MSSN: An Attribute-Aware Transmission Algorithm Exploiting Node Similarity for Opportunistic Social Networks

Abstract
1. Introduction
- By effectively collecting node information, the message applications can accurately assess the comprehensive similarity (social and mobile similarity) between neighbor nodes and destination nodes and determine the special transmission relationship between them.
- Through setting a mobile similarity threshold, we can narrow down the screening range of reliable relay nodes, thereby make the next calculation of node social similarity more accurate and obtain more suitable relay nodes.
- To take the social attributes of neighbor nodes and destination nodes as the main analysis basis, an effective data transmission strategy based on node socialization is proposed. Message carriers can obtain more reliable relay nodes.
- In light of the simulation results in the Opportunistic Networking Environment (ONE), the performance of the MSSN algorithm is better than other algorithms in the aspects of the delivery ratio, network overhead, and end-to-end data transmission delay.
2. Related Works
2.1. The Existing Algorithms Based on Mobility Attributes for Opportunistic Social Networks
2.2. The Existing Algorithms Based on Social Attributes for Opportunistic Social Networks
3. System Model Design
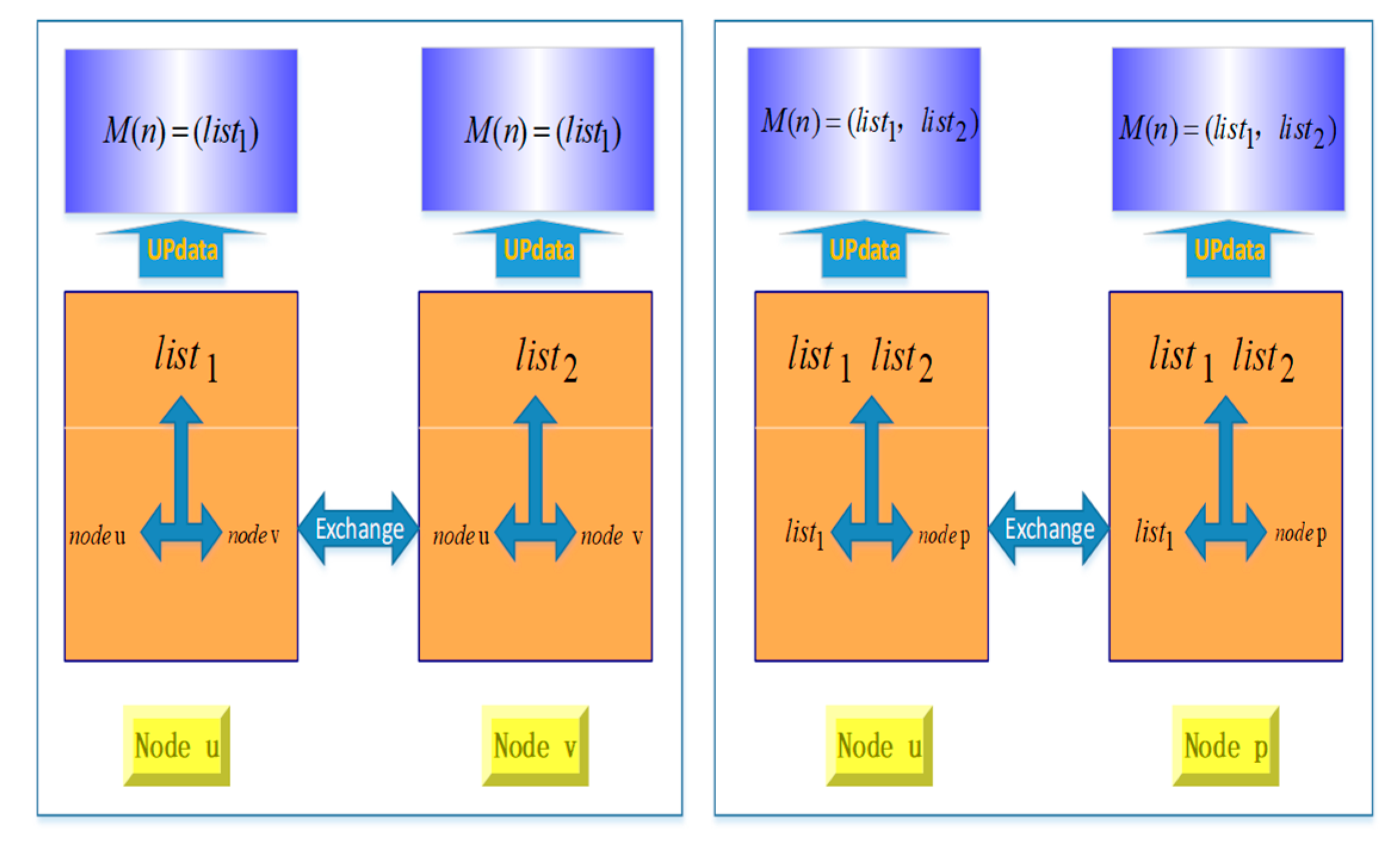
3.1. Collecting Information about Nodes in Network
3.1.1. Defining and Collecting Information about Mobile Nodes
3.1.2. Information Updating between Mobile Nodes
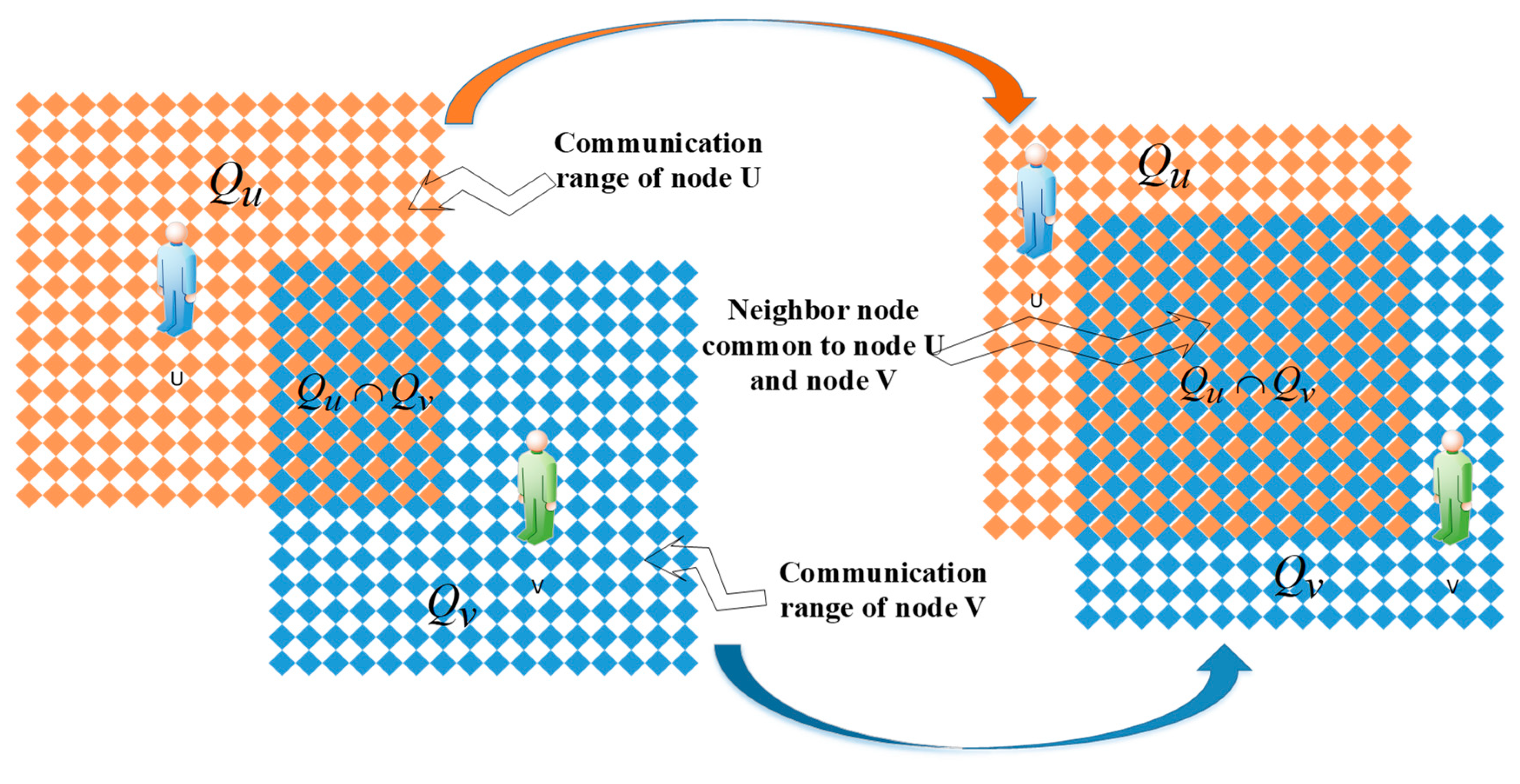
3.2. Calculating Mobile Similarity of Node and Narrowing the Node Range by a Single Threshold
3.2.1. Computation of the Mobile between Nodes
3.2.2. Reducing Node Range by Setting Threshold
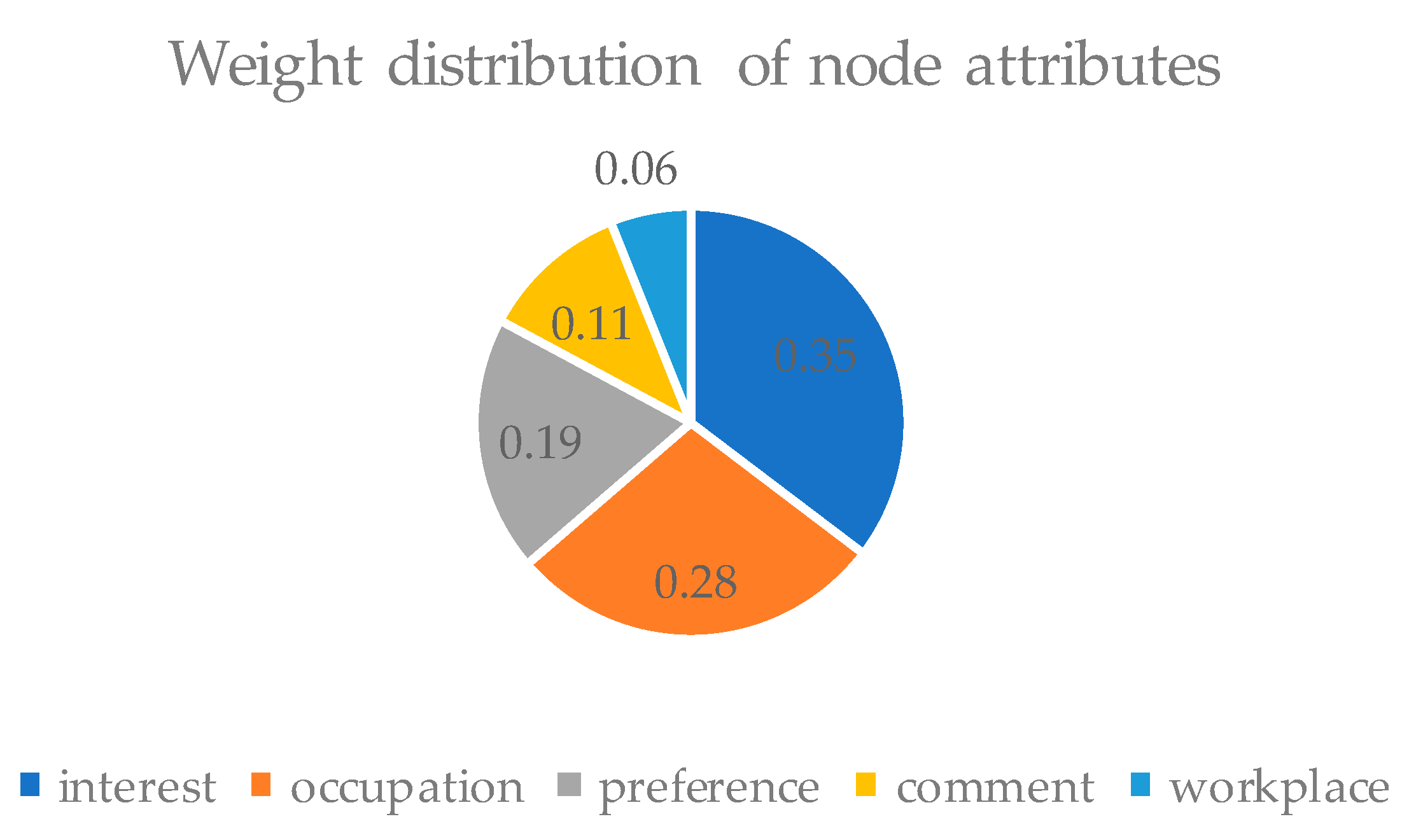
3.3. Calculating the Social Similarity between Mobile Nodes in the Networks
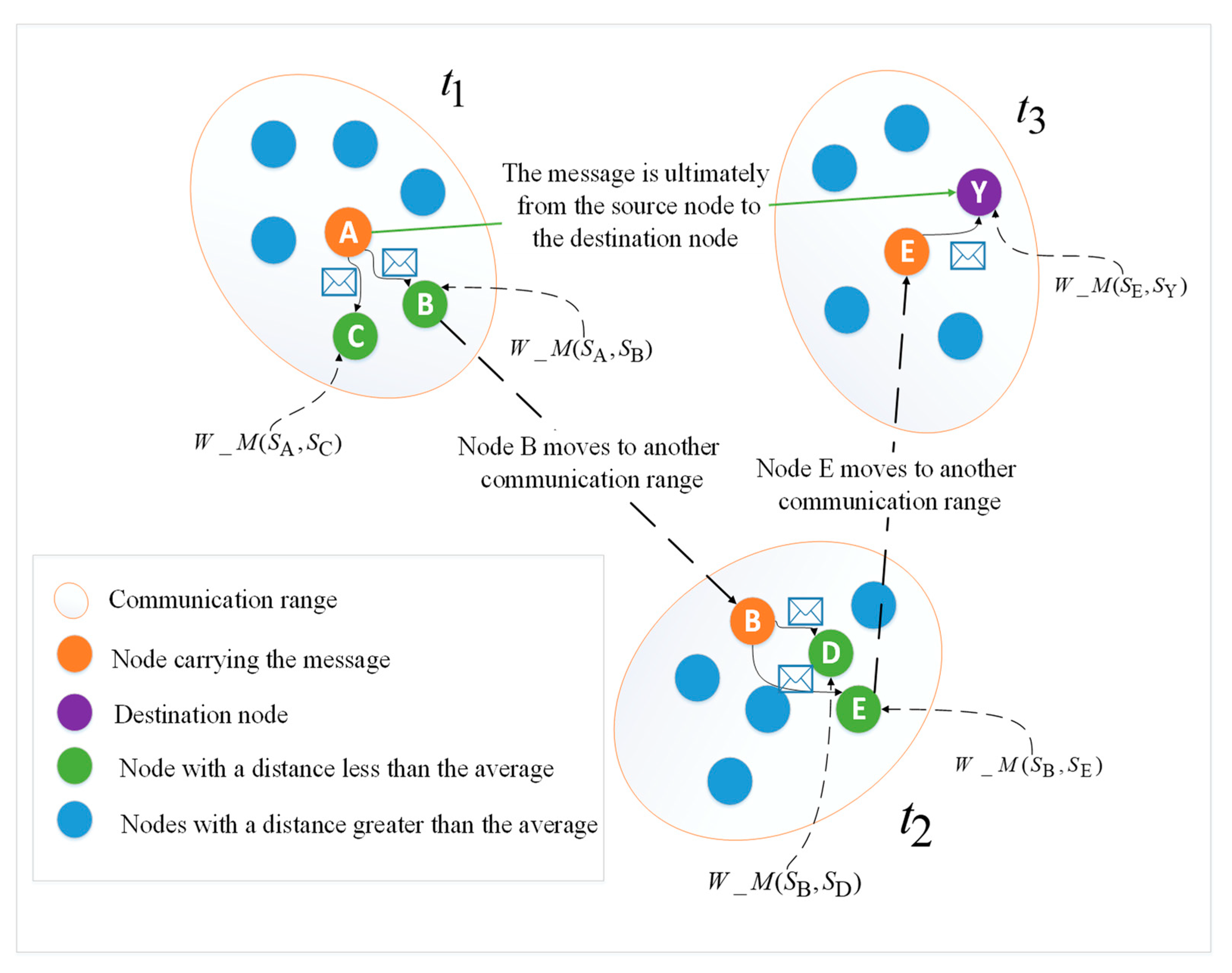
3.4. Message Forwarding Strategy in Social Opportunity Networks
3.5. Complexity Analysis of this Algorithm
- In the information gathering stage of the algorithm, we build a sequence of information by preparing the data information collection and update in the previous stage, which contains the data information needed later. In order to provide accurate and timely data, our information sequence needs to be constantly integrated integration.
- Secondly, based on the collected information sequence, the mobile node’s mobile similarity is calculated by the neighbor nodes of the node and the movement trajectory of the node. Then, the node range is reduced by a single threshold, leaving nodes with similar similarity and deleting nodes with similar similarity.
- In the algorithm, we calculate the distance between social attributes by the Minkowski distance and VDM distance in the clustering algorithm. According to the larger the distance, the smaller the similarity between social attributes, mark each node.
- Finally, we take the appropriate relay node by the average method, calculate the average value by the distance of the social attribute, and take the node below the average value as the relay node. The purpose of this is that the message is not easy to be lost. Through this mechanism, the security and continuity of the message transmission of the opportunistic social networks is guaranteed.
| Algorithm: MSSN. |
| Input: Message carrier and its neighbor nodes sequence And the encounter matrix of each node |
| Output: the relay node |
| Begin |
| Node classification: |
| For (; ; ) |
| If ( and meet); |
| Collect and update matrix ; |
| End for |
| Matrix gets a complete update, obtaining the relationship matrix of all nodes and the corresponding number of nodes: |
| For (i = 1; i < = n; i++) |
| Calculating the mobile similarity of nodes: |
| ; |
| If () then |
| Reserve the node L; |
| Else |
| Delete the node D; |
| End for |
| For (i = 1; i < = n; i++) |
| Calculating the social attribute distance of the remaining nodes |
| End for |
| Calculate the average of the distances between all nodes: ; |
| For (i = 1; i < = n; i++) |
| If (<) then |
| Output relay node |
| End for |
| Forwarding messages: |
| synthesizes all the calculation results to obtain the reliable relay node ; |
| forwards the messages to ; |
| End |
4. Experiment and analysis
4.1. Simulation Parameters and Simulation Process
4.2. Simulation Result Analysis
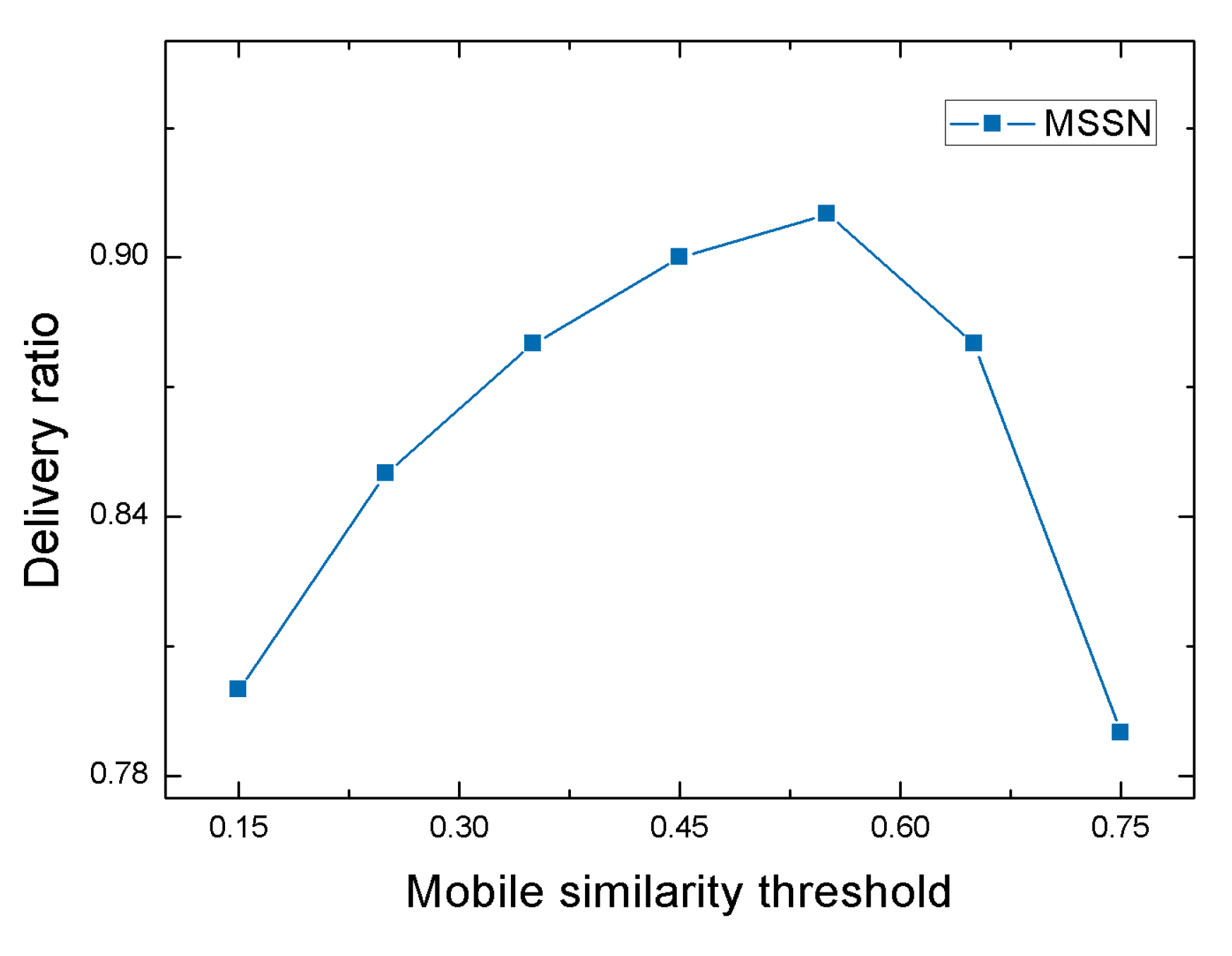
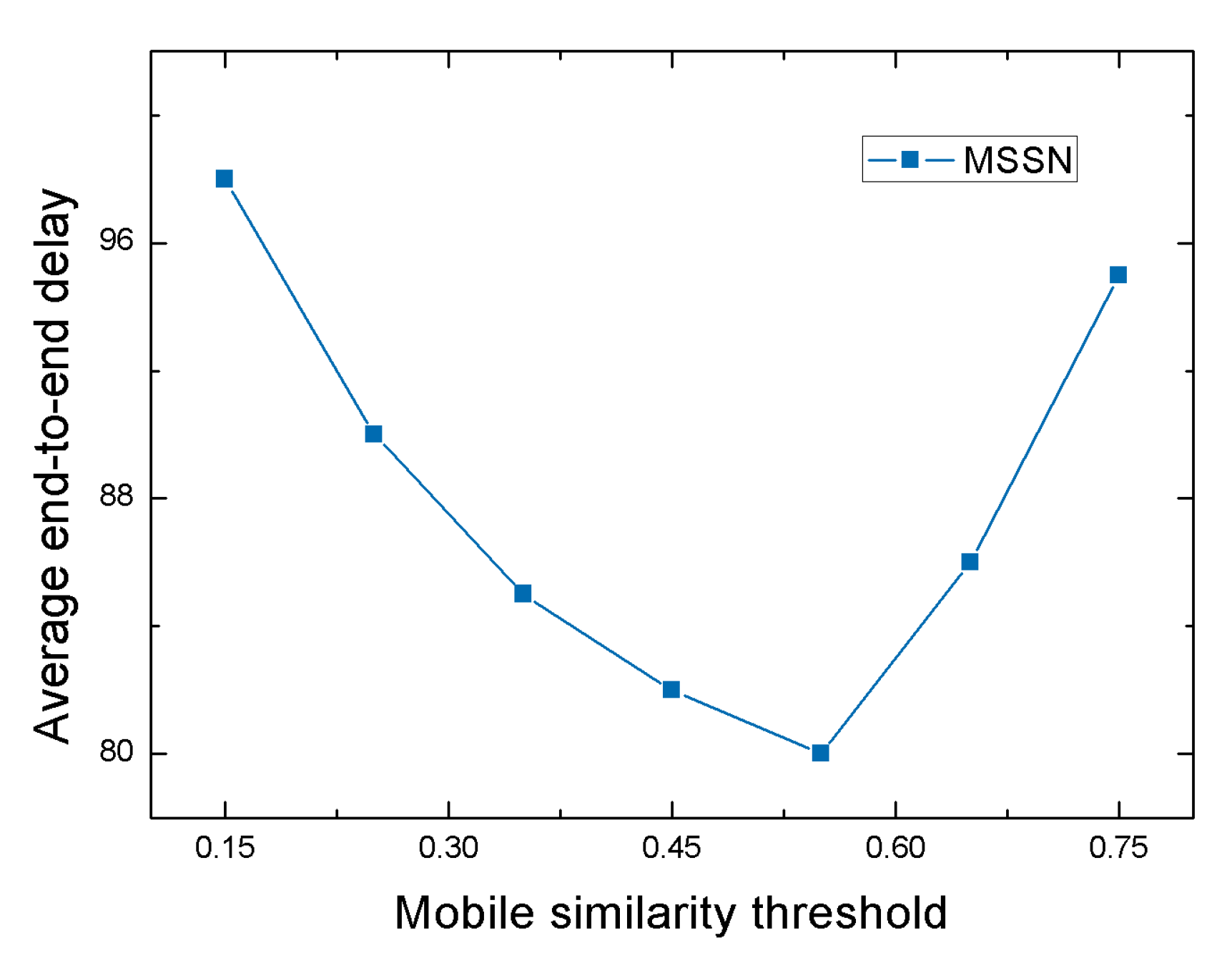
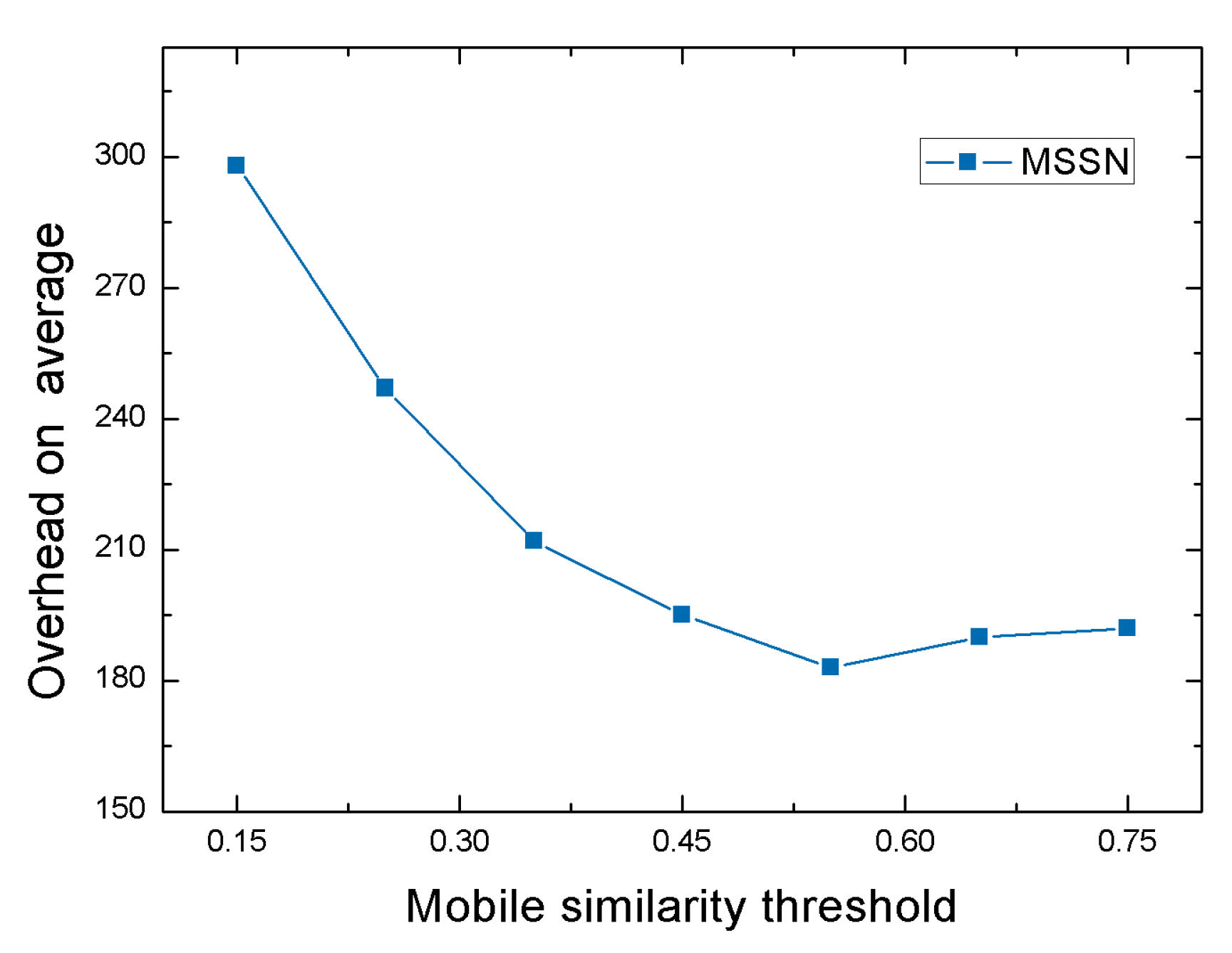
4.2.1. Performance of MSSN Algorithm under Different Mobile Similarity Thresholds
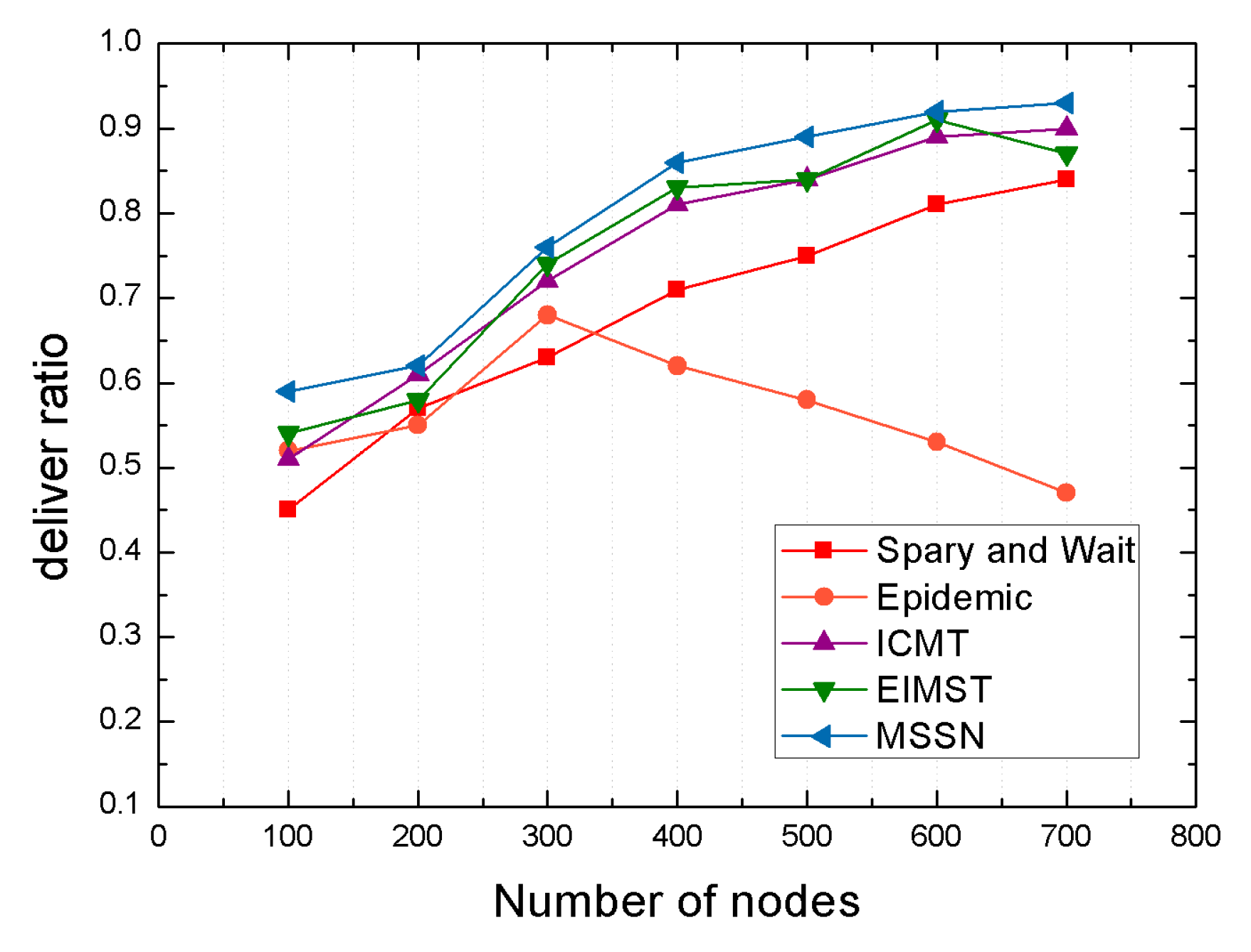
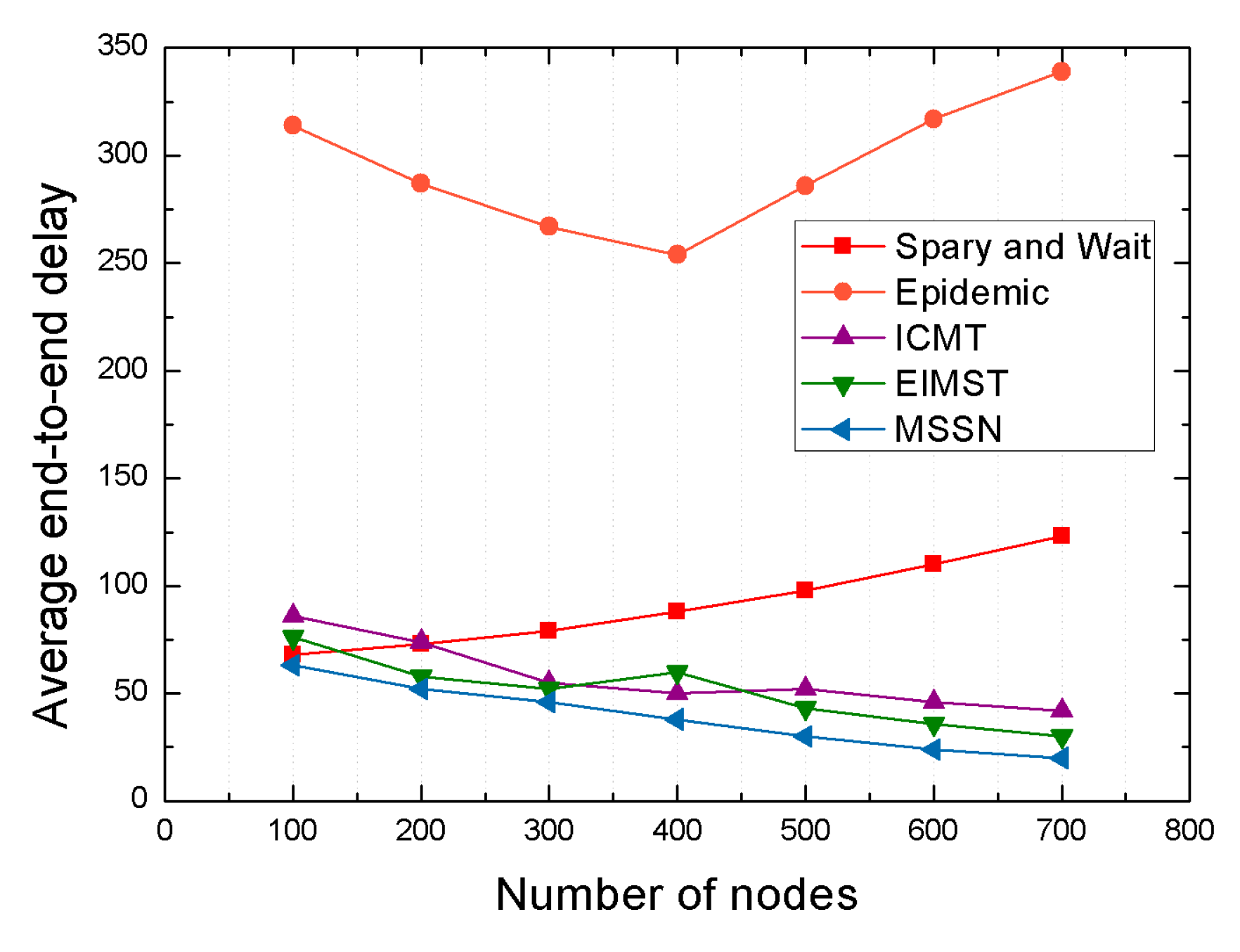
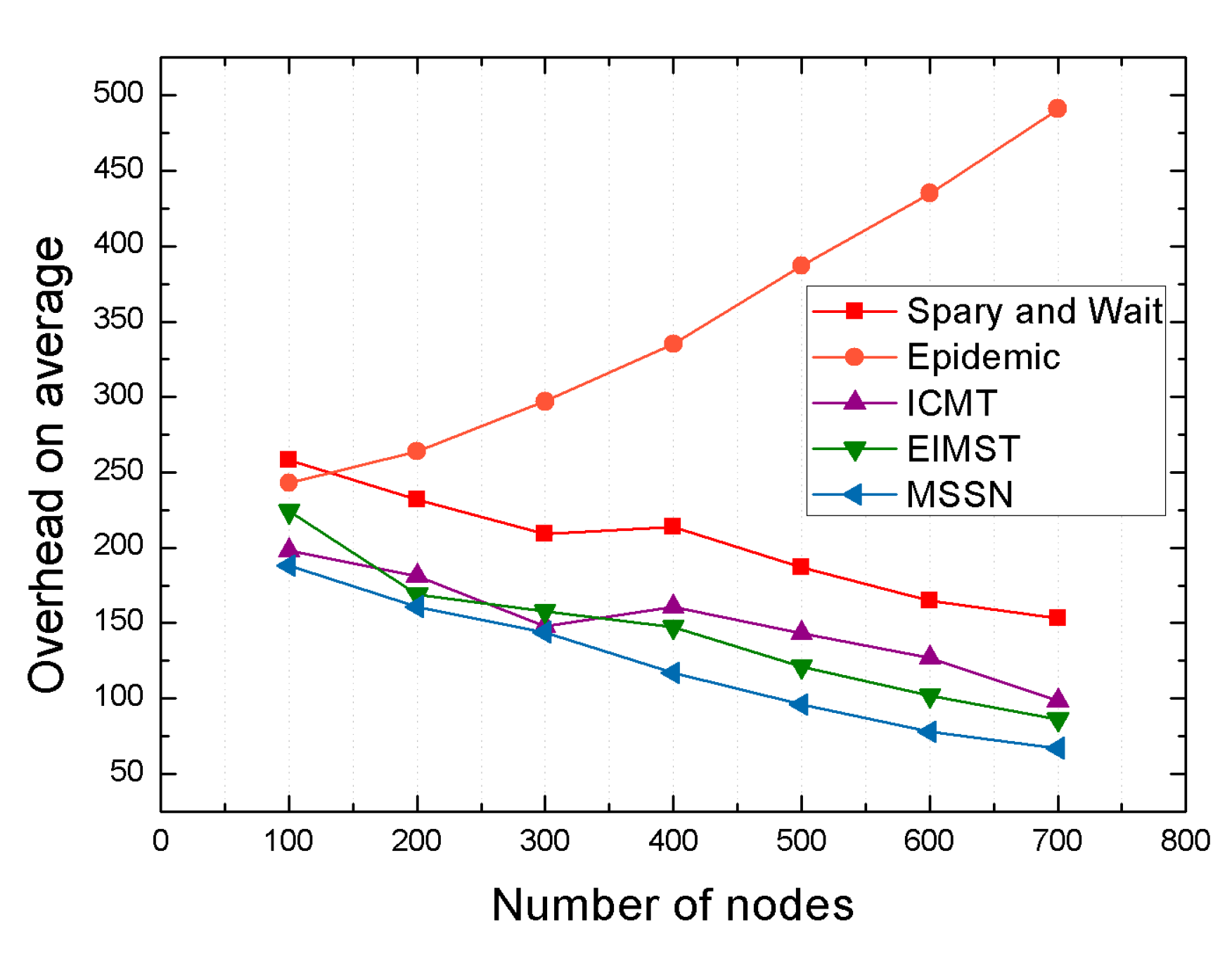
4.2.2. Comparison Result Analysis between Algorithms under Different Number of Nodes
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Conti, M.; Giordano, S. Mobile Ad Hoc Networking: Milestones, Challenges, and New Research Directions. Commun. Mag. IEEE 2014, 52, 85–96. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, L.; Lu, Y. Do you get tired of socializing? An empirical explanation of discontinuous usage behaviour in social network services. Inf. Manag. 2016, 53, 904–914. [Google Scholar] [CrossRef] [PubMed]
- Wu, D.; Zhang, F.; Wang, H. Security-oriented opportunistic data forwarding in Mobile Social Networks. Future Gener. Comput. Syst. 2018, 87, 803–815. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Chen, Z.; Wu, J.; Xiao, Y.; Zhang, H. Predict and Forward: An Efficient Routing-Delivery Scheme Based on Node Profile in Opportunistic Networks. Future Int. 2018, 10, 74. [Google Scholar] [CrossRef]
- Liu, K.; Chen, Z.; Wu, J.; Wang, L. FCNS: A fuzzy routing-forwarding algorithm exploiting comprehensive node similarity in opportunistic social networks. Symmetry Basel 2018, 10, 338. [Google Scholar] [CrossRef]
- Kimura, T.; Matsuda, T.; Takine, T. Location-Aware Store-Carry-Forward Routing Based on Node Density Estimation. IEICE Trans. Commun. 2015, 98, 99–106. [Google Scholar] [CrossRef]
- Kimura, T.; Muraguchi, M. Buffer management policy based on message rarity for store-carry-forward routing. In Proceedings of the 2017 23rd Asia-Pacific Conference on Communications (APCC), Perth, WA, Australia, 11–13 December 2017; pp. 1–6. [Google Scholar]
- Peng, Y.; Guo, L.; Deng, Q.X. A Novel Hybrid Routing Forwarding Algorithm in SDN Enabled Wireless Mesh Networks. In Proceedings of the IEEE International Conference on High Performance Computing and Communications, New York, NY, USA, 24–26 August 2015; pp. 1806–1811. [Google Scholar]
- Ge, X.; Ye, J.; Yang, Y. User Mobility Evaluation for 5G Small Cell Networks Based on Individual Mobility Model. IEEE J. Sel. Areas Commun. 2016, 34, 528–541. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, Y.; Riguidel, M. Security and trust management in opportunistic networks: A survey. Secur. Commun. Netw. 2015, 8, 1812–1827. [Google Scholar] [CrossRef]
- Liu, K. Big Medical Data Decision-Making Intelligent System Exploiting Fuzzy Inference Logic for Prostate Cancer in Developing Countries. IEEE Access 2019, 7, 2348–2363. [Google Scholar] [CrossRef]
- Mumtaz, S.; Al-Dulaimi, A.; Frascolla, V. Guest Editorial Special Issue on 5G and Beyond—Mobile Technologies and Applications for IoT. IEEE Int. Things J. 2019, 6, 203–206. [Google Scholar] [CrossRef]
- Han, Q.; Liang, S.; Zhang, H. Mobile cloud sensing, big data, and 5G networks make an intelligent and smart world. IEEE Netw. 2015, 29, 40–45. [Google Scholar] [CrossRef]
- Han, S.; Xu, S.; Meng, W. An Agile Confidential Transmission Strategy Combining Big Data Driven Cluster and OBF. IEEE Trans. Veh. Technol. 2017, 66, 10259–10270. [Google Scholar] [CrossRef]
- Trifunovic, S.; Kouyoumdjieva, S.T.; Distl, B. A Decade of Research in Opportunistic Networks: Challenges, Relevance, and Future Directions. IEEE Commun. Mag. 2017, 55, 168–173. [Google Scholar] [CrossRef]
- Ke, C.K.; Chen, Y.L.; Chang, Y.C. Opportunistic large array concentric routing algorithms with relay nodes for wireless sensor networks. Comput. Electr. Eng. 2016, 56, 350–365. [Google Scholar] [CrossRef] [PubMed]
- Elsherief, M.; Alipour, B.; Qathrady, M.A. A novel mathematical framework for similarity-based opportunistic social networks. Perv. Mobile Comput. 2017, 42, 134–150. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Man, Y.; Huang, Z. Secure Routing based on Social Similarity in Opportunistic Networks. IEEE Trans. Wirel. Commun. 2015, 15, 594–605. [Google Scholar] [CrossRef]
- Gong, N.Z.; Talwalkar, A.; Mackey, L. Joint Link Prediction and Attribute Inference Using a Social-Attribute Network. ACM Trans. Int. Syst. Technol. 2014, 5, 1–20. [Google Scholar] [CrossRef]
- Jia, W.; Chen, Z.; Ming, Z. Information cache management and data transmission algorithm in opportunistic social networks. Wirel. Netw. 2019, 25, 2977–2988. [Google Scholar]
- Jiang, N.; Guo, L.; Li, J. Data Dissemination Protocols Based on Opportunistic Sharing for Data Offloading in Mobile Social Networks. In Proceedings of the.2016 IEEE International Conference on Parallel & Distributed Systems, Wuhan, China, 13–16 December 2016; pp. 705–712. [Google Scholar]
- Ying, B.D.; Xu, K.; Nayak, A. Fair and Social-Aware Message Forwarding Method in Opportunistic Social Networks. In Proceedings of IEEE Commun Lett. 2019, 23, 720–723. [Google Scholar] [CrossRef]
- Jia, W.; Chen, Z.; Ming, Z. SECM: Status estimation and cache management algorithm in opportunistic networks. J. Supercomput. 2019, 75, 2629–2647. [Google Scholar]
- Lin, C.J.; Chen, C.W.; Chou, C.F. Preference-aware content dissemination in opportunistic mobile social networks. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 1960–1968. [Google Scholar]
- Boldrini, C.; Conti, M.; Passarella, A. Design and performance evaluation of ContentPlace, a social-aware data dissemination system for opportunistic networks. Comput. Netw. 2010, 54, 589–604. [Google Scholar] [CrossRef]
- Conti, M.; Mordacchini, M.; Passarella, A. A Semantic-Based Algorithm for Data Dissemination in Opportunistic Networks. In Revised Selected Papers of Ifip Tc 6 International Workshop on Self-Organizing Systems; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Woungang, I.; Dhurandher, S.; Singh, J.; Borah, S. Energy Aware Routing for Efficient Green Communication in Opportunistic Networks. IET Netw. 2019, 8, 272–279. [Google Scholar] [CrossRef]
- Liaqat, H.B.; Ali, A.; Qadir, J. Socially-aware congestion control in ad-hoc networks: Current status and the way forward. Future Gener. Comput. Syst. 2019, 97, 634–660. [Google Scholar] [CrossRef]
- Mordacchini, M.; Passarella, A.; Conti, M. A social cognitive heuristic for adaptive data dissemination in mobile Opportunistic Networks. Pervasive Mobile Comput. 2017, 42, 371–392. [Google Scholar] [CrossRef] [PubMed]
- Borrego, C.; Joan, B.; Sergi, R. Efficient broadcast in opportunistic networks using optimal stopping theory. Ad Hoc Netw. 2019, 88, 5–17. [Google Scholar] [CrossRef]
- Yu, G.; Chen, Z.G.; Wu, J. Quantitative social relations based on trust routing algorithm in opportunistic social network. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 83. [Google Scholar] [CrossRef]
- Souza, C.; Mota, E.; Soares, D.; Manzoni, P.; Cano, J.C.; Calafate, C.T.; Hernández-Orallo, E. FSF: Applying Machine Learning Techniques to Data Forwarding in Socially Selfish Opportunistic Networks. Sensors 2019, 19, 2374. [Google Scholar] [CrossRef]
- Zhao, Y.; Song, W.; Han, Z. Social-Aware Data Dissemination via Device-to-Device Communications: Fusing Social and Mobile Networks with Incentive Constraints. IEEE Trans. Serv. Comput. 1939, 1. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, H.; Ma, J. Social-aware data dissemination in opportunistic mobile social networks. Int. J. Mod. Phys. C 2017, 28, 1750115. [Google Scholar] [CrossRef]
- Huang, W.; Zhang, S.; Zhou, W. Spray and Wait Routing Based on Position Prediction in Opportunistic Networks. In Proceedings of the 2011 3rd International Conference on Computer Research & Development, Shanghai, China, 11–13 March 2011; pp. 232–236. [Google Scholar]
- Halikul, L.; Mohamad, A. EpSoc: Social-Based Epidemic-Based Routing Protocol in Opportunistic Mobile Social Network. Mob. Inf. Sys. 2018, 2018, 1–8. [Google Scholar]
- Jia, W.U.; Chen, Z.; Zhao, M. Effective information transmission based on socialization nodes in opportunistic networks. Comput. Netw. 2017, 129, 129–297. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Attributes | Classes | Nodes |
|---|---|---|---|
| Infocom5 | 6 | 2 | 3276 |
| Infocom6 | 6 | 2 | 680 |
| Cambridge | 6 | 2 | 2310 |
| Intel | 6 | 2 | 837 |
| Simulation Environment | Description |
|---|---|
| Simulator | Opportunistic Network Environment (ONE) |
| Mobility model | MGMM |
| Communication area (m2) | 450000 |
| Total simulation time (h) | 2–6 |
| Number of nodes | 100, 200, 300,400, 500,600,700 |
| Cache space of a node (Mb) | 30 |
| Speech of a node (m/s) | 1–20 |
| Initial energy for a node (J) | 100 |
| Number of social attributes | 6 |
| Mobile similarity threshold | = 0.15 = 0.25 = 0.35 = 0.45 = 0.55 = 0.65 = 0.75 |
| Metric | Spray and Wait | Epidemic | ICMT | EIMST |
|---|---|---|---|---|
| Delivery ratio | 15% | 60% | 7% | 6% |
| Average end-to-end delay | 90% | 75% | 67% | 50% |
| Average network overhead | 68% | 44% | 24% | 13% |
| Metric | Average Confidence Level | Average Confidence Interval |
|---|---|---|
| Delivery ratio | 0.85 | 0.4–0.95 |
| Average end-to-end delay | 0.92 | 0–65 |
| Average network overhead | 0.95 | 25–200 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, M.; Xiao, M. MSSN: An Attribute-Aware Transmission Algorithm Exploiting Node Similarity for Opportunistic Social Networks. Information 2019, 10, 299. https://doi.org/10.3390/info10100299
Guo M, Xiao M. MSSN: An Attribute-Aware Transmission Algorithm Exploiting Node Similarity for Opportunistic Social Networks. Information. 2019; 10(10):299. https://doi.org/10.3390/info10100299
Chicago/Turabian StyleGuo, Mei, and Min Xiao. 2019. "MSSN: An Attribute-Aware Transmission Algorithm Exploiting Node Similarity for Opportunistic Social Networks" Information 10, no. 10: 299. https://doi.org/10.3390/info10100299
APA StyleGuo, M., & Xiao, M. (2019). MSSN: An Attribute-Aware Transmission Algorithm Exploiting Node Similarity for Opportunistic Social Networks. Information, 10(10), 299. https://doi.org/10.3390/info10100299