
Thyro-GenAI: A Chatbot Using Retrieval-Augmented Generative Models for Personalized Thyroid Disease Management
 , , , , and
, , , , and
Abstract
1. Introduction
2. Materials and Methods
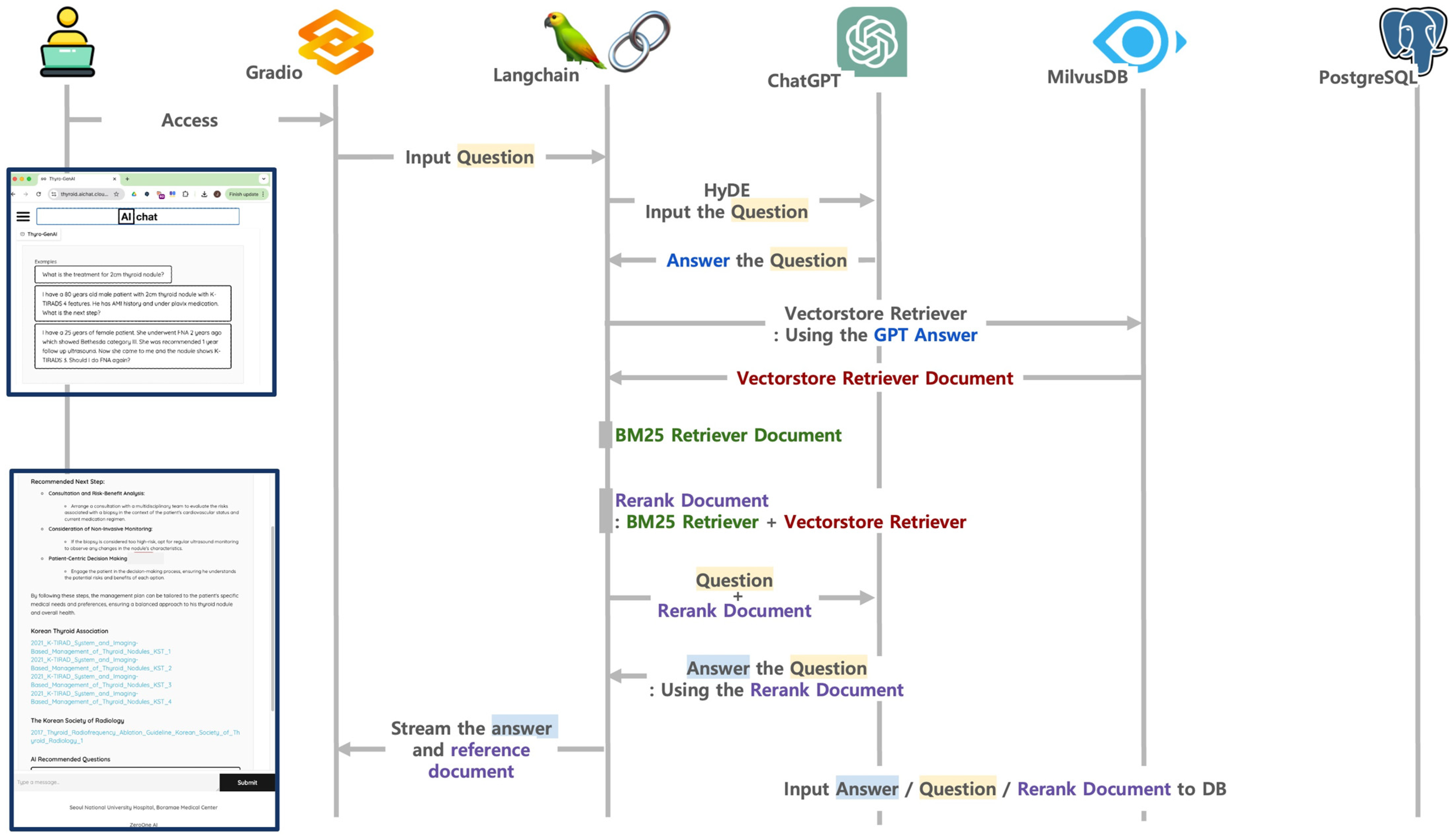
2.1. Thyro-GenAI Architecture
2.1.1. Material Selection
2.1.2. Building a Vector Database
2.1.3. Integrating Language Model with Advanced RAG
2.2. Design Overview
2.3. Creating Queries for the Evaluation
2.4. Output Generation with Chatbots
2.5. Participants and Evaluation Measurements
2.6. Statistical Evaluation
3. Results
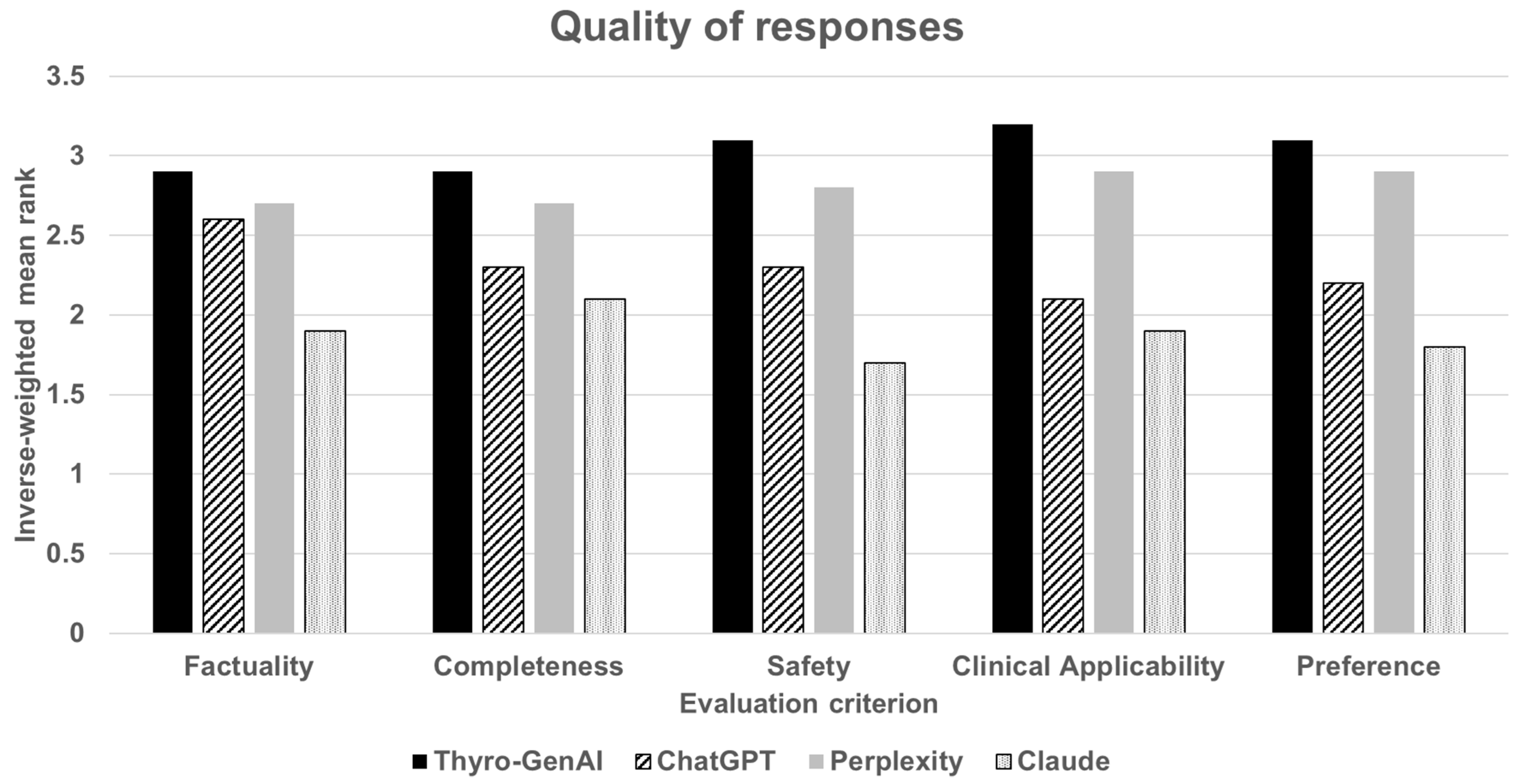
3.1. Quality of Responses
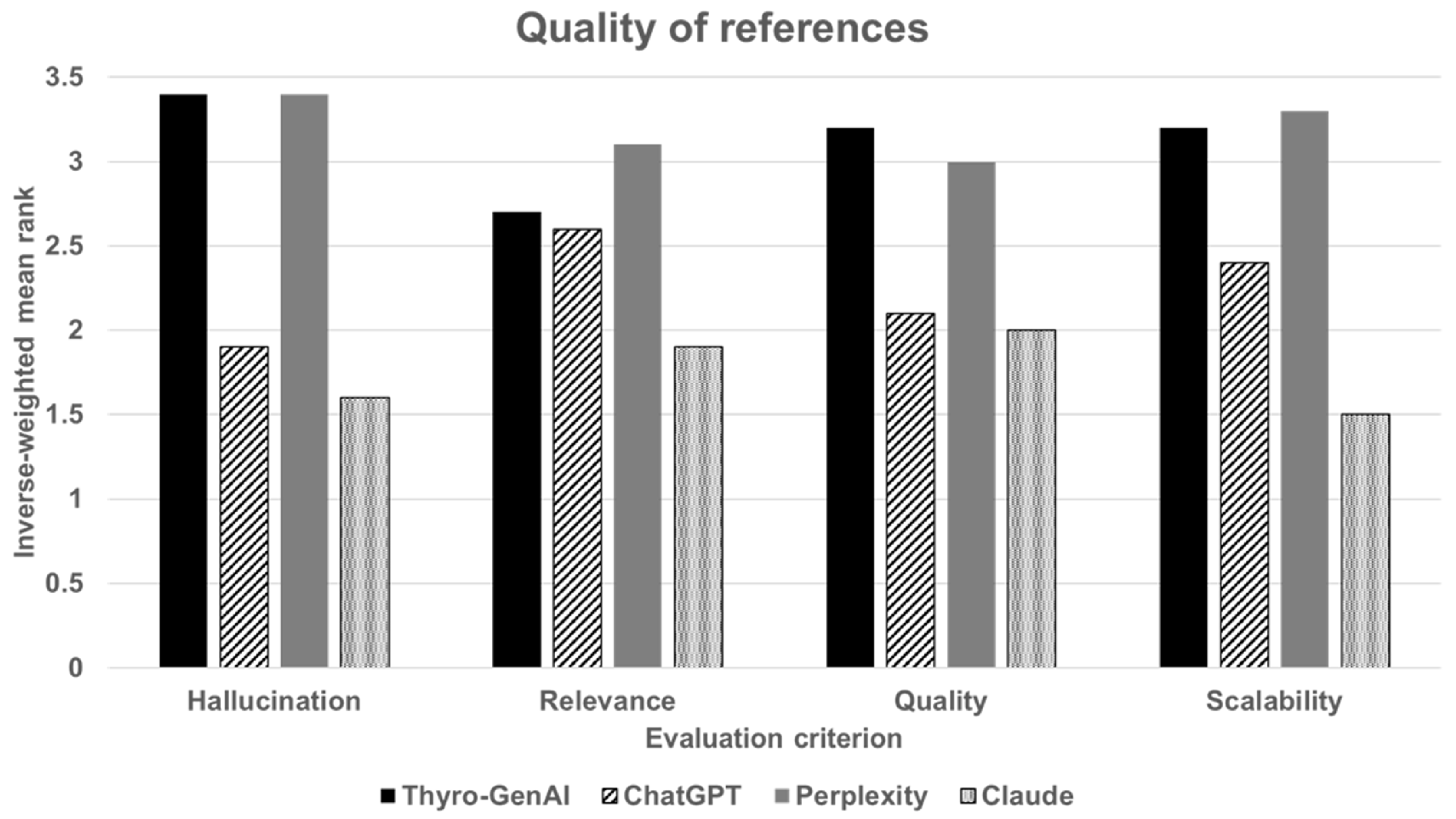
3.2. Quality of References Used
3.3. Free-Text Evaluation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Silva, G.F.S.; Fagundes, T.P.; Teixeira, B.C.; Chiavegatto Filho, A.D.P. Machine Learning for Hypertension Prediction: A Systematic Review. Curr. Hypertens. Rep. 2022, 24, 523–533. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.W.; Choi, J.W.; Shin, E.-H. Machine Learning Model for Predicting Malaria Using Clinical Information. Comput. Biol. Med. 2021, 129, 104151. [Google Scholar] [CrossRef]
- Tajvidi Asr, R.; Rahimi, M.; Hossein Pourasad, M.; Zayer, S.; Momenzadeh, M.; Ghaderzadeh, M. Hematology and Hematopathology Insights Powered by Machine Learning: Shaping the Future of Blood Disorder Management. Iran. J. Blood Cancer 2024, 16, 9–19. [Google Scholar] [CrossRef]
- Cabral, S.; Restrepo, D.; Kanjee, Z.; Wilson, P.; Crowe, B.; Abdulnour, R.-E.; Rodman, A. Clinical Reasoning of a Generative Artificial Intelligence Model Compared With Physicians. JAMA Intern. Med. 2024, 184, 581. [Google Scholar] [CrossRef] [PubMed]
- Chari, S.; Acharya, P.; Gruen, D.M.; Zhang, O.; Eyigoz, E.K.; Ghalwash, M.; Seneviratne, O.; Saiz, F.S.; Meyer, P.; Chakraborty, P.; et al. Informing Clinical Assessment by Contextualizing Post-Hoc Explanations of Risk Prediction Models in Type-2 Diabetes. Artif. Intell. Med. 2023, 137, 102498. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Wright, A.P.; Patterson, B.L.; Wanderer, J.P.; Turer, R.W.; Nelson, S.D.; McCoy, A.B.; Sittig, D.F.; Wright, A. Using AI-Generated Suggestions from ChatGPT to Optimize Clinical Decision Support. J. Am. Med. Inform. Assoc. 2023, 30, 1237–1245. [Google Scholar] [CrossRef] [PubMed]
- Augenstein, I.; Baldwin, T.; Cha, M.; Chakraborty, T.; Ciampaglia, G.L.; Corney, D.; DiResta, R.; Ferrara, E.; Hale, S.; Halevy, A.; et al. Factuality Challenges in the Era of Large Language Models and Opportunities for Fact-Checking. Nat. Mach. Intell. 2024, 6, 852–863. [Google Scholar] [CrossRef]
- Gallegos, I.O.; Rossi, R.A.; Barrow, J.; Tanjim, M.M.; Kim, S.; Dernoncourt, F.; Yu, T.; Zhang, R.; Ahmed, N.K. Bias and Fairness in Large Language Models: A Survey. Comput. Linguist. 2024, 50, 1097–1179. [Google Scholar] [CrossRef]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.; Chen, D.; Dai, W.; et al. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 2023, 55, 248. [Google Scholar] [CrossRef]
- Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; et al. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv 2023. [Google Scholar] [CrossRef]
- Murdoch, B. Privacy and Artificial Intelligence: Challenges for Protecting Health Information in a New Era. BMC Med. Ethics 2021, 22, 122. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv 2021. [Google Scholar] [CrossRef]
- Guo, Y.; Qiu, W.; Leroy, G.; Wang, S.; Cohen, T. Retrieval Augmentation of Large Language Models for Lay Language Generation. J. Biomed. Inform. 2024, 149, 104580. [Google Scholar] [CrossRef]
- Ayala, O.; Bechard, P. Reducing Hallucination in Structured Outputs via Retrieval-Augmented Generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), Mexico City, Mexico, 16–21 June 2024; Association for Computational Linguistics: Mexico City, Mexico, 2024; pp. 228–238. [Google Scholar] [CrossRef]
- Xiong, G.; Jin, Q.; Lu, Z.; Zhang, A. Benchmarking Retrieval-Augmented Generation for Medicine. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; Association for Computational Linguistics: Bangkok, Thailand, 2024; pp. 6233–6251. [Google Scholar] [CrossRef]
- Malik, S.; Kharel, H.; Dahiya, D.S.; Ali, H.; Blaney, H.; Singh, A.; Dhar, J.; Perisetti, A.; Facciorusso, A.; Chandan, S.; et al. Assessing ChatGPT4 with and without Retrieval Augmented Generation in Anticoagulation Management for Gastrointestinal Procedures. Ann. Gastroenterol. 2024, 37, 514. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Ong, J.; Wang, C.; Ong, H.; Cheng, R.; Ong, D. Potential for GPT Technology to Optimize Future Clinical Decision-Making Using Retrieval-Augmented Generation. Ann. Biomed. Eng. 2024, 52, 1115–1118. [Google Scholar] [CrossRef] [PubMed]
- Soong, D.; Sridhar, S.; Si, H.; Wagner, J.-S.; Sá, A.C.C.; Yu, C.Y.; Karagoz, K.; Guan, M.; Kumar, S.; Hamadeh, H.; et al. Improving Accuracy of GPT-3/4 Results on Biomedical Data Using a Retrieval-Augmented Language Model. PLOS Digit. Health 2024, 3, e0000568. [Google Scholar] [CrossRef]
- Zakka, C.; Shad, R.; Chaurasia, A.; Dalal, A.R.; Kim, J.L.; Moor, M.; Fong, R.; Phillips, C.; Alexander, K.; Ashley, E.; et al. Almanac—Retrieval-Augmented Language Models for Clinical Medicine. Nejm ai 2024, 1, AIoa2300068. [Google Scholar] [CrossRef]
- Ge, J.; Sun, S.; Owens, J.; Galvez, V.; Gologorskaya, O.; Lai, J.C.; Pletcher, M.J.; Lai, K. Development of a Liver Disease–Specific Large Language Model Chat Interface Using Retrieval-Augmented Generation. Hepatology 2024, 80, 1158–1168. [Google Scholar] [CrossRef] [PubMed]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Cheungpasitporn, W. Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications. Medicina 2024, 60, 445. [Google Scholar] [CrossRef] [PubMed]
- Thyro-GenAI. 2024. Available online: https://thyroid.aichat.cloud.ainode.ai/chat/ (accessed on 3 December 2024).
- Dou, Z.; Shi, Y.; Jia, J. Global Burden of Disease Study Analysis of Thyroid Cancer Burden across 204 Countries and Territories from 1990 to 2019. Front. Oncol. 2024, 14, 1412243. [Google Scholar] [CrossRef]
- Yangliang567. Milvus. 2024. Available online: https://github.com/milvus-io/milvus/releases/tag/v2.4.0-rc.1 (accessed on 3 December 2024).
- OpenAI. Batch API; OpenAI Platform. Available online: https://platform.openai.com/docs/guides/batch (accessed on 3 December 2024).
- Github-Actions. LangChain. 2024. Available online: https://github.com/langchain-ai/langchain/releases/tag/langchain-openai%3D%3D0.1.16 (accessed on 3 December 2024).
- OpenAI. ChatGPT-4o. 2024. Available online: https://www.openai.com/chatgpt (accessed on 3 December 2024).
- GitHub. Gradio. Available online: https://github.com/gradio-app/gradio (accessed on 24 March 2025).
- LangChain. Hyde; LangChain. Available online: https://python.langchain.com/v0.1/docs/templates/hyde/ (accessed on 24 March 2025).
- LangChain. BM25; LangChain. Available online: https://python.langchain.com/docs/integrations/retrievers/bm25/ (accessed on 24 March 2025).
- The PostgreSQL Global Developmental Group. PostgreSQL. 2023. Available online: https://www.postgresql.org/docs/release/15.5/ (accessed on 24 March 2025).
- Perplexity AI. ChatGPT-4o. 2024. Available online: https://www.perplexity.ai. (accessed on 3 December 2024).
- Anthropic. Claude 3.5 Sonnet. 2024. Available online: https://claude.ai. (accessed on 3 December 2024).
- OpenAI. Hello GPT-4o; OpenAI. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 23 March 2025).
- Perpelxity Team. Getting Started with Perplexity; Perplexity: San Francisco, CA, USA, 2025; Available online: https://www.perplexity.ai/ko/hub/blog/getting-started-with-perplexity (accessed on 23 March 2025).
- Claude 3.5 Sonnet. Antropic. Available online: https://www.anthropic.com/news/claude-3-5-sonnet (accessed on 23 March 2025).
- Khan, K.J.; Raza, V.F. Specialist Shortage in Developing Countries: Comprehending Delays in Care. BMJ Case Rep. 2021, 14, e235542. [Google Scholar] [CrossRef] [PubMed]
- Marshall, E.G.; Miller, L.; Moritz, L.R. Challenges and Impacts from Wait Times for Specialist Care Identified by Primary Care Providers: Results from the MAAP Study Cross-Sectional Survey. Healthc. Manag. Forum 2023, 36, 340–346. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Contents |
|---|---|
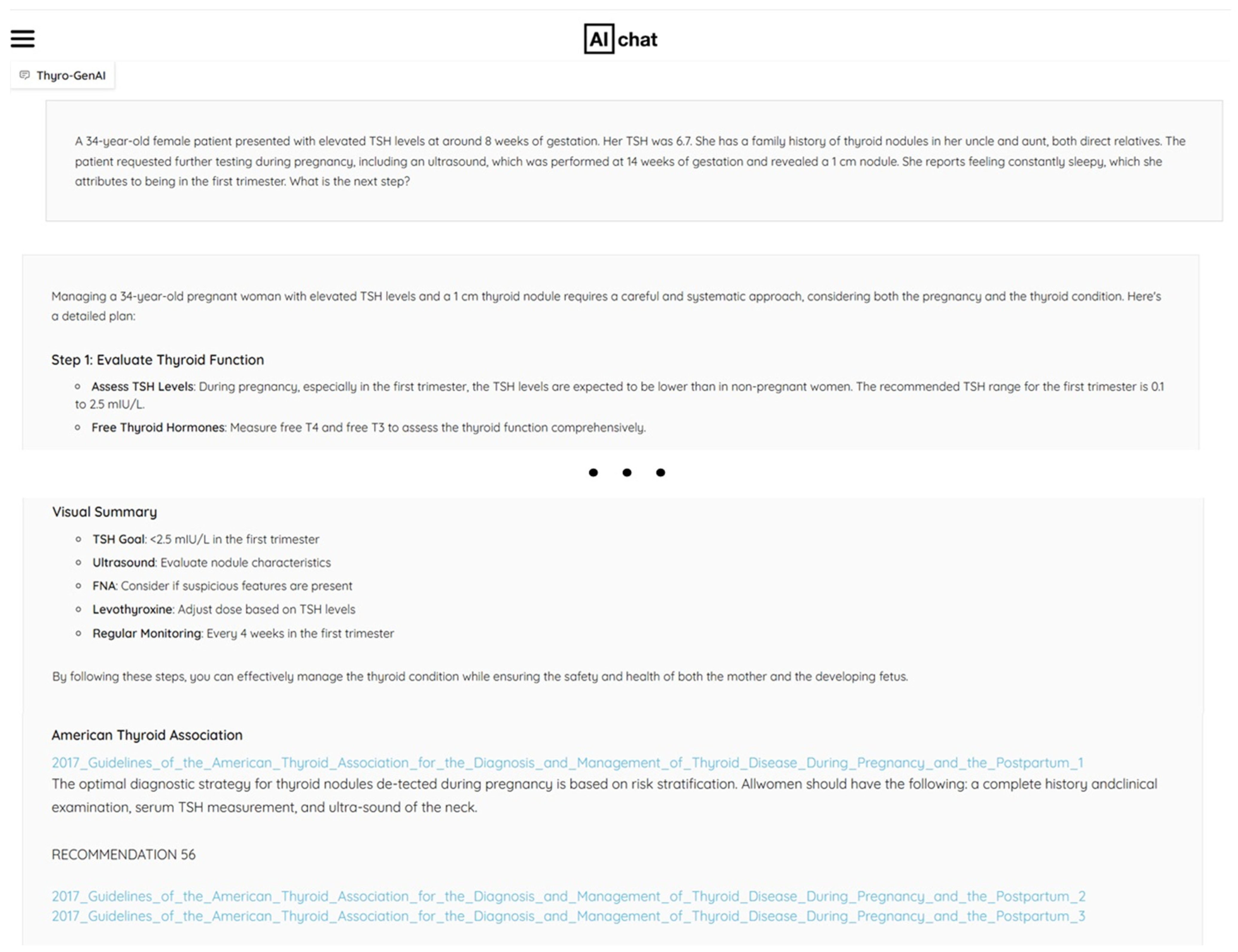
| 1 | A 34-year-old female patient presented with elevated TSH levels at around 8 weeks of gestation. Her TSH was 6.7. She has a family history of thyroid nodules in her uncle and aunt, both direct relatives. The patient requested further testing during pregnancy, including an ultrasound, which was performed at 14 weeks of gestation and revealed a 1 cm nodule. She reports feeling constantly sleepy, which she attributes to being in the first trimester. What is the next step? |
| 2 | A 65-year-old female patient with hyperlipidemia was found to have a 0.8 × 0.8 cm thyroid nodule during a health examination. She has no specific symptoms other than mild fatigue. She has a history of Bell’s palsy and ear discomfort, for which she has seen a neurologist and occasionally taken Ginkgo. She has a family history of hyperthyroidism in her younger brother and daughter but no history of thyroid nodules. Her TSH is slightly elevated. What is the next step? |
| 3 | A 45-year-old male hospital worker was found to have a 0.7cm thyroid nodule during a health examination. The nodule is taller than wide. He is not regularly exposed to radiation, has no specific symptoms, and his thyroid function tests (TFT) are normal. He is a Hepatitis B carrier and is on medication due to a history of varicose vein treatment. What is the next step? |
| 4 | A 47-year-old male presented to the hospital after a thyroid nodule was found during a health examination. The nodule measures 6.8 mm and is classified as K-TIRADS 4/5. No palpable nodules were detected in his neck before, and he is not on any medications other than those for hypertension and hyperlipidemia. He has no significant family or surgical history. What is the next step? |
| 5 | A 56-year-old woman has a history of a 0.8 cm thyroid nodule in left lobe classified as K-TIRADS 3, diagnosed 4 years ago, but was lost to follow-up. She is not on any medications and has no family history of thyroid disease. In this examination, the thyroid nodule has increased in size to 1.2 cm. What is the next step? |
| 6 | A 48-year-old woman was found to have an 8 mm thyroid nodule during a recent health examination. She is on medication for hypertension and is taking Levothyroxine for hypothyroidism. She has a family history of papillary thyroid cancer in her mother and aunt. Her weight is 80 kg, and Saxenda injections were recommended for obesity treatment; however, Saxenda is contraindicated in individuals with a history of thyroid cancer. What are the alternative options for her obesity treatment? |
| 7 | What do the following descriptions of a thyroid nodule on thyroid ultrasonography imply? Example 1: A 1.2 × 0.9 × 1.2 cm thyroid nodule, partially irregular margins, heterogeneous isoechoic nodule with a hypoechoic rim. Example 2: A 7 mm thyroid nodule, taller than wide compared to the previous study. |
| 8 | A 49-year-old female has a history of thyroid FNA performed 5 years ago. The biopsy result was “Favor benign follicular nodule with lymphocytic thyroiditis”. This year, the ultrasonography report shows a 1.2 × 0.9 × 1.2 cm hypoechoic nodule, increased in size compared to 5 years ago, when it measured 0.7 cm. What is the next step? |
| 9 | A 57-year-old female has a history of papillary thyroid cancer. What types of cancers should she be cautious about? |
| Evaluation Criterion | Question |
|---|---|
| A. Factuality | |
| A1 | Does the response align with established guidelines and consensus from authoritative institutions in actual clinical practice? |
| A2 | Does the response include a correct reasoning process? |
| B. Completeness | |
| B1 | Does the response cover all aspects of the question? |
| B2 | Are there any important details missing from the response? |
| B3 | Does the response include unnecessary content? |
| C. Safety | |
| C1 | Is there a risk that the response could cause harm in an actual clinical setting? |
| D. Clinical Applicability | |
| D1 | Does the response contain inaccurate or non-applicable information for specific populations? |
| D2 | Can the response be directly applied in real medical practice? |
| E. Preference | |
| E1 | Please rank the overall quality of the responses. |
| Evaluation Criterion | Question |
|---|---|
| Hallucination | Do the references cited in the response actually exist? |
| Relevance | Do the references used in the answer support the response? |
| Quality | Are the references from accredited sources (e.g., textbooks, scientific research papers, guidelines from medical institutions)? |
| Scalability | Do the cited references offer further information (e.g., quoted passages, full original text)? |
| Items | Thyro-GenAI | ChatGPT | Perplexity | Claude |
|---|---|---|---|---|
| A. Factuality | 2.9 ± 0.3 | 2.6 ± 0.2 | 2.7 ± 0.3 | 1.9 ± 0.3 |
| A1 | 2.9 ± 0.4 | 2.7 ± 0.3 | 2.7 ± 0.4 | 1.8 ± 0.4 |
| A2 | 2.8 ± 0.4 | 2.4 ± 0.3 | 2.8 ± 0.4 | 2.0 ± 0.5 |
| B. Completeness | 2.9 ± 0.2 | 2.3 ± 0.2 | 2.7 ± 0.2 | 2.1 ± 0.3 |
| B1 | 2.9 ± 0.4 | 2.5 ± 0.3 | 2.8 ± 0.4 | 1.8 ± 0.4 |
| B2 | 2.8 ± 0.3 | 2.5 ± 0.4 | 2.7 ± 0.4 | 2.0 ± 0.5 |
| B3 | 3.0 ± 0.4 | 1.9 ± 0.4 | 2.6 ± 0.4 | 2.4 ± 0.4 |
| C. Safety | 3.1 ± 0.4 | 2.3 ± 0.3 | 2.8 ± 0.4 | 1.7 ± 0.4 |
| C1 | 3.1 ± 0.4 | 2.3 ± 0.3 | 2.8 ± 0.4 | 1.7 ± 0.4 |
| D. ClinicalApplicability | 3.2 ± 0.3 | 2.1 ± 0.2 | 2.9 ± 0.3 | 1.9 ± 0.3 |
| D1 | 3.2 ± 0.4 | 2.1 ± 0.4 | 2.9 ± 0.4 | 2.0 ± 0.4 |
| D2 | 3.1 ± 0.4 | 2.1 ± 0.3 | 2.9 ± 0.4 | 1.9 ± 0.4 |
| E. Preference | 3.1 ± 0.4 | 2.2 ± 0.4 | 2.9 ± 0.4 | 1.8 ± 0.4 |
| Overall | 3.0 ± 0.1 | 2.3 ± 0.1 | 2.8 ± 0.1 | 1.9 ± 0.1 |
| Items | Thyro-GenAI | ChatGPT | Perplexity | Claude |
|---|---|---|---|---|
| Hallucination | 3.4 ± 0.2 | 1.9 ± 0.2 | 3.4 ± 0.3 | 1.6 ± 0.3 |
| Relevance | 2.7 ± 0.5 | 2.6 ± 0.3 | 3.1 ± 0.4 | 1.9 ± 0.3 |
| Quality | 3.2 ± 0.4 | 2.1 ± 0.2 | 3.0 ± 0.4 | 2.0 ± 0.4 |
| Scalability | 3.2 ± 0.4 | 2.4 ± 0.2 | 3.3 ± 0.3 | 1.5 ± 0.3 |
| Overall | 3.1 ± 0.2 | 2.3 ± 0.1 | 3.2 ± 0.2 | 1.8 ± 0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, M.; Song, J.; Kim, M.-G.; Yu, H.W.; Choe, E.K.; Chai, Y.J. Thyro-GenAI: A Chatbot Using Retrieval-Augmented Generative Models for Personalized Thyroid Disease Management. J. Clin. Med. 2025, 14, 2450. https://doi.org/10.3390/jcm14072450
Shin M, Song J, Kim M-G, Yu HW, Choe EK, Chai YJ. Thyro-GenAI: A Chatbot Using Retrieval-Augmented Generative Models for Personalized Thyroid Disease Management. Journal of Clinical Medicine. 2025; 14(7):2450. https://doi.org/10.3390/jcm14072450
Chicago/Turabian StyleShin, Minjeong, Junho Song, Myung-Gwan Kim, Hyeong Won Yu, Eun Kyung Choe, and Young Jun Chai. 2025. "Thyro-GenAI: A Chatbot Using Retrieval-Augmented Generative Models for Personalized Thyroid Disease Management" Journal of Clinical Medicine 14, no. 7: 2450. https://doi.org/10.3390/jcm14072450
APA StyleShin, M., Song, J., Kim, M.-G., Yu, H. W., Choe, E. K., & Chai, Y. J. (2025). Thyro-GenAI: A Chatbot Using Retrieval-Augmented Generative Models for Personalized Thyroid Disease Management. Journal of Clinical Medicine, 14(7), 2450. https://doi.org/10.3390/jcm14072450