
A Feasible Domain Segmentation Algorithm for Unmanned Vessels Based on Coordinate-Aware Multi-Scale Features


Abstract
1. Introduction
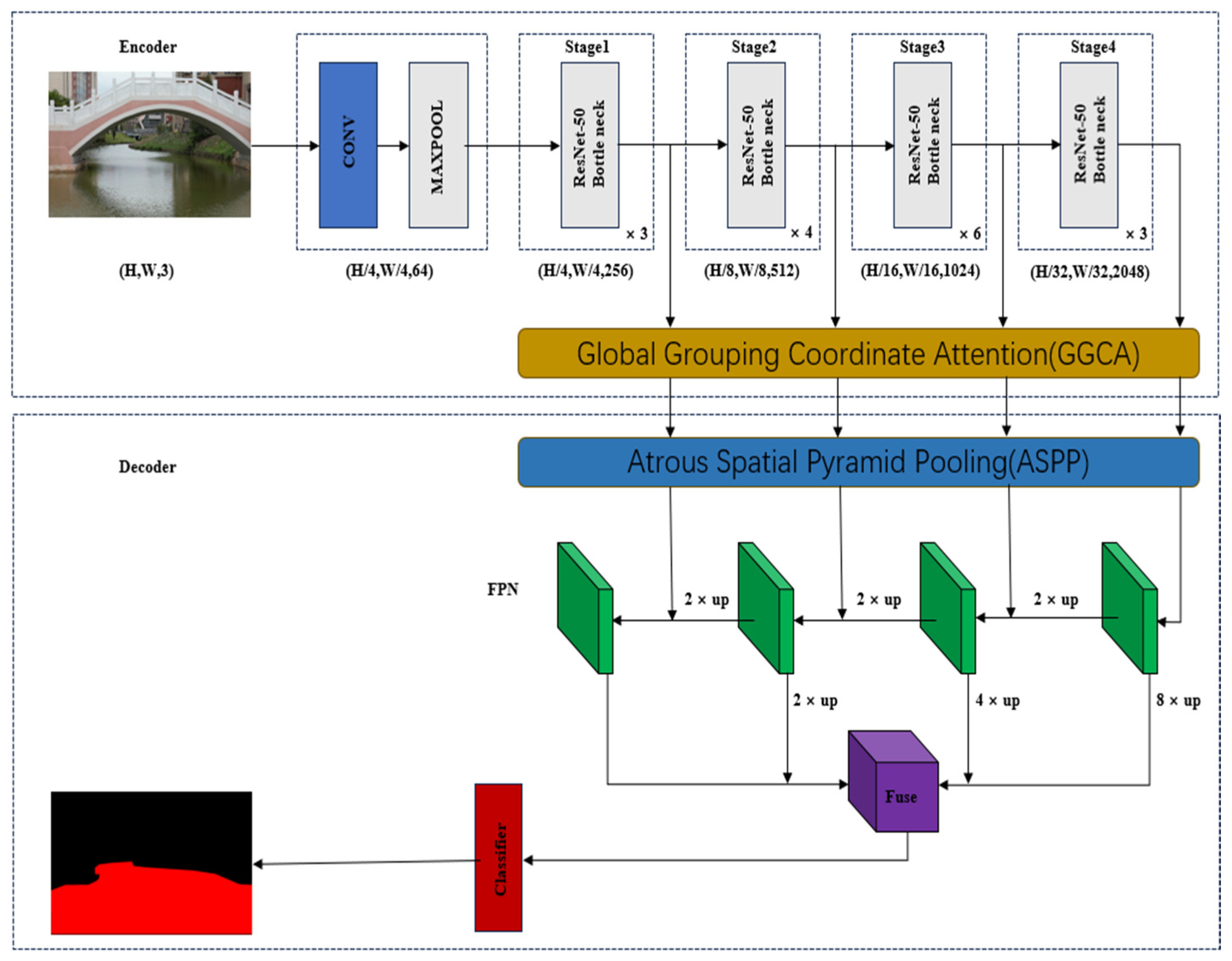
2. General Model Architecture
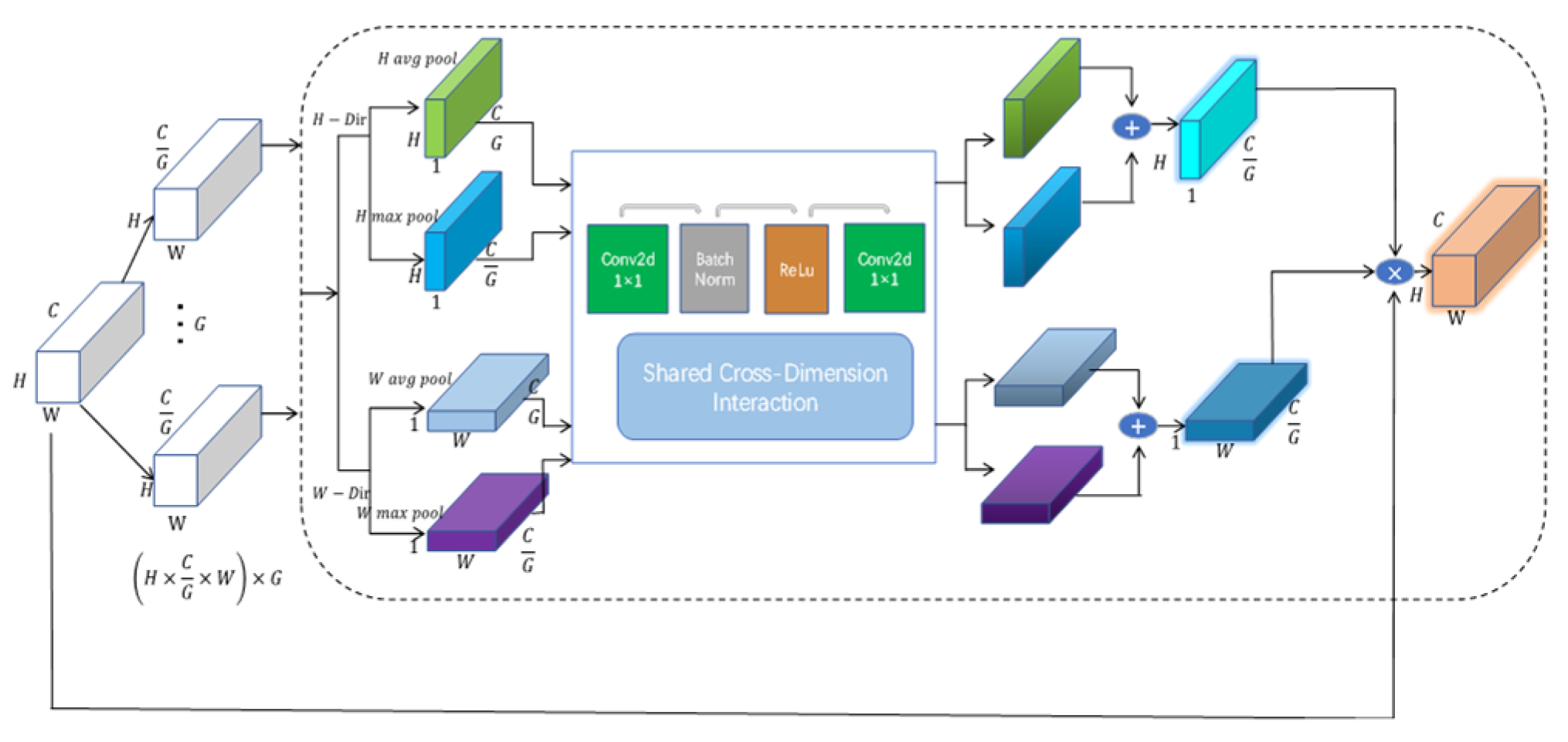
2.1. Global Grouped Coordinate Attention Enhanced Encoder
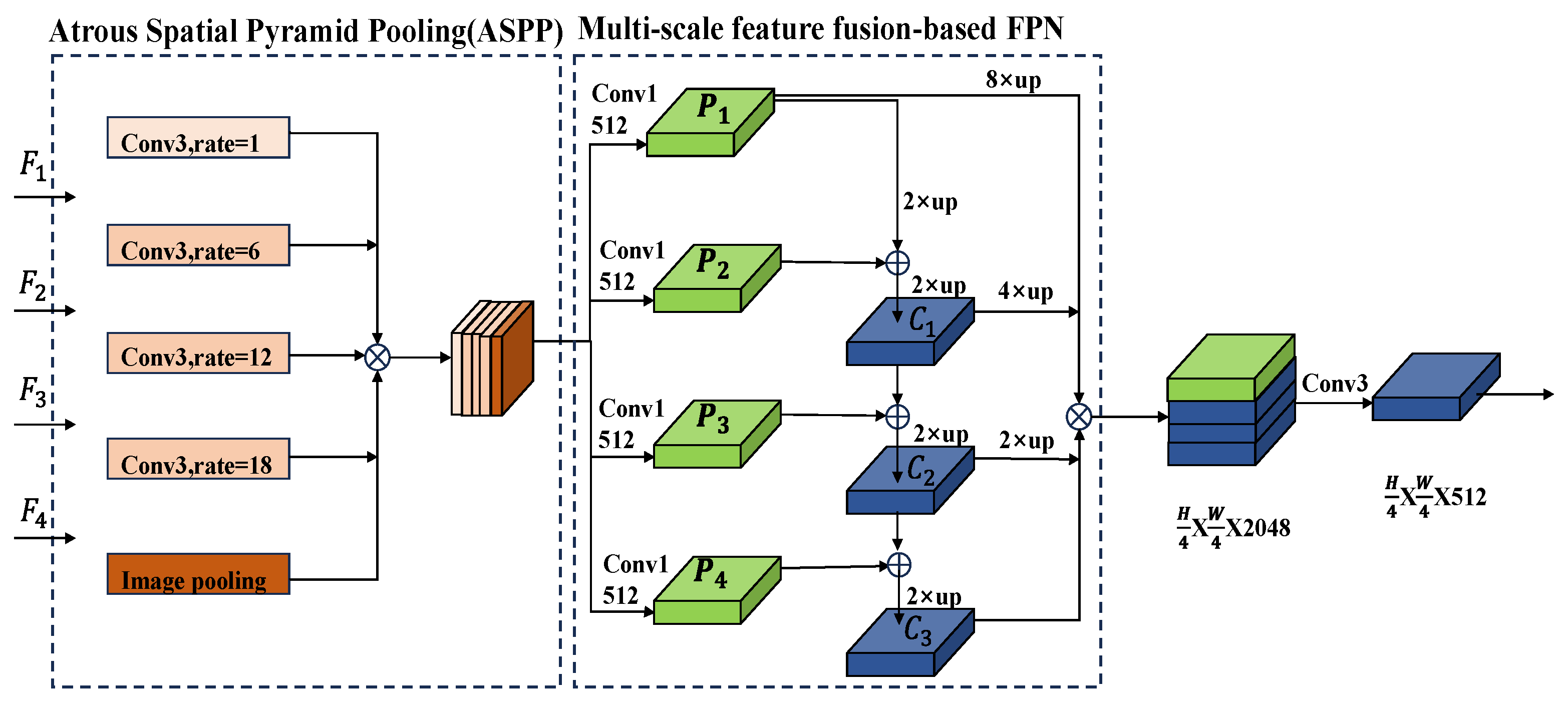
2.2. Multi-Scale Feature Fusion Decoder
2.3. Model Loss Function
3. Experimental Data and Processing
3.1. Overview of the Experimental Dataset
3.2. Experimental Environment and Parameter Settings
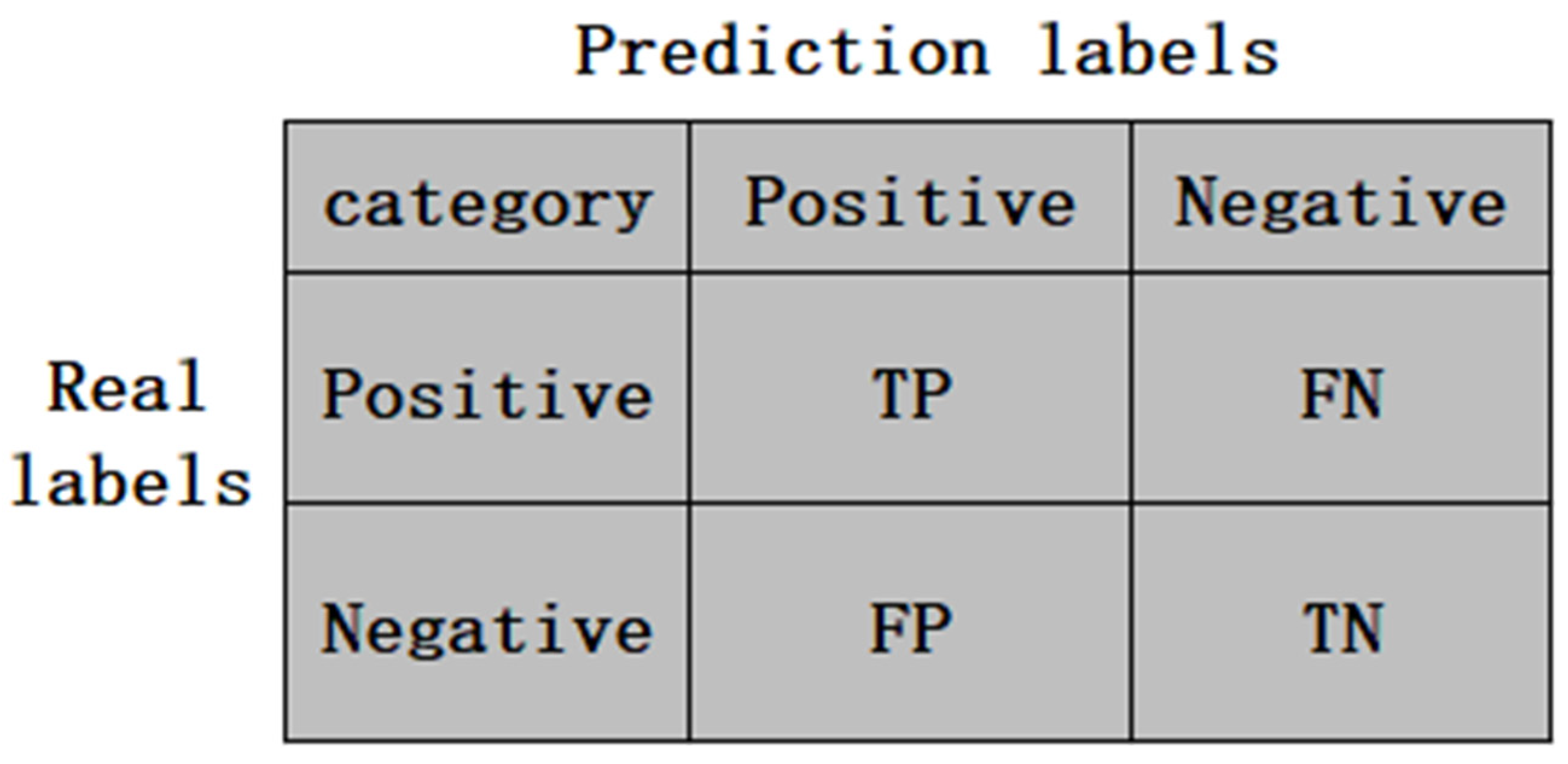
3.3. Experimental Evaluation Indicators
- (1)
- TP (True Positive): The actual case is positive, and the model correctly predicts it as positive.
- (2)
- FP (False Positive): The model incorrectly predicts a positive case when the actual case is negative.
- (3)
- FN (False Negative): The model incorrectly predicts a negative case when the actual case is positive.
- (4)
- TN (True Negative): The actual case is negative, and the model correctly predicts it as negative.
4. Experimental Results and Analysis
4.1. Evaluation of Various Models During the Training Process
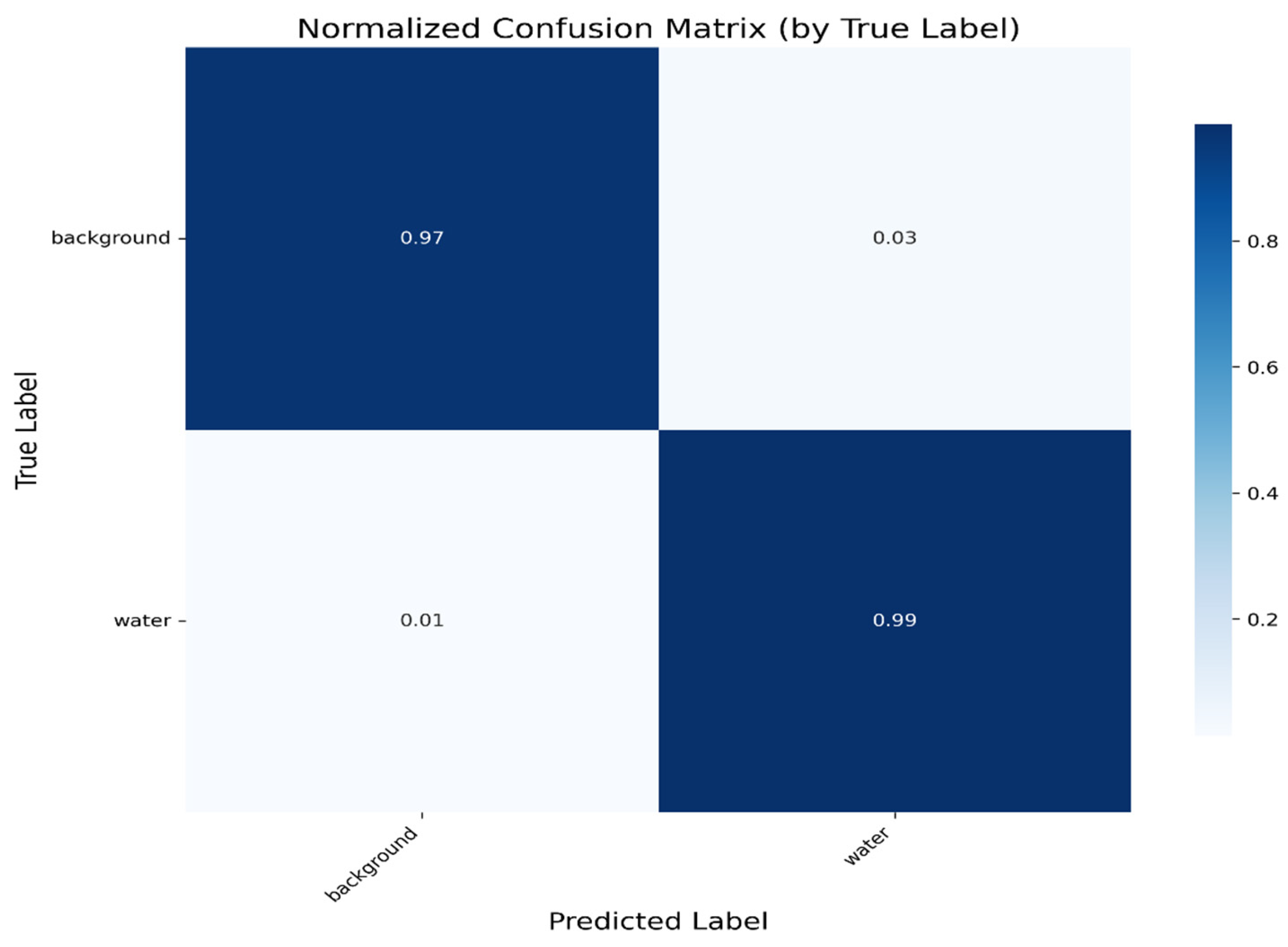
4.2. Analysis of Comparative Experimental Outcomes
4.3. Findings and Evaluation from Ablation Studies
- (1)
- In experiment ①, the model encoder’s attention enhancement module was taken out, resulting in reductions of 1.2% and 0.57% in the mIoU and mPA, respectively, when compared with the complete model in experiment ⑦. It is indicated that the more accurate acquisition of key target features is facilitated by the attention enhancement module, while interference from background noise is mitigated.
- (2)
- In experiment ②, the multi-scale feature fusion step was omitted, and only the ASPP module was used for segmenting the high-level semantic features. It was shown that the model’s capacity to detect targets at various scales was diminished, leading to decreases of 0.93% and 0.59% in the mIoU and mPA compared to the complete model ⑦. This indicates that multi-scale feature fusion is important for enhancing target feature representation and improving the segmentation effect.
- (3)
- In experiment ③, the ASPP module was eliminated, and only features from the backbone network were employed for direct multi-scale fusion. It was observed that the model’s performance experienced a slight decline, with increases of 0.8% and 0.57% in the mIoU and mPA, respectively, when compared to the full model ⑦. This suggests that the ASPP component is vital in expanding the receptive field and improving the extraction of multi-scale contextual features.
- (4)
- In experiment ④, the multi-scale feature aggregation and ASPP components were excluded, with segmentation relying solely on high-level semantic features. Reductions of 1.06% and 0.68% in the mIoU and mPA, respectively, were observed compared to the complete model ⑦. This suggests that the combined utilization of both modules can greatly enhance segmentation effectiveness, particularly in the detection and handling of fine boundary details. Since GGCA belongs to the encoder part, there is no need to consider its compatibility with the decoder.
- (5)
- In experiment ⑤, the attention enhancement module and the ASPP module in the model encoder are omitted, and the multi-scale feature fusion is performed directly, which shows that the model performance decreases by 1.22% and 0.76% in the mIoU and mPA, respectively, when compared with the full model ⑦. This indicates that an important role is played by these two modules in enhancing the key feature representation and improving the overall feature extraction capability.
- (6)
- In experiment ⑥, the attention enhancement component within the encoder part of the model and the multi-scale feature integration were removed, with segmentation carried out solely after the ASPP module. Compared to experiment ⑦, decreases of 1.38% and 0.86% in the mIoU and mPA were observed, respectively. This suggests that the attention enhancement component of the encoder and multi-scale feature aggregation aid in capturing multi-dimensional global context, enlarging the network’s receptive field and emphasizing key features, thereby enhancing segmentation performance.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ruangpayoongsak, N.; Sumroengrit, J.; Leanglum, M. A Floating Waste Scooper Robot On Water Surface. In Proceedings of the 2017 17th International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 18–21 October 2017; pp. 1543–1548. [Google Scholar]
- Mendonca, R.; Marques, M.M.; Marques, F.; Lourenco, A.; Pinto, E.; Santana, P.; Coito, F.; Lobo, V.; Barata, J. A cooperative multi-robot team for the surveillance of shipwreck survivors at sea. In Proceedings of the OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–6. [Google Scholar]
- Wang, W.; Gheneti, B.; Mateos, L.A.; Duarte, F.; Ratti, C.; Rus, D. Roboat: An Autonomous Surface Vehicle for Urban Waterways. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6340–6347. [Google Scholar]
- Bae, I.; Hong, J. Survey on the Developments of Unmanned Marine Vehicles: Intelligence and Cooperation. Sensors 2023, 23, 4643. [Google Scholar] [CrossRef] [PubMed]
- Gatesichapakorn, S.; Takamatsu, J.; Ruchanurucks, M. ROS Based Autonomous Mobile Robot Navigation Using 2D LiDAR and RGB-D Camera. In Proceedings of the 2019 First International Symposium on Instrumentation, Control, Artificial Intelligence, and Robotics (ICA-SYMP), Bangkok, Thailand, 16–18 January 2019; pp. 151–154. [Google Scholar] [CrossRef]
- An, C.-J.; Chen, Z.-P. SAR image watershed segmentation algorithm based on Otsu and improved CV model. Signal Process. 2011, 27, 221–225. [Google Scholar]
- Yu, S.F. A Watershed Segmentation Extraction Method for Bridge Recognition. Electro-Opt. Control. 2011, 18, 72–75. [Google Scholar]
- Qiu, X.; Chen, S.; Huang, Y. An Algorithm for Identification of Inland River Shorelines based on Phase Correlation Algorithm. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; IEEE: New York, NJ, USA; pp. 2047–2053. [Google Scholar]
- Li, N.; Lv, X.; Xu, S.; Li, B.; Gu, Y. An improved water surface images segmentation algorithm based on the Otsu method. J. Circuits Syst. Comput. 2020, 29, 2050251. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Y.; Zhu, Y.; Xu, W.; Hou, D.; Huang, P.; Zhang, G. Segmentation of river scenes based on water surface reflection mechanism. Appl. Sci. 2020, 10, 2471–2489. [Google Scholar] [CrossRef]
- Santana, P.; Ca, M.R.; Barata, J. Water detection with segmentation guided dynamic texture recognition. In Proceedings of the 2012 IEEE International Conference on Robotics and Biomimetics (ROBIO), Guangzhou, China, 11–14 December 2012; IEEE: New York, NJ, USA; pp. 1836–1841. [Google Scholar]
- Lyu, X.; Jiang, W.; Li, X.; Fang, Y.; Xu, Z.; Wang, X. MSAFNet: Multiscale Successive Attention Fusion Network for Water Body Extraction of Remote Sensing Images. Remote Sens. 2023, 15, 3121. [Google Scholar] [CrossRef]
- Zhang, J.T.; Gao, J.T.; Liang, J.S.; Wu, Y.Q.; Li, B.; Zhai, Y.; Li, X.M. Efficient Water Segmentation with Transformer and Knowledge Distillation for USVs. J. Mar. Sci. Eng. 2023, 11, 901. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Z.; Tian, S.; Ye, F.; Ding, J.; Kong, J. Convolutional Neural Networks for Water Body Extraction From Landsat Imagery. Int. J. Comput. Intell. Appl. 2017, 16, 1750001. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface Water Mapping by Deep Learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet:A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water Body Extraction from Very High-Resolution Remote Sensing Imagery Using Deep U-Net and a Superpixel-Based Conditional Random Field Model. IEEE Geosci. Remote Sens. Lett. 2019, 16, 618–622. [Google Scholar] [CrossRef]
- Xia, M.; Cui, Y.; Zhang, Y.; Xu, Y.; Liu, J. DAU-Net: A Novel Water Areas Segmentation Structure for Remote Sensing Image. Int. J. Remote Sens. 2021, 42, 2594–2621. [Google Scholar] [CrossRef]
- Duan, L.; Hu, X. Multiscale Refinement Network for Water-Body Segmentation in High-Resolution Satellite Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 686–690. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Jonnala, N.S.; Siraaj, S.; Prastuti, Y.; Chinnababu, P.; Babu, B.P.; Bansal, S.; Upadhyaya, P.; Prakash, K.; Faruque, M.R.I.; Al-Mugren, K.S. AER U-Net: Attention-enhanced multi-scale residual U-Net structure for water body segmentation using Sentinel-2 satellite images. Sci. Rep. 2025, 15, 16099. [Google Scholar] [CrossRef] [PubMed]
- Jonnala, N.S.; Bheemana, R.C.; Prakash, K.; Bansal, S.; Jain, A.; Pandey, V.; Faruque, M.R.I.; Al-Mugren, K.S. DSIA U-Net: Deep shallow interaction with attention mechanism UNet for remote sensing satellite images. Sci. Rep. 2025, 15, 549. [Google Scholar] [CrossRef]
- Gao, Y.; Yu, H. Lightweight wheat fertility identification model based on improved Vision Transformer. J. Anhui Inst. Sci. Technol. 2024, 1–10. Available online: http://kns.cnki.net/kcms/detail/34.1300.N.20241213.0846.002.html (accessed on 10 May 2025).
- Li, A.; Jiao, L.; Zhu, H.; Li, L.; Liu, F. Multitask Semantic Boundary Awareness Network for Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5400314. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.S.; Khan, F.S. Transformers in Remote Sensing: A Survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- Hong, Y.; Zhou, X.; Hua, R.; Lv, Q.; Dong, J. WaterSAM: Adapting SAM for Underwater Object Segmentation. J. Mar. Sci. Eng. 2024, 12, 1616. [Google Scholar] [CrossRef]
- Zhang, Z.; Cai, H.; Han, S. Efficientvit-sam: Accelerated segment anything model without performance loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2024, Seattle, WA, USA, 16–22 June 2024; pp. 7859–7863. [Google Scholar]
- Fu, J.; Yu, Y.; Li, N.; Zhang, Y.; Chen, Q.; Xiong, J.; Yin, J.; Xiang, Z. Lite-sam is actually what you need for segment everything. In Proceedings of the European Conference on Computer Vision, Milano, Italy, 29 September–4 October 2024; Springer Nature: Cham, Switzerland, 2024; pp. 456–471. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer VISION and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Cross Validations | mPA (%) | mIoU (%) |
|---|---|---|
| 1 | 99.18 | 98.51 |
| 2 | 99.12 | 98.45 |
| 3 | 99.15 | 98.43 |
| 4 | 99.10 | 98.50 |
| 5 | 99.17 | 98.47 |
| average value | 99.14 | 98.47 |
| Standard Deviation | 0.032 | 0.031 |
| 95% Confidence Interval | [99.10, 99.18] | [98.43, 98.51] |
| Model | PA/% | IOU/% | mPA/% | mIOU/% | mF1/% | Quantity of Participants/M | ||
|---|---|---|---|---|---|---|---|---|
| Body of Water | Land | Body of Water | Land | |||||
| FCN | 96.95 | 96.99 | 93.9 | 94.6 | 96.97 | 94.25 | 95.79 | 47.105 |
| U-Net | 97.01 | 97.05 | 93.61 | 94.68 | 97.03 | 94.35 | 95.86 | 28.991 |
| DeepLabv3 | 98.5 | 99.26 | 97.66 | 98.22 | 98.88 | 97.94 | 97.96 | 65.72 |
| Uper-Net | 97 | 97.34 | 94.29 | 94.94 | 97.17 | 94.61 | 96.06 | 64.042 |
| Dmnet | 97.3 | 98.02 | 95.3 | 95.86 | 97.66 | 95.58 | 97.76 | 50.803 |
| GASF-ResNet | 99.1 | 99.52 | 98.43 | 98.79 | 99.31 | 98.61 | 98.01 | 62.15 |
| Model | PA/% | IOU/% | mPA/% | mIOU/% | mF1/% | Quantity of Participants/M | ||
|---|---|---|---|---|---|---|---|---|
| Body of Water | Land | Body of Water | Land | |||||
| FCN | 97.10 | 97.32 | 94.38 | 95.85 | 97.21 | 95.12 | 95.72 | 47.105 |
| U-Net | 97.20 | 97.30 | 94.46 | 95.91 | 97.25 | 95.19 | 95.85 | 28.991 |
| DeepLabv3 | 99.00 | 99.04 | 97.94 | 98.43 | 99.02 | 98.18 | 97.98 | 65.72 |
| Uper-Net | 96.50 | 97.86 | 94.3 | 95.79 | 97.18 | 95.05 | 96.17 | 64.042 |
| Dmnet | 97.97 | 97.99 | 95.88 | 96.91 | 97.98 | 96.40 | 97.30 | 50.803 |
| GASF-ResNet | 99.00 | 99.54 | 98.37 | 98.74 | 99.27 | 98.55 | 98.00 | 62.15 |
| Experiment Number | GGCA | Multi-Scale Feature Fusion | ASPP | mPA/% | mIoU/% |
|---|---|---|---|---|---|
| ① | × | √ | √ | 98.74 | 97.41 |
| ② | √ | × | √ | 98.72 | 97.68 |
| ③ | √ | √ | × | 98.81 | 97.81 |
| ④ | √ | × | × | 98.63 | 97.55 |
| ⑤ | × | √ | × | 98.55 | 97.39 |
| ⑥ | × | × | √ | 98.45 | 97.23 |
| ⑦ | √ | √ | √ | 99.31 | 98.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Li, W.; Wang, Y.; Liu, H.; Wu, N. A Feasible Domain Segmentation Algorithm for Unmanned Vessels Based on Coordinate-Aware Multi-Scale Features. J. Mar. Sci. Eng. 2025, 13, 1387. https://doi.org/10.3390/jmse13081387
Zhou Z, Li W, Wang Y, Liu H, Wu N. A Feasible Domain Segmentation Algorithm for Unmanned Vessels Based on Coordinate-Aware Multi-Scale Features. Journal of Marine Science and Engineering. 2025; 13(8):1387. https://doi.org/10.3390/jmse13081387
Chicago/Turabian StyleZhou, Zhengxun, Weixian Li, Yuhan Wang, Haozheng Liu, and Ning Wu. 2025. "A Feasible Domain Segmentation Algorithm for Unmanned Vessels Based on Coordinate-Aware Multi-Scale Features" Journal of Marine Science and Engineering 13, no. 8: 1387. https://doi.org/10.3390/jmse13081387
APA StyleZhou, Z., Li, W., Wang, Y., Liu, H., & Wu, N. (2025). A Feasible Domain Segmentation Algorithm for Unmanned Vessels Based on Coordinate-Aware Multi-Scale Features. Journal of Marine Science and Engineering, 13(8), 1387. https://doi.org/10.3390/jmse13081387