
Embodied Cross-Modal Interactions Based on an Altercentric Reference Frame

{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
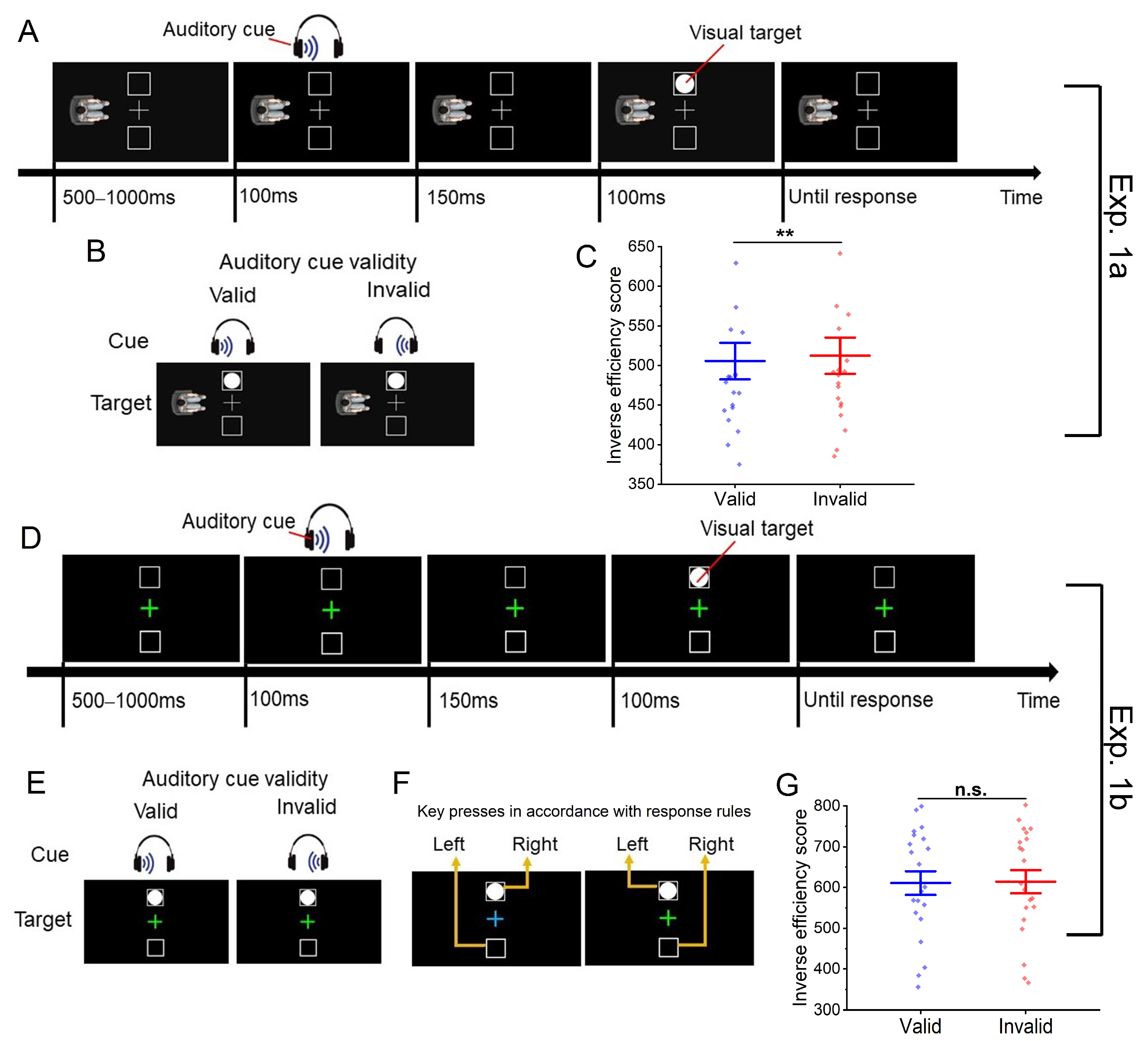
2. Experiment 1a
2.1. Method
2.1.1. Participants
2.1.2. Apparatus and Stimuli
2.1.3. Design and Procedure
2.2. Results
2.3. Discussion
3. Experiment 1b
3.1. Method
3.1.1. Participants
3.1.2. Apparatus and Stimuli
3.1.3. Design and Procedure
3.2. Results
3.3. Discussion
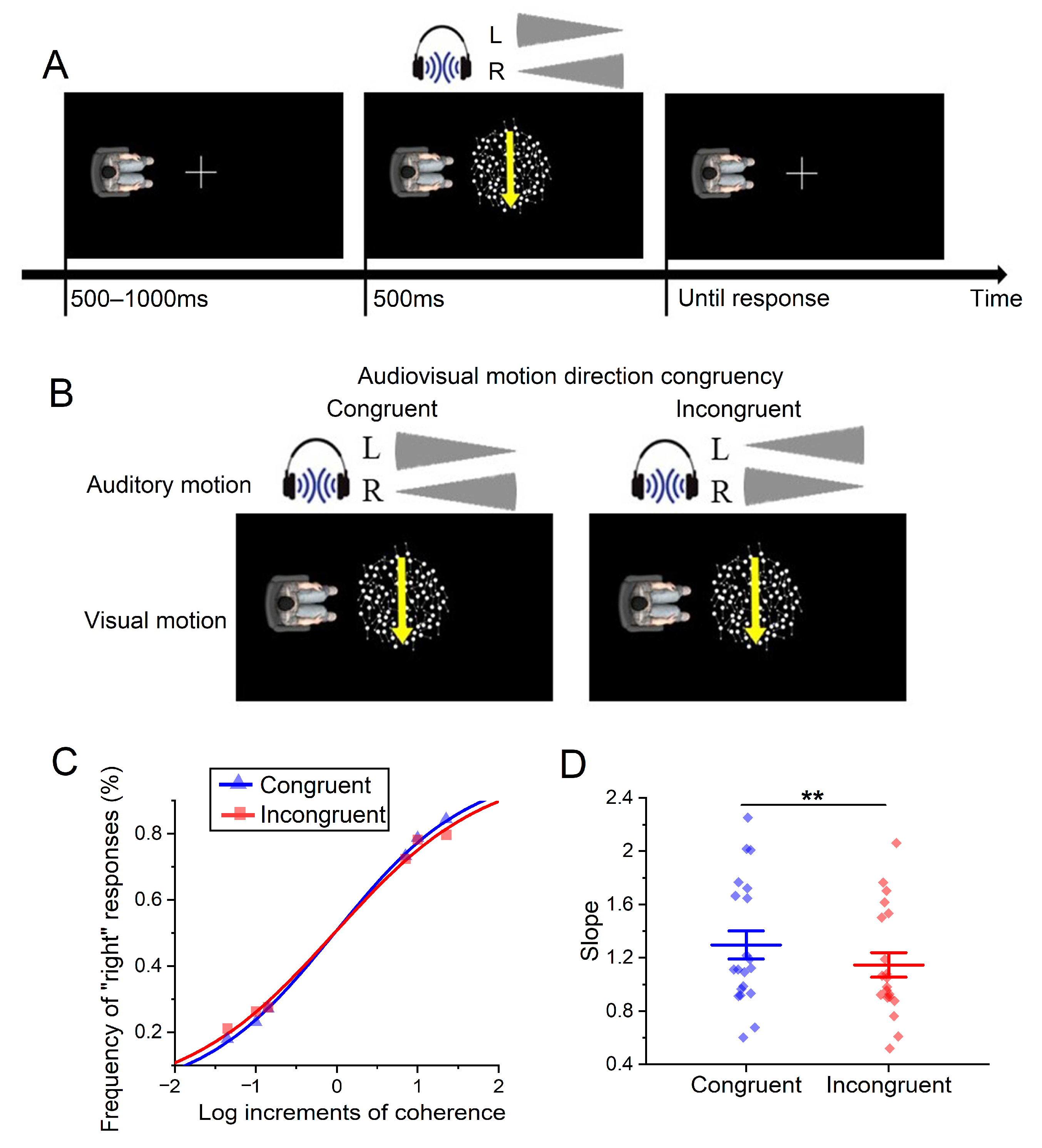
4. Experiment 2
4.1. Method
4.1.1. Participants
4.1.2. Apparatus and Stimuli
4.1.3. Design and Procedure
4.2. Results
4.3. Discussion
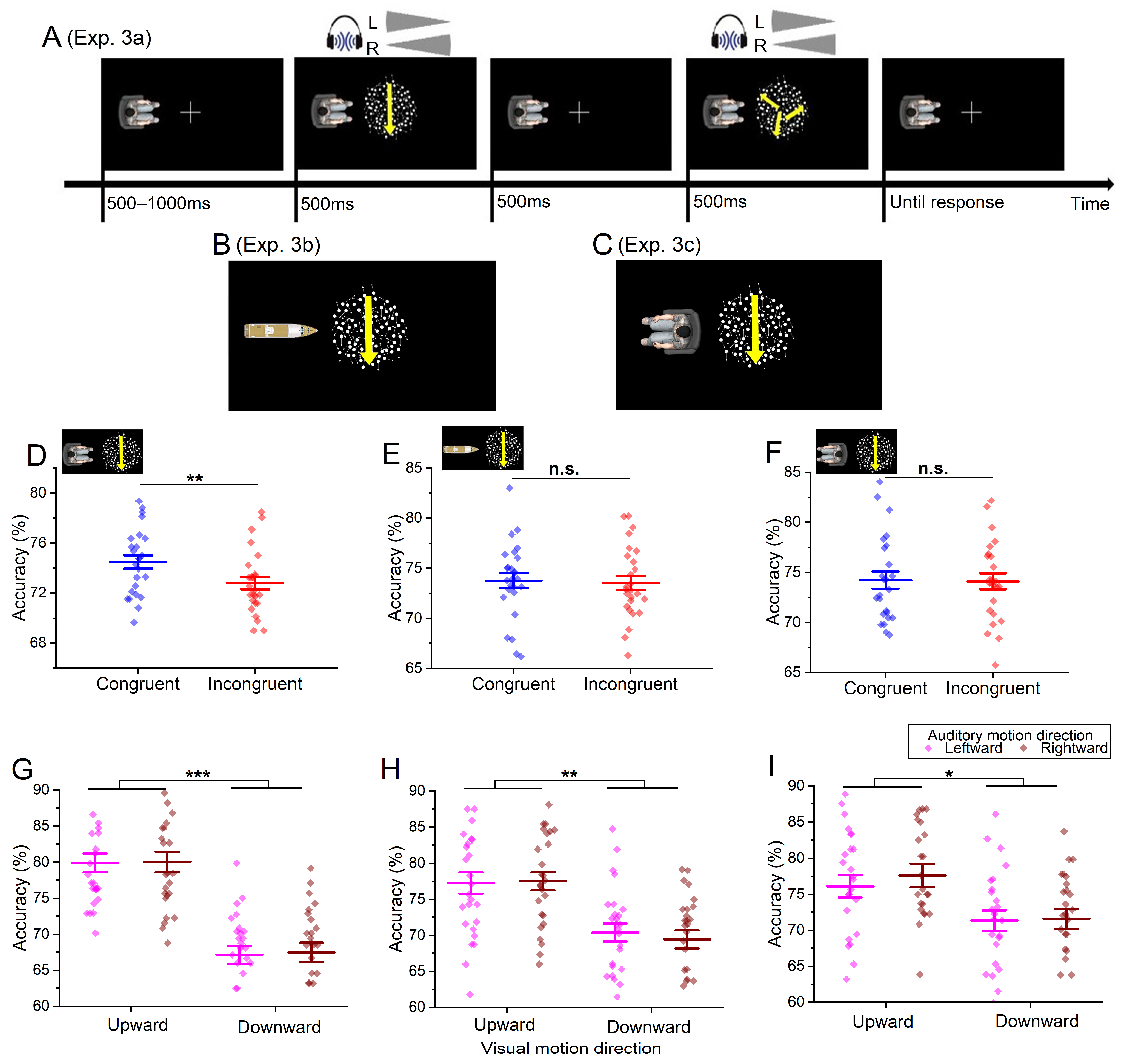
5. Experiment 3a
5.1. Method
5.1.1. Participants
5.1.2. Apparatus and Stimuli
5.1.3. Design and Procedure
5.2. Results
5.3. Discussion
6. Experiment 3b
6.1. Method
6.1.1. Participants
6.1.2. Apparatus and Stimuli
6.1.3. Design and Procedure
6.2. Result
6.3. Discussion
7. Experiment 3c
7.1. Method
7.1.1. Participants
7.1.2. Apparatus and Stimuli
7.1.3. Design and Procedure
7.2. Result
7.3. Discussion
8. General Discussion
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sherf, E.N.; Morrison, E.W. I do not need feedback! Or do I? Self-efficacy, perspective taking, and feedback seeking. J. Appl. Psychol. 2020, 105, 146–165. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhang, Z.; Jia, M. Understanding how leader humility enhances employee creativity: The roles of perspective taking and cognitive reappraisal. J. Appl. Behav. Sci. 2017, 53, 5–31. [Google Scholar] [CrossRef]
- Epley, N.; Caruso, E.M.; Bazerman, M.H. When perspective taking increases taking: Reactive egoism in social interaction. J. Personal. Soc. Psychol. 2006, 91, 872–889. [Google Scholar] [CrossRef]
- Kampis, D.; Southgate, V. Altercentric cognition: How others influence our cognitive processing. Trends Cogn. Sci. 2020, 24, 945–959. [Google Scholar] [CrossRef]
- Surtees, A.; Apperly, I.; Samson, D. The use of embodied self-rotation for visual and spatial perspective-taking. Front. Hum. Neurosci. 2013, 7, 698. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Wang, N.; Geng, H.; Zhang, S. Mentalizing another’s visual world—A novel exploration via motion aftereffect. Front. Psychol. 2017, 8, 1535. [Google Scholar] [CrossRef] [PubMed]
- Ward, E.; Ganis, G.; Bach, P. Spontaneous vicarious perception of the content of another’s visual perspective. Curr. Biol. 2019, 29, 874–880. [Google Scholar] [CrossRef]
- Galinsky, A.D.; Ku, G.; Wang, C.S. Perspective-taking and self-other overlap: Fostering social bonds and facilitating social coordination. Group Process. Intergroup Relat. 2005, 8, 109–124. [Google Scholar] [CrossRef]
- Ernst, M.O.; Bulthoff, H.H. Merging the senses into a robust percept. Trends Cogn. Sci. 2004, 8, 162–169. [Google Scholar] [CrossRef]
- Qi, Y.; Chen, Q.; Lin, F.; Liu, Q.; Zhang, X.; Guo, J.; Qiu, L.; Gao, T. Comparative study on birdsong and its multi-sensory combinational effects on physio-psychological restoration. J. Environ. Psychol. 2022, 83, 101879. [Google Scholar] [CrossRef]
- Labat, H.; Vallet, G.; Magnan, A.; Ecalle, J. Facilitating effect of multisensory letter encoding on reading and spelling in 5-year-old children. Appl. Cogn. Psychol. 2015, 29, 381–391. [Google Scholar] [CrossRef]
- Lange, E.B.; Fünderich, J.; Grimm, H. Multisensory integration of musical emotion perception in singing. Psychol. Res. 2022, 86, 2099–2114. [Google Scholar] [CrossRef]
- Spence, C. Crossmodal spatial attention. Ann. N. Y. Acad. Sci. 2010, 1191, 182–200. [Google Scholar] [CrossRef]
- Stein, B.E.; Stanford, T.R. Multisensory integration: Current issues from the perspective of the single neuron. Nat. Rev. Neurosci. 2008, 9, 255–266. [Google Scholar] [CrossRef]
- Spence, C.; Lloyd, D.; McGlone, F.; Nicholls, M.E.; Driver, J. Inhibition of return is supramodal: A demonstration between all possible pairings of vision, touch, and audition. Exp. Brain Res. 2000, 134, 42–48. [Google Scholar] [CrossRef]
- Baumann, O.; Greenlee, M.W. Neural correlates of coherent audiovisual motion perception. Cereb. Cortex 2006, 17, 1433–1443. [Google Scholar] [CrossRef]
- Kayser, S.J.; Philiastides, M.G.; Kayser, C. Sounds facilitate visual motion discrimination via the enhancement of late occipital visual representations. NeuroImage 2017, 148, 31–41. [Google Scholar] [CrossRef]
- Lewis, J.W.; Beauchamp, M.S.; Deyoe, E.A. A comparison of visual and auditory motion processing in human cerebral cortex. Cereb. Cortex 2000, 10, 873–888. [Google Scholar] [CrossRef]
- Alink, A.; Singer, W.; Muckli, L. Capture of auditory motion by vision is represented by an activation shift from auditory to visual motion cortex. J. Neurosci. 2008, 28, 2690–2697. [Google Scholar] [CrossRef]
- Getzmann, S.; Lewald, J. Modulation of auditory motion processing by visual motion: Early cross-modal interactions in human auditory cortices. J. Psychophysiol. 2014, 28, 82–100. [Google Scholar] [CrossRef]
- Cavallo, A.; Ansuini, C.; Capozzi, F.; Tversky, B.; Becchio, C. When far becomes near: Perspective taking induces social remapping of spatial relations. Psychol. Sci. 2017, 28, 69–79. [Google Scholar] [CrossRef]
- Michelon, P.; Zacks, J.M. Two kinds of visual perspective taking. Percept. Psychophys. 2006, 68, 327–337. [Google Scholar] [CrossRef] [PubMed]
- Todd, A.R.; Simpson, A.J.; Cameron, C.D. Time pressure disrupts level-2, but not level-1, visual perspective calculation: A process-dissociation analysis. Cognition 2019, 189, 41–54. [Google Scholar] [CrossRef]
- Zhou, J.; Peng, Y.; Li, Y.; Deng, X.; Chen, H. Spontaneous perspective taking of an invisible person. J. Exp. Psychol. Hum. Percept. Perform. 2022, 48, 1186–1200. [Google Scholar] [CrossRef]
- Kessler, K.; Thomson, L.A. The embodied nature of spatial perspective taking: Embodied transformation versus sensorimotor interference. Cognition 2010, 114, 72–88. [Google Scholar] [CrossRef]
- Martin, A.K.; Kessler, K.; Cooke, S.; Huang, J.; Meinzer, M. The right temporoparietal junction is causally associated with embodied perspective-taking. J. Neurosci. 2020, 40, 3089–3095. [Google Scholar] [CrossRef]
- Wang, H.; Callaghan, E.; Gooding-Williams, G.; McAllister, C.; Kessler, K. Rhythm makes the world go round: An MEG-TMS study on the role of right TPJ theta oscillations in embodied perspective taking. Cortex 2016, 75, 68–81. [Google Scholar] [CrossRef]
- Luo, W.Y.; Zhang, S.; Geng, H.Y. Embodied processing during social interactions: From a perspective of self-other shared representation. Chin. Sci. Bull. 2022, 67, 4236–4250. [Google Scholar] [CrossRef]
- Ward, E.; Ganis, G.; McDonough, K.L.; Bach, P. Perspective taking as virtual navigation perceptual simulation of what others see reflects their location in space but not their gaze. Cognition 2020, 199, 104241. [Google Scholar] [CrossRef]
- Ward, E.; Ganis, G.; McDonough, K.L.; Bach, P. Is implicit Level-2 visual perspective-taking embodied? Spontaneous perceptual simulation of others’ perspectives is not impaired by motor restriction. Q. J. Exp. Psychol. 2022, 75, 1244–1258. [Google Scholar] [CrossRef] [PubMed]
- Becchio, C.; Del Giudice, M.; Dal Monte, O.; Latini-Corazzini, L.; Pia, L. In your place: Neuropsychological evidence for altercentric remapping in embodied perspective taking. Soc. Cogn. Affect. Neurosci. 2013, 8, 165–170. [Google Scholar] [CrossRef]
- Heed, T.; Buchholz, V.N.; Engel, A.K.; Roder, B. Tactile remapping: From coordinate transformation to integration in sensorimotor processing. Trends Cogn. Sci. 2015, 19, 251–258. [Google Scholar] [CrossRef]
- Heed, T.; Röder, B. Common anatomical and external coding for hands and feet in tactile attention: Evidence from event-related potentials. J. Cogn. Neurosci. 2010, 22, 184–202. [Google Scholar] [CrossRef]
- Kelly, J.W.; Avraamides, M.N. Cross-sensory transfer of reference frames in spatial memory. Cognition 2011, 118, 444–450. [Google Scholar] [CrossRef]
- Lappe, M.; Schut, M.J.; Van der Stoep, N.; Van der Stigchel, S. Auditory spatial attention is encoded in a retinotopic reference frame across eye-movements. PLoS ONE 2018, 13, e0202414. [Google Scholar] [CrossRef]
- Cohen, Y.E.; Andersen, R.A. Reaches to sounds encoded in an eye-centered reference frame. Neuron 2000, 27, 647–652. [Google Scholar] [CrossRef]
- Mullette-Gillman, O.A.; Cohen, Y.E.; Groh, J.M. Eye-centered, head-centered, and complex coding of visual and auditory targets in the intraparietal sulcus. J. Neurophysiol. 2005, 94, 2331–2352. [Google Scholar] [CrossRef]
- Pouget, A.; Ducom, J.; Torri, J.; Bavelier, D. Multisensory spatial representations in eye-centered coordinates for reaching. Cognition 2002, 83, B1–B11. [Google Scholar] [CrossRef]
- Lokša, P.; Kopčo, N. Toward a unified theory of the reference frame of the ventriloquism aftereffect. Trends Hear. 2023, 27, 23312165231201020. [Google Scholar] [CrossRef]
- Watson, D.M.; Akeroyd, M.A.; Roach, N.W.; Webb, B.S. Distinct mechanisms govern recalibration to audio-visual discrepancies in remote and recent history. Sci. Rep. 2019, 9, 8513. [Google Scholar] [CrossRef] [PubMed]
- Rohe, T.; Zeise, M.L. Inputs, Outputs, and Multisensory Processing. In Neuroscience for Psychologists: An Introduction; Zeise, M.L., Ed.; Springer: Berlin/Heidelberg, Germany, 2021; pp. 153–192. [Google Scholar]
- Sach, A.J.; Hill, N.I.; Bailey, P.J. Auditory spatial attention using interaural time differences. J. Exp. Psychol. Hum. Percept. Perform. 2000, 26, 717–729. [Google Scholar] [CrossRef]
- Faul, F.; Erdfelder, E.; Buchner, A.; Lang, A.G. Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behav. Res. Methods 2009, 41, 1149–1160. [Google Scholar] [CrossRef]
- Lupiáñez, J.; Milán, E.G.; Tornay, F.J.; Madrid, E.; Tudela, P. Does IOR occur in discrimination tasks? Yes, it does, but later. Percept. Psychophys. 1997, 59, 1241–1254. [Google Scholar] [CrossRef]
- Spence, C.; Driver, J. Audiovisual links in exogenous covert spatial orienting. Percept. Psychophys. 1997, 59, 1–22. [Google Scholar] [CrossRef]
- Liesefeld, H.R.; Janczyk, M. Combining speed and accuracy to control for speed-accuracy trade-offs(?). Behav. Res. Methods 2018, 51, 40–60. [Google Scholar] [CrossRef]
- Qureshi, A.W.; Apperly, I.A.; Samson, D. Executive function is necessary for perspective selection, not Level-1 visual perspective calculation: Evidence from a dual-task study of adults. Cognition 2010, 117, 230–236. [Google Scholar] [CrossRef]
- Turner, B.M.; van Maanen, L.; Forstmann, B.U. Informing cognitive abstractions through neuroimaging: The neural drift diffusion model. Psychol. Rev. 2015, 122, 312–336. [Google Scholar] [CrossRef]
- Cappe, C.; Thut, G.; Romei, V.; Murray, M.M. Selective integration of auditory-visual looming cues by humans. Neuropsychologia 2009, 47, 1045–1052. [Google Scholar] [CrossRef]
- Gleiss, S.; Kayser, C. Oscillatory mechanisms underlying the enhancement of visual motion perception by multisensory congruency. Neuropsychologia 2014, 53, 84–93. [Google Scholar] [CrossRef]
- Kestler, H.A.; May, K.A.; Solomon, J.A. Four theorems on the psychometric function. PLoS ONE 2013, 8, e74815. [Google Scholar] [CrossRef]
- Elekes, F.; Varga, M.; Király, I. Evidence for spontaneous level-2 perspective taking in adults. Conscious. Cogn. 2016, 41, 93–103. [Google Scholar] [CrossRef]
- Freundlieb, M.; Kovács, Á.M.; Sebanz, N. Reading your mind while you are reading—Evidence for spontaneous visuospatial perspective taking during a semantic categorization task. Psychol. Sci. 2018, 29, 614–622. [Google Scholar] [CrossRef]
- Freundlieb, M.; Sebanz, N.; Kovacs, A.M. Out of your sight, out of my mind: Knowledge about another person’s visual access modulates spontaneous visuospatial perspective-taking. J. Exp. Psychol. Hum. Percept. Perform. 2017, 43, 1065–1072. [Google Scholar] [CrossRef]
- Kim, R.; Peters, M.A.K.; Shams, L. 0 + 1 > 1: How adding noninformative sound improves performance on a visual task. Psychol. Sci. 2012, 23, 6–12. [Google Scholar] [CrossRef]
- Tversky, B.; Hard, B.M. Embodied and disembodied cognition: Spatial perspective-taking. Cognition 2009, 110, 124–129. [Google Scholar] [CrossRef]
- Claassen, J.; Bardins, S.; Spiegel, R.; Strupp, M.; Kalla, R. Gravity matters: Motion perceptions modified by direction and body position. Brain Cogn. 2016, 106, 72–77. [Google Scholar] [CrossRef]
- Harris, L.R.; Herpers, R.; Hofhammer, T.; Jenkin, M. How much gravity is needed to establish the perceptual upright? PLoS ONE 2014, 9, e106207. [Google Scholar] [CrossRef]
- Miwa, T.; Hisakata, R.; Kaneko, H. Effects of the gravity direction in the environment and the visual polarity and body direction on the perception of object motion. Vis. Res. 2019, 164, 12–23. [Google Scholar] [CrossRef]
- Nielsen, M.K.; Slade, L.; Levy, J.P.; Holmes, A. Inclined to see it your way: Do altercentric intrusion effects in visual perspective taking reflect an intrinsically social process? Q. J. Exp. Psychol. 2015, 68, 1931–1951. [Google Scholar] [CrossRef]
- Marshall, J.; Gollwitzer, A.; Santos, L.R. Does altercentric interference rely on mentalizing? Results from two level-1 perspective-taking tasks. PLoS ONE 2018, 13, e0194101. [Google Scholar] [CrossRef]
- Chu, S.; Haiyan, G. Dynamic information processing under self and another’s perspectives: A behavioral oscillation study. Acta Psychol. Sin. 2023, 55, 224–236. [Google Scholar]
- Samuel, S.; Salo, S.; Ladvelin, T.; Cole, G.G.; Eacott, M.J. Teleporting into walls? The irrelevance of the physical world in embodied perspective-taking. Psychon. Bull. Rev. 2022, 30, 1011–1019. [Google Scholar] [CrossRef]
- Sandhu, R.; Dyson, B.J. Cross-modal perceptual load: The impact of modality and individual differences. Exp. Brain Res. 2015, 234, 1279–1291. [Google Scholar] [CrossRef]
- Jacoby, O.; Hall, S.E.; Mattingley, J.B. A crossmodal crossover: Opposite effects of visual and auditory perceptual load on steady-state evoked potentials to irrelevant visual stimuli. NeuroImage 2012, 61, 1050–1058. [Google Scholar] [CrossRef]
- Matusz, P.J.; Broadbent, H.; Ferrari, J.; Forrest, B.; Merkley, R.; Scerif, G. Multi-modal distraction: Insights from children’s limited attention. Cognition 2015, 136, 156–165. [Google Scholar] [CrossRef]
- Arnold, G.; Spence, C.; Auvray, M. Taking someone else’s spatial perspective: Natural stance or effortful decentring? Cognition 2016, 148, 27–33. [Google Scholar] [CrossRef]
- Tosi, A.; Pickering, M.J.; Branigan, H.P. Speakers’ use of agency and visual context in spatial descriptions. Cognition 2020, 194, 104070. [Google Scholar] [CrossRef]
- Samuel, S.; Hagspiel, K.; Eacott, M.J.; Cole, G.G. Visual perspective-taking and image-like representations: We don’t see it. Cognition 2021, 210, 104607. [Google Scholar] [CrossRef]
- Cole, G.G.; Samuel, S.; Eacott, M.J. A return of mental imagery: The pictorial theory of visual perspective-taking. Conscious. Cogn. 2022, 102, 103352. [Google Scholar] [CrossRef]
- Cole, G.G.; Millett, A.C. The closing of the theory of mind: A critique of perspective-taking. Psychon. Bull. Rev. 2019, 26, 1787–1802. [Google Scholar] [CrossRef]
- Todd, A.R.; Cameron, C.D.; Simpson, A.J. The goal-dependence of level-1 and level-2 visual perspective calculation. J. Exp. Psychol. Learn. Mem. Cogn. 2020, 47, 948–967. [Google Scholar] [CrossRef]
- Zacks, J.M.; Tversky, B. Multiple systems for spatial imagery: Transformations of objects and bodies. Spat. Cogn. Comput. 2005, 5, 271–306. [Google Scholar] [CrossRef]
- Roelfsema, P.R.; de Lange, F.P. Early visual cortex as a multiscale cognitive blackboard. Annu. Rev. Vis. Sci. 2016, 2, 131–151. [Google Scholar] [CrossRef]
- Avillac, M.; Ben Hamed, S.; Duhamel, J.R. Multisensory integration in the ventral intraparietal area of the macaque monkey. J. Neurosci. 2007, 27, 1922–1932. [Google Scholar] [CrossRef]
- Deneve, S.; Pouget, A. Bayesian multisensory integration and cross-modal spatial links. J. Physiol. 2004, 98, 249–258. [Google Scholar] [CrossRef]
- Pouget, A.; Deneve, S.; Duhamel, J. A computational perspective on the neural basis of multisensory spatial representations. Nat. Rev. Neurosci. 2002, 3, 741–747. [Google Scholar] [CrossRef]
- Duhamel, J.; Avillac, M.; Denève, S.; Olivier, E.; Pouget, A. Reference frames for representing visual and tactile locations in parietal cortex. Nat. Neurosci. 2005, 8, 941–949. [Google Scholar] [CrossRef]
- Gonzales, M.G.; Backer, K.C.; Yan, Y.; Miller, L.M.; Bortfeld, H.; Shahin, A.J. Audition controls the flow of visual time during multisensory perception. iScience 2022, 25, 104671. [Google Scholar] [CrossRef]
- Miller, R.L.; Pluta, S.R.; Stein, B.E.; Rowland, B.A. Relative unisensory strength and timing predict their multisensory product. J. Neurosci. 2015, 35, 5213–5220. [Google Scholar] [CrossRef]
- Dalmaso, M.; Castelli, L.; Galfano, G. Social modulators of gaze-mediated orienting of attention: A review. Psychon. Bull. Rev. 2020, 27, 833–855. [Google Scholar] [CrossRef]
- Brunyé, T.T.; Ditman, T.; Giles, G.E.; Mahoney, C.R.; Kessler, K.; Taylor, H.A. Gender and autistic personality traits predict perspective-taking ability in typical adults. Personal. Individ. Differ. 2012, 52, 84–88. [Google Scholar] [CrossRef]
- Sun, Y.; Fuentes, L.J.; Humphreys, G.W.; Sui, J. Try to see it my way: Embodied perspective enhances self and friend-biases in perceptual matching. Cognition 2016, 153, 108–117. [Google Scholar] [CrossRef]
- Ye, T.; Furumi, F.; Catarino da Silva, D.; Hamilton, A. Taking the perspectives of many people: Humanization matters. Psychon. Bull. Rev. 2020, 28, 888–897. [Google Scholar] [CrossRef]
- Martin, A.K.; Perceval, G.; Davies, I.; Su, P.; Huang, J.; Meinzer, M. Visual perspective taking in young and older adults. J. Exp. Psychol. Gen. 2019, 148, 2006–2026. [Google Scholar] [CrossRef]
- Conson, M.; Mazzarella, E.; Esposito, D.; Grossi, D.; Marino, N.; Massagli, A.; Frolli, A. “Put myself into your place”: Embodied simulation and perspective taking in autism spectrum disorders. Autism Res. 2015, 8, 454–466. [Google Scholar] [CrossRef]
- Pearson, A.; Ropar, D.; Hamilton, A. A review of visual perspective taking in autism spectrum disorder. Front. Hum. Neurosci. 2013, 7, 652. [Google Scholar] [CrossRef]
- Kaiser, E. Consequences of sensory modality for perspective-taking: Comparing visual, olfactory and gustatory perception. Front. Psychol. 2021, 12, 701486. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, G.; Wang, N.; Sun, C.; Geng, H. Embodied Cross-Modal Interactions Based on an Altercentric Reference Frame. Brain Sci. 2024, 14, 314. https://doi.org/10.3390/brainsci14040314
Guo G, Wang N, Sun C, Geng H. Embodied Cross-Modal Interactions Based on an Altercentric Reference Frame. Brain Sciences. 2024; 14(4):314. https://doi.org/10.3390/brainsci14040314
Chicago/Turabian StyleGuo, Guanchen, Nanbo Wang, Chu Sun, and Haiyan Geng. 2024. "Embodied Cross-Modal Interactions Based on an Altercentric Reference Frame" Brain Sciences 14, no. 4: 314. https://doi.org/10.3390/brainsci14040314
APA StyleGuo, G., Wang, N., Sun, C., & Geng, H. (2024). Embodied Cross-Modal Interactions Based on an Altercentric Reference Frame. Brain Sciences, 14(4), 314. https://doi.org/10.3390/brainsci14040314