
PMOT2023: A Large-Scale Multi-Object Tracking (MOT) Dataset with Application to Phytoplankton Observation



Abstract
1. Introduction
2. Phytoplankton Visual Tracking
3. Procedure for Constructing PMOT2023
3.1. Phytoplankton Sampling
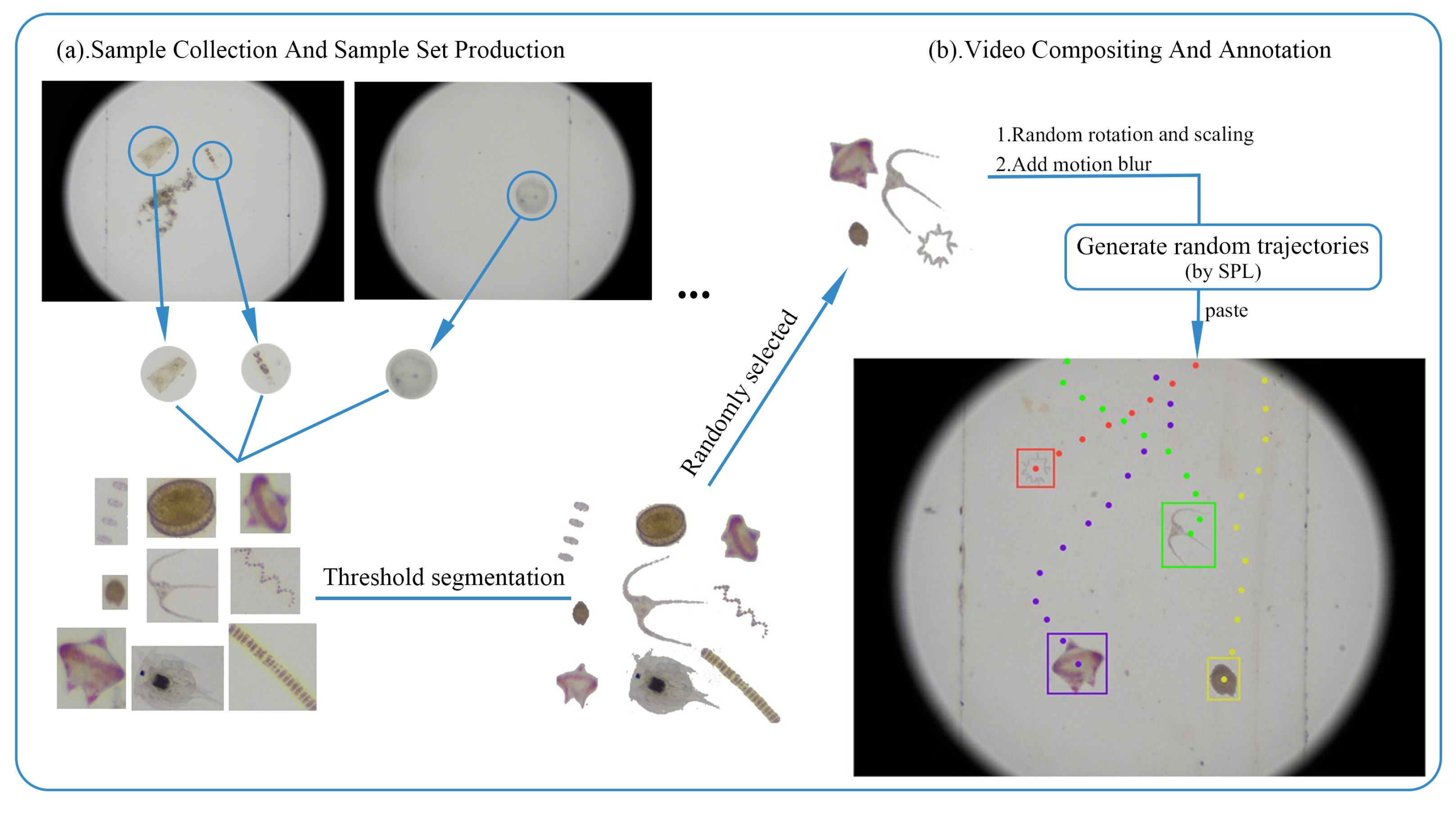
3.2. Dataset Design and Production Process
- DENSE-FAST: We designed a 8 min video; in the extreme case, we assumed a control water flow rate of 5 L/min flowing through the microscope head; the 8 min synthetic video contains 950 phytoplankton tracks; we set the video frame rate to 25; the whole video contains a many of categories switching and phytoplankton individual occlusion. The DENSE-FAST represents the most challenging situation for the automatic identification algorithm during in situ phytoplankton observation.
- DENSE-SLOW: The 8 min video contains 405 phytoplankton trajectories, simulating a 3 L/min flow rate through the microscope head during the observation process. The phytoplankton in the video have a slower movement speed than DENSE-FAST.
- SPARSE: The 8 min video contains 630 phytoplankton tracks, in which the phytoplankton also have a slower movement speed. It represents the general situation of phytoplankton occurrence during in situ observation of phytoplankton.
- CHALLENGE: This video sequence is more challenging. Eight minutes of video contain 1160 phytoplankton tracks. The speed of movement of each individual has greater variability and is accompanied by a change in appearance and size. PMOT2023-CHALLENGE was designed to train and evaluate the stability and generalization of the automatic phytoplankton identification algorithm for the specific case of in situ phytoplankton observation.
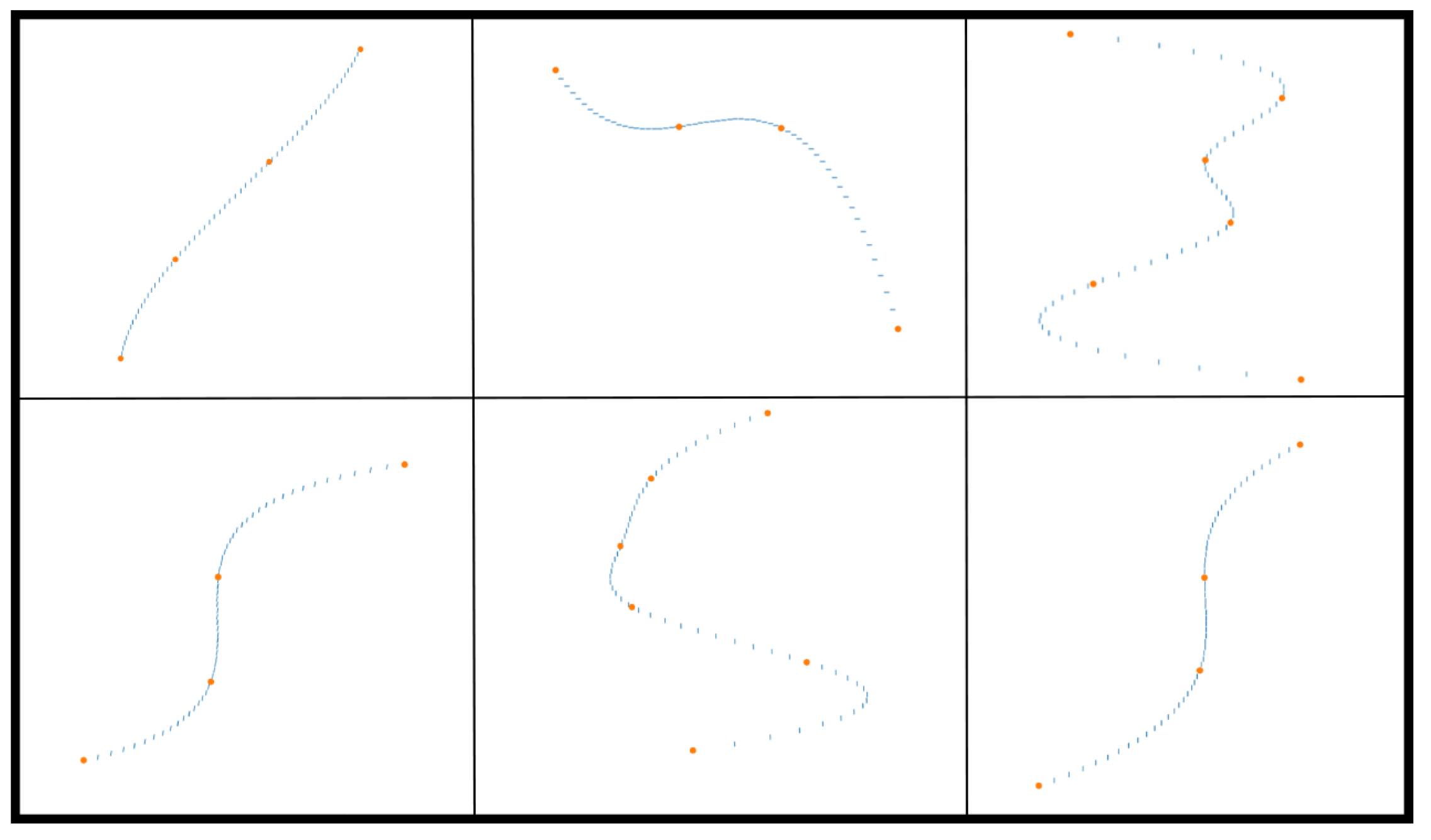
3.3. Video Data Production and Annotation Generation
4. PMOT2023 Statistics and Analysis
4.1. Dataset Setup and Statistics
4.2. Comparison of Existing Datasets
5. Result
5.1. MOT Evaluation Criteria
5.2. Comparison of Different Multi-Object Tracking Methods
5.3. Phytoplankton Counts and Density Estimates
5.4. Visualization Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Charlson, R.J.; Lovelock, J.E.; Andreae, M.O.; Warren, S.G. Oceanic phytoplankton, atmospheric sulphur, cloud albedo and climate. Nature 1987, 326, 655–661. [Google Scholar] [CrossRef]
- Paul, J.; Scholin, C.; van den Engh, G.; Perry, M.J. In situ instrumentation. Oceanography 2007, 20, 70–78. [Google Scholar] [CrossRef]
- Stelmakh, L.; Kovrigina, N.; Gorbunova, T. Phytoplankton Seasonal Dynamics under Conditions of Climate Change and Anthropogenic Pollution in the Western Coastal Waters of the Black Sea (Sevastopol Region). J. Mar. Sci. Eng. 2023, 11, 569. [Google Scholar] [CrossRef]
- Zhang, M.; Jiang, R.; Zhang, J.; Li, K.; Zhang, J.; Shao, L.; He, W.; He, P. The Impact of IMTA on the Spatial and Temporal Distribution of the Surface Planktonic Bacteria Community in the Surrounding Sea Area of Xiasanhengshan Island of the East China Sea. J. Mar. Sci. Eng. 2023, 11, 476. [Google Scholar] [CrossRef]
- Park, K.W.; Oh, H.J.; Moon, S.Y.; Yoo, M.H.; Youn, S.H. Effects of Miniaturization of the Summer Phytoplankton Community on the Marine Ecosystem in the Northern East China Sea. J. Mar. Sci. Eng. 2022, 10, 315. [Google Scholar] [CrossRef]
- Wang, X.; Sun, J.; Yu, H. Distribution and Environmental Impact Factors of Phytoplankton in the Bay of Bengal during Autumn. Diversity 2022, 14, 361. [Google Scholar] [CrossRef]
- Baohong, C.; Kang, W.; Xu, D.; Hui, L. Long-term changes in red tide outbreaks in Xiamen Bay in China from 1986 to 2017. Estuar. Coast. Shelf Sci. 2021, 249, 107095. [Google Scholar] [CrossRef]
- Warren, J.; Stanton, T.; Benfield, M.; Wiebe, P.; Chu, D.; Sutor, M. In situ measurements of acoustic target strengths of gas-bearing siphonophores. ICES J. Mar. Sci. 2001, 58, 740–749. [Google Scholar] [CrossRef]
- Roesler, C.; Uitz, J.; Claustre, H.; Boss, E.; Xing, X.; Organelli, E.; Briggs, N.; Bricaud, A.; Schmechtig, C.; Poteau, A.; et al. Recommendations for obtaining unbiased chlorophyll estimates from in situ chlorophyll fluorometers: A global analysis of WET Labs ECO sensors. Limnol. Oceanogr. Methods 2017, 15, 572–585. [Google Scholar] [CrossRef]
- Sullivan-Silva, K.B.; Forbes, M.J. Behavioral study of zooplankton response to high-frequency acoustics. J. Acoust. Soc. Am. 1992, 92, 2423. [Google Scholar] [CrossRef]
- Picheral, M.; Grisoni, J.M.; Stemmann, L.; Gorsky, G. Underwater video profiler for the “in situ” study of suspended particulate matter. In Proceedings of the IEEE Oceanic Engineering Society, OCEANS’98, Conference Proceedings (Cat. No. 98CH36259). Nice, France, 28 September–1 October 1998; Volume 1, pp. 171–173. [Google Scholar]
- Olson, R.J.; Sosik, H.M. A submersible imaging-in-flow instrument to analyze nano-and microplankton: Imaging FlowCytobot. Limnol. Oceanogr. Methods 2007, 5, 195–203. [Google Scholar] [CrossRef]
- Poulton, N.J. FlowCam: Quantification and classification of phytoplankton by imaging flow cytometry. In Imaging Flow Cytometry; Springer: New York, NY, USA, 2016; pp. 237–247. [Google Scholar]
- Blok, R.D.; Debusschere, E.; Tyberghein, L.; Mortelmans, J.; Hernandez, F.; Deneudt, K.; Sabbe, K.; Vyverman, W. Phytoplankton dynamics in the Belgian coastal zone monitored with a Cytosense flowcytometer. In Book of Abstracts; Vliz: Oostende, Belgium, 2018. [Google Scholar]
- Dubelaar, G.; Gerritzen, P.L. CytoBuoy: A step forward towards using flow cytometry in operational oceanography. Sci. Mar. 2000, 64, 255–265. [Google Scholar] [CrossRef]
- de Blok Reinhoud, L.T.; Mortelmans, J.; Sabbe, K.; Vanhaecke, L.; Vyverman, W. Near real-time monitoring of coastal phytoplankton. In Book of Abstracts; Vliz: Oostende, Belgium, 2015. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2022; pp. 1–21. [Google Scholar]
- Orenstein, E.C.; Beijbom, O.; Peacock, E.E.; Sosik, H.M. Whoi-plankton-a large scale fine grained visual recognition benchmark dataset for plankton classification. arXiv 2015, arXiv:1510.00745. [Google Scholar]
- Zheng, H.; Wang, R.; Yu, Z.; Wang, N.; Gu, Z.; Zheng, B. Automatic plankton image classification combining multiple view features via multiple kernel learning. BMC Bioinform. 2017, 18, 570. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Sun, X.; Dong, J.; Song, S.; Zhang, T.; Liu, D.; Zhang, H.; Han, S. Developing a microscopic image dataset in support of intelligent phytoplankton detection using deep learning. ICES J. Mar. Sci. 2020, 77, 1427–1439. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards real-time multi-object tracking. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 107–122. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust associations multi-pedestrian tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Miksch, M.; Yang, B.; Zimmermann, K. Motion compensation for obstacle detection based on homography and odometric data with virtual camera perspectives. In Proceedings of the Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010. [Google Scholar]
- Roy, S.; Paul, S.; Young, N.E.; Roy-Chowdhury, A.K. Exploiting Transitivity for Learning Person Re-identification Models on a Budget. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhou, J.; Bing, S.; Ying, W. Easy Identification from Better Constraints: Multi-shot Person Re-identification from Reference Constraints. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Munjal, B.; Amin, S.; Tombari, F.; Galasso, F. Query-Guided End-To-End Person Search. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sun, X.; Zheng, L. Dissecting Person Re-identification from the Viewpoint of Viewpoint. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tang, Z.; Naphade, M.; Liu, M.Y.; Yang, X.; Birchfield, S.; Wang, S.; Kumar, R.; Anastasiu, D.; Hwang, J.N. CityFlow: A City-Scale Benchmark for Multi-Target Multi-Camera Vehicle Tracking and Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, Y.; Chen, Z.; Feng, W.; Gang, W. Person Re-identification with Cascaded Pairwise Convolutions. In Proceedings of the IEEE Conference on Computer Vision & Pattern Reconigtion, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ferryman, J.; Shahrokni, A. Pets2009: Dataset and challenge. In Proceedings of the 2009 Twelfth IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, Snowbird, UT, USA, 7–12 December 2009; pp. 1–6. [Google Scholar]
- Leal-Taixé, L.; Milan, A.; Reid, I.; Roth, S.; Schindler, K. Motchallenge 2015: Towards a benchmark for multi-target tracking. arXiv 2015, arXiv:1504.01942. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Chavdarova, T.; Baqué, P.; Bouquet, S.; Maksai, A.; Jose, C.; Bagautdinov, T.; Lettry, L.; Fua, P.; Van Gool, L.; Fleuret, F. Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5030–5039. [Google Scholar]
- Yang, L.; Fan, Y.; Xu, N. Video instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5188–5197. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Liao, Y.; Xie, J.; Geiger, A. KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3292–3310. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Dave, A.; Khurana, T.; Tokmakov, P.; Schmid, C.; Ramanan, D. Tao: A large-scale benchmark for tracking any object. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 436–454. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Baek, S.S.; Jung, E.Y.; Pyo, J.C.; Pachepsky, Y.; Son, H.; Cho, K.H. Hierarchical deep learning model to simulate phytoplankton at phylum/class and genus levels and zooplankton at the genus level. Water Res. J. Int. Water Assoc. 2022, 218, 118494. [Google Scholar] [CrossRef]
- Gelzinis, A.; Verikas, A.; Vaiciukynas, E.; Bacauskiene, M. A novel technique to extract accurate cell contours applied for segmentation of phytoplankton images. Mach. Vis. Appl. 2015, 26, 305–315. [Google Scholar] [CrossRef]
- Rivas-Villar, D.; Rouco, J.; Carballeira, R.; Penedo, M.G.; Novo, J. Fully automatic detection and classification of phytoplankton specimens in digital microscopy images. Comput. Methods Programs Biomed. 2021, 200, 105923. [Google Scholar] [CrossRef]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M.; Olenina, I.; Olenin, S.; Vaiciukynas, E. Phase congruency-based detection of circular objects applied to analysis of phytoplankton images. Pattern Recognit. J. Pattern Recognit. Soc. 2012, 45, 1659–1670. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Unser, M.; Aldroubi, A. B-spline signal processing. I. Theory. IEEE Trans. Signal Process. 1993, 41, 821–833. [Google Scholar] [CrossRef]
- Xu, Y.; Ban, Y.; Alameda-Pineda, X.; Horaud, R. Deepmot: A differentiable framework for training multiple object trackers. arXiv 2019, arXiv:1906.06618. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 1–14. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DENSE_FAST | DENSE_SLOW | SPARSE | CHALLENGE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Duration | Frames | Tracks | Duration | Frames | Tracks | Duration | Frames | Tracks | Duration | Frames | Tracks | |
| train_set | 360 s | 9000 | 680 | 360 s | 9000 | 420 | 360 s | 9000 | 300 | 360 s | 9000 | 800 |
| val_set | 72 s | 1800 | 140 | 72 s | 1800 | 90 | 72 s | 1800 | 60 | 72 s | 1800 | 160 |
| test_set | 48 s | 1200 | 130 | 48 s | 1200 | 120 | 48 s | 1200 | 100 | 48 s | 1200 | 200 |
| Dataset | MOT17 [42] | MOT20 [43] | PMOT2023 (Proposed) |
|---|---|---|---|
| Videos | 14 | 8 | 12 |
| Avg. tracks | 96 | 432 | 267 |
| Total tracks | 1342 | 3456 | 3200 |
| Avg. len. (s) | 35.4 | 66.8 | 154 |
| Total len. (s) | 463 | 535 | 1920 |
| FPS | 30 | 25 | 25 |
| Total images | 11,235 | 13,410 | 48,000 |
| resolution | 2k or <2k | 2k or <2k | 4K |
| number of classes | 12 | 13 | 26 |
| Dataset | PMID2019 [21] | PMOT2023 (Proposed) |
|---|---|---|
| lotal images | 11,089 | 48,000 |
| number of bbox | 13,865 | 170,041 |
| number of classes | 24 | 21 |
| Methods | MOTA↑ | IDF1↑ | IDSW↓ | Recall↑ | IDRecall↑ | Prcn↑ |
|---|---|---|---|---|---|---|
| BYTEtrack [18] | 52.98 | 67.88 | 39.0 | 58.70 | 55.90 | 91.70 |
| SORT [28] | 35.80 | 45.43 | 502.0 | 42.45 | 38.18 | 95.45 |
| DeepSORT [17] | 43.60 | 58.30 | 112.3 | 52.48 | 47.18 | 84.33 |
| BoT-SORT [32] | 44.60 | 31.80 | 174.5 | 37.40 | 29.20 | 91.45 |
| DeepMot [59] | 36.15 | 22.82 | 27.5 | 51.20 | 21.30 | 71.03 |
| StrongSORT [60] | 39.33 | 53.88 | 141.3 | 48.56 | 40.40 | 82.48 |
| Test Set | Total | Ceratium furca | Skeletonema | Helicotheca | |
|---|---|---|---|---|---|
| groundtruth | DENSE-FAST | 130 | 7 | 9 | 5 |
| DENSE-SLOW | 120 | 5 | 8 | 3 | |
| SPARSE | 100 | 3 | 4 | 10 | |
| yolov7 [27] | DENSE-FAST | 141 | 5 | 8 | 7 |
| +Bytetrack [18] | DENSE-SLOW | 116 | 3 | 8 | 4 |
| SPARSE | 93 | 3 | 2 | 10 | |
| yolov7 [27] | DENSE-FAST | 153 | 4 | 8 | 10 |
| +DeepSORT [17] | DENSE-SLOW | 142 | 3 | 9 | 5 |
| SPARSE | 118 | 3 | 2 | 10 |
| Test Set | Total | Ceratium furca | Skeletonema | Helicotheca | |
|---|---|---|---|---|---|
| groundtruth | DENSE-FAST | 32.50 | 1.75 | 2.25 | 1.25 |
| DENSE-SLOW | 50.00 | 2.08 | 3.33 | 1.25 | |
| SPARSE | 41.67 | 1.25 | 1.67 | 4.17 | |
| yolov7 [27] | DENSEFAST | 35.25 | 1.25 | 2.00 | 1.75 |
| +Bytetrack [18] | DENSESLOW | 48.33 | 1.25 | 3.33 | 1.67 |
| SPARSE | 38.75 | 1.25 | 0.83 | 4.17 | |
| yolov7 [27] | DENSEFAST | 38.25 | 1.00 | 2.00 | 2.50 |
| +DeepSORT [17] | DENSESLOW | 59.17 | 1.25 | 3.75 | 2.08 |
| SPARSE | 49.17 | 2.08 | 0.83 | 4.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Lv, Q.; Li, Y.; Dong, J.; Zhao, H.; Li, Q. PMOT2023: A Large-Scale Multi-Object Tracking (MOT) Dataset with Application to Phytoplankton Observation. J. Mar. Sci. Eng. 2023, 11, 1141. https://doi.org/10.3390/jmse11061141
Yu J, Lv Q, Li Y, Dong J, Zhao H, Li Q. PMOT2023: A Large-Scale Multi-Object Tracking (MOT) Dataset with Application to Phytoplankton Observation. Journal of Marine Science and Engineering. 2023; 11(6):1141. https://doi.org/10.3390/jmse11061141
Chicago/Turabian StyleYu, Jiaao, Qingxuan Lv, Yuezun Li, Junyu Dong, Haoran Zhao, and Qiong Li. 2023. "PMOT2023: A Large-Scale Multi-Object Tracking (MOT) Dataset with Application to Phytoplankton Observation" Journal of Marine Science and Engineering 11, no. 6: 1141. https://doi.org/10.3390/jmse11061141
APA StyleYu, J., Lv, Q., Li, Y., Dong, J., Zhao, H., & Li, Q. (2023). PMOT2023: A Large-Scale Multi-Object Tracking (MOT) Dataset with Application to Phytoplankton Observation. Journal of Marine Science and Engineering, 11(6), 1141. https://doi.org/10.3390/jmse11061141