Abstract
The increasing application of underwater robotic systems in deep-sea exploration, inspection, and resource extraction has created a strong demand for reliable visual perception under challenging conditions. However, image quality is severely degraded in low-light underwater environments due to the combined effects of light absorption and scattering, resulting in color imbalance, low contrast, and illumination instability. These factors limit the effectiveness of visual-based autonomous operations. We propose ATS-UGAN, a Dual-domain Adaptive Synergy Generative Adversarial Network for low-light underwater image enhancement to confront the above issues. The network integrates Multi-scale Hybrid Attention (MHA) that synergizes spatial and frequency domain representations to capture key image features adaptively. An Adaptive Parameterized Convolution (AP-Conv) module is introduced to handle non-uniform scattering by dynamically adjusting convolution kernels through a multi-branch design. In addition, a Dynamic Content-aware Markovian Discriminator (DCMD) is employed to perceive the dual-domain information synergistically, enhancing image texture realism and improving color correction. Extensive experiments on benchmark underwater datasets demonstrate that ATS-UGAN surpasses state-of-the-art approaches, achieving 28.7/0.92 PSNR/SSIM on EUVP and 28.2/0.91 on UFO-120. Additional reference and no-reference metrics further confirm the improved visual quality and realism of the enhanced images.
1. Introduction
With the continued advancement of deep-sea exploration, remotely operated vehicle (ROV) operations, and underwater surveillance technologies, underwater vision systems (UVSs) have become a critical component of deep-sea missions [1,2]. However, the complex underwater optical environment significantly constrains the imaging system’s performance. The absorption and scattering of light underwater, particularly the nonlinear attenuation of long-wavelength light, result in color distortion and contrast degradation in underwater images. Additionally, forward scattering caused by suspended particles introduces localized blurring, while turbulence induced by water currents diminishes fine detail. These challenges are particularly severe in the low-light conditions of deep-sea environments due to image visibility being greatly reduced. Therefore, downstream vision tasks such as target detection, recognition, and localization become difficult, bringing potential safety hazards for underwater operations [3,4]. Effectively enhancing the quality of underwater images in low-light environments has thus emerged as a pressing research focus and a key challenge in underwater machine vision.
In recent years, various methods have been proposed to enhance the quality of underwater images, primarily falling into three categories: physical model-based methods, image processing-based methods, and deep learning-based methods [5]. Physical model-based approaches typically rely on the atmospheric scattering or Jaffe–McGlamery underwater imaging model. These methods estimate optical parameters in the scene, such as light attenuation, scattering, and color deviation, based on the physical properties of underwater light propagation and then construct mathematical models to enhance the images. The methods benefit from a solid physical foundation and flexibility due to directly modeling the light transmission process, which is applicable across various underwater environments without requiring large amounts of labeled data. However, its effectiveness is limited to shallow water scenarios. In deeper regions, performance deteriorates significantly due to the reliance on static parameter assumptions. Variations in suspended particle concentration and illumination conditions in deep-sea environments severely affect parameter estimation accuracy, often leading to over-enhancement or additional color distortions. Moreover, the effectiveness of key assumptions, such as the dark channels, declines under low-light deep-sea conditions, resulting in increased noise in the enhanced images. These methods also lack the ability to handle dynamic, non-uniform degradation and cannot adapt well to diverse underwater conditions, especially in real-world low-light scenarios.
Traditional image processing-based approaches primarily enhance the visual quality of underwater images by modifying pixel distributions through techniques such as histogram equalization, Retinex, and gamma correction. These methods adjust brightness, enhance edges, and equalize color channels to improve image visibility, which are easy to implement and computationally efficient without prior knowledge or training data. However, they commonly suffer from significant limitations. Due to the lack of physical modeling of the underwater environment, image processing-based approaches often introduce spatial inconsistencies, which lead to the loss of texture details in low-light regions and the appearance of halo artifacts in high-frequency areas. Moreover, reliance on fixed prior functions prevents them from distinguishing between signal attenuation and scattering noise, undermining their adaptability in low-light underwater environments. The limits often lead to unstable enhancement effects, including imbalanced signal-to-noise ratios, color distortion, overexposed details, and amplified noise. More critically, they are difficult to generalize across scenes with varying water types, lighting, and depth, which severely restricts their robustness in practical applications.
The emergence of deep learning (DL) has opened up promising avenues for enhancing low-light underwater images. By constructing the mapping between degraded and clear images, deep learning enables end-to-end recovery of underwater image quality. Compared with other methods, it exhibits strong adaptive learning capabilities, which are better equipped to handle complex degradations such as color shifts, scattering-induced blur, and low contrast, achieving more accurate and robust enhancements. However, its performance heavily depends on the quality and diversity of the training data, which can limit generalizability in specific or unseen scenarios. In addition, many learning-based methods often lack interpretability and are prone to generating artifacts or suffering from mode collapse. They may also fail to capture meaningful structure in extremely low-light settings where features are sparse. Moreover, high-performing models often come with increased computational costs during training and inference, making them less suitable for real-time deployment in resource-constrained underwater systems. Unlike standard underwater images, low-light underwater images commonly lack sufficient key features and structural cues, making it difficult for general enhancement models to learn color mapping. They often result in monochromatic or unnatural tones, compromising the interpretability and utility of the enhanced images.
Although generative adversarial networks (GANs) have attracted considerable attention for their powerful image generation capabilities, they encounter several significant limitations in underwater low-light image enhancement. First, the training process of GANs is inherently unstable and susceptible to mode collapse, leading to generating images that lack diversity, an issue particularly pronounced in underwater scenarios where training data are limited. Moreover, GAN-based models rely heavily on labeled data, and their performance degrades significantly without high-quality paired training samples. Experiments show that the enhancement results from EnlightenGAN suffer from overexposure in overall brightness and display noticeable artifacts along the edges of foreground objects, which severely undermine image realism and adversely impact subsequent downstream tasks. Therefore, it is essential to develop lightweight networks that achieve high-quality enhancement and support fast inference and low-resource consumption, making them more suitable for underwater vision systems to improve the accuracy and efficiency of underwater tasks.
To address the above issues, we propose an adaptive generative adversarial network, ATS-UGAN, based on dual-domain synergy to address the challenges associated with underwater low-light image degradation. Unlike existing approaches that often rely solely on spatial-domain enhancement or predefined priors, ATS-UGAN synergistically integrates both spatial and frequency domains through a novel Multi-scale Hybrid Attention (MHA) mechanism. This design adaptively leverages Fourier-based global perception to suppress large-scale scattering artifacts while enhancing critical local features via spatial attention, enabling a more balanced and content-aware enhancement. Furthermore, in contrast to conventional fixed-structure convolutions, we introduce an Adaptive Parameterized Convolution (AP-Conv), which dynamically adjusts convolutional behavior based on input content. This enhances the model’s adaptability and responsiveness to varying degradation levels in underwater scenes. Finally, to address the common limitation of poor color restoration in low-light GAN-based methods, we propose a Dynamic Content-aware Markovian Discriminator (DCMD), which synergistically perceives spatial and frequency features to improve texture realism and ensure more accurate, adaptive color correction. Coupled with a gradient constraint strategy, it ensures the global continuity of lighting, thereby improving the visual realism and consistency of the enhanced images. Comparison with the SOTA algorithms on reference and no-reference metrics is shown in Figure 1.
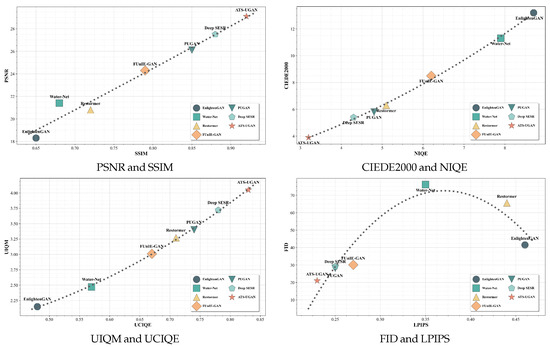
Figure 1.
Comparison of metrics with the SOTA algorithm on the EUVP dataset.
The main work of this article is summarized as follows:
- We designed a Multi-scale Hybrid Attention mechanism that operates across the frequency and spatial domains to achieve parameterized channel reorganization, enabling more effective feature selection and enhancement.
- To improve the network’s adaptability to low-light underwater degradations, we construct an Adaptive Parameterized Convolution that integrates adaptive kernel prediction to dynamically model and represent diverse underwater degradation patterns.
- We propose a Dynamic Content-aware Markovian Discriminator tailored for low-light underwater image features. A gradient constraint strategy is combined to improve the color mapping ability of the network in low light and enhance the color details and overall smoothness of the image.
2. Related Work
2.1. Physical Model-Based Methods
To solve the problem of underwater image degradation, MLLE [6] addressed color deviations and low visibility by locally adjusting colors and details, adapting contrast, and balancing color differences, resulting in improved underwater image visual quality. HFM [7] combined color correction, visibility recovery, and contrast enhancement modules to address white balance distortion, color shift, and low visibility. PhISH-Net [8] combined an underwater image formation model with a Retinex-based deep enhancement network to address color degradation and low visibility while achieving real-time performance and strong generalization across datasets. In addition, the performance of the physical model-based underwater image enhancement algorithm is further enhanced by combining Fast Fourier Transform (FFT) and wavelet transform (WT) [9,10]. Although the above methods offer strong physical interpretability, they often struggle in dynamic and complex underwater environments. Traditional static physical assumptions used in physical model-based methods tend to introduce assumption bias under extreme conditions, leading to issues such as color imbalance in the enhanced images. While integrating additional techniques can improve performance, these methods still fall short of meeting the demands of mission-critical tasks in low-light deep-sea scenarios, where environmental variability and degradation severity exceed the capabilities of enhancement strategies.
2.2. Image Processing-Based Methods
Image processing-based methods have seen development in underwater enhancement tasks due to flexibility and ease of deployment. They typically operate directly on image pixel distributions, making them suitable for various scenarios without extensive training data. Ma et al. [11] proposed a Retinex variational model incorporating information entropy smoothing and non-uniform illumination priors to address the challenges of uneven lighting in underwater images. Xiang et al. [12] proposed WLAB to address underwater image degradation by combining adaptive color correction, denoising, contrast enhancement, and bilateral weight fusion. Considering the CIELab color gamut of an image, Zhang et al. [13] proposed PCFB, which effectively improved underwater visibility by fusing contrast-enhanced foreground and dehazed background components using principal component analysis. Similarly, CBLA [14], which had locally enhanced underwater images by combining color restoration in RGB space with contrast and naturalness enhancement in CIELAB space, effectively restored scene details degraded by scattering and attenuation. In addition, single domain or hybrid enhancement for images in different color gamuts, such as HSV and YUV, has also produced good results, improving the adaptability and visibility based on the original algorithm [15,16,17]. However, these methods typically rely on fixed and simplistic transformation functions. In low-light underwater image enhancement, they face several significant limitations, including a limited capacity to model complex degradation mechanisms, inaccurate color correction, a tendency to amplify noise, and a lack of adaptability in the enhancement results. These shortcomings often lead to unstable enhancement performance and cannot satisfy the requirements of downstream tasks such as object detection, recognition, and semantic understanding.
2.3. Deep Learning-Based Methods
The development of deep learning (DL) in image vision has brought a new research avenue for underwater image enhancement tasks. A large number of underwater enhancement network models have achieved satisfactory performance. Xue et al. [18] proposed the S2D2 framework, which introduced a learnable color space and semantic-aggregated fusion strategy to decouple and eliminate underwater degradations, boosting performance in downstream semantic vision tasks. LiteEnhanceNet [19], a lightweight underwater image enhancement network, utilized depthwise separable convolutions and efficient feature aggregation to reduce computational complexity. The application of the transformer on the vision domain further enhanced the performance of the network [20,21]. Yang et al. [22] proposed a progressive aggregator with a feature-prompted transformer, effectively improving image texture and detail by integrating global and local attention mechanisms. Shang et al. [23] proposed the LGT framework, which leveraged a biologically inspired luminance-balancing curve and self-attention mechanism to adaptively fuse multi-scale features, improving image quality across diverse underwater scenes. Generative adversarial networks (GANs) further improve the color balance, human eye perception, and observability of the enhanced images. The emergence of diffusion models makes GANs further improve their performance [24,25]. In addition, the application of large models, reinforcement learning, and unsupervised techniques in the field of underwater image enhancement likewise improves the visual quality of the enhanced images [26,27,28]. However, the above methods are designed for general underwater image enhancement tasks, which confront significant limitations in low-light conditions. Under extremely low light, the image texture details and global colors are suppressed, rendering it challenging for general enhancement networks to model color mapping. Compared to other GenAIs [29,30,31], GANs generate clearer and more realistic images and can generate images quickly. In addition, GANs do not require multi-step sampling during generation and perform better in generating data in continuous space. Through conditional control, GANs can also flexibly realize tasks such as style migration and image generation, giving them a unique advantage in high-quality image generation and visual content [32]. However, GANs often suffer from unstable training and may produce unrealistic colors or hallucinated details in the absence of sufficient illumination cues. Additionally, the reliance on high-quality training data and substantial computational overhead restrict their applicability in complex and variable low-light underwater environments.
3. Methodology
To address the above challenges, we propose ATS-UGAN, an adaptive generative adversarial network based on dual-domain synergy. Unlike previous methods that rely solely on spatial features or handcrafted priors, ATS-UGAN adaptively and synergistically models both spatial and frequency information to better capture diverse degradation patterns in low-light underwater scenes. Specifically, we introduce a Multi-scale Hybrid Attention module to adaptively extract key features while suppressing noise across domains. An Adaptive Parameterized Convolution is employed to dynamically adjust convolutional kernels, enhancing the network’s adaptability to non-uniform scattering. Additionally, a Dynamic Content-aware Markovian Discriminator with gradient constraints is used to guide training by synergistically perceiving spatial and frequency information, improving color accuracy and perceptual realism. The overall architecture is shown in Figure 2.
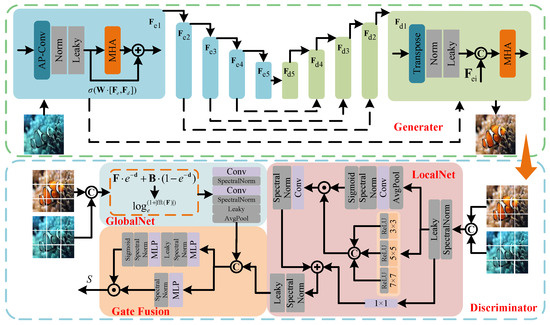
Figure 2.
ATS-UGAN architecture. In the generator, to and to represent the encoder and decoder features at each level, respectively, where denotes the feature at the i-th encoder stage. is a learnable matrix used for feature transformation, and is the Sigmoid activation function. After generating the enhanced image, the enhanced and original images are input to the discriminator to obtain the final confidence score S. In this stage, denotes the extracted features, and are learnable matrices, and denotes the Fast Fourier Transform (FFT).
3.1. Multi-Scale Hybrid Attention
Traditional frequency domain enhancement methods separate color bias components using the Fourier transform but lack the capacity to model the non-uniform distribution of scattering noise in the spatial domain, which leads to artifacts in the enhanced images. As illustrated in Figure 3, we propose a Multi-scale Hybrid Attention (MHA) module to enhance the network’s noise robustness through a cross-domain collaboration mechanism to compensate for local information ambiguity due to low light and scattering by capturing global semantics and remote dependencies in underwater images.
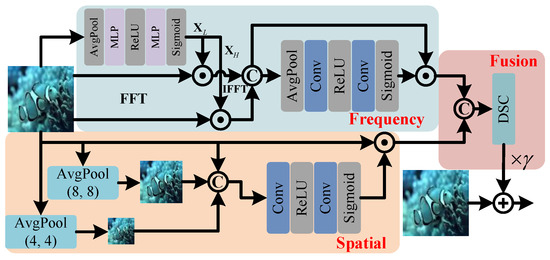
Figure 3.
Multi-scale Hybrid Attention structure, where is the learnable residual coefficient, and and are low- and high-frequency components.
In the frequency domain processing, the inputted feature is decomposed into a low-frequency component and a high-frequency component , which denote the illumination component and the edge texture in the image; the overall process is denoted as
where and are Multilayer Perceptrons (MLPs), and are Sigmoid and ReLU activation functions, and is Adaptive Average Pooling.
Subsequently, the different frequency domain components of the image are obtained through and and the information is weighted using the convolutional attention mechanism, which can be represented as
where and are convolution operations, and is the inputted frequency feature, which can be represented as
where is the Fast Fourier Transform (FFT), and is a feature-splicing operation.
In the spatial domain processing, Pyramid Pooling (PP) is first performed on to obtain the feature . The mathematical expression is as follows:
Subsequent feature extraction of the using convolutional attention yields , which can be represented as
Finally, we perform cross-domain fusion of different domain features to obtain the final fused feature . The process is denoted as
where is the depthwise separable convolution.
3.2. Adaptive Parameterized Convolution
Turbulent disturbances in low-light environments often lead to non-rigid deformation of the water body, causing traditional convolution operators to suffer from feature misalignment due to accumulated errors in offset field prediction. To address this challenge, we propose an Adaptive Parameterized Convolution (AP-Conv), as shown in Figure 4, which enhances the network’s robustness and adaptability by dynamically adjusting convolution kernels and aggregating features across branches. Unlike general dynamic convolutions that focus on kernel modulation or offset learning [33,34], AP-Conv incorporates a dual-branch design that explicitly balances semantic awareness and structural preservation, making it more suitable for the complex distortions in underwater environments.
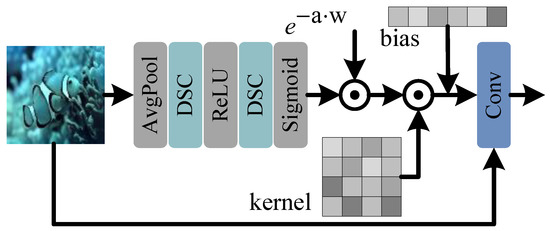
Figure 4.
Adaptive Parameterized Convolution structure, where and are the learnable physical parameters.
The adaptive convolutional weight operator is first obtained from the current input features and the process is represented as
where and are the learnable physical parameters, is the initialized learnable convolution operator, and denoted as
The adaptive convolution operator with initialization bias is convolved on the original features to obtain the final adaptive features. The overall process is represented as
3.3. Dynamic Content-Aware Markovian Discriminator
We propose a Dynamic Content-aware Markovian Discriminator (DCMD), as shown in Figure 2. It consists of two parallel branches: a local branch (LocalNet) and a global branch (GlobalNet). The LocalNet focuses on fine-grained texture consistency by evaluating local patches, while the GlobalNet captures holistic structural fidelity across the entire image. By jointly optimizing local detail and global semantic alignment, DCMD effectively enhances the discriminator’s ability to guide the generator toward producing perceptually realistic and spatially coherent underwater images.
In LocalNet, the original image is concatenated and partitioned into multiple patches together with the enhanced image , forming paired regions. These patches are then initialized to construct the input data , which can be represented as
where is Spectral Normalization, and is the Leaky activation function.
Subsequently, is fed into the multi-scale pyramid for multi-scale feature extraction and is feature-weighted. The overall process is represented as
where is represented as
Finally, we utilize the residual mechanism to accelerate the information flow and reduce the information loss to obtain the final feature . The process is denoted as
In GlobalNet, we first physically initialize the input features to emphasize the key features and suppress the background noise interference in the image, which is denoted as
where and are learnable physical parameters.
The processed physical features are then fed into the frequency domain processing layer for the global frequency domain processing, which is represented as
where is represented as
Finally, the obtained local and global features are fed into gated fusion to obtain the final score S, which is represented as
where is represented as
3.4. Loss Function
To improve the stability of the generator during training, we additionally introduce wavelet frequency domain loss and gradient penalty to assist the training. The specific optimization objective is defined as
where , , and are the correlation weight coefficients that are set to 1.0, 0.3, and 0.5, and , , and are the Wasserstein distance loss, wavelet frequency domain loss, and Sobel gradient loss, which are represented as
where is the wavelet transform and is the Sobel gradient computation.
For the discriminator, the loss function uses an adversarial loss with a gradient penalty term, denoted as
where is the gradient penalty term coefficient, set to 10.
4. Experiment
4.1. Datasets
4.1.1. EUVP
The EUVP dataset [35] is designed for underwater image enhancement and comprises 1112 pairs of low-quality underwater images and their corresponding reference images. These samples encompass a diverse range of low-light underwater conditions, enabling a comprehensive evaluation of model performance across various scenarios. Each image has a resolution of pixels and includes common underwater challenges such as contrast degradation, detail loss due to scattering, and uneven illumination. In experiments, the dataset was divided into 890 image pairs for training, 111 pairs for validation, and 111 pairs for testing.
4.1.2. UFO-120
The UFO-120 dataset [36] focuses on underwater image enhancement under extreme low-light conditions. It contains 1500 real-world underwater images, of which approximately 40% represent particularly challenging scenes characterized by severe darkness, color distortion, and noise. The image resolutions range from to . For our experiments, we randomly split the dataset into 1200 images for training, 150 for validation, and 150 for testing.
4.2. Experiment Details and Evaluation Metrics
4.2.1. Experiment Environment and Hyperparameters
The experimental environment was the Windows 10 system and PyTorch 1.10 framework. The server used for the experiment is configured with 256 GB RAM, Inter Xeon Gold 5318Y CPU (2.10 GHz), and NVIDIA A10 GPU. During the training process, the resolution of input images was , and a total of 200,000 iterations. The batch size was 8, and the optimizer was AdamW, where = 0.9 and = 0.999. The initial learning rate was . with a cosine annealing scheduling strategy.
4.2.2. Evaluation Metrics
On the reference metric, the Peak Signal Noise Ratio (PSNR) was used to measure the pixel-level fidelity between the generated image and the ground truth. A higher PSNR indicates less distortion of the image. Meanwhile, we utilized the structural similarity index (SSIM) to evaluate the structural similarity of the images. SSIM takes values between [0, 1], and when the value is closer to 1, it indicates that the structure of the image is better preserved. In addition, we used the CIEDE2000 color difference metric based on the LAB color space, where the smaller CIEDE2000 indicates the more accurate color reproduction of the image.
To assess the quality of underwater images comprehensively, we used the Underwater Image Quality Metric (UIQM) to evaluate the sharpness, color, and contrast. The larger the value of the UIQM, the better the quality of the image. We also used the Underwater Color Image Quality Evaluation Index (UCIQE) to quantify the balance of color distribution, contrast, and saturation. In addition, the Natural Image Quality Evaluator (NIQE), a non-referenced index based on natural scene statistics, has a lower value, indicating that the image is closer to the natural distribution, thus reflecting better image quality.
In addition, we employed the neural network-based metrics LPIPS and FID to evaluate image quality [37]. LPIPS measures the perceptual similarity between the enhanced and reference image, reflecting the visual quality from a human perceptual perspective. FID assesses the discrepancy between the overall distribution of enhanced images and real images, providing a comprehensive measure of the authenticity and diversity of the enhanced results.
4.3. Performance Comparison
4.3.1. EUVP
We selected extreme low-light underwater scenes from the EUVP dataset, characterized by severe color casts, color loss, and overexposure, to compare enhancement results with several state-of-the-art models. As shown in Table 1, Deep SESR and PUGAN exhibit relatively robust performance and achieve competitive results in full-reference metrics such as PSNR and SSIM. However, both models still show shortcomings in color fidelity and perceptual quality. Restormer demonstrates better color correction capabilities but performs less effectively in preserving structural information and image sharpness. FUnIE-GAN achieves moderate improvements across some metrics, yet its enhancement remains limited. WaterNet and EnlightenGAN display weaker comprehensive performance, particularly in no-reference metrics such as NIQE and UIQM, where the enhanced images show noticeable visual quality and naturalness deficiencies. In contrast, ATS-UGAN surpasses existing mainstream methods across all image evaluation metrics and delivers the best overall performance. Furthermore, regarding resource consumption and inference speed, ATS-UGAN maintains favorable computational efficiency while delivering strong performance. Under the same experimental conditions, ATS-UGAN requires 28.65 GFLOPs, significantly lower than Restormer (48.75 GFLOPs) and Deep SESR (36.28 GFLOPs). In inference time, ATS-UGAN processes each image in only 0.067 s, outperforming Restormer (0.125 s) and Deep SESR (0.086 s). Although ATS-UGAN exhibits some limitations compared to lighter models such as FUnIE-GAN and EnlightenGAN, it achieves a well-balanced trade-off between efficiency and effectiveness.

Table 1.
Quantitative performance comparison on the EUVP dataset.
A visual comparison of the enhancement results is presented in Figure 5. In complex low-light scenarios, EnlightenGAN tends to overexpose the image, while WaterNet improves dehazing and color balance but suffers from blurred textures, loss of high-frequency details, and underexposure. PUGAN fails to adequately model the color mapping, resulting in unbalanced color. Restormer exhibits noticeable color deviation due to its suboptimal color mapping performance. FUnIE-GAN remains sensitive to color distortions, with some scenes appearing overly faded. In contrast, ATS-UGAN achieves a trade-off between color fidelity and texture preservation under challenging low-light conditions, effectively restoring image details while reducing artifacts and noise typically caused by over-enhancement.

Figure 5.
Comparison of enhancement effects on EUVP dataset. (a) Raw Image. (b) WaterNet [39]. (c) FUnIE-GAN [35]. (d) PUGAN [41]. (e) Deep SESR [36]. (f) Restormer [40]. (g) EnlightenGAN [38]. (h) ATS-UGAN. (i) Ground Truth.
4.3.2. UFO-120
To further verify the generalizability and robustness of the proposed method across diverse underwater low-light conditions, we conducted a quantitative evaluation of networks on the UFO-120 dataset. As presented in Table 2, ATS-UGAN consistently achieves the best performance across all evaluation metrics, demonstrating superior stability and effectiveness. ATS-UGAN achieves the highest PSNR and SSIM, highlighting its capability to recover fine details and preserve structural integrity. In the no-reference quality assessments, the enhanced images generated by ATS-UGAN exhibit more natural color distributions and improved edge clarity. While Deep SESR and PUGAN show relatively competitive performance, they exhibit noticeable deficiencies in color correction. FUnIE-GAN and Restormer perform moderately well in color reproduction and detail enhancement but fall short in overall perceptual quality. WaterNet and EnlightenGAN demonstrate the weakest performance across all metrics, with particularly low scores in NIQE and UCIQE, indicating their enhanced results suffer from poor visual naturalness and limited color fidelity.
Table 2.
Quantitative performance comparison on the UFO-120 dataset.
Figure 6 illustrates an enhancement effects comparison on the UFO-120 dataset. WaterNet, EnlightenGAN, and Restormer result in persistent issues of underexposure, overexposure, and tonal shifts. Under highly complex low-light conditions, FUnIE-GAN and PUGAN also suffer from localized texture noise, leading to unnatural visual appearances. Deep SESR yields relatively balanced enhancements but still exhibits minor tonal inconsistencies. In contrast, ATS-UGAN successfully mitigates these problems, delivering enhanced images with minimal tonal deviations and a more natural appearance. It demonstrates clearer detail in shadowed regions without introducing color artifacts or distortions, effectively preserving image structure while significantly improving visual quality.

Figure 6.
Comparison of enhancement effects on UFO-120 dataset. (a) Raw Image. (b) WaterNet [39]. (c) FUnIE-GAN [35]. (d) PUGAN [41]. (e) Deep SESR [36]. (f) Restormer [40]. (g) EnlightenGAN [38]. (h) ATS-UGAN. (i) Ground Truth.
4.4. Ablation Experiments
In this section, we verify the effectiveness of the core components of the proposed algorithm on the overall algorithm by performing a series of ablation experiments on the EUVP and UFO-120 datasets.
4.4.1. Multi-Scale Hybrid Attention
To validate the effectiveness of the Multi-scale Hybrid Attention (MHA) module, we conducted an ablation study by removing MHA while keeping the rest of the network architecture unchanged. As shown in Table 3, removing MHA leads to a noticeable performance degradation on the EUVP dataset. Specifically, PSNR drops to 25.6, and SSIM decreases to 0.80, indicating reduced fidelity and structural consistency. Additionally, CIEDE2000 increases significantly to 7.4, suggesting severe color distortion. UIQM and UCIQE drop to 3.44 and 0.72, while LPIPS and FID increase to 0.30 and 30.21, respectively, reflecting poor perceptual quality and low contrast. The visual comparison in Figure 7 and Figure 8 further supports these quantitative results. Without the MHA, the enhanced images appear darker and exhibit unnatural color tones, especially in the background and marine organisms. Noticeable texture blur and a persistent blue-green color cast remain, highlighting the importance of the module in improving structure and color restoration.
Table 3.
Comparison of experimental metrics for ablation of network core components on the EUVP dataset.

Figure 7.
Comparison of experimental effects for ablation of network core components on the EUVP dataset.
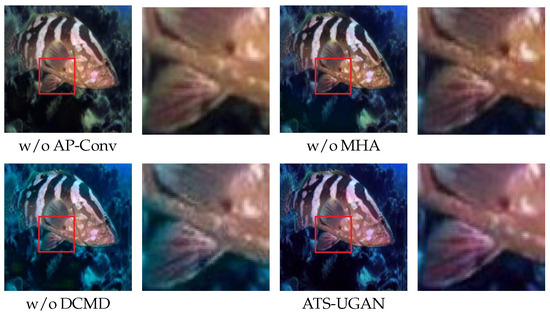
Figure 8.
Detailed comparison of enhancement effects on the EUVP dataset.
Similarly, on the UFO-120 dataset, Table 4 and Figure 9 and Figure 10, the absence of MHA causes PSNR to fall to 24.1, while CIEDE2000 increases sharply to 9.2. Although SSIM remains relatively high at 0.87, the overall clarity and perceptual quality degrade considerably. The enhanced images still suffer from a bluish color bias and incomplete tone mapping. These results indicate that conventional convolutional operations alone are insufficient for capturing the complex global dependencies in underwater low-light images, where issues like illumination inhomogeneity, suspended particle interference, and severe color degradation are prevalent. The MHA module addresses these challenges by modeling global contextual dependencies across frequency and spatial domains. By modeling global contextual dependencies across both frequency and spatial domains, MHA effectively captures long-range correlations that are essential for restoring coherent structures and maintaining perceptual consistency. Through parallel attention computation across multiple subspaces, MHA enhances the network’s ability to distinguish relevant features from blur and distortion, thereby improving the accuracy of color mapping and the preservation of fine structural details.
Table 4.
Comparison of experimental metrics for ablation of network core components on the UFO-120 dataset.

Figure 9.
Comparison of experimental effects for ablation of network core components on the UFO-120 dataset.

Figure 10.
Detailed comparison of enhancement effects on the UFO-120 dataset.
4.4.2. Adaptive Parameterized Convolution
As shown in Table 3, removing the AP-Conv module results in moderate performance degradation. Although the overall image structure remains relatively intact, noticeable over-enhancement and color deviation are observed. Specifically, the PSNR drops to 27.3, and SSIM decreases to 0.85, slightly better than the without MHA version, yet CIEDE2000 increases to 5.1, indicating a significant reduction in color accuracy. Visual results in Figure 7 and Figure 8 reveal that the enhanced images exhibit a warmer tone, with noticeable orange hues in certain regions. It leads to over-enhancement, particularly visible in the unnatural reddish highlights on marine organisms and the brightened coral textures. Such inconsistencies reflect a lack of uniform enhancement across regions, often manifesting as localized overfitting or under-enhancement.
On the UFO-120 dataset, Table 4 and Figure 9 and Figure 10, although PSNR improves to 26.9 compared to the one without the MHA model, SSIM drops to 0.82, indicating reduced structural fidelity. Color bias persists, and although the perceptual quality improves slightly over the one without the MHA variant, it still lags behind the complete model. AP-Conv enhances spatial adaptivity by enabling dynamic adjustment of convolutional responses based on input features. This flexibility helps the model effectively handle heterogeneous lighting and degradation common in underwater low-light scenes. By adapting to semantic content and local distortion severity, AP-Conv improves contextual perception, robustness, and overall enhancement quality.
4.4.3. Dynamic Content-Aware Markovian Discriminator
The DCMD integrates local shallow texture features and global deep semantic information, enhancing the network’s capacity for information mapping and image reconstruction. As shown in Table 3, removing DCMD results in a marked decline in performance. The SSIM drops to 0.70, the lowest among all variants, while the PSNR falls to 25.2. Although the CIEDE2000 remains at a moderate level, the perceptual quality metrics decline sharply, with UIQM decreasing to 3.20 and UCIQE to 0.69, and the LPIPS and FID increasing to 0.28 and 26.95, respectively, indicating a significant reduction in overall visual quality and clarity. Visual results in Figure 7 and Figure 8 further corroborate this, showing blurred image details, considerable loss of structural texture, and pronounced color tone deviations following the removal of DCMD.
On the UFO-120 dataset, similar degradation is observed. As shown in Table 4 and Figure 9 and Figure 10, SSIM drops substantially to 0.63 and PSNR to 24.7, highlighting the severe loss of structural fidelity. The enhanced images also exhibit inadequate detail recovery and low contrast. These results validate the effectiveness of DCMD in preserving fine-grained textures and global semantic structure. The DCMD module effectively preserves fine textures and global semantic structure through multi-scale discriminative guidance. It enhances the model’s ability to perform accurate color mapping and maintain structural consistency, resulting in improved visual clarity.
4.5. Model Analysis
The above experiments demonstrate that ATS-UGAN effectively addresses the challenges of underwater low-light image enhancement. This performance is primarily attributed to the algorithm’s integration of MHA, which enables synergistic extraction of information in both the frequency and spatial domains. This integration enhances contextual feature understanding and reinforces global consistency, particularly improving the preservation of fine textures and structural integrity. Additionally, the use of AP-Conv with dynamic convolutional kernels allows the network to better manage spatially varying degradations, such as uneven illumination and localized color biases. Furthermore, DCMD adaptively adjusts the network’s update strategy by leveraging spatial and frequency domain information. This facilitates more effective integration of structural and chromatic features, resulting in improved visual smoothness and more natural color reproduction.
Together, these components work in an adaptive and coordinated manner, enabling the network to generalize well across a variety of complex underwater low-light environments and effectively address the unique challenges of low-light imaging in underwater missions.
It is worth noting that this study specifically addresses the challenge of low-light underwater image enhancement. The dataset employed includes a substantial number of representative extreme low-light scenes, while also encompassing a wide range of complex environmental factors such as varying lighting conditions, granular noise, and background complexity. This data diversity encourages the model to learn more robust and adaptive feature representations during training. Moreover, the adaptive co-design of ATS-UGAN enhances the model’s ability to handle various types of image degradation, demonstrating stable enhancement performance across complex and dynamic test scenarios. Future work will explore the model’s performance in cross-dataset evaluations to further improve its generalization capability in real-world applications.
5. Conclusions
The article proposes a Dual-domain Adaptive Synergy GAN, ATS-UGAN, designed to address image degradation caused by light absorption and scattering in low-light underwater environments. Targeting common degradation issues such as color imbalance, contrast suppression, and local gradient inversion, ATS-UGAN integrates a Multi-scale Hybrid Attention (MHA) mechanism into the generator. This module jointly models frequency and spatial domain information to enhance the robustness and adaptability of feature extraction. In addition, an Adaptive Parameter Convolution (AP-Conv) is introduced to dynamically adjust convolutional kernel weights via a multi-branch structure, thereby improving the network’s ability to model spatially non-uniform underwater scattering patterns. On the discriminator side, a Dynamic Content-aware Markov Discriminator (DCMD) is designed to reinforce the physical plausibility of enhanced images in terms of texture detail and to improve the generator’s color mapping capability. Experiments on public datasets demonstrate that ATS-UGAN achieves superior performance compared to existing state-of-the-art methods, producing enhanced images that are perceptually more natural and closer to the real underwater visual experience. However, ATS-UGAN still faces limitations, including relatively high computational cost and reduced effectiveness in extremely dark or dynamically changing underwater environments. Additionally, its reliance on visual data alone limits robustness under severe degradation. In the future, we plan to explore lightweight network architectures to improve real-time inference efficiency for deployment on underwater platforms. Furthermore, we will incorporate cross-modal data to enhance the algorithm’s robustness under extreme low-light conditions, providing visual support for real-world underwater operations.
Author Contributions
Conceptualization, D.K.; methodology, J.M.; software, D.K. and J.M.; validation, D.K. and Y.Z.; formal analysis, D.K. and Y.Z.; investigation, J.M., Y.W. and S.W.; resources, D.K. and X.Z.; data curation, J.M., Y.W. and S.W.; writing—original draft preparation, D.K., J.M. and Y.Z.; writing—review and editing, D.K. and Y.Z.; visualization, Y.Z., Y.W. and S.W.; supervision, X.Z.; project administration, X.Z.; funding acquisition, D.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Science and Technology Project of Henan Province, grant numbers 242102211025, 252102211059, 232102211070 and the National College Student Innovation Training Program, grant number 202310467012.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- An, S.; Xu, L.; Deng, Z.; Zhang, H. DNIM: Deep-sea netting intelligent enhancement and exposure monitoring using bio-vision. Inf. Fusion 2025, 113, 102629. [Google Scholar] [CrossRef]
- Kang, F.; Huang, B.; Wan, G. Automated detection of underwater dam damage using remotely operated vehicles and deep learning technologies. Autom. Constr. 2025, 171, 105971. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, C.; Long, B.; Zhang, D.; Jiang, Q.; Muhammad, G. Degradation-Decoupling Vision Enhancement for Intelligent Underwater Robot Vision Perception System. IEEE Internet Things J. 2025, 12, 17880–17895. [Google Scholar] [CrossRef]
- Saleem, A.; Awad, A.; Paheding, S.; Lucas, E.; Havens, T.C.; Esselman, P.C. Understanding the Influence of Image Enhancement on Underwater Object Detection: A Quantitative and Qualitative Study. Remote Sens. 2025, 17, 185. [Google Scholar] [CrossRef]
- González-Sabbagh, S.P.; Robles-Kelly, A. A Survey on Underwater Computer Vision. ACM Comput. Surv. 2023, 55, 1–39. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.H.; Li, G.; Kwong, S.; Li, C. Underwater Image Enhancement via Minimal Color Loss and Locally Adaptive Contrast Enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- An, S.; Xu, L.; Deng, Z.; Zhang, H. HFM: A hybrid fusion method for underwater image enhancement. Eng. Appl. Artif. Intell. 2024, 127, 107219. [Google Scholar] [CrossRef]
- Chandrasekar, A.; Sreenivas, M.; Biswas, S. PhISH-Net: Physics Inspired System for High Resolution Underwater Image Enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 1506–1516. [Google Scholar]
- Zhang, W.; Zhou, L.; Zhuang, P.; Li, G.; Pan, X.; Zhao, W.; Li, C. Underwater Image Enhancement via Weighted Wavelet Visual Perception Fusion. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 2469–2483. [Google Scholar] [CrossRef]
- Vasamsetti, S.; Mittal, N.; Neelapu, B.C.; Sardana, H.K. Wavelet based perspective on variational enhancement technique for underwater imagery. Ocean Eng. 2017, 141, 88–100. [Google Scholar] [CrossRef]
- Ma, H.; Huang, J.; Shen, C.; Jiang, Z. Retinex-inspired underwater image enhancement with information entropy smoothing and non-uniform illumination priors. Pattern Recognit. 2025, 162, 111411. [Google Scholar] [CrossRef]
- Xiang, D.; He, D.; Wang, H.; Qu, Q.; Shan, C.; Zhu, X.; Zhong, J.; Gao, P. Attenuated color channel adaptive correction and bilateral weight fusion for underwater image enhancement. Opt. Lasers Eng. 2025, 184, 108575. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, Q.; Feng, Y.; Cai, L.; Zhuang, P. Underwater Image Enhancement via Principal Component Fusion of Foreground and Background. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10930–10943. [Google Scholar] [CrossRef]
- Jha, M.; Bhandari, A.K. CBLA: Color-Balanced Locally Adjustable Underwater Image Enhancement. IEEE Trans. Instrum. Meas. 2024, 73, 5020911. [Google Scholar] [CrossRef]
- Liu, C.; Shu, X.; Pan, L.; Shi, J.; Han, B. Multiscale Underwater Image Enhancement in RGB and HSV Color Spaces. IEEE Trans. Instrum. Meas. 2023, 72, 5021814. [Google Scholar] [CrossRef]
- Liang, Y.; Li, L.; Zhou, Z.; Tian, L.; Xiao, X.; Zhang, H. Underwater Image Enhancement via Adaptive Bi-Level Color-Based Adjustment. IEEE Trans. Instrum. Meas. 2025, 74, 5018916. [Google Scholar] [CrossRef]
- Chen, Z.; Sun, W.; Jia, J.; Huang, R.; Lu, F.; Chen, Y.; Min, X.; Zhai, G.; Zhang, W. Joint Luminance-Chrominance Learning for Image Debanding. IEEE Trans. Circuits Syst. Video Technol. 2025. [CrossRef]
- Xue, X.; Yuan, J.; Ma, T.; Ma, L.; Jia, Q.; Zhou, J.; Wang, Y. Degradation-Decoupled and semantic-aggregated cross-space fusion for underwater image enhancement. Inf. Fusion 2025, 118, 102927. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, S.; An, D.; Li, D.; Zhao, R. LiteEnhanceNet: A lightweight network for real-time single underwater image enhancement. Expert Syst. Appl. 2024, 240, 122546. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Yang, J.; Zhu, S.; Liang, H.; Bai, S.; Jiang, F.; Hussain, A. PAFPT: Progressive aggregator with feature prompted transformer for underwater image enhancement. Expert Syst. Appl. 2025, 262, 125539. [Google Scholar] [CrossRef]
- Shang, J.; Li, Y.; Xing, H.; Yuan, J. LGT: Luminance-guided transformer-based multi-feature fusion network for underwater image enhancement. Inf. Fusion 2025, 118, 102977. [Google Scholar] [CrossRef]
- Du, D.; Li, E.; Si, L.; Zhai, W.; Xu, F.; Niu, J.; Sun, F. UIEDP: Boosting underwater image enhancement with diffusion prior. Expert Syst. Appl. 2025, 259, 125271. [Google Scholar] [CrossRef]
- Zhang, D.; Wu, C.; Zhou, J.; Zhang, W.; Li, C.; Lin, Z. Hierarchical attention aggregation with multi-resolution feature learning for GAN-based underwater image enhancement. Eng. Appl. Artif. Intell. 2023, 125, 106743. [Google Scholar] [CrossRef]
- Wang, H.; Köser, K.; Ren, P. Large Foundation Model Empowered Discriminative Underwater Image Enhancement. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–17. [Google Scholar] [CrossRef]
- Xu, C.; Zhou, W.; Huang, Z.; Zhang, Y.; Zhang, Y.; Wang, W.; Xia, F. Fusion-based graph neural networks for synergistic underwater image enhancement. Inf. Fusion 2025, 117, 102857. [Google Scholar] [CrossRef]
- Saleh, A.; Sheaves, M.; Jerry, D.; Rahimi Azghadi, M. Adaptive deep learning framework for robust unsupervised underwater image enhancement. Expert Syst. Appl. 2025, 268, 126314. [Google Scholar] [CrossRef]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. CondConv: Conditionally Parameterized Convolutions for Efficient Inference. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception. arXiv 2020, arXiv:2002.01155. [Google Scholar]
- Setiadi, D.R.I.M.; Ghosal, S.K.; Sahu, A.K. AI-Powered Steganography: Advances in Image, Linguistic, and 3D Mesh Data Hiding—A Survey. J. Future Artif. Intell. Technol. 2025, 2, 1–23. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2020, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.L.; Huang, Q.; Kwong, S. PUGAN: Physical Model-Guided Underwater Image Enhancement Using GAN With Dual-Discriminators. IEEE Trans. Image Process. 2023, 32, 4472–4485. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).