Personal Data Market Optimization Pricing Model Based on Privacy Level


Abstract
1. Introduction
- We propose a fair privacy compensation mechanism. From the perspective of data publishers, they can be compensated according to their privacy attitudes. From the perspective of data market, their operating costs are effectively controlled.
- We present a nonlinear mathematical model that describes the relationship between consumer self-selection behavior and privacy-aware data utility.
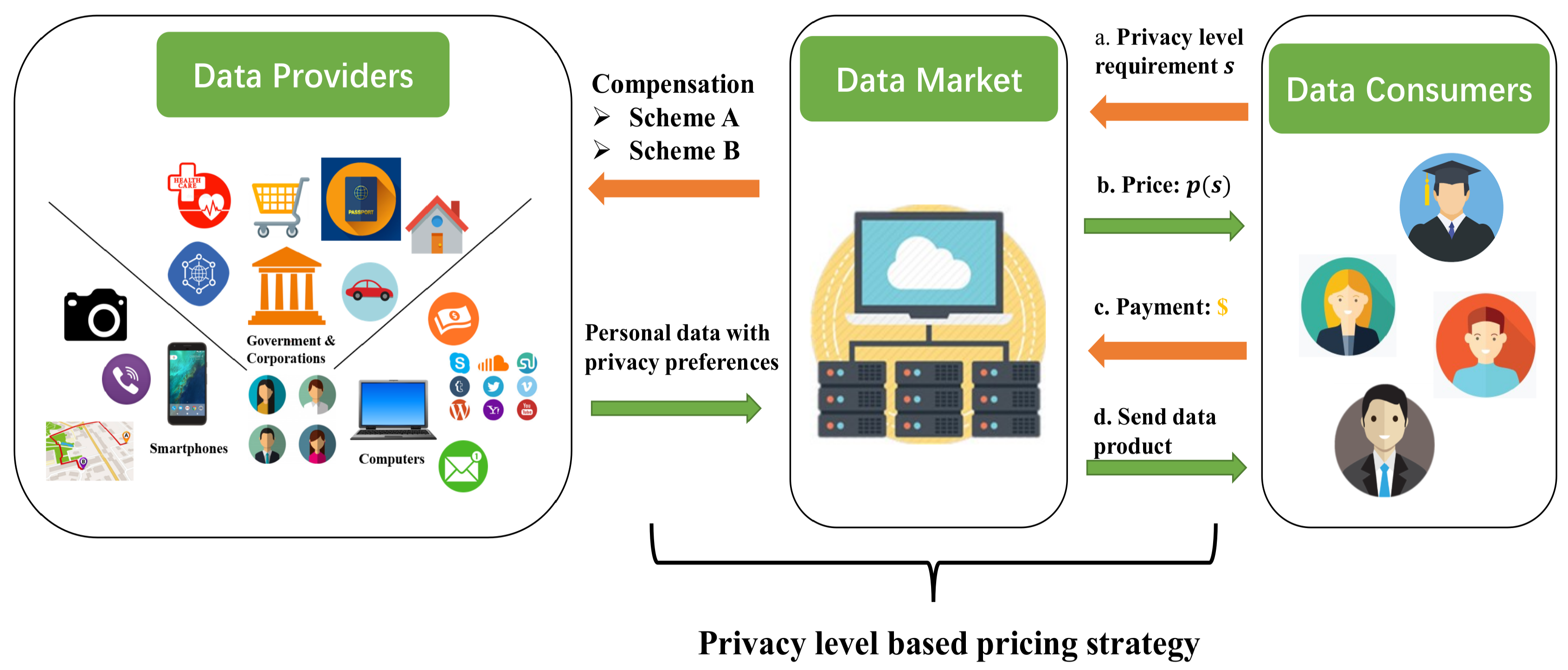
2. Framework Description
2.1. Stakeholder Description
- Data provider Let K denote the number of data providers who are willing to sell their private data. Each data provider is modeled with a non-decreasing function (i.e., compensation scheme) : , representing a promise between a data platform and a data provider on how much data provider should be compensated for their privacy loss (Privacy loss is the extent to which individual sensitive information is disclosed. The quantification of privacy loss to an individual is defined by differential privacy [11,12]), where is the quantification of privacy loss of data provider as and money are correlated [13,14]. In addition, the compensation scheme is determined by the data market according to the type of data provider (i.e., privacy preference). Therefore, a good compensation scheme can not only help data owners understand and determine their , but also make the cost of the data platform more transparent and controllable. In Section 2.2, we discuss how to design such a compensation scheme.
- Data market (a.k.a., data platform) is an intermediary between data consumers and data providers. It is trusted by both parties and collects privacy-aware personal data from data providers to compensate them appropriately. Instead of asking for their valuations, data providers are given a fixed number of options. Based on the compensation model selected by the data provider, the data platform determines privacy level and compensation amount for the data they provide. Meanwhile, the data platform also determines the data price for different privacy levels to cover its operating costs. Therefore, the data platform needs to jointly optimize purchase fees and privacy compensation fees to maximize profits.
- Data consumer is the terminal of the entire framework. For research and commercial purposes, the terminal consumer can decide whether to purchase the data or services provided by the data platform based on their willingness to pay (WTP). It is also worth mentioning that the purchase task can only be completed when the consumer’s willingness to pay is greater than the utility of the data provided. Otherwise, the purchase process is considered to be a failure.
2.2. Fair Privacy Compensation Mechanism
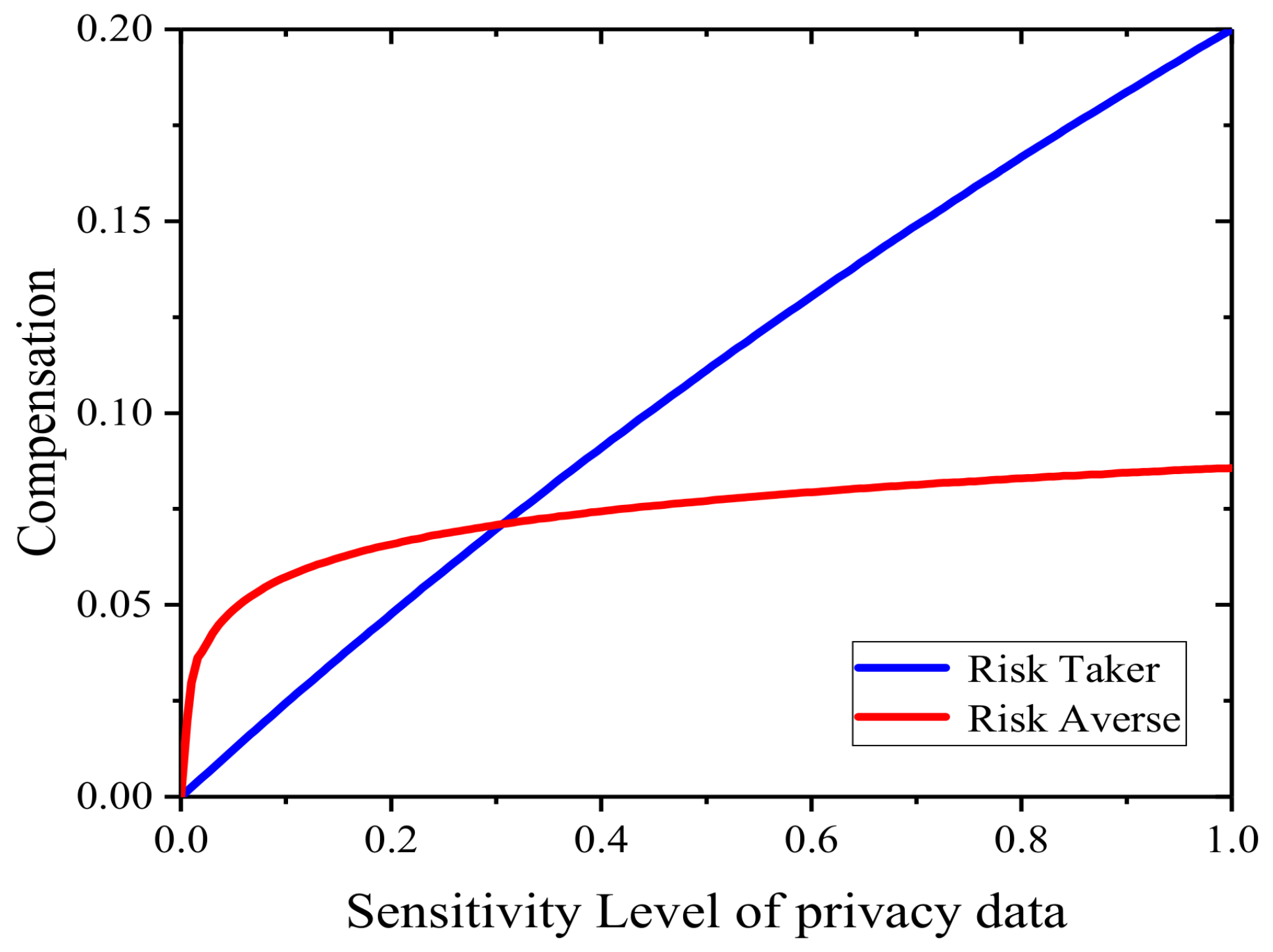
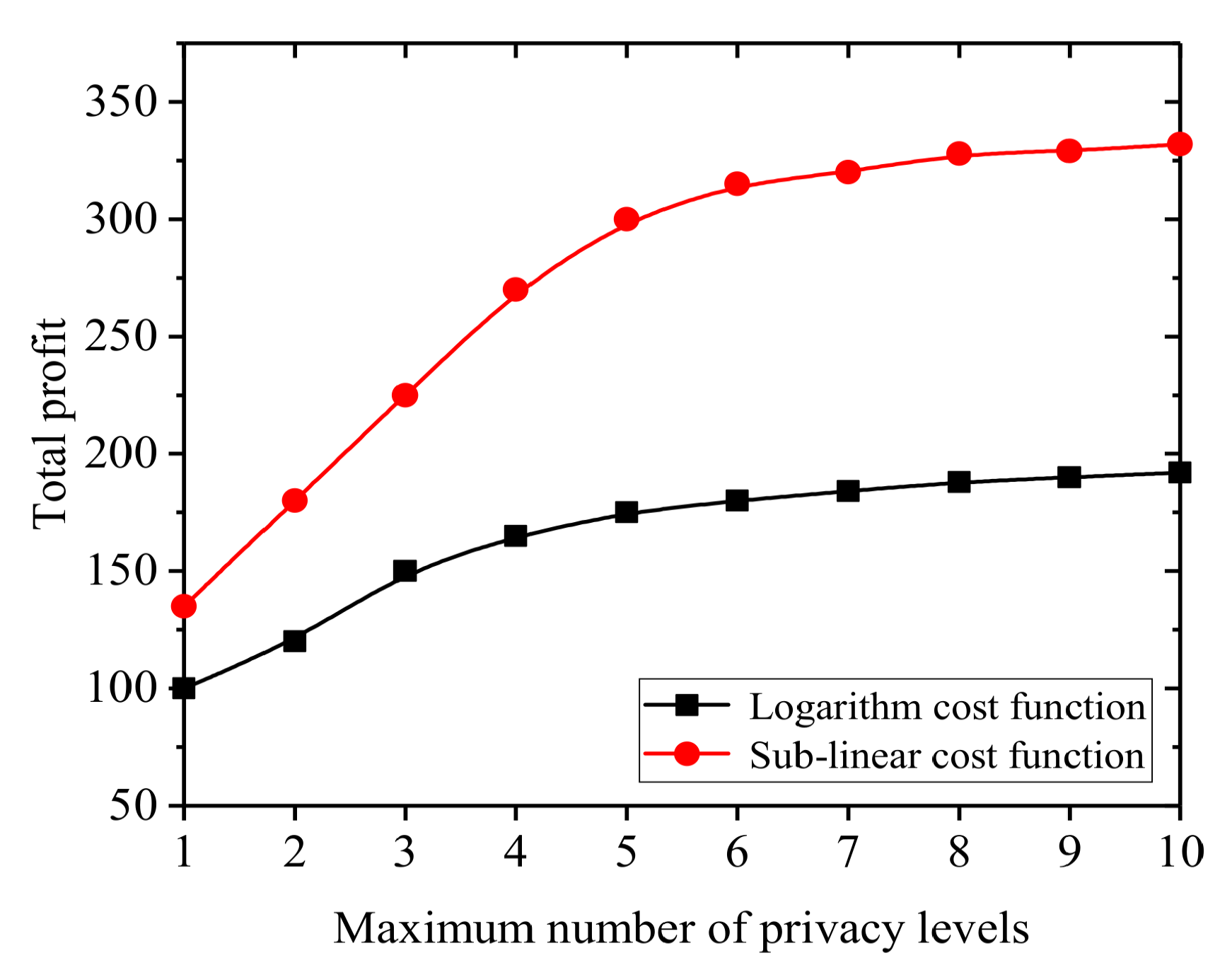
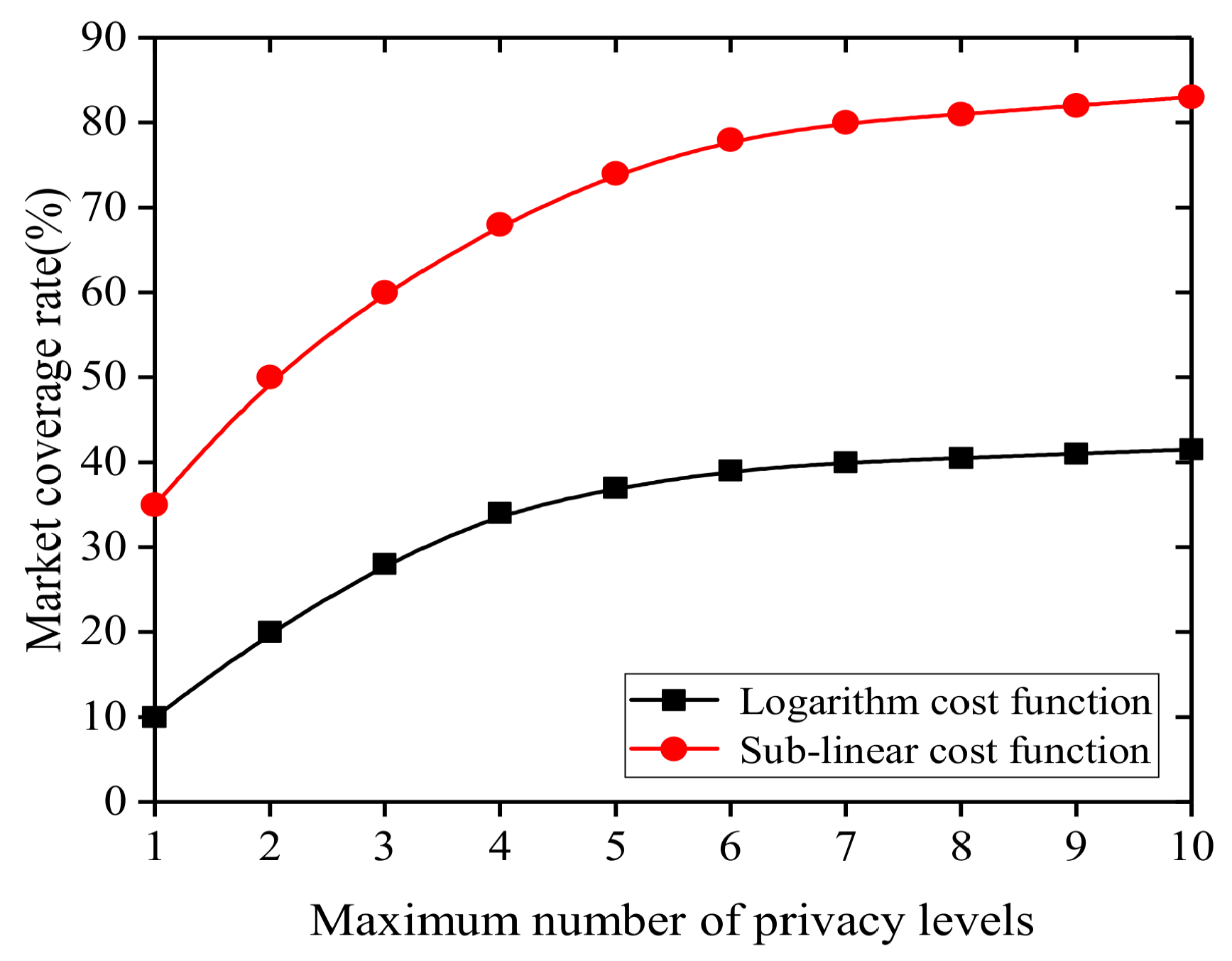
- A. Risk Taker Such data providers are subjectively willing to take risks and have strong risk tolerance. A privacy compensation mechanism based on sublinear functions is designed to support such data providers.
- B. Risk Averse Such data providers are relatively conservative and unwilling to take risks. A privacy compensation mechanism based on a logarithm function is designed to support such data providers.
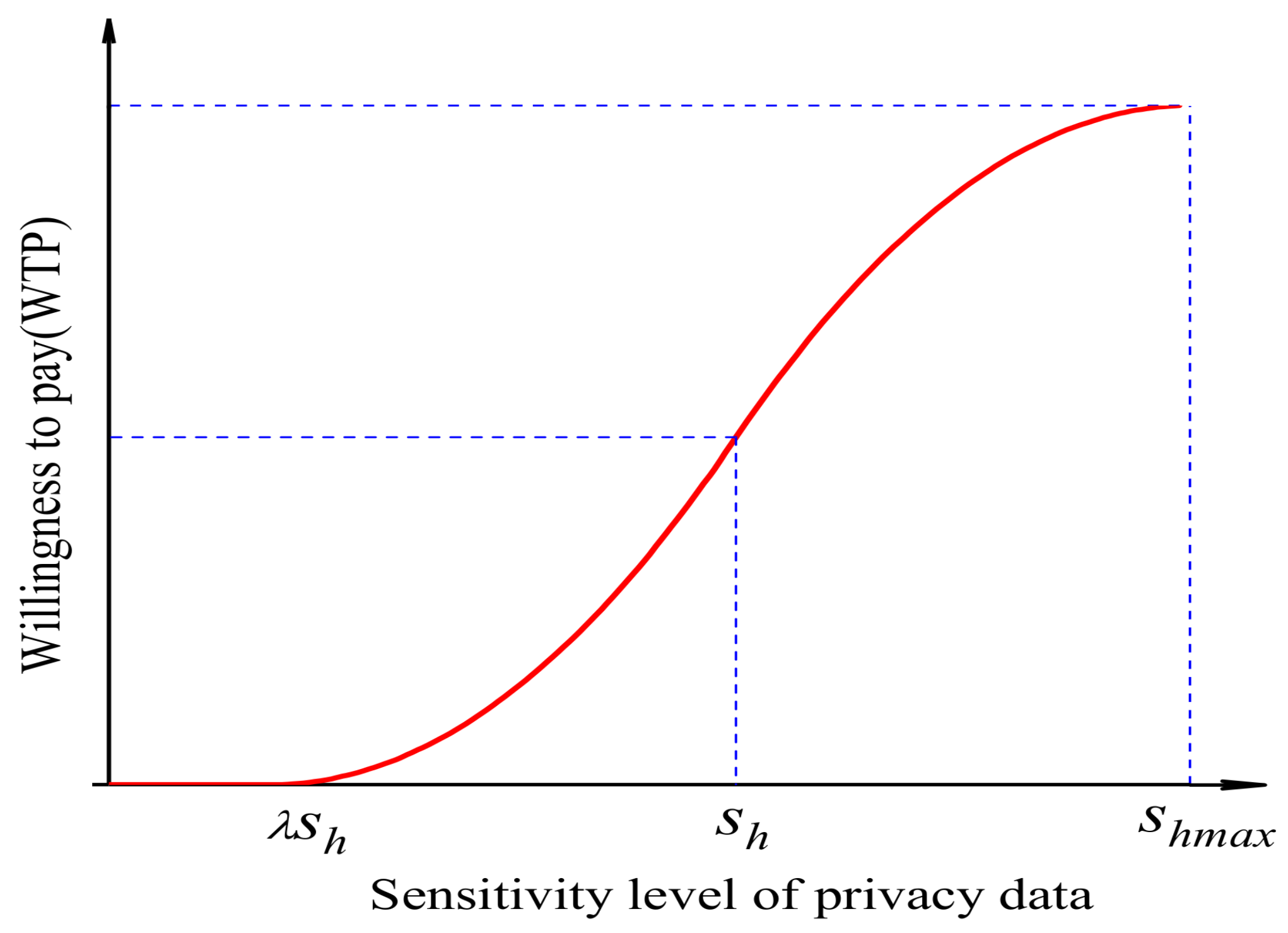
2.3. Customer’s Self-Selection Behavior Analysis
3. Bi-Level Programming Model of Pricing Privacy Data
- Provide N sensitivity levels for privacy data. When , the platform monopolist provides a non-hierarchical service, and when , the platform monopolist provides a level difference service.
- The different levels of sensitivity of the data correspond to different utility , indicating that the i-th level provides data utility for the consumer, and the corresponding price for each level is labeled .
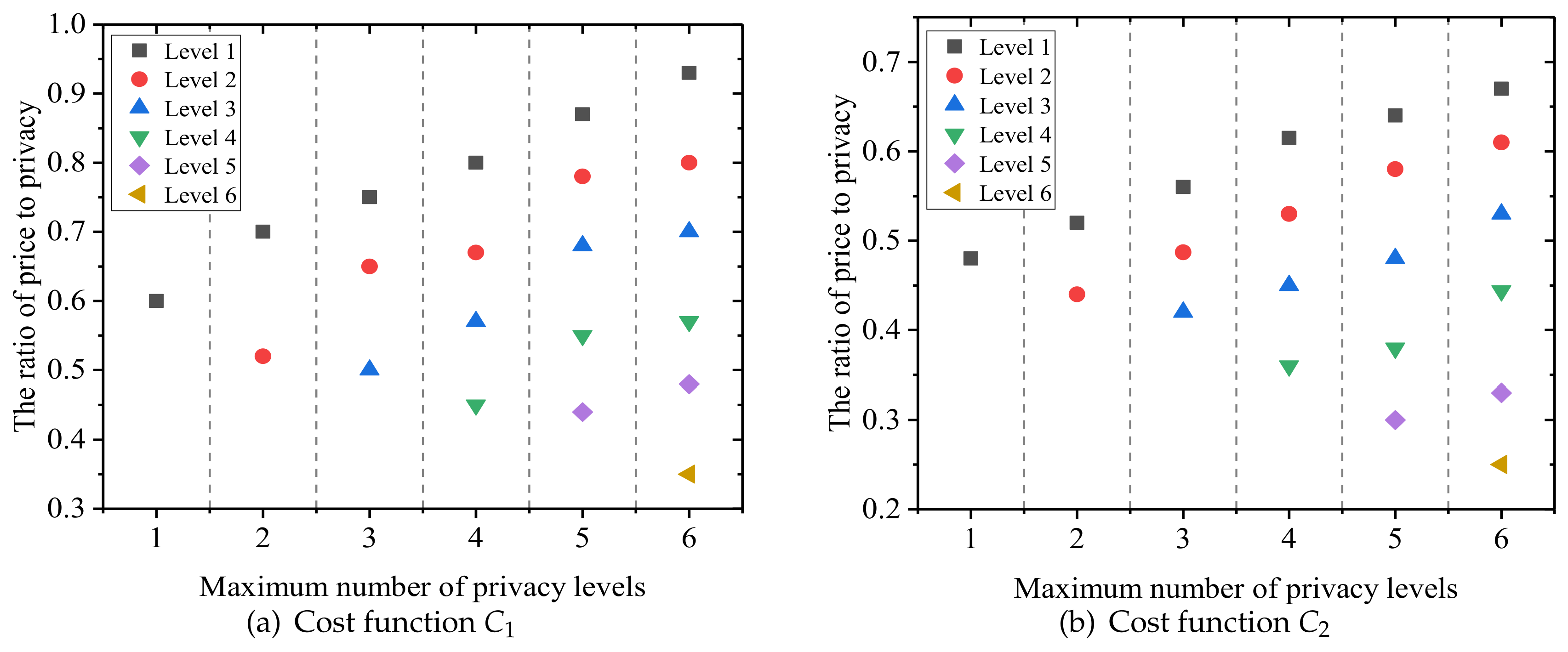
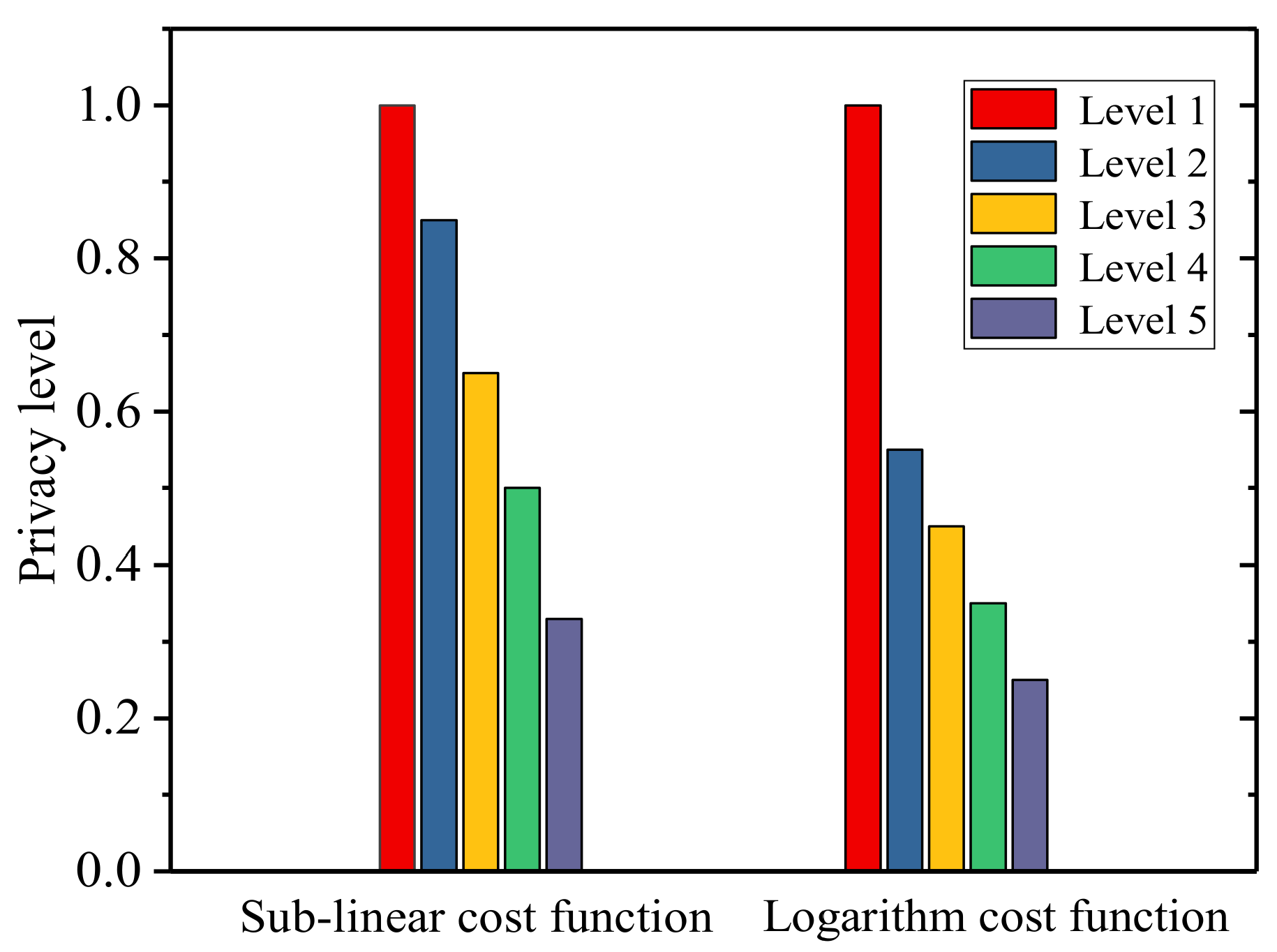
- The price increases as the level of data sensitivity increases.
- The utility of consumer j is for products with data sensitivity level i. If there are multiple privacy data sensitivity levels that meet expectations, consumer j will choose the data product that can produce the most utility, i.e., . If , the customer wouldn’t subscribe to data product with sensitivity level i.
- Each consumer can only subscribe to no more than one type of data product. Suppose we measure the consumer’s self-selection process through , Where i represents the sensitivity level of the privacy data. If = 1, the consumer accepts subscription for product with a sensitivity level i. If = 0, or not.
- The marginal willingness to pay for all potential data consumers h is between 0 and 1 () subject to a Gaussian distribution, and once a choice is made, there is no change.
- Leader level: data markplace’s decision
- Following level: data customer’s decision
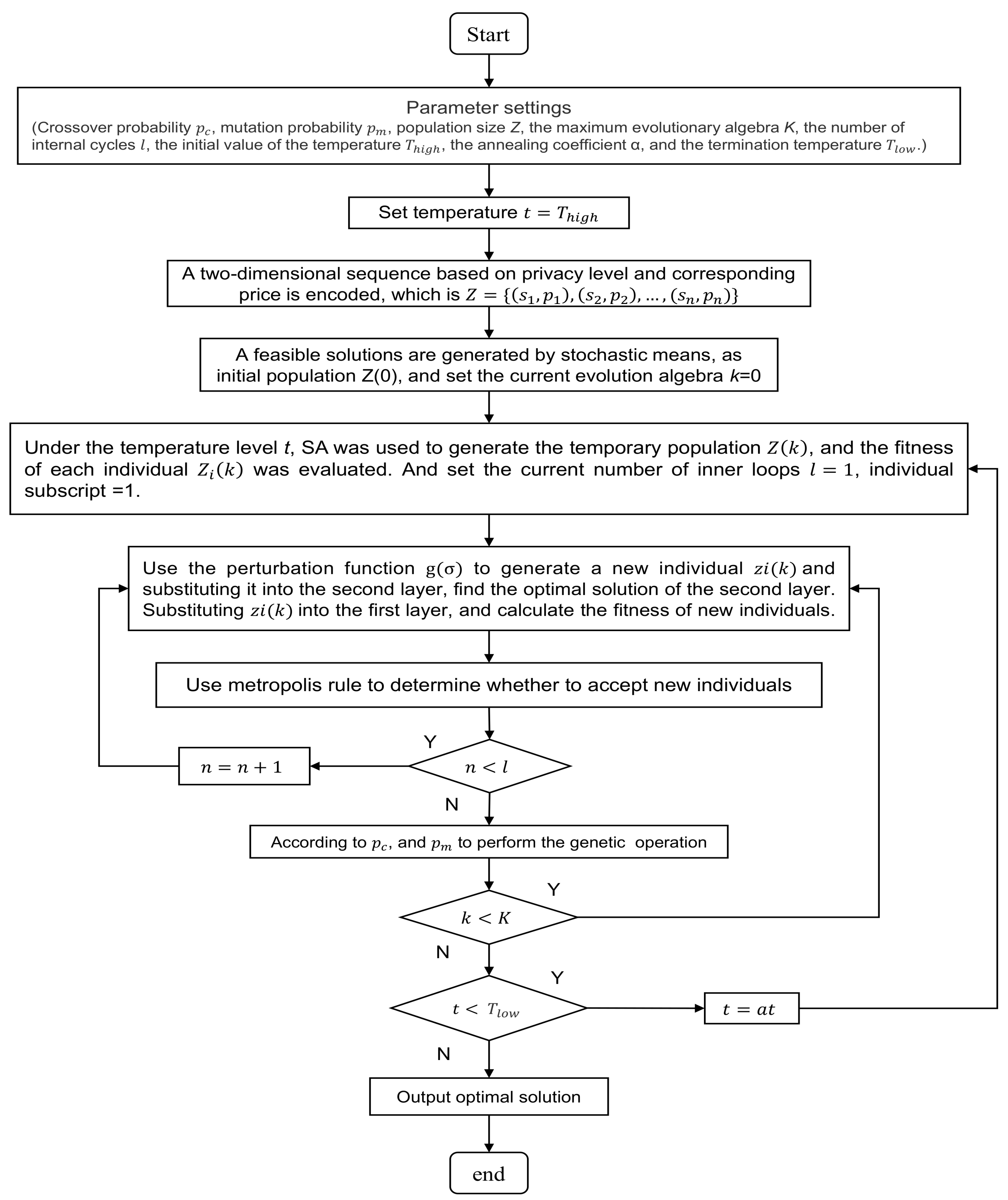
4. BLGASA for Obtaining Optimal Solutions
- Step.1 Select the parameters of . At this stage, the evaluation parameters of and need to be determined. In the genetic algorithm, take the crossover and mutation probability as and , the population size Z, the maximal generation K, and in the simulated annealing algorithm, take the number of internal cycles as l, the initial value of the temperature , the annealing coefficient as , and the termination temperature as .
- Step.2 Set temperature t = .
- Step.3 A two-dimensional sequence based on privacy level and corresponding price is encoded, i.e., Z = {, , …, }. According to the objective function of the leader level, the fitness of an individual is the total profit.
- Step.4 A feasible solutions are generated by stochastic method, taking it as the initial population , and set the current evolution algebra k = 0.
- Step.5 Under the temperature level t, was used to generate the temporary population , and the fitness of each individual was evaluated. Then, set the current number of inner loops l = 1, individual subscript i = 1.
- Step.6 Generate a new individual by using the perturbation function and substituting it into the second layer, find the optimal solution of the second layer, let = . Substituting into the first layer, and calculate the fitness of new individuals. Among them, the perturbation function is a random number in [−z, z], is the perturbation coefficient, and the default is 0.05.
- Step.7 Use metropolis rule to determine whether to accept new individuals , f = - :
- If f > 0, replace with .
- Otherwise, generate a random number ∈ (0, 1), if (−f/(t)) >, replace with
- Step.8 Set , if , return Step.6. Otherwise, execute Step.9.
- Step.9 The crossover and mutation operations are performed according to and , is generated, and the fitness of each individual is calculated.
- Step.10 Set , if , return Step.6. Otherwise, execute Step.11.
- Step.11 Set t = t, if t > , return Step.5. Otherwise, execute Step.12.
- Step.12 Output optimal solution
5. Numerical Experiment
5.1. Experimental Design
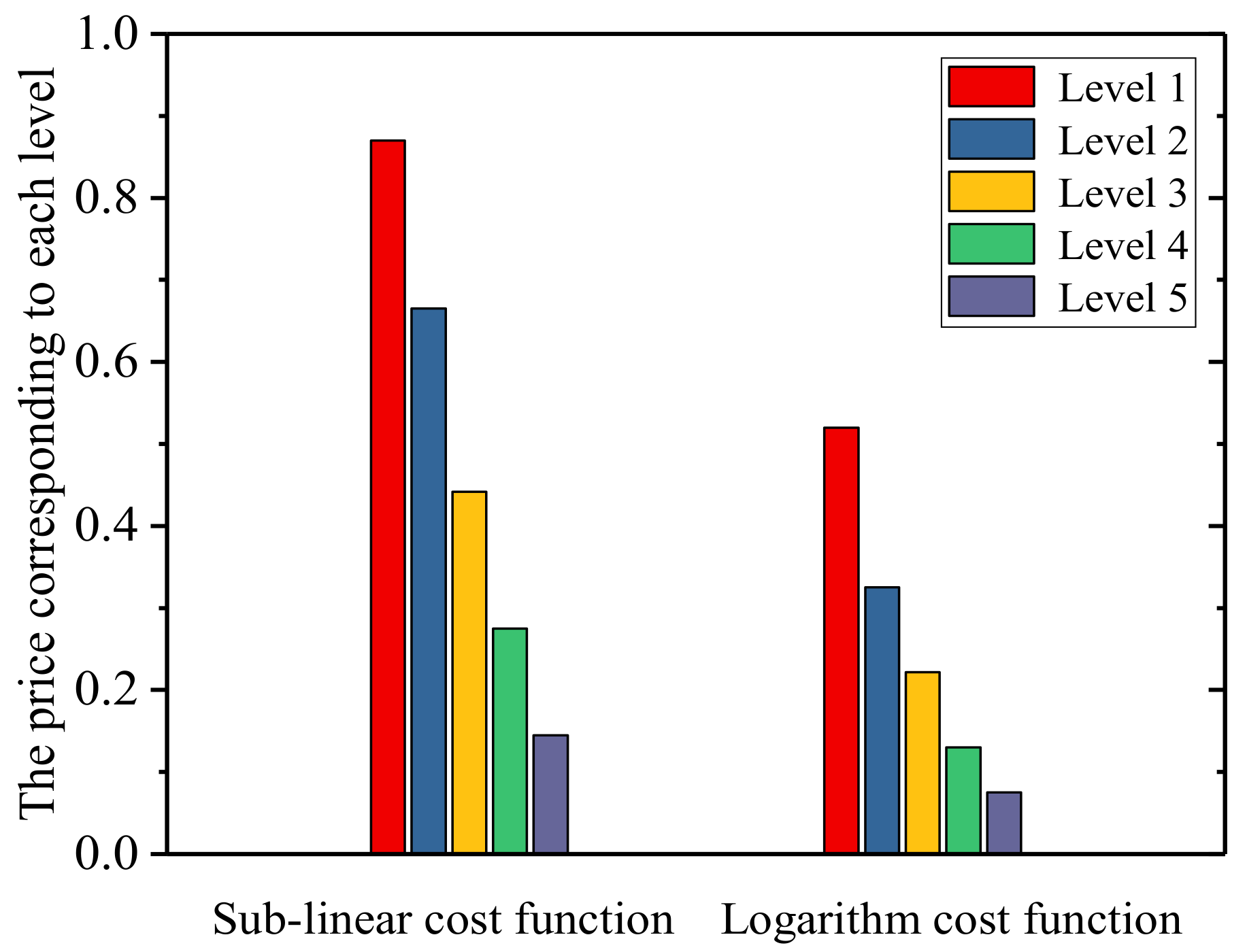
5.2. Experimental Results
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mai, J.E. Big data privacy: The datafication of personal information. Inf. Soc. 2016, 32, 192–199. [Google Scholar] [CrossRef]
- Carey, P. Data Protection: A Practical Guide to UK and EU Law; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Stahl, F.; Schomm, F.; Vossen, G. Data marketplaces: An emerging species. In Databases and Information Systems VIII; Haav, H.-M., Kalja, A., Robal, T., Eds.; IOS Press: Amsterdam, The Netherlands, 2014; pp. 145–158. [Google Scholar]
- Jorgensen, Z.; Yu, T.; Cormode, G. Conservative or liberal? Personalized differential privacy. In Proceedings of the IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 1023–1034. [Google Scholar]
- Datacoup. Available online: http://datacoup.com/ (accessed on 27 February 2019).
- Gerber, H.U.; Pafum, G. Utility functions: From risk theory to finance. N. Am. Actuar. J. 1998, 2, 74–91. [Google Scholar] [CrossRef]
- Gao, S.; Ma, J.; Sun, C.; Li, X. Balancing trajectory privacy and data utility using a personalized anonymization model. J. Netw. Comput. Appl. 2014, 38, 125–134. [Google Scholar] [CrossRef]
- Homburg, C.; Koschate, N.; Hoyer, W.D. Do satisfied customers really pay more? A study of the relationship between customer satisfaction and willingness to pay. J. Mark. 2004, 69, 84–96. [Google Scholar] [CrossRef]
- Amirtaheri, O.; Zandieh, M.; Dorri, B.; Motameni, A.R. A bi-level programming approach for production-distribution supply chain problem. Comput. Ind. Eng. 2017, 110, 527–537. [Google Scholar] [CrossRef]
- Wang, G.; Ma, L.; Chen, J. A bilevel improved fruit fly optimization algorithm for the nonlinear bilevel programming problem. Knowl. Based Syst. 2017, 138, 113–123. [Google Scholar] [CrossRef]
- Ligett, K.; Neel, S.; Roth, A.; Waggoner, B.; Wu, Z.S. Accuracy first: Selecting a differential privacy level for accuracy-constrained ERM. arXiv, 2017; arXiv:1705.10829v1. [Google Scholar]
- Li, C.; Li, D.Y.; Miklau, G.; Suciu, D. A theory of pricing private data. ACM Trans. Database Syst. 2012, 39, 1–28. [Google Scholar] [CrossRef]
- Parra-Arnau, J. Optimized, direct sale of privacy in personal data marketplaces. Inf. Sci. 2018, 424, 354–384. [Google Scholar] [CrossRef]
- Malgieri, G.; Custers, B. Pricing privacy—The right to know the value of your personal data. Comput. Law Secur. Rev. 2017, 34, 289–303. [Google Scholar] [CrossRef]
- Nget, R.; Cao, Y.; Yoshikawa, M. How to balance privacy and money through pricing mechanism in personal data market. arXiv, 2018; arXiv:1705.02982v2. [Google Scholar]
- Aperjis, C.; Huberman, B.A. A market for unbiased private data: Paying individuals according to their privacy attitudes. arXiv, 2012; arXiv:1205.0030v1. [Google Scholar]
- Donoghue, T.O.; Somerville, J. Modeling risk aversion in economics. J. Econ. Perspect. 2018, 32, 91–114. [Google Scholar] [CrossRef]
- Yu, H.; Zhang, M. Data pricing strategy based on data quality. Comput. Ind. Eng. 2017, 112, 1–10. [Google Scholar] [CrossRef]
- Li, M.; Feng, H.; Chen, F.; Kou, J. Optimal versioning strategy for information products with behavior-based utility function of heterogeneous customers. Comput. Oper. Res. 2013, 40, 2374–2386. [Google Scholar] [CrossRef]
- Sitepu, R.; Puspita, F.M.; Pratiwi, A.N.; Novyasti, I.P. Utility function-based pricing strategies in maximizing the information service provider’s revenue with marginal and monitoring costs. Int. J. Electr. Comput. Eng. 2017, 7, 877–887. [Google Scholar] [CrossRef]
- Greene, J.; Baron, J. Intuitions about declining marginal utility. J. Behav. Decis. Mak. 2001, 255, 243–256. [Google Scholar] [CrossRef]
- Bard, J.F. An efficient point algorithm for a linear two-stage optimization problem. Oper. Res. 1983, 31, 670–684. [Google Scholar] [CrossRef]
- Dempe, S.; Zemkoho, A.B. On the Karush-Kuhn-Tucker reformulation of the bilevel optimization problem. Nonlinear Anal. Theory Methods Appl. 2012, 75, 1202–1218. [Google Scholar] [CrossRef]
- Vicente, L.; Savard, G.; Júdice, J. Descent approaches for quadratic bilevel programming. J. Optim. Theory Appl. 1994, 81, 379–399. [Google Scholar] [CrossRef]
- Ben-Ayed, O.; Blair, C.E. Computational difficulties of bilevel linear programming. Informs 1990, 38, 374–566. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Jiao, Y. Solution for integer linear bilevel programming problems using orthogonal genetic algorithm. J. Syst. Eng. Electron. 2014, 25, 443–451. [Google Scholar] [CrossRef]
- Kuo, R.J.; Lee, Y.H.; Zulvia, F.E.; Tien, F.C. Solving bi-level linear programming problem through hybrid of immune genetic algorithm and particle swarm optimization algorithm. Appl. Math. Comput. 2015, 266, 1013–1026. [Google Scholar] [CrossRef]
- Yan, X.; Zhu, Z.; Wu, Q. Hybrid genetic algorithm for engineering design problems. J. Comput. Theor. Nanosci. 2016, 13, 6312–6319. [Google Scholar] [CrossRef]
- Assad, A.; Deep, K. A hybrid harmony search and simulated annealing algorithm for continuous optimization. Inf. Sci. 2018, 450, 246–266. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| i | The number of privacy data sensitivity levels i = 1, 2,..., N |
| j | The number of data consumers, j = 1, 2,..., M |
| p | Unit price of privacy data |
| The maximum tolerance privacy loss by data providers | |
| The privacy compensation of risk taker data providers | |
| The privacy compensation of risk averse data providers | |
| s | The sensitivity level of privacy data |
| h | The type of heterogeneous customer |
| The consumer h’s demand for data sensitive level s | |
| The willingness to pay of consumer type h for data sensitivity level s | |
| The utility of consumer j for data sensitivity level i | |
| The purchasing decision of consumer j for data sensitivity level i, = 0 or 1 |
| Related Variable | Parameterization on the Customer Side |
|---|---|
| Customer type | h∈ [0, ], |
| Customer distributions | |
| = 0.5, = 0.25 | |
| Customer specific privacy level requirement | |
| Customer willingness to pay function | = 0.2, = 0.6 |
| The total number of potential data consumers | M = 10,000 |
| Related Variable | Parameterization on the Data Product Side | |
|---|---|---|
| Maximum level number | N∈ {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} | |
| Highest data sensitivity level | ||
| Cost function | Sublinear | |
| Logarithm |
| Parameter | Notation | Value |
|---|---|---|
| Population size | Z | 50 |
| Crossover rate | 0.8 | |
| Crossover operator | - | Uniform |
| Mutation rate | 0.01 | |
| Mutation operator | - | Bit-flip |
| Maximum generation | K | 500 |
| Initial temperature | 250 | |
| Annealing coefficient | 0.9 | |
| Number of internal cycles | l | 8 |
| Termination temperature | 0.01 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Xing, C. Personal Data Market Optimization Pricing Model Based on Privacy Level. Information 2019, 10, 123. https://doi.org/10.3390/info10040123
Yang J, Xing C. Personal Data Market Optimization Pricing Model Based on Privacy Level. Information. 2019; 10(4):123. https://doi.org/10.3390/info10040123
Chicago/Turabian StyleYang, Jian, and Chunxiao Xing. 2019. "Personal Data Market Optimization Pricing Model Based on Privacy Level" Information 10, no. 4: 123. https://doi.org/10.3390/info10040123
APA StyleYang, J., & Xing, C. (2019). Personal Data Market Optimization Pricing Model Based on Privacy Level. Information, 10(4), 123. https://doi.org/10.3390/info10040123