Three-Dimensional Path Tracking Control of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning


Abstract
1. Introduction
- (1)
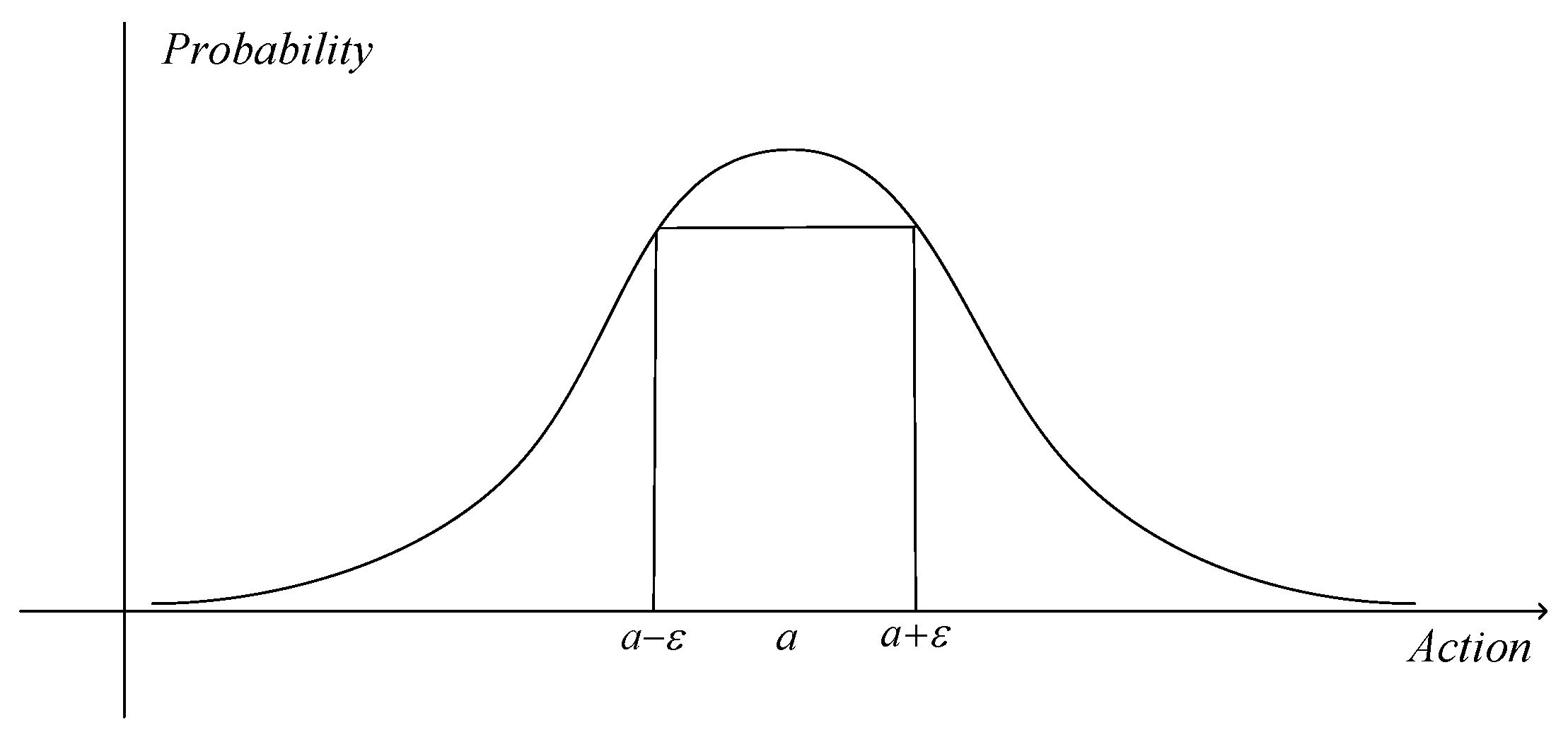
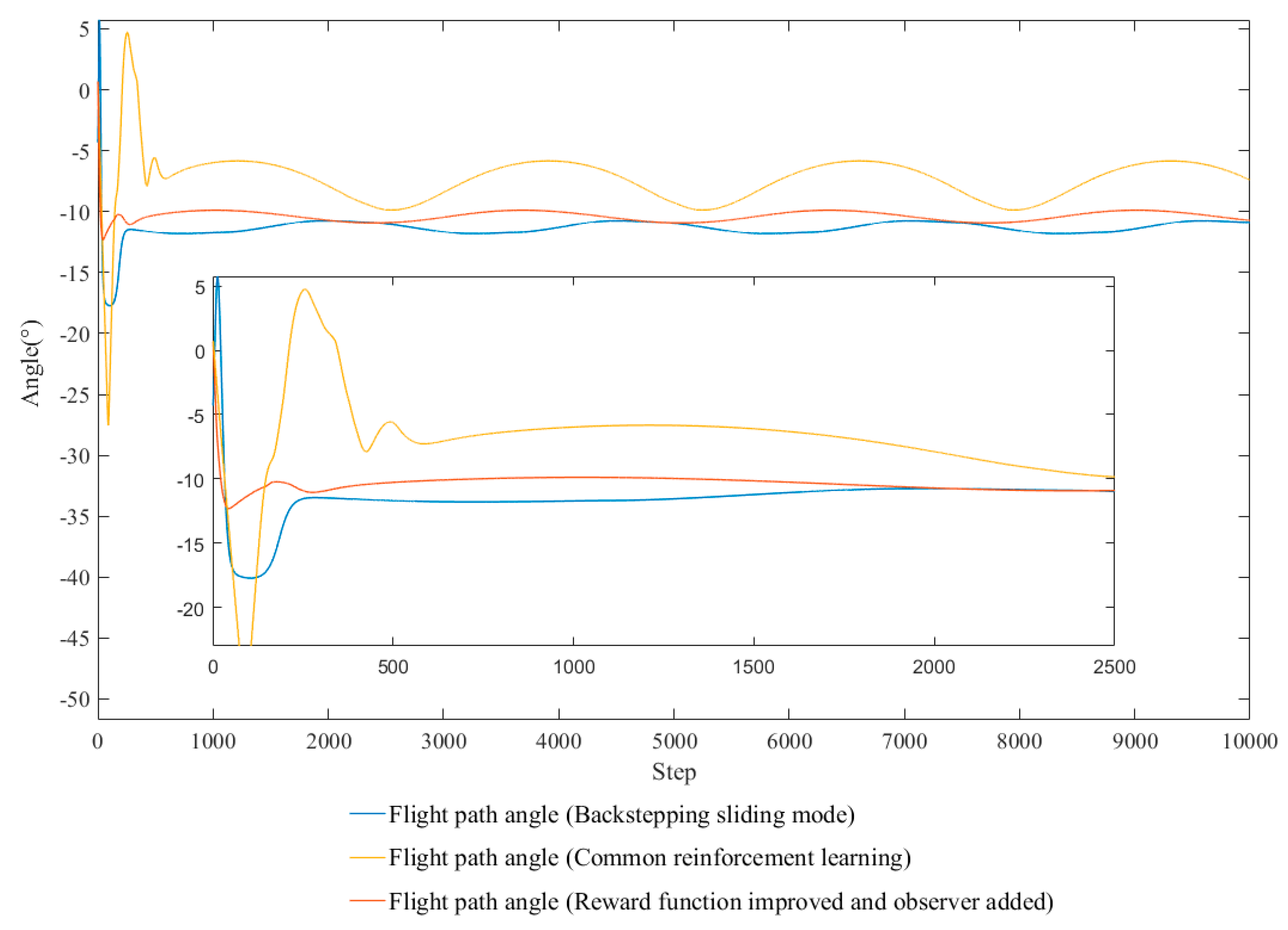
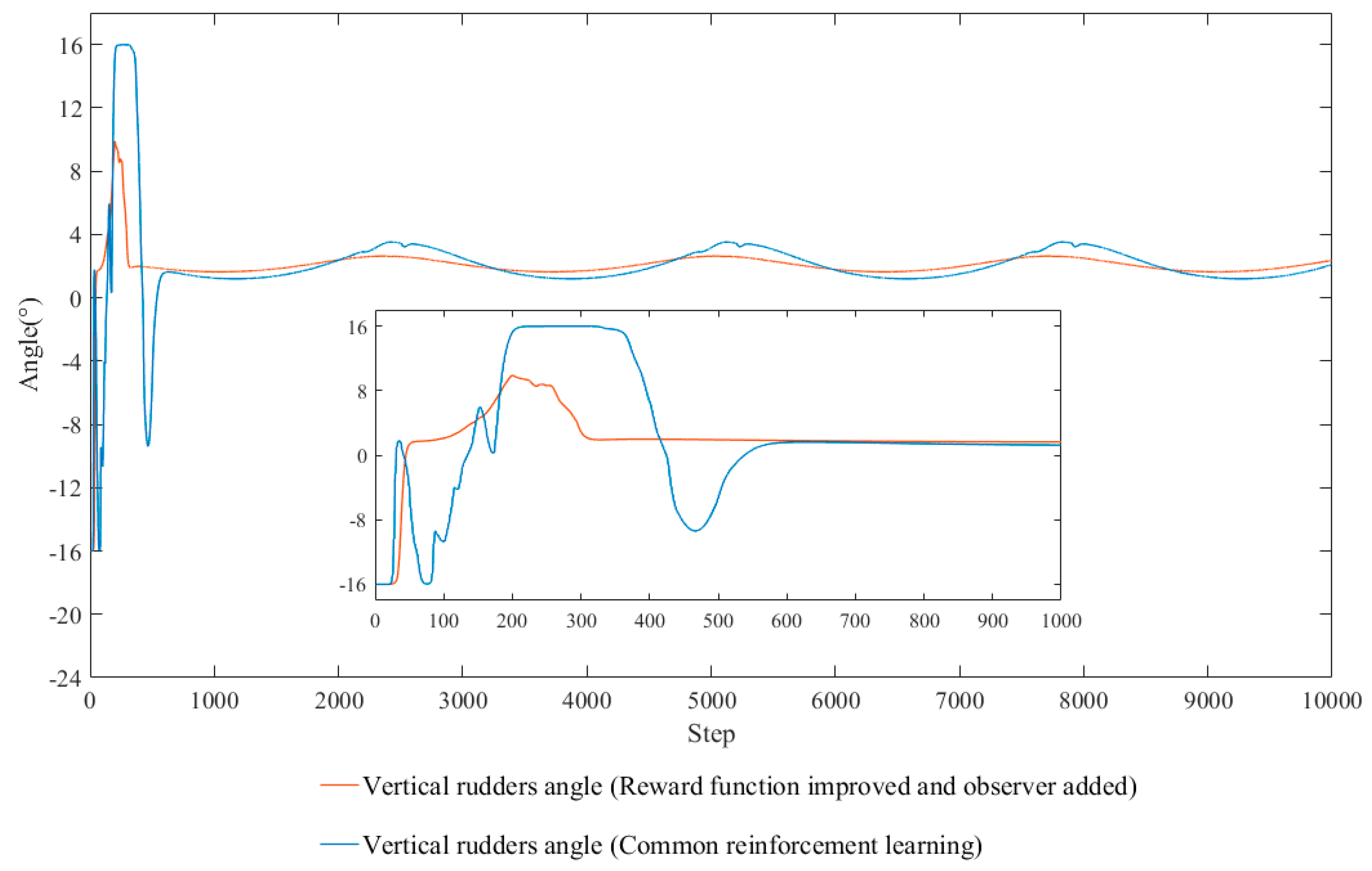
- Rational optimization methods for reward function are studied. The rudders angle and their rate of change are used to form a second-order Gaussian function, which is a part of reward function. The steering frequency is successfully reduced, as the tracking performance was not affected.
- (2)
- As for the ocean currents disturbance, a current disturbance observer is added to perceive currents and optimize the output. The observer provides the capacity of anti-current and improves the tracking performance.
- (3)
- A boundary reward function is proposed to provide additional rewards when the AUV arrives at specific positions and maintains a correct angle, which improves the stability of path tracking.
- (4)
- Combined with the improved line-of-sight method, the DDPG controller is designed. The guiding method using virtual AUV is researched and long-term stable path tracking is carried out successfully.
2. Modeling and Theory
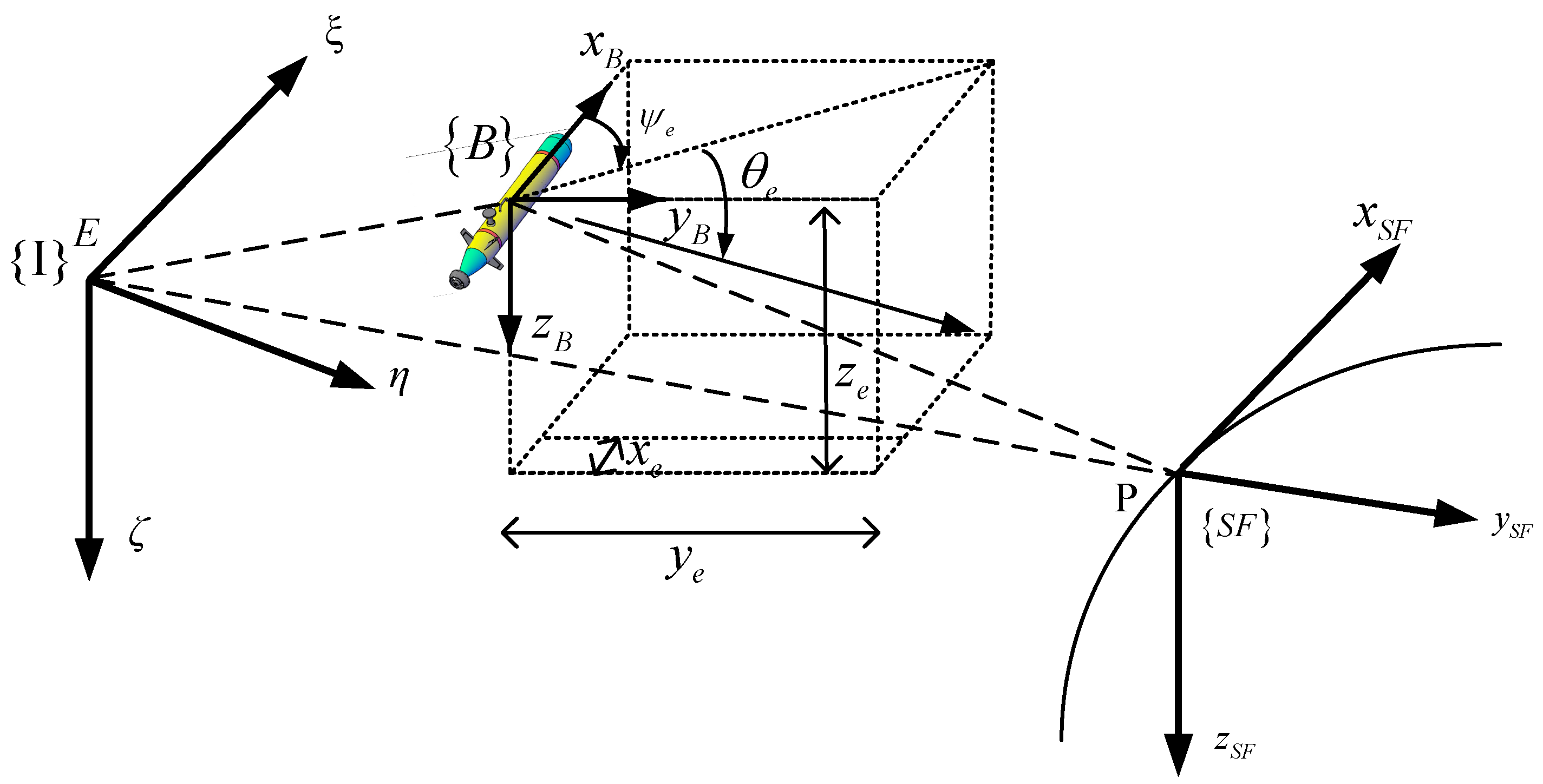
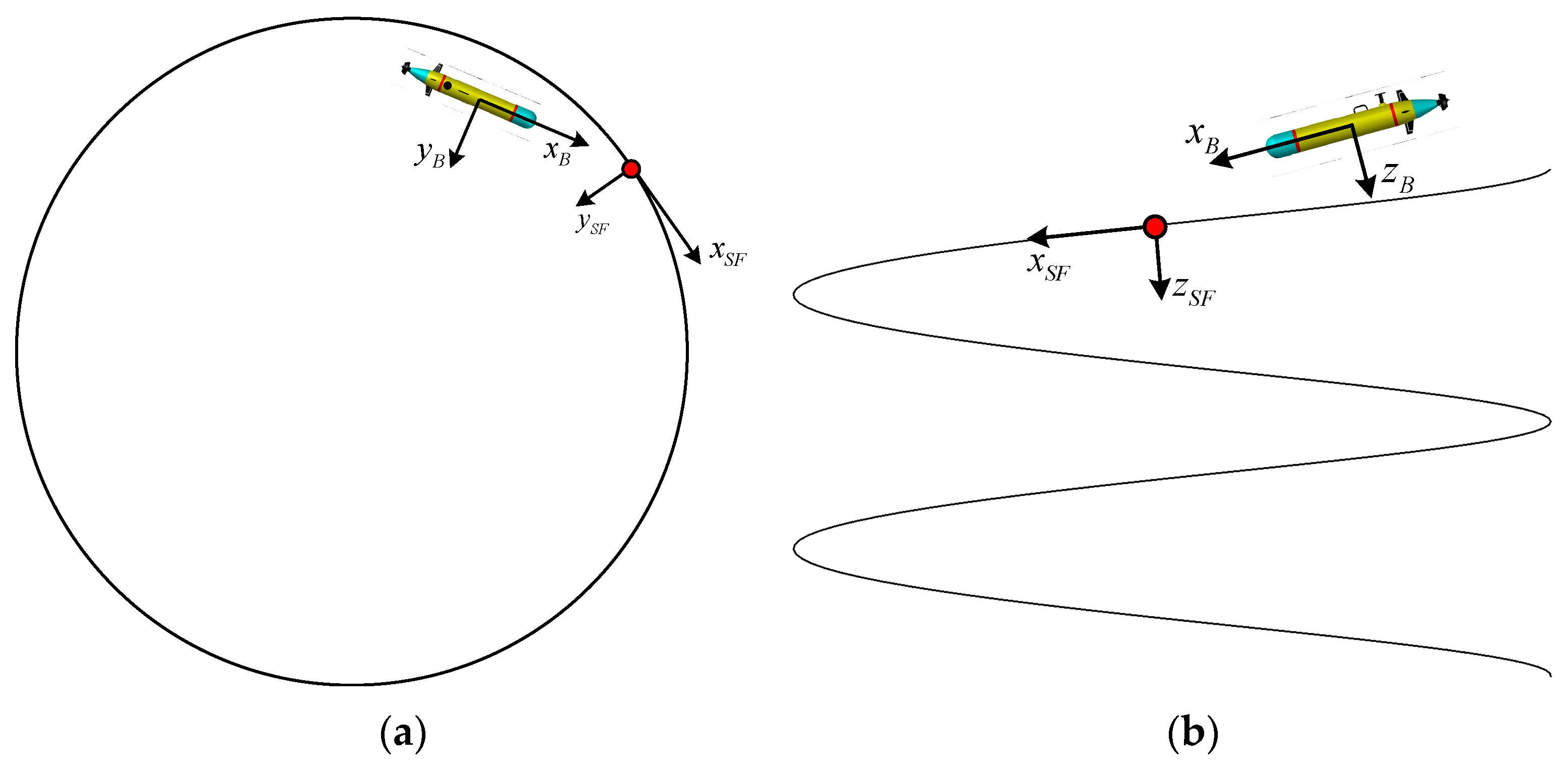
2.1. Coordinate System and Parameter Definition
2.2. AUV Model
- : Actual vertical rudders angle.
- : Actual horizontal rudders angle.
- : Time constants of steering engines.
2.3. Deep Reinforcement Learning Theory
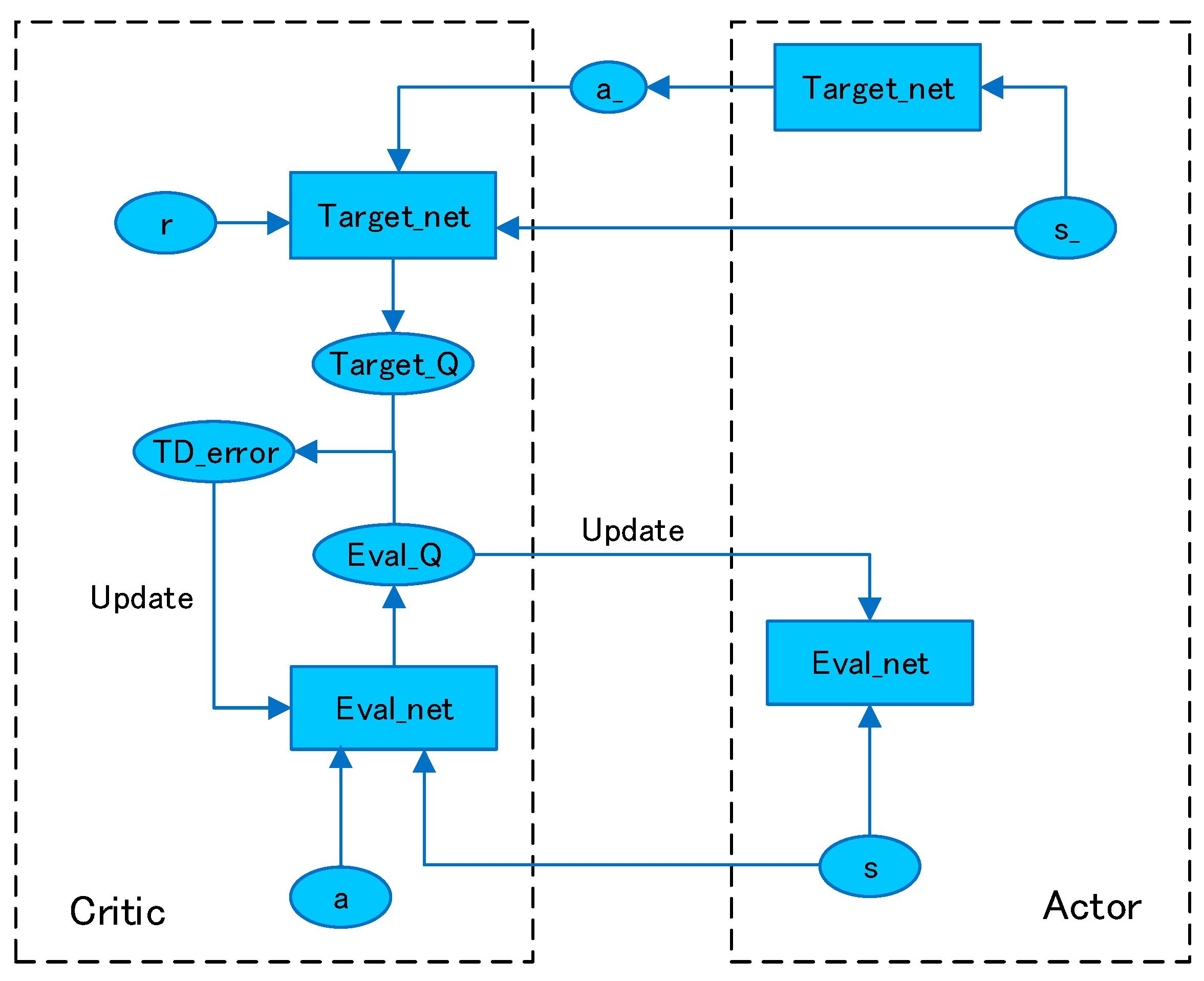
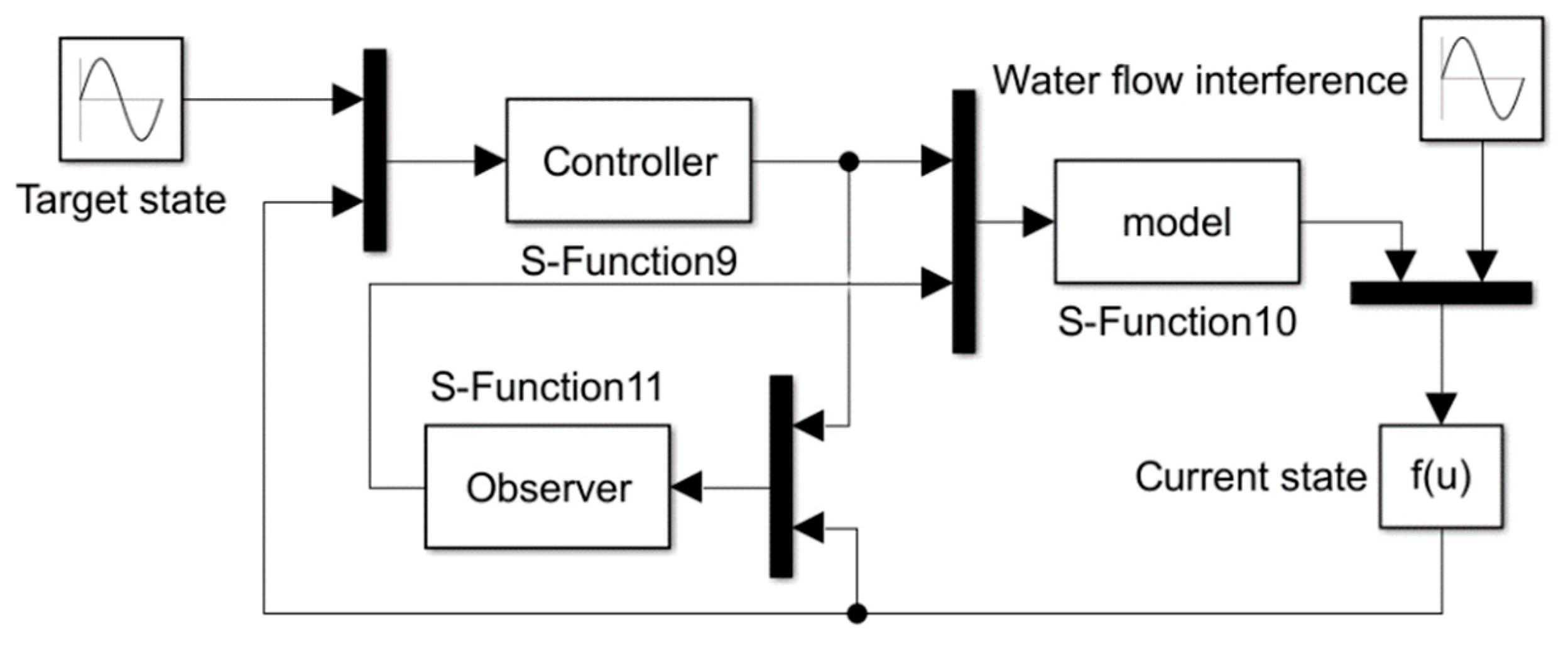
3. Tracking Control Method and Deep Deterministic Policy Gradient Algorithm
- (1)
- (2)
- (3)
- (4)
- s: Current state
- s_: State of the next moment
- a: Current action
- a_: Next action
- r: Reward
- Target_Q: The target value calculated by the next state_s, the estimated value of the predicted action a_, and the reward value.
- Eval_Q: The current value obtained by importing the current state and current action into Eval_net.
- TD_error: The difference between target_q and eval_q, which is used to backpropagate to approach the parameters.
4. Simulation and Improvement
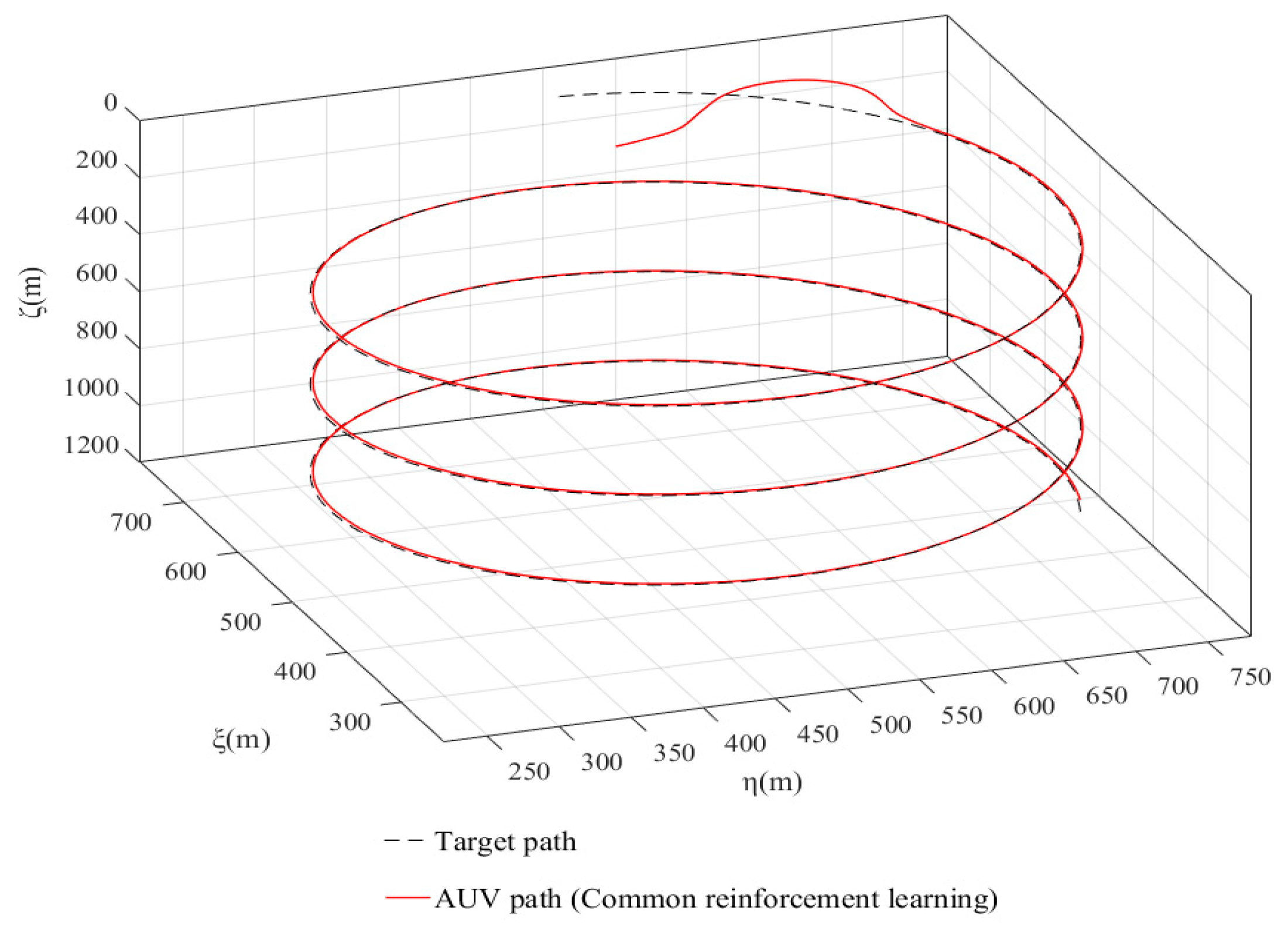
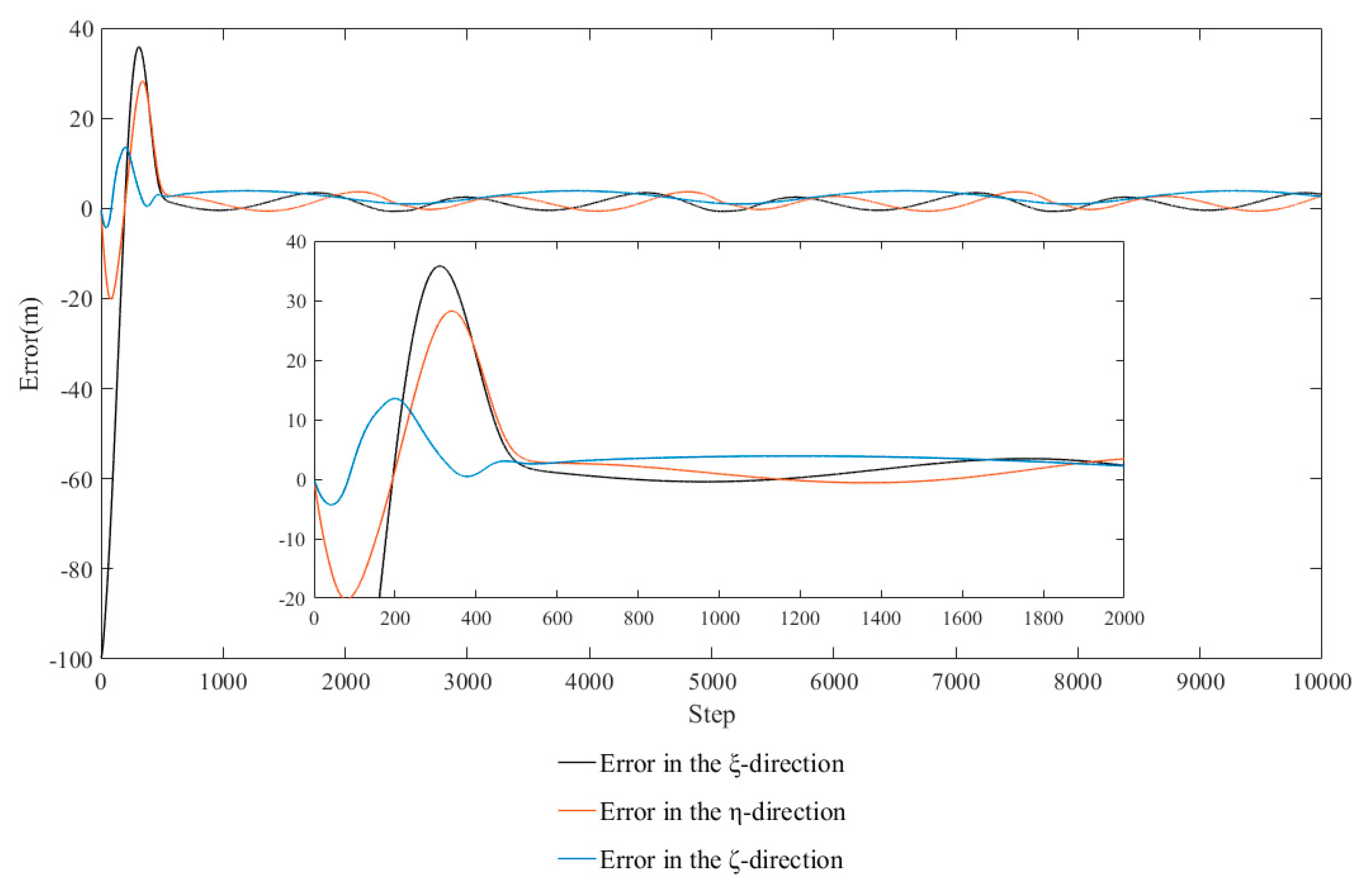
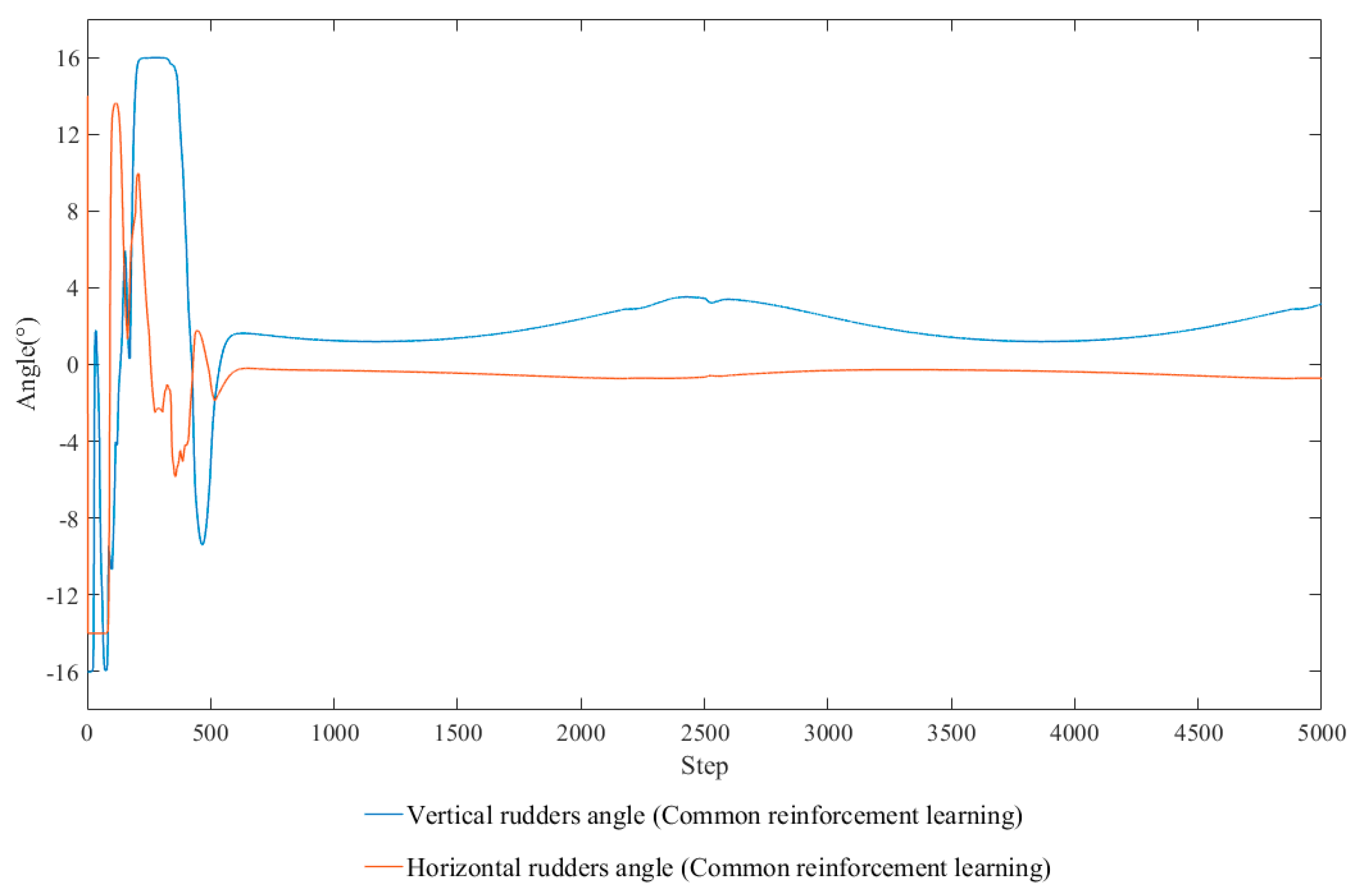
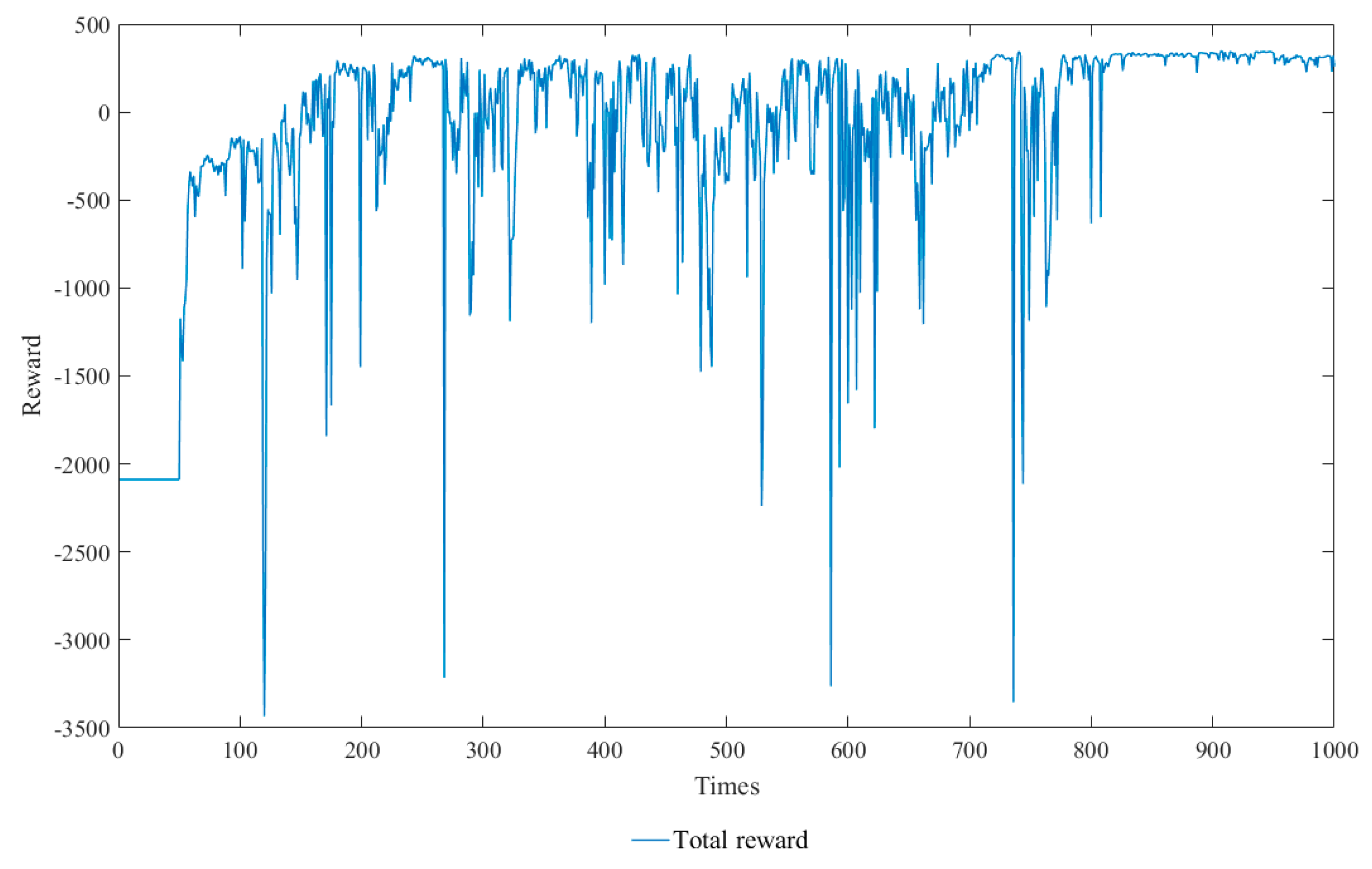
4.1. Preliminary Simulation Experiment
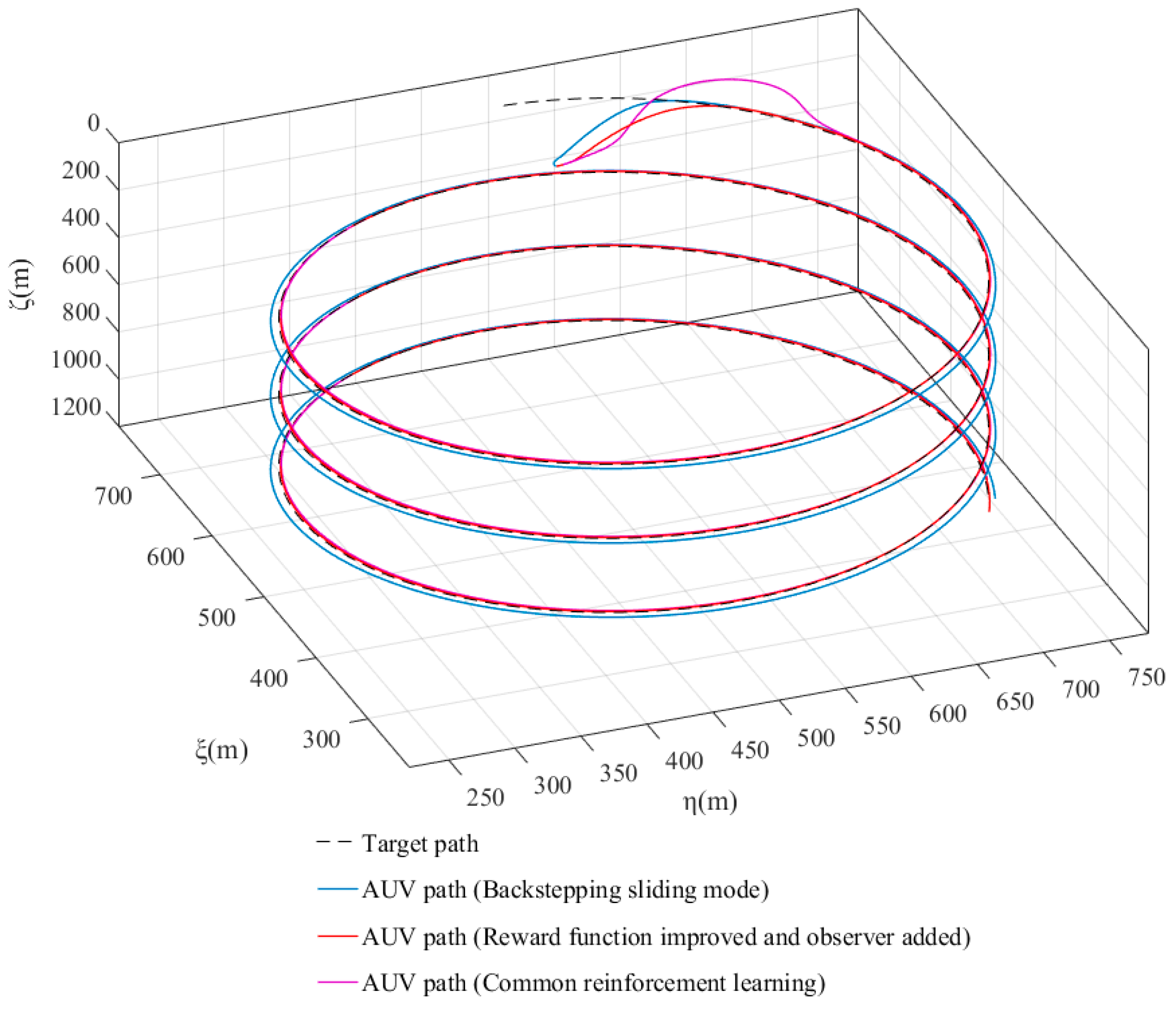
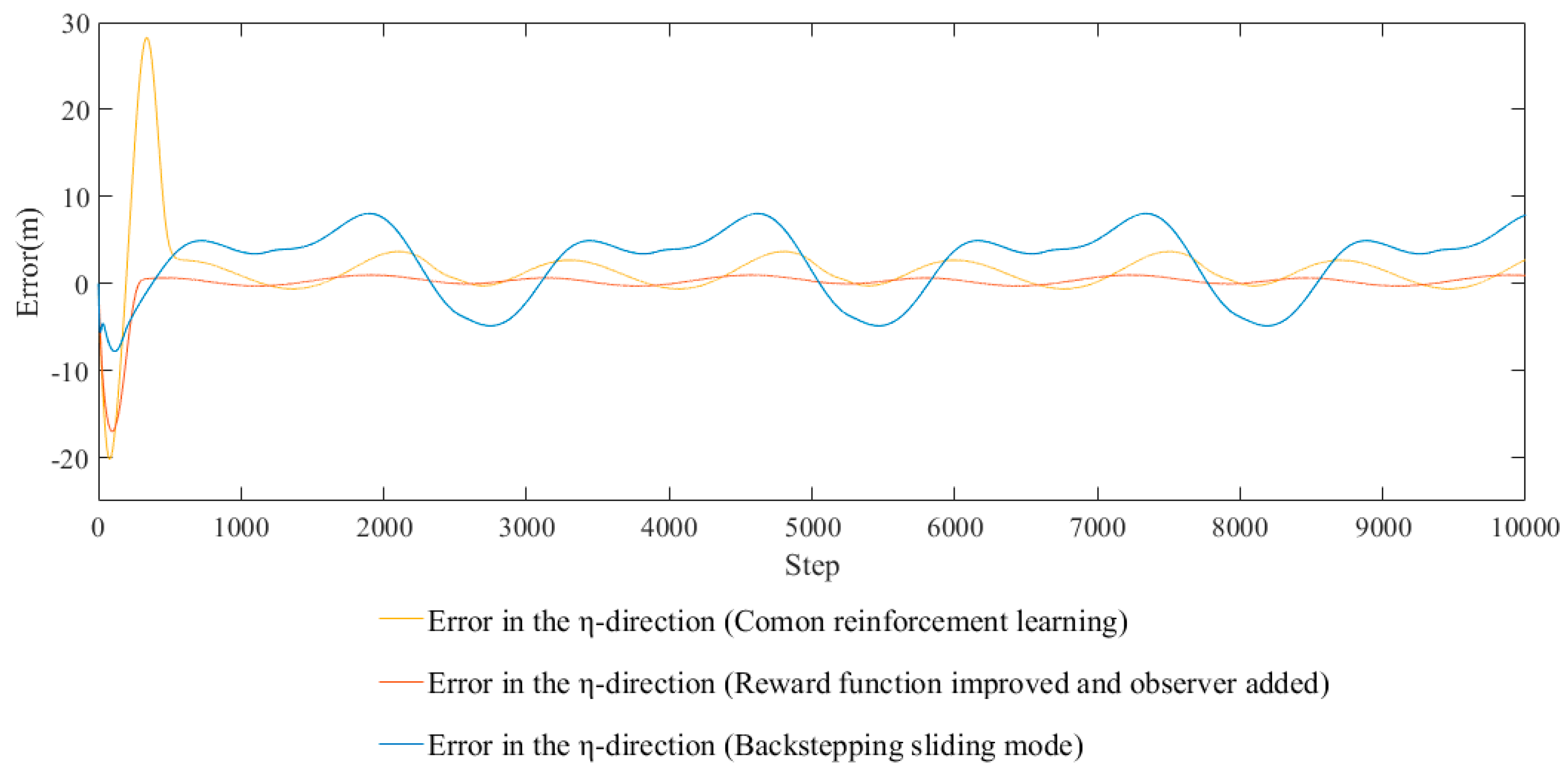
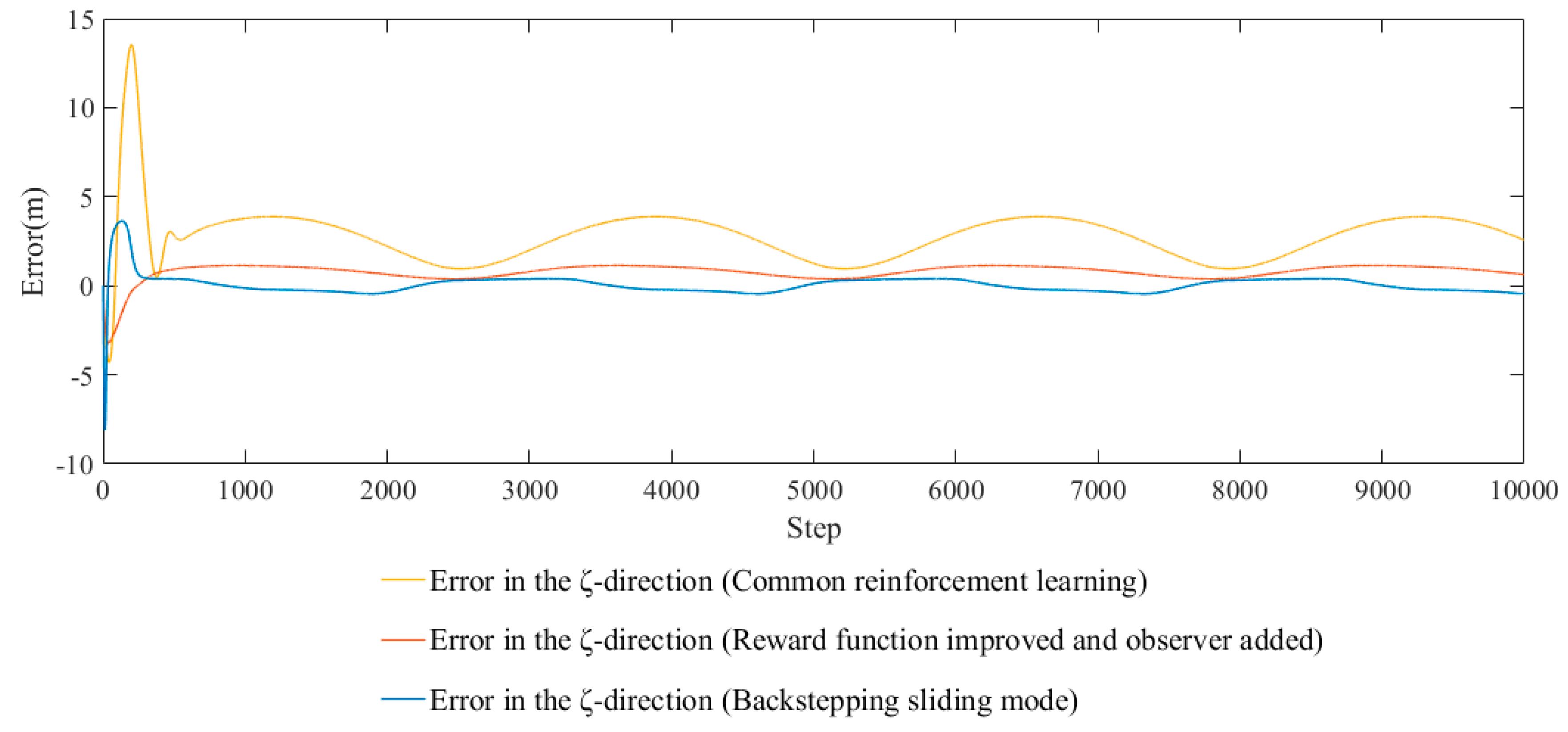
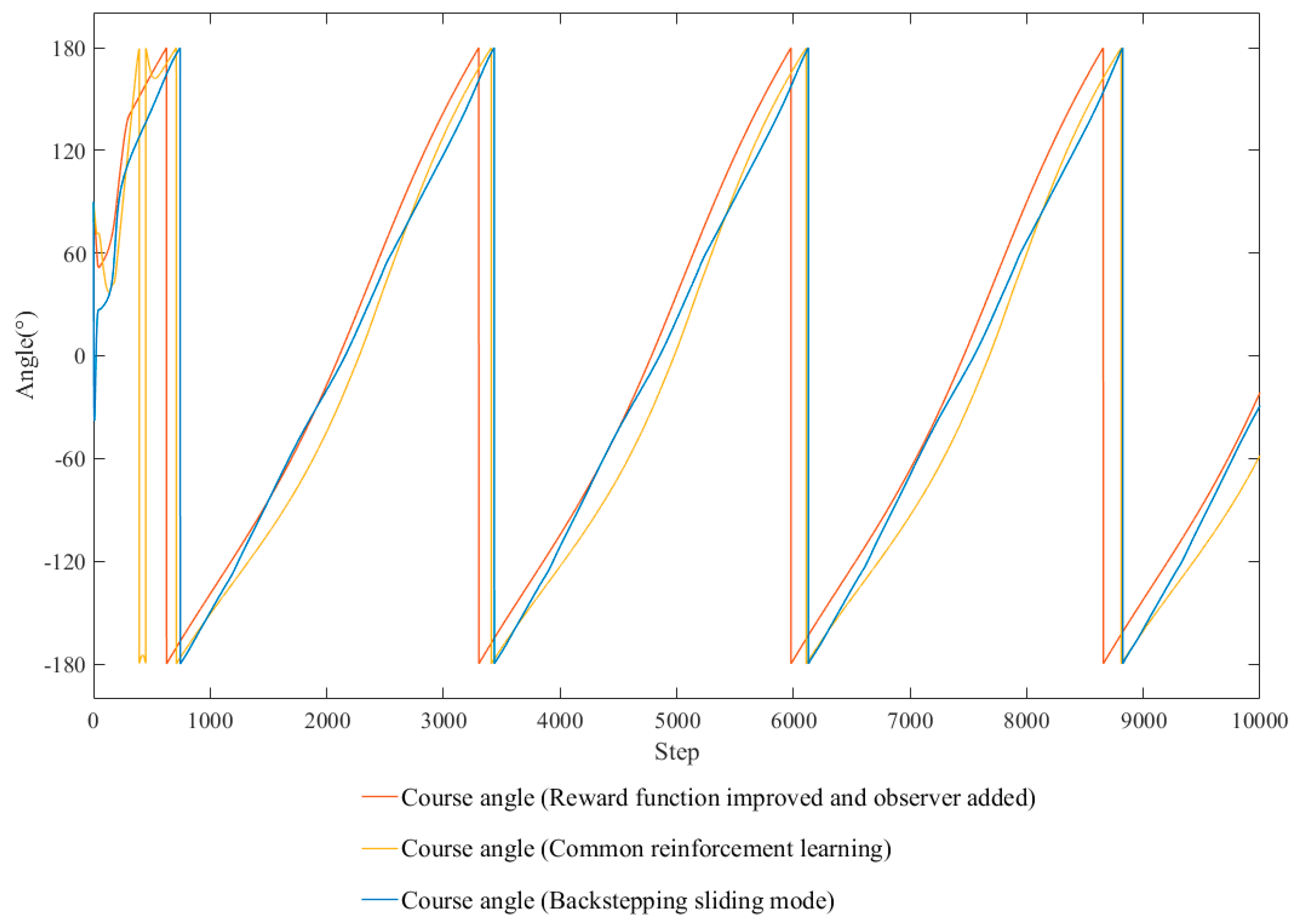
4.2. Improve
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, J.; Li, Q.; Zhang, A. Neural network adaptive control of underwater robot. Control Theory Appl. 2008, 25, 9–13. [Google Scholar]
- Lapierre, L.; Soetanto, D. Nonlinear path-following control of an AUV. Ocean Eng. 2007, 34, 1734–1744. [Google Scholar] [CrossRef]
- Xu, Y.; Li, P. Underwater robot development trend. J. Nat. 2011, 33, 125–132. [Google Scholar]
- Li, Y.; Jiang, Y.Q.; Wang, L.F.; Cao, J.; Zhang, G.C. Intelligent PID guidance control for AUV path tracking. J. Cent. South Univ. 2015, 22, 3440–3449. [Google Scholar] [CrossRef]
- Wei, Y.; Jia, X.; Gao, Y.; Wang, Y. Command filtered backstepping path tracking control for ROV based on NDO. Chin. J. Sci. Instrum. 2017, 38, 112–119. [Google Scholar]
- Yao, X.; Wang, X.; Jiang, X.; Wang, F. Control for 3D path-following of underactuated autonomous underwater vehicle under current disturbance. J. Harbin Inst. Technol. 2019, 51, 37–45. [Google Scholar]
- Fjerdingen, S.A.; Kyrkjeboe, E.; Transeth, A.A. AUV Pipeline Following using Reinforcement Learning. In Proceedings of the ISR 2010 (41st International Symposium on Robotics) and ROBOTIK 2010 (6th German Conference on Robotics), Munich, Germany, 7–9 June 2010. [Google Scholar]
- El-Fakdi, A.; Caner, M.; Palomeras, N.; Ridao, P. Autonomous underwater vehicle control using reinforcement learning policy search methods. Oceans Eur. 2005, 2, 793–798. [Google Scholar] [CrossRef]
- Carlucho, I.; De Paula, M.; Wang, S.; Petillot, Y.; Acosta, G.G. Adaptive low-level control of autonomous underwater vehicles using deep reinforcement learning. Robot. Auton. Syst. 2018, 107, 71–86. [Google Scholar] [CrossRef]
- Carlucho, I.; de Paula, M.; Acosta, G.G. Double Q-PID algorithm for mobile robot control. Expert Syst. Appl. 2019, 137, 292–307. [Google Scholar] [CrossRef]
- Nie, C.; Zheng, Z.; Zhu, M. Three-Dimensional Path-Following Control of a Robotic Airship with Reinforcement Learning. Int. J. Aerosp. Eng. 2019, 7854173. [Google Scholar] [CrossRef]
- Pearre, B.; Brown, T.X. Model-free trajectory optimisation for unmanned aircraft serving as data ferries for widespread sensors. Remote Sens. 2012, 4, 2971–3005. [Google Scholar] [CrossRef]
- Dunn, C.; Valasek, J.; Kirkpatrick, K.C. Unmanned Air System Search and Localization Guidance Using Reinforcement Learning; Infotech@ Aerospace: Garden Grove, CA, USA, 2012; pp. 1–8. [Google Scholar]
- Ko, J.; Klein, D.J.; Fox, D.; Haehnel, D. Gaussian processes and reinforcement learning for identification and control of an autonomous blimp. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 742–747. [Google Scholar]
- Shen, Z.; Dai, C. Iterative sliding mode control based on reinforced learning and used for path tracking of underactuated ship. J. Harbin Eng. Univ. 2017, 38, 697–704. [Google Scholar]
- Gu, W.; Xu, X.; Yang, J. Path Following with Supervised Deep Reinforcement Learning. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 448–452. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Yu, R.; Shi, Z.; Huang, C.; Li, T.; Ma, Q. Deep reinforcement learning based optimal trajectory tracking control of autonomous underwater vehicle. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017. [Google Scholar]
- Qin, H.; Chen, H.; Sun, Y.; Chen, L. Distributed finite-time fault-tolerant containment control for multiple ocean Bottom Flying node systems with error constraints. Ocean Eng. 2019. [Google Scholar] [CrossRef]
- Fossen, T.I. Handbook of Marine Craft Hydrodynamics and Motion Control; Wiley: Trondheim, Norway, 2016. [Google Scholar]
- Yin, Q. Path Following Control of Underactuated AUV Based on Backstepping Sliding Mode. Ph.D. Thesis, Dalian Maritime University, Dalian, China, 2016. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Boston, MA, USA, 2018. [Google Scholar]
- Sutton, R.S. On the Significance of Markov Decision Processes. In Proceedings of the Artificial Neural Networks - ICANN 1997 - 7th International Conference Proceeedings, Lausanne, Switzerland, 8–10 October 1997. [Google Scholar]
- Sun, Y.; Cheng, J.; Zhang, G.; Xu, H. Mapless Motion Planning System for an Autonomous Underwater Vehicle Using Policy Gradient-based Deep Reinforcement Learning. J. Intell. Robot. Syst. 2019, 96, 591–601. [Google Scholar] [CrossRef]
- Wang, Y.; Tong, H.; Fu, M. Line-of-sight guidance law for path following of amphibious hovercrafts with big and time-varying sideslip compensation. Ocean Eng. 2019, 172, 531–540. [Google Scholar] [CrossRef]
- Sampedro, C.; Rodriguez-Ramos, A.; Bavle, H.; Carrio, A.; de la Puente, P.; Campoy, P. A Fully-Autonomous Aerial Robot for Search and Rescue Applications in Indoor Environments using Learning-Based Techniques. J. Intell. Robot. Syst. 2019, 95, 601–627. [Google Scholar] [CrossRef]
- Manish, S.; Ajay, V. Wavelet reduced order observer based adaptive tracking control for a class of uncertain nonlinear systems using reinforcement learning. Int. J. Control Autom. Syst. 2013, 11, 496–502. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, G.; Sun, Y.; Cao, J.; Wan, L.; Sheng, M.; Liu, Y. AUV near-wall-following control based on adaptive disturbance observer. Ocean Eng. 2019, 190, 106429. [Google Scholar] [CrossRef]
- Liu, J. Sliding Mode Control Design and MATLAB Simulation. In The Basic Theory and Design Method, 3rd ed.; Tsinghua University Press: Beijing, China, 2015. [Google Scholar]
- Jia, H. Study of Spatial Target Tracking Nonlinear Control of Underactuated UUV Based on Backstepping. Ph.D. Thesis, Harbin Engineering University, Harbin, China, 2012. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mass Coefficients | |||
| Hydrodynamic Added Mass Coefficients | = −0.00158 | = −0.030753 | = −0.0308 |
| = −0.001597 | = −0.0016 | ||
| Viscous Damping Coefficients | = −0.0059 | = 0 | = 0 |
| = −0.000985 | = 0.0222 | = −0.0450 | |
| = −0.1668 | = −0.0171 | = −0.0427 | |
| = −0.1297 | = −0.00114 | = −0.01021 | |
| = 0.0103 | = −0.0094 | = −0.0069 | |
| = −0.0117 | |||
| Shape Parameters |
| Common Reinforcement Learning | Reward Function Improved and Observer Added | |
|---|---|---|
| Average of horizontal rudders angle | −0.477° | −0.556° |
| Variance of horizontal rudders angle | 3.13 | 0.27 |
| Average of vertical rudders angle | 3.00° | 2.06° |
| Variance of vertical rudders angle | 7.00 | 1.78 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Zhang, C.; Zhang, G.; Xu, H.; Ran, X. Three-Dimensional Path Tracking Control of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. J. Mar. Sci. Eng. 2019, 7, 443. https://doi.org/10.3390/jmse7120443
Sun Y, Zhang C, Zhang G, Xu H, Ran X. Three-Dimensional Path Tracking Control of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering. 2019; 7(12):443. https://doi.org/10.3390/jmse7120443
Chicago/Turabian StyleSun, Yushan, Chenming Zhang, Guocheng Zhang, Hao Xu, and Xiangrui Ran. 2019. "Three-Dimensional Path Tracking Control of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning" Journal of Marine Science and Engineering 7, no. 12: 443. https://doi.org/10.3390/jmse7120443
APA StyleSun, Y., Zhang, C., Zhang, G., Xu, H., & Ran, X. (2019). Three-Dimensional Path Tracking Control of Autonomous Underwater Vehicle Based on Deep Reinforcement Learning. Journal of Marine Science and Engineering, 7(12), 443. https://doi.org/10.3390/jmse7120443