
Communicating Risk: Developing an “Efficiency Index” for Dementia Screening Tests

Abstract
:1. Introduction
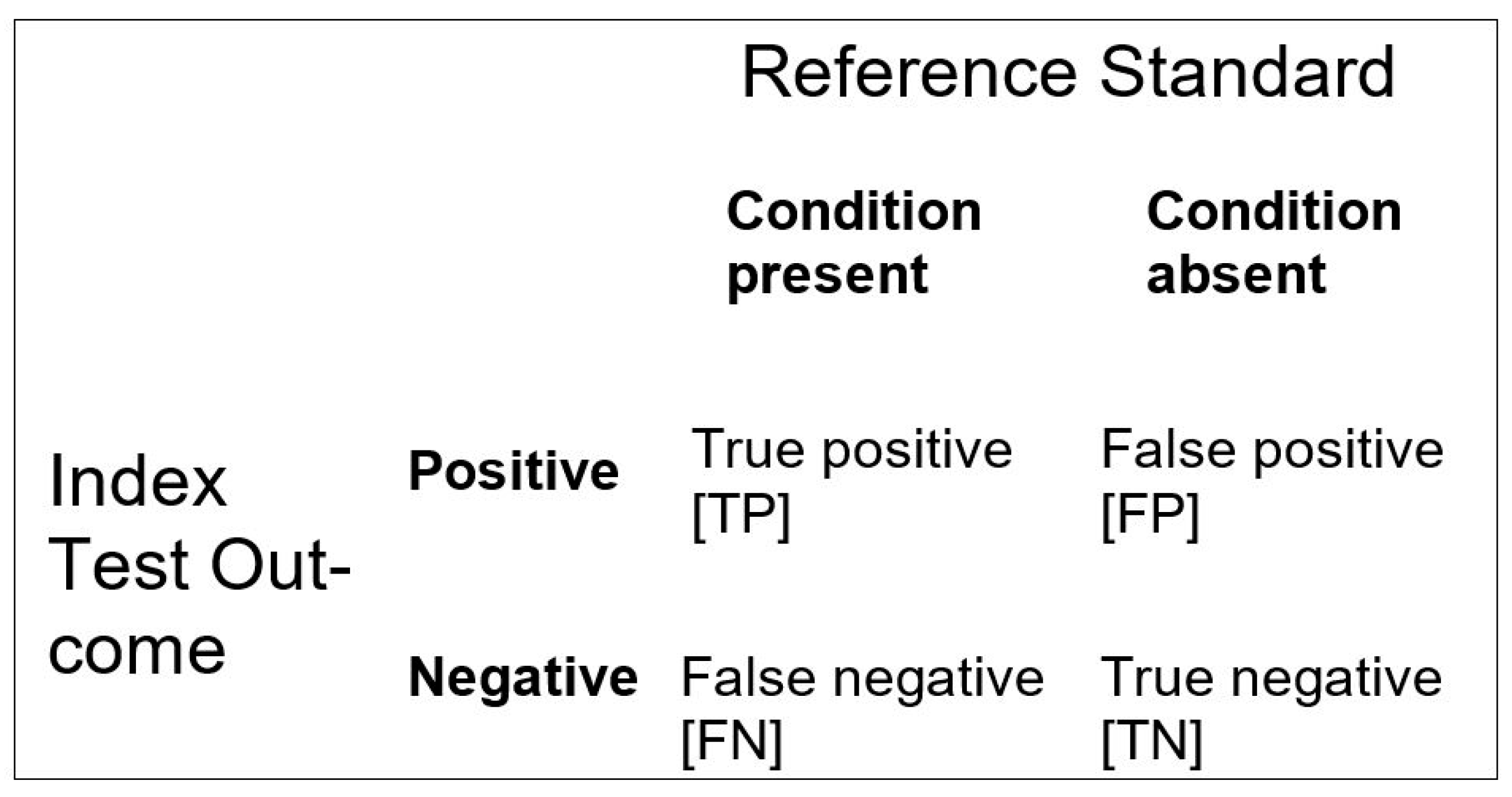
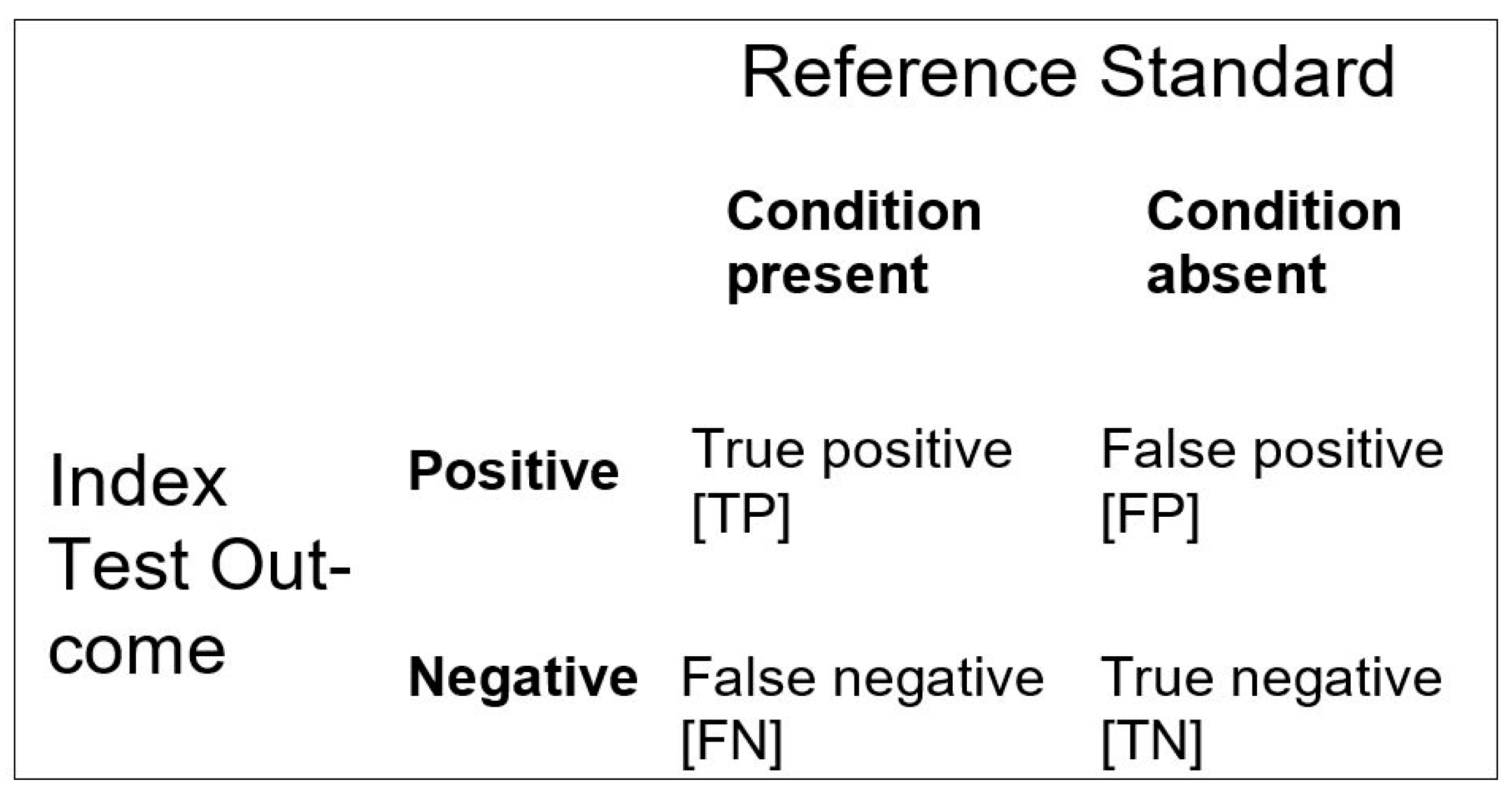
| Sensitivity (Sens) = TP/(TP + FN) Specificity (Spec) = TN/(FP + TN) Positive predictive value (PPV) = TP/(TP + FP) Negative predictive value (NPV) = TN/(FN + TN) Positive likelihood ratio (LR+) = TP/(TP + FN)/FP/(FP + TN) Negative likelihood ratio (LR−) = FN/(TP + FN)/TN/(FP + TN) Accuracy (Acc) = (TP + TN)/(TP + FP + FN + TN) Inaccuracy (Inacc) = (FP + FN)/(TP + FP + FN + TN) |
2. Methods
3. Results
4. Discussion
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naik, G.; Ahmed, H.; Edwards, A.G. Communicating risk to patients and the public. Br. J. Gen. Pract. 2012, 62, 213–216. [Google Scholar] [CrossRef] [PubMed]
- Schrager, S.B. Five Ways to Communicate Risks So That Patients Understand. Fam. Pract. Manag. 2018, 25, 28–31. [Google Scholar]
- Gigerenzer, G.; Gaissmaier, W.; Kurz-Milcke, E.; Schwartz, L.M.; Woloshin, S. Helping Doctors and Patients Make Sense of Health Statistics. Psychol. Sci. Public Interest 2007, 8, 53–96. [Google Scholar] [CrossRef] [PubMed]
- Larner, A.J. The 2x2 Matrix: Contingency, Confusion and the Metrics of Binary Classification; Springer: London, UK, 2021; in press. [Google Scholar] [CrossRef]
- Larner, A. Number Needed to Diagnose, Predict, or Misdiagnose: Useful Metrics for Non-Canonical Signs of Cognitive Status? Dement. Geriatr. Cogn. Disord. Extra 2018, 8, 321–327. [Google Scholar] [CrossRef]
- Larner, A.J. Evaluating cognitive screening instruments with the “likelihood to be diagnosed or misdiagnosed” measure. Int. J. Clin. Pract. 2019, 73, e13265. [Google Scholar] [CrossRef] [PubMed]
- Cook, R.J.; Sackett, D.L. The number needed to treat: A clinically useful measure of treatment effect. BMJ 1995, 310, 452–454. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zermansky, A. Number needed to harm should be measured for treatments. BMJ 1998, 317, 1014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Citrome, L.; Ketter, T.A. When does a difference make a difference? Interpretation of number needed to treat, number needed to harm, and likelihood to be helped or harmed. Int. J. Clin. Pract. 2013, 67, 407–411. [Google Scholar] [CrossRef]
- Habibzadeh, F.; Yadollahie, M. Number Needed to Misdiagnose: A measure of diagnostic test effectiveness. Epidemiology 2013, 24, 170. [Google Scholar] [CrossRef] [PubMed]
- Linn, S.; Grunau, P.D. New patient-oriented summary measure of net total gain in certainty for dichotomous diagnostic tests. Epidemiol. Perspect. Innov. 2006, 3, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larner, A.J. Manual of Screeners for Dementia. In Pragmatic Test Accuracy Studies; Springer: London, UK, 2020. [Google Scholar] [CrossRef]
- Williamson, J.C.; Larner, A.J. ‘Likelihood to be diagnosed or misdiagnosed’: Application to meta-analytic data for cognitive screening instruments. Neurodegener. Dis. Manag. 2019, 9, 91–95. [Google Scholar] [CrossRef] [PubMed]
- Jaeschke, R.; Guyatt, G.; Sackett, D.L. Users’ guides to the medical literature. III. How to use an article about a diagnostic test. B. What are the results and will they help me in caring for my patients? JAMA 1994, 271, 703–707. [Google Scholar] [CrossRef] [PubMed]
- National Institute for Health and Care Excellence. Dementia: Assessment, Management and Support for People Living with Dementia and Their Carers (NICE Guideline 97); Methods, evidence and recommendations; NICE: London, UK, 2018. [Google Scholar]
- Kraemer, H.C. Evaluating medical tests. In Objective and Quantitative Guidelines; Sage: Newbery Park, CA, USA, 1992; pp. 27, 34, 115. [Google Scholar]
- Folstein, M.F.; Folstein, S.E.; McHugh, P.R. “Mini-mental state”: A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 1975, 12, 189–198. [Google Scholar] [CrossRef]
- Nasreddine, Z.S.; Phillips, N.A.; Bédirian, V.; Charbonneau, S.; Whitehead, V.; Collin, I.; Cummings, J.L.; Chertkow, H. The Montreal Cognitive Assessment, MoCA: A Brief Screening Tool for Mild Cognitive Impairment. J. Am. Geriatr. Soc. 2005, 53, 695–699. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, S.; McGrory, S.; Leslie, F.; Dawson, K.; Ahmed, S.; Butler, C.; Rowe, J.; Mioshi, E.; Hodges, J.R. The Mini-Addenbrooke’s Cognitive Examination: A New Assessment Tool for Dementia. Dement. Geriatr. Cogn. Disord. 2015, 39, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Burns, A.; Harrison, J.R.; Symonds, C.; Morris, J. A novel hybrid scale for the assessment of cognitive and executive function: The Free-Cog. Int. J. Geriatr. Psychiatry 2021, 36, 566–572. [Google Scholar] [CrossRef]
- McGee, S. Simplifying likelihood ratios. J. Gen. Intern. Med. 2002, 17, 647–650. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, A.J. Index test. In Encyclopedia of Medical Decision Making; Kattan, M.W., Ed.; Sage: Los Angeles, CA, USA, 2009; pp. 613–617. [Google Scholar]
- Larner, A.J. Mini-Addenbrooke’s Cognitive Examination: A pragmatic diagnostic accuracy study. Int. J. Geriatr. Psychiatry 2015, 30, 547–548. [Google Scholar] [CrossRef] [PubMed]
- Larner, A.J. Mini-Addenbrooke’s Cognitive Examination diagnostic accuracy for dementia: Reproducibility study. Int. J. Geriatr. Psychiatry 2015, 30, 1103–1104. [Google Scholar] [CrossRef] [PubMed]
- Larner, A. MACE versus MoCA: Equivalence or superiority? Pragmatic diagnostic test accuracy study. Int. Psychogeriatrics 2017, 29, 931–937. [Google Scholar] [CrossRef] [PubMed]
- Larner, A.J. MACE for Diagnosis of Dementia and MCI: Examining Cut-Offs and Predictive Values. Diagnostics 2019, 9, 51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larner, A.J. Free-Cog: Pragmatic Test Accuracy Study and Comparison with Mini-Addenbrooke’s Cognitive Examination. Dement. Geriatr. Cogn. Disord. 2019, 47, 254–263. [Google Scholar] [CrossRef] [PubMed]
- Bossuyt, P.M.; Reitsma, J.B.; Bruns, D.E.; Gatsonis, C.A.; Glasziou, P.; Irwig, L.M.; Moher, D.; Rennie, D.; De Vet, H.C.W.; Lijmer, J.G. The STARD Statement for Reporting Studies of Diagnostic Accuracy: Explanation and Elaboration. Clin. Chem. 2003, 49, 7–18. [Google Scholar] [CrossRef] [PubMed]
- Noel-Storr, A.H.; McCleery, J.M.; Richard, E.; Ritchie, C.W.; Flicker, L.; Cullum, S.J.; Davis, D.; Quinn, T.J.; Hyde, C.; Rutjes, A.W.; et al. Reporting standards for studies of diagnostic test accuracy in dementia: The STARDdem Initiative. Neurology 2014, 83, 364–373. [Google Scholar] [CrossRef] [Green Version]
- Brown, J.; Pengas, G.; Dawson, K.; Brown, L.A.; Clatworthy, P. Self administered cognitive screening test (TYM) for detection of Alzheimer’s disease: Cross sectional study. BMJ 2009, 338, b2030. [Google Scholar] [CrossRef] [Green Version]
- Hancock, P.; Larner, A.J. Test Your Memory test: Diagnostic utility in a memory clinic population. Int. J. Geriatr. Psychiatry 2011, 26, 976–980. [Google Scholar] [CrossRef] [PubMed]
- Larner, A. The ‘attended alone’ and ‘attended with’ signs in the assessment of cognitive impairment: A revalidation. Postgrad. Med. 2020, 132, 595–600. [Google Scholar] [CrossRef]
- Larner, A.J. New unitary metrics for dementia test accuracy studies. Prog. Neurol. Psychiatry 2019, 23, 21–25. [Google Scholar] [CrossRef] [Green Version]
- Brenner, H.; Gefeller, O. Variation of sensitivity, specificity, likelihood ratios and predictive values with disease prevalence. Stat. Med. 1997, 16, 981–991. [Google Scholar] [CrossRef]
- Larner, A.J. Cognitive screening instruments for dementia: Comparing metrics of test limitation. Dement. Neuropsychol. 2021, 15. in press. [Google Scholar]
- Fagerlin, A.; Peters, E. Quantitative information. In Communicating Risks and Benefits: An Evidence-Based User’s Guide; Fischhoff, B., Brewer, N.T., Downs, J.S., Eds.; Department of Health and Human Services, Food and Drug Administration: Silver Spring, MD, USA, 2011; pp. 53–64. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| CSI | N | P = Prevalence of Dementia = (TP + FN)/N | Age, Median (years) | Gender (F:M; %F) | Test Threshold for Dementia | Ref(s) |
|---|---|---|---|---|---|---|
| MMSE | 244 | 0.18 | 60 | 117:127; 48 | <26/30 | [23,24] |
| MoCA | 260 | 0.17 | 59 | 118:142; 45 | <26/30 | [25] |
| MACE | 755 | 0.15 | 60 | 352:403; 47 | ≤20/30 | [26] |
| Free-Cog | 141 | 0.11 | 62 | 61:80; 43 | ≤22/30 | [27] |
| CSI | Acc | Inacc | Y (=Sens + Spec − 1) | LDM (=NNM/NND) | II (=2.Acc − 1) | EI (=Acc/Inacc) |
|---|---|---|---|---|---|---|
| MMSE | 0.676 | 0.324 | 0.497 | 1.536 | 0.352 | 2.089 |
| MoCA | 0.427 | 0.573 | 0.313 | 0.547 | −0.146 | 0.745 |
| MACE | 0.738 | 0.262 | 0.619 | 2.360 | 0.475 | 2.817 |
| Free-Cog | 0.709 | 0.291 | 0.670 | 2.320 | 0.418 | 2.439 |
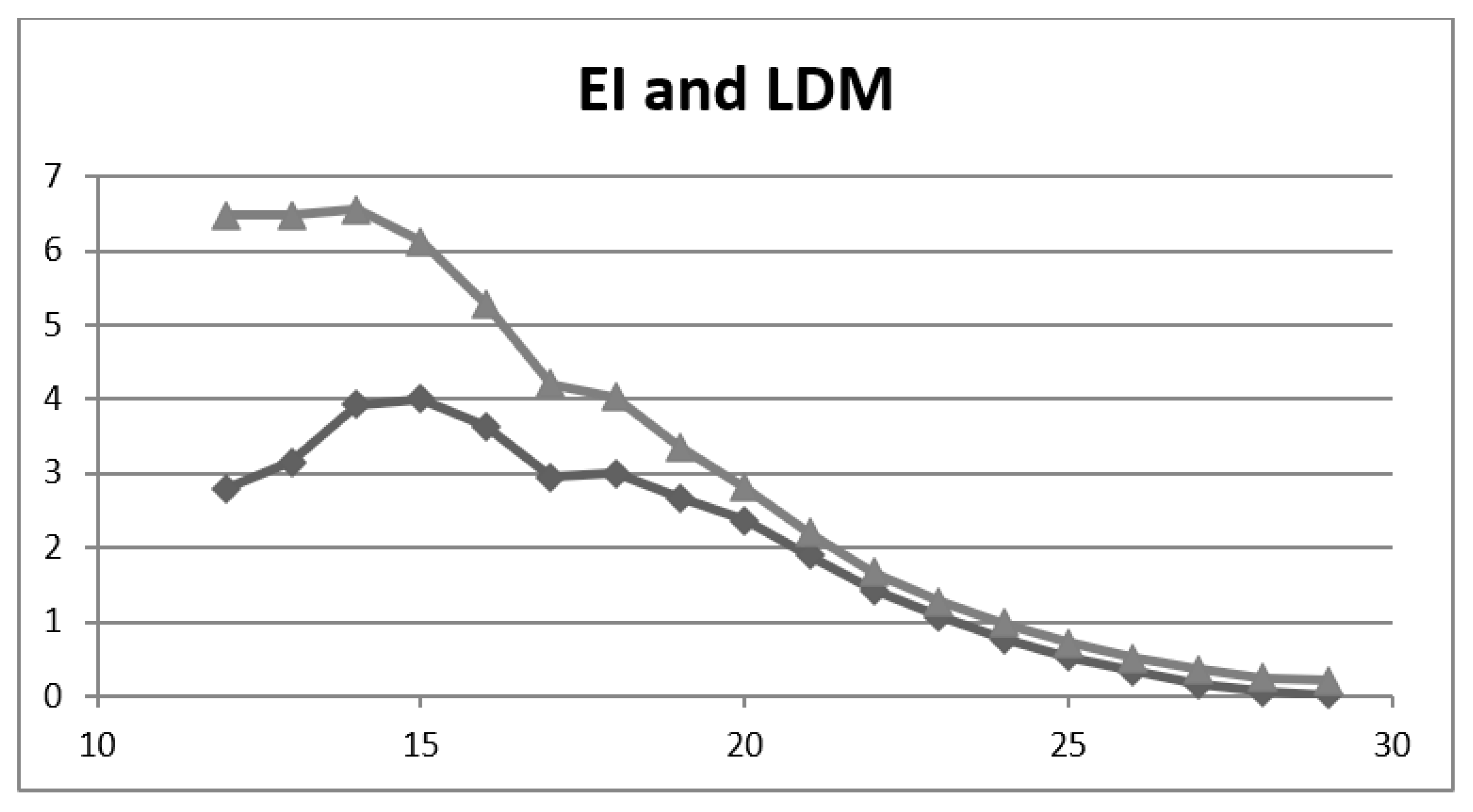
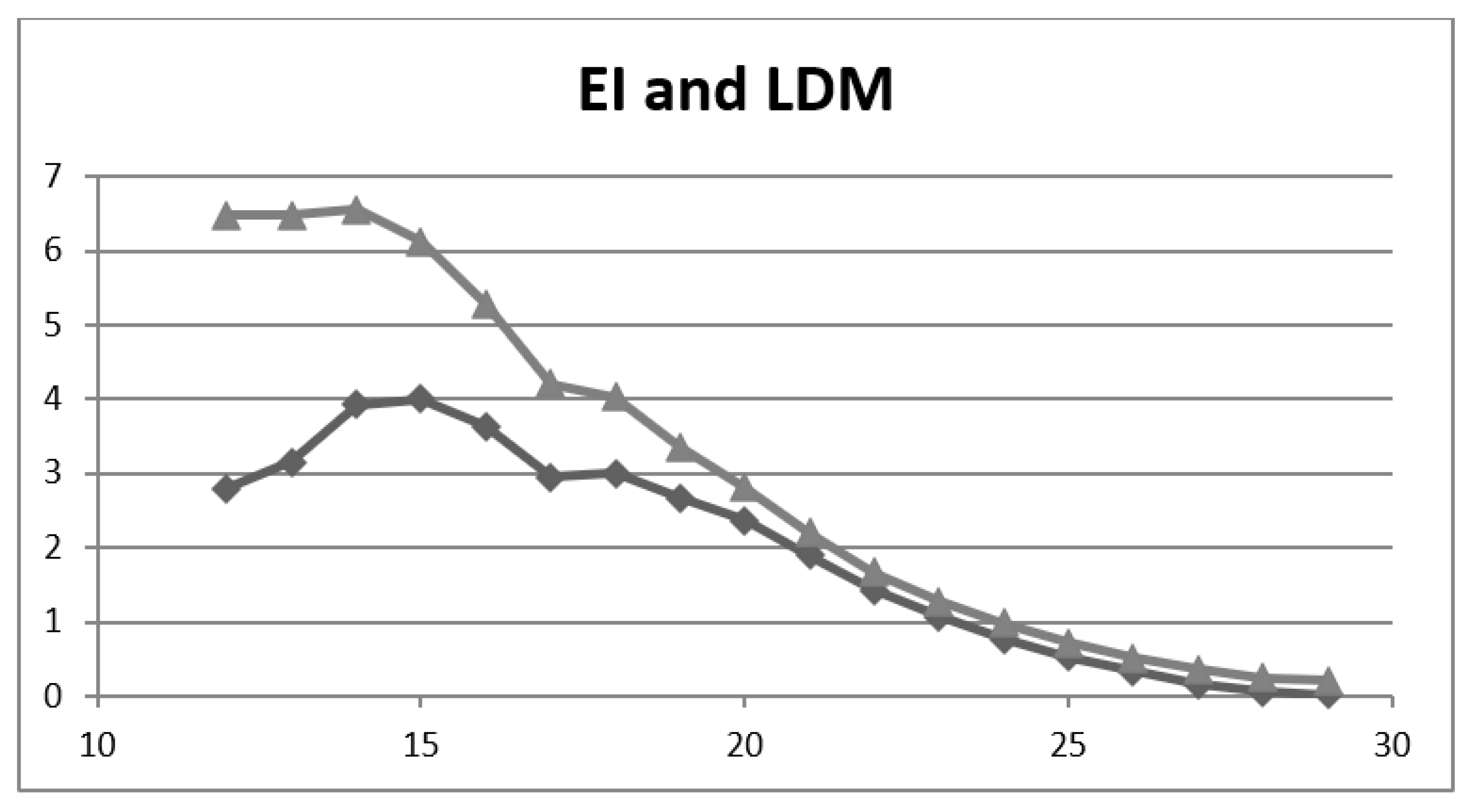
| Cut-Off | Acc | Inacc | Y | LDM | II | EI |
|---|---|---|---|---|---|---|
| ≤29/30 | 0.170 | 0.830 | 0.02 | 0.02 | −0.66 | 0.204 |
| ≤28/30 | 0.197 | 0.803 | 0.05 | 0.06 | −0.61 | 0.246 |
| ≤27/30 | 0.262 | 0.738 | 0.12 | 0.16 | −0.48 | 0.355 |
| ≤26/30 | 0.336 | 0.664 | 0.21 | 0.33 | −0.33 | 0.507 |
| ≤25/30 | 0.417 | 0.583 | 0.31 | 0.53 | −0.17 | 0.716 |
| ≤24/30 | 0.495 | 0.505 | 0.39 | 0.76 | −0.01 | 0.982 |
| ≤23/30 | 0.560 | 0.440 | 0.47 | 1.07 | 0.12 | 1.27 |
| ≤22/30 | 0.625 | 0.375 | 0.53 | 1.43 | 0.25 | 1.67 |
| ≤21/30 | 0.687 | 0.313 | 0.59 | 1.90 | 0.37 | 2.20 |
| ≤20/30 | 0.738 | 0.262 | 0.62 | 2.36 | 0.48 | 2.82 |
| ≤19/30 | 0.771 | 0.229 | 0.61 | 2.67 | 0.54 | 3.36 |
| ≤18/30 | 0.801 | 0.199 | 0.60 | 3.00 | 0.60 | 4.03 |
| ≤17/30 | 0.808 | 0.192 | 0.56 | 2.95 | 0.62 | 4.21 |
| ≤16/30 | 0.841 | 0.159 | 0.58 | 3.63 | 0.68 | 5.29 |
| ≤15/30 | 0.860 | 0.140 | 0.56 | 4.00 | 0.72 | 6.12 |
| ≤14/30 | 0.868 | 0.132 | 0.51 | 3.92 | 0.74 | 6.55 |
| ≤13/30 | 0.866 | 0.134 | 0.41 | 3.15 | 0.73 | 6.48 |
| ≤12/30 | 0.866 | 0.134 | 0.37 | 2.79 | 0.73 | 6.48 |
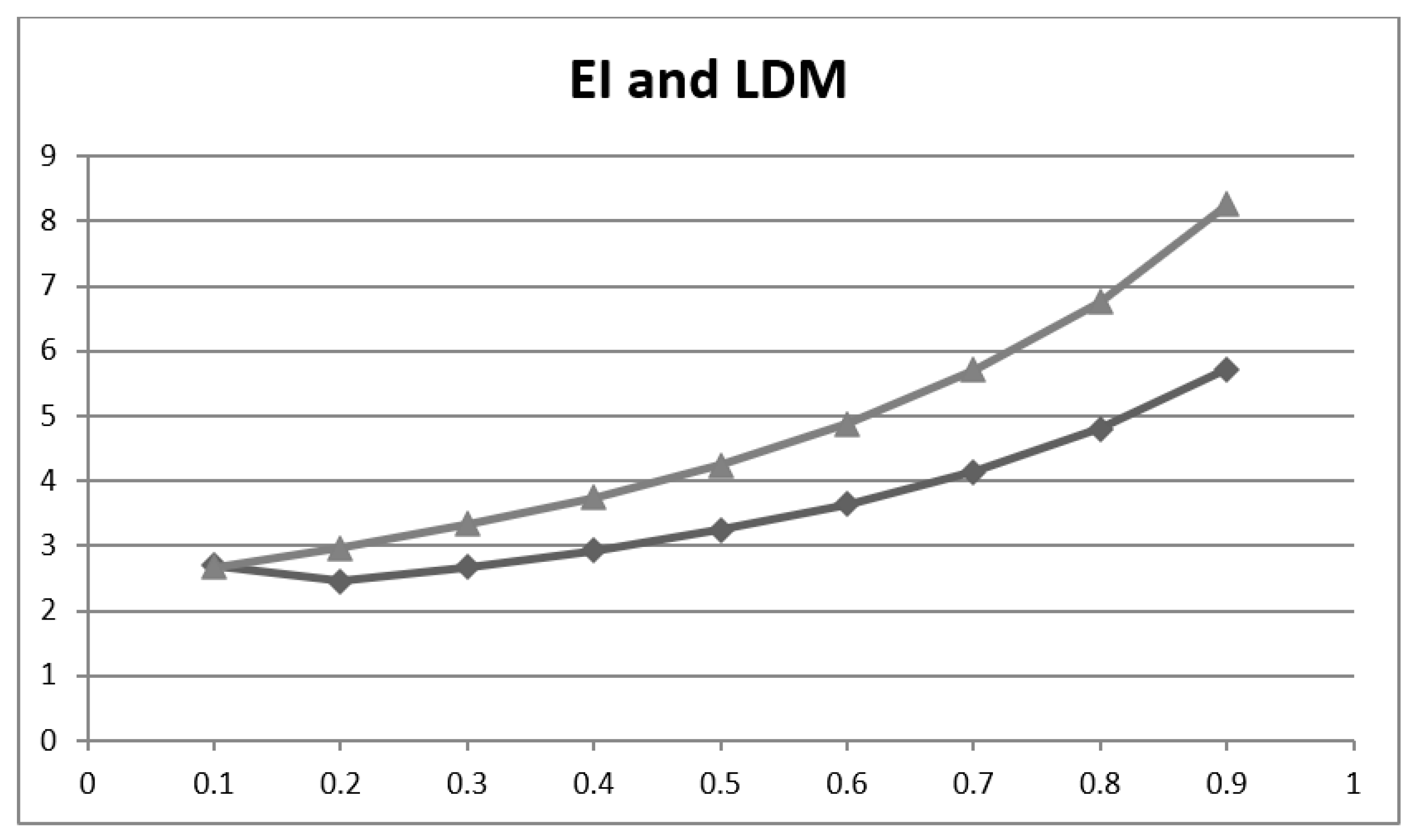
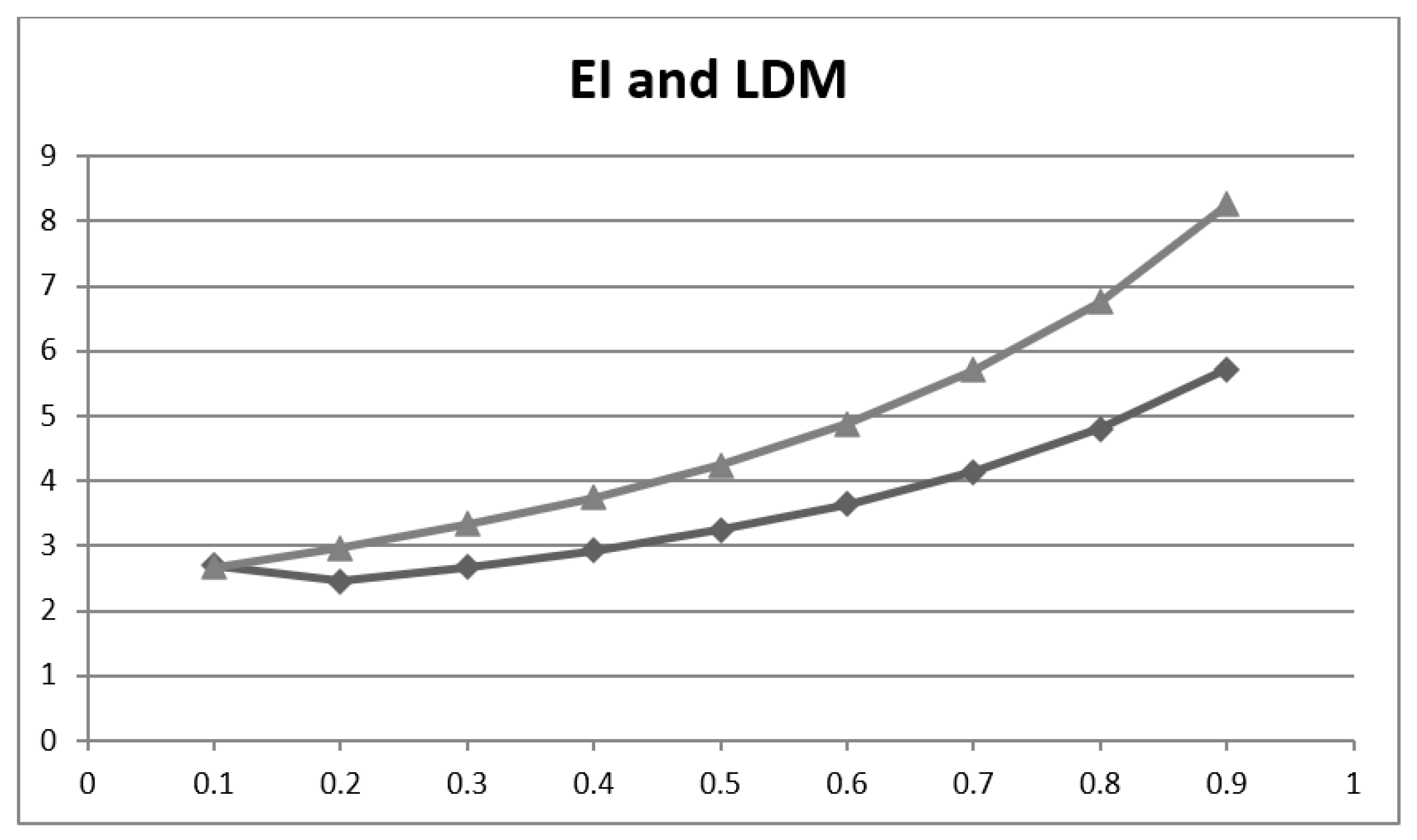
| P, P′ | Acc | Inacc | LDM (=NNM/NND =Y/Inacc) | EI (=NNM/NND* =Acc/Inacc) |
|---|---|---|---|---|
| 0.1, 0.9 | 0.728 | 0.272 | 2.70 | 2.68 |
| 0.2, 0.8 | 0.748 | 0.252 | 2.45 | 2.97 |
| 0.3, 0.7 | 0.768 | 0.232 | 2.67 | 3.33 |
| 0.4, 0.6 | 0.789 | 0.211 | 2.93 | 3.74 |
| 0.5, 0.5 | 0.809 | 0.191 | 3.25 | 4.24 |
| 0.6, 0.4 | 0.830 | 0.170 | 3.64 | 4.88 |
| 0.7, 0.3 | 0.851 | 0.149 | 4.14 | 5.71 |
| 0.8, 0.2 | 0.871 | 0.129 | 4.80 | 6.75 |
| 0.9, 0.1 | 0.892 | 0.108 | 5.72 | 8.26 |
| EI | % Change in Diagnostic Probability Calculated Independent of Pre-Test Probability as 0.19 × loge(EI) | MACE: % Change in Diagnostic Probability Based on Pre-Test Probability (0.15) [26] | MoCA: % Change in Diagnostic Probability Based on Pre-Test Probability (0.17) [25] | TYM: % Change in Diagnostic Probability Based on Pre-Test Probability (0.35) [31] |
|---|---|---|---|---|
| 10.0 | +43.7 | +49 | +54 | +49 |
| 5.0 | +30.5 | +32 | +34 | +38 |
| 4.882 (TYM) | +30.1 | - | - | +37 |
| 2.817 (MACE) | +19.7 | +18 | - | - |
| 2.0 | +13.2 | +11 | +12 | +17 |
| 1.0 | 0 | 0 | 0 | 0 |
| 0.745 (MoCA) | −5.6 | - | −4 | - |
| 0.5 | −13.2 | −7 | −8 | −14 |
| 0.2 | −30.5 | −12 | −13 | −25 |
| 0.1 | −43.7 | −13 | −15 | −30 |
| EI Value | Qualitative Classification of Change in Probability of Diagnosis (after Jaeschke et al. [14]) | Approximate % Change in Probability of Diagnosis (after McGee [21]) |
|---|---|---|
| ≤0.1 | Very large decrease | - |
| 0.1 | Large decrease | –45 |
| 0.2 | Large decrease | –30 |
| 0.5 | Moderate decrease | –15 |
| 1.0 | 0 | |
| 2.0 | Moderate increase | +15 |
| 5.0 | Moderate increase | +30 |
| 10.0 | Large increase | +45 |
| ≥10.0 | Very large increase | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larner, A.J. Communicating Risk: Developing an “Efficiency Index” for Dementia Screening Tests. Brain Sci. 2021, 11, 1473. https://doi.org/10.3390/brainsci11111473
Larner AJ. Communicating Risk: Developing an “Efficiency Index” for Dementia Screening Tests. Brain Sciences. 2021; 11(11):1473. https://doi.org/10.3390/brainsci11111473
Chicago/Turabian StyleLarner, Andrew J. 2021. "Communicating Risk: Developing an “Efficiency Index” for Dementia Screening Tests" Brain Sciences 11, no. 11: 1473. https://doi.org/10.3390/brainsci11111473
APA StyleLarner, A. J. (2021). Communicating Risk: Developing an “Efficiency Index” for Dementia Screening Tests. Brain Sciences, 11(11), 1473. https://doi.org/10.3390/brainsci11111473