3.2.1. Experimental Results of MI-EEG Decoding
Since left/right-hand MI are classic tasks in motor imagery BCI, the left/right-hand MI-EEG decoding experiment was conducted first.
Table 5 lists the confusion matrix of the proposed MSEI-ENet applied on left- and right-hand MI-EEG recognition on BCIIV 2a. It can be observed from
Table 5 that the metrics of
PR,
RE, and
F1 for left/right-hand MI tasks all achieve or exceed 98%, and the performance of our model on left- and right-hand MI tasks is comparable, with
F1-scores of 98.26% and 98.27%. This shows that our proposed model performs well in left- and right-hand MI decoding.
Additionally, we also conducted a multi-task MI-EEG decoding experiment involving left-hand, right-hand, both-feet, and tongue motor imagery. The implementation details are consistent with the left/right-hand experiment.
Table 6 lists the confusion matrix of the proposed MSEI-ENet applied on BCIIV 2a for multi-task MI-EEG decoding. It is observed that the
RE values of the left- and right-hand MI tasks achieve 93.44% and 95.37%, respectively, which are lower than the results obtained for the left/right-hand classification tasks (
Table 5). Notably, the
F1-scores of multi-task MI are similar, reaching approximately 94%, which is slightly lower compared to the left/right-hand MI tasks. It is noteworthy that the
RE of the both-feet MI task is the highest, reaching 95.75%. Although the
RE of the tongue MI task is the lowest at 92.66%, its precision (
PR) is the highest at 96.00%. It can be seen that MSEI-ENet also exhibits excellent performance in multi-task MI-EEG decoding, particularly in the challenging lower-limb MI task. Moreover, misclassification is more severe for four MI tasks compared to the left/right-hand MI tasks. This stems from the fact that the motor cortex of the lower-limb MI task might be located in a deep brain area, which is challenging.
To further validate the generalization of the proposed model, the multi-task MI-EEG decoding experiment was then conducted on the Physionet dataset.
Table 7 shows the confusion matrix and the related performance indices. The
PR,
RE, and
F1-score of the both-feet MI task achieve 100%, 98.81%, and 99.40%, respectively, which indicates that MSEI-ENet performs well on both-feet MI tasks. Except for the
PR of 94.74 for the both-hands MI task, all other metrics of left/right hand and both hands are lower than 90%. It can be seen from the confusion matrix that the proportion of misclassifications between left- and right-hand MI tasks is relatively high, and labels of the both-hands task are misclassified to those of the left or right hand. The reason for this phenomenon may be that when the both-hands MI task is involved, it makes the recognition of upper-limb MI tasks complex.
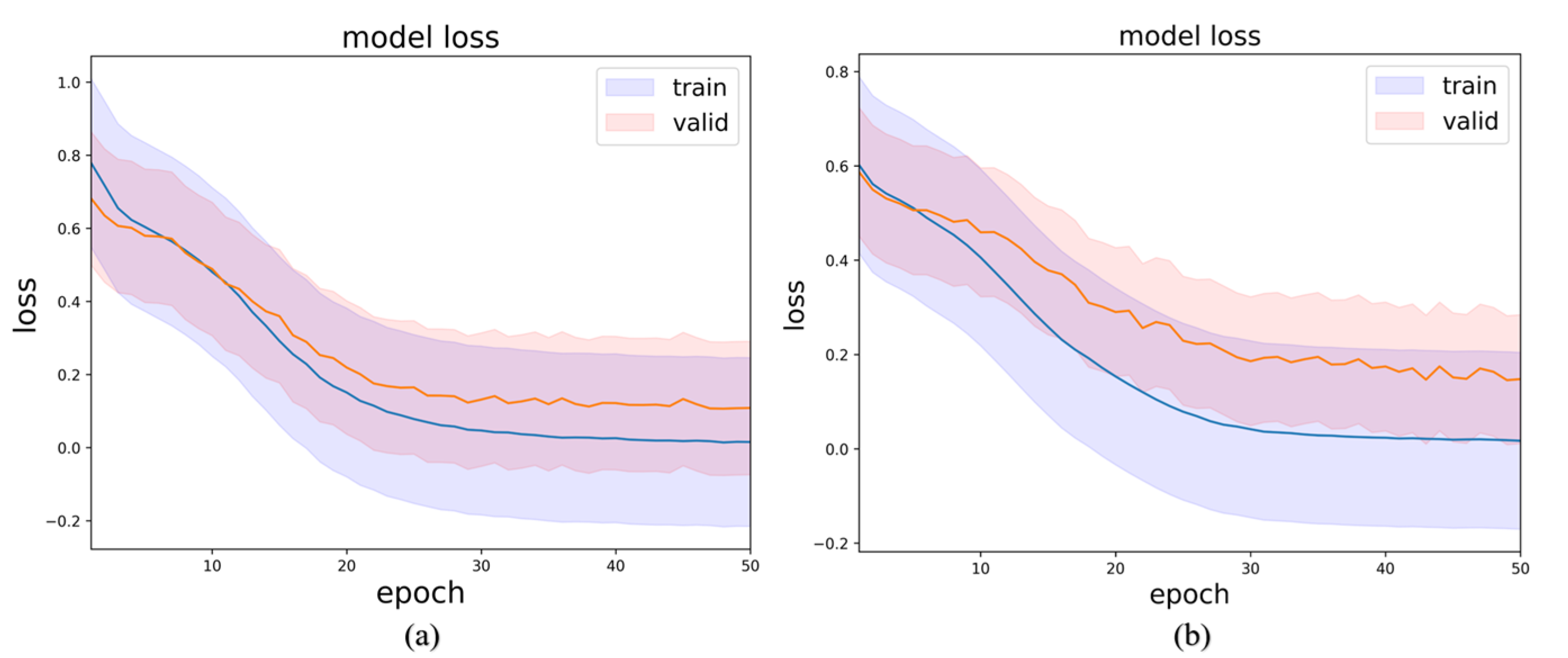
In order to evaluate the fitting performance of the MSEI-ENet model, the average loss within 50 epochs during the training course was calculated. For left/right-hand binary classification and multiple classification tasks, the training and validation loss on BCIIV2a are shown in
Figure 7. The shaded regions of the training and validation loss curves are obtained by calculating the standard deviations of the loss, which exhibit the stability of the model. Notably, the loss curve levels off after the 30th epoch, and the validation loss value is below 0.2, which indicates that the proposed model rapidly converges to a stable value.
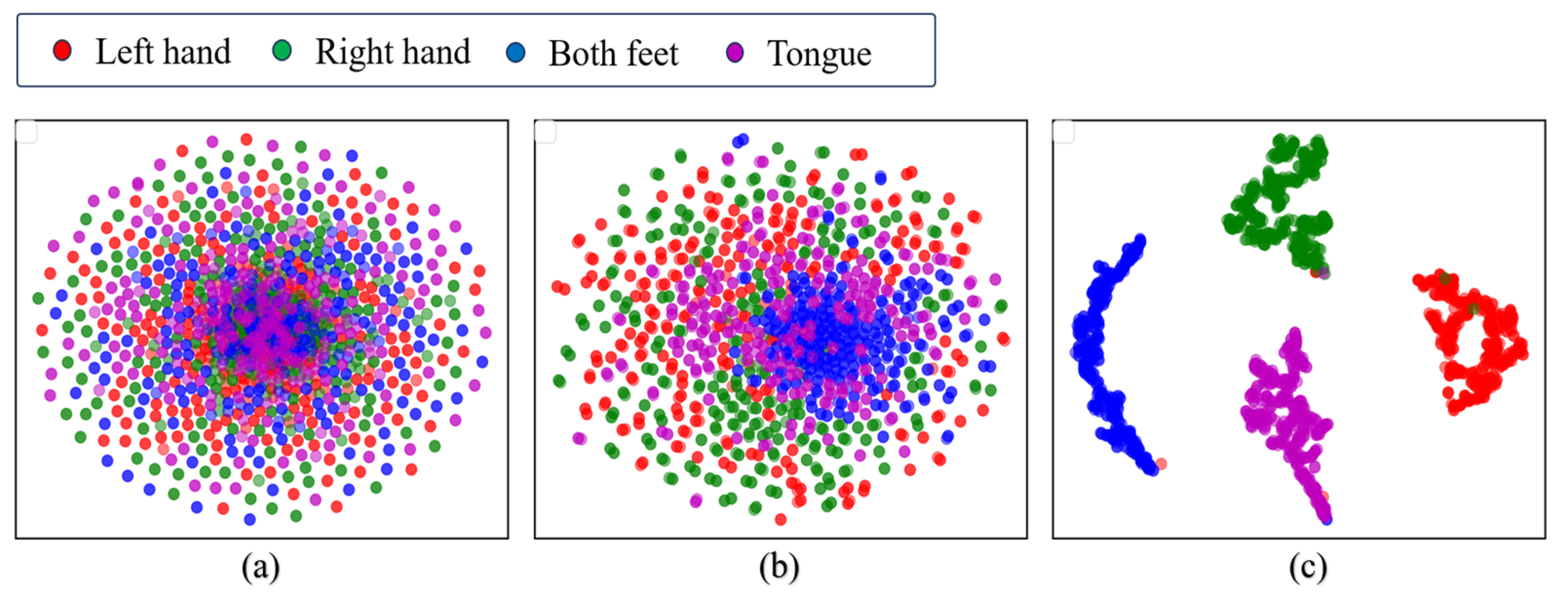
To provide an intuitive understanding of the features learned by our proposed model, we visualized the extracted features from the relevant modules using
t-distributed stochastic neighbour embedding (
t-SNE) [
45]. This technique reduces the dimensionality of high-dimensional features.
Figure 8 displays the
t-SNE visualization of the raw MI-EEG data and the visualization of the features extracted by the MSEI module, as well as those extracted by the encoder module. It can be observed from
Figure 8a that the raw MI-EEG data are difficult to cluster. As shown in
Figure 8b, there is still some mixing among the features extracted by the MSEI module. In contrast,
Figure 8c demonstrates that features from each class can be clearly distinguished. This indicates that when the model uses only a single feature extraction module, it has limited learning capability, whereas the combination of MSEI with the encoder module further enhances the feature representation, thereby improving the overall discriminative ability of the model.
3.2.2. Ablation Experiment
(1) Comparison of MSEI-ENet modules
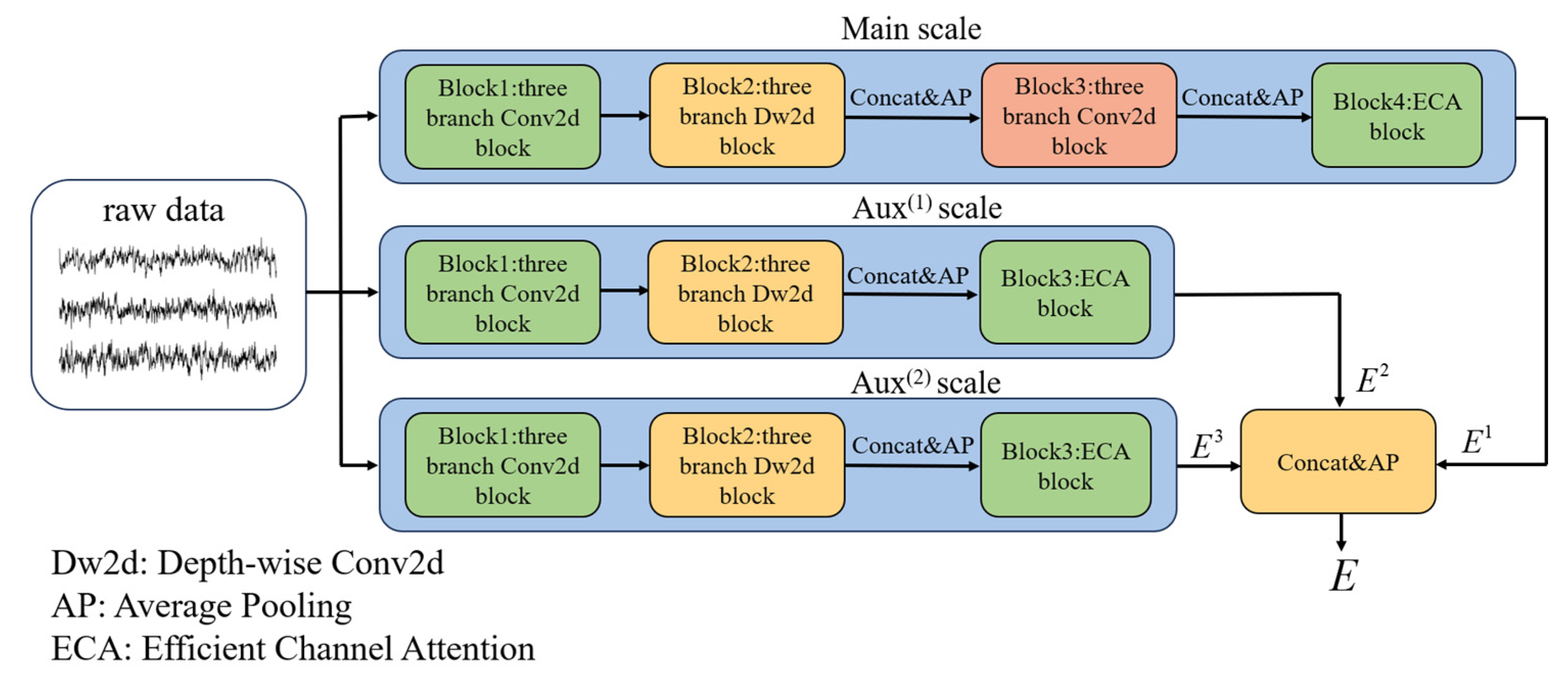
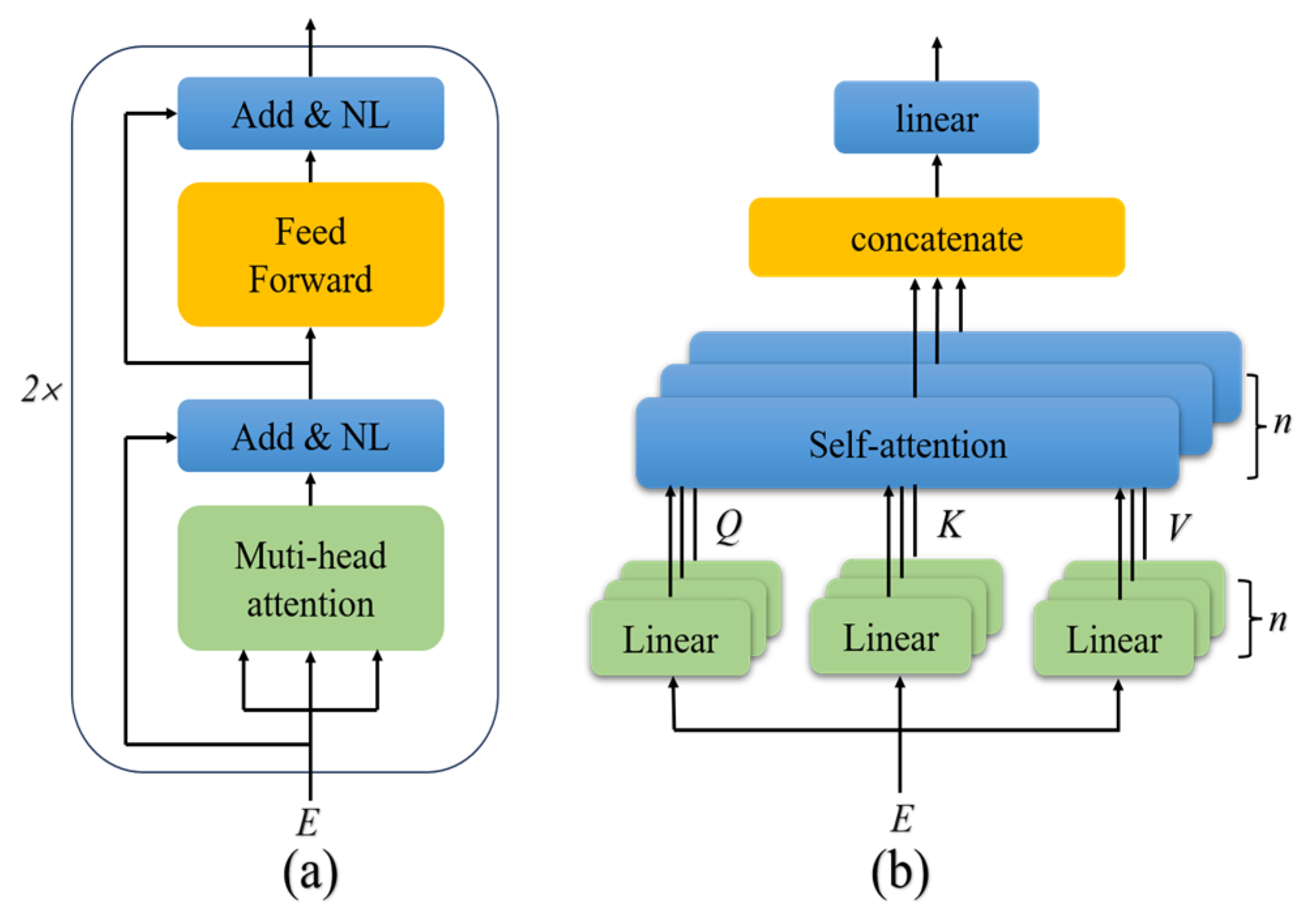
The proposed model contains two crucial modules, as described in
Section 2.2. To validate their effectiveness, we conducted ablation experiments on BCIIV 2a. Two variant models were designed. For variant 1, the Aux
(1) and Aux
(2) scales of MSEI and the encoder were removed; for variant 2, only the encoder was removed. The details of the experimental setup are listed in
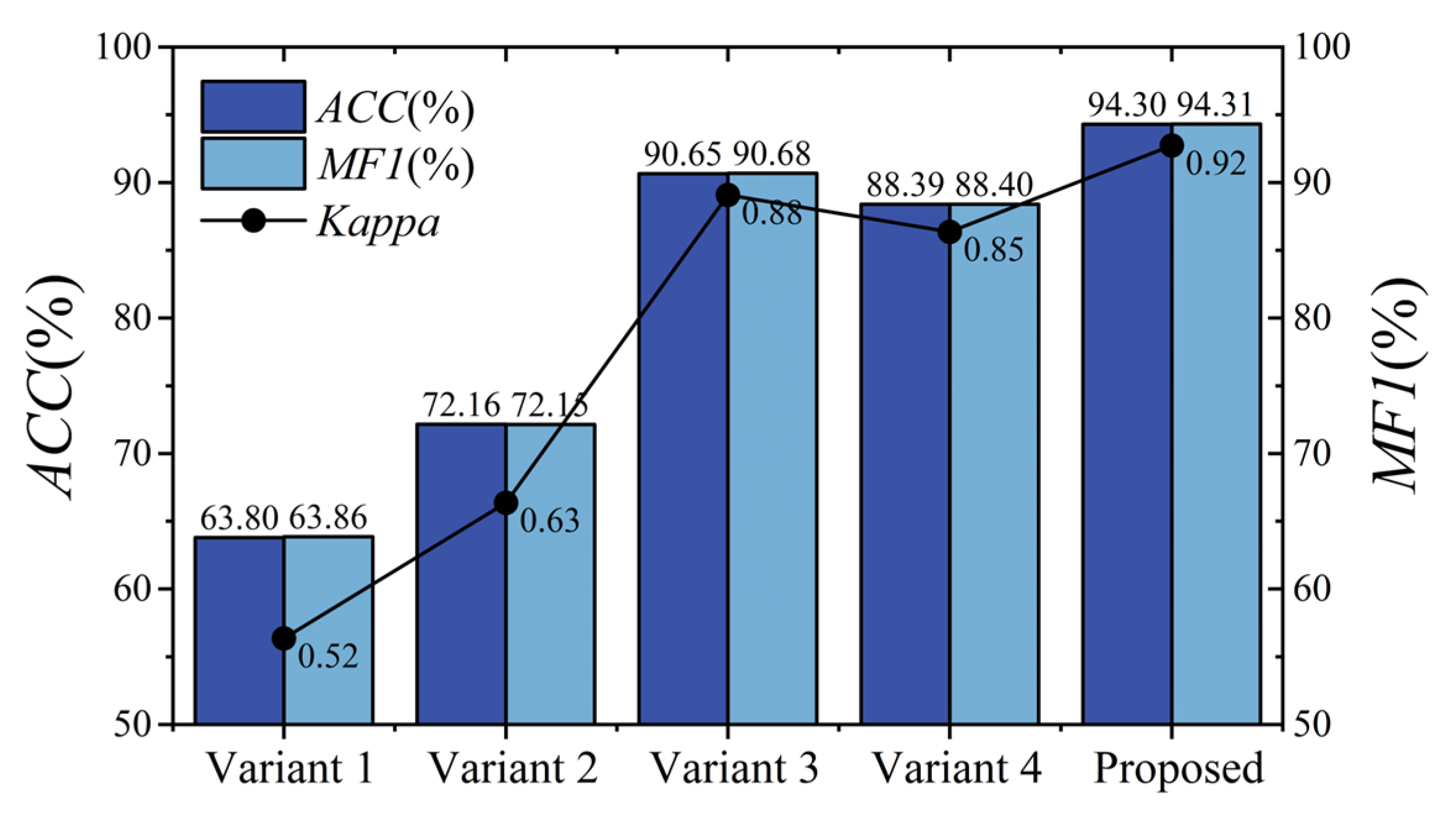
Table 8. The results of the ablation experiment on BCIIV 2a of the binary and multiple classification tasks are illustrated in
Figure 9 and
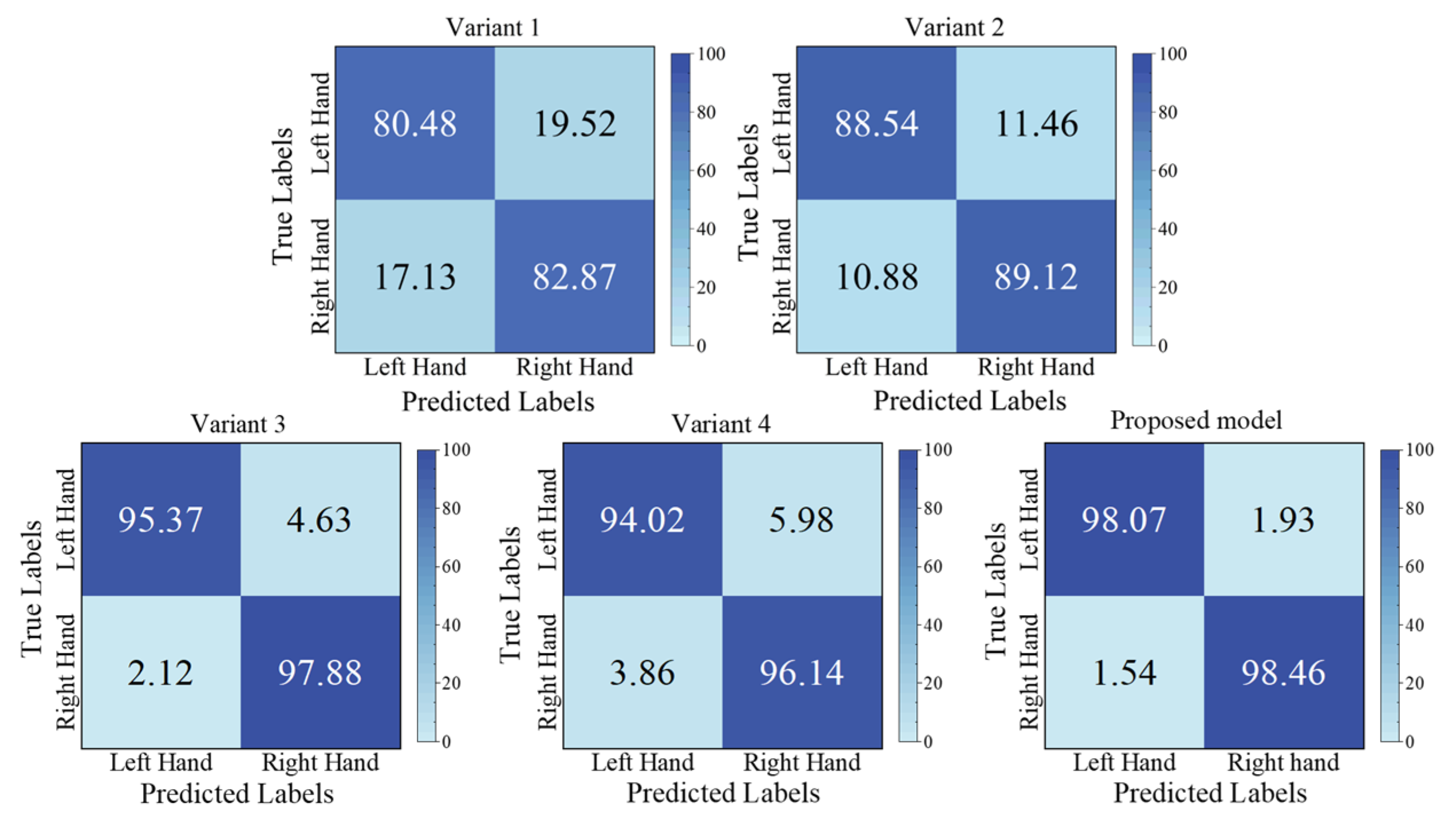
Figure 10. Furthermore, the corresponding confusion matrices of the variant models are shown in
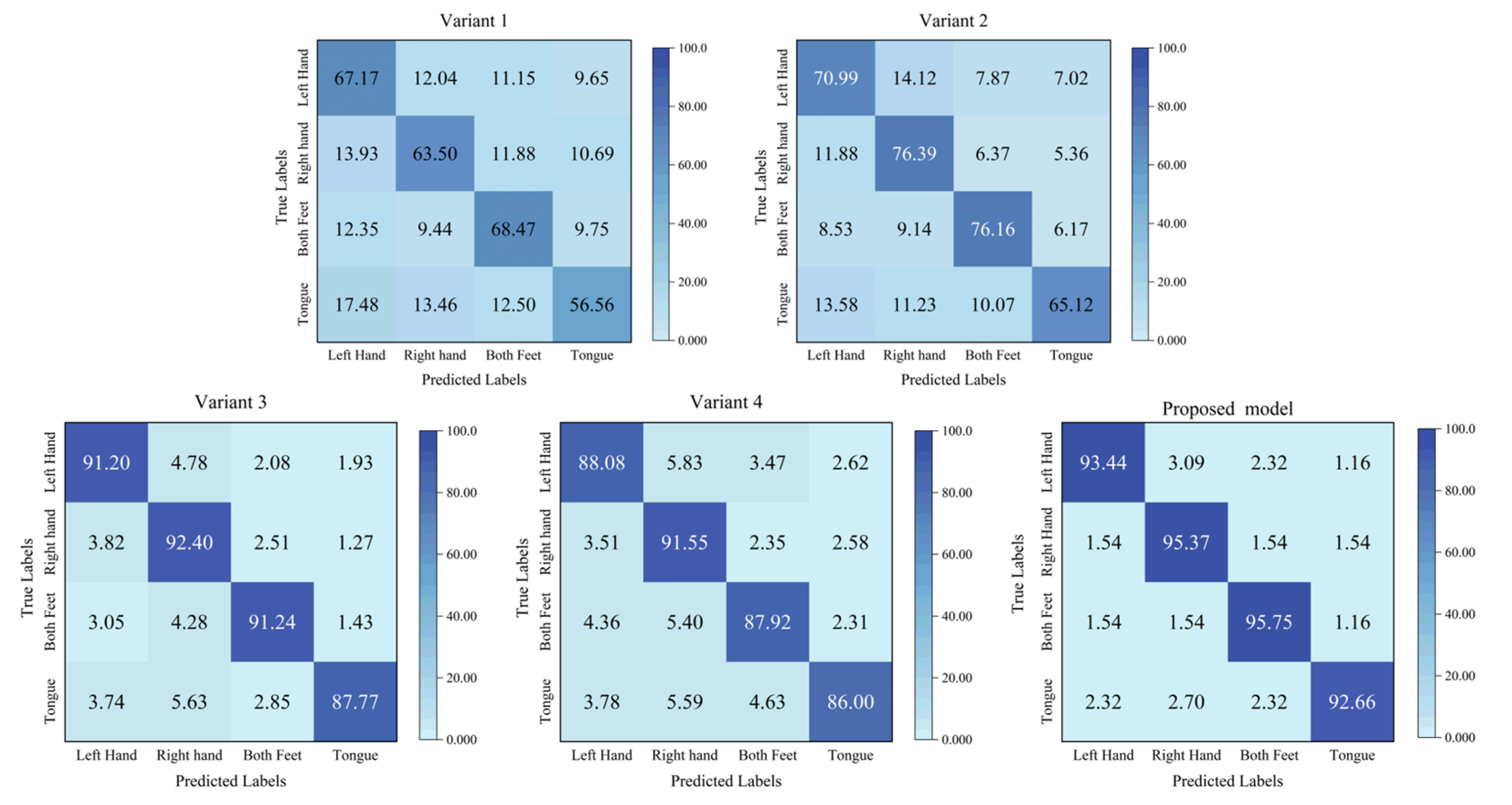
Figure 11 and
Figure 12.
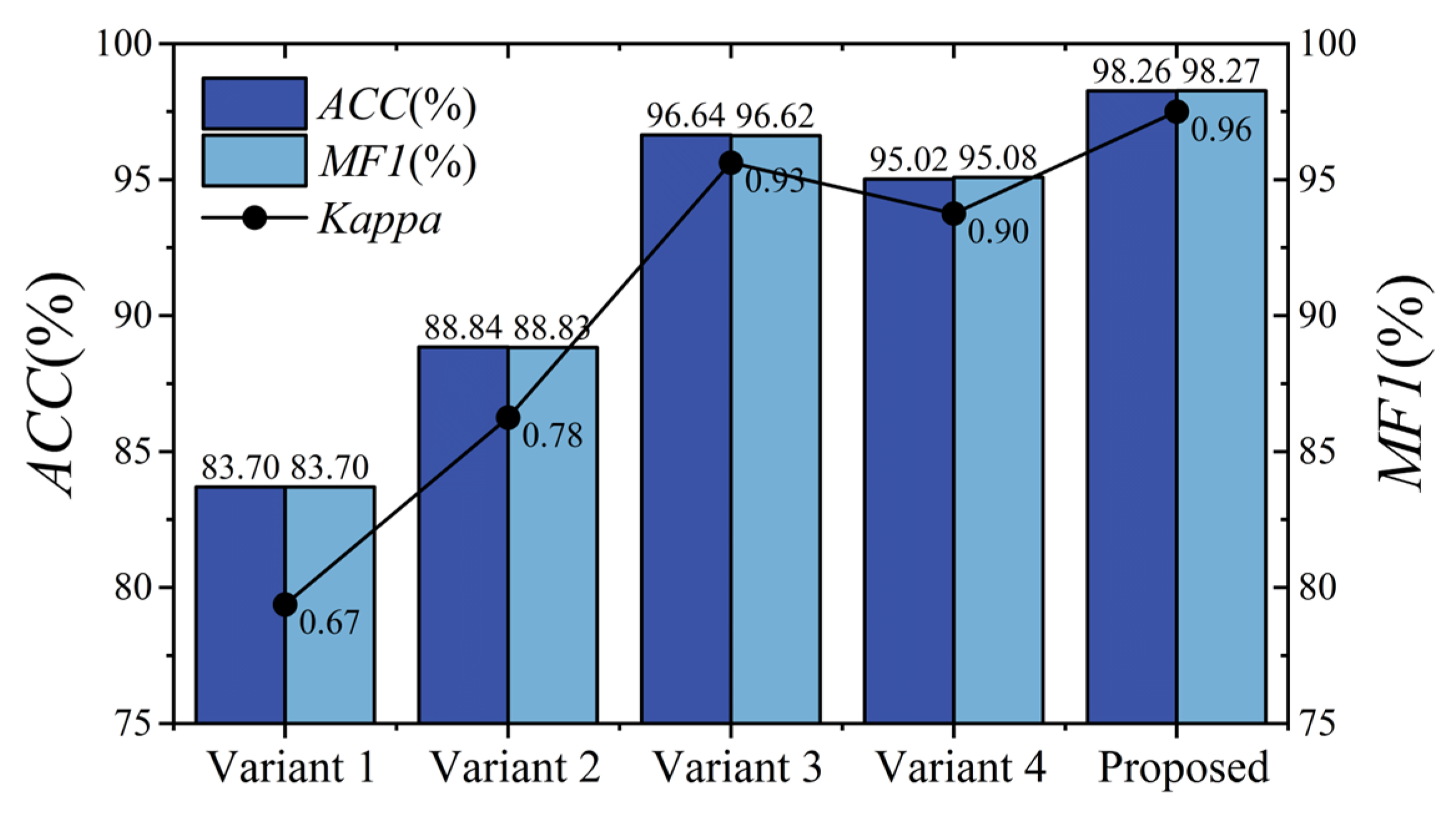
As shown in
Figure 9 and
Figure 10, for the left/right-hand MI task, the proposed model achieves an overall accuracy of 98.26%, an MF1 value of 98.27%, and a kappa value of 0.96. For the multiple classification task, the proposed model attains an overall accuracy of 94.30%, an MF1 value of 94.31%, and a kappa value of 0.92. Furthermore, Variant 2 shows a slight improvement over Variant 1 in both binary left/right-hand and multi-task MI-EEG decoding because the multi-scale structure captures comprehensive information compared to a single structure. Notably, for the left/right-hand MI task, the accuracies of Variant 1 and Variant 2 are lower than that of the proposed model by 14.56% and 9.42%, respectively. For multi-task recognition, the proposed model outperforms Variant 1 and Variant 2 by 30.50% and 22.14% in accuracy, respectively. This suggests that our proposed MSEI-ENet can recognize complex brain activity patterns even when lower-limb or tongue tasks are involved.
From
Figure 11 and
Figure 12, it is clearly observed that our proposed model exhibits significant performance improvement across all MI tasks. For the binary left/right-hand MI task, the three models (Variant 1, Variant 2, and the proposed model) perform similarly in the recognition of left-hand and right-hand MI tasks. However, for the multiple classification tasks, there is a noticeable performance disparity among them, which might be because the motor cortex of the lower-limb MI task is located in a deep brain area, which is challenging. This is different from the MI task only involving the upper limbs. Specifically, Variant 1 performs better in recognizing left-hand and both-feet MI tasks, whereas Variant 2 shows better performance in recognizing right-hand and both-feet MI tasks. This indicates that different model architectures have varied recognition abilities for relevant brain activity patterns associated with different MI tasks. Furthermore, Variant 1 and Variant 2 show relatively lower performance on the tongue MI task compared to the other tasks. However, our proposed model significantly improves tongue task recognition, with the metrics of all MI tasks equalling or surpassing 92.66%, and the metric of tongue MI is only 3.09% lower than that of the both-feet MI task. These results demonstrate that the integration of the MSEI and encoder module significantly enhances the effectiveness of MI-EEG decoding.
(2) Comparison of MSEI-ENet hyperparameters
To compare the influence of different configurations of convolution kernels of the MSEI module on the model performance, Variant 3 and Variant 4 were designed for the ablation experiment. For Variant 3, the convolution kernels of Block 1 of the Main scale were exchanged with Block 1 of the Aux(1) scale, i.e., the kernel sizes of the first three-branch conv2d block of the Main scale were (125, 1), (64, 1), and (32, 1); the sizes of the second one in the Main scale were (32, 1), (16, 1), and (8, 1); and the kernel sizes of the three-branch conv2d block in the Aux(1) scale were (500, 1), (250, 1), and (125, 1). The convolution kernel sizes of the Aux(2) scale were unchanged.
For Variant 4, the convolution kernels of Block 1 of the Main scale were exchanged with Block 1 of the Aux(2) scale, i.e., the kernel sizes of the first one of the Main scale were (32, 1), (16, 1), and (8, 1); the sizes of the second one were changed to (8, 1), (4, 1), and (2, 1); and the kernel sizes of the Aux(2) scale were (500, 1), (250, 1), and (125, 1). The convolution kernel sizes of the Aux(1) scale were unchanged.
The related results of the ablation experiment for the left/right-hand MI task on BCIIV 2a are shown in
Figure 9. It can be seen that Variant 3 achieves an accuracy of 96.64% and Variant 4 achieves an accuracy of 95.02%, which are 1.62% and 3.24% lower than the proposed model, respectively. From the confusion matrix in
Figure 11, the decoding performance of the left and right hands in Variant 3 and Variant 4 have small differences compared with those of the proposed model. We can observe that the variation in the size of the convolutional kernels within the MSEI module has a minor impact on the performance of the model for the left/right-hand MI task.
Figure 10 shows the related results of the ablation experiment for multi-task MI-EEG decoding on BCIIV 2a. Variant 3 achieves an accuracy of 90.65% and a kappa of 0.88. However, the accuracy and kappa values of Variant 4 are 5.91% and 0.07 lower than those of the proposed model.
Figure 12 shows the confusion matrix of the multi-task MI-EEG decoding. We can observe that the metrics of the four MI tasks of Variant 3 and Variant 4 are distinctively inferior to those of the proposed model. Among them, the metric of the tongue MI task of Variant 4 declines severely. This indicates that the model is more sensitive to the changes in the convolution kernel size in multi-task MI-EEG decoding. Designing appropriate convolution kernel sizes for different tasks has an influence on the performance of the network. Additionally, regardless of binary or multiple classification tasks, the
PR,
RE, and
F1-score of each class can be ordered from the lowest to the highest as follows: Variant 4, Variant 3, and proposed model. As the convolution kernel size of the Main scale decreases, the performance of the model becomes worse. This indicates that convolutional kernels achieve decent feature learning only when the relevant parameters are appropriately configured.
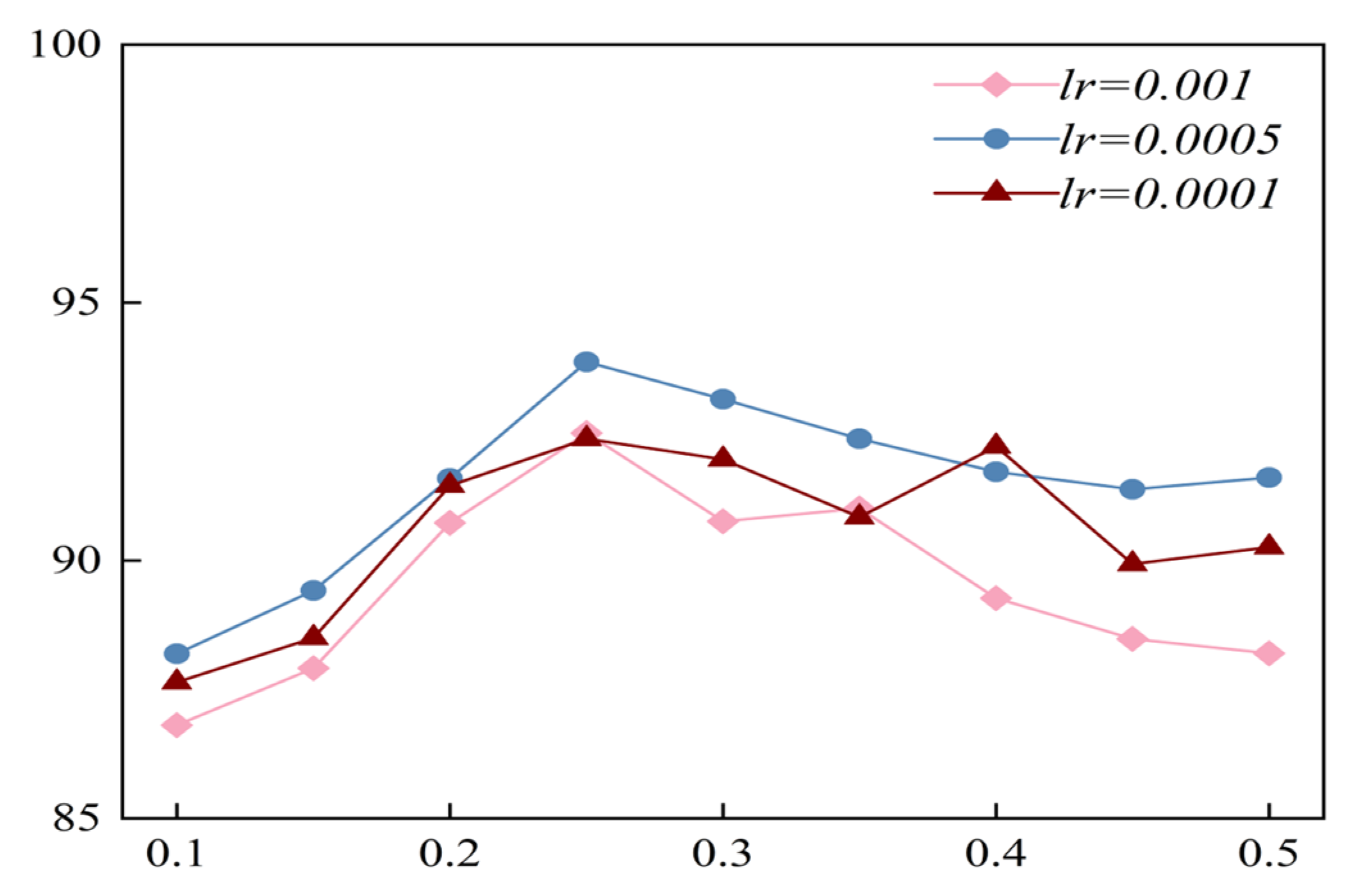
The learning rate (
lr) and dropout rate are two important hyperparameters in deep learning models. An appropriate learning rate can enable the model to converge quickly to an optimal solution. Moreover, dropout can effectively prevent overfitting in complex networks. Hence, we tested the influence of variations in these two hyperparameters on the performance of the model (
lr ∈ {0.001, 0.0005, 0.0001}; dropout rate ∈ {0.1:0.05:0.5}). The result of the optimization process on the test set under the scenario of global-CV is shown in
Figure 13. We can conclude that under the setting of the same learning rate, the variation in dropout has a distinct influence on the performance of the model (the difference between the maximum and minimum accuracy values is approximately 8%). The reason might be that a too-high dropout rate would cause a substantial number of neurons to be dropped during training, resulting in a deterioration in the learning ability of the model. On the other hand, a too-low dropout rate might cause a degraded ability of the model to predict new data. Additionally, when the dropout rate was unchanged, the accuracy of the model with a learning rate of 0.0005 was generally higher than those with a learning rate of 0.001 and 0.0001. This implies that if the learning rate is too high, it may cause severe instability. Conversely, if the learning rate is too low, learning might become stuck with a high-cost value.
3.2.3. Comparison of MSEI-ENet with Other Models
To verify the rationality and classification performance of the constructed network, this section compares MSEI-ENet with other models. We conducted experiments by using six state-of-the-art models on the BCIIV 2a and Physionet datasets with the same experimental design. These six models include EEGNet, EEGinception, MMCNN, SMTransformer, Conformer, and Deformer. The first three belong to the CNN framework; the others combine a CNN with Transformer.
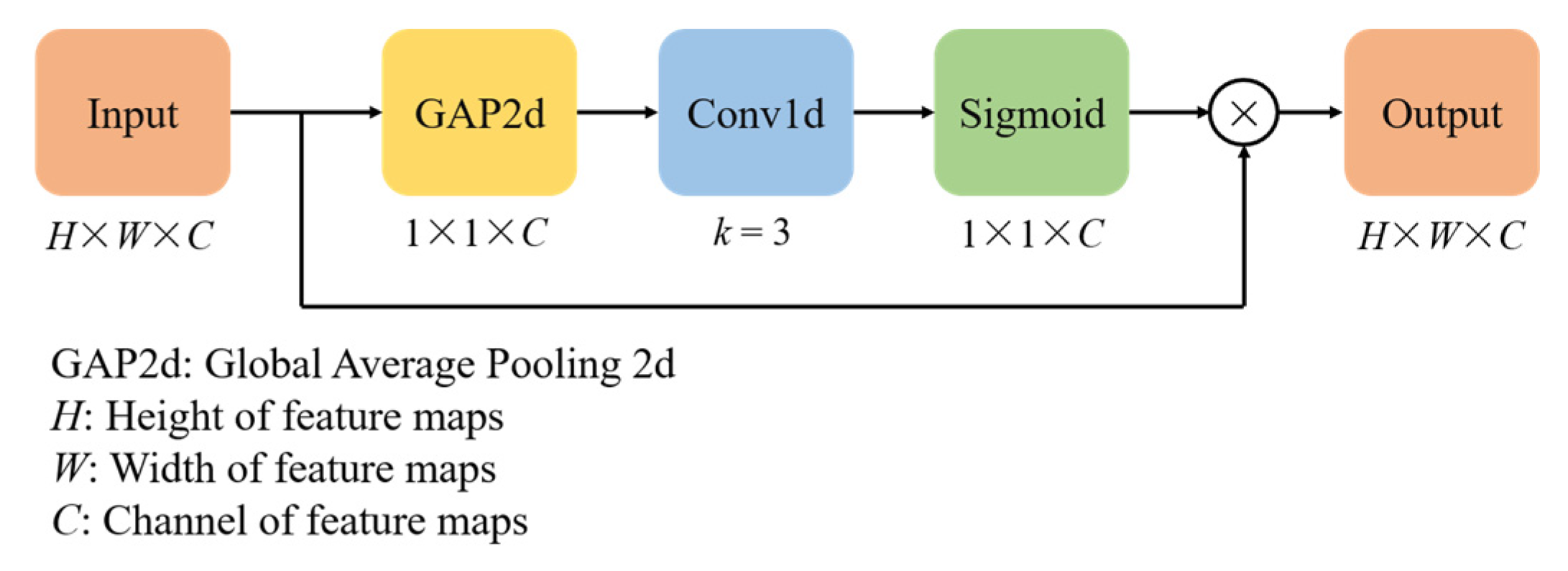
Table 9 lists the corresponding performance indices of accuracy and kappa using comparison models on multi-task MI-EEG decoding. It can be seen that the proposed model MSEI-ENet achieves a remarkable accuracy of 94.30% and a kappa value of 0.92 on the BCIIV 2a dataset. On the Physionet dataset, MSEI-ENet also achieves good results with an accuracy of 90.48% and a kappa of 0.87. For both datasets, it can be concluded that the performance of the combination models (referred to as CNN with Transformer) is superior to those of CNNs (EEGNet, EEG-inception, and MMCNN). The reason is that the multi-head attention mechanism of Transformer can extract global features and help elevate the performance of the combined models on challenging multi-task MI-EEG decoding. Notably, our proposed model MSEI-ENet outperforms SMTransformer, Conformer, and Deformer, this might be because the employment of a single-branch structure in the CNN limited their efficacy of feature learning. In contrast, the multi-scale structure of MSEI-ENet can extract features more comprehensively, and the adoption of the mechanism of ECA can screen the features of important channels automatically.
To further validate the performance of our proposed model on new subjects, we performed subject-independent experiments on the BCIIV 2a dataset by using the LOSO-CV method. The related results are shown in
Table 10, and the largest value is marked with bold font. It can be seen that by using our model, more than half of the subjects (S1, S2, S3, S6, and S8) achieve a higher accuracy than those of the other baseline models. The accuracy of the proposed model on subject 7 is 2.62% lower than that of EEG-inception. On subject 9, it is only 0.46% lower than that of Deformer, while the accuracies on subjects 4 and 5 are lower than those of the two Transformer models. The possible reason for this phenomenon might be that there is significant individual variability in motor imagery tasks, and the adaptability of the deep learning models to different subjects also varies greatly. However, the average accuracy of our model on the nine subjects is 62.10%, which is higher than that of all the comparison models. These encouraging results demonstrate the effectiveness and robustness of the proposed model in handling the challenges posed by multi-task MI-EEG decoding on new subjects.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}