Multimodal Object Classification Models Inspired by Multisensory Integration in the Brain


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
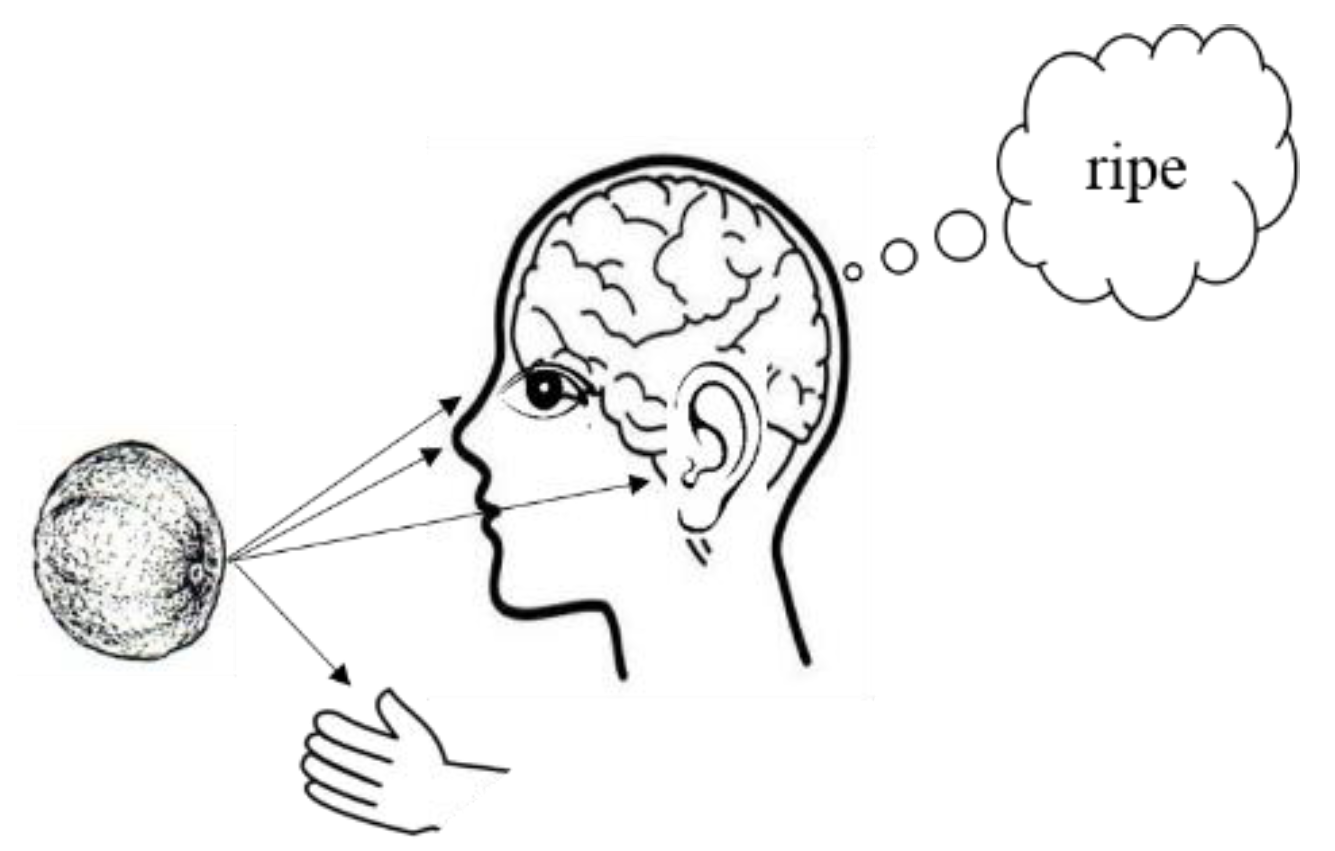
1.1. Multisensory Integration
1.2. Scope of Research
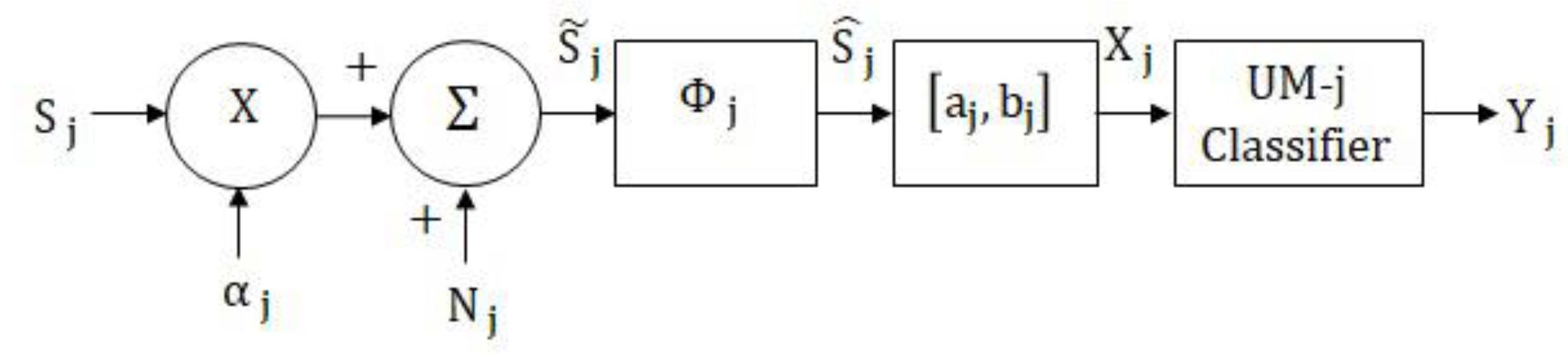
2. Unimodal Classification Model
2.1. Unimodal MLP Network Classifier
2.2. Unimodal MAP Classifier
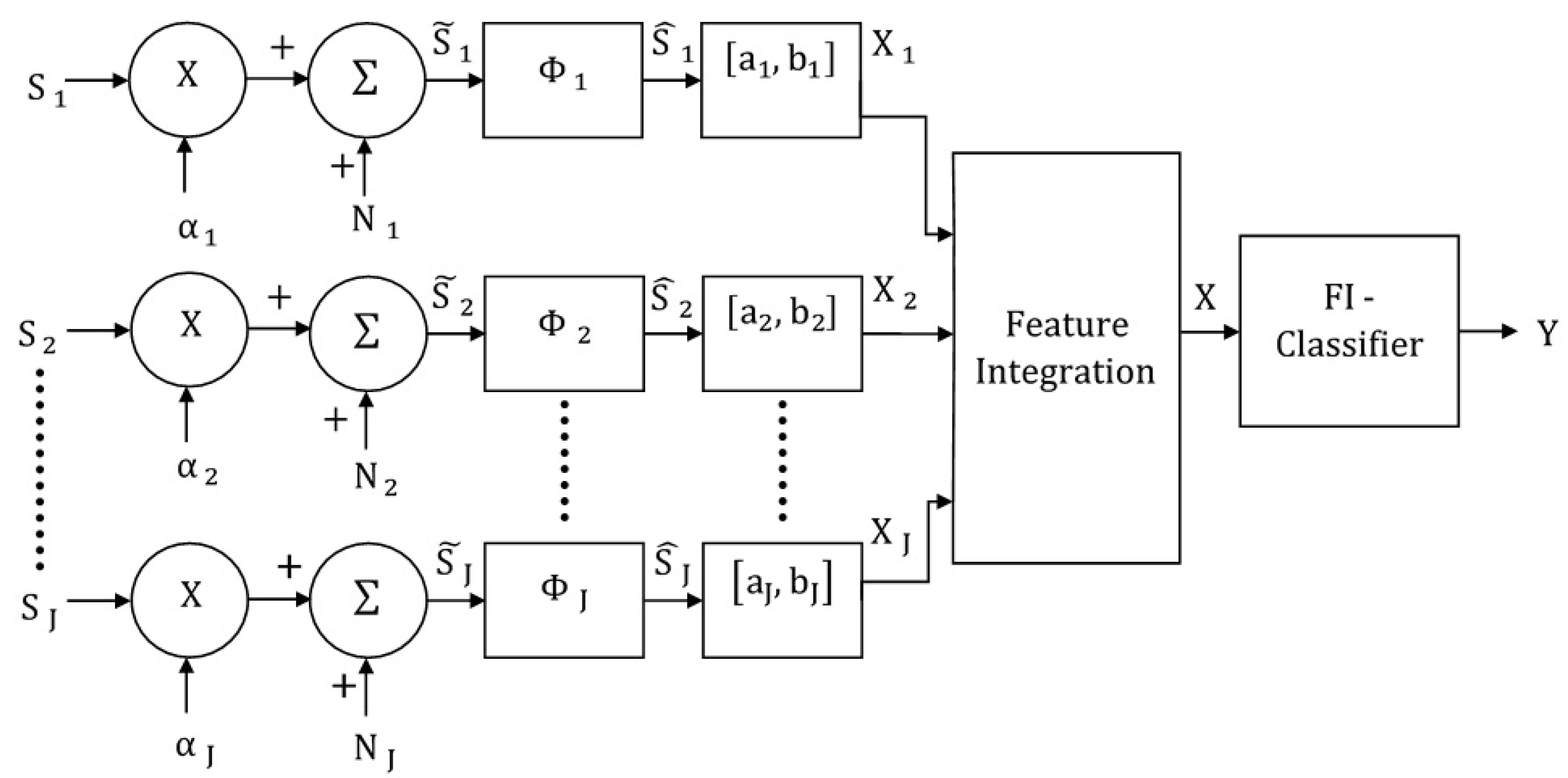
3. Feature-Integrating Multimodal Classification Model
3.1. Multimodal Feature-Integrating MLP Classifier
3.2. Multimodal Feature-Integrating MAP Classifier
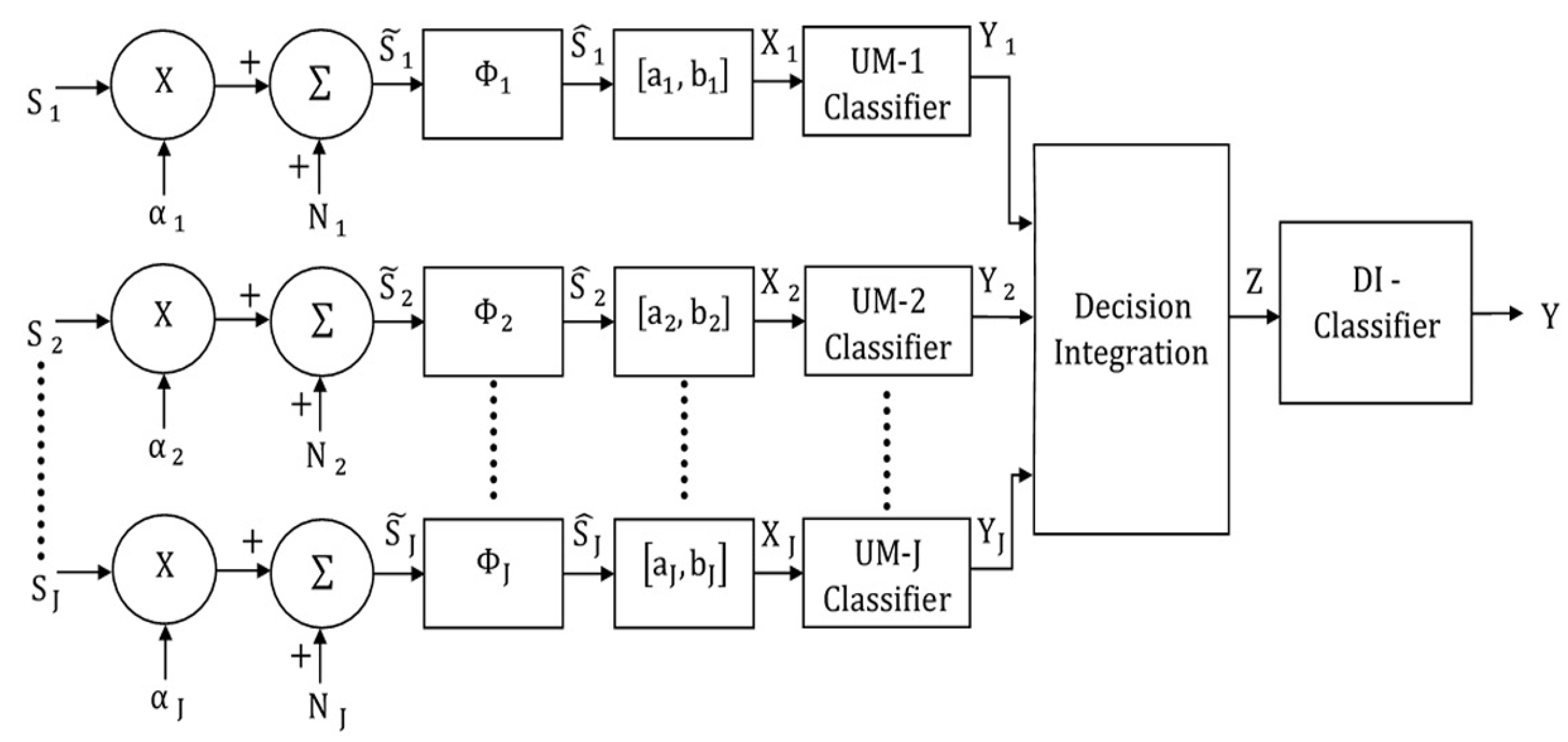
4. Decision-Integrating Multimodal Classification Model
4.1. Decision-Integrating MLP Classifier
4.2. Decision-Integrating MAP Classifier
5. Classification Experiments
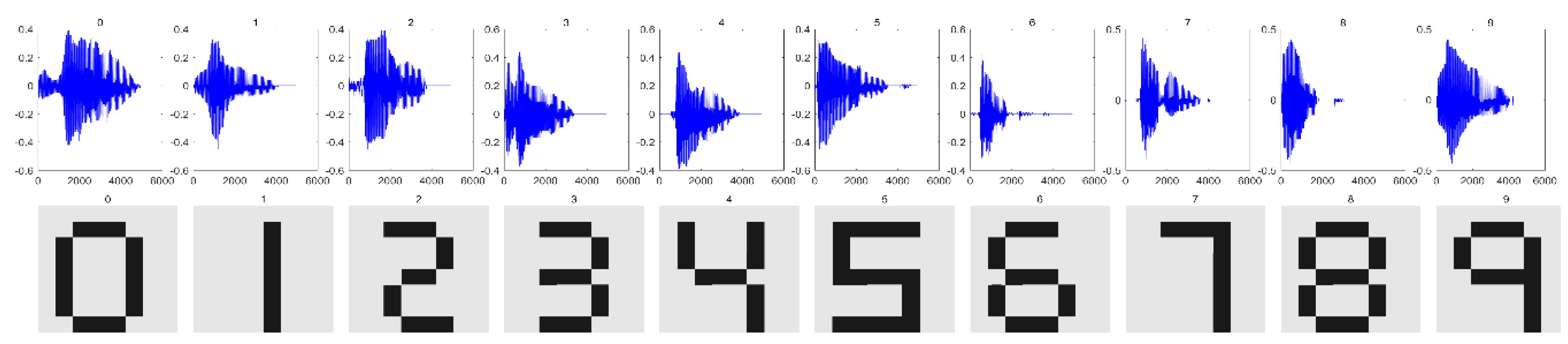
5.1. Noise Generation
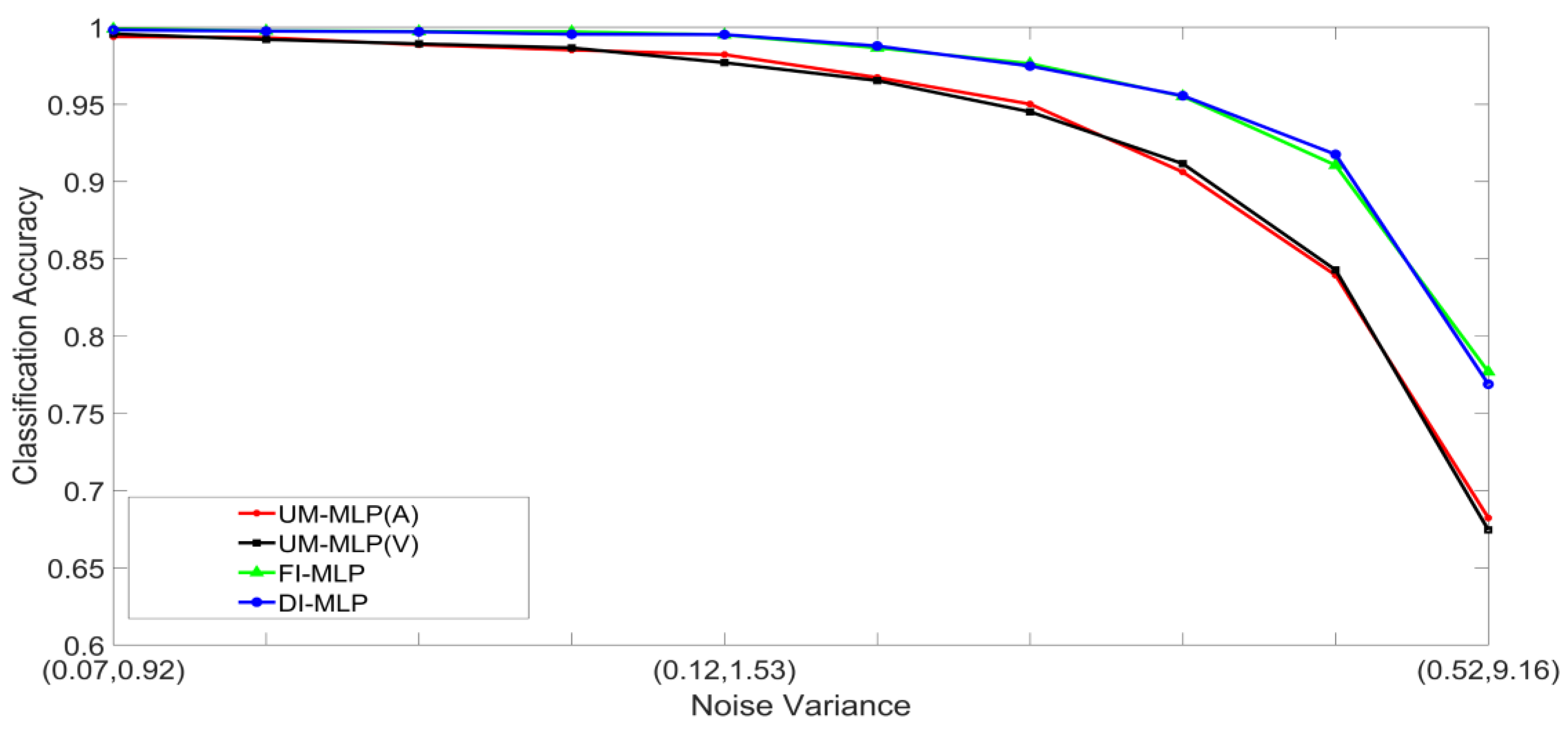
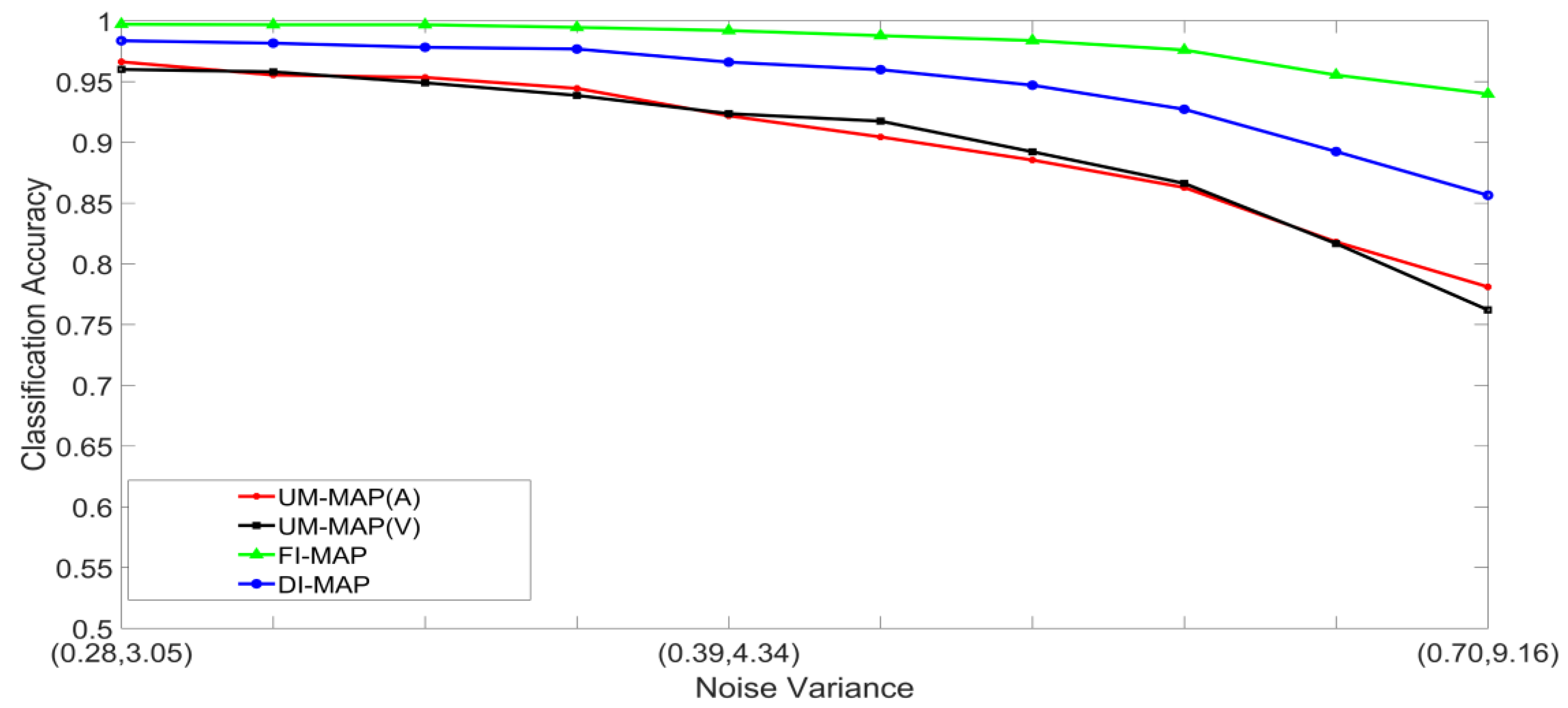
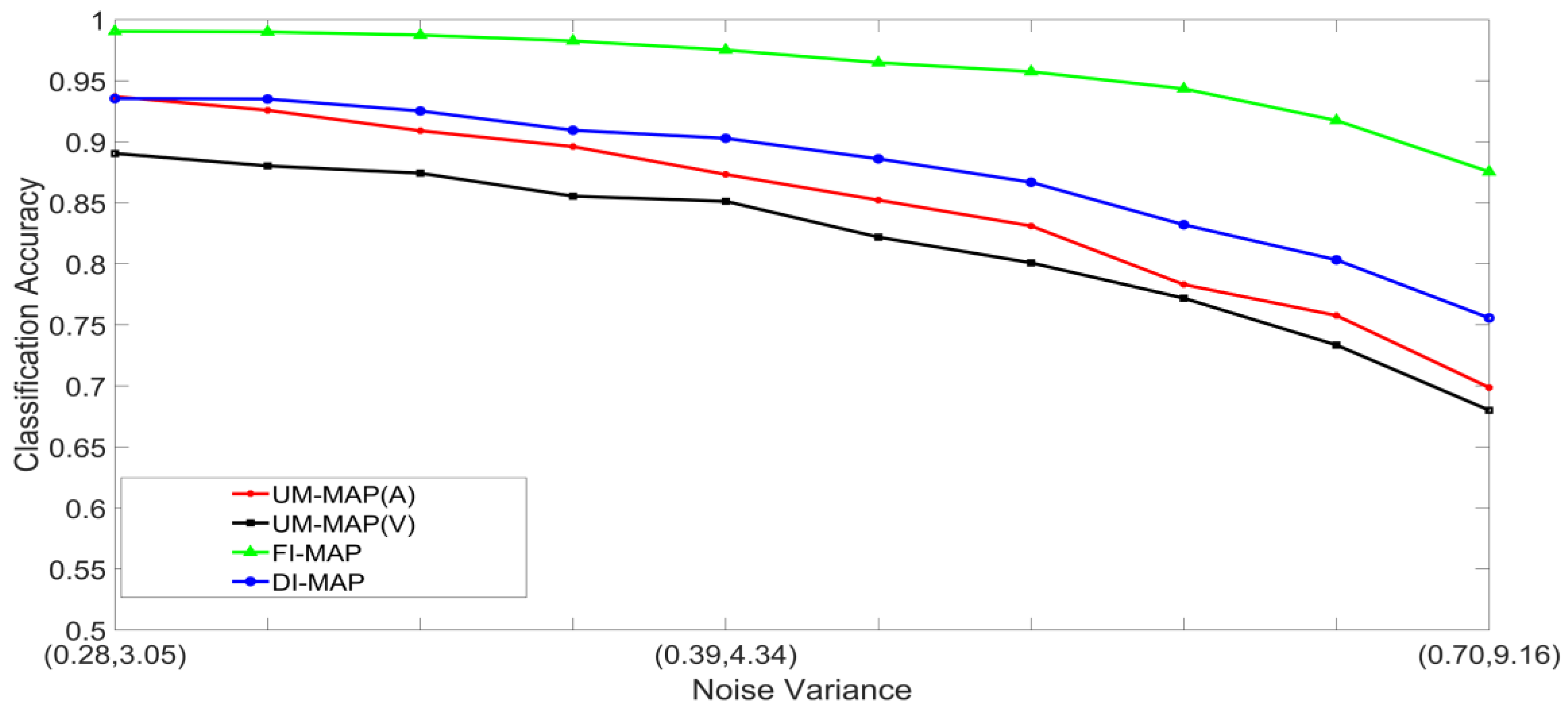
- Set 1: Classification of noisy stimuli—These experiments were designed to evaluate the performance of the unimodal and multimodal classification systems with noisy stimuli. The noise levels in the test stimuli were varied while the attenuation factor was set to 1. The classification accuracies, as functions of paired noise variances, are shown in Figure 7 and Figure 8.
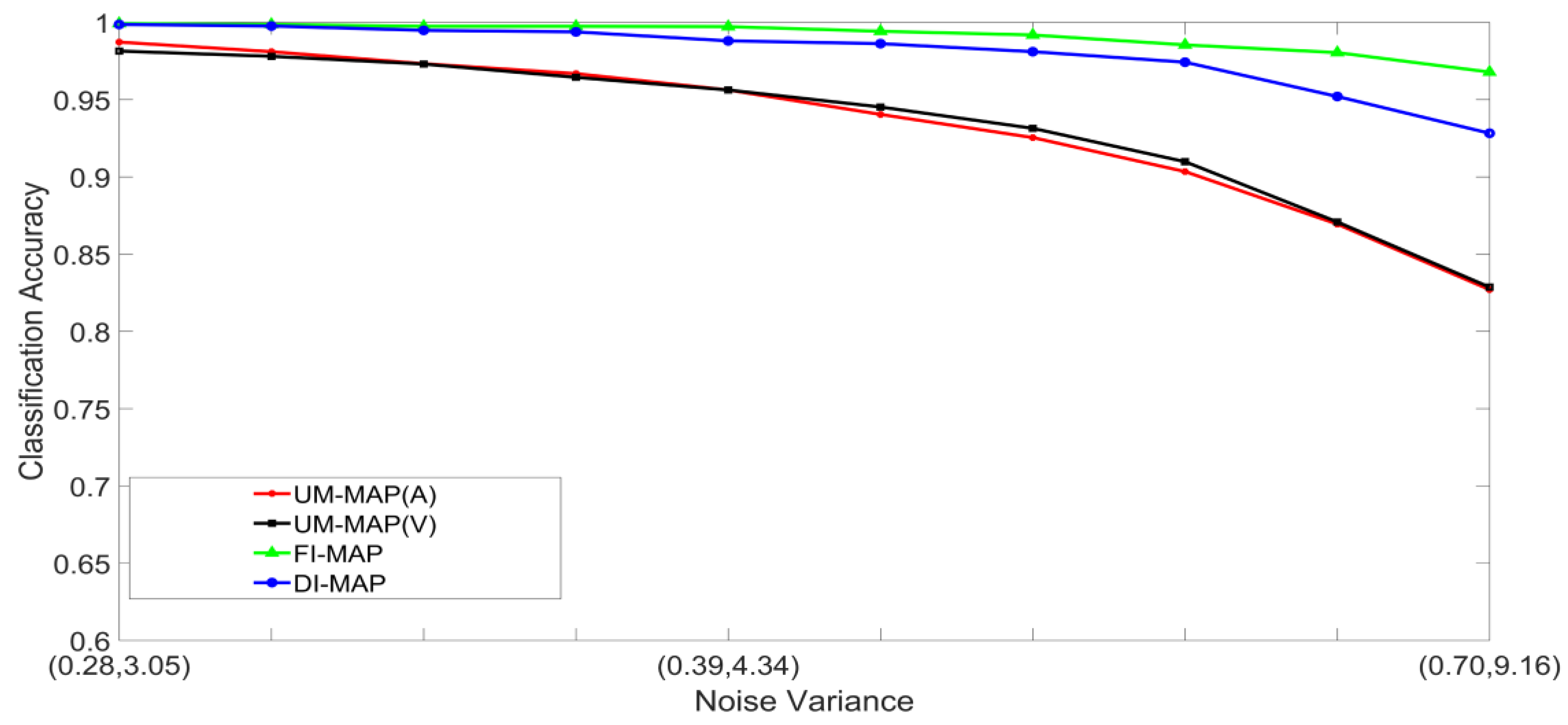
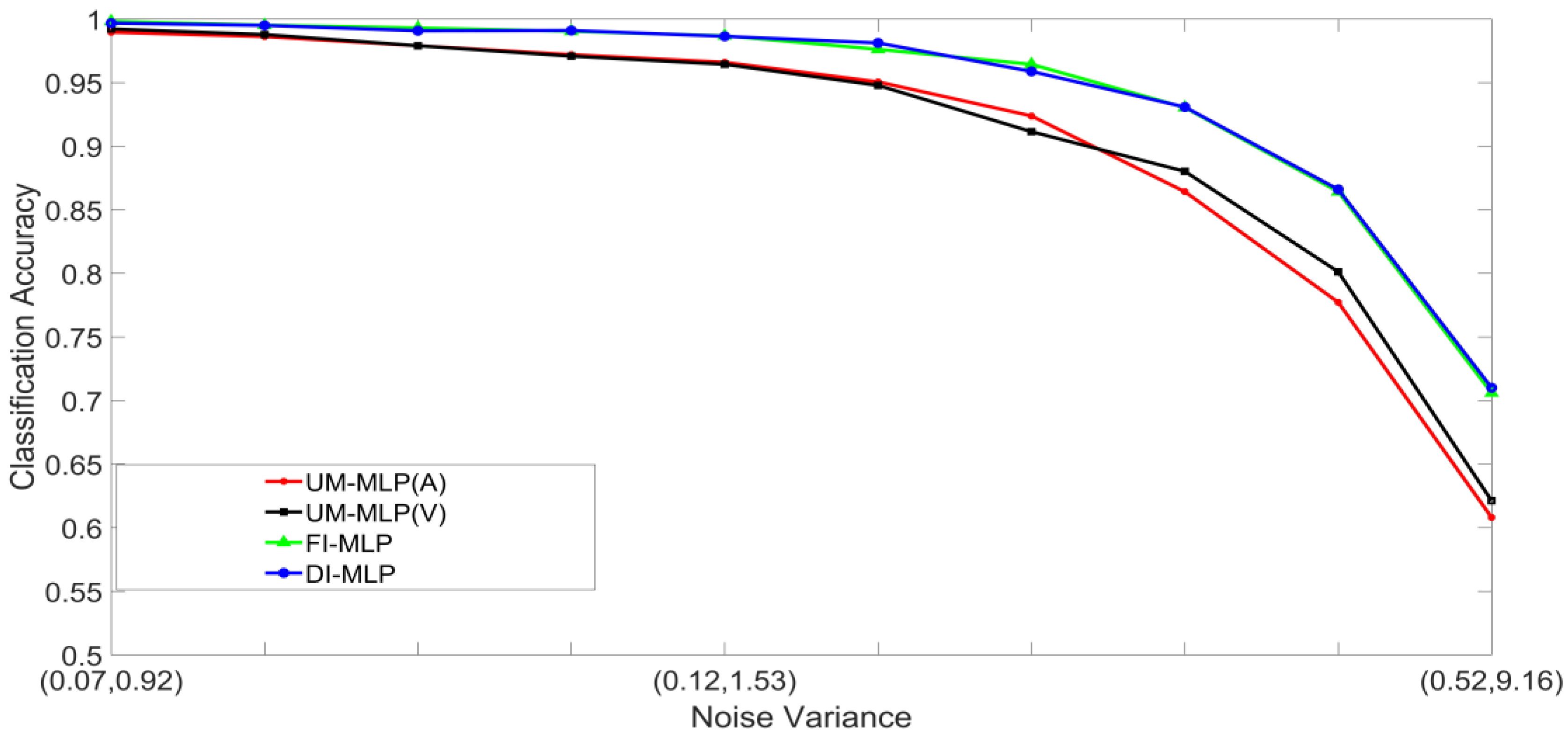
- Set 2: Classification of noisy attenuated stimuli—These experiments were designed to evaluate the performance of the unimodal and multimodal classification systems with stimuli that were both noisy and attenuated. The experiments in Set 1 were repeated using and for both stimuli. The classification accuracies are shown in Figure 9, Figure 10, Figure 11 and Figure 12.
5.2. Discussion of Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Keeley, B.L. Making sense of the senses: Individuating modalities in humans and other animals. J. Philos. 2002, 99, 5–28. [Google Scholar] [CrossRef]
- Ernst, M.O.; Bülthoff, H.H. Merging the senses into a robust percept. Trends Cogn. Sci. 2004, 8, 162–169. [Google Scholar] [CrossRef] [PubMed]
- Driver, J.; Noesselt, T. Multisensory interplay reveals crossmodal influences on ‘sensory-specific’ brain regions, neural responses, and judgments. Neuron 2008, 57, 11–23. [Google Scholar] [CrossRef] [PubMed]
- Stein, B.E. The New Handbook of Multisensory Processing; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Stein, B.E.; Stanford, T.R. Multisensory integration: Current issues from the perspective of the single neuron. Nature Rev. Neurosci. 2008, 9, 255. [Google Scholar] [CrossRef] [PubMed]
- Koelewijn, T.; Bronkhorst, A.; Theeuwes, J. Attention and the multiple stages of multisensory integration: A review of audiovisual studies. Acta Psychol. 2010, 134, 372–384. [Google Scholar] [CrossRef]
- Shams, L.; Kamitani, Y.; Shimojo, S. Illusions: What you see is what you hear. Nature 2000, 408, 788. [Google Scholar] [CrossRef] [PubMed]
- Vroomen, J.; Bertelson, P.; De Gelder, B. The ventriloquist effect does not depend on the direction of automatic visual attention. Percept. Psychophys. 2001, 63, 651–659. [Google Scholar] [CrossRef]
- Bertelson, P.; Vroomen, J.; De Gelder, B.; Driver, J. The ventriloquist effect does not depend on the direction of deliberate visual attention. Percept. Psychophys. 2000, 62, 321–332. [Google Scholar] [CrossRef] [PubMed]
- Alais, D.; Burr, D. The ventriloquist effect results from near-optimal bimodal integration. Curr. Biol. 2004, 14, 257–262. [Google Scholar] [CrossRef]
- McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746. [Google Scholar] [CrossRef]
- Bertelson, P.; Vroomen, J.; De Gelder, B. Visual recalibration of auditory speech identification: A McGurk aftereffect. Psychol. Sci. 2003, 14, 592–597. [Google Scholar] [CrossRef] [PubMed]
- Meredith, M.A.; Stein, B.E. Interactions among converging sensory inputs in the superior colliculus. Science 1983, 221, 389–391. [Google Scholar] [CrossRef] [PubMed]
- Meredith, M.A.; Stein, B.E. Visual, auditory, and somatosensory convergence on cells in superior colliculus results in multisensory integration. J. Neurophysiol. 1986, 56, 640–662. [Google Scholar] [CrossRef] [PubMed]
- Wallace, M.T.; Meredith, M.A.; Stein, B.E. Multisensory integration in the superior colliculus of the alert cat. J. Neurophysiol. 1998, 80, 1006–1010. [Google Scholar] [CrossRef] [PubMed]
- Felleman, D.J.; Van, D.E. Distributed hierarchical processing in the primate cerebral cortex. Cereb. Cortex (New York, NY: 1991) 1991, 1, 1–47. [Google Scholar] [CrossRef]
- Ghazanfar, A.A.; Schroeder, C.E. Is neocortex essentially multisensory? Trends Cogn. Sci. 2006, 10, 278–285. [Google Scholar] [CrossRef] [PubMed]
- Ursino, M.; Cuppini, C.; Magosso, E.; Serino, A.; Di Pellegrino, G. Multisensory integration in the superior colliculus: a neural network model. J. Comput. Neurosci. 2009, 26, 55–73. [Google Scholar] [CrossRef]
- Holmes, N.P. The principle of inverse effectiveness in multisensory integration: Some statistical considerations. Brain Topogr. 2009, 21, 168–176. [Google Scholar] [CrossRef]
- Anastasio, T.J.; Patton, P.E.; Belkacem-Boussaid, K. Using Bayes’ rule to model multisensory enhancement in the superior colliculus. Neural Comput. 2000, 12, 1165–1187. [Google Scholar] [CrossRef]
- Stein, B.E.; Meredith, M.A. The Merging of the Senses; The MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Amerineni, R.; Gupta, L.; Gupta, R.S. Classification models inspired by multisensory integration. In Proceedings of the 2018 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Las Vegas, NV, USA, 4–7 March 2018; pp. 255–258. [Google Scholar] [CrossRef]
- Gupta, L.; Chung, B.; Srinath, M.D.; Molfese, D.L.; Kook, H. Multichannel fusion models for the parametric classification of differential brain activity. IEEE Transact. Biomed. Eng. 2005, 52, 1869–1881. [Google Scholar] [CrossRef]
- Gupta, L.; Kota, S.; Molfese, D.L.; Vaidyanathan, R. Pairwise diversity ranking of polychotomous features for ensemble physiological signal classifiers. Proc. Inst. Mech. Eng. Part H J. Eng. Med. 2013, 227, 655–662. [Google Scholar] [CrossRef] [PubMed]
- Polikar, R. Ensemble learning. In Ensemble Machine Learning; Zhang, C., Ma, Y.Q., Eds.; Springer: New York, NY, USA, 2012; pp. 1–34. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Combining Pattern Classifiers: Methods and Algorithms, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Gupta, L.; Kota, S.; Murali, S.; Molfese, D.L.; Vaidyanathan, R. A feature ranking strategy to facilitate multivariate signal classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 40, 98–108. [Google Scholar] [CrossRef]
- Gupta, L.; Sayeh, M.R.; Tammana, R. A neural network approach to robust shape classification. Pattern Recogn. 1990, 23, 563–568. [Google Scholar] [CrossRef]












© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amerineni, R.; Gupta, R.S.; Gupta, L. Multimodal Object Classification Models Inspired by Multisensory Integration in the Brain. Brain Sci. 2019, 9, 3. https://doi.org/10.3390/brainsci9010003
Amerineni R, Gupta RS, Gupta L. Multimodal Object Classification Models Inspired by Multisensory Integration in the Brain. Brain Sciences. 2019; 9(1):3. https://doi.org/10.3390/brainsci9010003
Chicago/Turabian StyleAmerineni, Rajesh, Resh S. Gupta, and Lalit Gupta. 2019. "Multimodal Object Classification Models Inspired by Multisensory Integration in the Brain" Brain Sciences 9, no. 1: 3. https://doi.org/10.3390/brainsci9010003
APA StyleAmerineni, R., Gupta, R. S., & Gupta, L. (2019). Multimodal Object Classification Models Inspired by Multisensory Integration in the Brain. Brain Sciences, 9(1), 3. https://doi.org/10.3390/brainsci9010003