1. Introduction
As the most important harvesting equipment implemented in the harvesting process, the combine harvester integrates multiple processes such as reaping, threshing, and screening, greatly improving the efficiency of farmers and increasing the economic benefits of agricultural work. In practice, the working efficiency of a combine harvester is often affected by various natural factors (such as crop moisture content, planting density, and field terrain), which primarily affect the feed rate of the combine harvester. When the actual feed rate exceeds the range of feed rates rated for a combine harvester, a blockage occurs in important rotating areas such as the stalk auger, conveyor, or threshing cylinder [
1]. The threshing cylinder, as the most important component [
2], is often installed in the center of a combine harvester. In cases of blockage in the threshing cylinder, halting the harvesting process may be necessary to resolve the issue [
3], which is not only laborious but also dangerous when disassembling the relevant parts of the threshing cylinder and removing any straw entangled in the spike teeth [
4]. During a harvest period, farmers must finish harvesting their crops within a week or even a few days. Diagnosing a blocked threshing cylinder for even a few hours can lead to high costs for farmers. With the increasing popularity of combine harvesters, rapid access to their operating status and diagnosis of threshing cylinder blockages are receiving more and more attention from farmers and manufacturers. As a result, considerable efforts have been made to propose strategies and to implement them in combine harvesters.
In the early stages of the development of blockage fault diagnosis technology for combine harvesters, model-driven diagnosis methods were widely used. This type of method relies on the relevant mechanical structure of a combine harvester to construct a dynamic or kinematics model and facilitates the identification of an abnormal state by observing the state of the model [
5,
6,
7]. In addition to constructing models based on mechanical structures, some studies rely on other types of models to diagnose blockage faults. For example, Chen et al. [
8] established a mathematical model of the hydraulic system based on the physical properties of the hydraulic system. Based on an analysis of the relationship between travel speed and the clogging pressure valve, a logic threshold control strategy was proposed to prevent blockage caused by excessive travel speed. Li et al. [
9] collected the speeds of the threshing cylinder, conveyor, and grain auger and proposed a diagnosis method for blockage based on instantaneous speed change trends, speed ratio differences, and their rate of change. And Qiu et al. [
10] proposed a fault diagnosis algorithm based on the velocity fusion index, component slip rate, and adaptive threshold recognition. Although all these methods have achieved promising results, constructing a model remains a time-consuming and difficult process due to the complex structure of the combine harvester and the coupling of working states among various components.
With the development of measurement and control technology and AI, the data-driven approach has been used in fault diagnosis [
11,
12]. Relying on a large amount of data collected by sensors, machine learning or deep learning can be utilized in the fault diagnosis process [
13]. One typical application of such a method is to import the data in a machine learning or deep learning model to uncover the hidden system and to drive machine thinking. Compared with model-driven methods, data-driven methods can effectively reduce the time required for model construction and derive a solution and can be utilized for diagnosing system faults without an accurate mathematical model of the system [
14,
15]. Currently, the application of data-driven methods of agricultural machinery fault diagnosis has been proven to be effective [
16,
17,
18,
19]. The data-driven approach has also been applied to combine harvester operating condition detection and fault diagnosis. For instance, Yong et al. [
20] used an RBF network to successfully determine whether a combine harvester has a fault state and the severity of the fault based on the collected rotational speed information. Zhang et al. [
21] optimized and enhanced SVM using IPSO, which allows for the diagnosis of broken auger drive chains, threshing cylinder blockages, clogged steppers, raked conveyor chains, and broken blower pulley belts during the operation of a combine harvester, and the accuracy rate reached 95.58%. Yang et al. [
22] applied RCMvMSE to the fault extraction of rolling bearings of threshing cylinder spindles and proposed a rolling bearing fault diagnosis method based on SDAE-RCmvMSE, and the enhanced method has robust anti-interference performance. Sun et al. [
23] selected the height of the header, moisture content, and torque of the power shaft of the header as the input and feed rate as the output and established a computational model using a PSO-BP neural network to achieve real-time monitoring of the feed rate. In addition, the utilization of data-driven methods in the remote fault diagnosis of combine harvesters enables managers to make informed decisions and provides technical support for the development and implementation of unmanned farms and smart farms [
24,
25]. Bai et al. [
26] constructed a remote operation and maintenance platform, which mainly includes modules for data monitoring, fault prediction and diagnosis, integrated operation, and maintenance. Within the fault diagnosis module, a neural network is utilized to discern and identify blockages occurring in the threshing cylinder. Chen et al. [
27] achieved dynamic monitoring of combine harvester operating performance based on the Markov model and employed it in the constructed online operating performance evaluation system.
From the analysis of these works, some overarching considerations can be derived:
(1) The model-driven approaches study the working mechanism of key components in the harvester and mainly rely on dynamics, kinematics, or mathematics to construct equations for representing their motions. Nevertheless, given the complex structure of the combine harvester and the many interferences from the working environment, such a method has issues related to difficult solutions and is time-consuming.
(2) Data-driven methodologies rely on an assortment of amassed data and enable swift identification of blockage faults through approaches such as machine learning or deep learning. However, these methods cannot express how and why blockages are diagnosed; in other words, they lack interpretation.
In order to overcome the aforementioned problems, this paper proposes a threshing cylinder blockage diagnosis method based on AC (association rule classification). AC is a descriptive data mining method derived from ARM (association rule mining) [
28]. This approach was originally implemented to analyze the shopping patterns of customers in malls to uncover the combinations of products that customers often buy together, thus helping malls optimize the arrangement of goods to increase revenue [
29]. Currently, AC is widely used in various fields, such as biomedicine [
30,
31], traffic safety [
32,
33], and phishing website detection [
34,
35]. Typically, the classification by AC involves three main phases [
36]: (1) adopting the methods in ARM to discover all association rules between attributes and classes; (2) filtering rules using relevant evaluation indicators to obtain strong association rules; and (3) using the obtained strong association rules as classifiers.
The blockage of the threshing cylinder usually occurs due to the excessive feed rate of crop materials beyond the rated capacity of the machine. However, the combine harvester is a time-delay system. It can be observed that as the feed rate increases, the response time of each component exhibits differentiation attributable to their respective mounted positions. Therefore, when the state changes of various components are regarded as different events, the occurrence of these events is non-simultaneous but follows a time sequence. In the traditional ARM approach, the mining of the correlation between events does not consider the temporal properties, and it only uses whether two events occur simultaneously as the criterion for evaluating whether they are correlated while disregarding the order in which the events occur. Consequently, preserving the time dependence of two related events is of great significance for revealing the behavior characteristics of involved components when threshing cylinder blocks. In this paper, we employ a method called temporal association rules mining (TARM), which is an extension of ARM, to investigate the sequential changes in the status of the remaining components. Specifically, we examine how these changes occur when there is an increase in the feed rate and the threshing cylinder experiences blockage. Association rules, as mined using TARM, are in the form of multiple sequences, and temporal features are mapped to the positions of the sequences. There are multiple items in the sequence. Moreover, the items in the front and back locations imply a causal relationship. By analyzing the distribution of items at different positions in the sequence, the study can investigate the order of changes in the status (such as changes in speed or torque) of the relevant components when the feed rate increases, thus, revealing the mechanism of threshing cylinder blockage caused by excessive feed rate. Developing a TARM-based blockage fault diagnostic method contributes to a primary novelty for combining the advantages of both model-driven and data-driven approaches as it achieves both automatic learning and interpretability.
The rest of the paper is structured as follows.
Section 2 elaborates on detailed elements of constructing an associative classifier on the basis of AC, mainly including data pre-processing methods, the process of converting data into transaction sets, as well as the specific implementation process of obtaining strong association rules based on TARM. Additionally, the approach employed to obtain the dataset concerning blockage occurrences in the threshing cylinder specifically focuses on non-manual intervention scenarios.
Section 3 outlines the implied mechanism information in the mined strong association rules and verifies the validity and accuracy of the classifier constructed based on the strong association rules. Final remarks are presented in the Conclusions section.
5. Conclusions
In this paper, a TRAM-based fault diagnosis method for threshing cylinder blockage of a combine harvester was proposed, which combines the advantages of autonomous learning and interpretability. cSpade was used to mine the association rules and filtered by setting the minimum thresholds of the three indicators of support, confidence, and lift to obtain strong association rules. Based on the obtained strong association rules, the relationship between each characteristic parameter and blockage fault was analyzed. The main conclusions can be listed as follows.
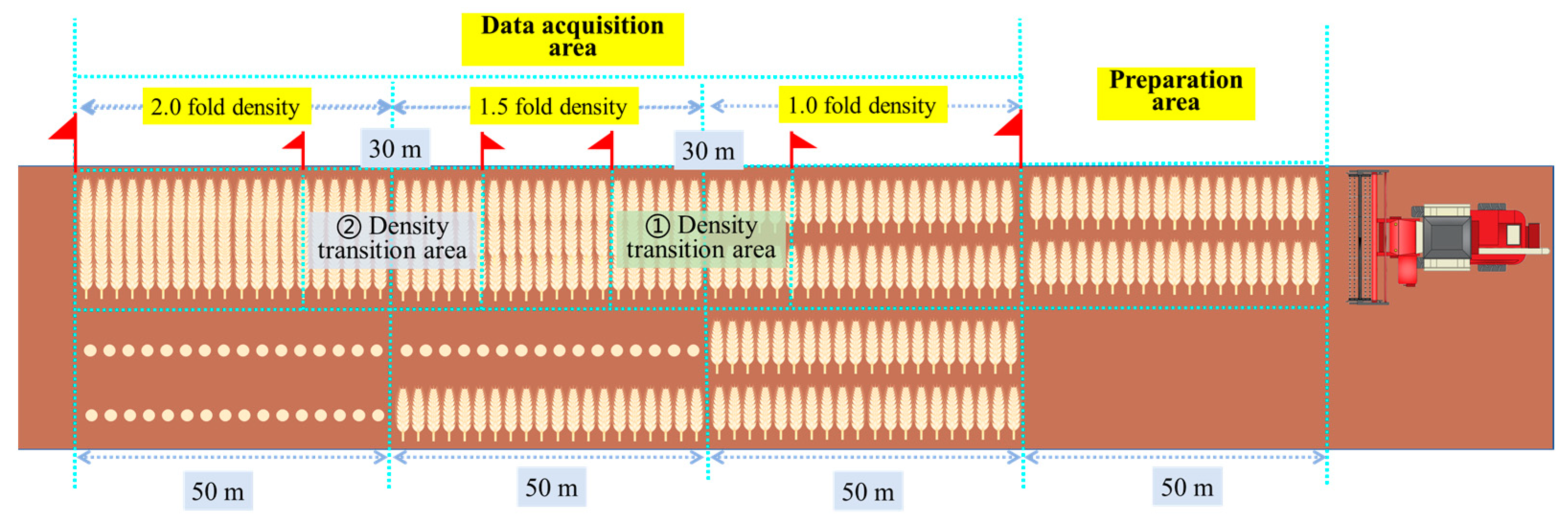
(1) A total of 10 parameters (such as stalk auger torque, conveyor torque, threshing cylinder torque, stalk auger speed, conveyor speed, threshing cylinder speed, reel speed, blower speed, grain auger speed, and tailing auger speed) were selected as characteristic parameters for threshing cylinder blockage faults. Then, the study obtained datasets of three levels (slight, medium, and severe) of threshing cylinder blockage. To effectively induce the blockage, we adjusted the travel speed of the harvester and manually increased crop density in the experiments. In order to efficiently mine association rules from data, the SAX method was used to transform the original time series data into a character string sequence, which was then constructed into transaction sets using a sliding window approach. After processing, the transaction set obtained contained a total of 1045 transactions. The results demonstrated that the application of the SAX method and sliding window approach effectively achieved dimensionality reduction, thereby improving the efficiency of mining association rules.
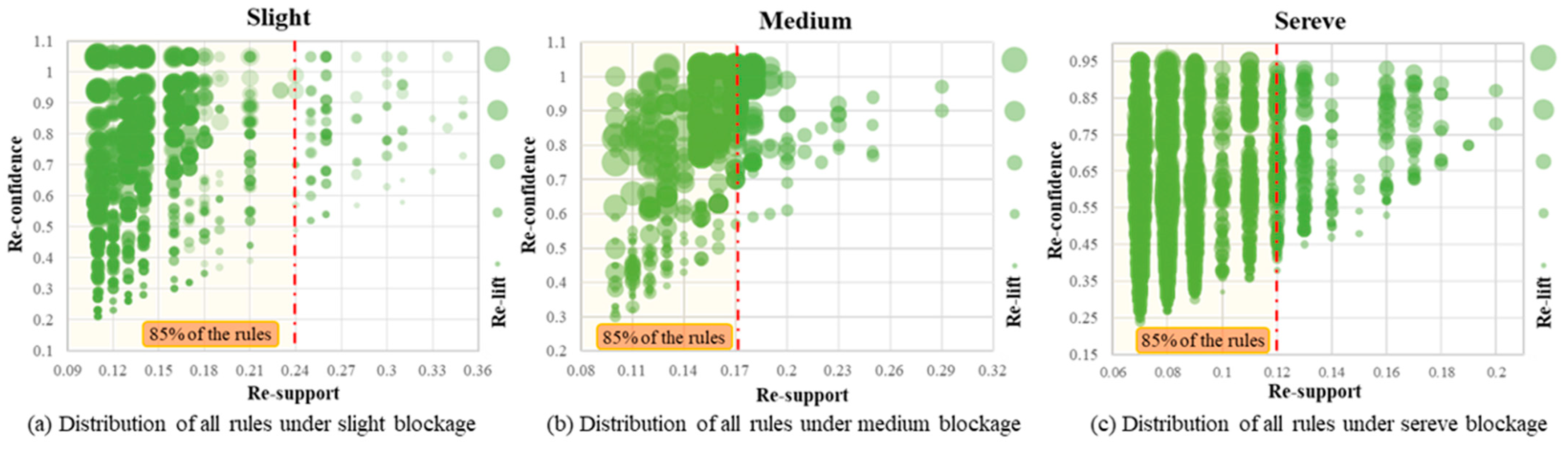
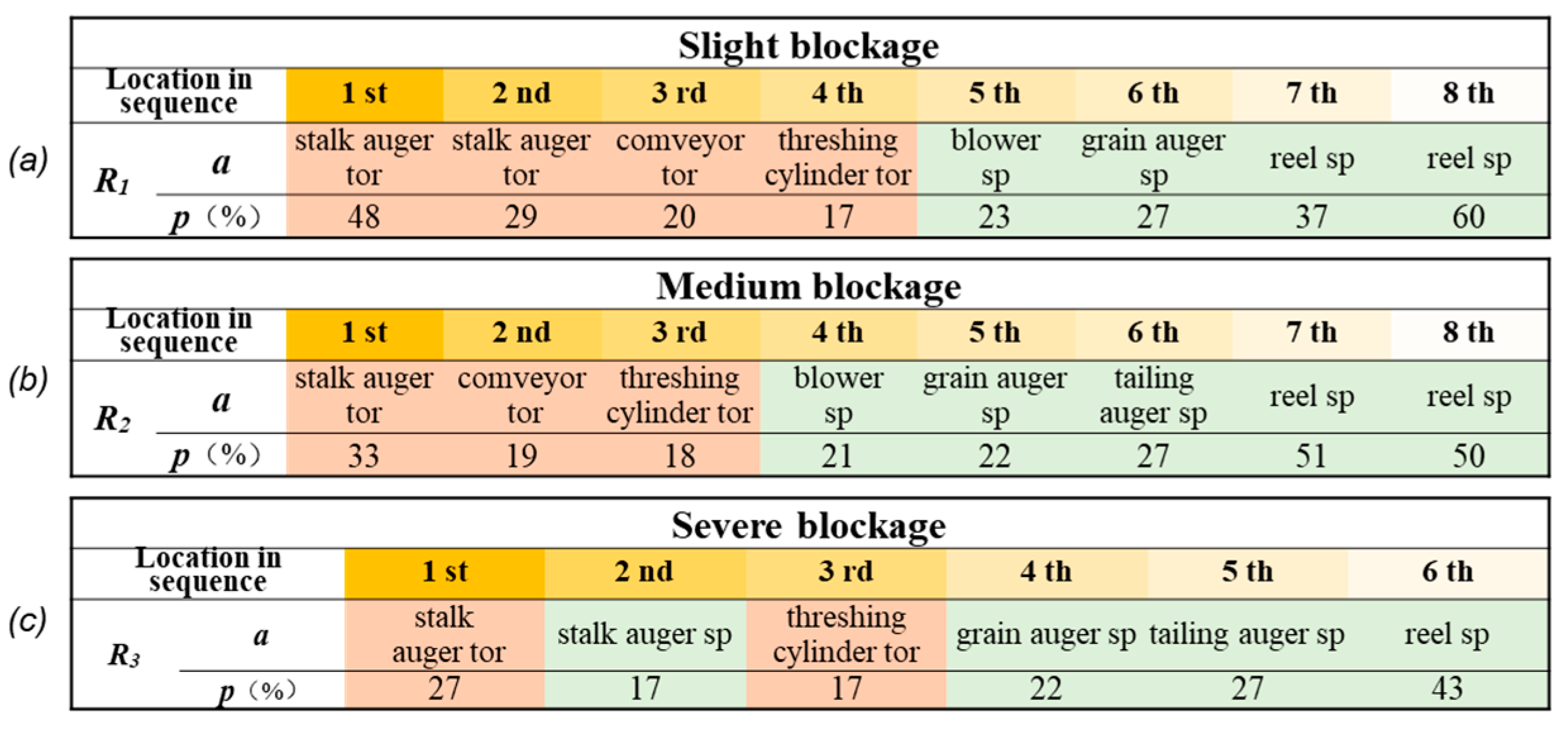
(2) The study employed cSpade to mine association rules in the transaction set. Initially, the method mined 3848 rules (under three blockage levels, 1091, 1068, and 1689 rules were obtained, respectively), and then it used the re-defined evaluation indicators re-support, re-confidence, and re-lift to filter the initially mined rules, which finally obtained 56 strong association rules. The results showed that the improved indicators minimized the impact of useless association rules. Additionally, by analyzing the positional information of the identified strong association rules, the study observed the varying levels of importance and sensitivity of the selected torque and speed feature parameters at different levels of blockage. This interpretation effectively reflected the changes in the working status of the crucial rotating components on the combine harvester when the threshing cylinder was obstructed.
(3) A threshing cylinder blockage classifier was developed based on the strong association rules mined. The model achieved an overall accuracy of 0.94 in testing. For slight, medium, and severe levels of blockage faults, the precisions were 0.90, 0.92, and 0.99, respectively, with a corresponding recall of 0.90, 0.93, and 0.98, respectively. Overall, the results obtained were robust and highly interpretable, demonstrating the effectiveness of the proposed method.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}