1. Introduction
Potatoes, as an important crop with multiple functions, are widely cultivated around the world and are one of the four major staple crops globally [
1]. However, in agricultural practice, potatoes face a variety of disease threats, among which early blight and late blight, caused by the pathogens
Alternaria solani and
Phytophthora infestans, respectively, are considered the most destructive fungal diseases due to their rapid spread and severe impact [
2,
3]. In addition to diseases, pest issues are also significant. Pests such as the
Epilachna vigintioctomaculata and the
Acanthoscelides obtectus cause compound damage by feeding on leaves and spreading pathogens, leading to yield losses of 15–30%. In severe cases, entire fields may be lost, significantly impacting the economic benefits of the industry. Therefore, establishing a comprehensive potato pest and disease control system is crucial for ensuring stable potato production [
4].
With the development of agricultural informatization, intelligent monitoring and decision-making systems based on agricultural data services are gradually replacing traditional experience-based agricultural production models [
5]. In this context, question-answering systems, due to their portability and efficiency, have become ideal tools for querying. Users interact with the system using natural language, and the system analyzes these inputs to generate useful answers, helping users obtain timely and accurate agricultural advice. Previous studies have shown that question-answering systems have demonstrated significant effectiveness in disease and pest identification, improving crop yields, and reducing pesticide use [
6]. In this regard, developing a question-answering system integrated with potato pest and disease knowledge is of great practical significance for reducing the threat of potato pests and diseases and minimizing economic losses for farmers.
In the process of building a question-answering system, question classification, also referred to as intent recognition, plays a crucial role. Its core function is to map the natural language questions input by the user into predefined semantic categories, thus laying the foundation for accurately interpreting user needs and generating targeted responses. In the field of agriculture, there are two commonly used text classification methods: machine learning-based methods and deep learning-based methods [
7]. In the context of classical machine learning paradigms, algorithms such as support vector machine (SVM) and naive Bayes (NB) have demonstrated significant application results. Notable studies include that by Wei et al. [
8], who, after constructing a keyword classification library, performed feature word selection and weight optimization strategies using linear SVM to classify Chinese agricultural texts. Cui et al. [
9] used the XGBoost parallelization algorithm within the Spark framework to accurately classify forestry texts. Espejo-Garcia et al. [
10], using pesticide usage documents from the Spanish Official Plant Health Products Registration Office as their data source, compared the accuracy of SVM, NB, logistic regression, and random forest models for agricultural regulation classification. Through training, machine learning models can adapt to different text data and classification tasks, demonstrating excellent flexibility and scalability. Although machine learning-based methods can automatically learn from data, they rely heavily on manually defined features, and the quality of these features directly impacts the model’s learning efficiency and final performance [
11]. Therefore, the careful design and selection of features are crucial for improving the performance of machine learning models.
Deep learning-based methods are currently the most mainstream approach in question classification tasks. Deep learning models such as convolutional neural networks (CNN), gated recurrent units (GRU), and long short-term memory networks (LSTM) can automatically learn complex feature representations from raw text data, thus eliminating the need for tedious manual feature engineering. Jin et al. [
12] proposed the BiGRU-MulCNN agricultural question classification model, which achieves good classification performance even on datasets with insufficient data and unclear features. Wang et al. [
13] constructed the Attention-DenseCNN model, which establishes dense connections (where each layer receives the outputs of all preceding layers as additional inputs, thereby avoiding the issue of information loss) between upstream and downstream convolutional blocks in CNNs. This effectively enhances feature propagation and gradient flow. Moreover, the attention mechanism assigns higher weights to key features, further improving the model’s focus on important information. The model significantly improved the accuracy of rice question classification. Feng et al. [
14] further broke through the performance bottleneck of the model through system architecture optimization. Their proposed RIC-Net model deeply integrates a 4-layer residual network with a capsule network. This not only alleviates the gradient vanishing problem through skip connections but also effectively models semantic hierarchical relationships using dynamic routing mechanisms. The model achieved an accuracy of 98.62% on a rice knowledge classification dataset.
Pre-trained models, such as BERT (Bidirectional Encoder Representations from Transformers) [
15] and ERNIE (Enhanced Representation through Knowledge Integration) [
16], have proven to be effective in various natural language processing tasks and represent a significant breakthrough in the field of deep learning. Agriculture, as a highly specialized domain, involves a vast array of complex terms and proprietary vocabulary. Traditional models, such as Word2Vec and GloVe, are limited by two major drawbacks due to their static nature: first, the generated word vectors are fixed and cannot dynamically capture contextual information; second, they may fail to accurately understand domain-specific terminology in agriculture, thereby impacting task performance. In contrast, pre-trained models, trained on large-scale corpora, can dynamically generate word vectors based on context and possess stronger semantic understanding capabilities, thus effectively overcoming these two major limitations. The BERT-Stacked LSTM model proposed by Li et al. [
17] utilizes multiple stacked LSTMs to learn complex semantic information from text, showing significant advantages over six other models in agricultural pest and disease question classification. Li et al. [
18] improved the DPCNN model by integrating the word vectors provided by the ERNIE pre-trained model, enabling efficient identification of cotton pest and disease questions. Duan et al. [
19] proposed a multimodal agricultural news text classification method, which extracts features from both text and images using ERNIE and Vision Transformer, respectively. An interactive attention mechanism is then applied to compute attention weights between the text and image features, extracting shared features and enhancing cross-modal synergy. Experimental results indicate that this multimodal model outperforms individual text or visual models in classification performance.
In response to the lack of publicly available question-answer datasets in the field of potato pests and diseases as well as the limitations of traditional question classification methods in terms of representational capacity, this paper proposes a dataset construction method that integrates prompt engineering and a question classification model based on gated fusion convolution. Specifically, a structured prompt is used to guide a large language model (LLM) in generating potato pest and disease question templates. These templates are then populated in bulk using entity information extracted from previous named entity recognition (NER) work [
20], resulting in the efficient construction of the Potato Pest and Disease Question Classification Dataset (PDPQCD). Moreover, this paper introduces the gated fusion–convolutional neural network (GF-CNN) to optimize the text feature extraction process. The model captures local features through parallel multi-scale convolutions and then employs both max-pooling and average-pooling to extract salient and global statistical features. A gating unit was designed to dynamically fuse these two feature representations, enhancing feature robustness while preserving critical information.
In summary, the main contributions of this paper can be summarized as follows:
- (a)
The construction of the first question classification dataset for the potato pest and disease domain, which achieves effective integration of LLM with domain knowledge through prompt engineering, outperforming existing datasets in both scale and granularity of categories;
- (b)
The proposal of the GF-CNN question classification model with dynamic feature fusion capability. This model adapts the feature weights of max-pooling and average-pooling through a gating mechanism, enhancing the model’s representational power while maintaining good interpretability;
- (c)
Experimental results on the PDPQCD, Subj, and THUCNews datasets show that GF-CNN not only accurately classifies potato pest and disease questions into predefined categories but also demonstrates strong generalization ability in cross-domain classification tasks.
2. Materials and Methods
2.1. Prompt Engineering
Prompt engineering aims to improve the quality and relevance of a model’s output by carefully designing the textual prompts input into the LLM. When conducting prompt engineering, users must consider how to precisely express their needs, select appropriate keywords, and structure sentences to guide the model in generating more accurate and relevant responses. For example, if the goal is to have the LLM analyze the sentiment of an article, a simple and vague prompt might be “Analyze this article”, whereas an optimized prompt might be more specific, such as “Please describe the primary sentiment of this article and provide specific examples to support your viewpoint”. Prompt engineering is not only about the skill of asking questions but also involves an understanding of the model’s responses. Through precise prompts, one can better leverage the potential of the LLM.
When writing effective prompts, keep the following principles in mind:
- (a)
Clarity and specificity: Avoid using ambiguous terms. For instance, when dealing with numerical issues, specify exact numbers for the desired output instead of using vague terms like “some” or “a few”;
- (b)
Role-playing: Specify the roles of the LLM and the user. For example, if you are seeking weight loss advice, using the prompt “Assume you are a professional personal fitness trainer, and I am your client. Please use your expertise and consider my physical condition to create a detailed weight loss plan for me” will often yield more professional advice and suggestions than simply saying, “Give me a weight loss plan”;
Of course, if the role definition is not clear enough, it may lead to ambiguous or irrelevant outputs from the model. Additionally, when an LLM is assigned a specific role, its responses may become overly constrained by stereotypical assumptions associated with that role. These issues also require the user to make flexible adjustments based on the specific context;
- (c)
Output formatting: To achieve more consistent output, specify the format in which you would like the LLM to deliver the response. LLMs can handle various common data formats, such as TXT and JSON.
2.2. Classification of Intentions
After the preliminary organization of the data from the team’s previous NER work, we classified the questions into 11 categories. This means that if we successfully construct the question-answering system, the system will be able to answer the 11 types of questions shown in
Table 1.
2.3. Dataset Template Generation Based on Prompt Engineering
After defining the question categories, we began generating question classification dataset templates using the LLM. In this study, the ChatGPT 4 model was chosen, and taking the “disease symptoms” category as an example, the prompt and model’s response are shown in
Figure 1.
The prompt is divided into four parts: Role Definition, Task Description, Task Requirements, and Output Format. This structure is designed to make the process easier for readers to follow. However, in actual input to the model, these sections should be omitted. In the Role Definition section, the LLM is specified as an experienced NLP engineer. The implicit intention here is to guide the model toward processing NLP-related content and to communicate the real need for constructing a PDPQCD. The Task Description section further refines the requirements, asking the LLM to generate training templates specifically for the “Disease Symptoms” category. In the Task Requirements section, constraints are placed on the content generated by the LLM. The generated questions should simulate real-world scenarios and the way people naturally ask questions, including short, conversational queries and longer, descriptive sentences. Additionally, placeholders like [Disease] are used in place of specific disease names, allowing for the templates to be adapted to any particular disease during practical use. At the end of each question, the label “disease symptoms” is added, directly tagging the question for subsequent classification tasks. Finally, the Output Format section provides two examples to further standardize the model’s output, ensuring consistency across all generated content. This step guarantees that the results are structured and ready for use in the intended application, making the training data clean, organized, and effective for building the intent recognition model.
Using prompt engineering to generate dataset templates offers several distinct advantages over manual construction: First, in terms of efficiency and speed, LLMs can generate large volumes of data in a very short time, whereas manual writing may take several hours or even days. Second, in terms of diversity and creativity, manual construction is often limited by an individual’s imagination and linguistic habits, whereas LLMs, trained on large-scale text corpora, are capable of producing more diverse and innovative sentence structures, thereby increasing the coverage and complexity of the corpus. Lastly, in terms of customizability, LLMs can flexibly adjust the output based on the input prompts, allowing for the generation of text in specific styles or formats as required.
2.4. Construction of a PDPQCD
After generating various question templates using the LLM, a manual review of each template was conducted to assess alignment with question topics and human linguistic conventions. Templates that were deemed irrelevant were excluded. Finally, we bulk-imported the potato pest and disease entities extracted from the previous NER work to replace the placeholders in the templates. Using the data from the “disease symptoms” category as an example, the algorithmic logic is shown in
Figure 2.
Three lists—Diseases, Templates, and Questions—were initialized. The Diseases and Templates lists store potato disease entities and question templates, respectively, while the Questions list is initially empty and is used to store the generated real data. The algorithm iterates over the Diseases list externally and the Templates list internally. During each iteration, the algorithm identifies placeholders in the templates and replaces them with the corresponding disease entities, generating a real data. Simultaneously, a counter assigns a unique identifier to each question to facilitate the subsequent counting of questions in that category. Finally, by iterating through the Questions list, all real data for the “disease symptoms” category can be obtained.
Through the above method, a dataset containing 20,260 entries was finally constructed, with its distribution shown in
Figure 3. As can be seen from
Figure 3, the data in the dataset exhibit a certain degree of uneven distribution. This is due to the differing number of entities in each category and the varying number of templates retained for each category, with both factors collectively contributing to this discrepancy.
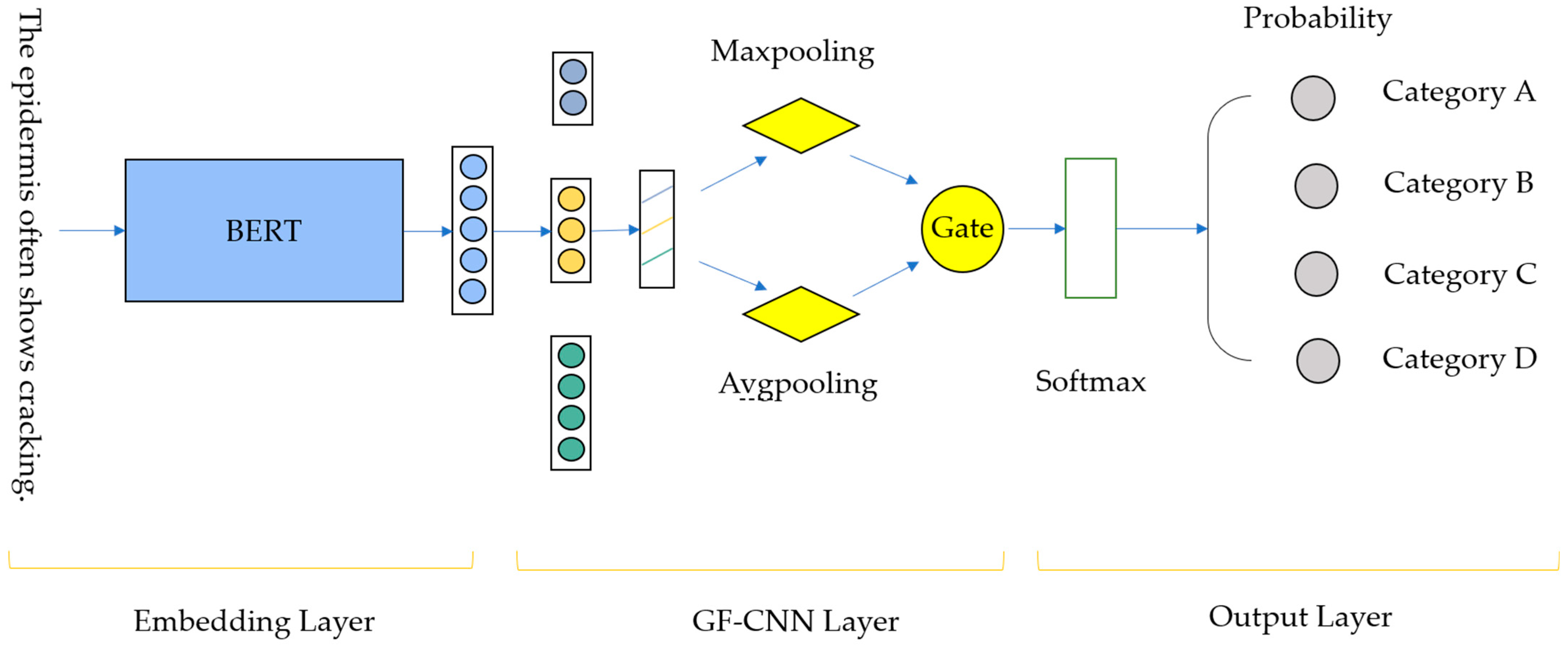
3. Model Structure
This study utilizes BERT as the pre-trained model, upon which the proposed GF-CNN is employed for feature extraction. Finally, the softmax function is applied for question classification. The overall architecture of the system is illustrated in
Figure 4.
3.1. BERT
BERT, proposed by Devlin et al. [
15], is a pre-trained language model. Compared to other language models, such as FastText and GloVe, BERT provides dynamic word embeddings, meaning that the generated word vectors are dynamically adjusted based on the context in which the word appears. This allows the model to distinguish different meanings of the same word in different contexts.
The core innovation of BERT lies in its use of two pre-training tasks: masked language model (MLM) and next-sentence prediction (NSP). In the MLM task, BERT randomly masks some words in the input data and then predicts the original words for these masked positions. This process requires the model to accurately understand and retain contextual information. The NSP task, on the other hand, enhances the model’s understanding of sentence relationships by predicting whether the second sentence fragment is a continuation of the first sentence fragment.
3.2. GF-CNN
Since max-pooling efficiently reduces the dimensionality of feature maps without significantly increasing computational cost, most question classification models, such as TextCNN [
21] and DPCNN [
22], utilize max-pooling for downsampling. Max-pooling is highly effective in scenarios where it is necessary to highlight strong features. However, relying solely on max-pooling has some drawbacks. First, there is the issue of information loss. Max-pooling only retains the maximum value, and any non-maximum values within the feature region, regardless of their importance, are ignored. This can make the model less sensitive to subtle changes in the input data, causing it to lose information that, although not reflected in the local maximum, is important at a global level. Second, max-pooling is particularly sensitive to noise. Since max-pooling focuses on the maximum value, incidental high values in the data might be mistakenly interpreted as important features, which could affect the overall performance and reliability of the model.
To address these issues, this paper proposes the GF-CNN model, which simultaneously incorporates both max-pooling and average-pooling strategies. Through a gating mechanism, it dynamically adjusts the weights of the outputs from the different pooling layers, allowing the model to leverage both local important features and global distributional information, thus achieving a richer data representation. The structure of the GF-CNN model is shown in
Figure 5.
For the original input features,
X, the model first applies three convolutional kernels of different sizes to extract multi-scale information, resulting in feature maps
U1,
U2, and
U3. Next,
U1,
U2, and
U3 are concatenated together.
After activating the fused features, both max-pooling and average-pooling are applied separately.
The gating fusion unit assigns weights to
S1 and
S2 and performs a weighted fusion.
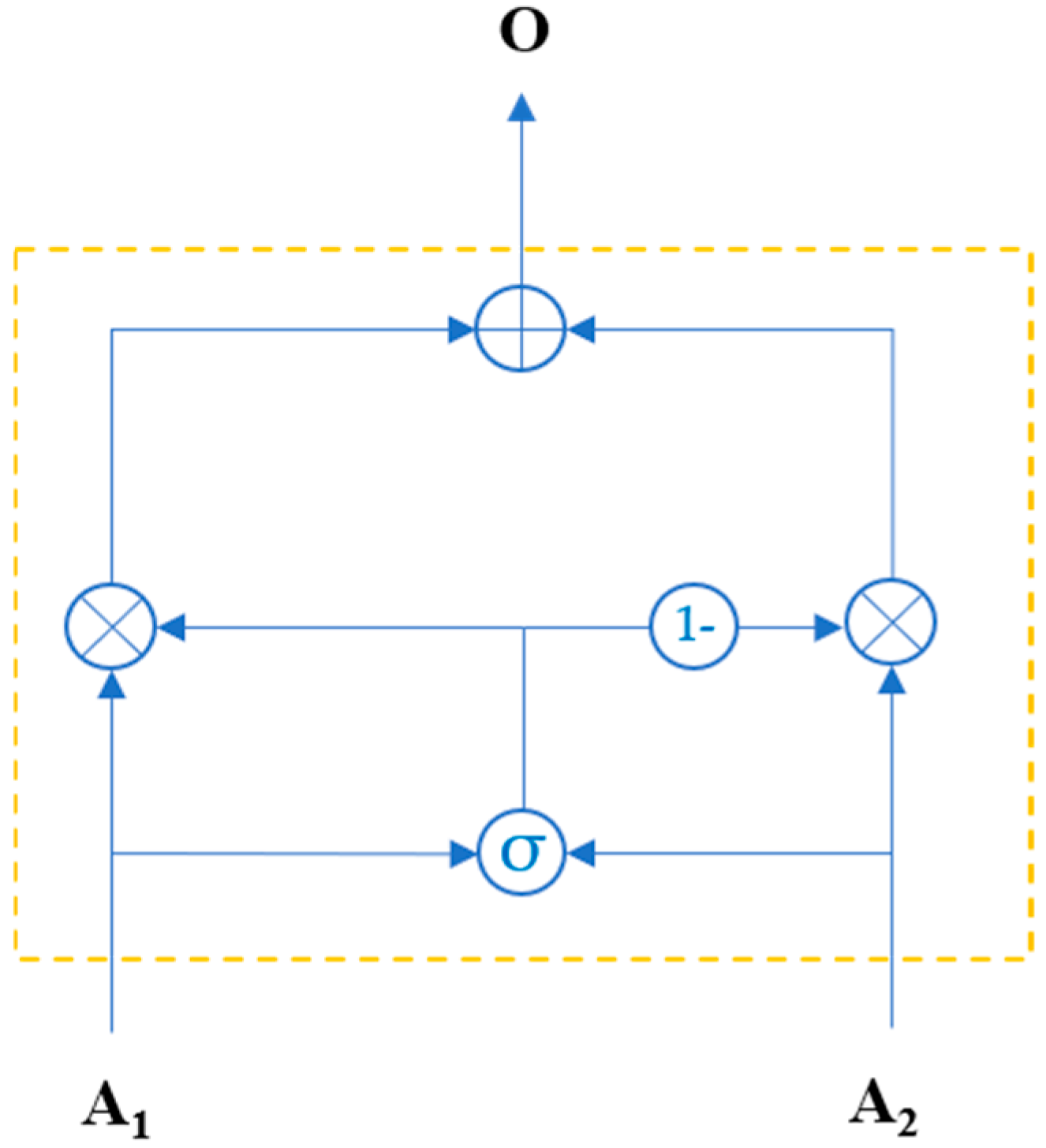
The structure of the gating fusion unit is illustrated in
Figure 6. Suppose the gating fusion unit receives two inputs,
A1 and
A2. First, two learnable parameters,
w1 and
w2, are initialized for these inputs. Then, the sigmoid function is applied to generate the weight representation
B.
Subsequently, the two parts are weighted and summed according to the weight representation
B, resulting in the final output
O.
In summary, given inputs A1 and A2, the two are first linearly transformed via learnable parameter matrices w1 and w2, respectively. The transformed results are then element-wise added together to generate interaction features. These features are subsequently mapped to the interval (0, 1) using a sigmoid function, forming a weight matrix B. This weight reflects the importance of A1 across various feature dimensions, while the weight of A2 is automatically assigned as 1-B. The final output O is obtained by computing the weighted sum of A1 and A2 with weights B and 1-B, respectively. The gated fusion unit models the interaction relationships between inputs in a parametric manner, enabling fine-grained feature adaptive fusion. The normalization constraint further prevents redundancy or conflicts in weight allocation.
GF-CNN extracts and integrates features at multiple levels, enabling the model to respond to various data types more flexibly and effectively, thereby enhancing its generalization ability.
3.3. Softmax Function
The softmax function is an activation function commonly used in multi-class classification tasks. It transforms a real-valued vector into a probability distribution. Softmax is primarily applied to the final layer of a neural network to ensure that the output values represent probabilities, meaning that the sum of all output values equals 1, and each value falls within the range (0, 1).
For an input vector
z = [
z1,
z2, …,
zn], the calculation formula of softmax is as follows:
In the formula, represents the exponential operation applied to each input, while the denominator is the sum of the exponentials of all the inputs.
6. Discussion
Although this study has made certain progress in classifying questions related to potato pest and disease, there are still some limitations that need to be addressed in future research.
First, at the data construction level, while the dataset generated based on LLM ensures standardization and consistency, it carries the potential risk of homogeneity. These highly standardized training samples may weaken the model’s ability to generalize to natural language variations, especially in real-world application scenarios where user inputs often involve non-standard linguistic phenomena such as spelling errors, grammatical mismatches, and semantic ambiguity. However, the models trained in a controlled environment have not yet undergone rigorous multimodal noise testing. In the future, we plan to collect natural language expressions from real-world scenarios and combine data augmentation strategies to construct a hybrid dataset with ecological validity.
Second, in terms of model architecture, although the existing GF-CNN network demonstrates good feature extraction capabilities, there is still a gap between its computational complexity and the real-time response requirements in agricultural production scenarios. The research team plans to implement a dual-path optimization approach: on one hand, we will advance lightweight architecture improvements, reducing the number of parameters through channel pruning and quantization compression; on the other hand, we will explore knowledge distillation techniques to improve computational efficiency while maintaining classification accuracy.
7. Conclusions
This study has addressed the current lack of high-quality question-answer datasets in the field of potato pest and disease and achieved dual breakthroughs at the methodological level. On the one hand, it innovatively constructed the first domain-specific question-answer dataset for this field, and on the other hand, it designed a classification model with feature fusion advantages. Specifically, this research proposes a question classification dataset construction method based on prompt engineering. First, prompts are used to guide the LLM in generating question templates, and then, entities extracted from previous NER work are batch-inserted into the question templates, resulting in the construction of a high-quality PDPQCD. Additionally, this study introduces the GF-CNN question classification model, which employs (a) a parallel dual-pooling structure, using max-pooling to capture key semantic features and average-pooling to retain global statistical information, and (b) a learnable gating fusion module to dynamically adjust the feature weights from the dual channels. Experimental results show that GF-CNN achieves F1 scores of 100.00%, 96.70%, and 93.55% on the PDPQCD, Subj, and THUCNews datasets, respectively, outperforming other models.
Future work includes the completion of a potato pest and disease intelligent question-answering system, with exploration of LLM integration to enhance text-generation capabilities.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}