
An Automated Lexical Stress Classification Tool for Assessing Dysprosody in Childhood Apraxia of Speech

 , , ,
, , ,
Abstract
:1. Introduction
1.1. Lexical Stress
1.2. Measuring Lexical Stress
1.3. Automated Analysis of Lexical Stress
- Peak-to-peak Teager energy operator (TEO) amplitude over syllable nucleus;
- mean TEO energy over syllable nucleus;
- maximum TEO energy over syllable nucleus;
- nucleus duration;
- syllable duration;
- maximum f0 over syllable nucleus;
- mean f0 over syllable nucleus;
- 27 Mel-scale energy bands over syllable nucleus.
1.4. Purpose
- An automated lexical stress classifier using acoustic features of duration, f0, intensity, and spectral energy across adjacent syllables in polysyllabic words will achieve:
- (a)
- ≥80% agreement with human perceptual judgments for TD speech;
- (b)
- Higher classification accuracy for TD speakers than for CAS speakers, for whom the likelihood of mispronunciation is high;
- (c)
- Higher classification accuracy when using a knowledge-driven system trained on the segmental errors represented in the disordered speech sample.
- Classification errors will be associated with within-word features known to reduce human inter-rater reliability, such as equivocal stress across the first two syllables (e.g., HAMBURger/ˈhæmˈbɜgʌ/); short-vowel phonemes in the stressed syllable (e.g., BUTterfly/ˈbʌtəˌflaɪ); ambiguous phoneme boundaries (i.e., liquid consonants at syllable onsets or offsets such as in “elephant”); or words in which weak syllables have low intensity and/or undetectable pitch (i.e., unstressed vowels between two unvoiced phonemes, such as “potato”).
2. Materials and Methods
2.1. Participants
2.2. Stimuli
2.3. Procedure
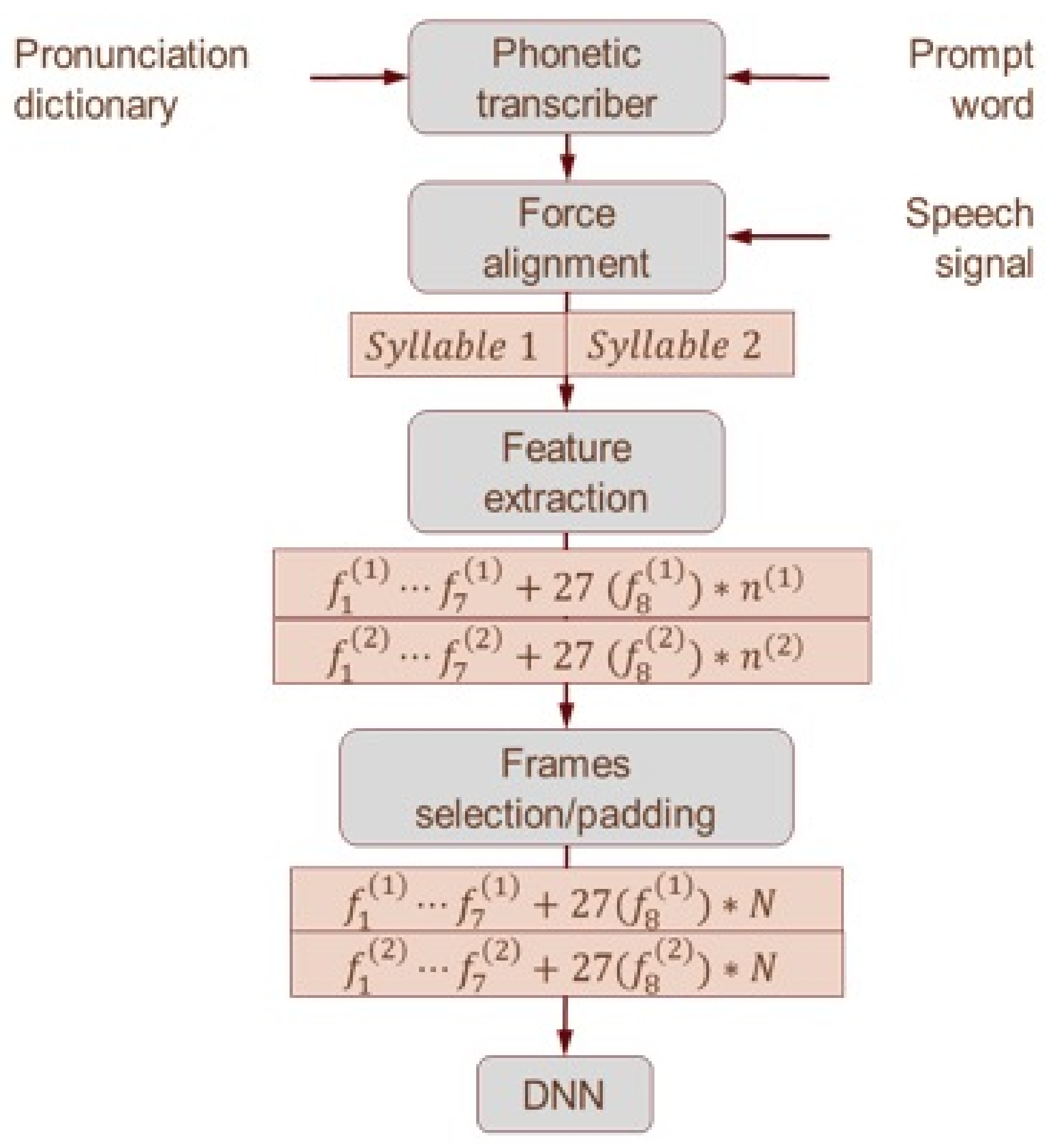
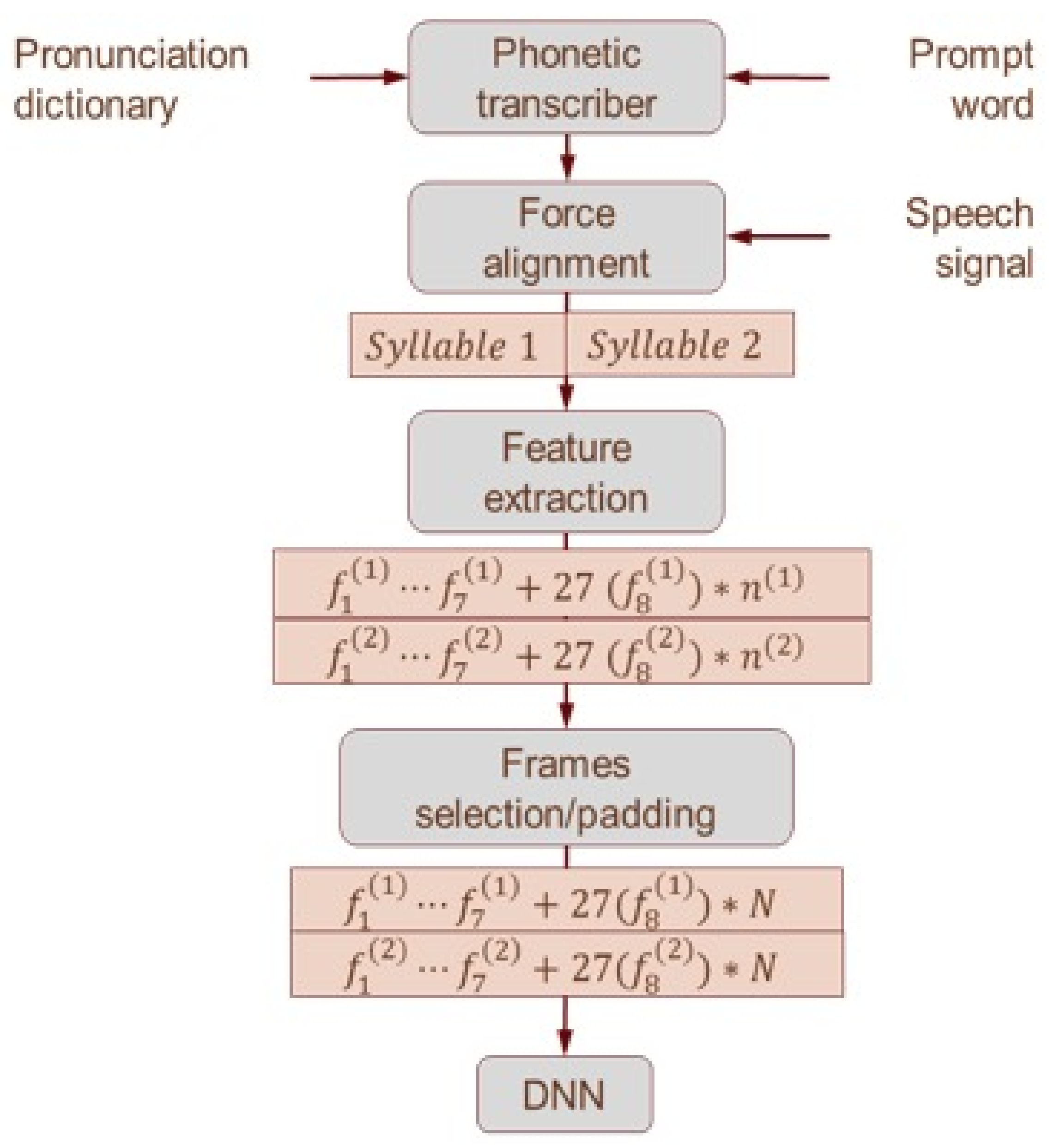
2.3.1. Forced Alignment
2.3.2. Feature Extraction
2.3.3. Concatenate Raw Features into 1 Wide Feature Vector
2.3.4. DNN Classifier
2.4. Statistical Analysis
3. Results
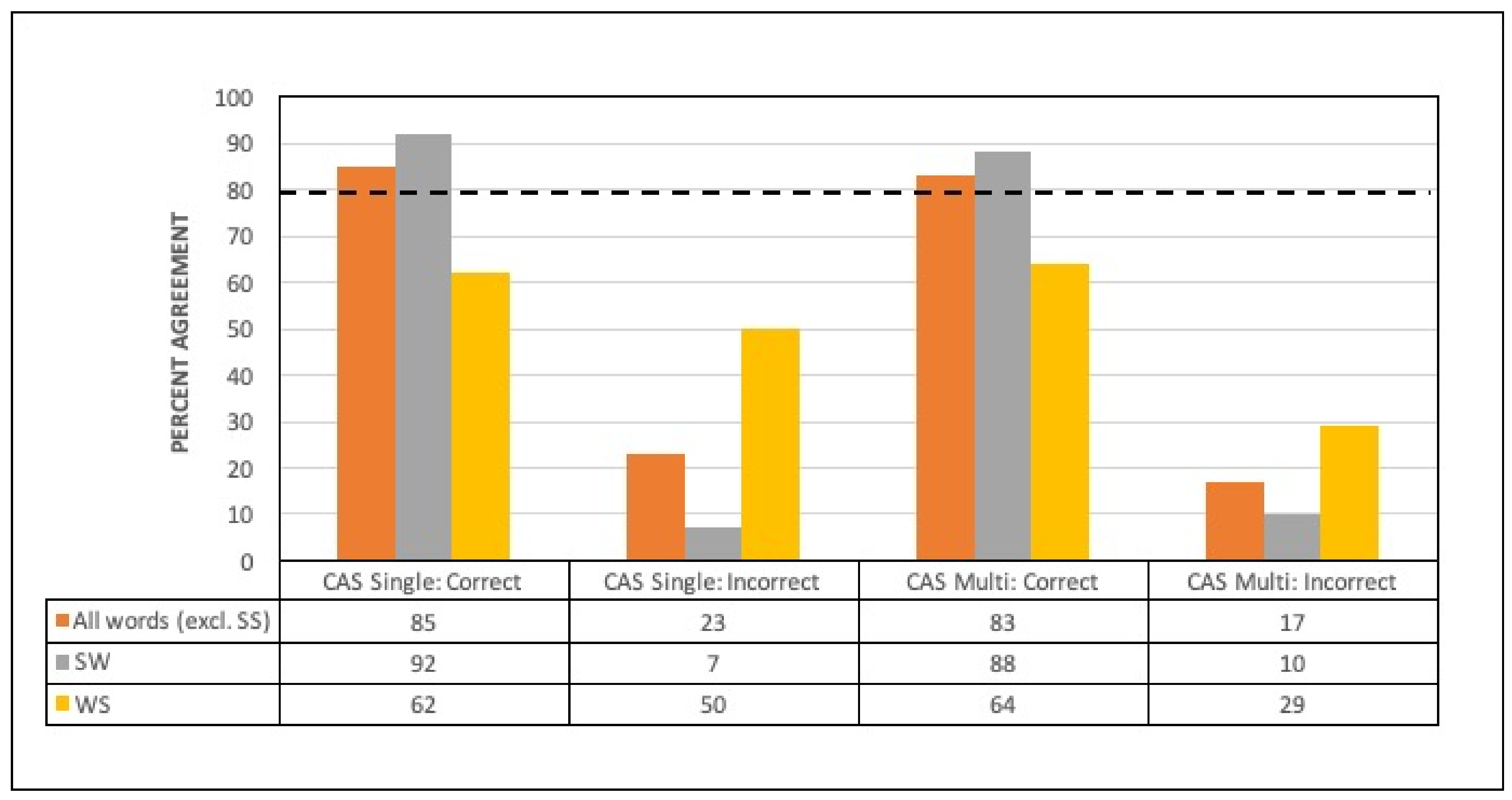
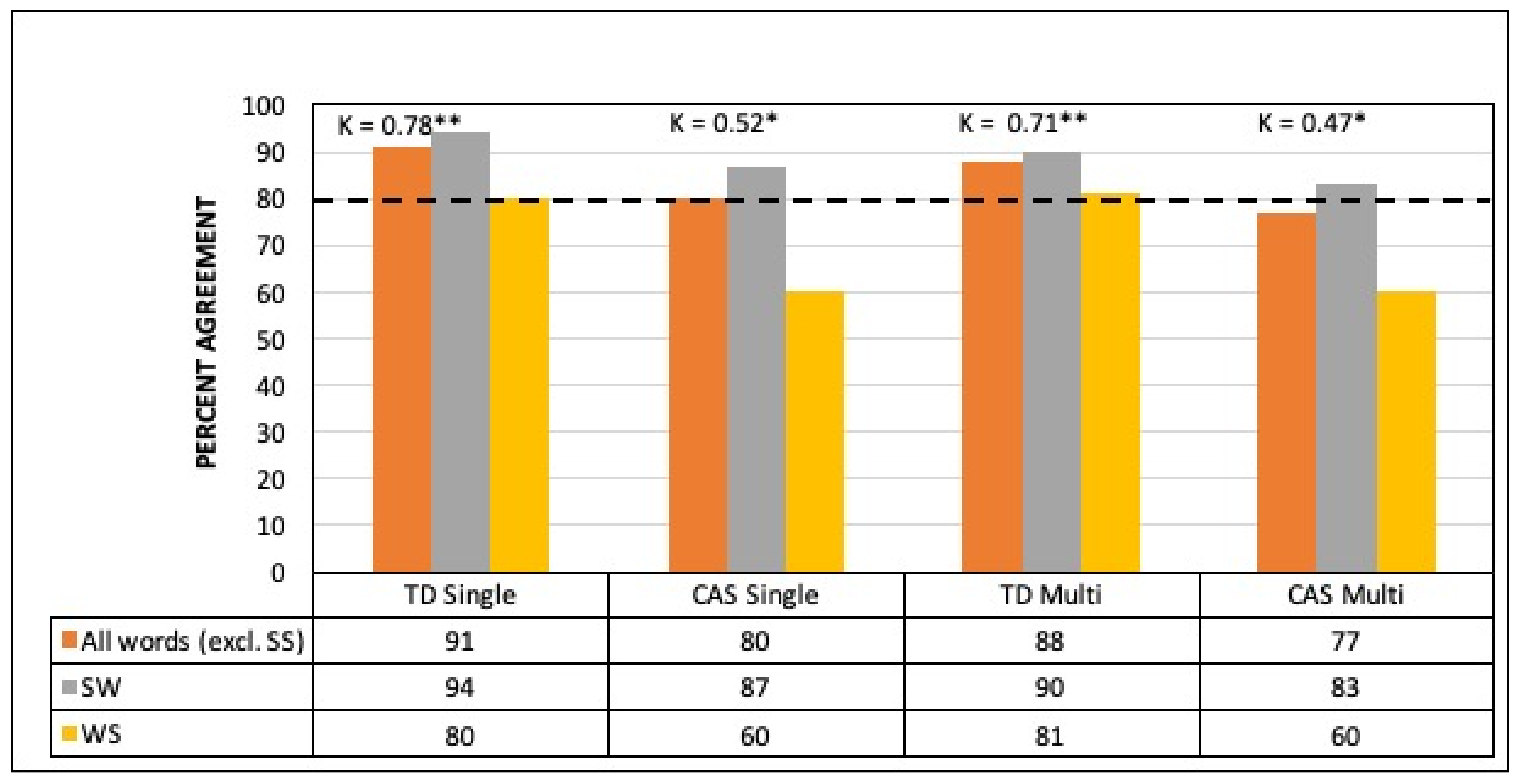
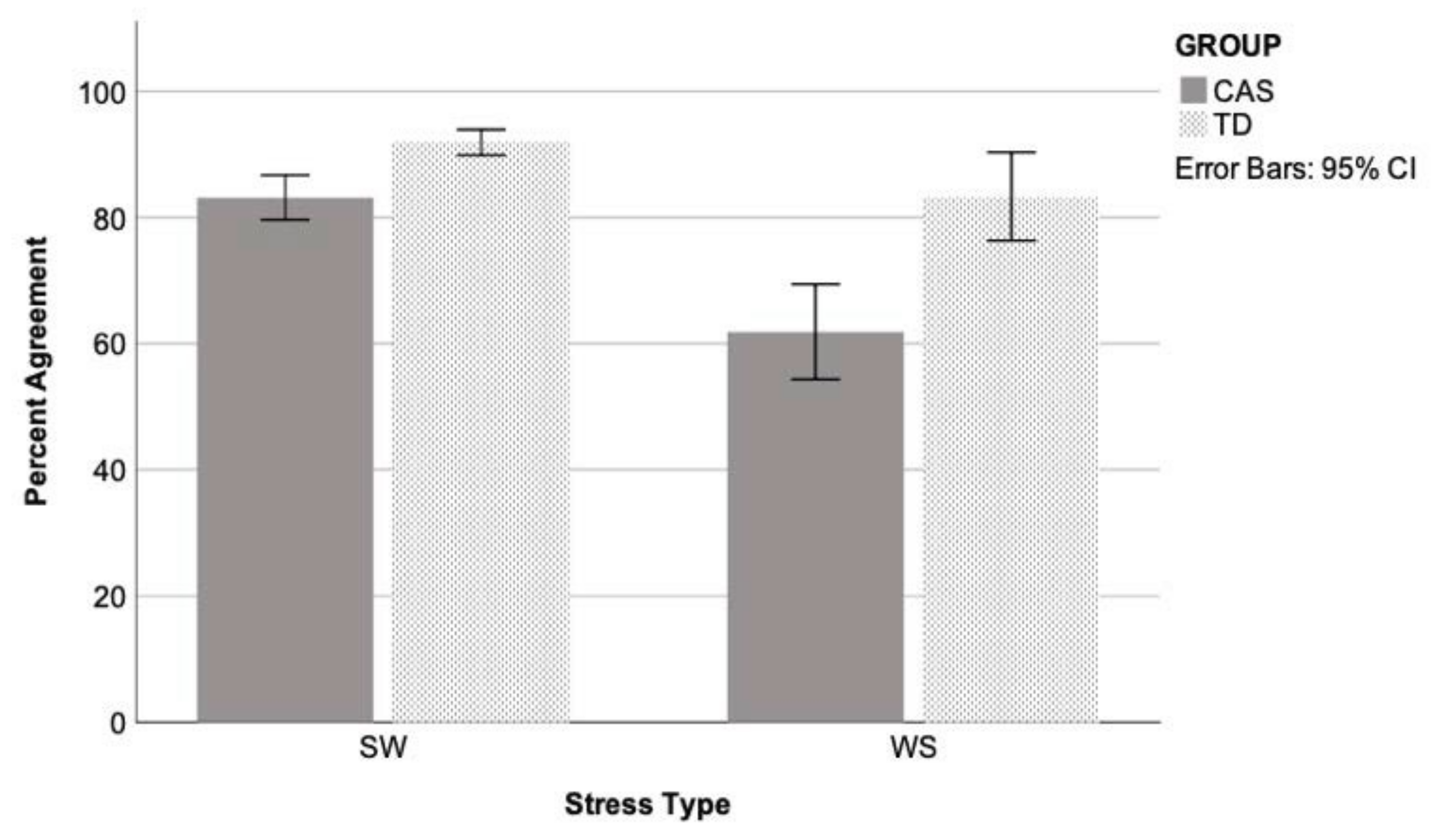
3.1. Agreement between Classifier and Human Judgment
3.2. Linear Mixed Effects Modelling
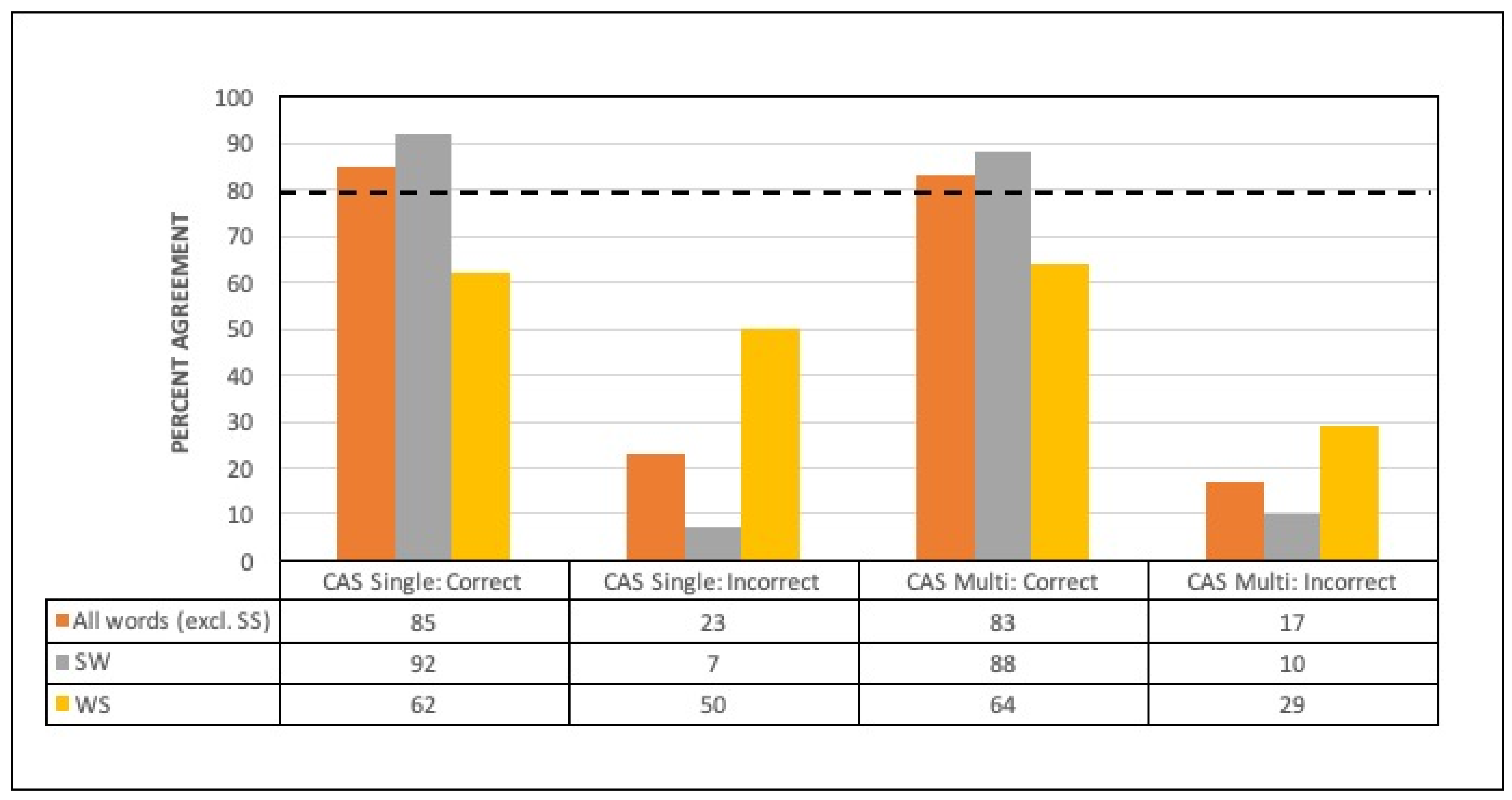
3.3. Words Perceived with Correct or Incorrect Lexical Stress
3.4. Confidence Estimates and Within-Word Features
3.5. Age and Severity
4. Discussion
Limitations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- American Speech-Language-Hearing Association. Childhood Apraxia of Speech. Technical Report; Retrieved from Rockville (MD). 2007. Available online: http://www.asha.org/policy/TR2007-00278 (accessed on 8 March 2012).
- Robin, D.A.; Schmmidt, R.A. Apraxia of speech: Definition, Differentiation, and Treatment. In Clinical Management of Sensorimotor Speech Disorders, 2nd ed.; McNeil, M.R., Ed.; Thieme: New York, NY, USA, 2009; pp. 249–268. [Google Scholar]
- Shriberg, L.D.; Aram, D.M.; Kwiatkowski, J. Developmental Apraxia of Speech: III. A subtype marked by inappropriate stress. J. Speech Lang. Hear. 1997, 40, 313–337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murray, E.; McCabe, P.; Heard, R.; Ballard, K. Differential Diagnosis of Children with Suspected Childhood Apraxia of Speech. J. Speech Lang. Hear. Res. 2015, 58, 43–60. [Google Scholar] [CrossRef] [PubMed]
- Ballard, K.J.; Savage, S.; Leyton, C.E.; Vogel, A.; Hornberger, M.; Hodges, J.R. Logopenic and Nonfluent Variants of Primary Progressive Aphasia Are Differentiated by Acoustic Measures of Speech Production. PLoS ONE 2014, 9, e89864. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peppé, S.J.E. Why is prosody in speech-language pathology so difficult? Int. J. Speech-Lang. Pathol. 2009, 11, 258–271. [Google Scholar] [CrossRef] [Green Version]
- Charter, R.A. A Breakdown of Reliability Coefficients by Test Type and Reliability Method, and the Clinical Implications of Low Reliability. J. Gen. Psychol. 2003, 130, 290–304. [Google Scholar] [CrossRef]
- Diehl, J.J.; Paul, R. The assessment and treatment of prosodic disorders and neurological theories of prosody. Int. J. Speech-Lang. Pathol. 2009, 11, 287–292. [Google Scholar] [CrossRef] [Green Version]
- Parnandi, A.; Karappa, V.; Lan, T.; Shahin, M.; McKechnie, J.; Ballard, K.; Gutierrez-Osuna, R. Development of a remote therapy tool for childhood apraxia of speech. ACM Trans. Access. Comput. 2015, 7, 1–23. [Google Scholar] [CrossRef]
- Shahin, M.; Ahmed, B.; Ballard, K.J. Automatic classification of unequal lexical stress patterns using machine learning algorithms. In Proceedings of the 14th Australasian Conference on Speech Science and Technology, Sydney, Australia, 3–6 December 2012. [Google Scholar]
- Shahin, M.; Ahmed, B.; Parnandi, A.; Karappa, V.; McKechnie, J.; Ballard, K.; Gutierrez-Osuna, R. Tabby Talks: An automated tool for the assessment of childhood apraxia of speech. Speech Commun. 2015, 70, 49–64. [Google Scholar] [CrossRef]
- Shahin, M.; Gutierrez-Osuna, R.; Ahmed, B. Classification of Bisyllabic Lexical Stress Patterns in Disordered Speech Using Deep Learning. In Proceedings of the 41st IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016. [Google Scholar]
- Hosom, J.-P.; Shriberg, L.; Green, J.R. Diagnostic Assessment of Childhood Apraxia of Speech Using Automatic Speech Recognition (ASR) Methods. J. Med. Speech Lang. Pathol. 2004, 12, 167–171. [Google Scholar]
- Shriberg, L.D.; Campbell, T.F.; Karlsson, H.B.; Brown, R.L.; Mcsweeny, J.L.; Nadler, C.J. A diagnostic marker for childhood apraxia of speech: The lexical stress ratio. Clin. Linguist. Phon. 2003, 17, 549–574. [Google Scholar] [CrossRef] [Green Version]
- Shriberg, L.D.; Lohmeier, H.L.; Strand, E.A.; Jakielski, K.J. Encoding, memory, and transcoding deficits in Childhood Apraxia of Speech. Clin. Linguist. Phon. 2012, 26, 445–482. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, J. The Prosody of Speech: Timing and Rhythm. In The Handbook of Phonetic Sciences; Blackwell Publishing Ltd.: Hoboken, NJ, USA, 2010; pp. 521–602. [Google Scholar]
- Greenberg, S. Speaking in shorthand—A syllable-centric perspective for understanding pronunciation variation. Speech Commun. 1999, 29, 159–176. [Google Scholar] [CrossRef] [Green Version]
- Baayen, R.H.; Pipenbrock, R.; Gulikers, L. The CELEX Lexical Database (CD-ROM); Linguistic Data Consortium University of Pennsylvania: Philadelphia, PA, USA, 1993. [Google Scholar]
- Arciuli, J.; Monaghan, P.; Seva, N. Learning to assign lexical stress during reading aloud: Corpus, behavioral, and computational investigations. J. Mem. Lang. 2010, 63, 180–196. [Google Scholar] [CrossRef]
- Kochanski, G.; Grabe, E.; Coleman, J.; Rosner, B. Loudness predicts prominence: Fundamental frequency lends little. J. Acoust. Soc. Am. 2005, 118, 1038–1054. [Google Scholar] [CrossRef] [Green Version]
- Ballard, K.J.; Djaja, D.; Arciuli, J.; James, D.; Van Doorn, J. Developmental Trajectory for Production of Prosody: Lexical Stress Contrastivity in Children Ages 3 to 7 Years and in adults. J. Speech Lang. Hear. Res. 2012, 55, 1822–1835. [Google Scholar] [CrossRef]
- Arciuli, J.; Slowiaczek, L.M. The where and when of linguistic word-level prosody. Neuropsychologia 2007, 45, 2638–2642. [Google Scholar] [CrossRef] [PubMed]
- McLeod, S. Speech Sound Acquisition. In Articulation and Phonological Disorders: Speech Sound Disorders in Children, 6th ed.; Bernthal, J.E., Bankson, N.W., Flipsen, P., Eds.; Pearson Education: Boston, MA, USA, 2009; pp. 385–405. [Google Scholar]
- Field, J. Intelligibility and the Listener: The Role of Lexical Stress. TESOL Q. 2005, 39, 399. [Google Scholar] [CrossRef]
- Paul, R.; Shriberg, L.D.; McSweeny, J.L.; Cicchetti, D.V.; Klin, A.; Volkmar, F.R. Brief Report: Relations between Prosodic Performance and Communication and Socialization Ratings in High Functioning Speakers with Autism Spectrum Disorders. J. Autism Dev. Disord. 2005, 35, 861–869. [Google Scholar] [CrossRef] [PubMed]
- Skinder, A.; Strand, E.A.; Mignerey, M. Perceptual and acoustic analysis of lexical and sentential stress in children with developmental apraxia of speech. J. Med. Speech Lang. Pathol. 1999, 7, 133–144. [Google Scholar]
- Munson, B.; Bjorum, E.M.; Windsor, J. Acoustic and Perceptual Correlates of Stress in Nonwords Produced by Children With Suspected Developmental Apraxia of Speech and Children With Phonological Disorder. J. Speech Lang. Hear. Res. 2003, 46, 189–202. [Google Scholar] [CrossRef]
- Ballard, K.J.; Robin, D.A.; McCabe, P.; McDonald, J. A Treatment for Dysprosody in Childhood Apraxia of Speech. J. Speech, Lang. Hear. Res. 2010, 53, 1227–1245. [Google Scholar] [CrossRef]
- Fear, B.D.; Cutler, A.; Butterfield, S. The strong/weak syllable distinction in English. J. Acoust. Soc. Am. 1995, 97, 1893–1904. [Google Scholar] [CrossRef] [Green Version]
- Ling, L.E.; Grabe, E.; Nolan, F. Quantitative Characterizations of Speech Rhythm: Syllable-Timing in Singapore English. Lang. Speech 2000, 43, 377–401. [Google Scholar] [CrossRef]
- Arciuli, J.; Simpson, B.S.; Vogel, A.; Ballard, K. Acoustic Changes in the Production of Lexical Stress during Lombard Speech. Lang. Speech 2013, 57, 149–162. [Google Scholar] [CrossRef] [PubMed]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer, Version 5.3. 2011. Available online: http://www.praat.org (accessed on 8 March 2012).
- McLeod, S.; Baker, E. Speech-language pathologists’ practices regarding assessment, analysis, target selection, intervention and service delivery for children with speech sound disorders. Clin. Linguist. Phon. 2014, 28, 508–531. [Google Scholar] [CrossRef] [PubMed]
- Skahan, S.M.; Watson, M.; Lof, G.L. Speech-Language Pathologists’ Assessment Practices for Children with Suspected Speech Sound Disorders: Results of a National Survey. Am. J. Speech Lang. Pathol. 2007, 16, 246–259. [Google Scholar] [CrossRef]
- Ferrer, L.; Bratt, H.; Richey, C.; Franco, H.; Abrash, V.; Precoda, K. Classification of lexical stress using spectral and prosodic features for computer-assisted language learning systems. Speech Commun. 2015, 69, 31–45. [Google Scholar] [CrossRef]
- Shahin, M.; Epps, J.; Ahmed, B. Automatic Classification of Lexical Stress in English and Arabic Languages Using Deep Learning. Proc. Interspeech 2016, 2016, 175–179. [Google Scholar] [CrossRef] [Green Version]
- Hair, A.; Ballard, K.J.; Markoulli, C.; Monroe, P.; Mckechnie, J.; Ahmed, B.; Gutierrez-Osuna, R. A Longitudinal Evaluation of Tablet-Based Child Speech Therapy with Apraxia World. ACM Trans. Access. Comput. 2021, 14, 1–26. [Google Scholar] [CrossRef]
- Sztaho, D.; Nagy, K.; Vicsi, K. Subjective Tests and Automatic Sentence Modality Recognition with Recordings of Speech Impaired Children. In Development of Multimodal Interfaces: Active Listening and Synchrony. Lecture Notes in Computer Science; Esposito, A., Campbell, N., Vogel, C., Hussain, A., Nijholt, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 5967, pp. 397–405. [Google Scholar] [CrossRef]
- Van Santen, J.P.; Prud’Hommeaux, E.T.; Black, L.M. Automated assessment of prosody production. Speech Commun. 2009, 51, 1082–1097. [Google Scholar] [CrossRef] [Green Version]
- Shriberg, L.D.; Lof, L. Reliability studies in broad and narrow phonetic transcription. Clin. Linguist. Phon. 1991, 5, 225–279. [Google Scholar] [CrossRef]
- McKechnie, J.; Ahmed, B.; Gutierrez-Osuna, R.; Monroe, P.; McCabe, P.; Ballard, K.J. Automated speech analysis tools for children’s speech production: A systematic literature review. Int. J. Speech Lang. Pathol. 2018, 20, 583–598. [Google Scholar] [CrossRef] [PubMed]
- Rubin, Z.; Kurniawan, S. Speech Adventure: Using speech recognition for cleft speech therapy. In Proceedings of the 6th International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes, Greece, 29–31 May 2013; pp. 1–4. [Google Scholar]
- Peterson, G.E.; Lehiste, I. Duration of syllable nuclei in English. J. Acoust. Soc. Am. 1960, 32, 693–703. [Google Scholar] [CrossRef]
- Shriberg, L.D.; Kwiatkowski, J. Phonological disorders III: A procedure for assessing severity of involvement. J. Speech Lang. Hear. Res. 1982, 47, 256–270. [Google Scholar] [CrossRef]
- Gozzard, H.; Baker, E.; McCabe, P. Single word test of polysyllables. Unpublished work. 2004. [Google Scholar]
- Robbins, J.; Klee, T. Clinical Assessment of Oropharyngeal Motor Development in Young Children. J. Speech Hear. Disord. 1987, 52, 271–277. [Google Scholar] [CrossRef] [PubMed]
- Dodd, B.; Zhu, H.; Crosbie, S.; Holm, A.; Ozanne, A. Diagnostic Evaluation of Articulation and Phonology (DEAP); Psychology Corporation: London, UK, 2002. [Google Scholar]
- Gozzard, H.; Baker, E.; McCabe, P. Requests for clarification and children’s speech responses: Changing ‘pasghetti’ to ‘spaghetti’. Child. Lang. Teach. Ther. 2008, 24, 249–263. [Google Scholar] [CrossRef]
- Semel, E.; Wiig, E.; Secord, W. Clinical Evaluation of Language Fundamentals, Australian Standardised; Pearson Australia: Melbourne, Australia, 2006. [Google Scholar]
- Wiig, E.; Secord, W.; Semel, E. Clinical Evaluation of Language Fundamentals Preschool, Australian and New Zealand Standardised Edition, 2nd ed.; Pearson: Sydney, Australia, 2006. [Google Scholar]
- Iuzzini-Seigel, J.; Hogan, T.P.; Guarino, A.J.; Green, J.R. Reliance on auditory feedback in children with childhood apraxia of speech. J. Commun. Disord. 2015, 54, 32–42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wren, Y.; Miller, L.L.; Peters, T.J.; Emond, A.; Roulstone, S. Prevalence and Predictors of Persistent Speech Sound Disorder at Eight Years Old: Findings from a Population Cohort Study. J. Speech Lang. Hear. Res. 2016, 59, 647–673. [Google Scholar] [CrossRef] [Green Version]
- Smith, A.B.; Robb, M.P. The Influence of Utterance Position on Children’s Production of Lexical Stress. Folia Phoniatr. Logop. 2006, 58, 199–206. [Google Scholar] [CrossRef]
- Mazzoni, D.; Dannenberg, R. Audacity, version 1.3.9. 2000. Available online: http://www.audacityteam.org (accessed on 3 September 2011).
- Millar, J.; Vonwiller, J.; Harrington, J.; Dermody, P. The Australian National Database of Spoken Language. In Proceedings of the ICASSP’94. IEEE International Conference on Acoustics, Speech and Signal Processing, Adelaide, Australia, 19–22 April 1994. [Google Scholar]
- Teager, H. Some observations on oral air flow during phonation. IEEE Trans. Acoust. Speech Signal. Process. 1980, 28, 599–601. [Google Scholar] [CrossRef]
- Boersma, P. Accurate short-term analysis of the fundamental frequency and the harmonics-to-noise ratio of a sampled sound. IFA Proc. 1993, 17, 97–110. [Google Scholar]
- Kim, Y.J.; Beutnagel, M.C. Automatic assessment of American English lexical stress using machine learning algorithms. In Proceedings of the SLaTE, Speech and Language Technology in Education, Venice, Italy, 24–26 August 2011. [Google Scholar]
- Li, K.; Qian, X.; Kang, S.; Meng, H. Lexical stress detection for L2 English speech using deep belief networks. Proc. Interspeech 2013, 2013, 1811–1815. [Google Scholar] [CrossRef]
- Tepperman, J.; Narayanan, S. Automatic Syllable Stress Detection Using Prosodic Features for Pronunciation Evaluation of Language Learners. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23 March 2005; Volume 1, p. I-937. [Google Scholar] [CrossRef]
- Zhao, J.; Yuan, H.; Liu, J.; Xia, S. Automatic lexical stress detection using acoustic features for computer assisted language learning. In Proceedings of the APSIPA ASC, Xi’an, China, 18–21 October 2011; pp. 247–251. [Google Scholar]
- Cole, R.; Muthusamy, Y. OGI Multilanguage Corpus LDC94S17; Linguistic Data Consortium: Pennsylvania, PA, USA, 1994; Available online: https://catalog.ldc.upenn.edu/LDC94S17 (accessed on 8 March 2011).
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hedges, L.V. Distribution theory for Glass’estimator of effect size and related estimators. J. Educ. Behav. Stat. 1981, 6, 107–128. [Google Scholar] [CrossRef]
- Peter, B.; Stoel-Gammon, C. Timing errors in two children with suspected childhood apraxia of speech (sCAS) during speech and music-related tasks. Clin. Linguist. Phon. 2005, 19, 67–87. [Google Scholar] [CrossRef]
- Terband, H.; Maassen, B.; Guenther, F.H.; Brumberg, J. Computational Neural Modeling of Speech Motor Control in Childhood Apraxia of Speech (CAS). J. Speech Lang. Hear. Res. 2009, 52, 1595–1609. [Google Scholar] [CrossRef] [Green Version]
- Arciuli, J.; Ballard, K.J. Still not adult-like: Lexical stress contrastivity in word productions of eight- to eleven-year-olds. J. Child. Lang. 2016, 44, 1274–1288. [Google Scholar] [CrossRef]
- Ahmed, B.; Ballard, K.J.; Burnham, D.; Tharmakulasingam, S.; Mehmood, H.; Estival, D.; Baker, E.; Cox, F.; Arciuli, J.; Benders, T.; et al. AusKidTalk: An Auditory-Visual Corpus of 3- to 12-year-old Australian Children’s Speech. In Proceedings of the INTERSPEECH 2021, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Morrill, T.H.; Dilley, L.C.; McAuley, J.D. Prosodic patterning in distal speech context: Effects of list intonation and f0 downtrend on perception of proximal prosodic structure. J. Phon. 2014, 46, 68–85. [Google Scholar] [CrossRef]
- Hosom, J.P. Computer processing for analysis of speech disorders. In Speech Sound Disorders in Children: In Honour of Laurence, D. Shriberg; Paul, R., Flipsen, P., Eds.; Plural Publishing: San Diego, CA, USA, 2009; pp. 115–140. [Google Scholar]
- Arciuli, J.; Cupples, L. Effects of stress typicality during spoken word recognition by native and nonnative speakers of English: Evidence from onset gating. Mem. Cogn. 2004, 32, 21–30. [Google Scholar] [CrossRef] [Green Version]
- Arciuli, J.; Cupples, L. The processing of lexical stress during visual word recognition: Typicality effects and orthographic correlates. Q. J. Exp. Psychol. 2006, 59, 920–948. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal. Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Asami, T.; Masumura, R.; Yamaguchi, Y.; Masataki, H.; Aono, Y. Domain adaptation of DNN models using knowledge distillation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | TD (n = 16) | CAS (n = 26) | Statistics a | ||
|---|---|---|---|---|---|
| M (SD) | Range | M (SD) | Range | ||
| Demographic | |||||
| Age (years) | 6.1 (2.0) | 4–10 | 5.9 (2.5) | 4–12 | Z = −0.71 ns |
| Sex | 7 male 9 female | 22 male 4 female | χ = 7.7 * | ||
| Test of Polysyllables b | |||||
| PPC | 95.2 (4.2) | 85.6–99.3 | 61.8 (21.1) | 23.9–96.7 | t = 6.24 ** |
| PCC | 95.4 (4.8) | 81.4–100 | 57.5 (24.7) | 13.0–98.6 | t = 5.66 ** |
| PVC | 93.9 (5.3) | 82.5–100 | 67.5 (17.6) | 38.5–94.2 | t = 5.82 ** |
| % Lexical stress matches | 88.8 (8.4) | 77.3–100 | 51.0 (26.6) | 6.3–93.8 | t = 5.5 ** |
| Severity Rating c | |||||
| Typical–mild | 15/16 | 5/26 | |||
| Mild–moderate | 1 d | 5 | |||
| Moderate–severe | 0 | 5 | |||
| Severe | 0 | 11 | |||
| Feature | Description |
|---|---|
| f1 | Peak-to-peak TEO amplitude over syllable nucleus |
| f2 | Mean TEO energy over syllable nucleus |
| f3 | Maximum TEO energy over syllable nucleus |
| f4 | Nucleus duration |
| f5 | Syllable duration |
| f6 | Maximum pitch over syllable nucleus |
| f7 | Mean pitch over syllable nucleus |
| f8 | 27 Mel-scale energy bands over syllable nucleus |
| Source | Numerator df | Denominator df | F | p |
|---|---|---|---|---|
| Intercept | 1 | 49.346 | 365.151 | <0.001 |
| Group | 1 | 32.858 | 18.645 | <0.001 |
| Stress | 1 | 35.302 | 20.836 | <0.001 |
| Model | 1 | 36.087 | 1.235 | 0.274 |
| Age (covariate) | 1 | 38.518 | 8.208 | 0.007 |
| Group × Stress | 1 | 35.328 | 4.314 | 0.045 |
| Group × Model | 1 | 36.084 | 0.118 | 0.733 |
| Stress × Model | 1 | 34.934 | 4.007 | 0.053 |
| Group × Stress × Model | 1 | 34.946 | 0.715 | 0.404 |
| Source | Numerator df | Denominator df | F | p |
|---|---|---|---|---|
| Intercept | 1 | 29.545 | 88.358 | <0.001 |
| Stress | 1 | 20.894 | 22.864 | <0.001 |
| Model | 1 | 22.420 | 0.214 | 0.648 |
| PPC (covariate) | 1 | 23.196 | 9.529 | 0.005 |
| Stress × Model | 1 | 20.592 | 3.362 | 0.081 |
| Single Pronunciation | Multiple Pronunciation | |||||
|---|---|---|---|---|---|---|
| Comparison | Statistic | p | g | Statistic | p | g |
| All (excl. SS) | U = 26 z = 4.95 | <0.0001 | 3.215 | U = 25 z = 4.98 | <0.0001 | 3.617 |
| SW | U = 0 z = 5.48 | <0.0001 | 7.468 | U = 0 z = 5.48 | <0.0001 | 6.683 |
| WS | U = 131.5 z = 0 | 1 | 0.079 | U = 78.5 z = 1.17 | 0.242 | 0.430 |
| Classification Accuracy for TD | Classification Accuracy for CAS | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Single Pronunciation | Multiple Pronunciation | Single Pronunciation | Multiple Pronunciation | |||||||||
| Confidence a | ||||||||||||
| Single pronunciation | 0.73 ** | — | 0.39 ** | — | ||||||||
| Multiple pronunciation | — | 0.35 * | — | 0.58 ** | ||||||||
| Segmental features a | ||||||||||||
| Nasal phoneme adjacent to vowel | −0.05 | −0.13 | −0.14 | −0.12 | ||||||||
| Liquid/glide adjacent to vowel | −0.28 * | −0.27 | −0.21 | −0.26 | ||||||||
| Nonschwa unstressed vowel | −0.35 * | −0.33 * | −0.22 | −0.25 | ||||||||
| Long stressed vowel | 0.01 | 0.02 | −0.21 | 0.01 | ||||||||
| Unvoiced plosive + schwa vowel | −0.09 | −0.02 | −0.20 | −0.09 | ||||||||
| Single Pronunciation | Multiple Pronunciation | Single Pronunciation | Multiple Pronunciation | |||||||||
| SW + WS | SW | WS | SW + WS | SW | WS | SW + WS | SW | WS | SW + WS | SW | WS | |
| Age b | 0.18 | 0.21 | 0.34 | 0.47 | 0.33 | 0.47 | 0.41 * | 0.22 | 0.56 ** | 0.43 * | 0.31 | 0.52 ** |
| Speech disorder severity b | ||||||||||||
| PCC | 0.04 | −0.10 | 0.38 | 0.58 * | 0.47 | 0.42 | 0.33 | 0.38 | 0.28 | 0.45 * | 0.46 * | 0.40 * |
| PVC | 0.11 | 0.05 | 0.42 | 0.35 | 0.23 | 0.40 | 0.39 * | 0.41 * | 0.34 | 0.50 * | 0.49 * | 0.45 * |
| PPC | 0.08 | 0.02 | 0.38 | 0.40 | 0.24 | 0.38 | 0.36 | 0.40 * | 0.31 | 0.48 * | 0.48 * | 0.43 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McKechnie, J.; Shahin, M.; Ahmed, B.; McCabe, P.; Arciuli, J.; Ballard, K.J. An Automated Lexical Stress Classification Tool for Assessing Dysprosody in Childhood Apraxia of Speech. Brain Sci. 2021, 11, 1408. https://doi.org/10.3390/brainsci11111408
McKechnie J, Shahin M, Ahmed B, McCabe P, Arciuli J, Ballard KJ. An Automated Lexical Stress Classification Tool for Assessing Dysprosody in Childhood Apraxia of Speech. Brain Sciences. 2021; 11(11):1408. https://doi.org/10.3390/brainsci11111408
Chicago/Turabian StyleMcKechnie, Jacqueline, Mostafa Shahin, Beena Ahmed, Patricia McCabe, Joanne Arciuli, and Kirrie J. Ballard. 2021. "An Automated Lexical Stress Classification Tool for Assessing Dysprosody in Childhood Apraxia of Speech" Brain Sciences 11, no. 11: 1408. https://doi.org/10.3390/brainsci11111408
APA StyleMcKechnie, J., Shahin, M., Ahmed, B., McCabe, P., Arciuli, J., & Ballard, K. J. (2021). An Automated Lexical Stress Classification Tool for Assessing Dysprosody in Childhood Apraxia of Speech. Brain Sciences, 11(11), 1408. https://doi.org/10.3390/brainsci11111408