Abstract
Reconstructing natural stimulus images using functional magnetic resonance imaging (fMRI) is one of the most challenging problems in brain decoding and is also the crucial component of a brain–computer interface. Previous methods cannot fully exploit the information about interactions among brain regions. In this paper, we propose a natural image reconstruction method based on node–edge interaction and a multi–scale constraint. Inspired by the extensive information interactions in the brain, a novel graph neural network block with node–edge interaction (NEI–GNN block) is presented, which can adequately model the information exchange between brain areas via alternatively updating the nodes and edges. Additionally, to enhance the quality of reconstructed images in terms of both global structure and local detail, we employ a multi–stage reconstruction network that restricts the reconstructed images in a coarse–to–fine manner across multiple scales. Qualitative experiments on the generic object decoding (GOD) dataset demonstrate that the reconstructed images contain accurate structural information and rich texture details. Furthermore, the proposed method surpasses the existing state–of–the–art methods in terms of accuracy in the commonly used n–way evaluation. Our approach achieves 82.00%, 59.40%, 45.20% in n–way mean squared error (MSE) evaluation and 83.50%, 61.80%, 46.00% in n–way structural similarity index measure (SSIM) evaluation, respectively. Our experiments reveal the importance of information interaction among brain areas and also demonstrate the potential for developing visual–decoding brain–computer interfaces.
1. Introduction
Understanding the neural mechanisms of the human visual system is a hot topic in neuroscience. When the visual system receives external stimuli, the human brain encodes the information and produces specific neural responses. Human visual decoding aims to establish the mapping from the given brain activity to the input stimulus information [1,2]. Functional magnetic resonance imaging (fMRI) indirectly reflects the neuron population response by measuring the local variation in the blood oxygen level. Due to the non–invasive and high–spatial–resolution properties, fMRI is widely used in human visual decoding [1,2]. According to the task, human visual decoding research can be divided into three categories: semantic classification [3], image recognition [4], and image reconstruction [2]. The aim of semantic classification is to predict the stimulus category from brain activity. Image recognition requires the model to identify the seen image from a set of candidate stimuli. Due to the complexity and the low signal–to–noise ratio (SNR) property of the fMRI signal, image reconstruction is the most challenging task, intending to reconstruct the entire stimulus from the brain activity pattern. Developing a natural image reconstruction model can theoretically help us to understand how the brain encodes stimulus information, while practically exploring potential solutions for brain–computer interfaces.
Traditional image reconstruction methods rely on machine learning tools such as linear regression [5,6], Bayesian modeling [7,8], and principle component analysis [9] to estimate the pixel values or hand–crafted features from the fMRI. These methods can decode simple stimulus images, such as letters and numbers. However, when applied to complex natural scenes, these algorithms often fail to produce faithful reconstructions due to the simplicity of the models.
With the rapid development of deep neural networks, deep–learning–based image reconstruction methods have been proposed [2,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25]. These approaches are classified into two categories: approximation–based approaches [10,11,12,13,14,15,16,17,18] and generation–based approaches [19,20,21,22,23,24,25]. Approximation–based approaches aim to improve the pixel–level similarity between the stimulus and the reconstruction via training well–designed networks from scratch, while generation–based approaches aim to improve the semantic–level consistency by utilizing the powerful pre–trained generative models such as generative adversarial network (GAN), variational autoencoder (VAE), and diffusion model (DM).
Although significant progress has been made in deep–learning–based image reconstruction methods, there is still room for improvement in several aspects. Firstly, the input fMRI signals originate from different brain regions, and there are extensive information interactions between these areas in the underlying mechanisms of the visual system. However, previous studies merely consider the fMRI signals from different regions as a whole high–dimensional vector input of the reconstruction model [11,12,13,14,15,16,17,18,19,20,21,22,23,24,25], which neglects the nature of information exchange that should be considered during the processing. As a result, the limited extracted features lead to poor performance of the model. Secondly, the information contained within an image at multiple scales has a powerful expressive capability. Lower–resolution scales provide the global image structure and higher–resolution scales describe the fine image details. Previous single–scale approaches are insufficient for fully exploiting image information [10,11,12,13,14,15,16,17,19,20,21,22,23,24,25], resulting in blurry reconstructed images under the situation of limited training samples.
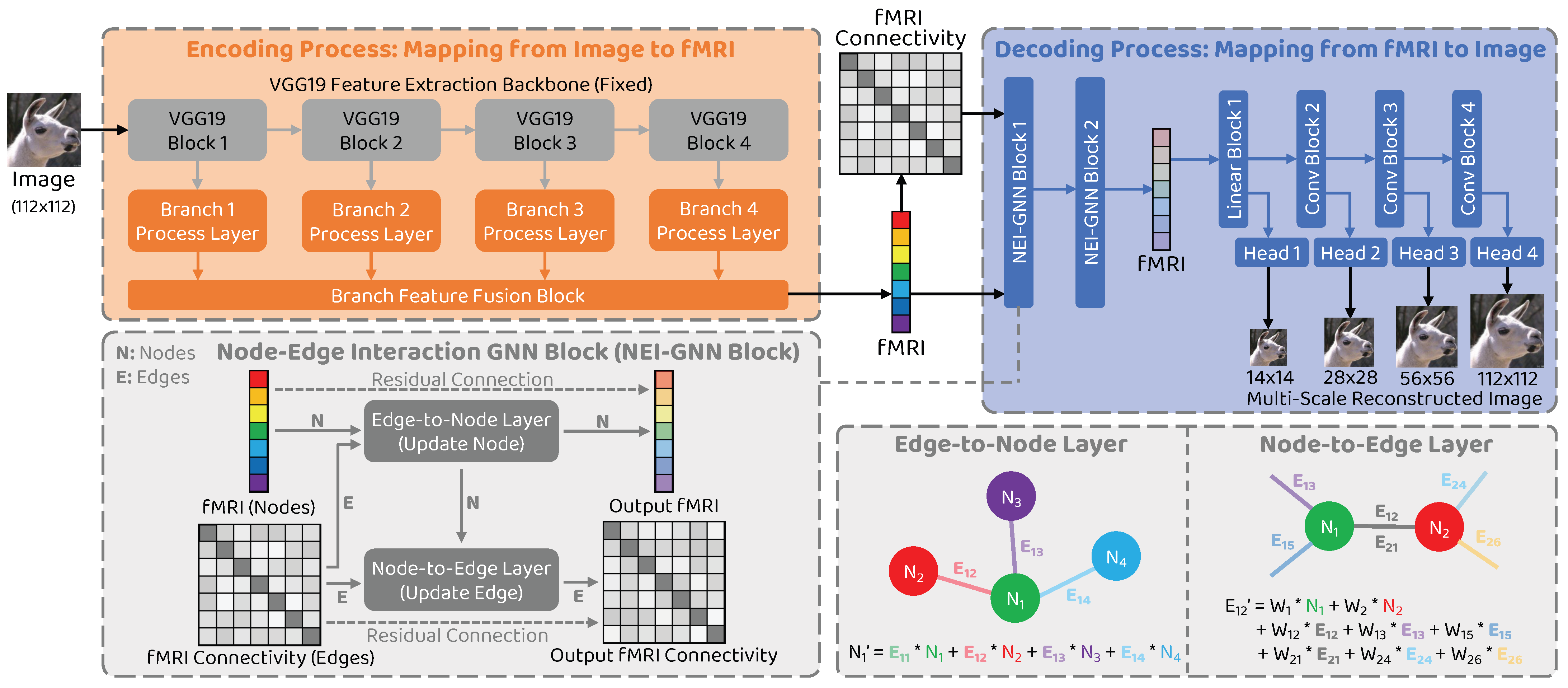
Driven by the preceding limitation analysis, we propose a novel natural image reconstruction approach to recover the seen image from the given fMRI brain activity that incorporates node–edge interaction in the graph network to fully model the interactions between different brain regions and introduces multi–scale constraint to improve the reconstructed image quality. Our approach is shown in Figure 1. Following the encoder–decoder methods [11,12,13], two types of model are trained: an encoding model to map from stimulus image to corresponding fMRI activity and a decoding model to map from fMRI signal to the seen image. To overcome the limitation of neglecting information interactions, we consider individual brain regions as nodes and connectivity between them as edges in the graph and develop a novel graph neural network block with node–edge interaction (NEI–GNN block) to model the interactions. Additionally, a multi–scale decoding model is employed to restrict the reconstructed image at various scales, thereby promoting global structure similarity and local detail consistency simultaneously.
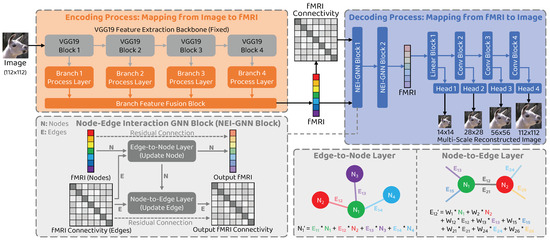
Figure 1.
Overview of the proposed approach. The proposed framework comprises two processes: the encoding process and the decoding process. The graph neural network block with node–edge interaction (NEI–GNN block) with edge–to–node and node–to–edge layers models the interaction among brain regions via alternatively updating nodes and edges in the graph. The final reconstructed image is produced by the multi–scale reconstruction network.
Our contributions are as follows: (1) We propose a novel natural image reconstruction approach to recover the seen image from the given fMRI brain activity that incorporates node–edge interaction in the graph network to fully model the interactions between different brain regions and introduces multi–scale constraint to improve the reconstructed image quality in terms of global structure and local detail. (2) To overcome the limitation of neglecting information interactions in the previous study, we consider individual brain regions as nodes and connectivity between them as edges in the graph and develop a novel NEI–GNN block to model the interactions. By stacking multiple NEI–GNN blocks, the high–order long–range dependencies can be captured without introducing additional computational overhead in a single NEI–GNN block. (3) Additionally, a multi–scale decoding model is employed to restrict the reconstructed image at various scales, thereby promoting global structure similarity and local detail consistency simultaneously in a coarse–to–fine manner. (4) Extensive qualitative and quantitative experiments on a publicly available dataset demonstrate the superiority of the proposed methods in terms of visual inspection and objective assessments. In the subjective inspection, the reconstructions obtained by our model successfully retain accurate contours and produce abundant texture details. In the objective evaluation, our method surpasses the existing state–of–the–art methods in the commonly used n–way evaluation metrics.
2. Related Work
2.1. Natural Image Reconstruction Methods Based on Deep Learning
2.1.1. Approximation–Based Methods
Approximation–based methods often involve designing the effective network and training the model from scratch, without relying on excessive pre–trained components. The characteristic of these methods is high pixel–level similarity. Three types of implementations can be divided: (1) Iterative optimization. Shen et al. [10] estimated the reconstructed image by continuously iterating the image with the objective of minimizing the distance between the features of the reconstructed image and the features decoded from fMRI. (2) Autoencoder. Beliy et al. [11] utilized the encoder–decoder structure to integrate self–supervised learning (SSL) into the decoding model. The encoder learns the mapping from image to fMRI, while the decoder learns the mapping from fMRI to image. By stacking the encoder and decoder, the model can be trained in an SSL manner using unlabeled data. Gaziv et al. [12] and Qiao et al. [13] further improved this method via multi–level feature similarity loss and alternative encoder–decoder regularization, respectively. (3) Generative adversarial network. Seeliger et al. [14] employed the DCGAN as the generator and trained a conversion network to transfer the fMRI activity to the input latent variable of the generator. Shen et al. [15] achieved end–to–end image reconstruction training using image, feature, and adversarial loss. Fang et al. [16] proposed Shape–Semantic GAN, with a shape decoder to decode the shape from low–level visual areas and a semantic decoder to decode the category from high–level visual regions. The outputs from the shape and semantic decoders were used as inputs to an image generation network to reconstruct the stimulus. Ren et al. [17] utilized a dual–path VAE–GAN network structure and trained the model using the knowledge distillation paradigm. Meng et al. [18] adopted a hierarchical network for image feature extraction and reconstruction, combining an fMRI decoder to produce intermediate features for the network to obtain faithful reconstructions.
2.1.2. Generation–Based Methods
Generation–based methods often exploit powerful pre–trained generative models, combine relatively simple fMRI decoders to convert the brain activity to the input or intermediate variables of the generative models, or obtain reconstructions with high semantic–level consistency via the strong generation ability. Two types of implementations can be divided: (1) Generative adversarial network. Mozafari et al. [19] trained a vanilla linear regression model as an fMRI decoder to learn the mapping from fMRI to the input latent variables of the pre–trained BigBiGAN [26]. Reconstructions with high fidelity were obtained by combining the above components. Ozcelik et al. [20] further enhanced this model with another powerful model called ICGAN [27]. Lin et al. [21] utilized the pre–trained CLIP model [28] to extract image and text features from the stimulus image and corresponding caption. An fMRI decoder comprising convolutional operations and linear layers was employed to align the fMRI activity to the CLIP feature space via contrastive learning. Finally, a pre–trained StyleGAN2 [29] was adopted to achieve stimulus image reconstruction. (2) Diffusion model. Chen et al. [22] trained an fMRI feature extraction model using the masked signal modeling learning paradigm [30] and used the fMRI features as the conditional inputs to fine–tune the pre–trained latent diffusion model (LDM) [31]. Ni et al. [23] optimized the implementation of masked signal modeling to further improve the image quality. Meng et al. [24] developed a vanilla linear network to map the fMRI signal to the features extracted by the pre–trained CLIP model [28]. The decoded features were then combined with the reverse process of LDM [31] to produce reconstructions. Lu et al. [25] adopted an LDM [31] to obtain initial reconstruction and then iteratively updated the input variables with the objective of structural similarity between the reconstruction and the corresponding groundtruth.
2.2. Graph Neural Network
A graph is a kind of data structure consisting of objects (nodes) and the relationships between them (edges). It is used to represent data in non–Euclidean spaces such as social networks, knowledge dependencies, and so on. Graph neural network (GNN) is a deep learning model that extracts features from the topological information of graphs via information exchange between the nodes and has shown promising results in a variety of node–, edge– and graph–level tasks [32]. In fMRI activity, brain regions and the functional connectivity between them exhibit an explicit graph structure. Therefore, some researchers have attempted to incorporate GNN into the processing model. Kawahara et al. [33] proposed BrainNetCNN for neurodevelopment prediction using novel edge–to–edge, edge–to–node, and node–to–graph layers to capture the topological relationship between brain areas. Li et al. [34] further advanced this approach by introducing multi–order path information aggregation. Meng et al. [35] developed a visual stimulus category decoding model based on the graph convolutional neural network, which is used to extract the functional correlation features between different brain regions. Saeidi et al. [36] employed a graph neural network to decode task–fMRI data, combining a graph convolutional operation and various node embedding algorithms. However, previous approaches based on graph neural network have focused solely on either nodes or edges, neglecting the importance of interactions between them, which restricts the expressive power of the model. In our work, the limitation mentioned above has been taken into consideration, resulting in the proposed novel NEI–GNN block, which highlights the interactions between nodes and edges.
2.3. Multi–Scale Constraint
In modern convolutional neural networks, the feature extraction process is typically divided into several stages to extract multi–scale features from images [37]. Features with high resolution contain fine details, while features with low resolution provide coarse image structure. By adding multi–scale constraint to the network, the model can effectively utilize the information at different levels, resulting in improved performance and robustness. For instance, SSD [38] advanced the object detection system performance by predicting on feature maps of various scales simultaneously. DeepLabV3+ [39] boosted the semantic segmentation accuracy by integrating local and global embedding through the atrous convolution and multi–scale feature fusion module. In the field of natural image reconstruction from brain activity, Miyawaki et al. [5] reconstructed the arbitrary binary contrast patterns by separately predicting on predefined multi–scale local image bases. Luo et al. [40] proposed DA–HLGN–MSFF, which combines the hierarchical feature extraction and multi–scale feature fusion block to improve the reconstruction performance. Meng et al. [18] exploited a similar multi–scale encoder–decoder architecture to achieve promising natural image reconstruction. Inspired by Miyawaki et al. [5], our work introduces multi–scale constraint to natural image reconstruction and establishes the joint optimization between scales, instead of a separate restraint on each scale, as in [5].
3. Materials and Methods
3.1. Dataset
In this study, the experiment was conducted on the generic object decoding (GOD) dataset [3], which is used to fully evaluate the visual image reconstruction performance. The GOD dataset consists of stimulus images from ImageNet [41] and the corresponding fMRI recordings of five subjects. The fMRI SNR values for the five subjects are 0.0649, 0.0613, 0.1045, 0.0924, and 0.0654. It should be noted that the categories of the 1200 training images do not overlap with the categories of the 50 testing images. Each training image was presented once, while each testing image was presented 35 times. To obtain multi–resolution stimulus images, the original 112 × 112 images were downsampled using cubic interpolation. Seven regions of interest (ROI) were used, containing V1, V2, V3, V4, LOC, FFA, and PPA, each with a varying number of voxels. The V1–V4 are identified via the standard retinotopy experiment, and the LOC, FFA, and PPA are delineated using the functional localizers that capture the voxels with significantly higher activations to objects, faces, or scenes than the scrambled images. The voxel numbers for each ROI of the five subjects are as follows: Subject 1—1004, 1018, 759, 740, 540, 568, and 356; Subject 2—757, 944, 810, 544, 834, 435, and 316; Subject 3—872, 1031, 861, 754, 996, 928, and 496; Subject 4—719, 855, 929, 704, 668, 725, and 398; Subject 5—659, 891, 907, 860, 566, 929, and 550. To eliminate the dimension discrepancy, the fMRI vectors of different ROIs were padded with values close to zero to align them. Refer to the original paper of GOD [3] for more details.
3.2. Model Overview
The overall structure of the proposed network is illustrated in Figure 1. We denote I and F to represent the image data and the corresponding fMRI data, respectively. Our framework comprises two processes: the encoding process , which maps a stimulus image to the corresponding fMRI activity (), and the decoding process , which reconstructs the entire seen image from the given brain signal (). The aim of developing the encoding model is to promote the decoding model by stacking them together and training them in a self–supervised manner using unlabeled image data. To address the issue of ignoring the interactions between brain areas, we introduce a novel NEI–GNN block to model the information exchange between the brain regions, considering brain regions as nodes and their connectivity as edges in the graph. Furthermore, the decoding model consists of multiple stages to produce multi–scale reconstructed images. We restrict the reconstructions at various scales to promote the reconstruction performance in a coarse–to–fine fashion.
In the training phase, the input stimulus image is first transferred to the estimated fMRI response via the encoding model, which is described as follows:
where and denote the stimulus image and the estimated corresponding fMRI signal, respectively.
Next, the estimated fMRI activity is separated according to the ROIs, and the initial fMRI connectivity matrix is obtained by taking the dot–product of the fMRI signal from different ROIs, which is described as follows:
where denotes the estimated fMRI connectivity between ROI i and ROI j, denotes the fMRI activity from a specified ROI r, and .
Then, the estimated fMRI activity and connectivity are fed into the NEI–GNN blocks, allowing full information exchange by integrating information from adjacent nodes, which outputs the fMRI signals after interaction. The above process can be described as follows:
Finally, the output multi–scale reconstructed images are acquired via prediction heads of the reconstruction model at different stages, which is described as follows:
where , , , and denote the reconstructed image with 14 × 14, 28 × 28, 56 × 56, and 112 × 112 spatial resolution, respectively.
3.3. Network Structure: Encoder
The structure of the encoder network in the proposed approach is identical to that in the previous study [12]. A pre–trained VGG19 model is employed as the backbone for image feature extraction, without updating its parameters during the training process. The features from the layers relu1_2, relu2_2, relu3_4, and relu4_4 are regarded as multi–branch features. The features of each branch then pass through the branch–specific processing layer, which includes a spatial feature processing module and a channel feature processing module. The output fMRI estimation is obtained by fusing the multi–branch outcomes through the branch feature fusion block. Please refer to the original paper of GazivEncDec [12] for further details.
3.4. Network Structure: Decoder
The decoder comprises two NEI–GNN blocks, along with the multi–stage reconstruction network. Further information on the NEI–GNN block is provided in the following section. To enhance the quality of reconstructed images, we propose the multi–stage reconstruction network that constrains the image in global structure and local detail. This approach differs from the use of multiple models to predict stimulus images at different scales separately [5], as we uniformly constrain multiple scales in a single model. This is achieved by the reconstruction backbone network with multiple scale–specific reconstruction heads. Please refer to Table 1 for the detailed network configuration.

Table 1.
Network configuration of the multi–stage recontruction network in the decoder.
3.5. Network Structure: Node–Edge Interaction GNN (NEI–GNN) Block
The visual system’s underlying brain mechanisms involve numerous brain area information interactions that enable various brain regions to collaborate and achieve complex visual system functions. For instance, the processing of edge information is supported by the interaction between V1 and V2 [42]. The dorsal pathway extensively interacts with the ventral pathway [43]. The above descriptions illustrate the numerous interactions of information in the brain. Functional connectivity is an expression of the interaction between brain regions, indicating the degree of similarity of signals between them [44]. Previous studies have shown that decoding can be accomplished based on either brain area signals [5] or connectivity signals [45], indicating that both types of signals contain effective features. Thus, by combining signals from different brain regions and their connectivity in a specific manner, more comprehensive features can be extracted.
To model the brain area information interaction behaviour, we consider individual brain regions as nodes and the connections between them as edges in the graph, respectively. The NEI–GNN block takes into account not only the nodes and edges in the graph but also the interactions between them. Figure 1 shows the schematic diagram of the module, which is divided into an edge–to–node layer and a node–to–edge layer. The functions of each layer are described below in detail.
In the edge–to–node layer, each node value after interaction is obtained by aggregating the values of itself and its directly adjacent nodes, using the edges as weights. This is calculated using the following equation:
where denotes the vector of the fMRI from a specified ROI r and is a scalar and denotes the connectivity between the ROI i and j.
In the node–to–edge layer, each edge value after interaction is computed by collecting the values of itself, its directly related nodes, and their edges. Learnable parameters are used to fuse this information, and the calculation is performed using the following equation:
where denotes the learnable vector used to weight the voxel activations in , and denotes the learnable scalar used to weight the connectivity between ROI and . The first two terms compute the contribution of the vertexes by calculating the dot–product of the learnable vector and the corresponding node data, and the following two terms determine the contribution of the adjacent edges.
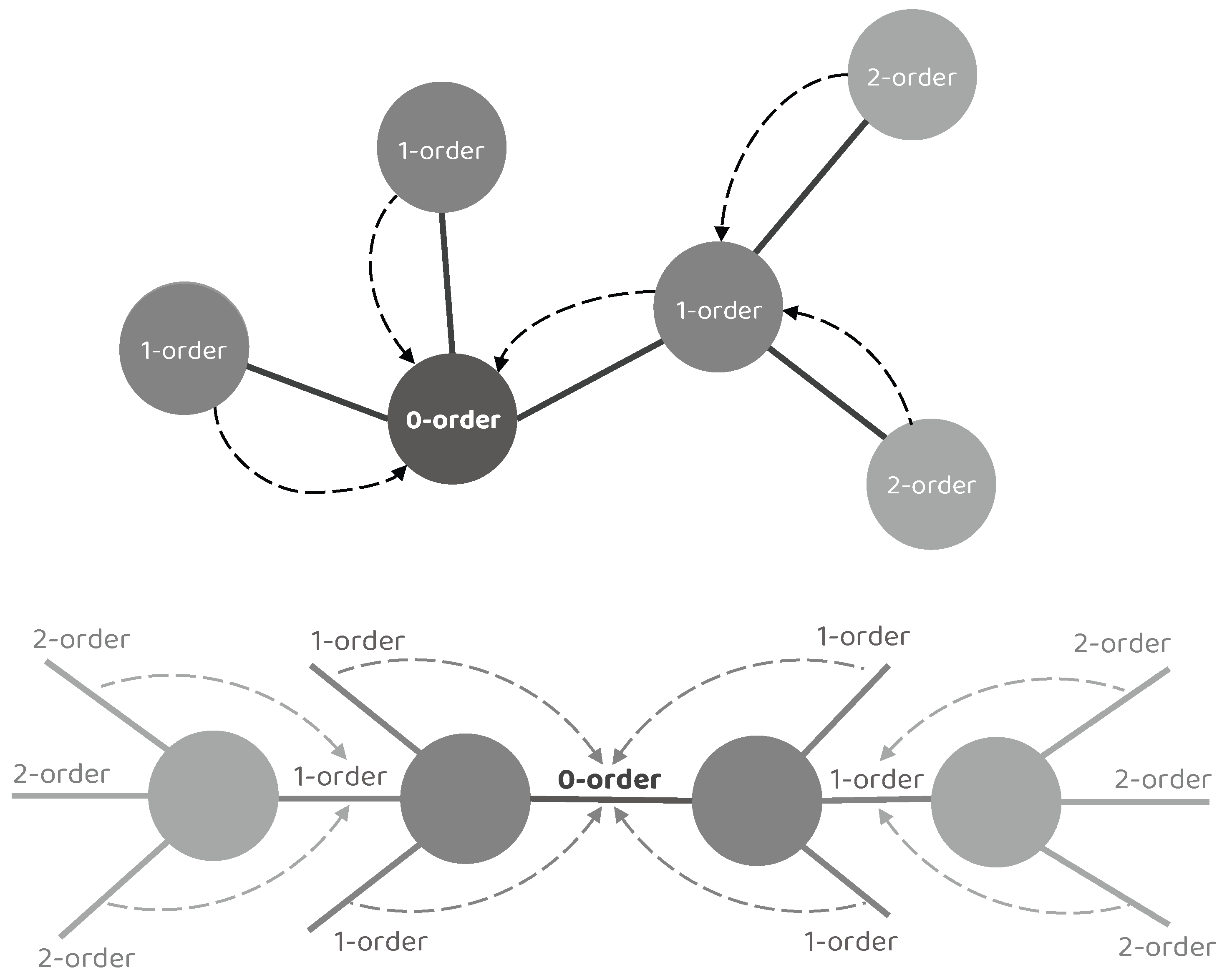
Concretely, we denote the target node/edge to be updated as a 0–order node/edge, its adjacent node/edge as a 1–order node/edge, the adjacent node/edge of the 1–order node/edge as a 2–order node/edge, and so on. It is worth noting that a single NEI–GNN block only gathers the information from adjacent nodes or edges, resulting in limited information utilization of merely 0–order and 1–order collection. However, numerous indirect connections also exhibit significant impact. By stacking multiple NEI–GNN blocks together, the high–order long–range dependencies can be captured without introducing additional computational overhead in a single NEI–GNN block, as the high–order node/edge information could be aggregated by the 1–order node/edge in the previous NEI–GNN block. Figure 2 illustrates the aforementioned concept.
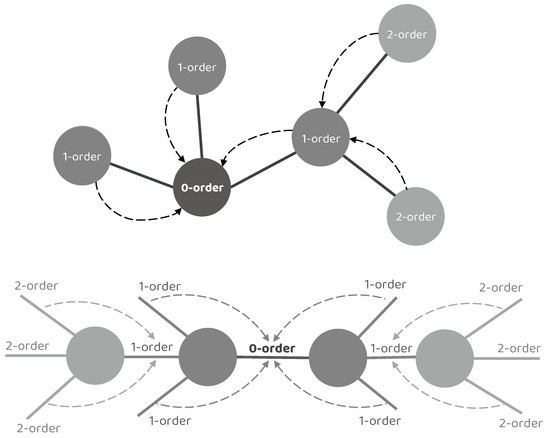
Figure 2.
Illustration of the high–order interaction modeling by stacking multiple NEI–GNN blocks. A single NEI–GNN block only gathers the information from adjacent nodes or edges, resulting in limited information utilization of merely 0–order and 1–order collection. By stacking multiple NEI–GNN blocks together, the high–order node/edge information could first be aggregated by the 1–order node/edge in the previous NEI–GNN block, then the high–order long–range dependencies can be captured by the following NEI–GNN blocks.
3.6. Training Strategy
The training process of the proposed network is mainly divided into two phases, the encoder training phase and the decoder training phase, as illustrated in Figure 3. All experiments in this paper are conducted using an Intel 12700KF CPU and an NVIDIA RTX3080 GPU with 12GB memory. The proposed network is implemented using PyTorch 1.7.1, with an overall training time of approximately 3 h.
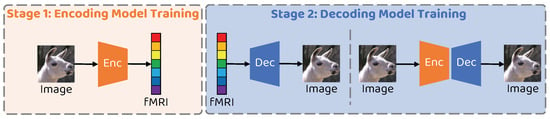
Figure 3.
Schematic illustration of the two–stage training strategy of the proposed method.
3.6.1. Training Stage 1: Encoder Training
During the encoder training stage, supervised training is used with image–fMRI paired data. The stimulus images serve as the encoder input, and the corresponding fMRI records are used as the training labels. The loss function consists of the mean squared error loss and the cosine similarity loss [46], as shown below:
where N denotes the number of elements in the fMRI data and and denote the estimated and groundtruth fMRI data, respectively.
3.6.2. Training Stage 2: Decoder Training
During the decoder training phase, the encoder’s parameters remain fixed and are not updated. The training objectives consist of two parts: (1) Supervised training using paired fMRI–image data. The fMRI signals are used as inputs to the decoder, while the corresponding images are used as labels. (2) Self–supervised training using unlabeled image data by stacking the encoder and decoder to form an autoencoder architecture. The loss function of the above two parts consists of the mean absolute error loss, the perceptual loss [47], and the total variation loss [48], as illustrated below:
where H and W denote the height and width, respectively, of the images or feature maps, L denotes the total number of layers used to calculate the perceptual loss, denotes the fixed VGG16 feature extraction network, and and denote the estimated and groundtruth image data, respectively. Note that the perceptual loss is only applied to restrict the 112 × 112 scale, while the other losses are applied to all scales.
3.7. Evaluation Metric
We use the n–way metric to fully evaluate the performance of the model, which is commonly used in the field of natural image reconstruction from fMRI activity [2]. For each target test stimulus image, N–1 different stimulus images are randomly selected together to form a set of N candidate images. The similarity function between the reconstructed image and each candidate image is then calculated. If the similarity value between the reconstructed image and the target test groundtruth is equal to or even more optimal than any similarity values between the reconstructed image and other candidate images, this test stimulus image is regarded as passing the evaluation. The pass rate across all test stimulus images reflects the performance of the reconstruction approach. In our experiment, the values of N are 2, 5, and 10. Mean squared error (MSE) and structural similarity index measure (SSIM) are used as the similarity function. Aiming to reduce the influence of random selection during the evaluation process, the n–way evaluation is repeated 10 times and the average pass rate is denoted as the final “n–way accuracy”.
In addition to the comparison–based n–way evaluation metrics described above, we also employ image–level metrics to evaluate the reconstruction performance in terms of low–level similarity and high–level consistency. Firstly, the raw MSE and SSIM are utilized to measure the low–level similarity between the stimulus and the reconstructions. Secondly, to fully evaluate the performance, following the previous study [49], we employ the pre–trained CLIP model [28] as the high–level feature extractor and measure the high–level consistency by calculating the distance in the CLIP feature space.
4. Results
In this section, we verify the effectiveness of the proposed approach through extensive qualitative and quantitative experiments on the GOD dataset. Firstly, the proposed method is compared with a series of state–of–the–art natural image reconstruction methods in terms of visual inspection and objective assessments. In the following, the ablation experiment results related to the NEI–GNN block and multi–scale constraint are illustrated. Finally, we conduct some analysis experiments to demonstrate the effect of some factors on our method, such as image scale, visual area, and subject. The experiments in this study are mainly conducted on the fMRI data from Subject 3, except for the comparison experiments among different subjects.
4.1. Qualitative and Quantitative Comparison Results
4.1.1. Qualitative Comparison
Figure 4 presents the comparison between the proposed method and seven existing state–of–the–art approaches, including five approximation–based methods (QiaoEncDec [13], GazivEncDec [12], ShenDNNGAN [10], BeliyEncDec [11], and SeeligerDCGAN [14]) and two generation–based methods (ChenMindVis [22] and OzecelikICGAN [20]). As demonstrated in Figure 4, our approach successfully achieves natural image reconstruction from the fMRI activity and exhibits accurate contour similarity and superior texture consistency compared to other approximation–based methods. Despite being inferior to generation–based methods in terms of image naturalness, generation–based methods suffer from strong semantic discrepancy in the resulting images.

Figure 4.
Qualitative comparison between the proposed method and several state–of–the–art methods (Qiao et al., 2022 [13], Gaziv et al., 2022 [12], Shen et al., 2019 [10], Beliy et al., 2019 [11], Seeliger et al., 2018 [14], Chen et al., 2023 [22], and Ozecelik et al., 2022 [20]).
4.1.2. Quantitative Comparison via N–Way Evaluation Metrics
From an objective perspective, quantitative comparisons are conducted using the n–way identification accuracy mentioned above. The results are illustrated in Table 2. The proposed method achieves promising performance in both MSE n–way accuracy and SSIM n–way accuracy, indicating the effectiveness of the NEI–GNN block and multi–scale constraint in realizing faithful visual stimulus reconstruction.
Table 2.
Quantitative comparison between the state–of–the–art methods and the proposed method using n–way evaluation metrics. Higher accuracy means better reconstruction performance. The best results are emphasized in bold.
4.1.3. Quantitative Comparison via Image–Level Metrics
Unlike the comparison–based n–way evaluation metrics, the image–level metrics assess the performance from the perspective of each single image. Table 3 demonstrates the corresponding results. Our method reaches the best results in the raw MSE metric and achieves comparable results in the raw SSIM metric, which exhibits promising performance in terms of low–level similarity. However, due to the approximation–based method nature of the proposed method, the high–level CLIP distance metric obtained by our method still has a gap with that of generation–based methods.
Table 3.
Quantitative comparison between the state–of–the–art methods and the proposed method using image–level evaluation metrics. Lower MSE, higher SSIM, and lower CLIP distance mean better reconstruction performance. The best results are emphasized in bold.
4.2. Ablation Study
4.2.1. Effectiveness of the Node–Edge Interaction GNN Block
Ablation experiments are designed to investigate the role of the proposed novel NEI–GNN block in natural image construction and determine the optimal number of NEI–GNN blocks. As demonstrated in Figure 5, the model with two NEI–GNN blocks produces the best reconstruction results, while the other variants result in more blurry outcomes. It is worth noting that the model without any NEI–GNN blocks outperforms the model with only one NEI–GNN block in certain cases, which can be explained by insufficient modeling of the brain region interaction due to the shallow network. The quantitative results in Table 4 also indicate that K = 2 is the optimal selection for the number of NEI–GNN blocks, which surpasses other variants in n–way accuracies, except for two–way SSIM accuracy, but with comparable metrics. Employing more NEI–GNN blocks degrades the model performance, which can be explained by the over–smooth effect inherent in the deep GNN [50].

Figure 5.
Qualitative comparison between models with different number of NEI–GNN blocks.
Table 4.
Quantitative comparison between models with different number of NEI–GNN block using n–way evaluation metrics. Higher accuracy means better reconstruction performance. The best results are emphasized in bold.
4.2.2. Effectiveness of the Multi–Scale Constraint
Similarly, we remove the constraints on the 14 × 14, 28 × 28, and 56 × 56 scale on the basis of the full method. The obtained results are shown in Figure 6. Without the constraints, on all scales, the reconstructed images suffer from many degradations, such as unclear edges, color distortion, and noisy outcomes, which highlights the significance of the multi–scale restrictions considered in the proposed method.

Figure 6.
Qualitative comparison between models with different multi–scale constraint.
Table 5 presents the corresponding quantitative results of this ablation study. All the leading metrics demonstrate the effectiveness of the multi–scale constraint. Specifically, removing the 56 × 56 scale constraint may not be quite harmful to the performance, while wiping off the restriction on 28 × 28 scale significantly degrades the metrics, which indicates the important role of the intermediate scale.
Table 5.
Quantitative comparison between models with different multi–scale constraint using n–way evaluation metrics. Higher accuracy means better reconstruction performance. The best results are emphasized in bold.
4.3. Effect of Different Scales
In order to analyze the effect of different scales on our method, the multi–scale outcomes are visualized in Figure 7. Several patterns could be recognized in the results: Firstly, reconstructions with higher resolution contain rich detail information, whereas low–resolution reconstructions also capture the global structure of the stimuli. Secondly, the 112 × 112 and 56 × 56 scales share similar characteristics of fine details, while the 28 × 28 and 14 × 14 scales share similar characteristics of accurate coarse structure. From Table 5 and Figure 7, we can infer that the reason the performance of the model without the 28 × 28 scale constraint drops significantly is that the 28 × 28 scale provides crucial overall structure guidance to the model and restricts the reconstructions with sharper contours, compared to the 14 × 14 scale with more blurry outputs.

Figure 7.
Examples of reconstructed images from different scales of the proposed method.
4.4. Effect of Different Visual Areas
Here, we demonstrate how different visual areas influence the reconstruction process. Following the previous studies [12,17] which divide the whole visual cortex into subareas, we define the set of brain regions V1, V2, V3, and V4 as the LVC region; the set of brain regions LOC, FFA, and PPA as the HVC region; and the set of all brain regions mentioned above as the VC region. The fMRI activity from LVC, HVC, and VC are used to train the model. Figure 8 and Table 6 illustrate the subjective and objective comparison experiment results. In Figure 8, the model with the LVC region is able to reconstruct most of the structural information but still lacks enough contrast, while no meaningful information could be observed in the reconstructed images from the model with the HVC region. By comparing the results with those of the full method, it could be inferred that the LVC region encodes more structural features, whereas the HVC region encodes more high–level semantic features that effectively improve the image quality. The quantitative results from Table 6 are also in line with the above analysis, with higher metrics from LVC and lower metrics from HVC but topmost metrics from the whole VC.

Figure 8.
Qualitative comparison between the reconstructed images obtained by models trained using different brain regions.
Table 6.
Quantitative comparison between the reconstructed images obtained by models trained using different brain regions using n–way evaluation metrics. Higher accuracy means better reconstruction performance. The best results are emphasized in bold.
4.5. Effect of Different Subjects
Ultimately, the effect of different subjects is explored by training the model using fMRI activity from various subjects. The SNR of the fMRI signal is a crucial factor behind the subjects. As observed in Figure 9 and Table 7, individuals with higher SNR produce reconstructions that closely resemble the original stimuli. Conversely, as the SNR decreases, the reconstructed images deteriorate, making it more challenging to identify the predominant object in the image.

Figure 9.
Qualitative comparison between the reconstructed images obtained by models trained using fMRI activity from different subjects.
Table 7.
Quantitative comparison between the reconstructed images obtained by models trained using fMRI activity from different subjects using n–way evaluation metrics. Higher accuracy means better reconstruction performance. The best results are emphasized in bold.
5. Discussion
In this paper, we proposed a promising natural image reconstruction method to tackle the problem of reconstructing the visual stimuli from fMRI data. The interactions between different brain regions are modeled via the NEI–GNN blocks, considering not only the nodes and edges in the graph but also the interactions between them. Additionally, we exploit the multi–scale constraint to improve the performance in a coarse–to–fine manner. With the help of the above components, our method outperforms several state–of–the–art methods in both qualitative observation and quantitative evaluation.
Extensive experiments illustrate the superiority of the proposed method. In the subjective inspection, the reconstructions obtained by our model successfully retain accurate contours and produce abundant texture details. In the objective evaluation, our method surpasses the existing approaches in terms of MSE n–way accuracy and SSIM n–way accuracy. What makes the presented model outstanding is mainly attributed to the following reasons: Firstly, we employed the NEI–GNN blocks to fully consider the interactions between brain regions, producing more expressive fMRI features that are helpful for the reconstruction. Furthermore, we restrict the reconstructed images in both structural similarity and texture consistency through the multi–scale constraint, resulting in significant performance improvements.
However, due to the approximation–based nature of the proposed method, our method also suffers from lacking enough semantic information and image fidelity. A potential solution to this limitation is introducing the brain region interaction and multi–scale constraint into the generation–based methods, which holds the promise of obtaining promising reconstructed images with not only abundant structural and semantic information but also high image fidelity. For instance, a decoding network with NEI–GNN blocks could be trained to map the fMRI signal to the latent vector of the pre–trained diffusion models, and the latent vector could be fine–tuned to minimize the similarity between the stimulus and the reconstruction in a multi–scale fashion.
As shown in Figure 9, the variability of the reconstructed images obtained using fMRI data from different subjects is another limitation of the methodology in this paper. Future work aims to improve the image quality of reconstructed images in low–SNR scenarios. One potential solution is to construct a noise estimation network to fully characterize the noise in the fMRI signal [51,52]. By removing the noise properly, it can enhance the model’s performance from a data perspective.
Eventually, the current model represents connections between brain regions using adjacency matrices. With the development of the fMRI acquisition, more detailed brain region delineation could be provided. Using adjacency matrices in the implementation is improper as the graph of brain regions is sparse rather than fully connected. Future work could involve exploring a sparse graph representation that is compatible with existing deep learning frameworks. Although this may not enhance the model’s performance, it will certainly improve the method’s practicality.
6. Conclusions
A novel natural image reconstruction approach based on node–edge interaction and multi–scale constraint is proposed and demonstrates promising performance in reconstructing the seen image from fMRI data. The proposed method considers individual brain regions as nodes and connectivity between them as edges in the graph. Then, our approach leverages the novel NEI–GNN block to fully model the extensive interactions between brain regions. By stacking multiple NEI–GNN blocks, the high–order long–range dependencies can be well–captured. Additionally, we incorporate the multi–scale constraint into the decoding model to enhance the reconstruction quality in terms of both coarse structure and fine detail. Our method has been demonstrated to be superior through qualitative and quantitative experiments. In the aspect of subjective inspection, the reconstructions of the proposed method present accurate contours and abundant texture details. In the aspect of objective evaluation, our approach surpasses the state–of–the–art methods in the commonly used n–way evaluation process. Despite its strengths, there are still some challenges faced by the proposed model. The lack of enough semantic information and image fidelity should be considered, aiming to produce more realistic reconstructions. In addition, the low–SNR scenarios in the fMRI processing should be taken into account to increase the robustness under the circumstances of acquiring multiple fMRI recordings at different periods or by various subjects. Finally, with the increase in brain regions that could be identified, for the method’s practicality, some compatible improvements should be made, such as sparse graph representation. In conclusion, our method holds the potential to develop promising and practical visual decoding models.
Author Contributions
Conceptualization, M.K.; methodology, M.K. and Z.Z.; software, M.K. and Z.Z.; validation, M.K. and Z.Z.; resources, Z.Z.; data curation, M.K. and Z.Z.; writing—original draft preparation, M.K.; writing—review and editing, M.K., Z.Z. and S.G.; project administration, Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Sichuan University Innovation Spark Project (2019SCUH0007).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The fMRI data used in this research are publicly available at [3].
Acknowledgments
We would like to thank the anonymous reviewers for their valuable comments and constructive suggestions that have improved the presentation of this paper. We would like to thank Roman Beliy, Guy Gaziv, Guohua Shen, Furkan Ozcelik, and Zijiao Chen for the open–source code of their work. We would like to thank K. Seeliger and Kai Qiao for the provided experiment results of their work.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Du, B.; Cheng, X.; Duan, Y.; Ning, H. fMRI Brain Decoding and Its Applications in Brain–Computer Interface: A Survey. Brain Sci. 2022, 12, 228. [Google Scholar] [CrossRef] [PubMed]
- Rakhimberdina, Z.; Jodelet, Q.; Liu, X.; Murata, T. Natural image reconstruction from fmri using deep learning: A survey. Front. Neurosci. 2021, 15, 795488. [Google Scholar] [CrossRef] [PubMed]
- Horikawa, T.; Kamitani, Y. Generic decoding of seen and imagined objects using hierarchical visual features. Nat. Commun. 2017, 8, 15037. [Google Scholar] [CrossRef] [PubMed]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef] [PubMed]
- Miyawaki, Y.; Uchida, H.; Yamashita, O.; Sato, M.a.; Morito, Y.; Tanabe, H.C.; Sadato, N.; Kamitani, Y. Visual image reconstruction from human brain activity using a combination of multiscale local image decoders. Neuron 2008, 60, 915–929. [Google Scholar] [CrossRef] [PubMed]
- Schoenmakers, S.; Barth, M.; Heskes, T.; Van Gerven, M. Linear reconstruction of perceived images from human brain activity. NeuroImage 2013, 83, 951–961. [Google Scholar] [CrossRef]
- Naselaris, T.; Prenger, R.J.; Kay, K.N.; Oliver, M.; Gallant, J.L. Bayesian reconstruction of natural images from human brain activity. Neuron 2009, 63, 902–915. [Google Scholar] [CrossRef]
- Fujiwara, Y.; Miyawaki, Y.; Kamitani, Y. Modular encoding and decoding models derived from Bayesian canonical correlation analysis. Neural Comput. 2013, 25, 979–1005. [Google Scholar] [CrossRef]
- Cowen, A.S.; Chun, M.M.; Kuhl, B.A. Neural portraits of perception: Reconstructing face images from evoked brain activity. Neuroimage 2014, 94, 12–22. [Google Scholar] [CrossRef]
- Shen, G.; Horikawa, T.; Majima, K.; Kamitani, Y. Deep image reconstruction from human brain activity. PLoS Comput. Biol. 2019, 15, e1006633. [Google Scholar] [CrossRef]
- Beliy, R.; Gaziv, G.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI. Adv. Neural Inf. Process. Syst. 2019, 32, 6517–6527. [Google Scholar]
- Gaziv, G.; Beliy, R.; Granot, N.; Hoogi, A.; Strappini, F.; Golan, T.; Irani, M. Self-supervised natural image reconstruction and large-scale semantic classification from brain activity. NeuroImage 2022, 254, 119121. [Google Scholar] [CrossRef]
- Qiao, K.; Chen, J.; Wang, L.; Zhang, C.; Tong, L.; Yan, B. Reconstructing natural images from human fMRI by alternating encoding and decoding with shared autoencoder regularization. Biomed. Signal Process. Control. 2022, 73, 103397. [Google Scholar] [CrossRef]
- Seeliger, K.; Güçlü, U.; Ambrogioni, L.; Güçlütürk, Y.; van Gerven, M.A. Generative adversarial networks for reconstructing natural images from brain activity. NeuroImage 2018, 181, 775–785. [Google Scholar] [CrossRef]
- Shen, G.; Dwivedi, K.; Majima, K.; Horikawa, T.; Kamitani, Y. End-to-end deep image reconstruction from human brain activity. Front. Comput. Neurosci. 2019, 13, 21. [Google Scholar] [CrossRef]
- Fang, T.; Qi, Y.; Pan, G. Reconstructing perceptive images from brain activity by shape-semantic gan. Adv. Neural Inf. Process. Syst. 2020, 33, 13038–13048. [Google Scholar]
- Ren, Z.; Li, J.; Xue, X.; Li, X.; Yang, F.; Jiao, Z.; Gao, X. Reconstructing seen image from brain activity by visually-guided cognitive representation and adversarial learning. NeuroImage 2021, 228, 117602. [Google Scholar] [CrossRef]
- Meng, L.; Yang, C. Semantics-guided hierarchical feature encoding generative adversarial network for natural image reconstruction from brain activities. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–9. [Google Scholar]
- Mozafari, M.; Reddy, L.; VanRullen, R. Reconstructing natural scenes from fMRI patterns using bigbigan. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Ozcelik, F.; Choksi, B.; Mozafari, M.; Reddy, L.; VanRullen, R. Reconstruction of perceived images from fmri patterns and semantic brain exploration using instance-conditioned gans. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Lin, S.; Sprague, T.; Singh, A.K. Mind reader: Reconstructing complex images from brain activities. Adv. Neural Inf. Process. Syst. 2022, 35, 29624–29636. [Google Scholar]
- Chen, Z.; Qing, J.; Xiang, T.; Yue, W.L.; Zhou, J.H. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22710–22720. [Google Scholar]
- Ni, P.; Zhang, Y. Natural Image Reconstruction from fMRI Based on Self-supervised Representation Learning and Latent Diffusion Model. In Proceedings of the 15th International Conference on Digital Image Processing, Nanjing, China, 19–22 May 2023; pp. 1–9. [Google Scholar]
- Meng, L.; Yang, C. Dual-Guided Brain Diffusion Model: Natural Image Reconstruction from Human Visual Stimulus fMRI. Bioengineering 2023, 10, 1117. [Google Scholar] [CrossRef]
- Lu, Y.; Du, C.; Zhou, Q.; Wang, D.; He, H. MindDiffuser: Controlled Image Reconstruction from Human Brain Activity with Semantic and Structural Diffusion. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 5899–5908. [Google Scholar]
- Donahue, J.; Simonyan, K. Large scale adversarial representation learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Casanova, A.; Careil, M.; Verbeek, J.; Drozdzal, M.; Romero Soriano, A. Instance-conditioned gan. Adv. Neural Inf. Process. Syst. 2021, 34, 27517–27529. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Kawahara, J.; Brown, C.J.; Miller, S.P.; Booth, B.G.; Chau, V.; Grunau, R.E.; Zwicker, J.G.; Hamarneh, G. BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage 2017, 146, 1038–1049. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Nie, J.; Zhang, G.; Fang, R.; Xu, X.; Wu, Z.; Hu, D.; Wang, L.; Zhang, H.; et al. Brain connectivity based graph convolutional networks and its application to infant age prediction. IEEE Trans. Med. Imaging 2022, 41, 2764–2776. [Google Scholar] [CrossRef]
- Meng, L.; Ge, K. Decoding Visual fMRI Stimuli from Human Brain Based on Graph Convolutional Neural Network. Brain Sci. 2022, 12, 1394. [Google Scholar] [CrossRef]
- Saeidi, M.; Karwowski, W.; Farahani, F.V.; Fiok, K.; Hancock, P.; Sawyer, B.D.; Christov-Moore, L.; Douglas, P.K. Decoding Task-Based fMRI Data with Graph Neural Networks, Considering Individual Differences. Brain Sci. 2022, 12, 1094. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder–decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Luo, J.; Cui, W.; Liu, J.; Li, Y.; Guo, Y.; Xu, S.; Wang, L. Visual Image Decoding of Brain Activities using a Dual Attention Hierarchical Latent Generative Network with Multi-Scale Feature Fusion. IEEE Trans. Cogn. Dev. Syst. 2022, 15, 761–773. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Neumann, H.; Sepp, W. Recurrent V1–V2 interaction in early visual boundary processing. Biol. Cybern. 1999, 81, 425–444. [Google Scholar] [CrossRef]
- Milner, A.D. How do the two visual streams interact with each other? Exp. Brain Res. 2017, 235, 1297–1308. [Google Scholar] [CrossRef]
- Shafi, M.M.; Westover, M.B.; Fox, M.D.; Pascual-Leone, A. Exploration and modulation of brain network interactions with noninvasive brain stimulation in combination with neuroimaging. Eur. J. Neurosci. 2012, 35, 805–825. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Y.; Sun, X.; Wang, Y.; Fang, F. Decoding six basic emotions from brain functional connectivity patterns. Sci. China Life Sci. 2023, 66, 835–847. [Google Scholar] [CrossRef] [PubMed]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Rudin, L.I.; Osher, S. Total variation based image restoration with free local constraints. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 1, pp. 31–35. [Google Scholar]
- Ozcelik, F.; Vanrullen, R. Natural scene reconstruction from fMRI signals using generative latent diffusion. Sci. Rep. 2023, 13, 15666. [Google Scholar] [CrossRef] [PubMed]
- Gasteiger, J.; Bojchevski, A.; Günnemann, S. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv 2018, arXiv:1810.05997. [Google Scholar]
- Yang, Z.; Zhuang, X.; Sreenivasan, K.; Mishra, V.; Curran, T.; Cordes, D. A robust deep neural network for denoising task-based fMRI data: An application to working memory and episodic memory. Med. Image Anal. 2020, 60, 101622. [Google Scholar] [CrossRef]
- Heo, K.S.; Shin, D.H.; Hung, S.C.; Lin, W.; Zhang, H.; Shen, D.; Kam, T.E. Deep attentive spatio-temporal feature learning for automatic resting-state fMRI denoising. NeuroImage 2022, 254, 119127. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).