


A Semantic Segmentation Method Based on Image Entropy Weighted Spatio-Temporal Fusion for Blade Attachment Recognition of Marine Current Turbines



Abstract
1. Introduction
- An IEWSTF-based semantic segmentation method is proposed in this paper for the attachment recognition of MCT blades, which aims to improve robustness against the variations in rotational speed of the MCT;
- The STF mechanism is proposed for learning the ST features between the adjacent frames to alleviate the degradation of feature extraction due to motion blur;
- An IEW mechanism is proposed to obtain the optimal fusion features by adaptively adjusting the fusion weights by measuring the degree of difference between the adjacent frames.
2. Related Works
2.1. Semantic Segmentation
2.2. Image Entropy
3. Data and Methods
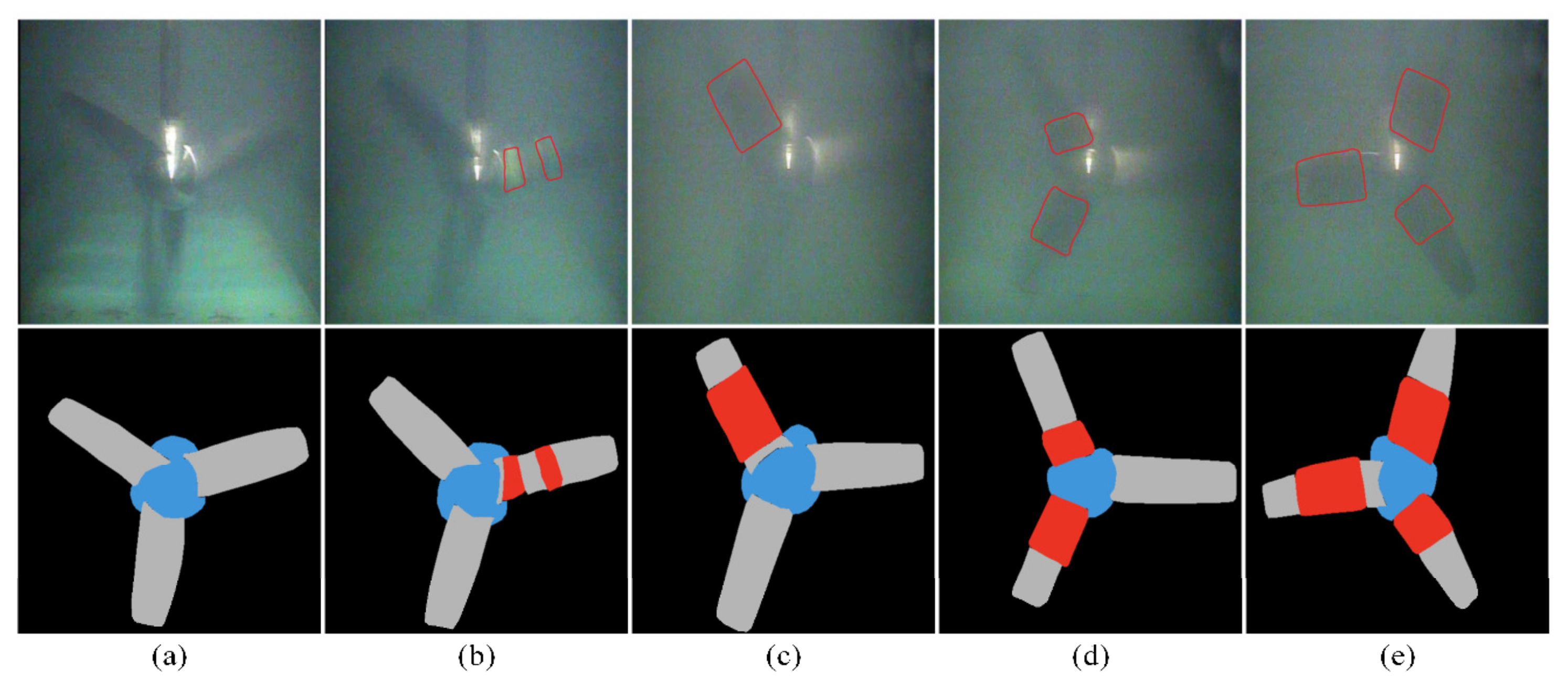
3.1. Image Dataset for MCT
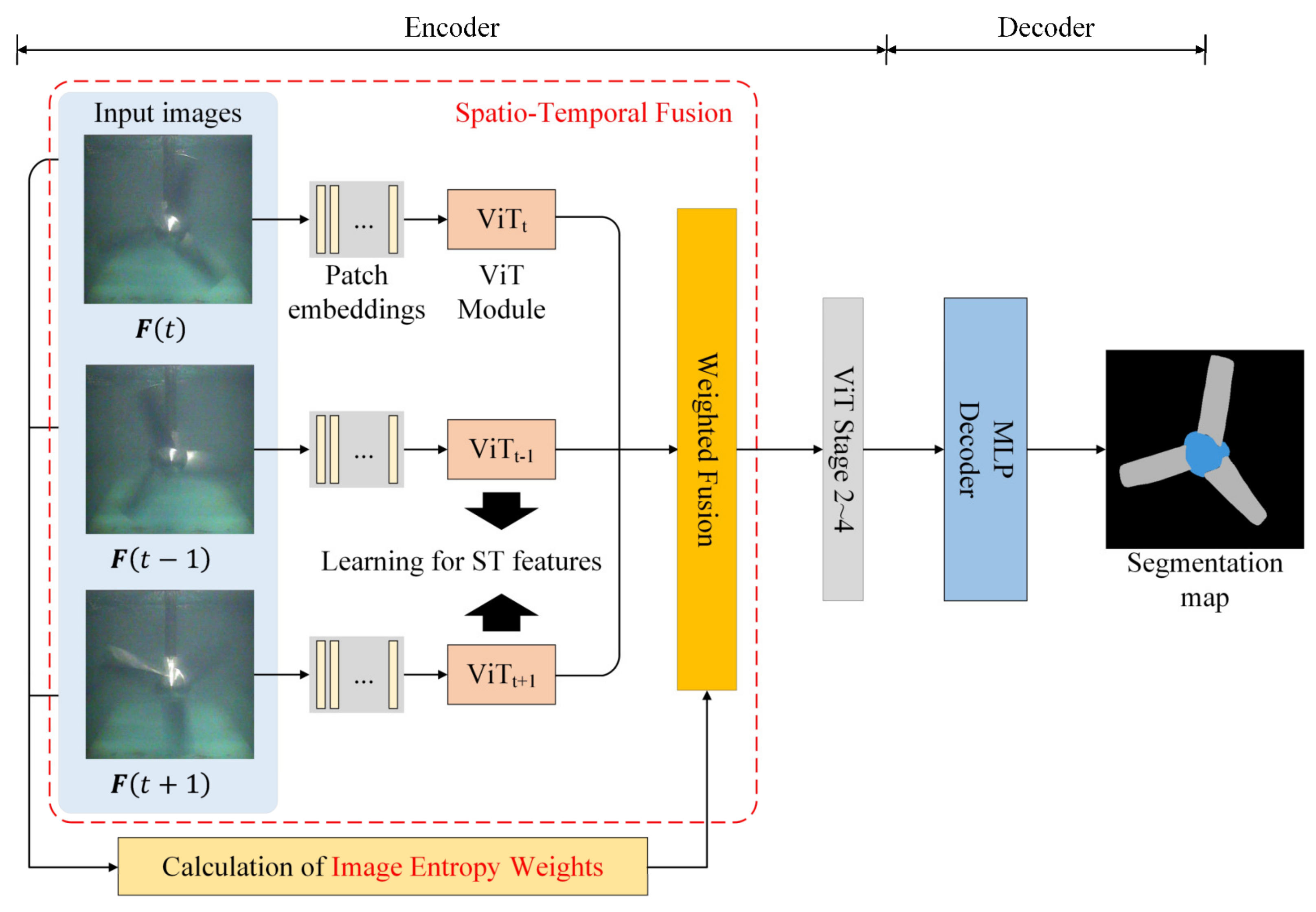
3.2. The Image Entropy Weighted Spatio-Temporal Fusion-Based SS Method
3.2.1. Spatio-Temporal Fusion
3.2.2. Image Entropy Weighting
4. Results and Discussion
4.1. Configuration of the Training Process
4.2. Evaluation Metrics
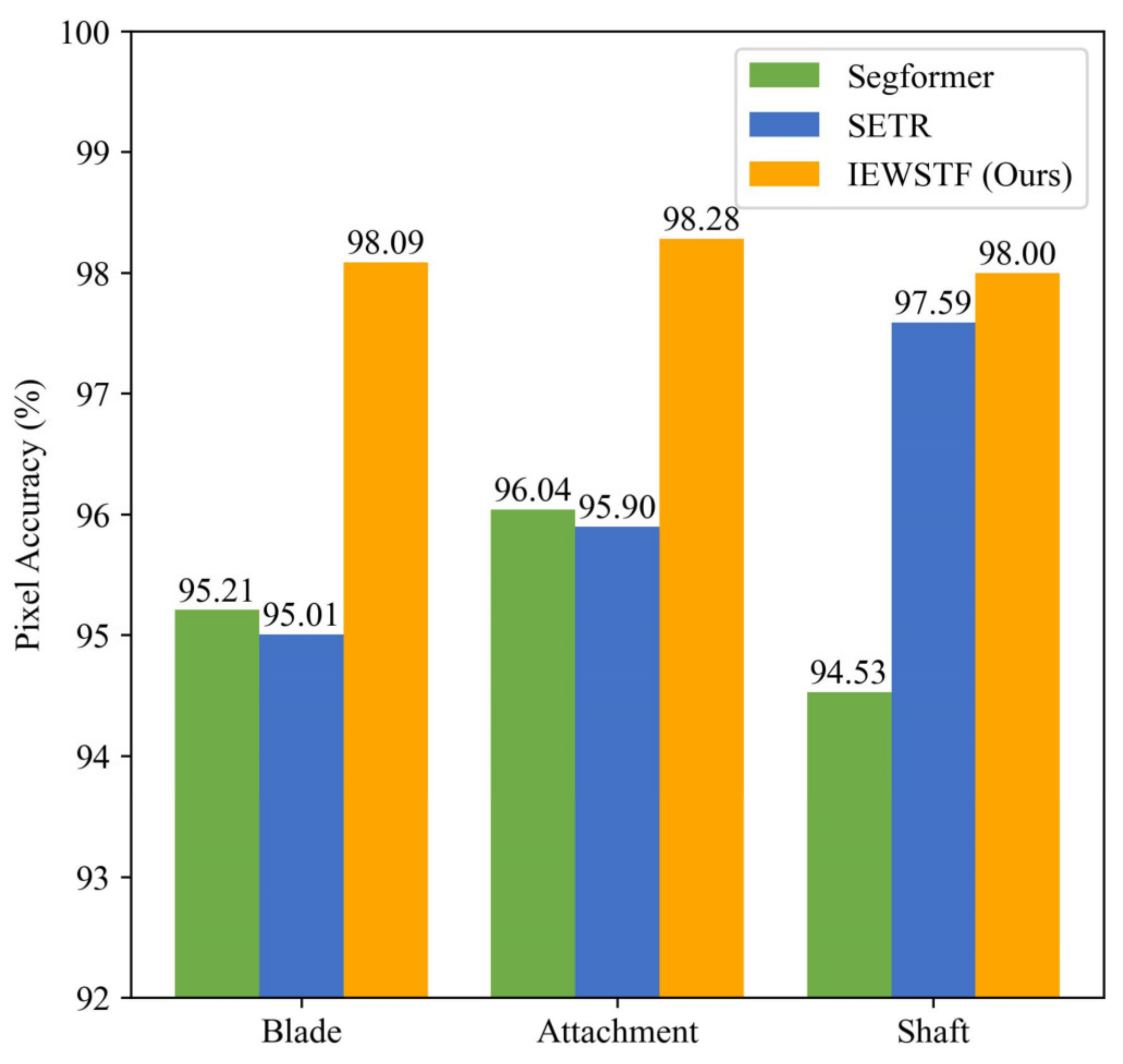
4.3. Overall Accuracy Evaluation of SS on MCT Dataset
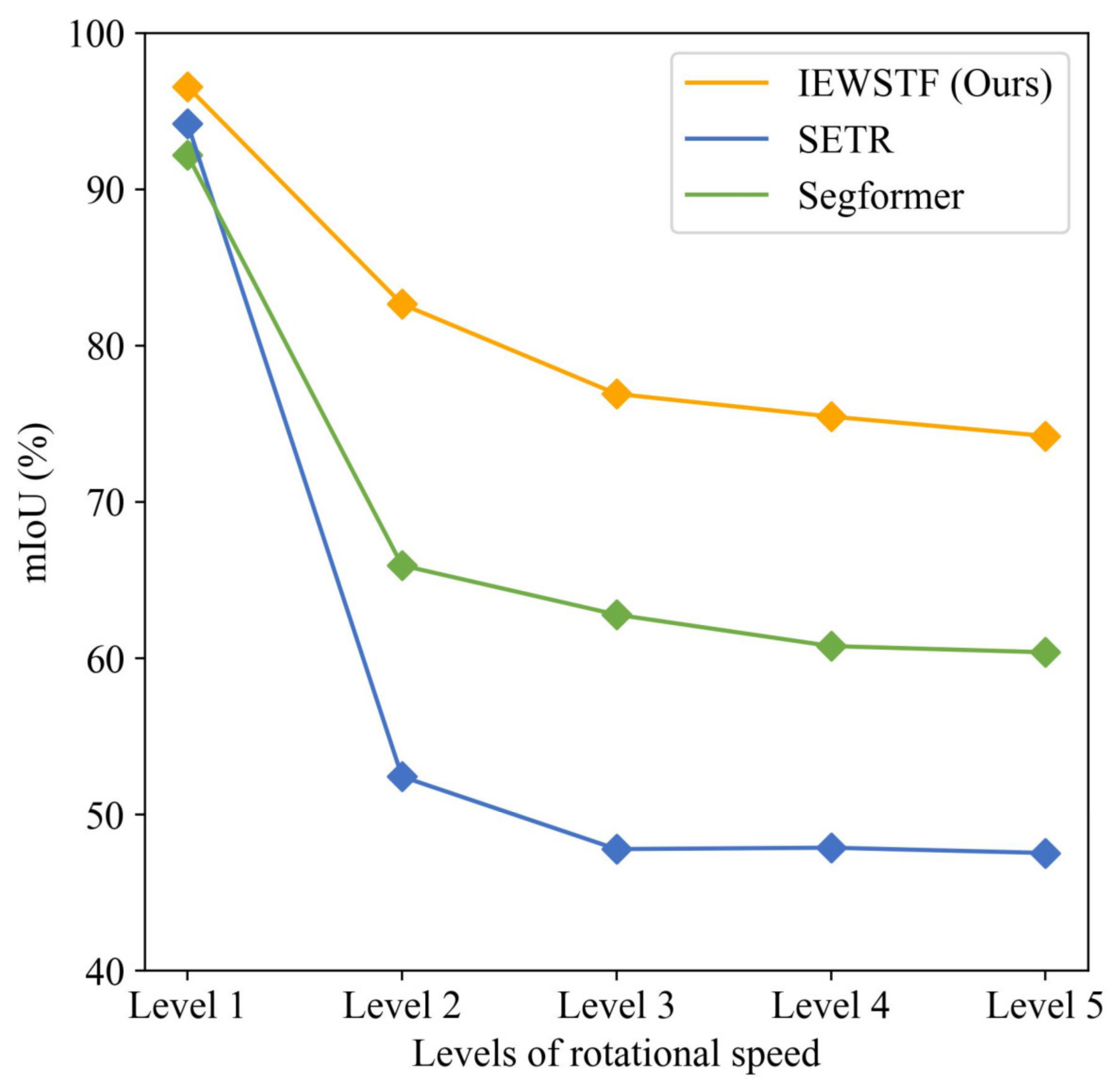
4.4. Evaluation of the Robustness against the Variations in Rotational Speed
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heidarian, A.; Cheung, S.C.P.; Rosengarten, G. The effect of flow rate and concentration on the electrical conductivity of slurry electrodes using a coupled computational fluid dynamic and discrete element method (CFD–DEM) model. Electrochem. Commun. 2021, 126, 107017. [Google Scholar] [CrossRef]
- Heidarian, A.; Cheung, S.C.P.; Ojha, R.; Rosengarten, G. Effects of current collector shape and configuration on charge percolation and electric conductivity of slurry electrodes for electrochemical systems. Energy 2022, 239, 122313. [Google Scholar] [CrossRef]
- Segura, E.; Morales, R.; Somolinos, J.A. A Strategic Analysis of Tidal Current Energy Conversion Systems in the European Union. Appl. Energy 2018, 212, 527–551. [Google Scholar] [CrossRef]
- Myers, L.; Bahaj, A.S. Simulated electrical power potential harnessed by marine current turbine arrays in the Alderney Race. Renew. Energy 2005, 30, 1713–1731. [Google Scholar] [CrossRef]
- Xie, T.; Wang, T.; He, Q.; Diallo, D.; Claramunt, C. A review of current issues of marine current turbine blade fault detection. Ocean. Eng. 2020, 218, 108194. [Google Scholar] [CrossRef]
- Farkas, A.; Degiuli, N.; Martić, I.; Barbarić, M.; Guzović, Z. The impact of biofilm on marine current turbine performance. Renew. Energy 2022, 190, 584–595. [Google Scholar] [CrossRef]
- Walker, J.S.; Green, R.B.; Gillies, E.A.; Phillips, C. The effect of a barnacle-shaped excrescence on the hydrodynamic performance of a tidal turbine blade section. Ocean. Eng. 2020, 217, 107849. [Google Scholar] [CrossRef]
- Song, S.; Demirel, Y.K.; Atlar, M.; Shi, W. Prediction of the fouling penalty on the tidal turbine performance and development of its mitigation measures. Appl. Energy 2020, 276, 115498. [Google Scholar] [CrossRef]
- Grosvenor, R.I.; Prickett, P.W.; He, J. An Assessment of Structure-Based Sensors in the Condition Monitoring of Tidal Stream Turbines. In Proceedings of the 2017 Twelfth International Conference on Ecological Vehicles and Renewable Energies (EVER), Monte Carlo, Monaco, 11–13 April 2017. [Google Scholar]
- Yang, C.; Xie, T.; Wang, T.; Wang, Y.; Jia, D. Blade attachment degree classification for marine current turbines using AGMF-DFA under instantaneous variable current speed. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2022, in press. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, T.; Tang, T. A multi-mode process monitoring method based on mode-correlation PCA for Marine Current Turbine. In Proceedings of the 2017 IEEE 11th International Symposium on Diagnostics for Electrical Machines, Power Electronics and Drives (SDEMPED), Tinos, Greece, 29 August–1 September 2017. [Google Scholar]
- Zhang, M.; Wang, T.; Tang, T.; Benbouzid, M.; Diallo, D. An Imbalance Fault Detection Method Based on Data Normalization and EMD for Marine Current Turbines. ISA Trans. 2017, 68, 302–312. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, T.; Xin, B.; Xie, T.; Wang, Y. A Sparse Autoencoder and Softmax Regression Based Diagnosis Method for the Attachment on the Blades of Marine Current Turbine. Sensors 2019, 19, 826. [Google Scholar] [CrossRef]
- Xin, B.; Zheng, Y.; Wang, T.; Chen, L.; Wang, Y. A diagnosis method based on depthwise separable convolutional neural network for the attachment on the blade of marine current turbine. Proc. Inst. Mech. Eng. Part I J. Syst. Control. Eng. 2021, 235, 1916–1926. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Peng, H.; Yang, D.; Wang, T.; Pandey, S.; Chen, L.; Shi, M.; Diallo, D. An Adaptive Coarse-Fine Semantic Segmentation Method for the Attachment Recognition on Marine Current Turbines. Comput. Electr. Eng. 2021, 93, 107182. [Google Scholar] [CrossRef]
- Zhao, S.; Oh, S.-K.; Kim, J.-Y.; Fu, Z.; Pedrycz, W. Motion-blurred image restoration framework based on parameter estimation and fuzzy radial basis function neural networks. Pattern Recognit. 2022, 132, 108983. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015-Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587v3. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929v2. [Google Scholar]
- Li, J.; Chen, J.; Tang, Y.; Wang, C.; Landman, B.A.; Zhou, S.K. Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives. Med. Image Anal. 2023, 85, 102762. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Li, W.; Zhao, Y.; Li, F.; Wang, L. MIA-Net: Multi-information aggregation network combining transformers and convolutional feature learning for polyp segmentation. Knowl.-Based Syst. 2022, 247, 108824. [Google Scholar] [CrossRef]
- Wu, R.; Wen, X.; Yuan, L.; Xu, H. DASFTOT: Dual attention spatiotemporal fused transformer for object tracking. Knowl.-Based Syst. 2022, 256, 109897. [Google Scholar] [CrossRef]
- Zhao, Q.; Yang, H.; Zhou, D.; Cao, J. Rethinking Image Deblurring via CNN-Transformer Multiscale Hybrid Architecture. IEEE Trans. Instrum. Meas. 2023, 72, 1–15. [Google Scholar] [CrossRef]
- Hou, Z.; Li, F.; Wang, S.; Dai, N.; Ma, S.; Fan, J. Video object segmentation based on temporal frame context information fusion and feature enhancement. Appl. Intell. 2023, 53, 6496–6510. [Google Scholar] [CrossRef]
- Ji, G.; Fan, D.; Fu, K.; Wu, Z.; Shen, J.; Shao, L. Full-duplex strategy for video object segmentation. Comput. Vis. Media 2023, 9, 155–175. [Google Scholar] [CrossRef]
- Wang, L.; Liu, H.; Zhou, S.; Tang, W.; Hua, G. Instance Motion Tendency Learning for Video Panoptic Segmentation. IEEE Trans. Image Process. 2023, 32, 764–778. [Google Scholar] [CrossRef]
- Zhao, D.; Liu, L.; Yu, F.; Heidari, A.A.; Wang, M.; Liang, G.; Muhammad, K.; Chen, H. Chaotic random spare ant colony optimization for multi-threshold image segmentation of 2D Kapur entropy. Knowl.-Based Syst. 2021, 216, 106510. [Google Scholar] [CrossRef]
- Lei, B.; Fan, J. Adaptive granulation Renyi rough entropy image thresholding method with nested optimization. Expert Syst. Appl. 2022, 203, 117378. [Google Scholar] [CrossRef]
- Naidu, M.S.R.; Rajesh Kumar, P.; Chiranjeevi, K. Shannon and Fuzzy entropy based evolutionary image thresholding for image segmentation. Alexandria Eng. J. 2018, 57, 1643–1655. [Google Scholar] [CrossRef]
- Li, J.; Wang, W.; Chen, J.; Niu, L.; Si, J.; Qian, C.; Zhang, L. Video Semantic Segmentation via Sparse Temporal Transformer. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 20–24 October 2021. [Google Scholar]
- Zhang, R.; Xiao, Q.; Du, Y.; Zuo, X. DSPI Filtering Evaluation Method Based on Sobel Operator and Image Entropy. IEEE Photonics J. 2021, 13, 1–10. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.O.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Optimizer | AdamW |
| Batch size | 4 |
| Initial learning rate | 0.001 |
| Epochs | 100 |
| Shuffle | True |
| Photometric Distortion | True |
| Methods | mIoU |
|---|---|
| SegFormer-MiT-B0 | 92.95 |
| SETR-Naive-Base | 94.26 |
| IEWSTF (Ours) | 96.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, F.; Wang, T. A Semantic Segmentation Method Based on Image Entropy Weighted Spatio-Temporal Fusion for Blade Attachment Recognition of Marine Current Turbines. J. Mar. Sci. Eng. 2023, 11, 691. https://doi.org/10.3390/jmse11040691
Qi F, Wang T. A Semantic Segmentation Method Based on Image Entropy Weighted Spatio-Temporal Fusion for Blade Attachment Recognition of Marine Current Turbines. Journal of Marine Science and Engineering. 2023; 11(4):691. https://doi.org/10.3390/jmse11040691
Chicago/Turabian StyleQi, Fei, and Tianzhen Wang. 2023. "A Semantic Segmentation Method Based on Image Entropy Weighted Spatio-Temporal Fusion for Blade Attachment Recognition of Marine Current Turbines" Journal of Marine Science and Engineering 11, no. 4: 691. https://doi.org/10.3390/jmse11040691
APA StyleQi, F., & Wang, T. (2023). A Semantic Segmentation Method Based on Image Entropy Weighted Spatio-Temporal Fusion for Blade Attachment Recognition of Marine Current Turbines. Journal of Marine Science and Engineering, 11(4), 691. https://doi.org/10.3390/jmse11040691