UXmood—A Sentiment Analysis and Information Visualization Tool to Support the Evaluation of Usability and User Experience

 , , , and
, , , and
Abstract
1. Introduction
2. Theoretical Foundation
2.1. Usability
2.2. User Experience
2.3. Multimodal Sentiment Analysis
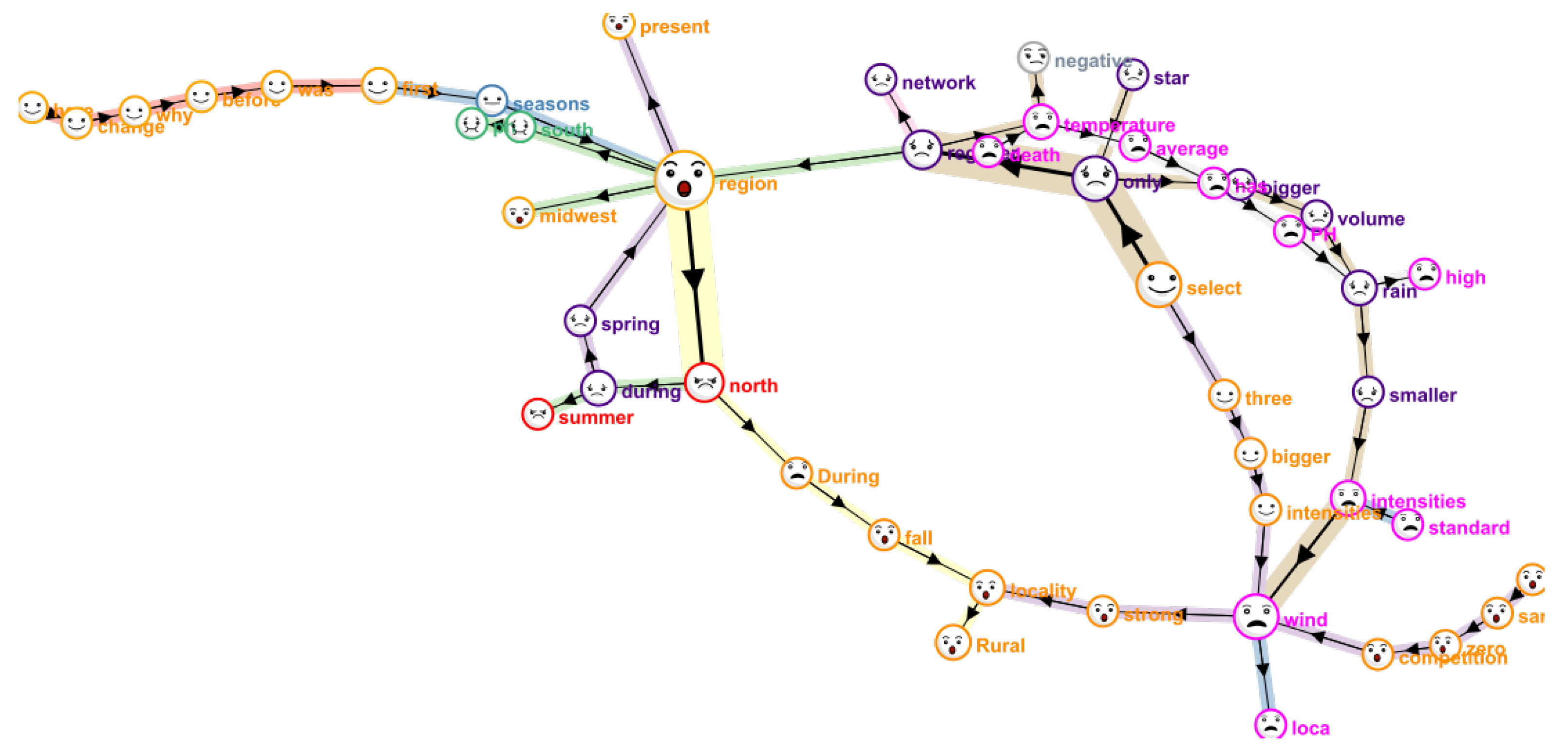
2.4. Information Visualization Techniques
3. Related Works
4. UXmood
4.1. Architecture
4.2. Technologies
4.3. Functionalities
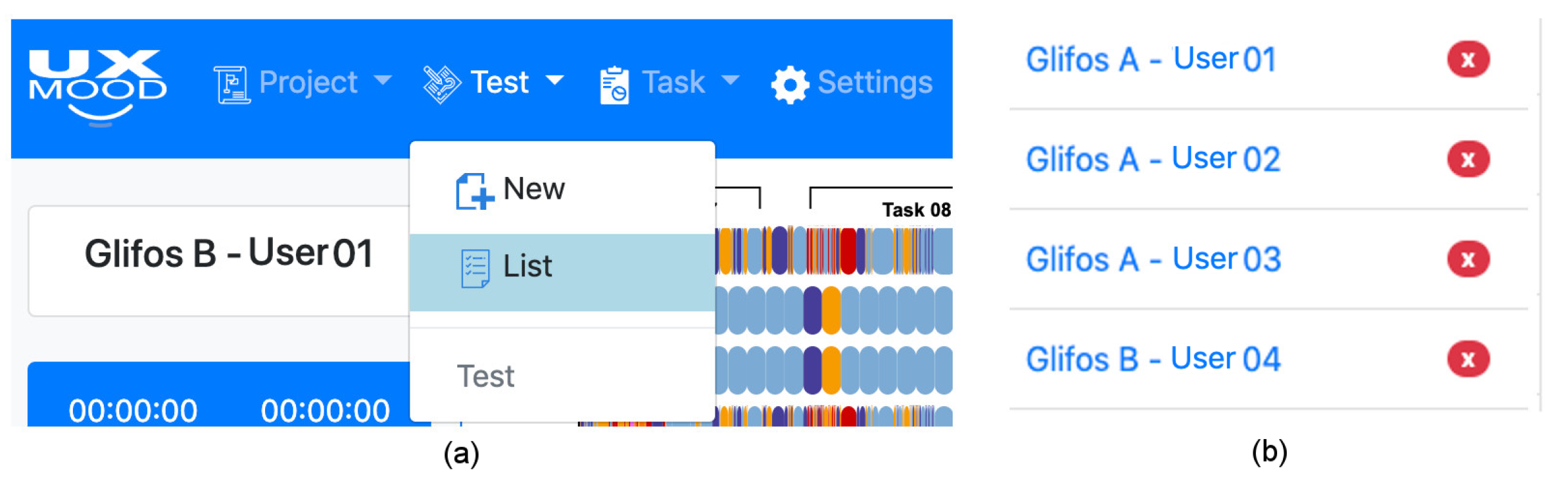
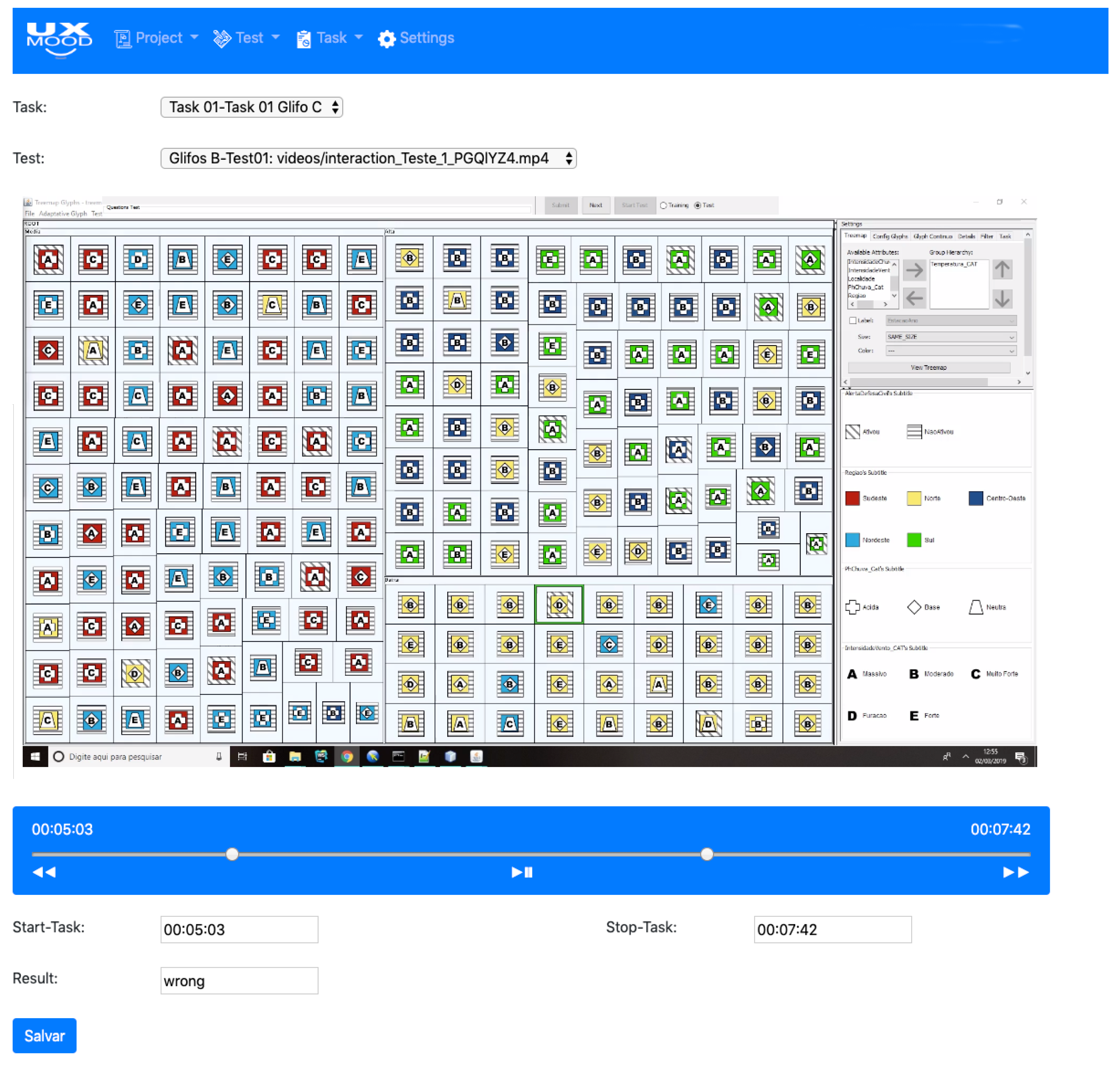
4.3.1. Projects, Test, and Task Organization
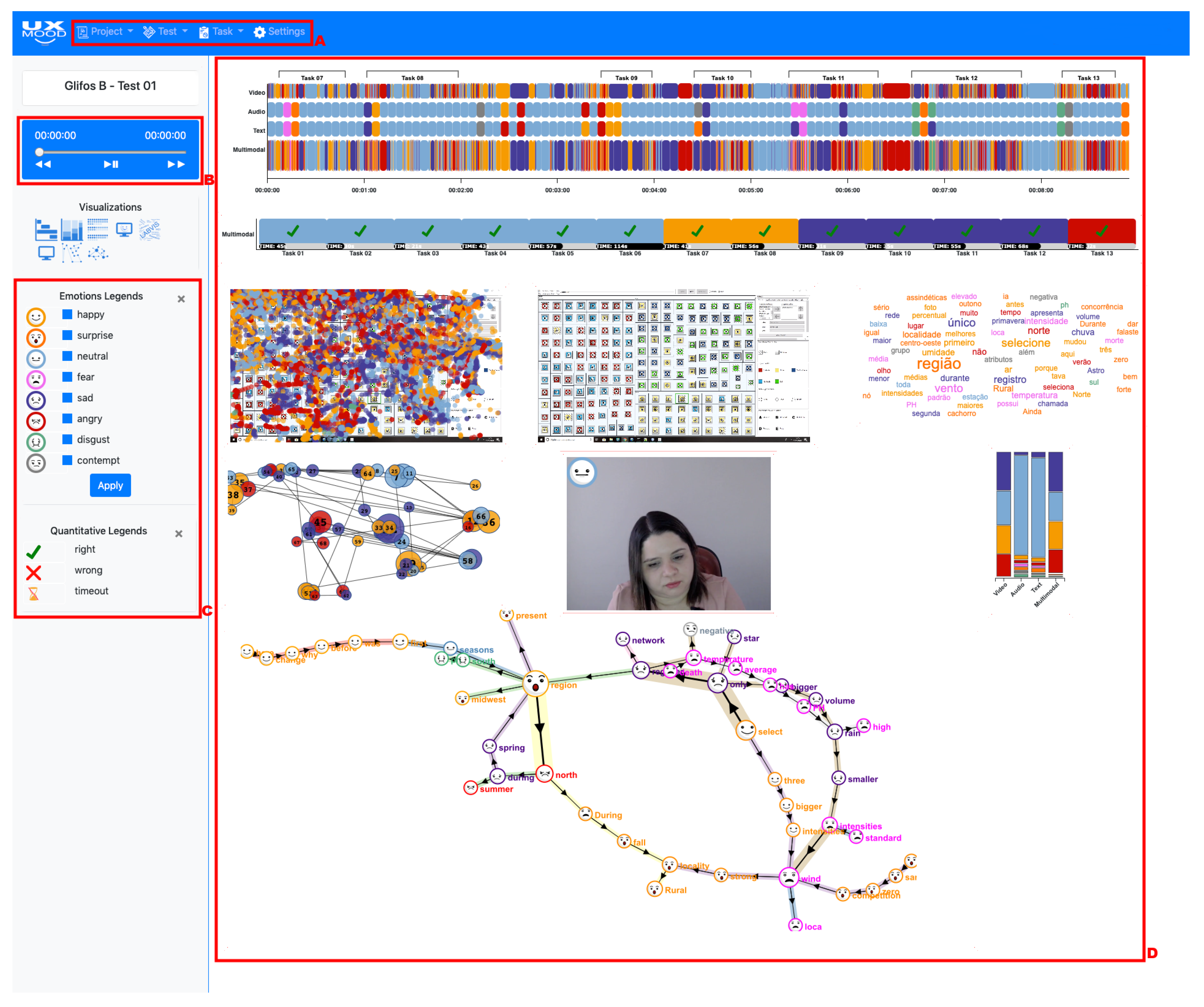
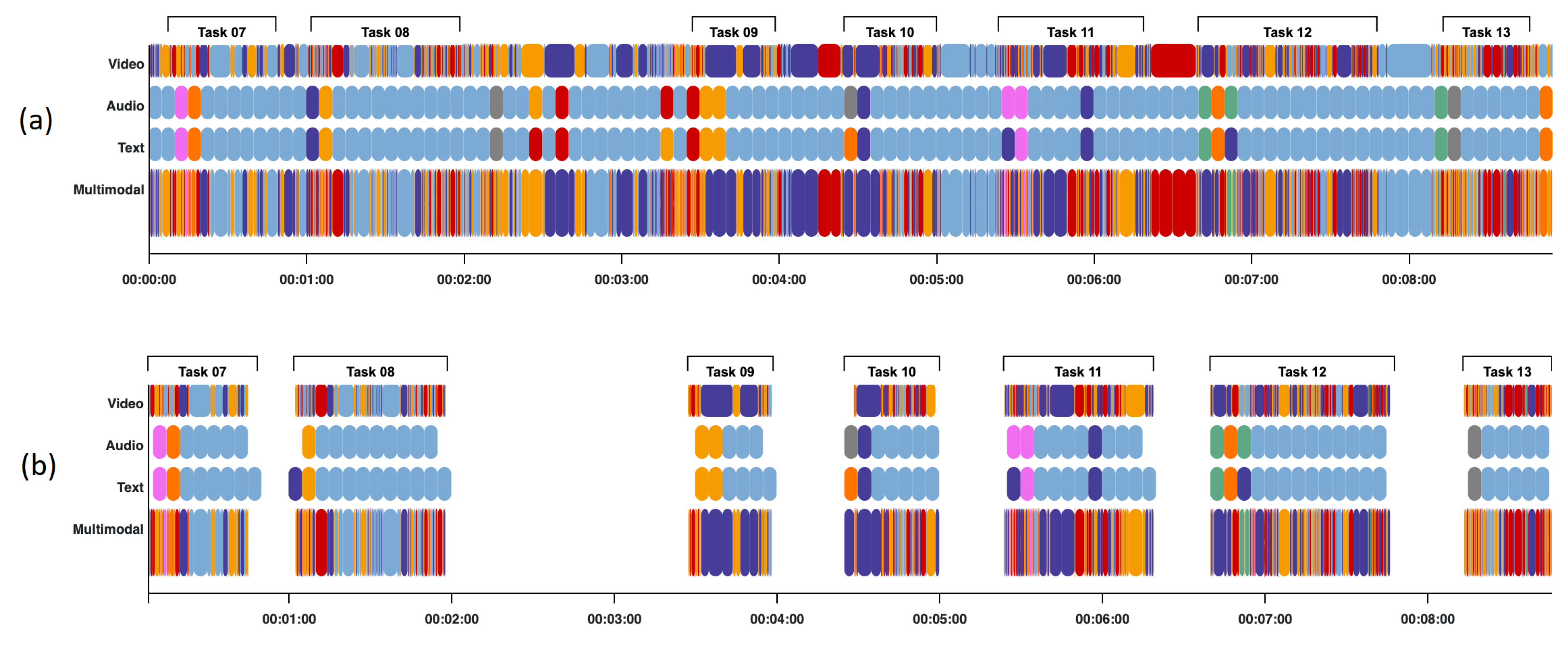
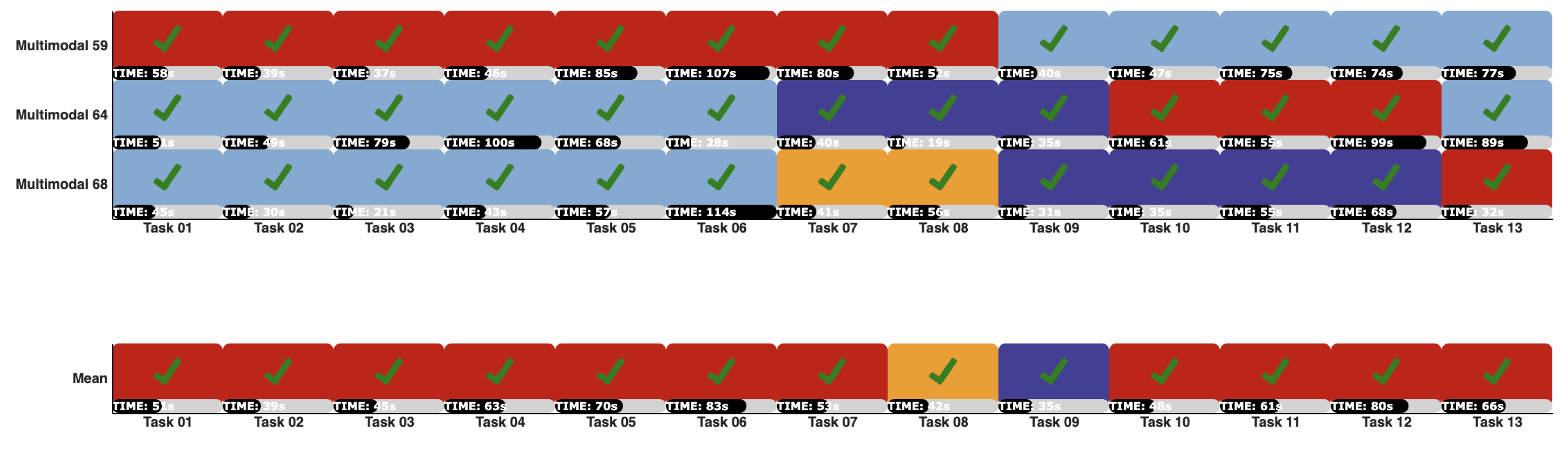
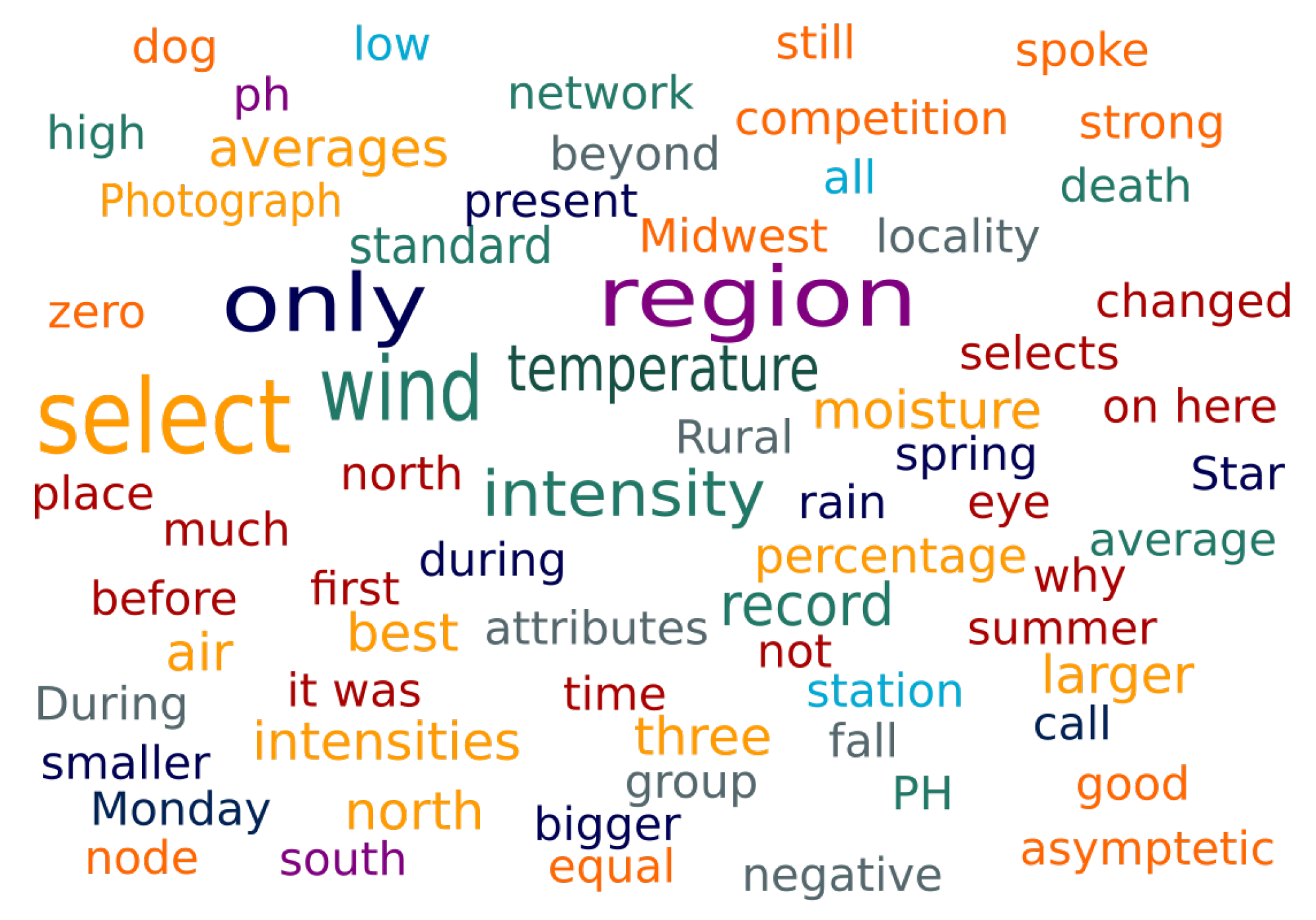
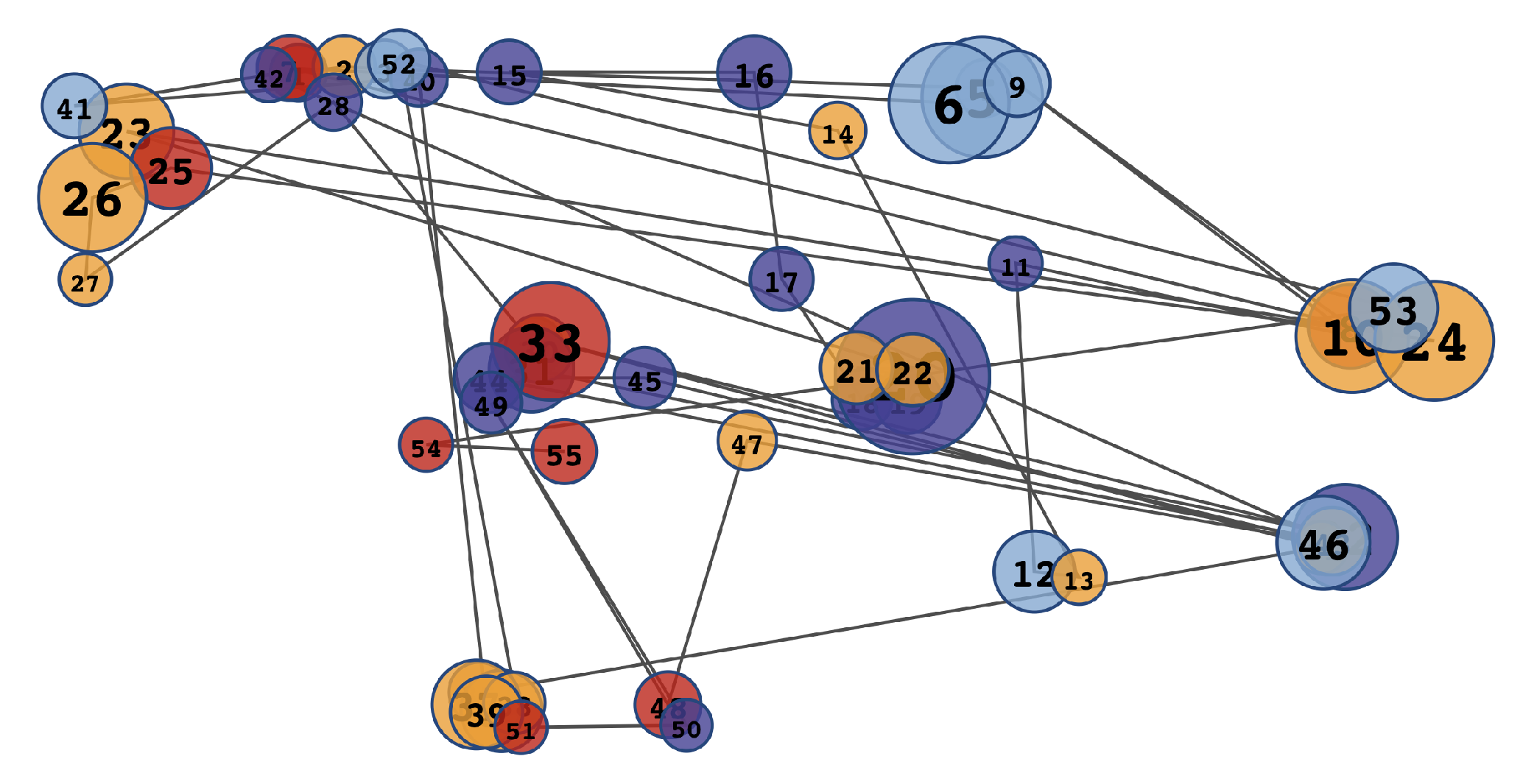
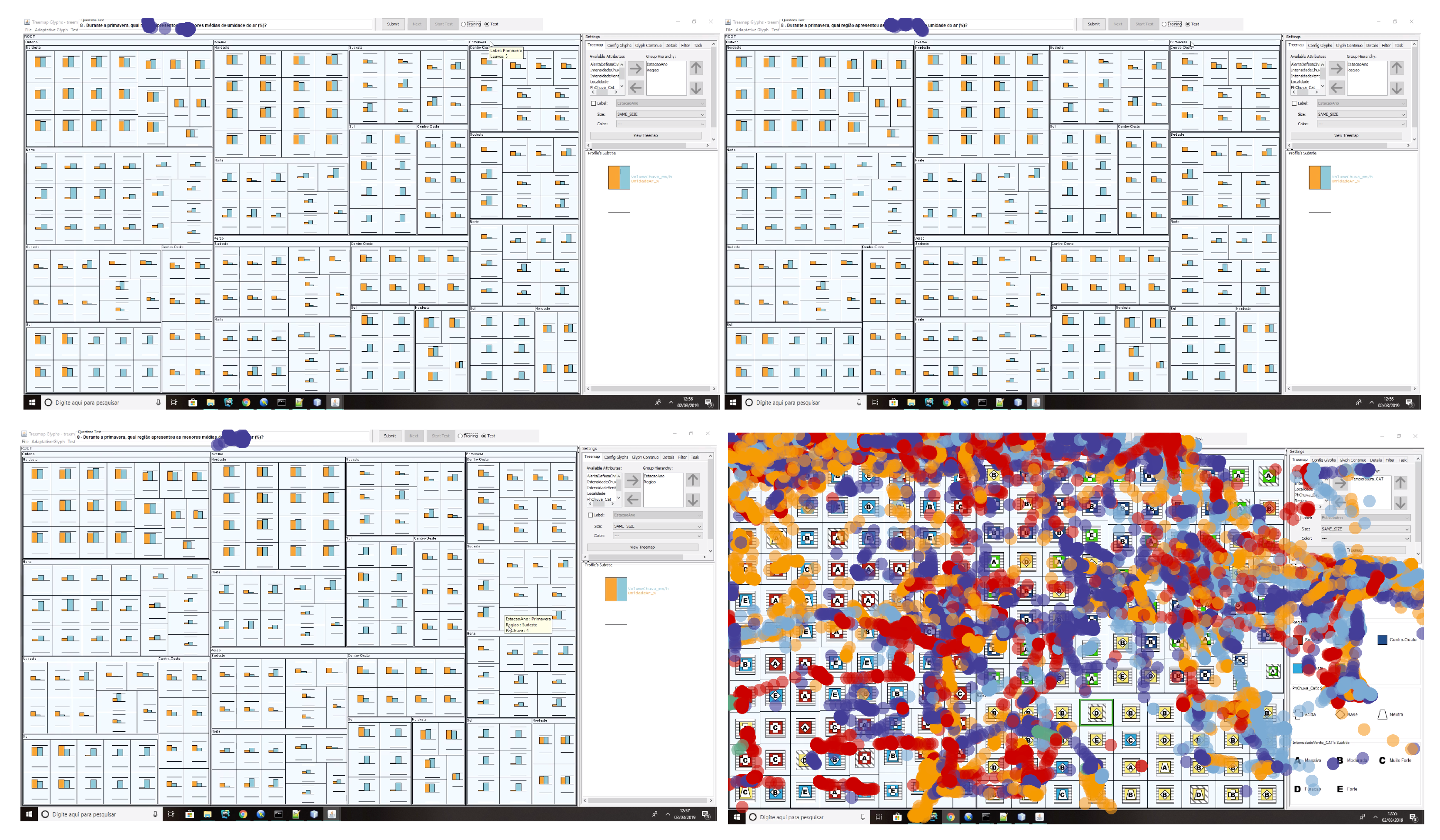
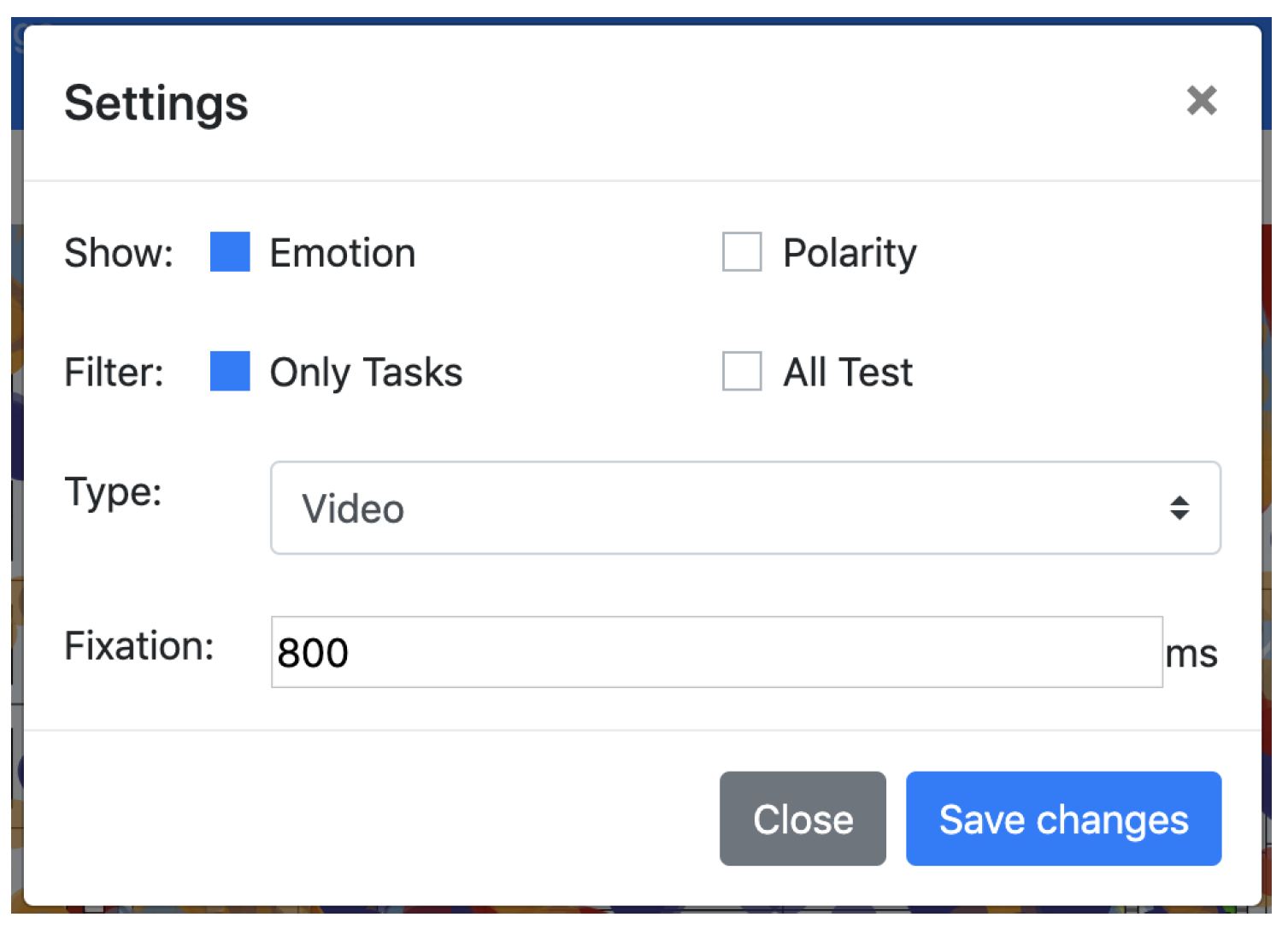
4.3.2. Visualization Dashboard
- Choose to output the sentiment analysis by emotion (angry, fear, happy, sad, surprise, disgust, contempt and neutral) or polarization (positive, negative, and neutral).
- Choose to display only the intervals that are related to tasks, disregarding the interval between them if wanted.
- Define which types of sentiment analysis to display, choosing between audio, video, text and multimodal.
- Define the duration of time that characterizes a fixation in eye-tracking.
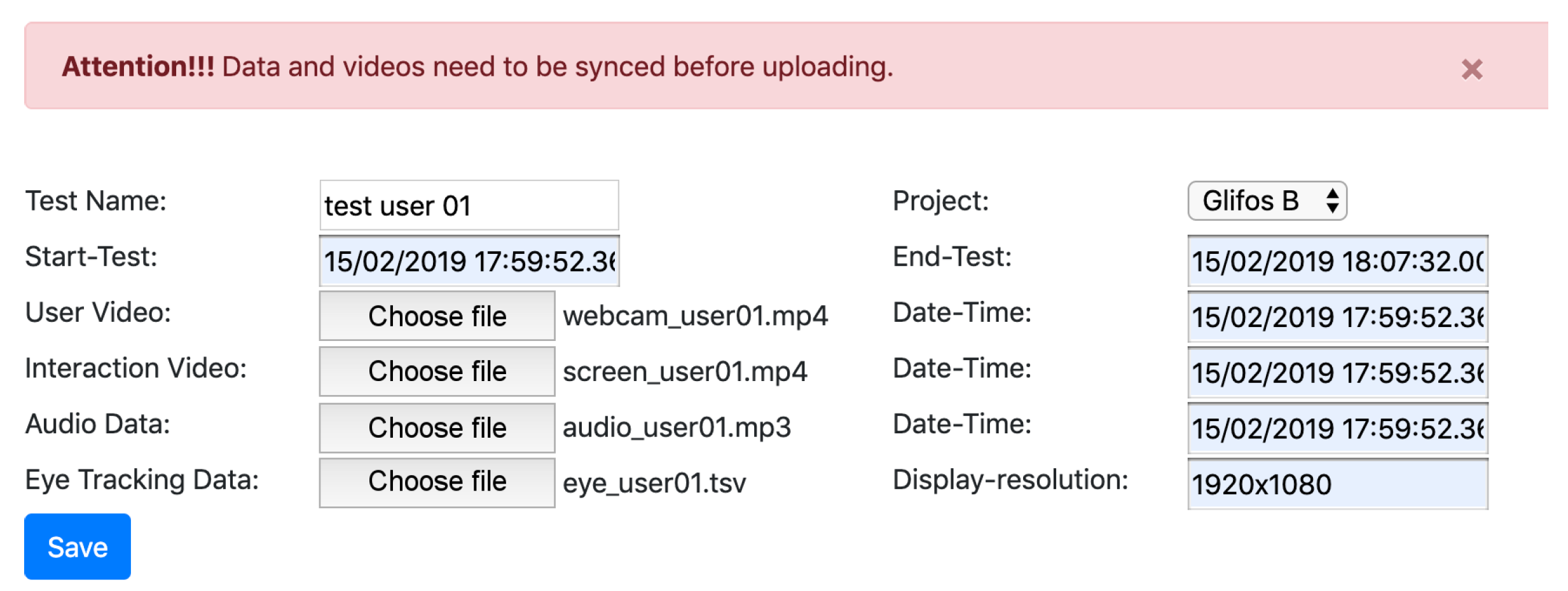
4.3.3. Media and Log Synchronization
4.3.4. Sentiment Classification
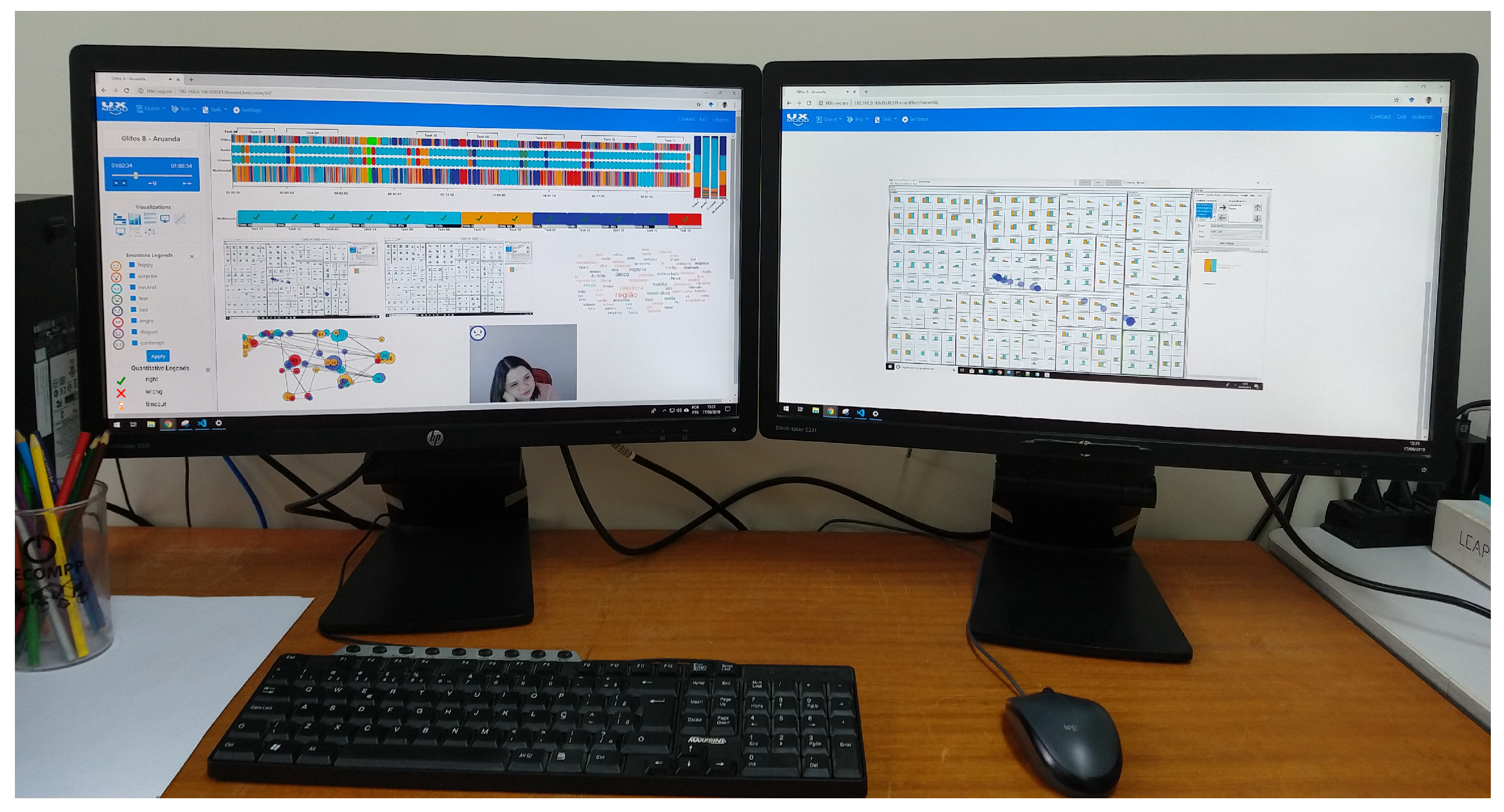
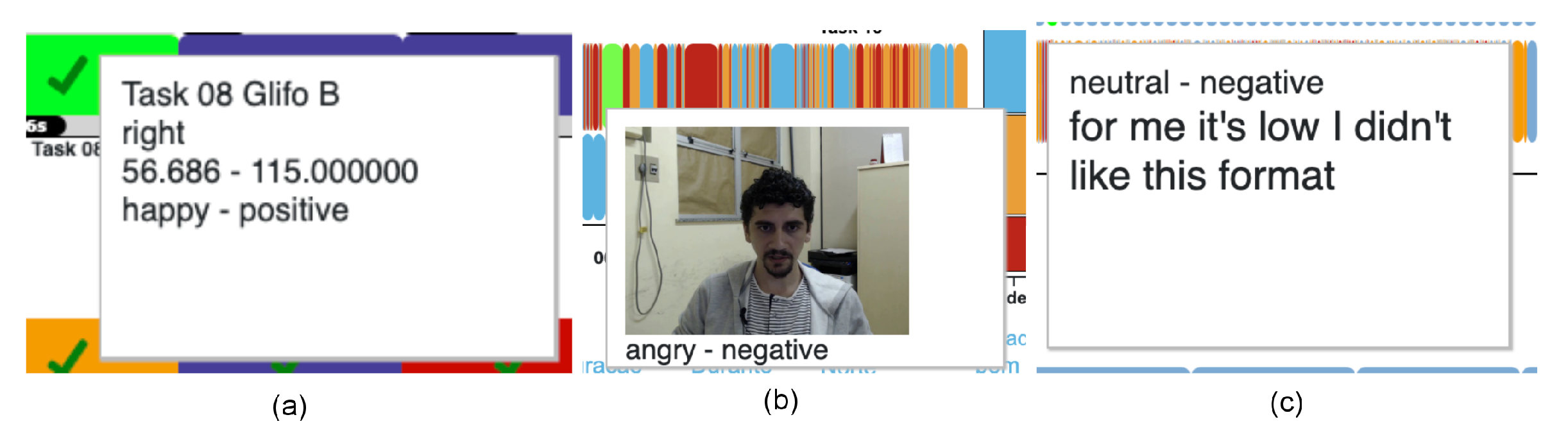
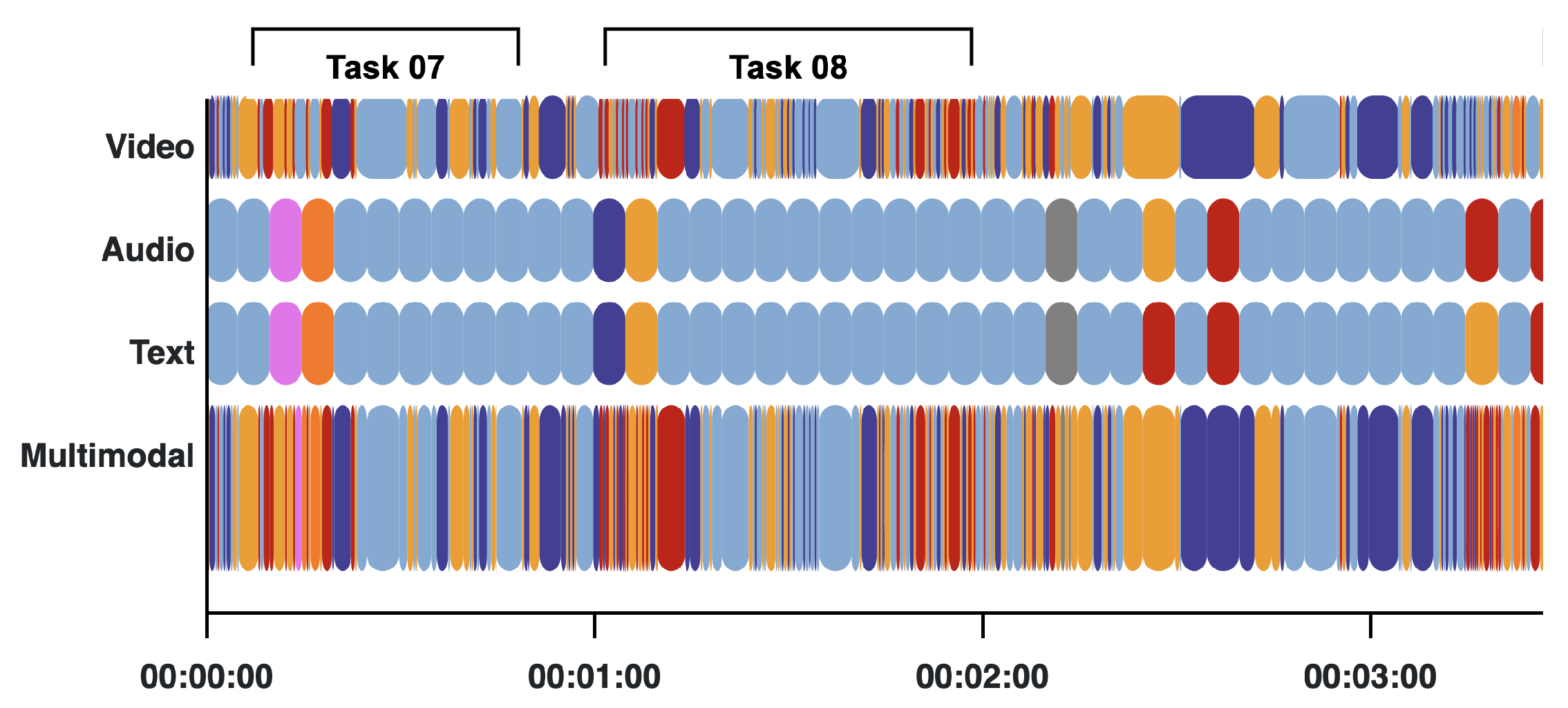
4.4. Usage Example
5. Evaluation Methodology
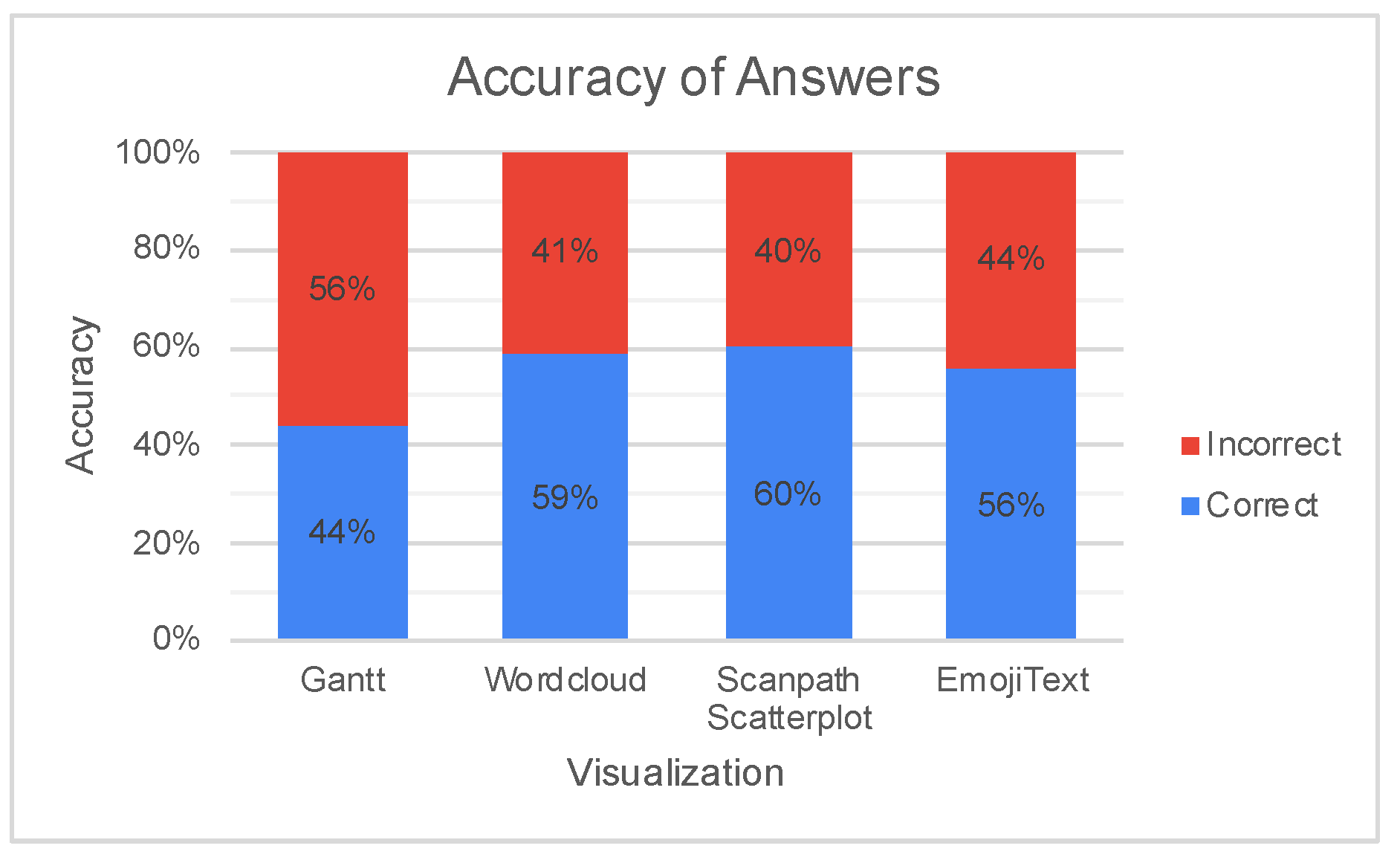
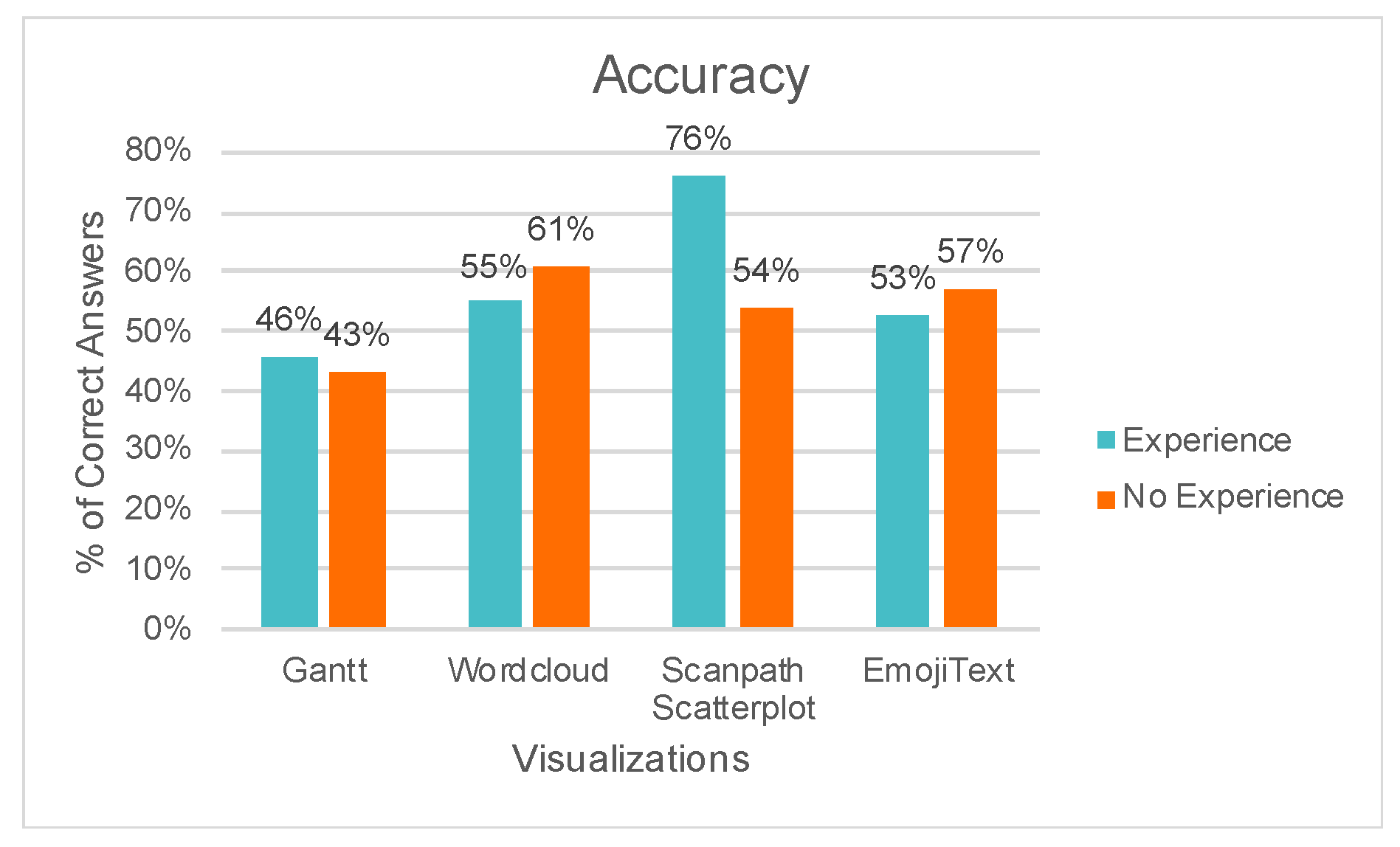
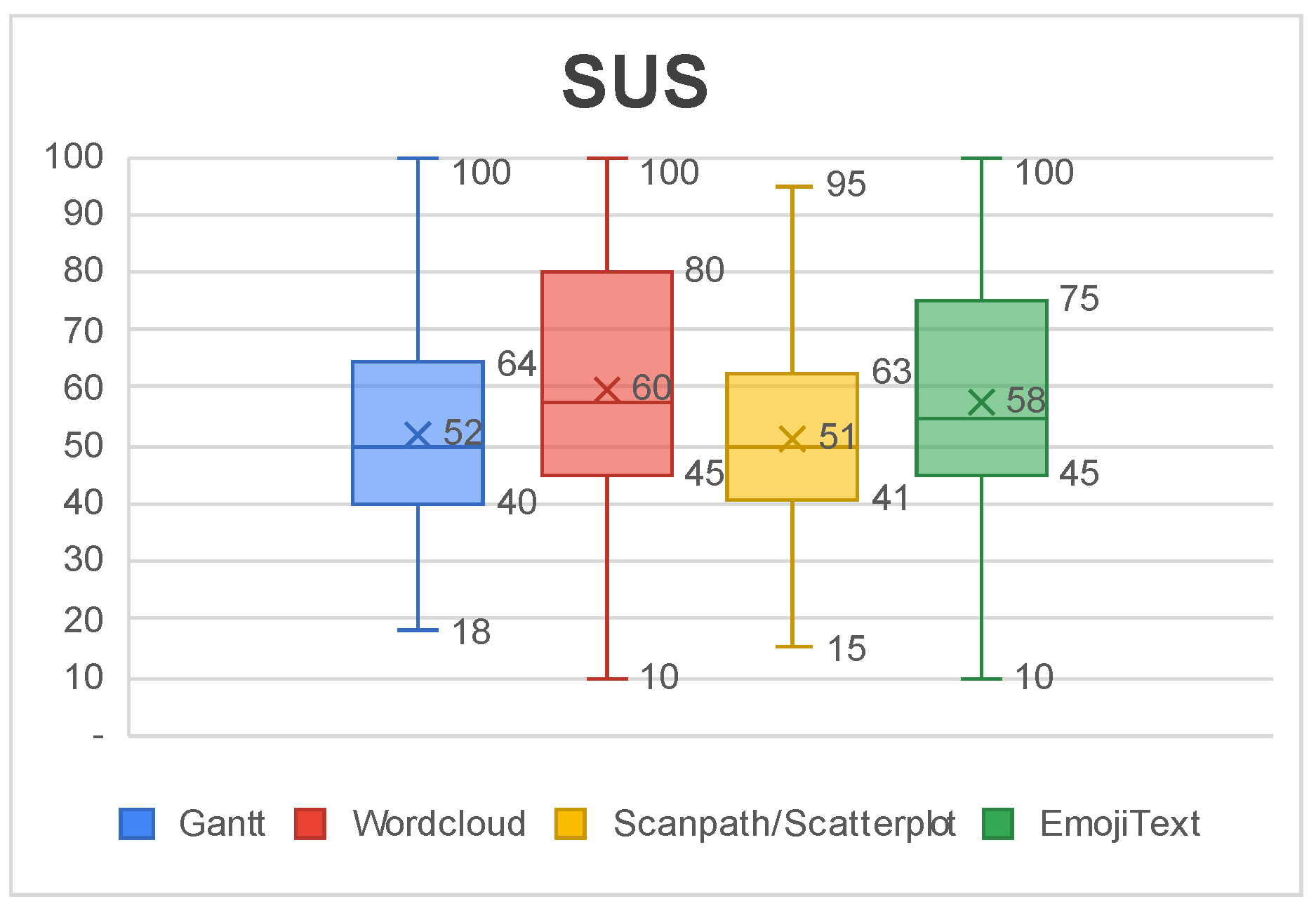
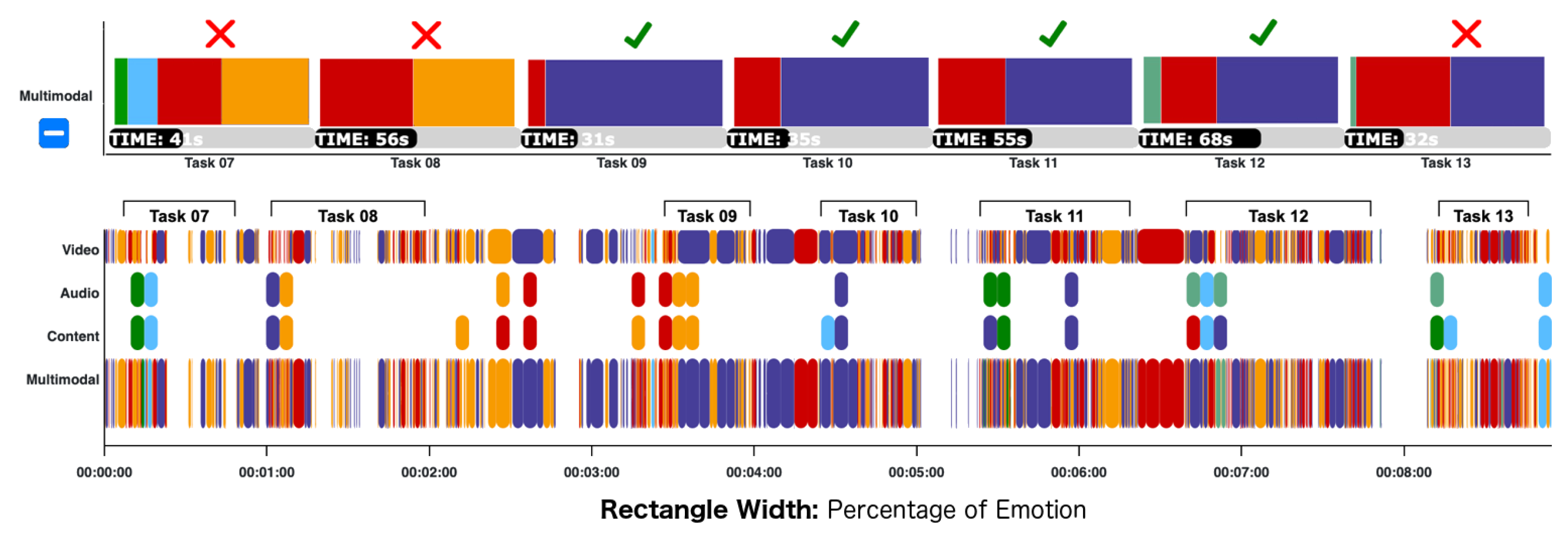
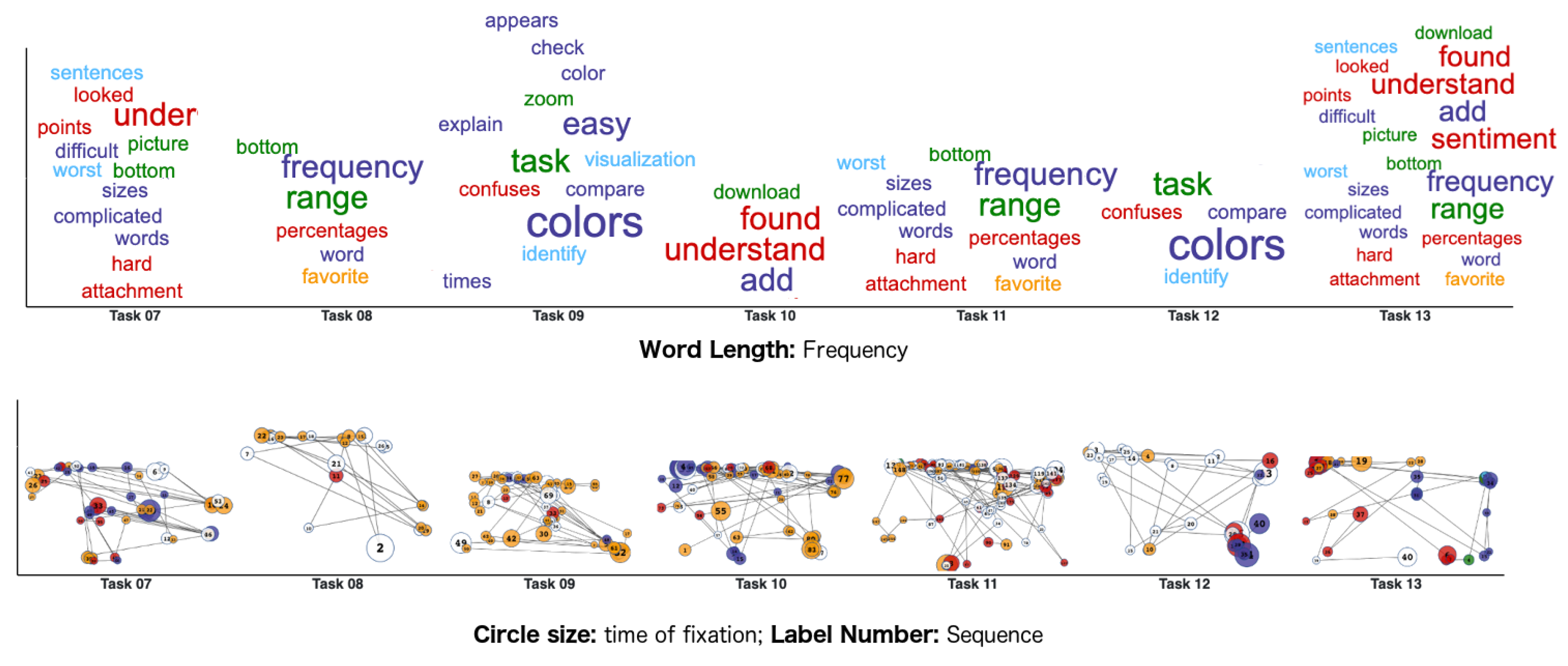
6. Results and Discussion
7. Final Remarks and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Voigt, C.; Kieslinger, B.; Schäfer, T. User Experiences Around Sentiment Analyses, Facilitating Workplace Learning. In International Conference on Social Computing and Social Media; Springer: Cham, Switzerland, 2017; pp. 312–324. [Google Scholar]
- Law, E.L.C.; Roto, V.; Hassenzahl, M.; Vermeeren, A.P.; Kort, J. Understanding, scoping and defining user experience: A survey approach. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 719–728. [Google Scholar]
- Hartson, R.; Pyla, P.S. The UX Book: Process and Guidelines for Ensuring a Quality User Experience; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Jokela, T.; Iivari, N.; Matero, J.; Karukka, M. The standard of user-centered design and the standard definition of usability: Analyzing ISO 13407 against ISO 9241–11. In Proceedings of the Latin American conference on Human-computer interaction, Rio de Janeiro, Brazil, 17–20 August 2003; pp. 53–60. [Google Scholar]
- Lallemand, C.; Gronier, G.; Koenig, V. User experience: A concept without consensus? Exploring practitioners’ perspectives through an international survey. Comput. Hum. Behav. 2015, 43, 35–48. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and subjectivity. In Handbook of Natural Language Processing, 2nd ed.; Chapman and Hall/CRC: London, UK, 2010; pp. 627–666. [Google Scholar]
- Ekman, P. Basic emotions. Handb. Cogn. Emot. 1999, 98, 16. [Google Scholar]
- Hussain, J.; Khan, W.A.; Hur, T.; Bilal, H.S.M.; Bang, J.; Hassan, A.U.; Afzal, M.; Lee, S. A multimodal deep log-based user experience (UX) platform for UX evaluation. Sensors 2018, 18, 1622. [Google Scholar] [CrossRef]
- Kwiatkowska, J.; Szóstek, A.; Lamas, D. Design and business gaps: From literature to practice. In Proceedings of the 2014 Mulitmedia, Interaction, Design and Innovation International Conference on Multimedia, Interaction, Design and Innovation, Warsaw, Poland, 24–25 June 2014; pp. 1–7. [Google Scholar]
- Matthews, T.; Judge, T.; Whittaker, S. How do designers and user experience professionals actually perceive and use personas? In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1219–1228. [Google Scholar]
- Shields, M. Information literacy, statistical literacy, data literacy. IASSIST Q. 2005, 28, 6. [Google Scholar] [CrossRef]
- Sauro, J. A Practical Guide to Measuring Usability: 72 Answers to the Most Commom Questions about Quantifying the Usability of Websites and Software; Measuring Usability LCC; CreateSpace Independent Publishing Platform: Scotts Valley, CA, USA, 2010. [Google Scholar]
- Sauro, J.; Lewis, J.R. Quantifying the User Experience: Practical Statistics for User Research, 1st ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2012. [Google Scholar]
- Law, E.L.C. The measurability and predictability of user experience. In Proceedings of the 3rd ACM SIGCHI Symposium on Engineering Interactive Computing Systems, Pisa, Italy, 13–16 June 2011; pp. 1–10. [Google Scholar]
- Albert, W.; Tullis, T. Measuring the User Experience: Collecting, Analyzing, and Presenting Usability Metrics; Newnes: Oxford, UK, 2013. [Google Scholar]
- Alves, R.; Valente, P.; Nunes, N.J. The state of user experience evaluation practice. In Proceedings of the 8th Nordic Conference on Human-Computer Interaction: Fun, Fast, Foundational, Helsinki, Finland, 26–30 October 2014; pp. 93–102. [Google Scholar]
- Arriaga, O.; Valdenegro-Toro, M.; Plöger, P. Real-time convolutional neural networks for emotion and gender classification. arXiv 2017, arXiv:1710.07557. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training deep networks for facial expression recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar]
- Ghai, M.; Lal, S.; Duggal, S.; Manik, S. Emotion recognition on speech signals using machine learning. In Proceedings of the 2017 International Conference on Big Data Analytics and Computational Intelligence (ICBDAC), Chirala, India, 23–25 March 2017; pp. 34–39. [Google Scholar] [CrossRef]
- Yan, W.J.; Wu, Q.; Liang, J.; Chen, Y.H.; Fu, X. How fast are the leaked facial expressions: The duration of micro-expressions. J. Nonverbal Behav. 2013, 37, 217–230. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd annual meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a word—Emotion association lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. Affective norms for English words (ANEW): Instruction Manual and Affective Ratings; Technical Report C-1; University of Florida: Gainesville, FL, USA, 1999. [Google Scholar]
- Rudovic, O.; Pavlovic, V.; Pantic, M. Context-sensitive dynamic ordinal regression for intensity estimation of facial action units. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 944–958. [Google Scholar] [CrossRef]
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Shneiderman, B.; Plaisant, C. Strategies for evaluating information visualization tools: multi-dimensional in-depth long-term case studies. In Proceedings of the 2006 AVI Workshop on BEyond Time and Errors: Novel Evaluation Methods for Information Visualization, Venice, Italy, 23 May 2006; pp. 1–7. [Google Scholar]
- Few, S. Information Dashboard Design; O’reilly: Sebastopol, CA, USA, 2006. [Google Scholar]
- Vasa, R.; Hoon, L.; Mouzakis, K.; Noguchi, A. A preliminary analysis of mobile app user reviews. In Proceedings of the 24th Australian Computer-Human Interaction Conference, Melbourne, Australia, 26–30 November 2012; pp. 241–244. [Google Scholar]
- Yadav, S.K.; Bhushan, M.; Gupta, S. Multimodal sentiment analysis: Sentiment analysis using audiovisual format. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; pp. 1415–1419. [Google Scholar]
- Setchi, R.; Asikhia, O.K. Exploring User Experience with Image Schemas, Sentiments, and Semantics. IEEE Trans. Affect. Comput. 2017, 10, 182–195. [Google Scholar] [CrossRef]
- Porat, T.; Schclar, A.; Shapira, B. MATE: A mobile analysis tool for usability experts. In CHI’13 Extended Abstracts on Human Factors in Computing Systems; ACM: New York, NY, USA, 2013; pp. 265–270. [Google Scholar]
- Hedegaard, S.; Simonsen, J.G. Extracting usability and user experience information from online user reviews. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 2089–2098. [Google Scholar]
- Munim, K.M.; Islam, I.; Khatun, M.; Karim, M.M.; Islam, M.N. Towards developing a tool for UX evaluation using facial expression. In Proceedings of the 2017 3rd International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 7–9 December 2017; pp. 1–6. [Google Scholar]
- Bauman, K.; Liu, B.; Tuzhilin, A. Recommending Items with Conditions Enhancing User Experiences Based on Sentiment Analysis of Reviews. In Proceedings of the CBRecSys@ RecSys, Boston, MA, USA, 16 September 2016; pp. 19–22. [Google Scholar]
- Dodd, C.; Athauda, R.; Adam, M. Designing user interfaces for the elderly: A systematic literature review. In Proceedings of the Australasian Conference on Information Systems, Sandy Bay, Australia, 4–6 December 2017; pp. 1–11. [Google Scholar]
- Figueiras, A. A review of visualization assessment in terms of user performance and experience. In Proceedings of the 2018 22nd International Conference Information Visualisation (IV), Fisciano, Italy, 10–13 July 2018; pp. 145–152. [Google Scholar]
- Bakiu, E.; Guzman, E. Which feature is unusable? Detecting usability and user experience issues from user reviews. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; pp. 182–187. [Google Scholar]
- Kharel, S.; Fernstrom, M. Quantifying User Experience of Mobile Applications Using a Sentimental Analysis Approach. In Proceedings of the 6th NUI GALWAY-UL Alliance Postgraduate Research Day 2016, Galway, Ireland, 29 April 2016; pp. 1–2. [Google Scholar]
- Moizer, J.; Lean, J.; Dell’Aquila, E.; Walsh, P.; Keary, A.A.; O’Byrne, D.; Di Ferdinando, A.; Miglino, O.; Friedrich, R.; Asperges, R.; et al. An approach to evaluating the user experience of serious games. Comput. Educ. 2019, 136, 141–151. [Google Scholar] [CrossRef]
- Sánchez-Adame, L.M.; Mendoza, S.; González-Beltrán, B.A.; Rodríguez, J.; Viveros, A.M. AUX and UX Evaluation of User Tools in Social Networks. In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; pp. 104–111. [Google Scholar]
- Yu, M.; Zhou, R.; Wang, H.; Zhao, W. An evaluation for VR glasses system user experience: The influence factors of interactive operation and motion sickness. Appl. Ergon. 2019, 74, 206–213. [Google Scholar] [CrossRef]
- Seguin, J.A.; Scharff, A.; Pedersen, K. Triptech: A Method for Evaluating Early Design Concepts. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; p. CS24. [Google Scholar]
- Syahrir, S.; Sfenrianto, S. User experience questioner and heuristics evaluation in online learning environment. J. Theor. Appl. Inf. Technol. 2019, 97, 1071–1081. [Google Scholar]
- Basri, N.H.; Adnan, W.A.W.; Baharin, H. E-participation service in malaysian e-government website: The user experience evaluation. In Proceedings of the 10th International Conference on E-Education, E-Business, E-Management and E-Learning, Tokyo, Japan, 10–13 January 2019; pp. 342–346. [Google Scholar]
- Dünser, A.; Billinghurst, M. Evaluating augmented reality systems. In Handbook of Augmented Reality; Springer: Cham, Switzerland, 2011; pp. 289–307. [Google Scholar]
- Paramitha, A.I.I.; Dantes, G.R.; Indrawan, G. The Evaluation of Web Based Academic Progress Information System Using Heuristic Evaluation and User Experience Questionnaire (UEQ). In Proceedings of the 2018 Third International Conference on Informatics and Computing (ICIC), Palembang, Indonesia, 17–18 October 2018; pp. 1–6. [Google Scholar]
- Corrêa, A.G.; Borba, E.Z.; Lopes, R.; Zuffo, M.K.; Araujo, A.; Kopper, R. User experience evaluation with archaeometry interactive tools in Virtual Reality environment. In Proceedings of the 2017 IEEE Symposium on 3D User Interfaces (3DUI), Los Angeles, CA, USA, 18–19 March 2017; pp. 217–218. [Google Scholar]
- Souza, K.E.; Seruffo, M.C.; De Mello, H.D.; Souza, D.D.S.; Vellasco, M.M. User Experience Evaluation Using Mouse Tracking and Artificial Intelligence. IEEE Access 2019, 7, 96506–96515. [Google Scholar] [CrossRef]
- Giannakopoulos, T.; Pikrakis, A.; Theodoridis, S. A dimensional approach to emotion recognition of speech from movies. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 65–68. [Google Scholar]
- Jain, V.K.; Kumar, S.; Fernandes, S.L. Extraction of emotions from multilingual text using intelligent text processing and computational linguistics. J. Comput. Sci. 2017, 21, 316–326. [Google Scholar] [CrossRef]
- Mehrabian, A.; Friar, J.T. Encoding of attitude by a seated communicator via posture and position cues. J. Consult. Clin. Psychol. 1969, 33, 330. [Google Scholar] [CrossRef]
- Bostock, M.; Ogievetsky, V.; Heer, J. D3 data-driven documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef]
- Holovaty, A.; Kaplan-Moss, J. The Definitive Guide to Django: Web Development Done Right; Apress: New York, NY, USA, 2009. [Google Scholar]
- Lei, X.; Jiang, X.; Wang, C. Design and implementation of a real-time video stream analysis system based on FFMPEG. In Proceedings of the 2013 Fourth World Congress on Software Engineering, Hong Kong, China, 3–4 December 2013; pp. 212–216. [Google Scholar]
- Pham, H. Pyaudio: Portaudio v19 Python Bindings. 2006. Available online: https://people.csail.mit.edu/hubert/pyaudio (accessed on 22 November 2019).
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Schuster, M. Speech recognition for mobile devices at Google. In Pacific Rim International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2010; pp. 8–10. [Google Scholar]
- Tripathi, S.; Beigi, H. Multi-modal emotion recognition on iemocap dataset using deep learning. arXiv 2018, arXiv:1804.05788. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining; Lrec: Baton Rouge, LA, USA, 2010; Volume 10, pp. 2200–2204. [Google Scholar]
- Soares, A.G.M.; dos Santos, D.H.; Barbosa, C.L.R.; Gonçalves, A.S.; dos Santos, C.G.R.; Meiguins, B.S.; Miranda, E.T.C. Visualizing Multidimensional Data in Treemaps with Adaptive Glyphs. In Proceedings of the 2018 22nd International Conference Information Visualisation (IV), Fisciano, Italy, 10–13 July 2018; pp. 58–63. [Google Scholar]
- Torres Neto, J.R.; Geraldo Filho, P.; Mano, L.Y.; Ueyama, J. Verbo: Voice emotion recognition database in Portuguese language. J. Comput. Sci. 2018, 14, 1420–1430. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8. [Google Scholar]
- Scherer, K.; Wallbott, H. International Survey on Emotion Antecedents and Reactions (ISEAR). 1990. Available online: http://www.affective-sciences.org/index.php/download_file/view/395/296/ (accessed on 22 November 2019).
- Borgo, R.; Micallef, L.; Bach, B.; McGee, F.; Lee, B. Information visualization evaluation using crowdsourcing. In Computer Graphics Forum; Wiley Online Library: Hoboken, NY, USA, 2018; Volume 37, pp. 573–595. [Google Scholar]
- Brooke, J. SUS: A quick and dirty usability scale. In Usability Evaluation in Industry; CRC Press: Boca Raton, FL, USA, 1996; pp. 4–7. [Google Scholar]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Similarity | Paper Type | Time | Correctness | Eye Tracker | Mouse Tracker | Questionnaire | Think Aloud | User Face Video | Interaction Video | User Audio | Audio Transcription | Product Review | Image Schemas | Video | Audio | Text | Multimodal | UX Expert Judgment | UX | Usability | Heatmap | Pie Chart | Stackedbar | Radar | Line Chart | Scanpath | EmojiText | Wordcloud | Gantt Chart | Scatterplot | Remote Access |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ✱ | 22 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| [8] | 16 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||
| [32] | 12 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||
| [30] | 12 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||
| [37] | 9 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||
| [33] | 8 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||
| [47] | 7 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||
| [38] | 7 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||
| [1] | 6 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||||
| [39] | 6 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||||
| [31] | 6 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||||
| [35] | 5 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [40] | 5 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [48] | 5 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [41] | 5 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [42] | 5 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [34] | 5 | Tool | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [49] | 5 | Method | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||||||||||||||||||
| [43] | 4 | Tool | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||||||
| [44] | 4 | Method | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||||||
| [45] | 4 | Method | ✓ | ✓ | ✓ | ✓ | ||||||||||||||||||||||||||
| [46] | 3 | Method | ✓ | ✓ | ✓ | |||||||||||||||||||||||||||
| [50] | 3 | Tool | ✓ | ✓ | ✓ | |||||||||||||||||||||||||||
| [39] | 3 | Tool | ✓ | ✓ | ✓ | |||||||||||||||||||||||||||
| [36] | 3 | Method | ✓ | ✓ | ✓ | |||||||||||||||||||||||||||
| Totals | 11 | 13 | 2 | 2 | 16 | 4 | 6 | 6 | 6 | 3 | 5 | 2 | 5 | 4 | 9 | 4 | 8 | 23 | 15 | 2 | 4 | 5 | 2 | 4 | 1 | 1 | 2 | 1 | 1 | 3 | ||
| ✱ | UXmood | Quantitative Data | Qualitative Data | Sentiment Analysis | Evaluation Type | Data Visualization | Other | |||||||||||||||||||||||||
| Most Cited Problems in Visualizations | |||
|---|---|---|---|
| Gantt Chart | Wordcloud | Scanpath/Scatterplot | EmojiText |
| Too much sentiments and colors. | Focus tends to be on the bigger words. | Visual clutter. | Sentence identification difficulty. |
| Small visualization. | Comparison difficulty. | Too much colors. | Confusion with node and edge colors. |
| Interpretation difficulty. | Unorganized layout. | Complex visualization. | Overlap in some labels. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
da Silva Franco, R.Y.; Santos do Amor Divino Lima, R.; Monte Paixão, R.d.; Resque dos Santos, C.G.; Serique Meiguins, B. UXmood—A Sentiment Analysis and Information Visualization Tool to Support the Evaluation of Usability and User Experience. Information 2019, 10, 366. https://doi.org/10.3390/info10120366
da Silva Franco RY, Santos do Amor Divino Lima R, Monte Paixão Rd, Resque dos Santos CG, Serique Meiguins B. UXmood—A Sentiment Analysis and Information Visualization Tool to Support the Evaluation of Usability and User Experience. Information. 2019; 10(12):366. https://doi.org/10.3390/info10120366
Chicago/Turabian Styleda Silva Franco, Roberto Yuri, Rodrigo Santos do Amor Divino Lima, Rafael do Monte Paixão, Carlos Gustavo Resque dos Santos, and Bianchi Serique Meiguins. 2019. "UXmood—A Sentiment Analysis and Information Visualization Tool to Support the Evaluation of Usability and User Experience" Information 10, no. 12: 366. https://doi.org/10.3390/info10120366
APA Styleda Silva Franco, R. Y., Santos do Amor Divino Lima, R., Monte Paixão, R. d., Resque dos Santos, C. G., & Serique Meiguins, B. (2019). UXmood—A Sentiment Analysis and Information Visualization Tool to Support the Evaluation of Usability and User Experience. Information, 10(12), 366. https://doi.org/10.3390/info10120366