1. Introduction
In recent decades, researchers have studied the problem of short-term forecasting energy consumption and its role in energy control systems [
1]. These studies prove that an accurate short-term load prediction represents a high potential for electric utility corporations. This importance can be recognized while load estimation is used to control operations decisions such as dispatch, unit commitment, fuel allocation, and maintenance [
2,
3].
The three main economic sectors with the highest amount of energy consumption are industry, transportation, and buildings, where buildings present the most significant portion [
4]. According to recent studies in European Union countries, 40% of the total energy consumption is consumed in buildings [
5]. Also, in the USA, the consumed energy by heating, ventilating, and air-conditioning (HVAC) systems in buildings correspond to around 44% of domestic energy consumption [
6].
Due to the amount of the energy consumption in buildings, prediction of this consumption is significant to improve the performance of energy systems, have better control on the energy distribution network, and reduce this amount of energy consumption. On the other hand, the energy system in buildings can be quite complex, depending on the types of building and types of energy consumers. Most of the considered building types are office, residential, and engineering buildings, varying from small rooms to big estates [
7]. The consumption of a building is mostly divided into lights, HVAC, and electrical sockets; therefore, many different factors must be considered to have a proper recognition of the consumption behavior, such as environmental variables, number of users, etc.
The complexity of energy consumption behavior in buildings makes it difficult to have a forecasting model to predict this behavior with acceptable performance. Many different studies have been published which propose various forecasting algorithms and models to predict the value of energy consumption. This approach can be categorized into statistical, engineering, and artificial intelligence models [
4]. In the engineering methods, physical principles are used to calculate thermal dynamics and energy behavior on the whole building level or for sub-level components [
7]. To have a good performance from these methods, a piece of high-level information about the structure of the building and different parameters are required, which might not be available. Moreover, to build a model which is based on complex physical principles, a high level of expertise is needed [
8].
Statistical models are linear models based on statistical approaches, using historical data to obtain the relationships between data. Clearly, in these models, historical data plays an important role in acquiring a reliable result. Unlike the engineering models, in the statistical models, no physical structure is included [
9]. The linear models consist of regression-type models, which are autoregressive (AR), autoregressive with exogenous variable (ARX), moving average (MA), autoregressive moving average (ARMA), autoregressive moving average with exogenous variable (ARMAX), and autoregressive integrated moving average (ARIMA) [
10,
11,
12].
Artificial intelligence models, which are also known as nonlinear statistical models, can be categorized as Artificial Neural Networks (ANN), Support Vector Machines (SVMs), Fuzzy Rule-Based Systems (FRBS), and hybrid approaches [
13,
14,
15]. Recently, these models have been widely used to solve many estimation problems. For example, in the study presented in [
8], the author implements a neural network model to forecast the electricity demand of a bioclimatic building, located in the south-east of Spain. The results of this work show that this model can predict this value by an error of 11.48%. In [
16], ANN is used to predict a day-ahead energy consumption profile for an office building. This work divides the total energy consumption of the building into three values, which present the consumption of lights, HVAC, and electrical sockets. For each one of these three consumers, a specific forecasting model is created using external facility data, such as temperature and humidity. The results prove that this approach predicts the total energy consumption by an error of 13.6%. Many fuzzy rule-based methods have been purposed to be used in various forecasting proposes. In [
17], five fuzzy rule-based methods, namely as Wang and Mendel’s method (WM), Hybrid neural Fuzzy Inference System (HyFIS), Genetic fuzzy systems for fuzzy rule learning based on the MOGUL methodology (GFS.FR.MOGUL), Genetic lateral tuning and rule selection of linguistic fuzzy systems (GFS.LT.RS), and the simplified TSK fuzzy rule-generation method using heuristics and gradient descent method (FS.HGD), are used to predict the hourly energy consumption of TRT-France buildings located in Paris, France. This study shows that in this case, the GFS.FR.MOGUL presents the most trustable results, followed by HyFIS and WM. In [
18], a hybrid probabilistic fuzzy ARIMA model is presented, which is used to obtain a consumption forecasting in commodity markets. This hybrid model offers a combination of artificial intelligence models with linear statistical models where computational intelligence tools are used as well as soft computing techniques. The work presented in [
19] proposes a model to forecast the energy consumption of public buildings to improve energy saving; Elman neural networks are used to make this prediction. Artificial intelligence models also can be used in other situation of forecasting. For example [
20], a study has been presented that uses SVM to estimate the short-term wind speed where the results are also compared to the results of several ANN-based approaches. More studies using these forecasting approaches to solve different prediction and estimation problems can be found in [
21,
22,
23].
Energy consumption estimation has an essential role in energy system management and the energy distribution network. However, to implement the forecasting models a high knowledge about programming languages, data storage systems, and data preparation is required. This fact can be a limitation for users working in this industry, which do not have this knowledge. In this way, this work proposes an application that makes it possible for the user to use different forecasting algorithms to predict the energy consumption of buildings. The proposed application, developed in the scope of the SIMOCE project (ANI|P2020 17690), is meant to be used by users who do not have enough knowledge to implement these methods and run the models on their own. Five forecasting methods are considered in this application, namely ANN, SVM, and three FRBS methods including, HyFIS, WM, and GFS.FR.MOGUL. Additionally, four different strategies to manage and prepare the data sets to train the methods are included. In this way, the users have access to several of the most relevant forecasting methods in this domain, as well as different approaches for data treatment and training. Besides facilitating the forecasting process for users with no experience in machine learning, the proposed application also enables mitigating the difficulties in choosing the best approaches for each prediction circumstance (amount of data, available data variables), as it provides the means to reach results with the different algorithms, and thus supports the user decisions in selecting the most suitable solution for each situation. In addition to the abovementioned benefits, which are mostly directed to users in the power and energy domain, the presented application also has direct advantages in multiple other domains, e.g., as facilitator for the implementation of energy management methods in manufacturing systems. By helping to reach suitable forecasts of energy consumption, the proposed application may be directly integrated with switch-off energy saving methods for production lines, such as the model proposed in [
24]; or even integrated in advanced optimization methods for energy saving, as presented in [
25]. Moreover, by being developed as a domain-agnostic application, it can be applied and used in multiple other application domains for forecasting purposes, simply needing access to the log of historic data.
After this introductory section,
Section 2 presents the proposed model, including the description of the considered forecasting methods, data management strategies, and the architecture of the application.
Section 3 presents a case study that shows the performance of the proposed application using real consumption data and compares the results achieved by the different forecasting methods under distinct prediction circumstances. Finally,
Section 4 presents and discusses the most relevant conclusions of this work.
3. Proposed Model
A Java-based forecasting application has been proposed in this work to be used by the users without any knowledge about the forecasting processes and programming languages. This application includes four forecasting strategies to create the required data sets and predict the energy consumption of an office building. Also, the user can predicts any other variable by using an excel file to insert the required data sets. This chapter includes the description of the forecasting strategies, the architecture and implantation phases of the application and presents the graphical user interface of the application.
3.1. Forecasting Strategies
Every forecasting method to estimate a value requires two sets of data, the train data, and the test data. The way that these two data sets have been selected and structured is one the most important facts to have a reliable forecast. All the decisions that the forecasting methods make are based on these input data (
Table 1). This way, this application includes four different strategies to collect the train and test data for an hour-ahead energy forecasting. These strategies have been chosen based on the most effective variables on the energy consumption and the behavior of the consumption in the target building. However, the application has the possibility of receiving any other structured data using an excel file.
The first strategy uses the value of the electricity consumption to train the methods. The objective is to forecast the value of the electricity consumption of the next hour. Therefore, the test data will include this value from the past 24 h before the hour which is meant to be forecasted. The train data in this strategy includes the value of the energy consumption from past 10 days before the date of the target value. This way, the method will be trained 10 times by the data from past 10 days.
The second strategy trains the methods by a combination of the electricity consumption and the environmental temperature values of the related place in the past 10 days. The environmental temperature has been chosen to be used in this strategy due to having a high influence on the value of the energy consumption. The test data in this strategy includes the value of these two variables from the last 24 hour before the target hour.
The third strategy works in a similar way as the first strategy and only uses the value of the electricity consumption to train the method. The difference between them is the dates of the train data. This strategy does not use the data from the last 10 days, but it includes a process that chooses special dates to train the methods, these dates are chosen base on two properties:
The difference between the average environmental temperature during these days and the target day should be a maximum of 2 °C.
These days should have the same type of working day (week or weekend) as the target day.
After the process of date selection, the method will be trained 10 times by the values of the energy consumption of these chosen dates. Also, the test data as same as the first strategy includes the energy consumption of the past 24 h before the target hour.
Finally, the fourth strategy is a combination of the second and the third strategies. Where it uses the same process of choosing special dates to train the methods as the third strategy and as same as the second strategy uses the value of the environmental temperature plus the value of the energy consumption as the input of the method. Also, the test data in this strategy is the same as the second one.
3.2. The Architecture of the Application
This section includes the details of the architecture of the application. The application is based on three parts, which are:
Forecasting app: This part includes the implementation of the forecasting algorithms and is based on Java and R programming languages.
Parse app: The implementations of the training strategies. All the connections between the application and the databases are also included in this part.
Main app: This part has the controllers of the application, the connections between the other components and the graphical interface of the application.
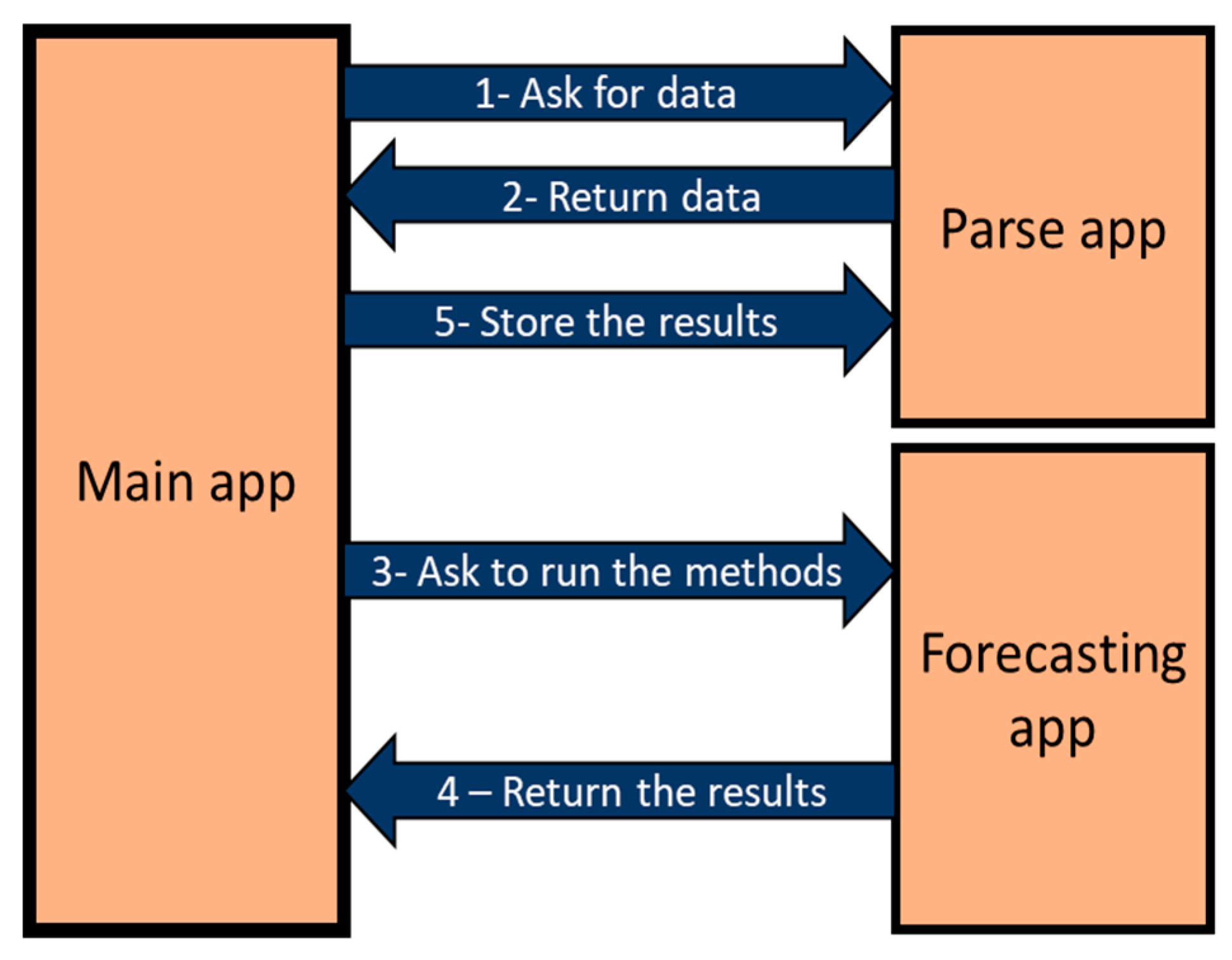
The main app is the central component of the application which connects the other two components. All the communications between the user and the application are a part of the responsibilities of the main app. Once the user chooses a date to start a forecasting process, the main app makes a connection to the parse app and asks for the needed data from the chosen date to run the forecasting algorithms. After receiving the data, the main app sends this data to the forecasting app. The forecasting app runs the forecasting methods by the received data from the main app and returns the results of the forecasting. The main app shows the results to the user and sends them to the parse app to be stored.
Figure 4 presents the connections between the components of the application.
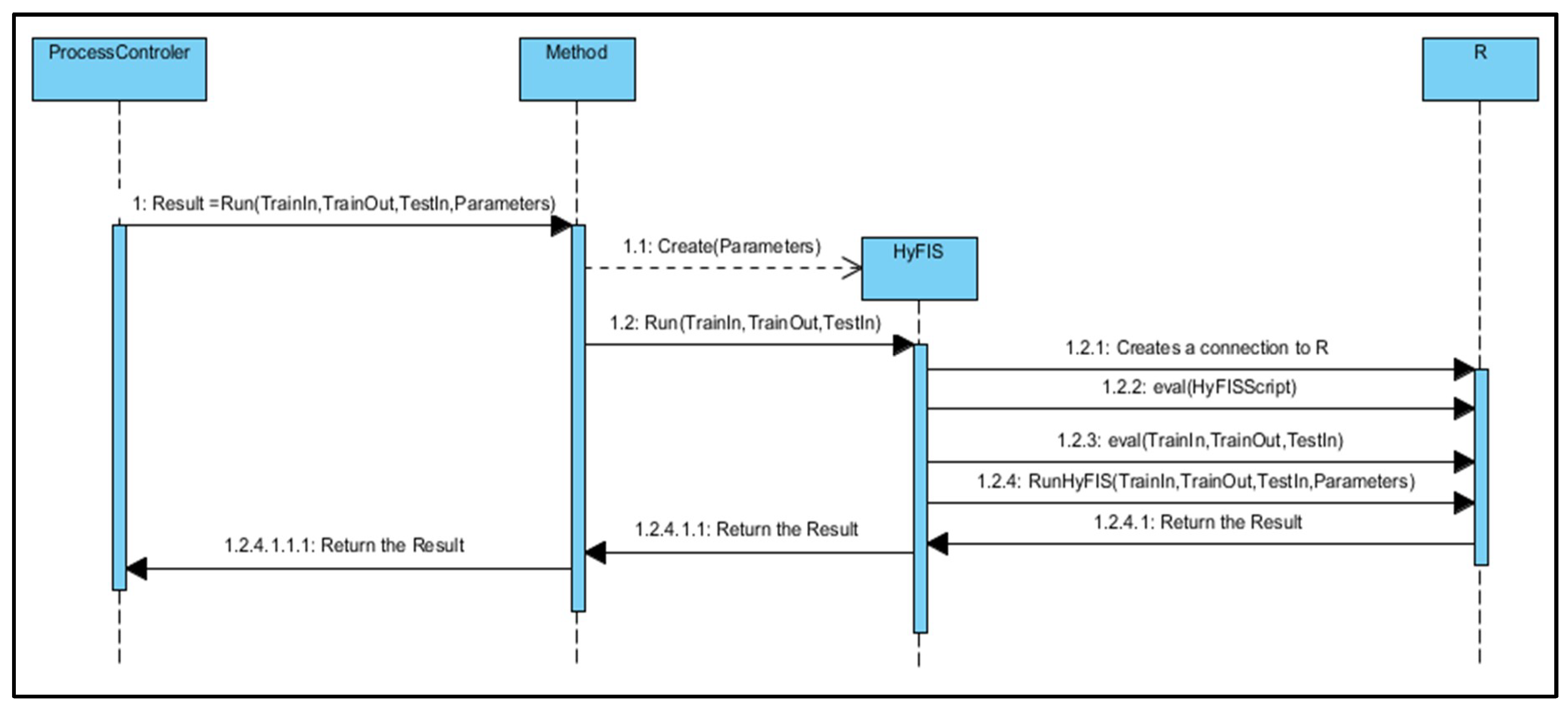
The forecasting app is based on the java and R programming languages and is responsible to receive the data from the main app and run the forecasting methods. This component of the application includes the implementation of the forecasting methods. Every algorithm has its own class which creates a connection to the R programing language to run the methods in this language. There are two available ways to run the methods. The first is run the algorithms by an excel file that the user should insert; and the second way is an automatic forecasting, in which the user chooses a date and hour and the application does the forecast automatically, the second way is where the application asks for data from parse app. For every forecasting method, there are two R scripts one for automatic forecasting and one for forecasting by an excel file.
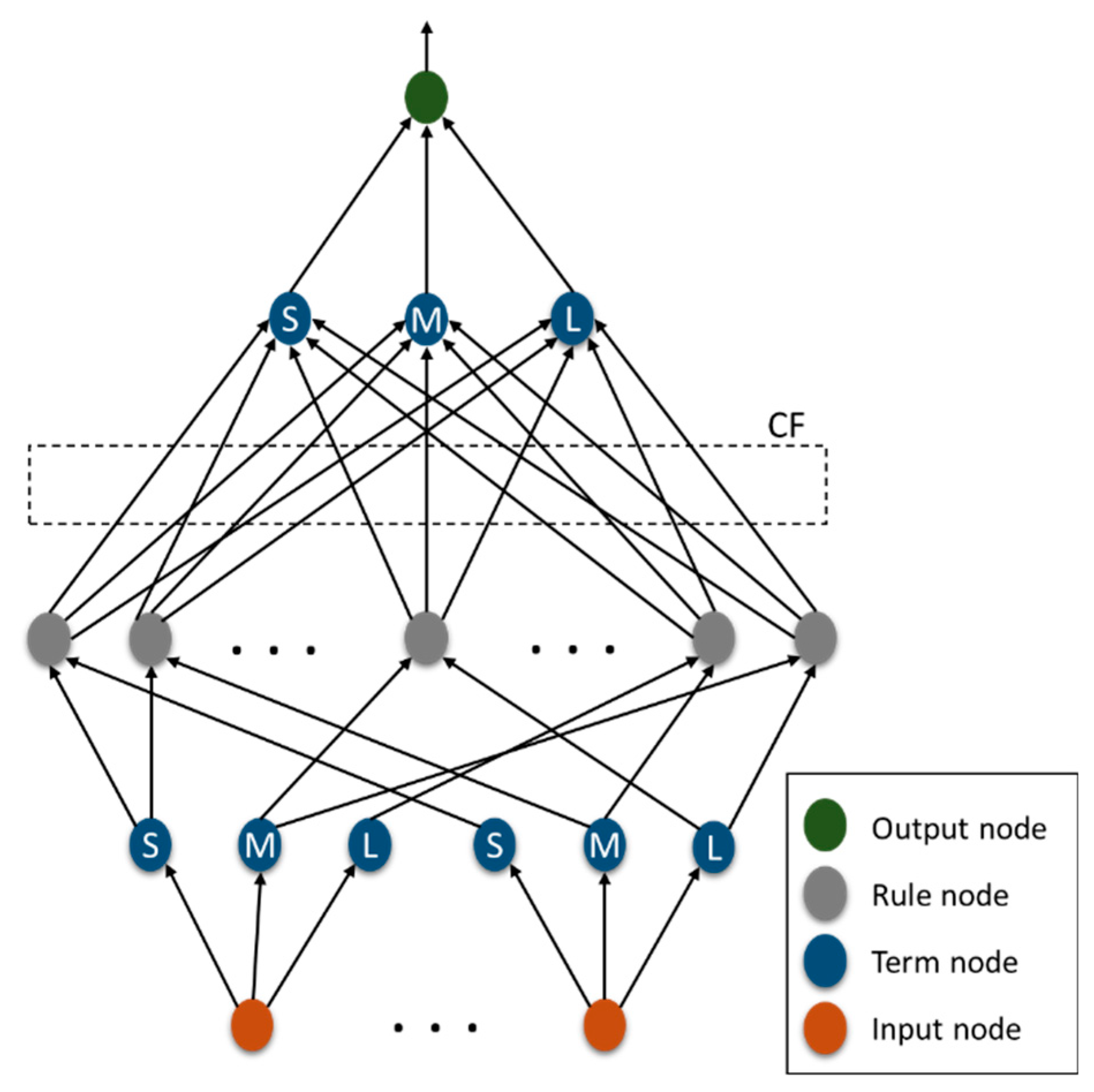
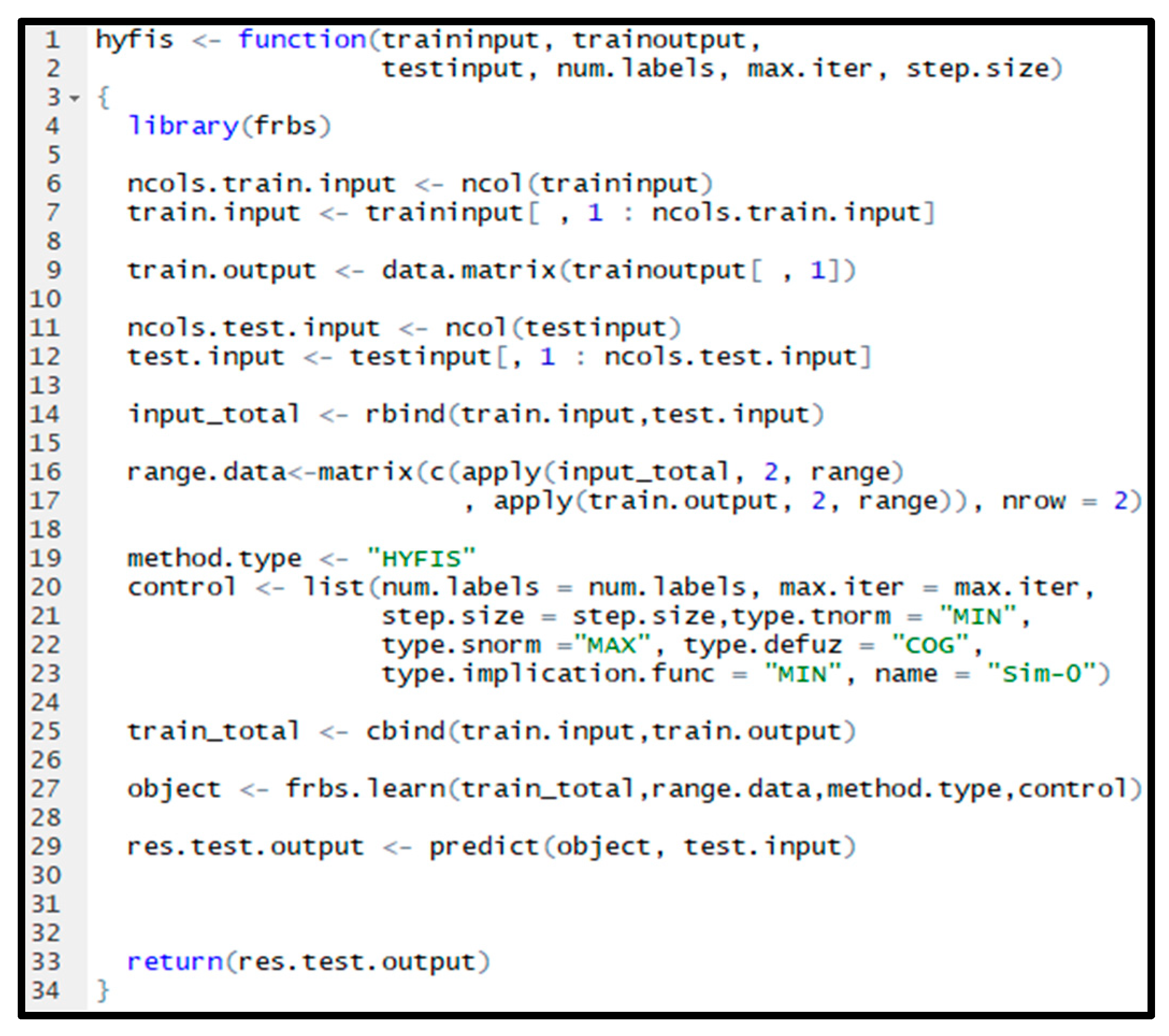
Figure 5 presents the R script of HyFIS method in case of automatic forecasting, where the FRBS library [
29] is used to implement this method.
As it is visible in
Figure 5, the
hyfiz function in R receives three data sets as well as the needed variables to configure the method that the user can insert during the process of the forecasting. The
traininput and
trainoutput are used as the training data, and the
testinput is meant to be used as the test data.
Figure 6 presents the sequence of running the HyFIS method in R language.
Parse app includes the implementation of the forecasting strategies, all the connections to the databases and the data storage processes. Every proposed forecasting strategy has its own class which is connected to the databases connection classes. Every time the user chooses a date and a strategy to run the forecasting process, this date will be sent to the class of the deliberate strategy. This class asks for the required data from the database connection classes and creates the needed data sets to forecast the energy consumption of the inserted hour by the chosen strategy. Once the application creates these data sets, it stores these data so the next time the application does not need to ask from the database for the data. This data storage process helps the application to reduce the duration of the expectation.
The main app is the central component of the application. The communications between the user and the application are included in this part as well as the communications between two other components of the application and the controller classes.
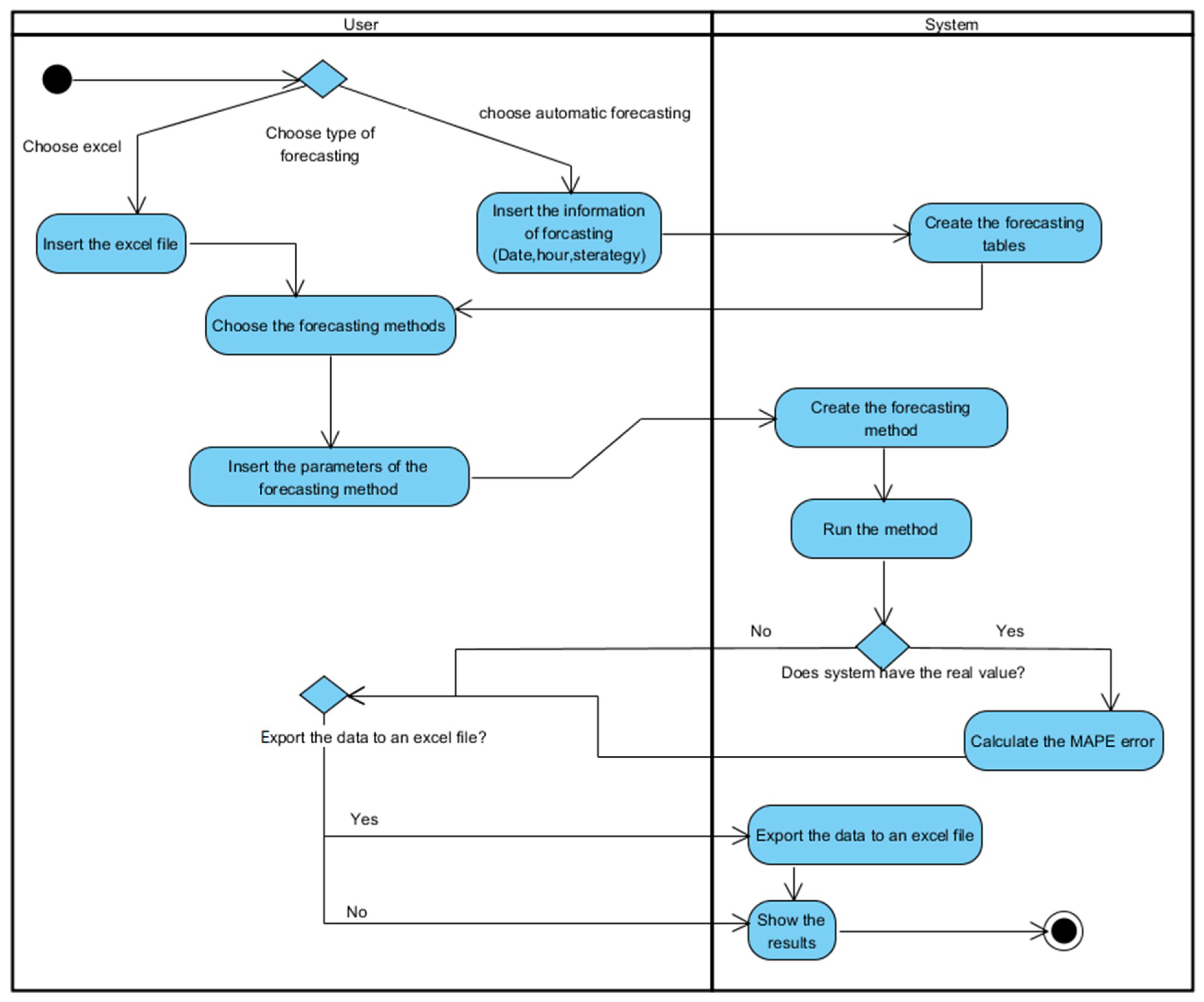
Figure 7 presents the activity diagram of the application where the sequence of the forecasting process is presented.
As it is visible in
Figure 7 when the forecasting methods return the predicted results in the case that the real value of the forecasting target is available the application also calculates the Mean Absolute Percentage Error (MAPE) of the predicted value and present it to the user. Also, at the end of the process in case of the automatic forecasting, the user can ask to export the forecasting data sets and the result to an excel file.
3.3. Graphical User Interface
The graphical user interface of this application is implemented based on JavaFX, which is a set of graphics and media APIs that can be used to create and deploy rich client applications. It allows developers to build rich cross-platform applications rapidly and supports modern GPUs through hardware-accelerated graphics [
39]. This section includes a sequence of figures which present the different pages of the application.
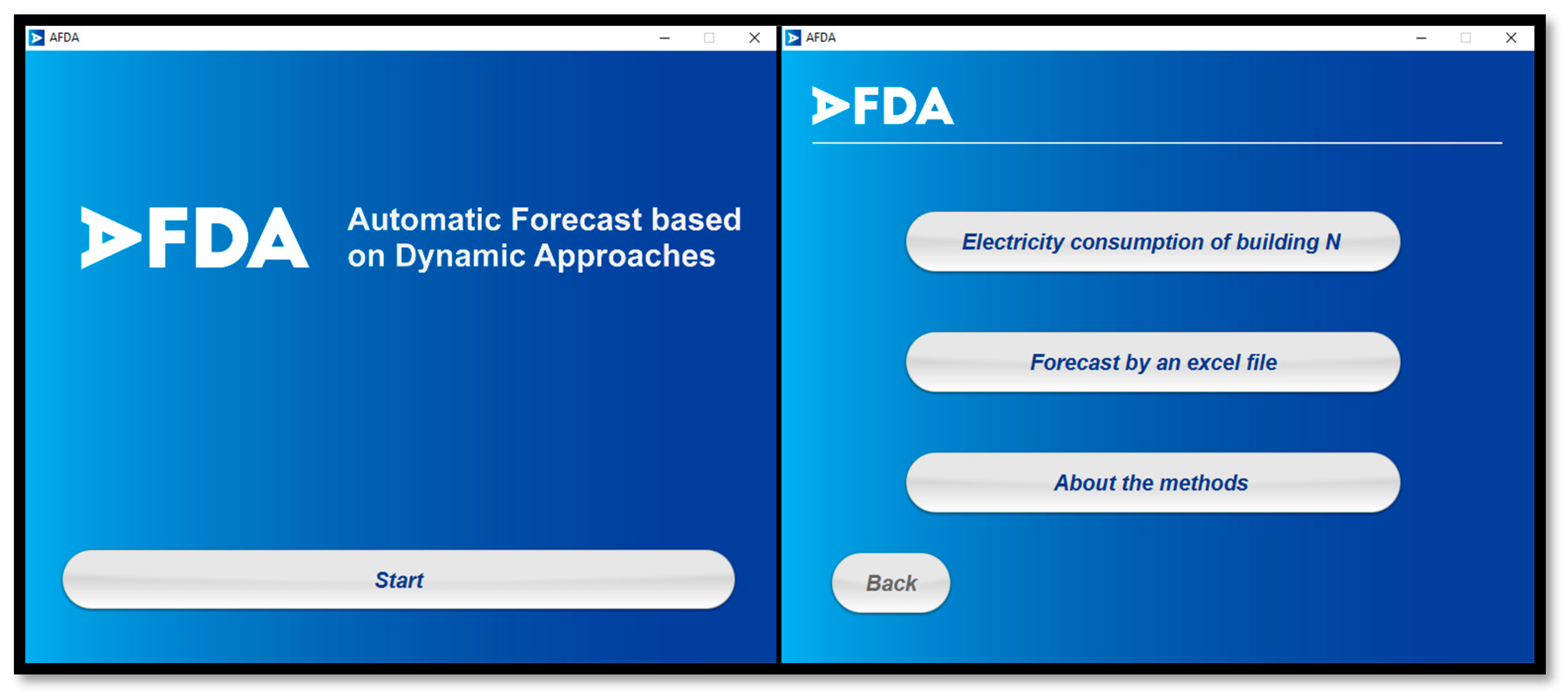
The application has a main page that opens when the user runs the application. This page includes the name of the application and the information about it as well as a start bottom. When the user starts the application the main menu of the application will open.
Figure 8 presents the main page and the main menu of the application.
The first bottom of the menu opens the menu of the building N, the second one starts the process of forecasting by an excel file, and the third bottom opens a menu where the user has a brief explanation about the forecasting methods.
As you can see in
Figure 9, the menu of the building N, includes all the use cases that are related to the building N, including, forecasting the electricity consumption, get the real data and list all the forecasted values.
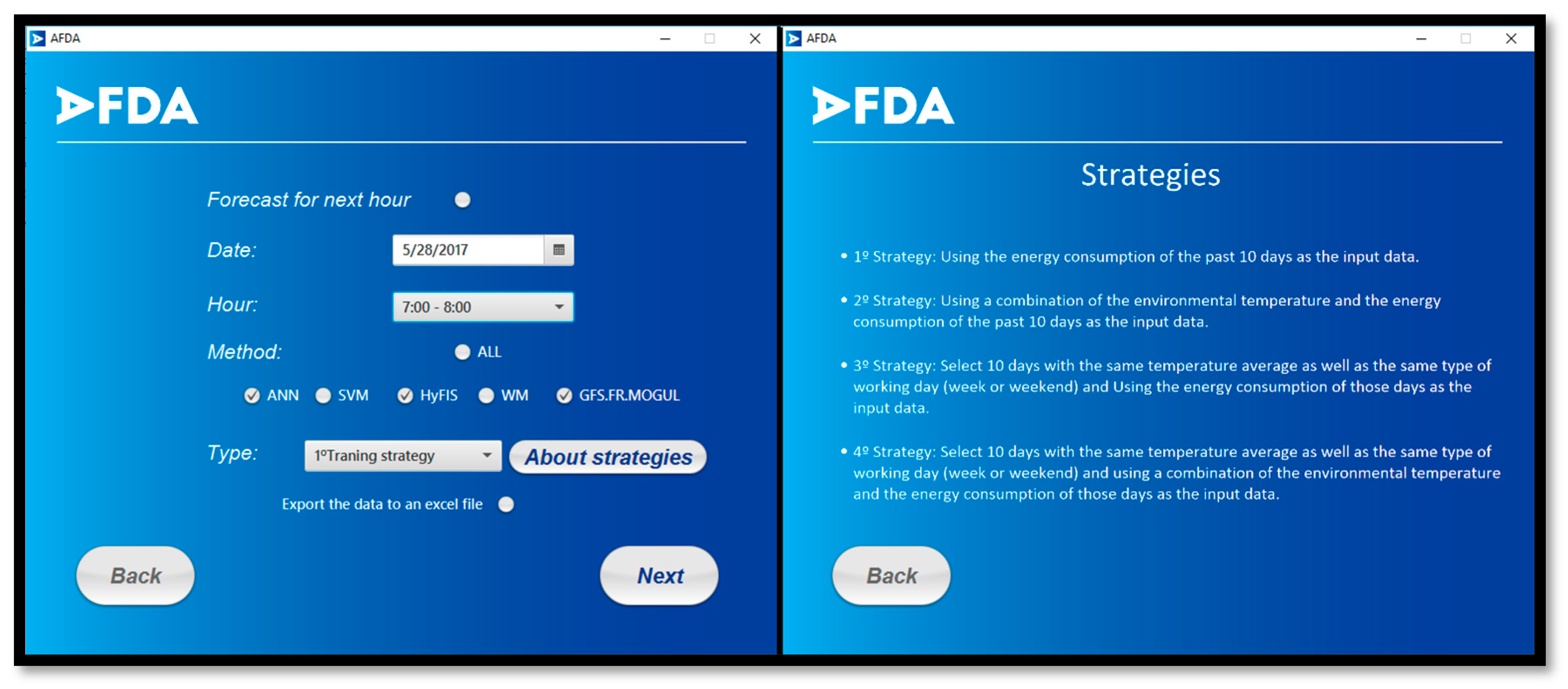
In case the user selects the first bottom, the process of the forecasting the electricity consumption of the building N will start. It opens a page where the user should choose a date, an hour, the training strategy, and at least one forecasting method. This page includes a bottom that opens an explanation of the strategies.
Figure 10 presents these two pages.
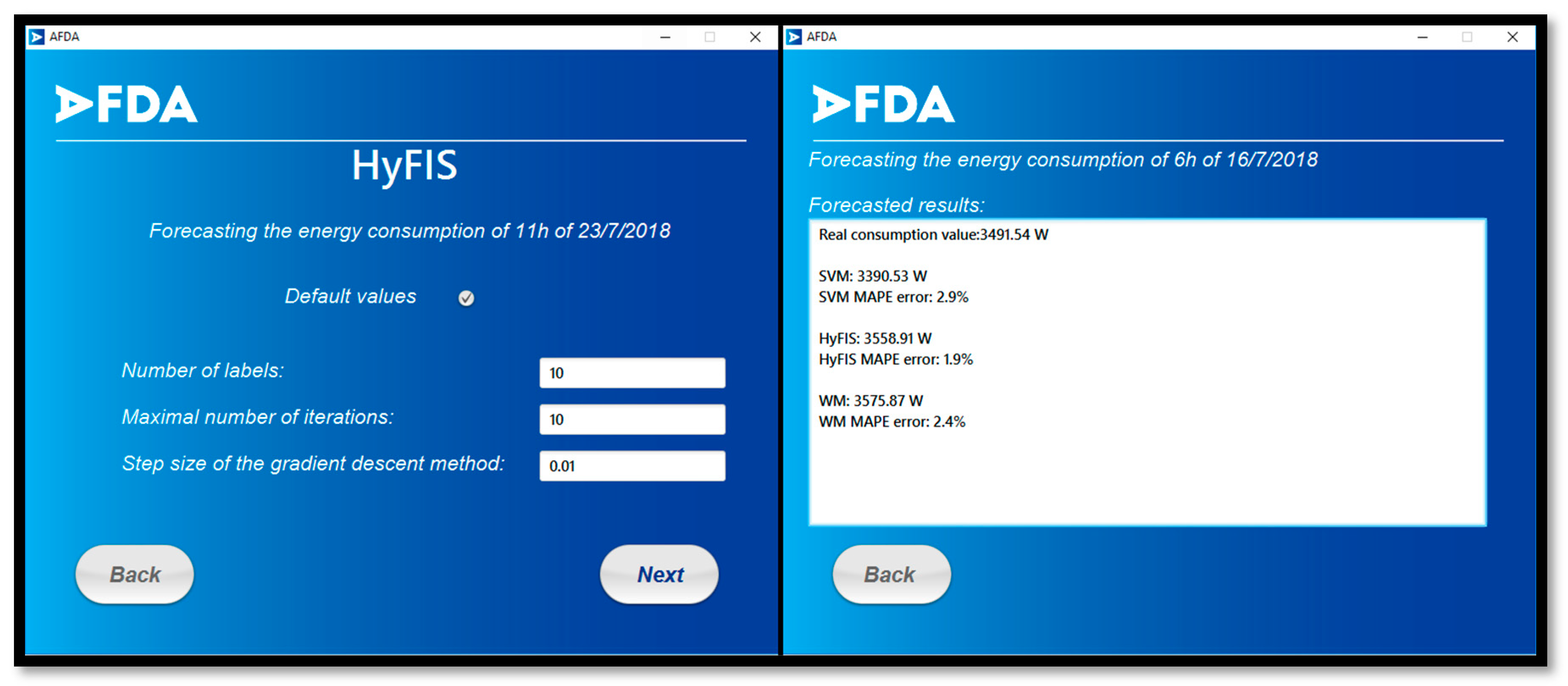
In the next step, the user must insert the required variables to configure the forecasting model. For each selected method, a page will appear where the user can introduce these values or select an option to use the default values of the application. At the end of this process the application presents the predicted result. In a case that the application has access to the real value of the target value, the MAPE error of the results will be presented as well.
Figure 11 presents these two phases.
4. Case Study
This section presents a case study in order to evaluate the performance of the proposed application, by assessing the accuracy of the proposed forecasting methods namely ANN [
16], SVM [
40], HyFIS [
31], WM [
33], GFS.FR.MOGUL [
36] and verify the influence of using different training strategies on the performance of the forecasting process. This case study includes the hour-ahead prediction of the energy consumption of GECAD’s building N during 24 h of a business day. The electricity consumption is forecasted based on 4 forecasting strategies using 5 forecasting algorithms from the proposed application.
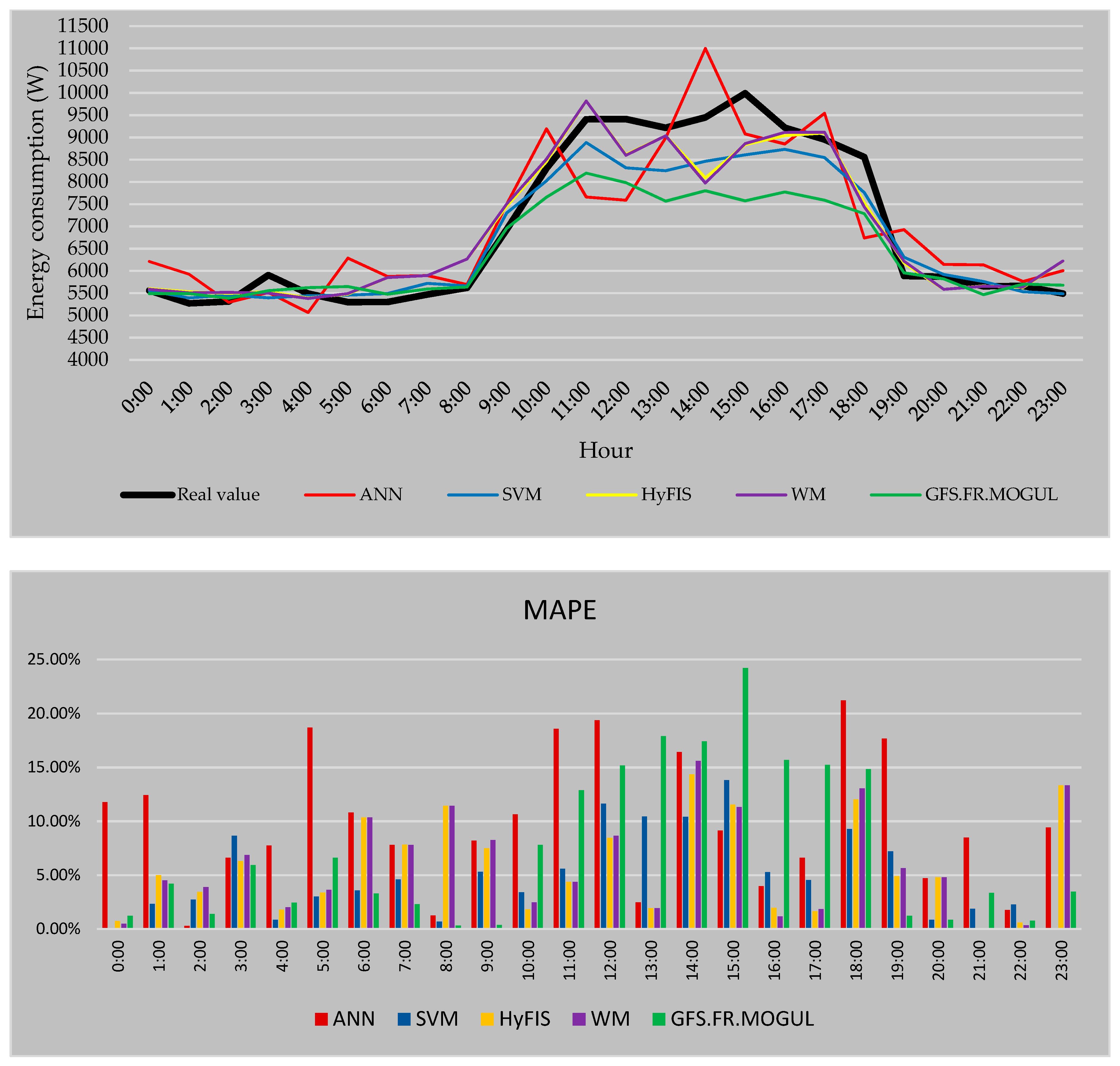
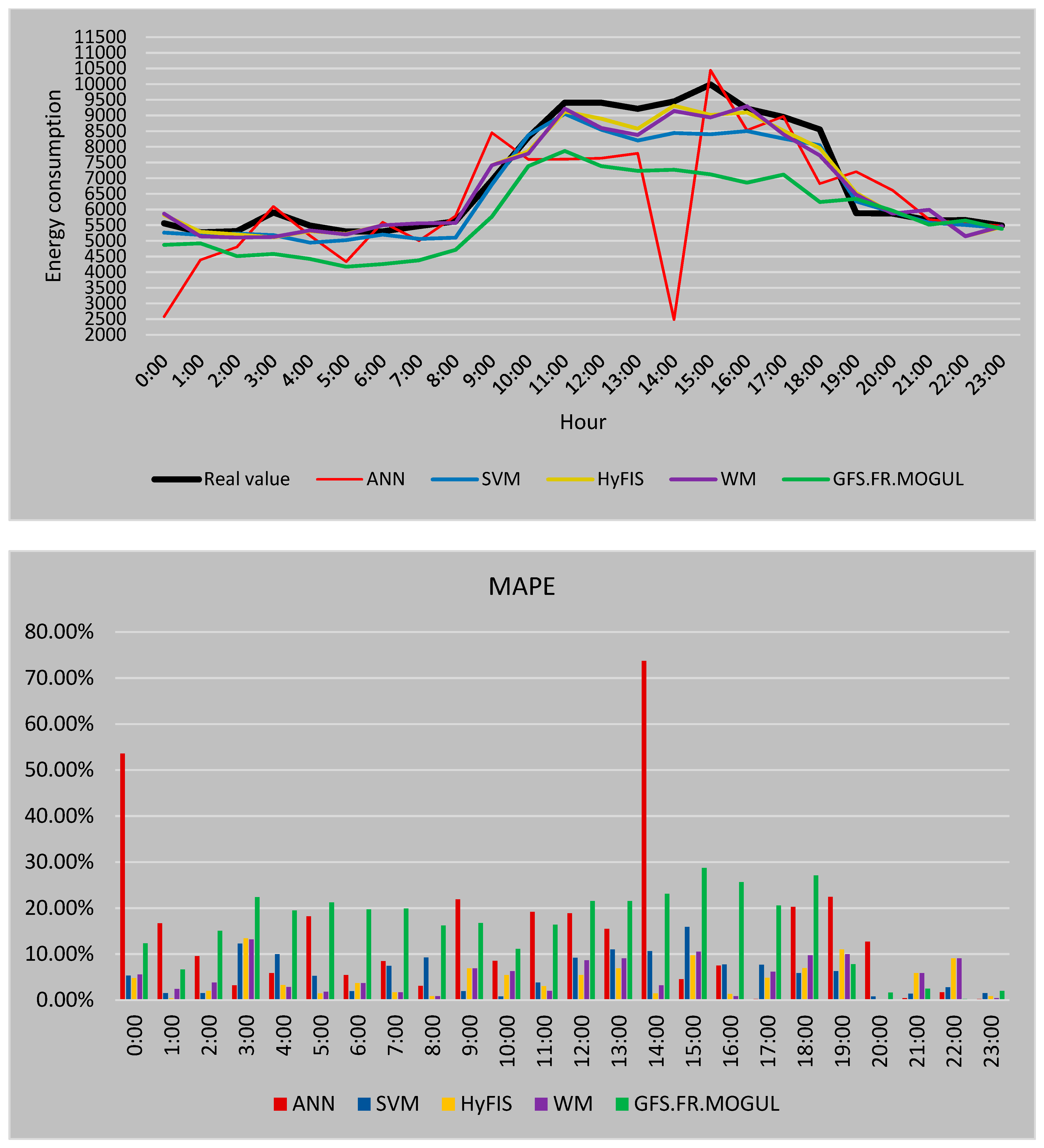
Figure 12 represents a comparison between the forecasted electricity consumption for 24 h of 2018/4/6 using 5 forecasting methods based on the first training strategy as well as the real consumption values. In this strategy, the methods are trained by the electricity consumption of the 10 past days before the target day.
In
Figure 12 the real consumption value of every hour is presented by the black line. As it is visible, during the peak hours of the consumption the predicted values are mostly lower than the real value. The MAPE is used to measure the accuracy of the forecasted values. For this strategy, the most reliable values by the average error of 4.93% are calculated by SVM followed by HyFIS with 5.81% and WM with 5.99%. Also, the GFS.FR.MOGUL by 7.45% error and ANN by 9.83% are the methods by the highest error in the case of the first forecasting strategy.
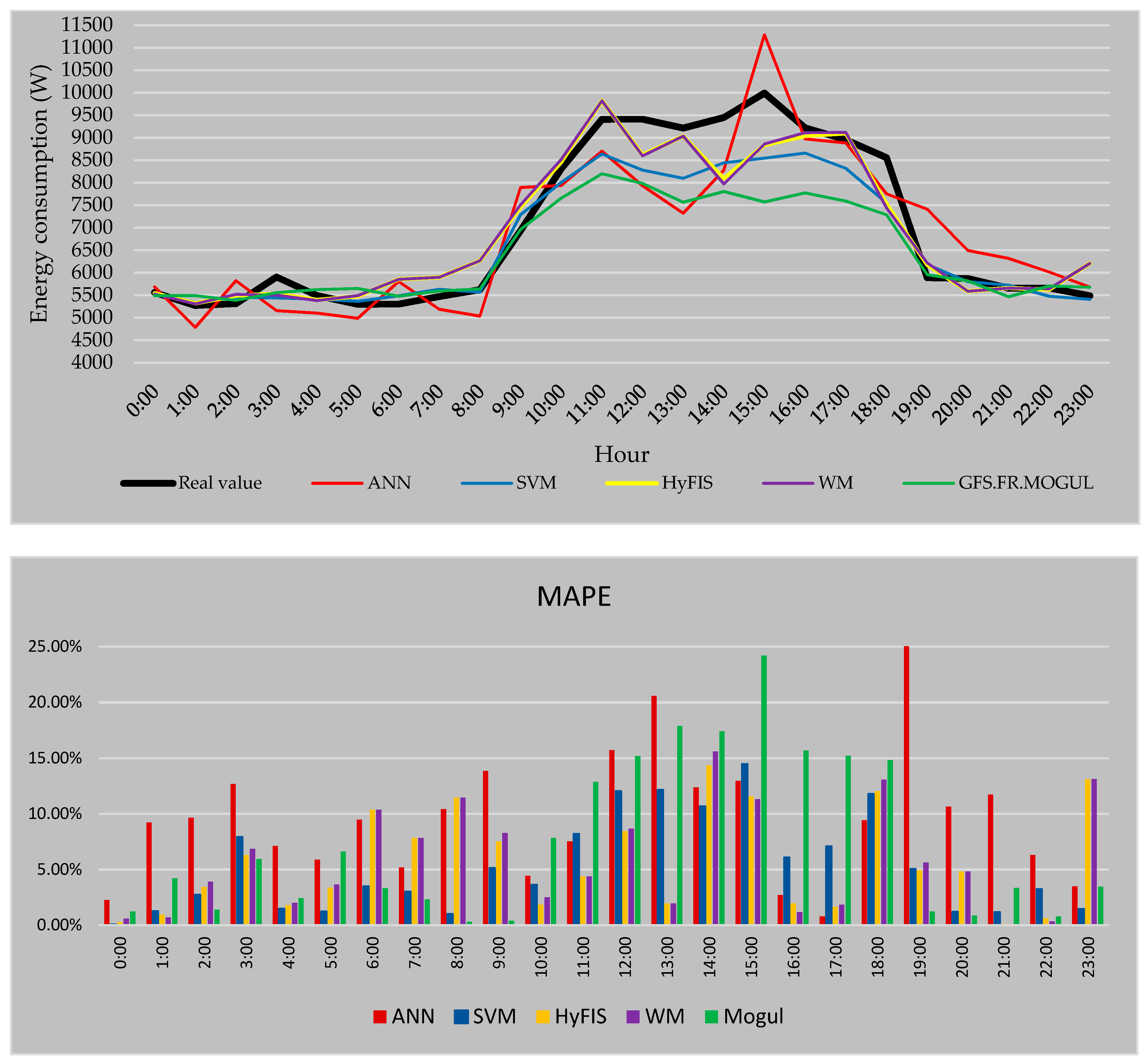
Figure 13 presents the forecasted results by the methods while using the second forecasting strategy to train the methods. The comparison between these results and the forecasted values by the first strategy shows that in the case of GFS.FR.MOGUL the results are the same and using the environmental template has no influence on the performance of this method and the error is still 7.45%. ANN by 9.58%, HyFIS by 5.61% and WM by 5.82% of MAPE error while using the second strategy, have a more reliable result than when the first strategy is used. The only method that has a higher error when the environmental temperature is used in the training data is SVM by the error of 5.21%; however, SVM still has the best result in the case of this strategy.
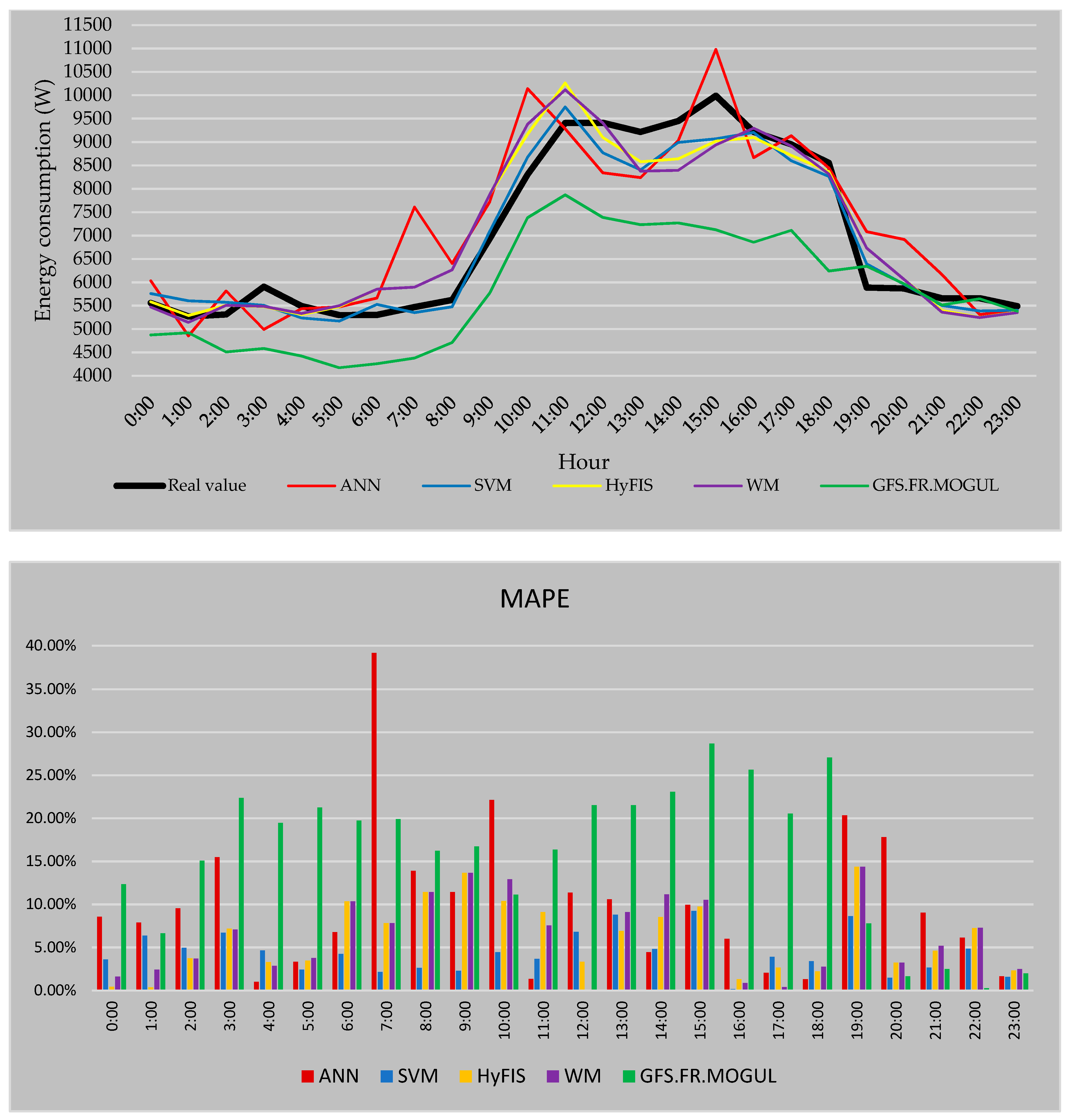
Figure 14 includes the forecasting result of the third strategy.
As can be seen in the results of
Figure 14, the GFS.FR.MOGUL in the most hours, predicts a much lower value than the real value which eventuates an error of 15.8% for this method when the third strategy is used. HyFIS and WM by an average error of 6.15% and 6.35% also have a higher error for this strategy compared to the errors of the first and second ones. For ANN, the calculated error is 10% which is a better error than the error of this method when the second strategy is used but the performance of this method when the first strategy has been used, stills the best performed results by this method. In contrast, the SVM by the error of 4.34% while the third strategy is used has the best results between the forecasting methods and has the best predicted results by SVM between these forecasting strategies.
As one can see in
Figure 15, the predicted results by ANN when the fourth strategy is used have a high variation and, in some cases, the method predicts a much lower value than the real value. The average MAPE error for the ANN using the fourth strategy is 14.64%, which is the worst performed value by this method. As it has been proved, using the environmental temperature in the training data has no effect on the results of GFS.FR.MOGUL, and this method has the same error as the third strategy which is 15.8%. When the fourth strategy is used, the HyFIS has the best error by an average error of 4.58% followed by WM with 5.19% and SVM by 5.9%.
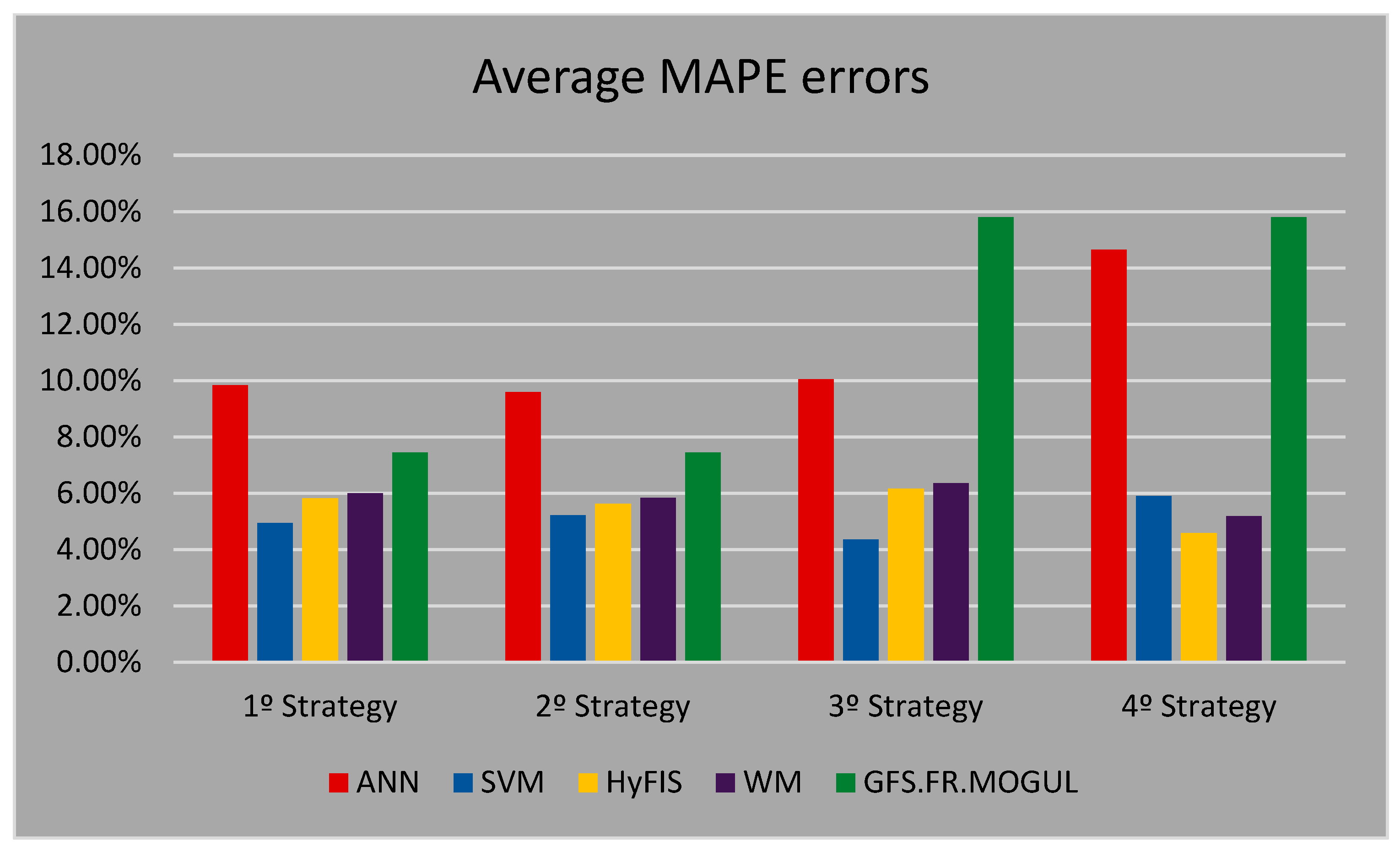
Figure 16 presents a comparison between the average MAPE error of the forecasting methods based on the four proposed forecasting strategies in this work.
It is not possible to conclude that there is an absolute forecasting strategy that has the best result for all the forecasting methods. For ANN, the best strategy is the first one, which has the simplest data set. About GFS.FR.MOGUL it is possible to say that using the environmental temperature has no influence on the results of this method. On the other hand, the process of selecting the particular date to collect the train data has a negative effect on the performance of this method. This way the best forecasting strategy for the GFS.FR.MOGUL is also the first one. The HyFIS and WM have similar efficiency. These two methods can predict a more reliable value when the environmental temperature is used in the train data. This conclusion is valid in both cases of the second and fourth strategy. The best calculated results from these two methods are when the fourth strategy is used. The HyFIS by using the fourth strategy has the second-best calculated error in this work. The SVM has the most stable and trustable results while different forecasting strategies are used. This method has the most accurate result in the case of three of four proposed forecasting strategies in this work. SVM by an error of 4.35% when the third strategy is used has the best calculated error in this case study.
5. Conclusions
This paper presents an automatic forecasting application based on Java and R programming languages. By using this application, the user can create different forecasting models using five forecasting methods and four data preparation strategies to predict the hour-ahead energy consumption of an office building. ANN, SVM, HyFIS, WM, and GFS.FR.MOGUL are the considered forecasting algorithms in this work as well as four data preparation strategies which are explained in
Section 2. The most important advantage that this application offers is that the user does not need to have knowledge about the programming languages, forecasting technics, and data storage systems and all the process is done by the application. Additionally, by making different algorithms and data treatment strategies available, the proposed work also enables the user to find the best method to be used in distinct prediction conditions. This is especially relevant considering that by being domain-agnostic, the proposed application can be applied to multiple application domains, such as manufacturing systems, health related management systems, internet-of-things problems, or many other problems that require forecasting solutions based on historical data regression.
The presented case studies using this application show that the proposed approaches in this work can forecast the hour-ahead energy consumption with acceptable performance. The SVM with the third proposed data preparation strategy presents an error of 4.35% which is a trustable performance compared to the other methods and previous work. Moreover, when using additional information for training, in this case, the temperature, as input for consumption forecasting, it is visible that both the HyFIS and WM can improve their results and reach better results than the SVM (in specific, using the 4th data strategy). Hence, the application can support users’ decisions on the best method, parameterization, and data treatment that should be used depending on the available data.
As future work, further forecasting methods will be included, to broaden the available learning capabilities from various methods. Probabilistic forecasting will also be included, as well as the possibility of working with other types of data and databases, not necessarily related to energy consumption.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}