
Explaining L2 Lexical Learning in Multiple Scenarios: Cross-Situational Word Learning in L1 Mandarin L2 English Speakers

Abstract
1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Stimuli
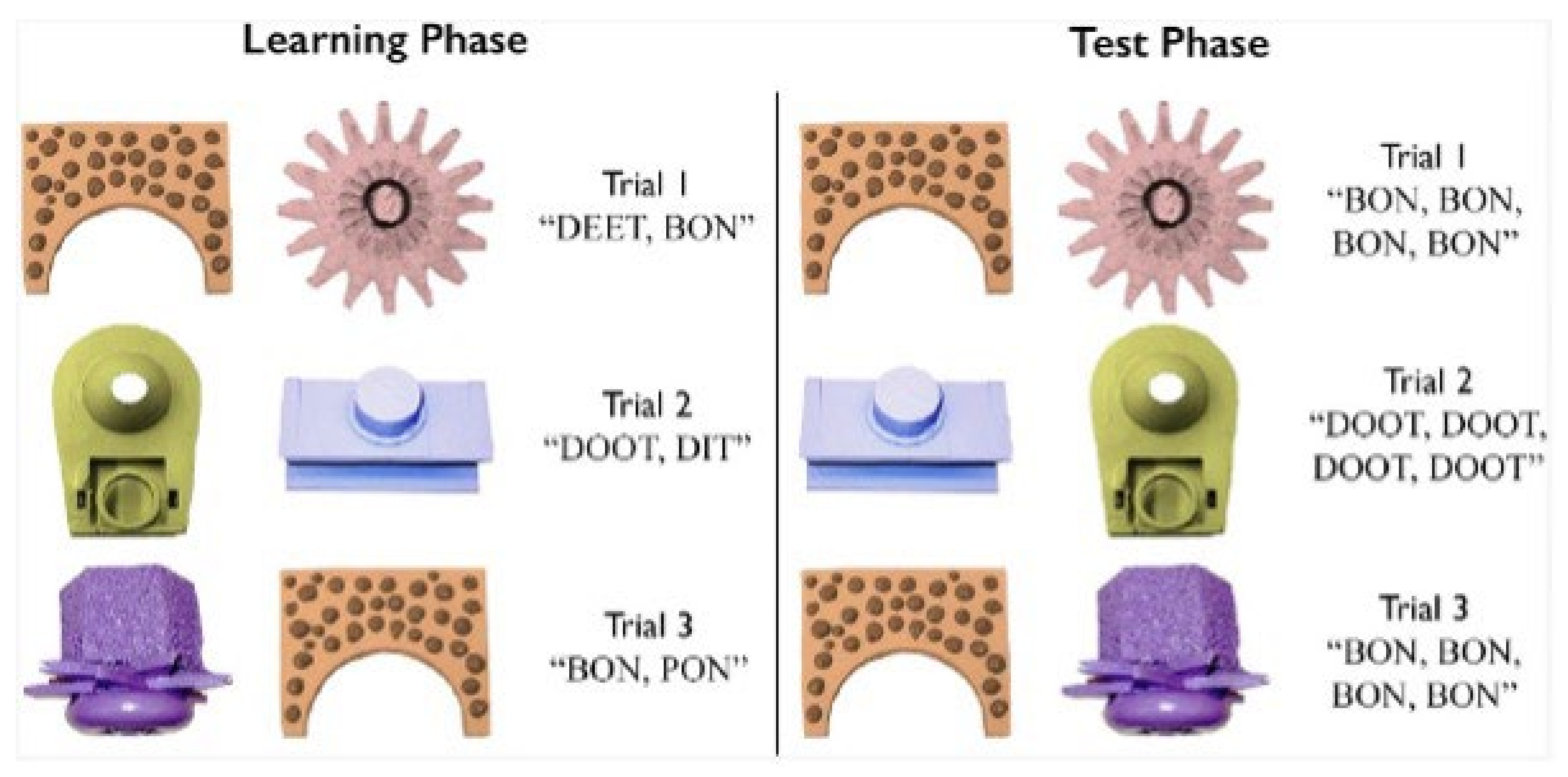
2.2.1. Pseudo Spoken Words
2.2.2. Pseudo Visual Referents
2.3. Procedure
2.4. Statistical Analysis
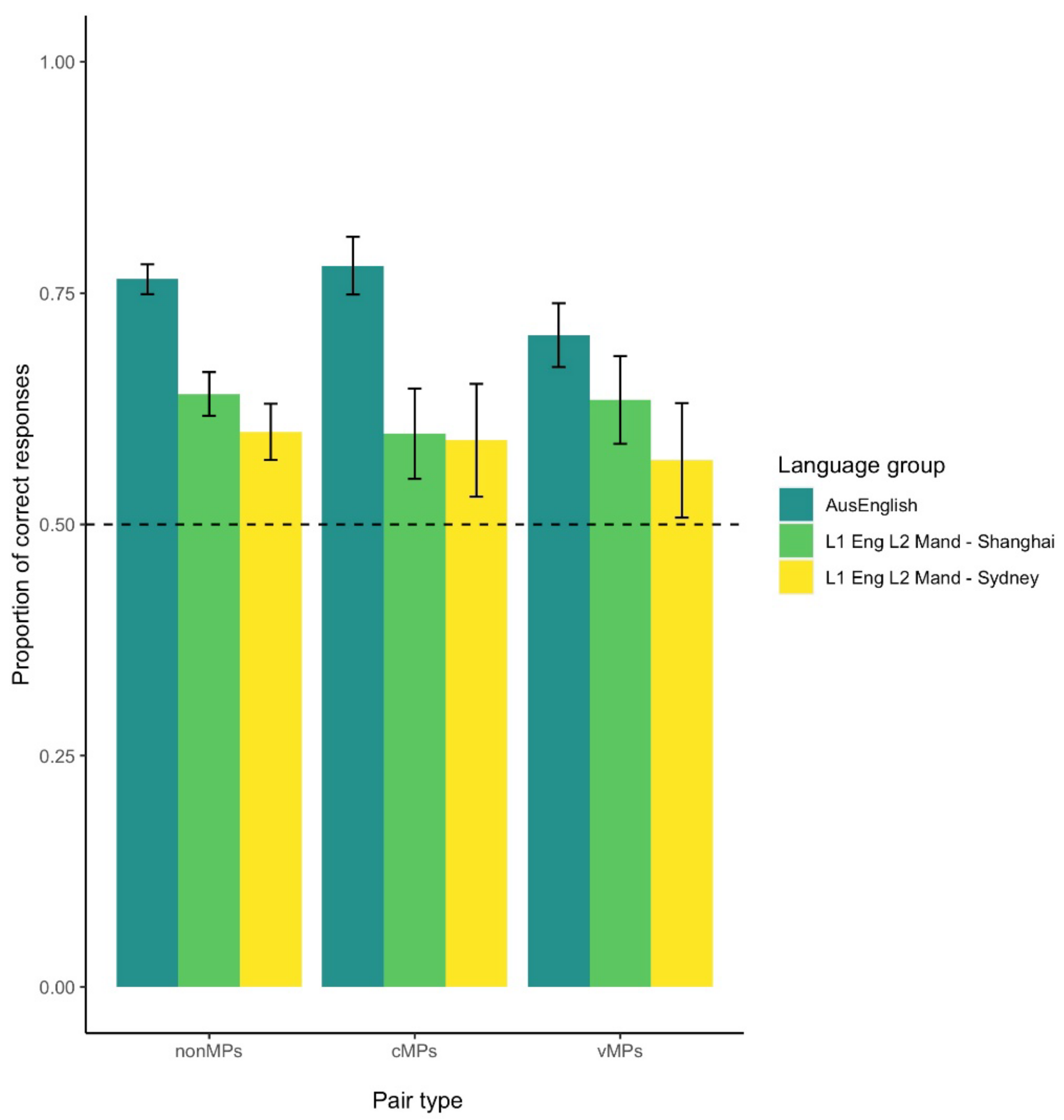
3. Results
Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- DeKeyser, R. The robustness of critical period effects in second language acquisition. Stud. Second Lang. Acquis. 2000, 22, 499–533. [Google Scholar] [CrossRef]
- Johnson, J.S.; Newport, E.I. Critical period effects in second language learning: The influence of maturational state on the acquisition of English as a second language. Cogn. Pyschol. 1989, 21, 60–99. [Google Scholar] [CrossRef] [PubMed]
- Oyama, S. A sensitive period for the acquisition of a nonnative phonological system. J. Psycholinguist. Res. 1976, 5, 261–283. [Google Scholar] [CrossRef]
- Piske, T.; MackKay, I.R.A.; Flege, J.E. Factors affecting degree of foreign accent in an L2: A review. J. Phon. 2001, 29, 191–215. [Google Scholar] [CrossRef]
- Seliger, H.W.; Krashen, S.D.; Ladefoged, P. Maturational constraints in the acquisition of second language accent. Lang. Sci. 1975, 36, 20–22. [Google Scholar]
- Tahta, S.; Wood, M.; Loewenthal, K. Foreign accents: Factors relating to transfer of accent from the first language to a second language. Lang. Speech. 1981, 24, 265–272. [Google Scholar] [CrossRef]
- Jared, D.; Kroll, J.F. Do bilinguals activate phonological representations in one or both of their languages when naming words? J. Mem. Lang. 2001, 44, 2–31. [Google Scholar] [CrossRef]
- Kroll, J.F.; Sunderman, G. Cognitive processes in second language learners and bilinguals: The development of lexical and conceptual representations. In The Handbook of Second Language Acquisition; Doughty, C.J., Long, M.H., Eds.; Blackwell Publishing: Oxford, UK, 2003; pp. 104–129. [Google Scholar]
- Best, C.T.; Tyler, M.D. Nonnative and second-language speech perception: Commonalities and complementaries. In Language Experience in Second Language Speech Learning: In Honor of James Emil Flege; Bohn, O.-S., Munro, M.J., Eds.; John Benjamins: Amsterdam, The Netherlands, 2007; pp. 13–34. [Google Scholar]
- Flege, J.E. Second language speech learning theory, findings and problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research; Strange, W., Ed.; York Press: Timonium, MD, USA, 1995; pp. 229–273. [Google Scholar]
- Escudero, P. Linguistic Perception and Second Language Acquisition: Explaining the Attainment of Optimal Phonological Categorization; Netherlands Graduate School of Linguistics: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Van Leussen, J.-W.; Escudero, P. Learning to perceive and recognize a second language: The L2LP model revised. Front. Psychol. 2015, 6, 1000. [Google Scholar] [CrossRef]
- Escudero, P.; Benders, T.; Lipski, S.C. Native, non-native and L2 perceptual cue weighting for Dutch vowels: The case of Dutch, German and Spanish Listeners. J. Phon. 2009, 37, 452–465. [Google Scholar] [CrossRef]
- Yazawa, K.; Whang, J.; Kondo, M.; Escudero, P. Language-dependent cue weighting: An investigation of perception modes in L2 learning. Second Lang. Res. 2020, 36, 557–581. [Google Scholar] [CrossRef]
- Escudero, P.; Simon, E.; Mulak, K.E. Learning words in a new language: Orthography doesn’t always help. Billing. Lang. Cogn. 2014, 17, 384–395. [Google Scholar] [CrossRef]
- Escudero, P.; Vasiliev, P. Cross-language acoustic similarity predicts perceptual assimilation of Canadian English and Canadian French vowels. J. Acoust. Soc. Am. 2011, 130, EL277. [Google Scholar] [CrossRef]
- Alispahic, S.; Mulak, K.E.; Escudero, P. Acoustic properties predict perception of unfamiliar Dutch vowels by adult Australian English and Peruvian Spanish listeners. Front. Psychol. 2017, 8, 52. [Google Scholar] [CrossRef]
- Lengeris, A. Perceptual assimilation and L2 learning: Evidence from the perception of Southern British English vowels by native speakers of Greek and Japanese. Phonetica 2009, 66, 169–187. [Google Scholar] [CrossRef]
- Boersma, P.; Escudero, P. Learning to perceive a smaller L2 vowel inventory. An optimality theory account. In Contrast in Phonology: Theory, Perception, Acquisition; Avery, P., Dresher, B.E., Rice, K., Eds.; De Gruyter Mouton: Berlin, Germany, 2008; pp. 271–301. [Google Scholar]
- Escudero, P.; Broersma, M.; Simon, E. Learning words in a third language: Effects of vowel inventory and language proficiency. Lang. Cogn. 2013, 28, 746–761. [Google Scholar] [CrossRef]
- Escudero, P. Orthography plays a limited role when learning the phonological forms of new words: The case of Spanish and English learners of novel Dutch vowels. Appl. Psycholinguist. 2015, 36, 7–22. [Google Scholar] [CrossRef]
- Elvin, J.; Williams, D.; Escudero, P. Learning to perceive, produce and recognise words in a non-native language. In Linguistic Approaches to Portuguese as an Additional Language; Molsing, K.V., Perna, C.B.L., Ibaños, A.M.T., Eds.; John Benjamins: Amsterdam, The Netherlands, 2020; pp. 61–82. [Google Scholar]
- Tuninetti, A.; Mulak, K.; Escudero, P. Cross-situational word learning in two foreign languages: Effects of native and perceptual difficulty. Front. Commun. 2020, 5, 602471. [Google Scholar] [CrossRef]
- Yu, C.; Smith, L.B. Rapid word learning under uncertainty via cross-situational statistics. Psychol. Sci. 2007, 18, 414–420. [Google Scholar] [CrossRef]
- Trueswell, J.C.; Medina, T.N.; Hafri, A.; Gleitman, L.R. Propose but verify: Fast mapping meets cross-situational word learning. Cogn. Psychol. 2013, 66, 126–156. [Google Scholar] [CrossRef]
- Escudero, P.; Mulak, K.E.; Fu, C.S.; Singh, L. More limitations to monolingualism: Bilinguals outperform monolinguals in implicit word learning. Front. Psychol. 2016, 7, 1218. [Google Scholar] [CrossRef]
- Escudero, P.; Mulak, K.E.; Vlach, H.A. Cross-situational word learning of minimal word pairs. Cogn. Sci. 2016, 40, 455–465. [Google Scholar] [CrossRef] [PubMed]
- Chen, F.; Wong, M.L.Y.; Zhu, S.; Wong, L.L.N. Relative contributions of vowels and consonants in recognizing isolated Mandarin words. J. Phon. 2015, 52, 26–34. [Google Scholar] [CrossRef]
- Jia, G.; Strange, W.; Wu, Y.; Collado, J. Perception and production of English vowels by Mandarin speakers: Age-related differences vary with amount of L2 exposure. J. Acoust. Soc. Am. 2006, 119, 1118–1130. [Google Scholar] [CrossRef] [PubMed]
- Mi, L.; Tao, S.; Wang, W.; Dong, Q.; Jin, S.-H.; Liu, C. English vowel identification in long-term speech-shaped noise and multi-talker babble for English and Chinese listeners. J. Acoust. Soc. Am. 2013, 113, EL391. [Google Scholar] [CrossRef] [PubMed]
- Tao, S.; Chen, Y.; Wang, W.; Dong, Q. English consonant identification in multi-talker babble: Effects of Chinese-native listeners’ English experience. Lang. Speech 2019, 62, 531–545. [Google Scholar] [CrossRef]
- Flege, J.E. Perception and production: The relevance of phonetic input to L2 phonological learning. In Cross Currents in Second Language Acquisition and Linguistic Theory; Huebner, T., Ferguson, A.C., Eds.; John Benjamins: Amsterdam, The Netherlands, 1991; pp. 249–290. [Google Scholar]
- Flege, J.E.; Bohn, O.-S.; Jan, S. Effects of experience on non-native speakers’ production and perception of English vowels. J. Phon. 1997, 25, 437–470. [Google Scholar] [CrossRef]
- Cebrian, J. Input and experience in the perception of an L2 temporal and spectral contrast. In Proceedings of the 15th International Congress of the Ponetics Sciences, Barcelona, Spain, 3–9 August 2003; Recasens, D., Solé, M.J., Romero, J., Eds.; Universitat Autònoma de Barcelona/Causal Productions: Barcelona, Spain, 2003; pp. 2297–2300. [Google Scholar]
- Flege, J.E.; Munro, M.J.; Fox, R.A. Auditory and categorical effects on cross-language vowel perception. J. Acoust. Soc. Am. 1994, 95, 3623–3641. [Google Scholar] [CrossRef]
- Escudero, P.; Mulak, K.E.; Vlach, H.A. Infants encode phonetic detail during cross-situational word learning. Front. Psychol. 2016, 7, 1419. [Google Scholar] [CrossRef]
- Curtin, S.A.; Fennell, C.; Escudero, P. Weighting of vowel cues explains patterns of word-object associative learning. Dev. Sci. 2009, 12, 725–731. [Google Scholar] [CrossRef]
- Escudero, P.; Smit, E.A.; Angwin, A. Investigating orthographic versus auditory cross-situational word learning with online and lab-based research. Lang. Learn. 2022; early view. [Google Scholar]
- Fikkert, P. Developing representations and the emergence of phonology: Evidence from perception and production. In Laboratory Phonology 10: Variation, Phonetic Detail and Phonological Representation; Fougeron, C., Kühnert, B., D’Imperio, M., Eds.; De Gruyter Mouton: Berlin, Germany, 2010; pp. 227–258. [Google Scholar]
- Mulak, K.E.; Vlach, H.A.; Escudero, P. Cross-situational word learning of phonologically overlapping words across degrees of ambiguity. Cogn. Sci. 2019, 42, e12731. [Google Scholar] [CrossRef]
- Kuhl, P.K.; Andruski, J.E.; Chistovich, I.A.; Chistovich, L.A.; Kozhevnikova, E.V.; Ryskina, V.L.; Stolyarova, E.I.; Sundberg, U.; Lacerda, F. Cross-language analysis of phonetic units in language addressed to infants. Science 1997, 277, 684–686. [Google Scholar] [CrossRef]
- Graf Estes, K.; Hurley, K. Infant-directed prosody helps infants map sounds to meanings. Infancy 2013, 18, 797–824. [Google Scholar] [CrossRef]
- Marian, V.; Spivey, M. Bilingual and monolingual processing of competing lexical items. Appl. Psycholinguist. 2003, 24, 173–193. [Google Scholar] [CrossRef]
- Ma, W.; Golinkoff, R.M.; Houston, D.M.; Hirsh-Pasek, K. Word learning in infant- and adult-directed speech. Lang. Learn. Dev. 2011, 7, 185–201. [Google Scholar] [CrossRef]
- Ellis, N.C. Salience, cognition, language complexity, and complex adaptive systems. Stud. Second Lang. Acquis. 2016, 38, 341–351. [Google Scholar] [CrossRef]
- Golinkoff, R.M.; Alioto, A. Infant-directed speech facilitates lexical learning in adults hearing Chinese: Implications for language acquisition. J. Child Lang. 1995, 22, 703–726. [Google Scholar] [CrossRef]
- Vlach, H.A.; Sandhofer, C.M. Retrieval dynamics and retention in cross-situational statistical word learning. Cogn. Sci. 2014, 38, 757–774. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing [Computer Software Manual]; The R Project for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Bürkner, P.-C. brms: An R package for Bayesian multilevel models using Stan. J. Stat. Softw. 2017, 80, 1–28. [Google Scholar] [CrossRef]
- Bürkner, P.-C. brms: Advanced Bayesian multilevel modelling with the R package brms. R J. 2018, 10, 395–411. [Google Scholar] [CrossRef]
- Van de Schoot, R.; Depaoli, S. Bayesian analyses: Where to start and what to report. Eur. J. Health Psychol. 2014, 16, 75–84. [Google Scholar]
- Escudero, P.; Jones Diaz, C.; Hajek, J.; Wigglesworth, G.; Smit, E.A. Probability of heritage language use at a supportive early childhood setting in Australia. Front. Educ. 2020, 5, 93. [Google Scholar] [CrossRef]
- Smit, E.A.; Milne, A.J.; Dean, R.T.; Weidemann, G. Perception of affect in unfamiliar musical chords. PLoS ONE 2019, 14, e0218570. [Google Scholar] [CrossRef] [PubMed]
- Smit, E.A.; Milne, A.J.; Escudero, P. Music perception abilities and ambiguous word learning: Is there cross-domain transfer in nonmusicians? Front. Psychol. 2022, 13, 801263. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A.; Hwang, J.; Vehtari, A. Understanding predictive information criteria for Bayesian models. Stat Comput. 2014, 24, 997–1016. [Google Scholar] [CrossRef]
- Gelman, A.; Lee, D.; Guo, J. Stan: A probabilistic programming language for Bayesian inference and optimization. J. Educ. Behav. Stat. 2015, 40, 530–543. [Google Scholar] [CrossRef]
- Jeffreys, H. The Theory of Probability; OUP: Oxford, UK, 1998. [Google Scholar]
- Kruschke, J.K. Rejecting or accepting parameter values in Bayesian estimation. Adv. Methods Pract. Psychol. Sci. 2018, 1, 270–280. [Google Scholar] [CrossRef]
- Milne, A.J.; Herff, S.A. The perceptual relevance of balance, evenness, and entropy in musical rhythms. Cognition 2020, 203, 104233. [Google Scholar] [CrossRef]
- Adesopa, O.O.; Lavin, T.; Thompson, T.; Ungerleider, C. A systematic review and meta-analysis of the cognitive correlates of bilingualism. Rev. Educ. Res. 2010, 80, 207–245. [Google Scholar] [CrossRef]
- Kaushanskaya, M.; Rechtzigel, K. Concreteness effects in bilingual and monolingual word learning. Psychon. Bull. Rev. 2012, 19, 935–941. [Google Scholar] [CrossRef]
- Majerus, S.; Poncelet, M.; Van der Linden, M.; Weeks, B.S. Lexical learning in bilingual adults: The relative importance of short-term memory for serial order and phonological knowledge. Cognition 2008, 107, 395–419. [Google Scholar] [CrossRef]
- Service, E.; Simola, M.; Metsänheimo, O.; Maury, S. Maturational constraints in the acquisition of second language accent. Eur. J. Cogn. Psychol. 2002, 14, 383–403. [Google Scholar] [CrossRef]
- Papagno, C.; Vallar, G. Phonological short-term memory and the learning of novel words: The effect of phonological similarity and item length. Q. J. Exp. 1992, 44, 47–67. [Google Scholar] [CrossRef]
- Gor, K. Phonological priming and the role of phonology in nonnative word recognition. Biling. Lang. Cogn. 2018, 21, 437–442. [Google Scholar] [CrossRef]
- Elvin, J.; Escudero, P. Perception of Brazilian Portuguese vowels by Australian English and Spanish listeners. In Proceedings of the International Symposium on the Acquisition of Second Language Speech (New Sounds 2013), Concordia Working Papers in Applied Linguistics. Montreal, Canada, 17–19 May 2013; pp. 15–156. Available online: http://doe.concordia.ca/copal/documents/12_Elvin_Escudero_Vol5.pdf (accessed on 1 May 2022).
- Chrabaszcz, A.; Gor, K. Quantifying contextual effects in second language processing of phonolexically ambiguous and unambiguous words. Appl. Psycholinguist. 2017, 38, 909–942. [Google Scholar] [CrossRef]
- Cutler, A.; Weber, A.; Otake, T. Asymmetric mapping from phonetic to lexical representations in second-language listening. J. Phon. 2006, 34, 269–284. [Google Scholar] [CrossRef]
- Escudero, P.; Hayes-Harb, R.; Mitterer, H. Novel second-language words and asymmetric lexical access. J. Phon. 2008, 36, 345–360. [Google Scholar] [CrossRef]
- Hayes-Harb, R.; Masuda, K. Development of the ability to lexically encode novel L2 phonemic contrasts. Second Lang. Res. 2008, 24, 5–33. [Google Scholar] [CrossRef]
- Weber, A.; Cutler, A. Lexical competition in non-native spoken-word recognition. J. Mem. Lang. 2004, 50, 1–25. [Google Scholar] [CrossRef]
- Houston-Price, C.; Law, B. How experiences with words supply all the tools in the toddler’s word—Learning toolbox. In Theoretical and Computational Models of Word Learning: Trends in Psychology and Artificial Intelligence; Gogate, L., Hollich, G., Eds.; IGI Global: Hershey, PA, USA, 2013; pp. 81–108. [Google Scholar]
- Han, M.; de Jong, N.H.; Kager, R. Lexical tones in Mandarin Chinese infant-directed speech: Age-related changes in the second year of life. Front. Psychol. 2018, 9, 434. [Google Scholar] [CrossRef]
- Escudero, P.; Boersma, P. The subset problem in L2 perceptual development: Multiple-category assimilation by Dutch learners of Spanish. In Proceedings of the 26th Annual Boston University Conference on Language Development, Somerville, MA, USA, 2–4 November 2001; Skarabela, B., Fish, S., Do, A.H.-J., Eds.; Cascadilla Press: Somerville, MA, USA; pp. 208–219. [Google Scholar]
- Escudero, P.; Hayes-Harb, R. The Ontogenesis Model may provide a useful guiding framework but lacks explanatory power for the nature and development of L2 lexical representation. Biling. Lang. Cogn. 2021, 25, 212–213. [Google Scholar] [CrossRef]
- Ong, J.H.; Burnham, D.; Escudero, P. Distributional learning of lexical tones: A comparison of attended vs. unattended listening. PLoS ONE 2015, 10, e0133446. [Google Scholar] [CrossRef] [PubMed]
- Ong, J.H.; Burnham, D.; Escudero, P.; Stevens, C.J. Effect of linguistic and musical experience on distributional learning of nonnative lexical tones. J. Speech Lang. Hear. Res. 2017, 60, 2769–2780. [Google Scholar] [CrossRef] [PubMed]
- Ong, J.H.; Wong, P.C.M.; Liu, F. Musicians show enhanced perception, but not production of native lexical tones. J. Acoust. Soc. Am. 2020, 148, 3443–3454. [Google Scholar] [CrossRef]
- Pino Escobar, G. Word Learning and Executive Functions in Preschool Children: Bridging the Gap between Vocabulary Acquisition and Domain-General Cognitive Processes. Ph.D. Thesis, Western Sydney University, Penrith, Australia, 2022. [Google Scholar]
- Pino Escobar, G.; Tuninetti, A.; Antoniou, M.; Escudero, P. Understanding pre-schoolers’ word learning success in different scenarios: Disambiguation meets statistical learning and eBook reading. Dev. Psychol. 2022; manuscript submitted for publication. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Hypothesis | Mean | 90% CI | ER | PP |
|---|---|---|---|---|
| AusE | ||||
| nonMP > cMP | 0.10 | [−0.24, 0.45] | 2.17 | 0.68 |
| nonMP > vMP | 0.35 | [0.01, 0.68] | 22.05 | 0.96 |
| cMP > vMP | 0.45 | [0.01, 0.89] | 21.06 | 0.95 |
| L1 Mand L2 Eng–Shanghai | ||||
| nonMP > cMP | 0.21 | [−0.19, 0.60] | 4.32 | 0.81 |
| nonMP > vMP | 0.06 | [−0.34, 0.45] | 1.48 | 0.60 |
| cMP > vMP | −0.15 | [−0.66, 0.36] | 0.45 | 0.31 |
| L1 Mand L2 Eng–Sydney | ||||
| nonMP > cMP | 0.05 | [−0.45, 0.54] | 1.30 | 0.57 |
| nonMP > vMP | 0.18 | [−0.32, 0.67] | 2.65 | 0.73 |
| cMP > vMP | 0.13 | [−0.50, 0.77] | 1.72 | 0.63 |
| Hypothesis AusEnglish > Mandarin | Mean | 90% CI | ER | PP |
|---|---|---|---|---|
| nonMPs | 0.78 | [0.33, 1.22] | 412.79 | 1.00 |
| cMPs | 1.03 | [0.46, 1.60] | 799.00 | 1.00 |
| vMPs | 0.51 | [−0.03, 1.05] | 15.20 | 0.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Escudero, P.; Smit, E.A.; Mulak, K.E. Explaining L2 Lexical Learning in Multiple Scenarios: Cross-Situational Word Learning in L1 Mandarin L2 English Speakers. Brain Sci. 2022, 12, 1618. https://doi.org/10.3390/brainsci12121618
Escudero P, Smit EA, Mulak KE. Explaining L2 Lexical Learning in Multiple Scenarios: Cross-Situational Word Learning in L1 Mandarin L2 English Speakers. Brain Sciences. 2022; 12(12):1618. https://doi.org/10.3390/brainsci12121618
Chicago/Turabian StyleEscudero, Paola, Eline A. Smit, and Karen E. Mulak. 2022. "Explaining L2 Lexical Learning in Multiple Scenarios: Cross-Situational Word Learning in L1 Mandarin L2 English Speakers" Brain Sciences 12, no. 12: 1618. https://doi.org/10.3390/brainsci12121618
APA StyleEscudero, P., Smit, E. A., & Mulak, K. E. (2022). Explaining L2 Lexical Learning in Multiple Scenarios: Cross-Situational Word Learning in L1 Mandarin L2 English Speakers. Brain Sciences, 12(12), 1618. https://doi.org/10.3390/brainsci12121618