Exploring Causes of Depression and Anxiety Health Disparities (HD) by Examining Differences between 1:1 Matched Individuals



Abstract
:1. Introduction
2. Conceptual Models for Health Disparities
3. Methods
3.1. Study Setting and Samples
3.2. Measures
3.3. Analytical Methods
4. Results
5. Discussion
5.1. Limitations
5.2. Extensions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- National Academies of Sciences, Engineering, and Medicine. Building Sustainable Financing Structures for Population Health. Insights from Non-Health Sectors: Proceedings of a Workshop; National Academies Press: Washington, DC, USA, 2018. [Google Scholar]
- US Department of Health and Human Services, Office of Disease Prevention and Health Promotion. Healthy People 2020. Available online: https://www.healthypeople.gov (accessed on 1 August 2018).
- Solar, O.; Irwin, A. A conceptual framework for action on the social determinants of health. Available online: http://www.who.int/sdhconference/resources/ConceptualframeworkforactiononSDH_eng.pdf (accessed on 1 August 2018).
- Marmot, M.; Commission on Social Determinants of Health. Achieving health equity: From root causes to fair outcomes. Lancet 2007, 370, 1153–1163. [Google Scholar] [CrossRef]
- Naimi, A.I.; Kaufman, J.S. Counterfactual theory in social epidemiology: Reconciling analysis and action for the social determinants of health. Curr. Epidemiol. Rep. 2015, 2, 52–60. [Google Scholar] [CrossRef]
- Kaufman, J.S.; Cooper, R.S.; McGee, D.L. Socioeconomic status and health in blacks and whites: The problem of residual confounding and the resiliency of race. Epidemiology 1997, 8, 621–628. [Google Scholar] [CrossRef] [PubMed]
- Assari, S.; Moazen-Zadeh, E. Ethnic variation in the cross-sectional association between domains of depressive symptoms and clinical depression. Fron. Psychiatry 2016, 7, 53. [Google Scholar] [CrossRef] [PubMed]
- Coman, E.N.; Iordache, E.; Schensul, J.J.; Coiculescu, I. Comparisons of CES-D depression scoring methods in two older adults ethnic groups. The emergence of an ethnic-specific brief three-item CES-D scale. Int. J. Geriatr. Psychiatry 2013, 28, 424–432. [Google Scholar] [CrossRef] [PubMed]
- Regier, D.A.; Narrow, W.E.; Rae, D.S. The epidemiology of anxiety disorders: The epidemiologic catchment area (ECA) experience. J. Psychiatr. Res. 1990, 24, 3–14. [Google Scholar] [CrossRef]
- Goldberg, D. On the Very Idea of Health Equity. J. Public Health Manag. Pract. 2016, 22, S11–S12. [Google Scholar] [CrossRef] [PubMed]
- McLaughlin, K.A.; Lane, R.D.; Bush, N.R. Introduction to the Special Issue of Psychosomatic Medicine: Mechanisms Linking Early-Life Adversity to Physical Health. Psychosom. Med. 2016, 78, 976–978. [Google Scholar] [CrossRef] [PubMed]
- Font, S.A.; Maguire-Jack, K. Pathways from childhood abuse and other adversities to adult health risks: The role of adult socioeconomic conditions. Child Abuse Negl. 2016, 51, 390–399. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Assari, S. Additive effects of anxiety and depression on body mass index among blacks: Role of ethnicity and gender. Int. Cardiovasc. Res. J. 2014, 8, 44. [Google Scholar] [PubMed]
- Macintyre, S.; Ellaway, A.; Cummins, S. Place effects on health: How can we conceptualise, operationalise and measure them? Soc. Sci. Med. 2002, 55, 125–139. [Google Scholar] [CrossRef]
- Lantos, P.M.; Hoffman, K.; Permar, S.R.; Jackson, P.; Hughes, B.L.; Kind, A.; Swamy, G. Neighborhood Disadvantage is Associated with High Cytomegalovirus Seroprevalence in Pregnancy. J. Racial Ethn. Health Dispar. 2017, 5, 782–786. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bernard, P.; Charafeddine, R.; Frohlich, K.L.; Daniel, M.; Kestens, Y.; Potvin, L. Health inequalities and place: A theoretical conception of neighbourhood. Soc. Sci. Med. 2007, 65, 1839–1852. [Google Scholar] [CrossRef] [PubMed]
- Zapata Moya, A.R.; Navarro Yáñez, C.J. Impact of area regeneration policies: Performing integral interventions, changing opportunity structures and reducing health inequalities. J. Epidemiol. Community Health 2017, 71, 239–247. [Google Scholar] [CrossRef] [PubMed]
- Stewart, R.; Lindesay, J. The epidemiology of depression and anxiety. In Principles and Practice of Geriatric Psychiatry, 3rd ed.; Abou-Saleh, M.T., Katona, C., Kumar, A., Eds.; Wiley: Hoboken, NJ, USA, 2011; pp. 616–623. [Google Scholar]
- Bucci, M.; Marques, S.S.; Oh, D.; Harris, N.B. Toxic Stress in Children and Adolescents. Adv. Pediatr. 2016, 63, 403–428. [Google Scholar] [CrossRef] [PubMed]
- Jencks, C.; Mayer, S.E. The social consequences of growing up in a poor neighborhood. In Inner-City Poverty in the United States; Lynn, L.E., Jr., McGeary, M.G.H., Eds.; National Academy Press: Washington, DC, USA, 1990; pp. 111–186. [Google Scholar]
- Harding, D.J. Counterfactual models of neighborhood effects: The effect of neighborhood poverty on dropping out and teenage pregnancy. Am. J. Sociol. 2003, 109, 676–719. [Google Scholar] [CrossRef]
- Crowder, K.; South, S.J. Spatial and temporal dimensions of neighborhood effects on high school graduation. Soc. Sci. Res. 2011, 40, 87–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garbarski, D. Racial/ethnic disparities in midlife depressive symptoms: The role of cumulative disadvantage across the life course. Adv. Life Course Res. 2015, 23, 67–85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levine, M.E.; Crimmins, E.M. Evidence of accelerated aging among African Americans and its implications for mortality. Soc. Sci. Med. 2014, 118, 27–32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neyman, J. On the application of probability theory to agricultural experiments. Essay on principles. Section 9. Stat. Sci. 1990, 5, 465–472. [Google Scholar] [CrossRef]
- Highered, I. The Numbers and the Arguments on Asian Admissions. Available online: https://www.insidehighered.com/admissions/article/2017/08/07/look-data-and-arguments-about-asian-americans-and-admissions-elite (accessed on 7 August 2017).
- VanderWeele, T.J.; Hernán, M.A. Causal effects and natural laws: Towards a conceptualization of causal counterfactuals for non-manipulable exposures with application to the effects of race and sex. In Causality: Statistical Perspectives and Applications; Berzuini, C., Dawid, P., Bernardinelli, L., Eds.; John Wiley & Sons: West Sussex, UK, 2012; pp. 101–113. [Google Scholar]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Hachette UK: London, UK, 2018. [Google Scholar]
- Bell, C.N.; Thorpe, R.J.; Bowie, J.V.; LaVeist, T.A. Race disparities in cardiovascular disease risk factors within socioeconomic status (SES) strata. Ann. Epidemiol. 2018, 28, 147–152. [Google Scholar] [CrossRef] [PubMed]
- Coman, E.N.; Weeks, M.R.; Yanovitzky, I.; Iordache, E.; Barbour, R.; Coman, M.A.; Huedo-Medina, T.B. The Impact of Information About the Female Condom on Female Condom Use Among Males and Females from a US Urban Community. AIDS Behav. 2012, 17, 2194–2201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yanovitzky, I.; Zanutto, E.; Hornik, R. Estimating causal effects of public health education campaigns using propensity score methodology. Eval. Progr. Plan. 2005, 28, 209–220. [Google Scholar] [CrossRef] [Green Version]
- Cochran, W.G. The comparison of percentages in matched samples. Biometrika 1950, 37, 256–266. [Google Scholar] [CrossRef] [PubMed]
- Morello-Frosch, R.; Shenassa, E.D. The Environmental “Riskscape” and Social Inequality: Implications for Explaining Maternal and Child Health Disparities. Environ. Health Perspect. 2006, 114, 1150–1153. [Google Scholar] [CrossRef] [PubMed]
- Adler, N.E.; Rehkopf, D.H. U.S. Disparities in Health: Descriptions, Causes, and Mechanisms. Annu. Rev. Public Health 2008, 29, 235–252. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- National Academies of Sciences, Engineering, and Medicine. The Root Causes of Health Inequity (Ch. 3). In Communities in Action: Pathways to Health Equity; National Academies Press: Washington, DC, USA, 2017; pp. 99–184. [Google Scholar]
- Robert Wood Johnson Foundation Commission to Build a Healthier America. Beyond Health Care: New Directions for a Healthier America. Available online: https://www.rwjf.org/en/library/research/2009/04/beyond-health-care.html (accessed on 1 August 2018).
- Wu, Z.H.; Tennen, H.; Hosain, G.M.M.; Coman, E.; Cullum, J.; Berenson, A.B. Stress Mediates the Relationship Between Past Drug Addiction and Current Risky Sexual Behaviour Among Low-income Women. Stress Health 2016, 32, 138–144. [Google Scholar] [CrossRef] [PubMed]
- Coman, E.N.; Wu, H. Examining Differential Resilience Mechanisms by Comparing ‘Tipping Points’ of the Effects of Neighborhood Conditions on Anxiety by Race/Ethnicity. Healthcare 2018, 6, 18. [Google Scholar] [CrossRef] [PubMed]
- Coman, E. Pregnancy and Mental Health among Black and White Women, V1 ed. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/9XPEPJ (accessed on 1 August 2018).
- Kessler, R.C.; Andrews, G.; Mroczek, D.; Ustun, B.; Wittchen, H.U. The World Health Organization composite international diagnostic interview short-form (CIDI-SF). Int. J. Methods Psychiatr. Res. 1998, 7, 171–185. [Google Scholar] [CrossRef]
- Association, A.P.; Association, A.P. Diagnostic and Statistical Manual of Mental Disorders, 4th ed.; American Psychiatric Association: Washington, DC, USA, 2000. [Google Scholar]
- Carver, C.S.; White, T.L. Behavioral inhibition, behavioral activation, and affective responses to impending reward and punishment: The BIS/BAS Scales. J. Person. Soc. Psychol. 1994, 67, 319. [Google Scholar] [CrossRef]
- Cagney, K.A.; Glass, T.A.; Skarupski, K.A.; Barnes, L.L.; Schwartz, B.S.; de Leon, C.F.M. Neighborhood-level cohesion and disorder: Measurement and validation in two older adult urban populations. J. Gerontol. Ser. B: Psychol. Sci. Soc. Sci. 2009, 64, 415–424. [Google Scholar] [CrossRef] [PubMed]
- Yanovitzky, I.; Hornik, R.; Zanutto, E. Estimating causal effects in observational studies: The propensity score approach. In The Sage Sourcebook of Advanced Data Analysis Methods for Communication Research; Hayes, A., Slater, M., Snyder, L., Eds.; Sage Publications: Los Angeles, CA, USA, 2008; pp. 159–184. [Google Scholar]
- Cochran, W.G. Matching in analytical studies. Am. J. Public Health Nations Health 1953, 43, 684–691. [Google Scholar] [CrossRef] [PubMed]
- Agresti, A. An Introduction to Categorical Data Analysis; Wiley: New York, NY, USA, 2008; Volume 135. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Kaufman, J.S.; Kaufman, S. Assessment of Structured Socioeconomic Effects on Health. Epidemiology 2001, 12, 157–167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stata Corp. Stata Statistical Software: Release 15; StataCorp LP: College Station, TX, USA, 2017. [Google Scholar]
- Coman, E.N.; Picho, K.; McArdle, J.J.; Villagra, V.; Dierker, L.; Iordache, E. The paired t-test as a simple latent change score model. Front. Quant. Psychol. Meas. 2013, 4, 738. [Google Scholar] [CrossRef] [PubMed]
- McArdle, J.J. Comments on “latent variable models for studying difference and changes”. In Best Methods for the Analysis of Change; Collins, L., Horn, J.L., Eds.; APA Press: Washington, DC, USA, 1991; pp. 164–169. [Google Scholar]
- Keyes, C.L. The Black–White paradox in health: Flourishing in the face of social inequality and discrimination. J. Person. 2009, 77, 1677–1706. [Google Scholar] [CrossRef] [PubMed]
- Barnes, D.M.; Keyes, K.M.; Bates, L.M. Racial differences in depression in the United States: How do subgroup analyses inform a paradox? Soc. Psychiatry Psychiatr. Epidemiol. 2013, 48, 1941–1949. [Google Scholar] [CrossRef] [PubMed]
- Nichols, A. Causal inference with observational data. Stata J. 2007, 7, 507–541. [Google Scholar] [CrossRef]
- Muthén, L.K.; Muthén, B.O. Mplus User’s Guide, 8th ed.; Muthén & Muthén: Los Angeles, CA, USA, 1998–2017. [Google Scholar]
- Arbuckle, J. AMOS 23 User’s Guide; IBM: Chicago, IL, USA, 2014. [Google Scholar]
- Kaufman, J.S. Dissecting disparities. Med. Decis. Mak. 2008, 28, 9–12. [Google Scholar] [CrossRef] [PubMed]
- Mahoney, J. Toward a unified theory of causality. Comp. Political Stud. 2008, 41, 412–436. [Google Scholar] [CrossRef]
- Marshall, A. Principles of Political Economy; Maxmillan: New York, NY, USA, 1890. [Google Scholar]
- Heckman, J.; Pinto, R. Causal Analysis after Haavelmo. Econom. Theory 2014, 31, 115–151. [Google Scholar] [CrossRef] [PubMed]
- Hoff, P.D.; Raftery, A.E.; Handcock, M.S. Latent space approaches to social network analysis. J. Am. Stat. Assoc. 2002, 97, 1090–1098. [Google Scholar] [CrossRef]
- Pearl, J. Causes of Effects and Effects of Causes. Sociol. Methods Res. 2015, 44, 149–164. [Google Scholar] [CrossRef]
- Pearl, J. Trygve Haavelmo and the emergence of causal calculus. Econom. Theory 2015, 31, 152–179. [Google Scholar] [CrossRef]
- Zhang, J.; Bareinboim, E. Fairness in Decision-Making–The Causal Explanation Formula. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Pearl, J. Letter to the editor: Remarks on the method of propensity score. Stat. Med. 2009, 28, 1415–1416. [Google Scholar] [CrossRef] [PubMed]
- Do, M.P.; Kincaid, D.L. Impact of an Entertainment-Education Television Drama on Health Knowledge and Behavior in Bangladesh: An Application of Propensity Score Matching. J. Health Commun. 2006, 11, 301–325. [Google Scholar] [CrossRef] [PubMed]
- Ray, K.N.; Chari, A.V.; Engberg, J.; Bertolet, M.; Mehrotra, A. Disparities in time spent seeking medical care in the United States. JAMA Internal Med. 2015. [Google Scholar] [CrossRef] [PubMed]
- Elwert, F. Graphical Causal Models. In Handbook of Causal Analysis for Social Research; Morgan, S.L., Ed.; Springer: New York, NY, USA, 2013; pp. 245–273. [Google Scholar] [Green Version]
- Kessler, R.C.; Greenberg, D.F. Linear Panel Analysis: Models of Quantitative Change; Academic Press: New York, NY, USA, 1981. [Google Scholar]
- De Haan, A.; Prinzie, P.; Sentse, M.; Jongerling, J. Latent difference score modeling: A flexible approach for studying informant discrepancies. Psychol. Assess. 2018, 30, 358–369. [Google Scholar] [CrossRef] [PubMed]
- Kievit, R.A.; Brandmaier, A.M.; Ziegler, G.; van Harmelen, A.-L.; de Mooij, S.M.M.; Moutoussis, M.; Goodyer, I.M.; Bullmore, E.; Jones, P.B.; Fonagy, P.; et al. Developmental cognitive neuroscience using latent change score models: A tutorial and applications. Dev. Cogn. Neurosci. 2018, 33, 99–117. [Google Scholar] [CrossRef] [PubMed]
- Assari, S. Health disparities due to diminished return among black Americans: Public policy solutions. Soc. Issues Policy Rev. 2018, 12, 112–145. [Google Scholar] [CrossRef]
- Mouzon, D.M. Relationships of choice: Can friendships or fictive kinships explain the race paradox in mental health? Soc. Sci. Res. 2014, 44, 32–43. [Google Scholar] [CrossRef] [PubMed]
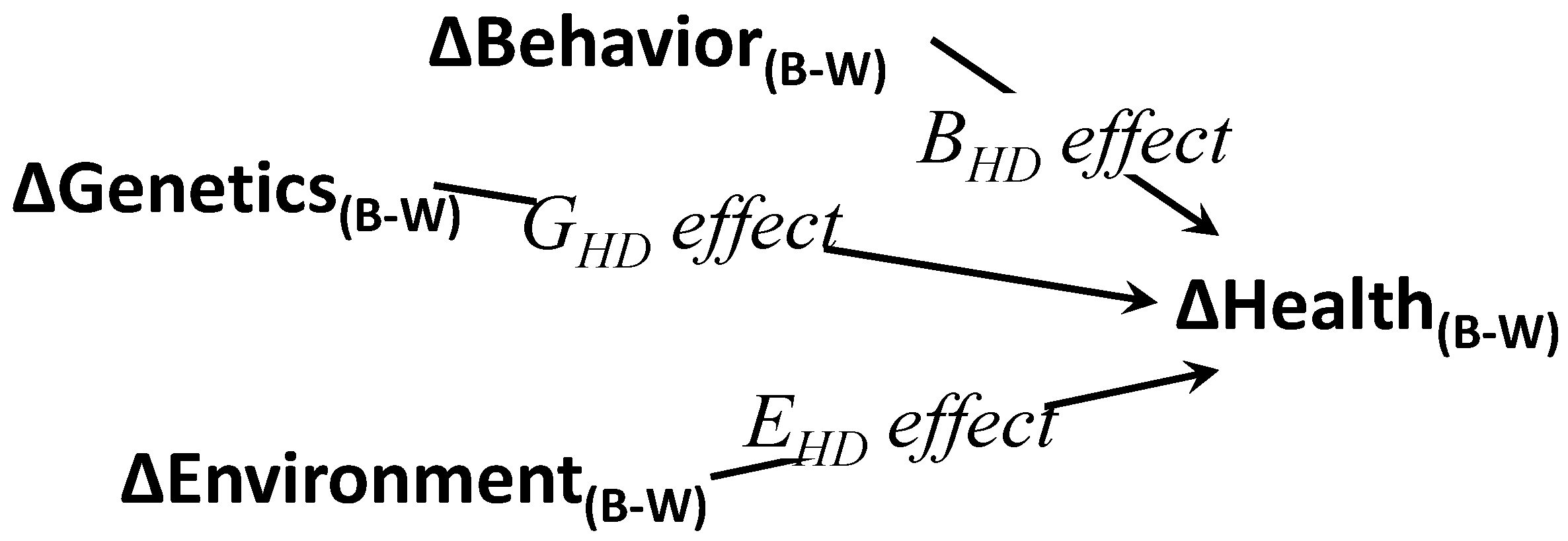

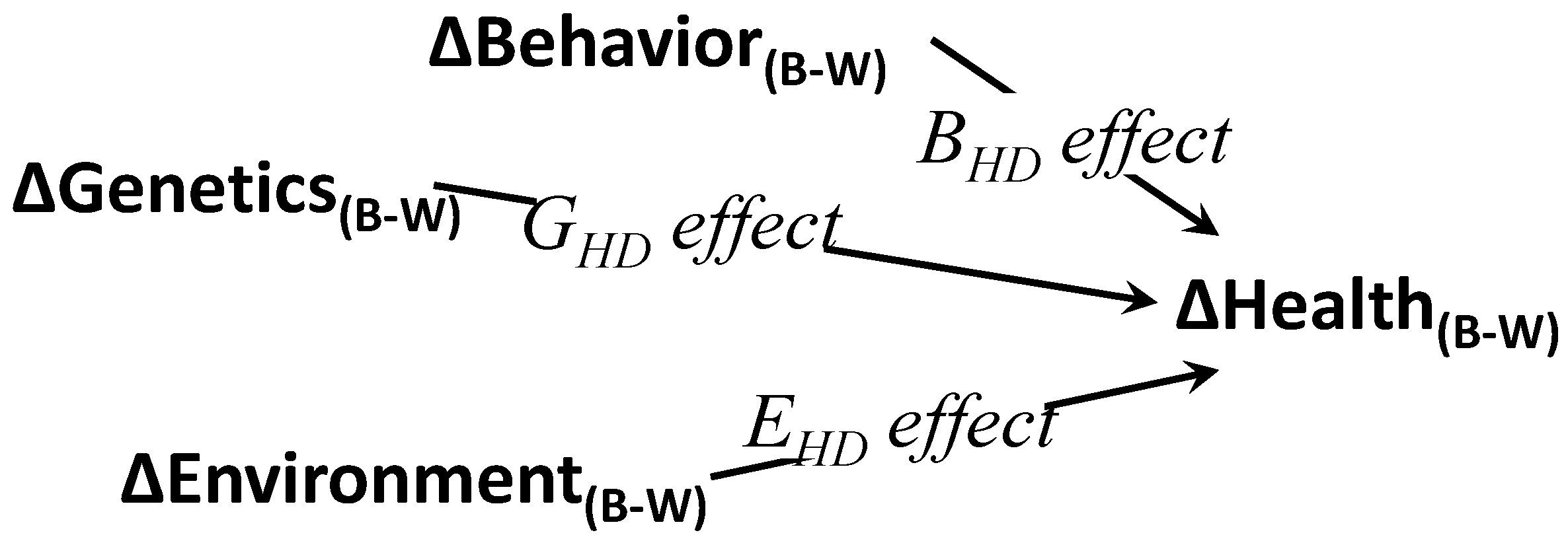{kind=link}
| White% | NW | Black% | NB | ∆W-B | |
|---|---|---|---|---|---|
| Age 18–20 years | |||||
| <High school | 26% | 19 | 0% | 13 | 26% |
| High school | 39% | 18 | 3% | 30 | 36% |
| >High school | 50% | 2 | 0% | 2 | 50% |
| Age 21–24 years | |||||
| <High school | 29% | 7 | 29% | 17 | −1% |
| High school | 29% | 14 | 11% | 19 | 18% |
| >High school | 0% | 6 | 38% | 8 | −38% |
| Age 25–30 years | |||||
| <High school | 0% | 3 | 26% | 19 | −26% |
| High school | 38% | 8 | 25% | 20 | 13% |
| >High school | 36% | 14 | 40% | 15 | −4% |
| Entire sample | 30% | 91 | 19% | 143 | 11% |
| White (%) | N | Black (%) | N | All (%) | N | p-Values | |
|---|---|---|---|---|---|---|---|
| Total | 92 | 145 | 237 | ||||
| EmploymentM | 0.165 | ||||||
| Unemployed | 38.6 | 34 | 45.8 | 66 | 43.1 | 100 | |
| Homemaker | 13.6 | 12 | 7.6 | 11 | 9.9 | 23 | |
| Part-time | 20.5 | 18 | 13.2 | 19 | 16.0 | 37 | |
| Fulltime | 27.3 | 24 | 33.3 | 48 | 31.0 | 72 | |
| Education | 0.523 | ||||||
| 0 < Grade < 12 | 32.6 | 30 | 33.8 | 49 | 33.3 | 79 | |
| Grade = 12 | 43.5 | 40 | 48.3 | 70 | 46.4 | 110 | |
| Grade > 12 | 23.9 | 22 | 17.9 | 26 | 20.3 | 48 | |
| Marital status | <0.001 | ||||||
| Married | 20.7 | 19 | 7.6 | 11 | 12.7 | 30 | |
| Co-habitating | 32.6 | 30 | 16.6 | 24 | 22.8 | 54 | |
| Not married w/boyfriend | 21.7 | 20 | 51.0 | 74 | 39.7 | 94 | |
| Not married w/o boyfriend | 25.0 | 23 | 24.8 | 36 | 24.9 | 59 | |
| Means | White | SEs | Black | SEs | All | SEs | p |
| Age | 22.59 | 0.38 | 23.11 | 0.30 | 22.24 | 0.35 | 0.280 |
| Neighborhood disorder | −0.15 | 0.08 | 0.18 * | 0.07 | 0.04 | 0.06 | 0.002 |
| Anxiety | 14.60 * | 0.29 | 13.73 | 0.20 | 13.91 | 0.22 | 0.014 |
| Depression (%s) | 29.7%† | 8.8% | 18.9% | 4.7% | 23.1% | 4.4% | 0.058 |
| Depression (odds) | 0.42† | 0.10 | 0.23 | 0.05 | 0.30 | 0.05 | 0.058 |
| Percent Depressed | White % | Black % | ∆W-B | p |
|---|---|---|---|---|
| NB = 143, NW = 91 | 30% | 19% | 11% | 0.056 |
| 1:1 NB=W = 59 | 32% | 20% | 12% | 0.161 |
| Matched Pairs | Black not Depressed | Black Depressed | Total |
|---|---|---|---|
| White not depressed | 78% ‡ | 23% | 100% |
| 31 ‡ | 9 | 40 | |
| 66% ‡ | 75% | ||
| 53% ‡,T | 15% T | ||
| White depressed | 84% | 16% ‡ | 100% |
| 16 | 3 ‡ | 19 | |
| 34% | 25% ‡ | 32% A | |
| 27 T | 5% ‡,T | ||
| Total | 20% A | ||
| 47 | 12 | 59 | |
| 100% | 100% | ||
| 100% |
| Test: Category | Chi Squared | McNemar 1:1 Matched in 61 Dyads | Logistic Regression with Covariates | Logit Regression (For Un-Matched) | Propensity Matching | Clustered Logit (Matched in 14 Clusters) |
|---|---|---|---|---|---|---|
| White women (nDW/NW) | 27/91 | 19/59 | 26/88 | 7/31 | 26/87 | 26/88 |
| White women (%) | 29.7% | 32.2% | 46.9% A | 22.6% | 29.9% | 29.5% |
| Black women (nDB/NB) | 27/143 | 12/59 | 88/142 | 15/83 | 18/121 | 28/141 |
| Black women (%) | 18.9% | 20.3% | 29.8% A | 18.1% | 14.9% | 19.7% |
| Test statistic value | 1.92 χ2 | 1.96 χ2 | 1.41 z | 0.54 z | 1.94 t | 1.68 z |
| p value W vs. B | 0.056 | 0.161 | 0.159 | 0.587 | 0.054 | 0.092 |
| Difference ∆B-W | 10.8% | 11.9% | 17.1% | 4.5% | 15.0% | 9.9% |
| Total | NAll = 234 | N1:1 = 118 | NAll = 230 | NUn-1:1 = 114 | Npsmatch2 = 230 | Nxtmelogit = 229 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coman, E.N.; Wu, H.Z.; Assari, S. Exploring Causes of Depression and Anxiety Health Disparities (HD) by Examining Differences between 1:1 Matched Individuals. Brain Sci. 2018, 8, 207. https://doi.org/10.3390/brainsci8120207
Coman EN, Wu HZ, Assari S. Exploring Causes of Depression and Anxiety Health Disparities (HD) by Examining Differences between 1:1 Matched Individuals. Brain Sciences. 2018; 8(12):207. https://doi.org/10.3390/brainsci8120207
Chicago/Turabian StyleComan, Emil N., Helen Z. Wu, and Shervin Assari. 2018. "Exploring Causes of Depression and Anxiety Health Disparities (HD) by Examining Differences between 1:1 Matched Individuals" Brain Sciences 8, no. 12: 207. https://doi.org/10.3390/brainsci8120207
APA StyleComan, E. N., Wu, H. Z., & Assari, S. (2018). Exploring Causes of Depression and Anxiety Health Disparities (HD) by Examining Differences between 1:1 Matched Individuals. Brain Sciences, 8(12), 207. https://doi.org/10.3390/brainsci8120207