In this section, the corresponding contiguous generative models HUISM and DPEM in HEGAN are first introduced. Then, the corresponding loss functions in their HEGAN are constructed.
3.1. Hybrid Underwater Image Synthesis Model
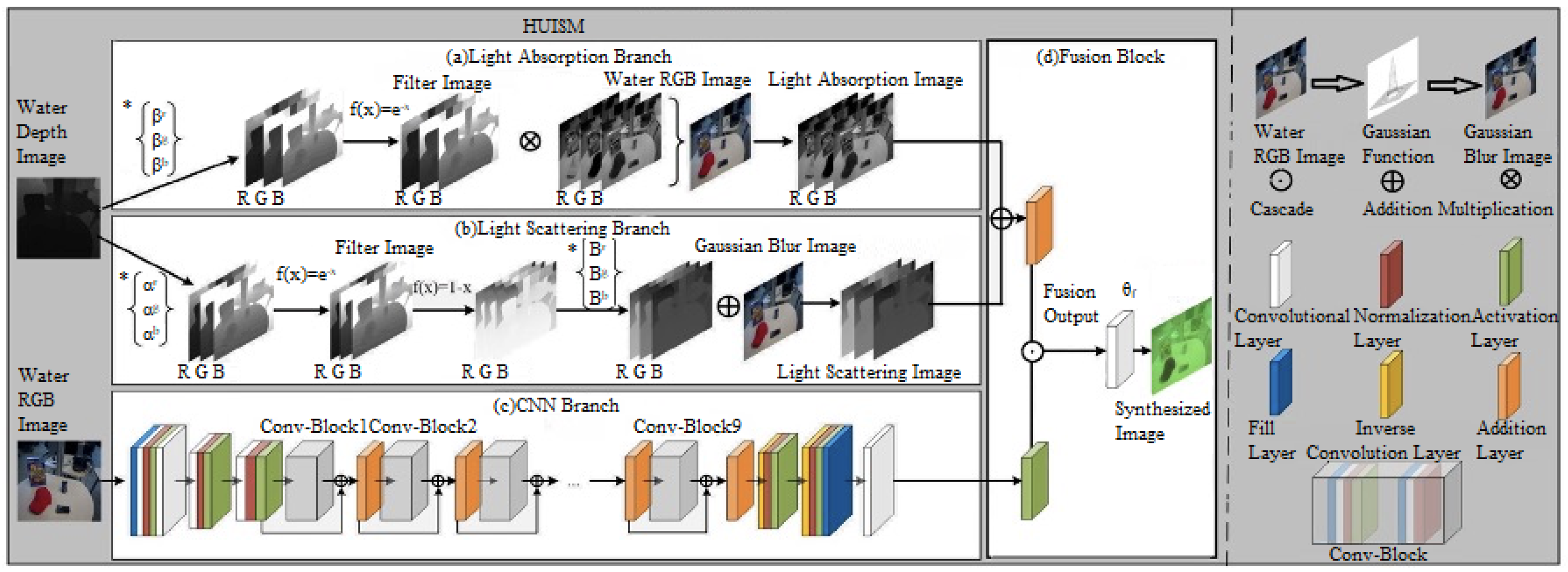
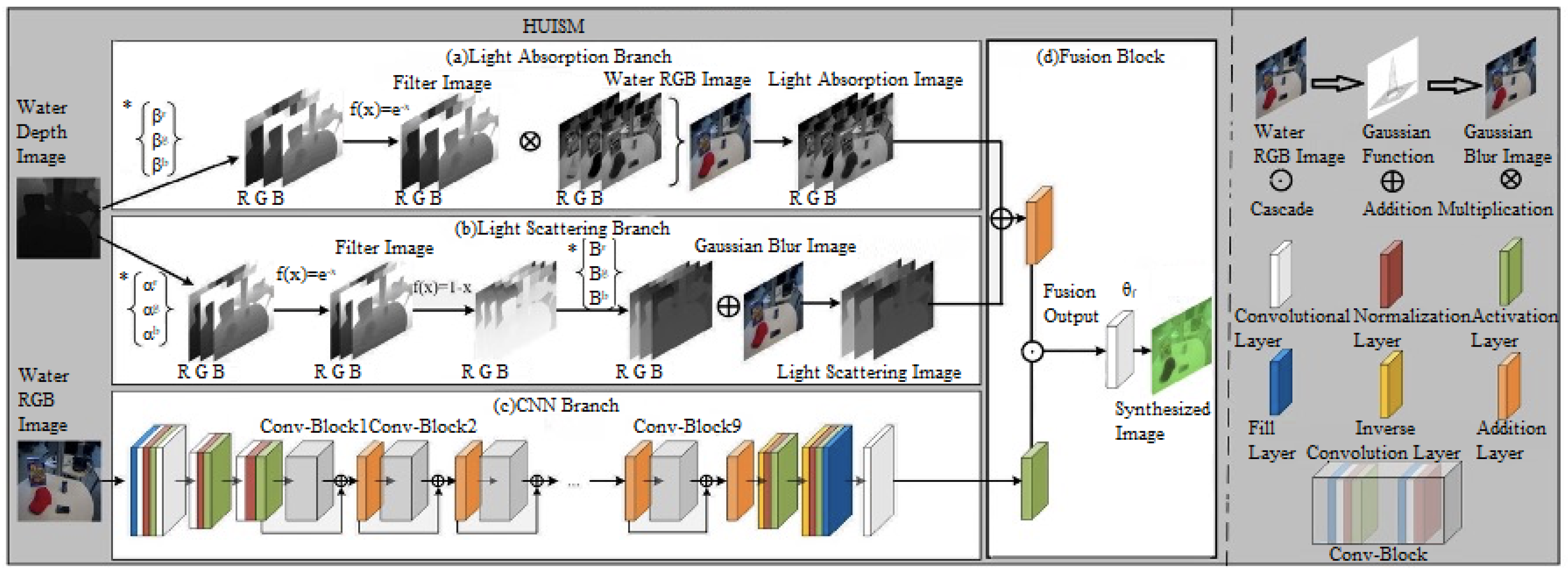
This section proposes a hybrid underwater image synthesis model (see
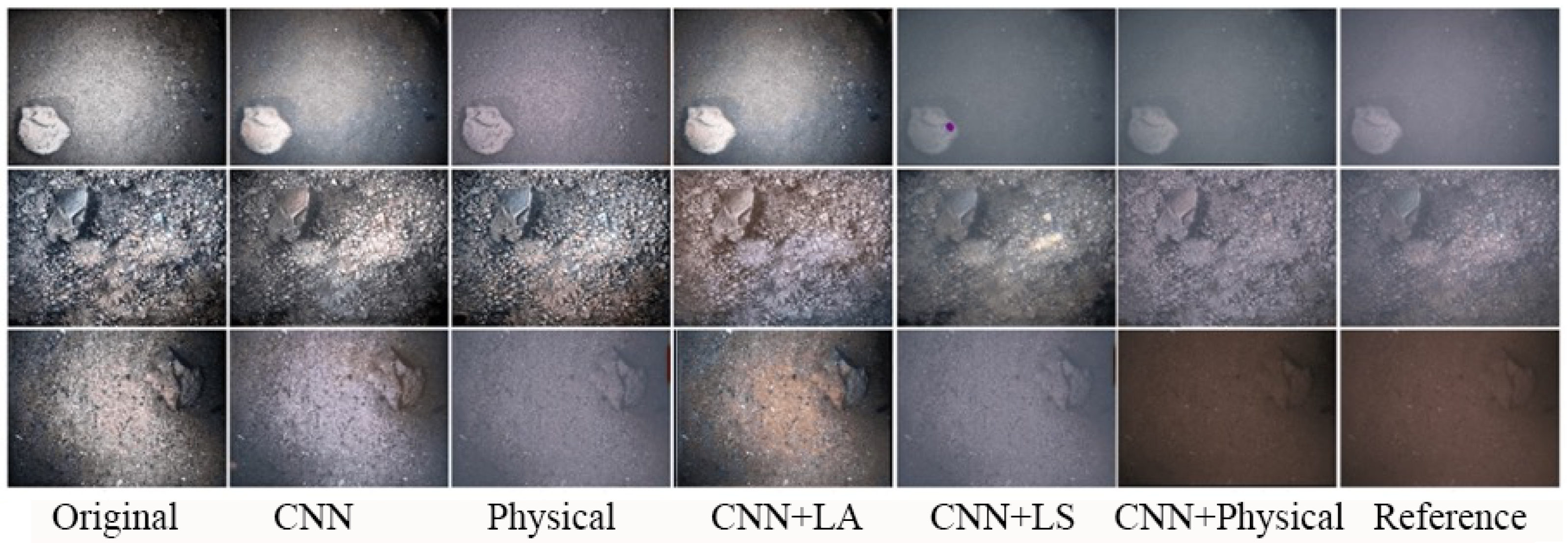
Figure 1), including four modules: (a) Light Absorption Module (LA), (b) Light Scattering Module (LS), (c) CNN Module (CNN), (d) Fusion Module, Fusion. Firstly, applying the a priori knowledge of light absorption and scattering to model the degradation features of underwater images is proposed. Then, a convolutional neural network is utilized to complement the physical model to simulate other degradation details of the underwater image. LA and LS are built based on optical a priori information to form a complete physical model and perform elemental operations with the CNN throughout the whole network, producing an acceptable result as an output.
Light Absorption module. LA aims to simulate the distortion effect of underwater images through the principle of light absorption. Since the degree of light absorption is affected in proportion to the length of the optical path, i.e., light absorption is related to the scene’s depth. Therefore, the light absorption module leads from the depth map over water and can be expressed as:
where
and
denote the light absorption map as well as the clear RGB map on the water, respectively.
shows the depth map on the water with the depth information
d, and
presents the absorption coefficients of different channels of the RGB image on the water. The ⊗ are the symbols for element-level multiplication operations.
First, the corresponding transition map
T is obtained according to the transition equation (Equation (
1)):
Then, the transition map is multiplied by the information of the three channels of the RGB map on the water to obtain the information of the image after the light absorption degradation effect.
Light Scattering module. LS aims to simulate the blurring effect of underwater images through the principle of light scattering. Light scattering
underwater can be divided into forward scattering
and backward scattering
. The LS module can be stated as follows:
Forward scattering refers to the scattering of light from the imaging device to the underwater scene in the collision process with aquatic organisms. This phenomenon can be well modelled using the Gaussian fuzzy function, representing the fog-like effect caused by forward scattering. On the other hand, backward scattering refers to the scattering of light from the imaging device to the underwater scene after it interacts with the surface of the scene again. Therefore, it can be indicated explicitly as:
where
and
B denote the background light coefficient and backscattering coefficient of different channels of the RGB image on water, respectively. The
can be expressed as the Gaussian function:
CNN module. The CNN complements the physical model consisting of LA and LS and is designed to simulate other more over-degraded details. There are other factors, based on the physical model, to consider, such as the presence of artificial light leading to uneven illumination on the image, motion of the imaging device will introduce noise in the captured image. Based on the fact that the physical model cannot be simulated, this section is refined and supplemented by the CNN module, which is used to construct a deep and densely connected network structure by using nine convolutional blocks stacked together to improve the feature representation capability of the deep network, learn more complex features and patterns, generate more fine-grained colour distortions, illumination variations, and noise.
Fusion module. Fusion aims to fuse physical model branches with CNNs. Its specific expression is as follows:
where
denotes the pixel value at each pixel point
of the synthesized image, and
shows the convolutional filter of size
, which is responsible for converting the outputs of the three branches into the three channels of information of the synthesized image. The
as the fused output of the three branches is denoted as follows:
where
presents the output of the CNN module, and ⊙ is the channel-level concatenation operation.
In this paper, this HUISM algorithm is applied to underwater images.
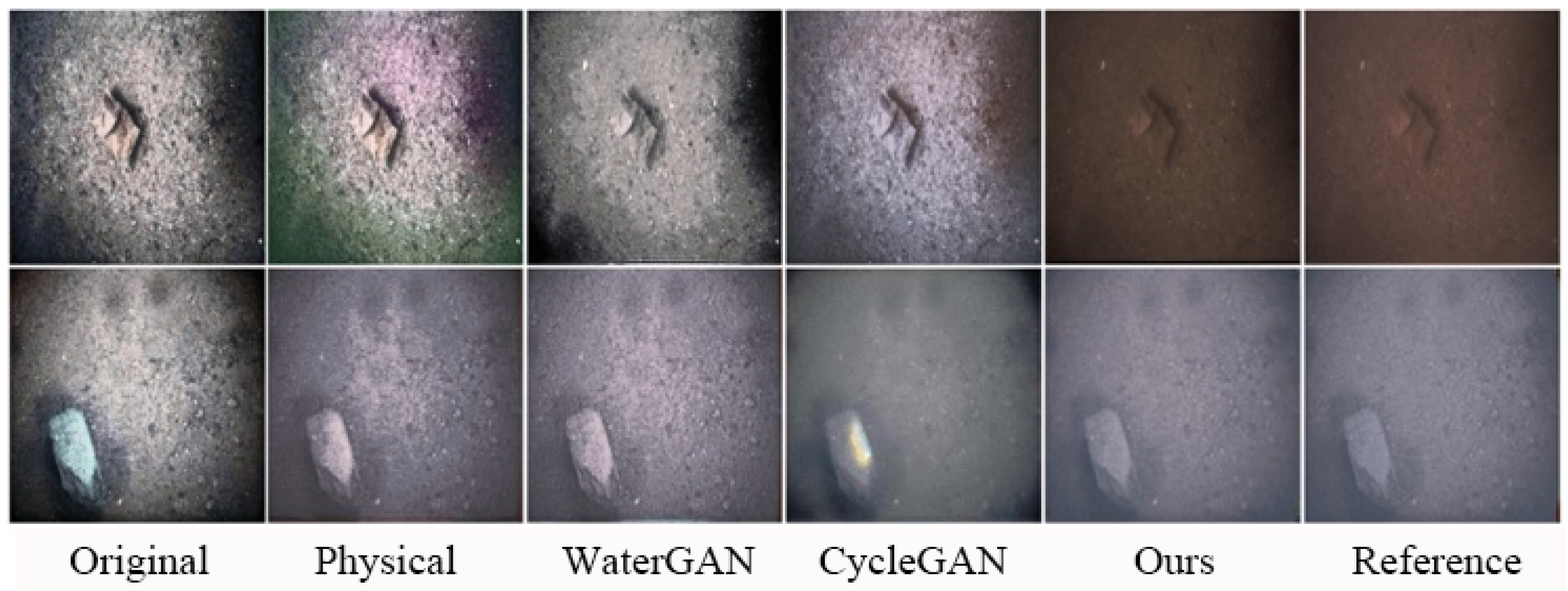
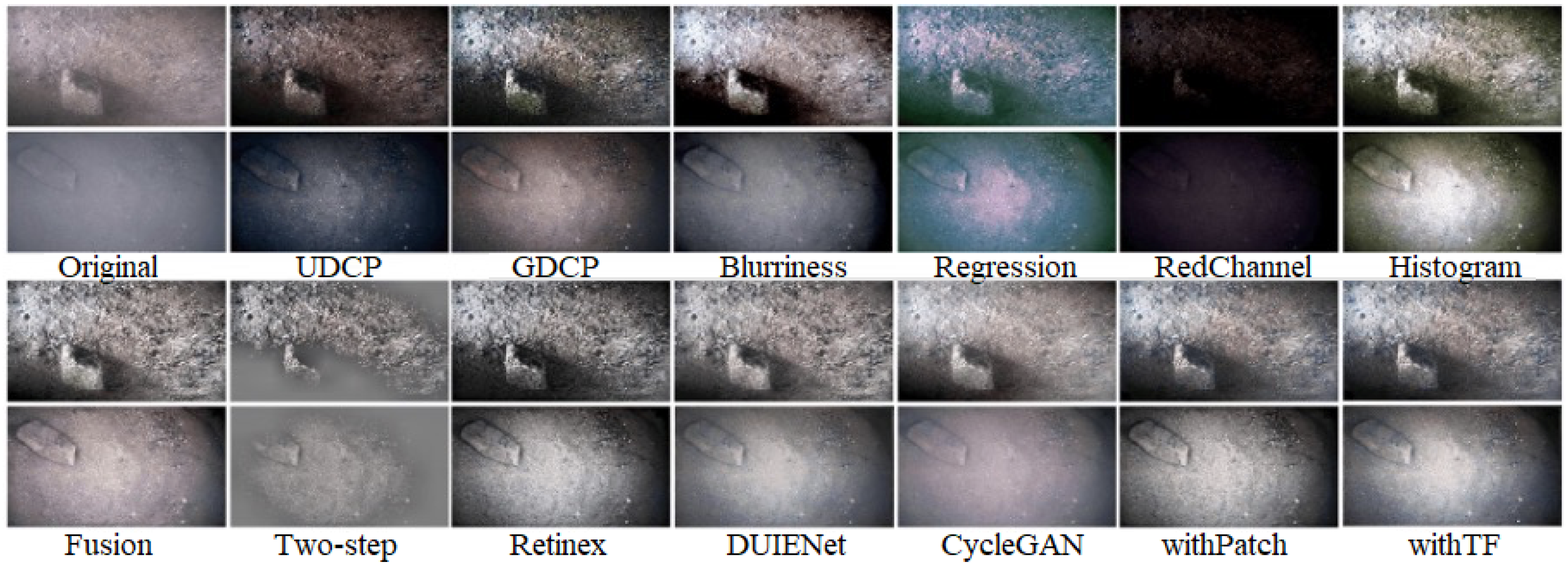
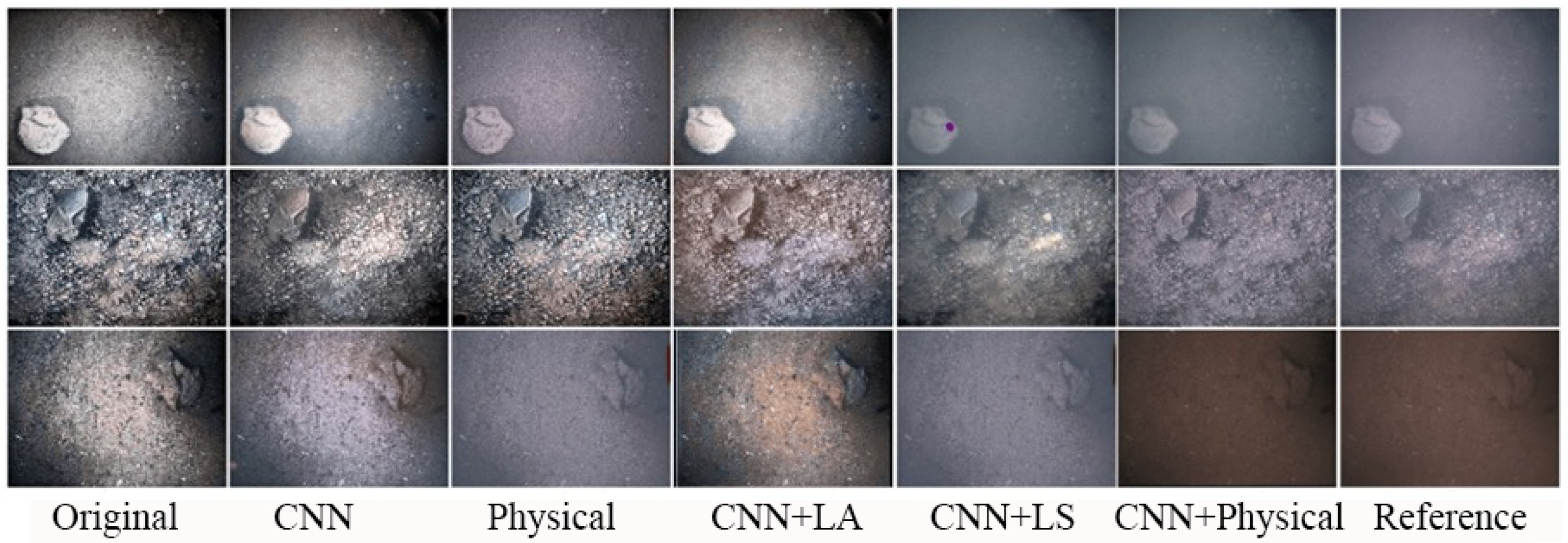
Figure 2 and
Figure 3 show the visual comparison of some of the synthesized effects (Physical, WaterGAN, CycleGAN, Ours) under Multiview dataset and OUC dataset. Ablation experiments were performed in
Section 4.5 to compare the effects of each branch.
3.2. Detecting Perceptually Enhanced Model
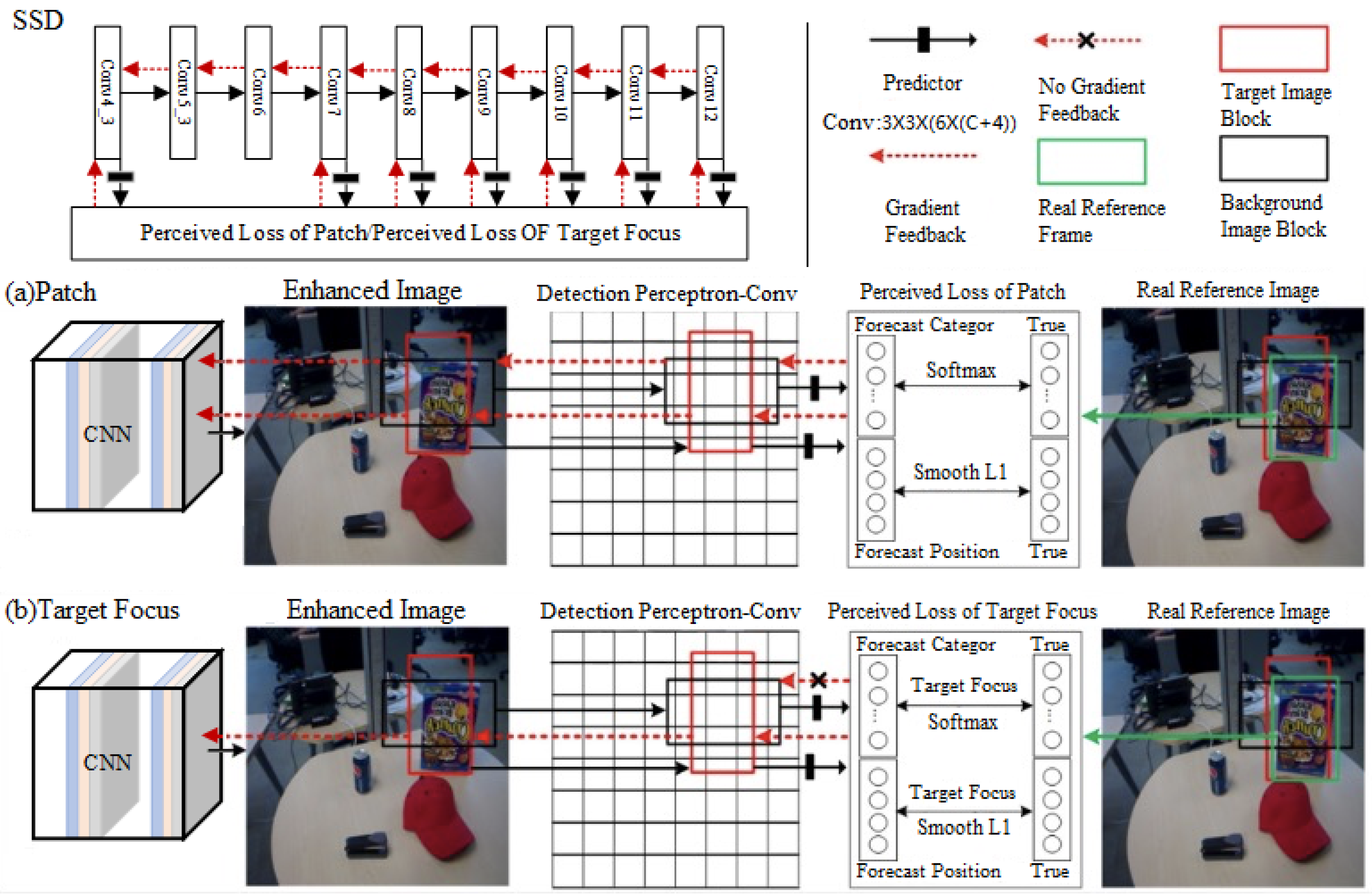
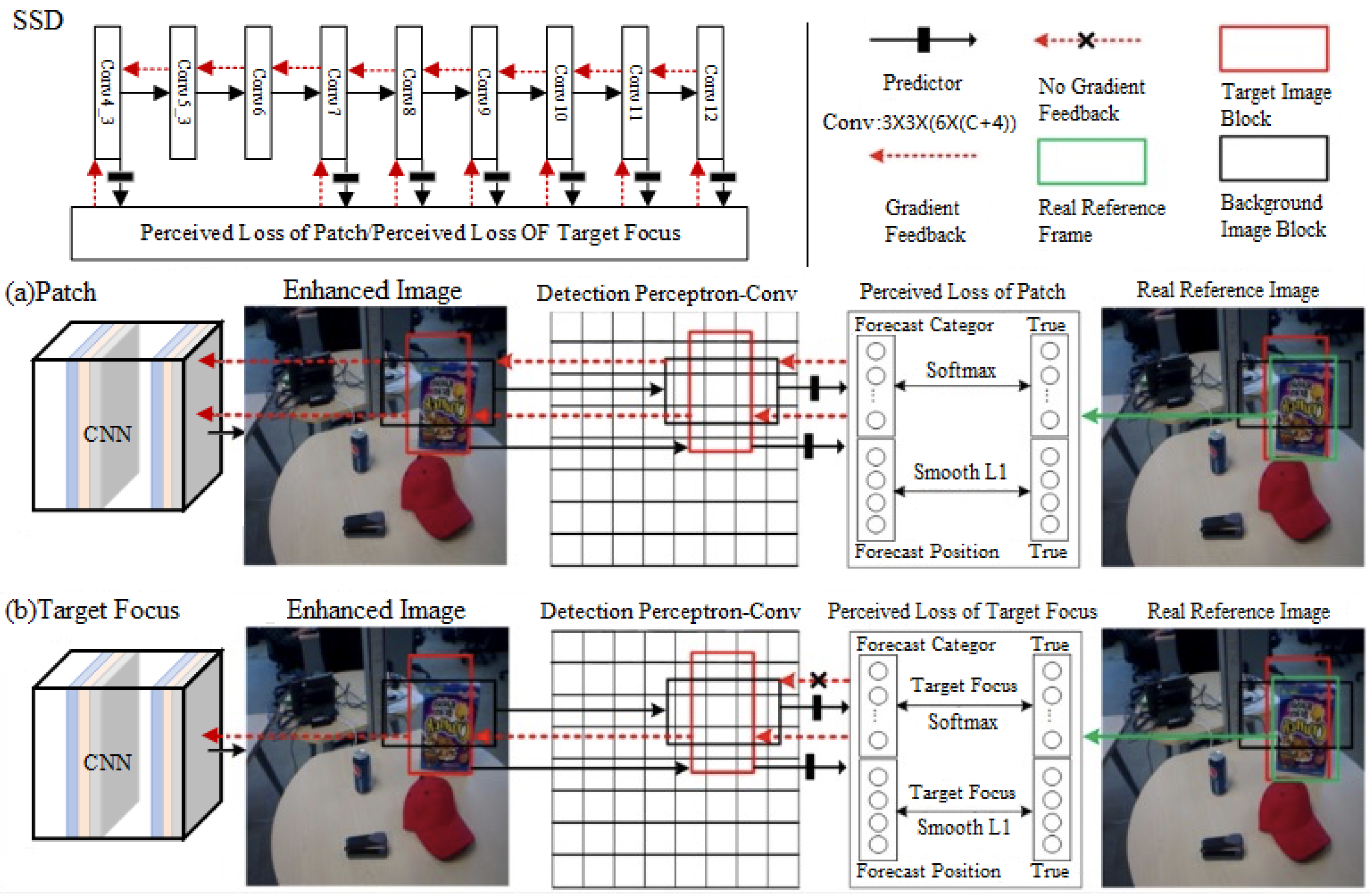
In this section, a Detecting Perceptually Enhanced Model (DPEM) is designed (see
Figure 4). First, two detection perceptrons designed based on the perceptual loss function are introduced, and then the image enhancement and the subsequent target detection are regarded as interactive tasks rather than separate individuals.
Based on the properties of the single-stage target detector of the SSD network [
16] and its grasp of multi-scale features, it is therefore combined as a detection perceptron, whose specific loss function algorithm, shown in Algorithm 1, provides practical perceptual information for the enhancement model in the subsequent adversarial training (see
Section 3.3), the augmented image is directly transmitted to the detection perceptron. First, the image undergoes a CNN module (as a preliminary enhancement model, consistent with the CNN module described in
Figure 1) to generate an enhanced clear image, then the detection perceptron associates six default patches with different scales and aspect ratios in the convolutional layer of the SSD model ( simply,
Figure 4 describes only two default patches in one of the convolutions), and makes a 3 × 3 convolutional kernel assigning four-dimensional position vectors to the patches, and at the same time, increases the category vectors in the dimensions of the background class number on top of the original number of object classes. Next, the reference classes and positions are determined according to the conditional matching rule of the intersection and concurrency ratio (
) between the default plaque and its overlapping reference objects as follows:
Finally, the difference between the augmented image patch and the actual reference image patch is computed by the perceptual loss of the detector, and its parameters are constantly updated to feed the difference back to the convolutional neural network model in the form of a gradient. This means the real over-water image scene is encoded into the detection perceptron space before the image enhancement operation. The water image is appropriately transformed to enhance the detailed information of the target in the water and to extract favourable information relevant to the target detection task. This processing can help the augmented model to better detect targets in complex over-water scenes and improve the accuracy and stability of the detection.
| Algorithm 1 SSD Loss |
| |
| |
| |
| |
| |
| |
| ▹ Total number of boxes per image |
| |
| |
| |
| |
| |
| |
| |
| ▹ Function calculate nonzero items number in M |
| if then | |
| | |
| else | |
| | |
| end if | |
| if then | |
| | |
| end if | |
| if then | |
| if then | |
| | ▹ Patch |
| else | |
| | |
| end if | |
| else | |
| | ▹ Target Focus |
| end if | |
| |
| |
| if then | |
| | |
| else | |
| | |
| end if | |
| |
As a result, the final output image after DPEM generates targeted enhanced images based on the different perceptual losses used to serve subsequent advanced visual processing tasks.
Perceptual loss function based on patch detection. The perceptual loss
with patch is designed to guide the convolutional neural network model to generate images closer to the exact location, i.e., to generate clear images at the patch level, with the following expression:
is the weighted sum of the classification loss
and the location loss
. Where
and
denote the predicted and true category vectors of the
ith default patch, respectively. Similarly,
and
denote the predicted and true position vectors of the
ith default patch,
denotes the set of all default patches, including the set of all target patches versus the set of background patches
, and
N and
denote the number of all default patches versus the number of target patches, respectively. The specific expressions for classification loss and location loss are as follows:
The categorization loss function uses the activation function SoftMax Loss, and the location loss function uses the function where and denote the cth element of the predicted and true category vectors, respectively. Where and denote the l-th element of the predicted and true position vectors separately.
In summary, the categorical loss function and the positional loss function encourage the enhancement of images in which the category differences and the positional differences between the image plaques and the genuine plaques are minimized. Therefore, the perceptual enhancement model for plaque detection that combines the two loss functions can learn the basic properties of authentic, clear images, guiding the accuracy of the convolutional neural network model with respect to the category and location of the target to be detected in the image, which helps to recover the details of the image plaques.
Perceptual loss function based on target focus detection. The perceptual loss
of withTF aims to guide the enhancement model to assign the positions of real categories and target frames on the enhanced image to improve the detection accuracy. The complexity of underwater environments leads to the fact that underwater targets to be detected often blend with the background and are difficult to be detected accurately, which becomes a challenging task. To solve this problem, the perceptual loss function of withTF is designed in this section with the following expression:
The complex background may reduce the detection accuracy of the detector. Therefore, this design only focuses on the feedback target’s patch information and ignores its background patch information. This approach allows the model to dynamically learn regions of the image that are closely related to the target and ignore background information that is not related to the target. This move will improve subsequent detection accuracy (ablation experiments are performed in
Section 4.5, demonstrating the superiority of this loss function design).
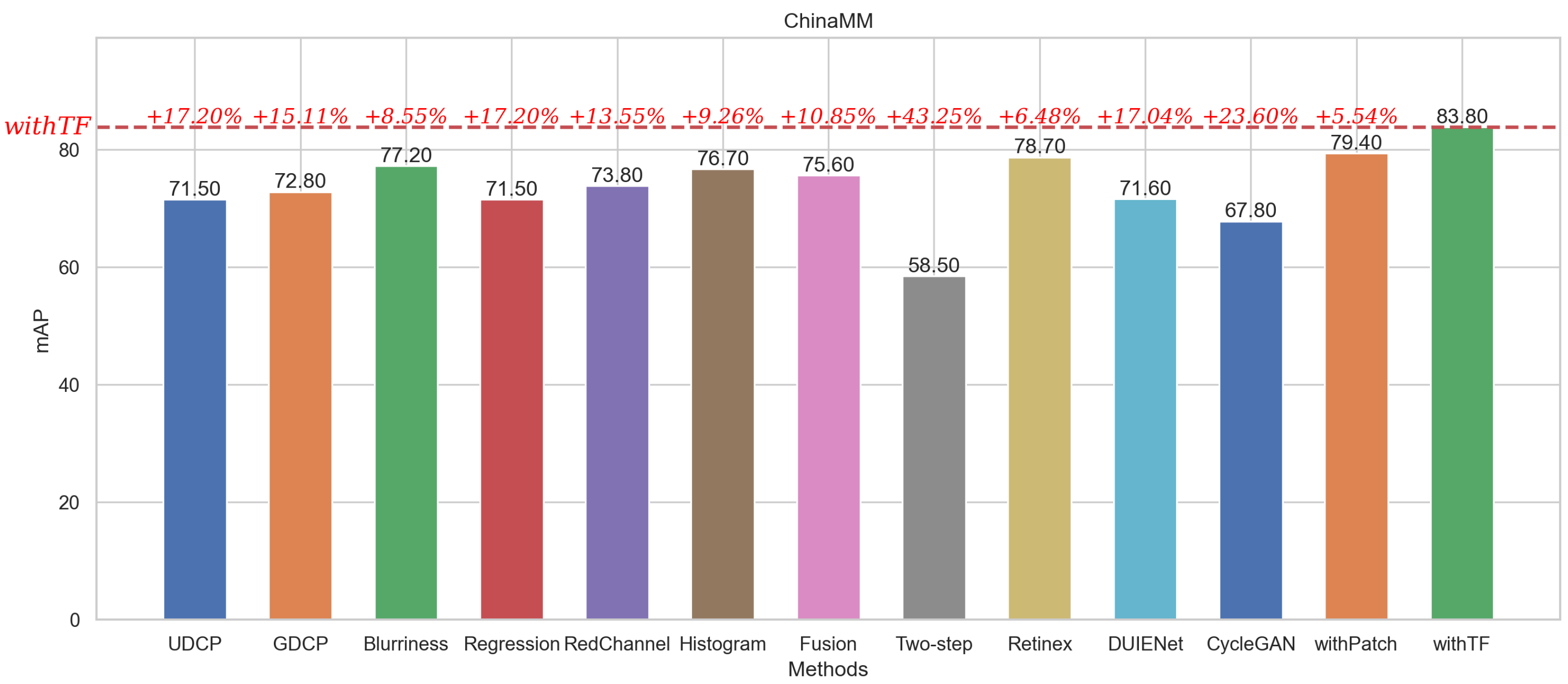
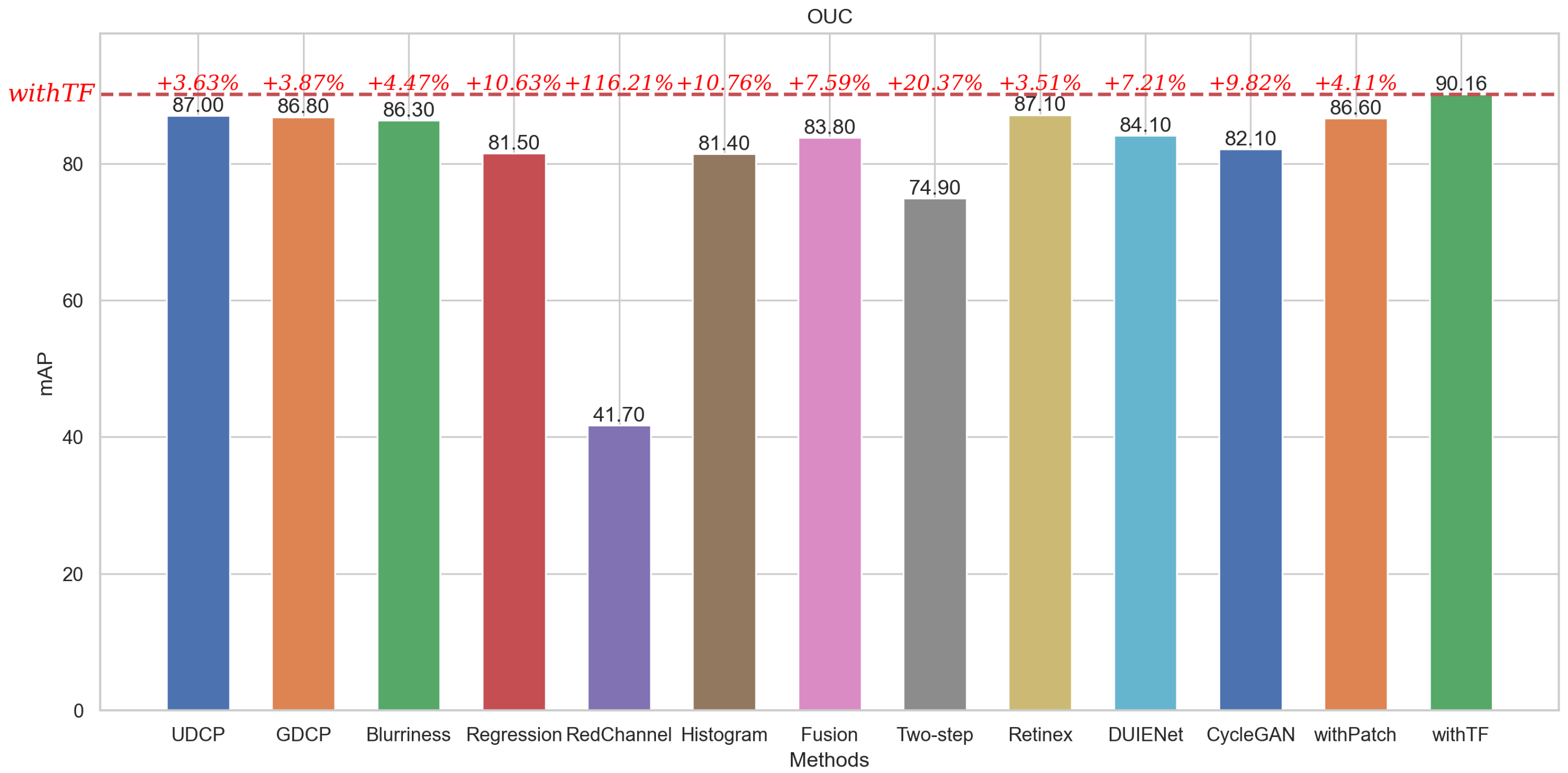
In summary, the detection perceptual models corresponding to the two perceptual loss functions described above each have their own target points. The perceptual loss function based on patch detection focuses on generating clear images at the patch level, which is more in line with the visual effect of the human eye. The perceptual loss function based on target focus detection focuses on generating salient target images, which enhances the target detection accuracy and better meets the machine vision effect. Therefore, the above characteristics determine that the detection performance of the perceptual model withTF is higher than that of the perceptual model withPatch, whereas the image performance of the perceptual model withPatch is higher than that of withTF (in
Section 4.4.1).
3.3. CycleGAN-Based Hybrid Enhanced Generative Adversarial Network
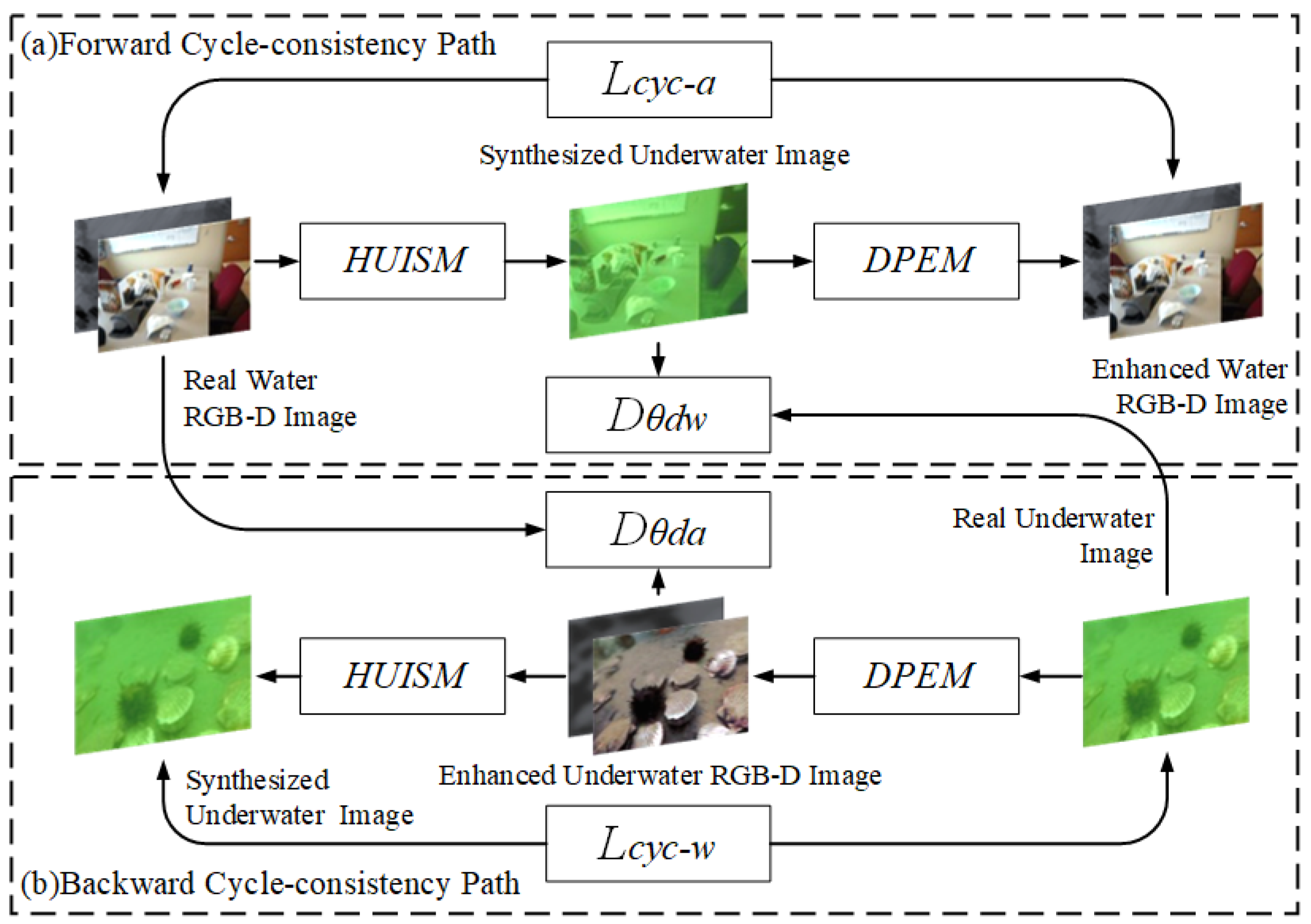
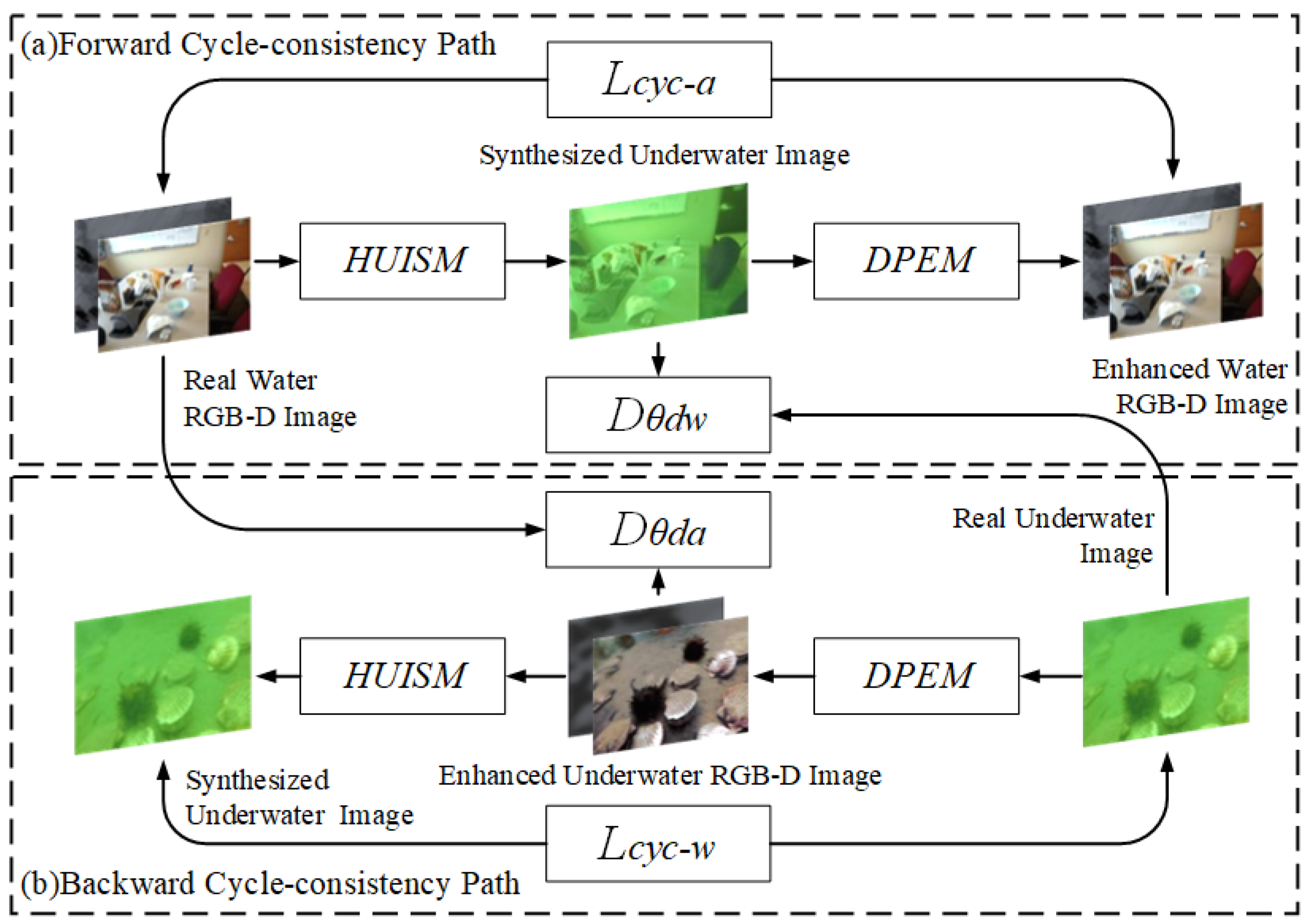
In this section, a Hybrid enhancement generative adversarial network (HEGAN) is designed (see
Figure 5). The general framework of the model is first introduced, followed by the design of the loss function for its encounters.
CycleGAN differs from traditional GAN by containing two generators and two discriminators, which realize the role of domain migration, and by learning the mapping relationship between the input domain image to the output domain image, it preserves the specific features of the original domain image while transforming it into an image that satisfies the target output features.
In this section, the CycleGAN structure is improved with the model algorithm shown in Algorithm 2. Among them, the generator includes a synthesis model and an augmentation model, which realize the functions of converting an overwater image to an underwater image, as well as converting an underwater image to an overwater image, respectively. The discriminators discriminate the converted synthetic image and the actual image, respectively. The whole framework will contain two cyclic consistency paths, in which the forward cyclic consistency path starts with the real underwater RGB-D image, generates the synthetic underwater image through HUISM, then generates the enhanced clear underwater RGB-D picture after DPEM as the end point. The reverse cyclic consistency path starts with a real underwater image, then generates an enhanced clear underwater RGB-D picture via DPEM, and finally ends with a reconstructed synthetic underwater image. Specifically, HUISM and DPEM act as model generators to complete the transformation between the underwater and overwater domains learnt from the unpaired images. and act as the discriminators of the model (where discriminates the synthetic underwater image from the real underwater image, and discriminates the augmented clear underwater RGB-D image from the real over-water RGB-D image) to perform adversarial training together with the generator using adversarial loss and cyclic consistency loss. In addition, during the training period of DPEM, the detection of favourable information is fed back in the form of a gradient through the perceptual loss of target focusing or plate detection to improve the subsequent target detection ability of the formed realistic image.
Corresponding loss function selection based on HUISM. The loss function
corresponding to the HUISM model consists of an adversarial loss function
and a cyclic consistency loss function
, which is formulated as follows:
where
is the adversarial loss generated by the discriminator
, parametrically expressed as
. Taking the clear RGB-D image on the water as input, the underwater synthetic image is generated by HUISM, and the discriminator discriminates it from the real underwater image, so that the minimum estimated probability that the discriminator considers the underwater synthetic image to be the real underwater image is
; thus, the specific expression of
is as follows:
where
denotes an underwater synthetic image, parametrically expressed as
.
During the training process, although the use of the adversarial loss function alone can enable the generator to produce sufficiently realistic underwater images, the phenomenon that multiple input images are all mapped to the same output image may occur during the training process, causing the network to crash. Therefore, the introduction of cyclic consistency loss function can effectively solve the problem.
| Algorithm 2 Hybrid Enhanced Generative Adversarial Network |
| ▹ Initialize cycle generators and discriminators |
| |
| |
| |
| |
| |
| ▹ Synthesized underwater image |
| ▹ Enhanced underwater image |
| ▹ Enhancement model to enhance synthetic underwater image |
| ▹ Synthesis model for enhanced underwater image |
| ▹ Perceptor feeds the gradient of favorable information back to augmentation model |
| |
| |
| |
| return | |
Where
denotes the distance between the synthesized underwater image and the real reference image underwater, with the expression:
Denotes the Manhattan distance between the synthesized underwater image .The cyclic consistency loss function ensures that the generated final image is as realistic as possible while preventing the model from crashing to generate the same image.
Corresponding loss function selection based on DPEM. The loss function
corresponding to the DPEM model consists of an adversarial loss function
, a cyclic consistency loss function
, and a perceptual loss of withTF
(or with Patch
), which is formulated as follows:
Similarly, is the adversarial loss generated by the discriminator , parametrically expressed as .
Taking the real underwater image as input, the enhanced clear underwater image is generated by DPEM, and the discriminator discriminates it from the real water image, so that the minimum estimated probability for the discriminator to consider the enhanced clear underwater synthetic image as the clear and real reference image on the water is
, which is formulated as follows:
Similarly, during the training process, although the use of the adversarial loss function alone can enable the generator to produce a sufficiently realistic clear image of the water, it is equally likely that a network crash will occur during the training process. Therefore, the introduction of a cyclic consistency loss function can effectively solve this problem. Therefore, the specific expression of
is as follows:
where
represents the real reference RGB image on water.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}