Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis




Abstract
:1. Introduction
2. Data-Driven Bearing Fault Detection
2.1. Data Collection
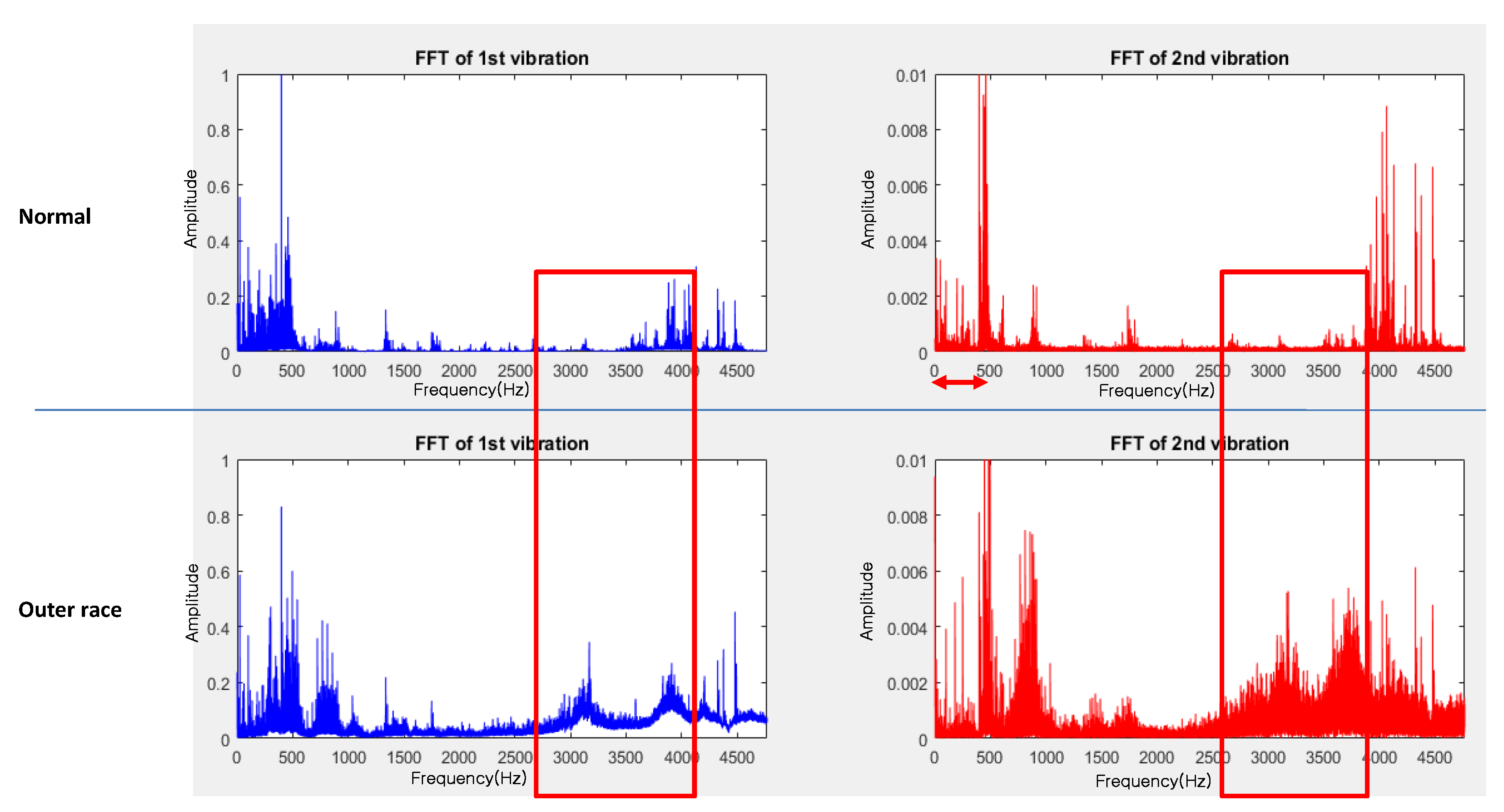
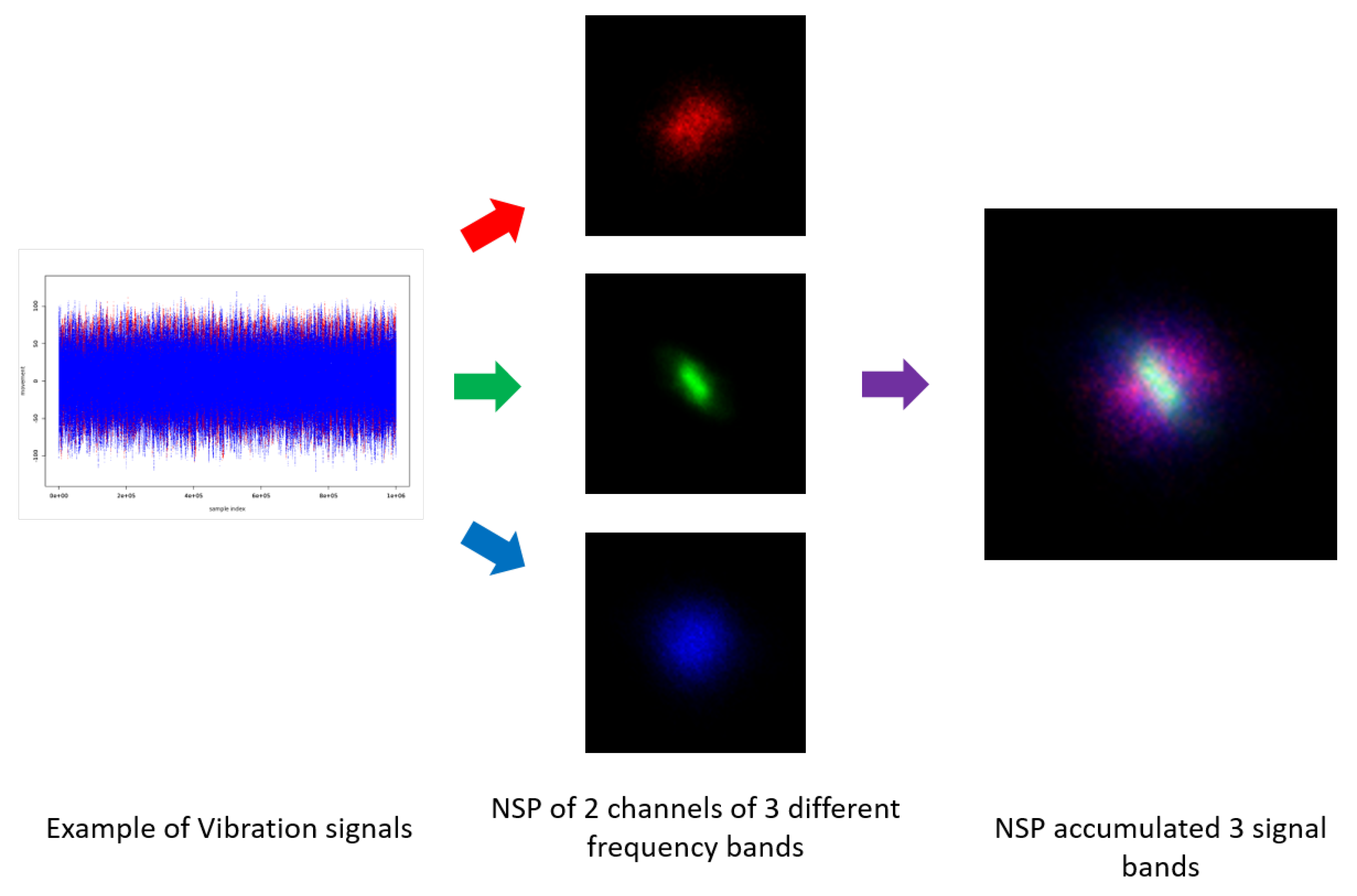
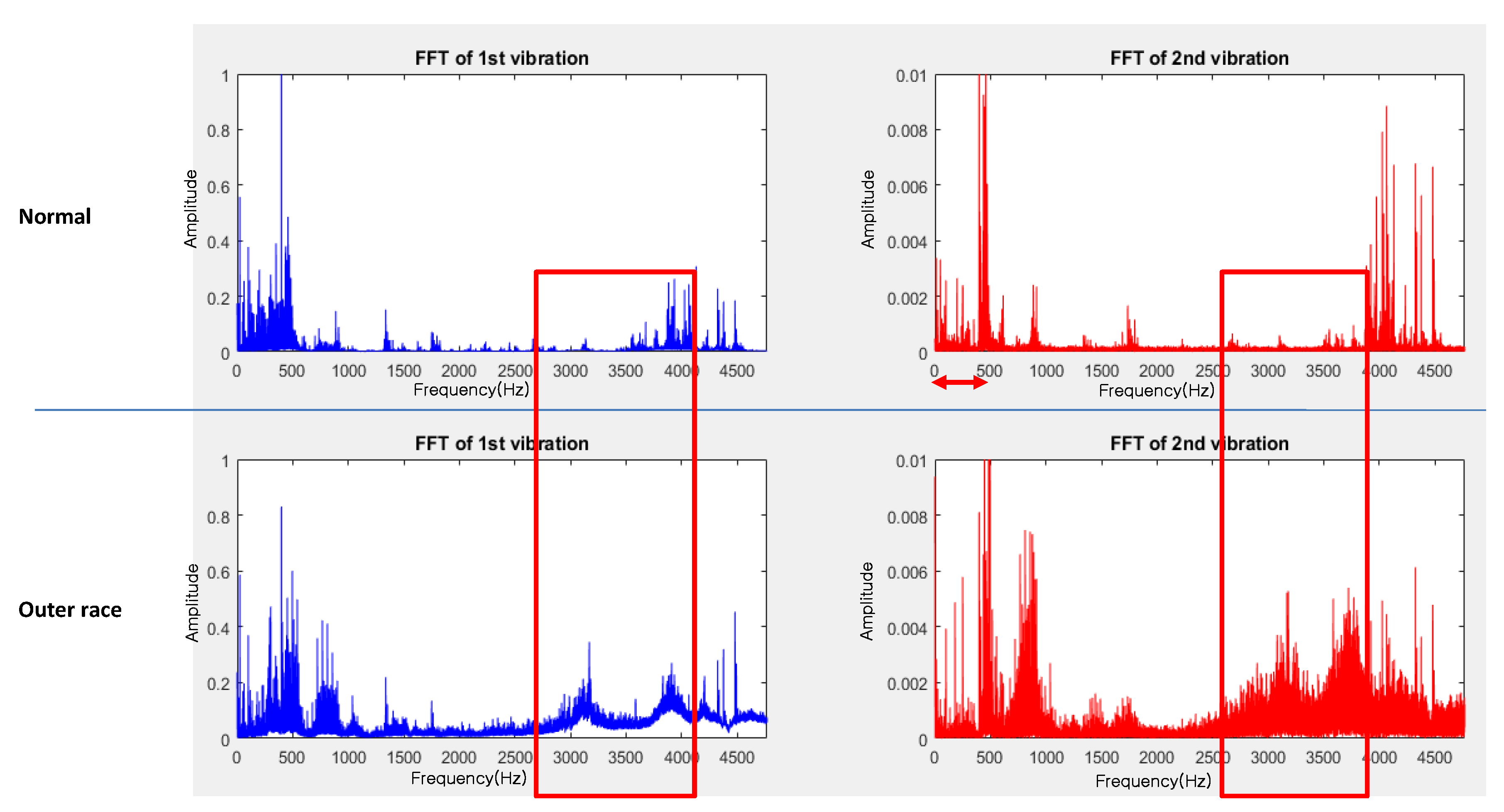
2.2. Image Transformation of Vibration Signals
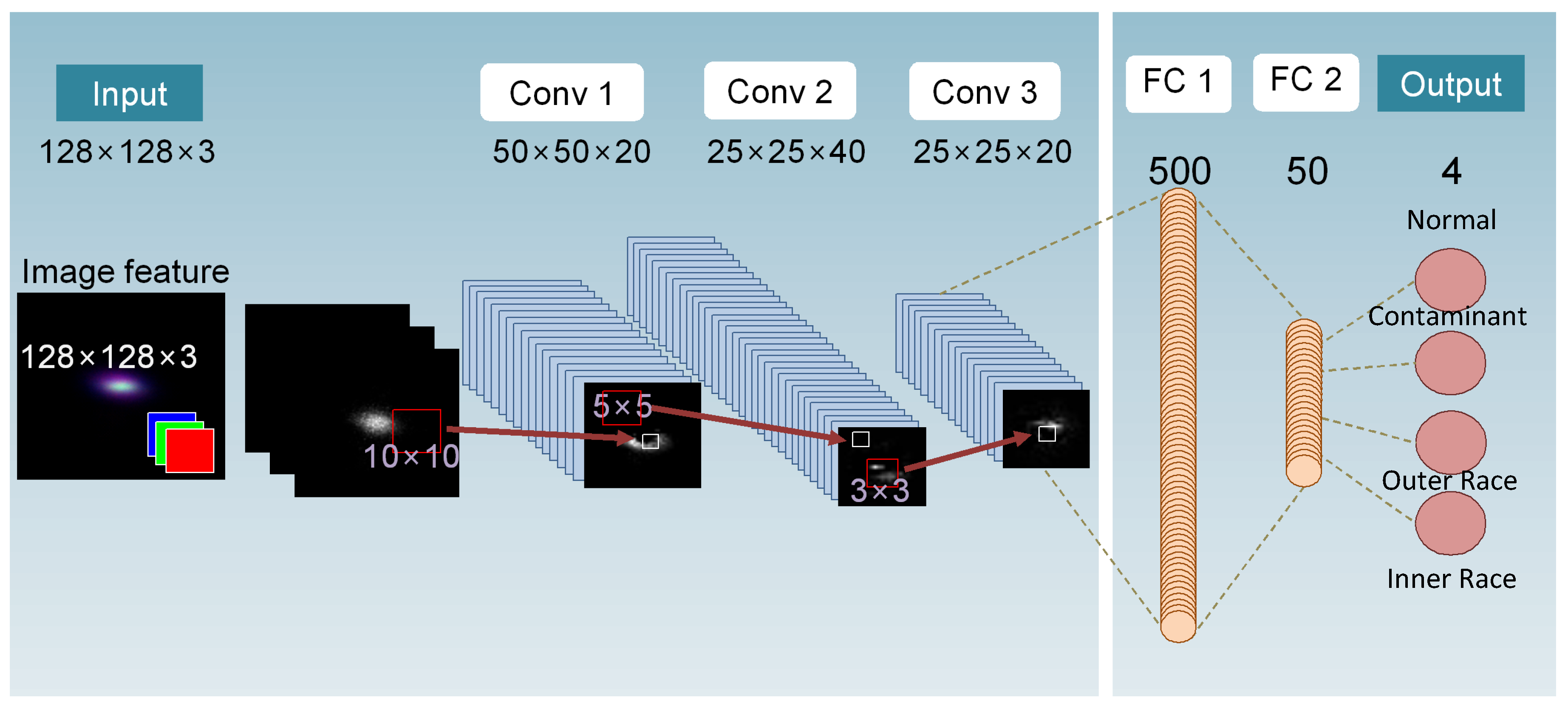
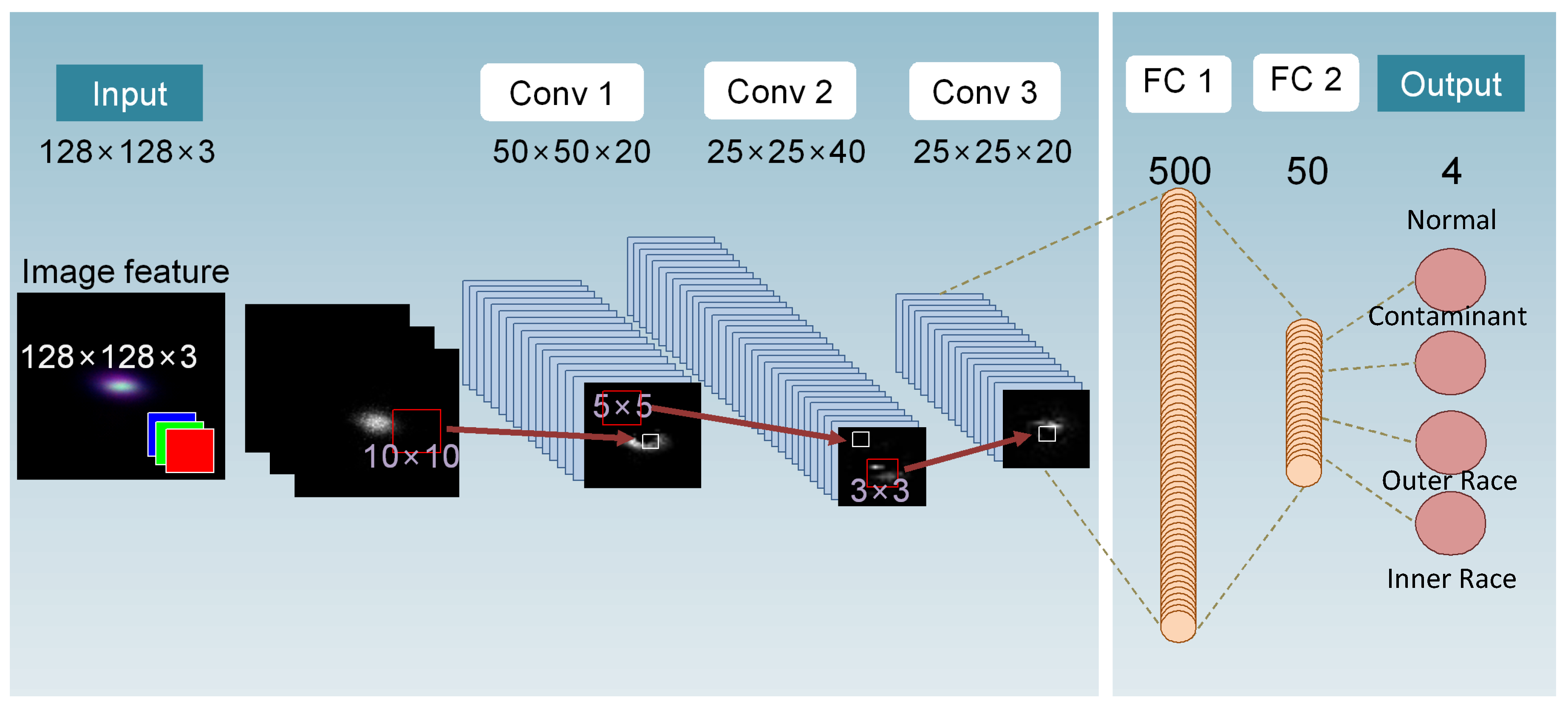
2.3. Fault Classification Using CNN
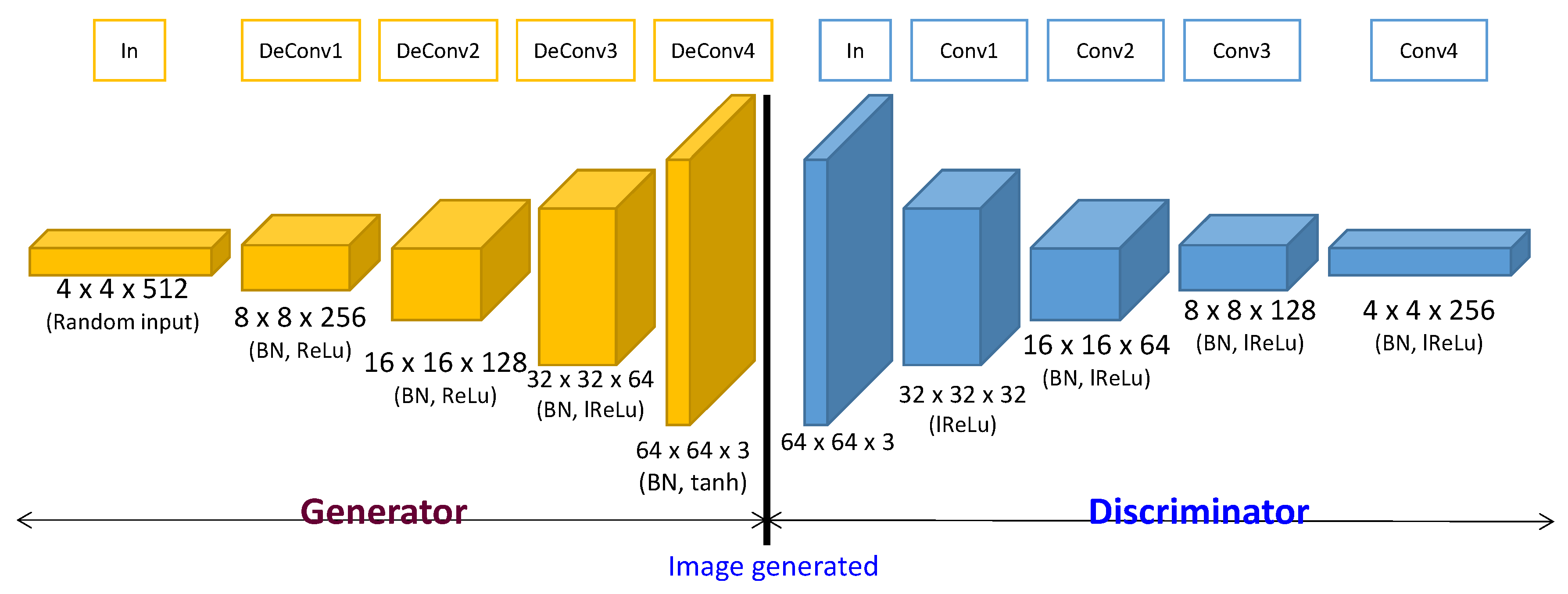
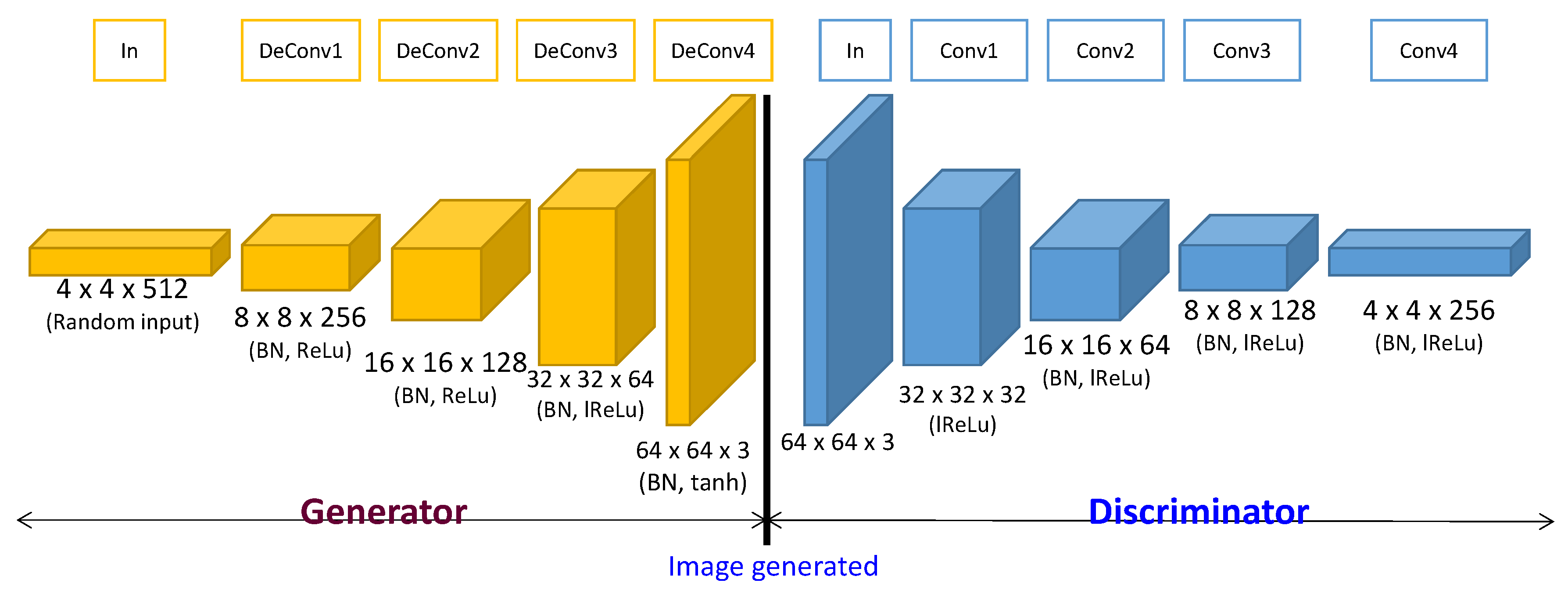
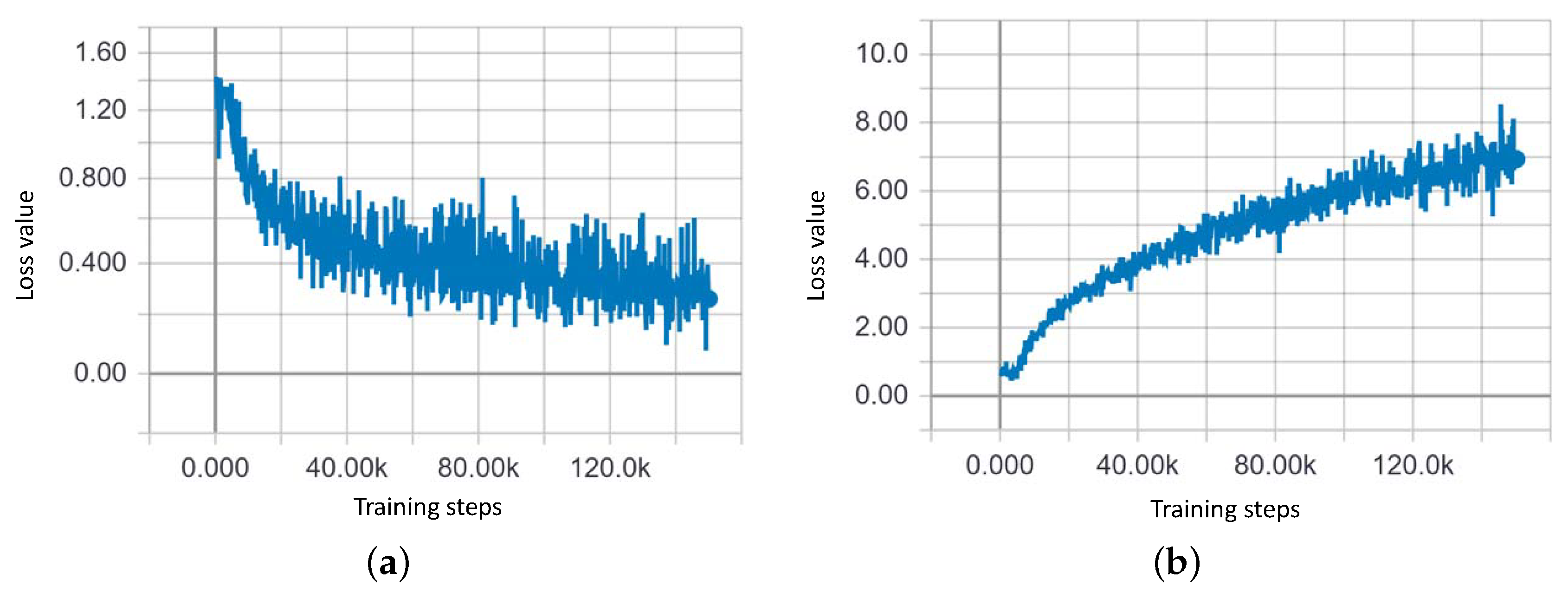
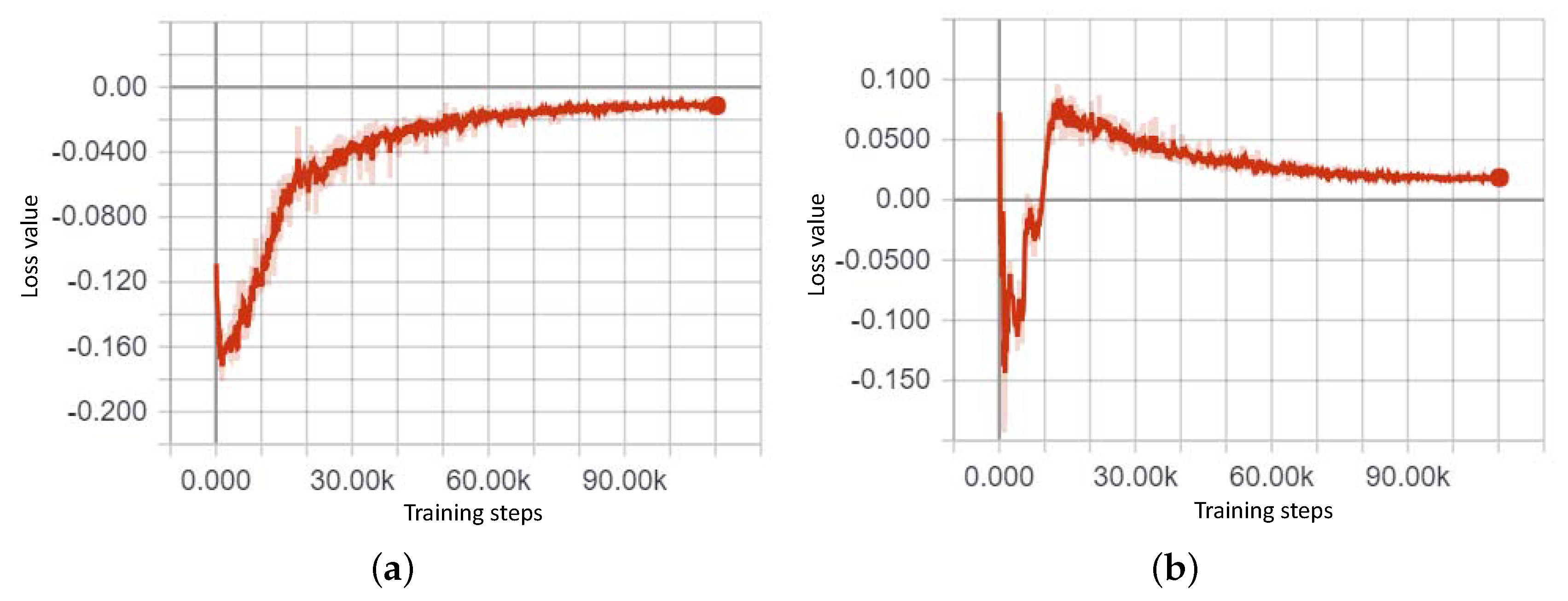
3. Generative Model for Oversampling Fault Condition Data
4. Experimental Results
4.1. Data Preparation and Runtime Environment
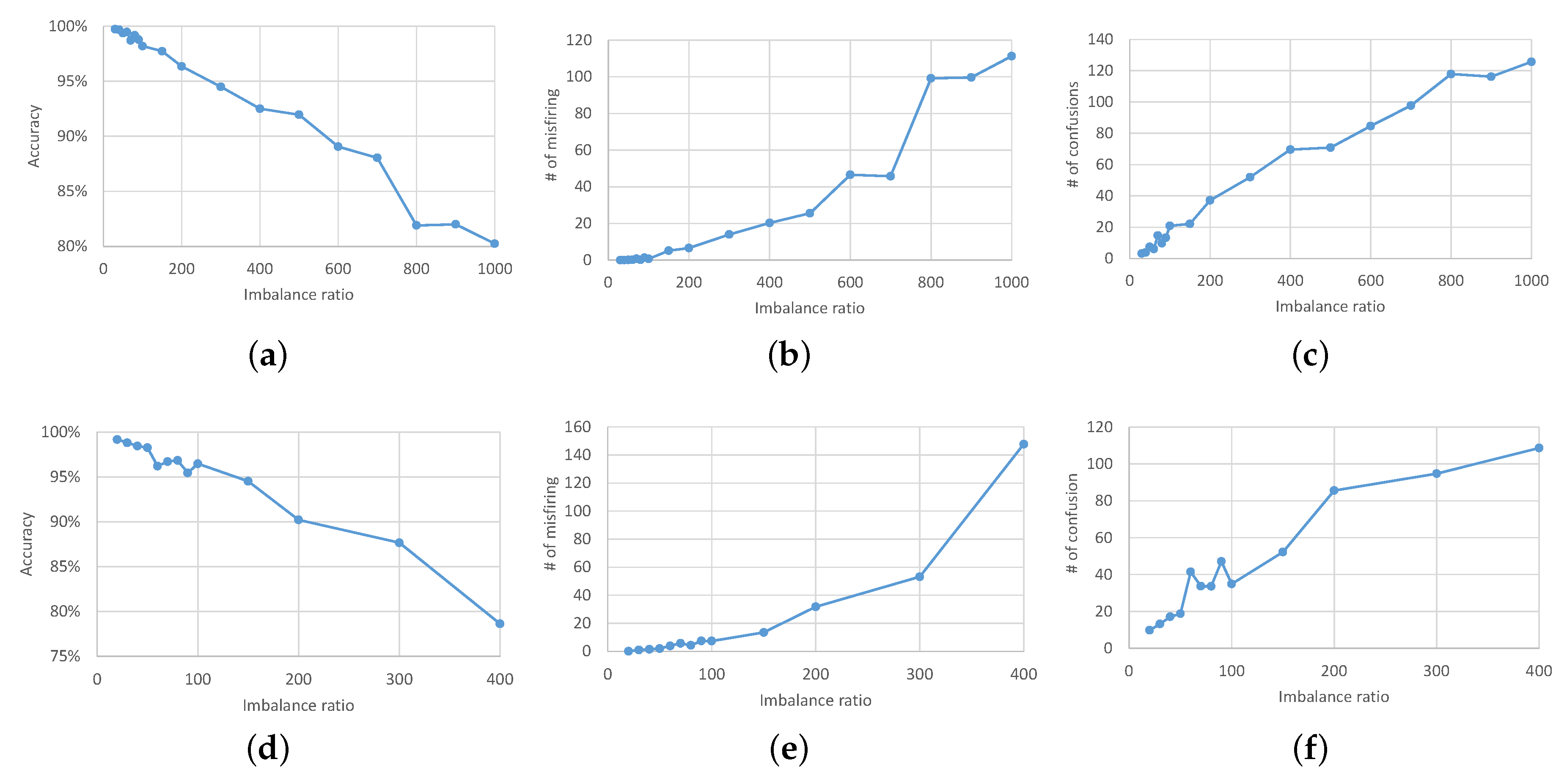
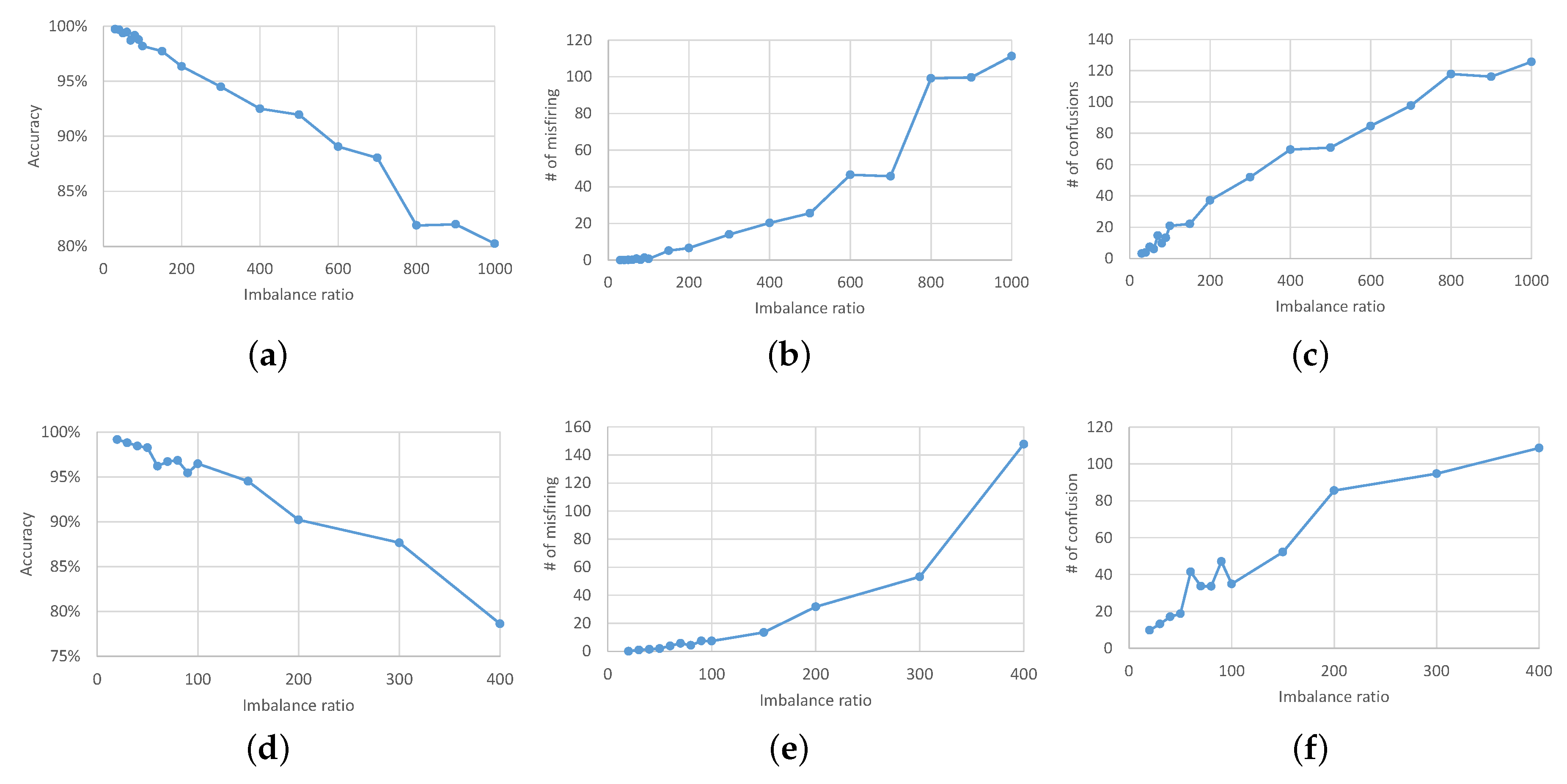
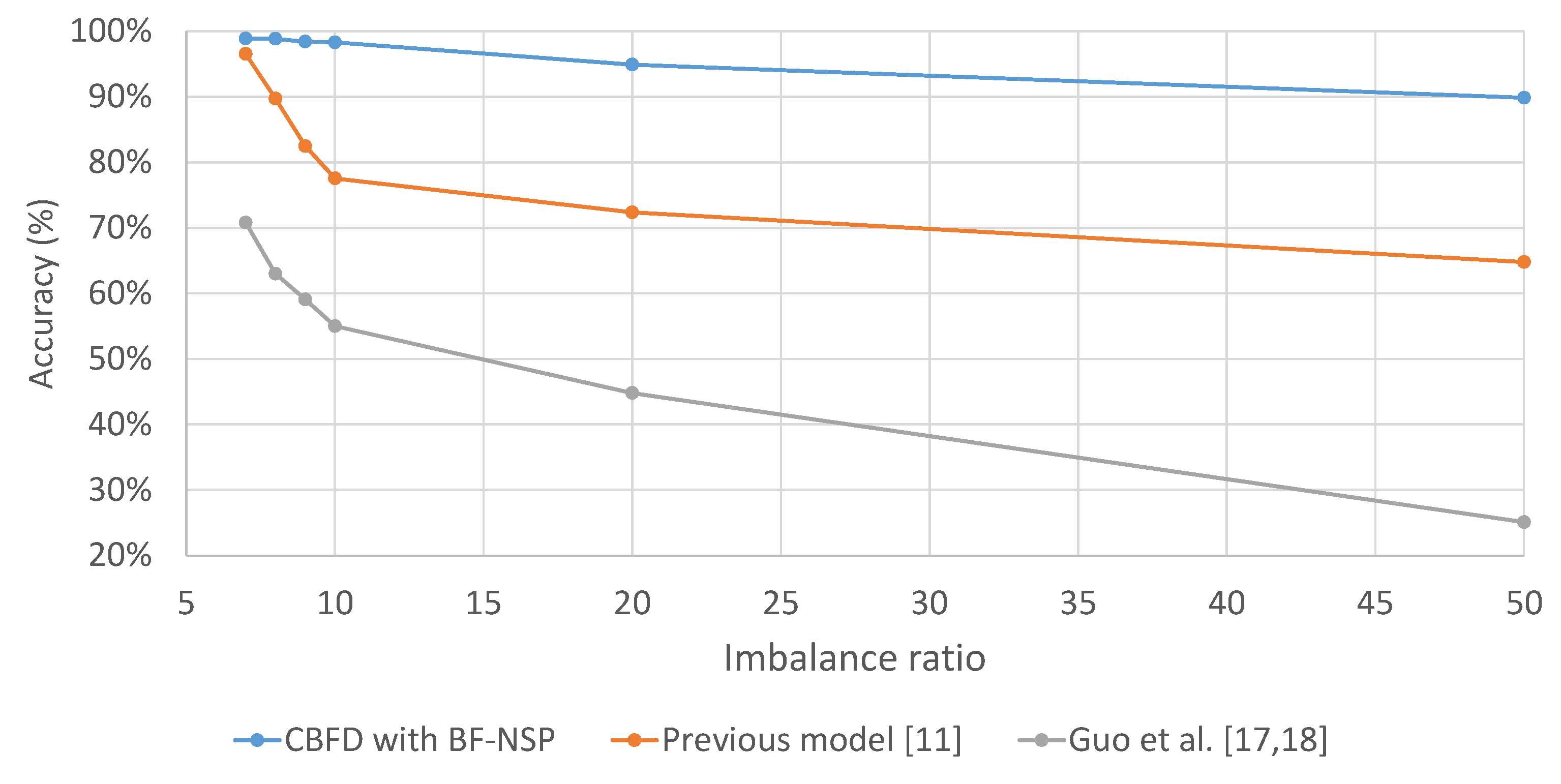
4.2. Testing Classification under Data Imbalanced Conditions
- False alarms, identified when FDD determines a fault despite normal condition;
- Misfiring, where ground truth observations show a fault condition, but FDD indicates normal condition;
- Confusion, where ground truth observations show one fault condition, but FDD determines another.
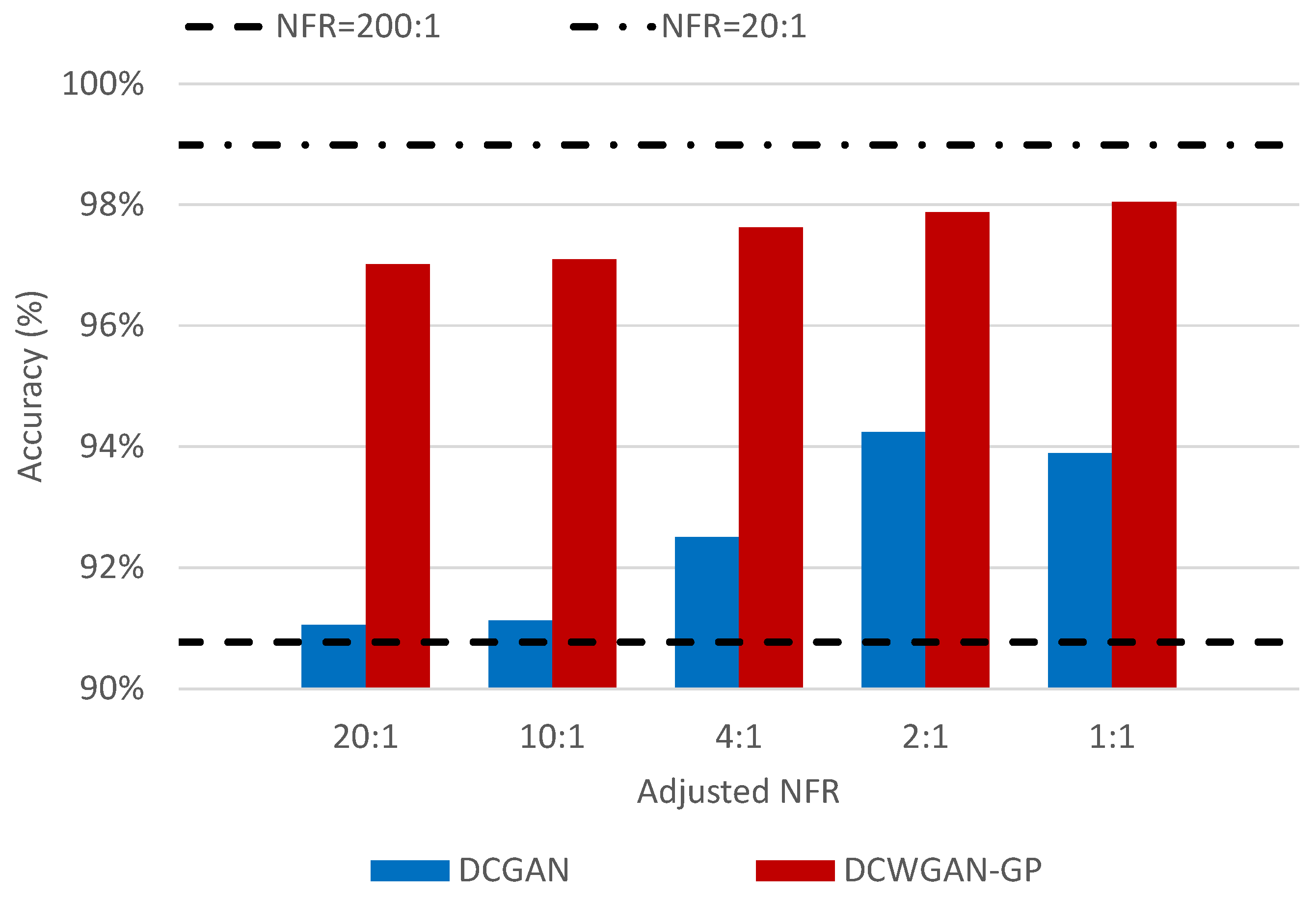
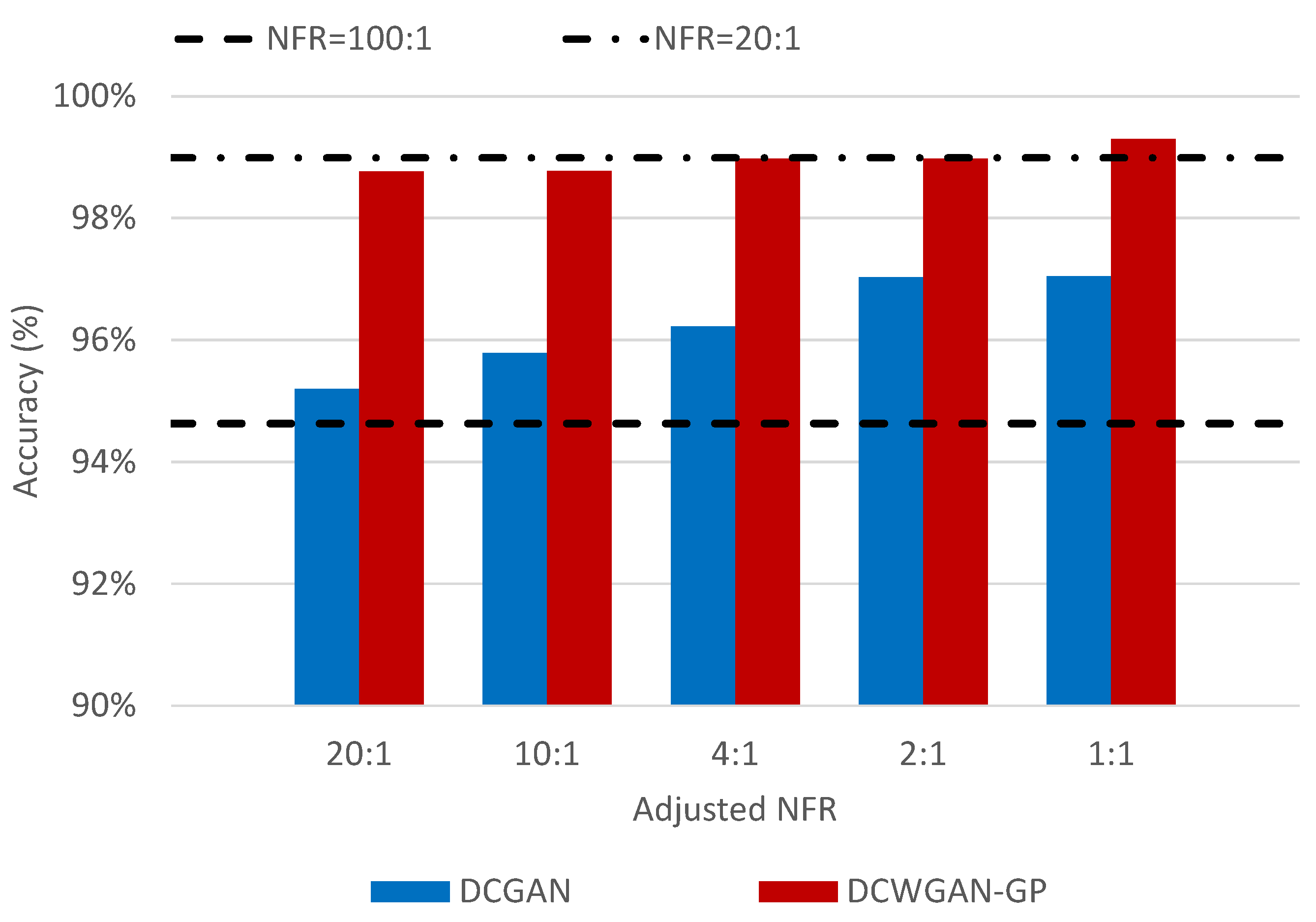
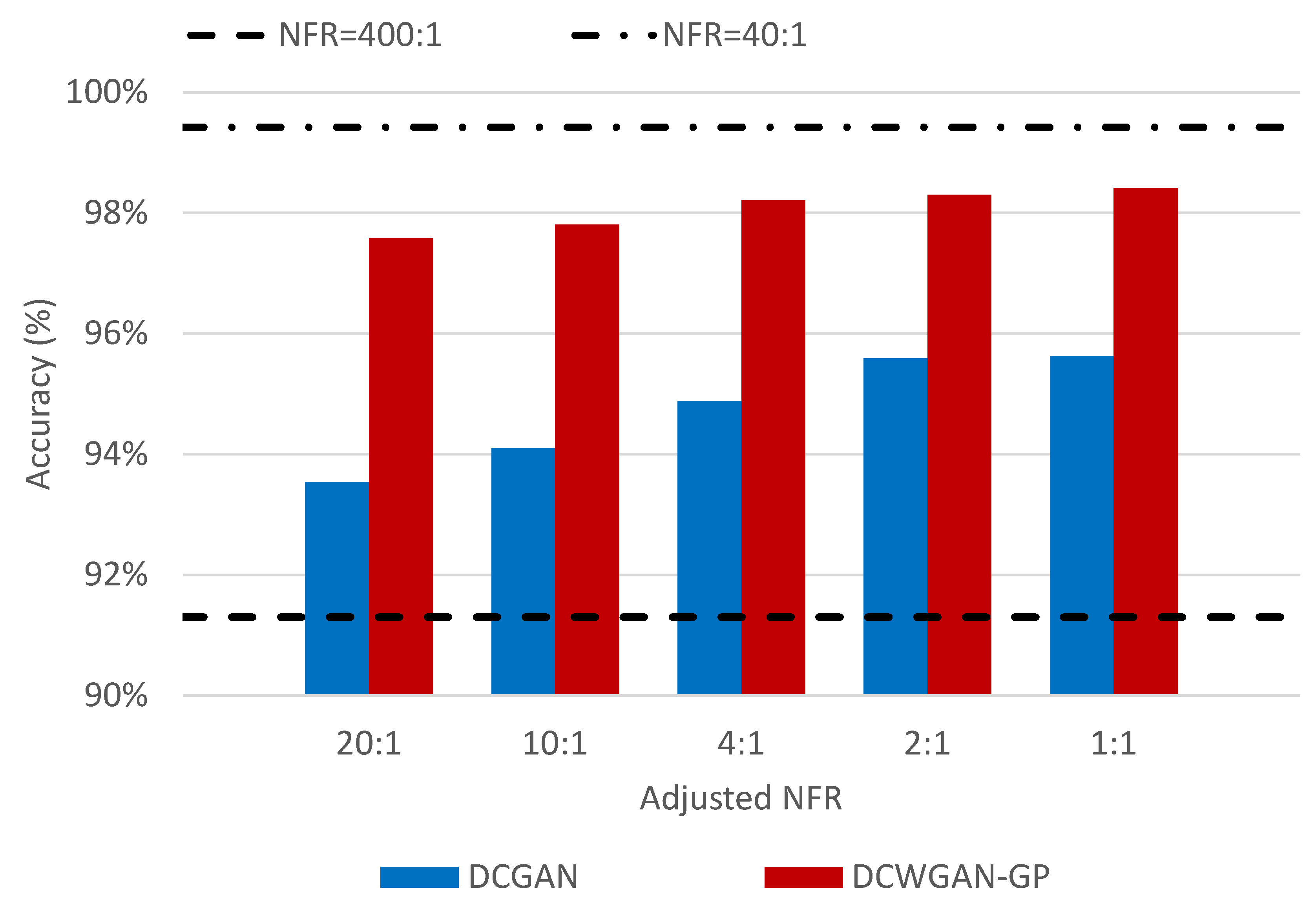
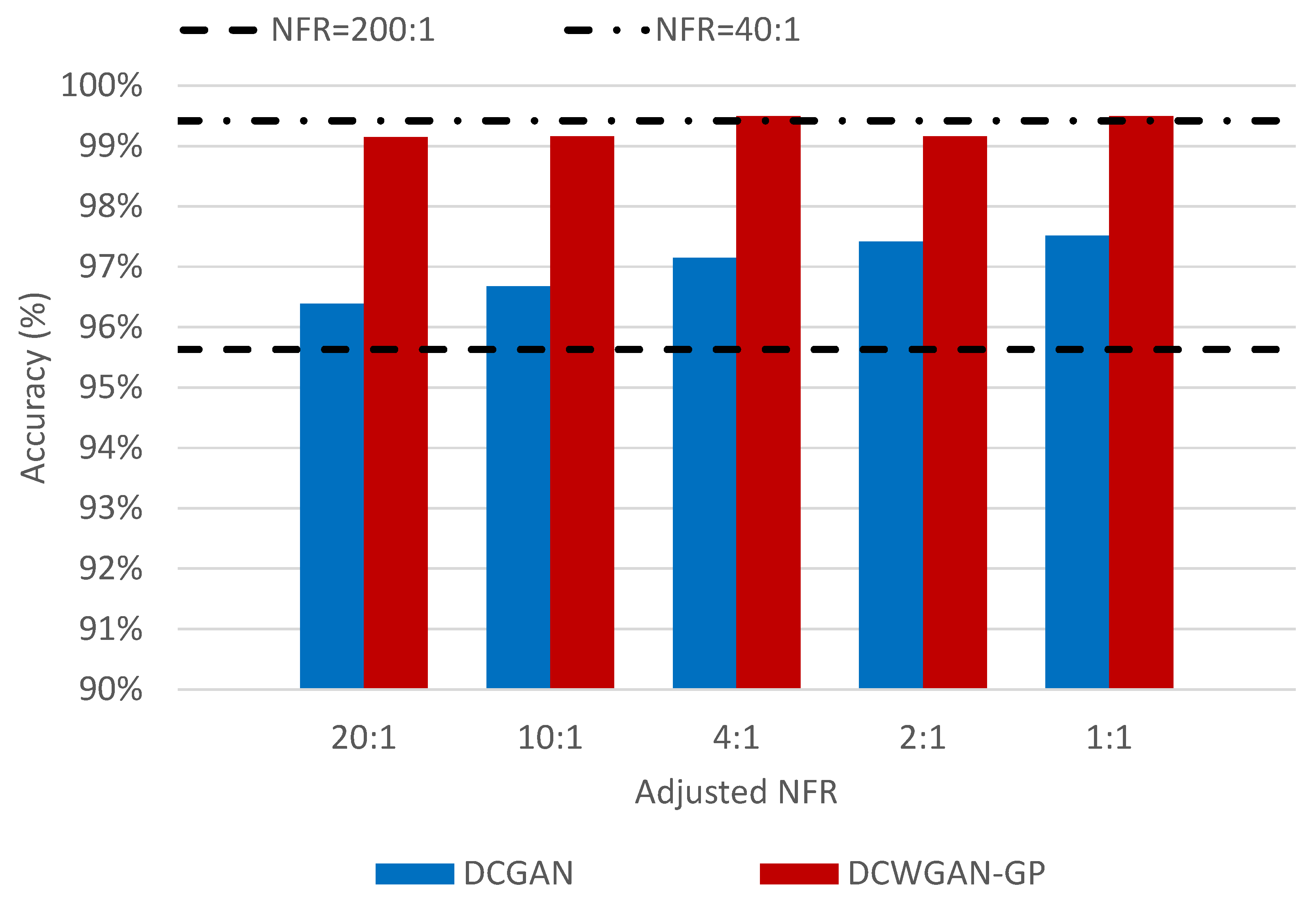
4.3. Testing Classification with Oversampling
- NFR = (# of normal data images): (# of fault data images),
- A-NFR = (# of normal data images): (# of fault data images) + (# of oversampled fault data images).
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FDD | Fault detection and diagnosis |
| DNN | Deep neural networks |
| HHT | Hilbert–Huang transformation |
| CNN | Convolutional neural network |
| NSP | Nested scatter plot |
| GAN | Generative adversarial networks |
| DCGAN | Deep convolution generative adversarial networks |
| BF-NSP | Bearing fault-nested scatter plot |
| CBFD | CNN-based bearing fault detector |
| WGAN | Wasserstein GAN |
| WGAN-GP | Wasserstein GAN with gradient penalty |
| DCWGAN-GP | WGAN-GP on DCGAN architecture model |
| EMD | Earth mover’s distance |
| CWTS | Continuous wavelet transform scalogram |
| NFR | Normal-to-fault ratio |
| A-NFR | Adjusted NFR |
References
- Baptista, M.; Sankararaman, S.; de Medeiros, I.P.; Nascimento, C., Jr.; Prendinger, H.; Henriques, E.M. Forecasting fault events for predictive maintenance using data-driven techniques and ARMA modeling. Comput. Ind. Eng. 2018, 115, 41–53. [Google Scholar] [CrossRef]
- Benbouzid, M.E.H.; Kliman, G.B. What stator current processing-based technique to use for induction motor rotor faults diagnosis? IEEE Trans. Energy Convers. 2003, 18, 238–244. [Google Scholar] [CrossRef]
- Antonino-Daviu, J.A.; Riera-Guasp, M.; Pineda-Sanchez, M.; Pérez, R.B. A critical comparison between DWT and Hilbert–Huang-based methods for the diagnosis of rotor bar failures in induction machines. IEEE Trans. Ind. Appl. 2009, 45, 1794–1803. [Google Scholar] [CrossRef]
- Nandi, S.; Toliyat, H.A.; Li, X. Condition monitoring and fault diagnosis of electrical motors—A review. IEEE Trans. Energy Convers. 2005, 20, 719–729. [Google Scholar] [CrossRef]
- Zhang, P.; Du, Y.; Habetler, T.G.; Lu, B. A survey of condition monitoring and protection methods for medium-voltage induction motors. IEEE Trans. Ind. Appl 2011, 47, 34–46. [Google Scholar] [CrossRef]
- Zhang, B.; Sconyers, C.; Byington, C.; Patrick, R.; Orchard, M.E.; Vachtsevanos, G. A probabilistic fault detection approach: Application to bearing fault detection. IEEE Trans. Ind. Electron. 2011, 58, 2011–2018. [Google Scholar] [CrossRef]
- Deng, F.; Guo, S.; Zhou, R.; Chen, J. Sensor multifault diagnosis with improved support vector machines. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1053–1063. [Google Scholar] [CrossRef]
- Gu, X.; Deng, F.; Gao, X.; Zhou, R. An Improved Sensor Fault Diagnosis Scheme Based on TA-LSSVM and ECOC-SVM. J. Syst. Sci. Complex. 2018, 31, 372–384. [Google Scholar] [CrossRef]
- Li, C.; de Oliveira, J.L.V.; Lozada, M.C.; Cabrera, D.; Sanchez, V.; Zurita, G. A systematic review of fuzzy formalisms for bearing fault diagnosis. IEEE Trans. Fuzzy Syst. 2018. [Google Scholar] [CrossRef]
- Esfahani, E.T.; Wang, S.; Sundararajan, V. Multisensor wireless system for eccentricity and bearing fault detection in induction motors. IEEE/ASME Trans. Mech. 2014, 19, 818–826. [Google Scholar] [CrossRef]
- Lee, Y.O.; Jo, J.; Hwang, J. Application of deep neural network and generative adversarial network to industrial maintenance: A case study of induction motor fault detection. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3248–3253. [Google Scholar]
- Chen, Z.; Li, W. Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, X.; Zou, J. The Optimized Deep Belief Networks With Improved Logistic Sigmoid Units and Their Application in Fault Diagnosis for Planetary Gearboxes of Wind Turbines. IEEE Trans. Ind. Electron. 2019, 66, 3814–3824. [Google Scholar] [CrossRef]
- Zhao, G.; Liu, X.; Zhang, B.; Zhang, G.; Niu, G.; Hu, C. Bearing Health Condition Prediction Using Deep Belief Network. In Proceedings of the Annual Conference of Prognostics and Health Management Society, Orlando, FL, USA, 15–18 April 2017; pp. 2–5. [Google Scholar]
- Tang, S.; Shen, C.; Wang, D.; Li, S.; Huang, W.; Zhu, Z. Adaptive deep feature learning network with Nesterov momentum and its application to rotating machinery fault diagnosis. Neurocomputing 2018, 305, 1–14. [Google Scholar] [CrossRef]
- Oh, H.; Jung, J.H.; Jeon, B.C.; Youn, B.D. Scalable and Unsupervised Feature Engineering Using Vibration-Imaging and Deep Learning for Rotor System Diagnosis. IEEE Trans. Ind. Electron. 2018, 65, 3539–3549. [Google Scholar] [CrossRef]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C. A Novel Fault Diagnosis Method for Rotating Machinery Based on a Convolutional Neural Network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Yang, T.; Gao, W.; Zhang, C.; Zhang, Y. An intelligent fault diagnosis method for bearings with variable rotating speed based on Pythagorean spatial pyramid pooling CNN. Sensors 2018, 18, 3857. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Xiang, J.; Zhong, Y.; Zhou, Y. Convolutional neural network-based hidden Markov models for rolling element bearing fault identification. Knowl.-Based Syst. 2018, 144, 65–76. [Google Scholar] [CrossRef]
- LIU, T.; LI, G. The imbalanced data problem in the fault diagnosis of rolling bearing. Comput. Eng. Sci. 2010, 32, 150–153. [Google Scholar]
- Ramentol, E.; Caballero, Y.; Bello, R.; Herrera, F. SMOTE-RSB*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowl. Inf. Syst. 2012, 33, 245–265. [Google Scholar] [CrossRef]
- Ng, W.W.; Hu, J.; Yeung, D.S.; Yin, S.; Roli, F. Diversified sensitivity-based undersampling for imbalance classification problems. IEEE Trans. Cybern. 2015, 45, 2402–2412. [Google Scholar] [CrossRef]
- Lu, X.; Chen, M.; Wu, J.; Chan, P. A Feature-Partition and Under-Sampling Based Ensemble Classifier for Web Spam Detection. Int. J. Mach. Learn. Comput. 2015, 5, 454. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed]
- Jo, J.; Lee, Y.O.; Hwang, J. Multi-layer Nested Scatter Plot—A data wrangling method for correlated multi-channel time series signals. In Proceedings of the 2018 IEEE International Conference on Artificial Intelligence for Industries, Laguna Hills, CA, USA, 26–28 September 2018. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv, 2015; arXiv:1511.06434. [Google Scholar]
- Veltman, A.; Pulle, D.W.; De Doncker, R.W. Fundamentals of Electrical Drives; Springer: Cham, Switzerland, 2007. [Google Scholar]
- McFadden, P.; Smith, J. Vibration monitoring of rolling element bearings by the high-frequency resonance technique–A review. Tribol. Int. 1984, 17, 3–10. [Google Scholar] [CrossRef]
- Yang, M.; Yin, J.; Ji, G. Classification methods on imbalanced data: A survey. J. Nanjing Normal Univ. 2008, 8, 8–11. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | No. of Images | |
|---|---|---|
| Normal | 21,000 | |
| Contaminant | 800 | |
| Inner Race | High | 1000 |
| Mid | 1000 | |
| Outer Race | High | 1000 |
| Mid | 1000 | |
| Low | 1000 | |
| Category | Specification |
|---|---|
| CPU | Intel Core i7-7700K |
| RAM | 64GB DDR4 memory |
| GPU | NVIDIA Titan XP 12GB GDDR5X |
| OS | Ubuntu 16.04 LTS (Linux) |
| SW libraries | Python 3.4/CUDA v8.0/ cuDNN v6.0/Tensorflow r1.4 |
| Training Time (s) | Testing Time (ms) | |
|---|---|---|
| CBFD with BF-NSP | 805.48 | 2.59 |
| DNN with HHT | 207.50 | 1.30 |
| CNN with CWTS | 66.15 | 0.38 |
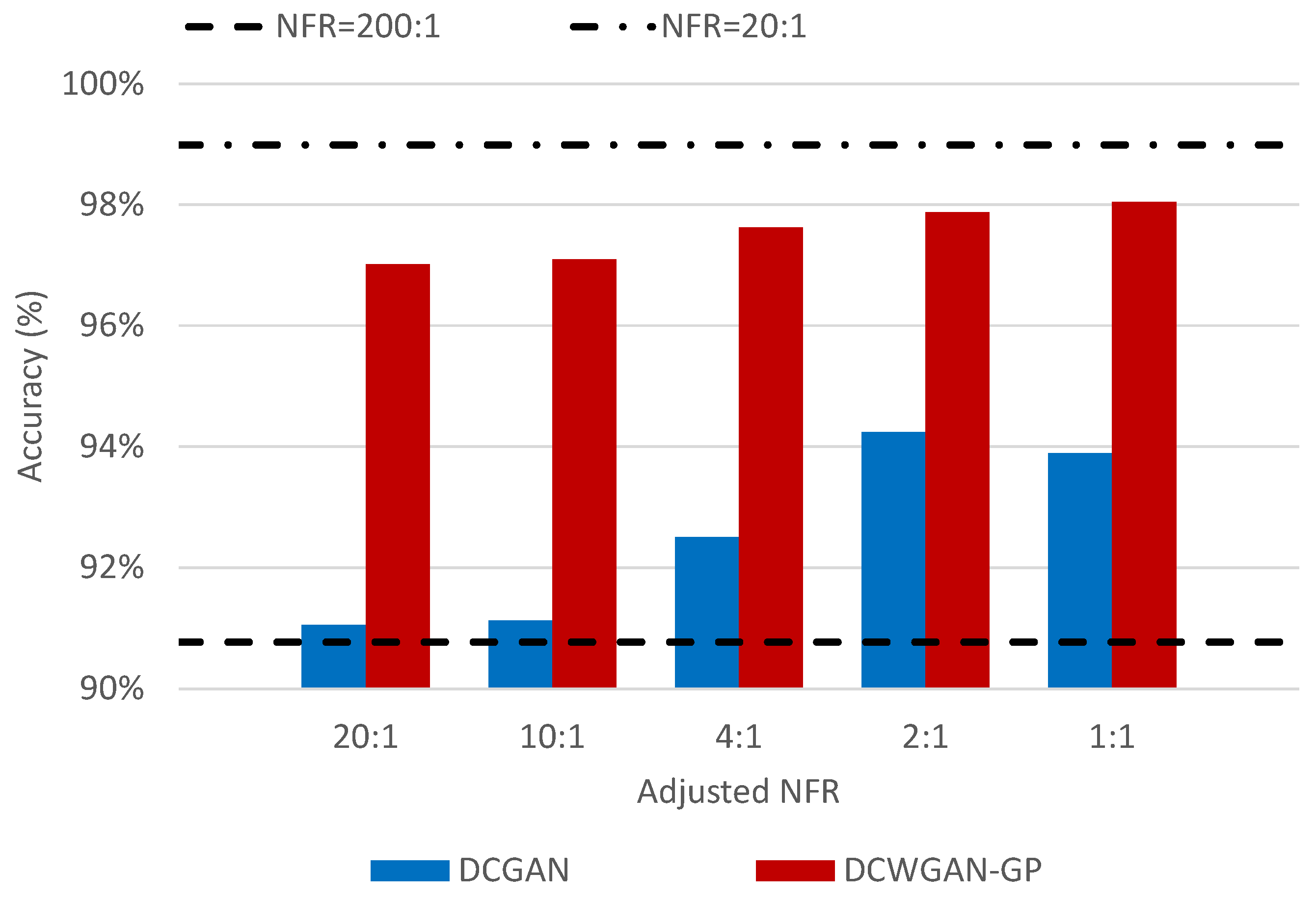
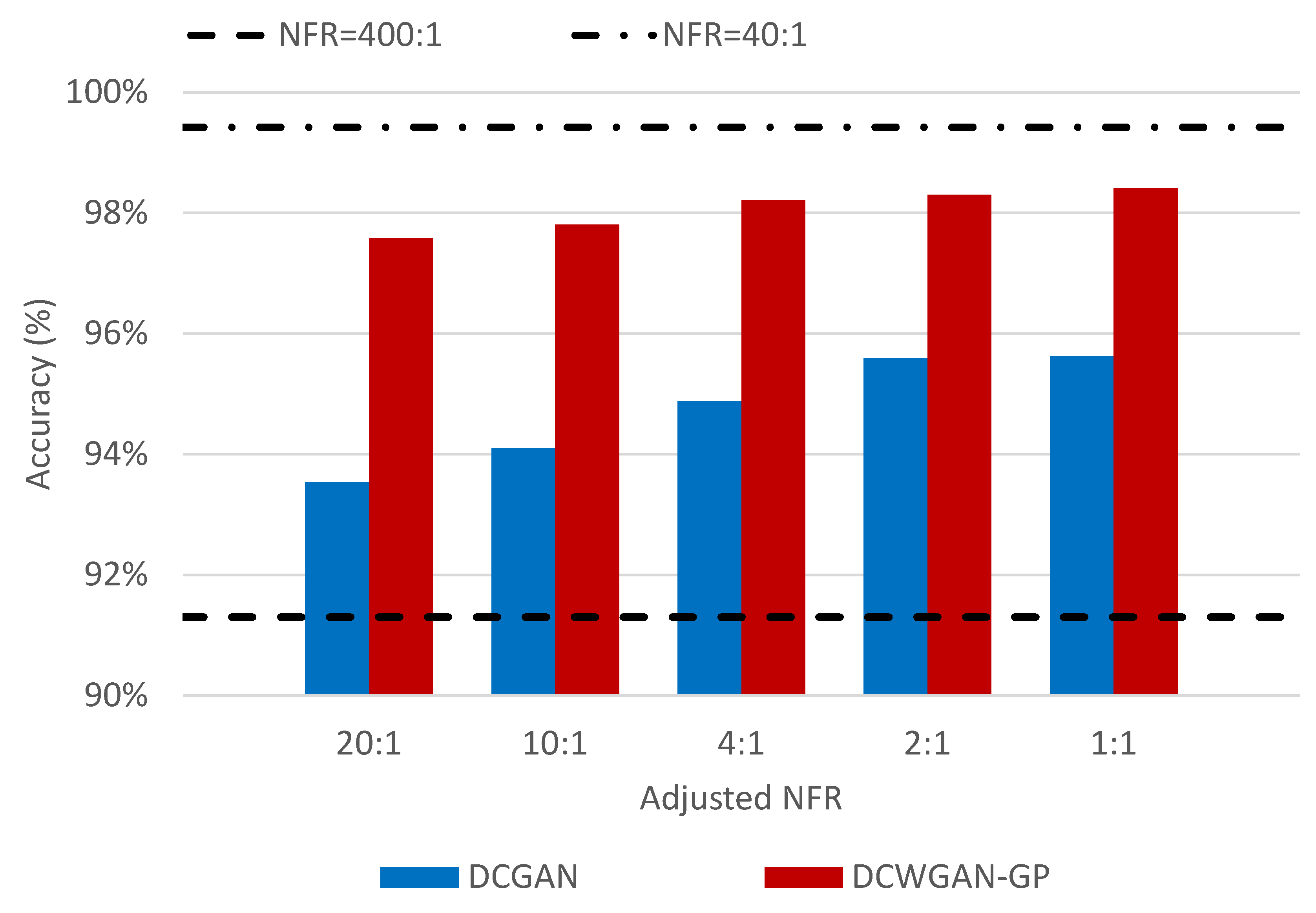
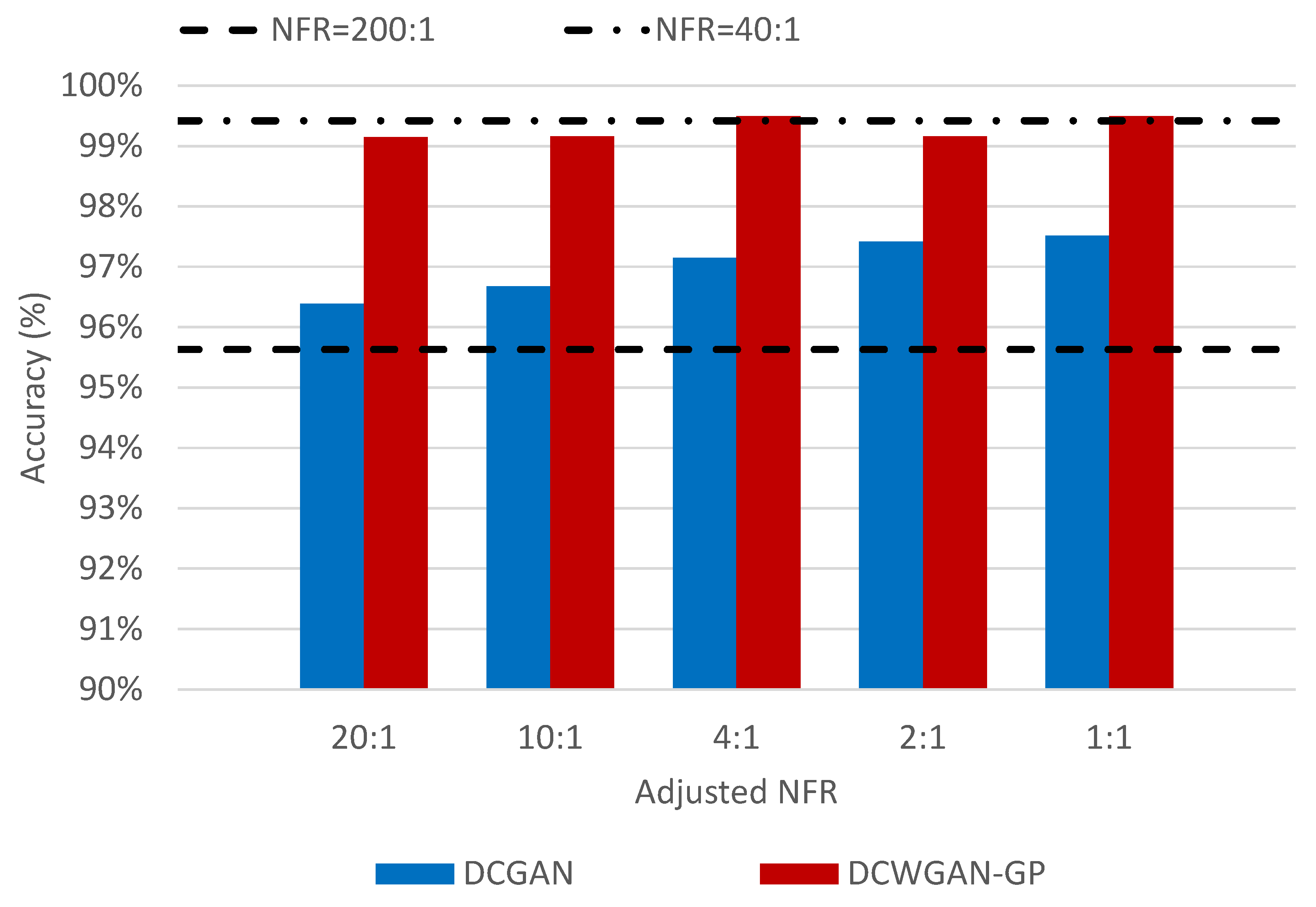
| A-NFR | ||||||
| 20:1 | 10:1 | 4:1 | 2:1 | 1:1 | ||
| DCGAN | (a) | 91.05% | 91.13% | 92.51% | 94.24% | 93.89% |
| (b) | 95.20% | 95.79% | 96.23% | 97.03% | 97.05% | |
| (c) | 93.54% | 94.10% | 94.88% | 95.59% | 95.63% | |
| (d) | 96.39% | 96.68% | 97.15% | 97.42% | 97.52% | |
| DCWGAN-GP | (a) | 97.02% | 97.10% | 97.63% | 97.88% | 98.05% |
| (b) | 98.77% | 98.78% | 98.98% | 98.98% | 99.30% | |
| (c) | 97.58% | 97.81% | 98.21% | 98.30% | 98.41% | |
| (d) | 99.15% | 99.16% | 99.50% | 99.16% | 99.50% | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suh, S.; Lee, H.; Jo, J.; Lukowicz, P.; Lee, Y.O. Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis. Appl. Sci. 2019, 9, 746. https://doi.org/10.3390/app9040746
Suh S, Lee H, Jo J, Lukowicz P, Lee YO. Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis. Applied Sciences. 2019; 9(4):746. https://doi.org/10.3390/app9040746
Chicago/Turabian StyleSuh, Sungho, Haebom Lee, Jun Jo, Paul Lukowicz, and Yong Oh Lee. 2019. "Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis" Applied Sciences 9, no. 4: 746. https://doi.org/10.3390/app9040746
APA StyleSuh, S., Lee, H., Jo, J., Lukowicz, P., & Lee, Y. O. (2019). Generative Oversampling Method for Imbalanced Data on Bearing Fault Detection and Diagnosis. Applied Sciences, 9(4), 746. https://doi.org/10.3390/app9040746