3D Behavior Recognition Based on Multi-Modal Deep Space-Time Learning


Abstract
:1. Introduction
2. Related Work
2.1. Behavior Recognition based on Space-Time Convolution Features
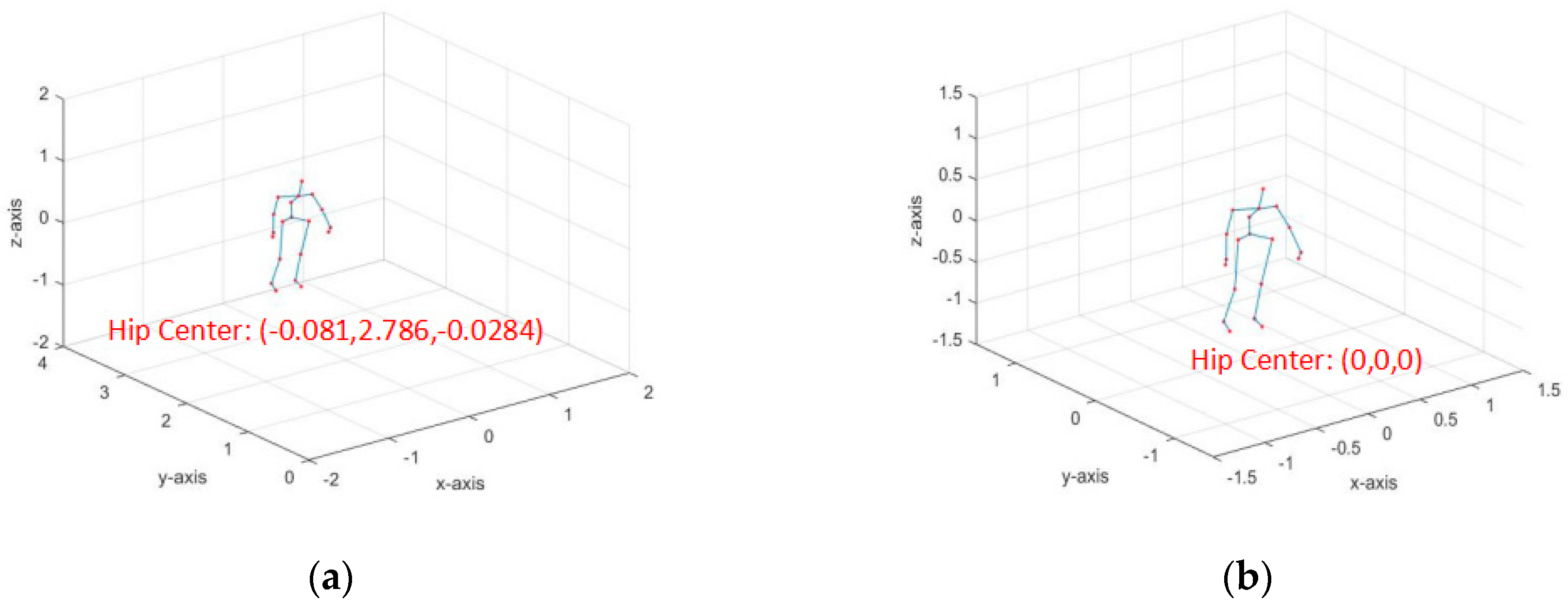
2.2. Behavior Recognition based on Skeleton Space-Time Expression
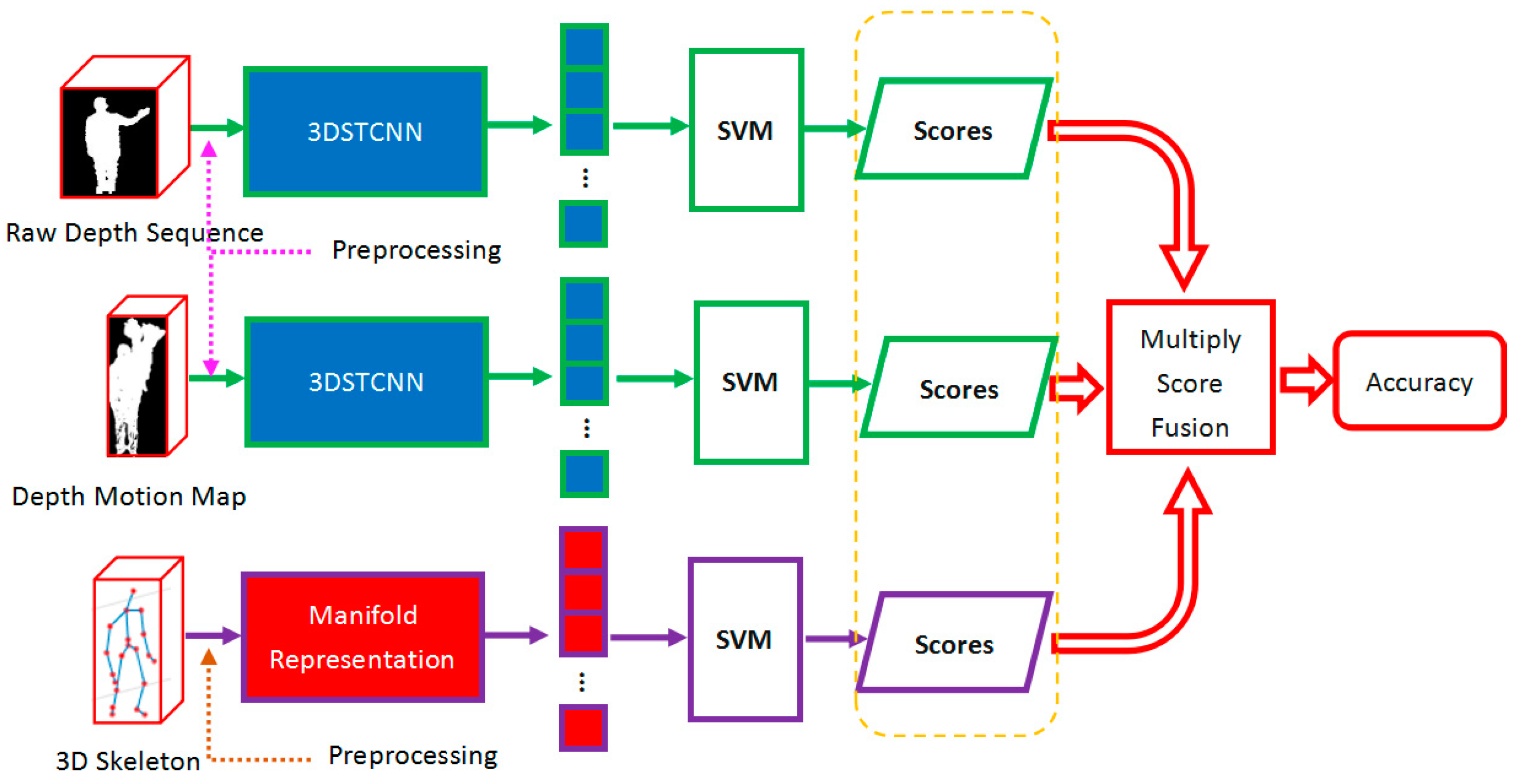
3. Multi-Modal 3D Space-Time Convolutional Framework
3.1. Space-Time Feature Learning of Depth Sequences
3.2. Space-Time Feature Learning of Depth Motion Map
3.3. Implementation of the Hybrid Model
4. Experimental Results
4.1. Datasets
4.2. Experimental Results on MSR-Action3D Dataset
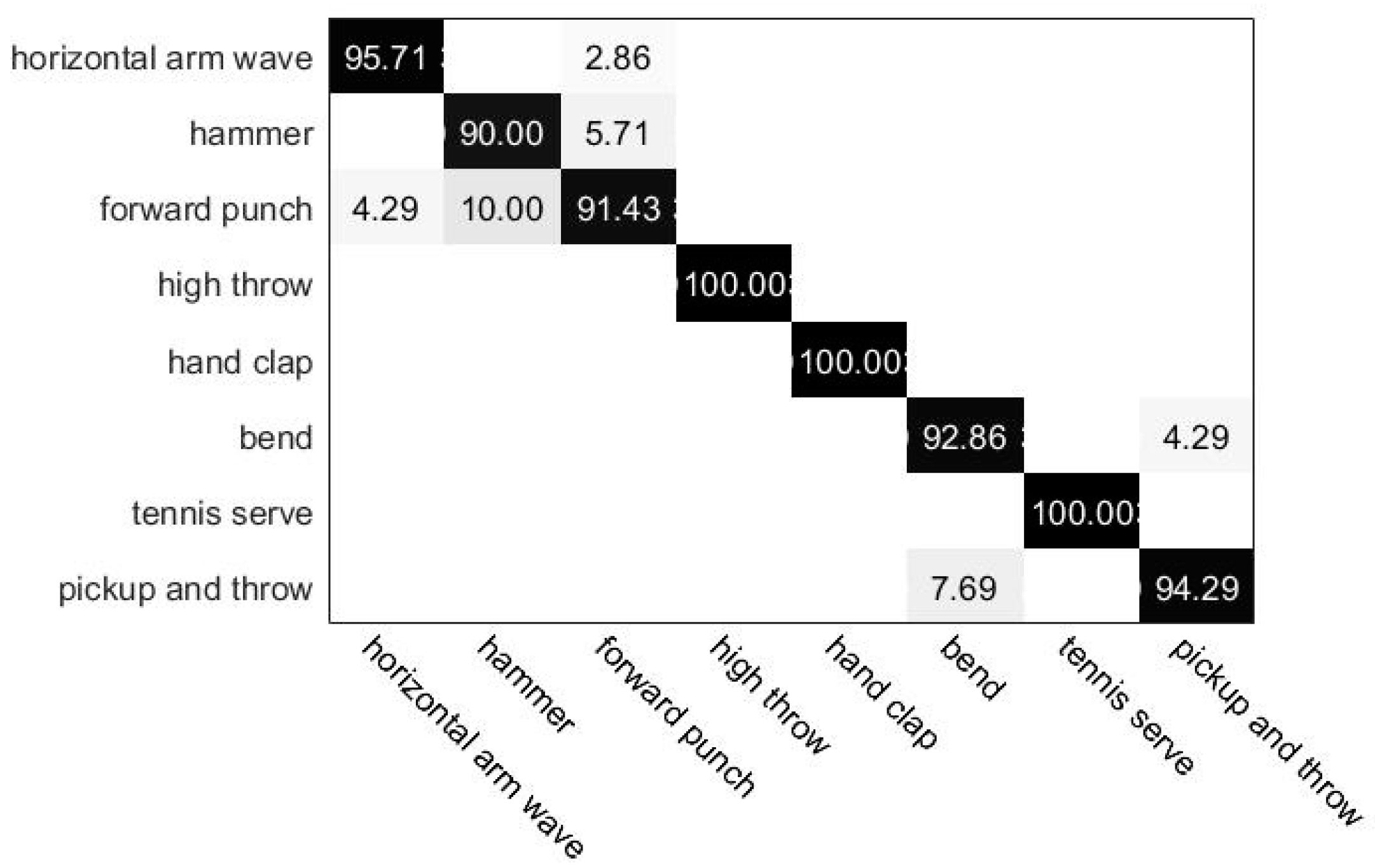
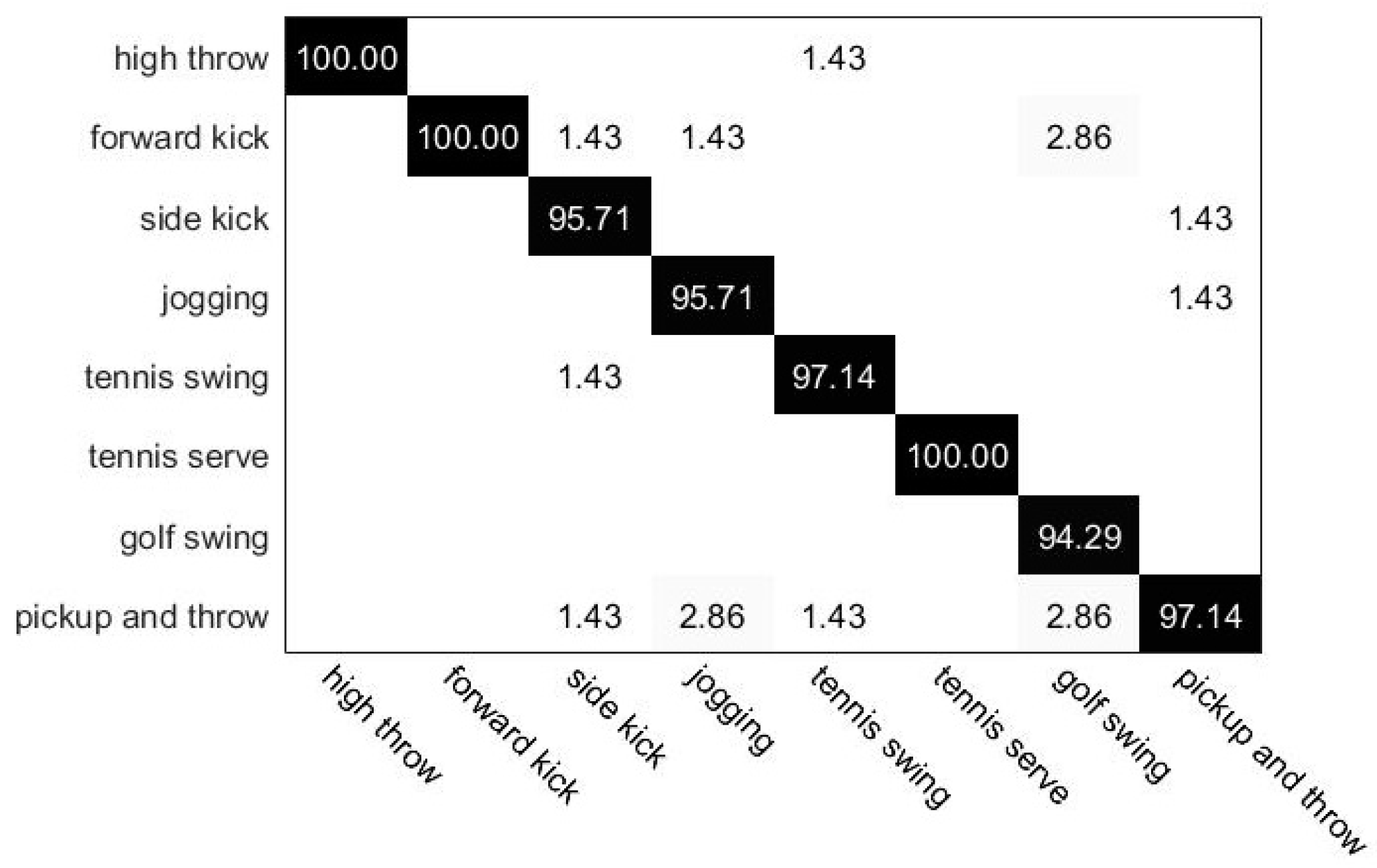
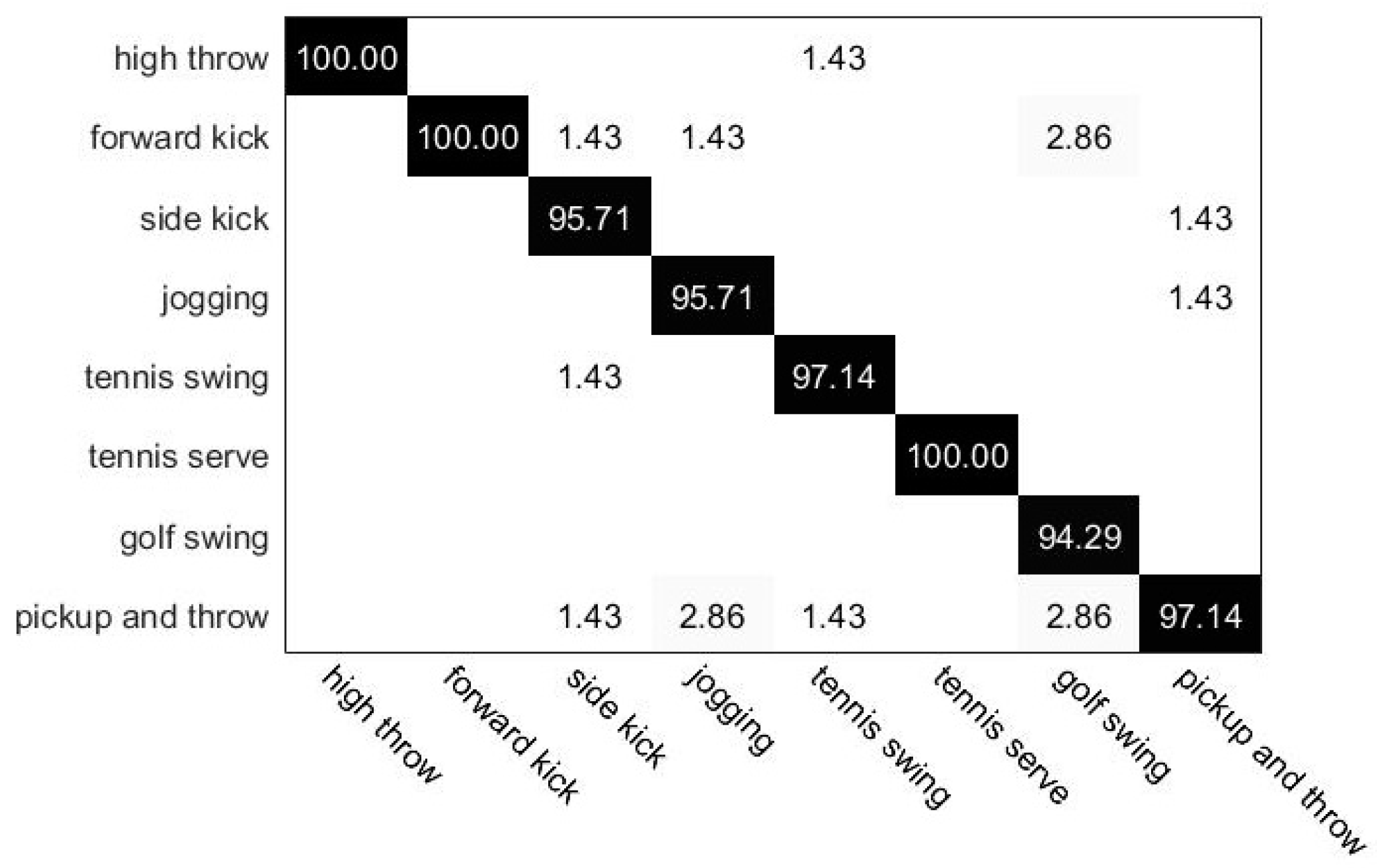
4.3. Experimental Results on UTD-MHAD Dataset
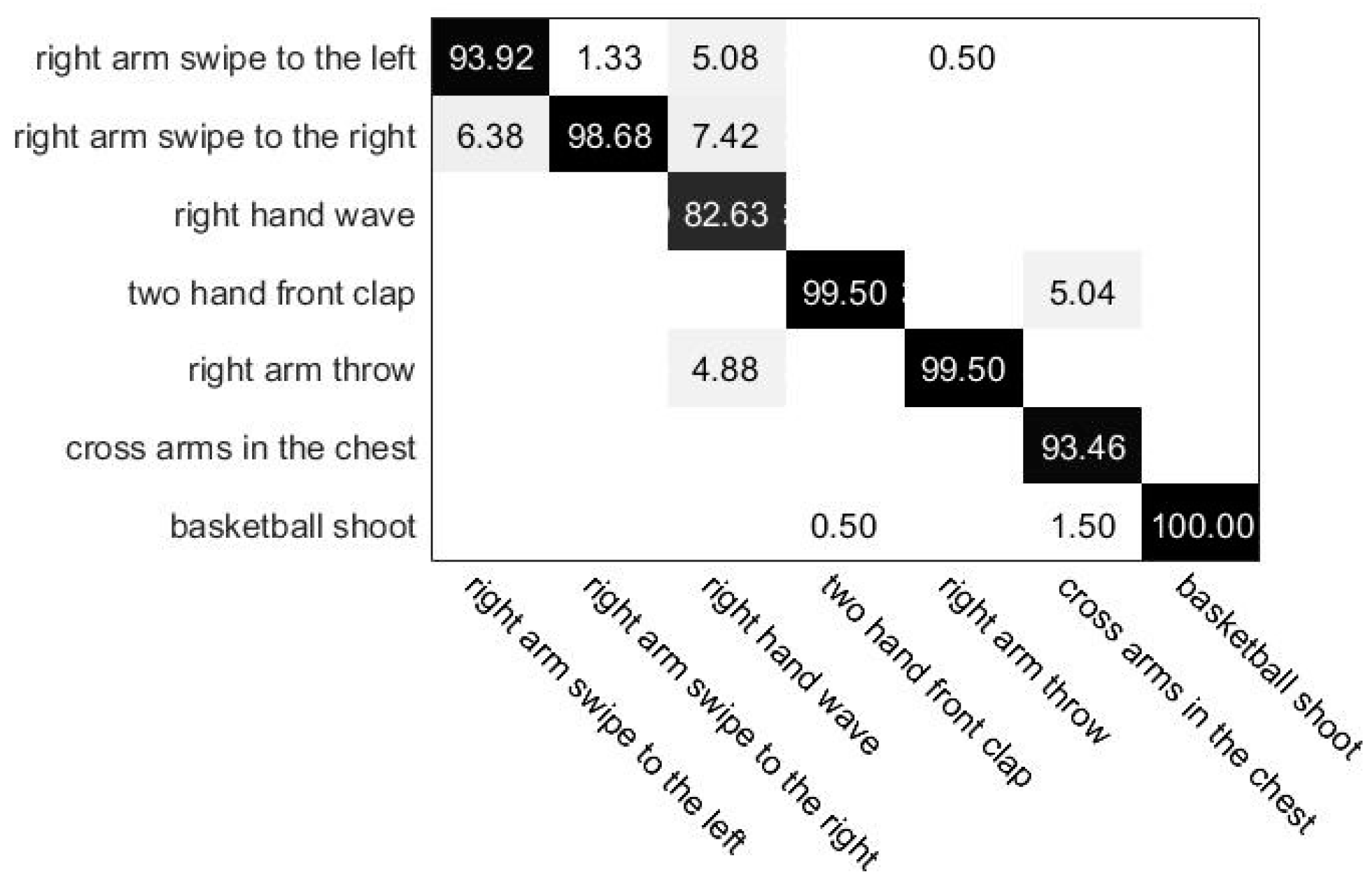
4.4. Experimental Results on UTKinect-Action3D Dataset
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Rahmani, H.; Mian, A.; Shah, M. Learning a deep model for human action recognition from novel viewpoints. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 667–681. [Google Scholar] [CrossRef] [PubMed]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. Learning clip representations for skeleton-based 3D action recognition. IEEE Trans. Image Proc. 2018, 27, 2842–2855. [Google Scholar] [CrossRef] [PubMed]
- Asif, U.; Bennamoun, M.; Sohel, F. RGB-D object recognition and grasp detection using hierarchical cascaded forests. IEEE Trans. Robot. 2017, 33, 547–564. [Google Scholar] [CrossRef]
- Sanchez-Riera, J.; Srinivasan, K.; Hua, K.; Cheng, W.; Hossain, M.; Alhamid, M. Robust RGB-D hand tracking using deep learning priors. IEEE Trans. Circ. Syst. Video Technol. 2018, 28, 2289–2301. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning actionlet ensemble for 3D human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 914–927. [Google Scholar] [CrossRef] [PubMed]
- Althloothi, S.; Mahoor, M.; Zhang, X.; Volyes, R. Human activity recognition using multi-features and multiple kernel learning. Pattern Recognit. 2014, 47, 1800–1812. [Google Scholar] [CrossRef]
- Chaaraoui, A.; Padilalopez, J.; Florezrevuelta, F. Fusion of skeletal and silhouette-based features for human action recognition with RGB-D devices. In Proceedings of the International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Lv, F.; Nevatia, R. Recognition and segmentation of 3D human action using HMM and multi-class Adaboost. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Azary, S.; Savakis, A. Grassmannian sparse representations and motion depth surfaces for 3D action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 25–27 June 2013. [Google Scholar]
- Anirudh, R.; Turaga, P.; Su, J.; Srivastava, A. Elastic functional coding of human actions: From vector-fields to latent variables. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Luo, J.; Wang, W.; Qi, H. Group sparsity and geometry constrained dictionary learning for action recognition from depth maps. In Proceedings of the International Conference on Computer Vision, Sydney, Australia, 3–6 December 2013. [Google Scholar]
- Gong, D.; Medioni, G. Dynamic manifold warping for view invariant action recognition. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Slama, R.; Wannous, H.; Daoudi, M.; Srivastava, A. Accurate 3D action recognition using learning on the Grassmann manifold. Pattern Recognit. 2015, 48, 556–567. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, W.; Guo, G. Evaluating spatiotemporal interest point features for depth-based action recognition. Image Vis. Comput. 2014, 32, 453–464. [Google Scholar] [CrossRef]
- Chen, C.; Liu, M.; Liu, H.; Zhang, B.; Han, J.; Kehtarnavaz, N. Multi-temporal depth motion maps-based local binary patterns for 3-D human action recognition. IEEE Access 2017, 5, 22590–22604. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012. [Google Scholar]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P. Deep convolutional neural networks for action recognition using depth map sequences. arXiv, 2015; arXiv:1501.04686. [Google Scholar]
- Gong, D.; Medioni, G.; Zhao, X. Structured time series analysis for human action segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1414–1427. [Google Scholar] [CrossRef]
- Lefebvre, G.; Berlemont, S.; Mamalet, F.; Garcia, C. BLSTM-RNN based 3D gesture classification. In Proceedings of the International Conference on Artificial Neural Networks, Sofia, Bulgaria, 10–13 September 2013. [Google Scholar]
- Serre, T.; Wolf, L.; Bileschi, S.; Riesenhuber, M.; Poggio, T. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 411–426. [Google Scholar] [CrossRef] [PubMed]
- Jhuang, H.; Serre, T.; Wolf, L.; Poggio, T. A biologically inspired system for action recognition. In Proceedings of the International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Le, Q.; Zou, W.; Yeung, S.; Ng, A. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Ji, S.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. C3D: Generic features for video analysis. arXiv, 2014; arXiv:1412.0767v1. [Google Scholar]
- Wang, P.; Cao, Y.; Shen, C.; Liu, L.; Shen, H. Temporal pyramid pooling-based convolutional neural network for action recognition. IEEE Trans. Circ. Syst. Video Technol. 2017, 27, 2613–2622. [Google Scholar] [CrossRef]
- Yang, X.; Tian, Y. EigenJoints-based action recognition using naïve-bayes-nearest-neighbor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Wang, C.; Wang, Y.; Yuille, A. An approach to pose-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Sheikh, Y.; Sheikh, M.; Shah, M. Exploring the space of a human action. In Proceedings of the International Conference on Computer Vision, Beijing, China, 17–20 October 2005. [Google Scholar]
- Chaudhry, R.; Ofli, F.; Kurillo, G.; Bajcsy, R.; Vidal, R. Bio-inspired dynamic 3D discriminative skeletal features for human action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–24 June 2013. [Google Scholar]
- Hussein, M.; Torki, M.; Gowayyed, M.; El-Saban, M. Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations. In Proceedings of the International Joint Conference on Artificial Intelligence, Beijing, China, 5–9 August 2013. [Google Scholar]
- Zanfir, M.; Leordeanu, M.; Sminchisescu, C. The moving pose: An efficient 3D kinematics descriptor for low-latency action recognition and detection. In Proceedings of the International Conference on Computer Vision, Sydney, Australia, 3–6 December 2013. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3D skeletons as points in a Lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Sharaf, A.; Torki, M.; Hussein, M.; El-Saban, M. Real-time multiscale action detection from 3D skeleton data. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2015. [Google Scholar]
- Devanne, M.; Wannous, H.; Berretti, P.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3D human action recognition by shape analysis of motion trajectories on Riemannian manifold. IEEE Trans. Cybern. 2015, 45, 1340–1352. [Google Scholar] [CrossRef] [PubMed]
- Hunter, D.; Yu, H.; Pukish, M.; Kolbusz, J.; Wilamowski, B. Selection of proper neural network sizes and architectures: A comparative study. IEEE Trans. Ind. Inform. 2012, 8, 228–240. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion map-based histograms of oriented gradients. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012. [Google Scholar]
- UTD-MHAD. Available online: http://www.utdallas.edu/~kehtar/UTD-MHAD.html (accessed on 12 December 2018).
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3D points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Xia, L.; Chen, C.; Aggarwal, J. View invariant human action recognition using histograms of 3D joints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Yang, X.; Tian, Y. Super normal vector for activity recognition using depth sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Yang, Y.; Deng, C.; Tao, D.; Zhang, S.; Liu, W.; Gao, X. Latent max-margin multitask learning with skelets for 3-D action recognition. IEEE Trans. Cybern. 2017, 47, 439–448. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Deng, C.; Gao, S.; Liu, W.; Tao, D.; Gao, X. Discriminative multi-instance multitask learning for 3D action recognition. IEEE Trans. Multimedia 2017, 19, 519–529. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, C.; Tian, Y. 3D-based deep convolutional neural network for action recognition with depth sequences. Image Vis. Comput. 2016, 55, 93–100. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AS1 | AS2 | AS3 |
|---|---|---|
| horizontal arm wave | high arm wave | high throw |
| hammer | hand catch | forward kick |
| forward punch | draw X | side kick |
| high throw | draw tick | jogging |
| hand clap | draw circle | tennis swing |
| bend | two hand wave | tennis serve |
| tennis serve | forward kick | golf swing |
| pickup and throw | side boxing | pickup and throw |
| Method of [43] | Method of [44] | Method of [31] | Our Method | |
|---|---|---|---|---|
| AS1 | 72.9% | 87.98% | 74.5% | 95.89% |
| AS2 | 71.9% | 85.48% | 46.1% | 87.68% |
| AS3 | 79.2% | 63.45% | 96.4% | 97.32% |
| Whole dataset | 74.7% | 78.97% | 82.3% | 94.15% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, C.; Chen, M.; Zhao, J.; Wang, Q.; Shen, Y. 3D Behavior Recognition Based on Multi-Modal Deep Space-Time Learning. Appl. Sci. 2019, 9, 716. https://doi.org/10.3390/app9040716
Zhao C, Chen M, Zhao J, Wang Q, Shen Y. 3D Behavior Recognition Based on Multi-Modal Deep Space-Time Learning. Applied Sciences. 2019; 9(4):716. https://doi.org/10.3390/app9040716
Chicago/Turabian StyleZhao, Chong, Minglin Chen, Jinhao Zhao, Qicong Wang, and Yehu Shen. 2019. "3D Behavior Recognition Based on Multi-Modal Deep Space-Time Learning" Applied Sciences 9, no. 4: 716. https://doi.org/10.3390/app9040716
APA StyleZhao, C., Chen, M., Zhao, J., Wang, Q., & Shen, Y. (2019). 3D Behavior Recognition Based on Multi-Modal Deep Space-Time Learning. Applied Sciences, 9(4), 716. https://doi.org/10.3390/app9040716