
Effect of Seabed Type on Image Segmentation of an Underwater Object Obtained from a Side Scan Sonar Using a Deep Learning Approach


Abstract
1. Introduction
- Applying equal weights in the cross-entropy loss function yielded superior performance compared to pixel-frequency-based weighting.
- Image segmentation for mud area images was easier than for sand area images.
- Networks trained using datasets from both seabed types demonstrated improved segmentation performance in challenging regions, such as sand areas, compared to networks trained on single-seabed datasets.
2. Sea Experiment and Dataset
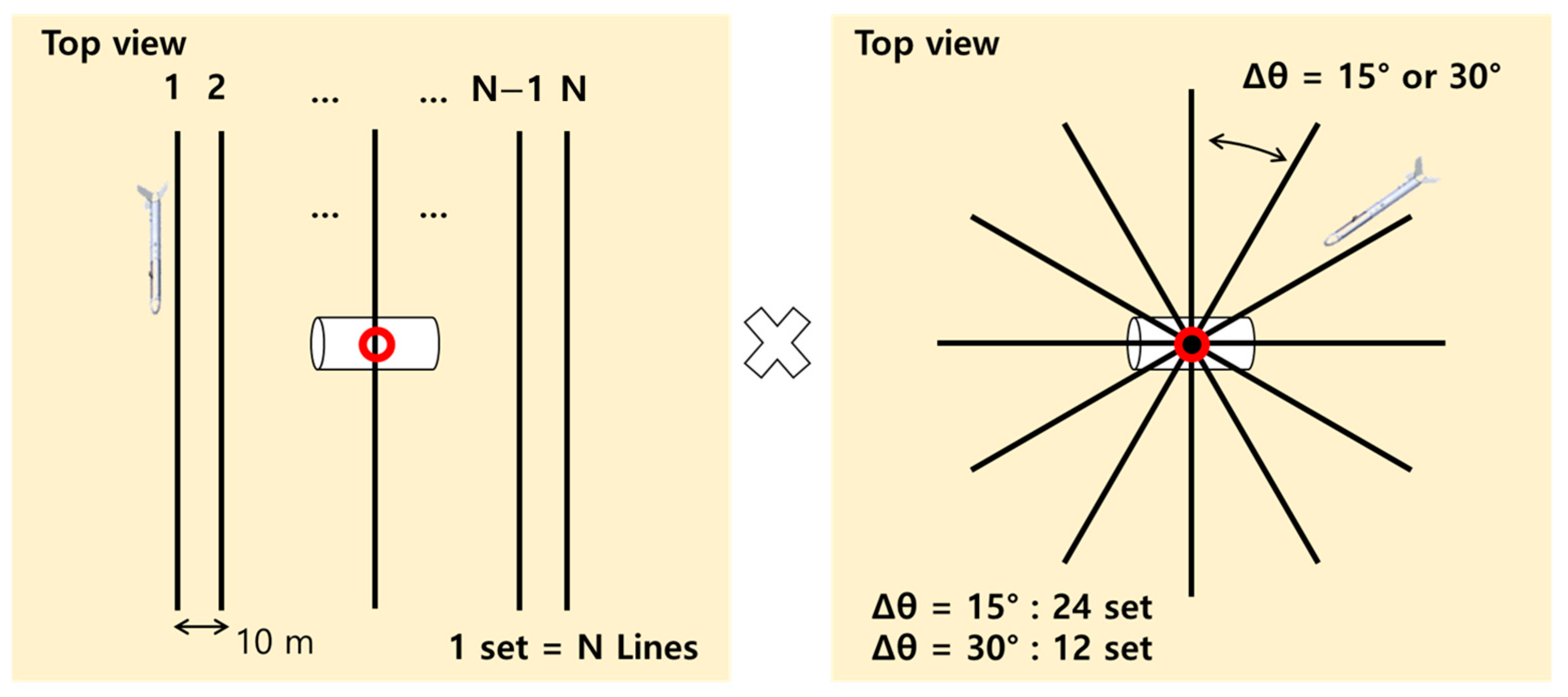
2.1. Sea Experiment
2.2. Target Dataset
3. Deep Learning Application Method
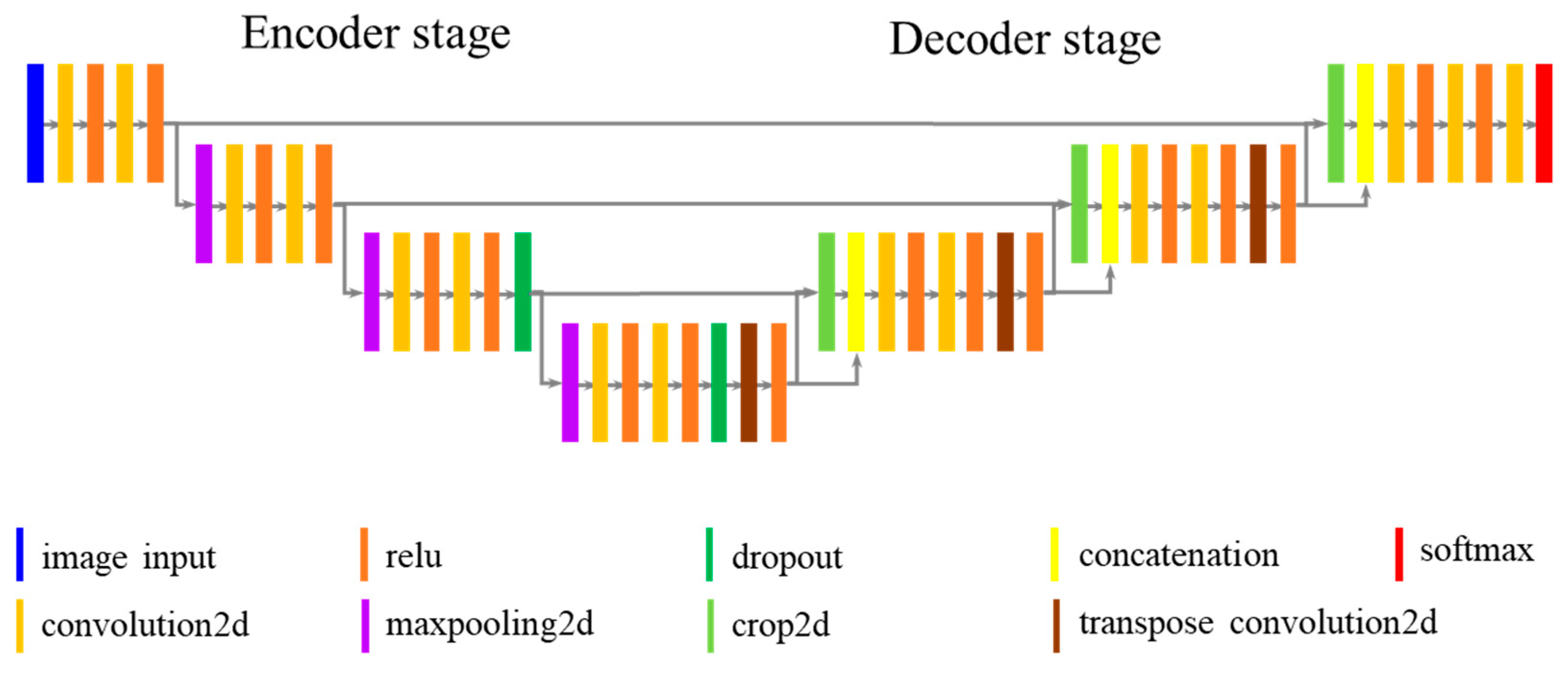
3.1. Network Design
3.2. Network Training Options
4. Results
- The case where train, validation, and test datasets are the same
- Weight type of loss function,
- Seabed type (dataset)
- The case where the dataset of train and validation and the dataset of test are different
- The network trained on a single dataset only,
- The network is trained on both datasets.
4.1. The Examples for the Image Segmentation
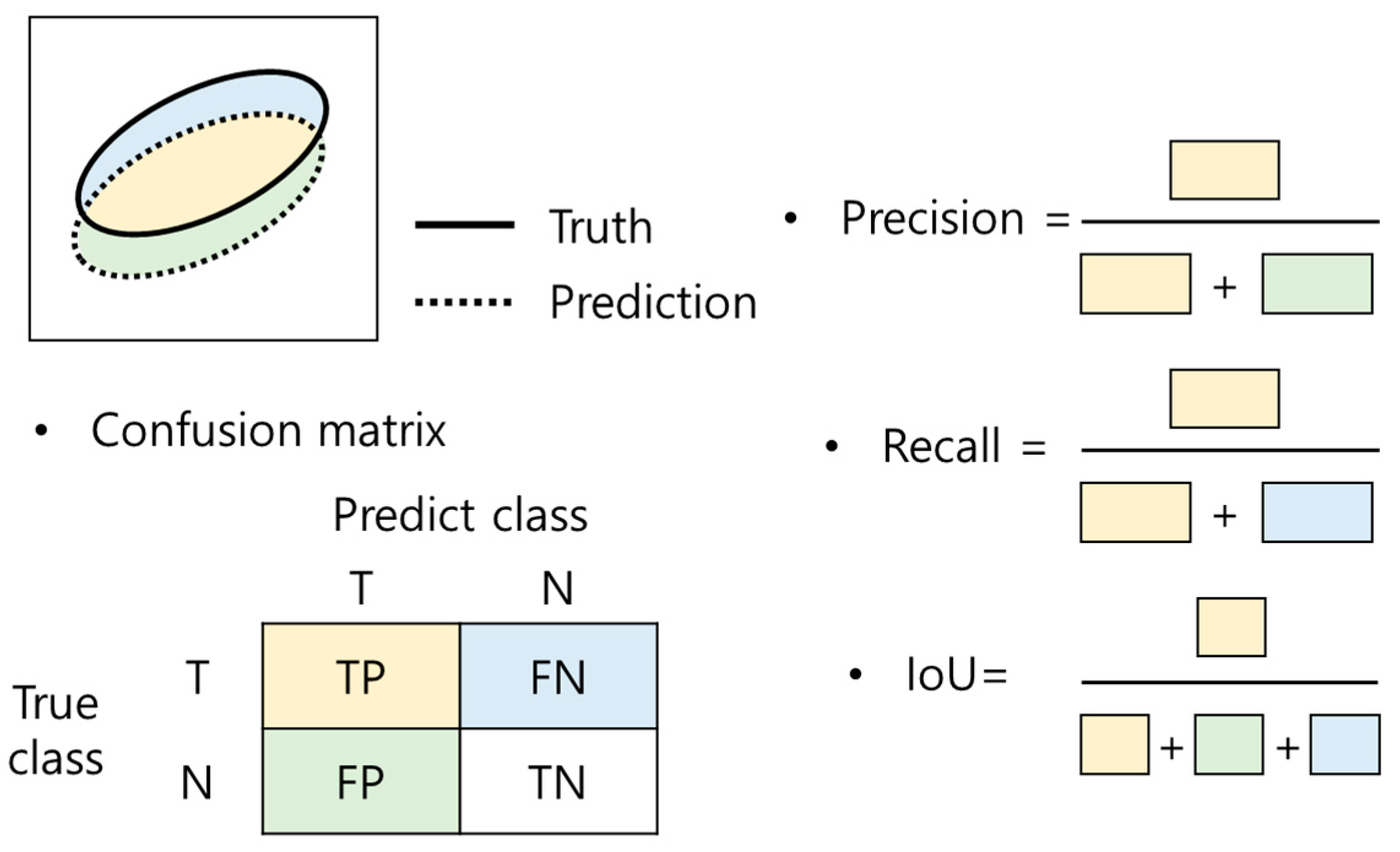
4.2. The Performance Metrics
4.3. The Case Where the Datasets of Train, Validation and Test Are the Same
4.3.1. Perspective for the Weight of Loss Function
4.3.2. Perspective for the Seabed Type (Dataset)
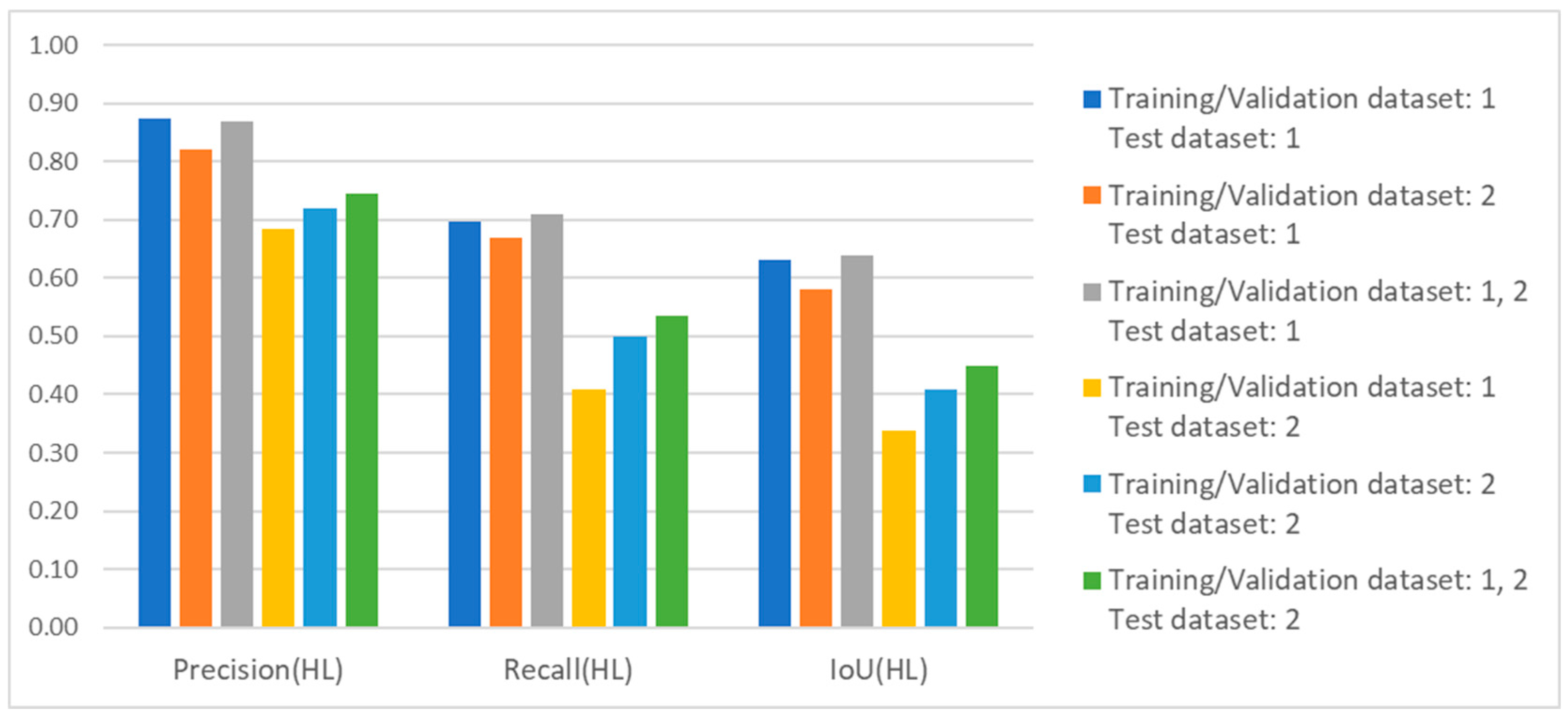
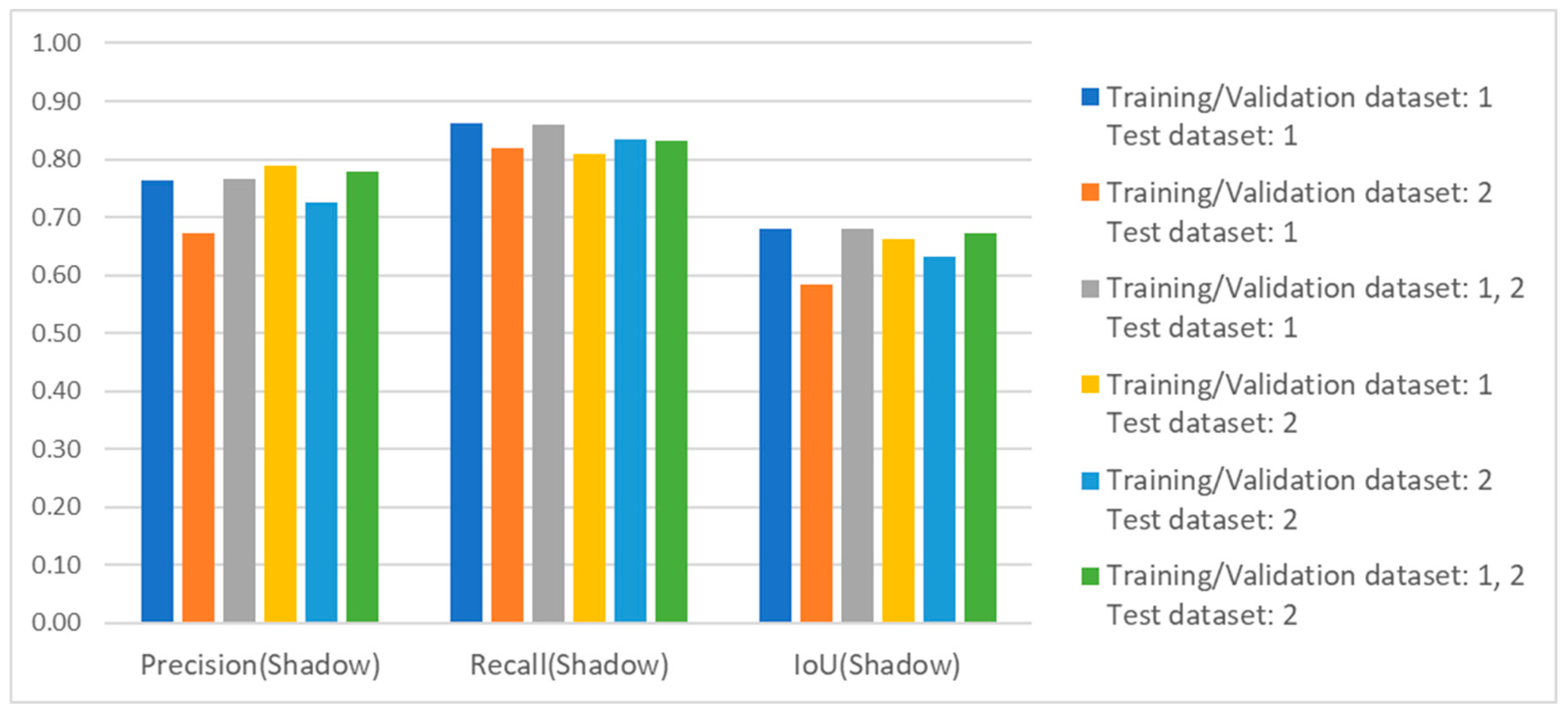
4.4. The Case Where the Dataset of Train and Validation and the Dataset of Test Are Different
4.4.1. Network Trained on Using Single Dataset Only
4.4.2. Network Trained on Using Dataset 1 and Dataset 2 Both
5. Conclusions
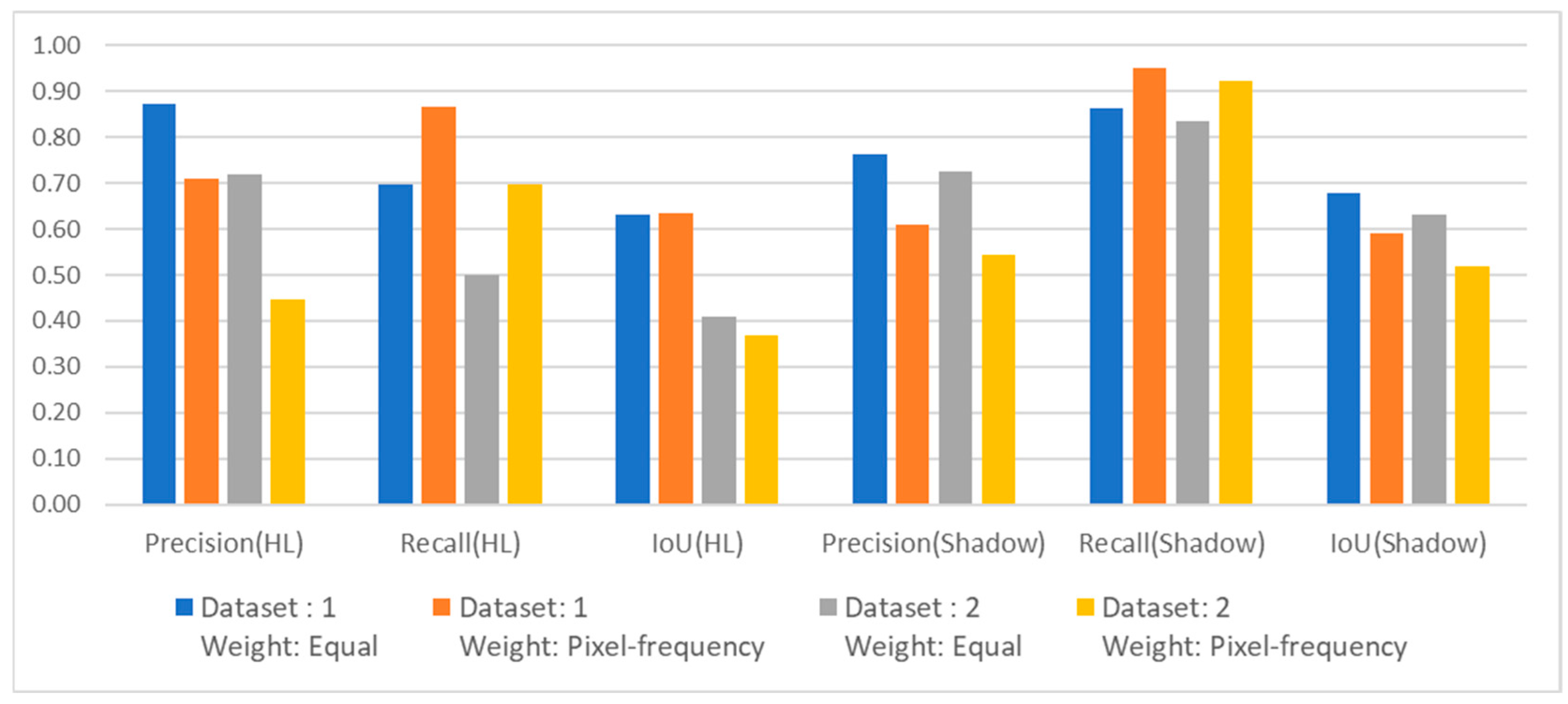
- When the training, validation, and test datasets are the same, comparing the loss function’s weight type, the segmentation metrics using equal weight are better than weight considering pixel frequency. This improvement is indicated by the IoU for the highlight class in dataset 2 (0.41 compared to 0.37).
- When the training, validation, and test datasets are the same, the segmentation performance for the target highlight class and shadow class is superior when using only the mud area dataset compared to using only the sand area dataset. This difference is indicated by the IoU for the highlight class (0.63 compared to 0.41) and the IoU for the shadow class (0.68 compared to 0.63). Hence, the target in the mud area is easier to distinguish from the bottom compared to the target in the sand area.
- When the network is trained and validated on mud area data, the image segmentation performance for the target shadow class was consistent across the mud and sand test dataset. This is indicated by the IoU values: 0.68 in the mud area and 0.66 in the sand area. However, the performance of the target highlight class dropped significantly in the sand test data compared to the mud test data. The IoU values indicate this difference: 0.63 in the mud area and 0.34 in the sand area.
- When the network was trained and validated on sand area data, the image segmentation performance for the target shadow class on mud test data decreased slightly. This is indicated by the IoU values: 0.58 in the mud area and 0.63 in the sand area. However, the performance of the target highlight class dropped significantly in the sand test data compared to the mud test data. The IoU values indicate this difference: 0.58 in the mud area and 0.41 in the sand area.
- The performance of the network training and validation using datasets obtained from both sand and mud areas was improved. When testing on the mud area dataset, no significant difference in performance was observed. However, when testing on the sand area dataset, we noted improved image segmentation performance for the target highlight class and shadow class compared to using only every single dataset throughout the training, validation, and test processes. The IoU values for the highlight class in sand area images are as follows: 0.34 for training on mud, 0.41 for training on sand, and 0.45 for training on both.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stewart, W.I.; Chu, D.; Malik, S.; Lerner, S.; Singh, H. Quantitative seafloor characterization using a bathymetric sidescan sonar. IEEE J. Ocean. Eng. 1994, 19, 599–610. [Google Scholar] [CrossRef]
- Iacono, C.L.; Gràcia, E.; Diez, S.; Bozzano, G.; Moreno, X.; Dañobeitia, J.; Alonso, B. Seafloor characterization and backscatter variability of the Almería Margin (Alboran Sea, SW Mediterranean) based on high-resolution acoustic data. Mar. Geol. 2008, 250, 1–18. [Google Scholar] [CrossRef]
- Yang, D.; Wang, C.; Cheng, C.; Pan, G.; Zhang, F. Semantic segmentation of side-scan sonar images with few samples. Electronics 2022, 11, 3002. [Google Scholar] [CrossRef]
- Burguera, A.; Bonin-Font, F. On-line multi-class segmentation of side-scan sonar imagery using an autonomous underwater vehicle. J. Mar. Sci. Eng. 2020, 8, 557. [Google Scholar] [CrossRef]
- Yan, J.; Meng, J.; Zhao, J. Real-time bottom tracking using side scan sonar data through one-dimensional convolutional neural networks. Remote Sens. 2019, 12, 37. [Google Scholar] [CrossRef]
- Yan, J.; Meng, J.; Zhao, J. Bottom detection from backscatter data of conventional side scan sonars through 1D-UNet. Remote Sens. 2021, 13, 1024. [Google Scholar] [CrossRef]
- Mignotte, M.; Collet, C.; Perez, P.; Bouthemy, P. Sonar image segmentation using an unsupervised hierarchical MRF model. IEEE Trans. Image Process. 2000, 9, 1216–1231. [Google Scholar] [CrossRef]
- Acosta, G.G.; Villar, S.A. Accumulated CA–CFAR process in 2-D for online object detection from sidescan sonar data. IEEE J. Ocean. Eng. 2015, 40, 558–569. [Google Scholar] [CrossRef]
- Tueller, P.; Kastner, R.; Diamant, R. A comparison of feature detectors for underwater sonar imagery. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, X.; Wang, L.; Li, G.; Xie, X. A robust and fast method for sidescan sonar image segmentation based on region growing. Sensors 2021, 21, 6960. [Google Scholar] [CrossRef]
- Gebhardt, D.; Parikh, K.; Dzieciuch, I.; Walton, M.; Vo Hoang, N.A. Hunting for naval mines with deep neural networks. In Proceedings of the OCEANS 2017—Anchorage, Anchorage, AK, USA, 18–21 September 2017; pp. 1–5. [Google Scholar]
- Kim, J.; Choi, J.W.; Kwon, H.; Oh, R.; Son, S.-U. The application of convolutional neural networks for automatic detection of underwater objects in side-scan sonar images. J. Acoust. Soc. Kor 2018, 37, 118–128. [Google Scholar] [CrossRef]
- Wu, M.; Wang, Q.; Rigall, E.; Li, K.; Zhu, W.; He, B.; Yan, T. ECNet: Efficient convolutional networks for side scan sonar image segmentation. Sensors 2019, 19, 2009. [Google Scholar] [CrossRef] [PubMed]
- Thanh Le, H.; Phung, S.L.; Chapple, P.B.; Bouzerdoum, A.; Ritz, C.H.; Tran, L.C. Deep gabor neural network for automatic detection of mine-like objects in sonar imagery. IEEE Access 2020, 8, 94126–94139. [Google Scholar] [CrossRef]
- Kim, W.K.; Bae, H.S.; Son, S.U.; Park, J.S. Neural network-based underwater object detection off the coast of the Korean Peninsula. J. Mar. Sci. Eng. 2022, 10, 1436. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, J.; Huang, W.; Zhang, S. Side-scan sonar image segmentation based on multi-channel fusion convolution neural networks. IEEE Sens. J. 2022, 22, 5911–5928. [Google Scholar] [CrossRef]
- Shi, P.; Sun, H.; He, Q.; Wang, H.; Fan, X.; Xin, Y. An effective strategy of object instance segmentation in sonar images. IET Signal Process. 2024, 2024, 1357293. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, Y.; Li, H.; Kang, Y.; Liu, L.; Chen, C.; Zhai, G. A novel target detection method with dual-domain multi-frequency feature in side-scan sonar images. IET Image Process. 2024, 18, 4168–4188. [Google Scholar] [CrossRef]
- Wen, X.; Wang, J.; Cheng, C.; Zhang, F.; Pan, G. Underwater side-scan sonar target detection: YOLOv7 model combined with attention mechanism and scaling factor. Remote Sens. 2024, 16, 2492. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, H.; Zhang, G.; Ren, J.; Shu, G. CGF-Unet: Semantic segmentation of sidescan sonar based on UNET combined with global features. IEEE J. Ocean. Eng. 2024, 49, 8346–8360. [Google Scholar] [CrossRef]
- Zhu, J.; Cai, W.; Zhang, M.; Pan, M. Sonar image coarse-to-fine few-shot segmentation based on object-shadow feature pair localization and level set method. IEEE Sens. J. 2024, 24, 8346–8360. [Google Scholar] [CrossRef]
- Huo, G.; Wu, Z.; Li, J. Underwater object classification in sidescan sonar images using deep transfer learning and semisynthetic training data. IEEE Access 2020, 8, 47407–47418. [Google Scholar] [CrossRef]
- Zhang, P.; Tang, J.; Zhong, H.; Ning, M.; Liu, D.; Wu, K. Self-trained target detection of radar and sonar images using automatic deep learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4701914. [Google Scholar] [CrossRef]
- Santos, N.P.; Moura, R.; Torgal, G.S.; Lobo, V.; de Castro Neto, M. Side-scan sonar imaging data of underwater vehicles for mine detection. Data Brief 2024, 53, 110132. [Google Scholar] [CrossRef] [PubMed]
- Talukdar, K.K.; Tyce, R.C.; Clay, C.S. Interpretation of Sea Beam backscatter data collected at the Laurentian fan off Nova Scotia using acoustic backscatter theory. J. Acoust. Soc. Am. 1995, 97, 1545–1558. [Google Scholar] [CrossRef]
- Chotiros, N.P. Seafloor acoustic backscattering strength and properties from published data. In Proceedings of the OCEANS 2006—Asia Pacific, Singapore, 16–19 May 2006; pp. 1–6. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Mud | Sand | Experiment | Site |
|---|---|---|---|---|
| 1 | 209 | 0 | 1, 2 | Geoje |
| 2 | 0 | 174 | 4 | Busan |
| Specification | |||||||
|---|---|---|---|---|---|---|---|
| Dataset | 1 | ||||||
| Optimizer | ADAM | ||||||
| Loss function | Cross entropy loss | ||||||
| k-fold | Loss function weight type | HL | Shadow | ||||
| Precision | Recall | IoU | Precision | Recall | IoU | ||
| 1 | Equal | 0.88 | 0.70 | 0.64 | 0.75 | 0.87 | 0.68 |
| 2 | 0.84 | 0.74 | 0.65 | 0.74 | 0.87 | 0.67 | |
| 3 | 0.90 | 0.66 | 0.62 | 0.76 | 0.87 | 0.68 | |
| 4 | 0.87 | 0.68 | 0.62 | 0.80 | 0.83 | 0.69 | |
| Mean | 0.87 | 0.70 | 0.63 | 0.76 | 0.86 | 0.68 | |
| 1 | Pixel- frequency | 0.67 | 0.90 | 0.62 | 0.62 | 0.96 | 0.61 |
| 2 | 0.63 | 0.92 | 0.60 | 0.66 | 0.91 | 0.62 | |
| 3 | 0.75 | 0.83 | 0.65 | 0.57 | 0.97 | 0.56 | |
| 4 | 0.78 | 0.81 | 0.66 | 0.59 | 0.97 | 0.58 | |
| Mean | 0.71 | 0.87 | 0.63 | 0.61 | 0.95 | 0.59 | |
| Specification | |||||||
|---|---|---|---|---|---|---|---|
| Dataset | 2 | ||||||
| Optimizer | ADAM | ||||||
| Loss function | Cross entropy loss | ||||||
| k-fold | Loss function weight type | HL | Shadow | ||||
| Precision | Recall | IoU | Precision | Recall | IoU | ||
| 1 | Equal | 0.77 | 0.28 | 0.26 | 0.71 | 0.85 | 0.63 |
| 2 | 0.69 | 0.56 | 0.44 | 0.69 | 0.86 | 0.62 | |
| 3 | 0.74 | 0.56 | 0.46 | 0.71 | 0.83 | 0.62 | |
| 4 | 0.68 | 0.60 | 0.47 | 0.78 | 0.80 | 0.66 | |
| Mean | 0.72 | 0.50 | 0.41 | 0.72 | 0.83 | 0.63 | |
| 1 | Pixel- frequency | 0.56 | 0.65 | 0.43 | 0.51 | 0.94 | 0.50 |
| 2 | 0.35 | 0.75 | 0.32 | 0.52 | 0.92 | 0.50 | |
| 3 | 0.51 | 0.68 | 0.41 | 0.58 | 0.92 | 0.55 | |
| 4 | 0.36 | 0.72 | 0.32 | 0.57 | 0.91 | 0.54 | |
| Mean | 0.45 | 0.70 | 0.37 | 0.54 | 0.92 | 0.52 | |
| Specification | ||||||||
|---|---|---|---|---|---|---|---|---|
| Optimizer | ADAM | |||||||
| Loss function | Cross entropy loss with equal weight | |||||||
| k-fold | Dataset | HL | Shadow | |||||
| Training/ Validiation | Test | Precision | Recall | IoU | Precision | Recall | IoU | |
| 1 | 1 | 1 | 0.88 | 0.70 | 0.64 | 0.75 | 0.87 | 0.68 |
| 2 | 0.84 | 0.74 | 0.65 | 0.74 | 0.87 | 0.67 | ||
| 3 | 0.90 | 0.66 | 0.62 | 0.76 | 0.87 | 0.68 | ||
| 4 | 0.87 | 0.68 | 0.62 | 0.80 | 0.83 | 0.69 | ||
| Mean | 0.87 | 0.70 | 0.63 | 0.76 | 0.86 | 0.68 | ||
| 1 | 2 | 1 | 0.86 | 0.55 | 0.51 | 0.65 | 0.80 | 0.56 |
| 2 | 0.79 | 0.70 | 0.59 | 0.65 | 0.83 | 0.57 | ||
| 3 | 0.81 | 0.72 | 0.62 | 0.66 | 0.86 | 0.59 | ||
| 4 | 0.82 | 0.71 | 0.62 | 0.73 | 0.79 | 0.61 | ||
| Mean | 0.82 | 0.67 | 0.58 | 0.67 | 0.82 | 0.58 | ||
| 1 | 1, 2 | 1 | 0.87 | 0.72 | 0.65 | 0.75 | 0.90 | 0.69 |
| 2 | 0.86 | 0.72 | 0.64 | 0.76 | 0.86 | 0.67 | ||
| 3 | 0.86 | 0.72 | 0.65 | 0.74 | 0.88 | 0.67 | ||
| 4 | 0.89 | 0.67 | 0.62 | 0.82 | 0.80 | 0.68 | ||
| Mean | 0.87 | 0.71 | 0.64 | 0.77 | 0.86 | 0.68 | ||
| 1 | 1 | 2 | 0.71 | 0.41 | 0.35 | 0.80 | 0.81 | 0.67 |
| 2 | 0.57 | 0.50 | 0.37 | 0.76 | 0.84 | 0.66 | ||
| 3 | 0.79 | 0.33 | 0.30 | 0.77 | 0.82 | 0.66 | ||
| 4 | 0.66 | 0.39 | 0.32 | 0.83 | 0.76 | 0.66 | ||
| Mean | 0.68 | 0.41 | 0.34 | 0.79 | 0.81 | 0.66 | ||
| 1 | 2 | 2 | 0.77 | 0.28 | 0.26 | 0.71 | 0.85 | 0.63 |
| 2 | 0.69 | 0.56 | 0.44 | 0.69 | 0.86 | 0.62 | ||
| 3 | 0.74 | 0.56 | 0.46 | 0.71 | 0.83 | 0.62 | ||
| 4 | 0.68 | 0.60 | 0.47 | 0.78 | 0.80 | 0.66 | ||
| Mean | 0.72 | 0.50 | 0.41 | 0.72 | 0.83 | 0.63 | ||
| 1 | 1, 2 | 2 | 0.74 | 0.58 | 0.48 | 0.74 | 0.86 | 0.66 |
| 2 | 0.71 | 0.57 | 0.47 | 0.79 | 0.85 | 0.69 | ||
| 3 | 0.72 | 0.50 | 0.42 | 0.76 | 0.85 | 0.67 | ||
| 4 | 0.81 | 0.48 | 0.44 | 0.82 | 0.79 | 0.67 | ||
| Mean | 0.75 | 0.53 | 0.45 | 0.78 | 0.83 | 0.67 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Bae, H.S. Effect of Seabed Type on Image Segmentation of an Underwater Object Obtained from a Side Scan Sonar Using a Deep Learning Approach. J. Mar. Sci. Eng. 2025, 13, 242. https://doi.org/10.3390/jmse13020242
Park J, Bae HS. Effect of Seabed Type on Image Segmentation of an Underwater Object Obtained from a Side Scan Sonar Using a Deep Learning Approach. Journal of Marine Science and Engineering. 2025; 13(2):242. https://doi.org/10.3390/jmse13020242
Chicago/Turabian StylePark, Jungyong, and Ho Seuk Bae. 2025. "Effect of Seabed Type on Image Segmentation of an Underwater Object Obtained from a Side Scan Sonar Using a Deep Learning Approach" Journal of Marine Science and Engineering 13, no. 2: 242. https://doi.org/10.3390/jmse13020242
APA StylePark, J., & Bae, H. S. (2025). Effect of Seabed Type on Image Segmentation of an Underwater Object Obtained from a Side Scan Sonar Using a Deep Learning Approach. Journal of Marine Science and Engineering, 13(2), 242. https://doi.org/10.3390/jmse13020242