
Investigation on Zoning Management of Saline Soil in Cotton Fields in Alar Reclamation Area, Xinjiang


Abstract
:1. Introduction
2. Materials and Methods
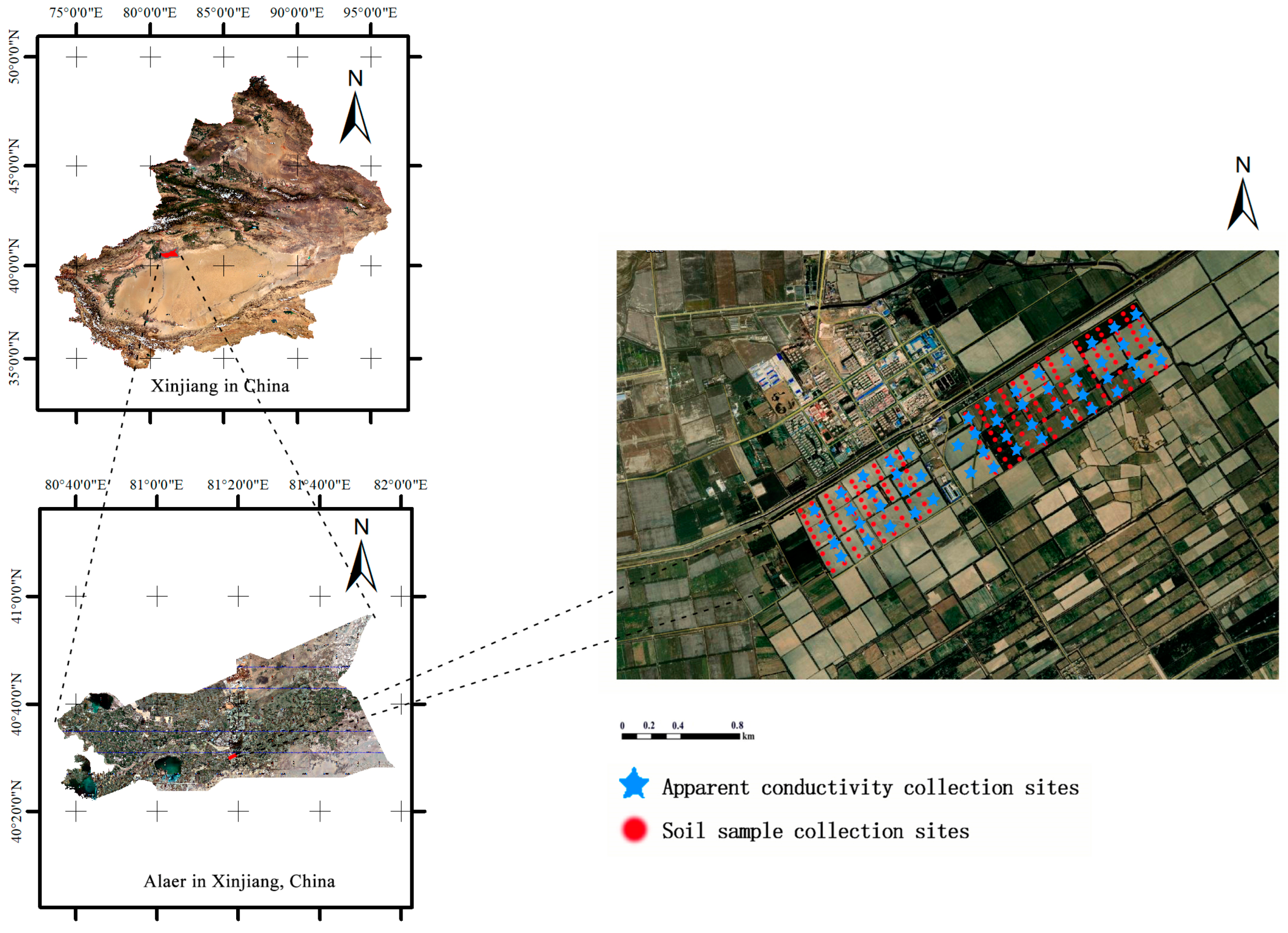
2.1. Overview
2.2. Soil Sample Collection and Processing
2.3. Principal Component Analysis
2.4. Fuzzy c-Means Clustering
2.5. Clustering Validity Test
3. Results and Analysis
3.1. Descriptive Statistics of Soil Properties
3.2. Correlation Analysis of Soil Properties
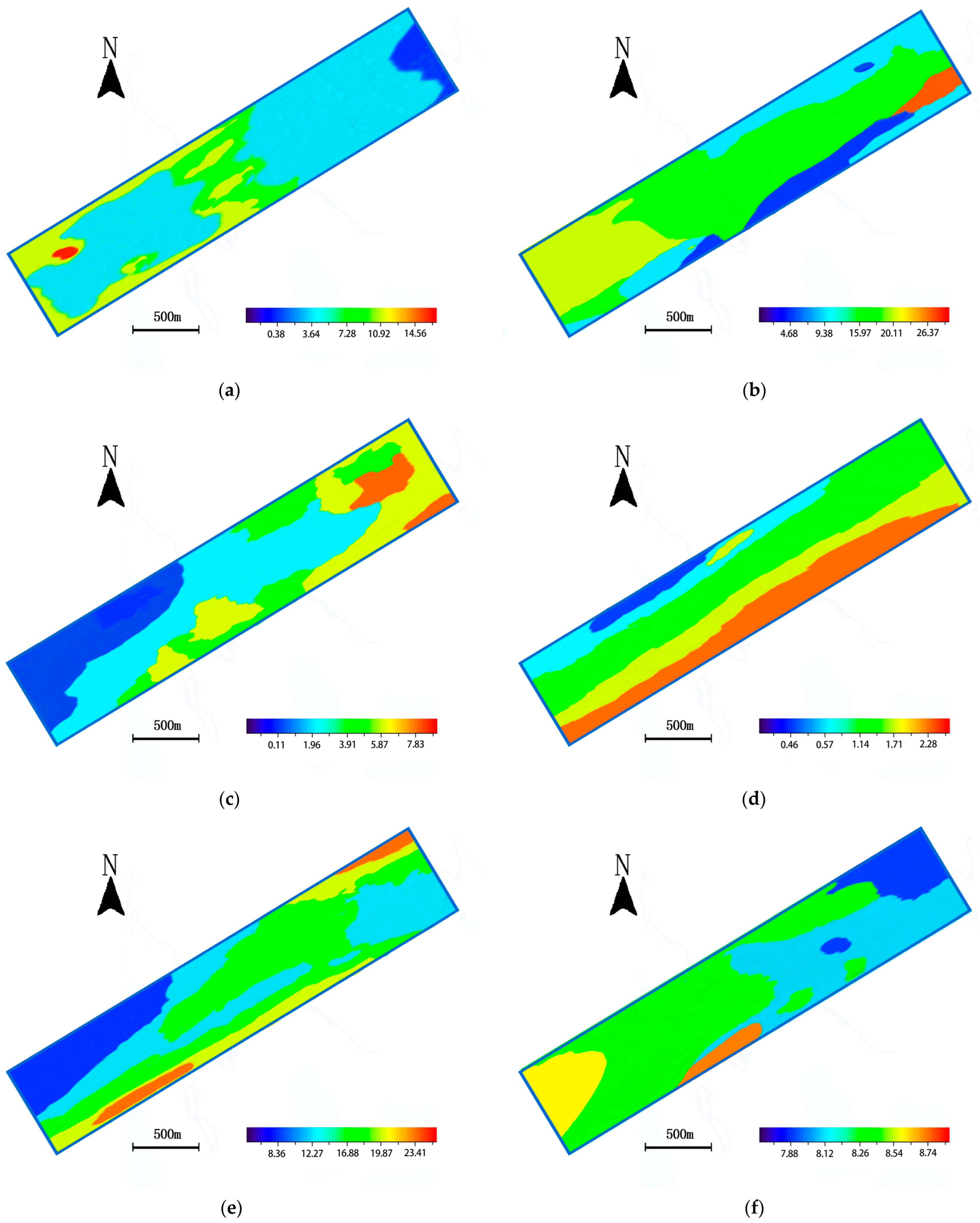
3.3. Spatial Distribution Characteristics of Soil Properties
3.4. Principal Component Analysis of Soil Properties
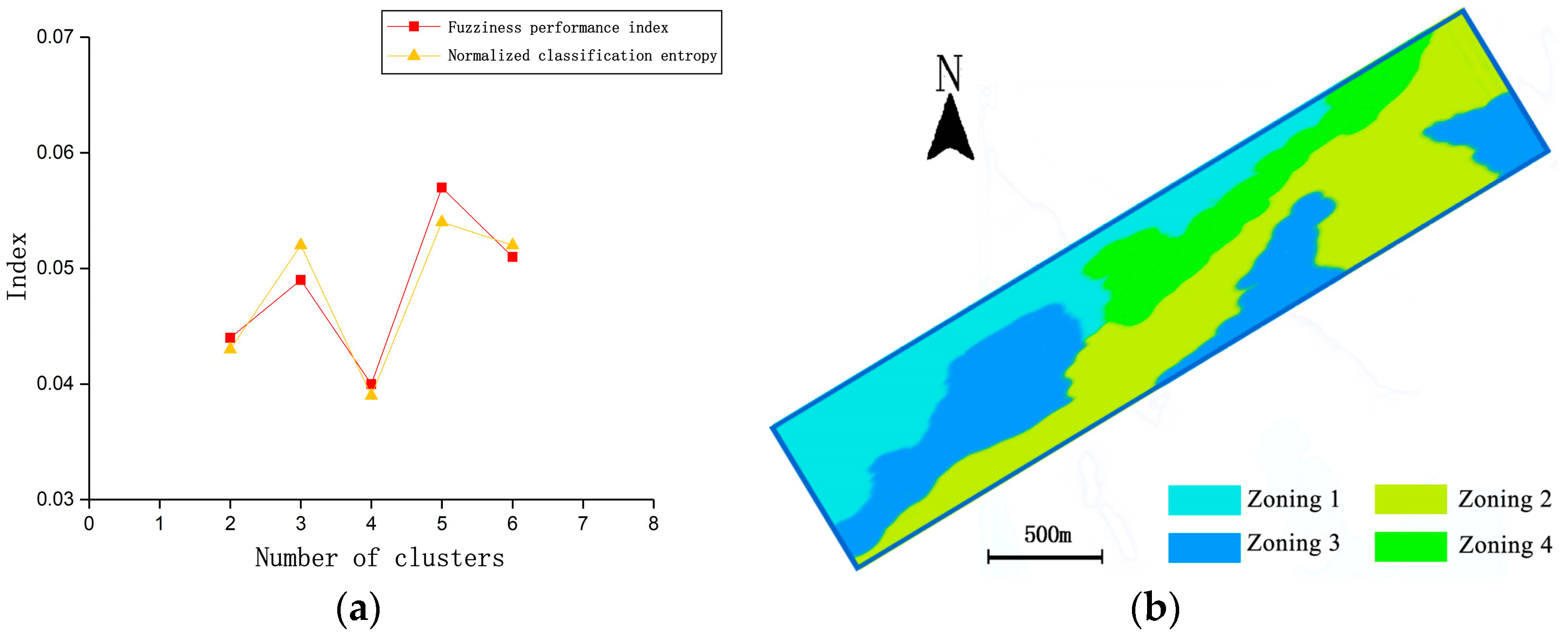
3.5. FCM Clustering Analysis and Managed Partitioning
3.6. Managing Partition Accuracy Checks
4. Conclusions
- (1)
- The soils in the study area were mildly saline, low in soil organic matter and total nitrogen, medium in total phosphorus, and high in conductivity, total potassium, and pH. The variability of all the soil properties was moderate except for pH, which was weak.
- (2)
- The interpolation results of the soil attributes showed that the six soil attributes have an obvious spatial structure, but different attributes have large differences in spatial distribution.
- (3)
- The results of the principal component analysis showed that the six soil attributes were classified into three principal components, and based on this, the study area was divided into four management zones using the FCM cluster analysis and two quantitative evaluation indicators, FPI and NCE.
- (4)
- The results of the ANOVA showed significant differences in soil properties such as the soil conductivity, organic matter, and soil nutrients in different management zones. Therefore, the FCM cluster analysis and different soil attributes can be used to determine the management zoning of farmland in the study area.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abuelgasim, A.; Ammad, R. Mapping soil salinity in arid and semi-arid regions using landsat 8 oli satellite data. Remote Sens. Appl. Soc. Environ. 2019, 13, 415–425. [Google Scholar] [CrossRef]
- Khan, M.; Almazah, M.M.; EIlahi, A.; Niaz, R.; Al-Rezami, A.; Zaman, B. Spatial interpolation of water quality index based on ordinary kriging and universal kriging. Geomat. Nat. Hazards Risk 2023, 14, 2190853. [Google Scholar] [CrossRef]
- Li, J.; Pu, L.; Han, M.; Zhu, M.; Zhang, R.; Xiang, Y. Soil salinization research in china: Advances and prospects. J. Geogr. Sci. 2014, 24, 943–960. [Google Scholar] [CrossRef]
- Hopmans, J.W.; Qureshi, A.; Kisekka, I.; Munns, R.; Grattan, S.; Rengasamy, P.; Ben-Gal, A.; Assouline, S.; Javaux, M.; Minhas, P.; et al. Critical knowledge gaps and research priorities in global soil salinity. Adv. Agron. 2021, 169, 1–191. [Google Scholar]
- Xiao, C.; Li, M.; Fan, J.; Zhang, F.; Li, Y.; Cheng, H.; Li, Y.; Hou, X.; Chen, J. Salt leaching with brackish water during growing season improves cotton growth and productivity, water use efficiency and soil sustainability in southern Xinjiang. Water 2021, 13, 2602. [Google Scholar] [CrossRef]
- Al-Ali, Z.; Bannari, A.; Rhinane, H.; El-Battay, A.; Shahid, S.A.; Hameid, N. Validation and comparison of physical models for soil salinity mapping over an arid landscape using spectral reflectance measurements and landsat-oli data. Remote Sens. 2021, 13, 494. [Google Scholar] [CrossRef]
- Kumar, N.; Singh, S.K.; Pandey, H. Drainage morphometric analysis using open access earth observation datasets in a drought-affected part of bundelkhand, india. Appl. Geomat. 2018, 10, 173–189. [Google Scholar] [CrossRef]
- Chen, H.; Zhao, G.; Li, Y.; Wang, D.; Ma, Y. Monitoring the seasonal dynamics of soil salinization in the yellow river delta of china using landsat data. Nat. Hazards Earth Syst. Sci. 2019, 19, 1499–1508. [Google Scholar] [CrossRef]
- Komarov, S.; Antropov, D.; Varlamov, A.; Galchenko, S.; Zhdanova, R. Zoning as a tool of land management. IOP Conf. Ser. Earth Environ. Sci. 2019, 350, 012060. [Google Scholar] [CrossRef]
- Zhang, H.; Liang, X.; Chen, H.; Shi, Q. Spatio-temporal evolution of the social-ecological landscape resilience and management zoning in the loess hill and gully region of china. Environ. Dev. 2021, 39, 100616. [Google Scholar] [CrossRef]
- Moharana, P.; Jena, R.; Pradhan, U.; Nogiya, M.; Tailor, B.; Singh, R.; Singh, S. Geostatistical and fuzzy clustering approach for delineation of site-specific management zones and yield-limiting factors in irrigated hot arid environment of india. Precis. Agric. 2020, 21, 426–448. [Google Scholar] [CrossRef]
- Yasir, M.; Sheng, H.; Fan, H.; Nazir, S.; Niang, A.J.; Salauddin, M.; Khan, S. Automatic coastline extraction and changes analysis using remote sensing and gis technology. IEEE Access 2020, 8, 180156–180170. [Google Scholar] [CrossRef]
- Perron, I.; Cambouris, A.N.; Chokmani, K.; Gutierrez, M.F.V.; Zebarth, B.J.; Moreau, G.; Biswas, A.; Adamchuk, V. Delineating soil management zones using a proximal soil sensing system in two commercial potato fields in new brunswick, Canada. Can. J. Soil Sci. 2018, 98, 724–737. [Google Scholar] [CrossRef]
- Metwally, M.S.; Shaddad, S.M.; Liu, M.; Yao, R.-J.; Abdo, A.I.; Li, P.; Jiao, J.; Chen, X. Soil properties spatial variability and delineation of site-specific management zones based on soil fertility using fuzzy clustering in a hilly field in jianyang, sichuan, china. Sustainability 2019, 11, 7084. [Google Scholar] [CrossRef]
- Shukla, M.K.; Sharma, P. Fuzzy k-means and principal component analysis for classifying soil properties for efficient farm management and maintaining soil health. Sustainability 2023, 15, 13144. [Google Scholar] [CrossRef]
- Jaynes, D.; Kaspar, T.; Colvin, T.; James, D. Cluster analysis of spatiotemporal corn yield patterns in an iowa field. Agron. J. 2003, 95, 574–586. [Google Scholar] [CrossRef]
- Techen, A.-K.; Helming, K.; Brüggemann, N.; Veldkamp, E.; Reinhold-Hurek, B.; Lorenz, M.; Bartke, S.; Heinrich, U.; Amelung, W.; Augustin, K.; et al. Soil research challenges in response to emerging agricultural soil management practices. Adv. Agron. 2020, 161, 179–240. [Google Scholar]
- Gavioli, A.; de Souza, E.G.; Bazzi, C.L.; Schenatto, K.; Betzek, N.M. Identification of management zones in precision agriculture: An evaluation of alternative cluster analysis methods. Biosyst. Eng. 2019, 181, 86–102. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Sun, J.; Huang, G. Optimizing water resources allocation and soil salinity control for supporting agricultural and environmental sustainable development in central asia. Sci. Total Environ. 2020, 704, 135281. [Google Scholar] [CrossRef]
- Montanarella, L.; Panagos, P. The relevance of sustainable soil management within the european green deal. Land Use Policy 2021, 100, 104950. [Google Scholar] [CrossRef]
- Asfaw, E.; Suryabhagavan, K.; Argaw, M. Soil salinity modeling and mapping using remote sensing and gis: The case of wonji sugar cane irrigation farm, Ethiopia. J. Saudi Soc. Agric. Sci. 2018, 17, 250–258. [Google Scholar] [CrossRef]
- Pansu, M. Handbook of Soil Analysis; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Uddin, M.P.; Mamun, M.A.; Hossain, M.A. PCA-based feature reduction for hyperspectral remote sensing image classification. IETE Tech. Rev. 2021, 38, 377–396. [Google Scholar] [CrossRef]
- Rahbar, A.; Vadiati, M.; Talkhabi, M.; Nadiri, A.A.; Nakhaei, M.; Rahimian, M. A hydrogeochemical analysis of groundwater using hierarchical clustering analysis and fuzzy c-mean clustering methods in arak plain, Iran. Environ. Earth Sci. 2020, 79, 1–17. [Google Scholar] [CrossRef]
- Damian, J.M.; Santi, A.L.; Fornari, M.; Da Ros, C.O.; Eschner, V.L. Monitoring variability in cash-crop yield caused by previous cultivation of a cover crop under a no-tillage system. Comput. Electron. Agric. 2017, 142, 607–621. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Fridgen, J.J.; Kitchen, N.R.; Sudduth, K.A.; Drummond, S.T.; Wiebold, W.J.; Fraisse, C.W. Management zone analyst (MZA) software for subfield management zone delineation. Agron. J. 2004, 96, 100–108. [Google Scholar]
- Zaman, M.; Shahid, S.A.; Heng, L.; Shahid, S.A.; Zaman, M.; Heng, L. Introduction to soil salinity, sodicity and diagnostics techniques. In Guideline for Salinity Assessment, Mitigation and Adaptation Using Nuclear and Related Techniques; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 1–42. [Google Scholar]
- Wei, Y.; Ding, J.; Yang, S.; Wang, F.; Wang, C. Soil salinity prediction based on scale-dependent relationships with environmental variables by discrete wavelet transform in the tarim basin. Catena 2021, 196, 104939. [Google Scholar] [CrossRef]
- Fu, Q.; Wang, Z.; Jiang, Q. Delineating soil nutrient management zones based on fuzzy clustering optimized by pso. Math. Comput. Model. 2010, 51, 1299–1305. [Google Scholar] [CrossRef]
- Shaver, T.; Peterson, G.; Ahuja, L.R.; Westfall, D. Soil sorptivity enhancement with crop residue accumulation in semiarid dryland no-till agroecosystems. Geoderma 2013, 192, 254–258. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Soil Properties | Max. | Min. | Average | S.D. | C.V. | Skewness | Kurtosis | K-S |
|---|---|---|---|---|---|---|---|---|
| Apparent conductivity (Eca) mS m−1 | 14.56 | 0.38 | 4.37 | 2.71 | 0.62 | 0.28 | 0.55 | 0.69 |
| Organic matter g kg−1 | 26.37 | 4.68 | 18.35 | 3.76 | 0.20 | −0.36 | 0.76 | 0.67 |
| Total nitrogen g kg−1 | 7.83 | 0.11 | 0.94 | 0.23 | 0.24 | 0.98 | 3.77 | 0.44 |
| Total phosphorus g kg−1 | 2.28 | 0.46 | 1.13 | 0.42 | 0.37 | 0.67 | 0.83 | 0.65 |
| Total potassium g kg−1 | 23.41 | 8.36 | 16.77 | 2.22 | 0.13 | −0.17 | 1.13 | 0.73 |
| pH | 8.74 | 7.88 | 8.29 | 0.29 | 0.03 | −0.29 | −0.87 | 0.47 |
| Soil Properties | Eca | Organic Matter | Total Nitrogen | Total Phosphorus | Total Potassium | pH |
|---|---|---|---|---|---|---|
| Eca | 1 | 0.279 | 0.271 | 0.223 | −0.084 | −0.512 ** |
| Organic matter | 0.279 | 1 | 0.713 ** | 0.224 | 0.461 ** | −0.097 |
| Total nitrogen | 0.271 | 0.713 ** | 1 | 0.406 ** | 0.507 ** | −0.188 |
| Total phosphorus | 0.223 | 0.224 | 0.406 ** | 1 | 0.374 * | −0.277 |
| Total potassium | −0.084 | 0.461 ** | 0.507 ** | 0.374 * | 1 | 0.137 |
| pH | −0.512 ** | −0.097 | −0.188 | −0.277 | 0.137 | 1 |
| Test Methods | Indexs | Value |
|---|---|---|
| KMO quantity of sample suitability | / | 0.787 |
| Bartlett sphericity test | Approximate chi-squared | 996.443 |
| Degrees of freedom | 20 | |
| Significance | 0 |
| PCA | Eigenvalue | Contribution Rate |
|---|---|---|
| PC1 | 2.21 | 43.29% |
| PC2 | 1.49 | 27.16% |
| PC3 | 1.13 | 17.12% |
| Totals | 87.57% | |
| Soil Properties | PC1 | PC2 | PC3 | Commonality |
|---|---|---|---|---|
| Eca | 0.41 | −0.74 | −0.03 | 0.72 |
| Organic matter | 0.61 | −0.03 | 0.61 | 0.71 |
| Total nitrogen | 0.84 | −0.07 | 0.32 | 0.82 |
| Total phosphorus | 0.61 | −0.14 | −0.52 | 0.69 |
| Total potassium | 0.81 | 0.39 | −0.51 | 0.81 |
| pH | −0.29 | 0.61 | 0.26 | 0.67 |
| Management Zone | Variables | ECa (mS m−1) | Organic Matter (g kg−1) | Total Nitrogen (g kg−1) | Total Phosphorus (g kg−1) | Total Potassium (g kg−1) | pH |
|---|---|---|---|---|---|---|---|
| Zoning 1 (n = 17) | Min. | 1.38 | 4.68 | 0.11 | 0.46 | 8.36 | 7.88 |
| Max. | 14.56 | 15.9 | 4.23 | 0.97 | 19.46 | 8.74 | |
| S.D. | 1.09 | 2.89 | 0.13 | 0.09 | 1.67 | 0.35 | |
| C.V. | 0.19 | 0.26 | 0.15 | 0.21 | 0.12 | 0.04 | |
| Zoning 2 (n = 19) | Min. | 0.38 | 7.96 | 0.28 | 0.77 | 11.36 | 7.92 |
| Max. | 6.79 | 26.37 | 7.83 | 2.28 | 23.41 | 8.13 | |
| S.D. | 0.81 | 1.77 | 0.19 | 0.18 | 1.36 | 0.76 | |
| C.V. | 0.27 | 0.09 | 0.08 | 0.10 | 0.07 | 0.09 | |
| Zoning 3 (n = 18) | Min. | 0.52 | 5.37 | 0.19 | 0.55 | 13.27 | 7.89 |
| Max. | 11.32 | 19.77 | 4.97 | 1.84 | 18.46 | 8.63 | |
| S.D. | 1.16 | 2.22 | 0.23 | 0.18 | 1.77 | 0.55 | |
| C.V. | 0.23 | 0.17 | 0.14 | 0.24 | 0.12 | 0.07 | |
| Zoning 4 (n = 21) | Min. | 0.79 | 6.32 | 0.23 | 0.63 | 9.74 | 7.94 |
| Max. | 8.34 | 16.32 | 5.22 | 1.76 | 21.33 | 8.52 | |
| S.D. | 2.13 | 2.89 | 0.57 | 0.11 | 1.67 | 0.47 | |
| C.V. | 0.29 | 0.26 | 0.31 | 0.12 | 0.10 | 0.06 | |
| Significant level | p | 0.03 * | 0.02 * | 0.02 * | 0.00 ** | 0.00 ** | 0.79 |
| Management Zone | Variables | ECa (mS m−1) | Organic Matter (g kg−1) | Total Nitrogen (g kg−1) | Total Phosphorus (g kg−1) | Total Potassium (g kg−1) | pH |
|---|---|---|---|---|---|---|---|
| Zoning 1 | Average | 5.76 | 11.32 | 0.86 | 0.42 | 14.31 | 8.27 |
| Zoning 2 | Average | 2.98 | 19.28 | 2.34 | 1.84 | 19.23 | 8.02 |
| Zoning 3 | Average | 5.11 | 13.22 | 1.67 | 0.76 | 15.17 | 8.31 |
| Zoning 4 | Average | 7.23 | 11.22 | 1.83 | 0.93 | 16.41 | 8.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Wang, H.; Zhao, X.; Jiang, Q. Investigation on Zoning Management of Saline Soil in Cotton Fields in Alar Reclamation Area, Xinjiang. Agriculture 2024, 14, 3. https://doi.org/10.3390/agriculture14010003
Zhang F, Wang H, Zhao X, Jiang Q. Investigation on Zoning Management of Saline Soil in Cotton Fields in Alar Reclamation Area, Xinjiang. Agriculture. 2024; 14(1):3. https://doi.org/10.3390/agriculture14010003
Chicago/Turabian StyleZhang, Fangshuo, Hengyou Wang, Xinyu Zhao, and Qingsong Jiang. 2024. "Investigation on Zoning Management of Saline Soil in Cotton Fields in Alar Reclamation Area, Xinjiang" Agriculture 14, no. 1: 3. https://doi.org/10.3390/agriculture14010003
APA StyleZhang, F., Wang, H., Zhao, X., & Jiang, Q. (2024). Investigation on Zoning Management of Saline Soil in Cotton Fields in Alar Reclamation Area, Xinjiang. Agriculture, 14(1), 3. https://doi.org/10.3390/agriculture14010003