A Web Service for Evaluating the Level of Speech in Korean

Abstract
:1. Introduction
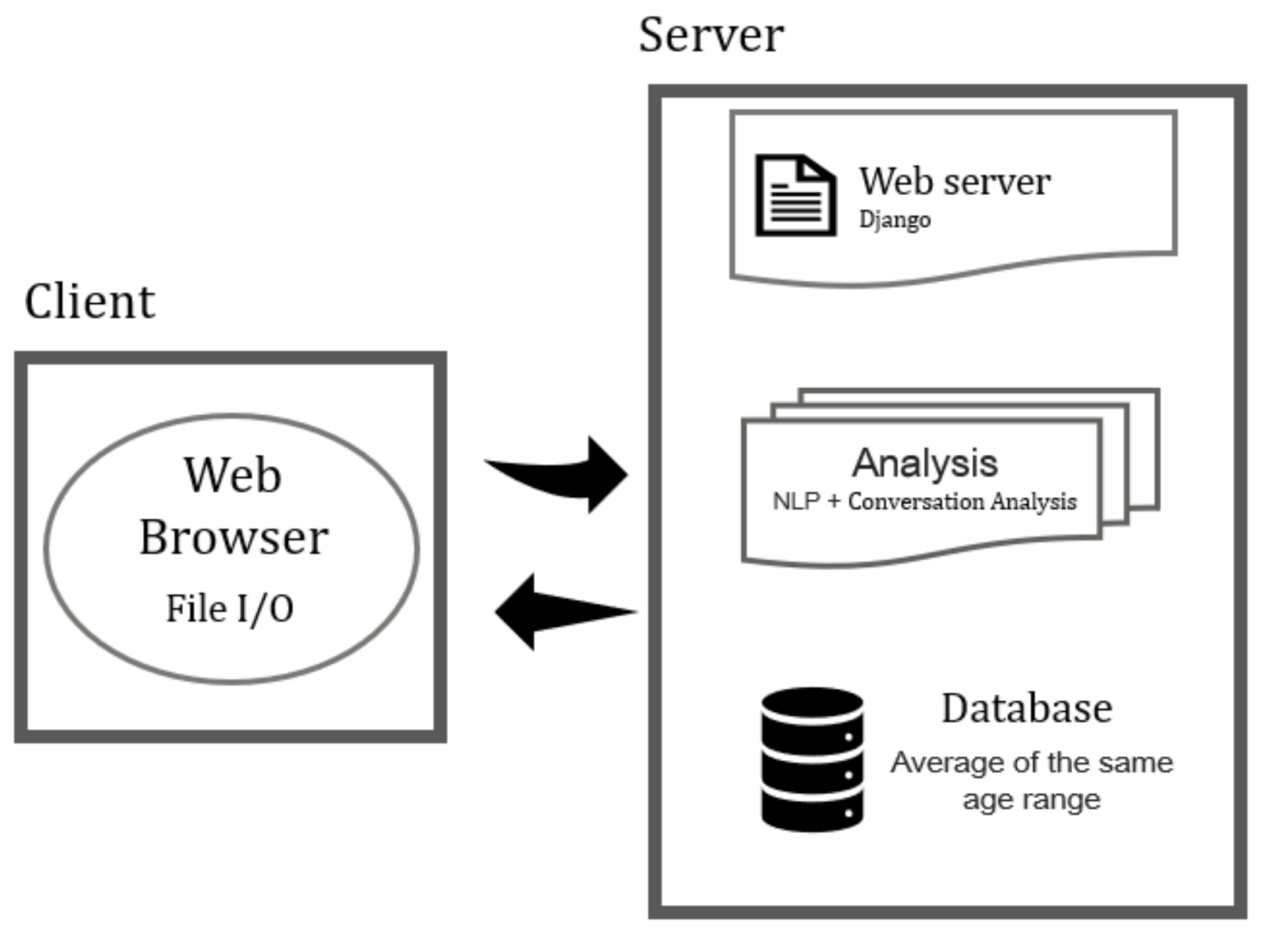
2. Materials and Methods
2.1. Client
2.2. Server
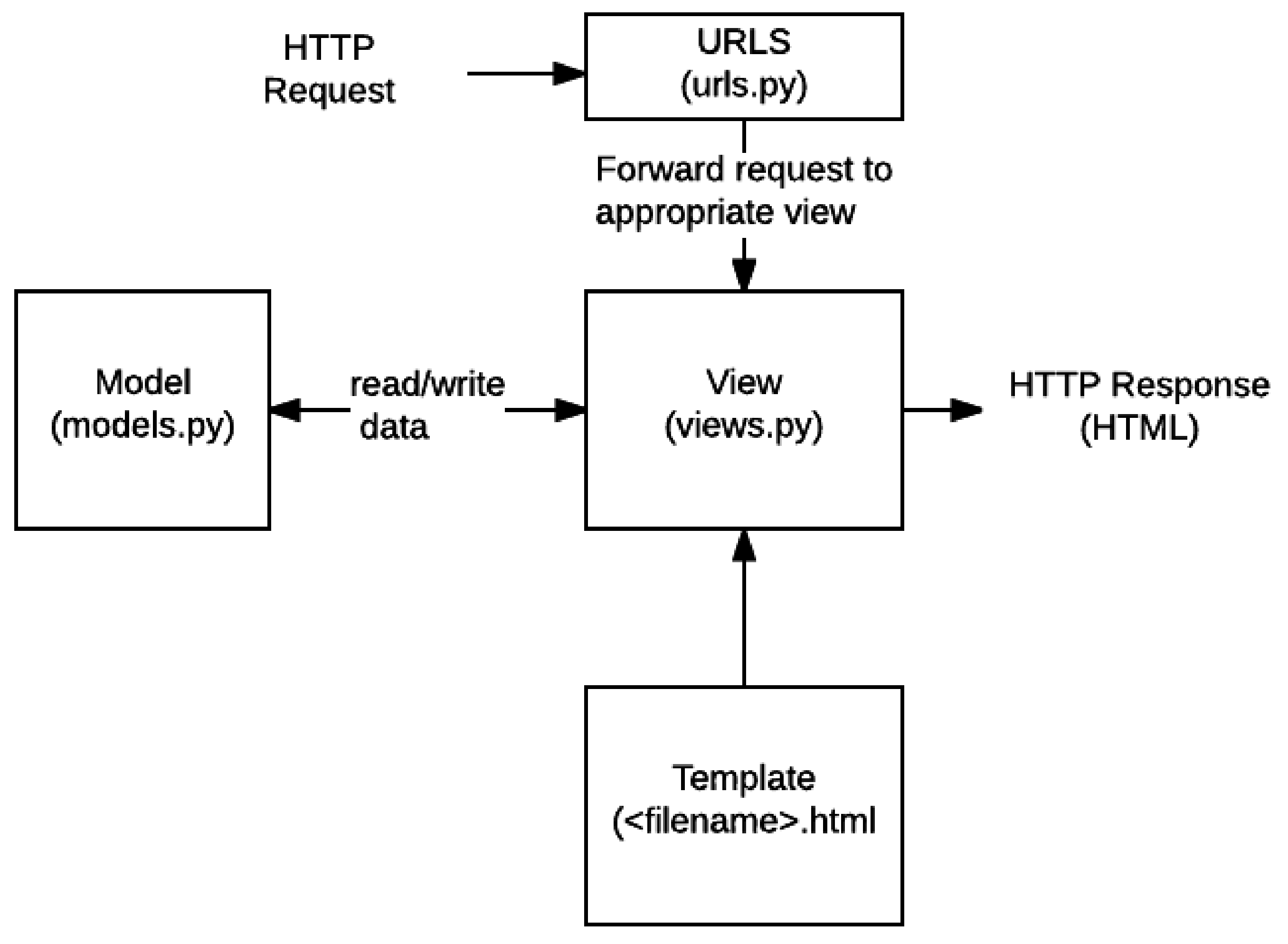
2.2.1. Web Server
2.2.2. Database
3. Analysis Modules
3.1. Natural Language Processing Module
3.2. Conversation Analysis Module
4. Implementation and Experiments
4.1. Transcription Utterances
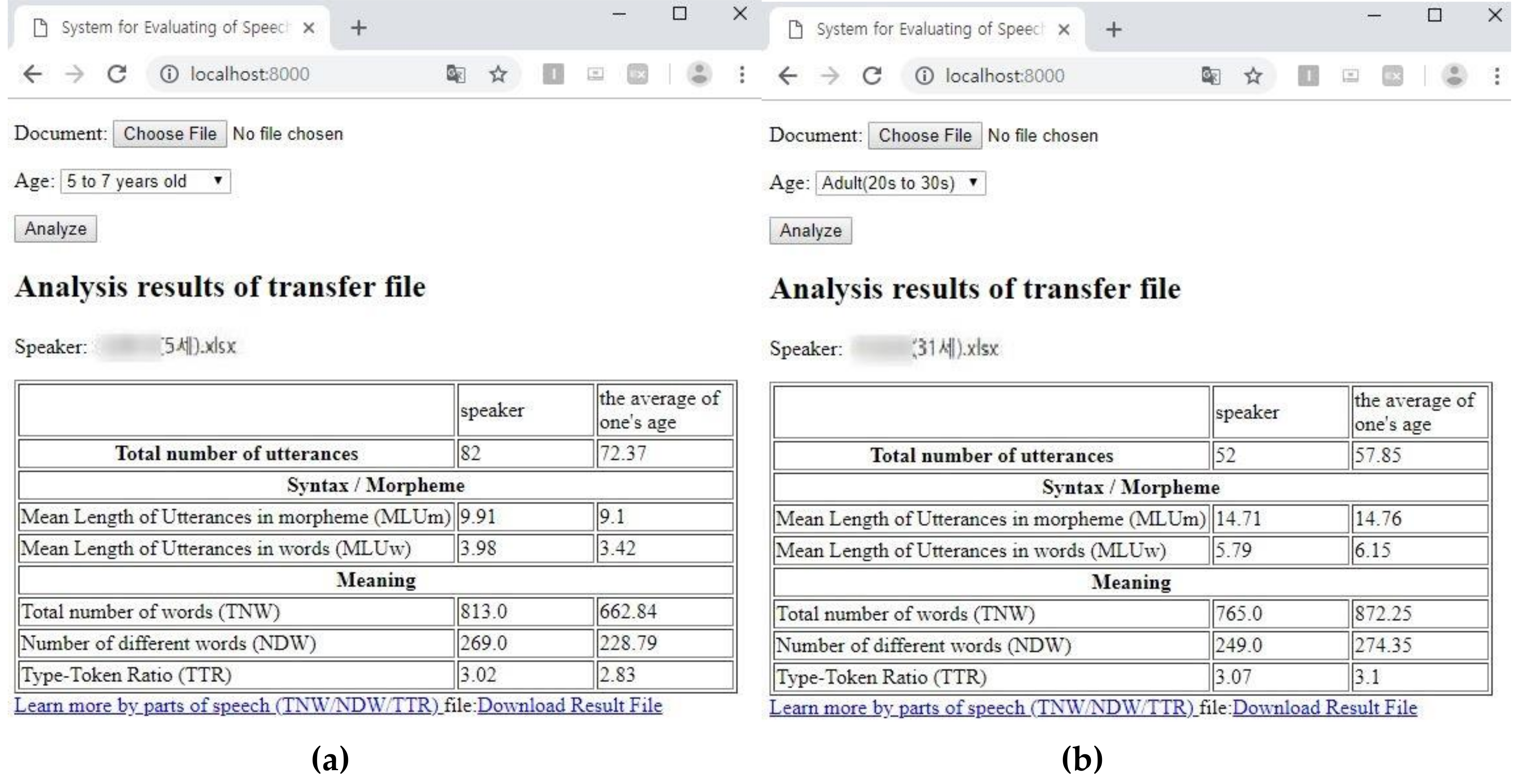
4.2. Execution Results
4.3. Comparison with Manual Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kim, J.-Y.; Yi, S.-H. Infants’ verbal, and nonverbal interaction with their teacher and peers in daycare center. J. Korean Psychol. Assoc. 1997, 10, 57–73. [Google Scholar]
- Crystal, D. Speaking of Writing and Writing of Speaking; Pearson: Harlow, UK, 2005. [Google Scholar]
- Kim, Y.-T. A Basic Study on Utterance Length of Korean Infants of 2-4 Years Olds. Commun. Sci. Disord. 1997, 2, 5–26. [Google Scholar]
- Lee, H.-J.; Kim, Y.-T. Measures of Utterance Length of Normal and Language-Delayed Children. Korean J. Communi. Disord. 1999, 4, 153–166. [Google Scholar]
- Kwon, M.-S.; Kim, H.-H.; Choi, S.-S.; Na, D.-L.; Lee, K.-H. A Study for Analyzing Spontaneous Speech of Korean Adults with CIU Scoring System. Korean J. Communi. Disord. 1998, 3, 35–49. [Google Scholar]
- Shin, J.-Y. Phoneme and Syllable Frequencies of Korean Based on the Analysis of Spontaneous Speech Data. Commun. Sci. Disord. 2008, 13, 193–215. [Google Scholar]
- Lee, M.-S.; Kim, H.-H. Cognitive-Pragmatic Language Assessment for Normal Aging: Study of Assessment Tools and Content Validity. J. Korea Contents Assoc. 2012, 12, 280–292. [Google Scholar] [CrossRef]
- Yang, S.-H.; Kim, Y.-S. A high-speed Korean morphological analysis method based on pre-analyzed partial words. J. KIISE Software Appl. 2000, 27, 290–301. [Google Scholar]
- Yoo, J.-H.; Lee, J.-H.; Lee, G.B. Post—Processing for Character Recognition Using Morphological Analysis and Linguistic Evaluation. J. KIISE 1995, 22, 880–891. [Google Scholar]
- Pae, S.-Y.; Kim, K.-S.; Sung, K.-H.; Sung, J.-A. Korean Computerized Language Analysis 1.0. Commun. Sci. Disord. 1998, 3, 123–138. [Google Scholar]
- Ha, S.-H.; Seol, A.-Y.; So, J.-M.; Pae, S.-Y. Speech and language development patterns of Korean two-year-old children from analysis of spontaneous utterances. Commun. Sci. Disord. 2016, 21, 47–59. [Google Scholar] [CrossRef]
- Yoon, M.-S.; Kim, S.-J.; Kim, J.-M.; Chang, M.-S.; Chac, J.-E. Reliable Sample Size for Mean Length of Utterance Analysis in Preschooler. Korean J. Communi. Disord. 2013, 18, 368–378. [Google Scholar] [CrossRef]
- Hwang, S.-S. A Study on Language Characteristics of Children according to ages in Culturally Diverse Family Environments. J. Spec. Educ.: Theor. Pract. 2009, 10, 265–281. [Google Scholar]
- Price, L.H.; Hendricks, S.; Cook, C. Incorporating Computer-Aided Language Sample Analysis into Clinical Practice. Lang. Speech Hear. Serv. Sch. 2010, 41, 206–222. [Google Scholar] [CrossRef]
- Kim, J.-S.; Kim, Y.-S. Language dependent value automatic analysis program for efficient language analysis. In Proceedings of the Korean International Statistical Society (KISS 2017), Seoul, Korea, 10–11 November 2017; pp. 1901–1903. [Google Scholar]
- Django. Available online: https://www.djangoproject.com/ (accessed on 20 September 2018).
- Kim, Y.-J.; Pae, S.-Y. Narrative Abilities of Korean Children with and without Specific Language Impairment. Korean J. Dev. Psychol. 2004, 17, 41–58. [Google Scholar]
- Ahn, J.-S.; Kim, Y.-T. The Effect of Syntactic Complexity on Sentence Repetition Performance and Intelligibility between Specific Language Impairment and Normal Children. Speech Sci. 2000, 7, 262–275. [Google Scholar]
- Yang, J.-H. The Concept of the Morpheme and the Description on the History of the Korean Language. Korean Culture 4th 2004, 12, 1–19. [Google Scholar]
- Lee, J.-S. Three-step probabilistic model for Korean morphological analysis. J. KIISE Software Appl. 2011, 38, 257–268. [Google Scholar]
- Kang, S.-S.; Zhang, B.-T. A General Morphological Analyzer and Spelling Checker for the Korean Language Using Syllable Characteristics. J. KIISE 1996, 23, 530–539. [Google Scholar]
- Park, E.-J.; Cho, S.-Z. KoNLPy: Korean natural language processing in Python. In Proceedings of the 26th Human & Cognitive Language Technology (HCLT 2014), Chuncheon, Korea, 11–14 October 2014; pp. 133–136. [Google Scholar]
- Kim, Y.-T. A Basic Study on Utterance Length of Korean 2–4 aged Children. Korean J. Communi. Disord. 1997, 2, 5–25. [Google Scholar]
- Owens, R.E. Language Disorders: A Functional Approach to Assessment and Intervention, 6th ed.; Pearson: Harlow, UK, 2013. [Google Scholar]
- Choi, J.; Lee, Y. Conversational Turn-Taking and Topic Manipulation Skills of Children with High-Functioning Autism Spectrum Disorders. Commun. Sci. Disord. 2013, 18, 12–23. [Google Scholar] [CrossRef]
- Choi, J.; Lee, Y. Contingency and Informativeness of Topic Maintenance in Children with High-Functioning Autism Spectrum Disorders. Commun. Sci. Disord. 2015, 20, 413–423. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Item | Number |
| Total number of utterances | 57 |
| Syntax/Morpheme | |
| Mean Length of Utterances in morpheme (MLUm) Mean Length of Utterances in words (MLUw) | 14.05 5.6 |
| Meaning | |
| Total number of words (TNW) Number of different words (NDW) Type-Token Ratio (TTR) | 801 290 2.76 |
| Input | Output |
|---|---|
| ‘아 뭐 이야기할걸 잘 모르겠네’(‘ I don’t know what to say.’) | [(‘뭐’, ‘NP’), (‘이야기’, ‘NNG’), (‘하’, ‘XSV’), (‘ㄹ’, ‘ETD’), (‘것’, ‘NNB’), (‘을’, ‘JKO’), (‘잘’, ‘MAG’), (‘모르’, ‘VV’), (‘겠’, ‘EPT’), (‘네’, ‘EFN’)] |
| ‘아 우리 할아버지랑 나랑 우리 딸네 집에 있어’ (‘My grandfather and I are at my daughter’s house.’) | [(‘우리’, ‘NP’), (‘할아버지’, ‘NNG’), (‘랑’, ‘JC’), (‘나’, ‘NP’), (‘랑’, ‘JC’), (‘우리’, ‘NP’), (‘딸’, ‘NNG’), (‘네’, ‘XSN’), (‘집’, ‘NNG’), (‘에’, ‘JKM’), (‘있’, ‘VV’), (‘어’, ‘ECD’)] |
| ‘아 우리 할아버지랑 아주 잘지내’ (‘I am very well with my grandfather.’) | [(‘우리’, ‘NP’), (‘할아버지’, ‘NNG’), (‘랑’, ‘JC’), (‘아주’, ‘MAG’), (‘잘’, ‘MAG’), (‘지내’, ‘VV’) |
| OOO (75 years old) | ||
|---|---|---|
| Turn | Utterance | Contents |
| 1 | 1 | Ah. I do not know what to say. |
| 2 | 2 | Oh, my grandfather and I are at my daughter’s house. |
| 3 | 3 | Oh, I am very well with my grandfather. |
| 4 | 4 | Oh, my grandchild works well in sk and got married to a woman who worked for Samsung and was doing very well. |
| 5 | Oh, I am happy. | |
| 5 | 6 | Oh, I want to see my grandchildren and grandchildren’s daughter-in-law. |
| 6 | 7 | Oh yeah, I want to see them every day. |
| 7 | 8 | Oh, that is right. |
| 8 | 9 | Ah, we usually go out to church. |
| 9 | 10 | Oh, and I buy meat with my family and eat meat. |
| Division | Total Number of Utterances | MLUm | MLUw | TNW | DNW | TTR |
|---|---|---|---|---|---|---|
| All ages | 1 | 0.966595 | 1 | 0.92529 | 0.95485 | 0.86812 |
| 5 to 7 years old | 1 | 0.995799 | 1 | 0.99564 | 0.9934 | 0.94724 |
| 8 to 13 years old | 1 | 0.998592 | 1 | 0.99863 | 0.99375 | 0.98357 |
| 14 to 19 years old | 1 | 0.998809 | 1 | 0.99407 | 0.99602 | 0.83191 |
| Adult (20s to 39s) | 1 | 0.996125 | 1 | 0.9963 | 0.98476 | 0.89463 |
| Adult (40s to 59s) | 1 | 0.998975 | 1 | 0.99866 | 0.9934 | 0.98355 |
| Adult (over 60s) | 1 | 0.99981 | 1 | 0.99981 | 0.99949 | 0.99195 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.-J.; Choi, J.-E.; Lee, Y.-K.; Yoon, J.H.; Kim, J.-D.; Park, C.-Y.; Kim, Y.-S. A Web Service for Evaluating the Level of Speech in Korean. Appl. Sci. 2019, 9, 594. https://doi.org/10.3390/app9030594
Song H-J, Choi J-E, Lee Y-K, Yoon JH, Kim J-D, Park C-Y, Kim Y-S. A Web Service for Evaluating the Level of Speech in Korean. Applied Sciences. 2019; 9(3):594. https://doi.org/10.3390/app9030594
Chicago/Turabian StyleSong, Hye-Jeong, Ji-Eun Choi, Yoon-Kyoung Lee, Ji Hye Yoon, Jong-Dae Kim, Chan-Young Park, and Yu-Seop Kim. 2019. "A Web Service for Evaluating the Level of Speech in Korean" Applied Sciences 9, no. 3: 594. https://doi.org/10.3390/app9030594
APA StyleSong, H.-J., Choi, J.-E., Lee, Y.-K., Yoon, J. H., Kim, J.-D., Park, C.-Y., & Kim, Y.-S. (2019). A Web Service for Evaluating the Level of Speech in Korean. Applied Sciences, 9(3), 594. https://doi.org/10.3390/app9030594