
SSMDA: Self-Supervised Cherry Maturity Detection Algorithm Based on Multi-Feature Contrastive Learning

Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Data
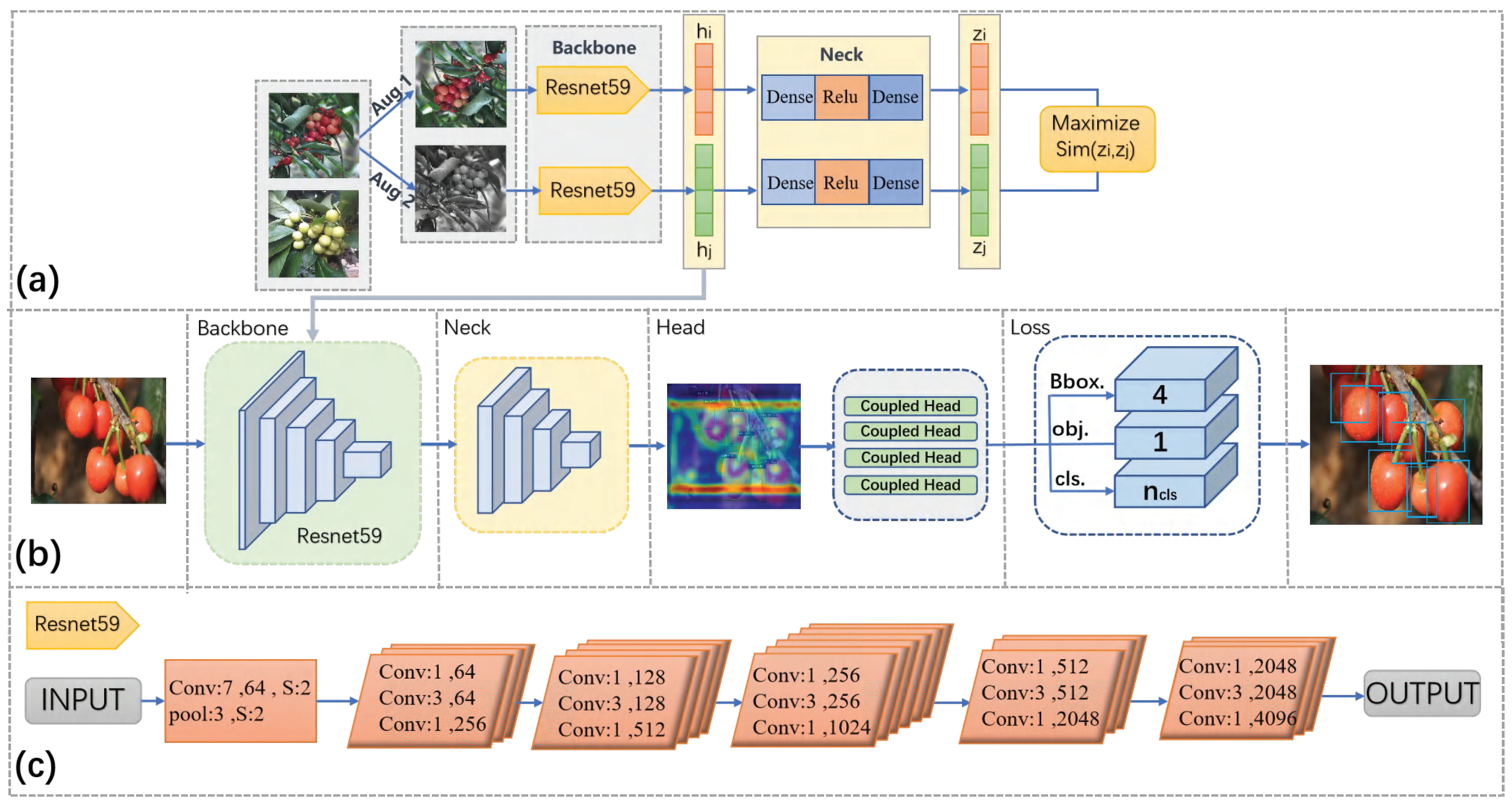
2.2. Algorithm Description
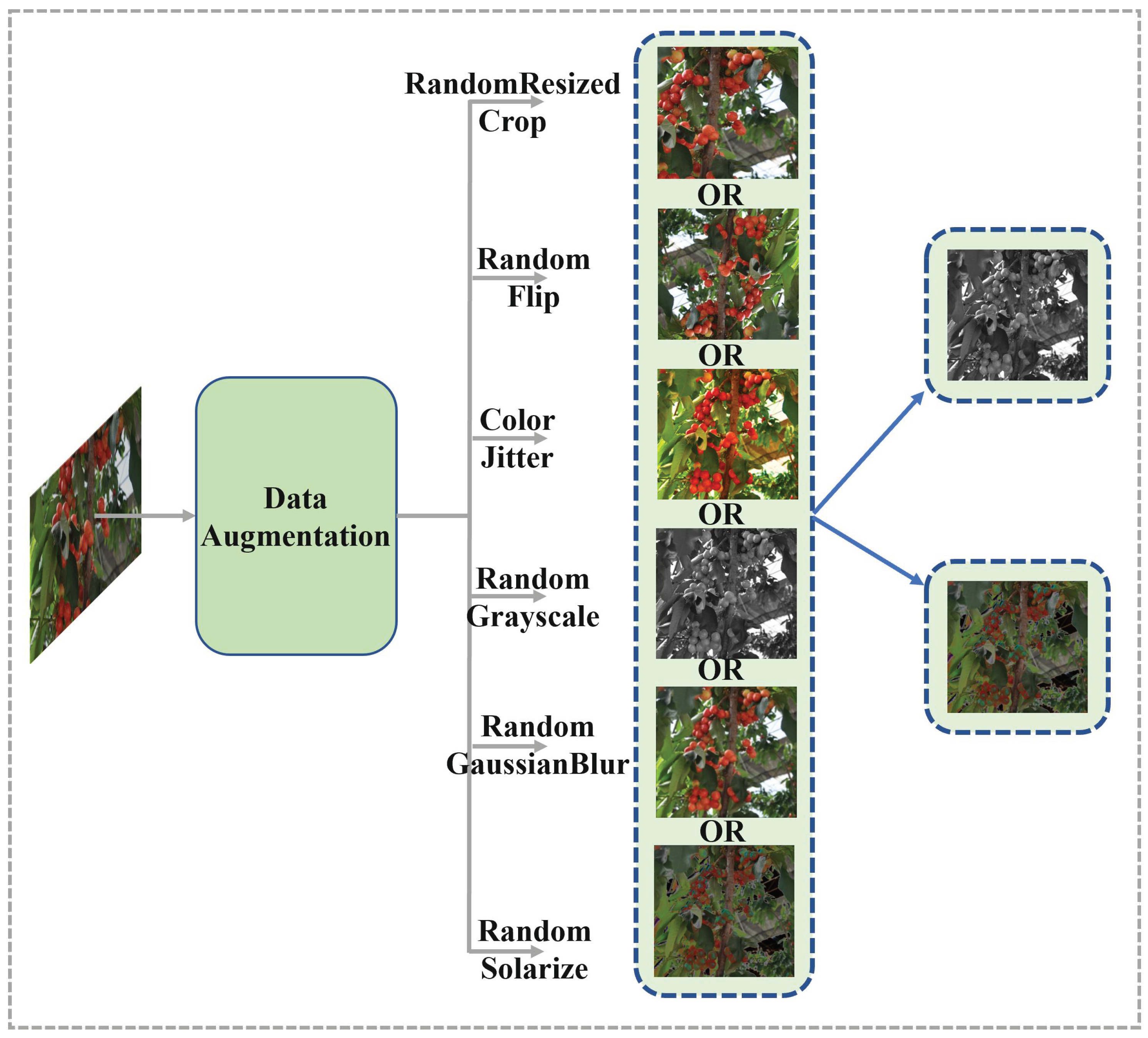
2.2.1. Multi-Feature Contrastive Self-Supervised Module
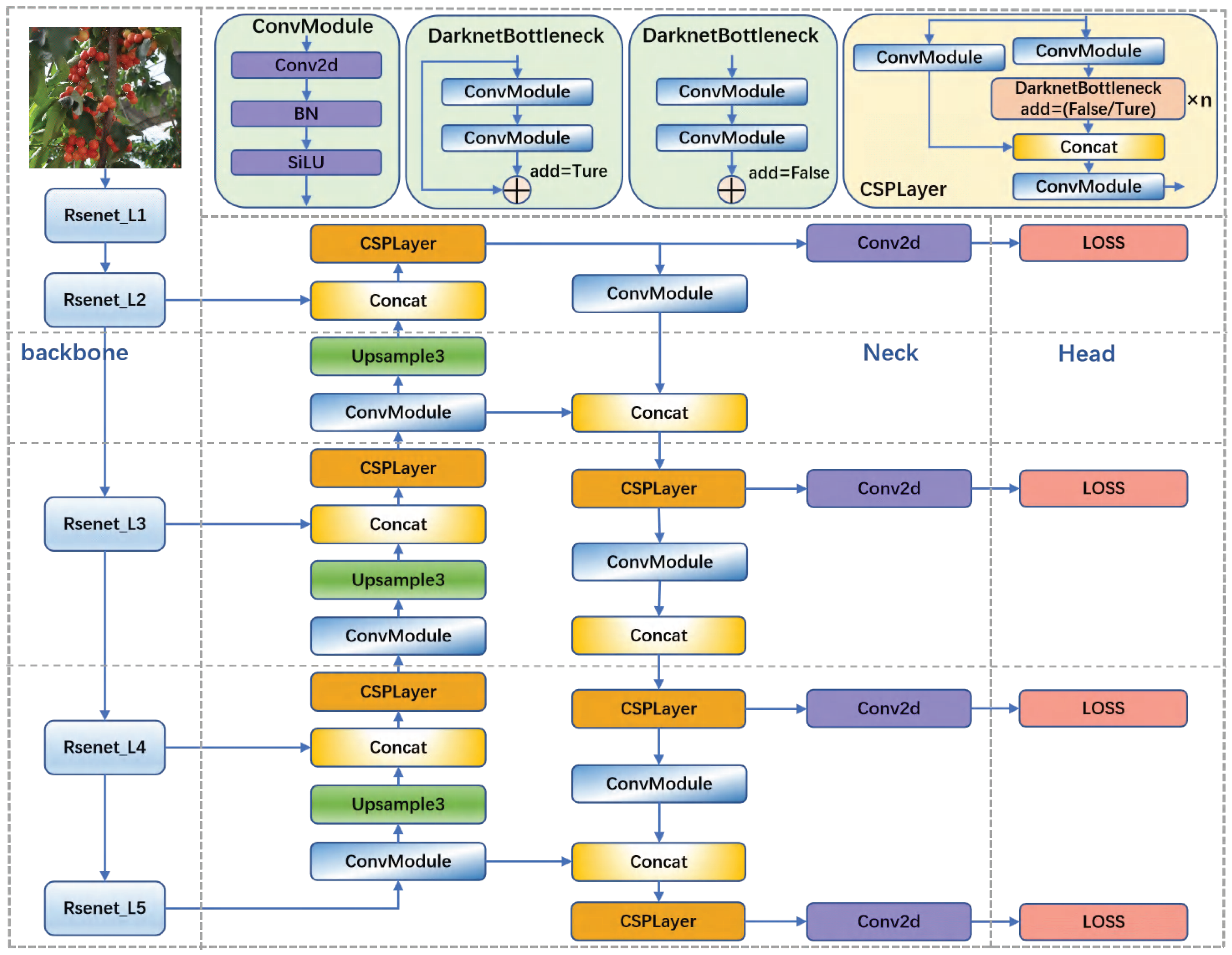
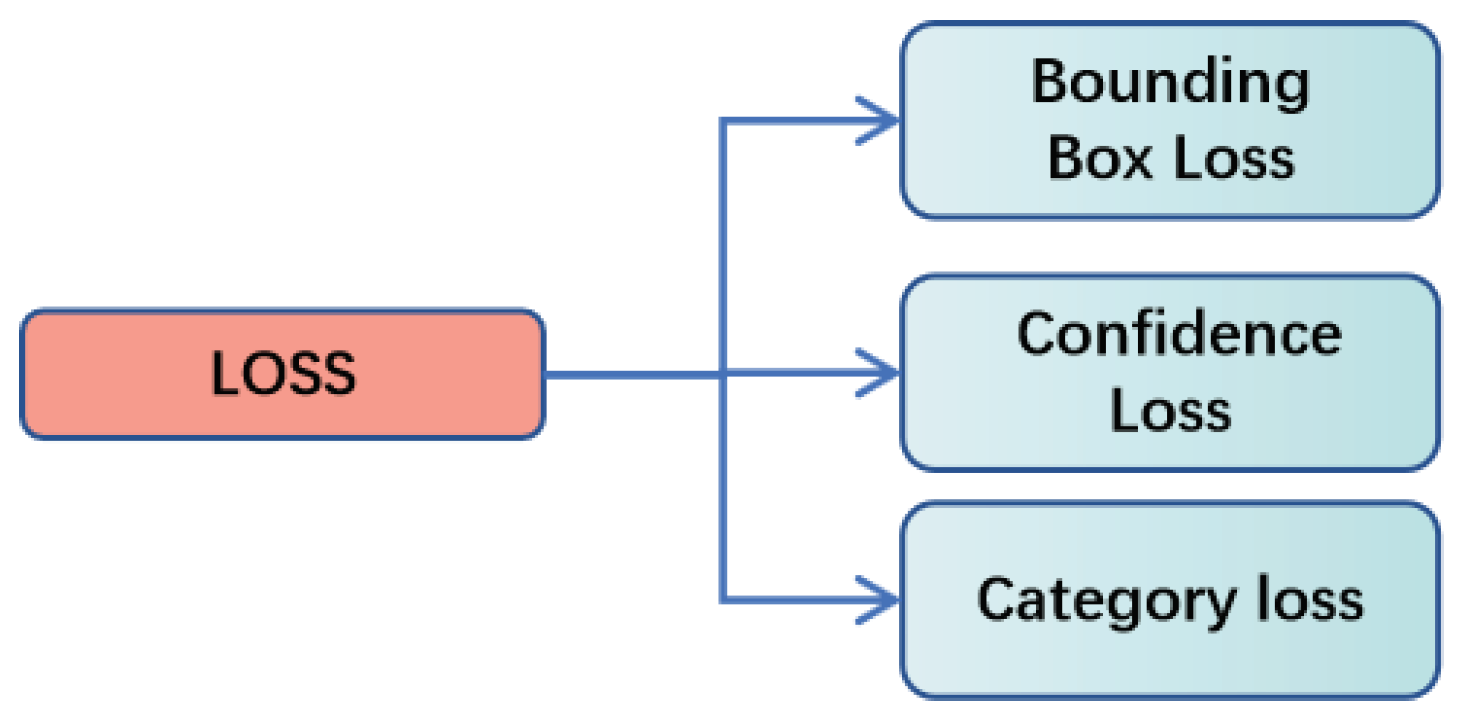
2.2.2. Object Detection Module
3. Results
3.1. Experimental Configuration
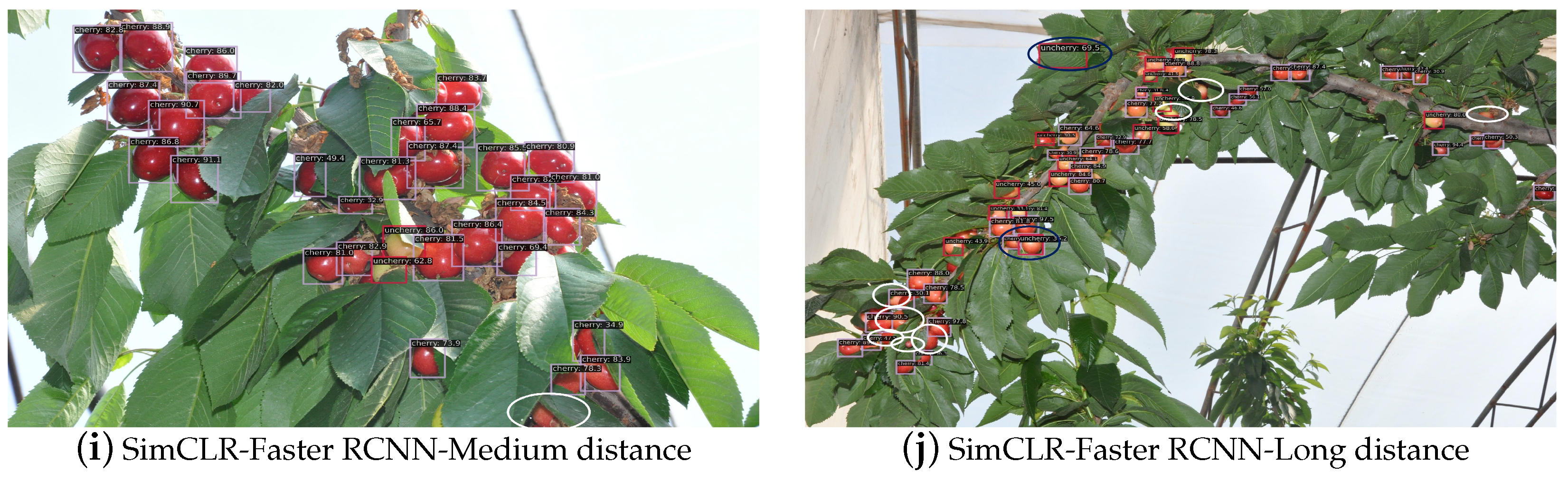
3.2. Compare to Baseline Method
3.3. Ablation Experiment
3.3.1. Object Detection Module Ablation Experiment
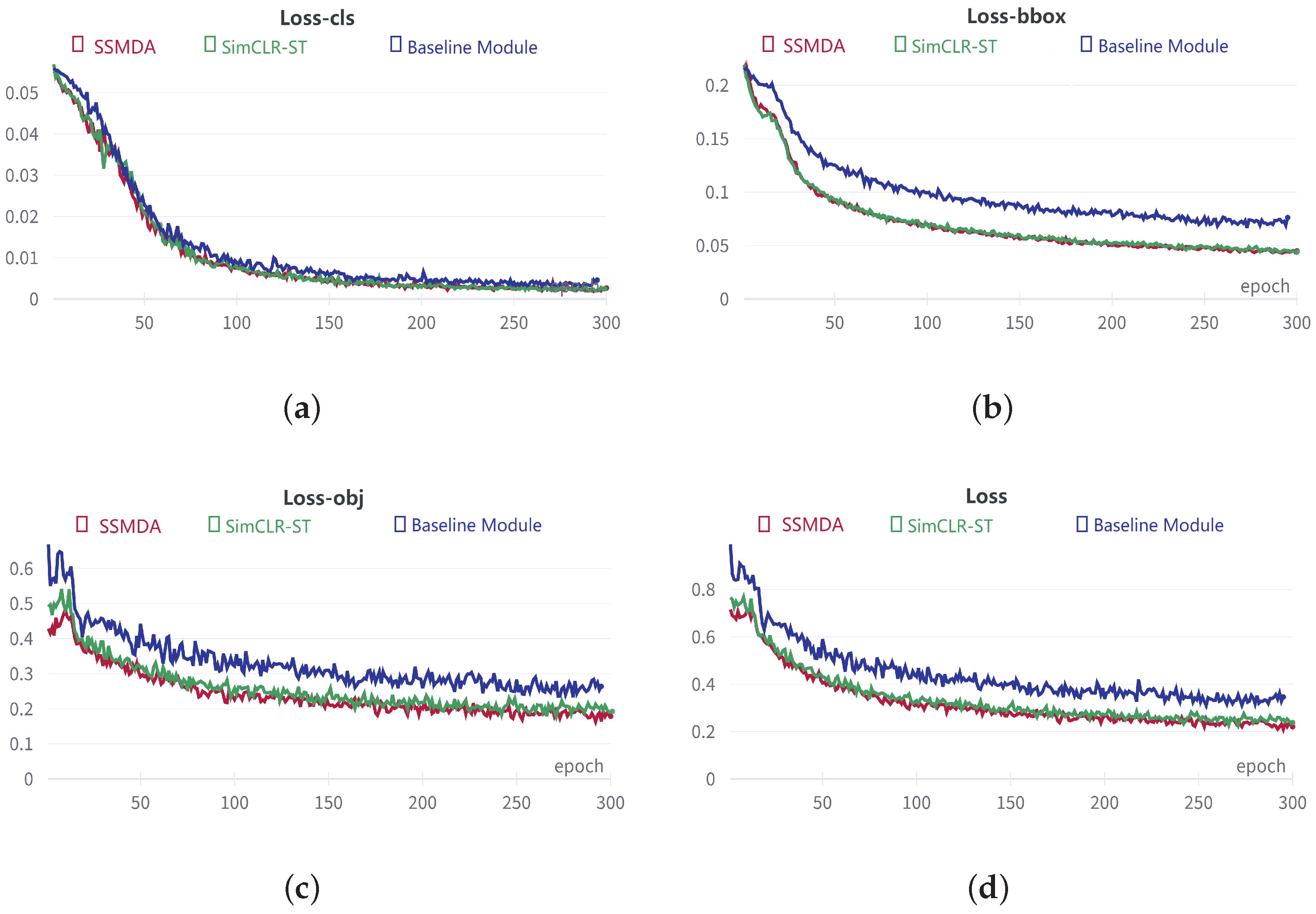
3.3.2. Self-Supervised Module Ablation Experiment
4. Discussion
4.1. Impact of Weight Loading Selection
4.2. Defects of SSMDA
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, P.; Pei, Y.; Wei, R.; Zhang, Y.; Gu, Y. Real-time detection of orchard cherry based on YOLOV4 model. Acta Agric. Zhejiangensis 2022, 34, 2522. [Google Scholar]
- Zhou, Z.; Guo, Y.; Dai, M.; Huang, J.; Li, X. Weakly supervised salient object detection via double object proposals guidance. IET Image Process. 2021, 15, 1957–1970. [Google Scholar] [CrossRef]
- Sparrow, R.; Howard, M. Robots in agriculture: Prospects, impacts, ethics, and policy. Precis. Agric. 2021, 22, 818–833. [Google Scholar] [CrossRef]
- Parvathi, S. Detection of maturity stages of coconuts in complex background using Faster R-CNN model. Biosyst. Eng. 2021, 202, 119–132. [Google Scholar] [CrossRef]
- Gao, F.; Fu, L.; Zhang, X.; Majeed, Y.; Li, R.; Karkee, M.; Zhang, Q. Multi-class fruit-on-plant detection for apple in SNAP system using Faster R-CNN. Comput. Electron. Agric. 2020, 176, 105634. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, G.; Meng, Q.; Yao, T.; Han, J.; Zhang, B. DSE-YOLO: Detail semantics enhancement YOLO for multi-stage strawberry detection. Comput. Electron. Agric. 2022, 198, 107057. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, J.; Tao, D. Sir: Self-supervised image rectification via seeing the same scene from multiple different lenses. IEEE Trans. Image Process. 2023, 32, 865–877. [Google Scholar] [CrossRef] [PubMed]
- Zheng, R.; Zhong, Y.; Yan, S.; Sun, H.; Shen, H.; Huang, K. MsVRL: Self-Supervised Multiscale Visual Representation Learning via Cross-Level Consistency for Medical Image Segmentation. IEEE Trans. Med. Imaging 2022, 42, 91–102. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 15750–15758. [Google Scholar]
- Wang, S.; Wang, Z.; Che, W.; Zhao, S.; Liu, T. Combining Self-supervised Learning and Active Learning for Disfluency Detection. Trans. Asian-Low-Resour. Lang. Inf. Process. 2021, 21, 1–25. [Google Scholar] [CrossRef]
- Jian, L.; Pu, Z.; Zhu, L.; Yao, T.; Liang, X. SS R-CNN: Self-Supervised Learning Improving Mask R-CNN for Ship Detection in Remote Sensing Images. Remote Sens. 2022, 14, 4383. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, Y.M.; Li, X.L.; Song, R.; Zhang, W. Maritime Object Detection Method Based on Self-Supervised Representation Learning. J. Underw. Unmanned Syst. 2020, 28. [Google Scholar]
- Cai, R.J.; Jiang, W.X.; Qi, L.Z.; Sun, Y.Q. Object Detection in Disinfection Scenes Based on Self-supervised Learning and SimDet Model under Condition of Few Samples. Comput. Syst. Appl. 2022, 31, 51–58. [Google Scholar]
- Wu, J.; Zhang, S.; Zou, T.; Dong, L.; Peng, Z.; Wang, H. A Dense Litchi Target Recognition Algorithm for Large Scenes. Math. Probl. Eng. 2022, 2022, 4648105. [Google Scholar] [CrossRef]
- Sun, M.; Xu, L.; Chen, X.; Ji, Z.; Zheng, Y.; Jia, W. Bfp net: Balanced feature pyramid network for small apple detection in complex orchard environment. Plant Phenomics 2022, 2022, 9892464. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.F.; Jia, R.S.; Liu, Y.B.; Zhao, C.Y.; Sun, H.M. Fast method of detecting tomatoes in a complex scene for picking robots. IEEE Access 2020, 8, 55289–55299. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Gai, R.; Li, M.; Wang, Z.; Hu, L.; Li, X. YOLOv5s-Cherry: Cherry Target Detection in Dense Scenes Based on Improved YOLOv5s Algorithm. J. Circuits Syst. Comput. 2023, 2350206. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2021, 1–12. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 11–12 December 2015; Volume 28. [Google Scholar]
- Jiang, B.; Wu, Q.; Yin, X.; Wu, D.; Song, H.; He, D. FLYOLOv3 deep learning for key parts of dairy cow body detection. Comput. Electron. Agric. 2019, 166, 104982. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cell Size | Prior Bounding Box Size (Original) | Prior Bounding Box Size (k-Means) |
|---|---|---|
| 20 × 20 | (116,90), (156,198), (373,326) | (496,478), (616,627), (723,753) |
| 40 × 40 | (30,61), (62,45), (59,119) | (259,264), (334,328), (408,400) |
| 80 × 80 | (10,13), (16,30), (33,23) | (129,129), (204,153), (191,198) |
| 160 × 160 | — | (10,10), (45,45), (87,81) |
| Model | mAP | mAP50 | Data_Time (Data/Epoch) | Size of Model | Reference |
|---|---|---|---|---|---|
| SSMDA | 64.4% | 95.0% | 0.018 s | 89 MB | — |
| YOLOv5s | 62.1% | 91.1% | 0.012 s | 13 MB | [25] |
| YOLOv4 | 60.3% | 85.4% | 0.022 s | 244 MB | [26] |
| Faster RCNN | 58.9% | 84.7% | 0.034 s | 326 MB | [27] |
| SimCLR-Faster RCNN | 60.7% | 92.1% | 0.034 s | 328 MB | — |
| Soft-NMS | Shallow Feature Fusion Network | Replace Resnet59 | K-Means | ||
|---|---|---|---|---|---|
| Baseline Module | 91.1% | ||||
| Baseline Module+ | √ | 91.3% | |||
| √ | √ | 92.2% | |||
| √ | √ | 92.6% | |||
| √ | √ | √ | 93.2% | ||
| √ | √ | √ | √ | 93.7% |
| Loss | Loss-cls | Loss-bbox | Loss-obj | |
|---|---|---|---|---|
| Baseline Module | 0.3472 | 0.0040 | 0.0752 | 0.2711 |
| SimCLR-ST | 0.2553 | 0.0022 | 0.0456 | 0.2135 |
| SSMDA | 0.2102 | 0.0021 | 0.0440 | 0.1648 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gai, R.-L.; Wei, K.; Wang, P.-F. SSMDA: Self-Supervised Cherry Maturity Detection Algorithm Based on Multi-Feature Contrastive Learning. Agriculture 2023, 13, 939. https://doi.org/10.3390/agriculture13050939
Gai R-L, Wei K, Wang P-F. SSMDA: Self-Supervised Cherry Maturity Detection Algorithm Based on Multi-Feature Contrastive Learning. Agriculture. 2023; 13(5):939. https://doi.org/10.3390/agriculture13050939
Chicago/Turabian StyleGai, Rong-Li, Kai Wei, and Peng-Fei Wang. 2023. "SSMDA: Self-Supervised Cherry Maturity Detection Algorithm Based on Multi-Feature Contrastive Learning" Agriculture 13, no. 5: 939. https://doi.org/10.3390/agriculture13050939
APA StyleGai, R.-L., Wei, K., & Wang, P.-F. (2023). SSMDA: Self-Supervised Cherry Maturity Detection Algorithm Based on Multi-Feature Contrastive Learning. Agriculture, 13(5), 939. https://doi.org/10.3390/agriculture13050939