A Sustainable and Open Access Knowledge Organization Model to Preserve Cultural Heritage and Language Diversity

 , ,
, ,
Abstract
:1. Introduction
2. The Role of Library and Information Science in Building a Global, Shared Knowledge Community
for Otlet the main questions were: how best was order to be introduced into this proliferating, disorderly mass in such a way that progress in the world of learning could continue efficiently and effectively ? How could rapid developments in all areas of knowledge, so characteristic of the modern period, be mobilised for the benefit of society ? How could the international flow of information, then obstructed (as it still is) by political, social and linguistic barriers on the one hand, and by cumbersome, unresponsive systems of publication, distribution and bibliographic processing on the other, become more open and more effective? How could accurate, up-to-date, ’integrated’ information tailored specifically and exactly to particular needs be derived from this mass and reworked to a form ensuring immediate and optimal usefulness. How could this especially processed information be made available without hindrance or delay, whatever such potentially infinite, unpredictable needs might be?
3. Related Work
4. New Paradigm for a Sustainable Knowledge Organization Model
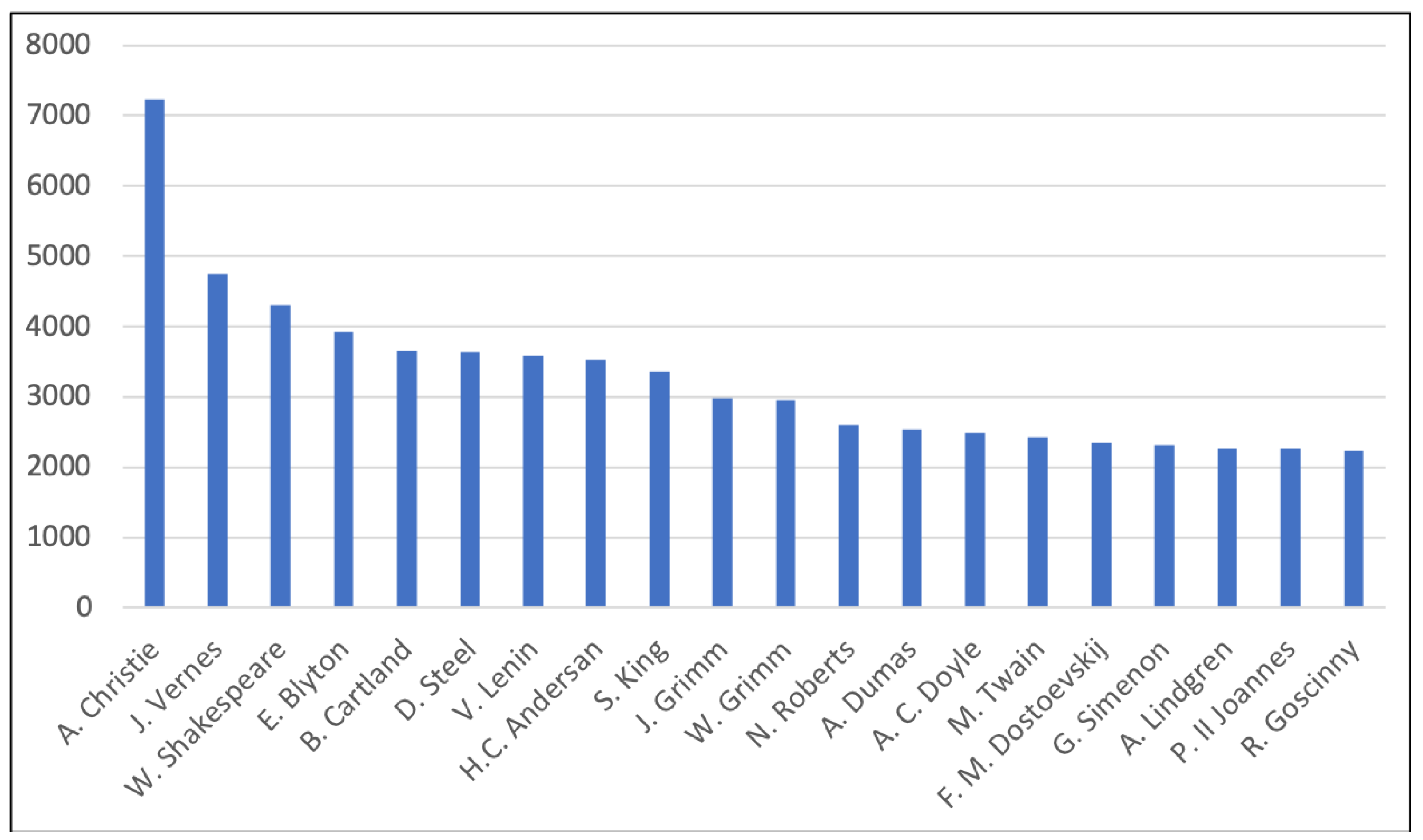
4.1. Why Focus on Translations?
4.2. Static Versus Interactive Knowledge Sharing Process
4.3. Non-Collaborative and Exclusive Versus Collaborative and Inclusive Knowledge Curation Processes
5. Experiments and Results
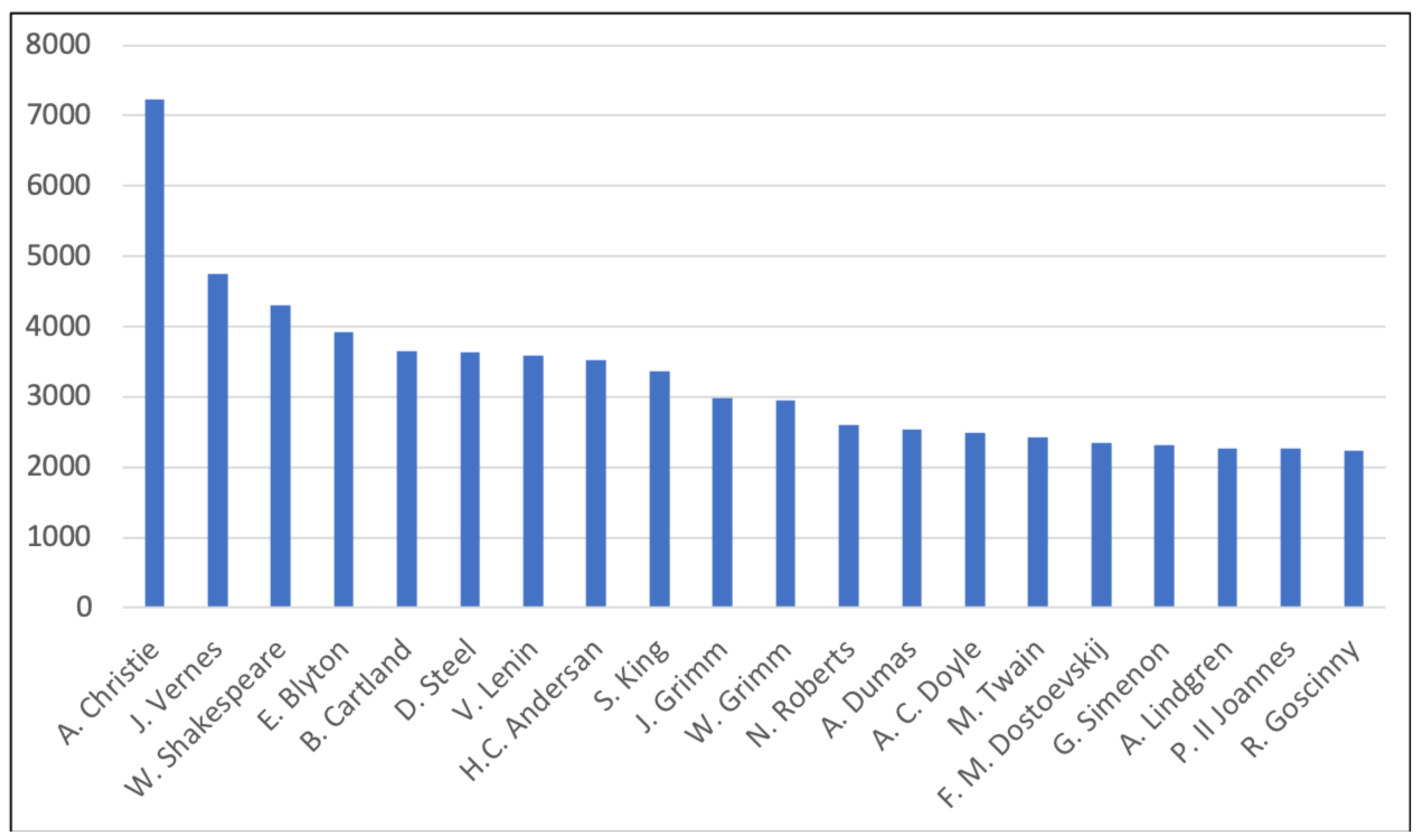
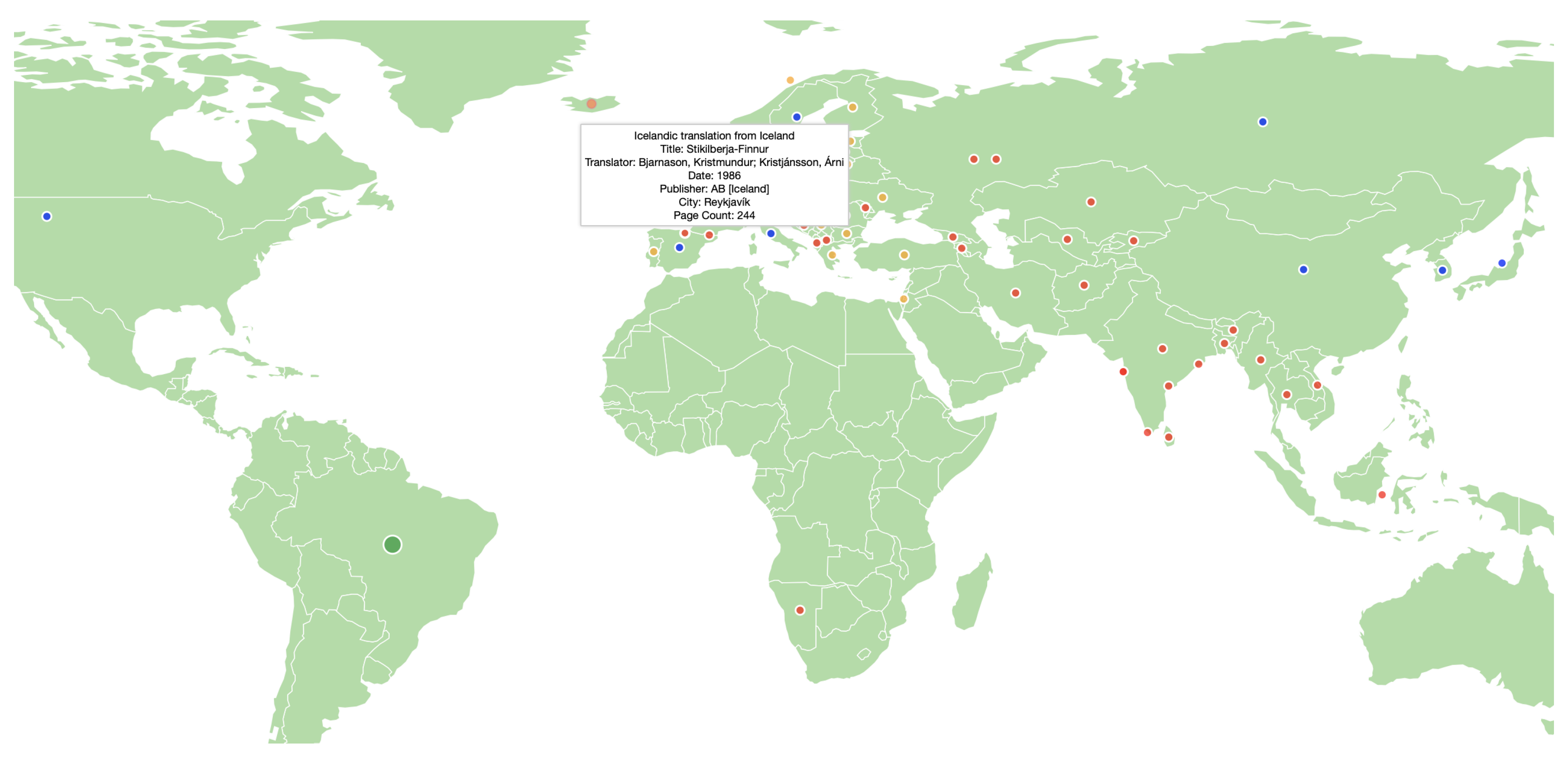
5.1. Data Curation
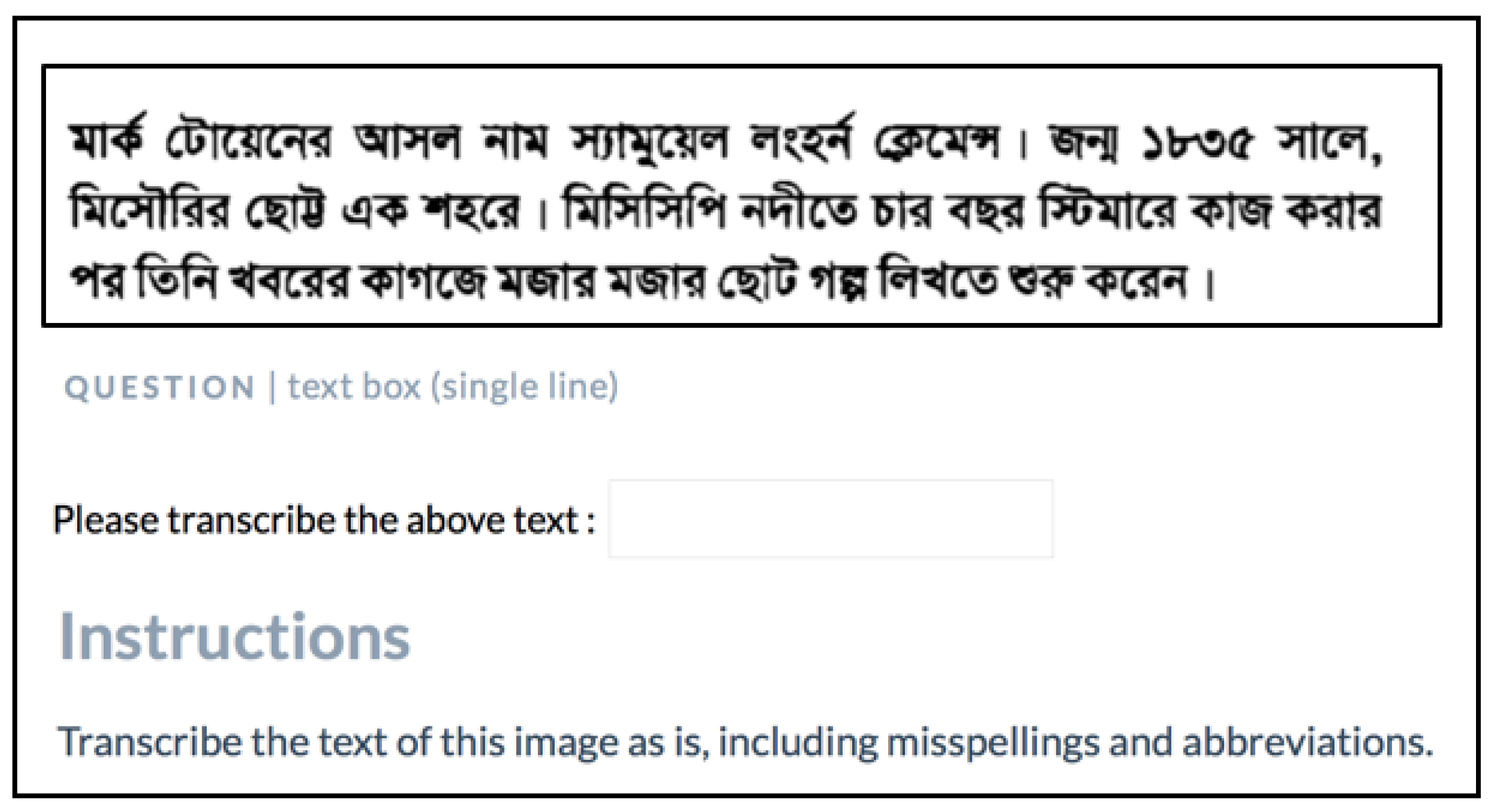
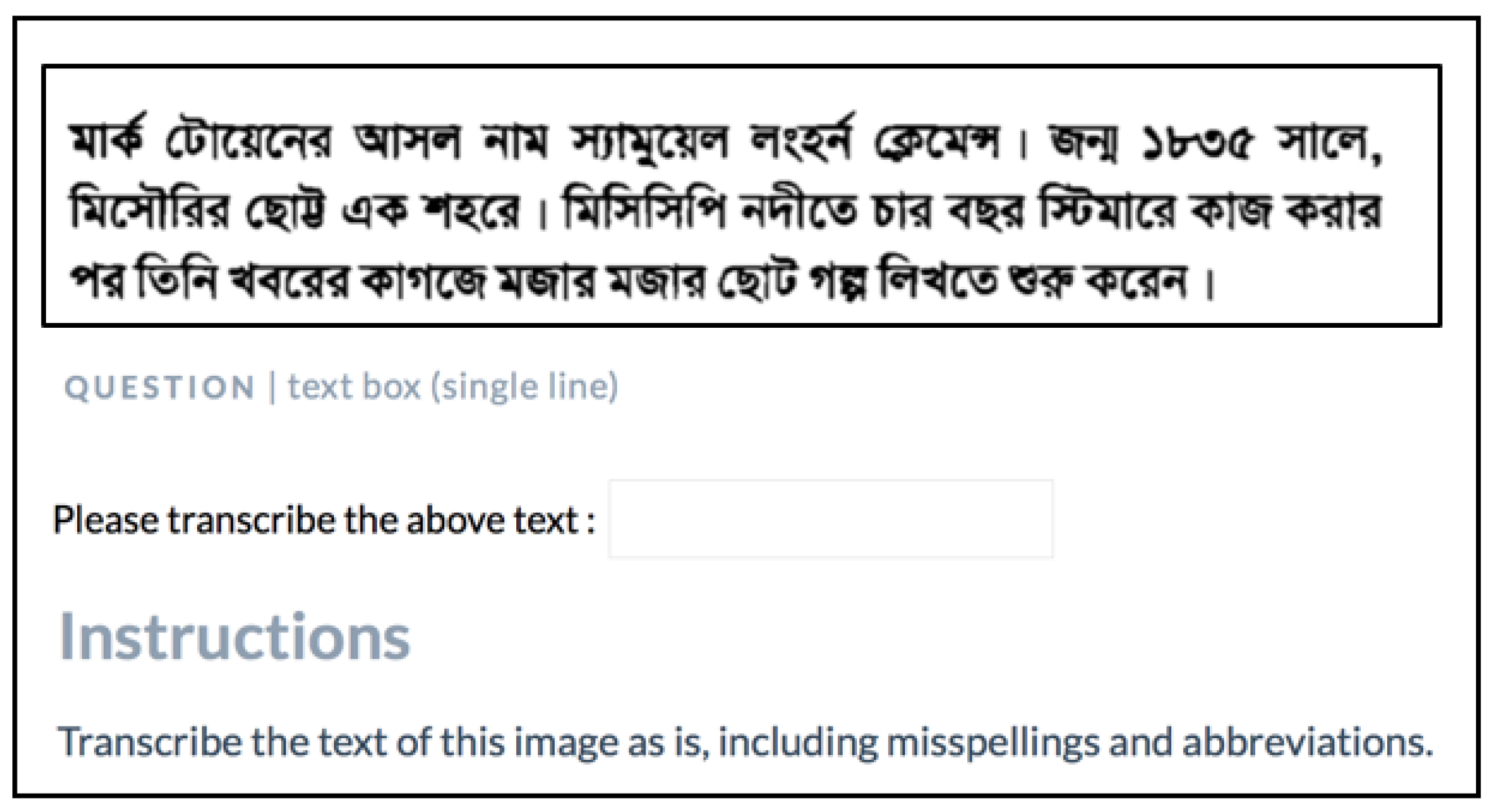
5.2. A Crowdsourcing Approach for Text Collection and Transcription
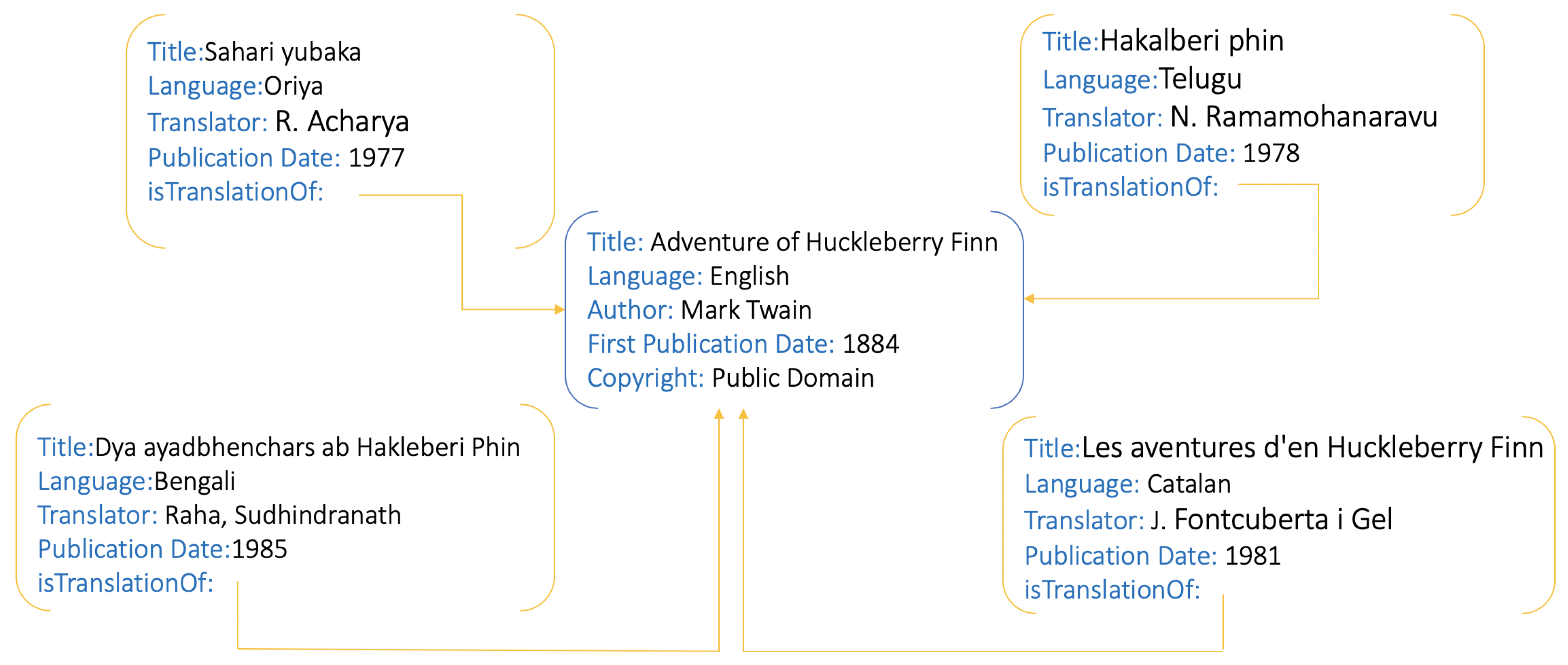
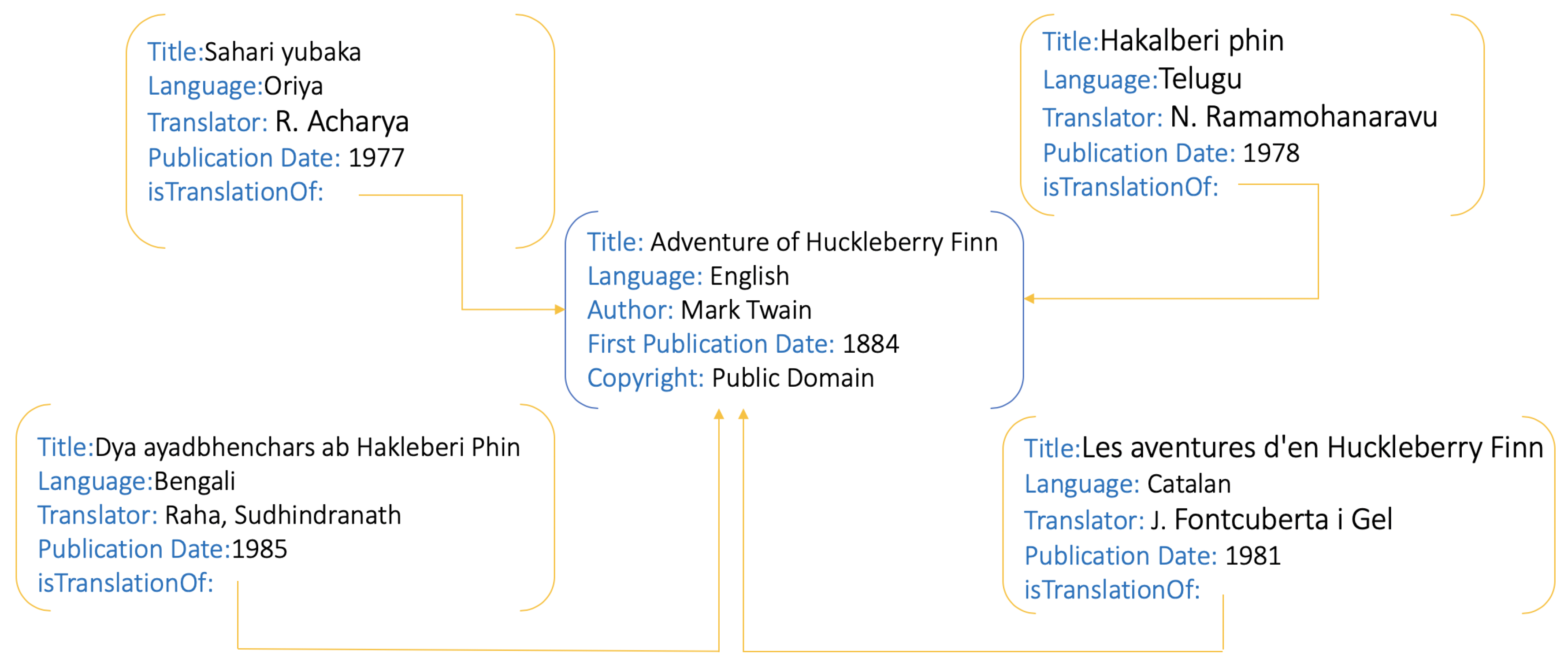
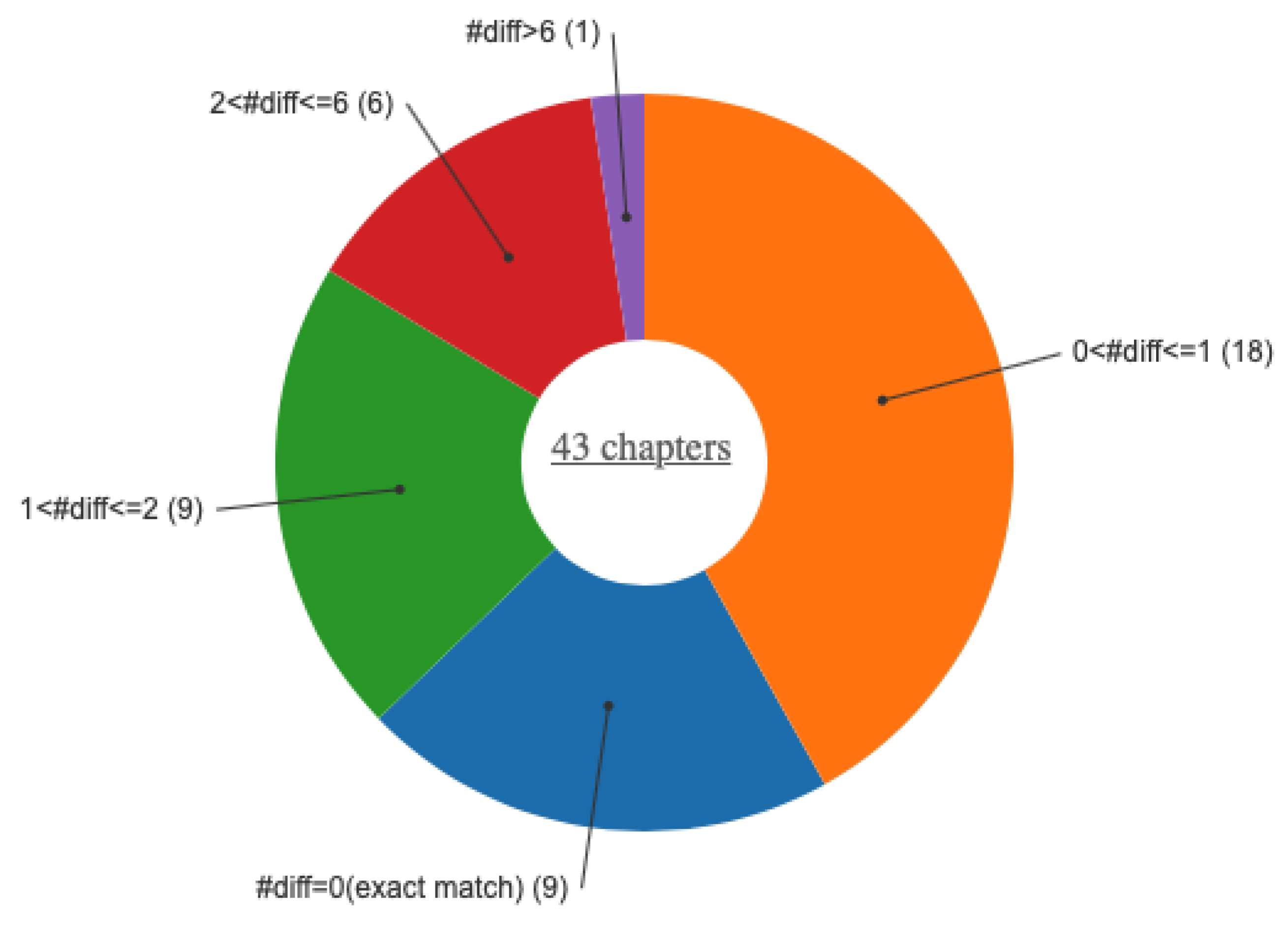
5.3. Data Alignment for Building Parallel Corpora
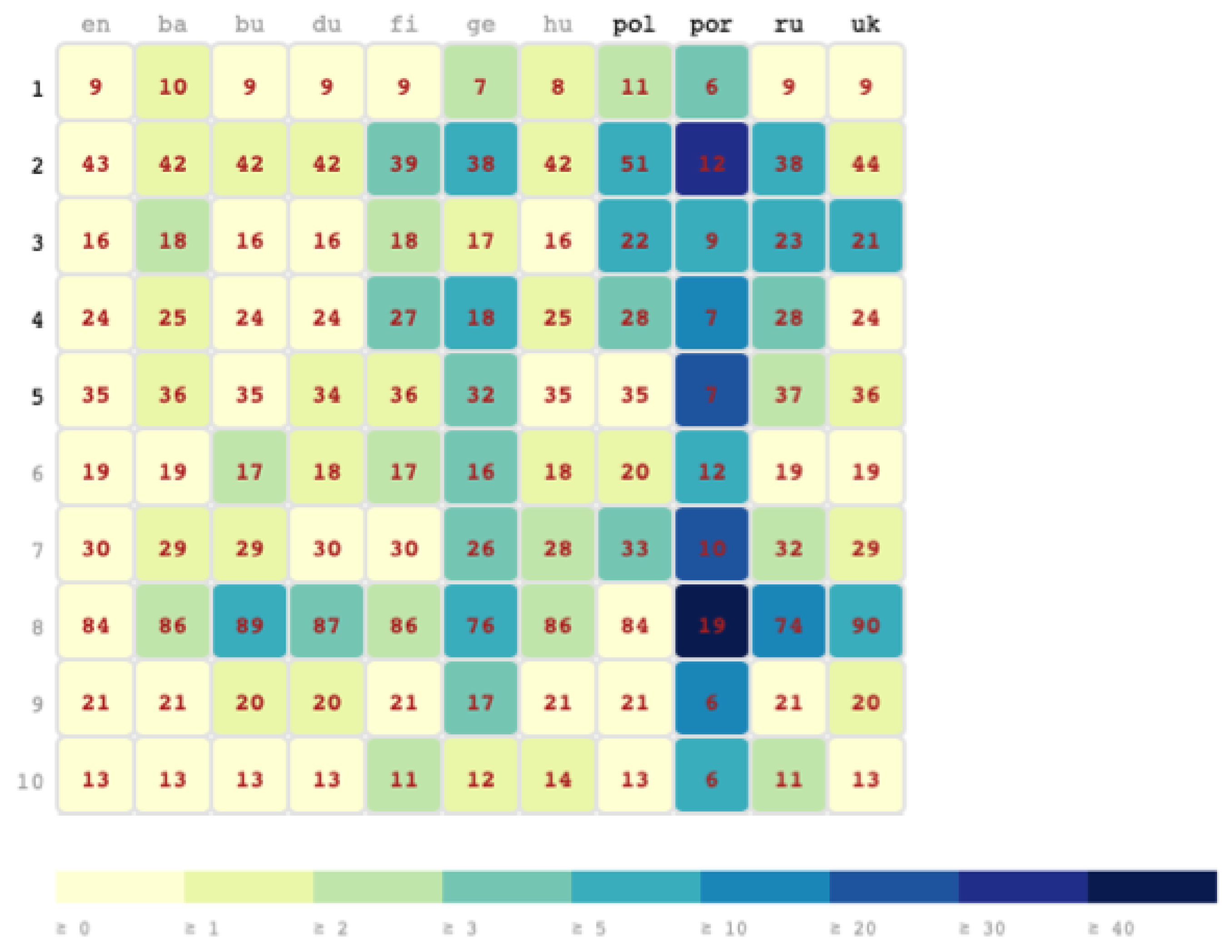
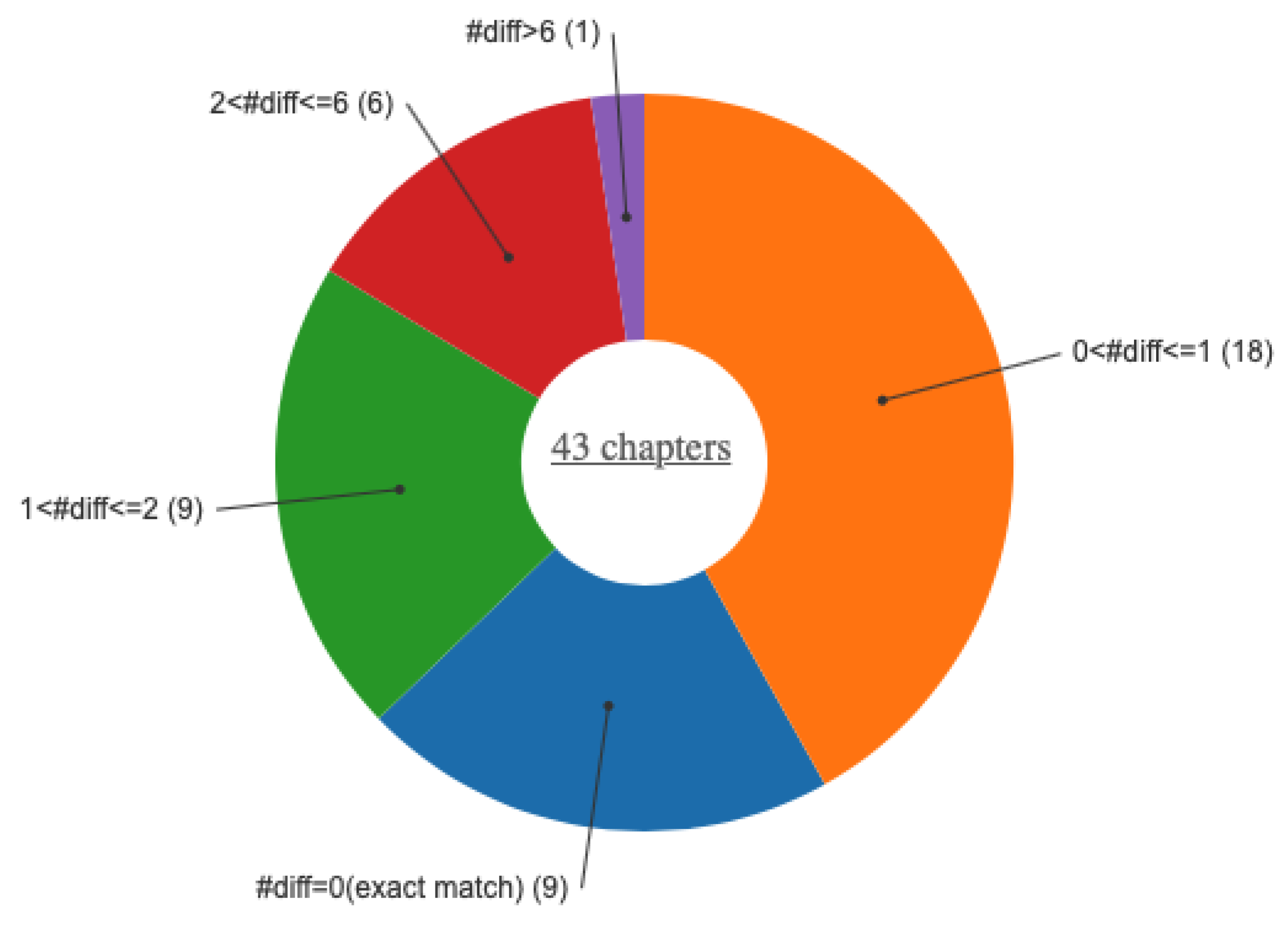
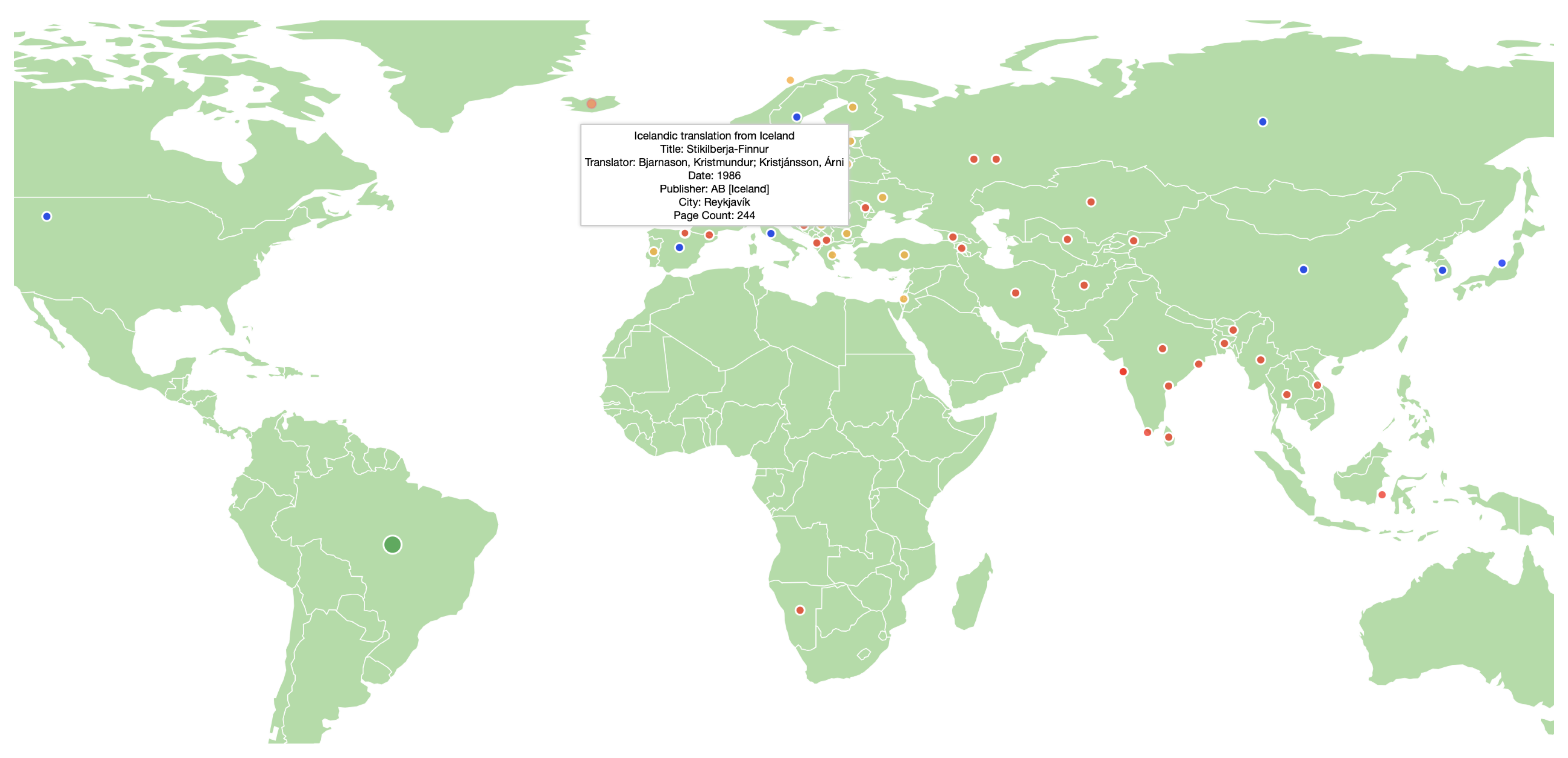
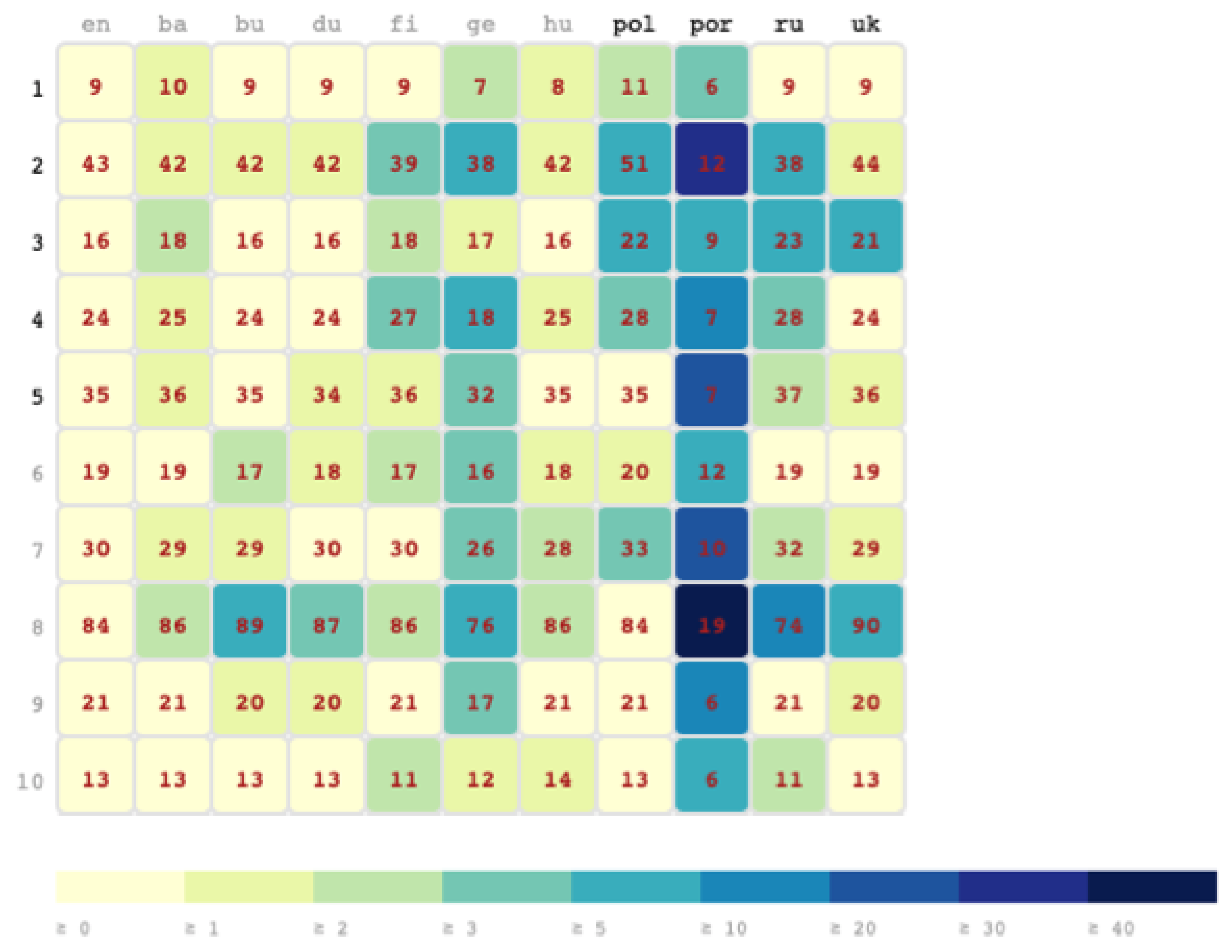
5.4. The Rosetta Dashboard for Fine-grained Knowledge Circulation Analysis
6. Materials and Methods
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Otlet, P. Traité de Documentation: Le livre sur le Livre: Théorie et Pratique; Mundaneum: Bruxelles, Belgium, 1934. [Google Scholar]
- Krauwer, S. The Basic Language Resource Kit (BLARK) as the First Milestone for the Language Resources Roadmap. In Proceedings of the International Workshop Speech and Computer, Moscow, Russia, 27–29 October 2003. [Google Scholar]
- Arppe, A.; Lachler, J.; Trosterud, T.; Antonsen, L.; Moshagen, S.N. Basic Language Resource Kits for Endangered Languages: A Case Study of Plains Cree. In Proceedings of the 2nd Workshop on Collaboration and Computing for Under-Resourced Languages Workshop (CCURL 2016), Portorož, Slovenia, 23 May 2016; pp. 1–8. [Google Scholar]
- Scannell, K. The Crubadan Project: Corpus building for under-resourced languages. In Building and Exploring Web Corpora: Proceedings of the 3rd Web as Corpus Workshop; University Press Leuven: Louvain-la-Neuve, Belgium, 2007; pp. 5–15. [Google Scholar]
- Fraisse, A.; Boitet, C.; Blanchon, H.; Bellynck, V. A Solution for in Context and Collaborative Localization of most Commercial and Free Software. In Proceedings of the 4th Language and Technology Conference (LTC 2009), Poznań, Poland, 6–8 November 2009; pp. 536–540. [Google Scholar]
- Fraisse, A.; Boitet, C.; Bellynck, V. An In Context and Collaborative Software Localisation Model. In Proceedings of the 24th International Conference on Computational Linguistics (COLING 2012), Mumbai, India, 8–15 December 2012; pp. 141–146. [Google Scholar]
- Roukos, S.; Graff, D.; Melamed, D. Hansard French/English; Linguistic Data Consortium: Philadelphia, PA, USA, 1995. [Google Scholar]
- Koehn, P. Europarl: A Parallel Corpus for Statistical Machine Translation. In Proceedings of the Tenth Machine Translation Summit, Phuket, Thailand, 12–16 September 2005; pp. 79–86. [Google Scholar]
- Ziemski, M.; Junczys-Dowmunt, M.; Pouliquen, B. The United Nations Parallel Corpus V1.0. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23–28 May 2016; pp. 3530–3534. [Google Scholar]
- Otlet, P. Monde: Essai d’universalisme: Connaissance du Monde, Sentiment du Monde, Action Organisée et Plan du Monde; Mundaneum: Brussels, Belgium, 1935. [Google Scholar]
- Rayward, W.B. The legacy of Paul Otlet, pioneer of information science. Aust. Libr. J. 1992, 41, 90–102. [Google Scholar] [CrossRef]
- Hudon, M. Multilingual Thesaurus Construction-Integrating the Views of Different Cultures in One Gateway to Knowledge and Concepts. Inf. Serv. Use 1997, 17, 11–123. [Google Scholar] [CrossRef]
- Hudon, M. Accessing Documents and Information in a World without Frontiers. Index 1999, 21, 156–159. [Google Scholar]
- Barát, Á.H. Knowledge Organization in the Cross-Cultural and Multicultural Society. Adv. Knowl. Org. 2008, 11, 91–97. [Google Scholar]
- Resnik, P.; Olsen, M.B.; Mona, D. The Bible as a Parallel Corpus: Annotating the ‘Book of 2000 Tongues’. Comput. Humanit. 1999, 33, 129–153. [Google Scholar] [CrossRef]
- Mayer, T.; Cysouw, M. Creating a Massively Parallel Bible Corpus. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, 26–31 May 2014; pp. 3158–3163. [Google Scholar]
- Christodouloupoulos, C.; Steedman, M. A massively parallel corpus: The Bible in 100 languages. Lang. Resour. Eval. 2015, 49, 375–395. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, N.; Jha, G.N. Creating Multilingual Parallel Corpora in Indian Languages. In Human Language Technology Challenges for Computer Science and Linguistics; Springer International Publishing: Cham, Germany, 2014; pp. 527–537. [Google Scholar]
- Jha, G.N. The TDIL Program and the Indian Language Corpora Initiative (ILCI). In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC 2010), Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Steinberger, R.; Pouliquen, B.; Widiger, A.; Ignat, C.; Erjavec, T.; Tufiş, D.; Varga, D. The JRC-Acquis: A multilingual aligned parallel corpus with 20+ languages. In Proceedings of the 5th International Conference on Language Resources and Evaluation, Genoa, Italy, 24–26 May 2006; pp. 2142–2147. [Google Scholar]
- Cysouw, M.; Walchli, B. Parallel texts: Using translational equivalents in linguistic typology. Sprachtypol. Univers. STUF 2007, 60, 95–99. [Google Scholar] [CrossRef]
- Druskat, S.; Gast, V.; Krause, T.; Zipser, F. corpus-tools. org: An Interoperable Generic Software Tool Set for Multi-layer Linguistic Corpora. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, 23–28 May 2016; pp. 4492–4499. [Google Scholar]
- Gilmanov, T.; Scrivner, O.; Kübler, S. SWIFT Aligner, A Multifunctional Tool for Parallel Corpora: Visualization, Word Alignment, and (Morpho)-Syntactic Cross-Language Transfer. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2014), Reykjavik, Iceland, 26–31 May 2014; pp. 2913–2919. [Google Scholar]
- Smith, N.; Jahr, M. Cairo: An Alignment Visualization Tool. In Proceedings of the Second International Conference on Language Resources and Evaluation (LREC 2000), Athens, Greece, 30 May–2 June 2000. [Google Scholar]
- Gomes, F.T.; Pardo, T.A.; de Medeiros Caseli, H. Visualtca: Uma ferramenta visual on-line para alinhamento sentencial de textos paralelos. In Proceedings of the Anais do XXVII Congresso da Sociedade Brasileira de Computação-V Workshop em Tecnologia da Informação e da Linguagem Humana (TIL), Rio de Janeiro, 5–6 July 2007; pp. 1729–1732. [Google Scholar]
- Fleury, S.; Zimina, M. Exploring Translation Corpora with MkAlign. Available online: https://www.researchgate.net/profile/Maria_Zimina5/publication/49135660_Exploring_Translation_Corpora_with_MkAlign/links/5baa93ab299bf13e604c87eb/Exploring-Translation-Corpora-with-MkAlign.pdf (accessed on 20 September 2019).
- Teets, M.; Goldner, M. Libraries’ Role in Curating and Exposing Big Data. Future Int. 2013, 5, 429–438. [Google Scholar] [CrossRef]
- Cassin, B.; Ducimetière, N. Les Routes de la traduction. Babel à Genève; Gallimard: Paris, France, 2017. [Google Scholar]
- Fishkin, S.F. DEEP MAPS: A Brief for Digital Palimpsest Mapping Projects (DPMPs) or ‘Deep Maps’. Available online: https://escholarship.org/uc/item/92v100t0 (accessed on 20 September 2019).
- Rodney, R.M. Mark Twain International: A Bibliography and Interpretation of His Wordwide Popularity; Greenwood Press: Westport, CT, USA, 1982. [Google Scholar]
- Twain, M. Adventures of Huckleberry Finn; Charles, L., Ed.; Webster and Company: Hartford, CT, USA, 1885. [Google Scholar]
- Fraisse, A.; Jenn, R.; Fishkin, S.F. Parallel Corpora for Under-Resourced Languages Using Translated Fictional Texts. In Proceedings of the LREC 2018 Workshop CCURL2018—Sustaining Knowledge Diversity in the Digital Age, Miyazaki, Japan, 7–12 May 2018; pp. 39–43. [Google Scholar]
- Gale, W.A.; Church, K.W. A Program for Aligning Sentences in Bilingual Corpora. Comput. Linguist. 1993, 19, 75–102. [Google Scholar]
- Brown, P.F.; Pietra, V.J.D.; Pietra, S.A.D.; Mercer, R.L. The Mathematics of Statistical Machine Translation: Parameter Estimation. Comput. Linguist. 1993, 19, 263–311. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Languages | |||
|---|---|---|---|
| 1. Afrikans | 17. Estonian | 33. Korean | 49. Slovak |
| 2. Albanian | 18. Farsi | 34. Latvian | 50. Slovenian |
| 3. Arabic | 19. Finnish | 35. Lithuanian | 51. Spanish |
| 4. Armenian | 20. French | 36. Macedonian | 52. Swedish |
| 5. Assamese | 21. Georgian | 37. Malay | 53. Tamil |
| 6. Basque | 22. German | 38. Malayalam | 54. Tatar |
| 7. Bengali | 23. Greek | 39. Marathi | 55. Telugu |
| 8. Bulgarian | 24. Hebrew | 40. Moldovan | 56. Thai |
| 9. Burmese | 25. Hindi | 41. Norwegian | 57. Turkish |
| 10. Catalan | 26. Hungarian | 42. Oriya | 58. Turkmen |
| 11. Chinese | 27. Icelandic | 43. Polish | 59. Ukrainian |
| 12. Chuvash | 28. Indonesian | 44. Portuguese | 60. Uzbech |
| 13. Croatian | 29. Italian | 45. Romanian | 61. Vietnamese |
| 14. Czech | 30. Japanese | 46. Russian | 62. Yiddish |
| 15. Danish | 31. Kazakh | 47. Serbian | |
| 16. Dutch | 32. Kirghiz | 48. Sinhalese | |
| Language | Under Resourced | Metadata Collected by | Full-Text Collected by | ||||
|---|---|---|---|---|---|---|---|
| Web Crawling | Volunteers/ Experts | Crowdsourcing | Web Crawling | Volunteers/ Experts | Crowdsourcing | ||
| 1. Albanian | * | ||||||
| 2. Armenian | * | ||||||
| 3. Assamese | * | * | |||||
| 4. Burmese | * | * | |||||
| 5. Chuvash | * | * | |||||
| 6. Estonian | * | ||||||
| 7. Farsi | * | * | |||||
| 8. Greek | * | ||||||
| 9. Hindi | * | * | |||||
| 10. Icelandic | * | ||||||
| 11. Indonesian | * | * | |||||
| 12. Kazakh | * | * | |||||
| 13. Kirghiz | * | * | |||||
| 14. Korean | * | ||||||
| 15. Latvian | * | ||||||
| 16. Lithuanian | * | ||||||
| 17. Macedonian | * | ||||||
| 18. Malay | * | ||||||
| 19. Malayalam | * | * | |||||
| 20. Marathi | * | * | |||||
| 21. Moldovan | * | * | |||||
| 22. Oriya | * | * | |||||
| 23. Serbian | * | ||||||
| 24. Sinhalese | * | * | |||||
| 25. Slovak | * | ||||||
| 26. Slovenian | * | ||||||
| 27. Tamil | * | * | |||||
| 28. Tatar | * | * | |||||
| 29. Telugu | * | * | |||||
| 30. Thai | * | ||||||
| 31. Turkmen | * | * | |||||
| 32. Uzbech | * | * | |||||
| 33. Afrikans | * | * | |||||
| 34. Chinese | * | * | |||||
| 35. Georgian | * | * | |||||
| 36. Hebrew | * | * | |||||
| 37. Japanese | * | * | |||||
| 38. Vietnamese | * | * | |||||
| 39. Yiddish | * | * | * | ||||
| 40. Arabic | * | * | |||||
| 41. Bengali | * | * | * | ||||
| 42. Catalan | * | * | * | ||||
| 43. Croatian | * | * | |||||
| 44. Czech | * | * | |||||
| 45. Danish | * | * | |||||
| 46. Dutch | * | * | |||||
| 47. Finnish | * | * | |||||
| 48. Hungarian | * | * | |||||
| 49. Norwegian | * | * | |||||
| 50. Polish | * | * | |||||
| 51. Portuguese | * | * | |||||
| 52. Romanian | * | * | |||||
| 53. Russian | * | * | |||||
| 54. Spanish | * | * | |||||
| 55. Swedish | * | * | |||||
| 56. Turkish | * | * | |||||
| 57. Ukrainian | * | * | |||||
| 58. Basque | * | * | * | ||||
| 59. Bulgarian | * | * | |||||
| 60. French | * | * | |||||
| 61. German | * | * | |||||
| 62. Italian | * | * | |||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fraisse, A.; Zhang, Z.; Zhai, A.; Jenn, R.; Fisher Fishkin, S.; Zweigenbaum, P.; Favier, L.; Mustafa El Hadi, W. A Sustainable and Open Access Knowledge Organization Model to Preserve Cultural Heritage and Language Diversity. Information 2019, 10, 303. https://doi.org/10.3390/info10100303
Fraisse A, Zhang Z, Zhai A, Jenn R, Fisher Fishkin S, Zweigenbaum P, Favier L, Mustafa El Hadi W. A Sustainable and Open Access Knowledge Organization Model to Preserve Cultural Heritage and Language Diversity. Information. 2019; 10(10):303. https://doi.org/10.3390/info10100303
Chicago/Turabian StyleFraisse, Amel, Zheng Zhang, Alex Zhai, Ronald Jenn, Shelley Fisher Fishkin, Pierre Zweigenbaum, Laurence Favier, and Widad Mustafa El Hadi. 2019. "A Sustainable and Open Access Knowledge Organization Model to Preserve Cultural Heritage and Language Diversity" Information 10, no. 10: 303. https://doi.org/10.3390/info10100303
APA StyleFraisse, A., Zhang, Z., Zhai, A., Jenn, R., Fisher Fishkin, S., Zweigenbaum, P., Favier, L., & Mustafa El Hadi, W. (2019). A Sustainable and Open Access Knowledge Organization Model to Preserve Cultural Heritage and Language Diversity. Information, 10(10), 303. https://doi.org/10.3390/info10100303