
Efficient Tobacco Pest Detection in Complex Environments Using an Enhanced YOLOv8 Model

 ,
, 

Abstract
1. Introduction
2. Materials and Methods
2.1. Image Dataset
2.2. Data Enhancement
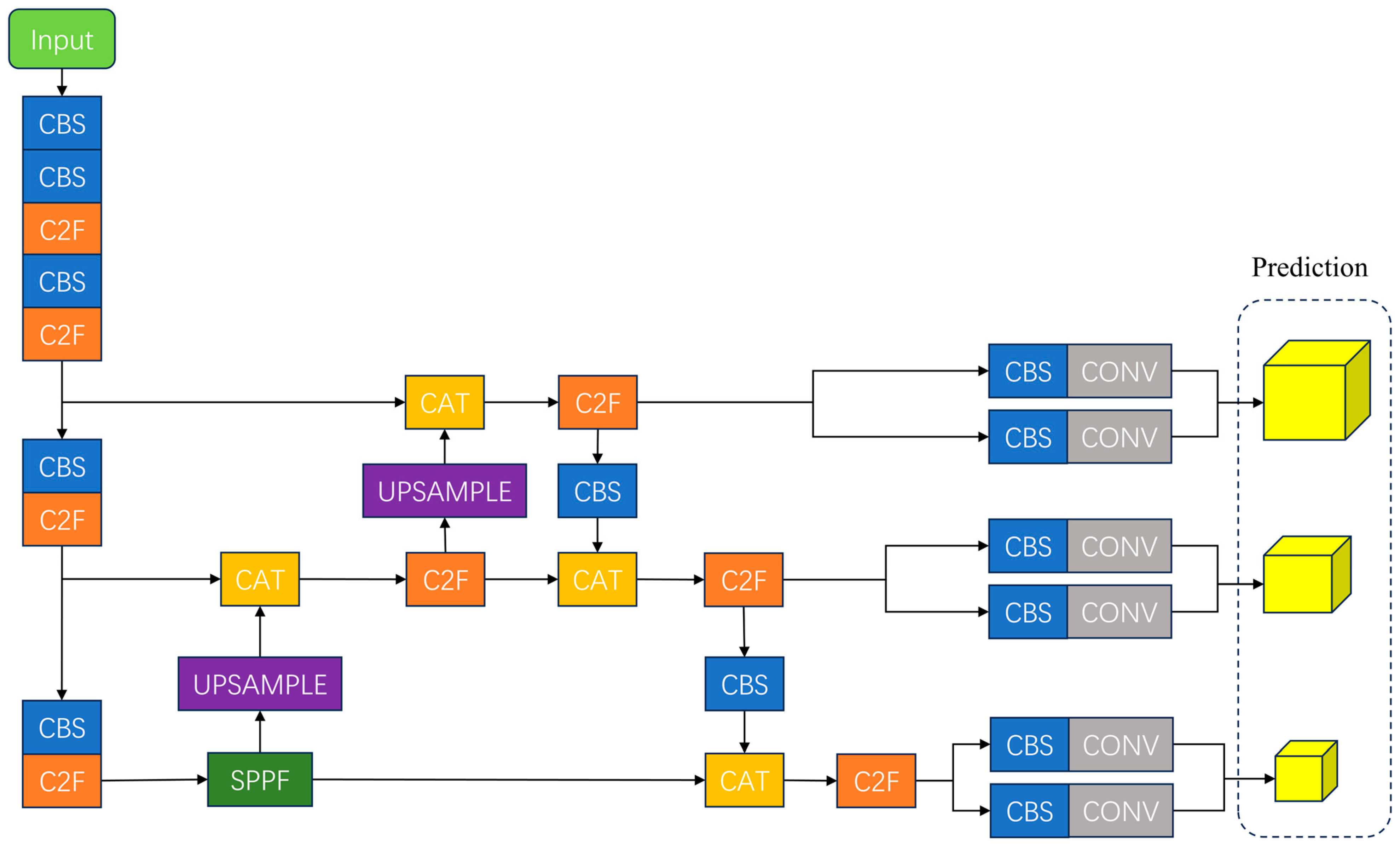
2.3. Standard YOLOv8 Model
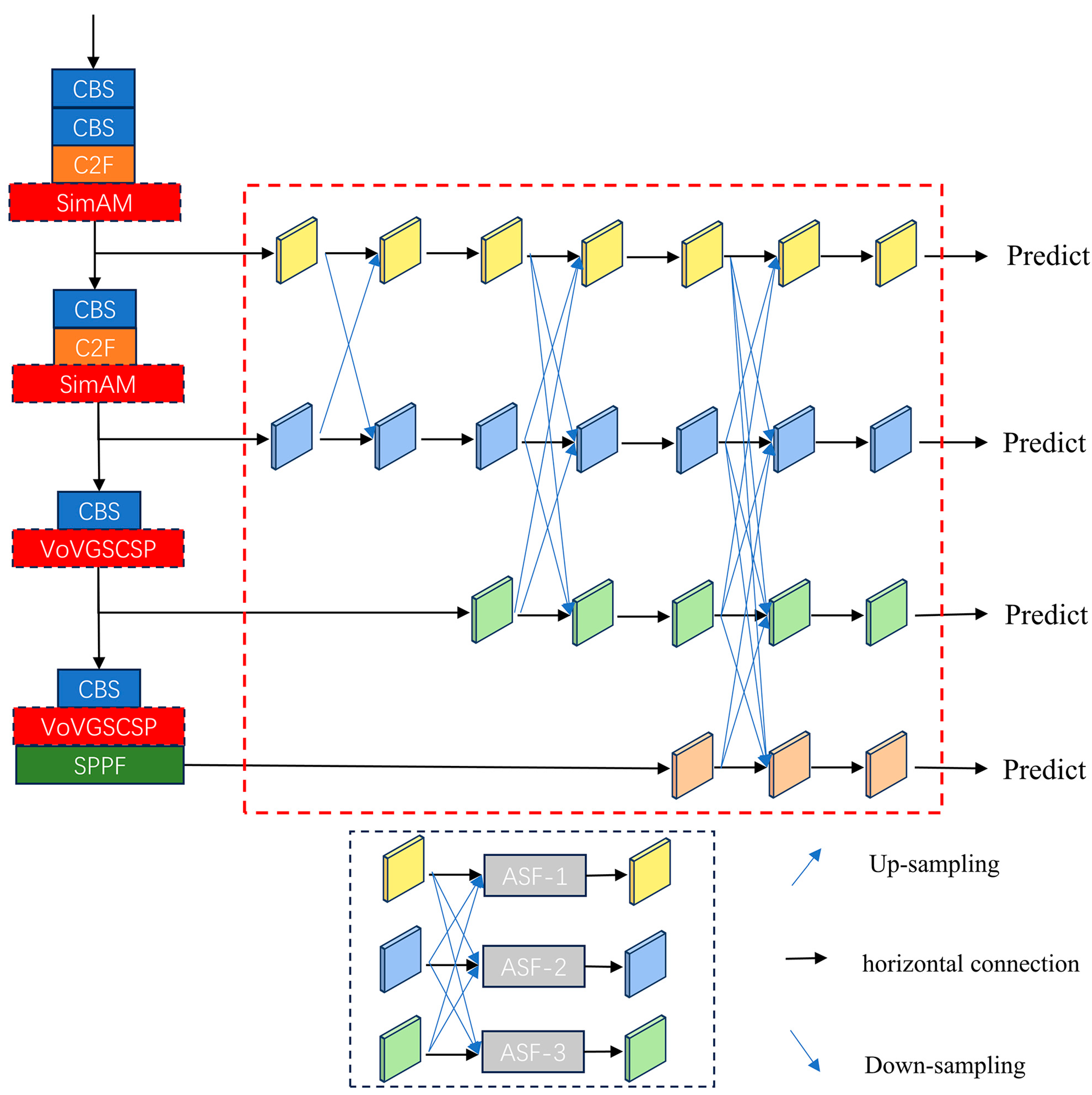
2.4. Improved YOLOv8 Model
2.4.1. YOLOv8 Model Improvement Strategy
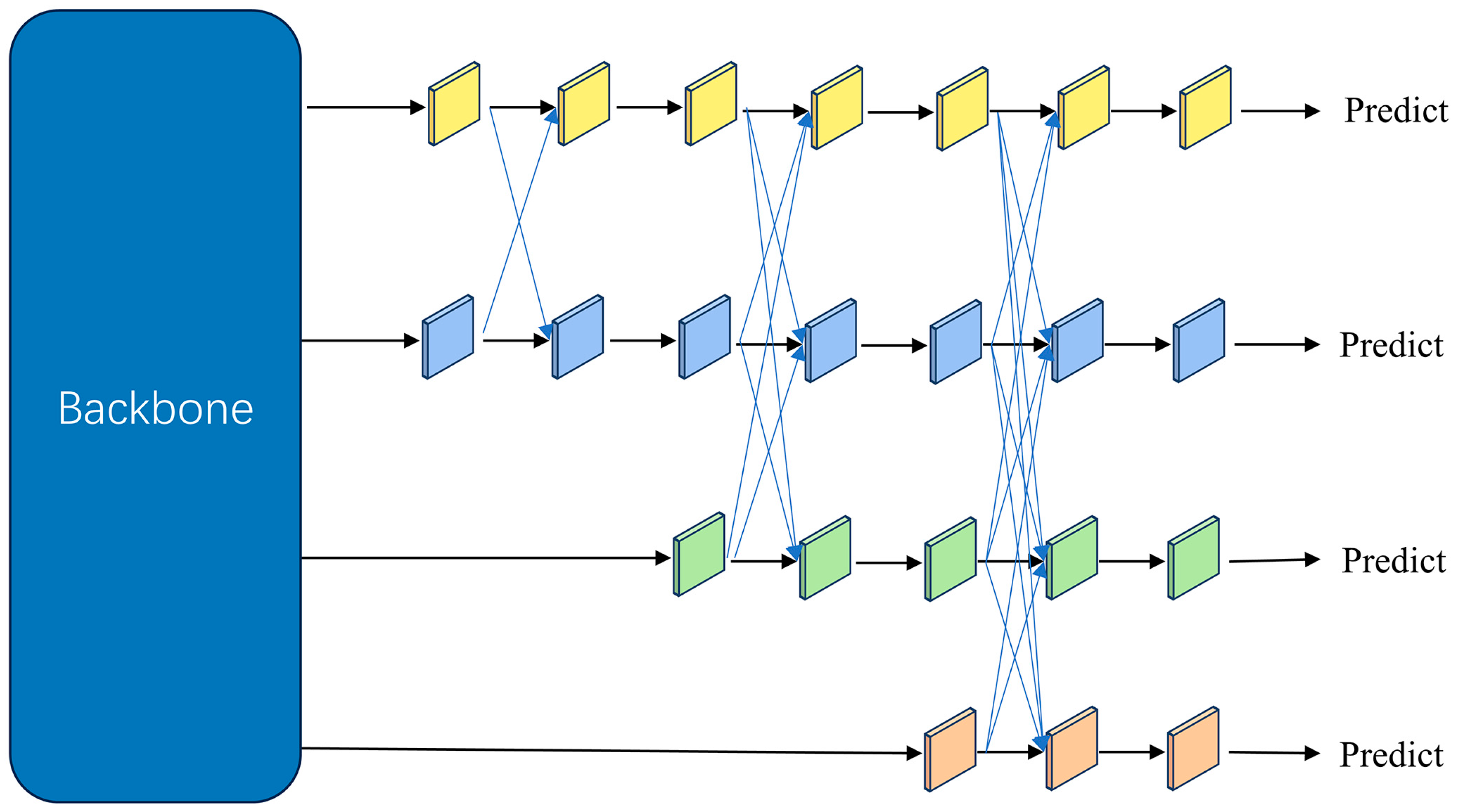
2.4.2. Asymptotic Feature Pyramid Network
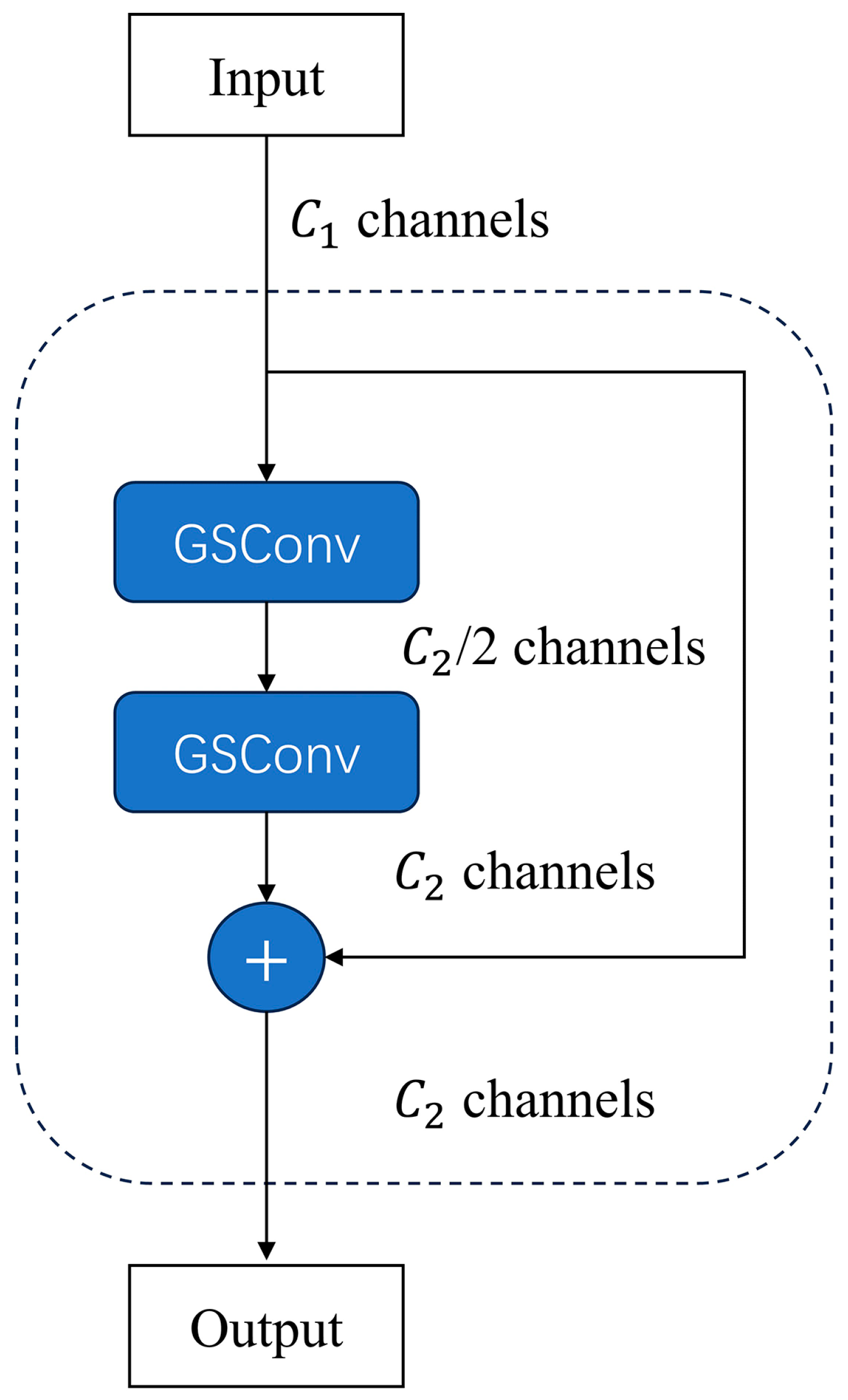
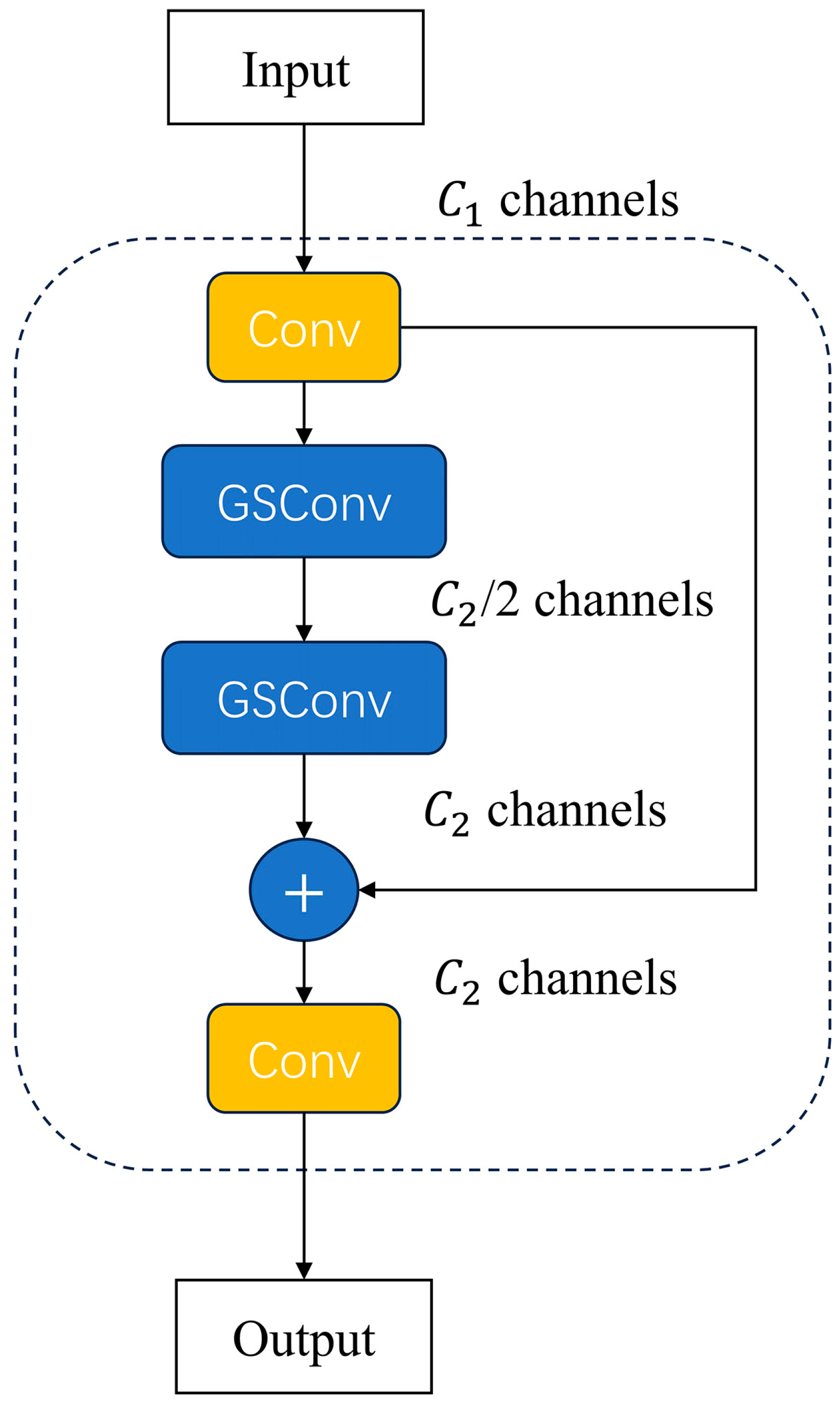
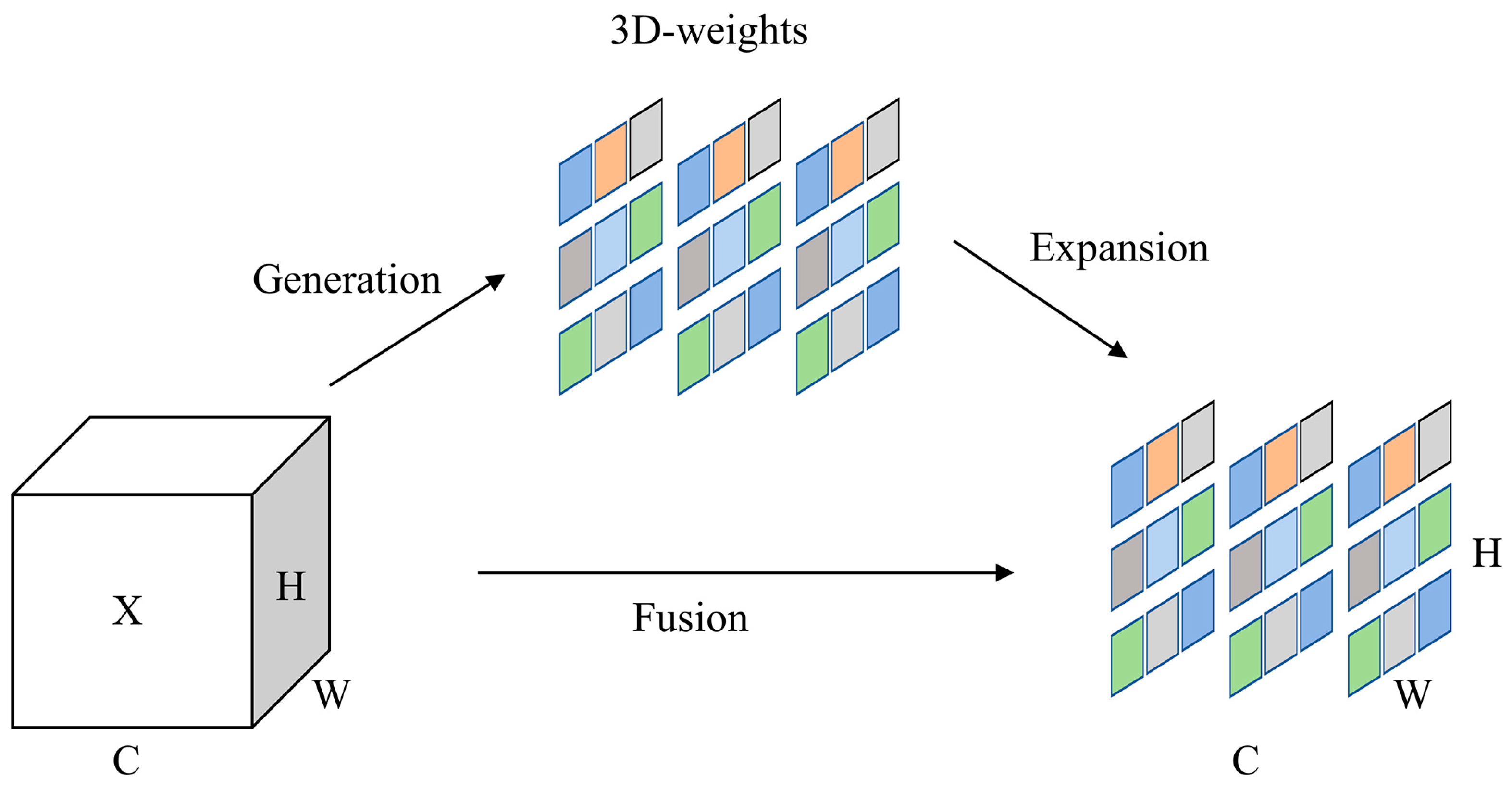
2.4.3. VoV-GSCSP Module
2.4.4. SimAM Attention Module
2.5. Model Evaluation Metrics
3. Results
3.1. Experiment Settings
3.1.1. Experimental Platform
3.1.2. Model Training Strategy
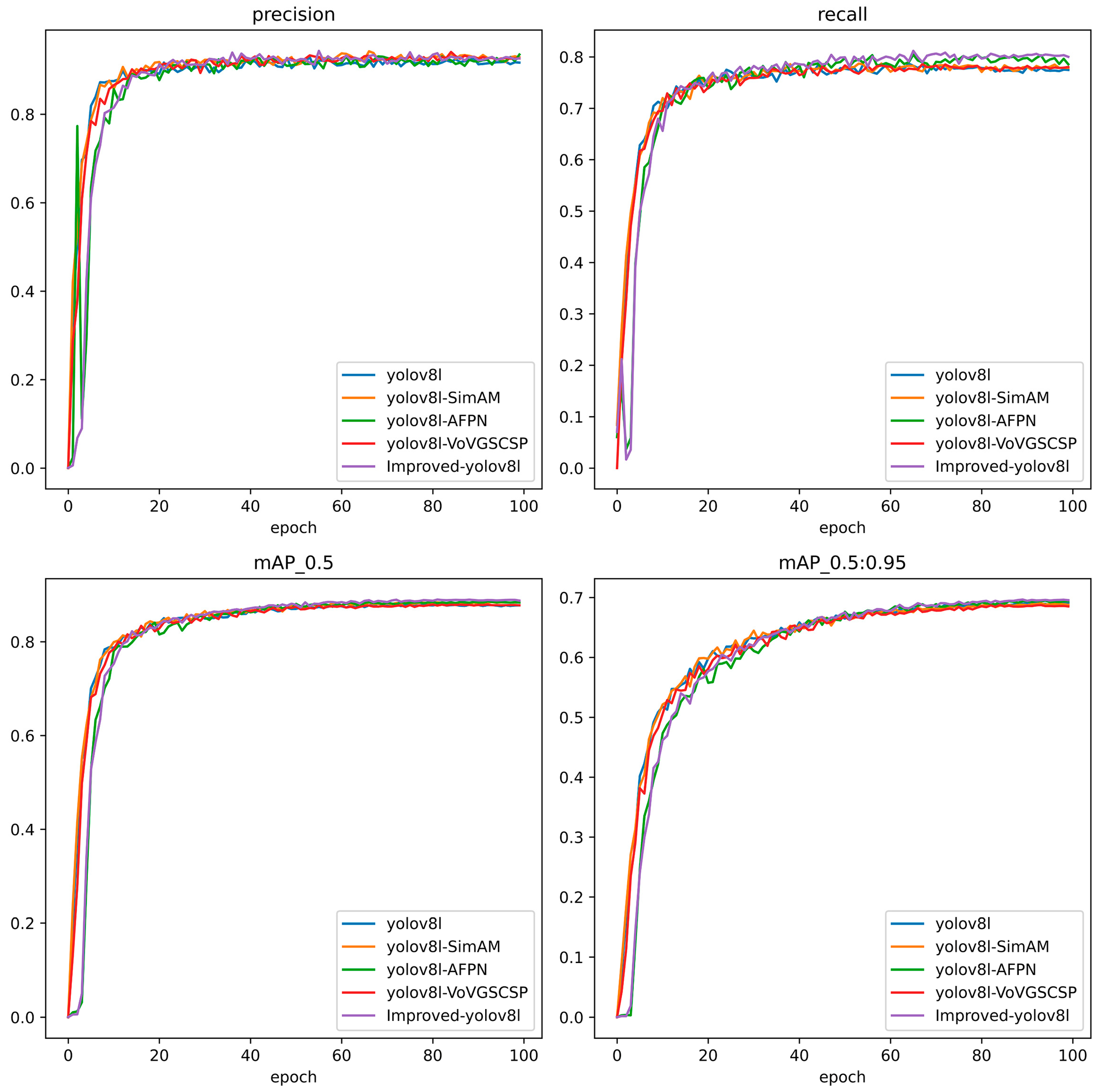
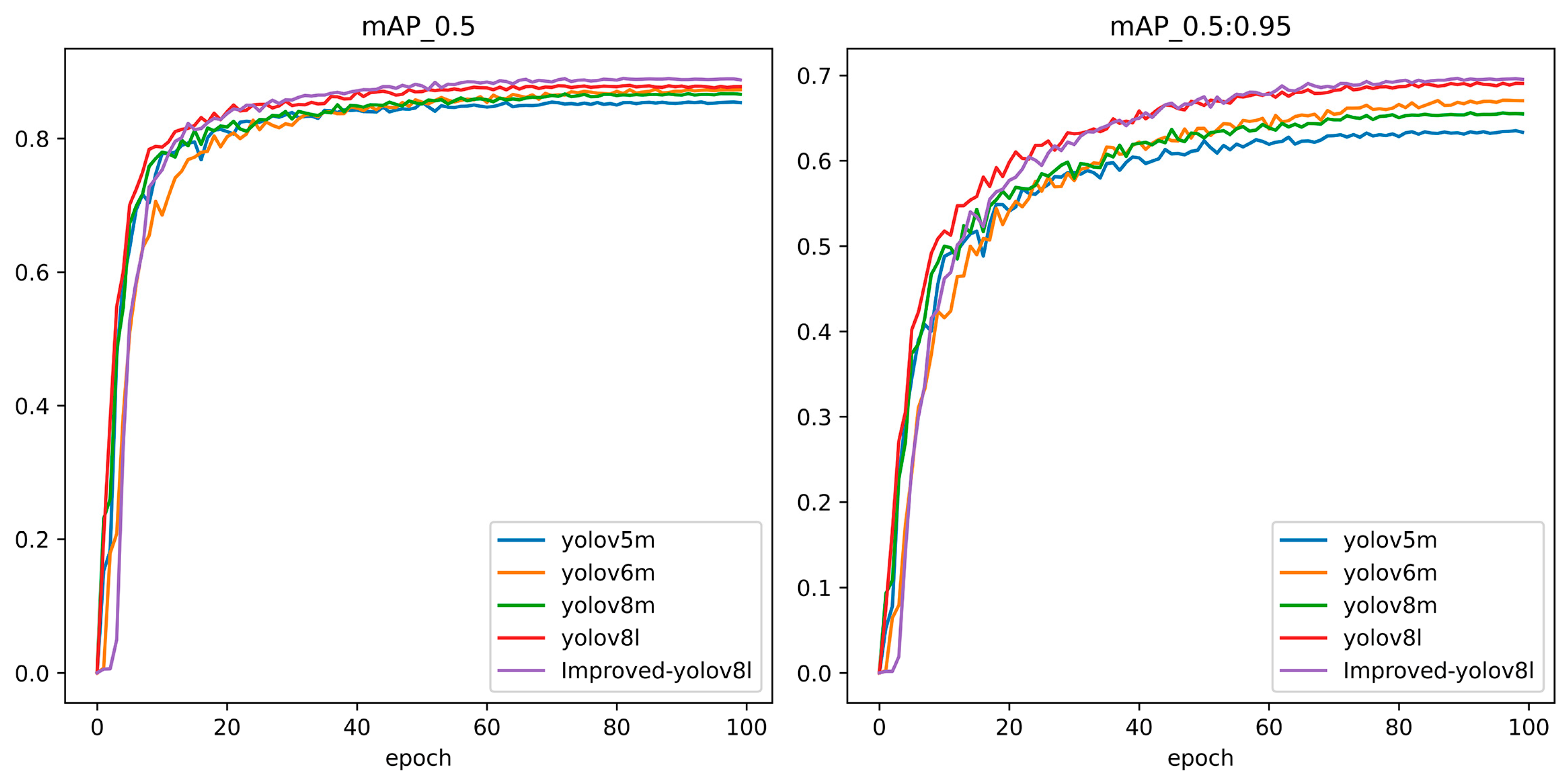
3.2. Comparison Experiment before and after Model Improvement
3.3. Ablation Experiments
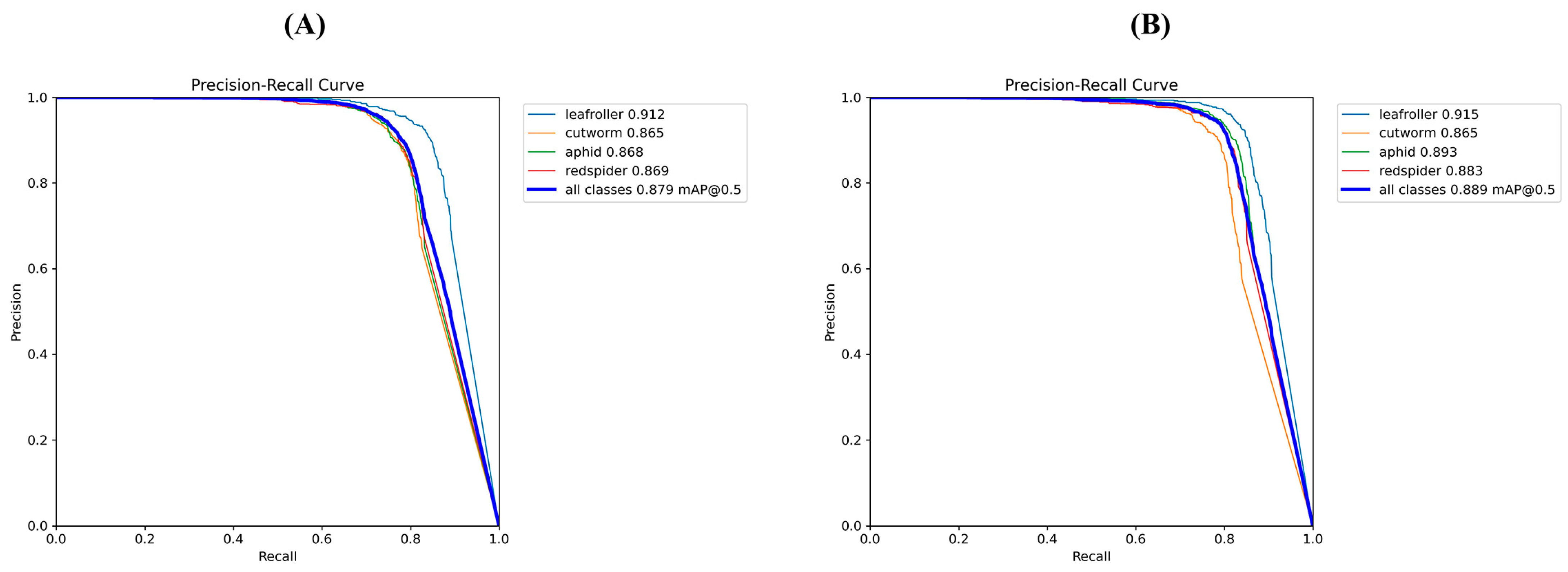
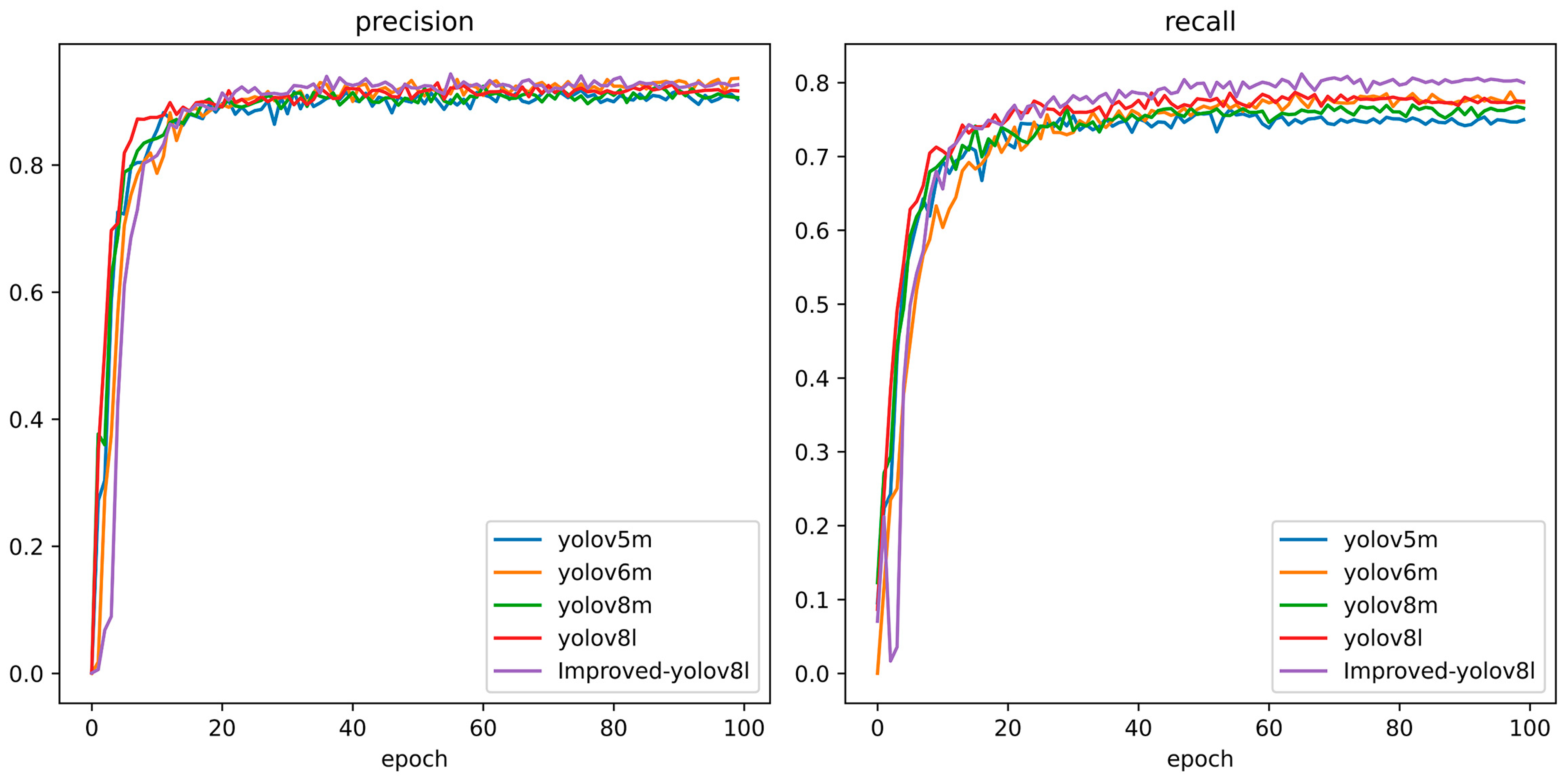
3.4. Different Model Performances
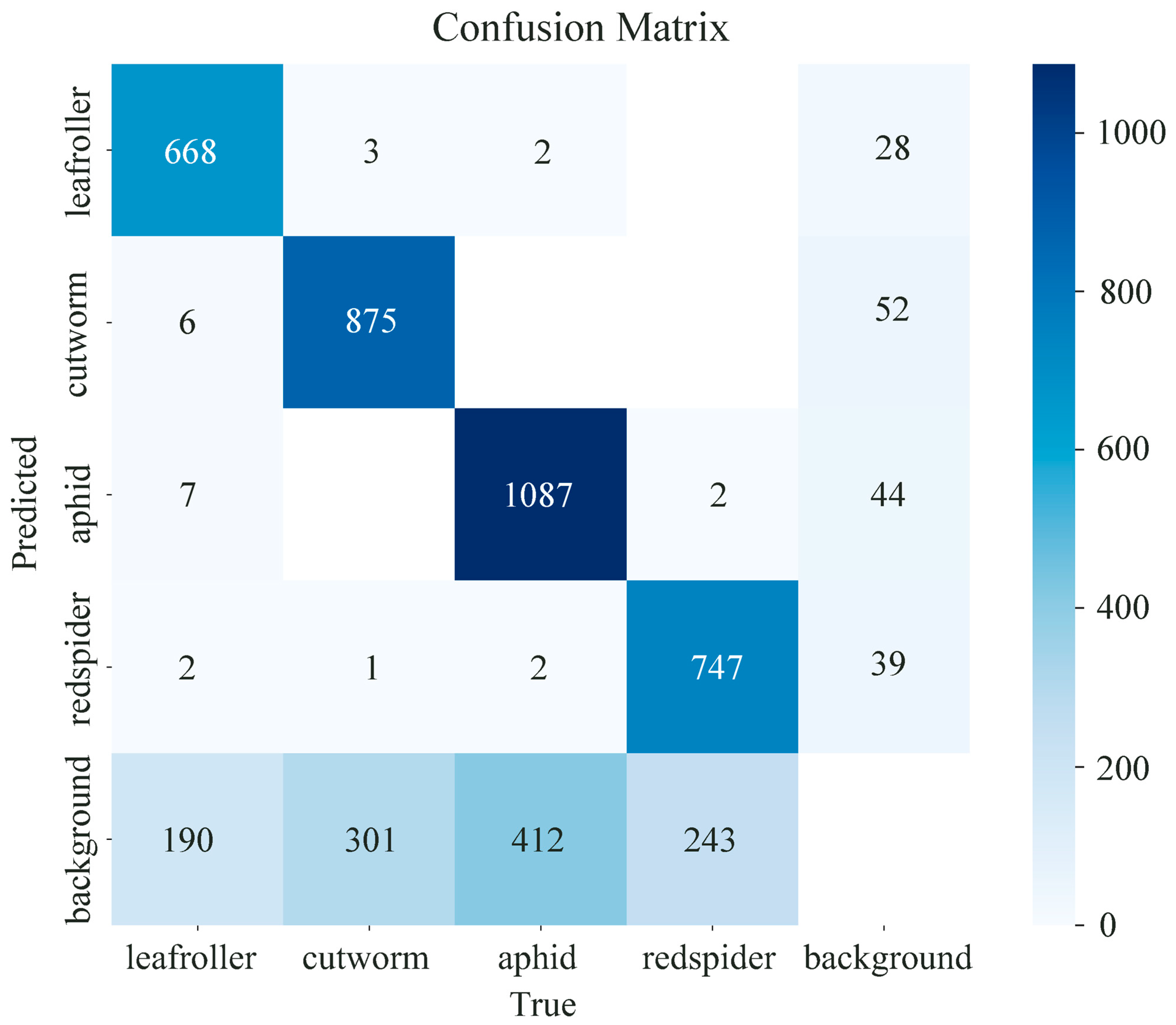
3.5. Model Detection Results
3.6. Model Interpretability Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, P.; Zhang, H.; He, W. Multi-scale feature fusion method for bundled tobacco leaf classification based on fine-grained classification network. J. Anhui Agric. Univ. 2022, 49, 1013–1021. [Google Scholar] [CrossRef]
- Qu, Y.; Li, J.; Chen, Z.; Wen, Z.; Liang, J.; Cao, Y.; Li, S.; Chen, J. Current Status and Future Development of Flue-cured Tobacco Production in Guangdong Province. Guangdong Agric. Sci. 2019, 46, 141–147. [Google Scholar] [CrossRef]
- Rabb, R.L.; Todd, F.A.; Ellis, H.C. Tobacco Pest Management. In Integrated Pest Management; Apple, J.L., Smith, R.F., Eds.; Springer: Boston, MA, USA, 1976; pp. 71–106. ISBN 978-1-4615-7269-5. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Santos, L.; Santos, F.N.; Oliveira, P.M.; Shinde, P. Deep Learning Applications in Agriculture: A Short Review. In Proceedings of the Robot 2019: Fourth Iberian Robotics Conference, Porto, Portugal, 20–22 November 2019; Springer: Cham, Switzerland, 2020; pp. 139–151. [Google Scholar]
- Bian, K.-C.; Yang, H.-J.; Lu, Y.-H.; Lu, Y.-H. Application Review of Deep Learning in Detection and Identification of Agricultural Pests and Diseases. Softw. Guide 2021, 20, 26–33. [Google Scholar]
- Liu, Z.; Gao, J.; Yang, G.; Zhang, H.; He, Y. Localization and Classification of Paddy Field Pests Using a Saliency Map and Deep Convolutional Neural Network. Sci. Rep. 2016, 6, 20410. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Zhang, J.; Dong, W.; Yu, J.; Xie, C.; Li, R.; Chen, T.; Chen, H. A Crop Pests Image Classification Algorithm Based on Deep Convolutional Neural Network. TELKOMNIKA (Telecommun. Comput. Electron. Control.) 2017, 15, 1239–1246. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, Y.; Chen, Y.; Wu, Y.; Yue, Y. Pest Identification via Deep Residual Learning in Complex Background. Comput. Electron. Agric. 2017, 141, 351–356. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Liu, J.; Wang, X. Tomato Diseases and Pests Detection Based on Improved Yolo V3 Convolutional Neural Network. Front. Plant Sci. 2020, 11, 898. [Google Scholar] [CrossRef]
- She, H.; Wu, L.; Shan, L. Improved Rice Pest Recognition Based on SSD Network Model. J. Zhengzhou Univ. (Nat. Sci. Ed.) 2020, 52, 49–54. [Google Scholar] [CrossRef]
- Liu, Q.; Yan, Z.; Wang, F.; Ding, C. Research on Object Detection Algorithm for Small Object of Pests Based on YOLOv3. In Proceedings of the 2021 International Conference on Computer Information Science and Artificial Intelligence (CISAI), Kunming, China, 17–19 September 2021; pp. 14–18. [Google Scholar]
- Zhang, W.; Chen, S.; Wang, Y.; Tie, J.; Ding, J.; Li, M.; Li, C.; Su, X.; Gan, Y. Identification of Lasioderma serricorne in Tobacco Leaf Raw Materials Based on Improved YOLOv3 Algorithm. J. Henan Agric. Sci. 2023, 52, 157–166. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Zhao, X.; Su, X.; Wu, W. Lightweight Detection Networks for Tea Bud on Complex Agricultural Environment via Improved YOLO V4. Comput. Electron. Agric. 2023, 211, 107955. [Google Scholar] [CrossRef]
- Zhang, C.; Kang, F.; Wang, Y. An Improved Apple Object Detection Method Based on Lightweight YOLOv4 in Complex Backgrounds. Remote Sens. 2022, 14, 4150. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, D.; Guo, X.; Yang, H. Lightweight Algorithm for Apple Detection Based on an Improved YOLOv5 Model. Plants 2023, 12, 3032. [Google Scholar] [CrossRef] [PubMed]
- Kang, J.; Zhang, W.; Xia, Y.; Liu, W. A Study on Maize Leaf Pest and Disease Detection Model Based on Attention and Multi-Scale Features. Appl. Sci. 2023, 13, 10441. [Google Scholar] [CrossRef]
- Wu, X.; Zhan, C.; Lai, Y.K.; Cheng, M.M.; Yang, J. IP102: A Large-scale Benchmark Dataset for Insect Pest Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8779–8788. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A Database and Web-Based Tool for Image Annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972v1. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO: From YOLOv1 and Beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-Neck by GSConv: A Better Design Paradigm of Detector Architectures for Autonomous Vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385v1. [Google Scholar]
- Hassanin, M.; Anwar, S.; Radwan, I.; Khan, F.S.; Mian, A. Visual Attention Methods in Deep Learning: An In-Depth Survey. arXiv 2022, arXiv:2204.07756. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; Tao, X.; Fang, J.; Imyhxy; et al. Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 9 November 2022).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Parameters | GFLOPs | mAP@0.5 | Recall | mAP@0.5:0.95 | Precision |
|---|---|---|---|---|---|---|
| YOLOv8l | 43.61 M | 164.8 | 87.9% | 77.4% | 69.1% | 90.3% |
| Improved-YOLOv8l | 20.65 M | 131.9 | 88.9% | 80.1% | 69.7% | 92.7% |
| Model | Parameters | GFLOPs | mAP@0.5 |
|---|---|---|---|
| YOLOv8l | 43.61 M | 164.8 | 87.9% |
| YOLOv8l+AFPN | 27.67 M | 151.6 | 88.4% |
| YOLOv8l+SimAM | 43.61 M | 164.8 | 88.4% |
| YOLOv8l+VoV-GSCSP | 36.60 M | 145.2 | 87.9% |
| YOLOv8l+AFPN+VoV-GSCSP | 20.65 M | 131.9 | 88.5% |
| YOLOv8l+AFPN+SimAM | 27.67 M | 151.6 | 88.7% |
| YOLOv8l+VoV-GSCSP+SIMAM | 36.60 M | 145.2 | 88.2% |
| Improved+YOLOv8l | 20.65 M | 131.9 | 88.9% |
| Model | mAP@0.5 | Recall | Precision | mAP@0.5:0.9 | Parameters |
|---|---|---|---|---|---|
| YOLOv5m | 85.5% | 74.6% | 90.3% | 63.5% | 25.05 M |
| YOLOv6m | 87.3% | 77.4% | 93.6% | 67.1% | 51.98 M |
| YOLOv8m | 86.7% | 76.5% | 90.6% | 65.6% | 25.84 M |
| YOLOv8l | 87.9% | 77.4% | 91.6% | 69.1% | 43.61 M |
| Improved-YOLOv8l | 88.9% | 80.1% | 92.7% | 69.7% | 20.65 M |
| Model | Leaf Roller | Cutworm | Aphid | Red Spider |
|---|---|---|---|---|
| YOLOv8l | 80.6% | 76.1% | 75.4% | 77.2% |
| Improved-YOLOv8l | 83.6% | 78.2% | 79% | 79.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, D.; Zhang, K.; Zhong, H.; Xie, J.; Xue, X.; Yan, M.; Wu, W.; Li, J. Efficient Tobacco Pest Detection in Complex Environments Using an Enhanced YOLOv8 Model. Agriculture 2024, 14, 353. https://doi.org/10.3390/agriculture14030353
Sun D, Zhang K, Zhong H, Xie J, Xue X, Yan M, Wu W, Li J. Efficient Tobacco Pest Detection in Complex Environments Using an Enhanced YOLOv8 Model. Agriculture. 2024; 14(3):353. https://doi.org/10.3390/agriculture14030353
Chicago/Turabian StyleSun, Daozong, Kai Zhang, Hongsheng Zhong, Jiaxing Xie, Xiuyun Xue, Mali Yan, Weibin Wu, and Jiehao Li. 2024. "Efficient Tobacco Pest Detection in Complex Environments Using an Enhanced YOLOv8 Model" Agriculture 14, no. 3: 353. https://doi.org/10.3390/agriculture14030353
APA StyleSun, D., Zhang, K., Zhong, H., Xie, J., Xue, X., Yan, M., Wu, W., & Li, J. (2024). Efficient Tobacco Pest Detection in Complex Environments Using an Enhanced YOLOv8 Model. Agriculture, 14(3), 353. https://doi.org/10.3390/agriculture14030353