
Drivable Agricultural Road Region Detection Based on Pixel-Level Segmentation with Contextual Representation Augmentation




Abstract
:1. Introduction
- (1)
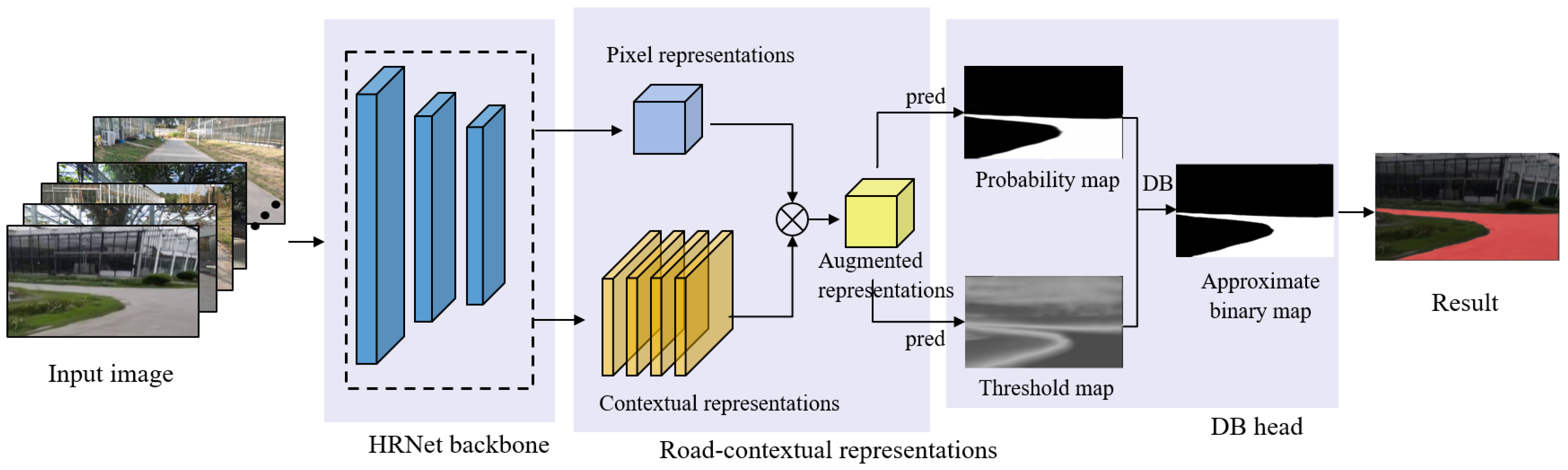
- This paper proposes a high-resolution detection network for semi-structured roads in facility agriculture. The network uses HRNet to extract high-resolution road features in parallel at multiple scales, then uses OCR to enhance the feature representations, and finally uses a DB decision head to segment road boundaries adaptively.
- (2)
- A loss function is designed, including segmentation and threshold map losses.
- (3)
- A dataset of semi-structured agricultural roads for greenhouses is produced, and the method in this paper is validated.
2. Theory and Method
2.1. Architecture of Agricultural Semi-Structured Road Detection Network
2.2. High-Resolution Road Feature Extraction
2.3. Road-Contextual Representations
2.4. Threshold-Adaptive Boundary Segmentation
2.5. Loss Function
3. Experiments
3.1. Dataset
3.2. Evaluation Metrics
3.3. Implementation and Training Details
4. Results and Discussion
4.1. Experimental Results and Comparison
4.1.1. Detection Results on the Dataset
4.1.2. Detection Results in Agricultural Scenarios
4.2. Discussion
4.2.1. The Effect of Threshold Map Supervision on Road Detection
4.2.2. Comparative Analysis of Different Loss Functions
4.2.3. Discussion of Different Deployment Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Gong, L.; Sun, Y.; Gao, B.; Yu, C.; Liu, C. Precise visual positioning of agricultural mobile robots with a fiducial marker reprojection approach. Meas. Sci. Technol. 2023, 34, 115110. [Google Scholar] [CrossRef]
- Bechar, A.; Vigneault, C. Agricultural robots for field operations: Concepts and components. Biosyst. Eng. 2016, 149, 94–111. [Google Scholar] [CrossRef]
- Qi, N.; Yang, X.; Chuanxiang, L.; Lu, R.; He, C.; Cao, L. Unstructured Road Detection via Combining the Model-based and Feature-based Methods. IET Intell. Transp. Syst. 2019, 13, 1533–1544. [Google Scholar] [CrossRef]
- Xiao, L.; Dai, B.; Liu, D.; Zhao, D.; Wu, T. Monocular Road Detection Using Structured Random Forest. Int. J. Adv. Robot. Syst. 2016, 13, 101. [Google Scholar] [CrossRef]
- Yang, G.; Wang, Y.; Yang, J.; Lu, Z. Fast and Robust Vanishing Point Detection Using Contourlet Texture Detector for Unstructured Road. IEEE Access 2019, 7, 139358–139367. [Google Scholar] [CrossRef]
- Shi, J.; Wang, J.; Fu, F. Fast and Robust Vanishing Point Detection for Unstructured Road Following. IEEE Trans. Intell. Transp. Syst. 2016, 17, 970–979. [Google Scholar] [CrossRef]
- Liu, Y.B.; Zeng, M.; Meng, Q.H. Unstructured Road Vanishing Point Detection Using Convolutional Neural Networks and Heatmap Regression. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Hernandez, D.E.; Blumenthal, S.; Prassler, E.; Bo, S.; Haojie, Z. Vision-based road boundary tracking system for unstructured roads. In Proceedings of the 2017 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 27–29 October 2017; pp. 66–71. [Google Scholar]
- Liu, G.; Worgotter, F.; Markelic, I. Stochastic Lane Shape Estimation Using Local Image Descriptors. IEEE Trans. Intell. Transp. Syst. 2013, 14, 13–21. [Google Scholar] [CrossRef]
- Perng, J.W.; Hsu, Y.W.; Yang, Y.Z.; Chen, C.Y.; Yin, T.K. Development of an embedded road boundary detection system based on deep learning. Image Vis. Comput. 2020, 100, 103935. [Google Scholar] [CrossRef]
- Cao, J.; Song, C.; Song, S.; Xiao, F.; Peng, S. Lane Detection Algorithm for Intelligent Vehicles in Complex Road Conditions and Dynamic Environments. Sensors 2019, 19, 3166. [Google Scholar] [CrossRef]
- Wang, K.; Huang, Z.; Zhong, Z. Algorithm for urban road detection based on uncertain Bezier deformable template. Jixie Gongcheng Xuebao Chin. J. Mech. Eng. 2013, 49, 143–150. [Google Scholar] [CrossRef]
- Yuan, Y.; Jiang, Z.; Wang, Q. Video-based road detection via online structural learning. Neurocomputing 2015, 168, 336–347. [Google Scholar] [CrossRef]
- Xiang, W.; Juan, Z.; Zhijun, F. Unstructured road detection based on contour selection. In Proceedings of the 4th International Conference on Smart and Sustainable City (ICSSC 2017), Shanghai, China, 5–6 June 2017; pp. 1–5. [Google Scholar]
- Li, J.; Liu, C. Research on Unstructured Road Boundary Detection. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; pp. 614–617. [Google Scholar]
- Alam, A.; Singh, L.; Jaffery, Z.A.; Verma, Y.K.; Diwakar, M. Distance-based confidence generation and aggregation of classifier for unstructured road detection. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 8727–8738. [Google Scholar] [CrossRef]
- Sturgess, P.; Alahari, K.; Ladicky, L.; Torr, P. Combining Appearance and Structure from Motion Features for Road Scene Understanding. In Proceedings of the British Machine Vision Conference, BMVC 2009, London, UK, 7–10 September 2009. [Google Scholar]
- Baheti, B.; Innani, S.; Gajre, S.; Talbar, S. Eff-UNet: A Novel Architecture for Semantic Segmentation in Unstructured Environment. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1473–1481. [Google Scholar]
- Wang, Q.; Fang, J.; Yuan, Y. Adaptive road detection via context-aware label transfer. Neurocomputing 2015, 158, 174–183. [Google Scholar] [CrossRef]
- Geng, L.; Sun, J.; Xiao, Z.; Zhang, F.; Wu, J. Combining CNN and MRF for road detection. Comput. Electr. Eng. 2018, 70, 895–903. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18, 2015. pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818, 833–851. [Google Scholar]
- Li, J.; Jiang, F.; Yang, J.; Kong, B.; Gogate, M.; Dashtipour, K.; Hussain, A. Lane-DeepLab: Lane semantic segmentation in automatic driving scenarios for high-definition maps. Neurocomputing 2021, 465, 15–25. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16, 2020. pp. 173–190. [Google Scholar]
- Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; Bai, X. Real-Time Scene Text Detection With Differentiable Binarization and Adaptive Scale Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 919–931. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Hao, Y.; Liu, Y.; Wu, Z.; Han, L.; Chen, Y.; Chen, G.; Chu, L.; Tang, S.; Yu, Z.; Chen, Z. Edgeflow: Achieving practical interactive segmentation with edge-guided flow. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1551–1560. [Google Scholar]
- Rateke, T.; Justen, K.A.; Von Wangenheim, A. Road surface classification with images captured from low-cost camera-road traversing knowledge (rtk) dataset. Rev. Inf. Teórica Apl. 2019, 26, 50–64. [Google Scholar] [CrossRef]
- Vatti, B.R. A generic solution to polygon clipping. Commun. ACM 1992, 35, 56–63. [Google Scholar] [CrossRef]
- Cheng, B.; Girshick, R.; Dollár, P.; Berg, A.C.; Kirillov, A. Boundary IoU: Improving object-centric image segmentation evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15334–15342. [Google Scholar]
- Sun, Y. A Comparative Study on the Monte Carlo Localization and the Odometry Localization. In Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 25–27 February 2022; pp. 1074–1077. [Google Scholar]
- Zhang, W.; Gong, L.; Huang, S.; Wu, S.; Liu, C. Factor graph-based high-precision visual positioning for agricultural robots with fiducial markers. Comput. Electron. Agric. 2022, 201, 107295. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIoU (%) | Boundary IoU (%) | Comparison of mIoU (%) | Comparison of Boundary IoU (%) |
|---|---|---|---|---|
| DeepLabV3+ (Baseline) | 95.12 | 85.36 | 0 | 0 |
| HRNet+OCR | 97.13 | 87.96 | 2.01% | 2.6 |
| Ours | 97.85 | 90.88 | 2.73% | 5.52 |
| Method | mIou (%) | PA (%) | Boundary IoU (%) |
|---|---|---|---|
| Unsupervised | 97.16 | 98.64 | 88.71 |
| Supervised | 97.64 | 98.81 | 90.88 |
| Comparison of results | 0.48 | 0.17 | 2.17 |
| Loss Function | Road IoU (%) | Boundary IoU (%) |
|---|---|---|
| BCE (Baseline) | 97.22 | 89.32 |
| WCE | 97.38 | 89.60 |
| Focal loss | 97.50 | 89.92 |
| OHEM | 97.85 | 90.88 |
| Deployment Method | mIoU (%) | PA (%) | Boundary IoU (%) |
|---|---|---|---|
| FP32 (Baseline) | 98.73 | 98.81 | 90.88 |
| FP16 | 98.72 | 98.80 | 90.74 |
| Data enhancements | 97.78 | 98.87 | 91.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Gong, L.; Zhang, W.; Gao, B.; Li, Y.; Liu, C. Drivable Agricultural Road Region Detection Based on Pixel-Level Segmentation with Contextual Representation Augmentation. Agriculture 2023, 13, 1736. https://doi.org/10.3390/agriculture13091736
Sun Y, Gong L, Zhang W, Gao B, Li Y, Liu C. Drivable Agricultural Road Region Detection Based on Pixel-Level Segmentation with Contextual Representation Augmentation. Agriculture. 2023; 13(9):1736. https://doi.org/10.3390/agriculture13091736
Chicago/Turabian StyleSun, Yefeng, Liang Gong, Wei Zhang, Bishu Gao, Yanming Li, and Chengliang Liu. 2023. "Drivable Agricultural Road Region Detection Based on Pixel-Level Segmentation with Contextual Representation Augmentation" Agriculture 13, no. 9: 1736. https://doi.org/10.3390/agriculture13091736
APA StyleSun, Y., Gong, L., Zhang, W., Gao, B., Li, Y., & Liu, C. (2023). Drivable Agricultural Road Region Detection Based on Pixel-Level Segmentation with Contextual Representation Augmentation. Agriculture, 13(9), 1736. https://doi.org/10.3390/agriculture13091736