1. Introduction
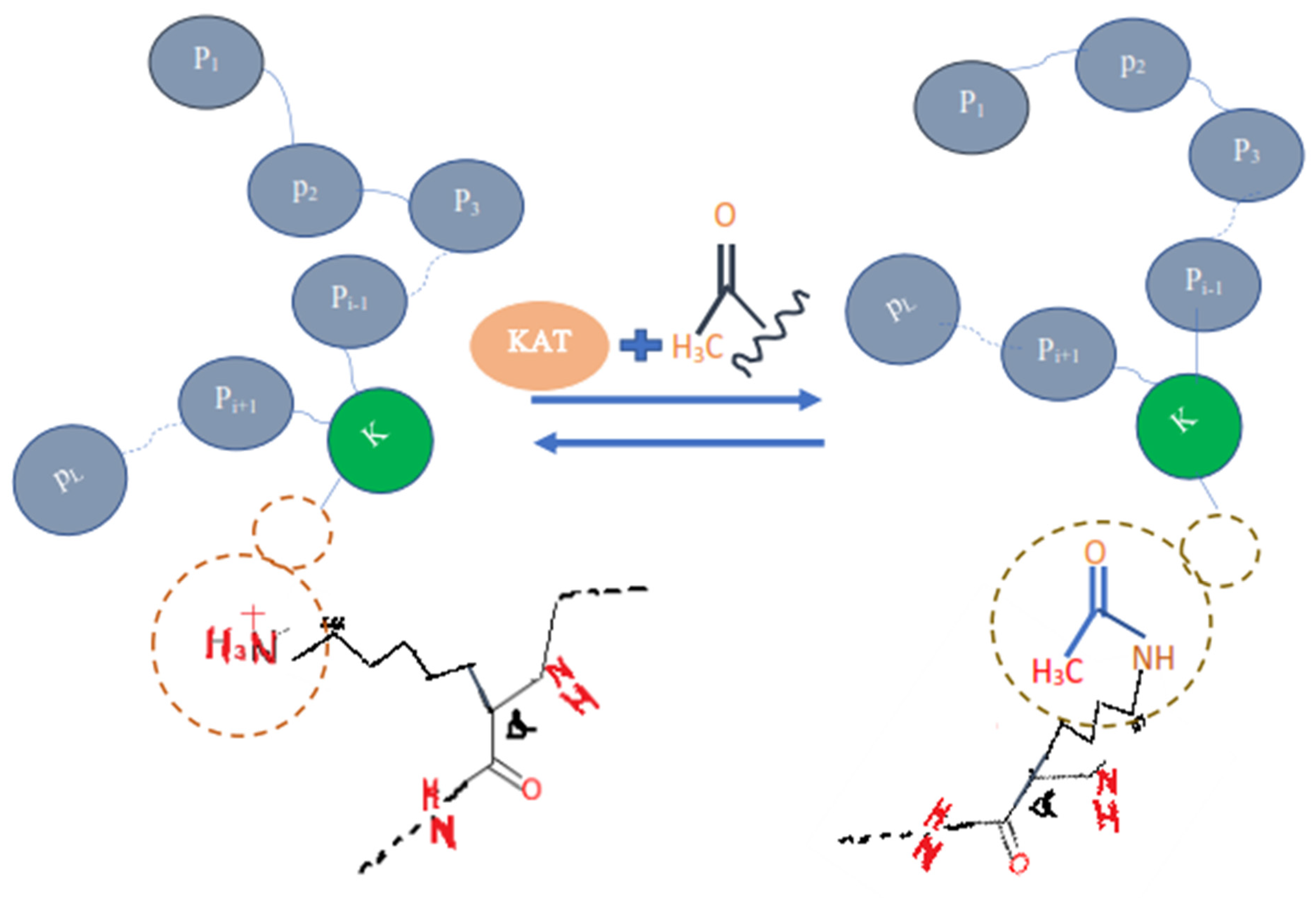
Proteins are the basic and key part of the human body that perform many kinds of major functions in and outside a cell. The proteins are translated or synthesized from messenger RNA which is first codified into ribosomes and makes a chain of amino acid or polypeptide. After the translation process, certain amino acids can experience chemical changes at the protein’s C-termini or N-termini or in amino acid side chains, known as post-translation modifications (PTLM or PTM). The PTM can modify or may introduce the new functional group to the protein, such as in Acetylation, an example of Acetyl-lysine is shown in the
Figure 1) [
1]. It plays a key role in making protein products [
2,
3,
4]. Each protein in the proteome may be altered either before or after it is translated. The charge state, hydrophobicity, conformation, and stability of a protein are all affected by various changes, which, in turn, influence its function. Protein modification has a variety of functions in different organs: (1) It ensure the fast and complex response of cells to regulate intra-cellular communication, division, and growth of cells (2) also pivotal for various physiological and pathological mechanism.
Protein acetylation can be achieved using a variety of methods, this adds the acetyl functional group into a chemical compound, which make another ester, the acetate.
Another form of lysine residue is usually acetylated [
1,
2,
3,
4]. The active substance, acetic anhydride, is commonly used to react with free hydroxyl groups as an acetylating agent. It is used in, for example, aspirin, heroin, and THC-O-acetate synthesis. Thousands of acetylated mammalian proteins have been identified [
1], in addition to protein analysis. The acetylation takes place, for example, via a co-translation and a post-translational adaptation of proteins, histone, and p53, in addition to tubulins. Among these proteins, there is a high representation of chromatin proteins and metabolic enzymes, suggesting that acetylation, in addition to digestion, has an extremely important influence on the appearance of the genetic material. Among the microbes, 90 percent of the proteins that are surrounded by the central metabolism of Salmonella Centrica are acetylated [
1,
2].
Further, acetylation sites also play an important role in regulating membrane protein functions of multiple families, as documented in Reference [
5]. It is supported by examples that acetylation is significantly enhanced in membrane-binding regions, where it is often located directly in critical membrane-binding pockets ideally positioned to modulate membrane interactions. Moreover, it was found that acetylation and acetylation mimetics strongly affected the membrane interaction of proteins, resulting in decreased membrane affinity and, in the case of amphiphysin and EHD2, altered membrane remodeling [
6]. In cells, mimicking even a single acetylation event within the membrane interaction region reduced the binding affinity to membranes, resulting in cytoplasmic dispersal. In another report, acetylation affected the effects on membrane interaction, as well as membrane remodeling [
7]. Similarly, the ability to control the membrane-binding activity of C2 domains via acetylation could allow the cell to further regulate Ca-dependent transmembrane transport and signaling events. It has also been documented that acetylation is present on the membrane-binding surface of the phosphatase domain of K163/K164, as it appears to be that Alanine mutations reduce membrane binding [
8]. In addition, two reports on proteins with PH domains indicate that acetylation has opposite effects on membrane localization in cells (either increased or decreased) [
9,
10]. Much has been learned about the acetyltransferases and deacetylases that regulate protein-DNA-protein-protein interactions [
2,
5,
11]. Some of these enzymes may also be involved in controlling protein membrane interactions. Consistent with this idea, localization of acetyltransferase in the cytoplasm and deacetylases in cell membranes have been observed [
12,
13,
14].
Acetylation also plays a prominent role in numerous important cellular processes, such as stability and localization of protein [
4,
5]. In addition, modification of S/T/Y sites by acetylation, glycosylation, sulfation, and nitration has been reported [
5,
6]. Moreover, it also plays a role in the modulation of gene expression by histone alteration, as well as is a very significant function in controlling cellular metabolism and protein folding [
15,
16,
17,
18].
From the above discussion it revealed that Acetylation is an important post-translation modification, and it is necessary to correctly identify them; however, it remains a major challenge to understand the functions and regulations of the molecular acetylation mechanism. Many traditional approaches are in use for their identification, including high-throughput mass spectrometry (MS) [
19,
20]. However, since the acetylation mechanism is complicated, rapid, and reversible, such methods remain time-consuming, expensive, and laborious [
21,
22].
To overcome the existing problems in its identification, many researchers have developed a computational model for fast and inexpensive prediction of PTM sites [
15,
16,
23,
24], such as the ubiquitination [
17,
18,
24], the phosphorylation [
15,
16,
19,
25,
26,
27], sumoylation [
28,
29,
30], and the acetylation [
31,
32,
33,
34], etc. The important step for the PTM prediction model to correctly transform the biological sequences into their equivalent numerical form, for this purpose, many feature extraction methods are developed which are documented like the amino acids composition (AAC), the dipeptides composition (DPC), and Pseudo Amino Acid Composition (PseAAC) [
35]. For such feature extractions many methods are discussed in Reference [
20].
Reference [
1] proposed a novel measurement procedure iAcet-PseFDA, a classification model for acetylation proteins by extracting features come from sequence conservation information using a gray structure model and KNN scoring based on functional domain annotation databases including GO [
36] and subcellular localization for acetylation protein recognition. The authors achieved 77.10 percent accuracy using 5-fold cross-validation on three datasets, with a significant amount of attribute analysis and the discovery algorithm for relief functionality.
Reference [
37] proposed a method ProAcePred to predict prokaryote-specific lysine acetylation sites, using SVM, 10-fold cross-validation, and the elastic net mathematical approach for optimizing the dimensionality of feature vectors, which greatly increased prediction accuracy and yielded promising results.
Wuyun et al. [
38], developed a model, KA-predictor, to predict species-specific lysine acetylation sites using the classifier SVM. They achieved highly competitive for the majority of species as compared with other methods.
Hou [
39] suggested a predictor for lysine acetylation prediction called LAceP, based on logistic regression classifiers and various biological characteristics. Using Random Forest classifiers, Li [
40] developed SSPKA, a tool for species-specific lysine acetylation prediction.
From the above discussion, it has been observed that many predictors have been developed for the identification of acetylation sites; however, the maximum prediction accuracy established in all previous models was 77.10%, which is very poor for a correct identification of the acetylation sites.
Therefore, in the present study, we use statistical moments as feature extractions and Random Forest and PNN as a classifier. Further, the model evaluation is done by 10-fold cross-validation, self-consistency, independent, and by jackknife testing. We obtained dominant results as compared to the existing models that were developed earlier.
Therefore, to improve the predictor model, we use statistical moments as feature extractions and Random Forest and PNN as classifiers. The model evaluation is carried out through 10-fold cross-validation, self-consistency, independently, and the jackknife tests. We achieved dominant results as compared to the existing models developed earlier.
3. Benchmark Dataset
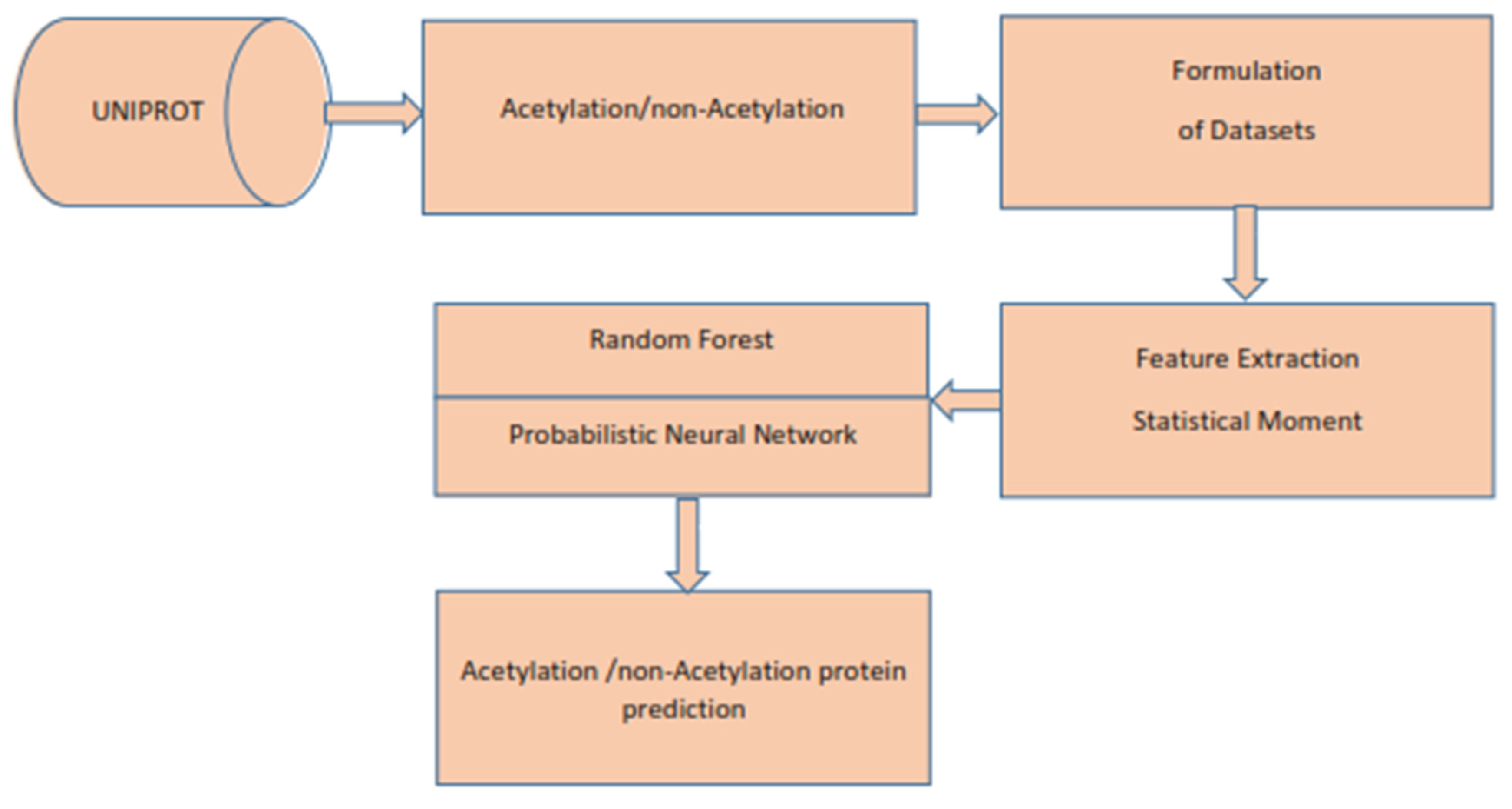
We begin with collection of a valid benchmark dataset for training and testing, which is the first step in the 5-step rule [
1]. The dataset is collected from the well-known data repository, the UNIPROT
http://www.uniprot.org, retrieved dated 8 December 2021. It contains 2900 protein samples, of which 725 were positive denoted by S
posi, and 2175 were negative denoted by S
negt. Further, for the effectiveness of the proposed predictor, the set of negative data samples is equally divided in three sets,
,
, and
as in Reference [
1] such that,
where the sign ∩ represents the intersection of sets. Furthermore, we individually combine these three negative datasets
,
and
with S_posi and created three new datasets with the same number of positive and negative samples as expressed in Equation (1) below:
The symbol
denotes the union of two sets. It is important to note that the dataset under discussion was used for prediction by [
1], whereas the positive dataset was collected based on the given three steps: (1) The possible proteins to be acetylated are identified by a single fixed keyword, i.e., {N acetylcysteine, N acetylserine, N acetylglutamate, N acetylglycine, N acetylcholine, N acetylthreonine, N acetylcholine, N acetylmethionine, N acetylmethionylc, N acetyltyrosine, O-acetylserine, or N6-acetyllysine O-acetyltheronine O}; (2) here, protein collection was validated using some assertion technique; and (3) the 30, or additional, amino acids in proteins, along with the redundant proteins, were removed as discussed in [
1].
Whereas the negative data was generated in a similar way to the positive data, except those proteins are not a member being searched by the above keywords? As a result, it produced a large number of negative samples, moreover, random selection is made from those that were balanced in size to positive samples.
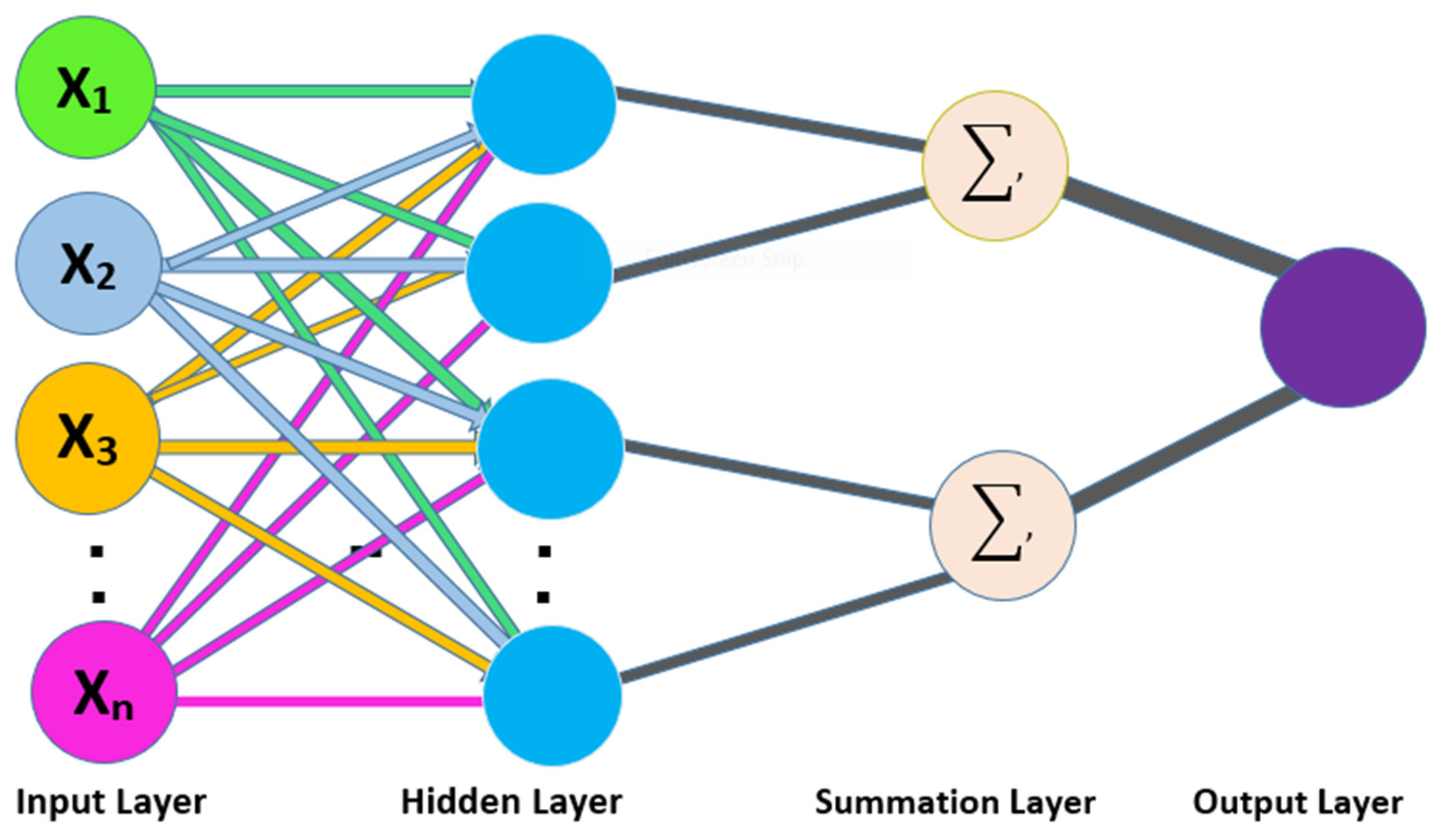
4. Feature Extraction
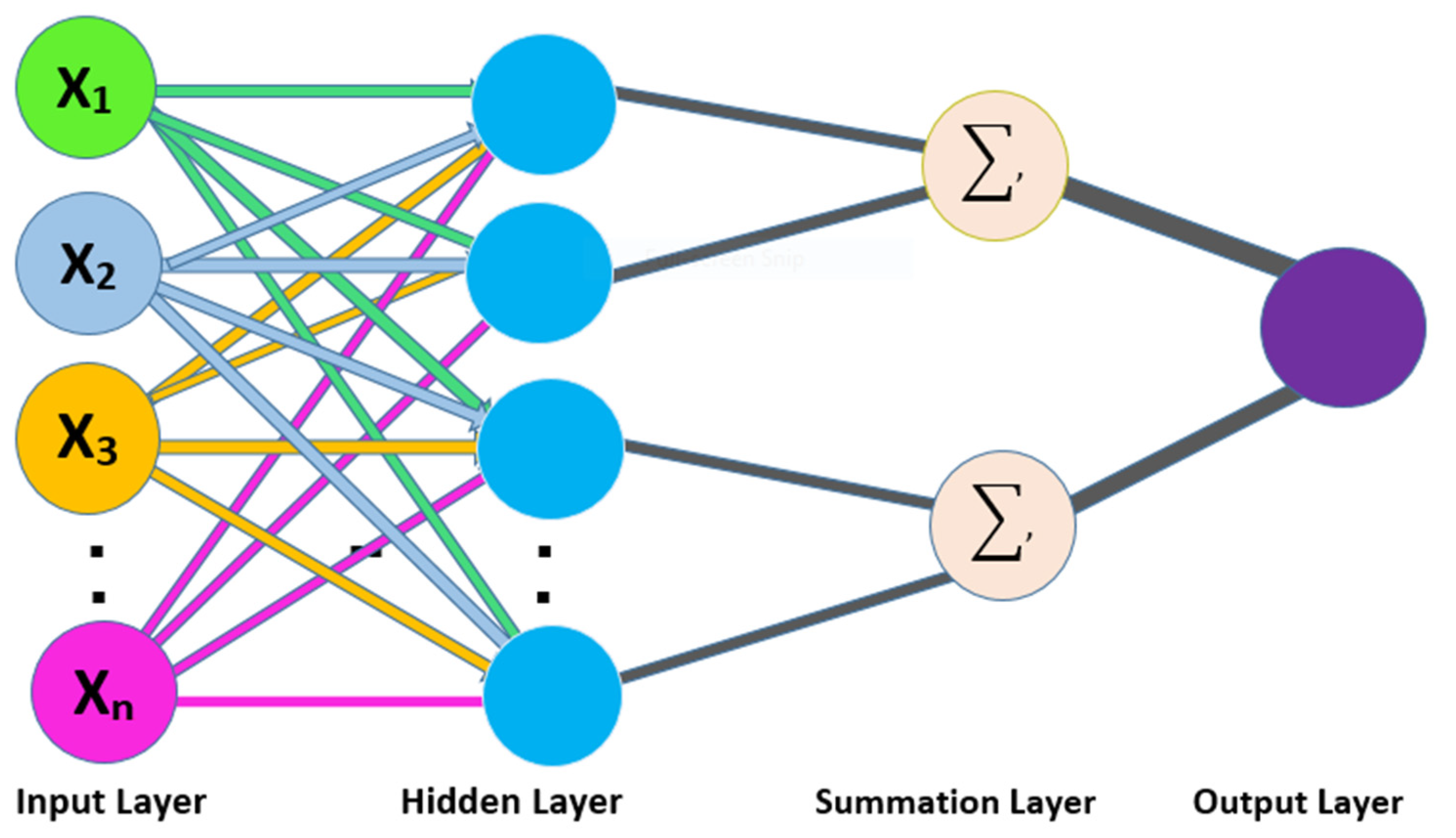
The existing traditional classifiers, such as SVM, KNN, ANN, and many others, are not as powerful in classifying the biological data and making the required prediction. Therefore, a medium is needed to convert biological data into the necessary numerical form to make it suitable for traditional classifiers. For this purpose, many models are developed to extract the required characteristics from biological data, e.g., PseAAC, AAC, Pse-in-One, Pse-Analysis, and many more [
27,
28,
29]. In feature extraction, the emphasis is on preserving the critical properties of the protein, its location, and functions. The statistical moment [
42] is used to derive features in this study, which is discussed in detail below.
4.1. Statistical Moments
In statistics and probability distributions, some form remains beneficial when performing analysis of a particular sequence. The study of such configuration of data collection in pattern matching is known as moments [
25]. There are useful moments when there are various pattern recognition problems related to feature development that do not depend on the pattern or sequence parameters provided [
27,
29,
30,
31,
43]. Particular moments are used to calculate data size, data alignment, and data eccentricity. In this study, we extract the necessary features of acetylation proteins using Hahn, raw, and central moments. The raw moment is used to estimate the probability distribution by using mean, variance, and asymmetry, these moments are neither location invariant nor scale invariant [
32]. Similarly, the same procedure is used in case of the central moment, but the calculation is based on the data centroid. This moment is a scale variant and location invariant. The Hahn moments, on the other hand, are dependent on Hahn polynomials, it is neither scale invariant nor location variant [
33,
34,
44]. These moments are very important for extracting obscure features from protein sequences, as they contain complex orderly details about biotic sequences. In the proposed work, a linearly planned structural of a protein sequence is used, as given in Equation (2).
where
is the 1st amino acid, represented in proteins P, the last amino acid is
, and total length is ‘L’. Transforming the information of the protein linear structure as given in Equation (2) into 2D matrix representation of dimension k as computed by the following equation.
where “P” represents the protein sequence length, and k represents the dimension of the obtained 2D square matrix.
Hence the Equation (4), represents the matrix denoted by
is constructed by using the order obtained from Equation (3) that is k
k
The raw moment R (a, b) is computed by the values of N’, which is a continuous 2D function of order (a + b), as shown in Equation (5):
Up to order 3, the equation calculates the raw moments. This raw moments are measured using the data’s roots as a starting point [
45,
46,
47,
48]. R
00, R
01, R
10, R
11, R
02, R
20, R
21, R
30, and R
03 are the raw moment’s characteristics, weighed up to order 3rd.
The centroid is a point from where all points are equivalently dispersed in all directions with a weighted average [
45,
48,
49,
50]. The following equation, which uses the centroid, calculates the special characteristics of central moments up to order 3 (6).
The unique features are calculated up to 3rd order as: C
00, C
01, C
10, C
11, C
02, C
20, C
30, and C
31. Further, the centroids are calculated, as given by Equations (7) and (8), as
and
.
The Hahn moments must be converted from 1D notation to a square matrix before they can be calculated. Discrete Hahn’s moments, also known as 2D moments, necessitate square matrix input data in a 2D structure [
51]. Since these moments are orthogonal possess inverse properties, therefore, the construction of original data can be constructed using the inverse discrete Hahn moment. The aforementioned remains observed, and the positional and compositional features are somehow preserved in the measured moments [
25,
32,
33,
34,
44,
52] Two-dimensional input data in the form N’ is used to calculate the orthogonal Hahn moments, as seen in Equation (9).
where ‘p’ and ‘q’ (p > −1, q > −1) controlling the shape of polynomials by using the adjustable parameters. The Pochhammer symbol is defined by Equation (10), as follows:
The equation is further simplified by the Gamma operator:
The raw values of Hahn moments are usually scaled using a square norm and weighting formula, as seen in Equation (12):
Meanwhile, in Equation (13),
Hahn moments are computed for the discrete 2D data up to the 3rd order through the following, Equation (14):
The special features based on the Hahn moments are represented by H00, H01, H10, H11, H02, H20, H12, H21, H30, and H03. For each protein sequence up to the third order, we produced 10 central, 10 raw, and 10 Hahn moments and added them to the miscellaneous Super Feature Vector at random (SFV).
4.2. Position Relative Incident Matrix (PRIM)
The amino acids’ order and location in a protein sequence have crucial importance for the recognition of protein characteristics [
47,
50,
53]. In any protein sequence, the relative position of an amino acid remains an essential pattern for understanding its physical properties. The Position Relative Incident Matrix (PRIM) uses a square matrix of order 20 to depict the relative location of amino acids in protein sequences, which is expressed by Equation (15):
represents the position of the jth amino acid for the first occurrence of the ith amino acid in the chain.
The score is of biological evolutional process accomplished by amino-acid of type ‘J’. The matrix, has 400 coefficients based on the relative position of amino acids occurrence.
Ten central moments, 10 raw moments, and 10 Hahn moments are calculated using the 2D and 30 additional special features randomly applied to the miscellaneous SFV.
4.3. Reverse Position Relative Incident Matrix (R-PRIM)
There are several instances of cell biology where biochemical sequences are homologous in origin. This normally occurs where a single ancestor is involved in the evolution process, and several sequences are derived from it. In such situations, using these homologous sequences has a significant impact on the classifier’s output. For the purpose of obtaining correct results, successful and efficient sequence similarity searching is carried out. In machine learning, efficiency and accuracy are urgently needed for the preciseness of feature extraction algorithms through which the most relevant features are extracted from biological data [
43,
47,
50,
53].
The methods used in R-PRIM and PRIM computations are the same, but R-PRIM is only useful for reverse protein sequence ordering. The R-PRIM computations revealed hidden trends in the data and removed ambiguities between homologous sequences. R-PRIM was created as a 20 × 20 matrix containing 400 hundred coefficients, as seen in Equation (16):
The NR-PRIM 2D matrix is used to measure 10 raw, 10 central, and 10 Hahn moments up to 3rd order, as well as more than 30 special features that are randomly applied to the SFV range.
4.4. Frequency Distribution Vector (FDV)
A frequency distribution vector (FDV) can be generated by using the distribution rate of each amino acid in a protein chain, as expressed in Equation (17).
Here is the occurrence of frequency of ith (1≤ i ≤ 20) amino acid in each protein chain. Twenty more special functions have been randomly added to the SFV’s miscellany.
4.5. AAPIV (Accumulative Absolute Position Incidence Vector)
The AAPIV was used to retrieve relevant amino acid positional information, which retrieves and stores amino acid positional information for 20 native amino acids in a protein sequence [
50,
53]. This creates 20 critical features associated with each amino acid in a sequence, as expressed by Equation (18). These 20 new features were thrown into the SFV at random.
where
is expressed by Equation (19).
The comes from the protein sequence Rx, which has a cumulative amino acid count of ‘n’, which can be determined using Equation (19).
4.6. R-AAPIV (Reverse Accumulative Absolute Position Incidence Vector)
R-AAPIV uses reverse sequence ordering to extract and store positional information of amino acids with respect to 20 native amino acids in a protein sequence, which is in reverse order relative to AAPIV [
50,
53].
This creates 20 critical features associated with each amino, as expressed by Equation (20).
where
is expressed by Equation (21).
where
are the ordinal locations at which the residue of protein sequence occurs in the reverse sequence? The values of an arbitrary element of
are given by Equation (21).
6. Performance Evaluation Parameters and Testing Methods
6.1. Performance Evaluation Parameters
The performance of the proposed model can be measured by effective evaluation metrics. We use the subsequent four metrics to measure the forecast quality: (1) Overall Accuracy (ACC), (2) Sensitivity (Sn), (3) Specificity (Sp), and (4) Mathews Correlation Coefficient (MCC). We computed these parameters using a binary confusion matrix. These metrics remain the most common metrics used to measure efficiency of the proposed model. We computed these parameters using the following equations.
where TP is True Positive, FN is False Negative, TN is True Negative, and FP is False Positive, respectively.
As per the given confusion matrix as shown in the
Table 1, we subsequently calculate the following:
TP: Production prognosis, such as True Positive (TP), where we found that acetylation subject stays properly categorized, as well as classified, then the subjects have acetylation proteins.
TN: Production forecast, such as True Negative (TN), where we found that an non-acetylation protein remains properly classified, and then the subject remains non-acetylation protein.
FP: Production prognosis, such as false positive (FP), where we found that non- acetylation protein remains inaccurately classified as containing acetylation proteins known as “type 1 error”.
FN: Forecast of production, such as false negative (FN), where we found that acetylation proteins remain inaccurately classified and that the subject has non- acetylation proteins, this is the “type 2 error”.
ROC and AUC: The optimistic receiver curves evaluate the predictability of the machine learning classifiers at various threshold settings. The ROC exam remains a graphical demonstration that relates the “true positive rate” to the “false positive rate” in the grouping results of the machine learning algorithm. AUC describes a classifier of the ROC. The higher value of the AUC more than 0.5, suggest discrimination, whereas the value of 0.5 doesn’t suggest any discrimination in true positive and true negative of classifier, more the AUC value more the efficiency in the performance of a classifier.
6.2. Testing Methods
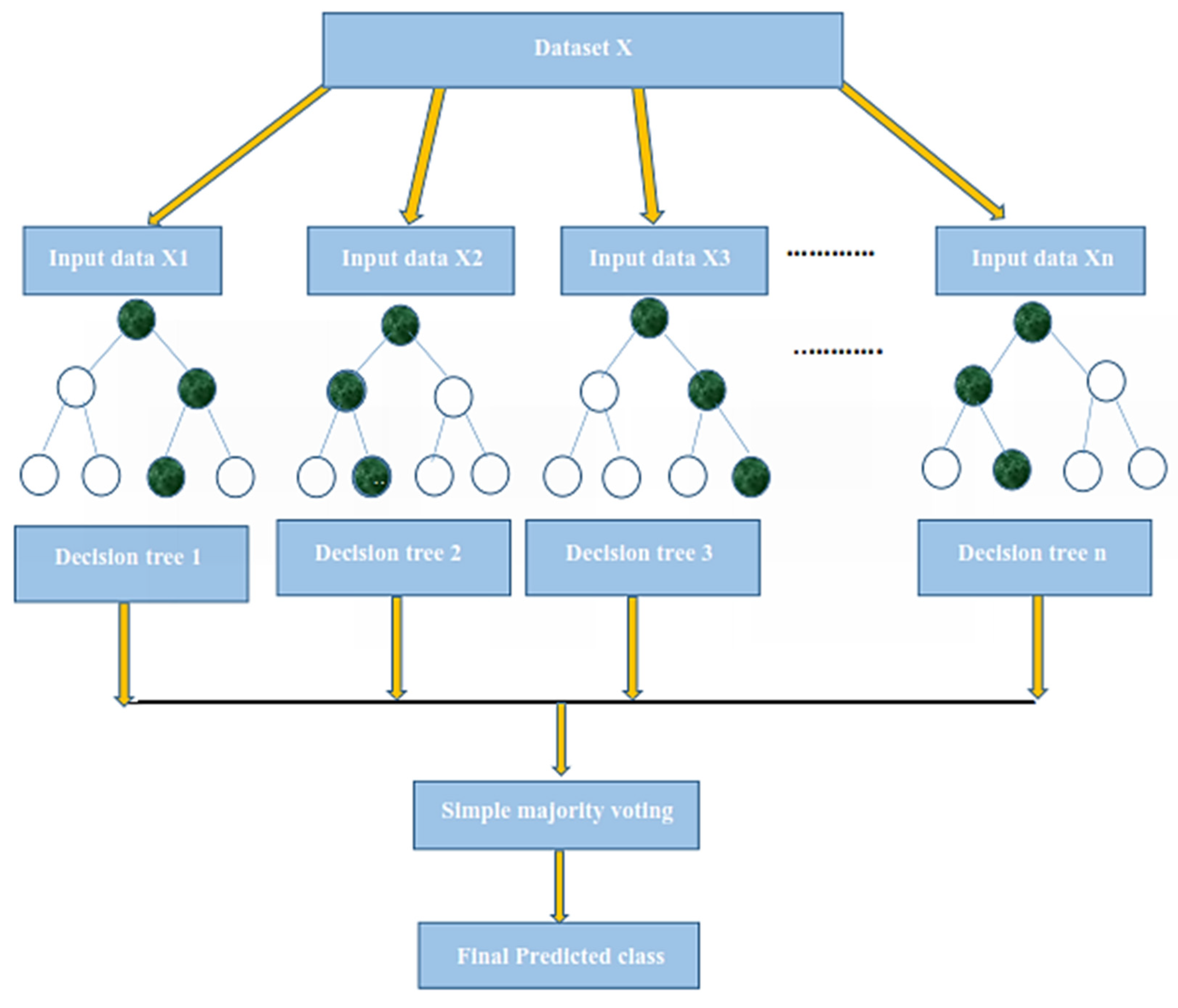
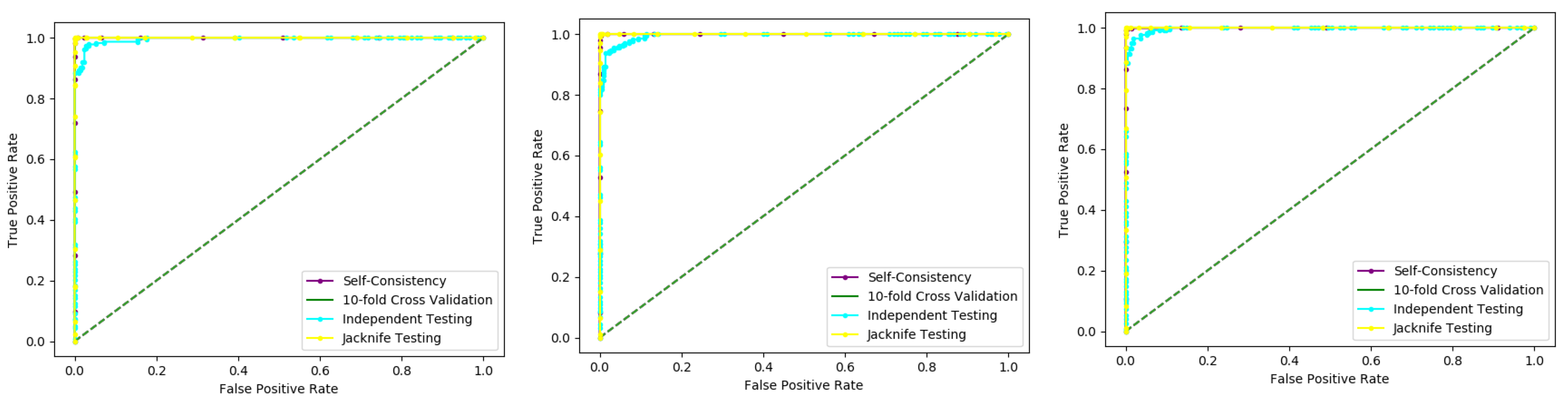
Several cross-validation techniques have been used to examine the statistical forecaster’s results in the literature. The jackknife test, independent dataset test, and k-fold cross-validation test are three experiments that are commonly used by various researchers.
When testing a forecaster designed for its efficiency, we use the following cross-validation methods in this paper to estimate the expected accuracy of the forecaster, self-consistency, independent, K-fold cross-validation, and jackknife testing for the assessment of the proposed model.
The following sub-sections contain the details.
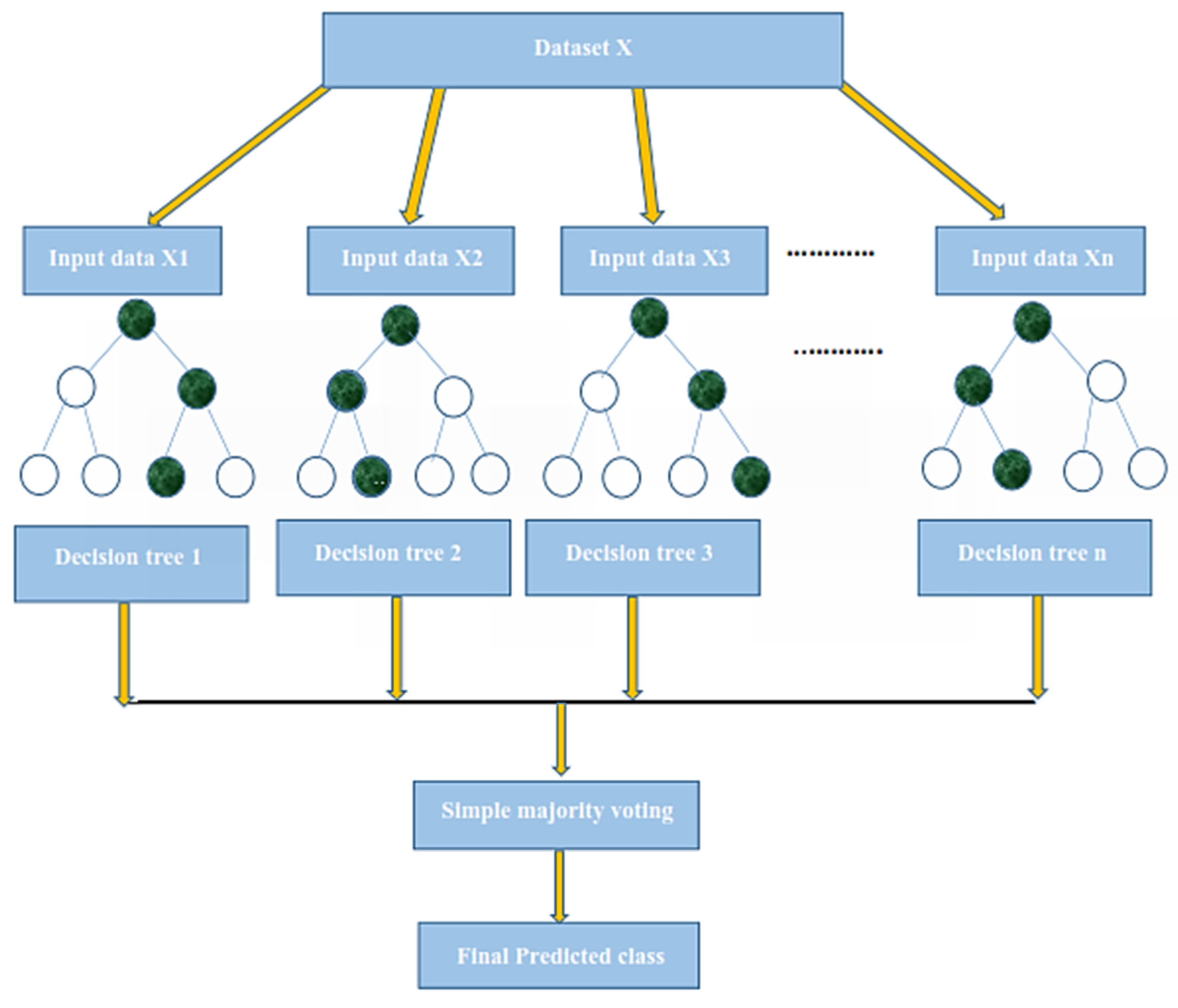
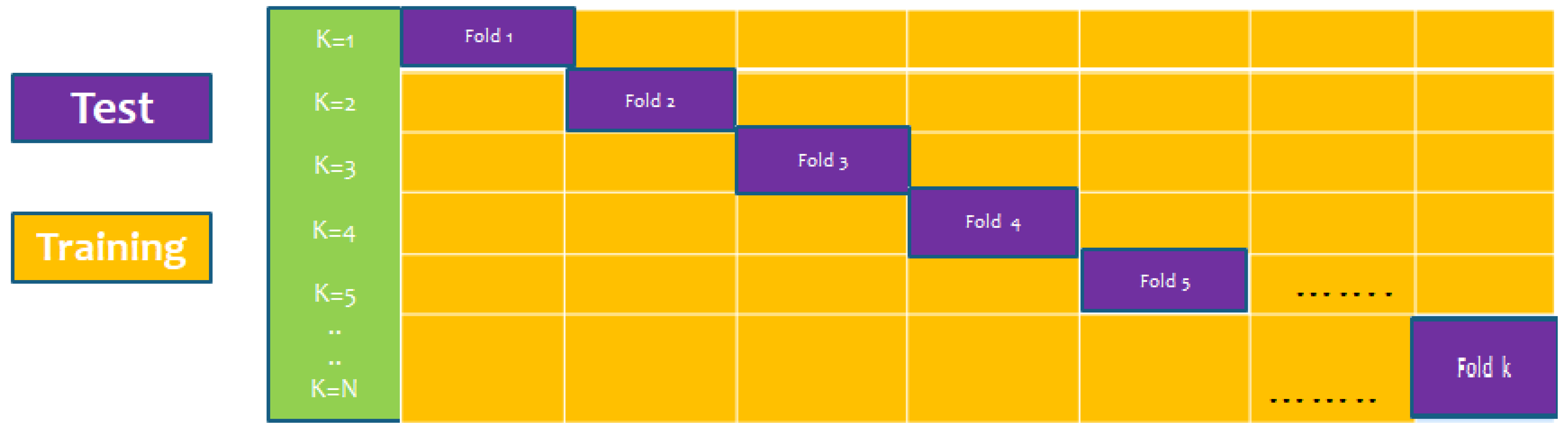
6.3. K-Fold (10-Fold) Cross-Validation Test
The K-fold cross-validation (KFCV) test is a technique to estimate predictive models by partitioning the original dataset A into disjoint k-folds {A
1, A
2, A
3, A
i…, A
k}, where it uses A-A
i folds for training, and the remaining ith fold A
i for testing, where i = 1, 2, 3, …k as shown in the
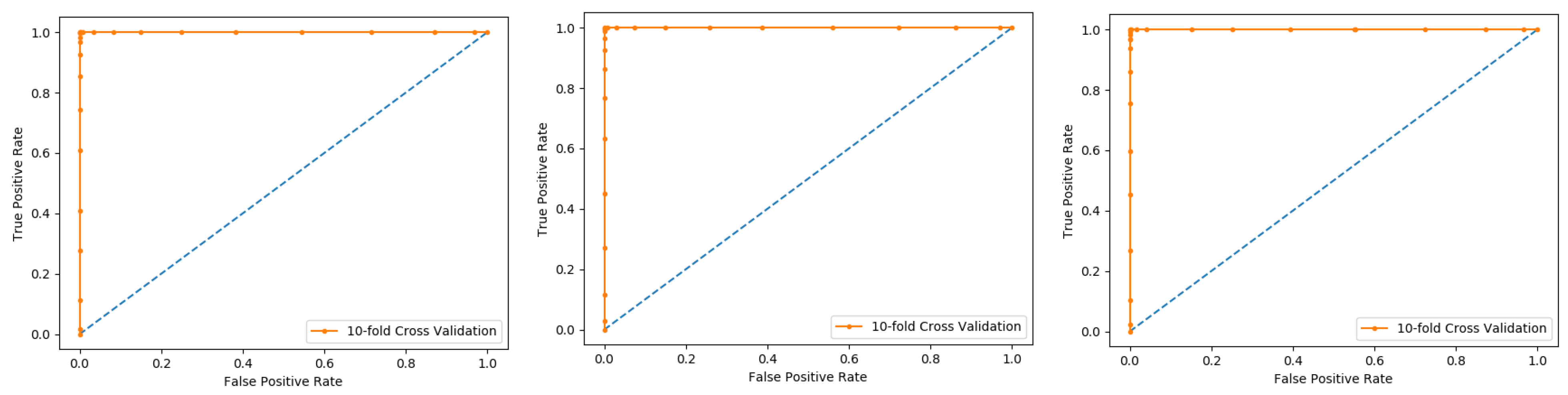
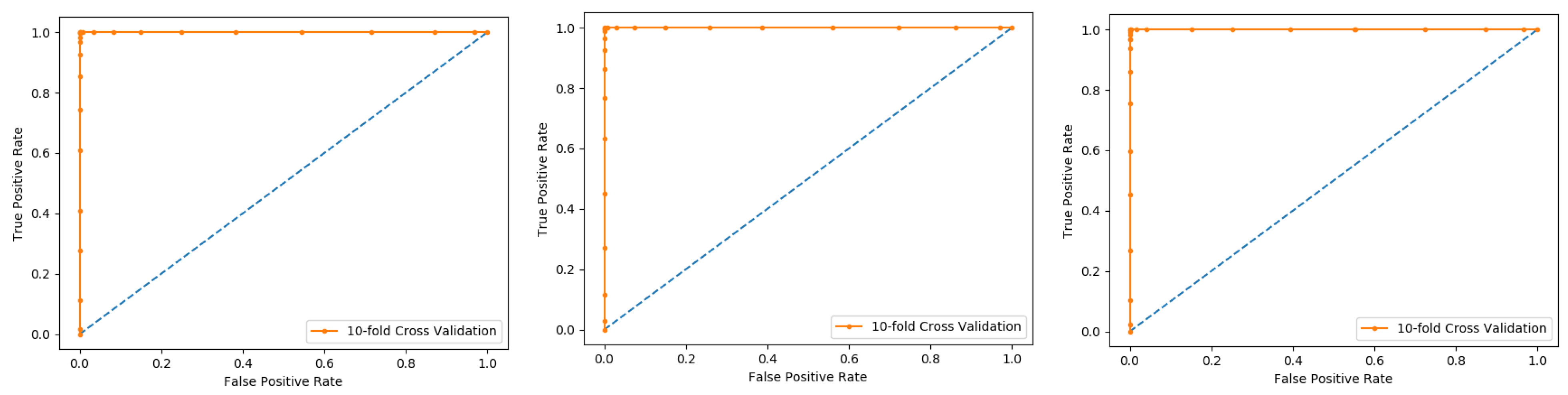
Figure 5. The method iterates the process for each i, and calculate the performance that is the accuracy, sensitivity, precession, recall, F-Measure, and MCC. Further, for the overall result, the average is taken of all the iterations performed for each fold. This technique has many benefits, such as the fact that it validates the model based on multiple datasets to reduce the bias and reach to a stable evaluation that how the model performs. This technique is much more powerful compared to other cross-validation techniques. In literature, the K-fold method is quite popular for k = 10 and 5. In this research, a 10-fold cross-validation is used: the overall result obtained is 100% with random forest classifier as presented in
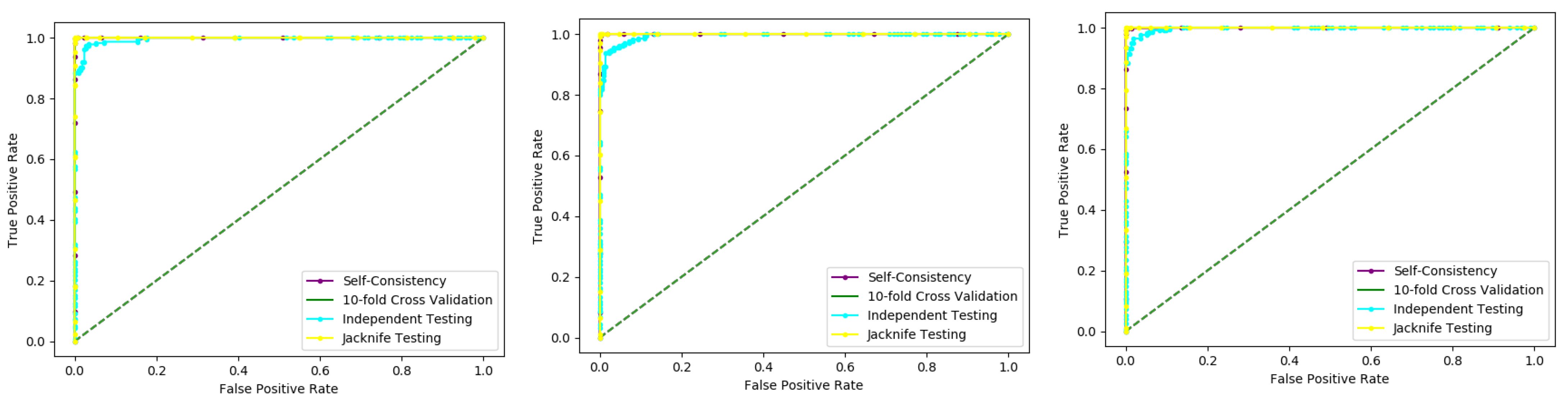
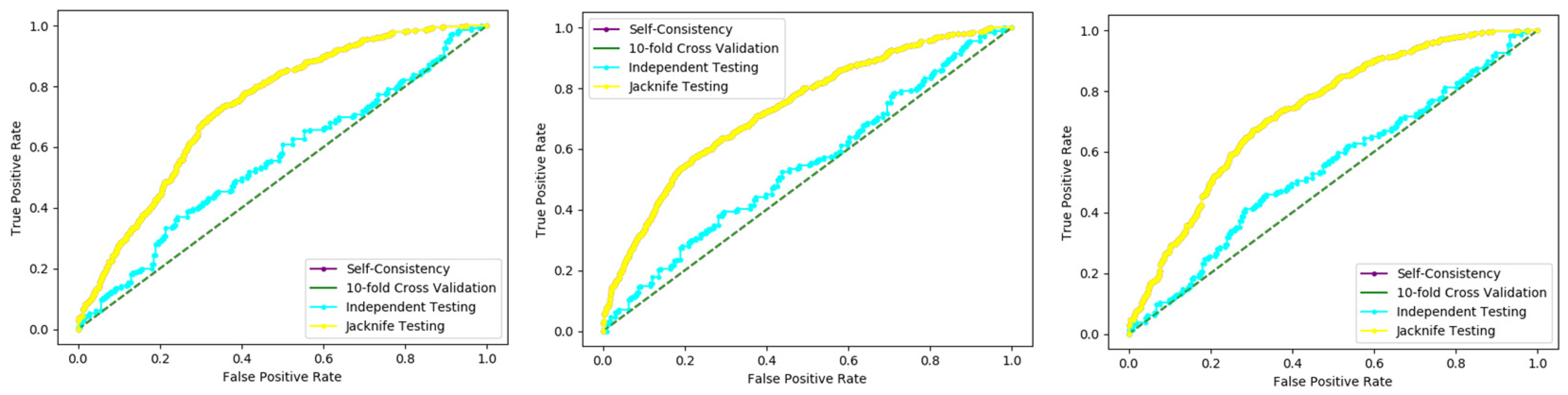
Table 2, and through ROC curves shown in
Figure 6.
The results obtained from three dataset using 10-folds Cross validation with the Random forest classifier, and achieved the best result with ACC 100%, MCC, Sn, Precision, and F-measure all are 1.
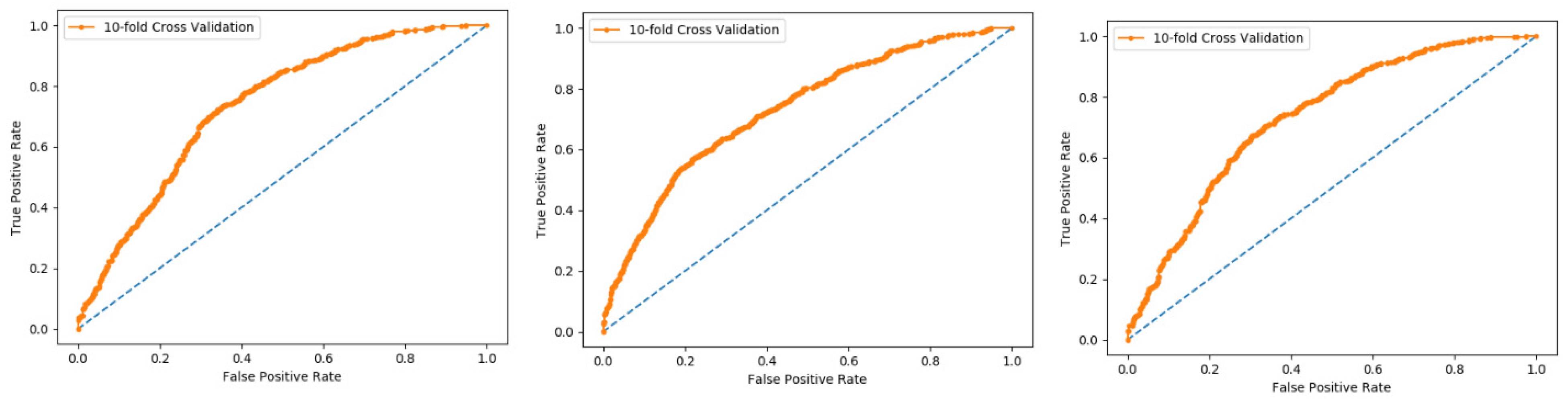
We also used a 10-fold cross-validation test to evaluate the PNN-based model on the three datasets, and obtained the ACC 66.83, MCC 0.36, Sn 0.72, Precision 0.65, and F-measure 0.72 as presented in the
Table 3 and by the ROC curve in the
Figure 7.
6.4. Jackknife Test
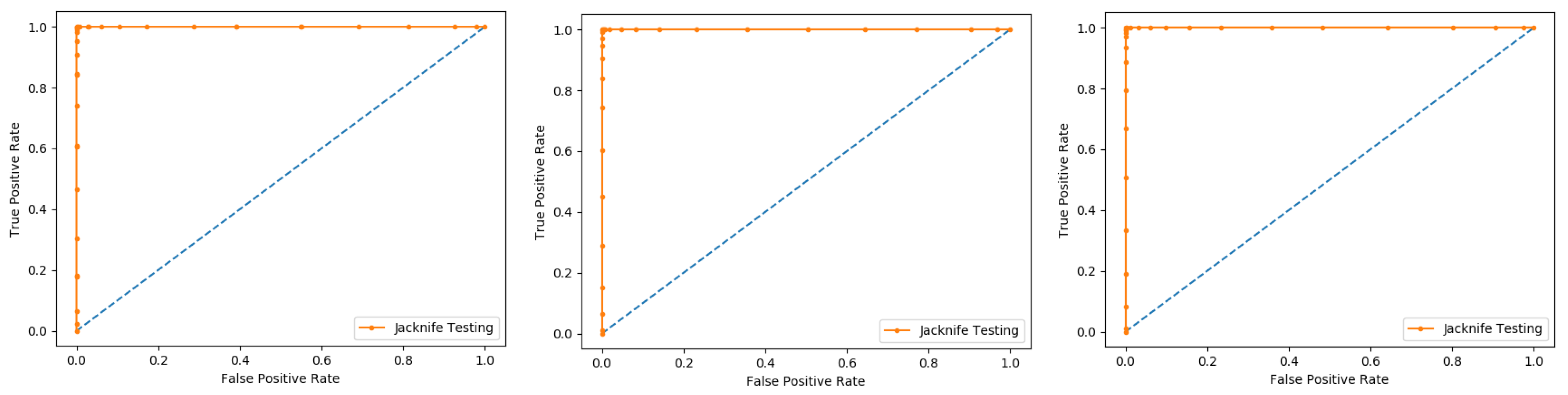
Several cross-validation tests are extensively useful to estimate the performance of the statistical predictors. Amongst these, the jackknife test is considered to be the supreme in being consistent and reliable. Consequently, the jackknife test is comprehensively applied by researchers to estimate the performance of the predictor model. In this test, if the dataset has N records in the dataset, then it trains the model for N − 1 records and tests the model for the remaining one record, which is why it is also called leave-one-out cross-validation. Further, this process is repeated N-times, and the label of each record is predicted. Finally, we accumulate all the results to make the overall prediction based on accuracy, sensitivity, precession, recall, F-measure, and MCC.
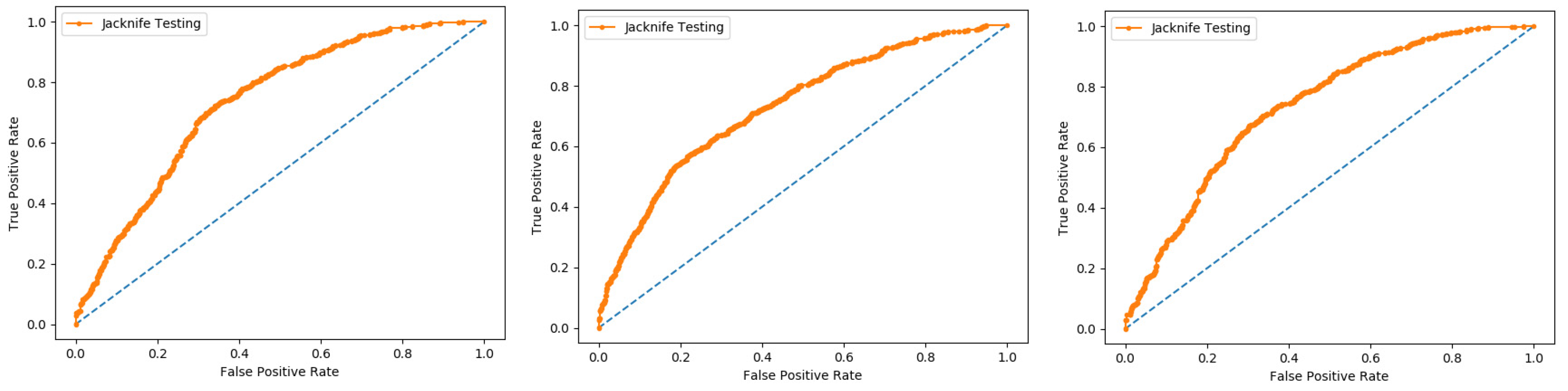
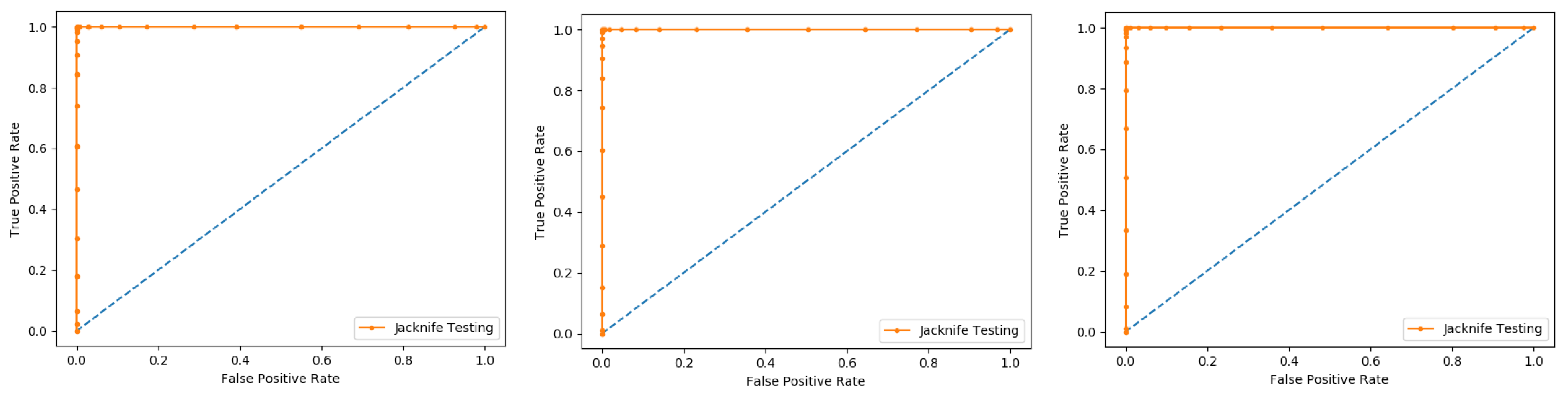
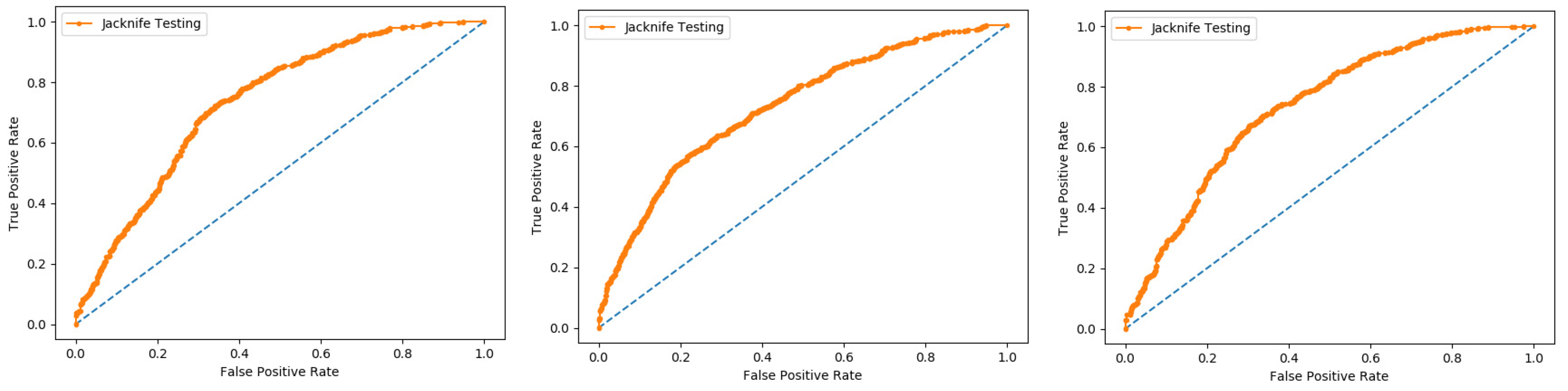
In present research work, the jackknife test is used to measure the performance of models by using the classifiers Random Forest and PNN, and we achieved the result of 100% through RF but got 66.87 through PNN, as presented in
Table 4 and
Table 5, and by the ROC curves in
Figure 8 and
Figure 9.
In this evaluation process, three datasets were used which give the overall accuracy, sensitivity, specificity, precession, MCC, Recall, and F-Measure, given in detail in
Table 4.
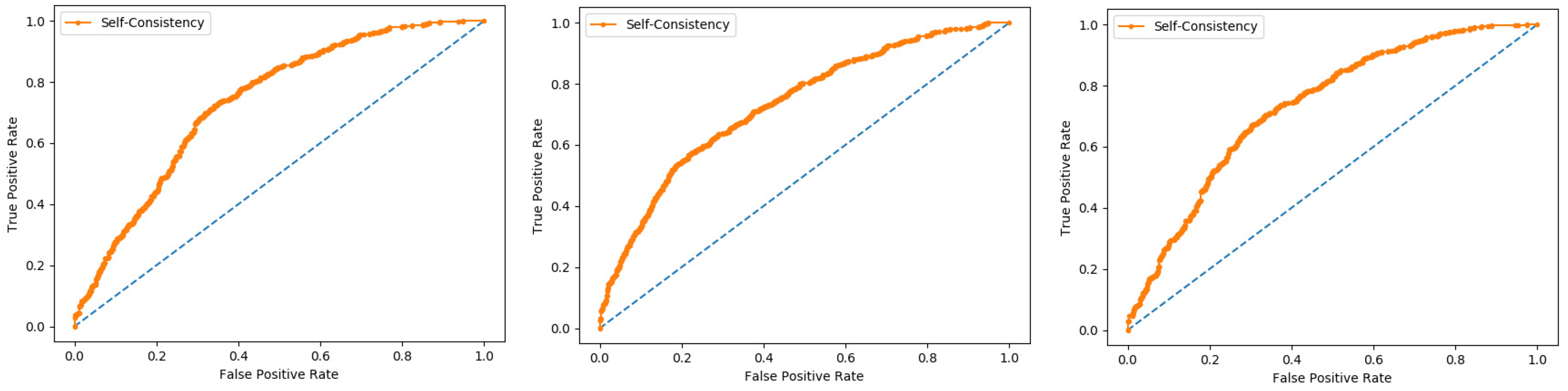
6.5. Self-Consistency Test
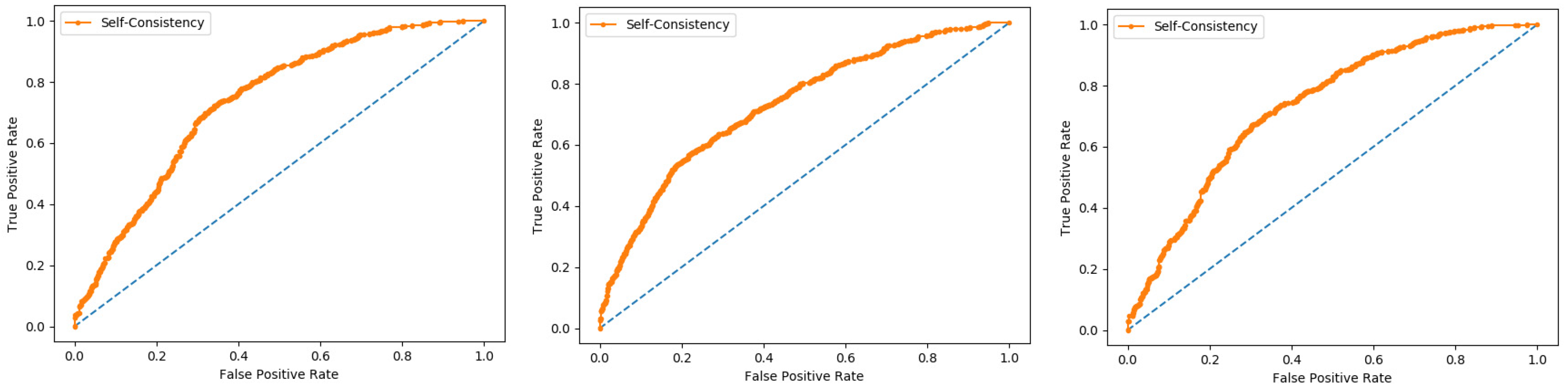
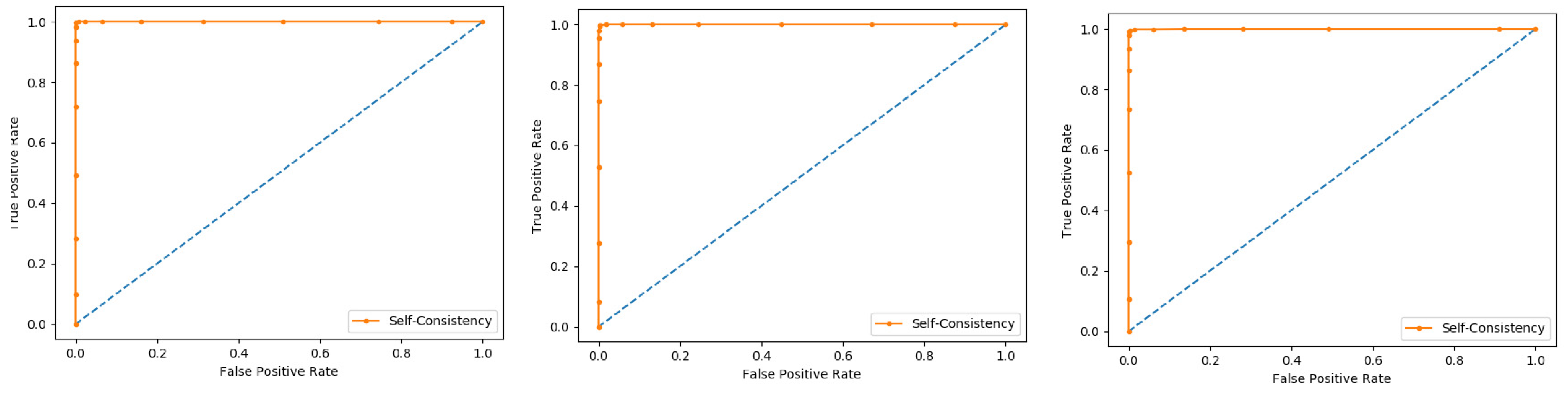
Self-consistency test is a technique referred to as the ultimate test for the validation of efficiency and efficacy of the prediction model, this method uses the same data for both training and testing A representation of these proposed parameters, by conducting the self-consistency testing, the results for the acetylation protein prediction based on the Random Forest classifier as presented in the
Table 6 and by the ROC curve is shown in the
Figure 10.
Similarly, the evaluation results based on the PNN for the three datasets, S1, S2, and S3, based on RF and PNN as presented in the
Table 7 and by the ROC curve as shown in the
Figure 11.
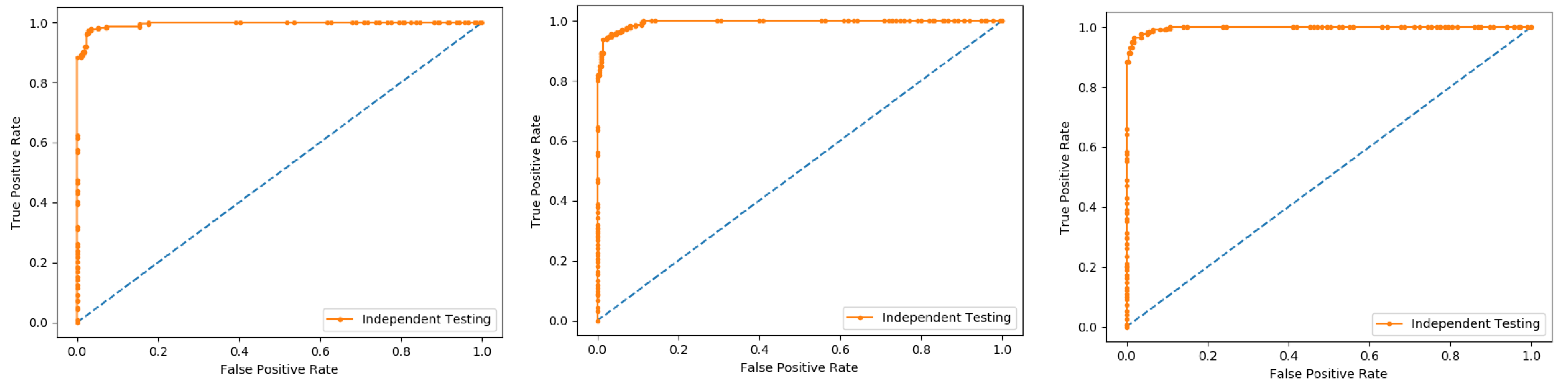
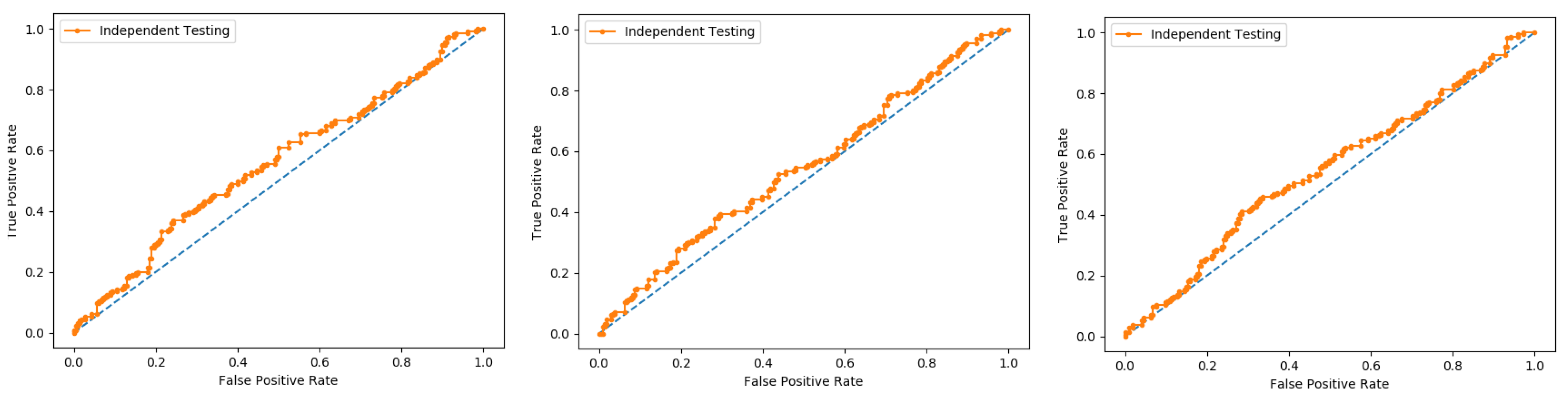
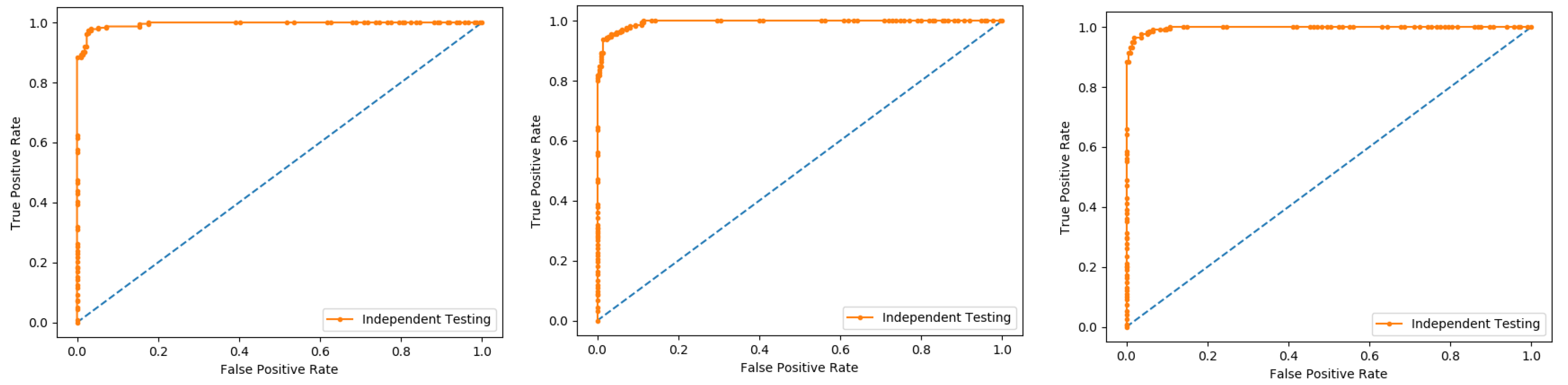
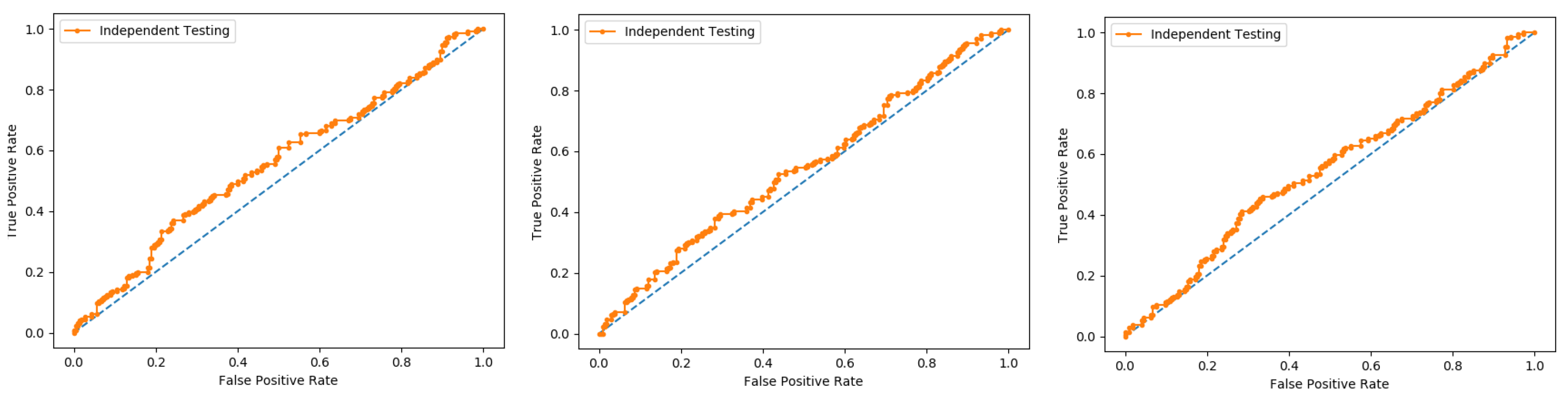
6.6. Independent Test
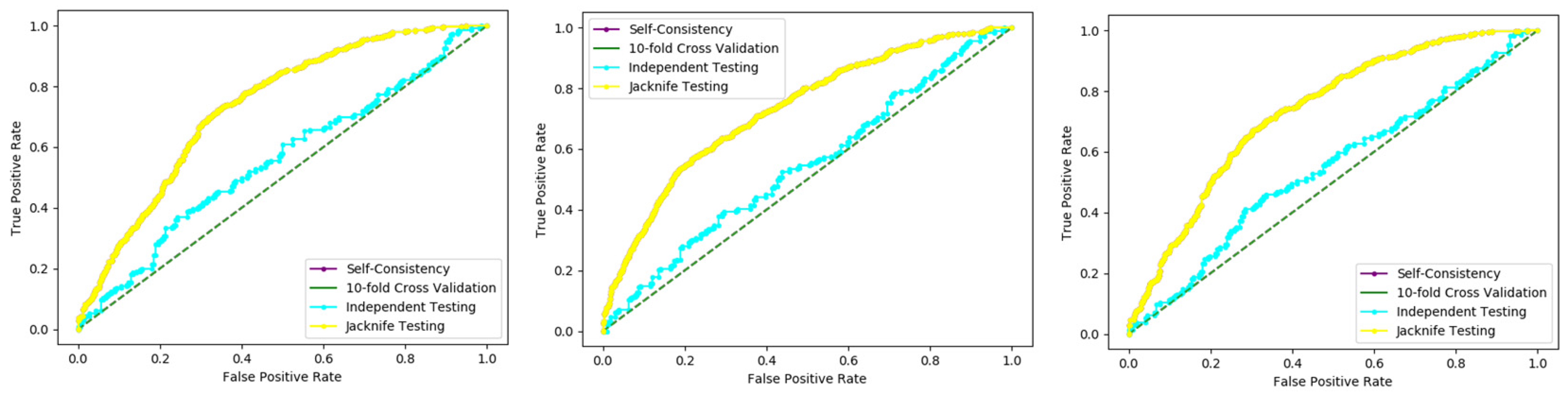
An independent test is a cross-validation method that objectively finds out the predictor’s performance metrics of the planned model, which obtains values from a confusion matrix to evaluate the performance of the model. In this method, the dataset is divided into two parts, training, and the testing part. In the proposed work the data is split in two parts that is 70% of the data for the training and the remaining 30% for the testing as shown in
Figure 12. The method used to train and test the models based on the classifiers, the Random Forest and the PNN, and we obtained the result of 98% through RF, and 50.8 through PNN. The area under the curve (AUC), obtained by Random Forest and PNN, is 98% and 50.8%, respectively. The remaining detailed results, based on the two classifiers, is presented in
Table 8 and
Table 9 and by the ROC curve in
Figure 13 and
Figure 14, respectively.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}