Name Lookup in Named Data Networking: A Review


Abstract
:1. Introduction
- We present an overview of NDN naming and name lookup challenges.
- We analyze and compare the currently proposed methods in NDN name lookup.
- To the best of our knowledge, this is the first paper that collects and compares the studies published in NDN name lookup.
2. NDN Review
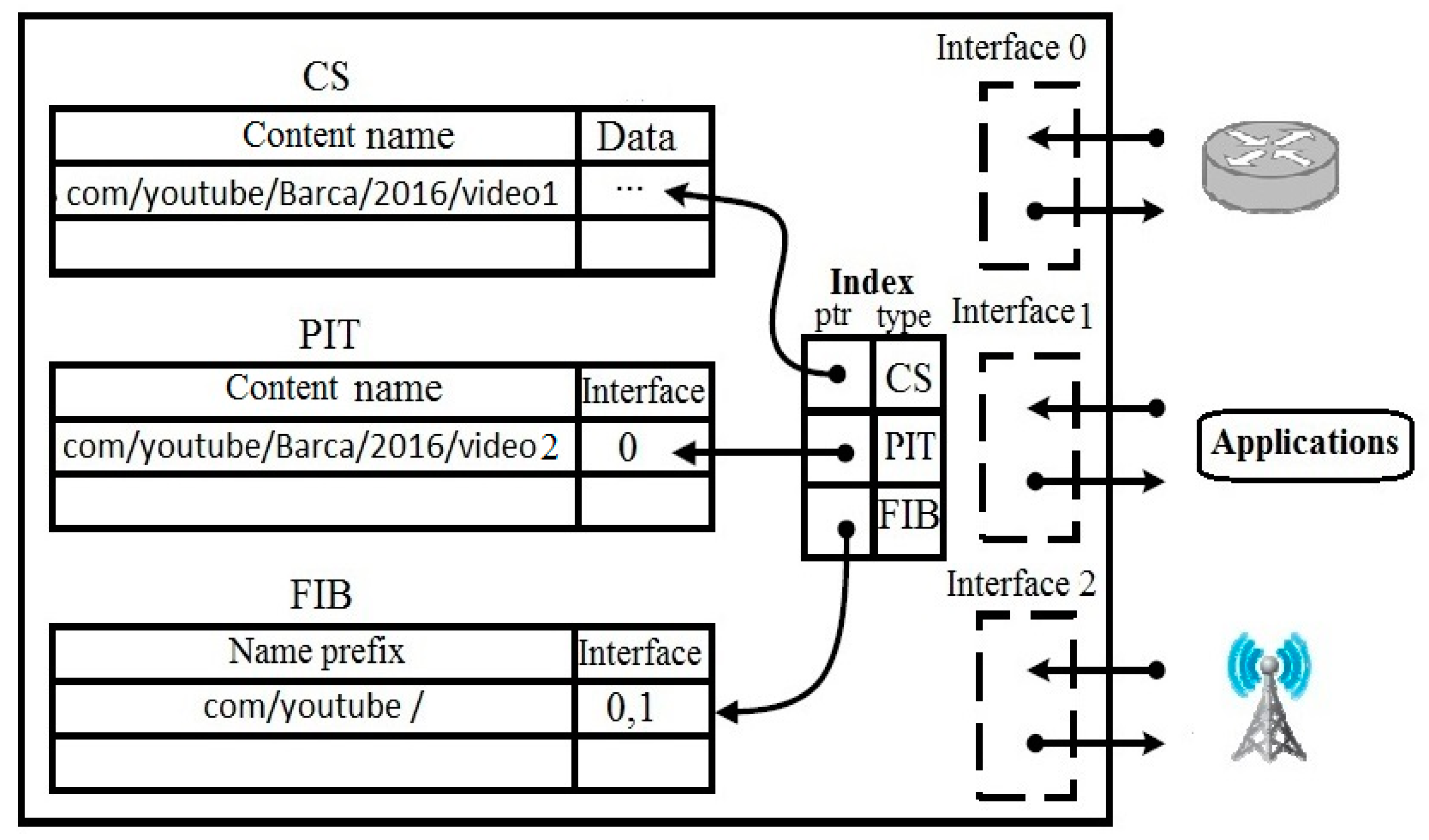
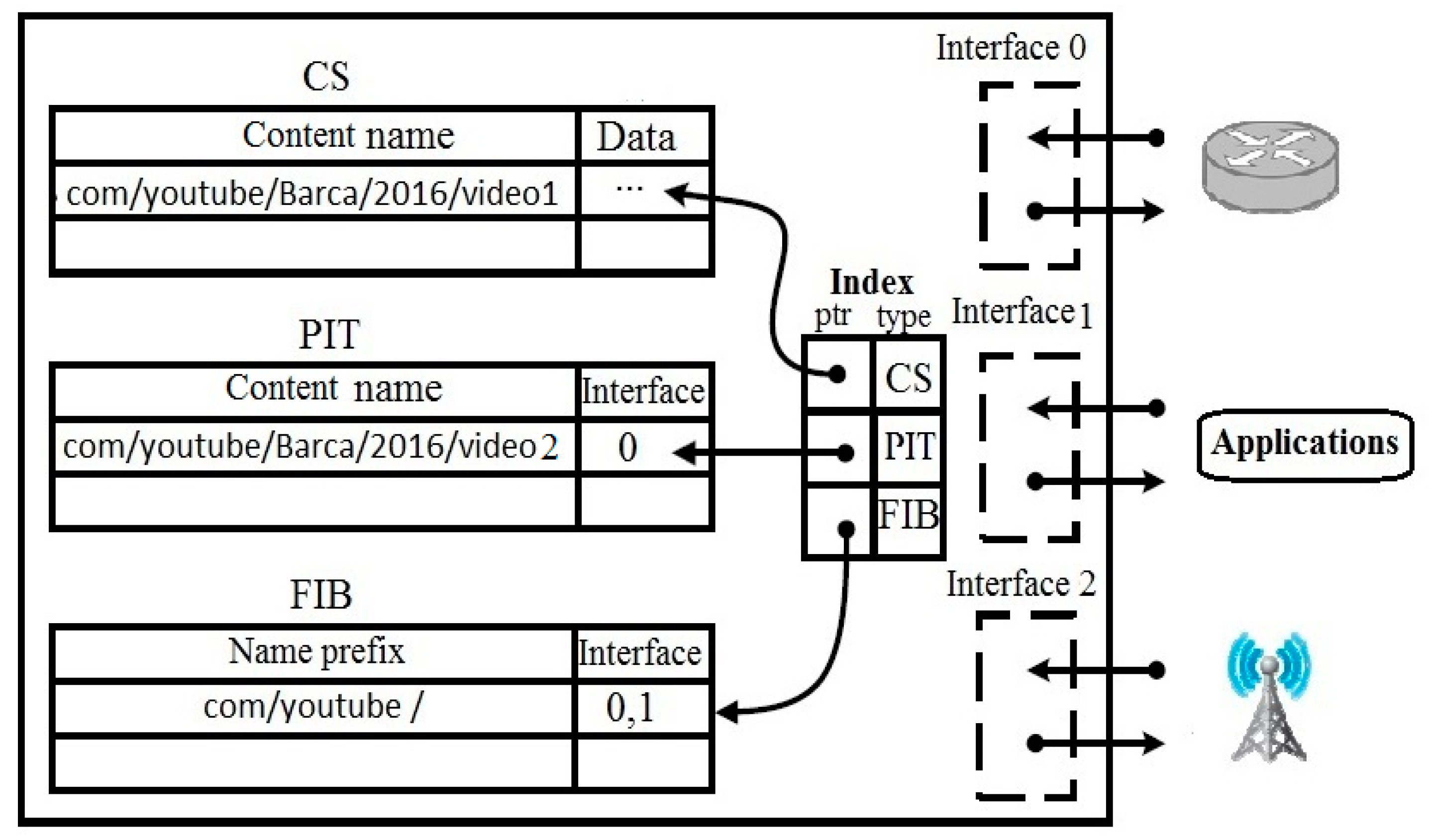
2.1. NDN Architecture
- FIB. It stores information about the interfaces of interest packet and forward it upstream to the next hop by using LPM. It maintains name prefixes and corresponding interfaces to the producer or provider, which may have the requested content.
- PIT. It maintains interest packets until either they are satisfied or their lifetime is expired. It uses the exact matching (EM) method for searching PIT entries and can forward multiple interest packets. When a specific content has multiple interest packets, the first interest packet is forwarded, while all others are pending in PIT and waiting for the corresponding data packet.
- CS. Its basic functionality is to optimize content retrieval time, delivery latency and save bandwidth. It is used as a temporary cache for data packets because several users may request the same content consequently, e.g., several users may watch the same video. CS also uses the EM method for searching CS entries.
- (1)
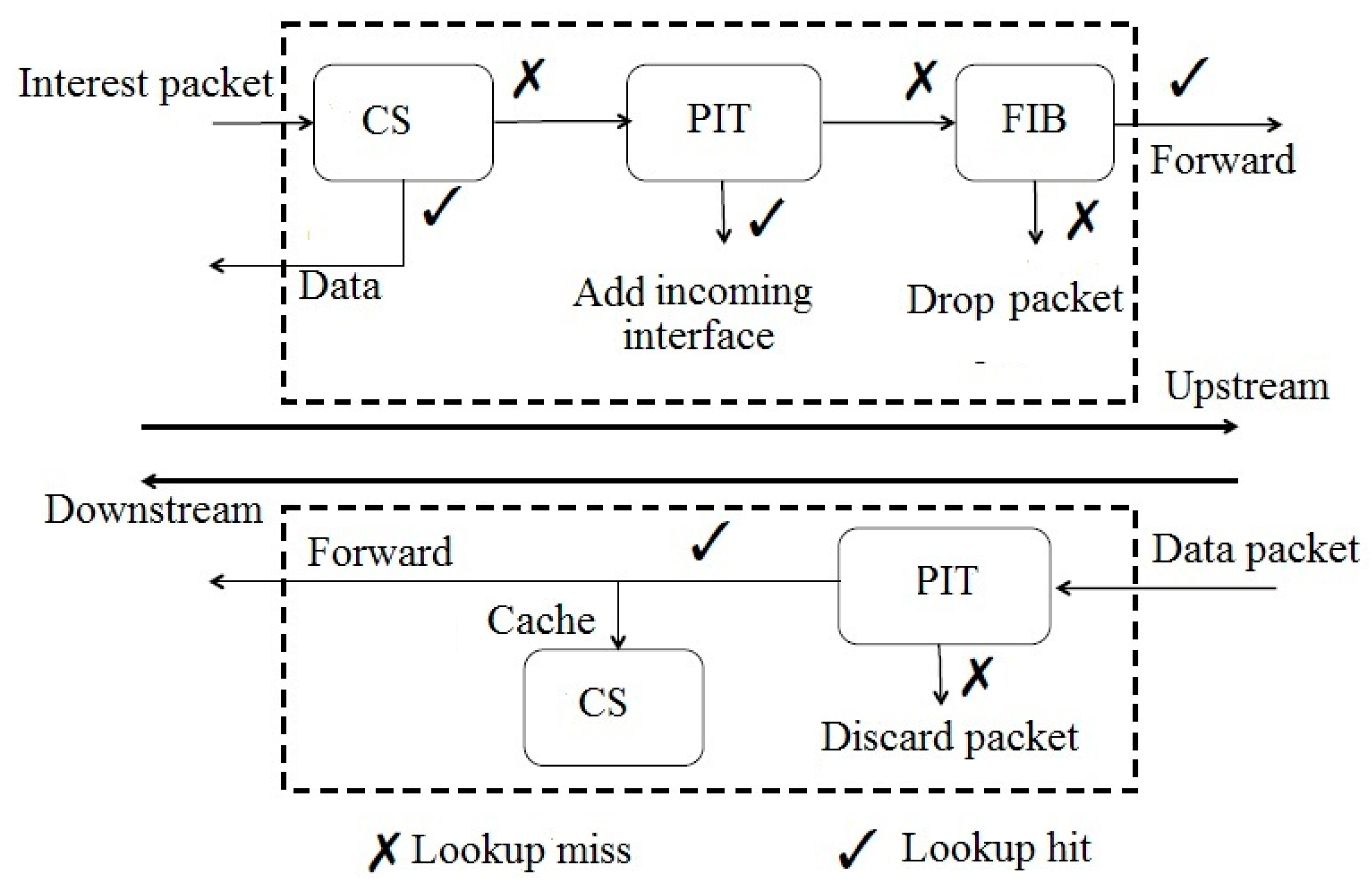
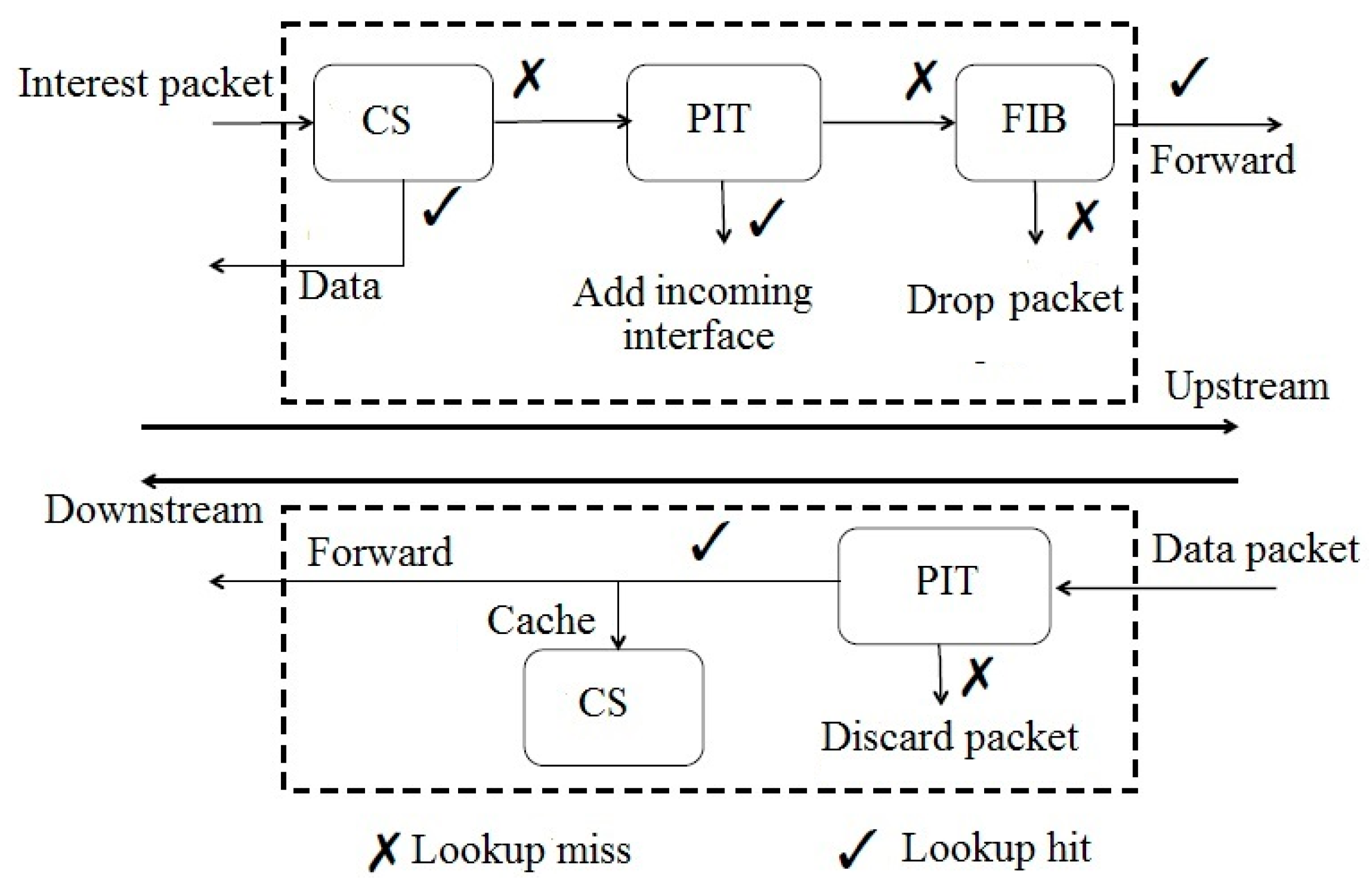
- The router consults its CS if the desired data packet is already cached. If a matching entry is available, then the data packet is sent following the reverse path of the interest packet.
- (2)
- If the CS has no available entry for the desired data packet, then the router searches the PIT to find an entry for corresponding interest packet. If a corresponding entry is available, then the given entry is aggregated in the list of incoming interfaces in the PIT.
- (3)
- If no entry is matching in the PIT, then the router inserts a new entry for the interest packet to the PIT and searches against the FIB based on LPM to select the next hop for the given interest packet and forwards the interest upstream.
- (1)
- The router searches all PIT entries. If a matching entry exists, then the router forwards the data packet to the interfaces that are linked with the PIT and deletes its corresponding entry in the PIT. The data packet can be cached according to the router’s caching policy, which may lead to the update of the CS.
- (2)
- If no matching entry exists in the PIT (because of lifetime or other reasons), then the data packet is dropped [9].
2.2. NDN Name Lookup
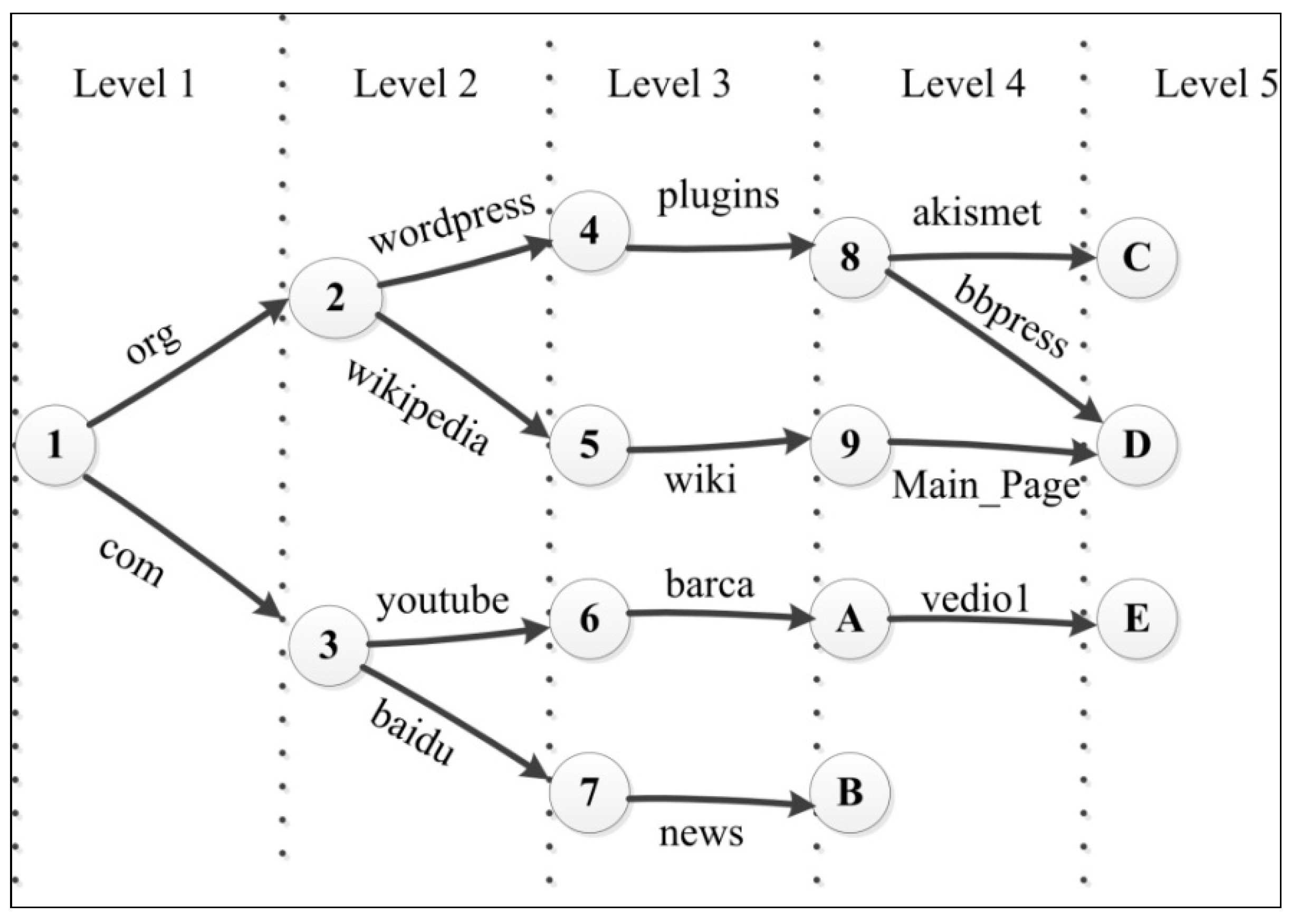
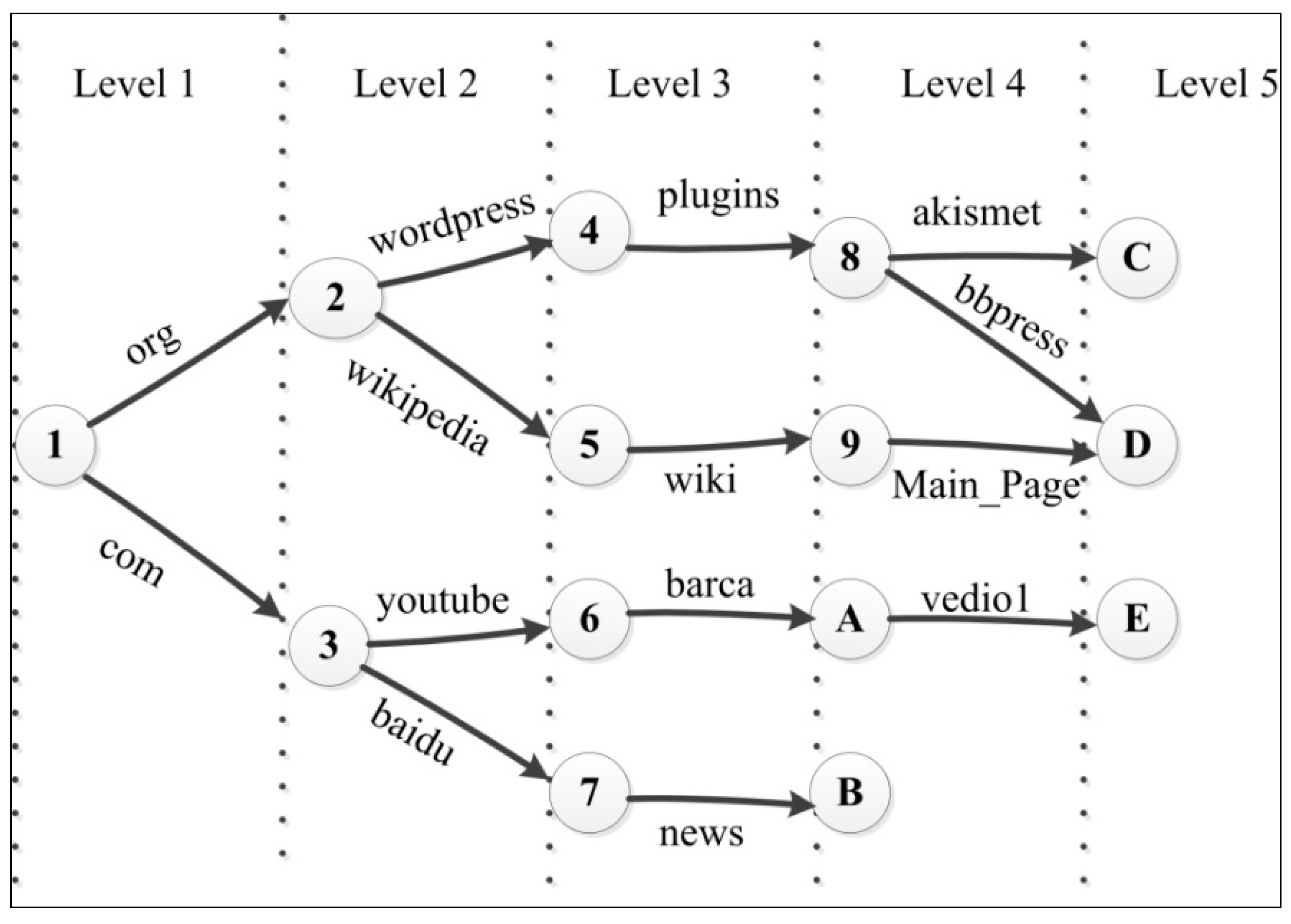
2.2.1. Naming in NDN
2.2.2. Packet Lookup
- (1)
- High-speed lookup. A new technology has been presented with wire speed lookup of 160 GBPS (gigabits per second). To execute NDN forwarding in a large-scale router, name lookup has to maintain the wire speed. At the same time, the NDN router has to reduce the packet forwarding latency to less than 100 μs (microseconds) [11]. Thus, sending packets with low latency while maintaining high-speed lookup is challenging [12].
- (2)
- Memory storage. An NDN router may contain tens of millions or even billions of names because each name may consist of tens or hundreds of characters and name length is variable. Thus, an NDN router may need tens of gigabytes of memory to perform name lookup in a large-scale router.
- (3)
- Fast update. An NDN router should process at least one new type of update when the content is inserted to or deleted from the NDN router. The corresponding name entry should be added to or deleted from the router, which renders the update operation recurrently. Therefore, the update operations in NDN router make the fast update issue more critical to address as well as affect the overall performance.
- (4)
- Scalability. As the number of contents increases, the table size of the NDN router grows fast. As a result, scalability is a considerable challenge.
3. NDN Name Lookup and Current Solutions
3.1. Name Lookup Classification
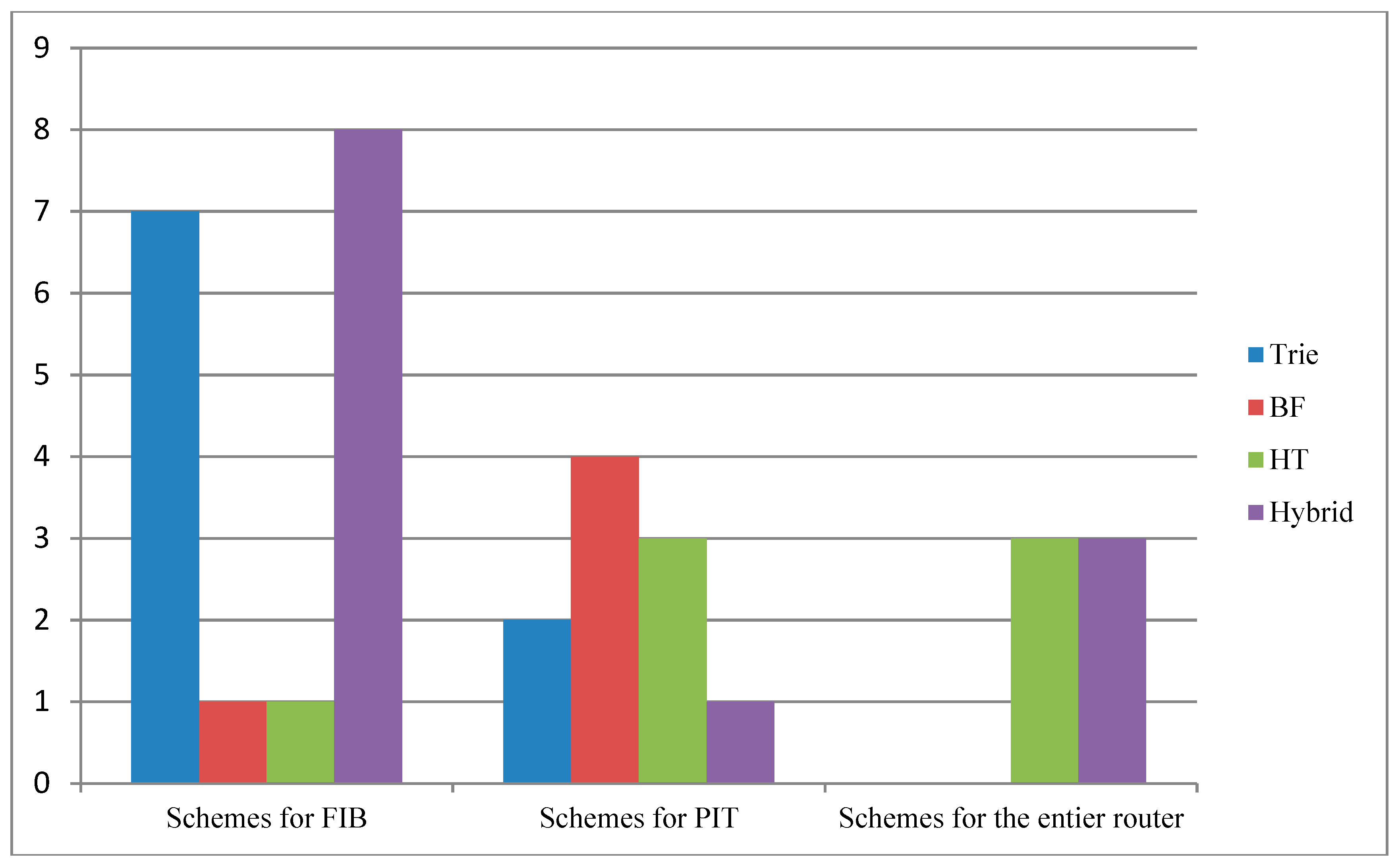
3.2. Current Solutions
3.2.1. FIB Schemes
3.2.2. PIT Schemes
3.3. Entire NDN Router Schemes
4. Comparative Analysis
4.1. Current Solution Analysis
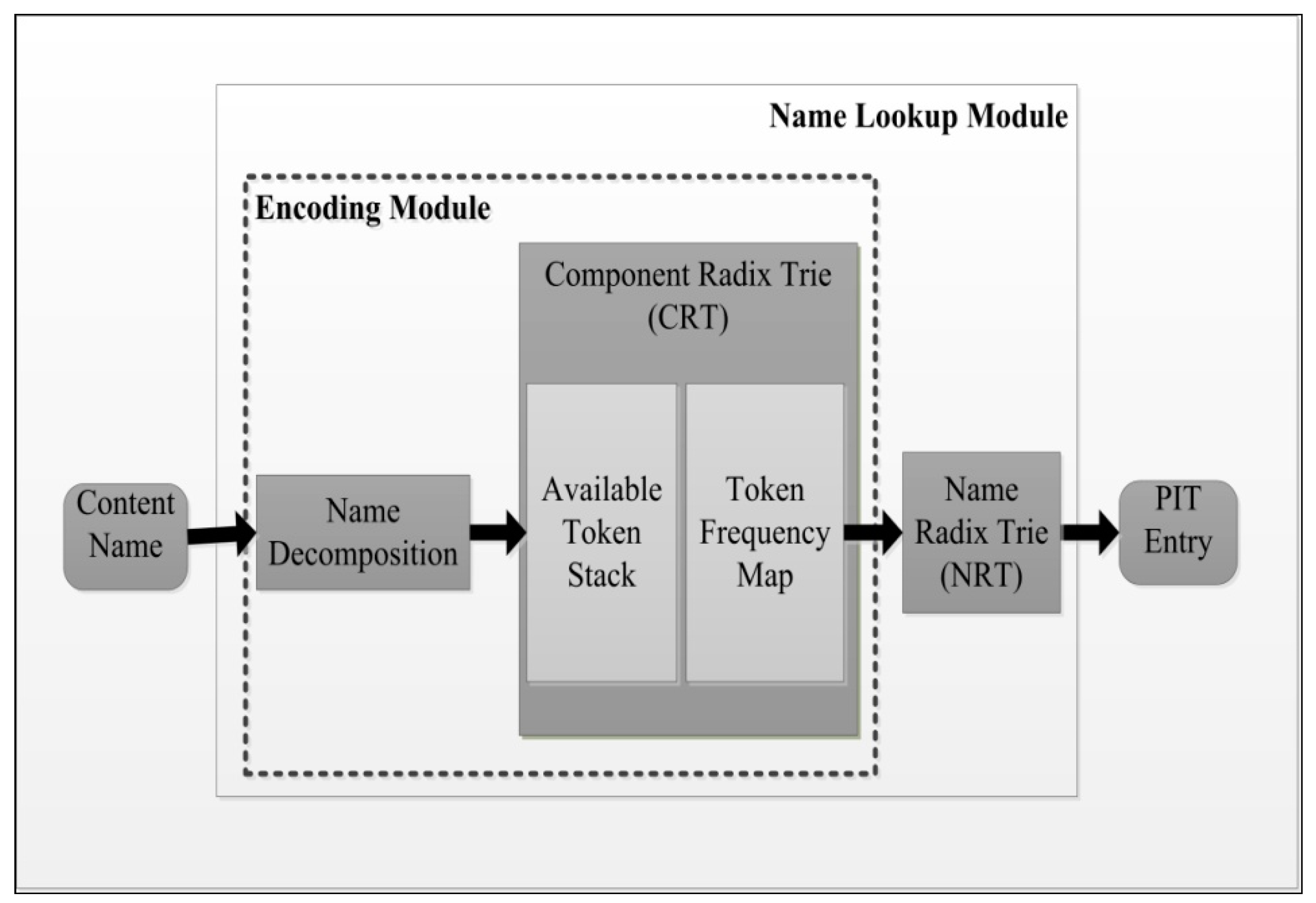
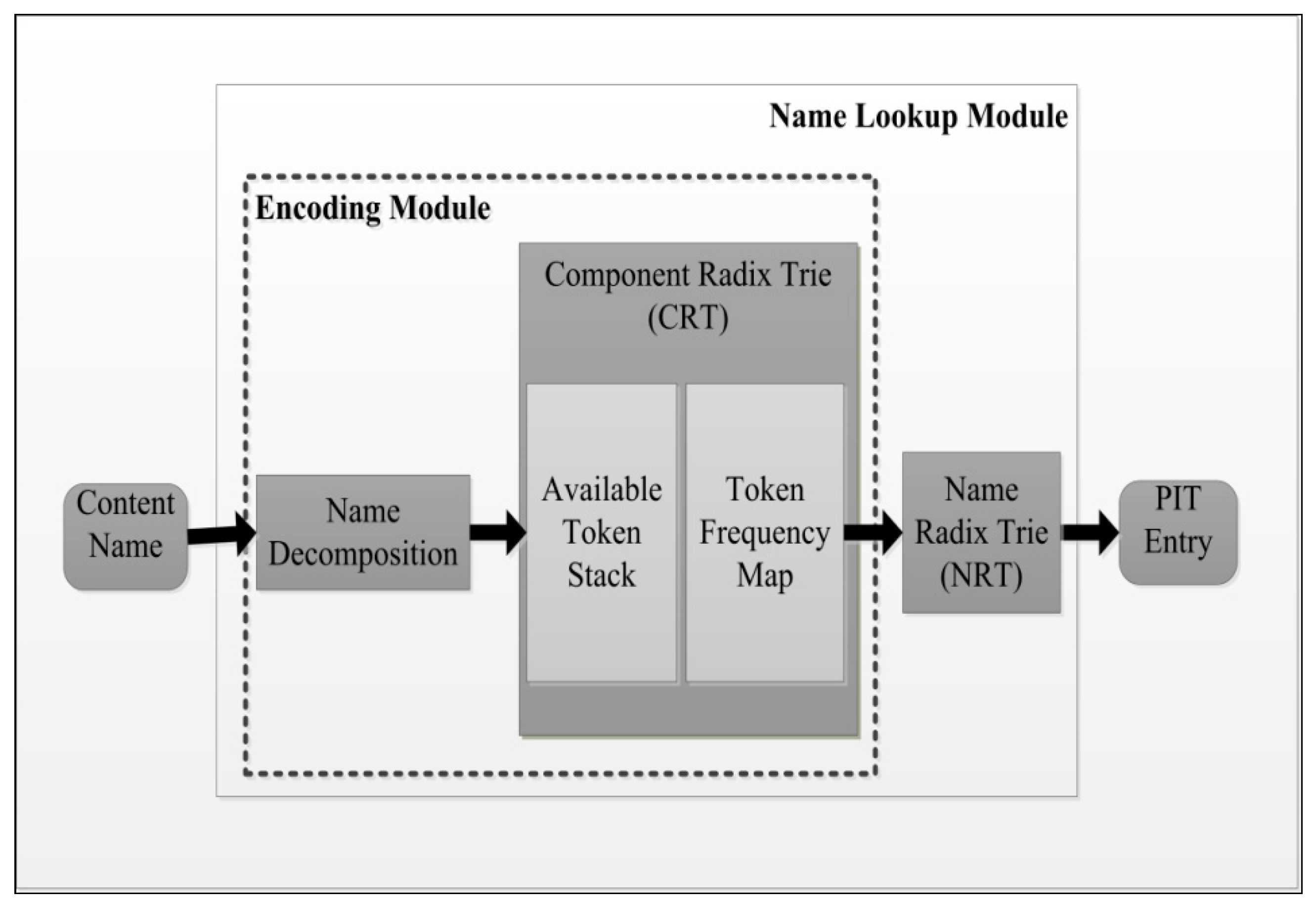
4.1.1. Trie-Based Schemes
4.1.2. HT-based Schemes
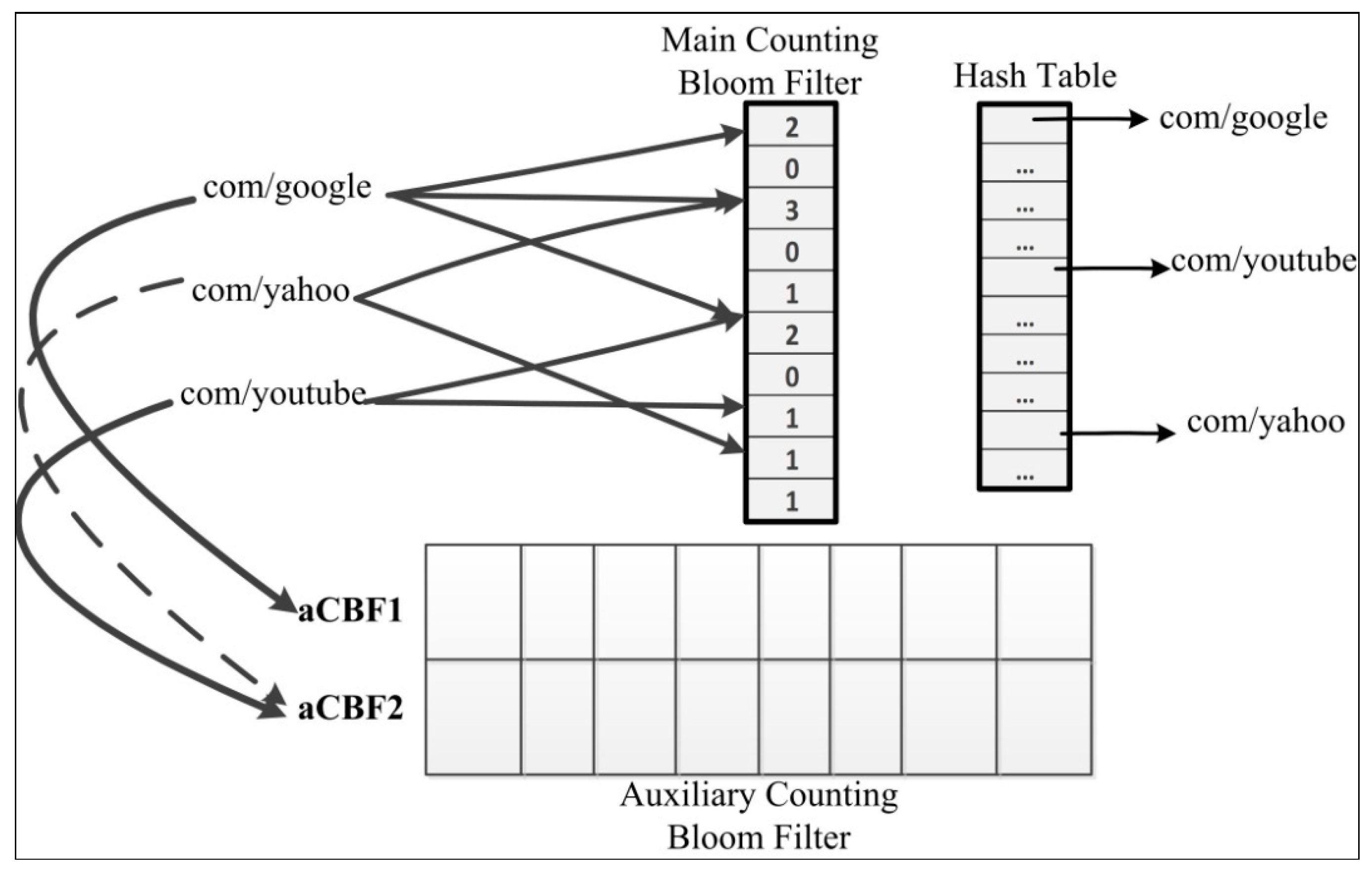
4.1.3. BF-Based Schemes
4.1.4. Hybrid Schemes
4.2. Performance Comparison
4.2.1. Lookup Performance
4.2.2. Memory Consumption
4.2.3. Scalability
4.2.4. Latency and Validity
5. Name Lookup Related Projects
6. Future Work
6.1. Trie-Based Approaches
6.2. BF-Based Approaches
6.3. HT-Based Approaches
6.4. Hybrid Approaches
6.5. General Suggestions
7. Conclusions
Funding
Conflicts of Interest
References
- NDN Project Team. Named Data Networking (NDN) Project, Technical Report NDN-0001. 2010. Available online: http://named-data.net/publications/techreports/ (accessed on 5 February 2019).
- Saxena, D.; Raychoudhury, V.; Suri, N.; Becker, C.; Cao, J. Named data networking: A survey. Comput. Sci. Rev. 2016, 19, 15–55. [Google Scholar] [CrossRef]
- Dai, H.; Liu, B.; Chen, Y.; Wang, Y. On pending interest table in named data networking. In Proceedings of the Eighth ACM/IEEE Symposium on Architectures for Networking and Communications Systems, Austin, TX, USA, 29–30 October 2012; pp. 211–222. [Google Scholar]
- Jacobson, V.; Smetters, D.K.; Thornton, J.D.; Plass, M.; Brigs, N.; Braynard, R. Networking named content. Commun. ACM 2012, 55, 117–124. [Google Scholar] [CrossRef]
- Wang, Y.; He, K.; Dai, H.; Meng, W.; Jiang, J.; Liu, B.; Chen, Y. Scalable name lookup in NDN using effective name component encoding. In Proceedings of the 2012 IEEE 32nd International Conference on Distributed Computing Systems (ICDCS), Macau, China, 18–21 June 2012; pp. 688–697. [Google Scholar]
- Saxena, D.; Raychoudhury, V. Radient: Scalable, memory efficient name lookup algorithm for named data networking. J. Netw. Comput. Appl. 2016, 63, 1–13. [Google Scholar] [CrossRef]
- Li, F.; Chen, F.; Wu, J.; Xie, H. Longest prefix lookup in named data networking: How fast can it be? In Proceedings of the 2014 9th IEEE International Conference on Networking, Architecture, and Storage (NAS), Tianjin, China, 6–8 August 2014; pp. 186–190. [Google Scholar]
- Zhang, L.; Afanasyev, A.; Burke, J.; Jacobson, V.; Crowley, P.; Papadopoulos, C.; Wang, L.; Zhang, B. Named data networking. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 66–73. [Google Scholar] [CrossRef]
- Yu, W.; Pao, D. Hardware accelerator to speed up packet processing in NDN router. Comput. Commun. 2016, 91, 109–119. [Google Scholar] [CrossRef]
- Dai, H.; Lu, J.; Wang, Y.; Liu, B. BFAST: Unified and scalable index for NDN forwarding architecture. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), San Francisco, CA, USA, 10–15 April 2015; pp. 2290–2298. [Google Scholar]
- Wang, Y.; Zu, Y.; Zhang, T.; Peng, K.; Dong, Q.; Liu, B.; Meng, W.; Dai, H.; Tian, X.; Wu, H.; et al. Wire Speed Name Lookup: A GPU-based Approach. In Proceedings of the NSDI, Lombard, IL, USA, 2–5 April 2013; pp. 199–212. [Google Scholar]
- Wang, Y.; Dai, H.; Jiang, J.; He, K.; Meng, W.; Liu, B. Parallel name lookup for named data networking. In Proceedings of the 2011 IEEE Global Telecommunications Conference (GLOBECOM 2011), Houston, TX, USA, 5–9 December 2011; pp. 1–5. [Google Scholar]
- Li, Y.; Zhang, D.; Yu, X.; Liang, W.; Long, J.; Qiao, H. Accelerate NDN name lookup using FPGA: Challenges and a scalable approach. In Proceedings of the 2014 24th International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–4. [Google Scholar]
- Song, T.; Yuan, H.; Crowley, P.; Zhang, B. Scalable name-based packet forwarding: From millions to billions. In Proceedings of the 2nd International Conference on Information-centric Networking, San Francisco, CA, USA, 30 September–2 October 2015; pp. 19–28. [Google Scholar]
- Li, D.; Li, J.; Du, Z. An improved trie-based name lookup scheme for Named Data Networking. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 1294–1296. [Google Scholar]
- Saxena, D.; Raychoudhury, V. N-FIB: Scalable, memory efficient name-based forwarding. J. Netw. Comput. Appl. 2016, 76, 101–109. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, B.; Tai, D.; Lu, J.; Zhang, T.; Dai, H.; Zhang, B.; Liu, B. Fast name lookup for named data networking. In Proceedings of the 2014 IEEE 22nd International Symposium of Quality of Service (IWQoS), Hong Kong, China, 26–27 May 2014; pp. 198–207. [Google Scholar]
- Wang, Y.; Pan, T.; Mi, Z.; Dai, H.; Guo, X.; Zhang, T.; Liu, B.; Dong, Q. Namefilter: Achieving fast name lookup with low memory cost via applying two-stage bloom filters. In Proceedings of the INFOCOM, Turin, Italy, 14–19 April 2013; pp. 95–99. [Google Scholar]
- Wang, Y.; Dai, H.; Zhang, T.; Meng, W.; Fan, J.; Liu, B. GPU-accelerated name lookup with component encoding. Comput. Netw. 2013, 57, 3165–3177. [Google Scholar] [CrossRef]
- Fukushima, M.; Tagami, A.; Hasegawa, T. Efficiently looking up non-aggregatable name prefixes by reducing prefix seeking. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013; pp. 340–344. [Google Scholar]
- Yuan, H.; Crowley, P. Reliably scalable name prefix lookup. In Proceedings of the 2015 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Oakland, CA, USA, 7–8 May 2015; pp. 111–121. [Google Scholar]
- Perino, D.; Varvello, M.; Linguaglossa, L.; Laufer, R.; Boislaigue, R. Caesar: A content router for high-speed forwarding on content names. In Proceedings of the Tenth ACM/IEEE Symposium on Architectures for Networking and Communications Systems, Los Angeles, CA, USA, 20–21 October 2014; pp. 137–148. [Google Scholar]
- Quan, W.; Xu, C.; Guan, J.; Zhang, H.; Grieco, L.A. Scalable name lookup with adaptive prefix bloom filter for named data networking. IEEE Commun. Lett. 2014, 18, 102–105. [Google Scholar] [CrossRef]
- Dharmapurikar, S.; Krishnamurthy, P.; Taylor, D.E. Longest prefix matching using Bloom filters. IEEE/ACM Trans. Netw. 2006, 14, 397–409. [Google Scholar] [CrossRef]
- So, W.; Narayanan, A.; Oran, D.; Wang, Y. Toward fast NDN software forwarding lookup engine based on hash tables. In Proceedings of the 2012 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Austin, TX, USA, 29–30 October 2012; pp. 85–86. [Google Scholar]
- Tan, Y.; Zhu, S. Efficient Name Lookup Scheme Based on Hash and Character Trie in Named Data Networking. In Proceedings of the 2015 12th Web Information System and Application Conference (WISA), Jinan, China, 11–13 September 2015; pp. 130–135. [Google Scholar]
- Yanbiao, L.; Zhang, D.; Huang, K.; He, D.; Long, W. A memory-efficient parallel routing lookup model with fast updates. Comput. Commun. 2014, 38, 60–71. [Google Scholar]
- Yuan, H.; Crowley, P.; Song, T. Enhancing Scalable Name-Based Forwarding. In Proceedings of the Symposium on Architectures for Networking and Communications Systems, Beijing, China, 18–19 May 2017; pp. 60–69. [Google Scholar]
- Varvello, M.; Perino, D.; Linguaglossa, L. On the design and implementation of a wire-speed pending interest table. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013; pp. 369–374. [Google Scholar]
- Yuan, H.; Crowley, P. Scalable pending interest table design: From principles to practice. In Proceedings of the 2014 IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 2049–2057. [Google Scholar]
- Carofiglio, G.; Gallo, M.; Muscariello, L.; Perino, D. Pending interest table sizing in named data networking. In Proceedings of the 2nd International Conference on Information-Centric Networking, San Francisco, CA, USA, 30 September–2 October 2015; pp. 49–58. [Google Scholar]
- You, W.; Mathieu, B.; Truong, P.; Peltier, J.F.; Simon, G. Dipit: A distributed bloom-filter based pit table for ccn nodes. In Proceedings of the 2012 21st International Conference on Computer Communications and Networks (ICCCN), Munich, Germany, 30 July–2 August 2012; pp. 1–7. [Google Scholar]
- Li, Z.; Bi, J.; Wang, S.; Jiang, X. The compression of pending interest table with bloom filter in content centric network. In Proceedings of the 7th International Conference on Future Internet Technologies, Seoul, Korea, 11–12 September 2012; p. 46. [Google Scholar]
- Li, Z.; Liu, K.; Zhao, Y.; Ma, Y. MaPIT: An enhanced pending interest table for NDN with mapping bloom filter. IEEE Commun. Lett. 2014, 18, 1915–1918. [Google Scholar] [CrossRef]
- Tsilopoulos, C.; Xylomenos, G.; Thomas, Y. Reducing forwarding state in content-centric networks with semi-stateless forwarding. In Proceedings of the 2014 IEEE INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 2067–2075. [Google Scholar]
- Yuan, H.; Song, T.; Crowley, P. Scalable NDN Forwarding: Concepts, Issues and Principles. In Proceedings of the International Conference on Computer Communications and Networks, Munich, Germany, 30 July–2 August 2012; pp. 1–9. [Google Scholar]
- So, W.; Narayanan, A.; Oran, D. Named data networking on a router: Forwarding at 20gbps and beyond. In Proceedings of the ACM SIGCOMM Computer Communication Review, Hong Kong, China, 12–16 August 2013; Volume 43, pp. 495–496. [Google Scholar]
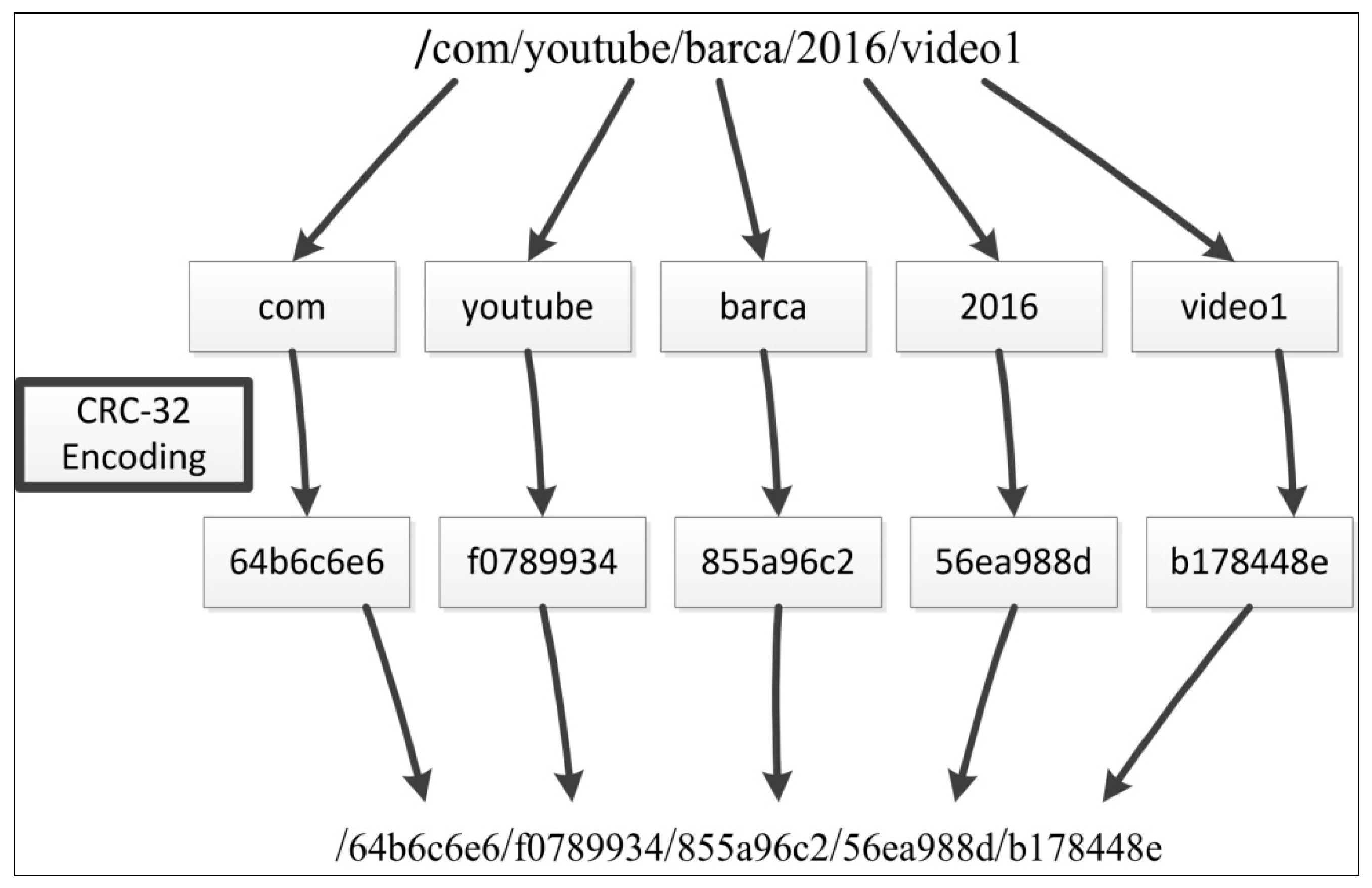
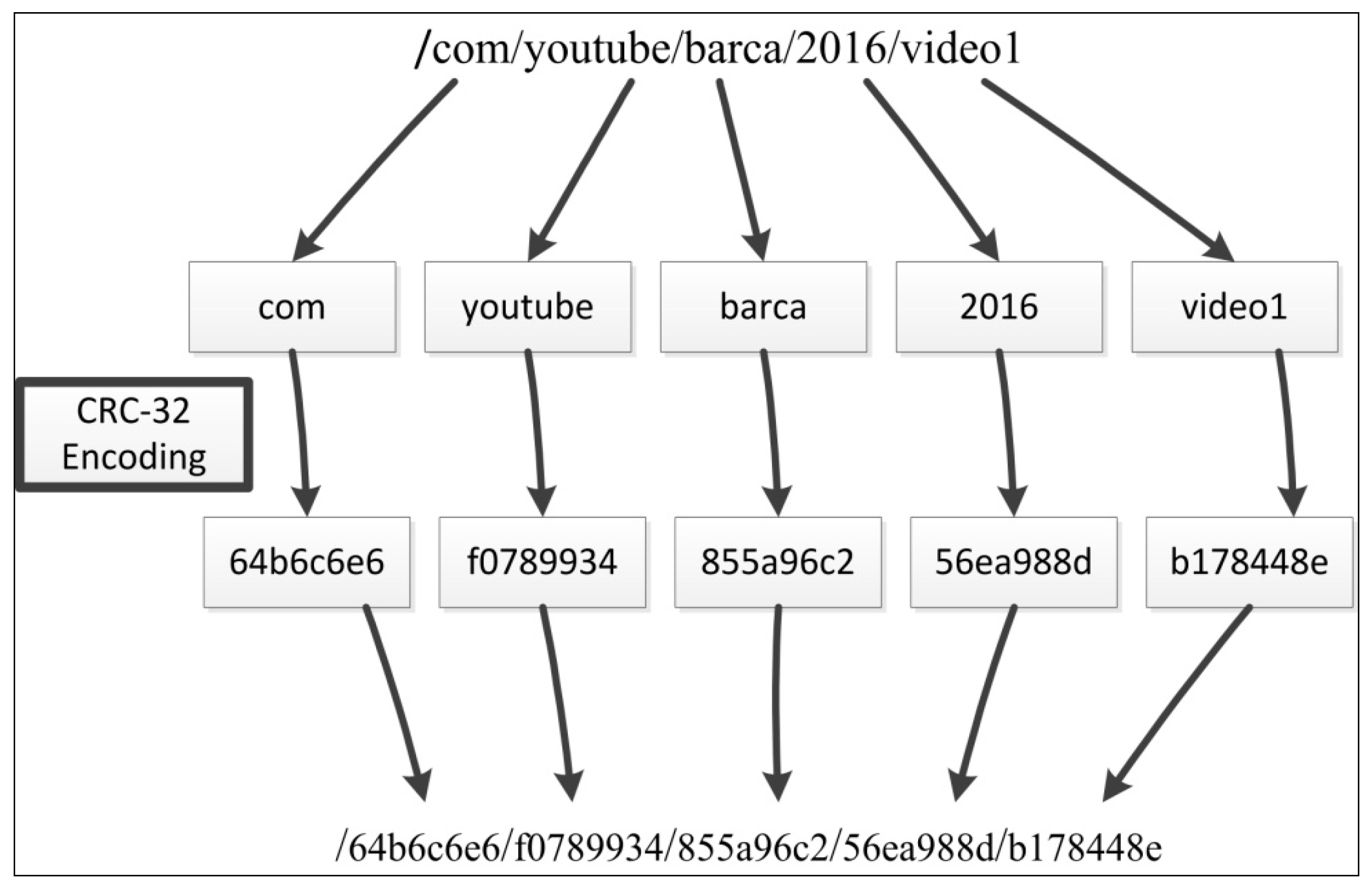
- Hsu, J.M.; Chang, J.Y. A CRC-32 Name Prefix Encoding in Named Data Networking. Int. J. Adv. Inf. Technol. (IJAIT) 2014, 8, 125–130. [Google Scholar]
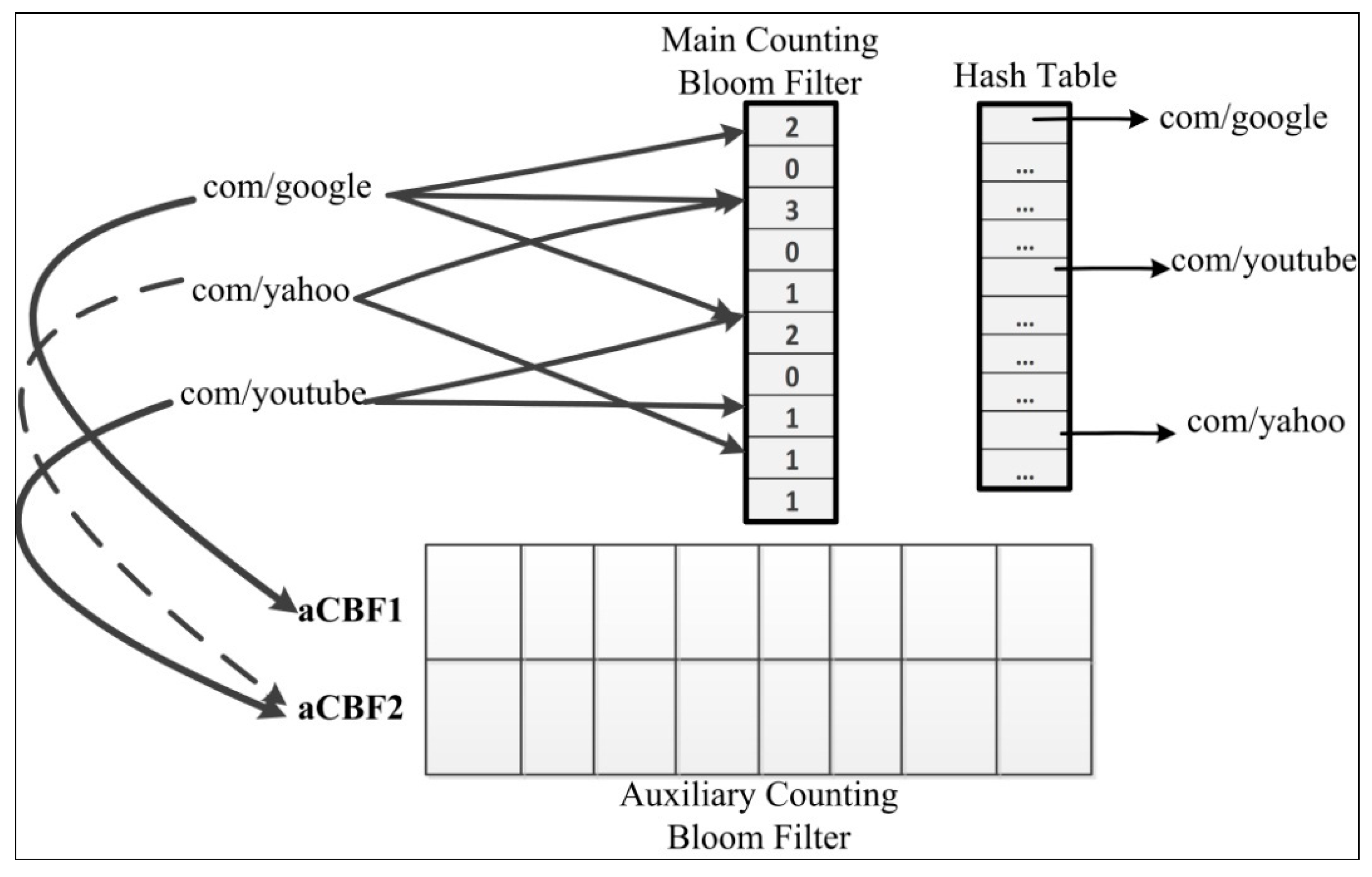
- Huang, S.; Xu, J.; Yang, X.; Wu, Z.; Niu, C. Steerable Name Lookup based on Classified Prefixes and Scalable One Memory Access Bloom Filter for Named Data Networking. Int. J. Future Gen. Commun. Netw. 2016, 9, 87–100. [Google Scholar] [CrossRef]
- Quan, W.; Xu, C.; Vasilakos, A.V.; Guan, J.; Zhang, H.; Grieco, L.A. TB2F: Tree-bitmap and bloom-filter for a scalable and efficient name lookup in content-centric networking. In Proceedings of the 2014 IFIP Networking Conference, Trondheim, Norway, 2–4 June 2014; pp. 1–9. [Google Scholar]
- Bari, M.F.; Chowdhury, S.R.; Ahmed, R.; Boutaba, R.; Mathieu, B. A Survey of Naming and Routing in Information-Centric Networks. IEEE Commun. Mag. 2012, 50, 44–53. [Google Scholar] [CrossRef]
- Carzaniga, A.; Rutherford, M.; Wolf, A. A Routing Scheme for Content-Based Networking. In Proceedings of the 3rd Annual Joint Conference IEEE Computer and Communication Societies (INFOCOM 2004), Hong Kong, China, 7–11 March 2004; pp. 918–928. [Google Scholar]
- Koponen, T.; Chawla, M.; Chun, B.G.; Ermolinskiy, A.; Kim, K.H.; Shenker, S.; Stoica, I. A Data-Oriented (and Beyond) Network Architecture. In Proceedings of the 2007 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Kyoto, Japan, 27–31 August 2007; pp. 181–192. [Google Scholar]
- Dannewitz, C.; Golic, J.; Ohlman, B.; Ahlgren, B. Secure Naming for a Network of Information. In Proceedings of the 2010 INFOCOM IEEE Conference on Computer Communications Workshops, San Diego, CA, USA, 15–19 March 2010; pp. 1–6. [Google Scholar]
- Lagutin, D.; Visala, K.; Tarkoma, S. Publish/Subscribe for Internet: PSIRP Perspective. In Towards the Future Internet Emerging Trends from European Research; IOS Press: Amsterdam, The Netherlands, 2010; pp. 75–84. [Google Scholar]
- Fagin, R.; Nievergelt, J.; Pippenger, N.; Strong, H.R. Extendible hashing—A fast access method for dynamic files. ACM Trans. Database Syst. 1979, 4, 315–344. [Google Scholar] [CrossRef]
- Kirsch, A.; Mitzenmacher, M.; Varghese, G. Hash-based techniques for high-speed packet processing. In Algorithms for Next Generation Networks; Springer: London, UK, 2010; pp. 181–218. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FIB | PIT | Entire NDN Router |
|---|---|---|
| Trie-based | Trie-based | HT-based |
| HT-based | HT-based | BF-based |
| BF-based | BF-based | Hybrid approaches |
| Hybrid approaches | Hybrid approaches |
| Terminology | Abbreviation | Terminology | Abbreviation |
|---|---|---|---|
| Named data networking | NDN | Hash table | HT |
| Information-centric networking | ICN | Bloom filter | BF |
| Content centric networking | CCN | Name component trie | NCT |
| Longest prefix matching | LPM | Encoded name component trie | ENCT |
| Exact matching | EM | Leaf prefix count table | LPCT |
| Content store | CS | Name lookup with adaptive prefix bloom filter | NLAPB |
| Pending interest table | PIT | Split name-character trie | SNT |
| Forwarding information base | FIB | Exact string differentiation | ESD |
| Parallel name lookup | PNL | Fingerprint-based Patricia trie | FPT |
| Million lookup per second | MLPS | Component radix trie | CRT |
| Name prefix trie | NPT | Name radix trie | NRT |
| Named component encoding | NCE | Linear chaining hash-table | LHT |
| Encoded name prefix trie | ENPT | D-left hash table | DHT |
| Graphics processing unit | GPU | Distributed PIT | DiPIT |
| State transition array | STA | United bloom filter | UBF |
| Field-programmable gate arrays | FPGA | Name prefix hash table | NPHT |
| Aligned transition arrays | ATA | Cyclic redundancy check | CRC-32 |
| Multiple aligned transition array | MATA | Deterministic finite automata | DFA |
| Hierarchical aligned transition array | HATA | Steerable name lookup based on bloom filter | SNLBF |
| Longest prefix classification | LPC |
| Method | Data Structure | Lookup Performance | Memory Consumption Ratio | Dataset | Dataset Size (MB) |
|---|---|---|---|---|---|
| NameFilter [18] | FIB | 37 MLPS | 30.1% (299 MB) | 3 M and 10 M | N/A |
| DiPIT [32] | PIT | N/A | 63% | 200 M packets per second | N/A |
| UBF [33] | PIT | N/A | 45% (110 MB) | 4 M | 200 MB |
| MaPIT [34] | PIT | N/A | 99.34% (2.097 MB) on on-chip memory | 2 M | 320 MB |
| Method | Data Structure | Lookup Performance | Memory Consumption Ratio | Dataset | Dataset Size (MB) |
|---|---|---|---|---|---|
| NCE [3] | PIT | 1.4 MLPS | 71.8% (167.85 MB) | 18 M | 595.04 MB |
| NCE [5] | FIB | 1.3 MLPS | 46.64% | 6 M | 957.33 MB |
| Radiant [6] | PIT | 0.051 MLPS | 87.63% (140.1 MB) | 29 M | 1132.65 MB |
| MATA [11] | FIB | 63.52 MLPS | 70.5% 149.92 MB 490.28 MB | 3 M and 10 M | Nearly 470 MB and 1700 MB |
| PNL [12] | FIB | N/A | N/A | 2M | N/A |
| HATA [13] | FIB | 125 MLPS | 63.45%, a reduction of 90% compared with [11] | 1 M 10 M | N/A |
| Patricia trie [14] | FIB | 142 MLPS for SRAM 20 MLPS for DRAM | 80.53% (7.32 GB) | 1B | 37.6 GB |
| P-trie [15] | FIB | 13 MLPS | N/A | 100 K | N/A |
| N-FIB [16] | FIB | 404 microseconds for 29 M | 96.94% (264.79 MB) | 29 M | 8617.595 MB |
| NCE-GPU [19] | FIB | 51.78 MLPS | 61.3% (650.49 MB) 120.86 MB 529.63 MB | 3 M and 10 M | 1680.89 MB |
| SNT [26] | FIB | N/A | 35.3% (110 MB) | 1 M | Nearly 170 MB |
| Method | Data Structure | Lookup Performance | Memory Consumption Ratio | Dataset | Dataset Size (MB) |
|---|---|---|---|---|---|
| NPHT [36] | FIB, PIT, CS | N/A | N/A | N/A | N/A |
| Greedy-SPHT [17] | FIB | 57.14 MLPS | 45.11% (320.15 MB) | 3 M and 10 M | 583.27 MB |
| LNPM [21] | FIB | 6 MLPS for 1 billion names of 7 components | 34.23% (111.8 GB) | 1 B | 170 GB |
| DHT [29] | PIT | 3.4 MLPS | N/A | N/A | N/A |
| D-left hash table [30] | PIT | 0.83 MLPS | 64.49 MB | 1M | N/A |
| Semi-stateless forwarding method [35] | PIT | N/A | 45–66% of CCN | N/A | N/A |
| SipHash [37] | FIB, PIT, CS | 8.8 MLPS at 20 Gbps | 35.82 MB | 1 M | N/A |
| CRC-32 hash function [38] | FIB, PIT, CS | Improving by 21.63% from the NDN proposal | 31.93% (618 KB) | 1 M | 908 KB |
| Method | Data Structure | Lookup Performance | Memory Consumption Ratio | Dataset | Dataset Size (MB) | Notes |
|---|---|---|---|---|---|---|
| Hybrid data structure of hash, fat trie, and array [7] | FIB | 37 MLPS (CPU) 70 MLPS (GPU) | N/A | 12 M | 1088 MB | Focuses on measuring the number of packet lookups per second |
| BF and linear-chained HT [9] | PIT | 56–60 MLPS | N/A | 2 M | N/A | Focuses on the packet processing rate |
| BFAST [10] | FIB, PIT, CS | 36.4 MLPS | 50.3% (419.32 MB) 48.5% (1517.6 MB) | 3 M and 10 M | High speed and low memory | |
| Non-aggregatable prefix [20] | FIB | 66 MLPS | N/A | 620 M | 1 GB | Focuses on measuring the number of packet lookups per second |
| Caesar [22] | FIB | 95 MLPS | N/A | 10 M | 42 MB | Focuses on measuring the number of packet lookups per second |
| NLAPB [23] | FIB | 800 KLPS | 500 MB | 10 M | N/A | |
| A chained HT with a linked list [25] | FIB, PIT, CS | 1.5 MLPS | N/A | Names with an average length of 33.9 bytes | N/A | |
| FHT [28] | FIB | N/A | 57% (3.2 GB) | 1 B | N/A | |
| SNLBF [39] | FIB, PIT, CS | 3.5 MLPS | 50 MB | 3 M | N/A |
| Approach | Future Directions |
|---|---|
| Trie-based approaches |
|
| BF-based approaches |
|
| HT-based approaches |
|
| Hybrid approaches |
|
| General suggestions |
|
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majed, A.-q.; Wang, X.; Yi, B. Name Lookup in Named Data Networking: A Review. Information 2019, 10, 85. https://doi.org/10.3390/info10030085
Majed A-q, Wang X, Yi B. Name Lookup in Named Data Networking: A Review. Information. 2019; 10(3):85. https://doi.org/10.3390/info10030085
Chicago/Turabian StyleMajed, Al-qutwani, Xingwei Wang, and Bo Yi. 2019. "Name Lookup in Named Data Networking: A Review" Information 10, no. 3: 85. https://doi.org/10.3390/info10030085
APA StyleMajed, A.-q., Wang, X., & Yi, B. (2019). Name Lookup in Named Data Networking: A Review. Information, 10(3), 85. https://doi.org/10.3390/info10030085