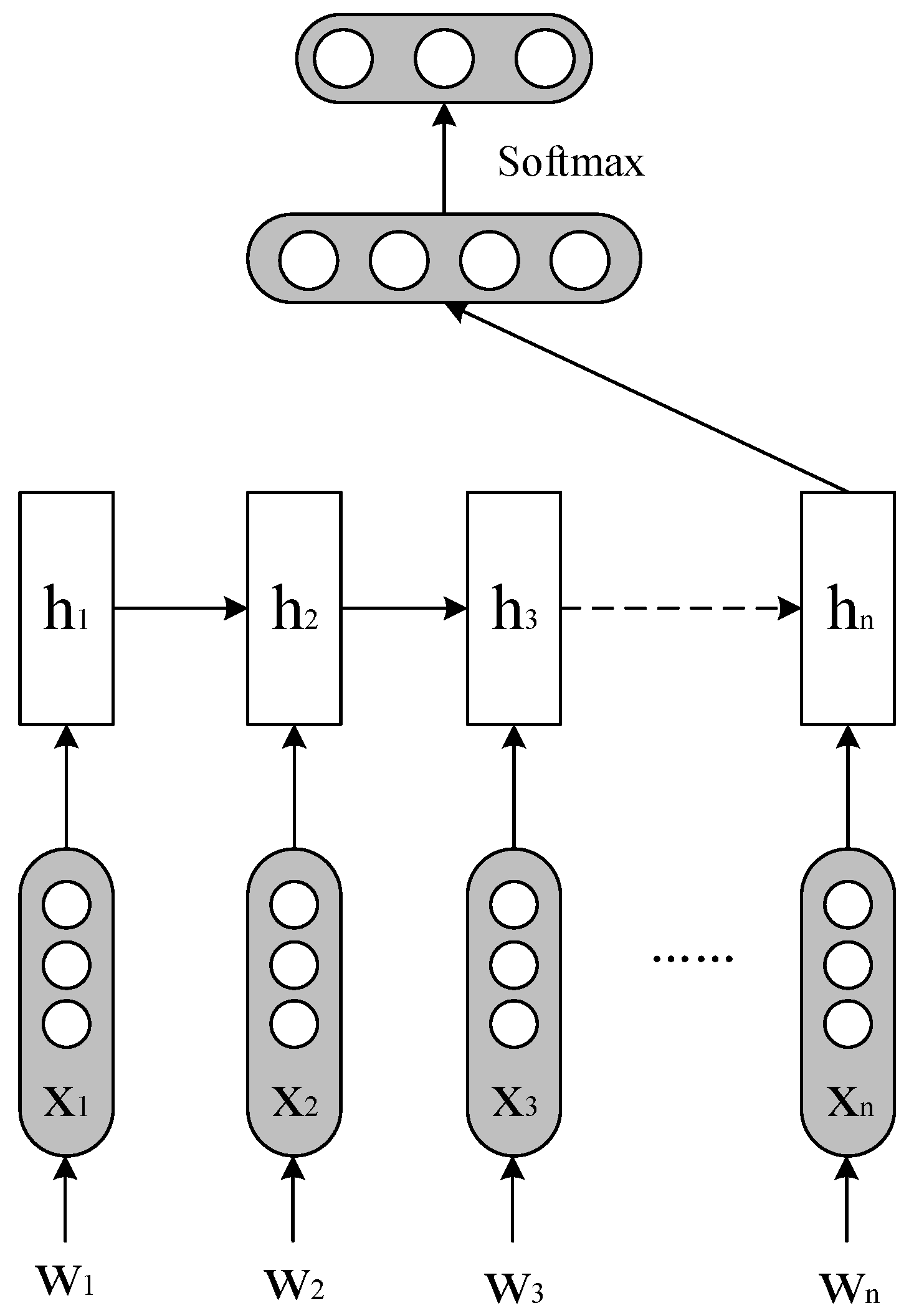
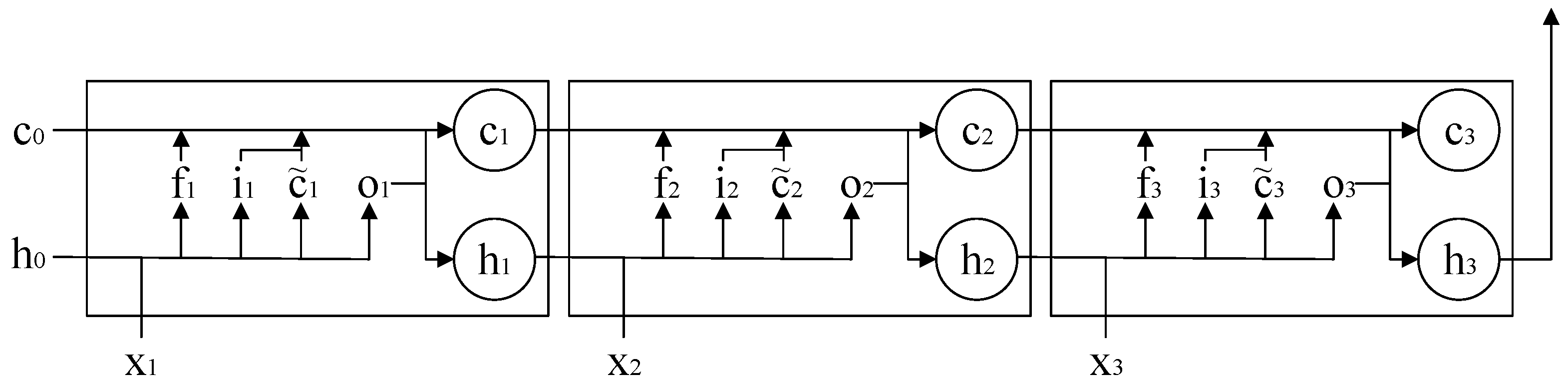
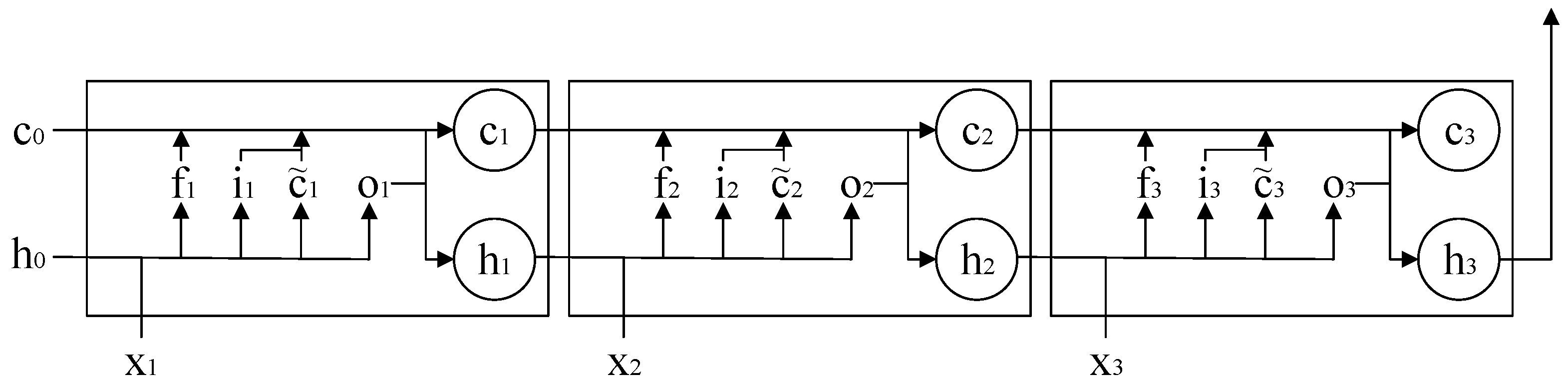
2.2.3. Standard LSTM
2.2.4. LSTM with Average Pooling (AVG-LSTM)
2.2.5. Bidirectional LSTM (Bi-LSTM)
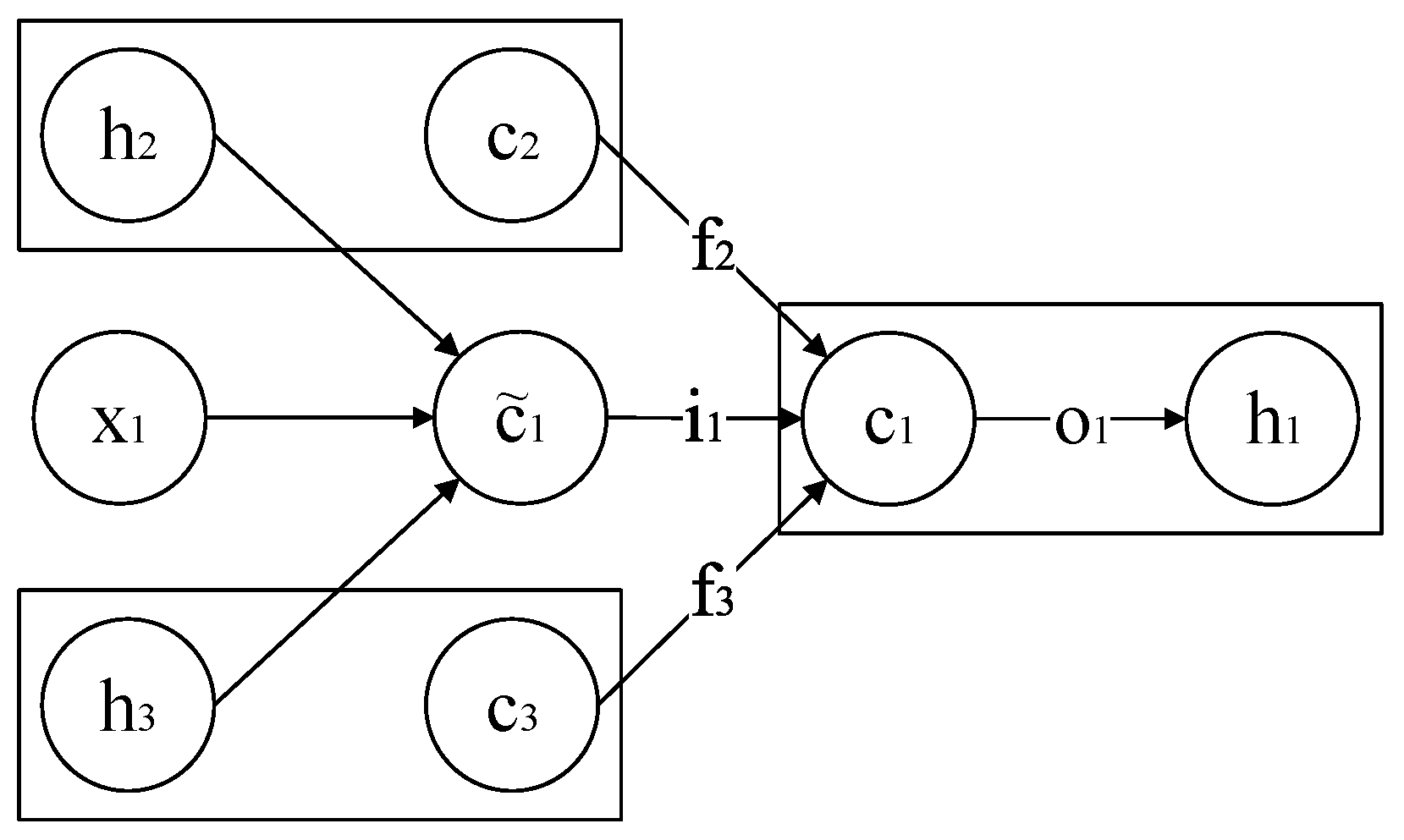
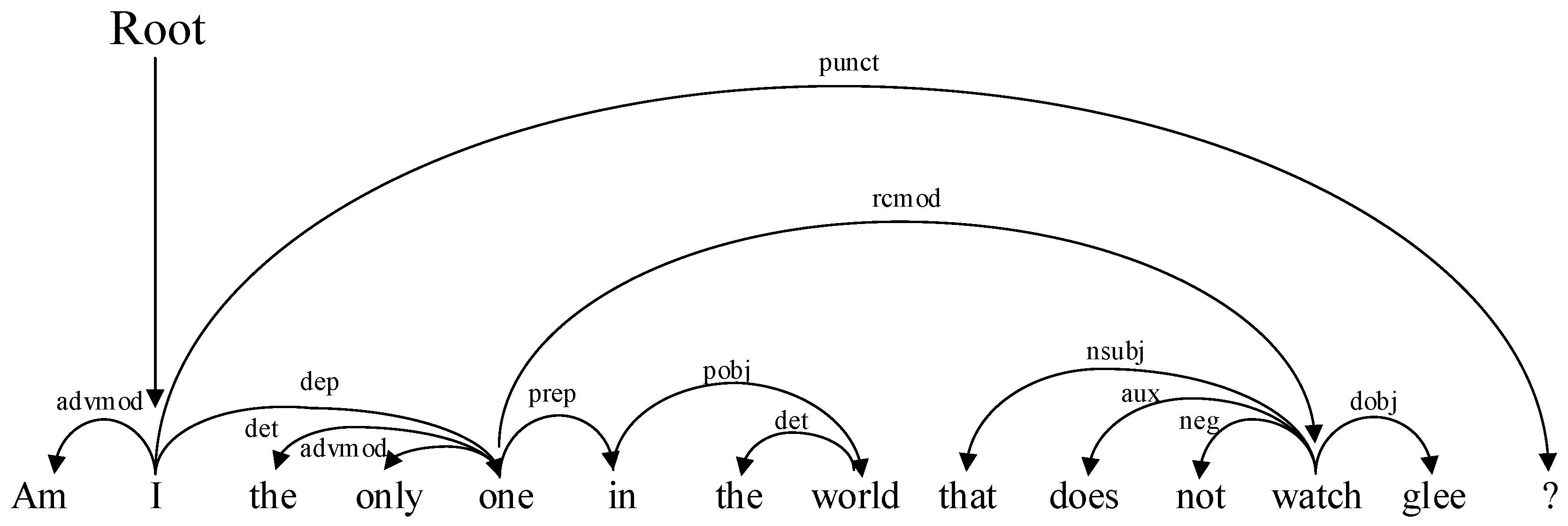
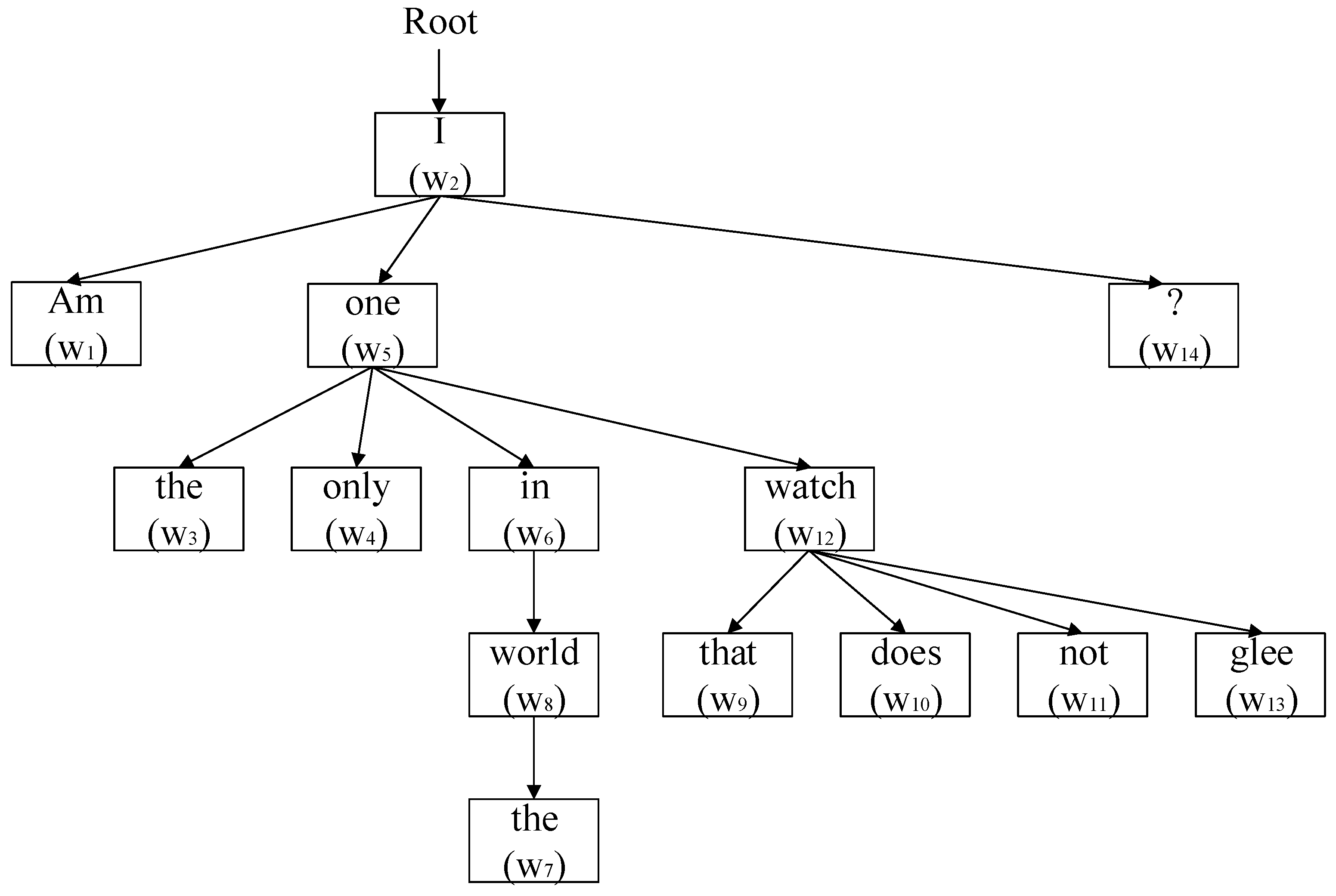
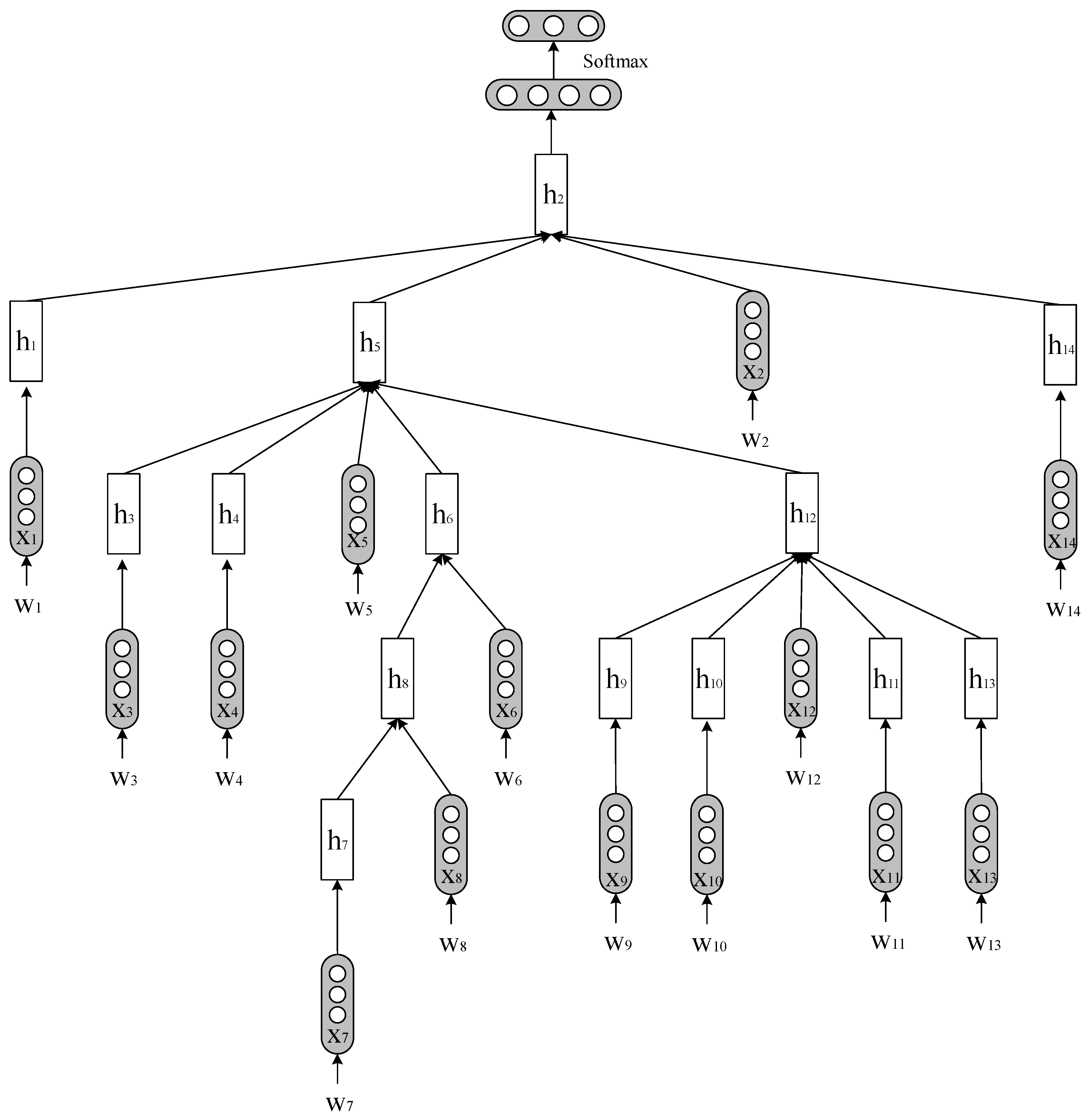
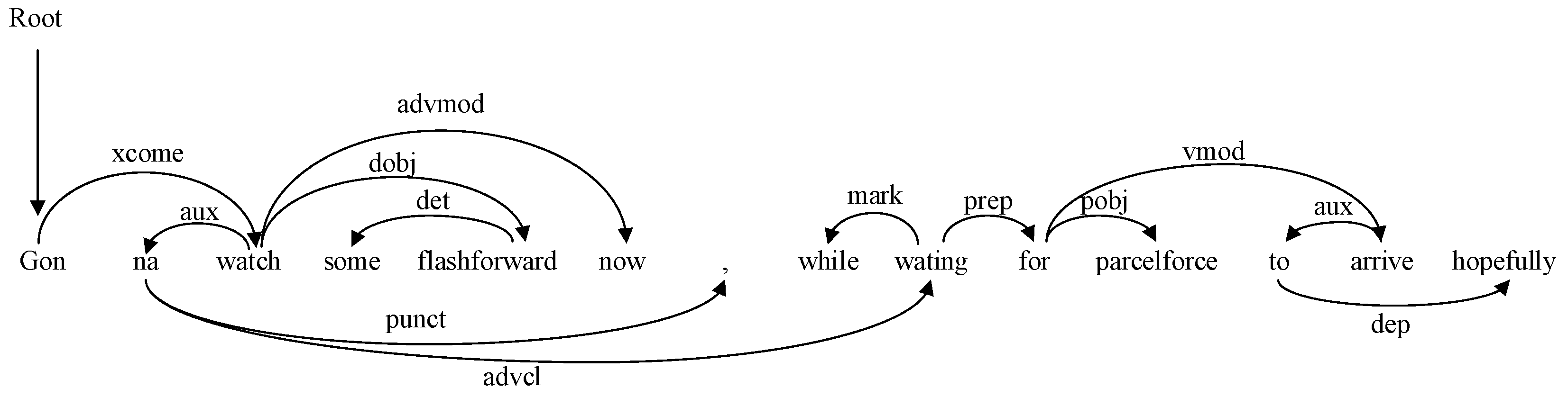
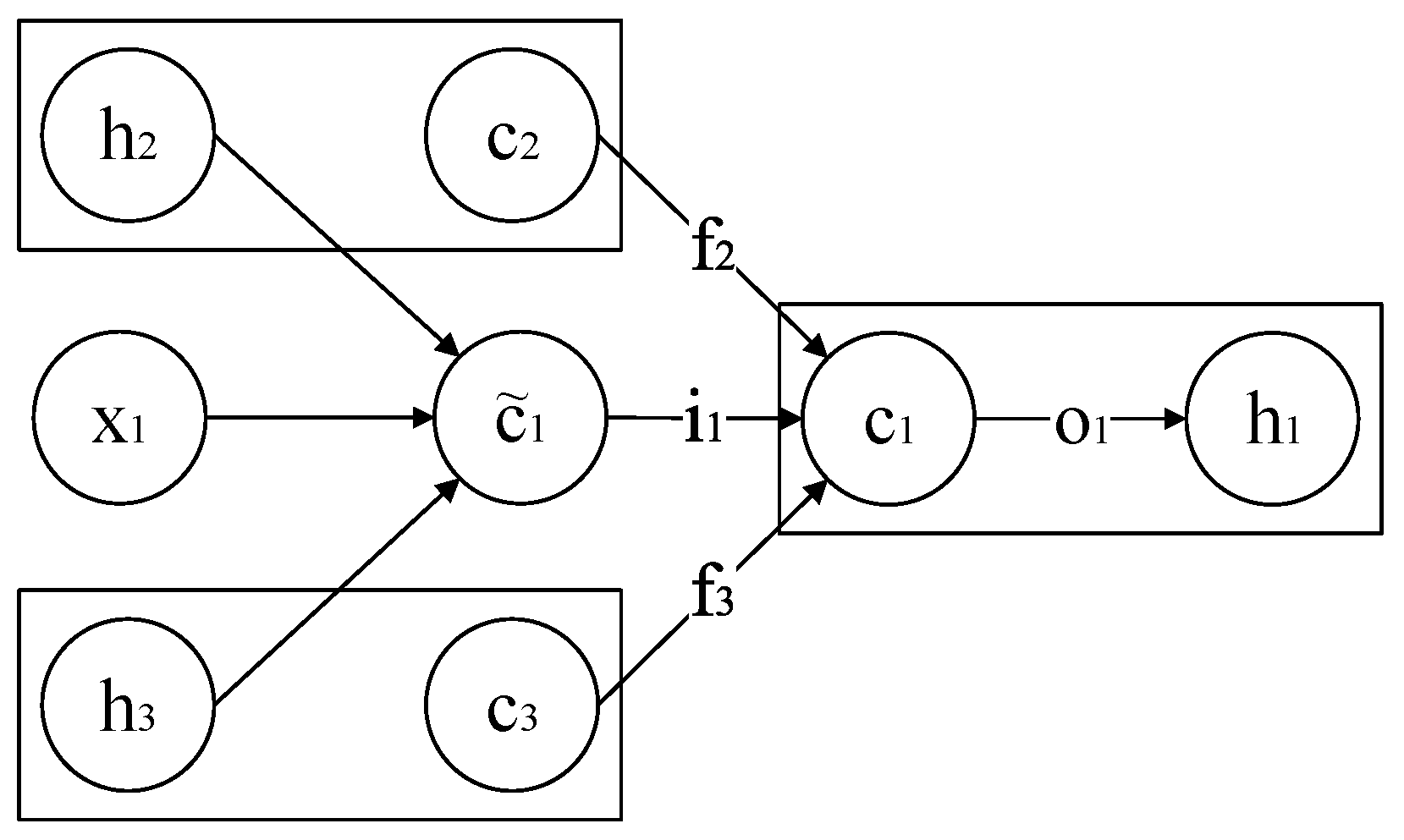
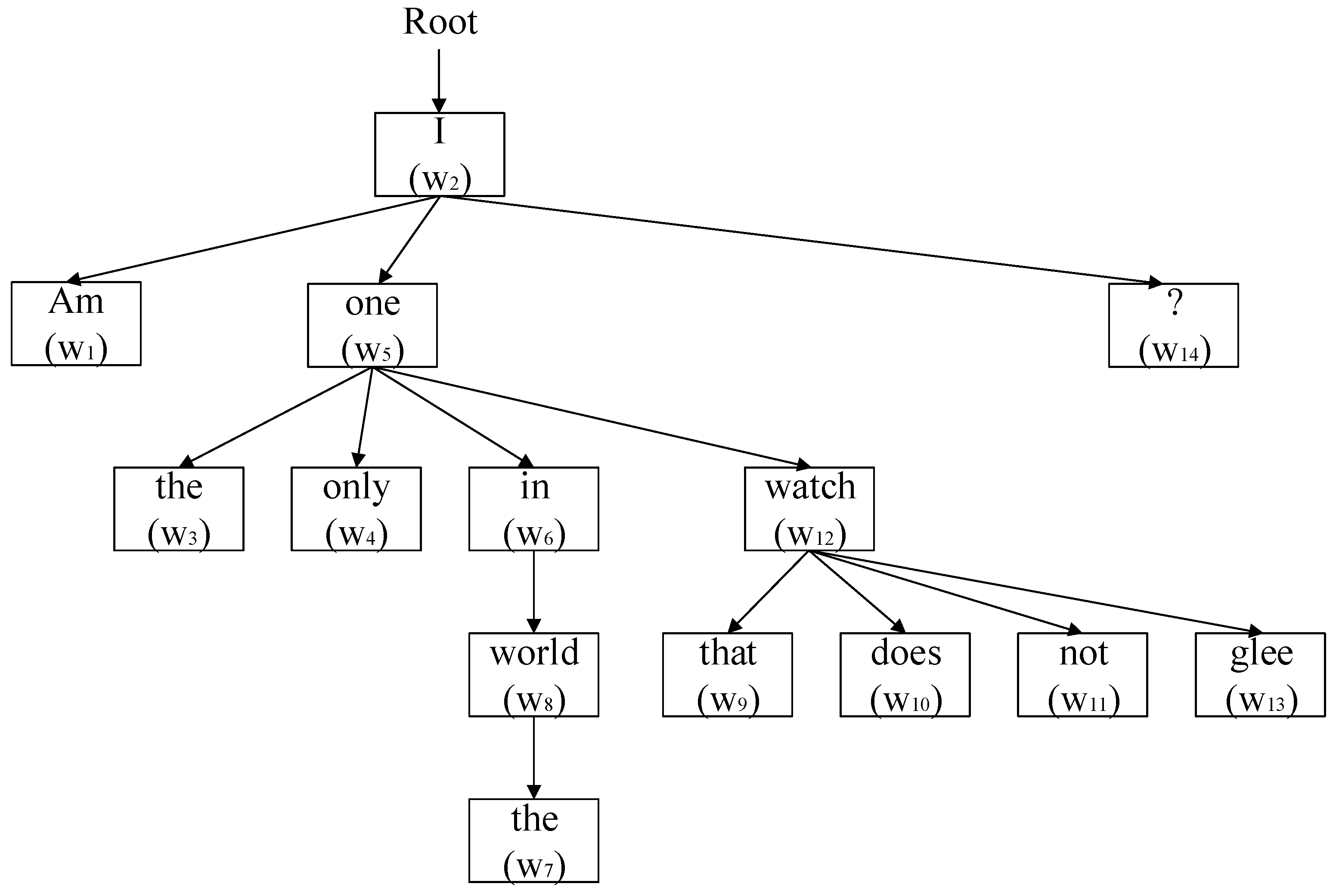
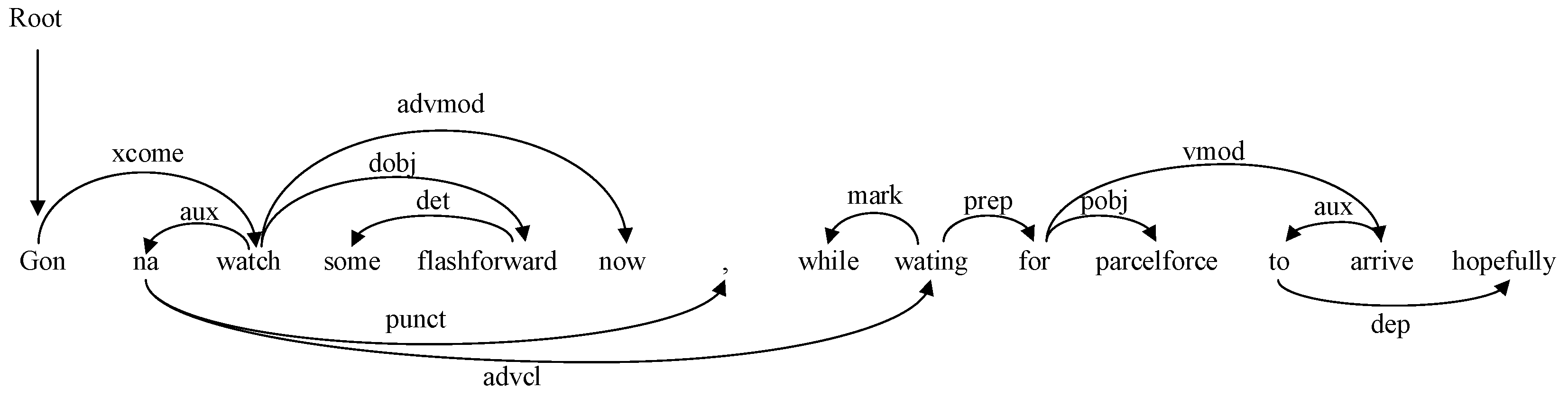
2.2.6. Tree-LSTM
2.2.7. Model Training
3. Experiment
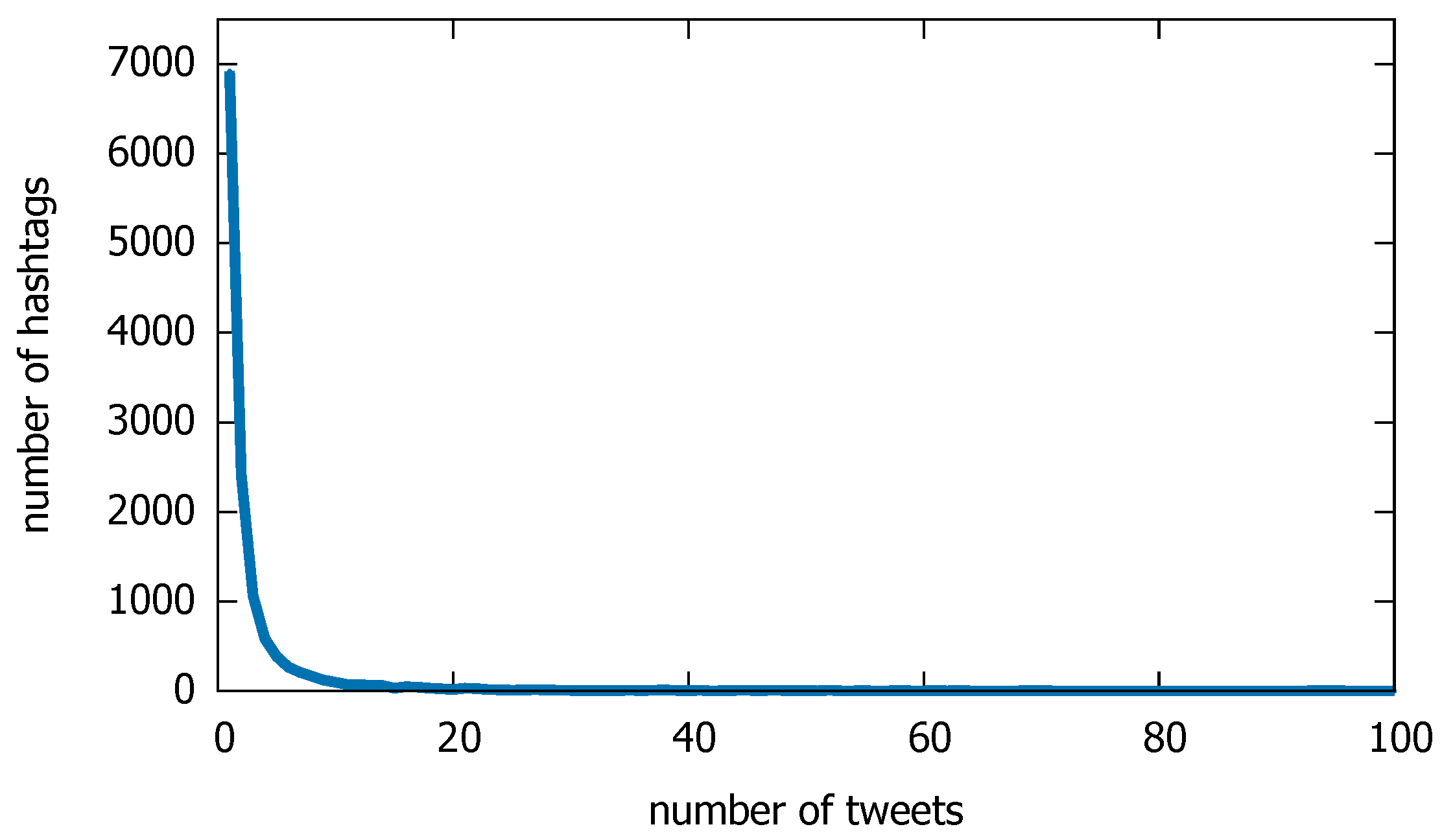
3.1. The Datasets
3.1.1. Twitter Dataset
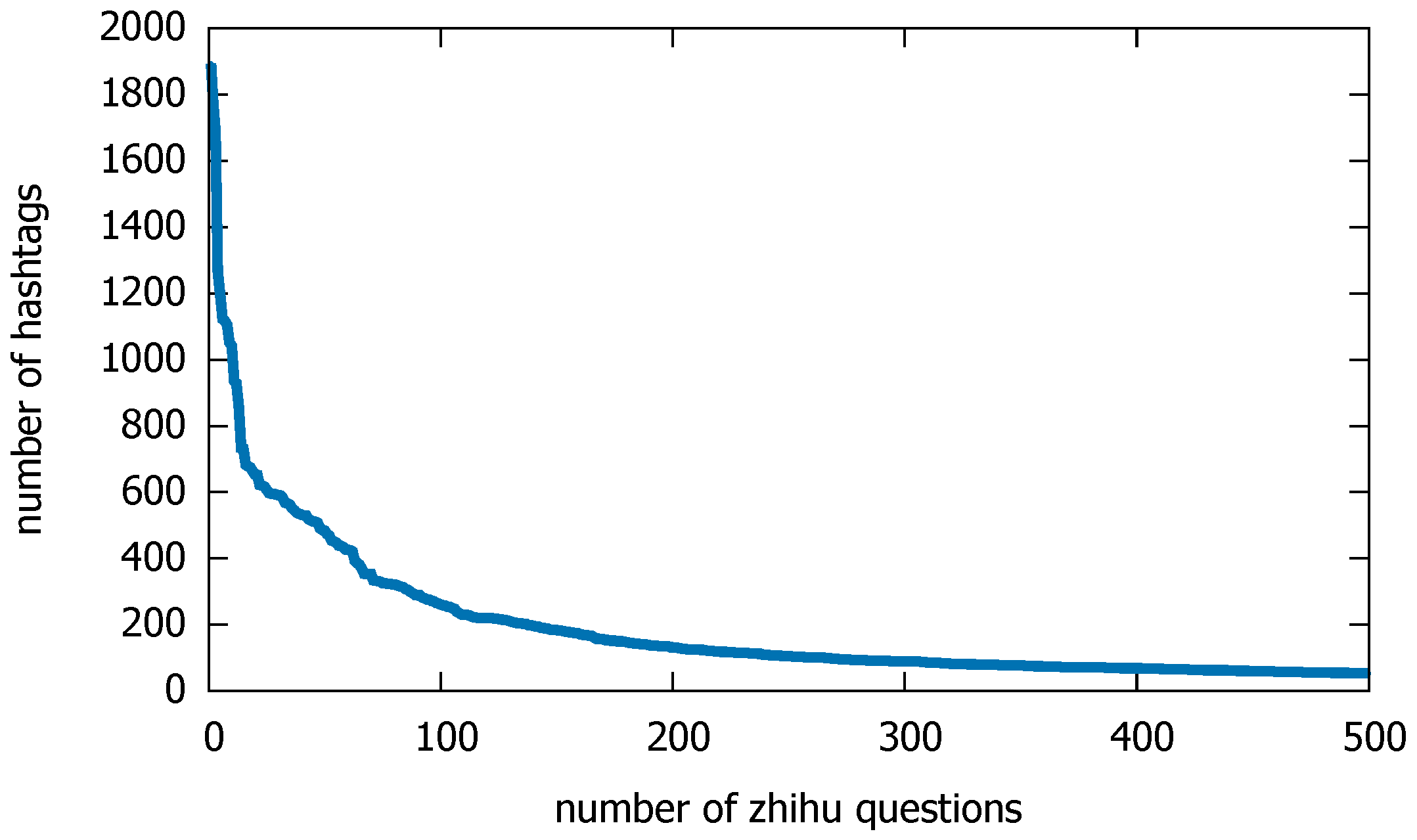
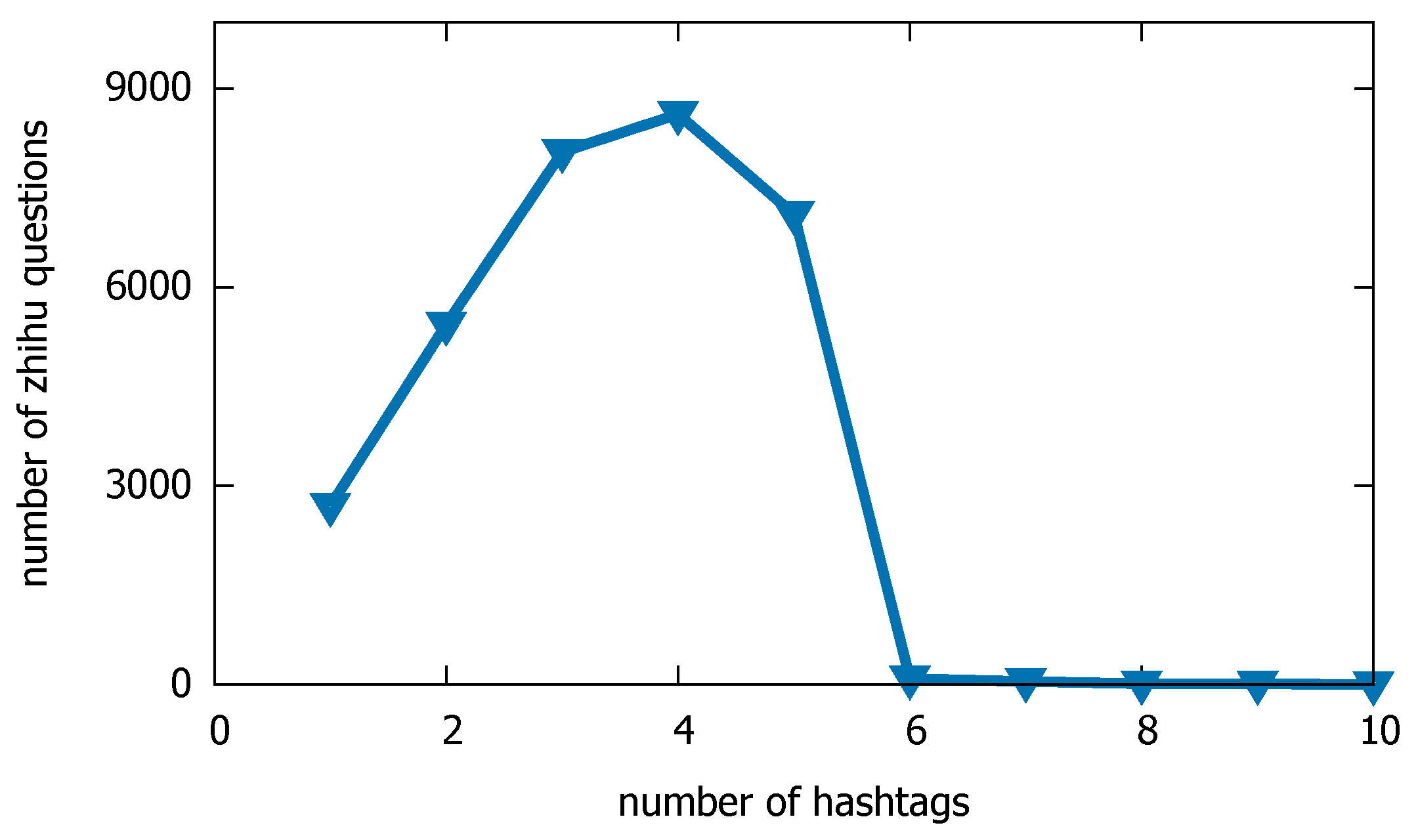
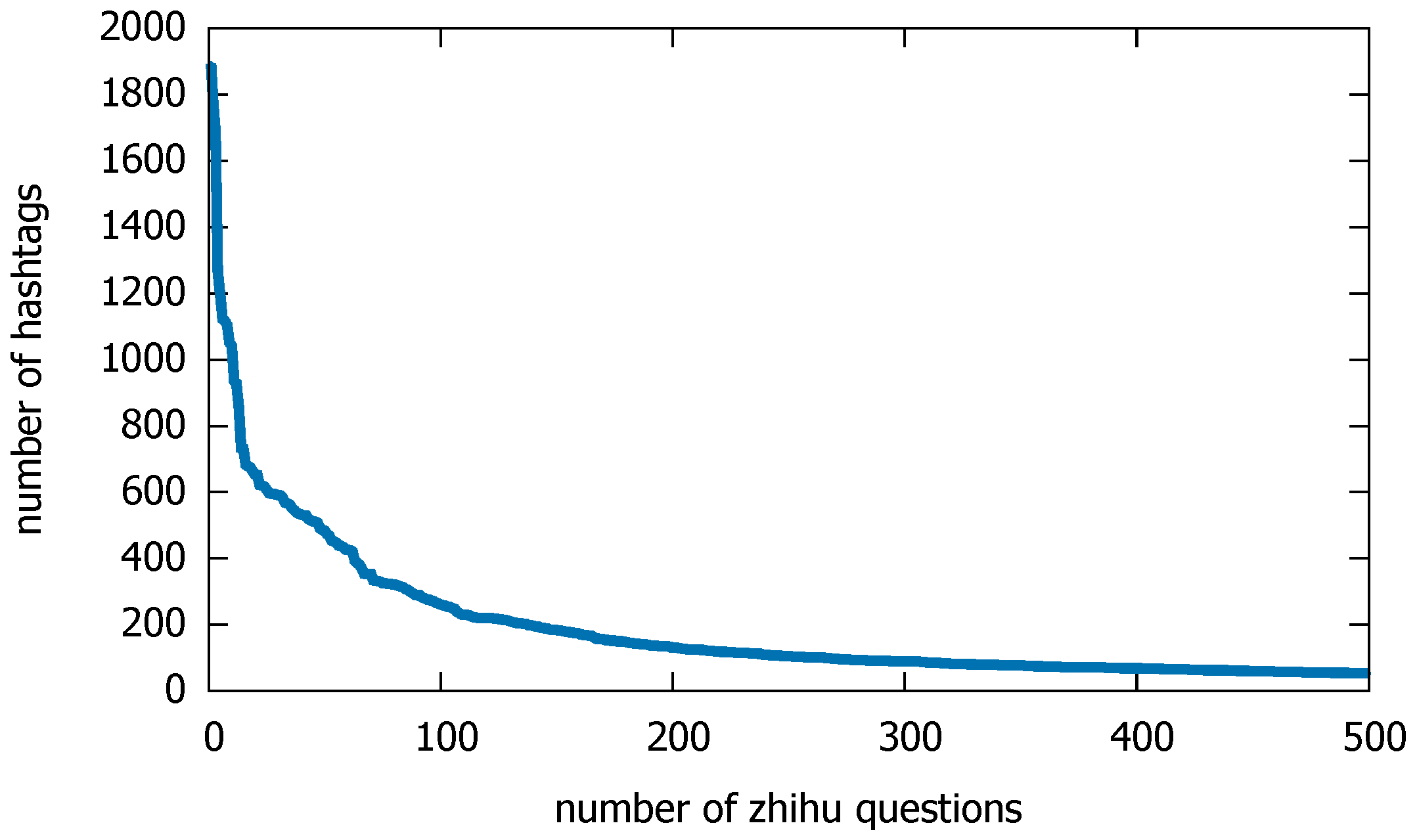
3.1.2. Zhihu Dataset
3.2. Experimental Settings
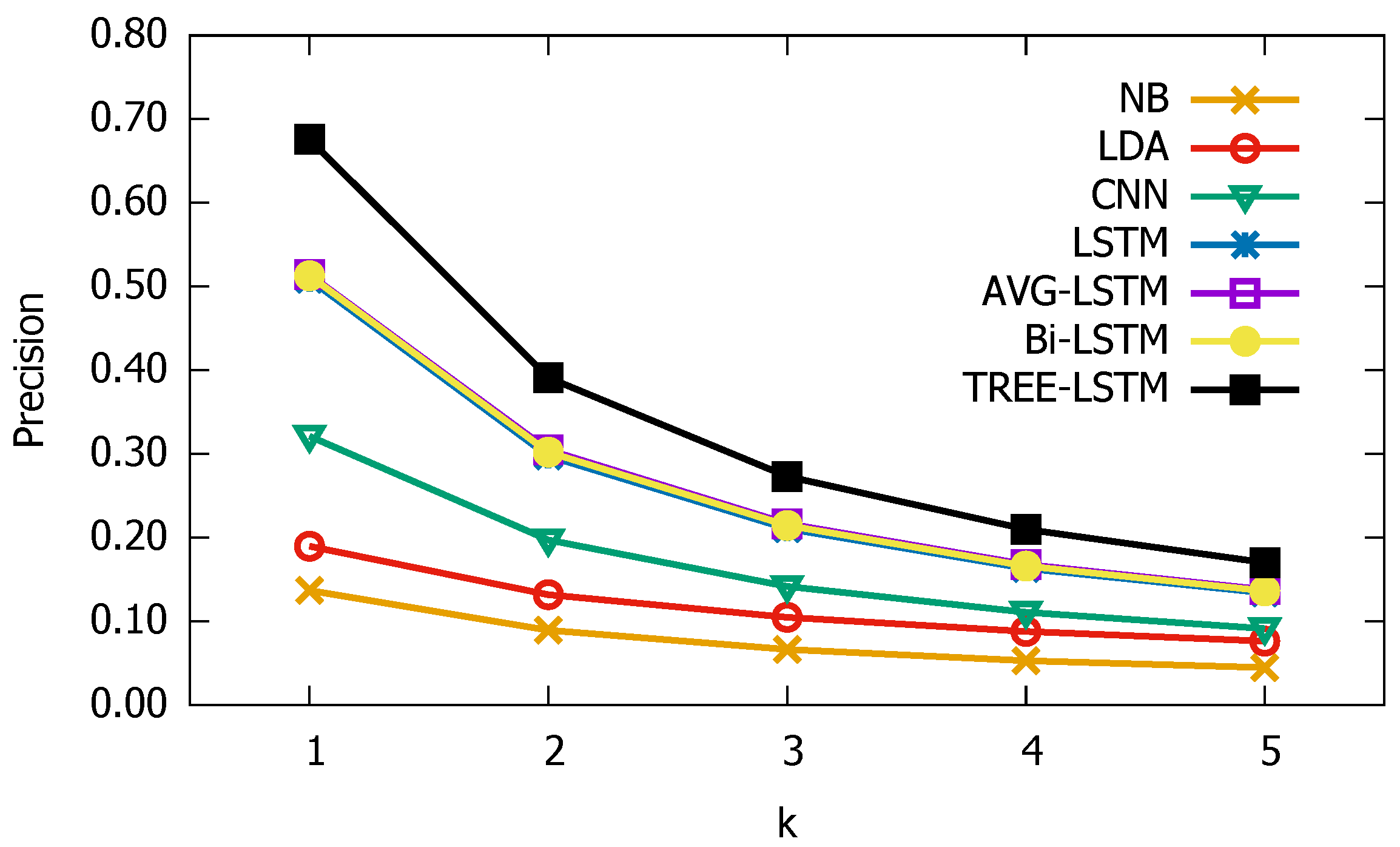
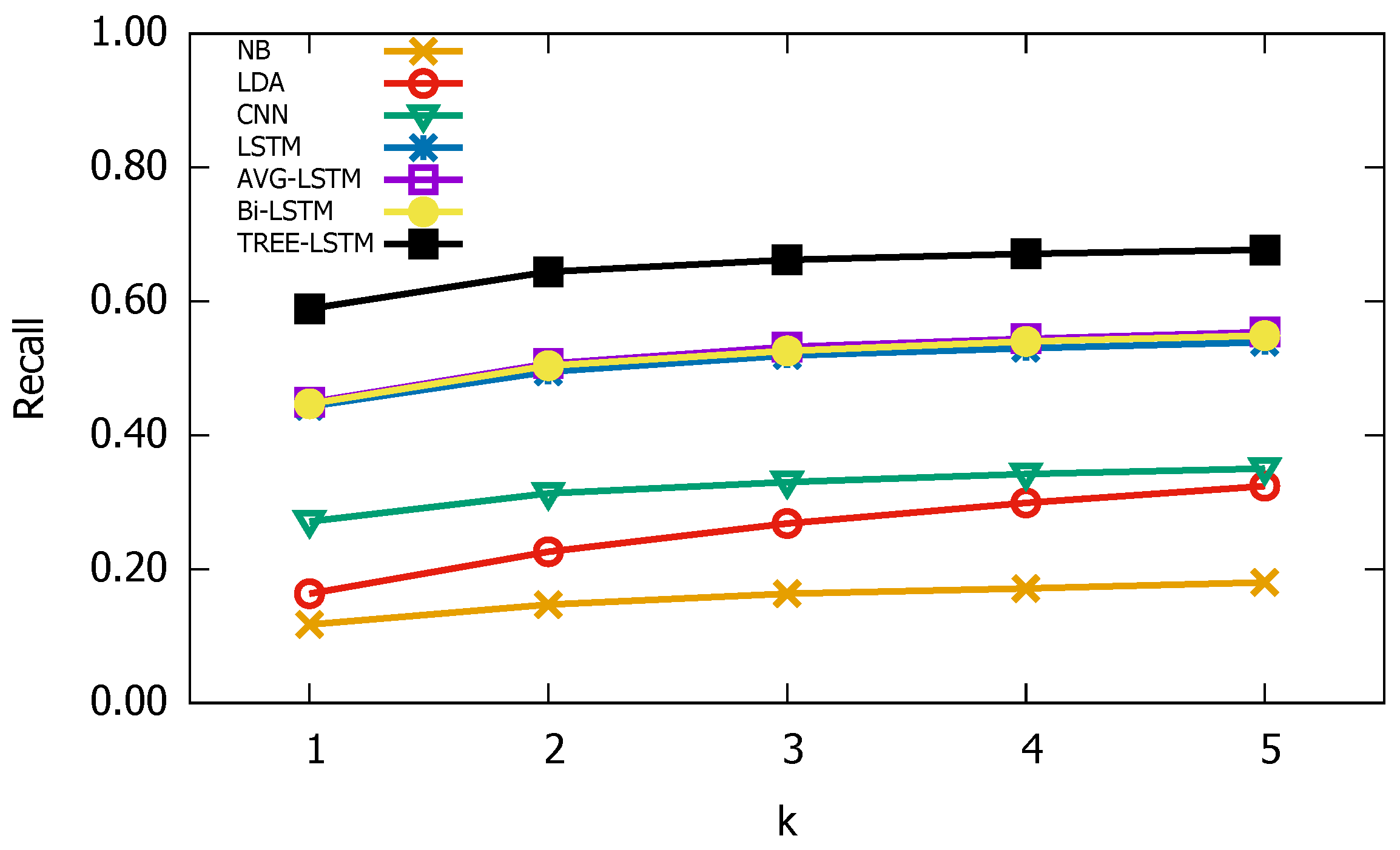
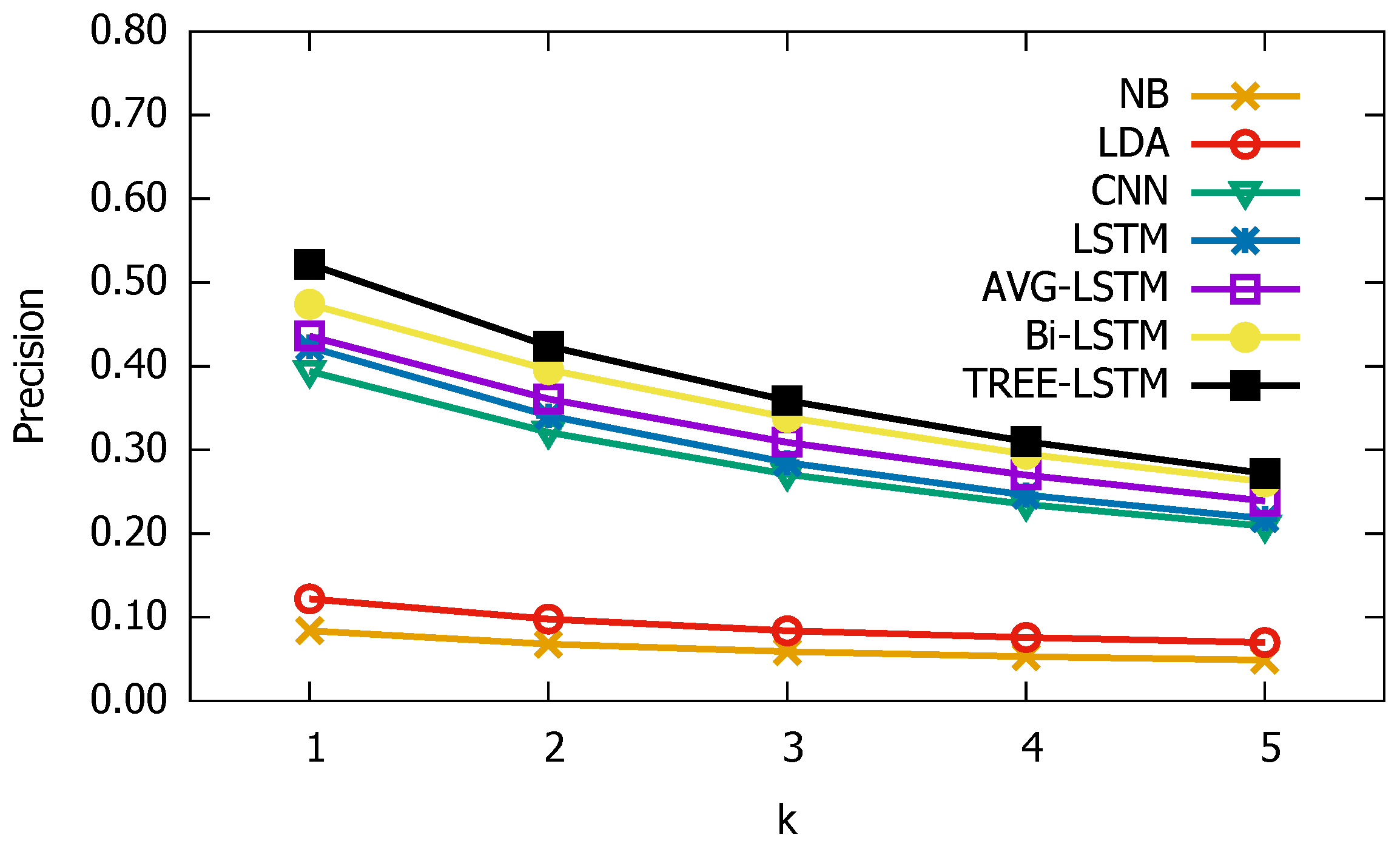
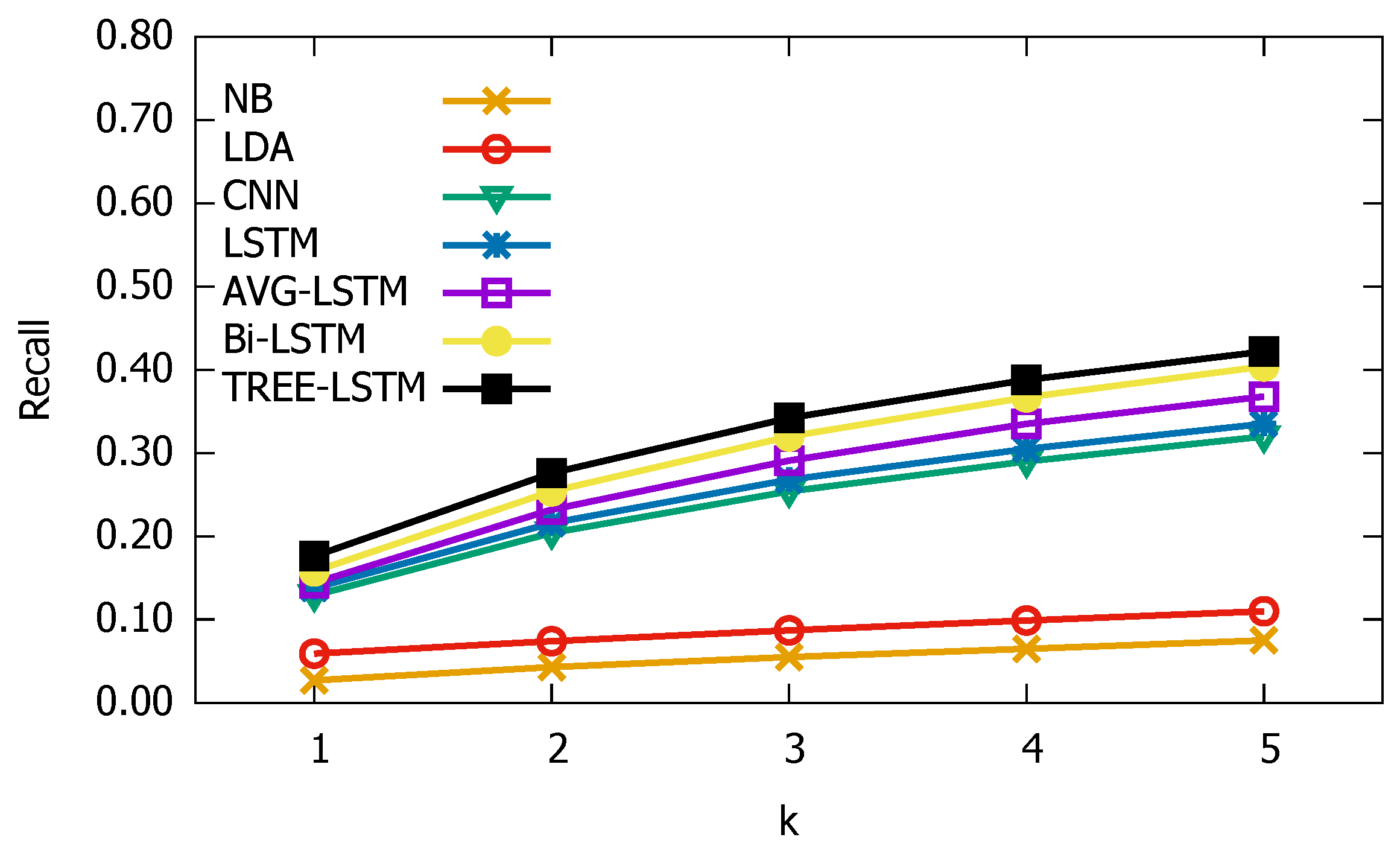
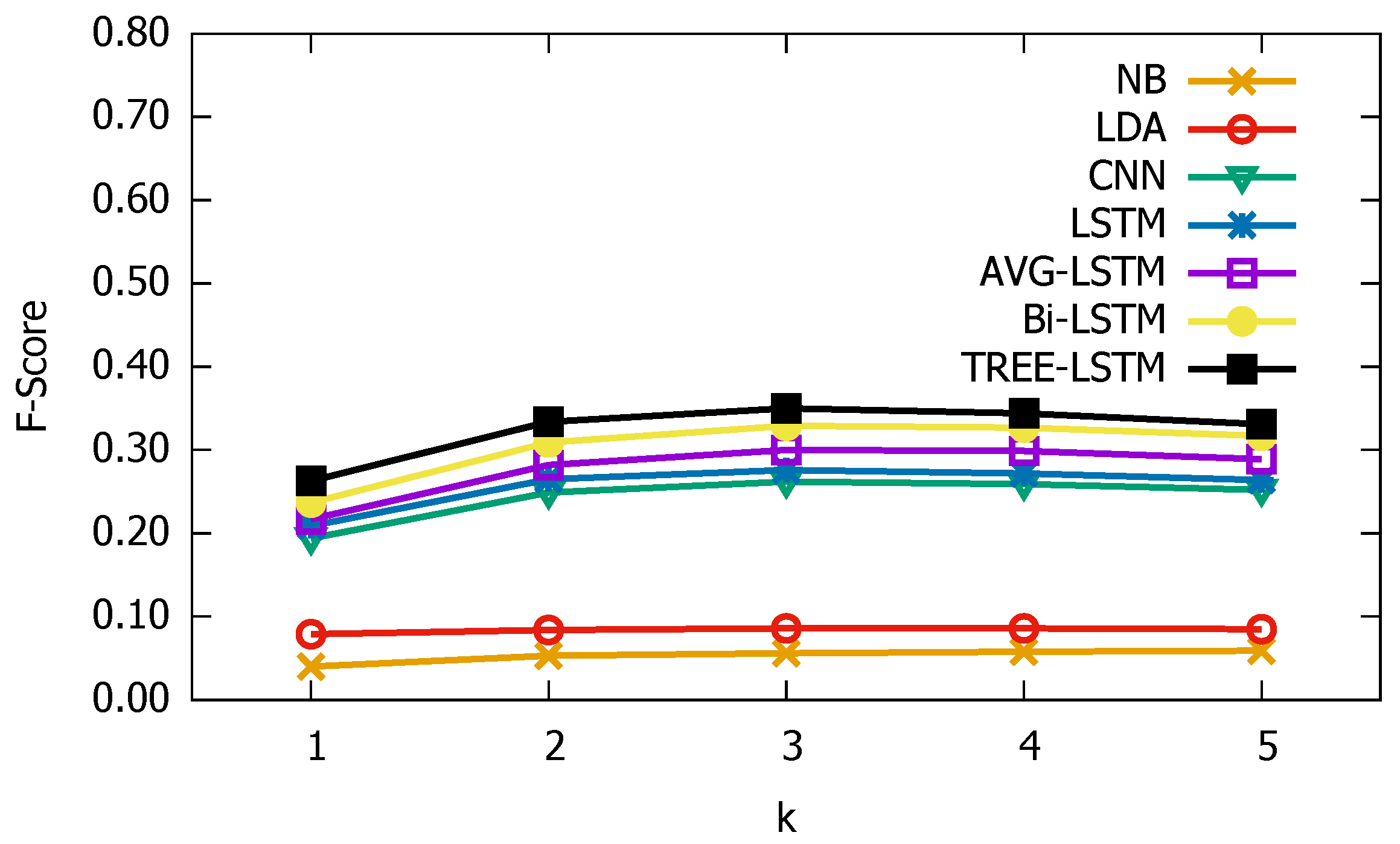
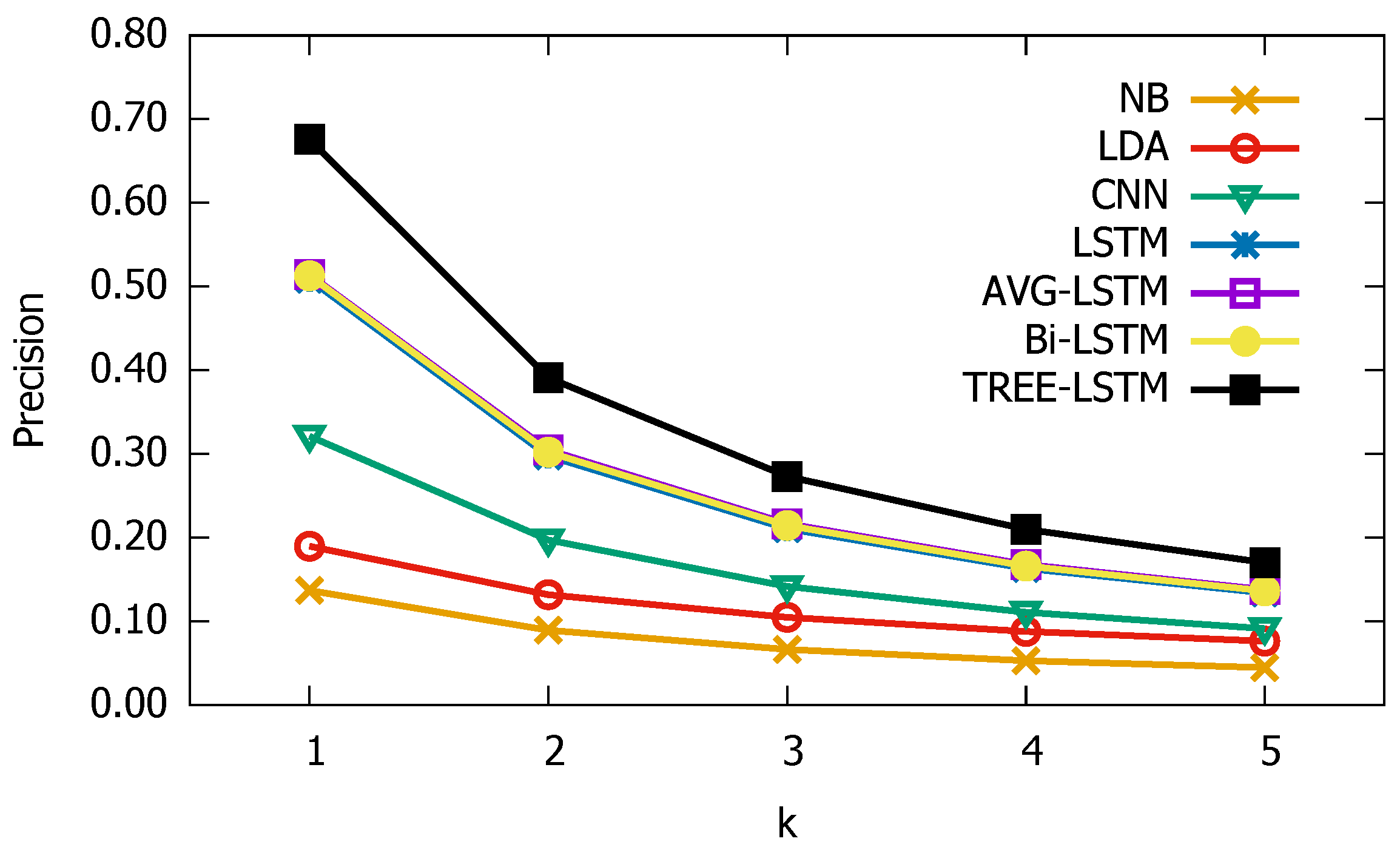
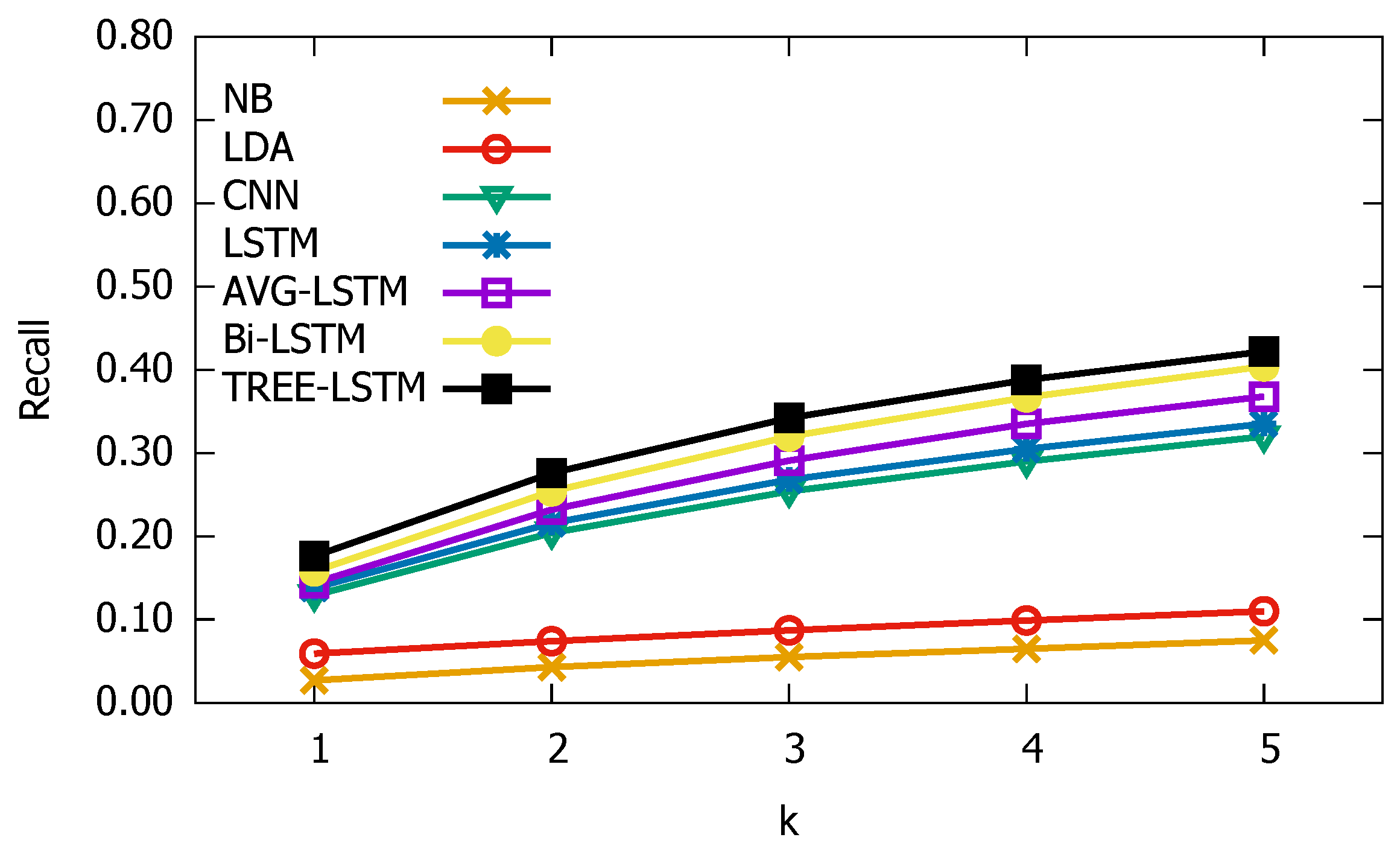
3.3. Experimental Results
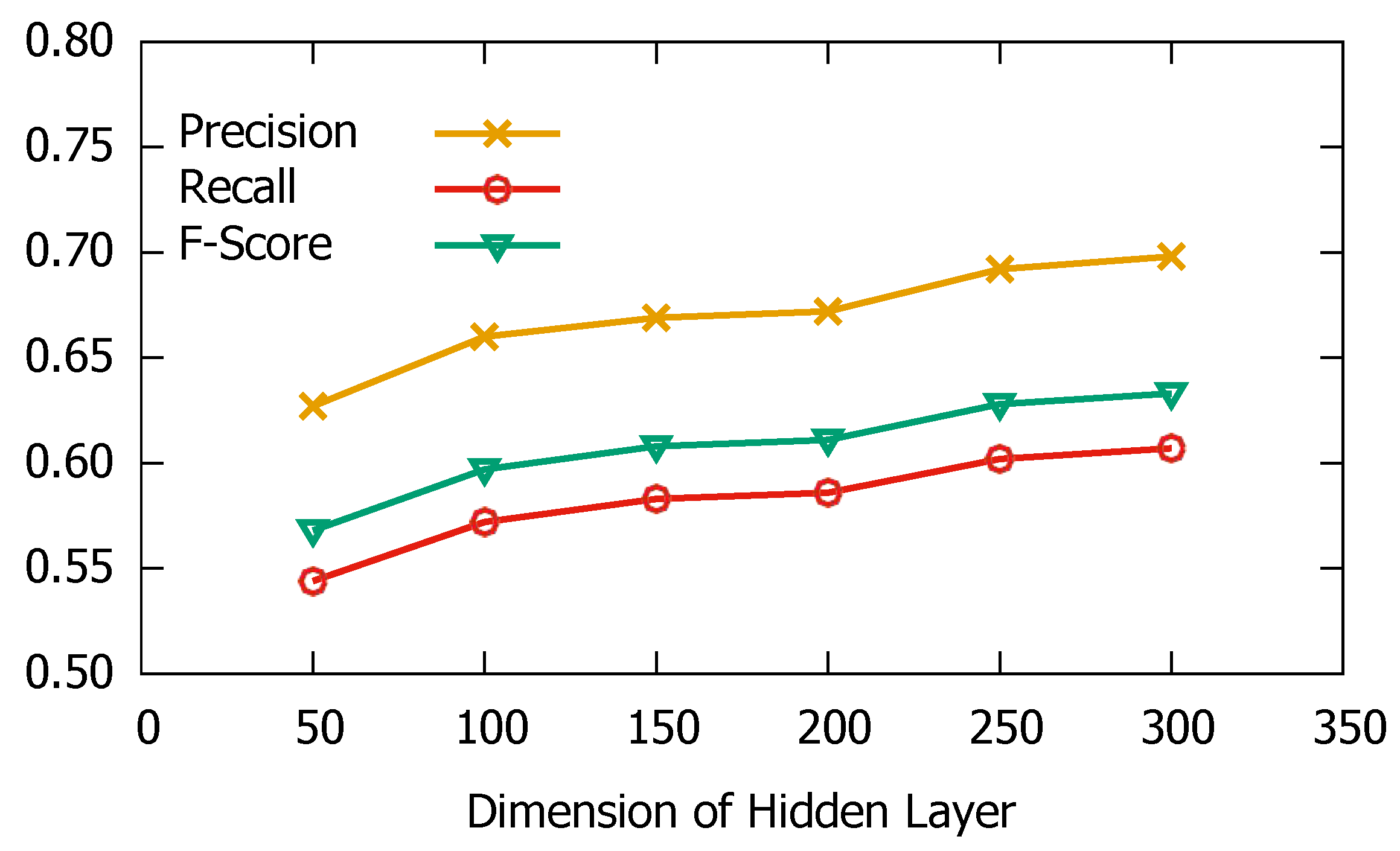
3.4. Parameter Sensitive Analysis
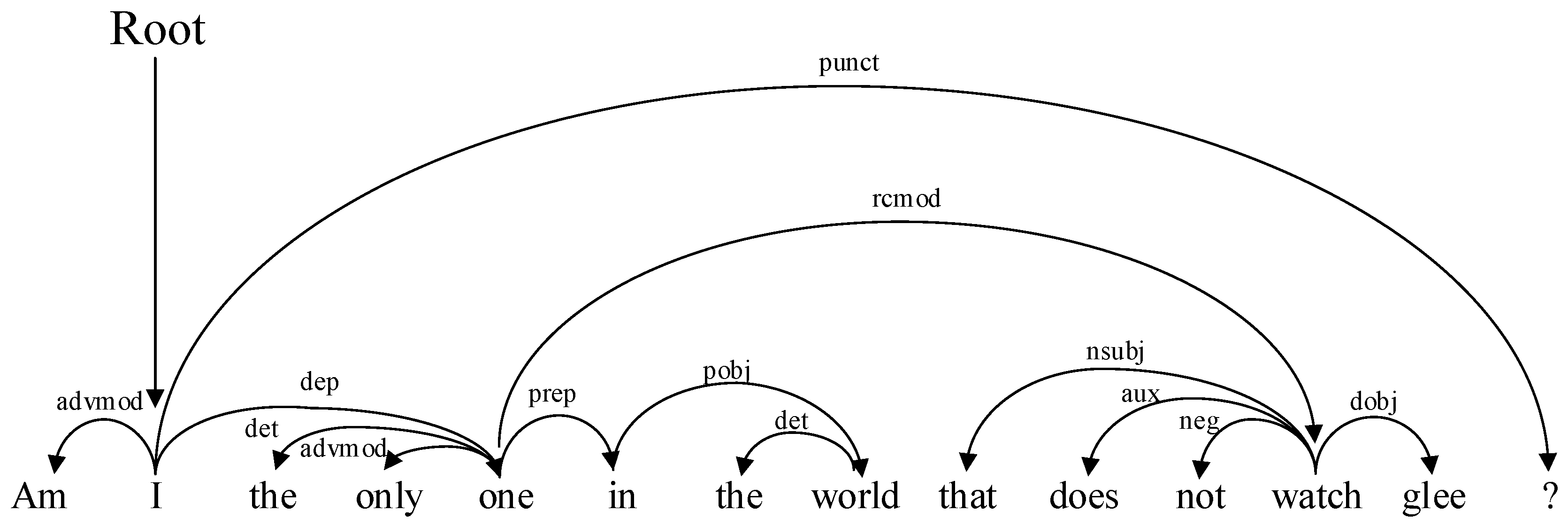
3.5. Qualitative Analysis
4. Related Work
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tran, V.C.; Hwang, D.; Nguyen, N.T. Hashtag Recommendation Approach Based on Content and User Characteristics. Cybern. Syst. 2018, 49, 368–383. [Google Scholar] [CrossRef]
- Twitter. Available online: https://www.twitter.com (accessed on 4 April 2019).
- Efron, M. Hashtag retrieval in a microblogging environment. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; pp. 787–788. [Google Scholar]
- Bandyopadhyay, A.; Ghosh, K.; Majumder, P.; Mitra, M. Query expansion for microblog retrieval. Int. J. Web. Sci. 2012, 1, 368–380. [Google Scholar] [CrossRef]
- Davidov, D.; Tsur, O.; Rappoport, A. Enhanced sentiment learning using twitter hashtags and smileys. In Proceedings of the 23rd International Conference on Computational Linguistics: Posters, Beijing, China, 23–27 August 2010; pp. 241–249. [Google Scholar]
- Wang, X.; Wei, F.; Liu, X.; Zhou, M.; Zhang, M. Topic sentiment analysis in twitter: A graph-based hashtag sentiment classification approach. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 1031–1040. [Google Scholar]
- Li, Y.; Jiang, J.; Liu, T.; Sun, X. Personalized Microtopic Recommendation with Rich Information. In Proceedings of the 4th National Conference on Social Media Processing (SMP 2015), Guangzhou, China, 16–17 November 2015; pp. 1–14. [Google Scholar]
- Hong, L.; Ahmed, A.; Gurumurthy, S.; Smola, A.J.; Tsioutsiouliklis, K. Discovering Geographical Topics in the Twitter Stream. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 769–778. [Google Scholar] [CrossRef]
- Zangerle, E.; Gassler, W.; Specht, G. Recommending#-tags in twitter. In Proceedings of the 2nd International Workshop on Semantic Adaptive Social Web (SASWeb 2011), Girona, Spain, 15 July 2011; Volume 730, pp. 67–78. [Google Scholar]
- Godin, F.; Slavkovikj, V.; De Neve, W.; Schrauwen, B.; Van de Walle, R. Using Topic Models for Twitter Hashtag Recommendation. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 593–596. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- yangdelu855/Tree-LSTM. Available online: https://github.com/yangdelu855/Tree-LSTM (accessed on 4 April 2019).
- Mazzia, A.; Juett, J. Suggesting Hashtags on Twitter; EECS 545m: Machine Learning; Computer Science and Engineering, University of Michigan: Ann Arbor, MI, USA, 2009. [Google Scholar]
- Krestel, R.; Fankhauser, P.; Nejdl, W. Latent Dirichlet Allocation for Tag Recommendation. In Proceedings of the Third ACM Conference on Recommender Systems (RecSys ’09), New York, NY, USA, 23–25 October 2009; pp. 61–68. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osman, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Li, Y.; Liu, T.; Jiang, J.; Zhang, L. Hashtag Recommendation with Topical Attention-Based LSTM. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 3019–3029. [Google Scholar]
- Gong, Y.; Zhang, Q. Hashtag Recommendation Using Attention-Based Convolutional Neural Network. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI 2016), New York, NY, USA, 9–15 July 2016; pp. 2782–2788. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 427–431. [Google Scholar]
- Chen, Q.; Zhu, X.; Ling, Z.; Wei, S.; Jiang, H. Enhancing and Combining Sequential and Tree LSTM for Natural Language Inference. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1657–1668. [Google Scholar]
- Chen, D.; Manning, C. A Fast and Accurate Dependency Parser using Neural Networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 740–750. [Google Scholar]
- Greg, D.; Dan, K. Neural CRF Parsing. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 302–312. [Google Scholar]
- Che, W.; Li, Z.; Liu, T. LTP: A Chinese Language Technology Platform. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010. [Google Scholar]
- Ji, F.; Gao, W.; Qiu, X.; Huang, X. FudanNLP: A Toolkit for Chinese Natural Language Processing with Online Learning Algorithms. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Sofia, Bulgaria, 4–9 August 2013; pp. 49–54. [Google Scholar]
- Yang, J.; Leskovec, J. Patterns of Temporal Variation in Online Media. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 177–186. [Google Scholar] [CrossRef]
- Gong, Y.; Zhang, Q.; Huang, X. Hashtag recommendation for multimodal microblog posts. Neurocomputing 2018, 272, 170–177. [Google Scholar] [CrossRef]
- Zhihu. Available online: https://www.zhihu.com/topics (accessed on 4 April 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ding, Z.; Zhang, Q.; Huang, X. Automatic hashtag recommendation for microblogs using topic-specific translation model. In Proceedings of the 24th International Conference on Computational Linguistics, COLING 2012, Mumbai, India, 8–15 December 2012; pp. 265–274. [Google Scholar]
- Kywe, S.M.; Hoang, T.A.; Lim, E.P.; Zhu, F. On Recommending Hashtags in Twitter Networks. In Social Informatics, Proceedings of the 4th International Conference, SocInfo 2012, Lausanne, Switzerland, 5–7 December 2012; Aberer, K., Flache, A., Jager, W., Liu, L., Tang, J., Guéret, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7710, pp. 337–350. [Google Scholar]
- Wang, Y.; Qu, J.; Liu, J.; Chen, J.; Huang, Y. What to Tag Your Microblog: Hashtag Recommendation Based on Topic Analysis and Collaborative Filtering. In Web Technologies and Applications, Proceedings of the 16th Asia-Pacific Web Conference, APWeb 2014, Changsha, China, 5–7 September 2014; Chen, L., Jia, Y., Sellis, T., Liu, G., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2014; Volume 8709, pp. 610–618. [Google Scholar]
- Zhao, F.; Zhu, Y.; Jin, H.; Yang, L.T. A personalized hashtag recommendation approach using LDA-based topic model in microblog environment. Future Gener. Comput. Syst. 2016, 65, 196–206. [Google Scholar] [CrossRef]
- Li, Q.; Shah, S.; Nourbakhsh, A.; Liu, X.; Fang, R. Hashtag Recommendation Based on Topic Enhanced Embedding, Tweet Entity Data and Learning to Rank. In Proceedings of the 25th ACM International Conference on Information and Knowledge Management (CIKM ’16), Indianapolis, IN, USA, 24–28 October 2016; pp. 2085–2088. [Google Scholar] [CrossRef]
- Ma, Z.; Sun, A.; Yuan, Q.; Cong, G. Tagging Your Tweets: A Probabilistic Modeling of Hashtag Annotation in Twitter. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management (CIKM ’14), Shanghai, China, 3–7 November 2014; pp. 999–1008. [Google Scholar] [CrossRef]
- Lu, H.; Lee, C. A Twitter Hashtag Recommendation Model that Accommodates for Temporal Clustering Effects. IEEE Intell. Syst. 2015, 30, 18–25. [Google Scholar] [CrossRef]
- Kowald, D.; Pujari, S.C.; Lex, E. Temporal Effects on Hashtag Reuse in Twitter: A Cognitive-Inspired Hashtag Recommendation Approach. In Proceedings of the 26th International Conference on World Wide Web Companion (WWW’17), Perth, Australia, 3–7 April 2017; pp. 1401–1410. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, J.; Huang, H.; Huang, X.; Gong, Y. Hashtag Recommendation for Multimodal Microblog Using Co-Attention Network. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), Melbourne, Australia, 19–25 August 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # Tweets | # Hashtags | Vocabulary Size | Nt(avg) |
|---|---|---|---|
| 60,000 | 14,320 | 106,348 | 1.352 |
| # Questions | # Hashtags | Vocabulary Size | Nt(avg) |
|---|---|---|---|
| 42,060 | 3487 | 37,566 | 3.394 |
| Methods | Precision | Recall | F1-Score |
|---|---|---|---|
| NB | 0.137 | 0.117 | 0.126 |
| LDA | 0.190 | 0.163 | 0.176 |
| TF-IDF | 0.249 | 0.221 | 0.234 |
| fastText | 0.276 | 0.234 | 0.253 |
| CNN | 0.321 | 0.271 | 0.294 |
| LSTM | 0.509 | 0.443 | 0.473 |
| AVG-LSTM | 0.514 | 0.449 | 0.479 |
| Bi-LSTM | 0.513 | 0.447 | 0.478 |
| Tree-LSTM | 0.676 | 0.589 | 0.629 |
| Methods | Precision | Recall | F1-Score |
|---|---|---|---|
| NB | 0.084 | 0.027 | 0.040 |
| LDA | 0.122 | 0.059 | 0.079 |
| TF-IDF | 0.100 | 0.032 | 0.048 |
| fastText | 0.347 | 0.109 | 0.166 |
| CNN | 0.394 | 0.129 | 0.194 |
| LSTM | 0.423 | 0.138 | 0.209 |
| AVG-LSTM | 0.437 | 0.144 | 0.217 |
| Bi-LSTM | 0.474 | 0.158 | 0.237 |
| Tree-LSTM | 0.522 | 0.176 | 0.263 |
| Trainingdata | Precision | Recall | F1-Score |
|---|---|---|---|
| 100K (20%) | 0.459 | 0.399 | 0.417 |
| 200K (40%) | 0.532 | 0.459 | 0.480 |
| 300K (60%) | 0.589 | 0.512 | 0.534 |
| 400K (80%) | 0.633 | 0.550 | 0.574 |
| 500K (100%) | 0.676 | 0.589 | 0.629 |
| Trainingdata | Precision | Recall | F1-Score |
|---|---|---|---|
| 100K (20%) | 0.379 | 0.123 | 0.178 |
| 200K (40%) | 0.442 | 0.148 | 0.211 |
| 300K (60%) | 0.474 | 0.159 | 0.227 |
| 400K (80%) | 0.502 | 0.171 | 0.242 |
| 500K (100%) | 0.522 | 0.176 | 0.263 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, R.; Yang, D.; Li, Y. Learning Improved Semantic Representations with Tree-Structured LSTM for Hashtag Recommendation: An Experimental Study. Information 2019, 10, 127. https://doi.org/10.3390/info10040127
Zhu R, Yang D, Li Y. Learning Improved Semantic Representations with Tree-Structured LSTM for Hashtag Recommendation: An Experimental Study. Information. 2019; 10(4):127. https://doi.org/10.3390/info10040127
Chicago/Turabian StyleZhu, Rui, Delu Yang, and Yang Li. 2019. "Learning Improved Semantic Representations with Tree-Structured LSTM for Hashtag Recommendation: An Experimental Study" Information 10, no. 4: 127. https://doi.org/10.3390/info10040127
APA StyleZhu, R., Yang, D., & Li, Y. (2019). Learning Improved Semantic Representations with Tree-Structured LSTM for Hashtag Recommendation: An Experimental Study. Information, 10(4), 127. https://doi.org/10.3390/info10040127