2. Materials and Methods
We developed a semi-automatic correction method to address segmentation errors in a database of images, including issues such as incomplete border coloring, hallucinated trabeculae in empty regions, and general inconsistencies.
Although the images generated from the proposed method here are automatic, we call it semi-automatic since many of the changes provided by these methods are not desired and should, therefore, be sorted out. For this reason, we developed a user-friendly application to refine and compare these segmentations efficiently.
2.1. Cross-Validation Method
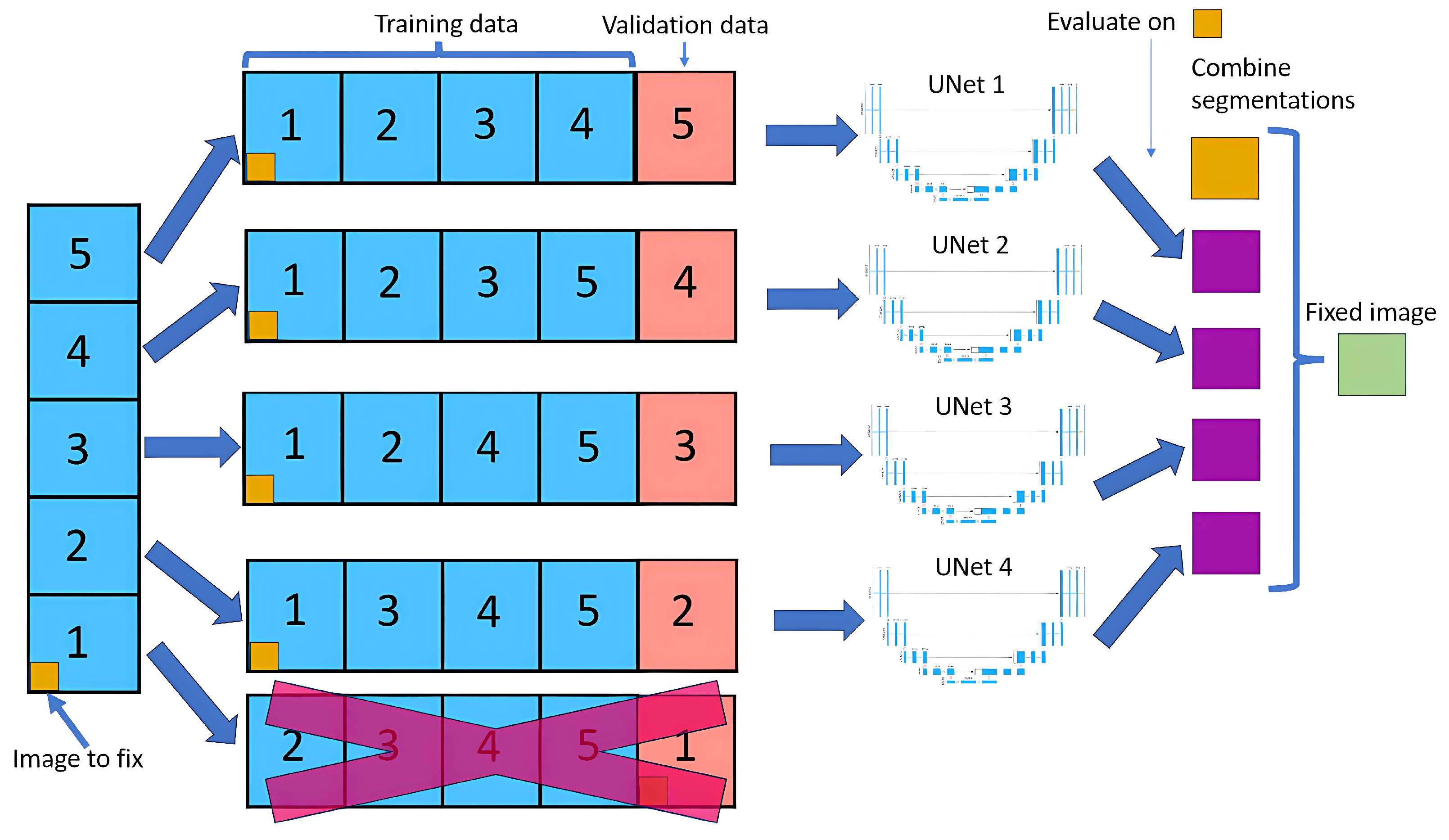
The cross-validation method splits the dataset into five equal parts (called folds). For each fold, one part is used as the validation set, while the remaining four are used to train the neural network model.
Figure 1 shows this method. This process is repeated five times, with each part used as the validation set precisely once, resulting in a total of five neural nets being trained.
For each image, we look at the four outputs of neural nets that have used that image in the training dataset. For each pixel of that image, we look at the four outputs, and if three of them contain the same output class, that will be the new value for that pixel; if not, the value will remain the same as the original.
Modifying only images in the training dataset allows the model to learn that image in depth, making it unlikely to do any big changes, leading to more stable results than if we did a normal cross-validation.
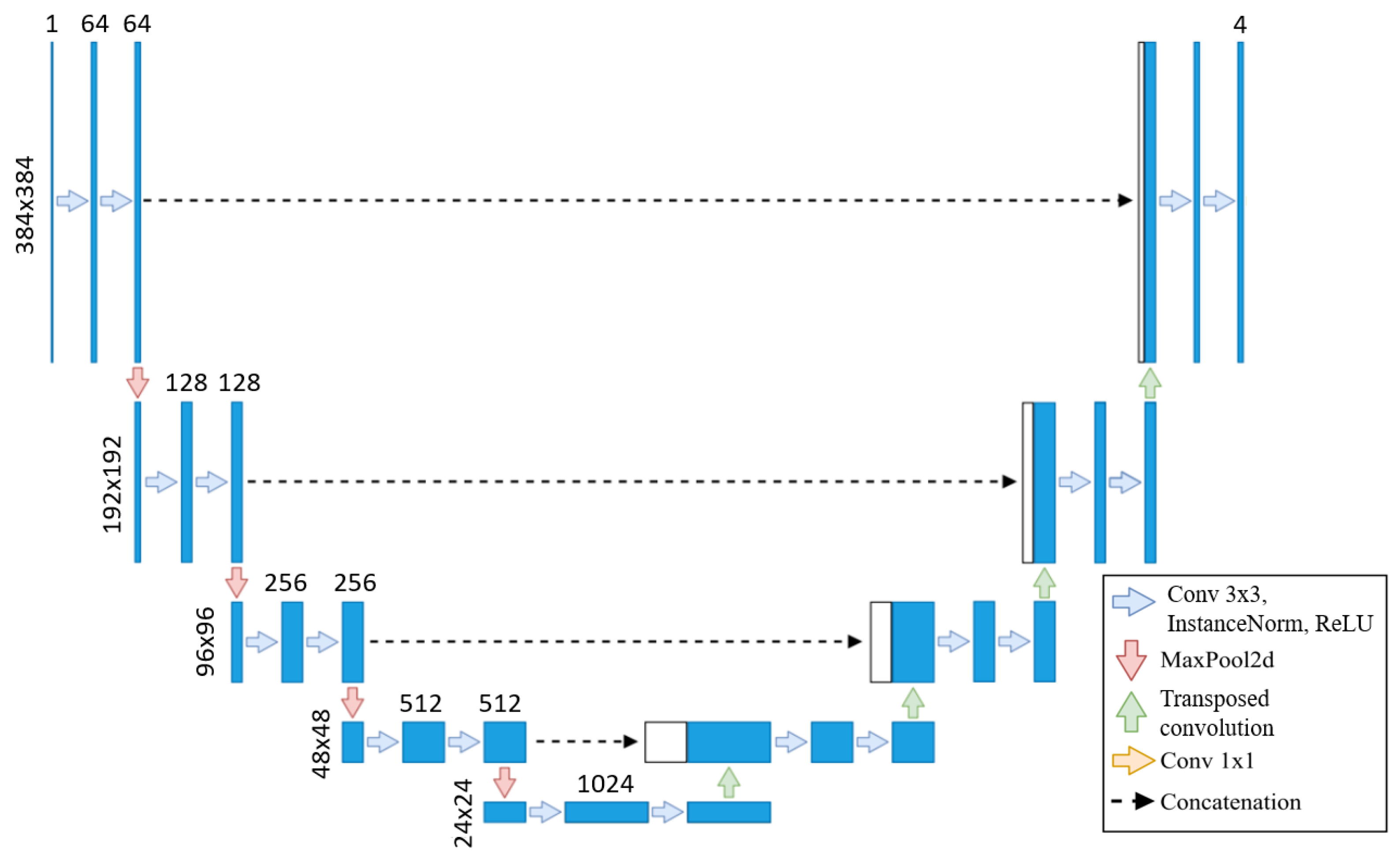
We use the baseline U-Net in this method due to the lengthy training times of neural networks, with the same architecture applied across all training sets, as shown in
Figure 2. As the original segmentations were made at 800 × 800, we upscale our images to 800 × 800 but then cropped them to 384 × 384 to focus on the left ventricle. Our U-Net takes these 384 × 384 images as input, as the images are crop to focus on the left ventricle, eliminating the need for additional downsampling. Each step of the encoder path includes two 3 × 3 convolutions with instance normalization and leaky ReLU (0.01 negative slope), followed by a stride-two convolution to reduce spatial dimensions. The resulting network has different filters in each convolutional block, ranging from 64 in the first layer to 1024 in the bottom layer. The U-Net then outputs a segmentation map with the same 384 × 384 resolution, with four channels representing each class’s probabilities.
This automated framework minimizes the need for manual segmentation adjustments by offering modification suggestions to clinical experts, enabling them to identify patterns that might otherwise go unnoticed.
2.2. Neural Nets Used for Testing
After fixing the images, we perform cross-validation with U-Net on train/val/test sets. We train on full-sized 800 × 800 images to allow a fair comparison to the U-Net model from our previous work [
18]. We adopt the same architecture as the prior study to handle these larger images effectively, incorporating additional layers designed to process 800 × 800 inputs. This ensures both consistency in architecture and the capacity to manage the increased resolution. First, images are downsampled to 200 × 200 using two 3 × 3 convolutions with instance normalization and leaky ReLU activations (negative slope 0.01), each with a stride of two, effectively halving each dimension. The model then processes this 200 × 200 input and outputs at the same resolution.
To upscale back to 800 × 800 before the final output, we add a decoding layer comprising two transposed convolutions (stride of two), each followed by two 3 × 3 convolutions with instance normalization and leaky ReLU. This configuration restores the spatial resolution to 800 × 800, preparing the model for the final segmentation output.
2.3. Image Fixer
Now, the goal is to obtain a segmentation for our image that is closest to what we believe to be as correct as possible. To facilitate this, we use two different segmentation methods.
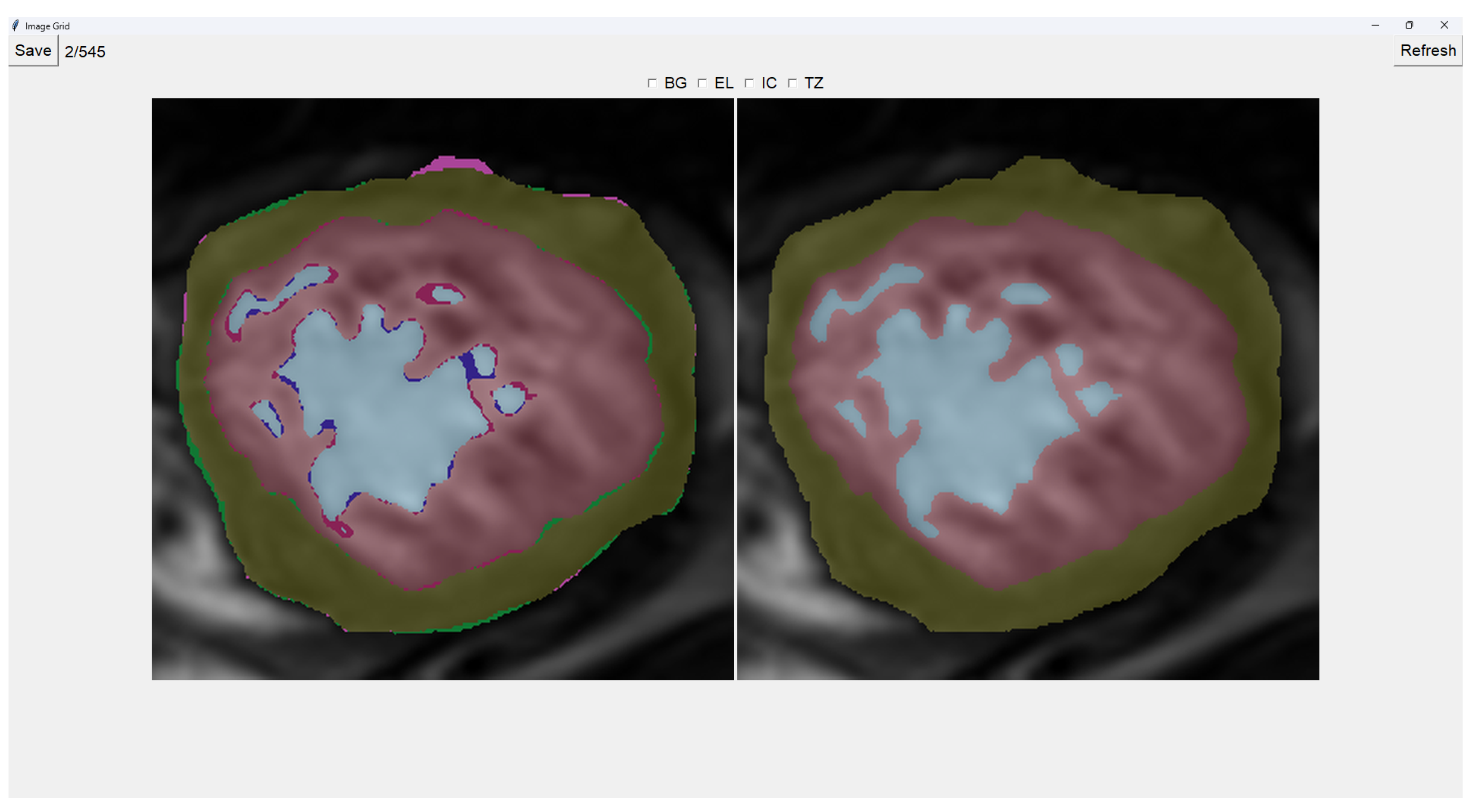
This program presents two images as shown in
Figure 3. The image on the left is obtained from our previous method (QLVTHC), while the one on the right is obtained from our neural networks (
Section 2.1). The final output of our program is the segmentation on the right.
We use a muted color scheme to make the colors distinguishable for colorblind people. In the image on the right, the External Layer is olive green, the Internal Cavity is cyan, and the Trabecular Zone is rose.
On the figure on the left, we mark the differences between both segmentations. This way, where there is an External Layer on the left and something else on the right, we mark it with green. For additional Internal Cavity, we mark it with blue; for Trabeculae, we mark it with wine red; for Background, we mark it with purple.
The differences between both images can be leveraged for easy transformations of the output image. The transformation is applied to the image on the right by simply clicking one of the differences. For example, if we click a blob that is colored green on the left (meaning an additional External Layer), an External Layer will appear in that zone of the image on the right. Some of these blobs are very small, so you can select them by right-clicking and dragging over them for ease of use.
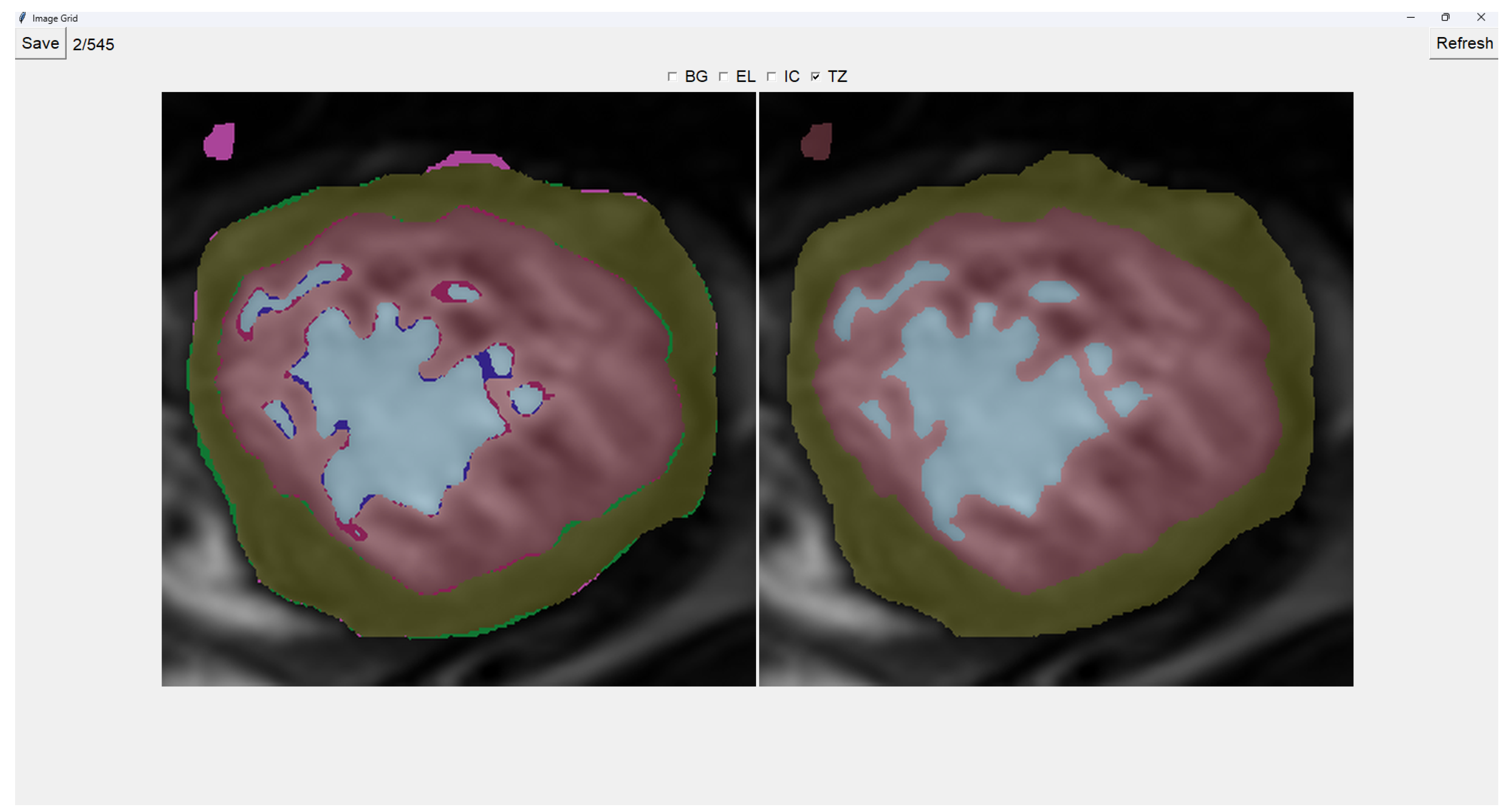
Painting directly on the output image (the image on the right) is also possible. For this, we select either BG (Background), EL (External Layer), IC (Internal Cavity), or TZ (Trabecular Zone). Then, we simply left-click where we want to paint (as shown in
Figure 4).
When we finish the image, we just save the image and go to the next image automatically. However, if we want to restart the editing of the image, we can refresh it and erase the modifications made.
Finally, we can also toggle the segmentation which helps us view the borders’ coloring. It is important to note that you can still paint when the image is toggled to the raw image.
2.4. Image Selector
This tool allows the user to select the most accurate segmentation for a given image from three different segmentations. The process is designed as a blind test to ensure an unbiased evaluation, allowing the user to choose the segmentation that most closely represents reality.
The program presents four images on a grid, as shown in
Figure 5. The raw image is presented in the top-left corner, while the other three images are segmentations obtained differently. These three images are randomly placed in each iteration to ensure that this is a blind test.
On top of each image, we show the percentage of image trabeculation for the given segmentation (Equation (
1)).
Again, we use a muted color scheme to make the colors distinguishable for colorblind people. The External Layer is olive, the Internal Cavity is cyan, and the Trabecular Zone is rose.
To select an image, you have to left-click on the image, and then a green box appears around the selected image (see
Figure 6). On the right, we can choose a mark of 1–5, indicating how good the image is.
Table 1 shows the subjective evaluation scale proposed in [
23]. Finally, we can save it, which automatically brings up the next batch.
In addition, we can give feedback in the textbox on the left. We can also indicate whether the quality of the image is bad by selecting the checkbox at the center top.
It is possible to zoom in on an image using the mouse wheel. It is also possible to toggle between viewing each image as the raw image for easy comparison between borders.
The three images presented (see
Figure 5 and
Figure 6) are obtained using the following methods:
2.5. Datasets
The datasets used in this study are derived from three hospitals: Virgen de la Arrixaca of Murcia (HVAM), Mesa del Castillo of Murcia (HMCM), and Universitari Vall d’Hebron of Barcelona (HUVHB). These hospitals provide the medical imaging data for the analysis and contribute a variety of patient profiles that enrich the study.
HVAM operates two scanners, one from Philips and one from General Electric, with a field strength of 1.5 T. The acquisition matrices for these scanners are 256 × 256 pixels and 224 × 224 pixels, respectively, with pixel spacing of 1.5 × 1.5 × 0.8 mm and 1.75 × 1.75 × 0.8 mm. HMCM uses a General Electric model scanner identical to HVAM’s, while HUVHB utilizes a 1.5 T Siemens Avanto scanner with an acquisition matrix of 224 × 224 pixels. For all institutions, the images were captured using balanced steady-state free precision (b-SSFP) sequences. The primary parameters for the scans, including echo time (1.7 ms), flip angle (60º), slice thickness (8 mm), slice gap (2 mm), and 20 imaging phases, were consistent across all hospitals. All patients underwent the scans while in apnea, synchronized with ECG, and without using contrast agents.
The original dataset comprises data from three subsets: P, X, and H. Set P, from HVAM, consists of 293 patients (2381 slices) with hypertrophic cardiomyopathy (HCM). Set X, from HMCM, includes 58 patients (467 slices) with various heart conditions, including HCM. Finally, set H, from HUVHB, comprises 28 patients (196 slices) diagnosed with left ventricular non-compaction cardiomyopathy (LVNC) according to the Petersen criteria.
Given the time-intensive nature of manual segmentation methods, we use a representative subset of 545 modified segmentations from the original dataset. This subset includes 355 slices from the P dataset, 75 from the X dataset, and 115 from the H dataset. The selection process ensures that the larger dataset’s diversity of heart conditions and image characteristics is still adequately represented in the smaller subset.
To enable comparison with the results of our previous U-Net model, we train our new models using a train/validation/test split. From our dataset of 545 images, we retain the 113 images used as a test in our prior work [
18]. The remaining 432 images were divided into 5 non-overlapping folds, ensuring no patient data were shared between folds, allowing us to create a cross-validation dataset. For the creation of these training folds, 297 images were from P, 53 from X, and 82 from H, while for testing, 58 were from P, 22 from X, and 33 were from H.
4. Discussion
As shown in
Table 2, the baseline U-Net model achieves Dice coefficients ranging from 0.82 to 0.87 for the Trabecular Zone. In comparison, the blob-selection and manually fixed methods (
Table 3 and
Table 4) exhibit improved Dice coefficients, with increases of up to 0.06 for the H population. This improvement is particularly noteworthy given that the baseline model was trained with seven times more data per neural network than the adjusted models. Despite having less training data, the blob-selection and manual methods yield higher accuracy and stability, especially in regions like the Trabecular Zone. For the P population, both methods achieve a 0.02 increase in Dice coefficients. However, for the X Trabecular Zone, no improvement is observed, potentially due to the lower representation of X images within the 432 images used in the training sets.
The blob-selection method consistently outperforms both the baseline and the manually fixed method, though the difference with the latter is slight. This is because the blob-selection method only allows changes proposed by the cross-validation method, which tends to homogenize results. While this approach reduces variability, it may also exclude changes that would increase accuracy by correctly capturing variations.
Modifying an image using the blob-selection method takes approximately 20 to 30 s, while manual correction requires around 2 to 3 min per image. This significant difference indicates that the blob-selection method is much more efficient in terms of time.
Table 5 shows that the blob-selection method achieves high Dice coefficients across all populations, with average values around 0.94. In contrast, the manual correction method yields lower Dice coefficients, as shown in
Table 6, with average values ranging from 0.80 to 0.89. The higher Dice coefficients for the blob-selection method indicate a closer similarity to the original segmentation targets. This is expected because the blob-selection method makes more conservative adjustments, while the manual correction method allows for more significant modifications that may deviate further from the original targets.
The results in
Table 7 indicate a slight improvement in Dice coefficients for the blob-selection method compared to those of the manual correction method and the original targets (
Table 6). This slight increase of approximately 0.03 suggests that the blob-selection method aligns segmentations closer to the desired outcomes. However, the difference may not be substantial enough to fully correct the images on its own.
Given the balance between accuracy and efficiency, a mixed-method approach could benefit larger datasets. Initially, a subset of images could be manually corrected to create a robust foundational model, enhancing cross-validation predictions. Subsequently, the remaining images could primarily utilize the blob-selection method, with manual adjustments as necessary. This approach not only ensures data quality and optimizes resource allocation but also leverages the strengths of both methods: the automatic blob-selection method provides a rapid and reliable baseline, while expert manual adjustments further refine the dataset, maintaining both high accuracy and flexibility for future modifications.
5. Conclusions
This paper enhances the approach to diagnosing left ventricular non-compaction cardiomyopathy (LVNC) by introducing a semi-automatic framework designed to improve the quality of segmentations in training datasets, ultimately yielding more robust models. Utilizing cross-validation with multiple neural networks, the framework includes tools such as the Image Fixer and Image Selector to refine segmentation quality within the training dataset. This approach addresses a primary bottleneck in model effectiveness: the quality of input segmentations.
Our results demonstrate that improving segmentation quality in the training data substantially impacts the effectiveness of neural network models. Notably, despite being trained on datasets with seven times fewer images per neural network than the baseline model, the models trained on adjusted datasets using the blob-selection and manual correction methods achieved superior performance.
The fast image modification method (blob-selection method) led to an alignment improvement of approximately 0.03 in the average Dice coefficient. This leaves significant room for improvement, making it necessary to first create good segmentations via the proposed manual method.
We intend to provide clinicians with the Image Fixer tool, allowing them to refine the automatically generated segmentation immediately after receiving it, as needed. This could potentially improve both the efficiency and accuracy of future model training datasets. Once we apply these methods to all the images, we anticipate a significantly improved model, as previous papers have shown that more data leads to better, more robust models.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}